Development
The links below lead to projects being worked on for the ongoing delevopment of the STAR database system.
Advanced DB Infrastructure : Hecate project
Hecate : integrated db infrastructure project
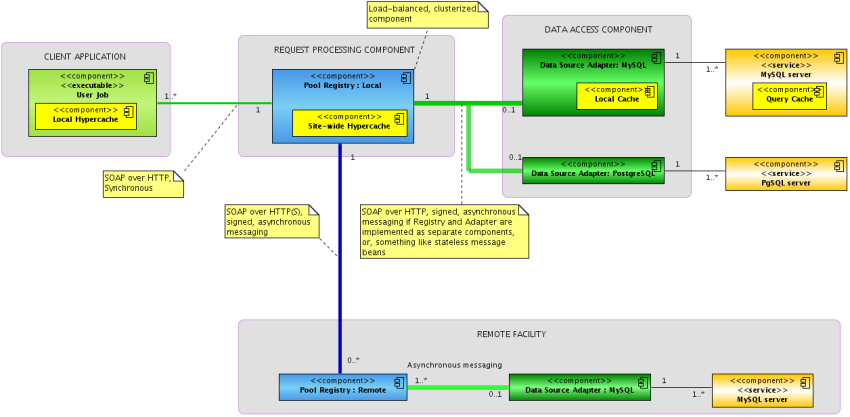
- Statistics Agent (MySQL) - collects CPU, RAM, Load, MySQL statistics and ships this to Pool Registry service via SOAP call (see attached src.rpm);
- Pool Registry service - keeps track of database pools (stats per node), provides load balancing and data transfer capabilities via exposed SOAP interface;
- Pool Manager - keeps track of database pools;
- Pool Registry Web UI - displays currently available pool list, node status, works as monitoring UI for collaboration;
- Fast In-Memory Cache - reduces the Pool Registry <-> Data Source Adapter communications burden;
- Data Source Adapter - announces Pools to Pool Registry, converts "generic" requests for datasets into db-specific commands, sends serialized data back to Pool Registry;
- (de)serialization Factory - converts dataset requests into DB queries, serializes DB response;
- DB native cache - provides caching capabilities, native to DB used in Pool;
- Local Disk Cache - persistent local cache
- Client Application - makes requests for data, using SOAP calls to Pool Registry. Data is fetched from either local or remote pool, transparently.
- Two-way db access - direct local db access interface + distributed data access interface;
- Local Load Balancing Interface - direct db access interface requires local load balancing information, retrieved from Pool Registry;
- Local Disk Cache - persistent local cache, reduces the Client App <-> Pool Registry communications burden;
Archive: unsorted documents
Temporary placeholder for two presentations made on :
a) Online data processing review
b) FileCatalog performance improvement
Please see attached files
Bridging EPICS and High-Level Services at STAR
Bridging EPICS and High-Level Services at STAR
Outline:
- Introduction: STAR, EPICS, MQ and MIRA/DCS
- R&D Topics
- Integration of EPICS, RTS and DAQ using MIRA
- Remote Access Capabilities (web+mobile)
- Advanced Alarm Handler
- Historical Data Browser
- Experiment Dashboard
- Advanced Data Archiver: Pluggable Storage Adapters
- SQL: MySQL
- DOC: MongoDB
- NoSQL: HyperTable
- Complex Event Processing
- Esper Engine
- WSO2 middleware
- Summary and Outlook
- Figures
1. General Concepts: STAR, EPICS, MQ and DCS/MIRA
An acronym for the Solenoidal Tracker At RHIC (Relativistic Heavy Ion Collider), STAR detector tracks thousands of particles produced by ion collision, searching for signatures of a state of matter called the quark-gluon plasma (QGP), a form that is thought to have existed just after the Big Bang, at the dawn of the universe. A primary goal of STAR is to bring about a better understanding of the universe in its earliest stages, by making it possible for scientists to better understand the nature of the QGP. The STAR collaboration consists of over 500 scientists and engineers representing 60 institutions in 12 countries. As the size of the collaboration and the scope of its work continues to grow, so does the challenge of having the computing power and data processing resources to carry out that work efficiently.STAR's detector control system (also referred as Slow Controls) is based on EPICS toolkit. EPICS is a set of Open Source software tools, libraries and applications developed collaboratively and used worldwide to create distributed soft real-time control systems for scientific instruments such as a particle accelerators, telescopes and other large scientific experiments. The STAR experiment started in 1999, with just one Time-Projection Chamber and a few trigger detectors, but today it is equipped of 18 subsystems. Initially, STAR Slow Control system had 40,000 control variables, now it is expanded to over 60,000 variables and this list is still growing due to the RHIC II upgrade, beam energy scan program, and possible upgrade to eRHIC in future. STAR had just 120 types of structures to migrate to the calibrations database at the early days of the experiment, and we now migrate over 3,000 types of structures annually. STAR’s Data Acquisition (DAQ) – physics data taking component – was upgraded three times, adding one order of magnitude to the rates each time.
STAR’s Messaging Interface and Reliable Architecture framework (MIRA), was created as an attempt to improve meta-data archiver operations in 2010. It relies on an advanced message-queuing middleware, which provides the asynchronous, payload-agnostic messaging, and has adapters to get data from EPICS- and CDEV-based data sources. We have selected AMQP as a messaging middleware standard for High-Level services, as well as MQTT for low-level intra-service communications. It allowed us to design a loosely coupled, modular framework architecture, resulting in a scalable service, suitable for a highly concurrent online environment. During the deployment validation phase in 2010, just three subsystems used the MIRA framework. By 2014, all eighteen subsystems were completely integrated, with over sixty collector services deployed and continuously monitored by the framework. The total number of messages passing through the system reached three billion messages per year, with rates varying between one hundred and fifty messages per second to over two thousand messages per second. MIRA provided STAR with a solution to handle the growing number of channels (x15), and data structures (x25), allowing smooth operation during Runs 10-15. In 2014 we have extended MIRA with the stream-based Complex Event Processing capability, which successfully passed our tests. A few alarms implemented for Run 14 saved months of work for the core team and collaborators.
The MIRA framework is still evolving. In near future, we are planning to add features, commonly encountered in the Detector Control Systems domain: experiment workflow and hardware control, as well as many High-Level Services, extending and generalizing the functionality of the underlying framework(s). This document is focused on the proposed R&D related to futher development of MIRA framework and related services.
2. R&D Topics
We expect STAR to double the number of channels in the next five years, hence, system scalability is our primary objective. To allow seamless migration from wide variety of existing legacy hardware to the modern detector control equipment, at the same time keeping the existing Detector Control system based on EPICS fully operational to avoid interruption of service, we propose a gradual functionality upgrade of existing tools and services. This means, our primary objective is to extend existing services like experiment's EPICS-based Alarm Handler, Meta-data Collectors, RTS- and DAQ-components and to provide improved ways to orchestrate this growing set of services.2.1 Integration of EPICS, RTS and DAQ using MIRA
The intent to integrate vide variety of STAR Online services is driven by the growth of the STAR experiment's complexity, and greatly increased data processing rates. We have identified the requirements for the software infrastructure, desired to maintan STAR for the next decade. The upgrade team has collected the following key demands from collaborational users and detector experts: Scalable Architecture, Low-overhead Inter-operable Messaging Protocol, Payload-agnostic Messaging, Quality of Service, Improved Finite State Machine, Real-time, web and mobile-friendly Remote Access. While some of these features are already covered by by MIRA framework, others require R&D studies to accomplish our goals.2.2 Remote Access Capabilties
With web and mobile-based data access and visualization, MIRA, as the Detector Control framework, can provide data when and where the user needs it, and tailor that data for specific user requirements. This will lead to the rapid sharing, knowledge creation, engaged users, and more opportunities for the efficient scientific data processing. As operators become more fully engaged, they are apt to grow their involvement, contributing in unexpected ways that could ultimately decrease operational overhead.Advanced Alarm Handler
Due to the geographically distributed nature of STAR collaboration users and detector experts, one of the highly demanded upgrade targets is the Alarm Handler improvement. It is desired to provide a real-time, web (and/or mobile) version of the existing alarm handler application, which is currently based on EPICS-MEDM interface. To accomplish this task, we need to investigate the following opportunities:
(a) bi-directional propagation of alarm messages to/from EPICS to MQ/MIRA
(b) create a web/mobile interface, resemblng the existing MEDM-based Alarm Handler, keeping the overall look and feel to reduce the learning curve for the detector operators and subsystem experts
Estimated Efforts: 6 months / 1 FTE (2 x 0.5)
Historical Data Browser
Both EPICS and MIRA framework have their versions of Historical Archive interfaces. While EPICS Archiver provides a detailed access to all meta-data collected by the experiment, and MIRA's interface is appraised by the users for an easy categorization and expanded set of plotting features, there is a demand for the user-customizable interface which may/should include scripting features for advanced users.
Estimated Efforts: 4 months / 0.5 FTE
Experiment Dashboard
The process of unification of STAR's components leads to the need of the creation of Experiment's Dashboard (EDash), which will provide a high-level summary of the activies happening in STAR Online domain. EDash will serve as a single entry-point for the aggregated status summaries coming from Slow Control System, Data Acquisition System, Run-Time System and other systems integrated via MIRA messaging capabilities.
Estimated Efforts: 8 months / 0.5 FTE
Images
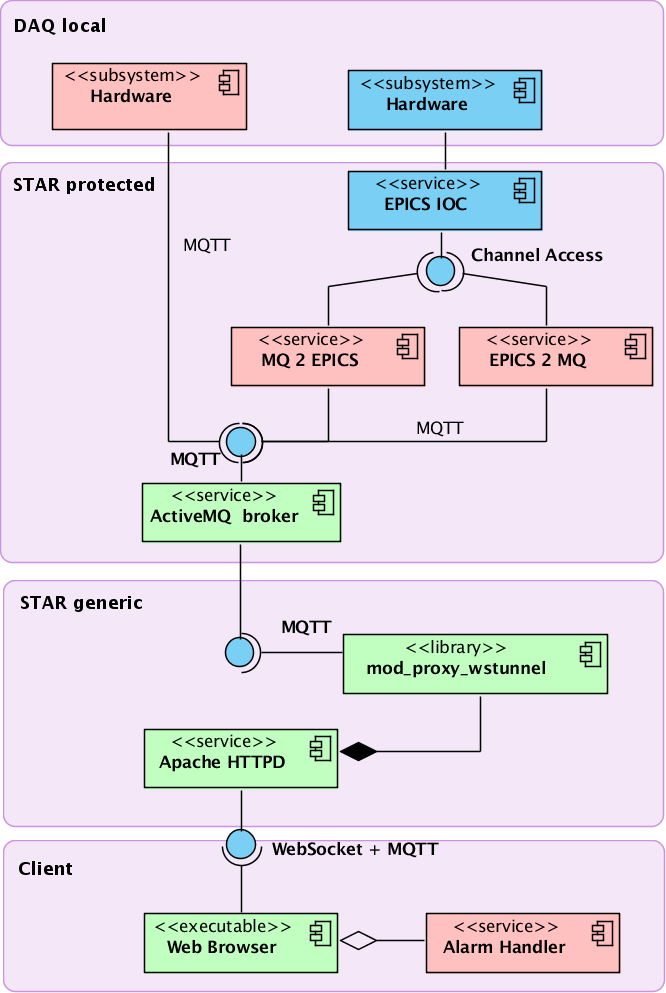
Figure 1. Component diagram for MQ-based Alarm Handler. Green components - existing infrastructure. Pink components - to be developed in a course of this R&D. Blue components - existing EPICS services, serving as data source for the test bed.
C++ DB-API
Work in progress. Page is located here .
Introduction
| The purpose of the C++ API is to provide a set of standardized access methods to Star-DB data from within (client) codes that is independent of specific software choices among groups within STAR. The standardized methods hide the "client" code from most details of the storage structure, including all references to the low-level DB infrastructure such as (My)SQL query strings. Specifically, the DB-API reformulates requests for data by name, timestamp, and version into the necessary query structure of the databases in order to retrieve the data requested. None of the low-level query structure is seen by the client.
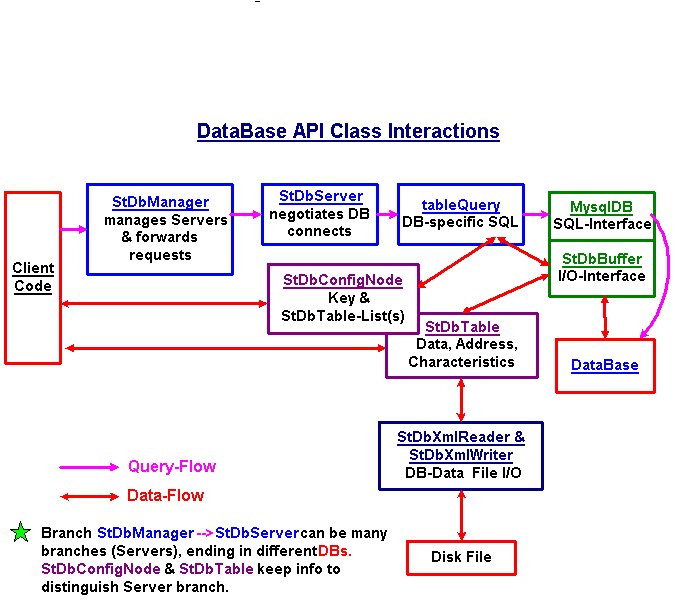
The API is contained withing a shared library StDbLib.so. It has two versions built from a common source. The version in Offline (under $STAR/lib) contains additional code generated by "rootcint" preprocessor in order to provide command line access to some methods. The Online version does not contain the preprocessed "rootcint" code. In addition to standard access methods, the API provides the tools needed to facilitate those non-standard access patterns that are known to exist. For example, there will be tasks that need special SQL syntax to be supplied by client codes. Here, a general use C++MySQL object can be made available to the user code on an as needed basis. The following write-up is intended as a starting point for understanding the C++ API components. Since most clients of database data have an additional software-layer between their codes and the DB-API (e.g St_db_Maker in offline), none of these components will be directly seen by the majority of such users. There will, however, be a number of clients which will need to access the API directly in order to perform some unique database Read/Write tasks. Click here To view a block diagram of how the C++ API fits general STAR code access. Click here To view a block diagram of how the C++ API classes work together to provide data to client codes The main classes which make up the C++ DB-API are divided here into four categories.
|
Access Classes
StDbManager | StDbServer | tableQuery & mysqlAccessor | StDbDefs
| StDbManager: (Available at Root CLI)
The StDbManager class acts as the principle connection between the DB-API and the client codes. It is a singleton class that is responcible for finding Servers & databases, providing the information to the StDbServer class in order that it may connect with the database requested, and forwarding all subsequent (R/W) requests on to the appropriate StDbServer object. Some public methods that are important to using the DB-API via the manager:
Some public methods that are primarily used internally in the DB-API:
The StDbServer class acts as the contact between the StDbManager and the specific Server-&-Database in which a requested data resides. It is initialized by the StDbManager with all the information needed to connect to the database and it contains an SQL-QueryObject that is specifically structured to navigate the database requested. It is NOT really a user object except in specific situations that require access to a real SQL-interface object which can be retrieved via this object. Public methods accessed from the StDbManager and forwarded to the SQL-Query Object:
The tableQuery object is an interface of database queries while mysqlAccessor object is a real implementation based on access to MYSQL. The real methods in mysqlAccessor are those that contain the specific SQL content needed to navigate the database structures. Public methods passed from StDbServer :
Not a class but a header file containing enumerations of StDbType and StDbDomain that are used to make contact to specific databases. Use of such enumerations may disappear in favor of a string lookup but the simple restricted set is good for the initial implementation.
|
Data Classes
| StDbTable: (Available at Root CLI)
The StDbTable class contains all the information needed to access a specific table in the database. Specifically, it contains the "address" of the table in the database (name, version, validity-time, ...), the "descriptor" of the c-struct use to fill the memory, the void* to the memory, the number of rows, and whether the data can be retrieved without time-stamp ("BaseLine" attribute). Any initial request for a table, either in an ensemble list or one-by-one, sets up the StDbTable class instance for the future data request without actually retrieving any data. Rather the database-name, table-name, version-name, and perhaps number of rows & id for each row, are assigned either by the ensemble query via the StDbConfigNode or simply by a single request. In addition, an "descriptor" object can also be requested from the database or set from the client code. After this initial "request", the table can be used with the StDbManager's timestamp information to read/write data from/to the database. if no "descriptor" is in the StDbTable class, the database provides one (the most recent one loaded in the database) upon the first real data access attempted. Some usefull public methods in StDbTable
StDbConfigNode: (Available at Root CLI) The StDbConfigNode class provides 2 functions to the C++ API. The first is as a container for a list of StDbTable objects over which codes can iterate. In fact, the StDbTable constructor need not be called directly in the user codes as the StDbConfigNode class has a method to construct the StDbTable object, add it to its list, and return to the user a pointer to the StDbTable object created. The destructor of the StDbConfigNode will delete all tables within its list. The second is the management of ensembles of data (StDbTables) in a list structure for creation (via a database configuration request) and update. The StDbConfigNode can build itself from the database and a single "Key" (version string). The result such a "ConfigNode" query will be several lists of StDbTables prepared with the necessary database addresses of name, version, & elementID as well as any characteristic information such as the "descriptor" and the baseline attribute. Some usefull public methods in StDbConfigNode
|
Mysql Utilities
MysqslDb class provides infrastructure (& sometimes client) codes easy use of SQL queries without being exposed to any of the specific/particular implementations of the MySQL c-api. That is, the MySQL c-api has specific c-function calls returning mysql-specific c-struct (arrays) and return flags. Handling of these functions is hidden by this class.
