Maintenance
Database maintenance tasks: monitoring, backup, upgrades, performance issues, server list etc...
Backups
<placeholder> Describes STAR's database backup system. </placeholder>
Sept. 5, 2008, WB -- seeing no documentation here, I am going to "blog" some as I go through dbbak to clean up from a full disk and restore the backups. (For the full disk problem, see http://www.star.bnl.gov/rt2/Ticket/Display.html?id=1280 .) I expect to get the details in and then come back to clean it up...
dbbak.starp.bnl.gov has Perl scripts running in cron jobs to get mysql dumps of nearly all of STAR's databases and store them on a daily basis. The four nightly (cron) backup scripts are attached (as of Nov. 24, 2008).
The scripts keep the last 10 dumps in /backups/dbBackups/{conditions,drupal,duvall,robinson,run}. Additionally, on the 1st and 15th of each month, the backups are put in "old" directories within each respective backup folder.
The plan of action as Mike left it was to, once or twice each year, move the "old" folders to RCF and from there put them into HPSS (apparently into his own HPSS space)
We have decided to revive the stardb RCF account and store the archives via that account. /star/data07/db has been suggested as the temporary holding spot, so we have a two-step sequence like this:
- As stardb on an rcas node, scp the "old" directories to /star/data07/db/<name>
- Use htar to tar each "old" directory and store in HPSS.
Well, that's "a" plan anyway. Other plans have been mentioned, but this is what I'm going to try first. Let's see how it goes in reality...
- Login to an interactive rcas node as stardb (several possible ways to do this - for this manual run, I login to rssh as myself, then ssh to stardb@rcas60XX . I added my ssh key to the stardb authorized_keys file, so no password is required, even for the scp from dbbak.)
- oops, first problem -- /star/data07/db/ is owned by deph and does not have group or world write permission, so "mkdir /star/data07/db_backup_temp" then make five subdirectories (conditions, drupal, duvall, robinson, run)
- [rcas6008] ~/> scp -rp root@dbbak.starp.bnl.gov:/backups/dbBackups/drupal/old /star/data07/db_backup_temp/drupal/
- [rcas6008] /star/data07/db_backup_temp/> htar -c -f dbbak_htars/drupal.09_05_2008 drupal/old
- Do a little dance for joy, because the output is: "HTAR: HTAR SUCCESSFUL"
- Verify with hsi: [rcas6008] /star/data07/db_backup_temp/> hsi
Username: stardb UID: 3239 CC: 3239 Copies: 1 [hsi.3.3.5 Tue Sep 11 19:31:24 EDT 2007]
? ls
/home/stardb:
drupal.09_05_2008 drupal.09_05_2008.index
? ls -l
/home/stardb:
-rw------- 1 stardb star 495516160 Sep 5 19:37 drupal.09_05_2008
-rw------- 1 stardb star 99104 Sep 5 19:37 drupal.09_05_2008.index
- So far so good. Repeat for the other 4 database bunches (which are a couple of orders of magnitude bigger)
Update, Sept. 18, 2008:
This was going fine until the last batch (the "run" databases). Attempting to htar "run/old" resulted in an error:
[rcas6008] /star/data07/db_backup_temp/> htar -c -f dbbak_htars/run.09_16_2008 run/old
ERROR: Error -22 on hpss_Open (create) for dbbak_htars/run.09_16_2008
HTAR: HTAR FAILED
I determined this to be a limit in *OUR* HPSS configuration - there is a 60GB max file size limit, which the run databases were exceeding at 87GB. Another limit to be aware of, however, is an 8GB limit on member files ( see the "File Size" bullet here: https://computing.llnl.gov/LCdocs/htar/index.jsp?show=s2.3 -- though this restriction was removed in versions of htar after Sept. 10, 2007 ( see the changelog here: https://computing.llnl.gov/LCdocs/htar/index.jsp?show=s99.4 ), HTAR on the rcas node is no newer than August 2007, so I believe this limit is present.)
There was in fact one file exceeding 8 GB in these backups (RunLog-20071101.sql.gz, at 13 GB). I used hsi to put this file individually into HPSS (with no tarring).
Then I archived the run database backups piecemeal. All in all, this makes a small mess of the structure and naming convention. It could be improved, but for now, here is the explanation:
| HPSS file (relative to /home/stardb) | Corresponding dbbak path (relative to /backups/dbBackups ) | Description | single file or tarball? |
| dbbak_htars/conditions.09_08_2008 | conditions/old/ | twice monthly conditions database backups (Jan. - Aug. 2008) | tarball |
| dbbak_htars/drupal.09_05_2008 | drupal/old | twice monthly drupal database backups (Nov. 2007 - Aug. 2008) | tarball |
| dbbak_htars/duvall.09_13_2008 | duvall/old | twice monthly duvall database backups (Jan. - Aug. 2008) | tarball |
| dbbak_htars/robinson.09_15_2008 | robinson/old | twice monthly robinson database backups (Jan. 2007 - Aug. 2008) | tarball |
| RunLog-20071101.sql.gz | run/old/RunLog-20071101.sql.gz | RunLog database backup (Nov. 1, 2007) | single file (13GB) |
| dbbak_htars/RunLog_2007.09_18_2008 | run/old/RunLog-2007* | twice monthly RunLog database backups (Jan. - Mar. 2007, Nov. 15 2007 - Dec. 2007 ) | tarball |
| dbbak_htars/RunLog_Jan-Feb_2008.09_18_2008 | run/old/RunLog-20080[12]* | twice monthly RunLog database backups (Jan. - Feb. 2008) | tarball |
| dbbak_htars/run.09_18_2008 | run/old/RunLog-20080[345678]* | twice monthly run database backups (Mar. - Aug. 2008) | tarball |
| dbbak_htars/Missing_Items.txt | N/A | a text file explaining that there are no backups for Sept. 1 or Sept 15, 2008. | single file |
Contact persons for remote db mirrors
| N | Server type | Server | Contact | Active? | |
|---|---|---|---|---|---|
| 1 | Offline | rhic23.physics.wayne.edu:3306 | Peter Chen | pchen@sun.science.wayne.edu | YES |
| 2 | Offline | pstardb1.nersc.gov:3306 | Jeff Porter | rjporter@lbl.gov | YES |
| 3 | Offline | stardb.ujf.cas.cz:3306 | Michal Zerola | zerola@matfyz.cz | NO |
| 4 | Offline | sampa.if.usp.br | Alex Suaide | suaide@dfn.if.usp.br | NO |
| 5 | Offline | star1.lns.mit.edu | TBD | NO | |
| 6 | Offline | rhilxs.ph.bham.ac.uk | Lee Barnby | lbarnby@bnl.gov | NO |
| 7 | Offline | stardb.tamu.edu | TBD | NO | |
| 8 | Offline | rhig.physics.yale.edu | Christine Nattrass | nattrass@rhig.physics.yale.edu | NO |
| 9 | Offline | hvergelmir.mslab.usna.edu:3316 | Richard Witt |
witt@usna.edu |
YES |
| 10 | FileCatalog | pstardb4.nersc.gov:3336, PDSF M/S | Jeff Porter | rjporter@lbl.gov | YES |
| 11 | Offline | MIT slave | Mattew Walker | mwalker@mit.edu | NO |
| 12 | Offline | osp2.lbl.gov:3316, LBL slave | Doug Olsen | dlolson@lbl.gov | YES |
| 13 | Offline | stardb2.sdfarm.kr:3316, KISTI slave | Xianglei Zhu | zhux@tsinghua.edu.cn | YES |
Monitoring
Database monitoring
Following tools are available for replication check:
1. Database health monitoring: Mon package, which allows to see what is going on with database health, integrity, and replication state at this very moment. It sends email notifications if it sees unreachable or overloaded hosts, along with replication error notifications.

2. Server-side replication check made by M.DePhillips. This script checks which slaves are connected to master (robinson) on daily basic. List of connected slaves is compared to the known slave list (stored at dbAdmin database at heston.star.bnl.gov)......
MySQL Version Upgrades
This section contains information about MySQL version upgrades and related issues. Mostly, it is required to keep track of nuances..
ChangeLog:
2010-03-08: all mysql servers upgraded to 5.0.77 version, using default rpms from SL5 package. Overview of existing mysql server versions is available through Mon interface.
MySQL ver 5 Update
This page describes rational for upgrading to version 5 of Mysql.
Change log for 5.0.x can be found here....
dev.mysql.com/doc/refman/5.0/en/news-5-0-x.html
Upgrade Rational:
1) 4.1.x will be deprecated very shortly - bugs no longer pursued.
2)Current release is 5.1 - 5.0. is one still major release behind with a shorten shelf life
3) 5.0 is in production mode at PDSF and RCF there are compatibility issues.
Issues with Client:
1) the only comment I would have that native
SL3 mysql version includes version 4 of mysql client (4.0.26 to
be exact) aka the same than under SL3.0.5. SL5 (much later in the
game) 4.1.11 so again from the V4 series.
2) Possibly, you will have to deal with special patching procedure
on nodes where you deploy V5 as it will unlikely be part of the
baseline erratas for V4 ... but that is probably a detail [as mysql
release the patches too]
3) There seem to be a few issues with the clients which need
upgrading (perl DBI being one).
--This issue is with the 4.1 client accessing the 5.0 servers...(Pavel trying to access rcf) I was not able to reproduce
The question is compatibility with
SL native distribution versions ... It would be an issue if our
PHP tools would break ... A full evaluation welcomed (with caveats).
Do you think you could get a PHP view of things?
--Tested and our PHP works fine with 5.0
4) With regard to prepared statements....
- client MySQL libs version 5.x: LIMIT ? would pass a quoted
string.
- client MySQL libs version 4.x: LIMIT ? would pass an integer
and ensure type SQL_INTEGER in bind
Additional information
+ server version 5.x: would allow LIMIT ? and treated differently
than in version 4.x (hence the client version behavior difference)
+ client version 4 / server version 4: all is fine
+ INSERT NOW()+0 used to work but now fails with MySQL version 5 and up
Evaluations:
So far I have tested the 4 client with 5 server and 5 client with 5 server - with regard to PHP, perl
and command line (script) access. Modulo the prepared statement issue stated above (limit ?) tests are successful and are in fact in production i.e., DRUPAL is php accessing a 5 server and the file catalog on heston is perl from a 4 client accessing a 5 server.
