2007
.
Inner Silicon Tracking
| ID | Task Name | Duration | Start | Finish | Resource Names | |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | TPC checks | 7 days | Fri 2/9/07 | Mon 2/19/07 | ||
| 3 | Laser drift+T0 | 7 days | Fri 2/9/07 | Mon 2/19/07 | Yuri[50%] | |
| 4 | SSD shift + East/West TPC tracks | 3 days | Fri 2/9/07 | Tue 2/13/07 | Spiros[25%] | |
| 5 | SVT aligment | 7 days? | Tue 2/20/07 | Wed 2/28/07 | ||
| 6 | SVT+SSD (cone) for each wafer | 1 wk | Tue 2/20/07 | Mon 2/26/07 | Ivan,Richard | |
| 7 | Shell/Sector for each magnetic field settings | 1 day? | Tue 2/27/07 | Tue 2/27/07 | ||
| 8 | Ladder by Ladder | 1 day? | Wed 2/28/07 | Wed 2/28/07 | ||
| 9 | Using TPC+SSD, Determining the SVT Drift velocity | 7 days | Fri 2/9/07 | Mon 2/19/07 | Ivan | |
| 10 | Drift velocity | 12 days | Fri 2/9/07 | Mon 2/26/07 | ||
| 11 | High stat sample processing preview | 7 days | Fri 2/9/07 | Mon 2/19/07 | Vladimir | |
| 12 | Final evaluation | 5 days | Tue 2/20/07 | Mon 2/26/07 | Vladimir | |
| 13 | ||||||
| 14 | Online QA (offline QA) | 7 days | Fri 2/9/07 | Mon 2/19/07 | Ivan,Helen | |
| 15 | ||||||
| 16 | Hit error calculation final pass | 1 wk | Fri 2/9/07 | Thu 2/15/07 | Victor | |
| 17 | Self-Alignement | 3 wks | Fri 2/16/07 | Thu 3/8/07 | Victor | |
| 18 | Code in place for library - aligement related | 1 wk | Fri 2/9/07 | Thu 2/15/07 | Yuri[10%],Victor[10%] | |
| 19 | ||||||
| 20 | Tasks without immediate dependencies | 60 days | Fri 2/9/07 | Thu 5/3/07 | ||
| 21 | Cluster (SVT+SSD) and efficiency studies | 1.5 mons | Fri 2/9/07 | Thu 3/22/07 | Artemios,Jonathan | |
| 22 | Slow/Fast simulators reshape | 3 mons | Fri 2/9/07 | Thu 5/3/07 | Jonathan,Polish students x2,Stephen | |
| 23 | ||||||
| 24 | ||||||
| 25 | Cu+Cu re-production | 87.5 days | Fri 3/9/07 | Tue 7/10/07 | ||
| 26 | Cu+Cu 62 GeV production | 3 wks | Fri 3/9/07 | Thu 3/29/07 | ||
| 27 | Cu+Cu 200 GeV production | 72.5 days | Fri 3/30/07 | Tue 7/10/07 | ||
| 28 | cuProdcutionMinBias (30 M) | 8.5 wks | Fri 3/30/07 | Tue 5/29/07 | ||
| 29 | cuProductionHighTower (17 M) | 6 wks | Tue 5/29/07 | Tue 7/10/07 |
Multi-core CPU era task force
Introduction
On 7/12/2007 23:42, a task force was assembled to evaluate the future of the STAR software
and its evolution in the un-avoidable multi-core era of hardware realities.
The task force was composed of: Claude Pruneau (Chair), Andrew Rose, Jeff Landgraf, Victor Perevozchikov, Adam Kocolosk. The task force was later joined by Alex Wither from the RCF as the local support personnel were interested in this activity.
The charges and background information are attached at the bottom of this page.