Essentially there are 3 public methods used in MysqlDb
-
- // Accept an SQL string: NOTE the key "endsql;" (like C++ "endl;") signals execute query
- MysqlDb &operator<<(const char *c);
-
- // Load Buffer with results of SQL query
- virtual bool Output(StDbBuffer *aBuff);
- // Read into table (aName) contents of Buffer
- virtual bool Input(const char *aName,StDbBuffer *aBuff);
The StDbBuffer class inherits from the pure virtual StDbBufferI class & implements MySQL I/O. The syntax of the methods were done to be similar with TBuffer as an aid in possible expanded use of this interface. The Buffer handles binary data & performs byte-swapping as well as direct ASCII I/O with MySQL. The binary data handler writes all data in Linux format into MySQL. Thus when accessing the buffer from the client side, one should always set it to "ClientMode" to ensure that data is presented in the architecture of the process.
Public methods used in StDbBufferI
-
- // Set & Check the I/O mode of the buffer.
- virtual void SetClientMode() = 0;
- virtual void SetStorageMode() = 0;
- virtual bool IsClientMode() = 0;
- virtual bool IsStorageMode() = 0;
-
- // Read-&-Write methods.
- virtual bool ReadScalar(any-basic-type &c, const char *aName) = 0;
- virtual bool ReadArray(any-basic-type *&c, int &len, const char *name) = 0;
- virtual bool WriteScalar(any-basic-type c, const char * name) = 0;
- virtual bool WriteArray(any-basic-type *c, int len, const char * name) = 0;
-
- // Not impemented but under discussion (see Tasks List)
- virtual bool ReadTable(void *&c, int &numRows, Descriptor* d, const char * name) = 0;
- virtual bool WriteTable(void *c, int numRows, Descriptor* d, const char * name) = 0;
SSL + Compression check
STAR MySQL API: SSL (AES 128/AES 256), Compression tests.
IDEAS:
a) SSL encryption will allow to catch mysterious network problems eary (integrity checks).
b) Data compression will allow more jobs to run simultaneously (limited network bandwidth);
BFC chain used to measure db response time: bfc.C(5,"pp2009a,ITTF,BEmcChkStat,btofDat,Corr3,OSpaceZ2,OGridLeak3D","/star/rcf/test/daq/2009/085/st_physics_10085024_raw_2020001.daq")
time is used to measure 20 sequential BFC runs :
1. first attempt:
SSL OFF, COMPRESSION OFF : 561.777u 159.042s 24:45.89 48.5% 0+0k 0+0io 6090pf+0w
WEAK SSL ON, COMPRESSION OFF : 622.817u 203.822s 28:10.64 48.8% 0+0k 0+0io 6207pf+0w
STRONG SSL ON, COMPRESSION OFF : 713.456u 199.420s 28:44.23 52.9% 0+0k 0+0io 11668pf+0w
STRONG SSL ON, COMPRESSION ON : 641.121u 185.897s 29:07.26 47.3% 0+0k 0+0io 9322pf+0w
2. second attempt:
SSL OFF, COMPRESSION OFF : 556.853u 159.315s 23:50.06 50.0% 0+0k 0+0io 4636pf+0w
WEAK SSL ON, COMPRESSION OFF : 699.388u 202.783s 28:27.83 52.8% 0+0k 0+0io 3389pf+0w
STRONG SSL ON, COMPRESSION OFF : 714.638u 212.304s 29:54.05 51.6% 0+0k 0+0io 5141pf+0w
STRONG SSL ON, COMPRESSION ON : 632.496u 157.090s 28:14.63 46.5% 0+0k 0+0io 1pf+0w
3. third attempt:
SSL OFF, COMPRESSION OFF : 559.709u 158.053s 24:02.37 49.7% 0+0k 0+0io 9761pf+0w
WEAK SSL ON, COMPRESSION OFF : 701.501u 199.549s 28:53.16 51.9% 0+0k 0+0io 7792pf+0w
STRONG SSL ON, COMPRESSION OFF : 715.786u 203.253s 30:30.62 50.2% 0+0k 0+0io 4560pf+0w
STRONG SSL ON, COMPRESSION ON : 641.293u 164.168s 29:06.14 46.1% 0+0k 0+0io 6207pf+0w
Preliminary results from 1st run :
SSL OFF, COMPRESSION OFF : 1.0 (reference time)
"WEAK" SSL ON, COMPRESSION OFF : 1.138 / 1.193 / 1.201
"STRONG" SSL ON, COMPRESSION OFF : 1.161 / 1.254 / 1.269
"STRONG" SSL ON, COMPRESSION ON : 1.176 / 1.184 / 1.210
Compression check:
1. bfc 100 evts, compression ratio : 0.74 [compression enabled / no compression]. Not quite what I expected, probably I need to measure longer runs to see effect - schema queries cannot be compressed well...
First impression: SSL encryption and Data compression do not significantly affect operations. For only ~15-20% slow-down per job, we get data integrity check (SSL) and 1.5x network bandwidth...
WORK IN PROGRESS...
Addendum :
1. Found an interesting article at mysql performance blog:
http://www.mysqlperformanceblog.com/2007/12/20/large-result-sets-vs-compression-protocol/
"...The bottom line: if you’re fetching big result sets to the client, and client and MySQL are on different boxes, and the connection is 100 Mbit, consider using compression. It’s a matter of adding one extra magic constant to your application, but the benefit might be pretty big..."
Database types
DB-Type Listing
listed items are linked to more detailed discussions on:
- Description & Use Cases
|
Conditions Database
| Description:
The Conditions Database serves to record the experimental running conditions. The database system is a set of "subsystem" independent databases written to by Online "subsystems" and used to develop calibration and diagnostic information for later analyses. Some important characteristics of the Conditions/DB are:
There are essentially 4 types of use scenarios for the Conditions/DB. (1) Online updates: Each Online sub-system server (or subsystem code directly) needs the capability to update thier database with the data representing the sub-system operation. These updates can be triggered by a periodic (automated) sub-system snap-shots, a manually requested snap-shot, or an alarm generated recording of relevant data. In any of these cases, the update record includes the TimeStamp associated with the measurement of the sub-system data for future de-referencing. (2) Online diagnostics: The snap-shots, which may include a running histogram of Conditions data, should be accessible from the sub-system monitors to diagnose the stability of the control & detector systems and correlations between detector performance and system conditions. (3) Offline diagnostics: The same information as (2) is needed from Offline codes (running, for example, in the Online-EventPool environment) to perform more detailed analyses of the detector performance. (4) Offline calibrations: The conditions/DB data represent the finest grained & most fundamental set of data from which detector calibrations are evaluated (excepting, of course, for the event data). The Conditions data is input to the production of Calibration data and, in some cases, Calibration data may simply be the re-time-stamp of Conditions data by the time interval of the Calibration's stability rather than that of some automated snap-shot frequency. |
Configurations Database
| Description:
The Configuration Database serves as the repository of detector-hardware "set-points". This repository is used to quickly configure the systems via several standard "named" configurations. The important characteristics of the Configuration/DB are;
There are essentially 3 types of use scenarios for the configurations database. (1) Online Registration: A configuration for a sub-system is created through the Online SubSystem Server control by direct manipulation of the subsystem operator. That is, a "tree-structured" object catalog is edited to specify the "named" objects included in the configuration. The individual named objects can, if new, have input values specified or, if old, will be loaded as they are stored. The formed configuration can then be registered for later access by configuration name. There exists an Online GUI to perform these basic tasks (2) Online Configuration: Once registered, a configuration is made available for enabling the detector sybsystem as specified by the configuration's content. The Online RunServer control can requesta named configuration under the Online protocols and parse the subsytem Keys (named collection) to the subsystem servers which access the Configurations/DB directly. (3) Offline use: In general Offline codes will use information derived from the conditions/DB to perform reconstruction/analysis tasks (e.g. not the set-points but the measured points). However, some general information about the setup can be quickly obtained from the Configurations/DB as referenced from the RunLog. This will tell, for example, what set of detectors were enabled for the period in question. |
Calibrations Database
| Description:
The Calibration/DB contains data used to correct signals from the detectors into their physically interpretable form. This data is largely derived from the conditions/DB information and event data by reformulating such information into usefull quantities for reconstruction &/or analysis tasks. There are essentially 3 types of use scenarios for the calibrations database. (1) Offline in Online: It is envisioned that much of the calibration data will be done produced via Offline processing running in the Online Event-Pool. These calibration runs will be fed some fraction of the real data produced by the DAQ Event-Builder. This data is then written or migrated into the Calibration/DB for use in Offline production and analyses. (2) Offline in Offline: Further reprocessing of the data in the Offline environment, again with specific calibration codes, can be done to produce additional calibration data. This work will include refinements to original calibration data with further iterations or via access on data not available in the Online Event Pool. Again the calibration data produced is written or migrated to the calibration database which resides in Offline. (3) Offline reconstruction & analyses: The calibration data is used during production and analysis tasks in, essentially, a read-only mode. |
Geometry Database
| Description:
The Geometry database stores the geometrical description of the STAR detectors and systems. It is really part of the calibration database except that the time-constant associated with valid entries into the database will be much longer than typical calibration data. Also, it is expected that many applications will need geometrical data from a variety of sub-systems while not needing similar access to detector-specific (signal) calibration data. Thus the access interface to the geometry database should be segragated from the calibration database in order to optimize access to its data. There are a few generic categories of geometry uses that while not independent may suggest indecate differen access scenarios. (1) Offline Simulations: (2) Offline Reconstruction: (3) Offline Analyses & Event Displays: |
RunLog Database
| Description:
The RunLog holds the summary information describing the contents of an experimental run and "pointers" to the detailed information (data files) that are associated with the run. A more complete description can be found on the Online web pages. (1) Online Generation: The RunLog begins in Online which the run is registered, stored when the run is enabled, and updated when the run has ended. Furhter updates from Online may be necessary e.g. once verification is made as to the final store of the event data on HPSS. (2) Online (& Offline) Summaries: The RunLog can be loaded and properties displayed in order to assertain progress toward overall goals that span Runs. (3) Offline Navigation : The RunLog will have a transient representation in the offline infrustructure which will allow the processes to navigate to other database entities (i.e. Configurations & Scalers) |
Distributed Control System - Conditions
Distributed Control System - Conditions
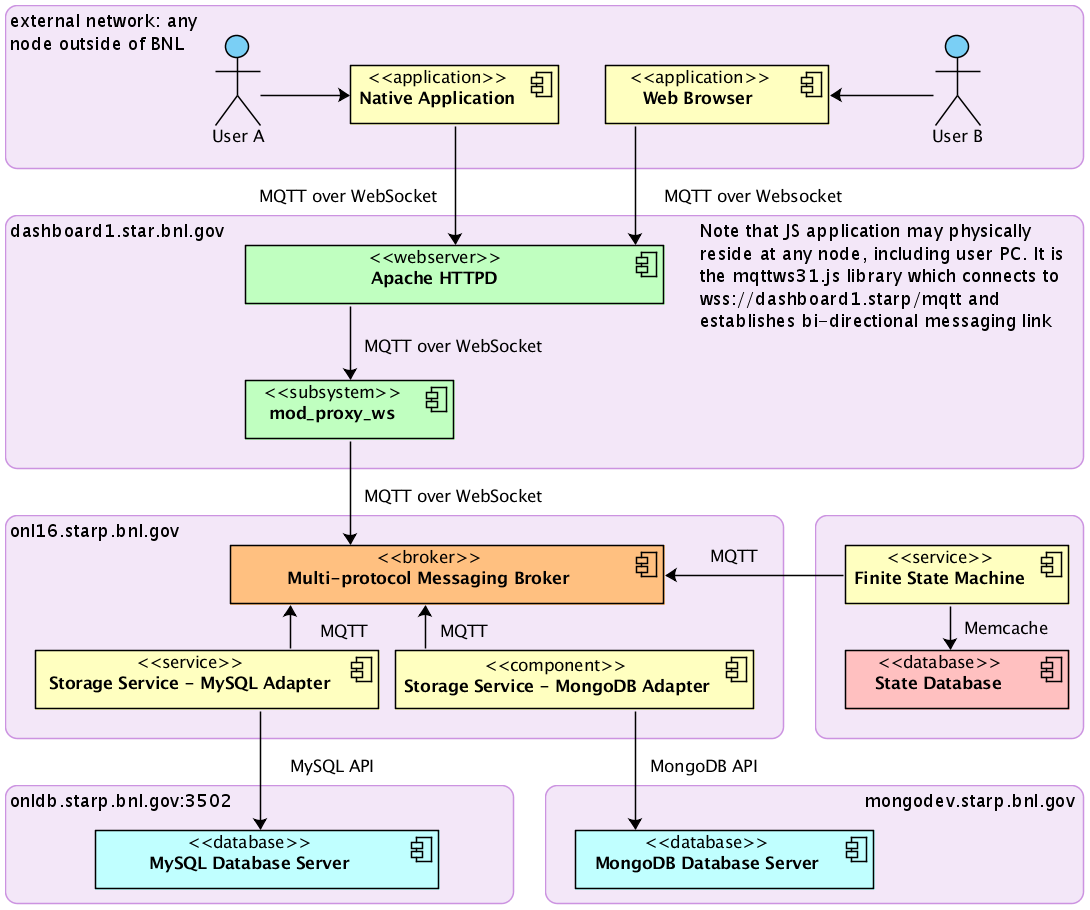
1. Intro: Conditions Database protocols using MQ-powered services. Typical workflow: sensor is booted, then it requests initial values from Conditions database, then it starts publishing updates on Conditions. At the same time, Web UI user may request to change Conditions for a specific sensor, and receive real-time updates on changes made by sensor.
