Work in progress. Page is located here .
| The purpose of the C++ API is to provide a set of standardized access methods to Star-DB data from within (client) codes that is independent of specific software choices among groups within STAR. The standardized methods hide the "client" code from most details of the storage structure, including all references to the low-level DB infrastructure such as (My)SQL query strings. Specifically, the DB-API reformulates requests for data by name, timestamp, and version into the necessary query structure of the databases in order to retrieve the data requested. None of the low-level query structure is seen by the client.
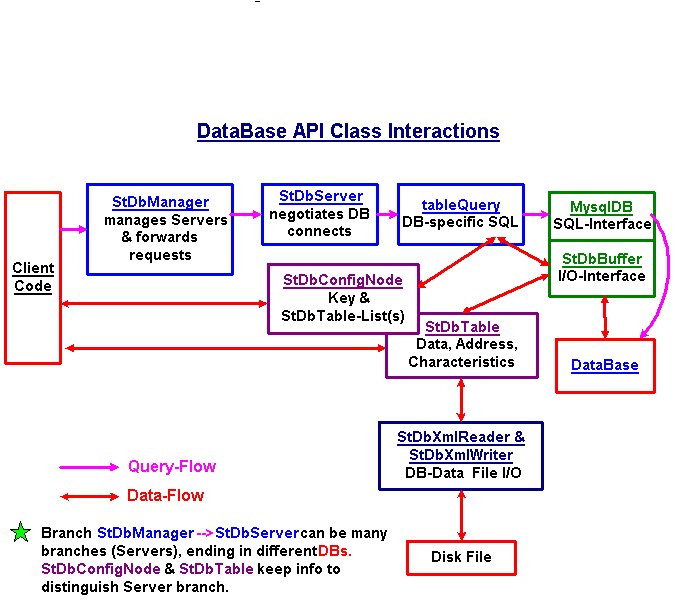
The API is contained withing a shared library StDbLib.so. It has two versions built from a common source. The version in Offline (under $STAR/lib) contains additional code generated by "rootcint" preprocessor in order to provide command line access to some methods. The Online version does not contain the preprocessed "rootcint" code. In addition to standard access methods, the API provides the tools needed to facilitate those non-standard access patterns that are known to exist. For example, there will be tasks that need special SQL syntax to be supplied by client codes. Here, a general use C++MySQL object can be made available to the user code on an as needed basis. The following write-up is intended as a starting point for understanding the C++ API components. Since most clients of database data have an additional software-layer between their codes and the DB-API (e.g St_db_Maker in offline), none of these components will be directly seen by the majority of such users. There will, however, be a number of clients which will need to access the API directly in order to perform some unique database Read/Write tasks. Click here To view a block diagram of how the C++ API fits general STAR code access. Click here To view a block diagram of how the C++ API classes work together to provide data to client codes The main classes which make up the C++ DB-API are divided here into four categories.
|
StDbManager | StDbServer | tableQuery & mysqlAccessor | StDbDefs
| StDbManager: (Available at Root CLI)
The StDbManager class acts as the principle connection between the DB-API and the client codes. It is a singleton class that is responcible for finding Servers & databases, providing the information to the StDbServer class in order that it may connect with the database requested, and forwarding all subsequent (R/W) requests on to the appropriate StDbServer object. Some public methods that are important to using the DB-API via the manager:
Some public methods that are primarily used internally in the DB-API:
The StDbServer class acts as the contact between the StDbManager and the specific Server-&-Database in which a requested data resides. It is initialized by the StDbManager with all the information needed to connect to the database and it contains an SQL-QueryObject that is specifically structured to navigate the database requested. It is NOT really a user object except in specific situations that require access to a real SQL-interface object which can be retrieved via this object. Public methods accessed from the StDbManager and forwarded to the SQL-Query Object:
The tableQuery object is an interface of database queries while mysqlAccessor object is a real implementation based on access to MYSQL. The real methods in mysqlAccessor are those that contain the specific SQL content needed to navigate the database structures. Public methods passed from StDbServer :
Not a class but a header file containing enumerations of StDbType and StDbDomain that are used to make contact to specific databases. Use of such enumerations may disappear in favor of a string lookup but the simple restricted set is good for the initial implementation.
