Offline Databases
Offline Databases
Offline databases are :
robinson.star.bnl.gov:3306 - master database
All hosts below are replication slaves.
db16.star.bnl.gov:3316 - production group nodes
db17.star.bnl.gov:3316
db11.star.bnl.gov:3316
db12.star.bnl.gov:3316 - user node pool
db15.star.bnl.gov:3316
db18.star.bnl.gov:3316
db06.star.bnl.gov:3316
db07.star.bnl.gov:3316 - these hosts belong to dbx.star.bnl.gov RR
db08.star.bnl.gov:3316 (visible to users, external to BNL)
db10.star.bnl.gov:3316
db13.star.bnl.gov:3316 - expert user pool
db14.star.bnl.gov:3316
db03.star.bnl.gov:3316 - online 2 offline buffer node
Database Snapshot Factory
STAR Offline Database Snapshot Factory
Snapshot factory consists of three scripts (bash+php), located at omega.star.bnl.gov. Those scripts are attached to cron, so snapshots are produced four times per day at 6:00, 12:00, 18:00, 24:00 respectively. Those snapshots are exposed to outer world by special script, located at STAR web server (orion), which allows single-stream downloads of snapshot archive file (lock-file protection) to avoid www overload.
Details
1. omega.star.bnl.gov :
- primary script is /db01/offline_snapshot_copy/scripts/run, which is started four times per day by /etc/cron.d/db-snapshot.sh cron rule;
- resulting file is copied to /var/www/html/factory/snapshot-2010.tgz, to be served to orion via http means;
- each (un)successful snapshot run sends an email to arkhipkin@bnl.gov, so database administrator is always aware on how things are going;
- run script is protected against multiple running instances (lock file + bash signal traps), thus preventing build-up of failed script instances at omega;
2. orion.star.bnl.gov :
- snapshot download script is located at /var/www/html/dsfactory/tmp/get_snapshot.sh, which is started every hour by /etc/cron.d/db-snapshot-factory cron rule;
- get_snapshot.sh is also protected against multiple running instances, + it will not download same file twice (if no changes since last download), thus conserving network traffic and keepin node load low;
- resulting file - actual database snapshot - could be accessed at http://drupal.star.bnl.gov/dsfactory/ link, which has internal protection against multiple downloads: only 1 download stream is allowed, other clients will receive HTTP 503 error, accompanied by explanations message (busy);
Recommended way to download snapshots
The following bash script could be used to safely download database snapshot :
#!/bin/bash
#
# Database snapshot download script (omega to orion)
# If you need help with this script, please contact
# "Dmitry Arkhipkin" <arkhipkin@bnl.gov>
#
set -u
set +e
# defaults
lockfile=/tmp/db-snapshot-factory.lock
EMAILMESSAGE=/tmp/emailmessage.txt
DOWNLOAD_DIR=http://www.star.bnl.gov/dsfactory
DOWNLOAD_FILE=snapshot-2010.tgz
LOCAL_DIR=/tmp/dsfactory
LOCAL_TMP_DIR=/tmp/dsfactory/tmp
LOCAL_NAME=db-snapshot-2010.tgz
SUBJECT="gridified database snapshot 2010 download completed"
EMAIL=arkhipkin@bnl.gov
if ( set -o noclobber; echo "$$" > "$lockfile") 2> /dev/null;
then
trap '/bin/rm -f "$lockfile"; exit $?' INT TERM EXIT
# protected area starts here :
cd $LOCAL_TMP_DIR
echo "This is an automated email message, please do not reply to it!" > $EMAILMESSAGE
START=$(date +%s)
echo "*** database snapshot update started at" `date` >> $EMAILMESSAGE
# Attempt to download the file. --progress=dot:mega is used to prevent
# WGET_OUTPUT from getting too long.
WGET_OUTPUT=$(2>&1 wget -O $DOWNLOAD_FILE --timestamping --progress=dot:mega \
"$DOWNLOAD_DIR/")
# Make sure the download went okay.
if [ $? -ne 0 ]
then
# wget had problems.
# send "FAILED" notification email
echo "*** wget output: $WGET_OUTPUT" >> $EMAILMESSAGE
SUBJECT="gridified database snapshot 2010 download FAILED"
/bin/mail -s "$SUBJECT" "$EMAIL" < $EMAILMESSAGE
echo 1>&2 $0: "$WGET_OUTPUT" Exiting.