2. Participating entities: Sensor, Storage service, Web UI (+ mq broker, mysql database)
2.1 Physical deployment details:
- Sensor = code running in the online domain (daq network), TBD
- Storage Service = C++ daemon, storage adapter handling MySQL (+MongoDB later on). Runs at onl16.starp.bnl.gov under 'dmitry' account
- Web UI = can be run from anywhere, given that it has access to https://dashboard1.star.bnl.gov/mqtt/ for mqtt proxy service. E.g. https://dashboard1.star.bnl.gov/dcs/ . Allows to read and update (time-series versioned, so all updates are inserts) predefined Conditions structures.
- MQ Broker = multi-protocol broker (Apache Apollo), running at onl16.starp.bnl.gov
- MySQL service, holding Conditions database. For now, online conditions database is used. It runs at onldb.starp.bnl.gov:3501, Conditions_fps/<bla>
3. Protocols:
- transport protocol: MQTT (sensors, storage), WebSocket + MQTT (web ui)
- message serialization protocol: JSON
4. Data Request API:
- REGISTER, SET, GET, STORAGE, SENSOR
(see examples below the service layout image)
4.1 Example: to SET value (received by sensor and storage) :
topic: dcs/set/Conditions/fps/fps_fee
message:
{
dcs_id: "<client_unique_id>",
dcs_uid: "<authenticated_login>",
dcs_header: ["field1", "field2", ... "fieldN"],
dcs_values: {
<row_id1>: [ value1, value2, ... valueN ],
...
<row_idN>: [ value1, value2, ... valueN ]
}
}
NOTE: one can set any combination of fields vs row ids, including one specific field and one specific row id.
4.2 Example: to GET values:
topic: dcs/get/Conditions/fps/fps_fee
message:
{
dcs_id: "<client_unique_id>",
dcs_uid: "<authenticated_login>",
dcs_header: ["field1", "field2" ... "fieldN"], // alternatively, ["*"] to get all available fields
dcs_values: {
"1": true, // <-- request row_id = 1, alternatively, do dcs_values = {} to get all avaliable rows
"2": true,
...
"N": true
}
}
NOTE: one can request any combination of fields vs row ids, including one specific field and one specific row id.
4.3 Example: subscribe to response from storage:
topic: dcs/storage/Conditions/fps/fps_fee
message:
{
dcs_id: "<client_unique_id>",
dcs_uid: "<authenticated_login>",
dcs_header: ["field1", "field2", ... "fieldN"],
dcs_values: {
<row_id1>: [ value1, value2, ... valueN ],
...
<row_idN>: [ value1, value2, ... valueN ]
}
}
DCS Interface & Behaviors
1. Hardware / PLC commands:
Format: COMMAND ( parameter1, parameter2, ... parameterN) = <description>
PV GET / SET:
- GET ( <list of PV names>, <reply-to address>)
- Requests cached value information.
- Reply instantly with the value from the in-memory copy, with name-value pairs for the requested PVs.
- If reply-to address exists, reply to the private address instead of a public channel.
- SET ( <list of PV name-value pairs> )
- Set values for the provided channels, if allowed to by internal configuration
PV SCANS:
- SCAN ( <list of PV names>, <group_reply = true|false>, <time_interval>, <reply-to address> )
- Requests one-time (if time_interval = 0) or periodic (if time_interval != 0) scan of live values.
- Register SCAN in a scan list: read out live values one by one.
- If group = true, reply once when all channels are scanned, otherwise send out individual updates.
- Reply instantly with registered SCAN_ID. If reply-to address provided, reply to the private channel instead of a public one.
- SCAN_CANCEL ( <SCAN_ID> )
- cancel existing scan for SCAN_ID if exists
- SCAN_MODIFY ( <SCAN_ID>, <group_reply = true|false>, <time_interval = milliseconds>, <reply-to address> )
- modify parameters of the defined scan
INFORMATIONAL:
- INFO_SYSTEM ()
- return the following:
- current state of the HW;
- configuration information for this HW;
- return the following:
- INFO_PV ( < pv_name = undefined | list of pv names > )
- if < pv_name = undefined >, return list of all configured PVs and their types;
- INFO_SCAN ( < scan_id = undefined | list of scan_ids > )
- if < scan_id = undefined > return list of all configured periodic scans from scan list, otherwise return specified scan details;
- if < scan_id = undefined > return list of all one-time scans remaining in a scan queue, otherwise return specified scan details;
OPERATIONAL:
- RESET ()
- clear all internal state variables, re-read configuration, restart operations from clean state.
- REBOOT ()
- request physical reboot of the device, if possible.
- reply with "confirmed" / "not available"
- ON ()
- request power up the device, if possible
- reply with "confirmed" / "not available"
- OFF ()
- request power off the device, if possible
- reply with "confirmed" / "not available"
2. HW internal organization:
NOTE: global variables, related to controller operations
- CONFIGURATION = list of [ < pv_name = STR > , <pv_type = INT | DBL | STR > , <pv_initial_value> , <pv_current_value> , <pv_flag = READ | WRITE | RW > ]
- i.e. list of controlled parameters;
- SCAN_LIST = list of < scan_item = [ ID, list of PV names, group = true | false, time_interval != 0, reply-to address, last_scan_ts ] >
- List/vector of registered periodic scans;
- SCAN_QUEUE = queue of <scan_item = [ ID, list of PV names, group = true | false, time_interval = 0, reply-to address ] >
- Queue of requested one-time scans;
- DEVICE_STATE = < int = ON | OFF >
- current global state of the controlled device
- DEVICE_OPERATION = < IDLE | GETTING | SETTING | SCANNING | POWERING_UP | POWERING_DOWN | RESETTING | REBOOTING >
- device current operation flag
- DEVICE_ID = < char_string >
- unique id of the controlled device
3. HW internal operations:
NOTE: implemented using FSM
I. BOOT sequence
- INITIALIZE core parameters (device info, scan list/queue, device state)
- POPULATE list of controlled variables
- SETUP persistent scans, if requested
- GO to OPERATING sequence
II. OPERATING sequence
- LISTEN for incoming commands for <N> microseconds (aka IDLE)
- if NETWORK ERROR occurs = pause OPERATING sequence, try RECONNECT to MQ in <N> seconds
- if RECONNECT succeeded = resume OPERATING sequence
- else GO to (1.1)
- IF external <comand> received within time interval, call <command> processing code
- ELSE proceed with <scan_queue> and <scan_list> processing
- LOOP to (1)
III. SHUTDOWN sequence
- CLEANUP internal state
- DESTROY internal objects
- DISCONNECT from MQ service
- call POWER OFF routine
DCS protocol v1
DCS protocol v1
modeled after RESTful principles and Open Smart Grid Protocol
courtesy of Yulia Zulkarneeva, Quinta Plus Technologies LLC
I. TOPIC: <site_uid> / <protocol> / <version> / <method> / <Process_Variable_URI>
topic example: BNLSTAR / DCS / 1 / GET / Conditions / fps / fee
II. MESSAGE contents: request body, encoded as JSON/txt or MsgPack/bin formats
a) message example: {
"uid": "<client-uid>",
"header": [ <column_name_A>, <column_name_B> ],
"values": {
"<offset_0>" : [ <value_for_A>,<value_for_B> ]
"<offset_N>" : [ <value_for_A>,<value_for_B> ]
}
}
..or..
b) message: {
"uid": "<client-uid>",
"values": {
"<column_name_A>.<offset_A>" : 3,
"<column_name_B>.<offset_B>.<offset_B_at_bit_level>" : 1
}
}
example: BNLSTAR / DCS / 1.0 / GET / Conditions / fps / fee
message: { "uid": "unique-identifier-of-the-client", "ts": 12345678 }
example: BNLSTAR / DCS / 1.0 / SET / Conditions / fps / fee
message: { "uid": "<client-uid>", "header": [A,B], "values": { "0" : [1,2] } }
message: { "uid": "<client-uid>", "values": { "A.0" : 1, "B.0" : 2 } }
III. METHODS
| METHOD | DESCRIPTION | NOTES |
|---|---|---|
| standard methods | ||
| GET | get latest entry => either storage or sensor may reply via personal REPLY | |
| PUT | store new entry | |
| POST | sensor entry change update | |
| DELETE | delete [latest] entry | |
| HEAD | request schema descriptor only, without data | |
| PATCH | modify schema descriptor properties | |
| OPTIONS | get supported methods | |
| extra methods | ||
| REPLY | personal reply address in REQUEST / RESPONSE pattern. Ex. topic: DCS / REPLY / <CLIENT_UID>. Example: COMMAND acknowledgements, GET replies | |
| COMMAND | commands from control system: ON / OFF / REBOOT / POWEROFF | |
| STATUS | retrieve status of the device: ON / OFF / REBOOT / POWEROFF / BUSY | |
Search capabilities
Search (essentially, Filter) Capabilities and Use-Cases
To request filtering of the result, special field could be added to the request body: "dcs_filter". Contents of the "dcs_filter" define the rules of filtering - see below.
-------------------------------------------------------------
[x] 1. Constraint: WHERE ( A = B )
dcs_filter: { "A" : B }
[x] 2. Constraint: WHERE ( A = B && C = "D" )
dcs_filter: { "A": B, "C": "D" }
[x] 3. Constraint: WHERE ( A = B || C = "D" )
dcs_filter: {
'_or': { "A": B, "C": "D" }
}
[x] 4. Constraint: WHERE ( A = B || A = C || A = D )
dcs_filter: {
"A": {
'_in': [ B, C, D ]
}
}
[x] 5. Constraint: WHERE ( A = B && ( C = D || E = F ) )
dcs_filter: {
"A": B,
"_or" : { C: D, E: F }
}
-------------------------------------------------------------
[x] 6.1 Constraint: WHERE ( A > B )
dcs_filter: {
A: { '_gt': B }
}
[x] 6.2 Constraint: WHERE ( A >= B )
dcs_filter: {
A: { '_ge': B }
}
[x] 7.1 Constraint: WHERE ( A < B )
dcs_filter: {
A: { '_gt': B }
}
[x] 7.2 Constraint: WHERE ( A <= B )
dcs_filter: {
A: { '_ge': B }
}
[x] 8. Constraint: WHERE ( A > B && A < C )
dcs_filter: {
A: { '_gt': B, '_lt': C }
}
-------------------------------------------------------------
...To Be Continued
Enhanced Logger Infrastructure
Enhanced Logger Infrastructure
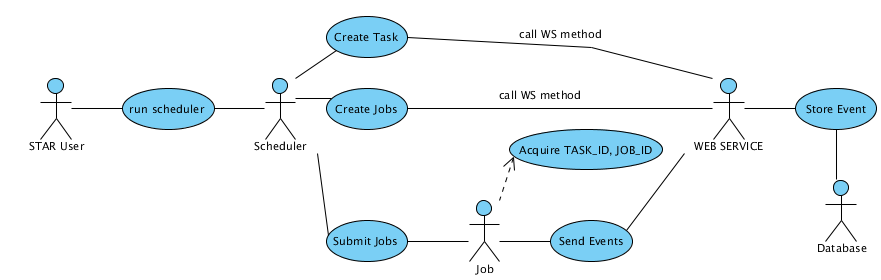
Use-Case Diagram
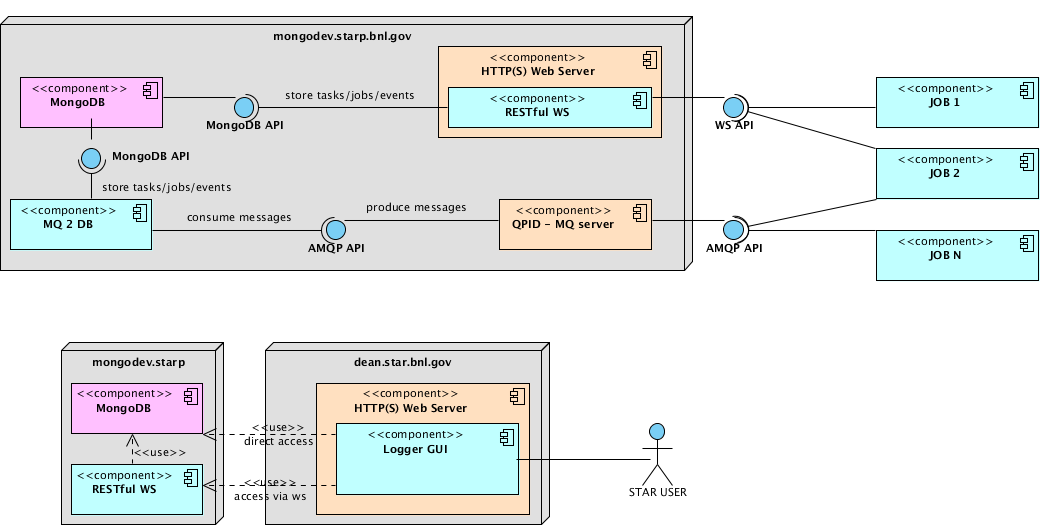
Deployment Diagram
IRMIS
Irmis
Instalation Recipe
- install MySQL & setup (set admin password, set user, set user password, set database called irmis, etc)
- download and install Java (/home/sysuser/jre-1_5_0_09-linux-i586-rpm.bin)
- download and install Mysql connector/j (I installed that in /usr/java/jre1.5.0_09/lib)
- download and install irmis somewhere (I installed in /usr/local/irmisBase)
- download and install ant 1.6 (apache-ant-1.6.5-bin.zip in /usr/local/apache-ant-1.6.5/)
- setup MySQL:
- mysql -u root -p < ./create_aps_ioc_table.sql
- mysql irmis -u root -p < ./create_component_enum_tables.sql
- mysql irmis -u root -p < ./create_component_tables.sql
- mysql irmis -u root -p < ./create_pv_client_enum_tables.sql
- mysql irmis -u root -p < ./create_pv_client_tables.sql
- mysql irmis -u root -p < ./create_pv_enum_tables.sql
- mysql irmis -u root -p < ./create_pv_tables.sql
- mysql irmis -u root -p < ./create_shared_enum_tables.sql
- mysql irmis -u root -p < ./create_shared_tables.sql
- mysql irmis -u root -p < ./alter_aps_ioc_table.sql
- mysql irmis -u root -p < ./alter_component_tables.sql
- mysql irmis -u root -p < ./alter_pv_client_tables.sql
- mysql irmis -u root -p < ./alter_pv_tables.sql
- mysql irmis -u root -p < ./alter_shared_tables.sql
- mysql irmis -u root -p < ./populate_form_factor.sql
- mysql irmis -u root -p < ./populate_function.sql
- mysql irmis -u root -p < ./populate_mfg.sql
- mysql irmis -u root -p < ./populate_component_type_if_type.sql
- mysql irmis -u root -p < ./populate_base_component_types.sql
- mysql irmis -u root -p < ./populate_core_components.sql
- edit site.build.properties file to reflect the local configuration.
- db.connection.host=localhost
- db.connection.database=irmis
- db.connection.url=jdbc:mysql://localhost:3306/irmis
- db.trust-read-write.username=MySQL user name
- db.trust-read-write.password=MySQL user password
- irmis.codebase=http://localhost/irmis2/idt
- build irmis as described in the README file:
- cd db
- ant deploy
- cd apps
- ant deploy
- run irmis desktop:
- cd apps/deploy
- tar xvf irmisDeploy.tar
- java -jar irmis.jar
- untar various crawlers located at /usr/local/irmisBase/db/deploy as well as make whatever necessary local changes accordingly.
Load Balancer
---
Configuration File
Load Balancer Configuration File
Local Configuration:
This file is for sites that have a pool of database servers they would like to load balance between (e.g., BNL, PDSF).
This file should be pointed to by the environmental variable DB_SERVER_LOCAL_CONFIG.
Please replace the DNS names of the nodes in the pools with your nodes/slave. Pools can be added and removed with out any problems but the needs to be at least one pool of available slaves for general load balancing.
