Operations
Welcome to the STAR Operations Home Page
Daily operations meeting at 10am on Zoom: https://bnl.zoomgov.com/j/1603605873pwd=NVk1aWs2OW5yb01rTzNtODhiaUJtQT09
(Zoom Meeting ID: 160 360 5873 Passcode: 110789)
Communications for STAR control room /shift/operation related on Zoom: https://bnl.zoomgov.com/j/1605144596?pwd=N3ExMDh3Q2txK0FxYTBVTzg4N0hHZz09
(Zoom Meeting ID: 160 514 4596 Passcode: 726787)
STAR online page: https://online.star.bnl.gov
STAR operations email list: https://lists.bnl.gov/mailman/listinfo/star-ops-l
Select the menu for information relevant to STAR Operations.
-
Operations information and checklists
- Plan for the day / Notes from Operations Meeting for Run24
- STAR Detector States for Run24 Au+Au 200 GeV collisions (Current Version 10/10/2024)
- STAR Data taking guide for Run24 (Updated 10/7/2024)
- STAR Expert Call List for Run24 (Current Version 10/08/2024)
- Checklist for recovery from power failure (08/02/2024)
- Old version: Checklist for recovering from power failure (2023)
- Detector manuals and procedures
- Trigger DAQ problems with deadtimes / crate failures DURING PHYSICS RUNS
- Reference Plots for Shift Crew
- Online Q/A Plots Manual (Jevp Plots) (updated 6/16/2020)
- Detector Operator Station Setup (Updated 12-Mar-21)
- TPC Operations
- EPD (updated 7-Mar-18)
- How to check and visualize the EPD mapping from tile to QT channel (updated 8-Jul-23)
- BEMC and FCS (updated 10-Dec-21)
- BSMD (updated 06-Jun-24)
- EEMC (updated 20-Dec-21)
- EMC (updated 17-Dec-02) - this link is dead
- GMT (updated 15-Jan-19)
- FST (updated 18-Jan-22)
- sTGC (updated 27-Jan-22)
- Magnet (updated 17-Dec-02)
- Magnet Monitoring
- Offline QA
- Current RunControl/DAQ issues (updated 5/5/2021)
- Current Trigger Deadtime Issues (updated 4/8/2022)
- Run Control (updated 3/2/18)
- Slow Controls Procedures
- TOF/MTD General Instructions (updated 05-Sep-2024)
- TOF Gas Bottle Switchover Procedure (updated 2024 Jul 15)
- TOF Pow Cycle Procedures (Run2023), [TOF Power Cycle Procedure(Old version with Anaconda)]
- TOF LVIOC Restart Procedure
- TOF/MTD HV IOC Restart Procedure (Updated 2023)
- MTD Power Cycle Procedure (Run2022), [ MTD Power Cycle Procedure (Old version with Anaconda)]
- MTD LVIOC Restart Procedure
- Canbus Restart Procedure, [Canbus Restart Procedure (Old version with Anaconda)]
- Solve MTD (eTOF) Isobutane Fraction Alarm Instructions
- eTOF General Instructions (updated 2024, May 27)
- Trigger (updated 5-Mar-13)
- BBC/ZDC/VPD LeCroy1440 Communication Problem Procedure
- V124 and STAR global timing
- C-AD Procedure for Exciting the STAR Magnet (normal user cannot connect to this)
- C-AD Procedure for Bypassing the STAR Safety Interlock Systems (normal user cannot connect to this)
- List of Authorized People for the STAR SGIS Interlock System (normal user cannot connect to this)
-
STAR Operations
- STAR Safety Review for Run19 (not a link)
- STAR FY19 Environmental emissions.doc (not a link)
- Procedures for detectors not currently available
- FPS/FPOST (updated 04-Apr-17)
- FMS UV curing procedure (updated 21-Mar-17)
- RP
- RP Slow control instructions (updated 2017-Mar-10 )
- Roman Pots Operations manual (updated 2017-Jun-24)
-
STAR Technical Support Group
Run-22 pp510 guides (SL desk printouts)
- Runs stopped by BBC/L2 (slow DMA) (updated 01/17/22) -- this is for L2 stopping the run or any trigger VME crate preventing run start.
BBC/ZDC/VPD HV system (LeCroy1440) communication problem
Loss of communication with LeCroy1445A.
It often happens when LeCroy was turned off, or loses its power due to power dip.
Indications are:
- "bbchv" app on sc3 shows black on/off
- "bbchv" app doesn't update readout voltages/current
- Cannot turn on/off from "bbchv"
Solution is:
Go to SC5 computer. There should be "Restore LeCroy Communication" window:
 LeCroyRestart
LeCroyRestart
Follow the instructions on the window.
If the window is not on SC5 - open a terminal and type ./scripts/restartLC.py
Make sure you have bermuda terminal open in the next monitor
(If not, open terminal, type "sys@bermuda" command. Password is the same as one in shift leader's binder for SC5 sysuser)
Controlled/Restricted Access Requests
- The period coordinator/shift leaders should have a list with controlled access requests.
- Leave your phone number if you want to be called for unscheduled controlled access.
- There are only 8 keys for controlled access.
- Always let the shift leader know when you go in and come out.
- Make a note in the elog about the work that was performed.
- Next maintenance day on Thursday, March 9, 2017 (7:30am-3:30pm).
Detector Readiness Checklist for Cosmics
prodution_pp200long2_2TOF+MTD+ETOW+BTOW+ESMD+BSMD+GMT+FPS+PP+IST+>>Feb. 27, 2018<<
Detector Readiness Checklist (Cosmic Data Taking, 2018)
1) Once Per Day
A) Reboot bdb.starp.bnl.gov (see section 3 in slow controls manual)B) Noise run for TOF/MTD pedAsPhys_tcd_only with TRG+DAQ+TOF+MTD (4M events, takes about 5-6 minutes)
C) EPD IV scan (can be in parallel with cosmics, mark run in elog)
2) Pedestals once per Shift
A) Take pedestal_tcd_only with TRG+DAQ+TPX+ITPC+ETOW+TOF+ETOF+MTD+GMT+FCS (1 event, run control will issue additional events automatically)B) Take pedestal_rhicclock_clean with TRG+DAQ (1k events)
3) Cosmic Data Taking
A) Check detector states for cosmic data takingB) Take CosmicLocalClock with TRG+DAQ+TPX+ITPC+ETOW+TOF+ETOF+MTD+GMT+L4 (30 minutes)
C) Laser runs every 4 hours (warm up in advance, 4k events)
Notes:
ETOF HV/FEE is still under expert control. In case the magnet needs to be ramped/trips, call experts!
Status of ETOF may change, check with outgoing shiftleader and elog!
Detector Readiness Checklist for current run
.jpg)
Detector Readiness (old)
(old - attachements hidden)
Detector States Spreadsheet

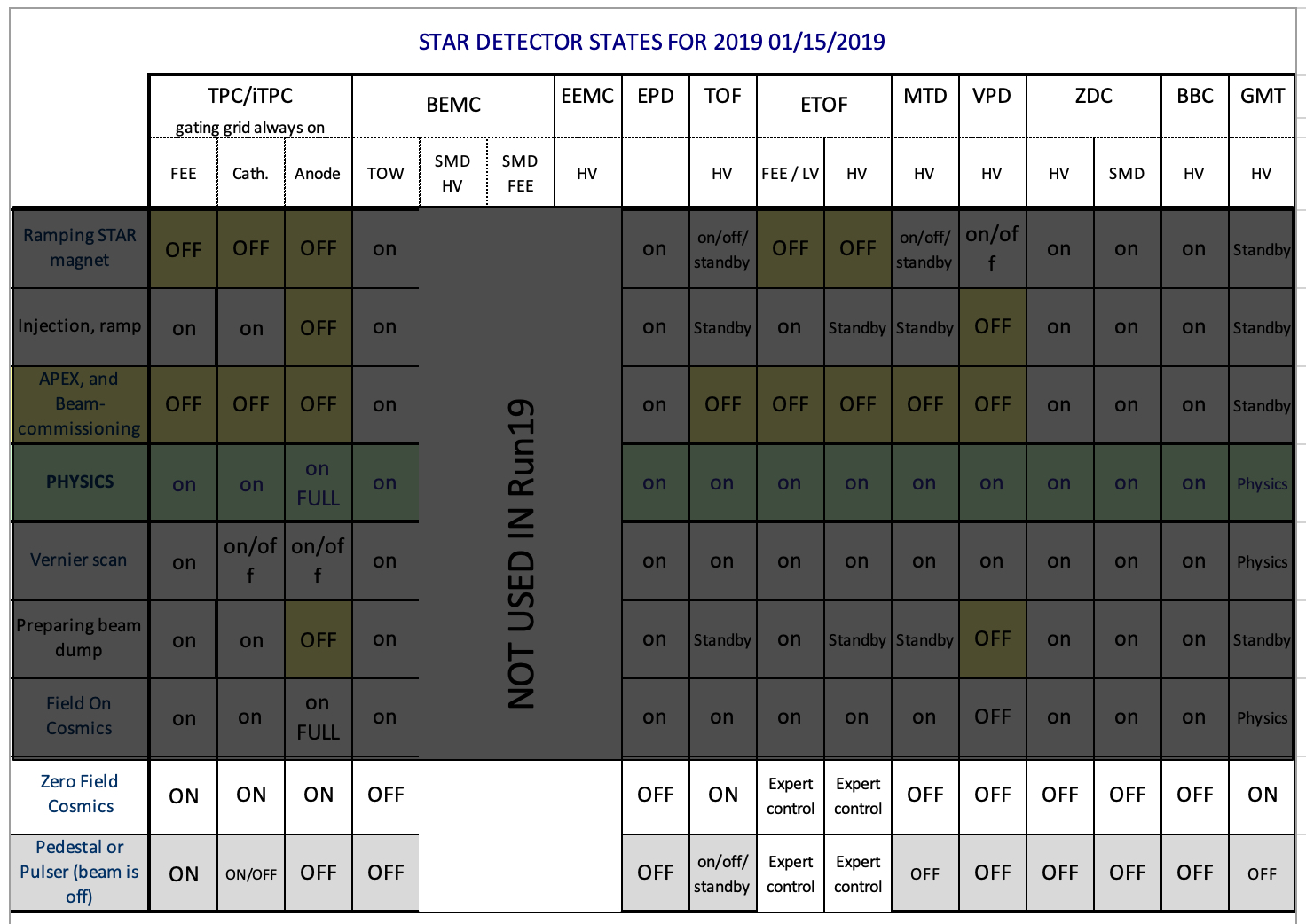
Detector States (old)
(old)
Notes from Operations Meeting
Recap of the Past 24 Hours:
- MCR provided 56x56 Au+Au collisions around 5 AM (with crossing angle but no rebucketing yet). Collisions were stable with low background. We focused on setting up global timing, made significant progress, and took one physics run. The beam was dumped at 9:25 AM. sPHENIX had a 20-30 minute access, followed by APEX and RHIC rebucketing.
- ZDC AND rate was 3 KHz. We started with tune_AuAu_2024. Global timing looked good, with TAC numbers for BBC (blue background was high, 2x collision rate). VPDs and TOF were turned on, starting with zdc-tac, then switching to zdc-mb.
- Ran tune_AuAu_2024 with TPC, TOF, BTOW, and L4 (no L4 events).
- Ran setup_AuAu_2024 with TPC, TOF, BTOW, and L4 (L4 events recorded, but no plots). Reached out to Jeff to resolve L4 issues, as plots were needed for global timing. Continued running without L4 until Jeff fixed the issue.
- The evp /a disk was 60% full; Jeff cleared files. l4Cali and l4Disp are still down. Diyu was contacted and will work on the calibration server within 2-3 hours.
- After receiving the L4 plot, global timing looked good, with only a 0.5 ns offset.
- Vz was off by ~20 cm. MCR wasn't seeing the real-time vertex, but this was fixed and improved.
- BBC setup plan: TAC is a bit off, but BBC looks good. Shift crew was instructed to take 5 runs per BBC HV setting, adjust config, collect 50k events, and log runs as BBC HV scan in ESL.
- Oleg initiated a cal_scan, timing within 1 ns. He will review the data later.
- Akio loaded BBC HV data.
- EPD experts took initial scans for TAC adjustment, with a follow-up planned.
- Run 25280025 was the first Au+Au 200 production setup; fastoffline was requested and is in progress (no forward tracker, eTOF, or GMT yet).
- Forward trackers (FST/sTGC) will be turned on after rebucketing (post-10 AM).
Issues Encountered:
- No major issues. BCW issue was solved after Tim accessed and fixed the create.
- l4Cali and l4Disp are still down, Diyu is working on it.
Plan for the Day (RHIC & STAR):
- Access now; RHIC will handle rebucketing.
- Forward trackers will be turned on mid-next fill (when background is low).
- EPD work is ongoing; experts will provide updates on EPD and calorimeters.
Looking Ahead:
- First Au+Au collisions at STAR (56x65) occurred this morning; one physics run was completed, and the next fill is expected in a few hours (delays likely).
- This fill wasn’t useful for sPHENIX; they’re taking access. They’ll request 6x6 for background studies when stable. RHIC is planning to install a 56 MHz RF on Monday for a narrow vertex. Stable beams are needed by Wednesday.
- Commissioning plan: compile a list of detector experts (EPD: Mike needs a call when the next fill starts, FST & sTGC experts need a call mid-fill, FST: time bin, sTGC performance will be checked and followed up, VPD will use run23 files).
- Update the detector readiness checklist (shift crew to continue with setup_AuAu_2024: TRG+DAQ+iTPC+TPX+TOF+BTOW+ETOW+L4+FCS).
- For 6x6, we’ll use minbias for regular production; fastoffline will be requested.
- Shift leader for the next owl found; the day shift will run with one DO.
Saturday, October 5th, 2024
Urgent Issues:
- BCW VME crate repair: Tim was informed, but repairs are on hold due to RHIC's beam development
- Shift leader missing: We have no shift leader for the next owl shift.
Recap of the Past 24 Hours:
- Collected cosmic data throughout the day as no beam development work was done (despite efforts).
- MCR called for APEX at 1:30 am but reported issues at 3 am.
- Encountered L0 trigger not starting and BCW components not working, which were removed.
- Yellow Abort Kicker issue continues.
- Blue & Yellow injection and ramp setup continues, updates expected in a few hours.
Encountered Issues:
-
BCW configuration error and FPGA failure:
- BCW and BCW_DSM2 nodes are missing from the component tree.
- The BCW VME crate requires repair (need to discuss access and coordination).
- Tim will replace the board and power cycle it locally, which should take 30 minutes (we have spare boards).
- Follow-up with Tim; we can run min-bias without the fix and should take opportunistic access if available.
-
L0/L1 not responding:
- Power cycling crate 62 failed initially.
- Prashanth went in manually, and David helped resolve it.
-
2000+ timeouts:
- Stopped the run.
- Shift leader consulted Akio, Jeff, and Hank.
- Jeff tried multiple power cycles of L0/L1, and it eventually came back.
-
EPD hot tiles:
- Restarted the run, and the issue was gone.
- Maria will investigate further.
-
EVB23 issue:
- EVB23 is still out of the run, with EVB22 and EVB24 expected to return soon.
- Awaiting further updates from Jeff.
Plan for the Day (RHIC & STAR):
- Continue Yellow Abort Kicker work.
- Blue & Yellow injection and ramp scheduled for the evening.
- Ramp development overnight.
- Continue taking cosmic runs when no beam is available; switch to APEX otherwise.
Looking Ahead:
- First Au+Au collisions at STAR expected Sunday evening (possible delay). First fill could be 56x56.
- October 4-8: sPHENIX requests 111x111 initially, then 6x6 for background study when stable.
- RHIC plans to install 56 MHz RF on Monday for narrow vertex; stable beam required before Wednesday.
- STAR needs/plans for bunches/luminosity:
- TPC group requests the same crossing angle for 6x6 (one or two fills based on sPHENIX needs).
- Detector commissioning plan:
- Compile a list of experts to call.
- VPD will use Run23 files.
- EPD requires calibration runs (contact experts).
- FST (time bin), sTGC, and others need timing adjustments (trigger and global timing with JH/Akio), followed by cal-scan.
- Follow up with experts.
- Update the detector readiness checklist:
- Use
tune_AuAu_2024 (zdc_mb),setup_AuAu_2024, andproduction_AuAu_2024.
- Use
- 6x6 production: We can use minbias and regular production settings.
- Shift sign-up issues: Dan is resolving these with various STAR institutions; we may run with one DO. Follow-up with Daniel/Pavel recommended.
Friday, October 4, 2024
Recap of the Past 24 Hours:
- Cosmic data: Collected cosmic data throughout the day due to no beam development work.
- Minor issues: Solved with help from experts.
- Yellow Abort Kicker: Still awaiting new tools to address the issue.
- RHIC power supply: Power supply work was completed; RF conditioning is ongoing.
Encountered Issues:
-
Run control GUI crash:
- The GUI crashed and disappeared at the start of the run.
- Re-established connection using XLaunch, which helped restart the GUI.
-
ETOW configuration failure:
- Crate 1 and 2 experienced a failure.
- After multiple unsuccessful reloads, ETOW was removed.
- Expert rebooted the crates, but DAQ mon still showed errors (Crate 1). The shift crew followed suggestions from experts, but the issue remains unresolved.
-
TRG L0 issue:
- Run failed to start due to a TRG L0 error.
- Power cycling the VME trigger crate resolved the issue.
-
FCS dead:
- The run was stopped multiple times (more than 60 seconds, three times consecutively) due to FCS dead errors.
- DOs performed a power cycle on the VME trigger crate, which fixed the issue.
-
EVB23 issue:
- EVB23 was dead in the component tree, preventing the run from starting.
- Awaiting further action from Jeff (work in progress).
Plan for the Day (RHIC & STAR):
- Yellow Abort Kicker work and g9-blw-ps work.
- Ramp development overnight.
- Blue & Yellow injection setup overnight.
- Continue collecting cosmic runs when no beam is available.
- Perform the usual pedestal runs (FCS LED and others).
- Possibility of controlled access for 4–6 hours (open for interest).
Looking Ahead:
- First Au+Au collisions at STAR expected Saturday overnight (possible delay); first fill may be 56x56.
- October 4–8: sPHENIX requests 111x111 initially, followed by 6x6 for background study once stable.
- RHIC plans to install 56 MHz RF on Monday for narrow vertex. Stable beam is needed before Wednesday.
- STAR needs/plans for bunches/luminosity:
- TPC group requests the same crossing angle for 6x6 (one or two fills driven by sPHENIX needs).
- Detector commissioning plan:
- Compile a list of experts to call.
- VPD will use Run23 files.
- EPD requires calibration runs (call experts).
- FST (time bin), sTGC, and others (timing adjustments, trigger, global timing with JH/Akio), then cal-scan. Follow up with experts.
- Update detector readiness checklist:
- Use
tune_AuAu_2024 (zdc_mb),setup_AuAu_2024, andproduction_AuAu_2024.
- Use
- 6x6 run can use minbias and regular production settings.
- Shift sign-up issues: Being resolved; Dan is working with various STAR institutions. May need to run with one DO.
Thursday, October 3, 2024
Recap of the Past 24 Hours:
- We ran cosmic data all day as no beam development work was done.
- Ongoing Yellow Abort Kicker work.
- RHIC power supply work completed, but RF conditioning will require more time.
Encountered Issues:
- iTPC/TPC issues overnight: Power-cycling RDOs 1-4 did not resolve the problem. Currently, iTPC sector 1 RDOs 1, 2, 3 are masked, and iTPC sector 1 RDO 4 is not masked. (this is not correct according to Tonko) ZhengXi will address this.
- EVB23 in the component tree prevented the run from starting yesterday. The shift crew removed it. Jeff will look into it, and I will follow up.
- A hot tile on the EPD was found yesterday. Maria is investigating it, and I will follow up.
Plan for the Day (RHIC & STAR):
- Continue work on DX training.
- Yellow Abort Kicker work.
- RF conditioning of storage cavities.
- Blue injection setup scheduled for tonight.
- Yellow injection setup planned for tomorrow.
- Continue taking cosmic runs.
- Take usual pedestal runs (FCS LED and others).
Looking Ahead:
- First Au+Au collisions at STAR: Scheduled for Saturday overnight*, with the first fill possibly 56x56. (There may be a delay.)
- Oct 4-8: sPHENIX requests 111x111 initially, then 6x6 for background study once stable. RHIC plans 56 MHz RF installation on Monday for narrow vertex; stable beams needed before Wednesday.
- STAR needs/plans for bunches/luminosity? Remove crossing angle for 6x6 (to be determined).
- Commissioning plans for detectors: VPD & EPD need calibration runs, FST (timebin), sTGC, and others (all timing adjustments, trigger, and global timing). Follow up with experts.
- Plan for eTOF during this Au+Au run should mirror p+p configuration.
- Update the detector readiness checklist (setup_auau200_2024_minbias, tune_auau200_2024_minbias, auau200_2024_minbias). Jeff will manage this, and the shift leader will review.
- Urgently need a shift leader and detector operator for next week’s owl shift. Dan Cebra is unreachable; Frank will follow up.
Wednesday, October 2, 2024
Recap of the Past 24 Hours:
- We ran cosmic data all day as no beam development work was done.
- Akio implemented the initial file for the BBC high-voltage run for Au+Au 2024.
- David Tlusty updated the TOF control for TOF West sector 5, resolving the previous issue.
- ESMD was turned off as per Jacobs' request and will be excluded from future runs.
- MCR postponed the Yellow Abort Kicker repair to today.
Encountered Issues:
- EVB23 in the component tree prevented the run from starting. The shift crew removed it, and Jeff will look into it.
- One hot tile on the EPD was identified. Maria is investigating.
Plan for the Day (RHIC & STAR):
- No significant progress on DX training yet; it may start this evening or tomorrow morning.
- Yellow Abort Kicker work is still ongoing.
- RF conditioning: Most parts are running smoothly, and most components are conditioned.
- Blue injection ramp setup is scheduled for tonight, with Yellow injection tomorrow.
- We continue to run cosmics but will prioritize expert needs.
Looking Ahead:
- First Au+Au collisions at STAR are expected Friday overnight, with the first fill potentially 56x56.
- Oct 4-8: sPHENIX ramp-up/stochastic cooling, aiming for 111x111 (or possibly fewer), followed by 6x6 for background studies (planned for Tuesday) once silicon and TPC are stable. RHIC plans to install 56 MHz RF, and we'll explore the use of 6x6 (Gene will advise).
- STAR needs/plans for bunches/luminosity: Remove the crossing angle for 6x6 (to be determined).
- RHIC DX training and Yellow Abort Kicker work access will be completed.
- eTOF plan for Au+Au should remain the same as for p+p runs.
- Update the detector readiness checklist (setup_auau200_2024_minbias, tune_auau200_2024_minbias, auau200_2024_minbias). Jeff will follow up.