exit 1
fi
# Copy the file to the new name if necessary.
if echo "$WGET_OUTPUT" | /bin/fgrep 'saved' &> /dev/null
then
/bin/cp -f "$LOCAL_TMP_DIR/$DOWNLOAD_FILE" "$LOCAL_DIR/$LOCAL_NAME"
# calculate time
END=$(date +%s)
DIFF=$(( $END - $START ))
HRS=$(( $DIFF / 3600 ))
MNT=$(( $DIFF % 3600 / 60 ))
SEC=$(( $DIFF % 3600 % 60 ))
echo "*** database snapshot download took $HRS:$MNT:$SEC HH:MM:SS to complete (TOTAL: $DIFF seconds)" >> $EMAILMESSAGE
# send "SUCCESSFUL" notification email
echo "*** database snapshot $LOCAL_NAME successfully updated." >> $EMAILMESSAGE
/bin/mail -s "$SUBJECT" "$EMAIL" < $EMAILMESSAGE
else
echo "!!! database snapshot $LOCAL_NAME does not need to be updated - same file." >> $EMAILMESSAGE
fi
# end of protected area
/bin/rm -f "$lockfile"
trap - INT TERM EXIT
else
echo "Failed to acquire lockfile: $lockfile."
echo "Held by $(cat $lockfile)"
fi
# end of scriptPerformance testing'13
I. Intro
Three nodes tested: my own laptop with home-quality SSD drive, reserve1.starp.bnl.gov (old db node), db04.star.bnl.gov (new node).
II. hdparm results:
extremely basic test of sequential read - baseline and sanity check [passed]
1. Dmitry's laptop (SSD):
/dev/disk/by-uuid/88ba7100-0622-41e9-ac89-fd8772524d65:
Timing cached reads: 1960 MB in 2.00 seconds = 980.43 MB/sec
Timing buffered disk reads: 532 MB in 3.01 seconds = 177.01 MB/sec
2. reserve1.starp.bnl.gov (old node):
/dev/md1:
Timing cached reads: 2636 MB in 2.00 seconds = 1317.41 MB/sec
Timing buffered disk reads: 252 MB in 3.02 seconds = 83.34 MB/sec
3. db04.star.bnl.gov (new node):
/dev/disk/by-uuid/53f45841-0907-41a0-bfa3-52cd269fdfb6:
Timing cached reads: 5934 MB in 2.00 seconds = 2969.24 MB/sec
Timing buffered disk reads: 884 MB in 3.00 seconds = 294.19 MB/sec
III. MySQL bench test results: test suite to perform "global" health check, without any particular focus, single thread..
1. laptop:
connect: Total time: 113 wallclock secs (44.75 usr 16.29 sys + 0.00 cusr 0.00 csys = 61.04 CPU)
create: Total time: 221 wallclock secs ( 7.22 usr 1.96 sys + 0.00 cusr 0.00 csys = 9.18 CPU)
insert: Total time: 894 wallclock secs (365.51 usr 64.07 sys + 0.00 cusr 0.00 csys = 429.58 CPU)
select: Total time: 240 wallclock secs (33.26 usr 3.86 sys + 0.00 cusr 0.00 csys = 37.12 CPU)
2. reserve1.starp.bnl.gov:
connect: Total time: 107 wallclock secs (44.85 usr 14.88 sys + 0.00 cusr 0.00 csys = 59.73 CPU)
create: Total time: 750 wallclock secs ( 6.37 usr 1.52 sys + 0.00 cusr 0.00 csys = 7.89 CPU)
insert: Total time: 1658 wallclock secs (378.28 usr 47.53 sys + 0.00 cusr 0.00 csys = 425.81 CPU)
select: Total time: 438 wallclock secs (48.92 usr 4.50 sys + 0.00 cusr 0.00 csys = 53.42 CPU)
3. db04.star.bnl.gov:
connect: Total time: 54 wallclock secs (18.63 usr 11.44 sys + 0.00 cusr 0.00 csys = 30.07 CPU)
create: Total time: 1375 wallclock secs ( 1.94 usr 0.91 sys + 0.00 cusr 0.00 csys = 2.85 CPU) [what's this??]