MySQL servers optimization
[Before optimization – current state]
-
orion.star.bnl.gov (3306, 3346), Apache, Drupal, SKM
-
duvall.star.bnl.gov (3336, 3306), FC slave, operations (many databases)
-
brando.star.bnl.gov (3336), FC slave
-
heston.star.bnl.gov (3306), Nova, logger, gridsphere + some outdated/not used dbs
-
connery.star.bnl.gov – Tomcat server
-
alpha.star.bnl.gov – test node (zrm backup, Monitoring, mysql 5.0.77)
-
omega.star.bnl.gov (3316) – Offline backup (mysql 5.0.77)
-
omega.star.bnl.gov (3336) – FC backup (mysql 5.0.77)
Most servers have bin.tgz MySQL 5.0.45a
[After optimization]
new orion, duvall, brando = beefy nodes
-
orion : Apache server, JBoss server (replaces Tomcat), FC slave db, drupal db, SKM db, Nova;
-
duvall: FC slave, copy of web server, drupal db slave, operations db, logger, gridsphere, jboss copy;
-
brando: FC slave, copy of web server, drupal db slave, operations db slave, jboss copy
-
alpha : test node (mysql upgrade, infobright engine, zrm backup(?));
-
omega : Offline backup slave, FC backup slave, operations db backup slave;
All servers will have MySQL 5.0.77 rpm – with possible upgrade to 5.1.35 later this year.
[free nodes after replacement/optimization]
-
connery
-
orion
-
duvall
-
brando
-
dbslave03
-
dbslave04
-
+ several nodes from db0x pool (db04, db05, db06, db11, bogart, etc...)
Non-root access to MySQL DB nodes
As outlined in Non-user access in our enclaves and beyond, and specifically "Check on all nodes the existence of a mysql account. Make sure the files belong to that user + use secondary groups wherever applies", the following work has been done recently:
ToDo list. To allow DB admin tasks under 'mysql' account (non-standard configuration), the following set of changes has been identified:
- add the mysql user account on each DB server to the STAR SSH key management system and add the DB administrator's SSH key;
- full read/write access to /db01/<..> - mysql data files;
- read/write access to /etc/my.cnf - mysql configuration file;
- read access to /var/log/mysqld.log - mysql startup/shutdown logs;
- standard /etc/init.d/mysqld startup script is removed and /etc/init.d/mysql_multi startup script (non-standard, allows multi-instance mysql) is installed;
- the mysqld_multi init script's start and stop functions check who is executing the script - if it is the mysql user, then nothing special is done, but if it is another user, then it uses "su - mysql -c <command>" to start and stop the MySQL server. The root user can do this without any authentication. If any other user tries it, it would require the mysql account password, which is disabled.;
- to prevent reinstallation of the /etc/init.d/mysqld script by rpm update procedure, specially crafted "trigger"-rpm is created and installed. It watches for rpm updates, and invokes "fix" procedure to prevent unwanted startup script updates;
- extra user with shutdown privilege is added to all mysql instances on a node, to allow safe shutdowns by mysql_multi;
- mysql accout (unix account) was configured to have restricted file limits (2k - soft, 4k - hard) [FIXME: for multi-instance nodes it needs to be increased];
Upgrade timeline. STAR has four major groups of database nodes: Offline, FileCatalog, Online and SOFI. Here is a coversion plan [FIXME: check with Wayne]:
- Offline db nodes (namely, dbXY.star series) are fully converted and tested (with the exceptions of db03 and db09);
- FileCatalog db nodes (fc1, fc2, fc4) are done (completed 8/7/2012);
- 8/7/2012: note that the rpm is being updated to clean up some triggering problems recently discovered and should be updated on all the hosts done previously
- SOFI db nodes (backups, archival, logger, library etc, including robinson, heston, omega, fc3, db09, db03) - conversion start date TBD;
- Online nodes (onldb.starp, onldb2.starp, dbbak?) - conversion start date is ~Sep 2012;
- additional nodes TBD: orion
Performance
Below is a listing of adjustable mysql performance parameters, their descriptions and their current settings. Where applicable, the reasons and decisions that went into the current setting is provied. Also presented is the health of the parameter with the date the study was done. These parmaters should be reveiwed every six months or when the system warrents a review.
| Parameter | Setting | Definition | Mysql Default | Reasoning | Health | Last Checked | ||
|---|---|---|---|---|---|---|---|---|
| bulk_insert_buffer_size | 8388608 | |||||||
| join_buffer_size | 131072 | |||||||
| table_cache | 1024 | Increases the amount of table that can be held open | 64 | |||||
| key_buffer_size | 268435456 | amount of memory available for index buffer | 523264 | |||||
| myisam_sort_buffer_size | 67108864 | |||||||
| net_buffer_length | 16384 | |||||||
| read_buffer_size | 1044480 | |||||||
| read_rnd_buffer_size | 262144 | |||||||
| sort_buffer_size | 1048568 | Each thread that needs to do a sort allocates a buffer of this size. Increasing the variable gives faster ORDER BY or GROUP BY operations |
"old" vs "new" nodes comparison, Jan-Feb 2011
"Old" vs "new" nodes comparison, Jan-Feb 2011
1. HARDWARE
| PARAMETER | OLD NODE | NEW NODE |
|---|---|---|
| CPU | ||
| Type | 2 x Intel(R) Xeon(TM) CPU 3.06GHz +HT | Quad-core Intel(R) Xeon(R) CPU X3450 @ 2.67GHz, +HT |
| Cache Size | 512 KB | 8 MB |
| Bogomips | 6110.44 / processor | 5319.95 / core |
| Arch | 32 bit | 64 bit |
| RAM | ||
| Total | 3 GB | 8GB |
| ECC Type | Multi-bit ECC | Multi-bit ECC |
| Type | DDR | DDR3 |
| Speed | 266 MHz | 1333 MHz |
| Slots | 4 (4 max), 2x512, 2x1024 MB | 4 (6 max), 4 x 2048 MB |
| DISKS | ||
| HDD | 3 x SEAGATE Model: ST3146807LC | 3 x SEAGATE Model: ST3300657SS-H |
| Size | 146.8 GB | 146.8 GB |
| Cache | 8 MB | 16 MB |
| Spin Rate | 10K RPM | 15K RPM |
| RAID | Software RAID | Software RAID |
2. Database Performance: First Pass, mostly Synthetics + random STAR Jobs
Test results : - unconstrained *synthetic* test using SysBench shows that new nodes perform ~x10 times better than old ones (mostly due to x2 more ram available per core => larger mysql buffers, fs cache etc); - real bfc job tests (stress-test of 100 simultaneous jobs, random stream daqs) show performance similar to old nodes, with ~5% less time spent in db (rough estimation, only able to run that 100 jobs test twice today). Similar disk performance assumes similar db performance for those random streams, I guess.. - nightly tests do not seem to affect performance of those new nodes (negligible load vs. twice the normal load for old nodes).
| PARAMETER | OLD NODE | NEW NODE |
|---|---|---|
| Temporary tables created on disk | 44% | 22% |
| Sorts requiring temporary tables | 2% | 1% |
| Table locks acquired immediately | 99% | 100% |
| Average system load during "stream"test |
60-80 | 2.0-3.5 |
| Average CPU consumption | 100% | 30-40% |
MySQL Performance Tuning
MySQL performance tuning
Primary purpose:
a) performance optimization of the existing Offline and FileCatalog databases at MySQL level (faster response time, more queries per second, less disk usage etc);
b) future db needs projections, e.g. what hardware we should use (or buy) to meet desired quality of service for STAR experiment in next few years;
c) STAR DB API performance bottlenecks search;
Expected speed-up factor from MySQL optimizations (buffers, query modes) is about 20-50%, API optimization gain *potentially* could be much higher than that.
Test node(s)
OFFLINE: dbslave03.star.bnl.gov, which is not included in Offline DB activies (backup-only); OFFLINE DB is READ-HEAVY.
FILECATALOG: dbslave04.star.bnl.gov, which is not included in FC DB activies (backup-only); FILECATALOG DB is WRITE-HEAVY.
Measured db response values
1. Queries Per Second (QPS) - defined as QPS = (Total Queries / Uptime ) for cold start, and QPS = (dQueries/dUptime) for hot start;
2. Time to process typical reco sample - a) 5, 50, 500 events single job; b) several parallel jobs 500 events each (N jobs - tbd) - defined as TPS = (first job start time - last job stop time) for both cold and hot regimes;
Both parameters would be estimated in two cases :
a) cold start - sample runs just after mysql restart - all buffers and caches are empty;
b) hot start - 1000 events already processed, so caches are full with data;
MySQL varied parameters
per thread buffers : preload_buffer_size, read_buffer_size, read_rnd_buffer_size, sort_buffer_size, join_buffer_size, thread_stack;
global buffers : key_buffer_size, query_cache_size, max_heap_table_size, tmp_table_size;
insert parameters : bulk_insert_buffer_size, concurrent_insert [e.g.=2 vs =1], pack_keys (enabled, disabled)
compression features : do we need compression for blobs at API level?
DNS parameters : HOST_CACHE_SIZE (default = 128);
Initial parameter values are :
| Per Thread Buffers | Default Value | Default HighPerf | Modified Value | Description |
|---|---|---|---|---|
| preload_buffer_size | 32K | 32K | The size of the buffer that is allocated when preloading indexes. | |
| read_buffer_size | 128K | 1M | Each thread that does a sequential scan allocates a buffer of this size (in bytes) for each table it scans. | |
| read_rnd_buffer_size | 256K | 256K | When reading rows in sorted order following a key-sorting operation, the rows are read through this buffer to avoid disk seeks.Setting the variable to a large value can improve ORDER BY performance by a lot. However, this is a buffer allocated for each client, so you should not set the global variable to a large value. Instead, change the session variable only from within those clients that need to run large queries. |
|
| sort_buffer_size | 2M | 2M | Each thread that needs to do a sort allocates a buffer of this size. Increase this value for faster ORDER BY or GROUP BY operations. |
|
| myisam_sort_buffer_size | 8M | 64M | The size of the buffer that is allocated when sorting MyISAM indexes during a REPAIR TABLE or when creating indexes with CREATE INDEX or ALTER TABLE. |
|
| join_buffer_size | 128K | 128K | The size of the buffer that is used for plain index scans, range index scans, and joins that do not use indexes and thus perform full table scans. Normally, the best way to get fast joins is to add indexes. Increase the value of join_buffer_size to get a faster full join when adding indexes is not possible. |
|
| thread_stack | 192K | 192K | The stack size for each thread. |
| Global Buffers | Default Value | Default HighPerf | Modified Value | Description |
|---|---|---|---|---|
| key_buffer_size | 8M | 256M | Index blocks for MyISAM tables are buffered and are shared by all threads. key_buffer_size is the size of the buffer used for index blocks. The key buffer is also known as the key cache. |
|
| query_cache_size | 0 | 0 | The amount of memory allocated for caching query results. The default value is 0, which disables the query cache. The allowable values are multiples of 1024; other values are rounded down to the nearest multiple. | |
| max_heap_table_size | 16M | 16M | This variable sets the maximum size to which MEMORY tables are allowed to grow. The value of the variable is used to calculate MEMORY table MAX_ROWS values. |
|
| tmp_table_size | system-dependent | 32M | The maximum size of internal in-memory temporary tables. If an in-memory temporary table exceeds the limit, MySQL automatically converts it to an on-disk MyISAM table. Increase the value of tmp_table_size (and max_heap_table_size if necessary) if you do many advanced GROUP BY queries and you have lots of memory. |
| Write operations | Default Value | HighPerf Value | Modified Value | Description |
|---|---|---|---|---|
| bulk_insert_buffer_size | 8M | 8M | MyISAM uses a special tree-like cache to make bulk inserts faster for INSERT ... SELECT, INSERT ... VALUES (...), (...), ..., and LOAD DATA INFILE when adding data to non-empty tables. This variable limits the size of the cache tree in bytes per thread. Setting it to 0 disables this optimization. |
|
| concurrent_insert | 1 | 1 | 0 = Off 1 = (Default) Enables concurrent insert for MyISAM tables that don't have holes2 = Enables concurrent inserts for all MyISAM tables, even those that have holes. For a table with a hole, new rows are inserted at the end of the table if it is in use by another thread. Otherwise, MySQL acquires a normal write lock and inserts the row into the hole. |
"concurrent_insert" is interesting for FileCatalog database - we do many inserts quite often.