Tuesday, October 1, 2024
Recap of Past 24 Hours:
- Yesterday we had access till from 8:00 till ~16:00
- Took cosmics for rest of the day, went to apex around 4 am and then cosmics again ~6 am.
- CAS brought the magnet down at the beginning of the access for some cleaning work. Ramped up at about noon.
- TOF: problem with W5 POS HV is fixed, so we are back to 100% ToF acceptance
- eToF: replaced TCD fanout box, works now (?)
- FST status checked, no further refilling needed
-
After the access, STAR detector was put in the APEX/beam development mode. Again took cosmic when no beam related work was performed
- BSMD: CAEN HV system failed; no spare parts (controller boar) are available. BSMD is off now and not included in the run configuration. Most probably BSMD will be unavailable till the end of the Run24.
- MXQ crate went off without apparent reason, fixed by power-cycling the crate
- Opportunity for restricted access from 8:00 – 18:00 (DX training for collider), some DX training for tomorrow (access opportunity tomorrow), please let us know if you want to use this
- We continue running cosmic but prioritize expert’s needs
- Separate work for Pulsed Power group for yellow abort kicker (need 6 hours of work)
- RF conditioning of storage cavities overnight
- Injection and ramp possible (APEX mode tonight !!)
- First Au+Au collisions at STAR expected Wednesday (Oct. 2nd) night or Thursday (Oct. 3rd)
- RHIC power supply not ready, DX training, access for yellow board kicker, crossing angles setup
- What is the plan for eTOF during this AuAu run ?
- Update the detector readiness checklist
-
Geary is asking about David’s schedule, IOC related work for TOF, Alex will contact him and cc Geary
Monday, September 30, 2024
Recap of Past 24 Hours:
- Overall: Physics and data taking, the last p+p store ended at 08:00,
Encountered Issues:
- BSMD HV did not turn ON. Shift team contacted Oleg, and then removed BSMD from the run configuration (starting at about midnight).A few common issues with TPC RDOs, Trigger/RunControl, and sTGC
Plan for the Day:
- access opportunity till ~16:00
- CAS brought the magnet down for some cleaning work. It needs coordination with Prashanth.
- Plans for the access:
- Inspection if FST cooling refill is needed
- TOF: W5 POS HV cable to be moved from 7.5 to 3.0
- Time permitting: eTOF: check TCD connection to the rack
- After the access:
- we plan to bring the magnet up
- STAR detector stays in the APEX/beam commissioning mode
Looking Ahead
Tuesday, Oct. 1st: We expect a few hours of access opportunity
The last 3 weeks of the Run24 will be Au+Au collisions.
First Au+Au collisions at STAR expected on October 3rd.
Sunday, September 29, 2024
Recap of Past 24 Hours:
- Overall: Physics and data taking
Encountered Issues:
- DAQ: EVB24 started causing problems at about 8 am today, removed from the run configuration after consulting Tonko. Jeff will work on solving this problem later today.
- ESMD: MAPMT FEE 4P1 turned red for a while, the problem fixed itself automatically
- A few common issues with TPC RDOs and Trigger/RunControl
- B1U polarization measurements not available for the current fill (#35153) due to broken target. The issue showed up at the end of fill #35152.
Plan for the Day:
- Physics
Looking Ahead
Monday, Sept. 30: Maintenance day
- the last p+p store ends at 08:00,
- then ~8 - 9 hour of maintenance
- Plans for the access:
- We plan to keep the magnet on
- Inspection if FST cooling refill is needed
Tuesday, Oct. 1st: We expect a few hours of access opportunity
The last 3 weeks of the Run24 will be Au+Au collisions.
First Au+Au collisions at STAR expected on October 3rd.
Saturday, September 28, 2024
Recap of Past 24 Hours:
- Most of the time: Physics and data taking
- Problems with FCS ECAL. Akio and Tim made access at 19:40, replaced one of MPOD modules for FCS ECAL power supply, reconfigured and turned back on.
- We are running with ToF without West Sector 5, so with 90% of ToF acceptance (and 90% of expected ToF multiplicity). Jeff modified IDs for triggers that include ToF Multiplicity to keep track of runs with this state.
Encountered Issues:
- Evening shift noticed 2 new cold tiles in the EPD West ADC plot. Performed "Reboot All" according to the EPD cold tile response manual, but that did not solve the issue. It should be resolved after running pedestal_rhicclock_clean. Run pedestal_rhicclock_clean was postponed to the end of the fill, and done in the morning.
- Note to shift teams: please follow the EPD instruction carefully: After “Reboot All”, one needs to run pedestal_rhicclock_clean, even if we have beams.
- A few common issues with TPC RDOs, Trigger/RunControl
Plan for the Day:
- Physics
Looking Ahead
Physics for the rest of the week
Monday, Sept. 30: Maintenance day
- the last p+p store ends at 08:00,
- then ~8 - 9 hour of maintenance
The p+p run ends on Sept. 30. The last 3 weeks of the Run24 will be Au+Au collisions.
First Au+Au collisions at STAR expected on October 3rd.
Friday, September 27, 2024
Recap of Past 24 Hours:
- One hour access for sPHENIX at 10 am, then some problems with injection.
- back to Physics at 13:49, then data taking
- EEMC HV monitoring is in "paused" mode to reduce the number of GUI crashes
Encountered Issues:
- TOF: "over current" alarms in TOF HV West Sector 5, followed by the "Positive - HV West Sector 5" internal trip.
- Shift team contacted Rongrong, no success with resolving the problem during the night. Geary was trying to fix this issue today in the morning, but no success so far. We can run with the current ToF state (without TOF West Sector 5),
which gives 90% of ToF acceptance, so 90% of ToF Multiplicity. We need to change the IDs for triggers that include ToF Multiplicity to keep track of this situation. To fix the problem, we need a short access.
- Shift team contacted Rongrong, no success with resolving the problem during the night. Geary was trying to fix this issue today in the morning, but no success so far. We can run with the current ToF state (without TOF West Sector 5),
- TOF+MTD gas system lost communication with Slow Control.
- Alexei solved the problem by restarting the program that provides the connection to the Slow Control database.
- Run Control disappeared, solved after contacting Jeff (RTS02 machine died)
- Jeff will work on preparing a spare machine in the case RTS02 dies for good.
- FCS trigger was running very high, which caused FST 100% dead in DAQ (two cases). Resolving the 1st one required “reboot all”, the 2nd - fixed after restarting the run.
- EEMC GUI communication problem, solved by the shift team.
- Note to shift teams: please read carefully the email from Will Jacobs on Sept. 26 about EEMC monitoring
- A few common issues with TPC RDOs, Trigger/RunControl
Plan for the Day:
- Physics
Looking Ahead
Physics for the rest of the week
Monday, Sept. 30: Maintenance day
- the last p+p store ends at 08:00,
- then ~8 - 9 hour of maintenance
The p+p run ends on Sept. 30. The last 3 weeks of the Run24 will be Au+Au collisions.
First Au+Au collisions at STAR expected on October 3rd.
Thursday, September 26, 2024
Recap of Past 24 Hours:
- APEX (10:00 – 16:00), then machine development (16:00 - 18:00)
- back to Physics at 19:16, then smooth data taking
Encountered Issues:
- A few common issues with TPC RDOs, Trigger/RunControl, and sTGC
- EEMC communication problem, resolved by the shift team
- Shift team noticed single hot channel in Sector-22 from the TPC Sec. 22 charge per pad plot, but no corresponding peak in the RDO-bytes plot. The were unable to identify the RDO, and not sure if it's a known issue.
- It is safe to continue data taking in such a case, but pay attention to TPC dead time.
- FCS trigger was running very high, which caused FST 100% dead in DAQ. Resolved after restarting the run.
- Note to shift leaders: Please pay attention to trigger rates. If the trigger rates are red, restart the run.
Plan for the Day:
- Physics
Looking Ahead
Monday, Sept. 30: Maintenance day
- the last p+p store ends at 08:00,
- then ~8 - 9 hour of maintenance
The p+p run ends on Sept. 30. The last 3 weeks of the Run24 will be Au+Au collisions.
First Au+Au collisions at STAR expected on October 3rd.
Wednesday, September 25, 2024
Recap of Past 24 Hours:
- Overall: Physics and data taking
- TPC Grid Leak: David reset the HV power supply, TPC Grid Leak is back to normal conditions
Encountered Issues:
- A few common issues with TPC RDOs, Trigger/RunControl, and sTGC
- EEMC communication problem, solved after calling the expert
Note to shift teams: this EEMC communication problem, and how to resolve it, is discussed in the EEMC manual. Please check it before
calling the expert.
Plan for the Day:
- APEX from 10:00 to 16:00,
- then 2 hours of machine development (16:00-18:00) (test of a new
polarimeter target) - return to Physics at about 19:00
Looking Ahead
Monday, Sept. 30: Maintenance day
- the last p+p store ends at 08:00,
- then ~8 - 9 hour on maintenance
The p+p run ends on Sept. 30. The last 3 weeks of the Run24 will be Au+Au collisions.
Tuesday, September 24, 2024
Recap of Past 24 Hours:
- Overall: Physics and data taking
- 1 hour access for sPHENIX at 2 pm, shift team took Cosmics during the access
- We are running with very stable beam condition, so there is no need to take bgRemedyTest_2024 runs. They were removed from Detector Readiness Checklist
Encountered Issues:
- TPC Grid Leak: sectors 20 and 24 lost their voltages. Alexei tried to fix the problem, but without success. Also intermittent alarms for
sector 23.- We will request ~0.5 hour access today, after the current fill, to fix the problem (change the board)
- FCS trigger rates were very high, which caused FST going 100% dead in DAQ. Restarting a run resolved the problem (cleared the bad FCS conditions)
- TPC gas PI-10 yellow alarm, shift team contacted Alexei, the alarm
cleared by itself. - A few common issues with TPC RDOs, Trigger/RunControl
- sTGC ROB #12 power cycled.
Note to shift leaders: please read carefully the "TPC reference plots and issue problem solving" manual. If there is a single hot channel,
there is no need to stop the run.
Plan for the Day: Physics
Looking Ahead
Wednesday, Sept. 25.:
- APEX from 10:00 to 16:00,
- then 2 hours of machine development (16:00-18:00) (test of a new
polarimeter target) - return to Physics at about 19:00
Monday, Sept. 30: Maintenance day
- the last p+p store ends at 08:00,
- then ~8 - 9 hour on maintenance
The p+p run ends on Sept. 30. The last 3 weeks of the Run24 will be Au+Au collisions.
Monday, September 23, 2024
Recap of Past 24 Hours:
- Overall: Physics and smooth data taking
- Prashanth worked on the sTGC gas system. Shift team needs to monitor sTGC PT-1 pressure through database since its alarm is disabled, and call Prashanth if its pressure drops below 19 psi.
Encountered Issues:
- A few common issues with TPC RDOs
- Yellow alarms for sTGC PT-2 and PT-3 pressure. Shift team consulted Prashanth. The pressure should be monitored. Call Prashanth if the pressure drops down to 14-15 psi.
Plan for the Day: Physics
Looking Ahead
- plan for tomorrow: Physics
- APEX on 9/25
- No maintenance on 9/25
- Maintenance moved to 9/30 (start of Au run)
- The p+p run ends on Sept. 30. The last 3 weeks of the Run24 will be Au+Au collisions.
Sunday, September 22, 2024
Recap of Past 24 Hours:
- Overall: Physics and smooth data taking
- Alexei refilled GMT gas bottle
Encountered Issues:
- A few common issues with TPC RDOs and Trigger/RunControl
- sTGC gas interlock alarm went off (PT1 gauge showing a high pressure). Shift team contacted Prashanth and turned down the pressure regulator on the gas tank outside the TPC gas room.
- sTGC ROB #8: was power cycled and after that its current was lower than expected (0.5A vs 0.7A). Shift team consulted Prashanth. After starting new run, the issue resolved itself.
- FCS: DEP05:1 failed. The shift team called Tonko, restarting the run solved the issue.
Note to shift leaders: Please read error messages carefully. In this case, one should try restarting the run one more time before calling the expert, as the error message describes.
Plan for the Day: Physics
Looking Ahead
- No maintenance on 9/25
- Maintenance moved to 9/30 (start of Au run)
- The p+p run ends on Sept. 30. The last 3 weeks of the Run24 will be Au+Au collisions.
Saturday, September 21, 2024
Recap of Past 24 Hours:
- Most of the time Physics and smooth data taking
- Beam dumped at 19:00 for access for sPHENIX
- Shift team took Cosmics during the access
- Back to Physics and data taking at 0:30
Encountered Issues:
- A few common issues with TPC RDOs and Trigger/RunControl
- BSMD: HV GUI lost connection, resolved after consulting the expert (Oleg)
- Important: If there is an issues with BSMD: do not wait for BSMD, remove BSMD from the run configuring and start the run. Then try to resolve the problem.
Plan for the Day: Physics
Looking Ahead
- Physics during the weekend
- No maintenance on 9/25
- Maintenance moved to 9/30 (start of Au run)
- The p+p run ends on Sept. 30. The last 3 weeks of the Run24 will be Au+Au collisions.
Friday, September 20, 2024
Most of the time Physics and smooth data taking
Encountered Issues:
- Shift team was confused what should be the state of the VME #55 GP-Pulser. It must be off!
- Trigger: Critical error message for run #25264020 and #25264018: "l1 CRITICAL l1Task l1Task.C:#281 Got an invalid token: 0"
- Shift team consulted Akio and continued data taking. Jeff will investigate this issue. If this error happens again, it is safe to ignore, but please make a note in the Shift log.
- Inconsistent temperature alarms on VME #51 and #55
- A few minor issues with TPC RDOs and configuring MXQ_QTD
- sTGC PT-2 and PT-3 gas alarms went off, shift team consulted Prashanth
- Shift team stopped the laser run when noticed peaks in the TPC ADC vs time plots.
- During laser runs, one should expect spikes in the TPC ADC distribution, so no reason to stop the run. Please consult the "TPC reference plots and issue problem solving" manual.
Plan for the Day: Physics
Looking Ahead
- Physics during the weekend
- No maintenance on 9/25
- Maintenance moved to 9/30 (start of Au run)
- The p+p run ends on Sept. 30. The last 3 weeks of the Run24 will be Au+Au collisions.
Thursday, September 19, 2024
Recap of Past 24 Hours:
- APEX till 23:30, then ~1 hour access for sPHENIX
- Unexpected beam loss during the first fill.
- Physics started at 3 am.
- eTOF: Do not include eTOF in a run until further notice from experts.
Encountered Issues:
- RunControl:
- Could not stop run from the run control. GUI froze. Resolved after calling Jeff.
- Configurations waiting for more than three minutes, runs were notstopping. Resolved by "reboot all" multiple times after consultingJeff.
- Hot channels in TPC
- If there is a single hot channel, there is no need to stop the run. Flemming has sent to STAR operations email list his detailed suggestions for dealing with the hot channels in TPC:
- Spike in RDO bytes
- Identify the RDO
- Is it a single hot channel?
- Yes: continue the run and reboot at end
- No: (for example: Noisy full RDO, Noisy FEE or parts)
- Stop run and reboot, unless it’s a laser run stop when there are >3000 events recorded.
- Example from last few days
- 261017 sector tpx 12-6 single hot pad
- 263013 (last night) ~16 channels in TPX 18-6
Plan for the Day: Physics
Looking Ahead
- No maintenance on 9/25
- Maintenance moved to 9/30 (start of Au run)
- The p+p run ends on Sept. 30. The last 3 weeks of the Run24 will be Au+Au collisions.
Wednesday, September 18, 2024
Recap of Past 24 Hours:
- Access for sPHENIX at 10:30 am yesterday, then some problems with cryo
- Shift team took cosmics during the accesses,
- Detector Readiness Checklist was updated (updated eTOF procedure, a note about GMT)
- Physics started at 5:16 pm, data taking till 7:30 am this morning
- Akio uploaded new FCS Ecal HV files
Encountered Issues:
- Run control GUI froze completely. Fixed by Jeff by terminating the Run Control GUI remotely on his end, then the shift leader started the GUI.
- A few minor issues with TPC RDOs.
- Error configuring MXQ_QTD Node -> Shift team powercycled VME crate MXQ, which resolved the issue.
- APEX from 8:00 till 23:00.
- Dmitry will do maintenance on databases.
- Tonko will work on RDOs and TCD.
- Access for sPHENIX at 23:00 to work on cooling of MVTX (estimated duration: 30 minutes)
- Back to physics at about midnight
- No maintenance on 9/25
- Maintenance moved to 9/30 (start of Au run)
- Pp run ends on Sept. 30. The last 3 weeks of the Run24 will be Au+Au collisions.
Tuesday, July 30, 2024
-
TPC sector 11 channel 8 anode tripped, clear the trip manually
-
spike for the TPX sector 5 in this run, power-cycled
-
sTGC ROB10 channel 1 fluctuating
1st power dip (~11:00):
-
Lost the control for all the detectors. We got the global and sTGC interlock alarm, lost the power to the platform, lost water, network, MTD gas, air blowers.
-
PMD Power was off in the interlock page
-
powercycle the VME EQ4 crate
-
All back on ~ 14:33
-
TPC LASER controls were reset, we see pico drivers alive now.
2st power dip (~15:10):
-
MCW is running, but magnet tripped
-
reset the FST cooling
-
Turn on the BBC and ZDC. VPD is responding, so turned them off
-
BCE in red in the component tree, then fixed
-
Will recovered EEMC
-
BTOW, BSMD, ETOW, ESMD, FCS have been tested and ready to go. (18:04)
-
Magenet tripped (18:41)
-
restored control of TOF/MTD/eTOF HV and LV.
-
pedAsPhys run with TOF+MTD+TRG+DAQ, now only TOF tray 117 error remains, Rongrong masked out this tray.
-
Rebooted crate #63 (MXQ), rebooted trg/daq/l2. Now this run finished properly without any errors.
-
Magenet tripped again (21:41)
-
unable to turn on the VPD
Current issue:
-
“Bermuda” computer has a problem, Wayne had an access but couldn’t fix it. Copy the disk to a new one now, it is running ~30% at ~9:30. Wayne is also preparing a new desktop for this in the meantime.
-
MCW was lost due to blown fuses on the 80T chiller (for the MCW). Water is back online. Only MCW was lost, everything else is fine. (~6:20),
-
Lost the communication of TPC air blower (didn’t trigger the global interlock). - David & Tim
-
VME processor in Crate80 initiallizing correctly, but not communication. But right now is BTOW is back
-
GLW lost communication, need to be checked during access/ or David can re-establish com. - recovered - Tim
-
Can't start run due to mxq_qtd: qt32d-52 VP003 QT32D is dead - 63 crate - Hank will call control room
-
mix, mix_dsm2 - 69 crate - Need a physical power-cycle - Tim
-
Laser can be turn on but can’t be tuned
To shifters:
-
Shiftleaders please pass all the informations to the next shift, walkthrough all the problems happened during the shift, and the remaining problems
-
check the weather before processing the recovery, just in case there will be another thunder storm/power-dip happens soon
-
clean the control room
Monday, July 29, 2024
Status & Issues:
-
TPC:
-
#25210022, a spike in the TPX RDO_bytes plot for sector 4. Power-cycled.
-
#25211009, ITPC RDO S04:1, power-cycled
-
#25211016, iTPC RDO iS17:2, TPX S13:4, power-cycled
-
TPC Anode Trip, Sector 11 channel 8, 5 times - apply 45V down, will also remind the SC expert
-
-
Laser:
-
The laser can turn on but is not able to tune. Prashanth will try to fix it during the next access (Monday afternoon/Wednesday).
-
Now the procedure for laser run is: 1) Warm up the laser in advance for 5 minutes and do not try to tune the laser. 2) After 5 minutes, start the laser run. Do not tune the laser during the laser run.
-
-
Trigger:
-
#25210037 couldn’t start the run, rebooted TRG+DAQ
-
Carl did a test for the new trigger configuration. Need to do a quick check at the end of this fill
-
-
sTGC:
-
Red alarm from sTGC Air blower AC failure, the problem cannot be fixed during the run, need to have access. It triggered sTGC interlock after about 20 minutes. DOs powered down the HV & LV. Shifters switch the bypass key from the left side to the right side following the instruction from David.
-
David had short access ~ 18:30, then the sTGC blower AC was restored. (~18:50)
-
sTGC ROB 10 channel 1 (sTGC::LV2::114::1::imon) keeps making yellow alarms repeatedly and quickly disappears. (~01:12).
-
-
TOF:
-
Prashanth & Jim restarted TOF/MTD archiver from the TOF machine in the gas room. Changed SF6 cylinder and Freon cylinder.
-
-
FCS:
-
Error in “FEE count 44, expected 55; FEE count 33, expected 55 -- restart run. If the problem persists contact expert”. Then got a “configuration error”. DOs power-cycled the FEEs and reboot the FCS in the run control. But still have the same issue. Called Oleg.
-
a problem with FCS ECal North. One of the MPOD PS boards shows 'outputfailure Maxs' all V and currents are at 0. It is not clear if it is a failure of MPOD itself, or if it is caused by one of the ECal FEE.
-
Gerard found that FCS power channel u4 configuration readback values were wrong, looked like all defaults. Likely, this channel got a radiation upset. Reconfiguring the MPOD with setup script 'setup_FCS_LV.sh' restored correct operation
-
FCS: DEP08:3 failed, restart the run fixed the problem
-
-
Network:
-
MQ01 server: Disconnected the MQ01 server, unplugged all 4 disks from the MQ01 server, installed in the backup server (labeled in STARGW1), and then connected the backup server online with Wayne’s help. After rebooting the server, things seem to be working fine. DB monitoring is also back online.
-
TOF/MTD Gas monitoring: went to the gas room, and started the EpicsToF program. The PVs start to update online. Alarms cleared.
-
EPD: Tim forced a reboot of TUFF1 and 2. Now the EPD GUI reports "connected". Working fine now.
-
Schedule & Plans:
-
cosmic 13:00-19:00 request by sPHENIX, access: AC. FCS S 10, VME 62, BBC East 1, the fan of TOF(east vpd); reboot scserv (Wayne), TPC Laser (Prashanth)
-
Physics for the rest of the time
-
Low luminosity tomorrow or Thursday (6x6)
Sunday, July 28, 2024
Status & Issues:
-
TPC:
-
#25209041, iTPC S13:1, DOs power-cycled it
-
#25209057, TPX S02:6, DOs power-cycled it
-
#25209065, 100% TPX/ITPC deadtime for over 1 mintue
-
#25210015, iTPC S09:3, DOs power-cycled it, but still get the same error, masked it out
-
#25210020 - TPX S22:04, higher value in the TPX Totall bytes per RDO, power-cycled it after the run
-
-
MTD:
-
#25209043, some hot strips in the MTD strips vs BL (CirticalShiftPlots->MTD-<StripsvsBL) plot
-
-
Network;
-
19:15, EPD, EPD: TUFF[2] dead - check TUFF if RUNNING!; 19:25, lost the connection; QA plots look okay
-
00:00, TOF/MTD Gas; lost the connection; The computers in the gas room running ok, it is just the online database stop updating
-
DOs visit the gas room once an hour, check the gas values in-person, Alexei provided some inputs on which value we can look for
-
Lost the control of laser for camera 1 and 3
-
call from Wayne. He said the online monitoring network issue is caused by MQ01 computer. He let us to reboot the MQ01 and check the net work connection of dashboard1 computer in the DAQ room. The MQ01 is dead, will try to replace the power supply.