insert: Total time: 470 wallclock secs (172.41 usr 31.71 sys + 0.00 cusr 0.00 csys = 204.12 CPU)
select: Total time: 185 wallclock secs (16.66 usr 2.00 sys + 0.00 cusr 0.00 csys = 18.66 CPU)
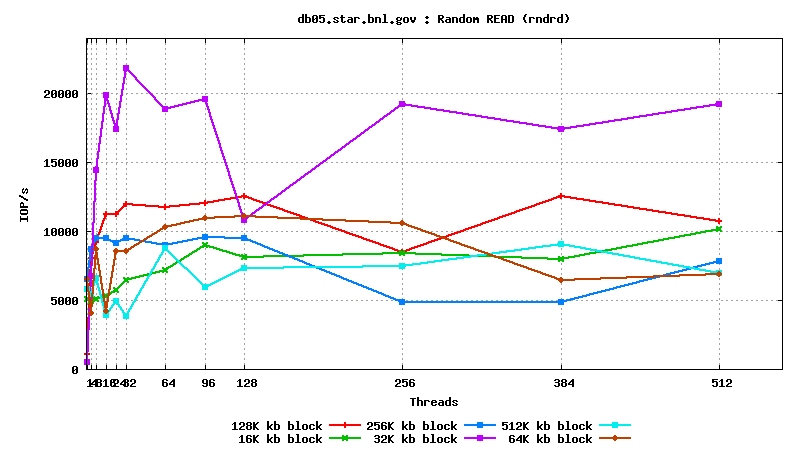
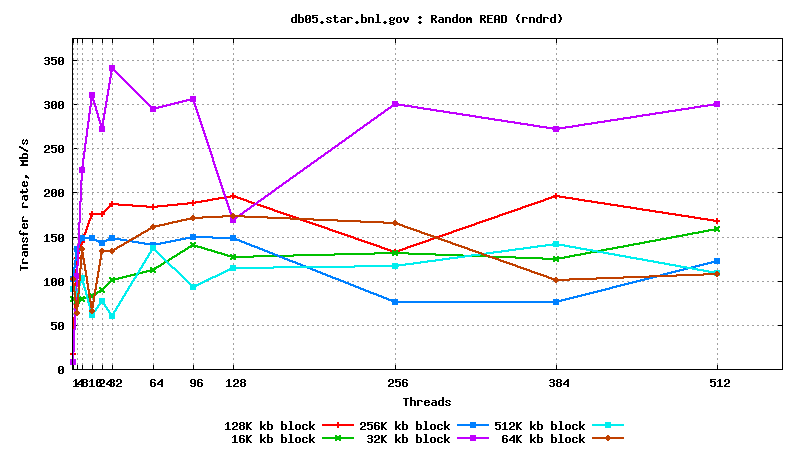
IV. SysBench IO test results: random reads, small block size, many parallel threads
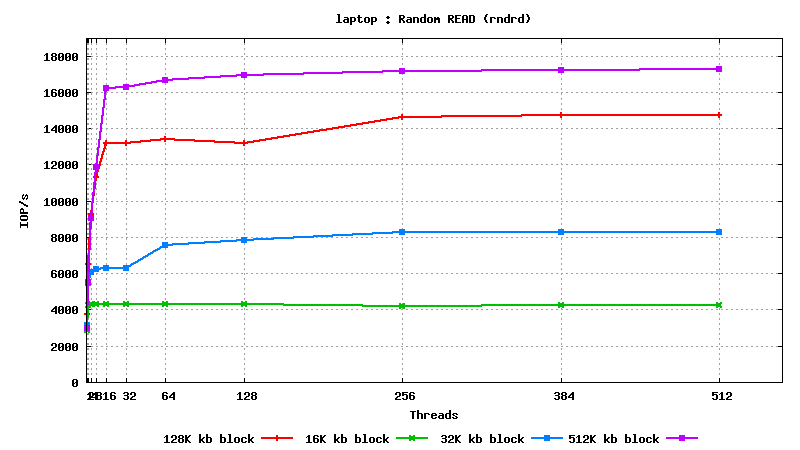 t
t
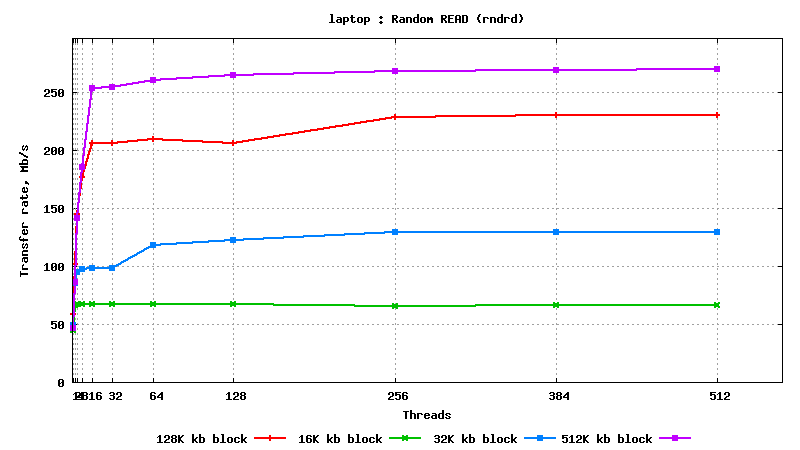
est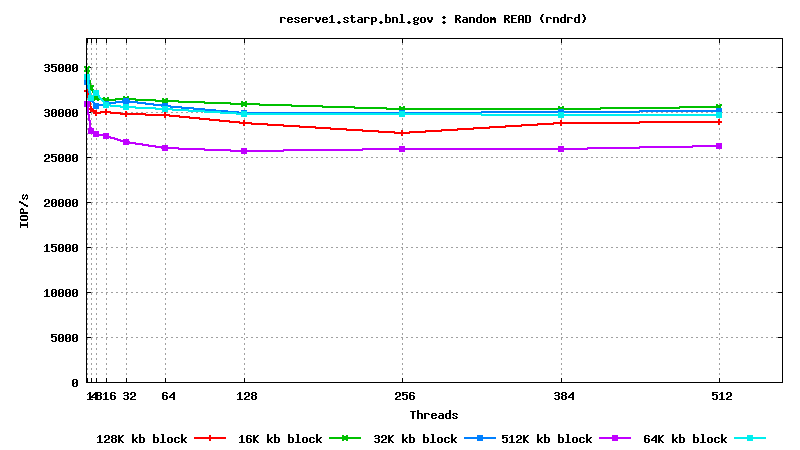
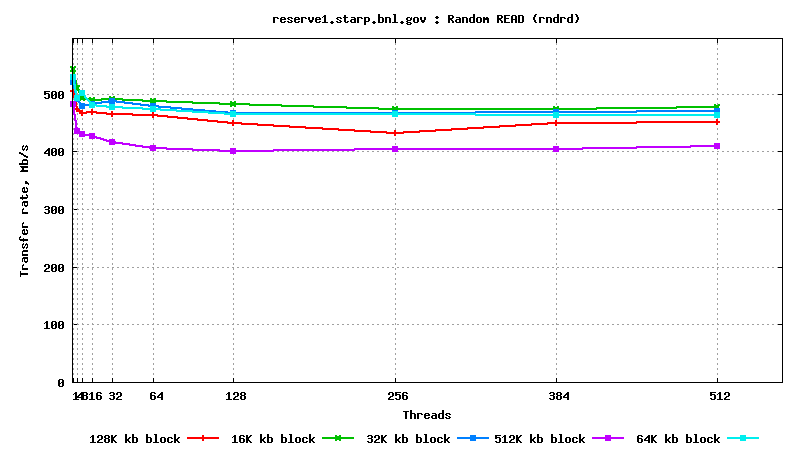
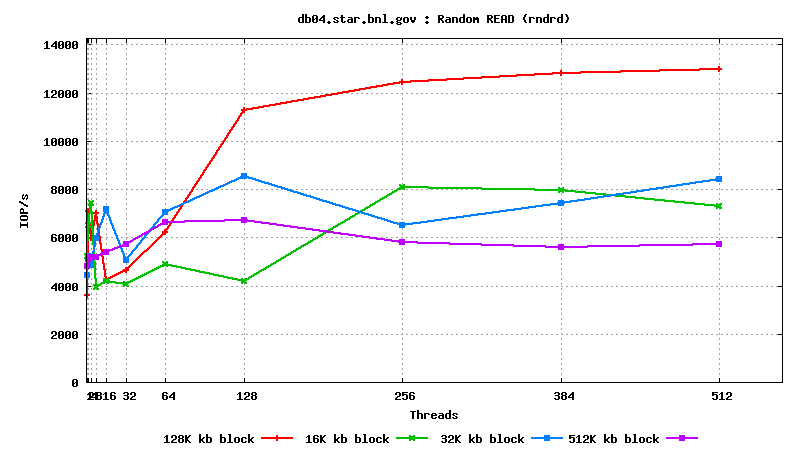
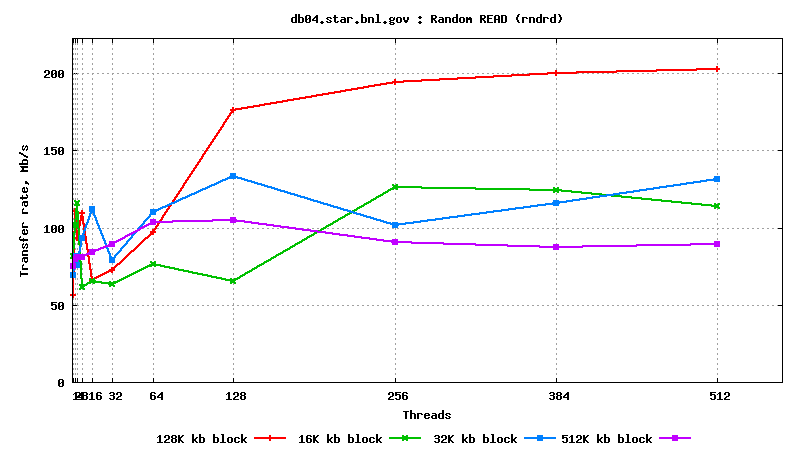
DB05.star.bnl.gov, with "noatime" option:
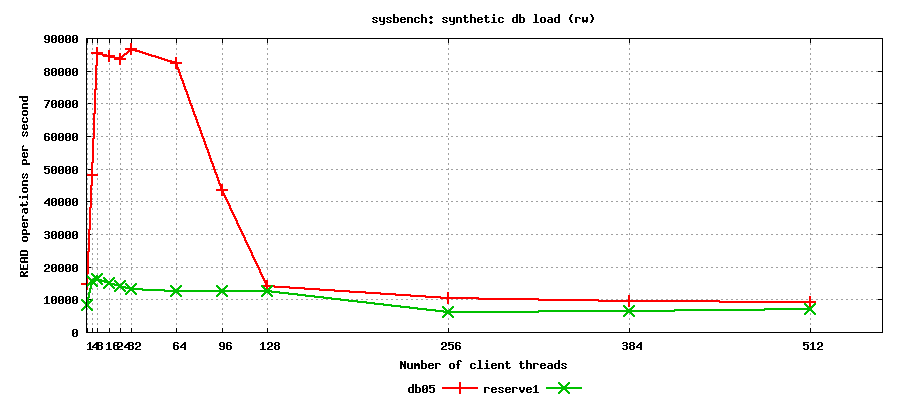