DNS
Quote from MySQL manual : "If you have a very slow DNS and many hosts, you can get more performance by either disabling DNS lookop with --skip-name-resolve or by increasing the HOST_CACHE_SIZE define (default: 128) and recompile mysqld." - we definitely have more than 128 hosts accessing our databases simultaneously, which means that we need to increase it to something like 2048 or so (to account for RCF farm nodes). Currently, both stock mysql distribution and HighPerformance version have 128 hosts set as buffer default.
Node FileSystem parameters
1. We should check "dir_index" feature of ext3 filesystem, which allows
Brando $> tune2fs -l /dev/hdb1 | grep "dir_index" => dir_index enabled
Duvall $> tune2fs -l /dev/sdc1 |grep "dir_index" => dir_index disabled
2. "noatime" mount option for /db0X disks, to reduce IO load a little bit. Both Duvall and Brando have no "noatime" attribute set (11 May 2009).
3. /tmp location (same disk, separate disk, RAM disk).
FC Duvall at duvall is using /dbtemp (ext. disk, raid?);
FC Brando is not using /dbtemp, because there's no /dbtemp defined in system yet;
Node varied parameters
Number of CPUs scaling (1,2,4);
CPU power dependence;
RAM capacity dependence (1 Gb, 2Gb, 2+ Gb);
HDD r/w speed;
FileCatalog DB performance study
FileCatalog DB is ~ 30% READ / 70% WRITE database. Spiders frequently update file locations (on local disks), new files constantly appear during Run period etc.. Therefore, INSERT/UPDATE performance will be studied first.
Typical R/W percentage could be seen here :
Duvall profile information,
or here :
Brando profile information
Offline DB performance study
Offline Database is READ-heavy (99% reads / 1% writes due to replication), therefore it should benefit from various buffers optimization, elimination of key-less joins and disk (ram) IO improvements.
Typical Oflline slave R/W percentage could be seen here :
db08 performance profile
First results :
================================================================================ Sample | 50 BFC events, pp500.ittf chain --------+----------------+------------------------------------------------------ Host | dbslave03.star.bnl.gov:3316 - Offline --------+----------------+------------------------------------------------------ Date | Fri, 08 May 2009 16:01:12 -0400 ================================================================================ SERVER GLOBAL VARIABLES ================================================================================ Variable Name | Config Value | Human-Readable Value ================================================================================ preload_buffer_size | 32768 | 32 KB -------------------------+------------------------------------------------------ read_buffer_size | 1048576 | 1 MB -------------------------+------------------------------------------------------ read_rnd_buffer_size | 262144 | 256 KB -------------------------+------------------------------------------------------ sort_buffer_size | 1048576 | 1 MB -------------------------+------------------------------------------------------ myisam_sort_buffer_size | 67108864 | 64 MB -------------------------+------------------------------------------------------ join_buffer_size | 131072 | 128 KB -------------------------+------------------------------------------------------ thread_stack | 196608 | 192 KB ================================================================================ key_buffer_size | 268435456 | 256 MB -------------------------+------------------------------------------------------ query_cache_size | 33554432 | 32 MB -------------------------+------------------------------------------------------ max_heap_table_size | 16777216 | 16 MB -------------------------+------------------------------------------------------ tmp_table_size | 33554432 | 32 MB ================================================================================ bulk_insert_buffer_size | 8388608 | 8 MB -------------------------+------------------------------------------------------ concurrent_insert | 1 | 1 ================================================================================ PERFORMANCE PARAMETERS ================================================================================ PARAMETER | Measured Value | Acceptable Range ================================================================================ Total number of queries | 6877 | > 1000. -------------------------+------------------------------------------------------ Total time, sec | 1116 | any -------------------------+------------------------------------------------------ Queries/second (QPS) | 6.16 | > 100. -------------------------+------------------------------------------------------ Queries/second - SELECT | 5.89 | > 100.0 -------------------------+------------------------------------------------------ Queries/second - INSERT | 0.17 | any -------------------------+------------------------------------------------------ Queries/second - UPDATE | 0 | any -------------------------+------------------------------------------------------ Query cache efficiency | 45 % | > 20% -------------------------+------------------------------------------------------ Query cache overhead | 6 % | < 5% -------------------------+------------------------------------------------------
Initial test revealed strange things: there seem to be too many queries (~7000 queries for only two real db sessions??!), and Query Cache efficiency is 45%! Logs revealed the mystery - we somehow allow many repetitive queries in our API. Further investigation found more issues - see below.
a) Repetitive ID requests (they are queried one after another, no changes or queries in between):
....
3 Query select elementID from ladderIDs
3 Query select elementID from ladderIDs
....
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
3 Query select elementID from CorrectionIDs
....
3 Query select elementID from SectorIDs where Sector=1
3 Query select elementID from SectorIDs where Sector=1
3 Query select elementID from SectorIDs where Sector=1
3 Query select elementID from SectorIDs where Sector=1
....
3 Query select elementID from HybridIDs where Barrel=1 AND Ladder=1 AND Wafer=1 AND Hybrid=1
3 Query select elementID from HybridIDs where Barrel=1 AND Ladder=1 AND Wafer=1 AND Hybrid=1
3 Query select elementID from HybridIDs where Barrel=1 AND Ladder=1 AND Wafer=1 AND Hybrid=1
3 Query select elementID from HybridIDs where Barrel=1 AND Ladder=1 AND Wafer=1 AND Hybrid=1
3 Query select elementID from HybridIDs where Barrel=1 AND Ladder=1 AND Wafer=1 AND Hybrid=1
c) Repetitive date/time conversions via mysql function, like those below :
4 Query select from_unixtime(1041811200) + 0 as requestTime
4 Query select unix_timestamp('20090330040259') as requestTime
b) Repetitive DB Initializations for no real reason :
3 Init DB Geometry_tpc
3 Init DB Geometry_ftpc
3 Init DB Geometry_tof
3 Init DB Geometry_svt
3 Init DB Geometry_ssd
3 Init DB Geometry_tpc
(that's what was need to do a query agains Geometry_tpc database)
Full logs could be found in attachment to this page.
PLOTS - Query Cache
Query cache does not seem to help under 150 connections.....
Note different Y axis for Bogart
Bogart - No Query Cache
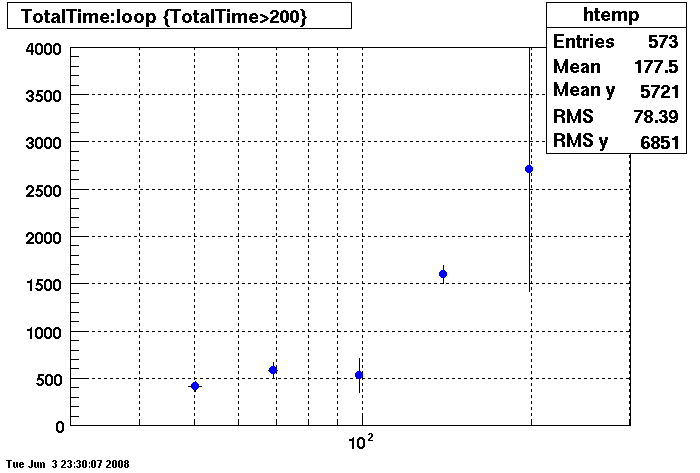
Bogart - Query Cache DEMAND Size = 26255360
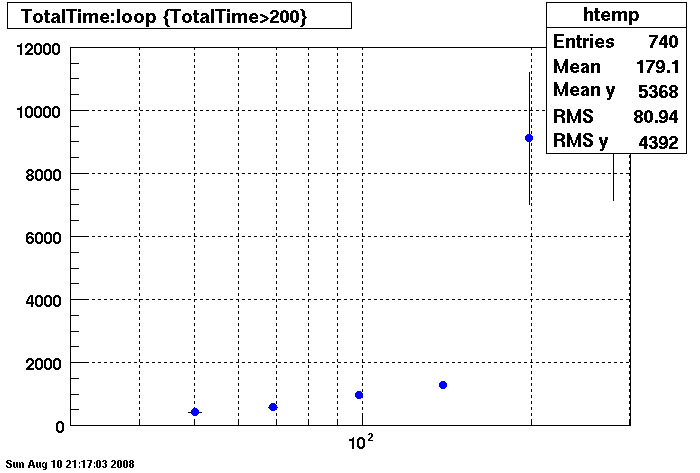
DB02- No Query Cache
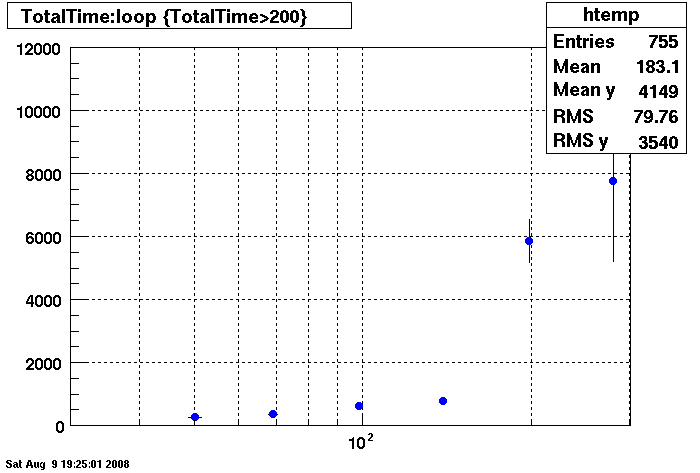
DB02- Query Cache DEMAND Size = 26255360
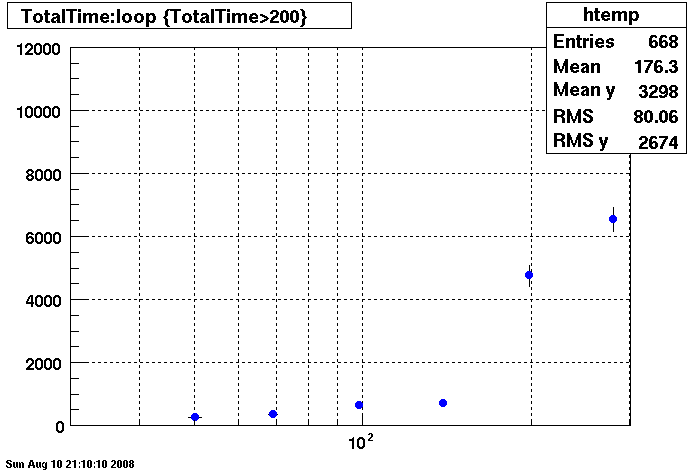
Plots - DB02 old/new Compare
Penguin Relion 230 vrs. Dell Precision 530 (specs here link to be added....)