Below is a sample xml with annotations:
<!--Below is a pool of servers accessble only by user priv2 in read only mode
This pool would be used for production or any other type of operation that needed
exclusive access to a group of nodes
--!>
<Server scope="Production" user="priv2" accessMode="read">
<Host name="db02.star.bnl.gov" port="3316"/>
<Host name="db03.star.bnl.gov" port="3316"/>
<Host name="db04.star.bnl.gov" port="3316"/>
<Host name="db05.star.bnl.gov" port="3316"/>
</Server>
<!--Below is a pool of servers access by ANYBODY in read only mode
This pool is for general consumption
--!>
<Server scope="Analysis" accessMode="read">
<Host name="db07.star.bnl.gov" port="3316"/>
<Host name="db06.star.bnl.gov" port="3316"/>
<Host name="db08.star.bnl.gov" port="3316"/>
</Server>
<!--Below is an example of Pool (one in this case) of nodes that Only becone active at "Night"
Night is between 11 pm and 7 am relative to the local system clock
--!>
<Server scope="Analysis" whenActive="night" accessMode="read">
<Host name="db01.star.bnl.gov" port="3316"/>
</Server>
<!--Below is an example of Pool (one in this case) of nodes that is reserved for the for users assigned to it.
This is useful for a development node.
--!>
<Server scope="Analysis" user="john,paul,george,ringo" accessMode="read">
<Host name="db01.star.bnl.gov" port="3316"/>
</Server>
<!--Below is an example of Pool (one in this case) of nodes that is reserved for write. Outside of BNL, this should only be allowed on
nodes ONLY being used for development and debugging. At BNL this is reserved for the MASTER. The element accessMode corresponds
to an environmental variable which is set to read by default
--!>
<Server scope="Analysis" accessMode="write">
<Host name="robinson.star.bnl.gov" port="3306"/>
</Server>
</Scatalog>
The label assigned to scope does not matter to the code, it is for bookkeeping purposes only.
Nodes can be moved in and out of pools at the administrators discretion. A node can also be a member of more than one pool.
a list of possible features is as follows:
for Sever - attributes are:
- scope
- accessMode
- whenActive
- user
host - attributes are:
- name
- port
- machinePower
- cap
Machine power is a weighting mechanism - determining the percentage of jobs that an administrator wants to direct to a particular node. The default value =1, So
a machine power of 100 means most requests will go to that node also a machinePower of 0.1 means propotional to the other nodes very few requests will go to that node.
For example
<Server scope="Analysis" whenActive="night" accessMode="read">
<Host name="db1.star.bnl.gov" port="3316" machinePower = 90/>
<Host name="db2.star.bnl.gov" port="3316"/>
<Host name="db3.star.bnl.gov" port="3316" machinePower = 10/>
</Server>
says that node db1 will get most requests
db2 almost nothing (default value = 1)
db3 very few requests
Cap is a limit of connections allowed on a particular node
Please refer to the attached paper for detailed discussion about each of these attributes/features.

Load Balancer Connection
The load balancer makes its decision as to which node to connect to, based on the number of active connections on each node.
It will choose the node with the least number of connections.
In order to do this it must make a connection to each node in a group.
The load balancer will need an account on the database server with a password associated with it.
The account is:
user = loadbalancer
please contact an administrator for the password associated with the account.
631-344-2499
The load this operation creates is minimal.
so
something like
grant process on *.* to 'loadbalancer'@'%.bnl.gov' identified by 'CALL 631-344-2499';
of coarse the location should be local.
MIRA: Fake IOC Development
Minutes from the meeting ( 2016-05-16 )
Attendees: Jerome, Tonko, Dmitry A.Discussion Topic: MIRA upgrade related to the Run 17 TPC controls upgrade planned by Tonko
Brief summary: Tonko wants Dmitry to create a Fake EPICS IOC service in MIRA, which will allow to emulate the existing EPICS IOCs controllling TPC gating grid. Internally, this emulator will convert all EPICS requests into MQTT calls, which allows Tonko to use MIRA/MQTT functionality directly while keeping EPICS/MEDM TPC Control UI as is for the transition period.
=========================================================
1. Details:
Current conditions: TPC gating grid hardware is controlled by EPICS TPC IOC. Users issue commands using EPICS/MEDM graphical interface (desktop app).
Proposed upgrade: replace EPICS TPC IOC with new MIRA-compatible service developed by Tonko, while keeping EPICS UI functional until we come up with proper replacement, likely web-based MIRA interface.
Action Item: Dmitry needs to develop an emulator of EPICS IOC, which will transparently convert EPICS requests into MQTT/MIRA requests and vice versa.
Deadline: Tonko wants to see draft version implemented by December 2016, so we can test it before the Run 17. Final version (both DAQ side and Controls side) is expected to be delivered by the beginning of first physics events of Run 17.
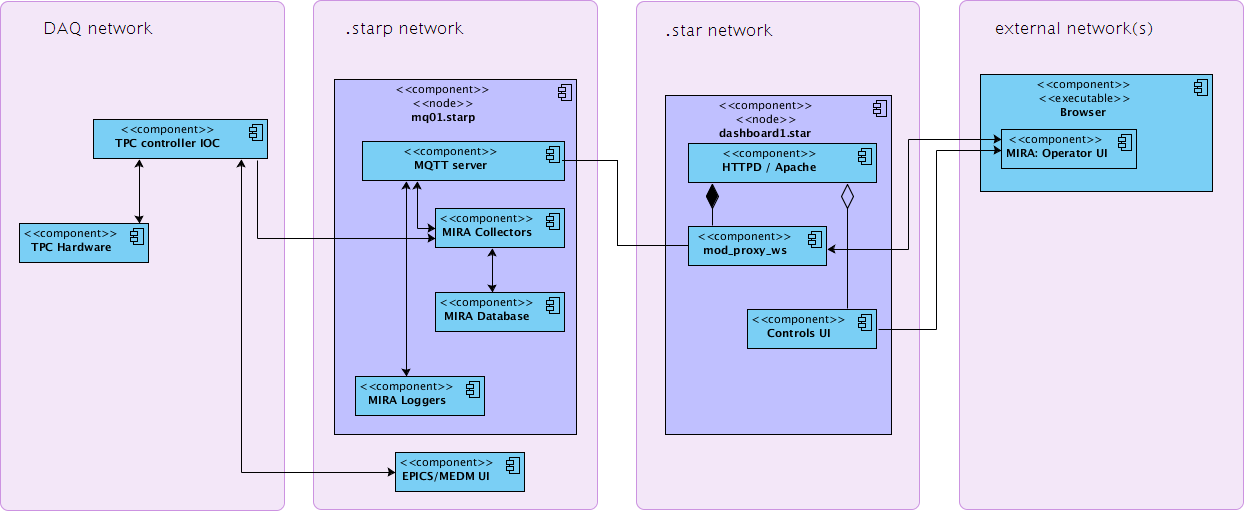
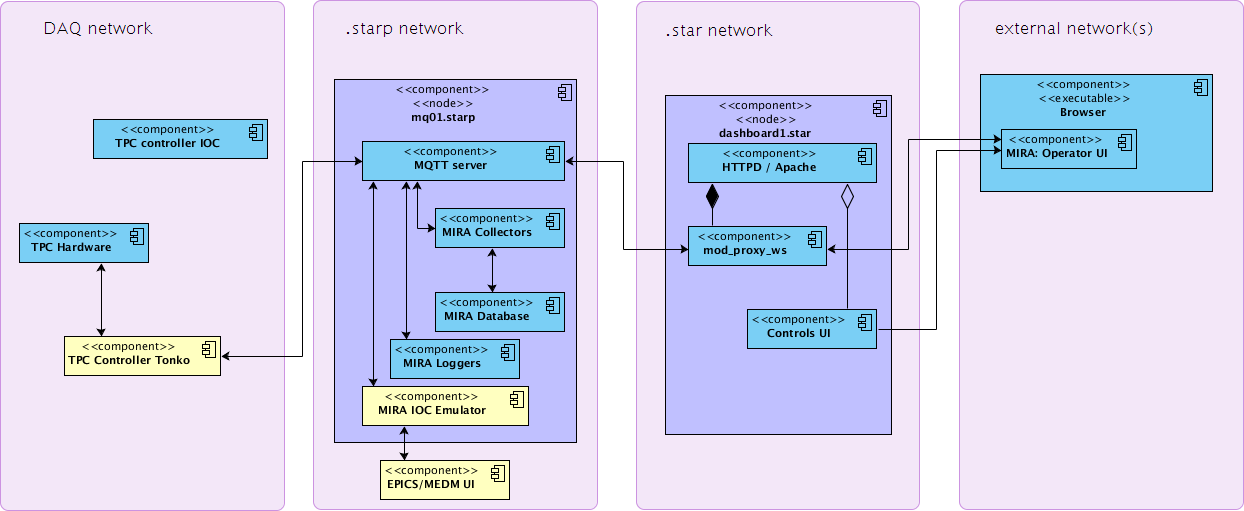
Possible Show-stopper: Currently, MIRA is limited to two nodes - mq01,mq02. Both nodes serve multiple roles, and have the following set of services installed: MQTT server, AMQP server, MIRA EPICS->MQ collectors, CDEV->MQ collectors, MQ->DB logger, MQTT->WebSocket forwarding service. Functioning EPICS IOC emulator will require a permanent binding to EPICS-specific TCP/UDP ports, which may (TBC) prevent existing EPICS->MQ collectors from being functional as they also use those ports. If this suspicion is confirmed (Dmitry), then IOC emulator service will require a separate node to be provided.
2. Diagrams:
Existing MIRA setup (before) :
Proposed MIRA upgrade (after) :
Online API
---
PXL database design
Pixel Status Mask Database Design
I. Overall stats:
- 400 sensors (10 sectors, 4 ladders per sector, 10 sensors per ladder)
- 960 columns vs 928 rows per sensor
- 400 x 960 x 928 = 357M individual channels in total
II. Definitions :
PXL status may have the following flags (from various sources):
1. Sensors:
- good
- perfect
- good but hot (?)
- bad (over 50% hot/missing)
- hot (less than 5% hot?)
- dead (no hits)
- other
- missing (not installed)
- non-uniform (less than 50% channels hot/missing)
- low efficiency (num entries very low after masking)
- good
- bad (over 20% bad pixels hot)
- expect: ~30 bad row/columns per sensor
- good
- bad (hot fires > 0.5% of the time)
- what exactly is hot pixel? Is it electronic noise or just background (hits from soft curlers)?
- is it persistent across runs or every run has its own set of hot individual pixels?
- is it possible to suppress it at DAQ level?
1. Generic observations:
- PXL status changes a lot in-between runs, thus "only a few channels change" paradigm cannot be aplied => no "indexed" tables possible
- Original design is flawed:
- we do not use .C or .root files in production mode, it is designed for debugging purposes only and has severe limitations;
- real database performs lookups back in time for "indexed" tables, which means one has to insert "now channel is good again" entries => huge dataset;
- hardcoded array sizes rely on preliminary results from Run 13, but do not guarantee anything for Run 14 (i.e. what if > 2000 pixels / sector will be hot in Run 14?);
- uchar/ushort sensors[400]; // easy one, status is one byte, bitmask with 8/16 overlapping states;
- matches the one from original design, hard to make any additional suggestions here..
- observations:
- seems to be either good or bad (binary flag)
- we expect ~10 masked rows per sector on average (needs proof)
- only bad rows recorded, others are considered good by default
- ROWS: std::vector<int row_id> => BINARY OBJ / BLOB + length => serialized list like "<id1>,<id2>..<idN>" => "124,532,5556"
- row_id => 928*<sensor_id> + k
- insert into std::map<int row_id, bool flag> after deserialization
- COLS: std::vector<int col_id> => BINARY OBJ / BLOB + length => ..same as rows..
- col_id => 960*<sensor_id> + k
- insert into std::map<int col_id, bool flag> after deserialization
- observation:
- seems to be either good or bad (binary flag)
- no "easy'n'simple" way to serialize 357M entries in C++
- 400 sensors, up to 2000 entries each, average is 1.6 channels per sector (???)
- store std::vector<uint pxl_id> as BINARY OBJ / BLOB + length;
- <pxl_id> = <row_id>*<col_id>*<sensor_id> => 357M max
- it is fairly easy to gzip blob before storage, but will hardly help as data is not text..
- alternatively: use ROOT serialization, but this adds overhead, and won't allow non-ROOT readout, thus not recommended;
Note: I investigated source codes for StPxlDbMaker, and found that Rows / Columns are accessed by scanning an array of std::vectors:
STAR DB API v2
STAR DB API v2
This page holds STAR database API v2 progress. Here are major milestones :
- Components Overview (UML)
- Core Components technology choice:
- [done] New version of XML configuration file + XML Schema for verification (.xsd available, see attachment);
- [done] New XML parser library :
- [done] rapidXML (header-only, fast, non-validating parser) - will use this one as a start;
- [not done] xerces-c (huge, validating, slow parser);
- [done] Encryption support for XML configuration :
- [done] XOR-SHIFT-BASE64;
- [done] AES128, AES256;
- [CYPHER-TYPE]-V1 means that [CYPHER-TYPE] was used with parameter set 1 (e.g.: predefined AES key 'ABC');
- [done] Threads support for Load Balancer, Data preload, Cache search
- pthreads - popular, widely used;
- pthreads - popular, widely used;
- [done] Database Abstraction Layer reshape :
- OpenDBX (MySQL, Postresql, Sqlite3, Oracle) - API level abstraction, will require "personalized" sql queries for our system;
- [done] In-memory cache support [requires C++ -> DB -> C++ codec update]:
- memcached (local/global, persistent, with expiration time setting);
- simple hashmap (local - in memory cache, per job, non-persistent);
- [in progress] Persistent cache support :
- hypercache (local, persistent, timestamped, file-based cache);
- Supported Features list
- OFFLINE DB: read-heavy
- ONLINE DB: write-heavy
- AOB
--------------------------------------------------------------------------------------------------------------
New Load Balancer (abstract interface + db-specific modules) :
- dbServers.xml, v1, v2 xml config support;
- db load : number of running threads;
- db load : response time;
- should account for slave lag;
- should allow multiple instances with different tasks and databases (e.g. one for read, another for write);
- should randomize requests if multiple "free" nodes found;
OPEN QUESTIONS
Should we support <databases></databases> tag with new configuration schema?
<StDbServer>
<server> run2003 </server>
<host> onldb.starp.bnl.gov </host>
<port> 3501 </port>
<socket> /tmp/mysql.3501.sock </socket>
<databases> RunLog, Conditions_rts, Scalers_onl, Scalers_rts </databases>
</StDbServer>Hypercache ideas and plans
--- HYPERCACHE ---
Definitions :
1. persistent representation of STAR Offline db on disk;
2. "database on demand" feature;
Each STAR Offline DB request is :
- fetched from original db server by timestamp (or run number);
- stored on disk in some format for later use;
- subsequent requests check disk cache first, try db next, eventually building local db cache accessible by db name/table + timestamp;
3. data on disk is to be partitioned by :
a) "db path" AND ("validity time" OR "run number");
POSSIBLE IMPLEMENTATIONS:
a) local sqlite3 database + data blobs as separate files, SINGLE index file like "/tmp/STAR/offline.sqlite3.cache" for ALL requests;
b) local sqlite3 database + data blobs as separate files, MULTIPLE index files, one per request path. Say, request is "bemc/mapping/2003/emcPed", therefore, we will have "/tmp/STAR/sha1(request_path).sqlite3.cache" file for all data entries;
c) local embedded MySQL server (possibly, standalone app) + data blobs as separate files;
d) other in-house developed solution;
-----------------------------------------------------------------------------------------------------------------------------
SQLITE 3 database table format : [char sha1( path_within_subsystem ) ] [timestamp: beginTime] [timestamp: endTime] [seconds: expire] [char: flavor]
SQLITE 3 table file : /tmp/STAR_OFFLINE_DB/ sha1 ( [POOL] / [DOMAIN] / [SUBSYSTEM] ) / index.cache
SQLITE 3 blob is located at : /tmp/STAR_OFFLINE_DB/ sha1 ( [POOL] / [DOMAIN] / [SUBSYSTEM] ) / [SEGMENT] / sha1( [path_within_subsystem][beginTime][endTime] ).blob.cache
[SEGMENT] = int [0]...[N], for faster filesystem access
database access abstraction libraries overview
| Name | Backends | C/C++ | Linux/Mac version | Multithreading lib/drivers | RPM available | Performance | Licence |
| OpenDBX | Oracle,MySQL, PostgreSQL, Sqlite3 + more | yes/yes | yes/yes | yes/yes | yes/authors | fast, close to native drivers | LGPL |
| libDBI | MySQL, PostgreSQL, Sqlite3 | yes/external | yes/yes | yes/some | yes/Fedora | fast, close to native drivers | LGPL/GPL |
| SOCI | Oracle,MySQL, PostgreSQL | no/yes | yes/yes | no/partial | yes/Fedora | average to slow | Boost |
| unixODBC | ALL known RDBMS | yes/external | yes/yes | yes/yes | yes/RHEL | slow | LGPL |
While other alternatives exist ( e.g. OTL,QT/QSql ), I'd like to keep abstraction layer as thin as possible, so my choice is OpenDBX. It supports all databases we plan to use in a mid-term (MySQL, Oracle, PostreSQL, Sqlite3) and provides both C and C++ APIs in a single package with minimal dependencies on other packages.