-
-
Others:
-
DAQ rate is a little bit high
-
TPC pulser crate #55 is in an unknown state! Please make sure it is OFF! - it is off
-
Schedule & Plans:
-
A short access after this fill (request by sPHENIX), physics for the rest of the day
-
Tomorrow afternoon - 6 hours cosmic request by sPHENIX
Saturday, July 27, 2024
Status & Issues:
-
TPC:
-
ITPC S11:2, masked out
-
TPX S19:3, power-cycled; Shift Crew should look for spikes in rdoNobytes, and if spikes look for appropriate sector adc plots—details in the TPC reference plots and issue problem-solving slides.
-
TPX S01:6 (#25208024), power-cycled
-
iTPC S21:2 (#25208045, #25208046), power-cycled
-
ITPC S16:4 (#25308048), power-cycled
-
(#25208050 - #25208053) ITPC S17:1, S04:1, S16:4, power-cycled
-
(#25208057) a spike in RDO_bytes plot TPX S11:4, power-cycled
-
(#25209003) ITPC S16:4, DOs power-cycled it
-
(#25209005) ITPC S07:1, DOs power-cycled it
-
(#25209007) ITPC S17:4, DOs power-cycled it
-
(#25209016) ITPC S04:1, DOs power-cycled it
-
(#25209019) ITPC S16:6, S16:3, DOs power-cycled them
-
-
Environment alarm:
-
Had a temperature alarm again (13:30), followed by a series of similar alarms for different subsystems on July 22. Called MCR and Jameela. The CAS watch and AC people came and fixed the problem (~15:14). Jameela scheduled an AC maintenance on the next maintenance day.
-
Schedule & Plans:
-
physics for all-day
Friday, July 26, 2024
Status & Issues:
-
TPC:
-
TPX: RDO S21:6, power-cycled
-
iTPC S02:1 power-cycled, still create problem, masked out
-
TPX[28] [0xBA1C] died/rebooted -- restart a new run and it looks good
-
25207049-25207052: ITPC: RDO S18:4 , many auto-recoverys, again in the late night (25207059), power-cycled the it
-
(22:48) TPC Anode sector-1 channel-5 tripped, shifters tried to clear the trip it didn't worked. So, individually cleared the trip following the manual.
-
ITPC: RDO S11:2 -- auto-recovery failed. Powercyle this RDO manually & restart run. (25208018, 25208019 )
-
-
FCS:
-
fcs10 issues: It gets stuck in fcs10 HCAL South FEE scan, Tonko increased the logging level to capture it in the log for the next occurence
-
New guide for FCS If the blinking issue happen again, try follows:
1) Powercycle FCS HCAL South FEEs in the FCS slow control.
2) "Reboot" FCS in the run control
3) Start a new run tun
4) If that failed, mask out the FCS[10] and record that in the shift log
-
TOF:
-
(#25208020) Several TOF trays in error and do the auto-recovery. got the a red alarm from TOF LV THUBNE at same time. After the auto-recovery done the red alarm disappeared.
-
The list of TOF tray in error:
TOF: tray # in error: 66 68 69 70 71 72 73 74 75 76 77 79 80 81 82 83 84 85 86 87 89 90 91 92 93 94 95 122 -- auto-recovery, wait 6 seconds…
-
(#25208022)TOF THUB NE auto-recovery and triggered the red alarm. Alarm disappeared after the auto-recovery finished
Schedule & Plans:
-
physics for all day and weekends
-
Cosmic in next Monday (likely) requested by sPHENIX, Carl & Xiaoxuan & JH will work on the triggers during that time
-
Works plans on the list: AC. FCS S 10, VME 62, BBC East 1 & bwoo6, the fan of TOF(east vpd); reboot scserv (Wayne)
Thursday, July 25, 2024
Beam until around 15:30 (extended since 7:00); We had a short access to fix bTOW problem after beam dump; APEX until midnight; running physics until this morning.
Status & Issues:
-
TPC:
-
(25206021 & 022) iS02:1, masked out; tpc.C:#621 RDO4: automatically masking FEE #7 error
-
-
Laser:
-
Jim showed shifters about how to operate Laser
-
Checked the magic crystals for the TPC lasers. The quantity of crystals is good and should last several more days.
-
Alexei and Jim decided to increase the amount of methane flowing to the TPC (slightly) to try to increase the drift velocity. (It has been falling in recent days). So I turned FM2 clockwise by 3mm at the end of the index needle.
-
-
TOF gas: DOs switched from TOF Freon Line B to Line A
-
BTOW: Oleg and Yu made an access, replaced blown fuses for crate 0x0b it is configuring OK. Powercycled PMT box 39 (on separate power supply) and restore communications with boxes 41,42 and 39. BTOW sysetm restored and ready to go.
-
FCS: DEP10:6 in unmasked at 22:30 during fcs_led_tcd_only; but create problem when try to start the emc-check at the beginning of the fill (1:04). Tried try reboot trg and fcs, doesnt’t work; tried to only mask the 10:6, doesn’t work; masked the 10; - Tonko will look at it
-
Run control: Run control was frozen this morning right before the beam dump, couldn't close the windows at the beginning. Force it to close with the windows task manager, but couldn't bring it back after several try. Called Jeff, found vcx-server was not running in the background. Run control is back after rebooted the vcx-server (xlaunch). Since it happened in the end of the fill when the beam is about to dump, the problem didn't affect any physics run. - shifters can use the old shitcrew PC (in front of shift leader desk, RTS02) to start the run control if this happens and stop us to start/stop a physics run in the future
-
Network:
-
Any new host attempting (e.g. yesterday rebooted sc3) to connect to scserv initially fails in the same way. Wayne want to reboot scserv to see if it changes anything, but want to hold off until a maintenance period.
-
Temporatory solusion: if this issue is encountered again, please wait two minutes and try connecting again.
-
-
Others:
-
#25207018:
-
06:03:03 1 tcd CRITICAL tExcTask mvmeIrqLib.c:#477 UNKNOWN EXCEPTION: Task 0x01DFE148 suspended, exception 0x00000400.
-
06:03:03 1 tcd CRITICAL tNetTask mvmeIrqLib.c:#477 UNKNOWN EXCEPTION: Task 0x01DEDA70 suspended, exception 0x00000700.
-
-
#25207019: EPD West hit count shows two (relatively) not-very-efficient areas. Issues disappeared in the next urn;
-
Schedule & Plans:
-
Machine development is cancelled, so physics for all day
-
sPHENIX is addressing the suggestions got from the safety walkthrough for the isobutane, no clear schedule yet; Carl and JH will try to test the low luminosity trigger configurations on Friday morning (Carl & JH), Carl will send a guide to summarize trigger configuration exam did last time
-
Works plans on the list: AC. FCS S 10, VME 62, BBC East 1 & bwoo6, the fan of TOF(east vpd); reboot scserv (Wayne)
Wednesday, July 24, 2024
Status & Issues:
-
SC3:
-
lost control on VPD,BBC,ZDC and VME crates due to sc3 CPU crash. David bought control of VPD/BBC/ZDC back at SC5; Wayne came and rebooted SC3
-
-
BTOW:
-
configuration failed error around 20:50; Tried restarting the run, but the caution persists. Then realized this might due to the crash of sc3
-
Oleg T. found three BEMC PMT boxes (39, 41, 42) are dead, and they are masked out for now.
-
Error at 05:21:09: 1 btow CAUTION btowMain emc.C:#467 BTOW: Errors in Crate IDs: 11;BTOW: configuration failed
-
At similar time, VME-9 emcvme9_i4val made a red temperature alarm. (5:43), Oleg suspects that the issue with the BTOW is due to the blown fuse.
-
Also have a problem on connecting to VME processes on the platform, for BTOW data collector and BTOW canbus,
-
An access is requested after this fill for Oleg, and Wayne (if needed)
-
now running without BTOW+BSMD
-
-
GMT: trip at u3 channel. DOs performed a reset trip operation.
-
Trigger: Hank points out the document about how to fix the trigger related problem for shifters (https://www.star.bnl.gov/public/trg/trouble)
-
FCS: DEP10:6 failed again, masked from the component tree. To the shifters:
-
If it is DEP 10:6 problem, masked 10:6 and run (already masked)
-
If it is entire DEP 10 problem, take FCS out from the run, contact Tonko
-
-
Others:
-
STAR control room door handle is fixed
-
An “umbrella” is installed to temporary fix the ceiling leaks
-
J.H. opened a BERT window for the beam-beam parameter. Now we can check the beam-beam parameter by it.
-
Schedule & Plans:
-
APEX for today (July 24) 8:00 - 00:00, - problem on AGS RF cooling water, the beam extended
-
Machine development assigned for tomorrow (July 25) 11:00-15:00
-
Still no clear timeline about when sPHENIX will flow the isobutane / have access / low luminosity runs - exam the trigger configurations on Friday morning (Carl & JH), Cail will send an guide to summarize trigger configuration exam did last time
-
Works plans on the list: AC. FCS S 10, VME 62, BBC East 1 & bwoo6, the fan of TOF(east vpd)
Tuesday, July 23, 2024
-
unexpected beam abort (~ 20:06)
-
MCR had a fake ODH alarm, but based on the safety procedure, still dump the beam earlier (~06:20)
Status & Issues:
-
TPC:
-
TPX: RDO S09:5, recovered after start a new run
-
#25204040, The TPC went 99% dead, this indicates it is external to TPC.( By doing a reply of daq you will see that at 12:27 the JP1 SCA triger rate goes to 3 mHz)
-
#25204053, many ITPC RDO auto-recoveries and 100% TPX/iTPC dead time
-
RDO4: automatically masking FEE #7
-
power-cycled TPX: RDO S15:6
-
-
EPD: Mariia Stefaniak tried to fix the EPD problem, reboot TRG and DAQ and take some pedestal_rhicclock_clean runs
-
sTGC: Before #25205016, shifters restarted the sTGC LV and found some empty lines in the sTGC hits/FOB and empty space in hits/Qudrant. Power cycled after this run, and thing back to normal in the next run.
-
EEMC:
-
(Day shift) red+blue indicator for sector 1, P1 (most inner circle) at the EEMC MAPMT FEE GUI. DOs followed the manual and solved the problem
-
a new noisy PMT in ESMD starting from Run# 25204041
-
-
Tigger:
-
(at 9:45am): 1) STP reset is failing. Runs will not work, please power cycle L0/L1 crate #62 2) STP reset finally worked. Do not power cycle L0/L1 crate
-
L0 and L1 got stuck on TRG + FCS, shifters rebooted all component; still fail to start the run, FCS keep blinking; called Jeff; take the fcs[10] out; run could start. But today’s morning it is working again
-
#25204066: There was a warning in daq monitor for L2. Event timed out by 97 ms, Token 861, Total Timeouts = 11, Timed Out Nodes = MIX_DSM2::dsm2-23. - Will be discussed in the trigger meeting
-
#25204068: BQ_QTD[trg] [0x801E] died/rebooted -- try restarting the Run. Shifters tried rebooting trigger, didn't work. Then rebooted all, run could be started.
-
-
Others:
-
Takafumi brings it up that the reference QA plot is out of date (https://drupal.star.bnl.gov/STAR/content/reference-plots-and-instructions-shift-crew-current-official-version), will add a list of recent good run as an example of additional reference
-
The control room AC is still leaking, Jamella came and said will try to fix it ASAP
-
The door handle (white door) to enter STAR control room is loose - call MCR and maintenence team
-
Schedule & Plans:
-
Physics for the rest of the day with 6 hours of fills
-
Possible chance to access after the sPHENIX isobutane safety walk-through (start at 11:00) in the afternoon. Works planed last time: AC. FCS S 10, VME 62, scaler board 5 (BBC E) & bwoo6 (Chris Perkins), the TOF east vpd - we decide to wait for the next access
Monday, July 22, 2024
Status & Issues:
-
TPC: power cycled TPX: RDO S02:3; RDO iS19:1 bad (#25203050, and a few runs after 25203051), powercycled this RDO, but did not work, masked it out
-
#25203031 & 25203044 - The shift crew noticed in the QA plots that RDO_bytes have a spike around 75 (TPX Total bytes per RDO), - may related to the dead time
-
FCS: Tim came and had access around 2 pm; Tonko with Tim checked the fPRE DAQ link for sector 10:6, the DEP board#13(from 1) in crate #3 (from 0). The issue remains after replacing the patch cable and SFP module...but in any case, from further evaluation, the issue seems to be w/ the DEP board. Time constraints for the access did not allow for enough time to replace + configure + test a new board in the system. DOs unmasked sector 10 RDO 6. Again not working at ~ 23:22, shifters took it out. But showing ok during the midnight shift.
-
EEMC: Will reconfigured MAPMT box 1P1 (a.k.a ESMD crate @71) at ~ 10:05. OTOH it very simply responded to a reconfigure so appears ok. Then it again tripped many times during the day. Still shows the errors in Crate IDs: 71. Follow the manual can clear the trip, I will notice all the shifters about clear this trip manually.
-
VME: VME62 got stuck. DOs reset it (14:56)
-
Environment alarm:
-
TOF LV -> (East vpd) Terminal voltage triggering the yellow alarm from time to time over from ~16:00
-
Wide Angle Hall temperature is 30.7 degrees at 17:36 (yellow alarm); raise to 31.1 at 18:29 (red alarm). VME Crate 55 (no in-used) temperature yellow alarm at ~ 19:00; sTGC LV ROB# 10 current alarm at ~17:16 (yellow); VME Crate 51 PS Air temperature transient yellow alarm at ~19:26. Called MCR, and they sent CAS Watch to STAR to have a look. Looks like the AC in the IR is not running, so the 2nd platform shows a high-temperature alarm, but the original diagnosis is they need to have access to fix it. Since the temperature is still ok to run, we scheduled access for the CAS watch and AC guys to come, investigate, and fix it at the end of the fill (midnight). Then they found both ACs for WAH were down. They have successfully turned on one AC, and the temperature has started to decrease. Since the temperature is gradually back to normal, and running ok now, we will keep running until the next access
-
-
Trigger:
-
#25203026, “The run got stopped due to: L2[trg] [0x8201] died/rebooted -- try restarting the Run”, could not start a new run for 2 times, reboot the trigger and everything was running again
-
Jeff updated the low rate prescale setting for fcsDiJPAsy*EPDveto - Good so far
-
Hank power-cycled scaler board 5. Tim checked the patch cable for the BBC E PMT signal. The cable is connected and visually seems fine. But still no response. We will need to check further at scheduled maintenance access.
-
-
Others:
-
water leak at STAR control room, which seems to be from a bad sealing of the AC, AC team got informed and ordered new parts to fix the problem;
-
Waters outside STAR assembly hall, maintenance team got informed. They shut the water down.
-
If similar thing happened, called MCR first (and/or Jameela), and then maybe water group x4668
-
-
BERT: the system freeze time to time so the notice doesn’t pop up, keep an eye on the BERT system, restart it if needed
Schedule & Plans:
-
Physics for the rest of the day with 6 hours of fills
-
We are now running with one AC on in the IR, looks fine so far, will try to schedule a work once there is a chance to have a long time access. So for the next access: AC. FCS S 10, VME 62, scaler board 5 (BBC E), the TOF east vpd
Sunday, July 21, 2024
It was quite a smooth day for our data-taking.
Status & Issues:
-
TPC: #25202047 stopped due to TPC dead time (TPX: RDO S18:3 -- auto-recovery)
-
Laser: DO and shift crew should check both drift velocity and charge distribution vs phi plot. The latter should show spikes at about the sector centers. Two examples are printed and left near the laser PC and shift leader's desk.
-
ETOF usually stocks about 3-5 minutes after the beginning of the run with the errors: ETOF has 1136>1000 EVB errors. It keeps happening. We are currently running without ETOF. Do we want to include it?
-
FCS: FCS10 is ready to go after Tonko power-cycled the DEP crate. The DEP10:6 remains masked. - request an access for 30 mins
-
ESMD warning: "ESMD: Errors in Crate IDs: 71 -- refer to Endcap Operations Guide, Data Transfer Issues", run with this warning error for the rest of the shift
-
EPD: Run 25202062 - The shift crew observed a new cold tile in the EPD West <ADC> plot.
-
Trigger: Hank noticed the BBC East Scaler board 5 has problem
-
Others: Ceiling leaks at STAR control room (at the top of the coffee maker table), called site maintenance, they are sending people here; another leaking is found in the assembling hall (in front of the gas room), called site maintenance
Schedule & Plans:
-
Physics for the rest of the day with 6 hours of fills (Significant more down time now, need to discuss if longer fill is ok in tomorrow’s meeting)
Saturday, July 20, 2024
Status & Issues:
-
TPC:
-
TPX S10:6 was masked out for #25201034, power-cycled, problem was fixed.
-
iTPC S13:3 was bad, restarting the run to fix the problem.
-
TPX S09:3; S23:4 bad, power-cycled it manually
-
iTPC S05:3 is masked out
-
BSMD: RDO 2 -- too many auto-recoveries stopped the run, Oleg looked at it, and it’s back now.
-
GMT: single-tripped HV module (u3). DOs manual to clear the trip by resetting and restoring the channel (section 2).
-
FCS: Yesterday morning DEP10:6 failed frequently in the early morning. Tonko looked at it and found many possible reasons (fiber optics interface is glitching, low voltage at the PS (unlikely), the fiber has been slightly dislodged, or some other board failure), but all need to have access. Tim found the location of the board (South: crate:#3, DEP board #13 (count from 0)), but we are not able to have access. Then FCS stopped the run to start a new run at around midnight, called Jeff, and tried to mask out 10:1, 10:6, or 10:8 but still couldn’t start the run. [fcs10 00:36:01 202] (fcsMain): ERROR: fcs_fee_c.C [line 1548]: S10:1 -- FEE scan failed [2]. Masked the whole sector (10) out. FCS->Pres->PresSouth is empty. Tonko looked at it this morning and fixed the problem in sector 10. We take a fcs_led_tcd_only run, looks ok so far. DEP10:6 still could have problem, mask it if it happened.
-
Trigger: Jeff: Changed prescales for some FCS triggers to increase rates of low threshold triggers when the luminosity is low, according to Carl's triggerboard suggestions.
-
The Windows machine to monitor the magnet is back online now.
-
#25201048: run stopped by: 3514|esbTask.C|Recovery failed for RDO(s): 1 -- stopping run. Try restarting. Fixed after restart. Not sure what’s the problem
Schedule & Plans:
-
Physics for the rest of the day with 6 hours fills
Friday, July 19, 2024
Beam quality improved after machine development
Fill 34826: Physics for sPHENIX started at 20:23; Physics for STAR started at 21:19. Production run started at 21:25 with ZDC rate ~ 20k
Fill 34829: Physics for sPHENIX started at 00:30; Physics for STAR started at 1:17. Production run started at 01:24, with ZDC rate at 22.4k
Status & Issues:
-
TPC:
-
Unmasked iTPC RDOs: iS08-1; iS09-4; iS10-3; iS11-3; iS13-1
-
Have problems again after replacement. Masked: TPX S11-3; S11-6; S20-4; S20-5
-
TPX[30] [0xBA1E] died/rebooted (#25201011 ) - reboot seems not working, but then come back by itself
-
TPX and ITPC are 100% dead due to ITPC S02:4; S18:4; S04:1 (#25200043); then ITPC S02:4 S02:2 (#25200044); ITPC RDO S10:3 (#25200051-cosmic); ITPC RDO S10:3 (failed multiple times, masket out) iTPC RDO S08-1 (#25201006, failed multiple times, masked out)
-
TPC Anode Trip (sector-23 channel 5)
-
TOF: TOF LV alarm (yellow) - power cycled TOF LV - cleared.
-
FCS: DEP10:6 failed - 4 times - Looks like the fiber optics interface is glitching. Tonko: Could be due to low voltage at the PS (unlikely) or the fiber has been slightly dislodged. Or some other board failure. - Need access?
-
Crate #84 on the 1st floor is yellow. Hear no alarm. The temperature of PS is about 46 and red status. The Fan Speed is 1200 and yellow status (evening shift)
-
BBC: Tim and Akio made access to fix the BBC scaler. It was a BBC-west discriminator which had offset from 0 in output. This was moved to working channel one below in the same module, and the output width was adjusted to 10nsec to match the old one. Now it's coming at a reasonable rate for noise & pocket pulser.
-
Windows:
-
Shift leader computer crashed at 00:53 and 1:30, rebooted. TPC caen-anode HV alarming during the second crash (25201005). DOs brought them back following the instructions by click "wake me up". Not be able to stop the run. After the Run control was back, this run already run over 15mins. The QA plots looks okay, so still mark this run as good. - the run control can run on any of the linux machine
-
The machine to monitor the magnet is not recovered yet
Schedule & Plans:
-
Physics for the rest of the day with 6 hours fill
TPC:
-
TPX S10:6 was masked out for #25201034, power-cycled, problem was fixed.
-
iTPC S13:3 was bad, restarting the run to fix the problem.
-
TPX S09:3; S23:4 bad, power-cycled it manually
-
iTPC S05:3 is masked out
BSMD: RDO 2 -- too many auto-recoveries stopped the run, Oleg looked at it, and it’s back now.
GMT: single-tripped HV module (u3). DOs manual to clear the trip by resetting and restoring the channel (section 2).
FCS: Yesterday morning DEP10:6 failed frequently in the early morning. Tonko looked at it and found many possible reasons (fiber optics interface is glitching, low voltage at the PS (unlikely), the fiber has been slightly dislodged, or some other board failure), but all need to have access. Tim found the location of the board (South: crate:#3, DEP board #13 (count from 0)), but we are not able to have access. Then FCS stopped the run to start a new run at around midnight, called Jeff, and tried to mask out 10:1, 10:6, or 10:8 but still couldn’t start the run. [fcs10 00:36:01 202] (fcsMain): ERROR: fcs_fee_c.C [line 1548]: S10:1 -- FEE scan failed [2]. Masked the whole sector (10) out. FCS->Pres->PresSouth is empty. Tonko looked at it this morning and fixed the problem in sector 10. We take a fcs_led_tcd_only run, looks ok so far. DEP10:6 still could have problem, mask it if it happened.
Trigger: Jeff: Changed prescales for some FCS triggers to increase rates of low threshold triggers when the luminosity is low, according to Carl's triggerboard suggestions.
The Windows machine to monitor the magnet is back online now.