Note the different time scales on the Y axis.
Summary: The new penguin has faster db access under 150 connection but responds much slower than the dell
when connections are greater than 150 connection.
There is an additional point under the htemp box for 350 connections, @~11000 seconds. This point was taken with 8 clients (instead of 4 clients) to see if the clients where influencing results, slope is the same, apparently not.
There are two plots of the Penguin each showing a differnent RAID array. The results are essentially identical under 150 connections. Over 150 connections the first RAID array is much better.
The first plot is of the Penguin with first RAID array (Wayne please edit with specifics:
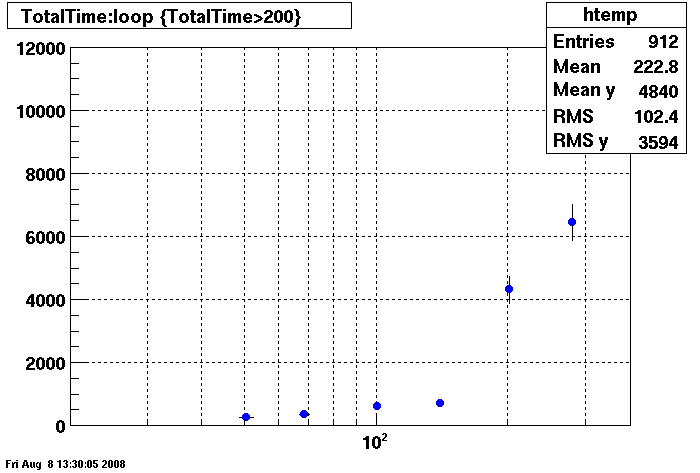
Penguin with Second RAID Array
Dell:
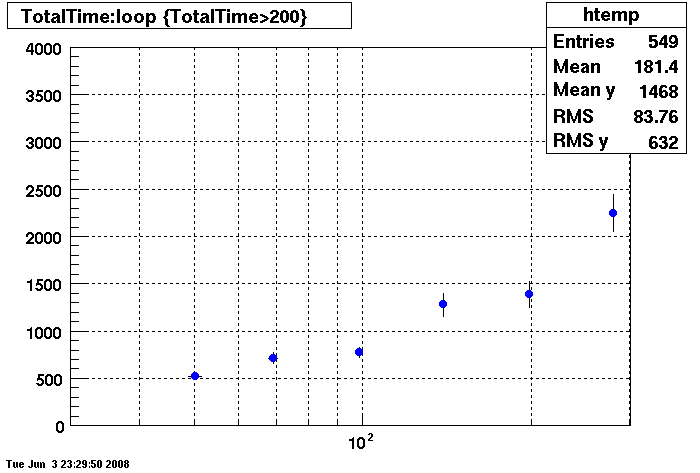
Plots - Key Buffer = 52
This plot shows x=number of connections , y=time it takes for the StDbLib to retrun a complete data set for all the Star Offline databases. This set of plot returns the key_buffer_size from the STAR defualt of 268435456 to the mysql defualt of 523264.
Bogart
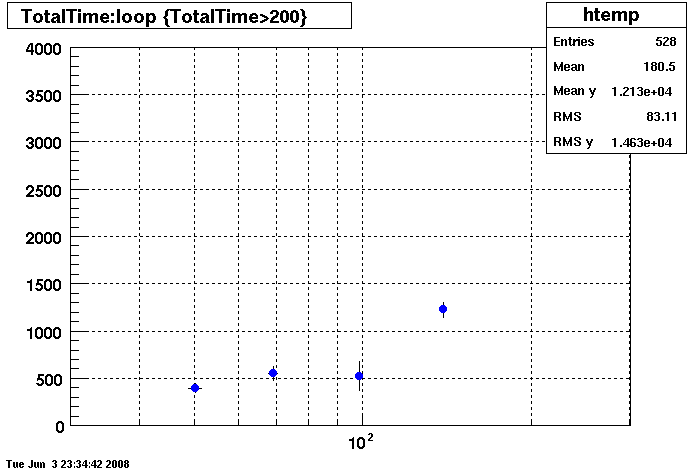
DB02
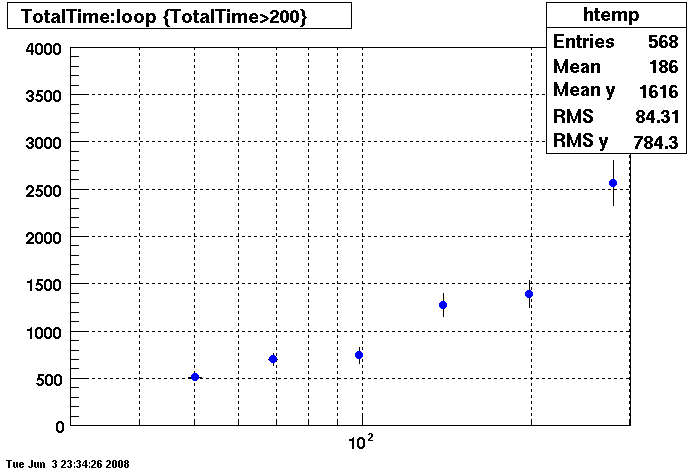
DB03
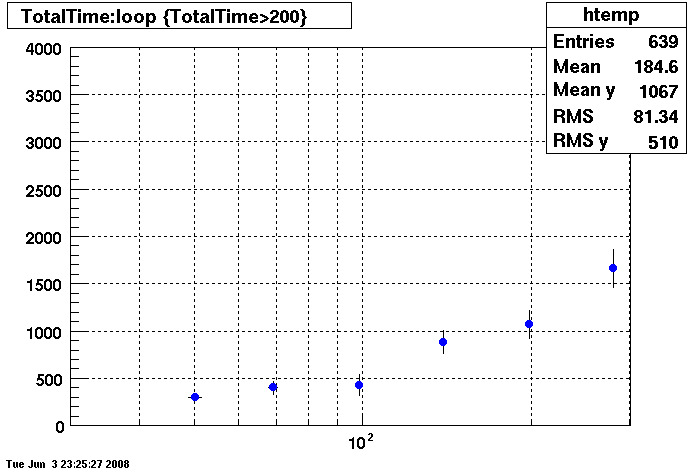
DB08
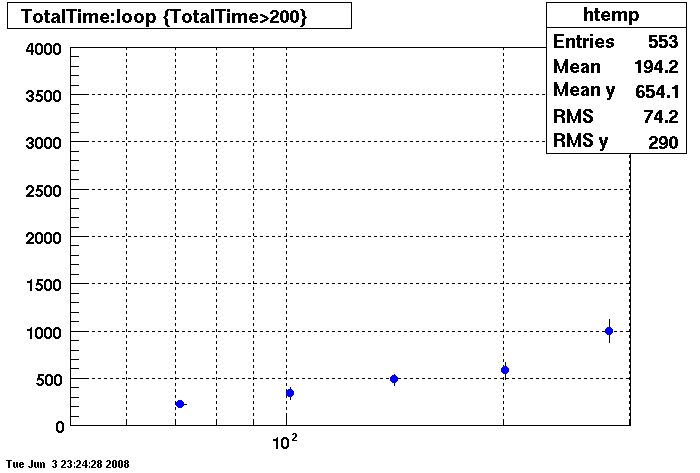
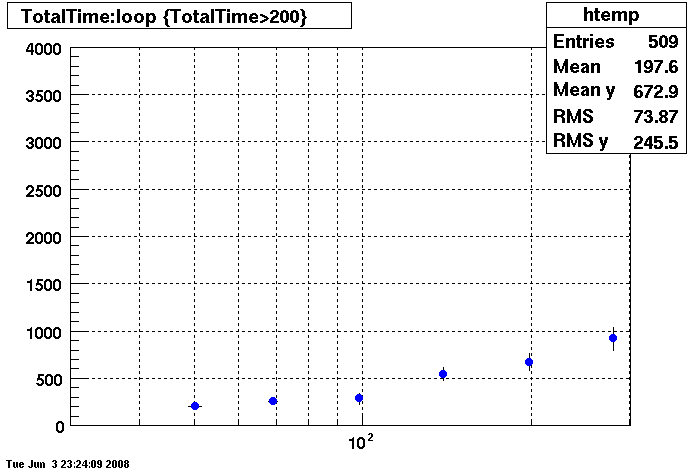
Plots - Star Default
This plot shows x=number of connections , y=time it takes for the StDbLib to retrun a complete data set for all the Star Offline databases. This set of plot uses the STAR defualt parameters as described one page up. This is to be used as a baseline for comparisions.
Bogart
DB02
DB03
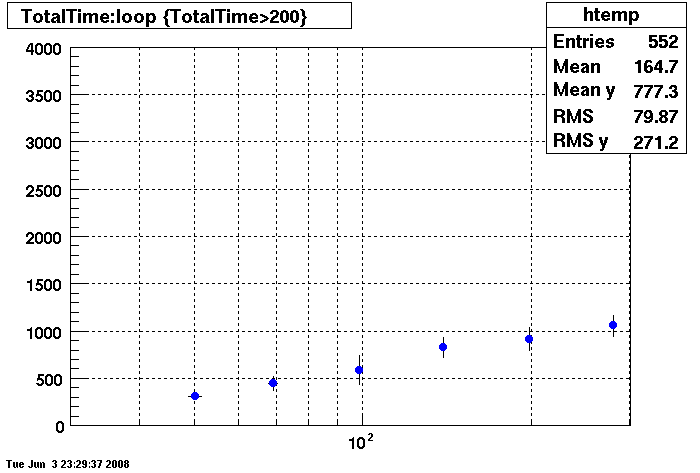
DB08
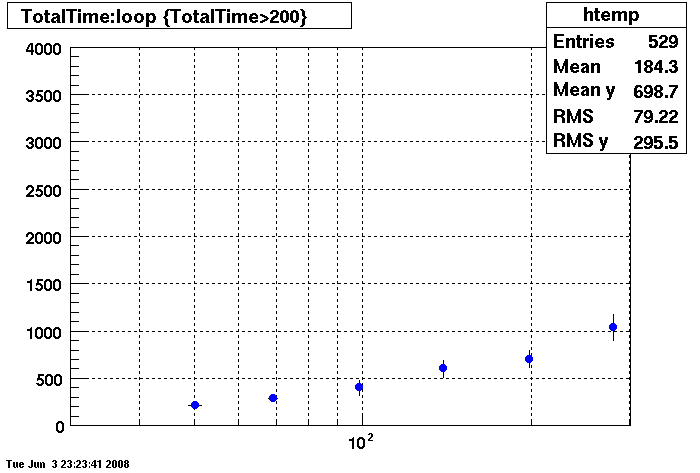
Plots = Table Cache 64
This plot shows x=number of connections , y=time it takes for the StDbLib to retrun a complete data set for all the Star Offline databases. This set of plot returns the table_cache from the STAR defualt of 1024 to the mysql defualt of 64.