|
| StDbTable: (Available at Root CLI)
The StDbTable class contains all the information needed to access a specific table in the database. Specifically, it contains the "address" of the table in the database (name, version, validity-time, ...), the "descriptor" of the c-struct use to fill the memory, the void* to the memory, the number of rows, and whether the data can be retrieved without time-stamp ("BaseLine" attribute). Any initial request for a table, either in an ensemble list or one-by-one, sets up the StDbTable class instance for the future data request without actually retrieving any data. Rather the database-name, table-name, version-name, and perhaps number of rows & id for each row, are assigned either by the ensemble query via the StDbConfigNode or simply by a single request. In addition, an "descriptor" object can also be requested from the database or set from the client code. After this initial "request", the table can be used with the StDbManager's timestamp information to read/write data from/to the database. if no "descriptor" is in the StDbTable class, the database provides one (the most recent one loaded in the database) upon the first real data access attempted. Some usefull public methods in StDbTable
StDbConfigNode: (Available at Root CLI) The StDbConfigNode class provides 2 functions to the C++ API. The first is as a container for a list of StDbTable objects over which codes can iterate. In fact, the StDbTable constructor need not be called directly in the user codes as the StDbConfigNode class has a method to construct the StDbTable object, add it to its list, and return to the user a pointer to the StDbTable object created. The destructor of the StDbConfigNode will delete all tables within its list. The second is the management of ensembles of data (StDbTables) in a list structure for creation (via a database configuration request) and update. The StDbConfigNode can build itself from the database and a single "Key" (version string). The result such a "ConfigNode" query will be several lists of StDbTables prepared with the necessary database addresses of name, version, & elementID as well as any characteristic information such as the "descriptor" and the baseline attribute. Some usefull public methods in StDbConfigNode
|
MysqslDb class provides infrastructure (& sometimes client) codes easy use of SQL queries without being exposed to any of the specific/particular implementations of the MySQL c-api. That is, the MySQL c-api has specific c-function calls returning mysql-specific c-struct (arrays) and return flags. Handling of these functions is hidden by this class.
Essentially there are 3 public methods used in MysqlDb
The StDbBuffer class inherits from the pure virtual StDbBufferI class & implements MySQL I/O. The syntax of the methods were done to be similar with TBuffer as an aid in possible expanded use of this interface. The Buffer handles binary data & performs byte-swapping as well as direct ASCII I/O with MySQL. The binary data handler writes all data in Linux format into MySQL. Thus when accessing the buffer from the client side, one should always set it to "ClientMode" to ensure that data is presented in the architecture of the process.
Public methods used in StDbBufferI
STAR MySQL API: SSL (AES 128/AES 256), Compression tests.
IDEAS:
a) SSL encryption will allow to catch mysterious network problems eary (integrity checks).
b) Data compression will allow more jobs to run simultaneously (limited network bandwidth);
BFC chain used to measure db response time: bfc.C(5,"pp2009a,ITTF,BEmcChkStat,btofDat,Corr3,OSpaceZ2,OGridLeak3D","/star/rcf/test/daq/2009/085/st_physics_10085024_raw_2020001.daq")
time is used to measure 20 sequential BFC runs :
1. first attempt:
SSL OFF, COMPRESSION OFF : 561.777u 159.042s 24:45.89 48.5% 0+0k 0+0io 6090pf+0w
WEAK SSL ON, COMPRESSION OFF : 622.817u 203.822s 28:10.64 48.8% 0+0k 0+0io 6207pf+0w
STRONG SSL ON, COMPRESSION OFF : 713.456u 199.420s 28:44.23 52.9% 0+0k 0+0io 11668pf+0w
STRONG SSL ON, COMPRESSION ON : 641.121u 185.897s 29:07.26 47.3% 0+0k 0+0io 9322pf+0w
2. second attempt:
SSL OFF, COMPRESSION OFF : 556.853u 159.315s 23:50.06 50.0% 0+0k 0+0io 4636pf+0w
WEAK SSL ON, COMPRESSION OFF : 699.388u 202.783s 28:27.83 52.8% 0+0k 0+0io 3389pf+0w
STRONG SSL ON, COMPRESSION OFF : 714.638u 212.304s 29:54.05 51.6% 0+0k 0+0io 5141pf+0w
STRONG SSL ON, COMPRESSION ON : 632.496u 157.090s 28:14.63 46.5% 0+0k 0+0io 1pf+0w
3. third attempt:
SSL OFF, COMPRESSION OFF : 559.709u 158.053s 24:02.37 49.7% 0+0k 0+0io 9761pf+0w
WEAK SSL ON, COMPRESSION OFF : 701.501u 199.549s 28:53.16 51.9% 0+0k 0+0io 7792pf+0w
STRONG SSL ON, COMPRESSION OFF : 715.786u 203.253s 30:30.62 50.2% 0+0k 0+0io 4560pf+0w
STRONG SSL ON, COMPRESSION ON : 641.293u 164.168s 29:06.14 46.1% 0+0k 0+0io 6207pf+0w
Preliminary results from 1st run :
SSL OFF, COMPRESSION OFF : 1.0 (reference time)
"WEAK" SSL ON, COMPRESSION OFF : 1.138 / 1.193 / 1.201
"STRONG" SSL ON, COMPRESSION OFF : 1.161 / 1.254 / 1.269
"STRONG" SSL ON, COMPRESSION ON : 1.176 / 1.184 / 1.210
Compression check:
1. bfc 100 evts, compression ratio : 0.74 [compression enabled / no compression]. Not quite what I expected, probably I need to measure longer runs to see effect - schema queries cannot be compressed well...
First impression: SSL encryption and Data compression do not significantly affect operations. For only ~15-20% slow-down per job, we get data integrity check (SSL) and 1.5x network bandwidth...
WORK IN PROGRESS...
Addendum :
1. Found an interesting article at mysql performance blog:
http://www.mysqlperformanceblog.com/2007/12/20/large-result-sets-vs-compression-protocol/
"...The bottom line: if you’re fetching big result sets to the client, and client and MySQL are on different boxes, and the connection is 100 Mbit, consider using compression. It’s a matter of adding one extra magic constant to your application, but the benefit might be pretty big..."
{kind=link}
{kind=link}