STAR Online Services Aggregator
STAR Online Services Aggregator
STAR @ RHIC v0.4.0
1. DESCRIPTION
STAR @ RHIC is cross-platform application, available for Web, Android, WinPhone, Windows, Mac and Linux operating systems, which provides a convenient aggregated access to various STAR Online tools, publicly available at STAR collaboration website(s).
STAR @ RHIC is the HTML5 app, packaged for Android platform using Crosswalk, a HTML application runtime, optimized for performance (ARM+x86 packages, ~50 MB installed). Crosswalk project was founded by Intel's Open Source Technology Center. Alternative packaging (Android universal, ~5 MB, WinPhone ~5 MB) is done via PhoneGap build service, which is not hardware-dependent, as it does not package any html engine, but it could be affected by system updates. Desktop OS packaging is done using NodeWebKit (NW.js) software.
Security: This application requires STAR protected password to function (asks user at start). All data transmissions are protected by Secure Socket Layer (SSL) encryption.
Source code is included within packages, and is also available at CVS location
Try web version using this link.
2. DOWNLOADS
2.1 Smartphones, Tablets
All packages are using self-signed certificates, so users will have to allow such packages explicitly at OS level otherwise they will not be installed. All app versions require just two permissions: network discovery and network access.- ANDROID app, optimized for ARM processors
- ANDROID app, optimized for x86 processors
- ANDROID app, universal, non-optimized
- WINPHONE app, universal
Note: sorry iOS users (iPhone, iPad) - Apple is very restrictive and does not allow to package or install applications using self-signed certificates. While there is a technical possibility to make iOS package of the application, it will cost ~$100/year to buy iOS developer access which includes certificate.
2.2 Desktop OS
Note: linux packages require fresh glibc library, and therefore are compable with RedHat 7 / Scientific 7 or latest Ubuntu distributions. Redhat 5/6 is NOT supported.STAR Online Status Viewer
STAR ONLINE Status Viewer
Location: development version of this viewer is located here : http://online.star.bnl.gov/dbPlots/
Rationale: STAR has many standalone scripts written to show online status of some specific subsystem during Run time. Usually, plots or histograms are created using either data from Online Database, or Slow Controls Archive or CDEV inteface. Almost every subsystem expert writes her own script, because no unified API/approach is available at the moment. I decided to provide generic plots for various subsystems data, recorded in online db by online collector daemons + some data fetched directly from SC Archive. SC Archive is used because STAR online database contains primarily subsystem-specific data like voltages, and completely ignores basic parameters like hall temperature and humidity (not required for calibrations). There is no intention to provide highly specialized routines for end-users (thus replacing existing tools like SPIN monitor), only basic display of collected values is presented.
Implementation:
- online.star.bnl.gov/dbPlots/ scripts use single configuration file to fetch data from online db slave, thus creating no load on primary online db;
- to reduce CPU load, gnuplot binary is used instead of php script to process data fetched from database and draw plots. This reduces overall CPU usage by x10 factor to only 2-3% of CPU per gnuplot call (negligible).
- Slow Controls data is processed in this way: a) cron-based script, located at onldb2(slave) is polling SC Archive every 5 minutes and writes data logs in a [timestamp] [value] format; b) gnuplot is called to process those files; c) images are shipped to dean.star.bnl.gov via NFS exported directory;
Maintenance: resulting tool is really easy to maintain, since it has only one config file for database, and only one config file for graphs information - setup time for a new Run is about 10 minutes. In addition, it is written in a forward-compatible way, so php version upgrade should not affect this viever.
Browser compatibility: Firefox, Konqueror, Safari, IE7+, Google Chrome are compatible. Most likely, old netscape should work fine too.
STAR database inrastructure improvements proposal
STAR database improvements proposal
D. Arhipkin
1. Monitoring strategy
Proposed database monitoring strategy suggests simultaneous host (hardware), OS and database monitoring to be able to prevent db problems early. Database service health and response time depends strongly on underlying OS health and hardware, therefore, solution, covering all aforementioned aspects needs to be implemented. While there are many tools available on a market today, I propose to use Nagios host and service monitoring tool.
Nagios is a powerful monitoring tool, designed to inform system administrators of the problems before end-users do. The monitoring daemon runs intermittent checks on hosts and services you specify using external "plugins" which return status information to Nagios. When problems are encountered, the daemon can send notifications out to administrative contacts in a variety of different ways (email, instant message, SMS, etc.). Current status information, historical logs, and reports can all be accessed via web browser.
Nagios is already in use at RCF. Combined the Nagios server ability to work in a slave mode, this will allow STAR to integrate into BNL ITD infrastructure smoothly.
Some of the Nagios features include:
Monitoring of network services (SMTP, POP3, HTTP, NNTP, PING, etc.)
Monitoring of host resources (processor load, disk and memory usage, running processes, log files, etc.)
Monitoring of environmental factors such as temperature
Simple plugin design that allows users to easily develop their own host and service checks
Ability to define network host hierarchy, allowing detection of and distinction between hosts that are down and those that are unreachable
Contact notifications when service or host problems occur and get resolved (via email, pager, or other user-defined method)
Optional escalation of host and service notifications to different contact groups
Ability to define event handlers to be run during service or host events for proactive problem resolution
Support for implementing redundant and distributed monitoring servers
External command interface that allows on-the-fly modifications to be made to the monitoring and notification behavior through the use of event handlers, the web interface, and third-party applications
Retention of host and service status across program restarts
Scheduled downtime for suppressing host and service notifications during periods of planned outages
Ability to acknowledge problems via the web interface
Web interface for viewing current network status, notification and problem history, log file, etc.
Simple authorization scheme that allows you restrict what users can see and do from the web interface
2. Backup strategy
There is an obvious need for unified, flexible and robust database backup system for STAR databases array. Databases are a part of growing STAR software infrastructure, and new backup system should be easy to manage and scalable enough to perform well under such circumstances
Zmanda Recovery Manager (MySQL ZRM, Community Edition) is suggested to be used, as it would be fully automated, reliable, uniform database backup and recovery method across all nodes. It also has an ability to restore from backup by tools included with standard MySQL package (for convenience). ZRM CE is a freely downloadable version of ZRM for MySQL, covered by GPL license.
ZRM allows to:
Schedule full and incremental logical or raw backups of your MySQL database
Centralized backup management
Perform backup that is the best match for your storage engine and your MySQL configuration
Get e-mail notification about status of your backups
Monitor and obtain reports about your backups (including RSS feeds)
Verify your backup images
Compress and encrypt your backup images
Implement Site or Application specific backup policies
Recover database easily to any point in time or to any particular database event
Custom plugins to tailor MySQL backups to your environment
ZRM CE is dedicated to use with MySQL only.
3. Standards compliance
OS compliance. Scientific Linux distributions comply to the Filesystem Hierarchy Standard (FHS), which consists of a set of requirements and guidelines for file and directory placement under UNIX-like operating systems. The guidelines are intended to support interoperability of applications, system administration tools, development tools, and scripts as well as greater uniformity of documentation for these systems. All MySQL databases used in STAR should be configured according to underlying OS standards like FHS to ensure effective OS and database administration during the db lifetime.
MySQL configuration recommendations. STAR MySQL servers should be configured in compliance to both MySQL for linux recommendations and MySQL server requirements. All configuration files should be complete (no parameters should be required from outer sources), and contain supplementary information about server primary purpose and dependent services (like database replication slaves).
References
http://www.zmanda.com/backup-mysql.html
http://proton.pathname.com/fhs/
Solid State Drives (SSD) vs. Serial Attached SCSI (SAS) vs. Dynamic Random Access Memory (DRAM)
INTRODUCTION
This page will provide summary of SSD vs SAS vs DRAM testing using SysBench tool. Results are grouped like this :
- FS IO performance tests;
- Simulated/artificial MySQL load tests;
- STAR Offline API load tests;
Filesystem IO results are important to understand several key aspects, like :
- system response to parallel multi-client access (read,write,mixed);
- cost estimation: $/IOP/s and $/MB of storage;
Simulated MySQL load test is critical to understand strengths and weaknesses of MySQL itself, deployed on a different types of storage. This test should provide baseline for real data (STAR Offline DB) performance measurements and tuning - MySQL settings could be different for SAS and SSD.
Finally, STAR Offline API load tests should represent real system behavior using SAS and SSD storage, and provide an estimate of the potential benefits of moving to SSD in our case of ~1000 parallel clients per second per db node (we have dozen of Offline DB nodes at the moment).
While we do not expect DRAM to become our primary storage component, these tests will allow to estimate the benefit of partial migration of our most-intensively used tables to volatile but fast storage.
Basic results of filesystem IO testing :
- Serial Attached SCSI drive testing results taken with default CFQ scheduler and noatime mount option;
- Solid State Drive testing results taken with default CFQ scheduler and noatime mount option;
- Dynamic Random Access Memory testing results
Summary :
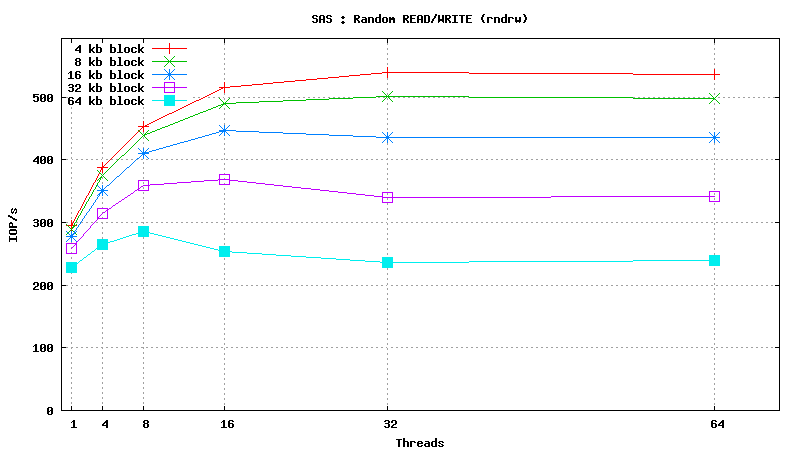
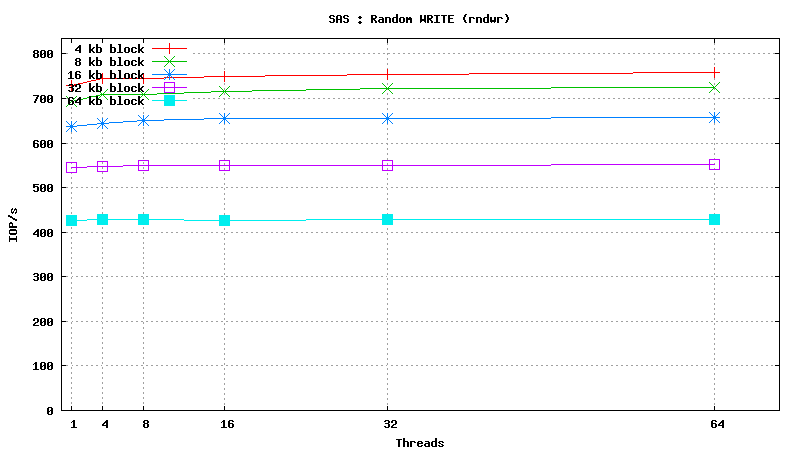
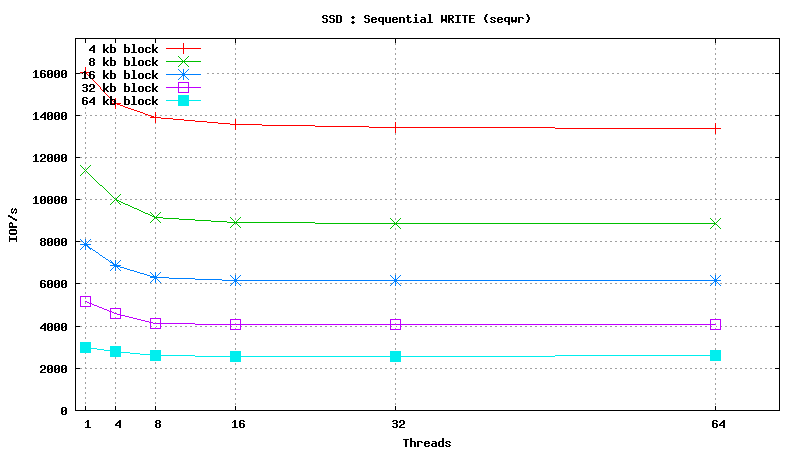
- DATABASE INDEX SEARCH or SPARSE DATA READ: SSD performs ~50 times better than SAS HDD in short random reads (64 threads, 4kb blocks, random read) : 24000 IOP/s vs 500 IOP/s
- SEQUENTIAL TABLE SCAN: SSD performs ~2 times better than SAS HDD in flat sequential reads (64 threads, 256kb blocks, sequential read) : 200 MB/s vs 90 MB/s
- DATABASE INSERT SPEED: SSD performs ~10 times better than SAS HDD in short random writes (64 threads, 4kb blocks, random write) : 6800 IOP/s vs 750 IOP/s
Simulated MySQL Load testing :
- Simulated DB Load : SAS
- Simulated DB Load : SSD
- Simulated DB Load : DRAM
- Simulated DB Load : DRAM vs SSD vs SAS
Summary : quite surprising results were uncovered.
- READONLY Operations : *ALL* Drives show roughly identical performance! Does it mean that MySQL treats all drives as SAS by default (Query Optimizer), or synthetic test is not quite great for benchmarking? Real data testing to follow...
- Mixed READ/WRITE Operations: SSD and DRAM results are practically identical, and SAS is x2 slower than SSD/DRAM!