The initial Email announcement launching the task force follows:
Startup Email (7/12/2007 23:42)
Date: Thu, 12 Jul 2007 23:42:40 -0400 From: Jerome LAURET <jlauret@bnl.gov> To: pruneau claude <aa7526@wayne.edu>, Andrew Rose <AARose@lbl.gov>, Jeff Landgraf <jml@bnl.gov>, Victor Perevozchikov <perev@bnl.gov>, Adam Kocoloski <kocolosk@MIT.EDU> Subject: Multi-core CPU era task force Dear Claude, Adam, Victor, Jeff and Andrew, Thank you once again for volunteering to participate to serve on a task force aimed to evaluate the future of our software and work habits in the un-avoidable multi-core era which is upon us. While I do not want to sound too dire, I believe the emergence of this new direction in the market has potentials to fundamentally steer code developers and facility personnel into directions they would not have otherwise taken. The work and feedback you would provide on this task force would surely be important to the S&C project as depending on your findings, we may have to change the course of our "single-thread" software development. Of course, I am thinking of the fundamental question in my mind: where and how could we make use of threading if at all possible or are we "fine" as it is and should instead rely on the developments made in areas such as ROOT libraries. In all cases, out of your work, I am seeking either guidance and recommendation as per possible improvements and/or project development we would need to start soon to address the identified issues or at least, a quantification of the "acceptable loss" based on cost/performance studies. As a side note, I have also been in discussion with the facility personnel and they may be interested in participating to this task force (TBC) so, we may add additional members later. To guide this review, I include a background historical document and initial charges. I would have liked to work more on the charges (including adding my expectations of this review as stated in this Email) but I also wanted to get them out of the door before leaving for the V-days. Would would be great would be that, during my absence, you start discussing the topic and upon my return, I would like to discuss with you on whether or not you have identified key questions which are not in the charges but need addressing. I would also like by then to identify a chair for this task force - the chair would be calling for meetings, coordinate the discussions and organize the writing of a report which ultimately, will be the result of this task force. Hope this will go well, Thank you again for being on board and my apologies for dropping this and leaving at the same time. -- ,,,,, ( o o ) --m---U---m-- Jerome -
Follow up EMail (8/3/2007 15:34)
Date: Fri, 03 Aug 2007 15:34:56 -0400 From: Jerome LAURET <jlauret@bnl.gov> CC: pruneau claude <aa7526@wayne.edu>, Andrew Rose <AARose@lbl.gov>, Jeff Landgraf <jml@bnl.gov>, Victor Perevozchikov <perev@bnl.gov>, Adam Kocoloski <kocolosk@MIT.EDU>, Alexander Withers <alexw@bnl.gov> BCC: Tim Hallman <hallman@bnl.gov> Subject: Multi-core CPU era task force Dear all, First of all, I would like to mention that I am very pleased that Claude came forward and offered to be the chair of this task force. Claude's experience will certainly be an asset in this process. Thank you. Second news: after consulting with Micheal Ernst (Facility director for the RACF) and Tony Chan (Linux group manager) as well as Alex Withers from the Linux group, I am pleased to mention that Alex has kindly accepted to serve on this task force. Alex's experience in the facility planing and work on batch system as well as aspects of how to make use of the multi-core trends in the parallel nascent era of virtualization may shade some lights on issues to identify and bring additional concepts and recommendations as per adapting our framework and/or software to take best advantage of the multi-core machines. I further discussed today with Micheal Ernst of the possibility to have dedicated hardware shall testing be needed for this task force to complete their work - the answer was positive (and Alex may help with the communication in that regard). Finally, as Claude has mentioned, I would very much like for this group to converge so a report could be provided by the end of October at the latest (mid-October best). This time frame is not arbitrary but is at the beginning of the fiscal year and at the beginning of the agency solicitations for new ideas. A report by then would allow shaping development we may possibly need for our future. With all the best for your work,
Background work
The following documents were produced by the task-force members and archived here for historical purpose (and possibly providing a starting point in future).