#25201048: run stopped by: 3514|esbTask.C|Recovery failed for RDO(s): 1 -- stopping run. Try restarting. Fixed after restart. Not sure what’s the problem
Physics for the rest of the day with 6 hours fills
Friday, July 19, 2024
TPC:
-
Unmasked iTPC RDOs: iS08-1; iS09-4; iS10-3; iS11-3; iS13-1
-
Have problems again after replacement. Masked: TPX S11-3; S11-6; S20-4; S20-5
-
TPX[30] [0xBA1E] died/rebooted (#25201011 ) - reboot seems not working, but then come back by itself
-
TPX and ITPC are 100% dead due to ITPC S02:4; S18:4; S04:1 (#25200043); then ITPC S02:4 S02:2 (#25200044); ITPC RDO S10:3 (#25200051-cosmic); ITPC RDO S10:3 (failed multiple times, masket out) iTPC RDO S08-1 (#25201006, failed multiple times, masked out)
-
TPC Anode Trip (sector-23 channel 5)
TOF: TOF LV alarm (yellow) - power cycled TOF LV - cleared.
FCS: DEP10:6 failed - 4 times - Looks like the fiber optics interface is glitching. Tonko: Could be due to low voltage at the PS (unlikely) or the fiber has been slightly dislodged. Or some other board failure. - Need access?
Crate #84 on the 1st floor is yellow. Hear no alarm. The temperature of PS is about 46 and red status. The Fan Speed is 1200 and yellow status (evening shift)
BBC: Tim and Akio made access to fix the BBC scaler. It was a BBC-west discriminator which had offset from 0 in output. This was moved to working channel one below in the same module, and the output width was adjusted to 10nsec to match the old one. Now it's coming at a reasonable rate for noise & pocket pulser.
Windows:
-
Shift leader computer crashed at 00:53 and 1:30, rebooted. TPC caen-anode HV alarming during the second crash (25201005). DOs brought them back following the instructions by click "wake me up". Not be able to stop the run. After the Run control was back, this run already run over 15mins. The QA plots looks okay, so still mark this run as good. - the run control can run on any of the linux machine
-
The machine to monitor the magnet is not recovered yet
Physics for the rest of the day with 6 hours fill
Thursday, July 18, 2024
-
Completed the scheduled access work during yesterday’s access: Network switch power supply (UPS), BSMD, ESMD crate 71, Magnet water for magnet, TPX, FST coolant refill, Powercycle main canbus
-
One fill so far since yesterday’s maintenance, 40 mins after sPHENIX declared physics, we start with the STAR ZDC coincidence rate ~ 22kHz
Status & Issues:
-
TPC:
-
RDO: power cycled RDO S02:2 and S02:4, also power cycled iS08:1 for 3 times, still frequently stopped the run, masked out
-
Anode trip once in the morning (sector-23, channel 5).
-
-
FST: FST -> HV -> ROD 3 and 4 in red, shifters brought them back manually.
-
The total daq rate > 5K and scalar rate were high in red (9M) for JP and BHT triggers (25200008-25200013, 25200020-25200025). DO originally thought it is a trigger problem, so called Jeff. Jeff mentioned it could be a problem due to the triggered detector. Shifters do not see any problem from QA plots. Tonko and Oleg called in, pointed out it is DSM crate problem (L0-L1). Shifters power-cycle the BC1, BCE, and BCW (VME 72, 73, 76). The rate looked reasonable now.
-
FCS triggers scalar rate is high > 9M (25200029), recovered in the next run
-
TOF gas is alarming for PT-2, changed the bottle
To shifters:
-
New expert call list is updated, contact Prashanth or/and Jim Tomas if there is any TPC related problems
-
Record to the log if the run is stopped due to the "TPC 100% dead" issues
-
If experts hang out the phone when you call in the mid-night, leave a message to experts, no need to call multiple times. Experts are getting to solve the problem as soon as possible after they received the messages
Schedule & Plans:
-
30 mins access requested by sPHENIX, possible to request another longer access after machine development - we used this time in the morning to access and try to fix the BBC problem, power-cycled the crate but it seems not working (Jamie & Akio). We will need to have a longer access if possible after machine development time
-
Machine development: 1000-1400 (put detector to APEX mode) - Toko will work on TPC during the APEX; request access after this if possible for BBC (Akio & Tim);
-
Physics: 1400+
Wednesday, July 17, 2024
Status & Issues:
-
General: Beam dump around 7:30, magnet is down, having access now
-
TPC: S17:3 tripped; RDO iS17:4 bad; iS09:4 bad error, power cycled S09-4 and S17-4; masked out iS09:4 in the end
-
TOF: PT-1 gas alarm, switched from B to A
-
ETOF: eTOF DAQ reconfiguration procedure is not working, "ETOF configuring front end, be patient!" for hours after restarting the eTOF DAQ. Geary called in and fixed the problem for the next run. Then it has >1000 EVB error again
-
FCS: Akio uploaded new FCS Ecal HV file
-
STGC: a yellow gas alarm for the Pentane Counter at 12:39; bottles refiled by 14:51
-
L4: L4 live events display has been updated to include the global tracks back. The space charge parameters for L4 have also been updated. Now it support the users to select global tracks or primary tracks themselves in UI..
-
Trigger:
-
Run 25199011 - By the end of this run, the rate increased to 4K, JP1 is 2.5K.
-
Cannot start run as trg-L0 get stuck, reboot trigger once
-
-
Others:
-
unexpected beam loss ~ 2:54 yesterday and then 16:30 yesterday - request extra polarization measurement in the middle? - get statistics about unexpected beam loss
-
40 mins delay after turn sPHENIX physics for the last fill, miscommunications MCR. We will keep 0 min or 40 min. Will be discussed during the spokersperson meeting
-
PC with BERT got frozen for about 5 minutes (day shift)
-
AC in the control room is back - don’t touch the thermostat, contact Jameela if needed
-
To shifters: write the shift log on time, and write the summary log with more details on the problems
-
Access plan for today (to 16:00):
-
Network switch power supply (UPS) - Wayne
-
BSMD (with magnet off) - Oleg
-
ESMD crate 71
-
Magnet water for magnet - Prashanth
-
TPX - Tonko & Tim
-
Laser tuning - Alexei
-
FST coolant refill - Prithwish & Yu
-
Powercycle main canbus - David
-
Tour to students- 11:30 & 13:20 by Jeff & Prashanth & Yu
Schedule & Plans:
-
sPHENIX will request a few hours cosmic and some fill with less bunch for low luminosity after changing to a new mixed gas: use this time for STAR to tune our trigger? (configuration changes should be discussed/finalized with more advance time due to EPIC collaboration meeting next week)
-
During nominal daytime hours (0800-2000) CAD will operate with 4-hour stores after STAR is brought into collisions. Polarization measurements will be taken at 0 and 4 hours (skipping the 2/3 hours measurement). Outside of daytime hours, resume the nominal 6-hour store length after bringing STAR into collisions and follow the existing store recipes (i.e. polarization measurements every 3 hours and dump) - will be revisit after get the statistics on how often is the unexpected beam loss
Tuesday, July 16, 2024
Status & Issues
• EQ1_QTD died/rebooted in run 2597030
• FCS power-cycled between fills (Oleg T.)
• Jeff updated some triggers after the trigger board meeting (FCS DiJP/DiJPAsy and EM0/1 with EPD veto); starting with run 25197047
• ETOW configuration error (crate 1 fixed by DO, crate 2 later required intervention by W. Jacobs)
• GMT u3 tripped and recovered by DO
• Beam dumped for SPHENIX access (EMCal); next fill lost due to QLI
• L0 stuck, rebooted (x2)
• iTPC/TPX 100% dead in three runs
• Filled dumped just after 9 am for another SPHENIX access to fix EMCal problems
• Issues with l2ped web page persist; the plots are all available but the archive is not updated properly which causes index.html to stop on July 3; (l2btowCal has similar problem, but stops on July 7)
Schedule & Plans
• Maintenance day, Wednesday 0800-1600
o Network switch power supply (UPS)
o BSMD (magnet off)
o ESMD crate 71
o Magnet water for magnet (Prashanth will check if water group is ready for valve replacement)
o iTPC/TPX recovery (Tonko, Tim)
o Laser tuning (Alexei)
• Then back to physics
• SPHENIX will request 56 bunch fill for low luminosity in a few days; possibilities to use this for STAR? (configuration changes should be discussed/finalized with more advance time due to EPIC collaboration meeting next week)
Monday, July 15, 2024
Status & Issues
• Connection to VME was lost at start of fill in the morning; DAQ warning about crate #55 (pulser); resolved in consultation with David; power-cycled following the slow control manual; VME 50 was still yellow; power-cycled between runs, lost connection to gating grid recovered by David and cathode interlock
• Beam abort with anode trip about an hour before scheduled dump time
• Cosmics for a few hours; observed higher rates than before
• iTPC deadtime spikes in run 24196057; L1 invalid token at start of run
• iTPC RDO iS13-1 masked after unsuccessful attempts at power-cycling
• Other RDOs which required manual power-cycle: iS13-2 iS13-4
• iTPC/TPX 100% dead (in three runs)
• high rates in forward triggers in run 25197028; stopped quickly and started new run
• level 2 monitoring plots have not been updated on the web page; the analysis is producing output, but it is not updated on online.star.bnl.gov/l2algo/l2ped
Schedule & Plans
• SPHENIX is asking for a short access after the current fill
• SPHENIX rates at the start of fill are currently below the 24 kHZ which are the threshold to bring STAR on; detectors should be brought up when physics is On for SPHENIX
• Continue with physics until Wednesday morning (maintenance day)
Sunday, July 14, 2024
Status & Issues
• 30 minute access turned into closer to 2 hours; new fill after 3 hours
• BTOW configuration errors while trying to take pedestals; rebooted trigger
• Then L0 hangs; reboot trigger; power-cycled VME-62 (twice)
• ESMD errors in crate #71 at start of every run; Will was informed and we can ignore this for now (EEMC MAPMT boxes 1S3 and 1P1)
• DAQ message “requesting reconfigure from Run Control” in combination with power-cycling RDO S20-5 and “critical: RECONFIG ERR tpx-34”; masked out S20-5; eventually able to start run after trigger rebooted
• Mostly smooth data taking through late afternoon and night; bgRemedyTest with 10k at start and end of each fill
• BTOW configuration failed in two more runs (not consecutive)
• EPD timing scan in runs 25195082 – 086
• sTGC hits/timebin has low counts early in fill 34799 (has happened before in some runs last week)
• L0 hangs one more time
• One run ends with 100% deadtime TPX & iTPC
Schedule & Plans
• Continue running physics until maintenance day (Wednesday)
• Include bgRemedyTest in fills as before (10k events)
• Discussion of beta* tomorrow
• Discussion of EPD timing cuts in trigger board meeting on Monday
Saturday, July 13, 2024
Status & Issues
• Akio power-cycled scaler crate; BBC And is back
• TPX RDO S11-3 and S11-6 are masked out due to power problems; Tim needs to take a look during maintenance day
• iTPC RDO iS09-3 investigation is continuing (added error messages for Tonko); mask again when it fails
• EPD veto on early hits is now in the production files (starting from run 25194034); shift crews have observed differences in EPD <TAC> (EPD expert suggested to reboot trigger and take pedestal_rhicclock_clean afterwards, this should have been added to the shiftlog)
• Stuck bit caused the high rates in EHT0; power-cycled TP-2 crate (Will J.)
• Rongrong tried to recover MTD BL 28; unsuccessful, still masked out
• Trigger group tested tier 1 file; everything back to default (?)
• Took some cosmics due to extended access/downtime
• Collisions at 1820
• Shift crew encountered: L0 died/rebooted, TPX[8] died/rebooted, iTP RDO iS10-3 power-cycle (repeatedly, then masked), iTPC[10] had to be power-cycled manually (Jeff)
• Power dip between fills at start of night shift with magnet trip, global interlock alarm, TPC FEE and RICH scalers white
• Magnet back up at 2:35 am
• Oleg T. recovered BEMC after MCW loss; HT TP 163 and 291 are masked out; BSMD is 50% dead and was turned off (until maintenance day)
• FST failure code 2 before first production run
• Combination of high rates in JP triggers and TPX/iTPC deadtime; rebooted trigger; power-cycled all RDOs; then again RDO S20-4/5 (again in the next run)
• Will J. recovered all MAPMT for ETOW; issue remaining MAPMT 1P1 (Will says it’s overheating, experts are aware)
• Run control was very slow in the morning, it seems to be running fine now
Schedule & Plans
• Continue physics data taking: pp200_production_radial
• bgRemedyTest_2024 at start and end fill
• EPD delay scan in next fill (non-intrusive during regular production run, see Hank’s email for details)
Friday, July 12, 2024
Status & Issues
• MTD HV trip in BL 15, 16 & 17 (early in fill 34785); power-cycled and back for next run
• Magnet trip at 10:30 am; strainers were cleaned during our downtime, but it is not completely clear where the problem is; valve replacement is ordered and should be replaced during maintenance; David Chan and team looked through temperature logs from different locations; magnet ramped up after 5 pm, temperatures looked fine and stabilized well under the trip threshold
• Network power switch died (splat-s60-2); Wayne was able to diagnose remotely; Jeff and Tim prepared access work; UPS was in “overheat error”; Tim plugged the network switch into the rack power
• MCR did a vernier scan for themselves while the magnet was down (and optimized our rate…?)
• Some problems coming back; Jeff, Rongrong, Gavin on zoom; one fill lost during ramp; everything was back for collisions at next fill
• MTD BL 28 is masked out
• FST problems with RDO 1-5 and 2-6; no problems when detector was at full HV
• BBC And is 0 in scaler GUI (Akio is looking at it)
• BTOW configuration failed in one run
• sTGC yellow/red gas alarm again this morning (Prashanth has been informed)
• elevated temperatures on VME-84 and 98 (EQ4, BDB)
• bgRemedyTest_2024; runs 25193…, 25194009, 017, 030
• ETOW HT trigger patch #81 is hot; EHT0 rate too high (prescaled at 50 now)
Schedule & Plans
• 1.5 hour access after this fill; dump time moved up to 10 am (condensation in tunnel, SPHENIX)
• STAR to get collisions at 24 kHz (SPHENIX)
• Carl’s bgRemedy studies confirm efficiency of background rejection for forward triggers; will send summary with configuration changes
• EPD delay scan (5 production runs) waiting for confirmation from Hank
Thursday, July 11, 2024
Status & Issues
• APEX study of spin direction at STAR was not successful and postponed
• Magnet trips at 12:17 pm and again at 1:26 pm; magnet at half field until 6pm, then back up to full field
• Collisions at 6:45 pm (75 minutes after SPHENIX)
• Several problems when starting run; BTOW configuration; TOF LV THUB NW tray 45, west 4 (power-cycled); iTPC RDO iS09-3 masked out
• Beam lost at start of second physics run
• East and west trim currents were not ramped up to full field; NMR showed 0.4965 T instead of 0.4988 T; ramped at 8:20 pm (mark the two runs as bad)
• Overnight fill with horrible yellow lifetime (tune changes during the ramp); STAR only 20 minutes behind SPHENIX but rates low from the start
• bgRemedyTest_2024 (runs 25192042, 25193016, did not include FCS)
• sTGC gas alarm (fluctuating, Prashanth was made aware)
• Tonko already looked at problematic RDOs from last night; iS01-1 reburned PROM; iS09-3 not clear what is wrong, unmasked again; iS09-4 disabled 4 FEEs
• STAR a little more than an hour behind SPHENIX
Schedule & Plans
• Physics until maintenance day (Wednesday, July 17)
• Vernier scan at the end of current fill (early afternoon)
• bgRemedyTest_2024 at start and end of two fills (Hank will double check tier 1 parameters and file/dates)
• Timing scan in regular runs on hold until after bgRemedyTest
Wednesday, July 10, 2024
Status & Issues
• TOF freon changed to bottle A
• epdTest-radial in new fill (run 25191030); cuts on early hits look good; in the process of being implemented -> bgRemedyTest_2024 is ready
• TPX RDO S01-5
• GMT u3 HV tripped (DO recovered, no further issues)
• L2 died/rebooted during configuration of one run; started new run without problem
• MTD low voltage THUBN alarm (run 25191041)
• iTPC RDO iS10-3 was masked out after repeated failure in pedAsPhys (waiting for collisions while SPHENIX was up already); masked out; Tonko reburned PROMs on iS06-2 and iS10-3 and unmasked them before APEX this morning
• Took cosmics data until APEX
• iTPC cluster occupancy in QA histogram is out of range early in the fill (e.g. compare runs 25191031 & 46)
Schedule & Plans
• Study of polarization vector during APEX today; take zdcPolarimetry runs when MCR does scan of different parameters (15-20 minutes x 2)
• Back to physics at 1600
• bgRemedyTest_2024 at start and end of fill
• trigger group requests five regular runs with modified settings (non-invasive to physics, details in Hank’s email)
Tuesday, July 9, 2024
Status & Issues
• iTPC RDO iS17-3 fixed and unmasked (Tonko)
• 3+ hours of cosmics data; first fill dumped after SPHENIX request for access (about one hour of collisions for SPHENIX)
• epdTest-radial with new TAC stop registers (run 25190055)
• ITPC RDO iS06-2 masked out after unsuccessful power-cycle
• Timeouts in l2ana01; low data rate (not sure if this is related, happened about 2 minutes apart)
• TPC anode trip S20-9
• TPX[24] died/rebooted
• iTPC RDO S02-4
• Fill extended due to problems with injection / BtA
Schedule & Plans
• bgRemedyTest_2024 updated after discussion in trigger board; ready for use once tier1 file is updated (Hank); take short run at start and end of each fill (TRG+DAQ+BEMC+EEMC+TOF+FCS)
• Wednesday APEX 0800-1600; continue physics until then
• Schedule a vernier scan in the near future (at the end of a fill)
Monday, July 8, 2024
Status & Issues
• GMT gas bottle replaced (reminder: even after switching to new bottle, the alarm keeps going until the empty bottle is replaced)
• TPX /iTPC RDOs: S11-6 (now masked out); iS02-4; power-cycled all after three failed attempts at run start
• TPX[31] died/rebooted during pedestal run
• Peak in TPC drift velocity is sometimes wide (run 25190013, improved in run 019)
• Magnet trip in fill 34764; restored without beam dump; polarization also looked ok in the next measurement
• Lost beam twice during injection / ramp
• Beam abort this morning; lead flows in sector 10 (problematic all week, being investigated now)
• EPD timing test looks good; background removed effectively (Hank)
Schedule & Plans
• Time between sPHENIX and STAR physics: over 100 minutes!
• Uptime 14 hours on Saturday; less than 9 hours on Sunday
• Short epdTest-radial in next fill
• Continue physics: pp200_production_radial until Wednesday morning (APEX)
Sunday, July 7, 2024
Status & Issues
• bgUpcTest with all detectors (25188041, 61, 68, 25189008)
• Lost laser view; no laser runs in fill 34758; Alexei got a short access between fills and restored the connection to laser platform
• STGC: ROB #03 bad FEB required power-cycle
• TPX[30] [0xBA1E] died/rebooted (running fine in the next run)
• Magnet trip at 6 pm; CAS were unable to clear the fault; clogged strainer for the supply; cleared by 6:55 pm when RHIC had just started injecting beam; ramped magnet and restarted RHIC fill
• TOF pt-2 alarm procedure updated (Alexei)
• GMT U3 HV tripped once
• Two peaks in “TPX Total bytes per RDO" (sectors 6 & 21); power-cycle cleared this
• sPHENIX had problems bringing down one of their detectors; unfortunately, MCR called us first while we were waiting for “ready to dump” from sPHENIX; ended up with 30 minute zdcPolarimetry
• Some issues with to many TOF recoveries; power-cycled LV; eventually had to go through CANbus restart procedure which solved the problem
• TPX RDO 17-5, 11-6, 11-3; iTPC RDO 02-4
Schedule & Plans
• Time between sPHENIX and STAR physics: 13, 8, 16, 32, 32, 59 minutes
• bgUpcTest is finished -> decision from trigger board (Monday)
• Continue physics: pp200_production_radial until Wednesday morning (APEX)
• Wayne is not available for next week (call Jeff for immediate help)
Saturday, July 6, 2024
Status & Issues
Schedule & Plans
Friday, July 5, 2024
Status & Issues
• At the start of fill 34747, problems starting with TPX[30] and failing STP resets. Run couldn’t be stopped properly and VME #62 power cycling wasn’t successful. Akio looked remotely, but also couldn’t help. Jeff eventually separated problems with trigger from TPX. pedAsPhys was successful on second try. Then hard reset of TPX[30] in the DAQ room. (Error in dsm2-3 in STP monitoring is not critical for data taking.)
This happened again when fill 34748 was lost. Shift crew tried to power-cycle VME #62; no success from control room or Jeff remotely. David got a short access, couldn’t power-cycle on the crate itself. Tim was not available, so we decided to hard reset (unplug). Fortunately, this solved the problem and VME #62 came back just as RHIC was about to reinject.