STAR Offline DB testing :
TBD
Summary :
CONCLUSIONS:
TBD
Dynamic Random Access Memory testing results
SysBench results for tmpfs using 6 GB of DRAM
[ SAMSUNG DDR3-1333 MHz (0.8 ns) DIMM, part number : M393B5673DZ1-CH9 ]
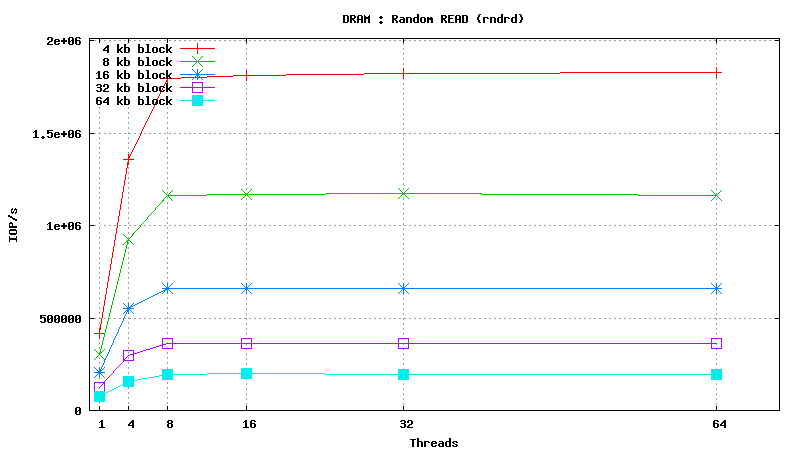
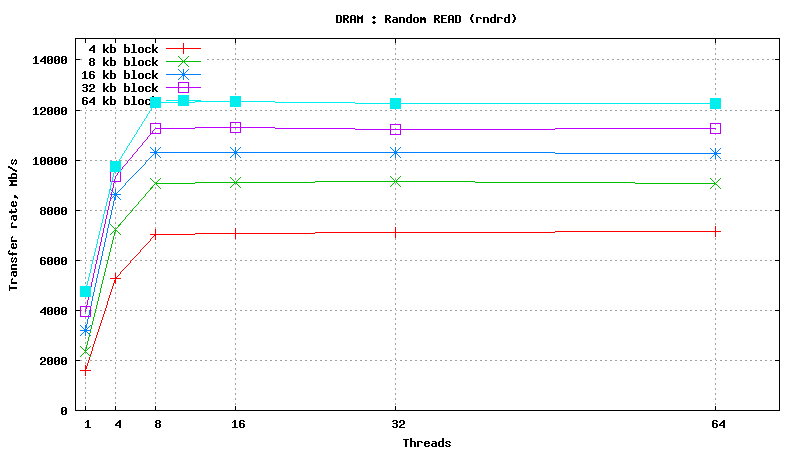
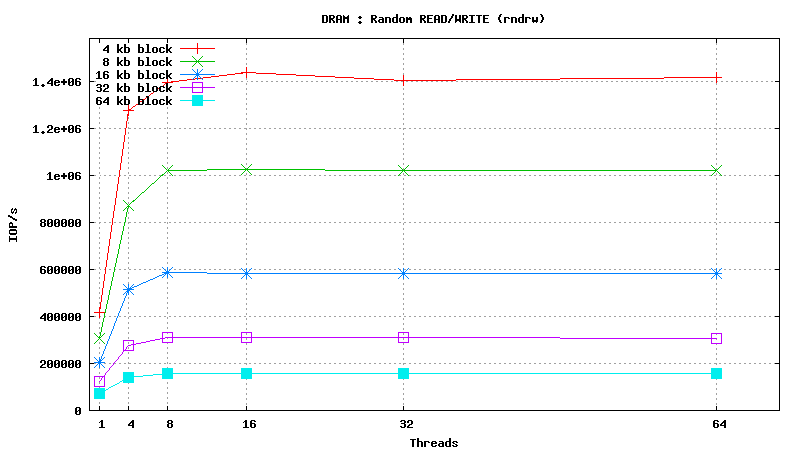
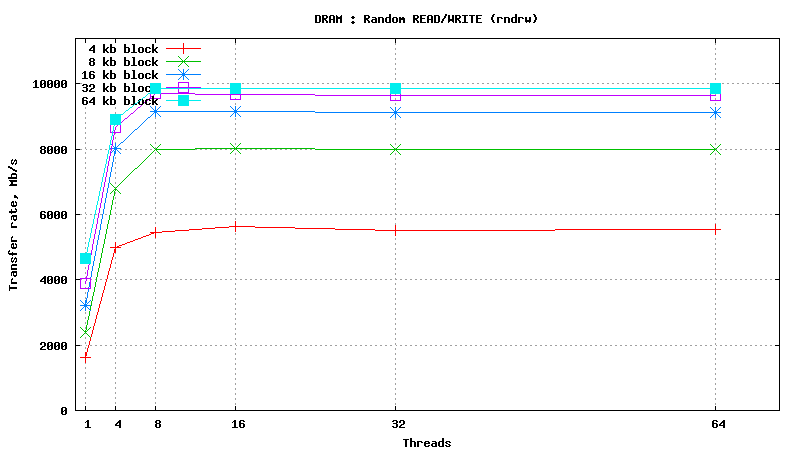
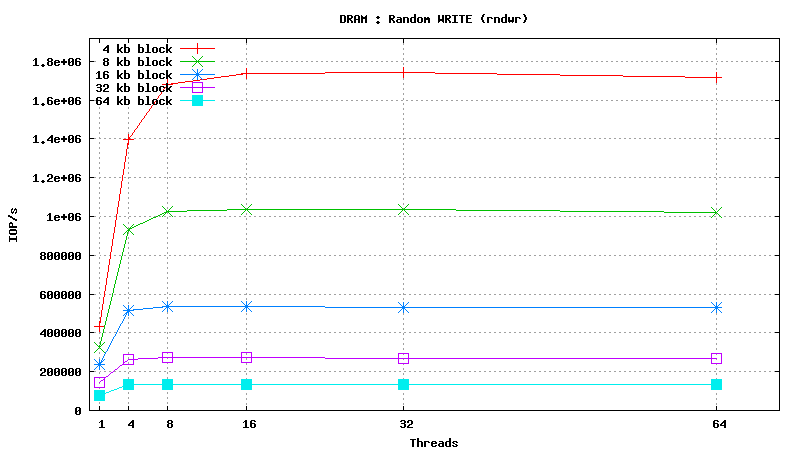
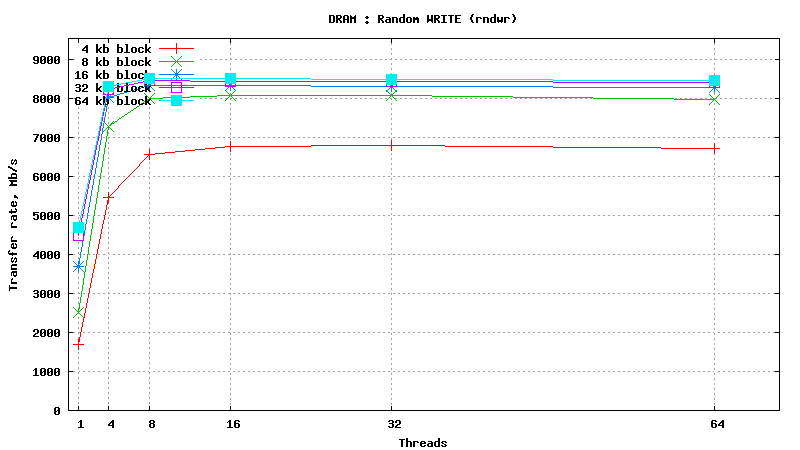
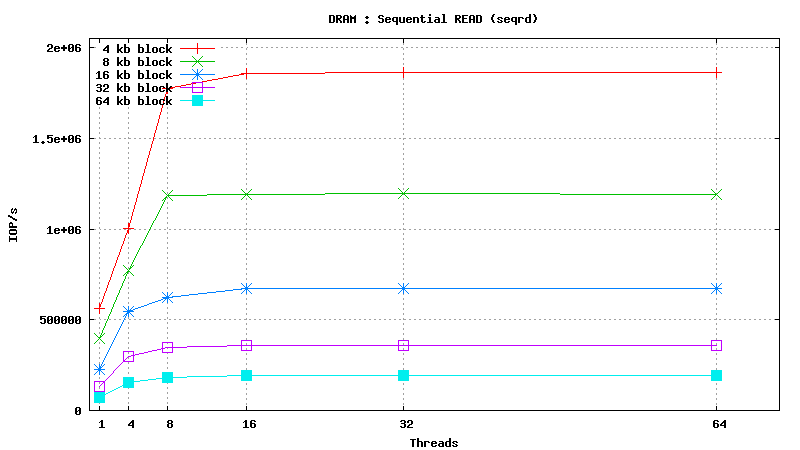
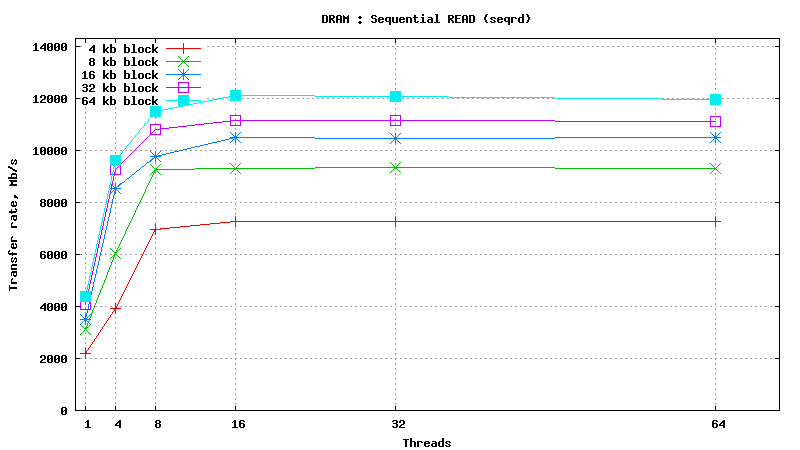
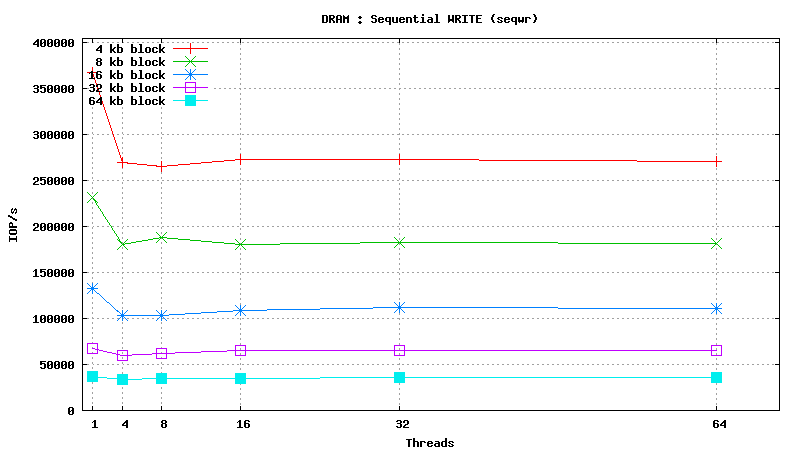
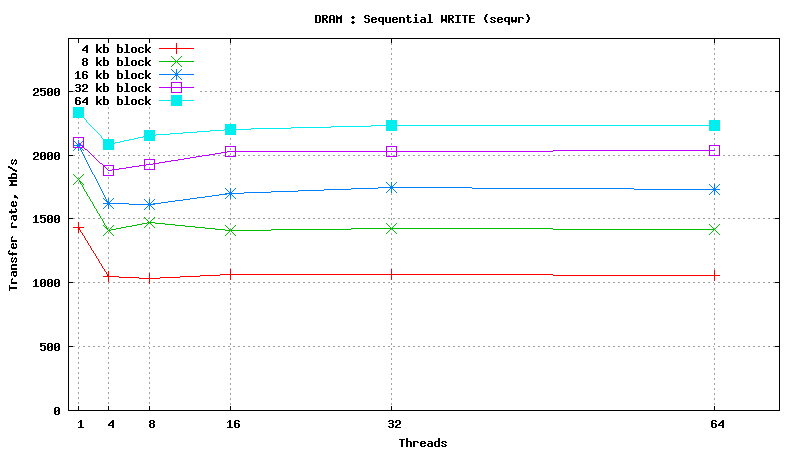
Serial Attached SCSI drive testing results
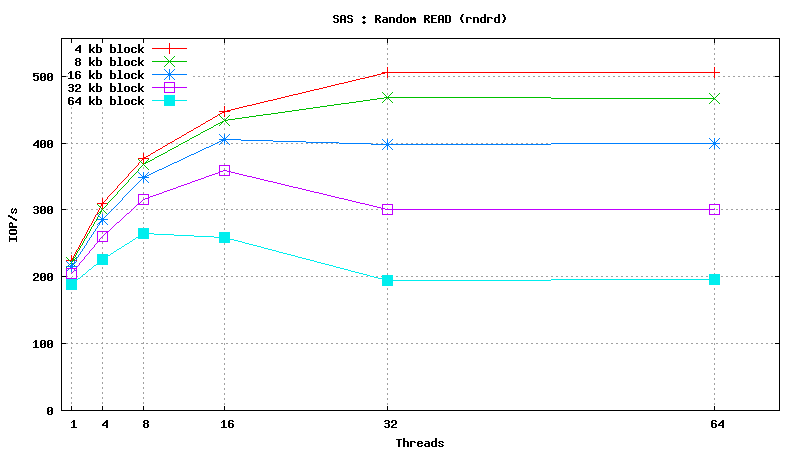
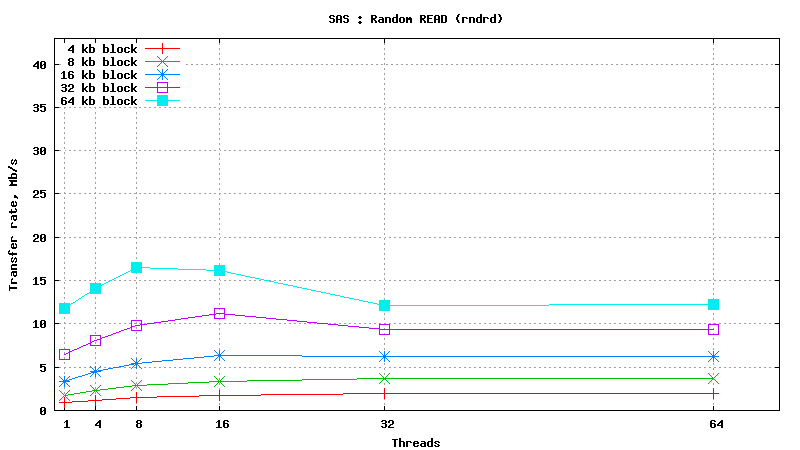
SysBench results for Fujitsu MBC2073RC
(size: 72 GB; 15,000 RPM; SAS; 16 MB buffer; cost is ~160$ per unit)
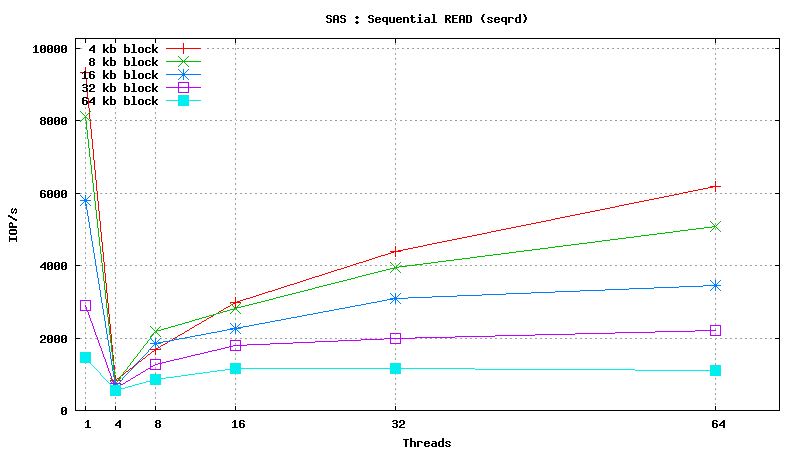
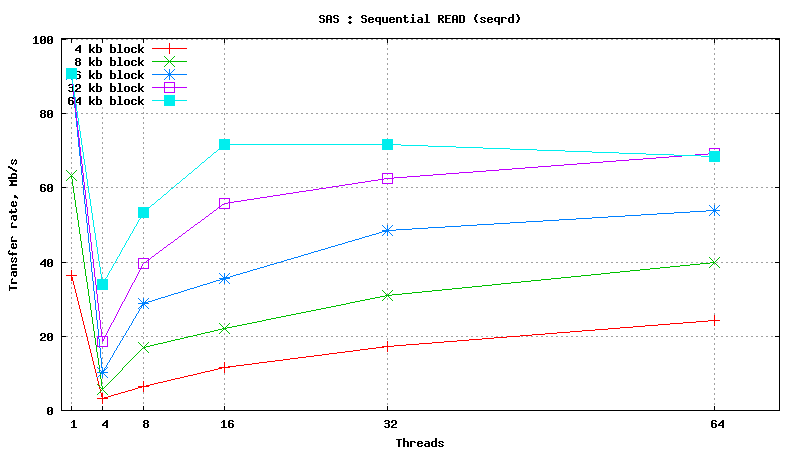
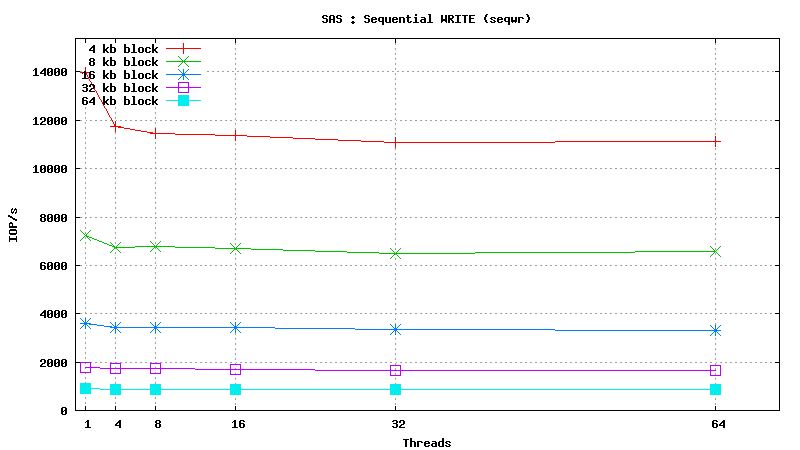
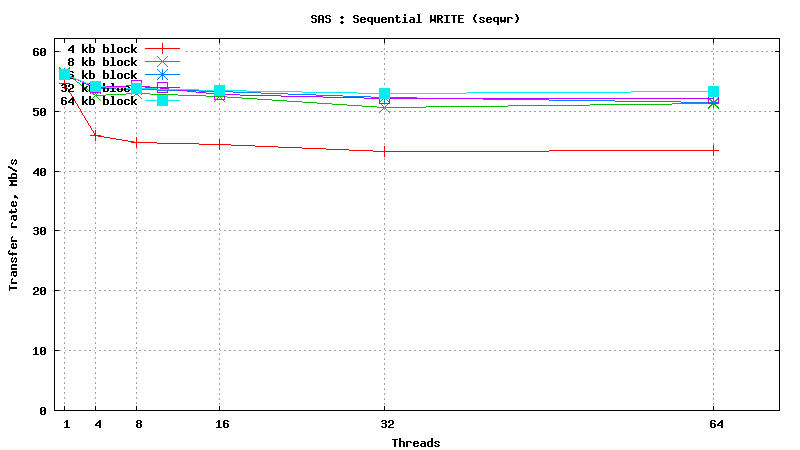
Simulated DB Load : DRAM
Simulated DB Load Testing Results : DRAM
SysBench parameters: table with 20M rows, readonly. No RAM limit, /dev/shm was used as MySQL data files location.