V. SysBench SQL test results: synthetic read-only
Interestingly, new system beats old one by a factor of x7 up to 128 clients, and is only marginally better at 128+ parallel threads..
V. STAR production chain testing (nightly test BFC):
Test setup:
- auau200, pp200, pp500 x 10 jobs each, run using db05 (new node) and db10 (old node, equivalent to reserve1.starp);
- jobs run in a single-user mode: one job at a time;
- every server was tested in two modes: query cache ON, and query cache OFF (cache reset between tests);
- database maker statistics was collected for analysis;
RESULTS:
auau200, old -> new :
qc_off: Ast = 2.93 -> 2.79 (0.1% -> 0.1%), Cpu = 0.90 -> 1.15 (0% -> 0%)
qc_on : Ast = 2.45 -> 2.26 (0.1% -> 0.1%), Cpu = 0.88 -> 0.86 (0% -> 0%)
pp200, old -> new :
qc_off: Ast = 2.72 -> 6.49 (5.59% -> 10.04%), Cpu = 0.56 -> 0.86 (1.36% -> 1.83%)
qc_on : Ast = 2.24 -> 3.20 (4.90% -> 6.49%), Cpu = 0.60 -> 0.55 (1.46% -> 1.32%)
pp500, old -> new:
qc_off: Ast = 2.65 -> 2.41 (15.9% -> 15.4%), Cpu = 0.55 -> 0.79 (5.05% -> 6.2%)
qc_on : Ast = 2.09 -> 1.94 (13.8% -> 14.8%), Cpu = 0.53 -> 0.53 (4.87% -> 4.88%)
Summary for this test:
- as expected, databases with query cache enabled were processing requests faster than databases;
- new node (having query cache on) is performing at the level very similar to old node, difference is not noticable/significant within test margins;
Additional studies: db11 (very new node):
![]()