• TPX, iTPC & FST deadtime issues in a few runs throughout the day. Clarified how to mark the runs and recovery with shift crew. (many auto-recoveries in early runs in new fill)
• sTGC pressure PT-1 yellow warning (fluctuating around threshold, may reappear during the daytime)
• FCS DEP 04:5 failed once (DAQ message has instructions for shift crew, no further issue)
• David changed the sTGC gas bottle
• Manual power-cycling of TPX RDOs 11:6 (many times), 22:6, 03:4, 14:6
Schedule & Plans
• Machine development today (~5 hours)
• Test run for trigger modifications; details will follow (Carl, Jeff)
• Continue physics: pp200_production_radial through the weekend
• Suggested to try to reproduce the VME #62 problems during next maintenance day for better diagnosis
Thursday, July 4, 2024
Status & Issues
• Lost beam before 10 am; then machine development
• BSMD shows high current at start of fill; Oleg T. said to run as is and power cycle later (~90 minutes)
• New cold channel in EPD (run 25185031)
• TPC 100% dead at start of one run (three other runs where it happened later; run 25185031 should not be marked as bad)
• Pentane refilled (David)
• NMR can be read from the control room now (David)
• Hank asked for repeat of epdTest_radial (run 25184043)
• “PCI Bus Error: status: 0x01” in emc-check and next run; reboot TRG + DAQ
• Few runs with TPX 100% deadtime after a few minutes; then L2 timeouts -> reboot all fixed it
• TPX RDO S11:3, S11:6; iTPC RDO S09:3 (many times this morning, now masked out)
• Beam abort around 5:20 am; beam permit dropped and couldn’t be cleared remotely; ran cosmics for a few hours; new fill coming up now
Schedule & Plans
• Machine development on Friday (about 5 hours)
• Continue physics: pp200_production_radial
Wednesday, July 3, 2024
Status & Issues
• BTOW crate 0x10 was recovered; trigger patches for this crate were un-masked and tested (Oleg T, Tim)
• MAPMT sectors 2&3 HVSys module replaced (Tim)
• TPX & iTPC maintenance done (S11-6 seemed ok, failed once during cosmics)
• Cosmics data throughout the afternoon
• TPC anode sector 23 channel 5 tripped; “clear trip” didn’t work; manual recovery
• Maintenance extended until 8 pm (request from sPHENIX); new fill up by 9 pm
• Jeff added log info for STP failure -> power cycle L0/L1 crate #62
• GMT HV gui wasn’t responding; DO power-cycled the crate following the manual
• Intermittent yellow alarm on sTGC PT2 & 3
• BEMC CANBus needed to be rebooted (white alarm on CANBus, VME-1, 12, 16, 20, 24, 27)
• epdTest runs (25184076, 077, 078 - all EPD detectors see the early hits now, detailed analysis is on-going)
• FST random noise (non-ZS) plots are empty (run 25185002)
• EEMC gui turned white after beam loss; two yellow warnings remain (VME-90, 97); expert was informed; ok to run for now
• ETOF was taken out of run control (Geary’s email); Norbert called around 2 am and said it should be ready again
• Power-cycle TPX RDO 20:6
Schedule & Plans
• Machine development from 10 am until 1 pm (or earlier); sPHENIX asked for 10 min. access
• Continue physics: pp200_production_radial
• APEX Wednesday. July 10 (maybe later)
Tuesday, July 2. 2024
Status & Issues
• Trigger configurations updated with TofMult0 after discussion in trigger board meeting; everything handled in the existing configuration files, no need to change the procedure for the shift crew (in effect from run 25183041, bgRemedyTest_2024 not needed for the time being)
• iTPC RDO 02:4 manual recovery
• FST deadtime 100% (Fleming suggested correlation with trigger rates at beginning of run, check run 25184013, mark runs as bad)
• BSMD HV not ready for first run in fill 34733
• TOF gas switched to line B (11:51 pm)
• TPX/iTPC 90% dead for three attempted runs, eventually masked TPX RDO S9:4 (Tonko, done)
• Maintenance day: beam dump at 8:10 am, magnet down
Schedule & Plans
• Sweep at 5:30 pm
• Wednesday: machine development (2nd storage ramp, 10 am, 3 hours)
• Next APEX: July 10 (possibly postponed / combined with next session)
Monday, July 1. 2024
Status & Issues
• BSMD trips at beginning of fill
• TPC gating grid error and anode trips (first run in fill)
• Investigation of “non-super-critical pedestal problem in EQ4” (Maria, Mike); slightly shifted ADC spectra, does not affect the trigger at the moment, will communicate with trigger group if this changes
• evbx2 connection error? (run 25182073), L2 died/rebooted in the next run; all ok in 076
• evb01 | sfClient | Can't stat "/d/mergedFile/SMALLFILE_st_upc_25182078_raw_2400007.daq" [no such file or directory] (run 25178079)
• New alarm (buzz) for critical alarms in DAQ log (DAQ_announcer.sh, David)
• Beam loss at 1:25 am; regulator card on yo1.tq6 replaced at 5:25 am
• VPD alarm on slot 15-13; DO couldn’t recover; Akio looked remotely and said to ignore for now; slow control should take a look and maybe change limits (3 V out of 2 kV
• Took cosmics data for the rest of the night
Schedule & Plans
• Background discussion
o Vertex study (special production with no vertex constraint, Ting’s fast offline analysis)
o bgRemedyTest_2024: 25182039, 047, 061, 069, 25183021
o Current bunch intensities are close to the loss limit at ramp (recent losses during rotator ramp)
• Test of separated collision setup for sPHENIX and STAR
• Continue physics: pp200_production_radial
• Maintenance day tomorrow (Tuesday, 9 am – 4:30 pm)
o Magnet ramp down after beam dump
o EEMC PS (Tim, Oleg)
o TPC electronics
o Laser (Alexei)
o Windows update shift leader desktop
Sunday, June 30, 2024
Status & Issues
• TPC RDO S11:6 remains masked
• ETOW configuration failed in one run
• L2 died in one run
• Isobutane fraction ratio was higher than expected, followed the procedure for restoring the ratio (after 30 min. wait)
• TPC, iTPC, FST hung a few runs on 100% deadtime; shift crew takes action within 2-3 minutes (when it doesn’t self-recover)
• “FCS: powercycling DEP02:4” turns into “K?[0m” in DAQ monitor
• TOF LV needed power cycling after too many errors (detector operators, tray 54 west 5 needed manual intervention)
• BSMD had some trips early in fill, excluded for one run
• Manual power-cycle on iTPC RDO iS13:3, TPX RDO S06:4
• sTGC: ROB #04 bad FEB (followed procedure to start new run, power-cycled eventually)
Schedule & Plans
• bgRemedyTest_2024: 25181040, 045, 059, 067, 25182019, 025
• Special fast offline production for background studies is running (and progressing nicely) [fills 34714, 16 after the most recent modifications to the beam on Thursday]
• Continue physics: pp200_production_radial
• Good turnaround times for RHIC with current bunch intensities; sampled luminosity still a little below 50% of 2015
• Windows update on shift leader desktop (maintenance day)
Saturday, June 29, 2024
Status & Issues
• “sTGC hits / timebin” high early in fill (25180030)
• TOF gas changed (PT-2), methane last night, isobutane this morning
• bgRemedyTest_2024 run 25180057
• FST 99% dead; start new run
• TPX & iTPC 100% dead repeatedly and not recovering; power cycled RDO S05:6, S11:3 and S11:6 (twice); S11:6 failed again twice the new fill and masked out for now
• BSMD had difficulty to ramp in new store; excluded for first few runs
Schedule & Plans
• Jamie updated the ZDC coincidence cross section: 0.23 mb (down from 0.264 mb previous years)
• Need gas bottle delivery; will run out in about 18 days (Alexei, Prashanth)
• sPHENIX is slow in ramping down (polarimetry & beam dump); we may gain 5 minutes before ZdcPolarimetry at beam dump
• Modifications to trigger configuration: get more data with bgRemedyTest_2024 with TRG+DAQ at beginning and end of fills throughout the weekend (takes about two minutes each with TOF, other detectors can ramp HV; bgRemedyTest before ZdcPolarimetry)
Friday, June 28, 2024
Status & Issues
• EEMC sectors 2&3 (maintenance day…)
• Follow-up on DSM board (Hank, may need an access)
• L2/L0 problems between fills (Akio/Hank, power cycled VME-72 & VME-100)
• Configuration errors in ESMD (emc-check and several runs after); sys-reset after call from Will
• BBQ, EQ2, EQ3 failed during pedestal run(s), success on 4th attempt
• sTGC ROB#3 power cycle
• Masked RDO iS01:2 after it couldn’t be recovered
• TPX RDO S11:6 power cycled manually
• One call to Jeff when TPX & iTPC went 100% dead repeatedly; power cycled all FEE’s
• Quality of laser events is often low, Alexei is following up with DO
Schedule & Plans
• Physics collisions until Tuesday morning
• Blue beam background studies (Ting looked at vertex distributions for abort gaps)
• Ask Gene to have FastOffline without vertex cuts for a few runs from fill 34714
• Modifications to TAC start to reduce early hits from background events (Hank)
• Modified trigger configuration for early runs has been prepared (bgRemedyTest_2024); will try to run test at next fill (needs TOF HV up, can run while others are still ramping)
• Updates to power-dip recovery work sheet (input from some subsystems still needed)
Thursday, June 27
Status & Issues
• EPD trigger test runs done (25178033, 25178040)
• 7-9 minutes from Physics On to data taking
• Cosmic data during Linac RF recovery in afternoon
• Severe thunderstorm warning in the evening; thunderstorm eventually came through at 2:30 am; then power dip with magnet trip
• MCW had a blown fuse; all VME crates were turned off (CAS watch & Prashanth, fixed at 7 am)
• tpcAirHygroF alarm; Prashanth reset the TPC air blower
• EEMC sectors 2&3 still tripping (looking for access opportunity)
• LeCroy communication lost (DO->David), Akio reset it remotely
• DSM board still causing trouble (Oleg -> Hank)
Schedule & Plans
• No APEX today
• Physics collisions: pp200_production_radial
• FastOffline data for abort gap studies of beam background (Ting?); trigger proposal postponed (Carl & Akio)
• Recovery procedure from power dip -> update detector check list
• Next maintenance on Tuesday, July 2
Wednesday, June 26
• Day of “Reflection on Safety” (Prashanth)
Status & Issues
• Eleanor requested changes to trigger registers in epdTest-emc-check and epdTest-radial (now using default values)
• Cogging adjustment: TPC vertex is -4 cm (BBC now at -10 cm ???)
• ETOF fails twice in first few hours of fill, not included afterwards as per updated instructions
• Glitch with BSMD HV GUI before pedestal run, restarted GUI (instructions updated)
• New BERT feature: “Prepare / Ready for Pol. Meas.”
• EEMC sectors 2&3 trip every few hours (Tim)
• TPX RDO 11:6 has to be power cycled manually about once per shift
• EVB11 is dead, taken out (3 am, Jeff)
• FST running 99% dead during laser run (stop and restart)
• Laser events are low, although bright spot on camera (Alexei)
Schedule & Plans
• Physics: pp200_production_radial
• Request for trigger test: epdTest-emc-check and epdTest-radial at the end of current fill (5 minutes each)
• Slow increase in bunch intensity (now 1.5e11), yellow polarization lifetime
• APEX still tentatively on Thursday (decision tonight, possibility for access in the morning 8 am, EEMC: Tim/Oleg)
• Next maintenance on Tuesday, July 2
From 06/05/2024 to 06/24/2024, Period Coordinator: Jaroslav Adam, notes:
06/25/24
I. RHIC schedule
a) Machine development today 10am till 1pm, then collisions also on Wednesday
b) APEX on Thursday Jun 27
c) Collisions on Friday Jun 28 and over the Weekend
d) Next maintenance on Tuesday July 2
II. STAR status and issues
a) Hot tower in BEMC eta-phi plot, trigger rates are normal, ignore it
b) Intermittent alarms from sTGC ROB#10, current fluctuating at threshold,
threshold to be moved
c) Gas alarms (intermittent) on boxes on window to DAQ room to be reported as log entry
d) TOF LV yellow alarms to be only reported as log entry (email by Geary
"Log entry at 14:55 yesterday")
e) Shift for z-vertex is seen for TPC L4, not for BBC (2 cm off), but similar shift
seen at sPHENIX, fast offline to be checked
f) Possibility for 3 hour access during APEX on Thursday Jun 27, during work hours
if it happens, BEMC is ready
g) No collision data yesterday, VPD west TAC looks same as for collisions,
result of blue beam background
h) Safety program tomorrow, 5 mins for safety during 10am meeting
i) Next period coordinator is Oleg Eyser
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial
06/24/24
I. RHIC schedule
a) Store with 0 mrad crossing angle for sPHENIX at noon for 3+ hours,
no collisions for STAR, consider this store as beam development
b) Physics today again at 4+pm
II. STAR status and issues
a) Smooth running yesterday
b) z-vertex is shifted by about -11 cm, seen only for TPC vertex finder (space charge),
+/-5 cm shift is ok, position to be checked with VPD
c) sPHENIX will be asking for 4 hours without beam (TPC distortions) soon when RHIC is off
for some other reason, opportunity for BTOW crate 0x10 and EEMC HVSys A controller
d) Question on including eTOF later in the fill, crews observed more BUSY problems
at the beginning of the fill, suggestion to try twice in each store to include eTOF back
III. Plans
a) No data to be taken for store at noon today, the store is aimed for 0 mrad at sPHENIX
b) Radially polarized data taking at high luminosity, pp200_production_radial, for store at 4+pm
06/23/24
I. RHIC schedule
a) Physics today, adjustments for yellow polarization
b) Test for zero crossing angle at sPHENIX tomorrow Jun 24
c) Machine development on Tuesday Jun 25
II. STAR status and issues
a) Smooth running yesterday
b) Pentane bottle changed for sTGC, DOs rebooted EEMC controls
c) Shifts in vertex z position are being corrected from RHIC side
d) eTOF BUSY, procedure in eTOF manual from May 27 (in production run,
no need to stop the run, take in out for the next run)
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial
06/22/24
I. RHIC schedule
a) Physics over the weekend
II. STAR status and issues
a) Zero field, low luminosity store took place yesterday 10pm till 3:30 am
b) VME crates were off from 1pm to 4pm, potential issue with MCW, reached 79F,
several issues when turning on (BCW turned on after several tries, multimeters
for field cage had to be power cycled during 5min access)
c) Inform David before turning off VMEs due to temperature
d) EEMC HV was restored with help of Will Jacobs and DOs configuring part
of it manually
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial
06/21/24
I. RHIC schedule
a) Machine development today 11am till 3pm, physics after
b) Physics over the weekend
II. STAR status and issues
a) Opportunity for low luminosity, 56 bunches, zero field store after the development
at 3+pm, 30kHz BBC rate was requested for the store, call Akio when we get
the store; the store will be polarized
b) BTOW crate 0x10 is still masked and disconnected, Tim dealing with one board
from that crate in lab, then an access for several hours with magnet off
would be needed
c) EEMC problematic HVSYs A controller was replaced by a spare (Tim), spare
did not work, original controller is in place now
d) EPD crate 4 early hits, two new configurations (Eleanor+Jeff) to be tested
with timing setup, to be run after emc_check during normal polarization run,
email by Hank with details to be sent
e) Lecroy1445 for BBC/VPD/ZDC, procedure to restore communication for DOs now works
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial,
after the potential low luminosity zero field store
06/20/24
I. RHIC schedule
a) Maintenance now 8am till 6pm, physics after
b) Friday Jun 21 machine development 9am till 1pm, then physics also over weekend
II. STAR status and issues
a) Maintenance now, restricted access, work on west trim magnet (had multiple
trips past days), TPC RDOs (Tonko), BTOW (Oleg + Prashanth + Tim)
b) For NMR readout, wait for magnet ramp to finish before reporting to shift log
(and green indicator 'NMR LOCK' to the left of field value should be lit for field
to be valid), now hold readouts till 6pm
c) Procedure for magnet ramp to update to instruct MCR to wait with ramping magnet
back until STAR informs them is ready to do so
d) Visit to STAR today afternoon
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial
06/19/24
I. RHIC schedule
a) Physics today, maintenance tomorrow, Thursday Jun 20
b) Friday Jun 21 machine development 9am till 1pm, then physics also over weekend
II. STAR status and issues
a) Magnet trip on all magnets after a power dip yesterday 6pm, CAS watch replaced
regulator card for west trim (current was ~10A lower than set value)
b) BCW crate #76 turned on only after several tries (was turning off itself after
several seconds), Jeff tested trigger, ok now
c) Lecroy1445 for BBC/VPD/ZDC lost communication, DOs could not recover because procedure
involves ssh login to one of SC machines on platform which did not work - now crews
should call David or me when it happens
d) +/-5V oscillation on power line, CAD investigating its cause
e) Current state of online QA plots to be checked by crews at shift change - TPC occupancy
may change over time depending on RDO availability, similar holds for BTOW
f) Maintenance tomorrow, Jun 20, work on west trim magnet (had multiple trips past days),
TPC RDOs (Tonko), BTOW (Oleg + Prashanth + Tim)
g) Visit to STAR tomorrow afternoon
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial
06/18/24
I. RHIC schedule
a) Machine development today 11am till 2pm, then physics
b) Physics Wednesday, maintenance on Thursday Jun 20
c) Friday Jun 21 machine development 9am till 1pm, then physics also over weekend
II. STAR status and issues
a) Access yesterday for BTOW radstoneBoards and DSM1 board in BCW crate finished ok
(DSM1 board was replaced in BCW crate and controller for BTOW crate #80 was replaced
- radstone were ok)
b) Maintenance on Thursday Jun 20, work on west trim magnet (had multiple trips past
days), TPC RDOs (Tonko), BTOW (Oleg + Prashanth + Tim)
c) Alignment data with field off when machine is in stable condition, by end of June
d) FCS ECAL voltage file changed by Akio to compensate for radiation damage
e) Online plots seen to fill slowly in the morning, Jeff working on automatic
restarts for Jevp plots
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial
06/17/24
I. RHIC schedule
a) Physics today, intensity increase 0.1e11/store
b) Next maintenance Thursday Jun 20 (not Wednesday because of holidays)
II. STAR status and issues
a) BTOW/BSMD out of the runs, radstoneBoards in crate #80 can't initialize,
access needed, end of current fill at 2:30
b) JP2 triggers firing hot, taken out, access needed for BW003 DSM board
(stuck bit)
c) Jevp plots crashed two times, recovered by Jeff and Wayne, new instruction
for shift crews to be provided
d) Multiple magnet trips for west trim, instruction for shift crews to first
put detectors to magnet ramp and then call CAS watch (they're very quick
in ramping the trim back), item for maintenance on Thursday from CAS side;
update instruction to call Prashanth in case of magnet trip
e) Alignment data with field off, tbd at coordination meeting Tuesday
f) NMR field inconsistent with readings on magnet current - variations in read
current values
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial
06/16/24
I. RHIC schedule
a) PS issues at RHIC, attempt for polarized beams ended in unexpected abort
at flattop at 4am
b) Next maintenance Thursday Jun 20 (not Wednesday because of holidays)
II. STAR status and issues
a) Magnet trips in west trim, 5 times
b) Jevp plots and run control window crashed, recovered by Jeff,
log at 17:52 yesterday
c) Cosmics since 4am
d) Alignment data with field off, tbd at coordination meeting Tuesday
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial,
after cold snake and PS issues are recovered
06/15/24
I. RHIC schedule
a) Unpolarized stores, polarization after cold snake is recovered,
expected later today
b) Physics over the weekend
c) Next maintenance Thursday Jun 20 (not Wednesday because of holidays)
II. STAR status and issues
a) Multiple trips after unexpected beam abort around 1:30am today (MTD, BSMD,
sTGC, EEMC, TPC), updating Detector Readiness Checklist to wait 5 minutes
after 'physics' is declared for a store to start bringing detectors to physics,
also no Flat Top state in Detector States
b) BERT screen on SL desk not allowing to select STAR status in pull-down menu,
still remains
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial,
after cold snake is recovered
06/14/24
I. RHIC schedule
a) Unpolarized stores today, cold snake to be recovered by 8pm, polarization
after
b) Physics over the weekend
c) Next maintenance Thursday Jun 20 (not Wednesday because of holidays)
II. STAR status and issues
a) Access yesterday for DSM1 boards (noisy JP triggers) and MTD HV was ok,
issues seem fixed
b) New protected password, please login to drupal link and scroll to the bottom
of the page
c) BERT screen on SL desk not allowing to select STAR status in pull-down menu,
also beam dump window does not appear
d) Shift crews, please pay attention to AC water drain, was full now, and keep
doors closed when the AC is running, DAQ room doors also to be closed
at all times
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial,
after cold snake is recovered
06/13/24
I. RHIC schedule
a) Access now at 10am for two hours, then machine development at noon till 4pm
b) Polarized physics at 4pm (cold snake will be recovered early afternoon)
c) Next maintenance Thursday Jun 20 (not Wednesday because of holidays)
II. STAR status and issues
a) Noisy JP triggers, access now to replace 2 possible DSM1 boards
b) MTD, power failure in CAEN PS crate, same access now to replace power module
c) Trigger thresholds for B/EMC are changed (to account for lower gain in PMTs),
email on star-ops, subject 'Changes to B/EMC threshold settings'
d) Configuration 'pp200_production_radial' to be used for physics at 4pm again
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial
06/12/24
I. RHIC schedule
a) APEX today starting 10am, polarization measurement today at 9pm (when cold
snake is restored), back to physics at midnight
b) Thursday 6/13 till Sunday 6/16: physics
c) Next maintenance Thursday Jun 20 (not Wednesday because of holidays)
II. STAR status and issues
a) Noisy JP triggers, 2+ hour access to replace 2 possible DSM1 boards, might
get such access tomorrow Thursday, after machine development ~2pm - to be updated
b) MTD, power failure in CAEN PS crate, power module to be replaced, 1 hour access
c) 7bit bunch Id, incorrect reset for counter, not happened since Monday morning
d) Trigger thresholds for barrel, test run 25163054 done last night (to compensate
for lower gains in PMTs), tba over star-ops by Carl
e) Online plots crashing from time to time, Jeff investigating
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial
06/11/24
I. RHIC schedule
a) Physics today, last store will start at 10pm to last till APEX tomorrow at 10am,
then polarization measurement tomorrow at 9pm (when cold snake is restored)
b) Thursday 6/13 till Sunday 6/16: physics
II. STAR status and issues
a) EPD missing sectors were caused by eq3_qtd and eq4_qtd nodes masked in run control,
no clear reason why, eq4 lost first, eq3 in run after
b) Noisy JP triggers, BC102, DSM#1, tbd at trigger meeting
c) 7bit bunch Id, incorrect reset for counter (Akio), tbd at trigger meeting
d) Thresholds for barrel triggers to be readjusted to compensate for aging effects,
Carl will instruct SL on zoom for control room
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial
06/10/24
I. RHIC schedule
a) Physics today and tomorrow, APEX on Wednesday, Jun 12
II. STAR status and issues
a) EPD has missing sectors, EQ3 and EQ4 not reading out, potential access
at noon or after (sPHENIX asked for 2 hours)
b) Noisy JP triggers, BC102, DSM#1, Hank looking into it
c) 7bit bunch Id, incorrect reset for counter (Akio)
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial
06/09/24
I. RHIC schedule
a) Physics now till Tuesday, Jun 11
II. STAR status and issues
a) eTOF not in the runs, repeated 'scDeamon.C:#1904 ETOF has 1018>1000 EVB' message
b) GUI for VME 70 (EEMC canbus) shows incorrect voltages, crate itself works ok
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial
06/08/24
I. RHIC schedule
a) Physics over the Weekend + Monday and Tuesday,
Jun 8 till 11
II. STAR status and issues
a) Recurrent trips for west trim magnet,
CAS worked on it yesterday
b) BSMD sector 2 and TPX[34] gave errors in pedestal run 25160019,
due to oncoming injection crews couldn't run the pedestal again
c) Transient TOF or MTD LV alarms can be ignored (not temperature),
log entry for persistent alarms, in email to star-ops by Geary
yesterday, subject 'TOF LV yellow alarms'
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial
06/07/24
I. RHIC schedule
a) today: store at 3am, machine development now till 11am (spin tune study for blue snake),
then physics
b) Weekend Jun 8,9: physics
II. STAR status and issues
a) Wrong production configuration (pp200_production_High_Luminosity) was in Detector Readiness Checklist,
(typo introduced yesterday when the checklist was updated), correct configuration is pp200_production_radial
b) BSMD is included in production runs
c) Shift crews should subscribe to star-ops mailing list, star-ops-l@lists.bnl.gov
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial
06/06/24
I. RHIC schedule
a) today: APEX was scheduled till 9pm, however no beam from AGS (Siemens exciter power supply),
some APEX sessions will be rescheduled, back to physics at 9pm
b) Friday Jun 7: spin tune study for blue snake (~ 2 hours) between stores
c) Weekend Jun 8,9: collisions
II. STAR status and issues
a) Maintenance completed yesterday
b) Cosmics overnight because of no beam
c) BSMD to be included, Oleg will give instruction
d) For crews: very humid these days, please keep control room and DAQ room doors closed
for AC to work properly. PS: also flush coffee water tray from time to time otherwise
it spills over the table
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial
06/05/24
I. RHIC schedule
a) today: maintenance 8am till 4pm, then collisions
b) Thursday Jun 6: apex from 8am till 9pm, investigation for longitudinal
component, STAR will take ZDC polarimetry runs, then collisions by 10pm
c) Friday Jun 7: spin tune study for blue snake (~ 2 hours) between stores
d) Weekend Jun 8,9: collisions
II. STAR status and issues
a) Smooth running
b) Maintenance day today:
c) Magnet to be turned off after morning beam dump for 200T chiller for magnet turn-on,
then turn magnet on to test the chiller
d) Turn off TPC FEEs + VMEs + TOF HV, LV + MTD LV HV due to work on condenser fan
for the 80T chiller (cools MCW)
e) EEMC MAPMT FEE box cooling (Bill S. and Prashanth), when magnet is off,
barriers down and access to the (south) poletip
f) TPX/iTPC RDOs masked out (3 of them), Tonko will work on it when FEEs are back on
g) eTOF, colors on HV GUI -> only sector 3 is at full, all others are zero / re-open GUI
may clear colors
h) Crews should lookup reference plots, SL are passing information to those who asked
i) EPD lower gain at 3 tiles (outer) Maria Stefaniak
j) BSMD to be included tomorrow
III. Plans
a) Radially polarized data taking at high luminosity, pp200_production_radial
From 05/15/2024 to 06/04/2024, Period Coordinator: Zilong Chang, notes
STAR daily operation meeting 05/14/2024
(Period Coordinator: Zhangbu Xu)
Incoming Period Coordinator: Zilong Chang
RHIC Schedule
Plan for this week,
- Maintenance day (Wednesday), APEX (Thursday), switch to Spin run
- Emittance is large, achieving 2.1x10^11 per bunch at injection and 1.9x10^11 at top (ultimate goal is 3x10^11);
- Yesterday: 28x28 and vernier scan for STAR Monday 6 hours (3-4PM); high-luminosity run 2 hours before hand;
- 56x56 sPHENIX not yet ready
- STAR leveling at 20KHz
STAR status
- Physics running at 7KHz. pp200-production-LowLuminosity
MB-EPD+forward: 1.4B evts, prescale (7-10); MB-EPD-TOF4: 1.55B evts, prescale 1
switch to leveling at 40KHz Monday and MB-EPD+forward all the way - Check prescale=1 for MB if we can have even higher DAQ rate (7—7.4KHz)
- sTGC:
Wednesday access change one of the bad FEES;
Zero-field Alignment dataset (56x56 third priority Monday)? - Shift operation. Any issues?