Bogart
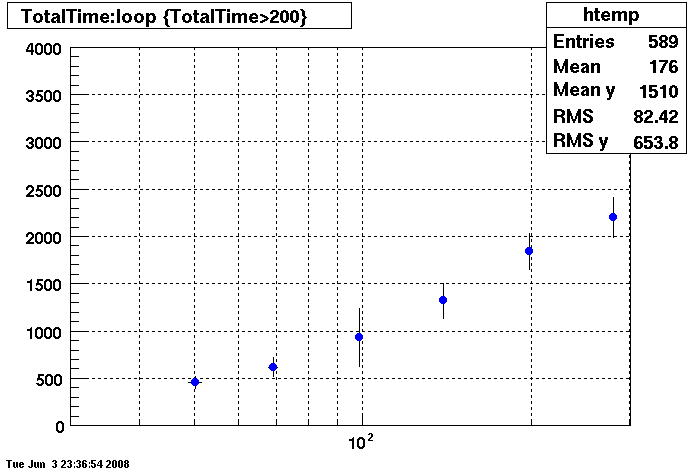
DB02
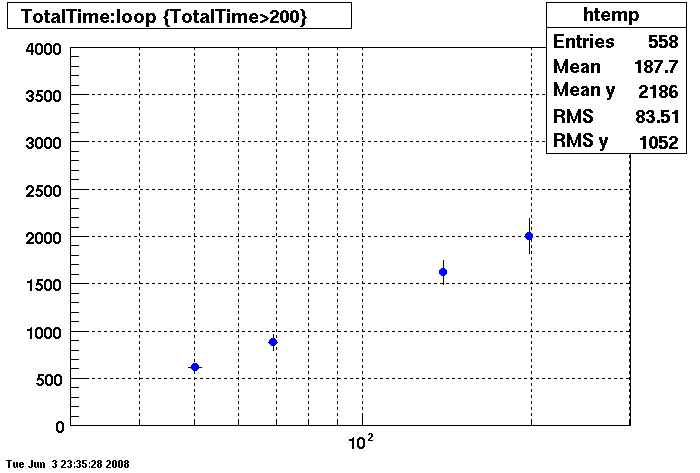
DB03
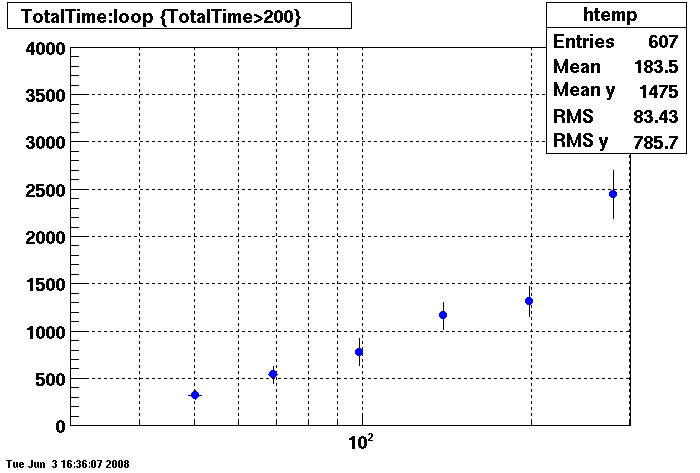
DB08
Replication
Replication enables data from one MySQL database server (called the master) to be replicated to one or more MySQL database servers (slaves). Replication is asynchronous - your replication slaves do not need to be connected permanently to receive updates from the master, which means that updates can occur over long-distance connections and even temporary solutions such as a dial-up service. Depending on the configuration, you can replicate all databases, selected databases, or even selected tables within a database.
The target uses for replication in MySQL include:
-
Scale-out solutions - spreading the load among multiple slaves to improve performance. In this environment, all writes and updates must take place on the master server. Reads, however, may take place on one or more slaves. This model can improve the performance of writes (since the master is dedicated to updates), while dramatically increasing read speed across an increasing number of slaves.
-
Data security - because data is replicated to the slave, and the slave can pause the replication process, it is possible to run backup services on the slave without corrupting the corresponding master data.
-
Analytics - live data can be created on the master, while the analysis of the information can take place on the slave without affecting the performance of the master.
-
Long-distance data distribution - if a branch office would like to work with a copy of your main data, you can use replication to create a local copy of the data for their use without requiring permanent access to the master.
Fixing Slave Replication In A STAR Offline Database Mirror
Mike's trick for fixing an offline database slave when it won't sync with the master is to be carried out as follows:
cd /var/run/mysqld
ls -lh | grep "mysqld-relay-bin"
Find the relay file with the largest number at the end (this is the latest one)
Make sure the first line of the text file "/db01/offline/data/relay-log.info" contains that file
ie:
ls -lh | grep "mysqld-relay-bin"
mysqld-relay-bin.000001
mysqld-relay-bin.000002
so this means that /db01/offline/data/relay-log.info should contain:
"/var/run/mysqld/mysqld-relay-bin.000002"
as the first line
Then login to mysql via "mysql -S /tmp/mysql.3316.sock -p -u root"
and issue the command "slave start;"
then check the status with "show slave status \G"
Slave_IO_Running should show "Yes"
Slave_SQL_Running should show "Yes"
You may need to repeat this procedure if you get an error the first time.
Master/Slave syncronization issues,tools,solutions etc...
This page is dedicated to variety of master/slave syncronization issues, tools and solutions used at STAR. It is made for internal usage, tutorial for offsite facilities would be created later.
Maatkit (formerly MySQL Toolkit) is a bunch of Perl scripts, designed to make MySQL daily management tasks easier. STAR makes use of 'mk-table-checksum' to get lock-free reliable checksumming of FileCatalog and Offline database tables, and 'mk-table-sync' to fix inconsistent tables on slaves.
I. FileCatalog replication checksums
Master server: robinson.star.bnl.gov:3336
mk-table-checksum uses "repl.checksum" (database.table) to store checksum results. If FC slave was added after Nov.2008, then such table should be created manually. If not done exactly as described, checksums will not work properly, and slave will stop replicating with error message stating that "table repl.checksum does not exist".
CREATE DATABASE repl;
CREATE TABLE checksum (
db char(64) NOT NULL,
tbl char(64) NOT NULL,
chunk int NOT NULL,
boundaries char(64) NOT NULL,
this_crc char(40) NOT NULL,
this_cnt int NOT NULL,
master_crc char(40) NULL,
master_cnt int NULL,
ts timestamp NOT NULL,
PRIMARY KEY (db, tbl, chunk)
);
HOW-TO calculate checksums for all FileCatalog tables on Master, results and queries will propagate to slaves :
shell> nohup ./mk-table-checksum --emptyrepltbl --replicate=repl.checksum --algorithm=BIT_XOR \ h=robinson.star.bnl.gov,P=3336,u=root,p=XYZ -d FileCatalog_BNL >> checkrepl.log.txt 2>&1
At this moment (Nov.2008), it takes about 20 min to checksum all FC tables.
HOW-TO show if there are any differences between master (robinson) and slaves (duvall, brando), when checksumming process is finished :
shell> mysql -u root --host duvall.star.bnl.gov --port 3336 -pXYZ -e "USE repl; SELECT db, tbl, chunk, this_cnt-master_cnt AS cnt_diff, this_crc <> master_crc OR ISNULL(master_crc) <> ISNULL(this_crc) AS crc_diff FROM checksum WHERE master_cnt <> this_cnt OR master_crc <> this_crc OR ISNULL(master_crc) <> ISNULL(this_crc);" > duvall.tablediff.txt shell> mysql -u root --host brando.star.bnl.gov --port 3336 -pXYZ -e "USE repl; SELECT db, tbl, chunk, this_cnt-master_cnt AS cnt_diff, this_crc <> master_crc OR ISNULL(master_crc) <> ISNULL(this_crc) AS crc_diff FROM checksum WHERE master_cnt <> this_cnt OR master_crc <> this_crc OR ISNULL(master_crc) <> ISNULL(this_crc);" > brando.tablediff.txt
HOW-TO show the differences (by row) between master and slave for selected table. In the example below, changes for table "TriggerWords" is requested for duvall.star.bnl.gov :
shell> ./mk-table-sync --print --synctomaster --replicate repl.checksum h=duvall.star.bnl.gov,P=3336,u=root,p=XYZ,D=FileCatalog_BNL,t=TriggerWords
To make an actual syncronization, one should replace "--print" option with "--execute" (please make sure you have a valid db backup first!). It is often good to check how many rows need resync and how much time it would take, because it might stop replication process for this time.
Replication monitoring
Following tools are available for replication check:
1. Basic monitoring script, which allows to see what is going on with replication at this very moment. It does not send any notifications and cannot be thought as complete solution to replication monitoring. Mature tools (like Nagios) should be used in near future.
2. Server-side replication check made by M.DePhillips. This script checks which slaves are connected to master (robinson) on daily basic. List of connected slaves is compared to the known slave list (stored at dbAdmin database at heston.star.bnl.gov).