- First meeting notes - Claude Pruneau
- CPU benchmarking (plenty of memeory context) - Andrew Rose
- Concurrent Computing for C++ Applications
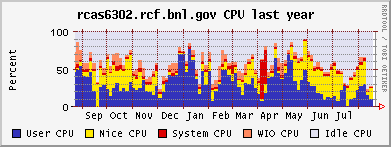
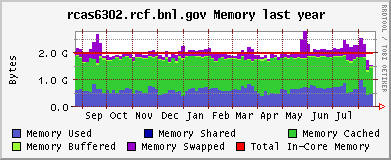
CPU and memeory usage on the the farm - Alex Wither
Opteron (CPU / memory)
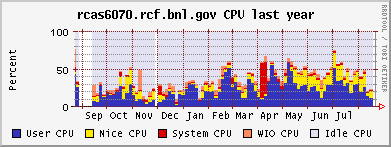
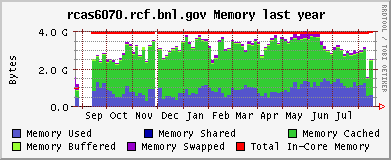
Xeon (CPU / memory)
CAS & CRS CPU usage, month and year
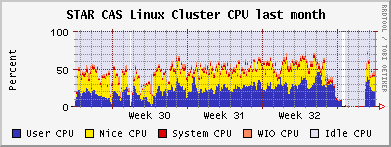
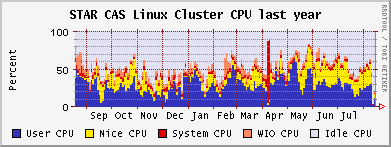

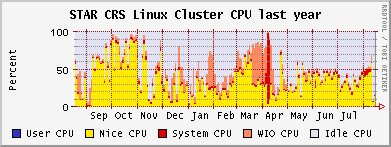
Outcome & Summary
A reminder as per the need for a reoprt was sent on 10/3/2007 to the chair (with a side track discussion on other issues which seemed to have taken attention). To accomodate for the busy times, a second reminder was sent on 11/19/2007 with a new due date for the end of november. Sub-sequent reminders were sent on the 12/10/2007 and 1/10/2008.
The task force has not deliverred the report as requested. A summary was sent in an Email as follow:
... a summary of the activities/conclusions of the committee. ... during the first meeting, all participants agreed that if there was anything to be done, it would be on reconstruction. Members of the committee felt that GEANT related activities are not in the perview of STAR and should not be STAR's responsibility. In view also of what we did next it also appears that not much would actually be gained. We also discussed (1st meeting) the possibility of multi-treading some aspects of user analysis. e.g. io, and perhaps some aspects of processing. Here people argued that there is too much variability in type of analyses carried by STAR users. And it is not clear that multi-treading would be in anyway faster - while adding much complexity to infrastructure - if not to the user code. Members of the committee thus decided to consider reconstruction processes only. In subsequent meetings, we realized (based on some references test conducted in the Industry) that perhaps not much would be gained if a given node (say 4 cores) can be loaded with 4 or 5 jobs simultaneously and provided sufficient RAM is available to avoid memory swapping to disk. Alex, and Andrew carried some tests. Alex's test were not really conclusive because of various problems with RCF. Andrew's test however clearly demonstrated that the wall clock time essentially does not change if you execute 1 or 4 jobs on a 4-core node. So the effective throughput of a multicore node scales essentially with the number of cores. No need for complexity involving multithreading. Instant benefits. Cost: PDSF and RCF are already committed according to Alex and Andrew to the purchase of multicore machines. This decision is driven in part by cost effectiveness and by power requirements. 1 four core machine consumes less power, and is less expensive than 4 1-core machine. Additionally, that's where the whole computing industry is going... So it is clear the benefits of multicore technology are real and immediate without invocation of multitreading. Possible exceptions to this conclusion would be for online processing of data for trigger purposes or perhaps for fast diagnostic of the quality of the data. Diagnostics (in STAR) are usually based on a fairly large dataset so the advantage of multi-threading are dubious at best in this case because the througput for one event is then irrelevant - and it is the aggregate throuput that matters. Online triggering is then the only justifiable case for use of multithreading. Multithreading would in principle enable faster throughput for each event thereby enabling sophisticated algorithms. This is however a very special case and it is not clear that adapting the whole star software for this purpose is a worthy endeavor - that's your call. I should say in closing that the mood of the committee was overall quite pessimistic from the onset. Perhaps a different group of people could provide a slightly different point of view - but I really doubt it.