- Shift vacancy issue? Working progress (Cebra)
- BBC QT in wrong bunch (prepost=-1) in some runs with some boards; production runs
- High-Lumi configuration:
Configuration run taken (BBCA 500KHz);
zdcpolarimetry (front/end thresholds run15 setting), analysis shows consistency with previous runs; new gain file produced; - 28x28 fill 8 hours
Vernier Scans at beginning and end; forward cross section data; Smooth runs;
Plans
- a full Maintenance Day on May 15th (Linda Horton’s visit at BNL); May 16, APEX;
STAR daily operation meeting 05/13/2024
RHIC Schedule
Plan for this week,
- 111x111 bunch collisions for experiments remaining of the week (mostly).
- Emittance is large, doing shorter fills (2 hours) to effectively scrub;
achieving 2.1x10^11 per bunch at injection and 1.9x10^11 at top (ultimate goal is 3x10^11); - 28x28 and vernier scan for STAR Monday 6 hours (3-4PM); high-luminosity run 2 hours before hand; 56x56 sPHENIX not yet ready
- Two abort gaps blue and yellow background asymmetry
- STAR leveling at 40KHz
STAR status
- Physics running at 6.2KHz. pp200-production-LowLuminosity
MB-EPD+forward: 1.2B evts, prescale (7-10); MB-EPD-TOF4: 1.55B evts, prescale 1
switch to leveling at 20KHz Monday and MB-EPD+forward all the way? - L4 died a couple of times, is this indicative of a hardware issue?
- sTGC:
1mV/HV 2900V/Bit ON, updated at 11:46AM yesterday after beam dump;
Wednesday access change one of the bad FEES;
Zero-field Alignment dataset (56x56 third priority Monday)? - Shift operation. Any issues?
shift leader desktop freezes from time to time (for 5 minutes), firefox issue (Wayne)?
Should be stand-down during thunderstorm request information from MCR; APEX mode;
AC unit above control roof. Permanent unit arrived, now only temporary unit (start to work). wiring done, work permit? - Shift vacancy issue? Working progress (Cebra)
- Scaler timing for Polarization monitoring. DONE;
3 scaler boards left, #3 ZDC, #5,6 BBC; no backup - BBC QT in wrong bunch (prepost=-1) in some runs with some boards; production runs;
- High-Lumi configuration:
When we are done, inform CAD. They will switch to 28x28;
BHT2 remove BBC TAC requirement; dimuon VPD TAC2 to VPD TAC (100cm);
UPC-J/Psi BHT bit bug fixed;
Jeff will take a couple of runs so that Carl and others can check the settings;
Plans
- Spin Trigger and polarimetry commissioning
production trigger configuration, optimize trigger rates
polarimetry scalers; Monday instead, removing cross angle and leveling at 20KHz, with high luminosity configuration file; scaler working; need to check ZDC polarimetry data and thresholds; ZDCSMD gain matching, >30 minutes zdcpolarimetry (high priority on Monday, 1 million evts beginning and end); afternoon-early evening Monday 28x28 bunches; vernier scan configuration file does have scaler readout every second and in the run control (second priority Monday); 6 hours - a full Maintenance Day on May 15th (Linda Horton’s visit at BNL); May 16, APEX;
STAR daily operation meeting 05/12/2024
RHIC Schedule
Plan for this week,
- 111x111 bunch collisions for experiments remaining of the week (mostly).
- Emittance is large, doing shorter fills (2 hours) to effectively scrub;
achieving 1.5x10^11 per bunch (ultimate goal is 3x10^11); - Beam since last evening; 2 hour store, high background, not the best for MB-EPD
- Continue short store over weekend, 28x28 and vernier scan for STAR likely Monday
- STAR leveling at 40KHz
- No 9AM meeting on the weekend;
STAR status
- Physics running at 5.8KHz. pp200-production-LowLuminosity
MB-EPD+forward: 1.1B evts, prescale (7-10); MB-EPD-TOF4: 1.3B evts, prescale 1
switch to leveling at 20KHz Monday and MB-EPD+forward all the way? - Need to make sure efficient running; data-taking right after PHYSICS ON;
do not wait for leveling; After luminosity leveling at BBCAnd~=40KHz is stable, stop and restart run. - sTGC:
gain 3mV/HV 2850V/Bit ON, mask two FEEs;
1mV/HV 2900V/Bit ON, NO on run control? Wednesday access change one of the bad FEES; 11:46AM beam dump;
Zero-field Alignment dataset Monday (56x56 third priority Monday)? - Shift operation. Any issues?
shift leader desktop freezes from time to time (for 5 minutes), firefox issue (Wayne)?
Should be stand-down during thunderstorm request information from MCR; APEX mode;
AC unit above control roof. Permanent unit arrived, now only temporary unit (start to work?). wiring done, work permit? - Shift vacancy issue? Working progress (Cebra)
- Scaler timing for Polarization monitoring. DONE;
3 scaler boards left, #3 ZDC, #5,6 BBC - BBC QT in wrong bunch (prepost=-1) in some runs with some boards; production runs;
Plans
- Spin Trigger and polarimetry commissioning
production trigger configuration, optimize trigger rates
polarimetry scalers; Monday instead, removing cross angle and leveling, with high luminosity configuration file; scaler working; need to check ZDC polarimetry data and thresholds; ZDCSMD gain matching, >30 minutes zdcpolarimetry (high priority on Monday); afternoon-early evening Monday 28x28 bunches; vernier scan configuration file need to have scaler readout every second (second priority Monday); - a full Maintenance Day on May 15th (Linda Horton’s visit at BNL); May 16, APEX;
STAR daily operation meeting 05/11/2024
RHIC Schedule
Plan for this week,
- 111x111 bunch collisions for experiments remaining of the week (mostly).
- Emittance is large, doing shorter fills (2 hours) to effectively scrub;
achieving 1.5x10^11 per bunch (ultimate goal is 3x10^11); - Beam since last evening; 2 hour store, high background, not the best for MB-EPD
- Continue short store over weekend, 28x28 and vernier scan for STAR likely Monday
- STAR leveling at 40KHz
- No 9AM meeting on the weekend;
STAR status
- Physics running at 5.8KHz. pp200-production-LowLuminosity
MB-EPD+forward: 1.05B evts, prescale (7-10); MB-EPD-TOF4: 1.1B evts, prescale 1 - Potential rate 8KHz, TPC hits the speed limit at 6KHz;
try TPC readout at 6KHz? - Overnight L0 power cycle; L4 down, Wayne/Diyu/Mike fixed it this morning;
- Need to make sure efficient running; data-taking right after PHYSICS ON;
do not wait for leveling; If DAQ rate <5KHz after luminosity leveling or BBCAnd~=40KHz, stop and restart run. - clean up coffee station (dump trays);
- VPD: DONE; VPD TAC2 windows; HT-VPD100;
- MTD timing window cuts;
- sTGC:
gain 3mV/HV 2850V/Bit ON, mask two FEEs;
Zero-field Alignment dataset later on
- Shift operation. Any issues?
cosmic ray without TPC yesterday;
Should be stand-down during thunderstorm request information from MCR; APEX mode;
AC unit above control roof. Permanent unit arrived, now only temporary unit (start to work?). wiring done, work permit? - Shift vacancy issue? Working progress (Cebra)
- Scaler timing for Polarization monitoring. DONE;
3 scaler boards left, #3 ZDC, #5,6 BBC - BBC QT in wrong bunch (prepost=-1) in some runs with some boards; production runs;
Plans
- Spin Trigger and polarimetry commissioning
production trigger configuration, optimize trigger rates
polarimetry scalers; Monday instead, removing cross angle and leveling, with high luminosity configuration file; scaler working; need to check ZDC polarimetry data and thresholds; ZDCSMD gain matching; afternoon-early evening Monday 28x28 bunches; - a full Maintenance Day on May 15th (Linda Horton’s visit at BNL)
STAR daily operation meeting 05/10/2024
RHIC Schedule
Plan for this week,
- 111x111 bunch collisions for experiments remaining of the week (mostly).
- Emittance is large, doing shorter fills (2 hours) to effectively scrub;
achieving 1.5x10^11 per bunch (ultimate goal is 3x10^11); - Beam since last evening; 2 hour store, high background, not the best for MB-EPD
- Continue short store over weekend, 28x28 and vernier scan for STAR likely Monday
- STAR leveling at 40KHz
- No 9AM meeting on the weekend;
- CAD PS access, no STAR access after this fill for 2 hours; after that, longer store 6 hours for sPHENIX TPC conditioning; after that, short fills again
STAR status
- Physics running at 5.8KHz. pp200-production-LowLuminosity
MB-EPD+forward: 980M evts, prescale (7-10); MB-EPD-TOF4: 950M evts, prescale 1 - Potential rate 8KHz, TPC hits the speed limit at 6KHz;
try TPC readout at 6KHz? - VPD: production ID; active splitter checks, no issue discovered but need to find the source of issue (Tim); VPD west ADC (6 MXQ even chs) progressing;
raise thresholds to 80 (one channel masked out), east 50; noise persists with HV OFF; commissioning on tune configuration file; - sTGC:
gain 3mV/HV 2850V/Bit ON, mask two FEEs? Later today
Zero-field Alignment dataset later on
- Shift operation. Any issues?
Should be stand-down during thunderstorm request information from MCR; APEX mode;
AC unit above control roof. Permanent unit arrived, now only temporary unit (start to work?). wiring done, work permit? - Shift vacancy issue? Working progress (Cebra)
- Scaler timing for Polarization monitoring. It’s on the to-do list of Chris.
3 scaler boards left, #3 ZDC, #5,6 BBC - BBC QT in wrong bunch (prepost=-1) in some runs with some boards; production runs;
Plans
- Spin Trigger and polarimetry commissioning
production trigger configuration, optimize trigger rates
polarimetry scalers; Monday instead, removing cross angle and leveling, with high luminosity configuration file; scaler working; need to check ZDC polarimetry data and thresholds; - a full Maintenance Day on May 15th (Linda Horton’s visit at BNL)
STAR daily operation meeting 05/09/2024
RHIC Schedule
Plan for this week,
- 111x111 bunch collisions for experiments remaining of the week (mostly).
- Emittance is large, doing shorter fills (2 hours) to effectively scrub
during the day and overnight long fills; - Blue injection kicker (arcing and oil blockage), AGS field unstable (Siemens PS)
no beam last 24 hours - Thursday Machine Development (until 16:00); 4-8PM scrubbing; 8PM physics
- STAR leveling at 40KHz
- Possible 58x58 (28x28) fill Monday
STAR status
- Physics running at 5.8KHz. pp200-production-LowLuminosity
MB-EPD+forward: 910M evts, prescale (7-10); MB-EPD-TOF4: 850M evts, prescale 1 - VPD: production ID; active splitter checks, no issue discovered but need to find the source of issue (Tim); VPD west ADC (6 MXQ even chs) progressing;
raise thresholds to 64 (one channel masked out), east 50; noise persists with HV OFF; commissioning on tune configuration file; - sTGC:
gain 3mV/HV 2850V/Bit ON, mask two FEEs? Later today
Zero-field Alignment dataset later on
- Shift operation. Any issues?
Should be stand-down during thunderstorm request information from MCR; APEX mode;
AC unit above control roof. Permanent unit arrived, now only temporary unit (doesnot work well). wiring done, work permit? - Shift vacancy issue? Working progress (Cebra)
- Scaler timing for Polarization monitoring. It’s on the to-do list of Chris.
3 scaler boards left, #3 ZDC, #5,6 BBC - BBC QT in wrong bunch (prepost=-1) in some runs with some boards; production runs;
- Remove VPDA from cosmic ray trigger configuration file;
Plans
- Spin Trigger and polarimetry commissioning
production trigger configuration, optimize trigger rates
polarimetry scalers; Monday instead, removing cross angle and leveling, with high luminosity configuration file; scaler working; need to check ZDC polarimetry data and thresholds; - a full Maintenance Day on May 15th (Linda Horton’s visit at BNL)
Tim is not available for that day?
STAR daily operation meeting 05/08/2024
RHIC Schedule
Plan for this week,
- 111x111 bunch collisions for experiments remaining of the week (mostly).
- Emittance is large, beam scrubbing for 4 hours;
limited success, maybe doing shorter fills (2 hours) to effectively scrub
during the day and overnight long fills; - Blue injection kicker (arcing and oil blockage) no beam last 24 hours
- APEX Wednesday 8AM-11PM using yellow beam for now; Thursday Machine Development (10AM-noon)
- STAR leveling at 40KHz
STAR status
- Physics running at 5.8KHz. pp200-production-LowLuminosity
MB-EPD: 800M evts, prescale (7-10); MB-EPD-TOF4: 850M evts, prescale 1 - VPD: production ID; active splitter checks, no issue discovered but need to find the source of issue (Tim); VPD west ADC (6 MXQ even chs) progressing;
raise thresholds; noise persists with HV OFF; commissioning on tune configuration file;
DSM VPD to MTD (MT101) =>QT board in the wrong slot, FIXED; Tim/Chris - sTGC:
gain 3mV/HV 2850V/Bit ON, mask two FEEs? Later today
increase forward components in MB-EPD and EPD-TOF4
MB-EPD-forward included MB-EPD evts?
Zero-field Alignment dataset later on
- Shift operation. Any issues?
Cosmic run #17 this morning, 40-60 auto-configuring during thunderstorm; not in elog;
Should be stand-down during thunderstorm request information from MCR; APEX mode;
AC unit above control roof. Permanent unit arrived, now only temporary unit (doesnot work well). wiring done, work permit?
- Shift vacancy issue? Working progress (Cebra)
14 worked on, 21 filled, - Scaler timing for Polarization monitoring. It’s on the to-do list of Chris.
3 scaler boards left, #3 ZDC, #5,6 BBC - BBC QT in wrong bunch (prepost=-1) in some runs with some boards; production runs;
- ePIC HCAL HV settings and threshold (restricted access);
Plans
- Spin Trigger and polarimetry commissioning
production trigger configuration, optimize trigger rates
polarimetry scalers; (Thursday/Friday 1-2 hour beam time) Monday instead, removing cross angle and leveling, with high luminosity configuration file; scaler working; need to check ZDC polarimetry data and thresholds; - a full Maintenance Day on May 15th (Linda Horton’s visit at BNL)
Tim is not available for that day?
STAR daily operation meeting 05/07/2024
RHIC Schedule
Plan for this week,
- 111x111 bunch collisions for experiments remaining of the week (mostly).
1.2x1011 per bunch from about 0.9 earlier - Emittance is large, beam scrubbing for 4 hours;
limited success, maybe doing shorter fills (2-4 hours) to effectively scrub
during the day and overnight long fills; - 6-hour access requested by sPHENIX/CeC/CEPS
- APEX Wednesday 8AM-11PM; Thursday Machine Development (10AM-noon)
- STAR leveling at 40KHz
STAR status
- Physics running at 5.8KHz. pp200-production-LowLuminosity
MB-EPD: 800M evts, prescale (7-10); MB-EPD-TOF4: 850M evts, prescale 1 - Readiness checklist update for physics available. Shift crew started to follow normal operation procedure.
- VPD: production ID; active splitter checks today (Tim);
VPD west ADC (6 MXQ even chs) progressing; if noise persists, raise thresholds;
should be done today/tomorrow; commissioning on tune configuration file;
DSM VPD to MTD (MT101) wrong slots=>QT board in the wrong slot; Tim/Chris - sTGC:
Access to gain change Monday also change prod ID?
HV scan, another iteration yesterday and today; (Tonko/Jeff/Daniel)
24 hours afterward final change.
gain 3mV/HV 2850V/Bit ON; increase forward components in MB-EPD and EPD-TOF4
MB-EPD-forward included MB-EPD evts? Zero-field Alignment dataset later on
- Shift operation. Any issues?
AC unit above control roof. Permanent unit arrived, now only temporary unit (doesnot work well). wiring done, should be done? - Shift vacancy issue? Working progress (Cebra)
14 worked on, 21 filled, - Scaler timing for Polarization monitoring. It’s on the to-do list of Chris.
3 scaler boards left, #3 ZDC, #5,6 BBC - BBC QT in wrong bunch (prepost=-1) in some runs with some boards; production runs;
- FST reference plots updated;
- ePIC HCAL HV settings and threshold (restricted access);
Plans
- Spin Trigger and polarimetry commissioning
production trigger configuration, optimize trigger rates
polarimetry scalers; Thursday/Friday 1-2 hour beam time, removing cross angle and leveling, with high luminosity configuration file; scaler working; need to check ZDC polarimetry data and thresholds; - a full Maintenance Day on May 15th (Linda Horton’s visit at BNL)
Tim is not available for that day?
STAR daily operation meeting 05/06/2024
RHIC Schedule
Plan for this week,
- 111x111 bunch collisions for experiments remaining of the week (mostly).
1.2x1011 per bunch from about 0.9 earlier - Emittance is large, beam scrubbing for 4 hours
- Potential 2-hour access requested by sPHENIX
- STAR leveling at 40KHz
STAR status
- Physics running at 5.6KHz. pp200-production-LowLuminosity
MB-EPD: 700M evts, prescale (5-7); MB-EPD-TOF4: 700M evts, prescale 1.1—1.5
possible options to be discussed at triggerboard meeting: leveling at 30KHz, change prescale, short run at 10KHz? BHT3 and BHT3-L2gamma triggers - Readiness checklist update for physics available. Shift crew started to follow normal operation procedure.
- VPD: tac offset correct (ONLINE), slewing upload and DONE (BBQ); production ID;
VPD west ADC (5 MXQ chs) progressing; power-cycle the active WEST splitters - eTOF included in the run (Geary)
- sTGC:
Access to gain change Monday also change prod ID?
HV scan, another iteration yesterday and today; (Tonko/Jeff/Daniel)
24 hours afterward final change.
Zero-field Alignment dataset later on - Shift operation. Any issues?
elog: Water on the floor near restroom near STAR control room. Maybe a new roof leak? Dry it. (leak from the roof)
MTD/sTGC gas alarms overnight; gas bottles changed;
TPC sector 12 RDO 1 masked out permanently
setRHICclock after using local clock;
AC unit above control roof. Permanent unit arrived, now only temporary unit, no cooling, been worked on.
wiring done, waiting for the permit?
- Shift vacancy issue? Working progress (Cebra)
5 vacancies coming weeks; no issue this week; - Scaler timing for Polarization monitoring. It’s on the to-do list of Chris.
3 scaler boards left, #3 ZDC, #5,6 BBC
Plans
- a full Maintenance Day on May 15th (Linda Horton’s visit at BNL)
Tim is not available for that day? - Now to May 14th, a short run to commission trigger rate/background and zdcpolarimetry with high luminosity and zero crossing angle?
STAR daily operation meeting 05/05/2024
RHIC Schedule
Plan for this week,
- 111x111 bunch collisions for experiments remaining of the week (mostly).
1.2x1011 per bunch from about 0.9 earlier - STAR leveling at 40KHz
STAR status
- Physics running at 5.6KHz. pp200-production-LowLuminosity
MB-EPD: 510M evts, prescale (5-7); MB-EPD-TOF4: 500M evts, prescale 1.1—1.5
Offline update on pileup and vertexing (Shengli) - Readiness checklist update for physics available. Shift crew started to follow normal operation procedure. removing the “prepare for physics” for BEMC.
- VPD: tac offset correct (ONLINE), slewing upload today (BBQ); production ID;
VPD west ADC (5 MXQ chs) progressing; - eTOF included in the run (Geary)
- sTGC:
Access to gain change Monday also change prod ID?
HV scan, another iteration yesterday and today; (Tonko/Jeff/Daniel)
24 hours afterward final change.
Zero-field Alignment dataset later on - Shift operation. Any issues?
TPC sector 12 RDO 1 masked out permanently
run38 last night took 20 minutes;
After the beam dump, turn on the VPD and take:
pedestal_rhicclock_clean with TRG+DAQ+FCS (1k events).
AC unit above control roof. Permanent unit arrived, now only temporary unit.
wiring done, should be done yesterday? - Shift vacancy issue? Working progress (Cebra)
- Scaler timing for Polarization monitoring. It’s on the to-do list of Chris.
3 scaler boards left, #3 ZDC, #5,6 BBC
Plans
- a full Maintenance Day on May 14th (Linda Horton’s visit at BNL)
Tim is not available for that day.