Server list and various parameters
Here will be a server list (only those servers participating in various replication scenarios)
1. FileCatalog master db server : fc1.star.bnl.gov:3336, ID: 880853336
slaves:
- fc2.star.bnl.gov:3336, ID: 880863336
- fc3.star.bnl.gov:3336, ID: 880873336 [ backup server, not used in round-robin ]
- fc4.star.bnl.gov:3336, ID: 880883336
2. Offline master db server: robinson.star.bnl.gov:3306, ID: 880673316
slaves:
- db01.star.bnl.gov:3316, ID: 880483316
- db02.star.bnl.gov:3316, ID: 880493316 - FAST rcf network
- db03.star.bnl.gov:3316, ID: 880503316 [ 23 Jul 09, new ID: 881083316 ] - FAST rcf network
- db04.star.bnl.gov:3316, ID: 880513316 [ 14 Jul 09, new ID: 881043316 ] - FAST rcf network
- db05.star.bnl.gov:3316, ID: 880523316 [ 16 Jul 09, new ID: 881053316 ] - FAST rcf network
- db06.star.bnl.gov:3316, ID 881023316 [old ID: 880533316 ]
- db07.star.bnl.gov:3316, ID: 880543316
- db08.star.bnl.gov:3316, ID: 880613316
- db10.star.bnl.gov:3316, ID: 880643316 [ 20 Jul 09, new ID 881063316 ]
- db11.star.bnl.gov:3316, 881033316 [ old ID: 880663316 ]
- db12.star.bnl.gov:3316, ID: 881013316, as of Apr 28th 2010, ID: 880253316
- db13.star.bnl.gov:3316 (former bogart), ID: 880753316 [ 22 Jul 09, new ID 881073316 ]
- omega.star.bnl.gov:3316, ID: 880843316 [3 Dec 09, backup server]
- db14.star.bnl.gov:3316, ID: 541043316
- db15.star.bnl.gov:3316, ID: 541053316
- db16.star.bnl.gov:3316, ID: 541063316
- db17.star.bnl.gov:3316, ID: 541073316
- db18.star.bnl.gov:3316, ID: 541083316
- onldb.starp.bnl.gov:3601, ID: 600043601 | resides in ONLINE domain
- onldb2.starp.bnl.gov:3601, ID: 600893601 | resides in ONLINE domain
External slaves :
Seo-Young Noh <rsyoung@kisti.re.kr>? KISTI (first server) : 990023316
Xianglei Zhu <zhux@tsinghua.edu.cn> KISTI (second server) : 991013316
Richard Witt <witt@usna.edu> : hvergelmir.mslab.usna.edu, 992073316 | USNA
Kunsu OH <kunsuoh@gmail.com> : 992083316 | Pusan National University
Peter Chen <pchen@sun.science.wayne.edu> : rhic23.physics.wayne.edu, 991063316| Wayne State University
Matt Walker <mwalker@mit.edu> : glunami.mit.edu, 992103316 | MIT
Jeff Porter <rjporter@lbl.gov>, pstardb1.nersc.gov, 1285536651 | PDSF
Douglas Olson <dlolson@lbl.gov> : 992113316 | LBNL
Server ID calculation :
SERVER_ID is created from the following scheme: [subnet][id][port], so 880613316 means 88 subnet, 061 id, 3316 port...
subnet '99' is reserved for external facilities, which will have something like 99[id][port] as server_id.
Setting Up A Star Offline Database Mirror
Set up an environment consistent with the STAR db environments.
- Create a user named 'mysql' and a group 'mysql' on the system.
- Create a directory for the mysql installation and data. The standard directory for STAR offline is /db01/offline
- In /db01/offline place the tarball of mysql version 5.0.51a (or greater) downloaded from here.
- Untar/zip it. Use "--owner mysql" in the tar command, or recursively chown the untarred directory so that mysql is the owner (eg. 'chown mysql:mysql mysql-5.0.51a-linux-i686-glibc23'). Delete the tarball if desired.
- Still in /db01/offline, create a soft link named 'mysql' that points to the mysql directory created by the untar (ln -s mysql-5.0.51a-linux-i686-glibc23 mysql'). /db01/offline should now have two items: mysql (a link), and mysql-standard-5.0.51a-linux-i686-glibc23.
- Create a directory /var/run/mysqld and set the owner to mysql, with 770 permissions. (This may be avoideable with a simple change to the my.cnf file (to be verified). If this change is made to the "official" my.cnf, then this step should be removed.)
Next, acquire a recent snapshot of the offline tables and a my.cnf file
There will be two files that need to be transfered to your server; a tarball of the offline database files (plus a handful of other files, some of which are discussed below) and a my.cnf file.
If you have access to RCF, a recent tar of the offline databases can be found here: /star/data07/db/offline_08xxxxx.tar.gz. Un-tar/zip the tarball (with "--owner mysql") in /db01/offline on your server to get a 'data' directory. (/db01/offline/data).
The my.cnf file can be found in /star/data07/db/my.cnf, and should be put in /etc/my.cnf. Before your server is started, either the master information should be commented out, or the server-id should be adjusted to avoid clashing with an existing production slave. Contact Dmitry Arkhipkin to determine an appropriate server-id.
Start the server
At this point you should be able to start the mysql server process. It should be as simple as the following command:
cd /db01/offline/mysql && ./bin/mysqld_safe --user=mysql &
The data directory
The databases
You will now find a complete snapshot of STARs offline data. We use MYSQLs MYISAM storage engine which stores its tables in three files under a directory that is the database name. For example, for database Calibrations_ftpc you will see a directory of the same name. If you descend into that directory you will see three files for each table name. The files are MYD which contain the data, MYI which contain the indexes and FRM which describes the table structure.
Other files
- master.info - This files contains information about the slaves master (aptly named). This includes who the master is, how to connect, and what was the last bit of data passed from the master to the slave. This is stored as an integer in this file.
- You will also find log files, bin files and their associated index files.
S&C Infrastructure Servers
| NAME | BASE HARDWARE | LINUX DISTRO | PROCESSOR(S) | RAM | NETWORK INFO | DISKS | PORTS: PURPOSES | LOCATION | HEALTH MONITORING |
ORIGINAL PURCHASE DATE |
Notes |
| robinson | Dell PowerEdge R420 | Sc.Linux 7.x | 2x Intel Xeon E5-2430 (Hex-core, 2.2GHz, 15MB cache, HT available but disabled) | 64GB + 32GB swap | 130.199.148.90: LACP: 2 x 1Gb/s |
PERC H710P RAID controller with 8 600GB 10K SAS drives (2.5") 6 drives form a RAID 10, with the remaining 2 drives set as hot spares /boot (1GB) / (150GB) swap (32GB) /db01 (1.5TB) |
3306: rh-mysql57-mysql-server, offline production/analysis master |
BCF Rack 4-10 | smartd (starsupport) disk space mon (starsupport) Ganglia MegaRAID Storage Manager (17.05.00.02) (starsupport) Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
May 2014 (inherited from RACF in 2018) | offline database master |
| db01 | Dell PowerEdge R410 | Sc.Linux 7.x | 2x Intel Xeon X5650 (Hex-core, 2.67GHz, 12MB cache, HT available but disabled) | 64GB + 24GB swap | 130.199.148.101: LACP: 2 x 1Gb/s |
PERC H700 with four 600GB 15K 3.5" SAS drives in a RAID 10, with four partitions: /boot: 1GB /: 200GB swap: 24GB /db01: 900GB (approx.) |
3316: rh-mysql57-mysql-server, offline production/analysis slave | BCF | smartd (starsupport) disk space mon (starsupport) Ganglia MegaRAID Storage Manager (17.05.00.02) (starsupport) Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
September 2011 (inherited from RACF in 2018) |
|
| db02 | Dell PowerEdge R710 | Sc.Linux 7.x | 2x Intel Xeon X5660 (Hex-core, 2.80GHz, 12 MB cache, HT available but disabled) | 96GB + 24GB swap | 130.199.148.102: LACP: 2 x 1Gb/s |
PERC H700 RAID controller with 6 2TB GB 7200RPM SAS drives in a RAID 10, partitioned as /boot (1GB) /db01 (5.3TB) / (187GB) swap (24GB) |
3316: rh-mysql57-mysql-server, offline production/analysis slave | BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) No Icinga |
February 2012 | |
| db04 | Dell PowerEdge R410 | Sc.Linux 7.x | 2x Intel Xeon X5650 (Hex-core, 2.67GHz, 12 MB cache, HT available but disabled) | 64GB + 32GB swap | 130.199.148.104: LACP: 2 x 1Gb/s |
PERC H700 RAID controller with 4 2TB GB 7200RPM SAS drives in a RAID 10, partitioned as /boot (1GB) /db01 (934GB) / (150GB) swap (32GB) |
3316: rh-mysql57-mysql-server (el7.x86_64) offline production/analysis slave | BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) No Icinga |
February 2012 | |
| ovirt-sdmz5 (old db05) | Dell PowerEdge R410 | Sc.Linux 7.x | 2x Intel Xeon X5650 (Hex-core, 2.67 GHz, 12MB cache, HT available but disabled) | 64GB + 32GB swap | 130.199.148.116: 1 x 1Gb/s |
PERC H700 RAID controller with 4 1 TB 7200RPM SAS drives, 2 in a RAID 1, partitioned as /boot (1GB) /data (794GB) / (99GB) swap 2 drives each in their own RAID 0 for GlusterFS bricks |
Ovirt GlusterFS |
BCF | smartd (starsupport) disk space mon (starsupport) MegaRAID Storage Manager (17.05.00.02) (starsupport) Ganglia Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
October 2011 (inherited from RACF in 2018) | Ovirt Hypervisor Gluster storage host |
| db06 | Dell PowerEdge R610 | Sc. Linux 7.x | 2x Intel Xeon X5670 (Hex-core, 2.93 GHz, 12MB cache, HT available but disabled) | 48 GB + 24GB swap | 130.199.148.106: LACP: 2 x 1Gb/s |
PERC H700 RAID controller with 6 2.5" 600 GB 10K SAS drives in a RAID 10, partitioned as /boot (1GB) /db01 (1.5TB) / (187GB) swap |
3316: rh-mysql57-mysql-server (el7.x86_64) offline production/analysis slave | BCF | smartd (starsupport) disk space mon (starsupport) Ganglia MegaRAID Storage Manager (17.05.00.02) (starsupport) Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
June 2011 | 1. part of the dbx.star.bnl.gov DNS round-robin |
|
db07 |