READ only operations

![]()
READ/WRITE operations
![]()
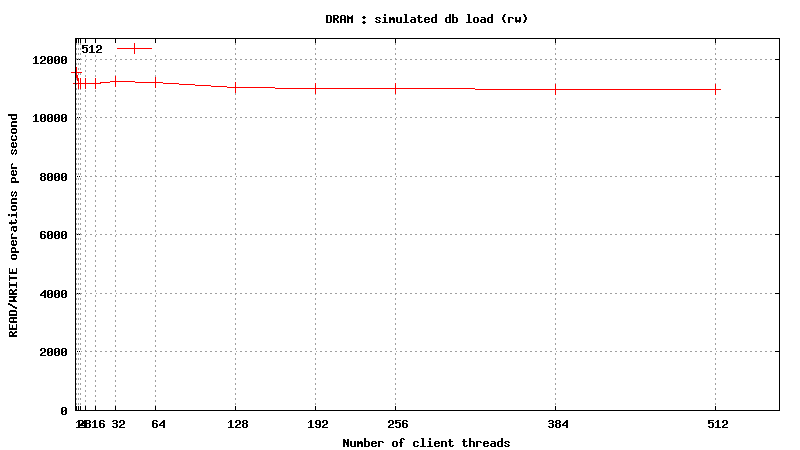
Same plots, focus on 1-128 threads
READ only operations
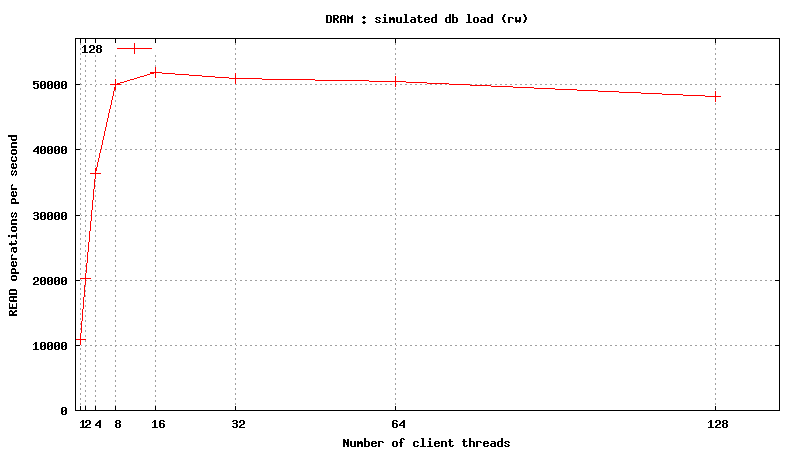
![]()
READ/WRITE operations
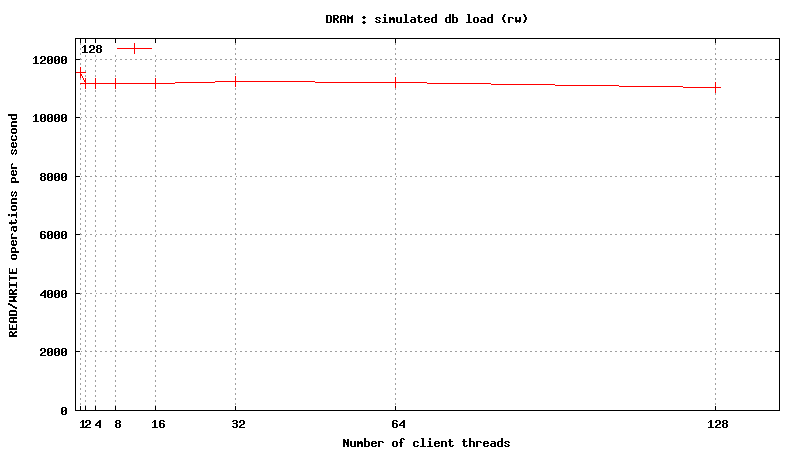
![]()
Simulated DB Load : DRAM vs SSD vs SAS
Simulated DB Load : DRAM vs SSD vs SAS
READ only operations
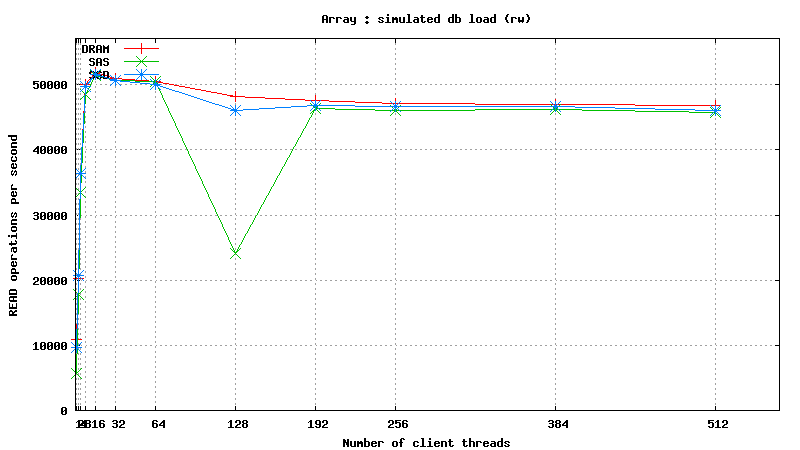
![]()
READ/WRITE operations
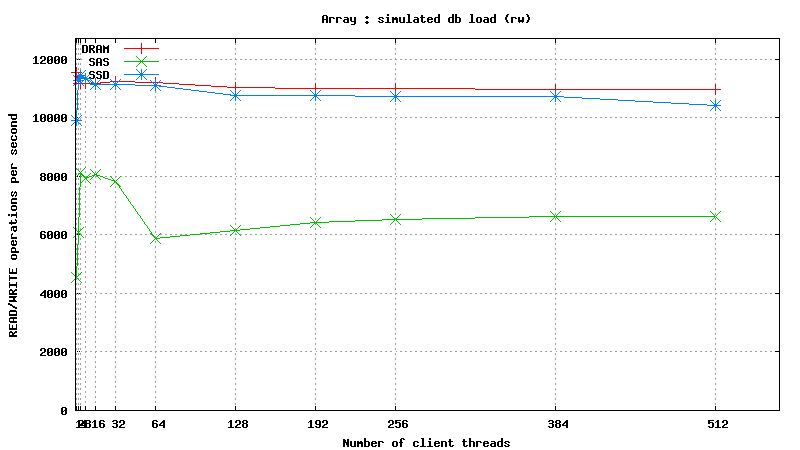
![]()
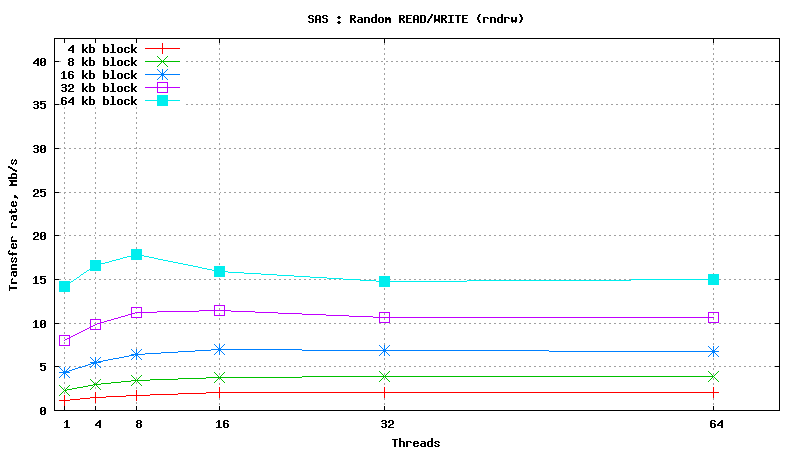
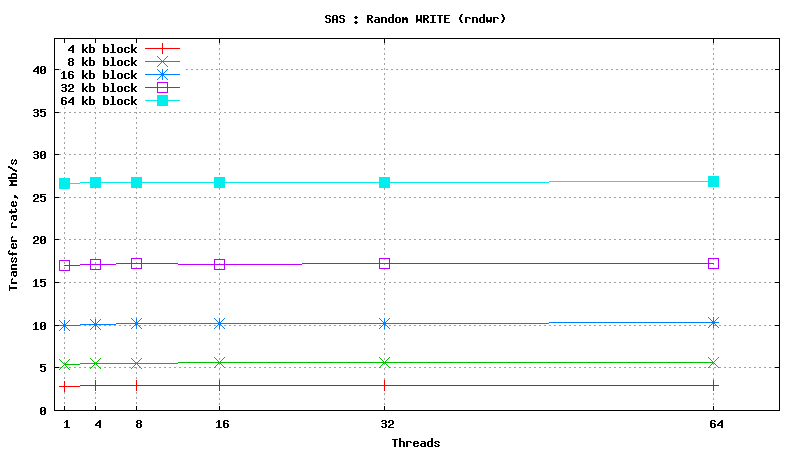
Simulated DB Load : SAS
Simulated DB Load : Serial Attached SCSI
SysBench parameters: table with 20M rows, readonly. Allowed RAM limit: 2Gb to reduce fs caching effects.