STAR daily operation meeting 05/04/2024
RHIC Schedule
Plan for this week,
- 111x111 bunch collisions for experiments remaining of the week (mostly).
- STAR leveling at 40KHz
- No CNI Polarization measurement in the middle of a store for now
STAR status
- Physics running at 5.6KHz. pp200-production-LowLuminosity
MB-EPD: 320M evts; MB-EPD-TOF4: 310M evts - Readiness checklist update for physics available. Shift crew started to follow normal operation procedure.
- EPD trigger timing – EPD timing scan DONE.
EQ gates need to be updated in the tier1 file (DONE) - VPD: tac offset correct (ONLINE), slewing upload today (BBQ); production ID;
VPD west ADC (5 MXQ chs) progressing - sTGC:
Access to gain change Monday also change prod ID?
HV scan last night, another iteration today;
24 hours afterward final change.
Zero-field Alignment dataset later on - Shift operation. Any issues?
TPC sector 12 RDO 1 masked out permanently
AC unit above control roof. Permanent unit arrived, now only temporary unit.
wiring done, should be done yesterday? - Shift vacancy issue? Working progress (Cebra)
- Scaler timing for Polarization monitoring. It’s on the to-do list of Chris.
3 scaler boards left, #3 ZDC, #5,6 BBC - Test run of gating grid at different rates (1 minute each)
went well, processing data, likely do another one with high luminosity
Plans
- a full Maintenance Day on May 14th (Linda Horton’s visit at BNL)
Tim is not available for that day. - After Flattop is achieved and the beams have been steered to achieve collisions, take:
emc-check with TRG + DAQ + BTOW + ETOW + ESMD + FCS (50k events)
Once beams reach PHYSICS ON status, turn on detectors according to Detector States Diagram. When detectors are ready, start running [pp200_production_lowlumisoty] with (all triggers included):
TRG+DAQ+TPX+ITPC+BTOW+ETOW+ESMD+TOF+eTOF+MTD+GMT+FST+sTGC+FCS+L4
For now, BSMD is not included in the production data-taking.
STAR daily operation meeting 05/03/2024
RHIC Schedule
Plan for this week,
- 111x111 bunch collisions for experiments remaining of the week (mostly).
- Access 13:30—14:30 today
- Machine Development 14:30—17:00
- STAR leveling at 40KHz; last fill this morning very high background first 1/2hour
- No CNI Polarization measurement in the middle of a store for now
STAR status
- Physics running at 5.6KHz. pp200-production-LowLuminosity
MB-EPD: 170M evts; MB-EPD-TOF4: 160M evts - Readiness checklist update for physics available. Shift crew started to follow normal operation procedure.
- EPD trigger timing – EPD timing scan DONE.
EQ gates need to be updated in the tier1 file? - ZDCSMD issue, swap out daughter card#1. DONE!
- Previous Issues:
- low rate with QT crate issue (done).
trigger deadtime at high rate but not an issue at the moment - high lumi at 3KHz, need low deadtime, not an issue
- low rate with QT crate issue (done).
- VPD: tac zero out. Be ready today for data-taking
Done? VPD west ADC - sTGC:
Access to gain change? Daniel?
Zero-field Alignment dataset later on - Shift operation. Any issues?
AC unit above control roof. Permanent unit arrived, now only temporary unit. - Shift vacancy issue? Working progress (Cebra)
- FST will switch back from 9 time bin to 3 time bin (DONE)
Plans
- Scaler timing for Polarization monitoring. It’s on the to-do list of Chris.
3 scaler boards left, #3 ZDC, #5,6 BBC - Test run of gating grid at different rates (1 minute each) 11:30AM
- a full Maintenance Day on May 14th (Linda Horton’s visit at BNL)
Tim is not available for that day.
· Once Beams reach FLAT TOP,
run EMC_check with TRG+DAQ+ BTOW+ETOW+ESMD+FCS
· When MCR issues “prepare for dump”, start bringing detectors to the "Preparing beam dump" state and the SL clicks “Prepare to dump”.
run zdcpolarimetry_2024 with DAQ+TRG
After all detectors are in the safe mode, the SL clicks “Ready to dump”. After beams dumped, stop run.
STAR daily operation meeting 05/02/2024
RHIC Schedule
Plan for this week,
- 111x111 bunch collisions for experiments remaining of the week (mostly).
- 10Hz Machine development with 12x12
- Access 10:30—11:30AM today (CEC)
- STAR leveling at 40KHz
STAR status
- Physics running at 5.6KHz. pp200-production-LowLuminosity
- EPD trigger timing – EPD timing scan again. Mike analyzing the data,
EQ gates need to be updated in the tier1 file (need to be done) - use EPD coincidence replacing BBCA as the main trigger component. EPD has wider gate which can see both signals and background. It works great!
- ZDCSMD issue, have to swap out daughter card#1, access right now.
- Previous Issues:
- low rate with QT crate issue (investigation ongoing).
Chris worked on it, needs elog entries.
QT rate seems to be up (4KHz, 40% dead) => 5.6KHz normal deadtime
- low rate with QT crate issue (investigation ongoing).
- VPD: tac zero out. Be ready today for data-taking
still zero out, and this is not good for the production run
NEXT FILL will be fixed. - EPD parameters were left in a different state from earlier in the production configuration last night.
- sTGC: time bin cut? Access to gain change? Zero-field Alignment dataset
- Readiness checklist update for physics available. Shift crew started to follow normal operation procedure. Prom_Check DAQ+TRG+iTPC once a day (no event, stop run after it starts).
- Shift operation. Any issues? AC unit above control roof. Permanent unit arrived, now only temporary unit. Detector operator (fill in two weeks, visa revoked at airport)
Plans
· Before run official production pp200_production_LowLuminosity, whenever possible, run zdcpolarimetry_2024 with DAQ+TRG
- FST will switch back from 9 time bin to 3 time bin (today)
- Scaler timing for Polarization monitoring. It’s on the to-do list of Chris.
- Test run of gating grid at different rates (1 minute each)
- a full Maintenance Day on May 14th (Linda Horton’s visit at BNL)
STAR daily operation meeting 05/01/2024
RHIC Schedule
Plan for this week,
- 111x111 bunch collisions for experiments remaining of the week (mostly).
- 10Hz Machine development with 12x12
- STAR leveling at 40KHz, two short fills this morning
STAR status
- Physics running started since Yesterday. pp200-production-LowLuminosity
- EPD trigger timing - one clock late issue resolved. Eleanor requested 4 EPD runs
last night. Status? Readout Crossing should be 8 instead of the default 7?
EQ gates need to be updated in the tier1 file - Once EPD finalized, proposed to use EPD coincidence replacing BBCA as the main trigger component. EPD has wider gate which can see both signals and background.
- ZDCSMD issue, Aihong took some pedestal runs and coordinated with Hank. The channel 4 has a high pedestal. ZDCSMD looks good in the fill since last night. There is a single run (25122011) from a short-lived fill this morning in which the same offending channel look a little suspicious, but it is not crazy. Aihong will continue monitoring it. May have to swap out daughter card#1
- Previous Issues:
- L0L1 turn-off issue (Tim changed fan tray for L0L1 crate 62)
fixed, no issue so far - low rate with QT crate issue (investigation ongoing).
Chris worked on it, needs elog entries.
QT rate seems to be up (4KHz, 40% dead) => 5KHz normal deadtime
- L0L1 turn-off issue (Tim changed fan tray for L0L1 crate 62)
- VPD: tac zero out. Be ready today for data-taking
- Gene analyzed data from Monday/Tuesday for studying the background effect.
see effects and need to keep BBC blue+1.7Yellow background <200KHz - sTGC: time bin cut? Access to gain change?
- Readiness checklist update for physics available. Shift crew started to follow normal operation procedure. Prom_Check DAQ+TRG+iTPC once a day (no event, stop run after it starts).
- Shift operation. Any issues?
- Jeff changed the logic how to include forward detectors in the trigger.
- Production configuration is needed. Jeff will clean up the file. Default configuration:pp200_production_LowLuminosity: done
- Determine the gain for the polarimeter at the beginning the fill. Jeff has a configuration for this: file is available, will put instruction in the checklist
Plans
- FST will switch back from 9 time bin to 3 time bin (today)
- Readiness checklist update for physics available.
- Scaler timing for Polarization monitoring. It’s on the to-do list of Chris.
- Test run of gating grid at different rates (1 minute each)
- a full Maintenance Day on May 14th (Linda Horton’s visit at BNL)
STAR daily operation meeting 04/30/2024
(Period Coordinator change: Kong Tu => Zhangbu Xu)
§ RHIC Schedule
4K cool down.
Plan for this week,
· 111x111 bunch collisions for experimental setup overnight.
· Machine development today (10:00 – 14:00).
· Crossing angle 1mrad at STAR; leveling at STAR made signal/background ratio very small. Reverted back to without leveling.
§ STAR status
· Physics running started around 4am this morning. We created a temporary configuration and promoted MB-BBC, MB-TOFmult4, BBC, ZDC, EPD.
· Global timing moved back 2ns. CAL SCAN was redone.
· EPD trigger timing - one clock late issue resolved. Eleanor fixed it! A few minor changes should be done. All detectors calibration done. VPD E and W max tac value changed from 1950 to 2100.
· ZDCSMD issue, Aihong took some pedestal runs and coordinated with Hank. The channel 4 has a high pedestal. Issue is associated with the QT broad. Will discuss in the trigger meeting.
· Previous Issues:
o L0L1 turn-off issue (Tim changed fan tray for L0L1 crate 62)
o low rate with QT crate in issue (investigation ongoing).
· Gene showed the space charge calibration plot and expressed concern about the space charge calibration.
· Drilling finished yesterday.
· Readiness checklist update for physics available. Shift crew started to follow normal operation procedure. (observation: a lot of not experienced shift crew and new trainee this year.)
· Shift operation. One of the DO failed the training exam (Oxygen Deficiency training) multiple times. The DO had to contact training coordinator and just showed up with training finished.
§ Plans
· Gene will analyze the first run this morning for studying the background.
· VPD: tac alignment will be next when we have collisions.
· FST will switch back from 9 time bin to 3 time bin.
· Jeff will change the logic how to include forward detectors in the trigger.
· Production configuration is needed. Jeff will clean up the file. Default configuration: pp200_production_LowLuminosity
· Determine the gain for the polarimeter at the beginning the fill. Jeff has a configuration for this.
· Readiness checklist update for physics available.
· Scaler timing for Polarization monitoring. It’s on the to-do list of Chris.
· a full Maintenance Day on May 14th (Linda Horton’s visit at BNL)
STAR daily operation meeting 04/29/2024
§ RHIC Schedule
4K cool down.
Plan for this week,
· 111x111 bunch collisions for experimental commission overnight.
· Maintenance today 08:00 to 17:00; machine development Tuesday.
§ STAR status
· The VPD earlistTAC was chopped off at 1950 (max). Since Run 25119110, global timing was moved by 2.5 ns early (Find delay 117 to 112). We might need another CAL SCAN to see with collisions. Endcap needs to scan anyway.
· EPD trigger timing - one clock late, status: Eleanor find a blank VT201. ZDC, BBC, VPD need to revert back to original parameters.
· ZDCSMD issue (west horizontal channel 4 was hot) and power cycle MXQ crate didn’t work. ZDCSMD gate scanning done, and default values are not changed. Hank: take another Ped run before evaluating this.
· Running since last evening, pp_200_commissioning. Details about elevating to physics triggers will be discussed at the Trigger Board meeting.
· L4 calibration. Diyu has received the calibration file from Gene from Run 15. Will investigate.
· Drilling seems to be in the IR only. All evaluation were done. Lijuan: we should have this discussion early for next time.
· VPD: tac alignment will be next when we have collisions. Will redo the voltage scan too. Call Daniel and Frank.
· Previous Issues:
o L0L1 turn-off issue.
o low rate with QT crate in issue (investigation ongoing).
§ Plans
· When we have beams tonight, call Oleg, VPD (Daniel. B), EPD (Maria, Mike), Prashanth, Akio.
· Put in sTGC later today.
· FST will switch back from 9 time bin to 3 time bin.
· Determine the gain for the polarimeter at the beginning the fill. Jeff has a configuration for this.
· Maintenance (access) today: 1) FCS moving in; 2) EEMC 5S2 box check and burp (Will J provided instruction and Prashanth received it); 3) Possible EPD air intake diverter; 4) L0L1 Crate work (Tim is planning to change the fan tray and change the voltage setting.) 5) Concrete drilling for ePIC (after 9 am).
· Crossing angle of 1mrad to be added after all calibrations or close to physics.
· Noise run should be taken.
· Readiness checklist update for physics today.
· Scaler timing for Polarization monitoring. It’s on the to-do list of Chris.
· a full Maintenance Day on May 14th (Linda Horton’s visit at BNL)
STAR daily operation meeting 04/28/2024
§ RHIC Schedule
4K cool down.
Plan for this week,
· 56x56 bunch collisions for experimental commission continue.
· 111x111 bunch collisions later tonight.
· Maintenance day 08:00 to 17:00 Monday; machine development Tuesday.
§ STAR status
· BBC, EPD (timing and bias scan), VPD, EMC are all commissioned. EPD still needs this trigger work - one clock late (trigger group will look into it).
· Running since last evening, pp_200_commissioning, with MB trigger (BBC+TOF0) and high multiplicity trigger (with TOFMult4 > 8 for QA purposes for now). Fast Offline data has been requested and running for Prithwish, Shengli, et al. Shengli already produced QA plot which looks reasonable. Discussion tomorrow at the Trigger Board meeting.
· L4 issue seems to be improved by Diyu with space charge calibration update [1]! Flemming suggested Diyu to consult with Gene about the pp 200 parameter for space charge calibration. Currently DCAz still looks strange.
· Previous Issues: 1) L0L1 turn-off issue, 3) low rate with QT crate in issue (not solved yet). Update from Jeff, Tim, Hank (after yesterday 11:30am discussion)?
· Aihong ZDCSMD work finished and currently still analyzing the data.
§ Plans
· Crossing angle of 1mrad to be added after all calibrations or close to physics.
· Maintenance (access) tomorrow: 1) FCS moving in; 2) EEMC 5S2 box check and burp (Will J provided instruction and Prashanth received it); 3) Possible EPD air intake diverter; 4) L0L1 Crate work (Tim is planning to change the fan tray and change the voltage setting.) 5) Concrete drilling for ePIC (after 9 am).
· Triggers promoted to physics discussion at Trigger Board meeting tomorrow.
· Readiness checklist update for physics next week.
· Polarization monitoring. It’s on the to-do list of Chris.
· a full Maintenance Day on May 14th (Linda Horton’s visit at BNL)
STAR daily operation meeting 04/27/2024
§ RHIC Schedule
4K cool down.
Plan for this week,
· 56x56 bunch collisions for experimental commission started around 12:30am.
· New store started at 7am.
· Detector commission overnight and continue this weekend.
§ STAR status
· No access.
· ZDC, BBC, VPD DSM timing are calibrated (was one tick late), while EPD still needs this timing calibration (Chris will work on it). VPD-tac offset was restored to last year’s value instead of zero.
· We observed the strange vertex z distribution on L4 but not L3 [1]. Diyu: calibration of the TPC? pp 500 parameters are used. Going to look at correlation between multiplicity and vertex distribution.
· Previous Issues: 1) L0L1 turn-off issue, 2) L2 crashing with prepost issue (fixed), 3) low rate with QT crate in issue (not solved yet). Tim and Jeff left instructions to the shift crew for L0L1 issue. Issue 1): Under voltage turned off the crate. David will communicate with Tim, Jeff, etc. Hank will ask Jack about the voltage setting.
· Forward detectors, not running yet. Will include them soon.
· Finished: Cal Scan (Oleg) within 1ns w.r.t last year, BBC (Akio), EPD ongoing (Maria). Global time can be set.
§ Plans
· Aihong should look at the ZDCSMD.
· Continue trigger commission: EPD (Maria, Mike),VPD (Geary, Daniel Brandenburg, Frank).
· VPD HV scan.
· To shift crew: ETOF and MTD HV should OFF instead of STANDBY.
· Polarization monitoring. It’s on the to-do list of Chris.
· Plan after the trigger detector commission later today: 1) BBC-AND + TOF > 0 as MB and/or maybe 2) BBC trigger + mult>20 (to start with); all configurations should have the crossing angle.
· Readiness checklist update for physics next week.
· ½ day (9-1PM? Prashanth will find out and keep us posted on staropsa) of Maintenance on April 29th (Monday) and a full Maintenance Day on May 14th (Linda Horton’s visit at BNL)
§ When we have access.
· (access needed) L0L1 crate shut off and check PS.
· (access needed) EPD cooling: fan blowing to the fee box needs to be improved. Prashanth is working on it.
· (access needed) ESMD issue, crate 85? Will: the issue is on the electronics or could be water flowing, but not understood yet. Someone can try to clear the bubbles by removing the quick release, etc…Prashanth/Will will email Bill to follow this up and try when we have access again.
STAR daily operation meeting 04/26/2024
§ RHIC Schedule
4K cool down.
Plan for this week,
· Beam setup last night and 12x12 store for experimental setup early this morning. Collisions!
· Global timing looked good, but the beam condition is not good with large background (see vertex z distribution run 25117023)
· Continue beam setup in the AM, and more experimental commission in the PM and over the weekend.
§ STAR status
· No access.
· There are three issues: 1) L0L1 turn-off issue, 2) L2 crashing with prepost issue, 3) low rate with QT crate in issue. Chris worked on Issue 2) and it seems to be fixed. Status: stable for 1.5 days. Jeff: 1) happened once this morning due to “under voltage error 43”. David will look into the alarm system. Tim: could be PS. (will need access)
§ Plans
· Trigger commission: Prepost (Chris), EPD (Maria, Mike), TOF, BBC (Akio), VPD (Daniel Brandenburg, Frank, Geary). We will have a call list when we have collisions, e.g., JH, Akio.
· VPD HV scan.
· Shift crew should pay attention to the events coming instead of deadtime.
· Shift crew should look at the issue from the VME crate.
· APEX mode for running single beams with the tune file.
· Readiness checklist update for physics next week.
· ½ day of Maintenance on May 1st (Wednesday) and a full Maintenance Day on May 14th (Linda Horton’s visit at BNL)
§ When we have access.
· (access needed) L0L1 crate shut off and check PS.
· (access needed) EPD cooling: fan blowing to the fee box needs to be improved. Prashanth is working on it.
· (access needed) ESMD issue, crate 85? Will: the issue is on the electronics or could be water flowing, but not understood yet. Someone can try to clear the bubbles by removing the quick release, etc…Prashanth/Will will email Bill to follow this up and try when we have access again.
STAR daily operation meeting 04/25/2024
§ RHIC Schedule
4K cool down.
Plan for this week,
· Beam setup last night.
· First collision is expected to be this evening (maybe 6x6 bunches).
· ½ day of Maintenance on May 1st (Wednesday) and a full Maintenance Day on May 14th (Linda Horton’s visit at BNL)
§ STAR status
· No access.
· There are three issues: 1) L0L1 turn-off issue, 2) L2 crashing with prepost issue, 3) low rate with QT crate in issue. Experts will investigate them.
· When we have access.
o (access needed) EPD cooling: fan blowing to the fee box needs to be improved. Prashanth is working on it.
o (access needed) ESMD issue, crate 85? Will: the issue is on the electronics or could be water flowing, but not understood yet. Someone can try to clear the bubbles by removing the quick release, etc…Prashanth/Will will email Bill to follow this up and try when we have access again.
§ Plans
· Trigger configuration for low lumi pp will be provided by Jeff.
· Trigger commission: EPD (Maria, Mike), TOF, BBC (Akio), VPD (Daniel Brandenburg). We will have a call list when we have collisions, e.g., JH, Akio.
· Will check the duration of the run.
· Shift crew should look at the issue from the VME crate.
· APEX mode for running single beams with the tune file.
· Readiness checklist update for physics next week.
· May 14th (Tuesday), RHIC will open for Linda H (DOE office of science)
STAR daily operation meeting 04/24/2024
§ RHIC Schedule
4K cool down.
Plan for this week,
· Blue injection kicker and PS work resolved/finished! Beam setup last night.
· First collision is expected to be tomorrow evening or Friday.
· ½ day of Maintenance on May 1st (Wednesday) and a full Maintenance Day on May 14th (Linda Horton’s visit at BNL)
· Emergency power test. Prashanth: 10:30am, Wednesday.
§ STAR status
· No access.
· Jeff and Chris worked on the L0L1 and L2 issue and confirmed the cosmic configuration with prepost enabled also crashed the L2 and L0L1. Update? Also, Run-25114053 around 19:30, L2 and L0 crashed (tune_2024_prepost) and shift crew brought it back by following the expert’s instruction. Related? Experts baffled.
· When we have access.
o (access needed) EPD cooling: fan blowing to the fee box needs to be improved. Prashanth is working on it.
o (access needed) ESMD issue, crate 85? Will: the issue is on the electronics or could be water flowing, but not understood yet. Someone can try to clear the bubbles by removing the quick release, etc…Prashanth/Will will email Bill to follow this up and try when we have access again.
§ Plans
· Trigger configuration for low lumi pp will be provided by Jeff. Trigger commission: EPD (Maria, Mike), TOF, BBC (Akio), VPD (Daniel Brandenburg). We will have a call list when we have collisions.
· APEX mode for running single beams with the tune file.
· Readiness checklist update for physics next week.
· May 14th (Tuesday), RHIC will open for Linda H (DOE office of science)
STAR daily operation meeting 04/23/2024
§ RHIC Schedule
4K cool down.
Plan for this week,
· Blue injection kicker and PS work continue. Beam setup early afternoon.
· First collision is expected to be delayed due to the ongoing works and checks.
· Maintenance on May 1st (Wednesday).
· Emergency power test next week. Prashanth: 10:30am, Wednesday.
§ STAR status
· No access.
· L2 seems to be running fine with prepost in tune configuration. (Hank and his team will investigate, as previous interpretation didn’t seem to explain). Jeff will do it when we have beams.
· L0L1 VME crate crashed when running the tune_2024_prepost. We will keep an eye on it.
· Same as yesterday.
o (access needed) EPD cooling: fan blowing to the fee box needs to be improved. Prashanth is working on it.
o (access needed) ESMD issue, crate 85? Will: the issue is on the electronics or could be water flowing, but not understood yet. Someone can try to clear the bubbles by removing the quick release, etc…Prashanth/Will will email Bill to follow this up and try when we have access again.
§ Plans
· Jeff will investigate the system with L0/L1 and L2 when there’s beam activity.
· APEX mode for running single beams with the tune file.
· Readiness checklist update for physics next week.
· May 14th (Tuesday), RHIC will open for Linda H (DOE office of science)
STAR daily operation meeting 04/22/2024
RHIC Schedule
4K cool down.
Plan for this week,
- Blue injection setup last night and saw some beam activities!
- Blue main quad PS diagnostics continue and with some other issues to investigate. Some checks will be done with Yellow but most or less ready for injection.