Dell PowerEdge R610 | Sc.Linux 7.x | 2x Intel Xeon X5670 (Hex-core, 2.93 GHz, 12 MB cache, HT available but disabled) | 48 GB + 24GB swap | 130.199.148.107: LACP: 2 x 1Gb/s |
PERC H700 RAID controller with 6 2.5" 600 GB 10K SAS drives in a RAID 10, partitioned as /boot (1GB) /db01 (1.5TB) / (187GB) swap |
3316: rh-mysql57-mysql-server (el7.x86_64) offline production/analysis slave |
BCF | smartd (starsupport) disk space mon (starsupport) Ganglia MegaRAID Storage Manager (17.05.00.02) (starsupport) Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
February 2011 | 1. part of the dbx.star.bnl.gov DNS round-robin |
| db08 | Dell PowerEdge R610 | Sc.Linux 7.x | 2x Intel Xeon X5670 (Hex-core, 2.93 GHz, 12 MB cache, HT available but disabled) | 48 GB + 24GB swap | 130.199.148.108: LACP: 2 x 1Gb/s |
PERC H700 RAID controller with 6 2.5" 600 GB 10K SAS drives in a RAID 10, partitioned as |
3316: rh-mysql57-mysql-server (el7.x86_64) offline production/analysis slave |
BCF | smartd (starsupport) disk space mon (starsupport) Ganglia MegaRAID Storage Manager (17.05.00.02) (starsupport) Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
February 2011 | 1. part of the dbx.star.bnl.gov DNS round-robin |
| db10 | Dell PowerEdge R610 | Sc.Linux 7.x | 2x Intel Xeon X5660 (Hex-core, 2.80GHz, 12MB cache, HT available but disabled) | 96GB + 32GB swap | 130.199.148.110: LACP: 2 x 1Gb/s |
PERC H700 RAID controller with 6 300 GB 15K SAS drives. Two form a RAID1 with /boot (500MB), swap, and / (244GB) Four drives are in a RAID 10 for /db01 (549GB) |
3316: rh-mysql57-mysql-server, offline production/analysis slave | BCF | smartd (starsupport) disk space mon (starsupport) Ganglia MegaRAID Storage Manager (17.05.00.02) (starsupport) Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
November 2012 (inherited from RACF in 2018) |
1. Core team offline db server (see STAR DB XML) |
| Dell PowerEdge R710 | Sc.Linux 7.x | 2x Intel Xeon X5550 (Quad-core, 2.67GHz, 8MB cache, HT available but disabled) | 48GB + 24GB swap | 130.199.148.111: LACP: 2 x 1Gb/s |
PERC H200 RAID controller |
3316: rh-mysql57-mysql-server, offline production/analysis slave | BCF | smartd (starsupport) disk space mon (starsupport) Ganglia MegaRAID Storage Manager (17.05.00.02) (starsupport) Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
April 2010 | ||
| ovirt-sdmz1 (old db12) | Dell PowerEdge R410 | Sc.Linux 7.x | 2x Intel Xeon X5650 (Hex-core, 2.67GHz, 12MB cache, HT available but disabled) | 64GB + 24GB swap | 130.199.148.105: 1 x 1Gb/s |
PERC H700 RAID controller with 4 1 TB 7200RPM SAS drives, 2 in a RAID 1, partitioned as /boot (1GB) /data (794GB) / (99GB) swap 2 drives each in their own RAID 0 for GlusterFS bricks
|
Ovirt GlusterFS |
BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) No Icinga |
February 2012 | Ovirt Hypervisor Gluster storage host |
| ovirt-sdmz2 (old db13) | Dell PowerEdge R410 | Sc.Linux 7.x | 2x Intel Xeon X5650 (Hex-core, 2.67GHz, 12MB cache, HT available but disabled) | 64GB + 24GB swap | 130.199.148.112: 1 x 1Gb/s |
PERC H700 RAID controller with 4 1 TB 7200RPM SAS drives, 2 in a RAID 1, partitioned as /boot (1GB) /data (794GB) / (99GB) swap 2 drives each in their own RAID 0 for GlusterFS bricks |
Ovirt GlusterFS |
BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) No Icinga |
February 2012 | Ovirt Hypervisor Gluster storage host |
| ovirt-sdmz3 (old db15) | Dell PowerEdge R410 | Sc.Linux 7.x | 2x Intel Xeon X5650 (Hex-core, 2.67GHz, 12MB cache, HT available but disabled) | 64GB + 24GB swap | 130.199.148.113: 1 x 1Gb/s |
PERC H700 RAID controller with 4 1 TB 7200RPM SAS drives, 2 in a RAID 1, partitioned as /boot (1GB) /data (794GB) / (99GB) swap 2 drives each in their own RAID 0 for GlusterFS bricks |
Ovirt GlusterFS |
BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) No Icinga |
February 2012 | Ovirt Hypervisor Gluster storage host |
| ovirt-sdmz4 (old db16) | Dell PowerEdge R410 | Sc.Linux 7.x | 2x Intel Xeon X5650 (Hex-core, 2.67GHz, 12MB cache, HT available but disabled) | 64GB + 24GB swap | 130.199.148.115: 1 x 1Gb/s |
PERC H700 RAID controller with 4 1 TB 7200RPM SAS drives, 2 in a RAID 1, partitioned as /boot (1GB) /data (794GB) / (99GB) swap 2 drives each in their own RAID 0 for GlusterFS bricks |
Ovirt GlusterFS |
BCF | smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) SKM |
February 2012 | Ovirt Hypervisor Gluster storage host |
| IBM System x3650 M3 -[7945AC1]- | Sc.Linux 7.x | 2x Intel Xeon E5645 (Hex-core, 2.40GHz, 12MB cache, HT available but disabled) | 96GB + 24GB swap | 130.199.148.117: LACP: 2 x 1Gb/s |
ServeRAID M1015 SAS/SATA Controller 2 160GB SATA 2.5" drives in a RAID 1 with: /boot: 1GB /: 125GB swap: 24GB 4 147GB SAS 15K RPM 2.5" drives in a RAID 10 with: /db01: 268GB |
3316: rh-mysql57-mysql-server, offline production/analysis slave | BCF | smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) SKM |
August 2011 | ||
| IBM System x3650 M3 -[7945AC1]- | Sc.Linux 7.x | 2x Intel Xeon E5645 (Hex-core, 2.40GHz, 12MB cache, HT available but disabled) | 96GB + 24GB swap | 130.199.148.118: LACP: 2 x 1Gb/s |
ServeRAID M1015 SAS/SATA Controller 2 160GB SATA 2.5" drives in a RAID 1 with: /boot: 1GB /: 125GB swap: 24GB 4 147GB SAS 15K RPM 2.5" drives in a RAID 10 with: /db01: 268GB |
3316: rh-mysql57-mysql-server, offline production/analysis slave | BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) SKM |
August 2011 | ||
| duvall (and db09 is an alias for duvall) | ASA/SuperMicro 1U, X9DRW motherboard | RHEL Workstation 6.x (64-bit) | 2x Intel Xeon E5-2620 v2 (6 cores each, 2.1GHz, 16MB cache, w/HT) |
32 GB+ 16GB swap | 130.199.148.93: LACP: 2 x 1Gb/s |
10 2.5" drive bays (0-7 on one controller, 8 & 9 on a different controller) 3x 1TB , each with 3 partitions for RAID 1 arrays (/, /boot and swap) - 2 active drives, 1 hot spare 2x 240GB SSD with 1 partition each. RAID1 array for /db01 |
3306: mysql-5.1.73 (RH), offlineQA, nova, LibraryJobs, OCS Inventory database (tbc), etc. | BCF | smartd (starsupport) disk space mon (starsupport) Ganglia Logwatch (WB) SKM OCS Inventory Osiris (starsupport) LogWatch (WB) No Icinga |
February 2015 | |
|
heston |
Penguin Relion 2600SA | RHEL Workstation 6.x (64-bit) | 2x Intel Xeon E5335 (Quad-core, 2.00GHz, 8MB cache) |
8GB + 10GB swap |
130.199.148.91: |
Six 750 GB (or 1TB) SATA drives identically partitioned: /db01: 2.6TB, ext4, RAID5 (5 drives + 1 spare) swap: 10GB, RAID5 (5 drives + 1 spare) |
3306: mysqld-5.1.73-8.el6_8 (RH) |
BCF |
mdmonitor (starsupport) smartd (starsupport) disk space mon. (starsupport) Ganglia (yes) Osiris (starsupport) LogWatch (WB) SKM |
August or November 2007 | former duvall, now a slave to duvall |
| |
130.199.148.92: LACP: 2 x 1Gb/s |
|
|||||||||
| onldb | IBM System x3650 M3 -[7945AC1]- | Sc.Linux 7.x | 2x Intel Xeon E5645 (hex-core, 2.4GHz, 12 MB cache, HT disabled at BIOS) | 96GB + 24GB swap |
130.199.60.70: 1Gb/s 172.16.0.10: 1Gb/s |
ServeRAID M1015 SAS/SATA controller with 12 disks: 2 x 150 GB SATA in a RAID 1 with: - /boot (1GB) - / (125GB) - swap 4 x 146 GB 15K SAS in a RAID 10 with /db01 (268GB) 6 x 900 GB 10K SAS in RAID 10 with /db02 (2.5TB) |
online current run DB master server | DAQ Room | MSM 17.05.00.02 (starsupport) smartd (starsupport) disk space mon. (starsupport) Ganglia Osiris (starsupport) LogWatch (WB) OCS Inventory (link needed) Icinga |
August 2011 | |
| onldb5 (former onldb) | Dell PowerEdge R510 | RHEL 6.x (64-bit) | Intel Xeon E5620 (quad-core, 2.4GHz, 12MB cache w/HT) | 8GB + 8GB swap |
130.199.60.29: 1Gb/s 172.16.128.10: 1Gb/s |
2 x 147 GB SAS (10K): -RAID 1, 8GB swap -RAID 1, 200MB /boot -RAID 1, 125 GB / 6 x 300 GB SAS (15K): -RAID 5, 550GB /mysqldata01 -RAID 5, 550GB /mysqldata02
|
former online current run DB server |
DAQ Room |
mdmonitor (starsupport) smartd (starsupport) disk space mon. (starsupport) Osiris (no) LogWatch (WB) SKM (no) Icinga |
December 2011 | |
| onldb2 | Dell Power Edge R310 | RHEL 6.x (64-bit) | Quad core (plus HT) Intel Xeon X3460 @ 2.80 GHz | 8GB + 8GB swap | em1: 130.199.60.89: 1Gb/s | 4x 2 TB SATA drives with four active partitions each. Four software RAID arrays across the four disks, used as follows: /boot: RAID1 (477MB ext4) swap: RAID10 (8GB) /: RAID10 (192GB ext4) /mysqldata00: RAID10 (3.4TB ext4) |
current run online DB server slave | DAQ Room | October 2010 | ||
| onldb3 | Dell PowerEdge 2950 | Sc.Linux 7.x | 2x Quad core Intel Xeon E5440 @ 2.83 GHz | 16GB + 8GB swap | 130.199.60.165: 1Gb/s | 6x 1TB 3.5" SATA drives with 4 partitions each, forming four software RAID arrays mounted as: /boot: 1GB /: 140GB /db01: 2.6TB swap: 8GB |
3316: rh-mysql57-mysql-server, offline production/analysis slave docker container with ScLinux 6 environment and mysql-5.1.73 for online database slaves |
DAQ Room |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) |
January 2009 | |
| onldb4 | Dell PowerEdge 2950 | Sc.Linux 7.x | 2x Quad core Intel Xeon E5440 @ 2.83 GHz | 16GB + 8GB swap | 130.199.60.203: 1Gb/s | 6x 1TB 3.5" SATA drives with 4 partitions each, forming four software RAID arrays mounted as: /boot: 1GB /: 140GB /db01: 2.6TB swap: 8GB |
3316: rh-mysql57-mysql-server, offline production/analysis slave docker container with ScLinux 6 environment and mysql-5.1.73 for online database slaves |