READ only operations
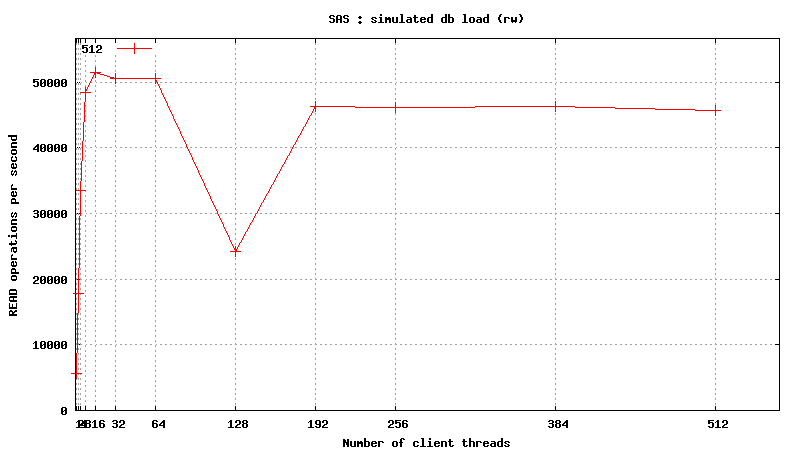
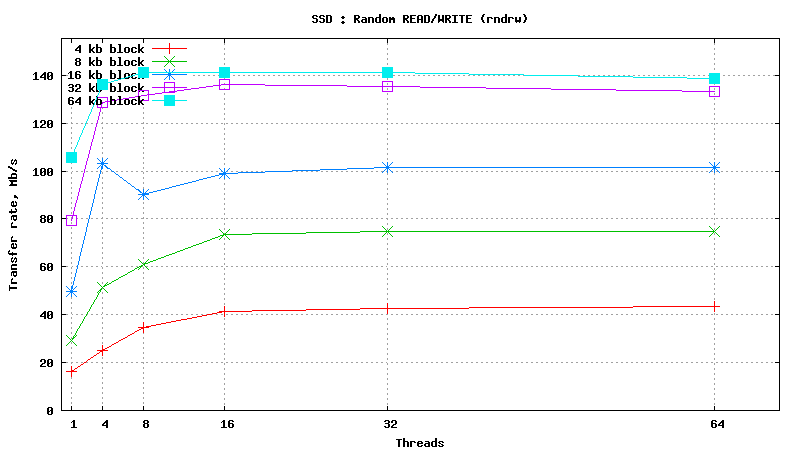
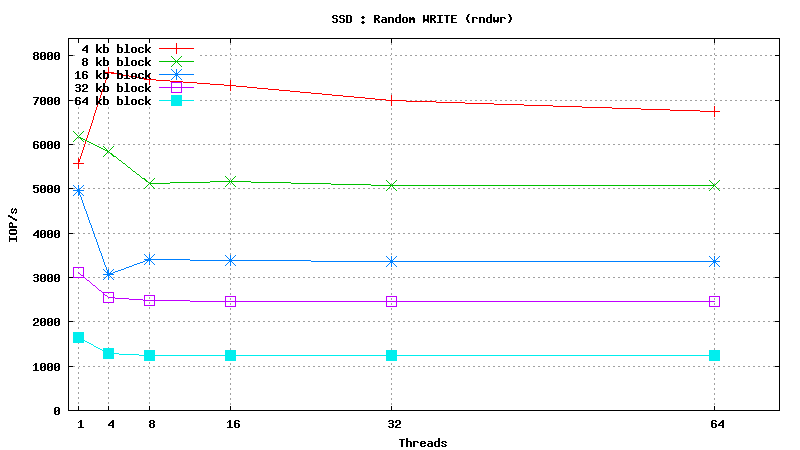
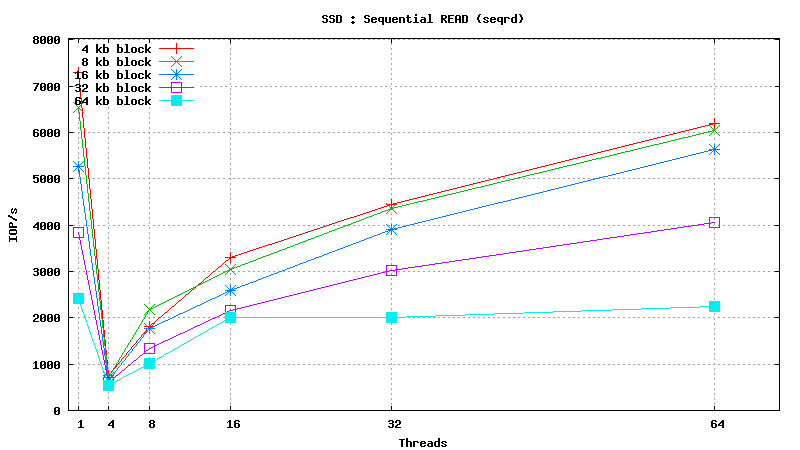
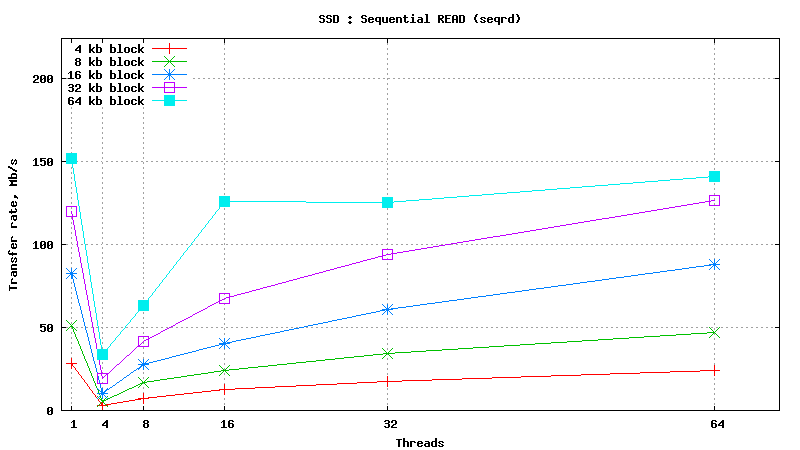
![]() <h1 class="rtecenter">Simulated DB Load : Solid State Disk</h1>
<h1 class="rtecenter">Simulated DB Load : Solid State Disk</h1>
READ/WRITE operations
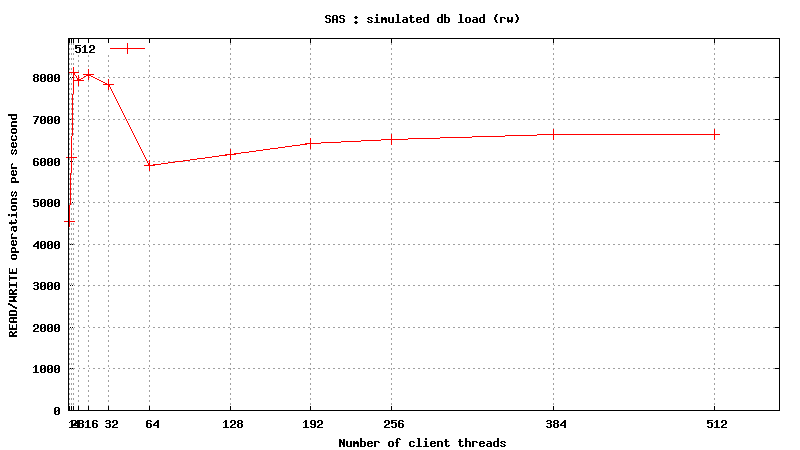
![]()
Same plots, focus on 1-128 threads
READ only operations
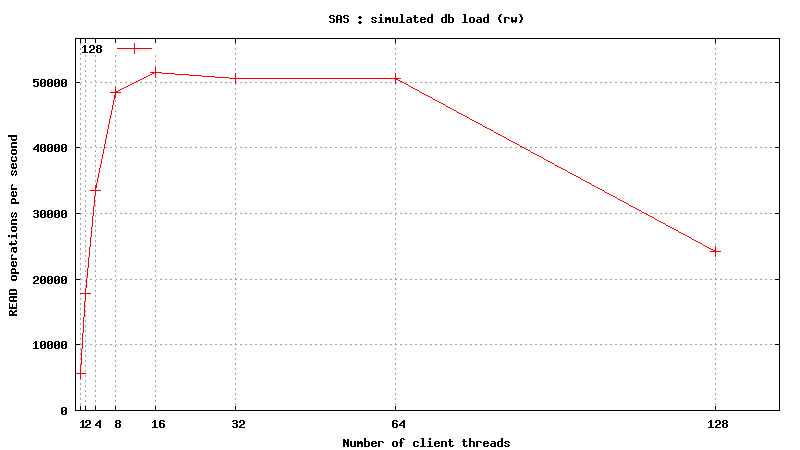
![]()
READ/WRITE operations
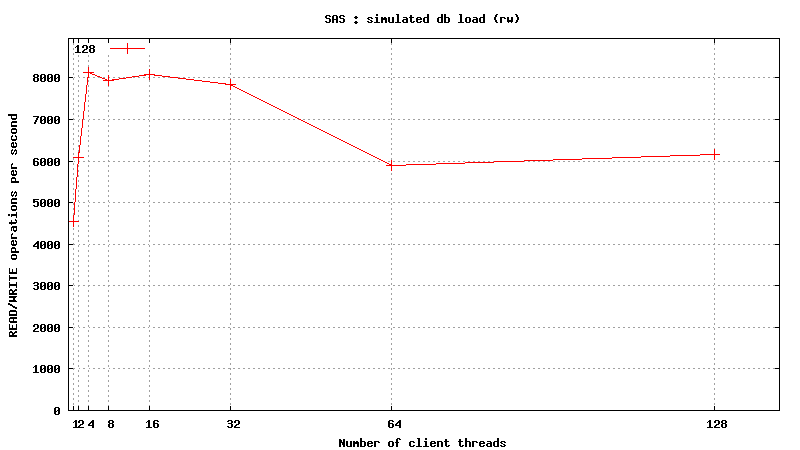
![]()
Simulated DB Load : SSD
Simulated DB Load : Solid State Disk
SysBench parameters: table with 20M rows, readonly. Allowed RAM limit: 2Gb to reduce fs caching effects.
READ only operations
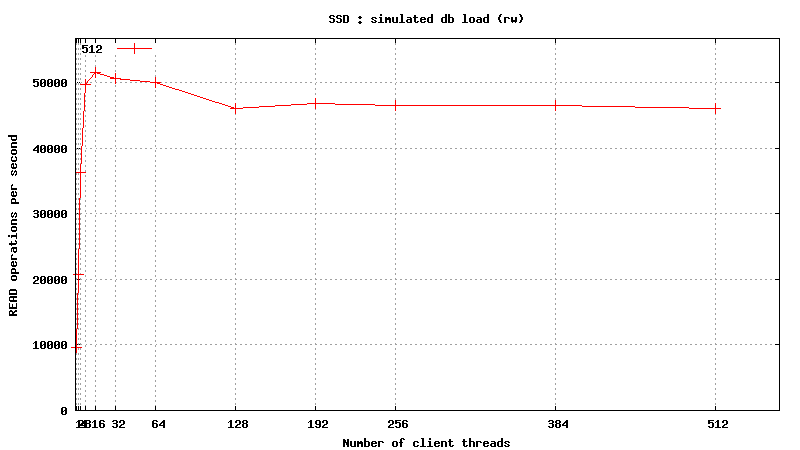
![]()
READ/WRITE operations
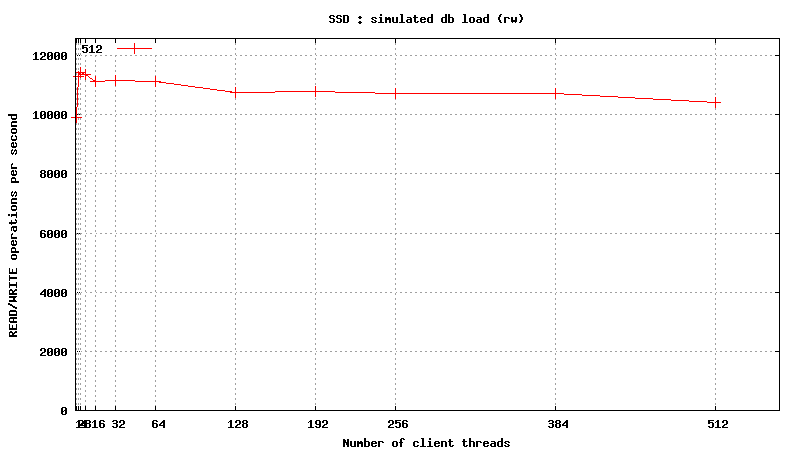
![]()
Same plots, focus on 1-128 threads
READ only operations
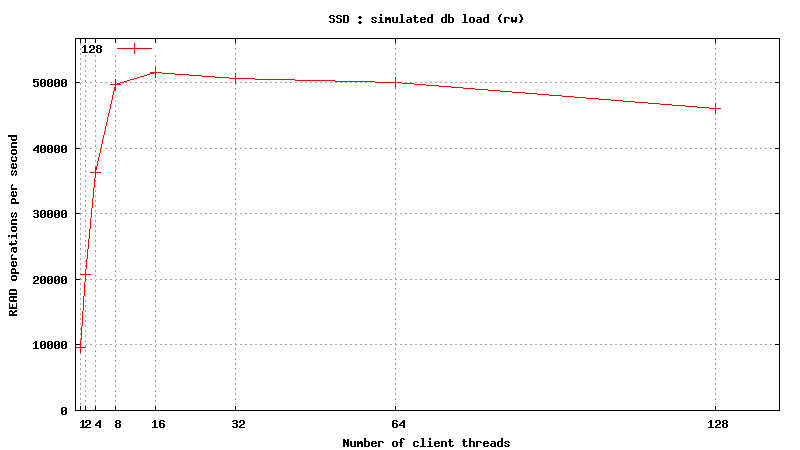
![]()
READ/WRITE operations
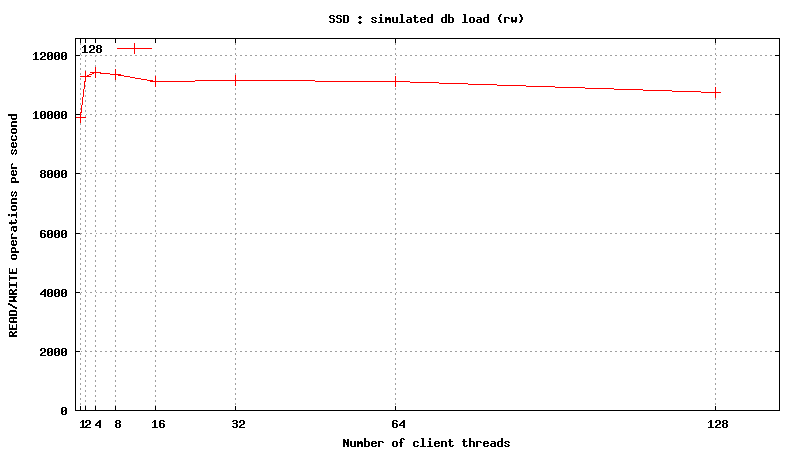
![]()
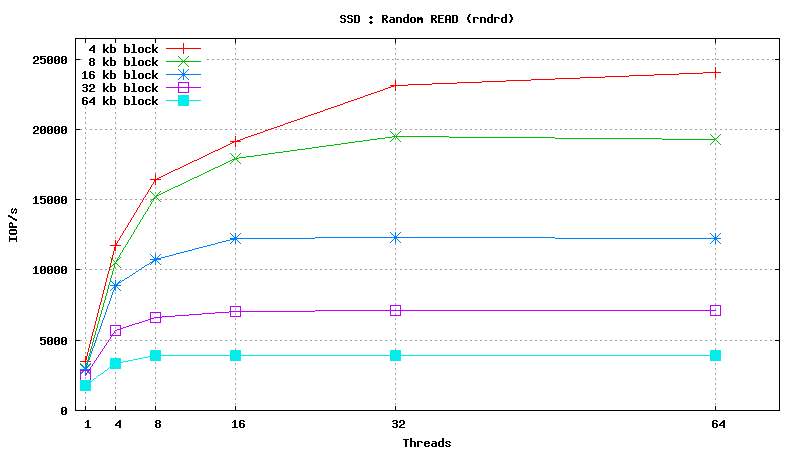
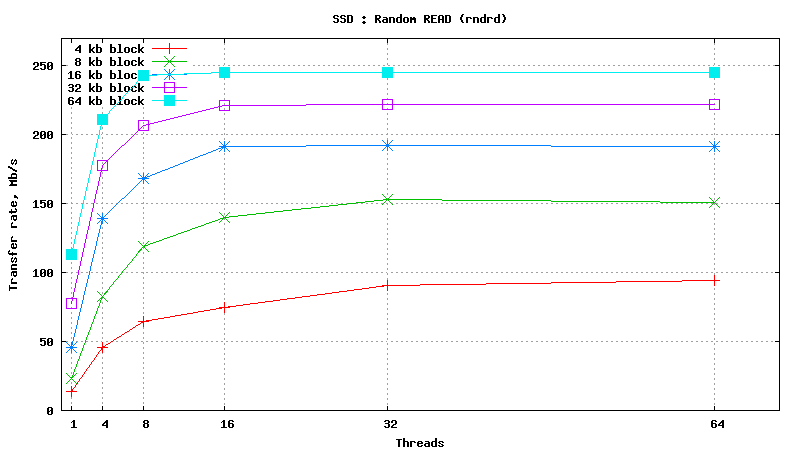
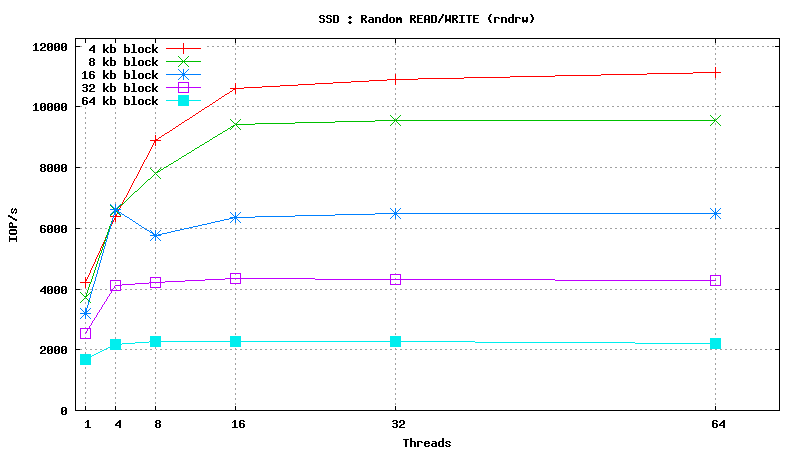

.png)
{kind=link}
{kind=link}