DAQ Room |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) |
January 2009 | |
| dbbak | Dell PowerEdge R320 | RHEL 6.x (64-bit) | Quad Core Intel E5-1410 @2.8GHz, w/HT | 24GB + 8GB swap |
dbbak: |
online past run DB server | DAQ | December 2013 | Osiris master | ||
| Dell OptiPlex 755 | Sc.Linux 6.x (64-bit) | Core2 Duo E8300 @ 2.83GHz | 4GB + 2GB swap | 130.199.60.168: 1Gb/s | Intel RAID Matrix Storage Manager with two 500GB disks mirrored | DAQ | June 2008 | ||||
| mongodev01-03 | |||||||||||
| dashboard1 | Dell PowerEdge R320 | RHEL 6.x (64-bit) | Quad Core Intel E5-1410 @2.8GHz, w/HT | 24GB + 8GB swap | 130.199.60.91: 1Gb/s | S&C operations monitoring host | DAQ | December 2013 | Icinga and sFlow | ||
| mq01-mq03 | |||||||||||
| cephmon01-03 | |||||||||||
| fc1 | IBM System x3650 M3 -[7945AC1]- | Sc.Linux 7.x | 2x Intel Xeon E5645 (Hex-core, 2.40GHz, 12MB cache, HT available but disabled) | 96GB + 24GB swap | 130.199.148.86: LACP: 2 x 1Gb/s |
ServeRAID M1015 SAS/SATA Controller 2x 147GB 2.5" 15K RPM SAS in a RAID 1 with: /boot: 1GB /: 113GB swap: 24GB 6x 300GB 2.5" 15K RPM SAS in a RAID 10 with: /db01: 823GB |
3336: rh-mysql57-mysql-server, master File Catalog server | BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) SKM |
August 2011 | |
| fc2 | IBM System x3650 M3 -[7945AC1]- | Sc.Linux 7.x | 2x Intel Xeon E5649 (Hex-core, 2.53GHz, 12MB cache, HT available but disabled) | 96GB + 24GB swap | 130.199.148.87: LACP: 2 x 1Gb/s |
ServeRAID M1015 SAS/SATA Controller 4x 300GB SAS 15K RPM 2.5" drives in a RAID 10 with: /boot: 1GB /: 120GB swap: 24GB /db01: 411GB |
3336: rh-mysql57-mysql-server, File Catalog slave | BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) SKM |
August 2011 | |
| fc3 | Dell PowerEdge R610 | Sc.Linux 7.x | 2x Intel Xeon X5660 (Hex-core, 2.80GHz, 12MB cache, HT available but disabled) | 96GB + 8GB swap | 130.199.148.88: LACP: 2 x 1Gb/s |
PERC H700 RAID Controller with 6 600GB 10K SAS (2.5") in a RAID 10 with / (150GB) /boot (1GB) swap (8GB) /db01 (1.5TB) |
rh-mysql57-mysql-server UCM monitoring node? |
BCF | smartd (starsupport) disk space mon (starsupport) Ganglia MegaRAID Storage Manager (17.05.00.02) (starsupport) Logwatch (WB) SKM OCS Inventory Osiris (starsupport) No Icinga |
February 2012 (inherited from RACF in 2018) | |
| fc4 | IBM System x3650 M3 -[7945AC1]- | Sc.Linux 7.x | 2x Intel Xeon E5649 (Hex-core, 2.53GHz, 12MB cache, HT available but disabled) | 96GB + 24GB swap | 130.199.148.89: LACP: 2 x 1Gb/s |
ServeRAID M1015 SAS/SATA Controller 4x 300GB SAS 15K RPM 2.5" drives in a RAID 10 with: /boot: 1GB /: 120GB swap: 24GB /db01: 411GB |
3336: rh-mysql57-mysql-server, File Catalog slave | BCF |
smartd (starsupport) disk space mon. (starsupport) Osiris (starsupport) LogWatch (WB) SKM |
August 2011 | |
| Dell PowerEdge R310 | RHEL Workstation 7.x (64-bit) | Intel Xeon X3460 (quad core) 2.8GHz, w/HT | 8GB + 6GB swap | 130.199.162.175: 1Gb/s |
4 software RAID arrays spread over four identically partitioned 2 TB SATA disks: swap: 6 GB, RAID 10 /boot: xfs, 236 MB, RAID 1 /: xfs, 46 GB, RAID 5 /export: xfs, 5.5 TB, RAID 5 |
80, 443: former primary online web server (replaced by ovirt virtual machine in late 2017) | DAQ |
mdmonitor (starsupport) smartd (no) disk space mon. (no) Ganglia (yes) Osiris (starsupport) LogWatch (no) SSH Key Mgmt. (yes) DB start-up scripts (N/A) |
December 2010 | online Ganglia gmetad and web interface OCS Inventory Tomcat for ESL and SUMS scheduler stats NFS server for online web content generation |
|
| stardns1 | Dell PowerEdge SC440 | Sc.Linux 6.x (64-bit) | Dual Core Intel Pentium D 2.80GHz | 2GB + 4GB swap | 130.199.60.150: 1Gb/s | One 200 GB and one 250 GB SATA disk, partitioned identically (so the larger disk is not fully used): |
53: BIND (named, DNS server)
|
DAQ | December 2006 | secondary DNS server, supplementing daqman and onlldap (slave to daqman for all zones) | |
| sun (aka drupal and www) | Dell PowerEdge R610 | RHEL WS 6.x (64-bit) | Quad Core Intel Xeon E5520, 2.26GHz, 8M cache, w/HT | 12GB + 10GB swap | 130.199.59.200: 1Gb/s |
Six 15K SAS drives of 73GB each on a PERC 6/i integrated (LSI megaraid) controller. first two are in a RAID 1, which contains /boot, / and swap (8GB) remaining four are in RAID 5 mounted under /data (200GB) |
80, 443: STAR primary webserver 25: postfix (SMTP server) |
BCF |
mdmonitor (N/A - HW RAID) smartd (starsupport) disk space mon. (WB) Ganglia (yes) Osiris (starsupport) LogWatch (no) SSH Key Mgmt. (yes) DB start-up scripts (N/A) |
July 2009 | STAR Webserver, eg: -- Drupal -- RT -- Ganglia STAR Hypernews |
| sunbelt | Penguin Relion 2600SA |
RHEL Workstation 6.x (64-bit) | 2x Intel Xeon E5335 (Quad-core, 2.00GHz, 8MB cache) | 16GB + 4GB swap | 130.199.59.199: 1Gb/s |
/boot 200MB RAID1 /db01 on 3.3TB RAID5 4GB swap on RAID5 array Five 750GB, 7200 RPM SATA - RAID 5. Plus one spare 750GB (6 disks total) |
BCF |
mdmonitor (WB, MA, DA) smartd (WB, MA, DA) disk space mon. (WB, DA) Ganglia (yes) Osiris (WB, MA) LogWatch (WB) SSH Key Mgmt. (yes) DB start-up scripts (yes) |
August or November 2007 | sun Webserver & MYSQL emergency backup use | |
| stargw3 | Dell Precision WorkStation T3400 | Sc.Linux 6.x (64-bit) | Intel Core2 Quad CPU Q9550 @ 2.83GHz | 8GB + 6GB swap | 130.199.60.93: 1Gb/s | Two 500GB SATA drives partitioned identically with RAID 1 arrays for: /boot: 239 MB, ext4 /: 453 GB, ext4 swap: 6GB |
22: OpenSSH server 9619-9620: Condor-CE |
DAQ | May 2009 | Online Grid gatekeeper | |
| stargw4 | Dell OptiPlex 755 | Sc.Linux 6.x (64-bit) | Intel Core2 Duo CPU E8400 @ 3.00GHz | 6GB + 6GB swap | 130.199.60.74: 1Gb/s | One 250GB and one 400GB SATA drive. The drives are partitioned identically with RAID 1 arrays (so only 250 GB is being used from the 400 GB disk): /boot: 500MB, ext4 /: 223 GB, ext4 swap: 6GB |
22: OpenSSH server | DAQ | January 2009 | SSH gateway to starp, part of "stargw.starp.bnl.gov" DNS round-robin | |
| stargw5 | Dell OptiPlex 755 | Sc.Linux 6.x (64-bit) | Intel Core2 Duo CPU E8500 @ 3.16GHz | 4GB + 6GB swap | 130.199.60.76: 1Gb/s | Two 160 GB SATA drives partitioned identically with RAID 1 arrays: /boot: 500MB, ext4 /: 141 GB, ext4 swap: 6GB |
22: OpenSSH server | DAQ | September 2008 | SSH gateway to starp, part of "stargw.starp.bnl.gov" DNS round-robin | |
| onlldap | Dell PowerEdge R310 | Sc.Linux 6.x (64-bit) | Intel Xeon X3440 (quad-core) @ 2.53GHz | 8GB + 8GB swap | 130.199.60.57: 2Gb/s (bonded 1Gb/s NICs) | Four 1.2TB SAS (10K, 2.5") HDD, identically partitioned with RAID arrays: /boot: 388MB, ext4, RAID1 /: 118GB, ext4, RAID5 /ldaphome: 3.1TB, ext4, RAID5 swap: 8GB, RAID1 |
53: named (BIND/DNS) NFS NIS |
DAQ | December 2011 | Online Linux Pool home directory NFS server online NIS server master |
|
| onlam3 | Dell PowerEdge R310 | Sc.Linux 6.x (64-bit) | Intel Xeon X3440 (quad-core) @ 2.53GHz | 8GB + 8GB swap | 130.199.60.153: 1Gb/s | Four 1.2TB SAS (10K, 2.5") HDD, identically partitioned with RAID arrays: /boot: 388MB, ext4, RAID1 /: 118GB, ext4, RAID5 /ldaphome: 3.1TB, ext4, RAID5 swap: 8GB, RAID1 |
DAQ | December 2011 | backup Online Linux Pool home directories (cron'ed rsyncs) online NIS server slave online HTCondor Central Manager (collector/negotiator) |
||
| cephnfs | |||||||||||
| dean and dean2 | oVirt Virtual Machines | ||||||||||
| ovirt1, ovirt2, ovirt3 | |||||||||||
| onlcs | |||||||||||
| onlcs2 | |||||||||||
| onlhome | |||||||||||
| onlhome2 |
There is a fairly comprehensive monitoring system for the database servers at http://online.star.bnl.gov/Mon/
Notes about the health and configuration monitoring items listed in the table:
(If a particular tool notifies anybody directly (email), then the initials of the notified parties are included.)
Failing disks and filling disks have led to most of the db problems that this writer is aware of. Towards that end, we have several basic monitoring tools:
1. smartd -- if it starts indicating problems, the safest thing to do is replace the disk. However, SMART frequently assesses a disk as healthy when it is not. Also, the configurations in use have yet to be demonstrated to actually detect anything - I've no way to simluate a gradually failing disk. Also, SMART's abilities and usefulness are highly dependent on the disk itself - even 2 similar disks from the same manufacturer can have very different SMART capabilities. In any case, if we do have more disk failures, it will be interesting to learn if smartd gives us any warning. At this point, it is a bit of crossing-the-fingers and hoping. Any warning is a good warning...
2. mdmonitor or MegaRAID Storage Manager -- monitors software or hardware RAID configurations.
3. disk space monitoring -- We have a perl disk space monitoring script run via cron job. The iniital warning point is any partition more than 90% full.
Other monitoring and configuration details:
Ganglia -- doesn't need much explanation here.
Osiris -- change detection system, in the manner of TripWire, but with additional details that can be monitored, such as users and network ports.
SSH Key management -- doesn't need much explanation here.
Security
This section contains references to database security-related topics like security scan information, access to db from outside of BNL firewall, user account privileges etc.