- First collision expected April 23-25 (?)
- Maintenance on May 1st (Wednesday).
- Emergency power test next week, but not sure what day yet.
STAR status
- No access, but we may go to restricted access later today.
- BTOW hot spots. No action needed from shift crew.
- L2 seems to be running fine with prepost in tune configuration. (Hank and his team will investigate, as previous interpretation didn’t seem to explain).
- L0L1 VME crate crashed when running the tune_2024_prepost. Experts may look into it.
- EPD is on now. EPD reduced the QT threshold to 3, and can bring it back to 35 after the scan.
- Same as yesterday but we may have access later.
- (access needed) EPD status: Mike: there are yellow and right lights on the TUFF box, need to look into what they mean. (Everything is fine.)
- (access needed) EPD cooling: fan blowing to the fee box needs to be improved. Prashanth is working on it.
- (access needed) ESMD issue, crate 85? Will: the issue is on the electronics or could be water flowing, but not understood yet. Someone can try to clear the bubbles by removing the quick release, etc…Prashanth/Will will email Bill to follow this up and try when we have access again.
- FST time bin shift. Ziyue will do it (Monday) and keep the shift crew posted. Jeff will adjust some setting and will document it on shiftlog.
Plans
- Jeff will investigate the system with L0/L1 and L2.
- Whether VPD should be on or off during single beam, experts will monitor and advise.
- APEX mode for running single beams with the tune file.
- Readiness checklist update for physics next week.
- May 14th (Tuesday), RHIC will open for Linda H (DOE office of science)
STAR daily Operation meeting 04/21/2024
RHIC Schedule
4K cool down.
Plan for this week,
- Blue injection failed yesterday again and continue today.
- Yellow will depend on the blue beam schedule. First collision expected April 23-25.
- Maintenance on May 1st (Wednesday).
- Emergency power test next week, but not sure what day yet (see Prashanth’s email)
STAR status
- Back to controlled access.
- Same as yesterday.
- (access needed) EPD status: Mike: there are yellow and right lights on the TUFF box, need to look into what they mean.
- (access needed) EPD cooling: fan blowing to the fee box needs to be improved. Prashanth is working on it.
- (access needed) ESMD issue, crate 85? Will: the issue is on the electronics or could be water flowing, but not understood yet. Someone can try to clear the bubbles by removing the quick release, etc…Prashanth/Will will email Bill to follow this up and try when we have access again.
- FST time bin shift. Ziyue will do it (Monday) and keep the shift crew posted.
- L2 died couple of times and experts (Hank, Akio, Eleanor) helped fixed it (eliminate the prepost seemed to fix the issue). Christ will look into it. New instruction here, https://www.star.bnl.gov/public/trg/trouble/L2_stop_run_recovery.txt).
Plans
- Jeff will make a different tune file without prepost for now. Run with prepost as the default tune file, but without it will be the plan B.
- Cosmic data taking with Reverse Full field.
- Can use APEX mode for running single beams.
- Readiness checklist update for physics next week.
- May 14th (Tuesday), RHIC will open for Linda H (DOE office of science)
STAR daily Operation meeting 04/20/2024
§ RHIC Schedule
4K cool down.
Plan for this week,
· Blue injection failed yesterday and continue today.
· Yellow PS checkout over the weekend (controlled access) and injection on April 22 (Monday); first collision expected April 23-25.
· Maintenance on May 1st (Wednesday).
· Emergency power test next week, but not sure what day yet (see Prashanth’s email)
§ STAR status
· BEMC HV fixed.
· Back to restricted access.
· (access needed) EPD status: Mike said it’s still a mystery and will have someone look at the lights on the EPD rack in the Hall (DO just did). Tonko made a comment on starops and mystery seems to be resolved. Mike: there are yellow and right lights on the TUFF box, need to look into what they mean.
· (access needed) EPD cooling: fan blowing to the fee box needs to be improved. Prashanth is working on it.
· (access needed) ESMD issue, crate 85? Will: the issue is on the electronics or could be water flowing, but not understood yet. Someone can try to clear the bubbles by removing the quick release, etc…Prashanth/Will will email Bill to follow this up and try when we have access again.
· (access needed) sTGC air blower alarm seems to have issues. Tim fixed it!
· L2 died and experts instructed the correct way of bringing L2 back (MXQ message suggests a link, and experts are looking to see if it is updated. https://www.star.bnl.gov/public/trg/trouble/L2_stop_run_recovery.txt ). Hank will update the instruction.
· FST time bin shift. Ziyue will do it (Monday) and keep the shift crew posted.
§ Plans
· Shift crew Check online plots timely.
· Cosmic data taking with Reverse Full field.
· Can use APEX mode for running single beams.
· Readiness checklist update for physics next week.
· May 14th (Tuesday), RHIC will open for Linda H (DOE office of science)
STAR daily Operation meeting 04/19/2024
RHIC Schedule
4K cool down.
Plan for this week,
- Blue and Yellow PS checkout and injection into blue? on April 19 (today).
- Yellow PS checkout over the weekend (controlled access) and injection on April 22 (Monday); first collision expected April 23-25.
- Maintenance on May 1st (Wednesday).
STAR status
- BEMC HV. Oleg: today, may need Tim to make cables to finish the work, depending on EPD.
- sTGC air blower alarm seems to have issues. Tim will look into it when possible.
- EPD status: Tim removed East EPD TUFF box from hall. Tim: reinstalled this morning. Tonko can take a look.
- EPD cooling: fan blowing to the fee box needs to be improved. Prashanth is working on it.
- ESMD issue, crate 85? Shift crew had asked, and Will. J said he will work on it today. Will: the issue is on the electronics or could be water flowing, but not understood yet. Someone can try to clear the bubbles by removing the quick release, etc…Prashanth/Will will email Bill to follow this up and try when we have access again.
- L2 had died and brought back, but L4 is still dead (the machine died). L4 issue we should call Diyu. L4 should be back now. Will give an updated instruction to deal with this for shift crew.
- TPC hot spots. Experts, please investigate. Flemming: tpc, there are 2 hotspots always there. itpc, there are hotspots come and go. Will update the reference plots Monday.
- Jeff already made a tune file. Jeff will put one prepost in BBC, EPD, ZDC etc.
- BCW has been running fine since yesterday.
Plans
- Will clarify the schedule for emergency power tests with RHIC.
- Cosmic data taking with Reverse Full field.
- Can use APEX mode for running single beams.
- Readiness checklist update for physics next week.
- May 14th (Tuesday), RHIC will open for Linda H (DOE office of science)
STAR daily operation meeting 04/18/2024
- RHIC Schedule
4K cool down.
Plan for this week,
- 26 GeV PS test tonight (STAR can stay open during this test)
- Blue beam (100 GeV) injection on April 19 evening (tomorrow evening).
- Yellow beam injection on April 21 (Sunday); first collision expected April 23-25.
- STAR status
- Maintenance: only TPC water work (temperature sensor) was done, but other tests were postponed to next Wednesday (April 24).
- sTGC air blower alarm seems to have issues, but the temperature is stable and has been included in the run. Tim will check this.
- BTOW issue with crate id 26 and VME 24. Oleg fixed it and he will put back the BSMD after this meeting.
- EPD status: Tim needs to replace TUFF box (aim for tomorrow.) Cooling: fan blowing to the fee box needs to be improved.
- ESMD issue, crate 85? Status?
- Will check to include ETOW in the run.
- Communications:
- Call MCR for communications to CAS.
- Plans
- Cosmic data taking with Reverse Full field.
- Readiness checklist update for physics next week.
- Akio wants to be on call list for beam tomorrow evening.
- Jeff will make a tune file today.
- BCW – need issue reports. Shift crews need to document all actions.
- May 14th (Tuesday), RHIC will open for Linda H (DOE office of science)
STAR daily Operation meeting 04/17/2024
§ RHIC Schedule
4K cool down.
Plan for this week,
· Blue beam injection on April 19 (Friday).
· Yellow beam injection on April 21 (Sunday)
· First collision expected April 23-25.
§ STAR status
· Power dip last night. Subdetectors were brought back on except a few issues:
o sTGC air blower.
o TPC air blower, Alexei will look into it with help from Tim.
o BEMC is back, and EEMC CANBUS are down, no control?
o Some works need to be done for the gas system of MTD. MTD can still be operated safely.
· Mike Lisa: EPD seemed to have issue with TUFF box and bad voltages. Shift crew turned EPD off during the evening shift. Mike turned them on this morning, and Tim needs to take a look. Cooling will be added to the FEE box.
· Geary: ETOF instruction was reminded on starops. Will remind shift crew and include ETOF for noise run later today after maintenance.
· Eleanor: fixed the BCW and gave instructions to the shift crew.
· Will J: EEMC chiller status and how to turn things off during the power tests. This is already noted.
· ESMD issue, crate 85? Tim will try to fix it after the power tests.
· Flemming: requested special run for TPC and was taken during the evening shift, Run 25107059
· RHIC status computer on shift leader desk (Jim Thomas sent an email to Angelika for username and password)
· CAS will come taking down the magnet.
§ Plans
· Downtime (10:30-17:00) today. Emergency power test, magnet power test, MCW maintenance (part change, postponed to next week!), TPC water maintenance (temperature sensor)
· Cosmic data taking with Reverse Full field.
· Detector status update.
· Readiness checklist update for physics next week.
· Power dip recovery instruction needs to be reprinted.
RHIC/STAR Schedule [calendar]
2023 ops meeting notes
Notes from STAR Operations Meeting, Run 23
August 7, 2023
RHIC Plan:
Shutdown early.
Notable items/recap from past 24 hours:
Day shift: Cosmics
“Magnet trimWest tripped again”
Evening shift: Cosmics
“Expert managed to bring the magnet back around 17:05."
Owl shift: Cosmics
“Smooth cosmics data taking during the whole night, no issues.”
Other items:
“I stopped TPC gas system ~8:10 at circulation mode and started high Ar flow. Magnet is down.”
“I started N2 flow for TOF, MTD and eTOF systems.”
“We turned off EPD and currently we are turning off VME crates”
“I powered down btow & gmt01 DAQ PCs. For now.”
Tonko will shut down iTPC and TPX after the meeting (leaving 1 for tests). Schedule time with Christian for maintenance.
Jeff will keep 1 or 2 evbs up but tomorrow will shut the rest down.
Cosmics summary: 17% runs bad. Final count: 51M (1.8x what Yuri wanted)
Shifters need to stay until end of morning shift (and help experts with shutdown). Officially cancel evening shift.
August 6, 2023
RHIC Plan:
Shutdown early.
Notable items/recap from past 24 hours:
Day shift: Cosmics
“Magnet trimWest tripped, called the CAD, they will try to bring it back” - no details
“Now, FST is completely shut down.”
“Alexei arrived, he solved the TPC oxygen alarm (gap gas O2) and confirmed that west laser does not work.” - will work on it tomorrow; will look at east laser today
Evening shift: Cosmics
“Magnet trimWest tripped. called the CAD.”
“Power dip and magnet dip around 10 PM."
“TR[G] component are blue but when all the components are included, the run won't start. When only include bbc and bbq, the run can start but DAQ Evts stays zero. DAQ: multiple VMEs are bad including VME1, we masked out all the bad VMEs.”
Owl shift: Cosmics
“L0 seem to have some issues, as Tonko also noted in the ops list; we rebooted the L0L1 VME, but still could not start a run after that, the daq was stuck in the configuring stage.”
Other items:
“GMT gas bottle was changed.”
“Alarm handler computer was completely stuck, we had to hard restart the machine.”
“We powercycled L0 crate once more and tried to run pedAsPhys with TRG + DAQ only and it worked.”
“Trigger rates were high, I called Jeff and he helped me to realize that majority of trigger nodes was taken out and I need to include them.”
5 hours of good cosmics (25/30M so far, ~1M/hr) — tomorrow morning will communicate with SL and start purging first thing in the morning assuming we hit the goal. If detector is not part of cosmic running, start earlier. sTGC will be done Monday.
Advice to shifters: cycle VME a few times. After 3 or 4 something might be wrong.
Tomorrow after end of run will turn off all trigger crates; all flammable gases.
August 5, 2023
RHIC Plan:
Shutdown early. (See email forwarded to STARmail by Lijuan at 3:30 PM yesterday for more details.)
Notable items/recap from past 24 hours:
Day shift: Cosmics
“Magnet is ramped up.”
“Temperature in the DAQ room is low enough, Tonko and Prashanth brought brouth machines back. Moving cooler in the DAQ room is turned off so the repaircrew repaircref could monitor how the AC runs”
“We turned on TPC, TOF, MTD and GMT for the cosmics”
“Tried to include L4 to the run, l4evp seems to be off”
“Alexei fixed the laser, both sides now work.”
Evening shift: Cosmics
“Will Jacobs called that he turned off the EEMC HV and LV to the FEE. We should leave EEMC out of the running over the weekend.”
"Trim west magnet tripped around 7:30 PM, called 2024 at 10:00 PM. They brought back the trim west magnet.” (Will follow up this evening) — these runs were marked as bad
Owl shift: Cosmics
“West camera is not showing anything” (Flemming sees no tracks) → “Both sides were working for us”
Other items:
Need to make sure shifters don’t come.
August 4, 2023
RHIC Plan:
Decision coming later today (fix starting in a week and resume vs. end and start early [STAR’s position]). Once official, will inform next shift crews.
Notable items/recap from past 24 hours:
Day shift: No data
“Magnet polarity is switched but the magnet is not ramped up yet.”
“MIX VME seems to have some hardware problem” -> fixed during the evening shift [Tim power cycled and cleared a memory error on the fan tray]
Evening shift: No data
“Nothing to report”
Owl shift: No data
“Nothing to report”
Other items:
Magnet up → waiting for DAQ room AC to be fixed this morning (hopefully) [UPDATE: fixed] → DAQ room computers turned back on → cosmics for 1.5-2 days → end Monday and purge → week after next, things coming down
Looks like we’re out of water again in the trailer
August 3, 2023
RHIC Plan:
No official decision yet. Likely end of tomorrow. Nothing changes (shift crews, etc.) until we have that info.
Notable items/recap from past 24 hours:
Day shift: No physics
Travis: “calibrated star gas detection system”
“etof_daq_reset command now works”
“FST Cooling was refilled. Reservoir level was filled from 66.6% to 90.4%. Swapped from pump 2 to pump 1.”
“We turned the detectors to save stages to prepare for the transfers switch test. Magnet is ramping down right now.” -> “The test is done and VMEs are back with David's help.”
“To reduce heat load while the DAQ Room A/C is offline, I'm starting to shutdown DAQ computers at this time (almost everything in the DA Rack Row is a candidate for shutdown).”
“DAQ computers which were shutted down by Wayne: tpx[1-36] except tpx[14] which is not remotely accessible (Dropped out of Ganglia at ~12:40 pm - possible hardware failure?); itpc[02-25]; fcs[01-10]; EVB[02-24]
Tim: “Replaced QTD in EQ3 with the non used QTD in EQ4”
“BCE crate: DSM1 board in slot 10 (Id9) and slot 11 (Id10) are swapped. Board address changed accordingly.”
Evening shift: No physics
Tonko “shut down even more DAQ machines; all stgc, all itpc, all tpx, all fcs, all fst, tof, btow,etow.”
Jeff and Hank fixed the trigger problems mentioned last time.
SL had a medical emergency and was transported to hospital. Thanks to Daniel for coming a bit early to take over. I will take her shift tonight.
Owl shift: No physics
Nothing to report
Other items:
Magnet polarity flipping today: 2 - 3 hours starting now. Will run cosmics for 1.5 - 2 days.
AC work yesterday, ongoing today. DAQ room still hot. Will not turn on unless this is fixed.
Just use TPC, TOF, MTD, BEMC
August 2, 2023
RHIC Plan:
Today: maintenance. Tomorrow - rest of run: ?
Notable items/recap from past 24 hours:
Day shift: Smooth physics runs + cosmics
At about 12:30, helium leak at 4 o’clock (blue — fixed target not possible either). Developing situation — may get the decision to end the run within the next few days. JH advocates for reversing polarity for two days after this maintenance before ending (because we couldn’t get it done before/during the run). STAR PoV: data-taking efficiency, machine status — best benefit from shutting down, save funds for next year. 4 months between end of this one and beginning of next one. Discussion point raised by Lijuan: how long do we need for cosmic data taking? Switch polarity immediately after maintenance for 2 to 3 days. Prashanth will talk to Jameela. When polarity is switched, Flemming will talk to Yuri.
Evening shift: Cosmics
“MCR called that due to the failure they won't be staffed over the night. In case anything happens, we need to call 2024”
Owl shift: Cosmics
“There was alaram in VME in first floor platform (cu_vme62_minus12volts, cu_vme62_plus12volts, cu_vme62_plus5volts & cu_vme62_fanspdm_nms). So we have turned on VME62 in first floor platfrom control. and alaram stops.”
“we had `L1[trg] [0x8002] died/rebooted -- try restarting the Run` critical message in the DAQ, then lots of `Error getting event_done client socket` messages. Also, vme-62_lol1 alarm sounded, DOs restarted crate. We rebooted all in the DAQ, then did the etof restart procedure as well.”
Summary: “had daq issues which we were not able to solve during the night, trigger was showing 100% dead (see details in shiftlog). We tried rebooting crates, first only BBC, then all of them one by one, but it did not solve the issue.” — Ongoing problem…To make sure TCD is ok do pedasphys_tcdonly w/ trigger and daq. Tonko thinks something is wrong with BBC.
Other items:
Modified ETOF procedures in detector readiness checklist and printed out/uploaded new ones (ETOF critical plot instruction, Canbus restart procedure also updated)
Should crate 54 still be out? — 54 is part of the old GG (control). And can be left off, yes.
Accesses? Tim for EQ3-QTD, Gavin: “Te-Chuan and I plan to refill the FST cooling system during the access tomorrow.” Alexei: west laser. Tim&Christian swapping BE-005, BE-006 to isolate missing 10 trigger patches which come and go.
Will make a list of detectors needed for cosmics and reduce shift staffing now. SL can decide (SL+DO minimum until gas watch mode).
Daq room temperature going up while AC is being worked on today.
August 1, 2023
RHIC Plan:
Today: physics. Wednesday: maintenance (7:00 - 16:00). Thursday - Monday: physics.
Notable items/recap from past 24 hours:
Day shift: Cosmics + mostly smooth physics running
“We tried to powercycle EQ3 crate and reboot trigger, the purple parts in the EPD plots belong to eq3_qtd and the orange to eq3.” — EQ3 problem seems to be fixed. EQ3_QTD problem won’t be until the board is swapped. Pedestals were not being subtracted correctly when qtd died
Evening shift: Cosmics + physics
“Two attempts for injection had failed at late stages; and a third one made it to the PHYSICS ON, but it lasted only for almost a couple of hrs”
Owl shift: Mostly smooth physics running
“ETOF critical plot had a new empty strip in Run 24213007, after run was stopped DOs followed the restart instructions, we rebooted ETOF in the daq [etof_daq_off], critical plots look fine in Run 24213008. Note: it should be clarified if this is indeed the right thing to do, because it takes more than 5 minutes between the runs which could be used for data taking.” — should be done between fills, as instructions say. Update: SL wrote an entry in the shift log clarifying the ETOF procedures.
“The very first physics run of the new fill (Run 24213004) was a complete 45 minute run without any noticable issue, however, strangely it only shows about 244K events (much less compared to the usual ~10M). Also, Run 24213012 was a complete 45 minute run, and it shows about half of the expected events, around 4.5M”. Database issue? Rate was fine. Talk to Jeff (out for the week). Flemming: if run is marked as good before counting is finished, shows a wrong number.
Other items:
“we just started the last big water bottle”
Another medical issue with SL trainee (SL starting today), but will hopefully not miss any shift.
“L3 Display: strange issue with lots of tracks [clusters?] at 7 o'clock in some events” (changeover checklist from owl shift) [check 24212006]
Large beta* test for sPHENIX (normal for STAR) with 12 bunches, lower lumi. Normal physics run after that. Update: sPHENIX requested no-beam time after that normal fill for 4 hrs.
Accesses tomorrow: Tim [removing bad board, EQ4 put in]
July 31, 2023
RHIC Plan:
Today-Tuesday: physics. Wednesday: maintenance
Notable items/recap from past 24 hours:
Day shift: Cosmics
"eq3_qtd is still out” — affects EPD. Hank is looking. Christian swapping in qtd or taking out of eq4 which is not being used and configuring fine (during Wednesday’s maintenance). Up to Hank. Haven’t heard back from Chris this morning.
ETOW: “_crate_ 1 lost its ID and so results that crate are junk.”
“sTGC yellow alarm for pentane counter, called Prashanth. He said that we should monitor it and if it changed rapidly, we should cal him again.”
Evening shift: Physics
“PHYSICS is ON @ 7:40 pm. Finally”
“low luminosity as it is almost 6.5 kHz at STAR ZDC.” — voted to dump. Refilled with higher rates ~ 13 kHz.
Owl shift: Physics
“Stopping the run did not succeed, attached is the trigger status (everything is in ready state on the webpage, including trigger)” “[E?]Q2 was in an incorrect state, it was at least a communication issue, and EQ2 needed a reboot, which could have been tried from the slow controls GUI (1st floor control platform), but Jeff did it from the command line. He also said in such a case (after realizing this is a trigger issue) a trigger expert could also have been contacted.” — procedure: reboot, power cycle if necessary, call Hank.
“There are two empty bins in BTOW HT plot. We saw it earlier today, too. This issue seems to come and go.” — be005 blank. No idea of cause of problem or of recovery right now.
“TPC:The iTPC #cluster vs sector QA plot has a hot spot for sector 19 (attached). This issue has persisted since the beginning of this fill (run 24211047)” — max # of clusters is a bit smaller in that sector. Has been going on the whole run and is not an issue.
“DO switched Freon line from line A to line B following an alarm that said that the pressure went below 5 psi.”
Other items:
Shifters doing better; one DO trainee returned to shifts, one may return today. Both seem set to assume their duties as DOs next week, with affirmative statements from their SLs.
Methane: identified methane source — 18 cylinders before running out, good for rest of run. (Also 2 bottles from national labs).
July 30, 2023
RHIC Plan:
Sunday—Monday: Physics
Notable items/recap from past 24 hours:
Day shift: Cosmics
“They have problems with injecting blue ring and need short access”
Evening shift: Cosmics
Storm => “Magnet trip at ~8:25”; “VME crates 63, 77 and 100 tripped…Lost Connection to BBC, VPD and EPD but we believe that this is because they all use BBC LeCroy. Will try to restore connections soon. TPC FEE were off before the storm.”
Owl shift: Cosmics
Persistent “ETOW: Errors in Crate IDs: 1 -- RESTART Run or call expert if the problem persists.” message. Continued after load write and read on individual fee crates and master reload. ETOW seemed to be recording normal data so they kept it in the run.” “Tonko said this issue should be fixed for physics.” — suggested power cycling crate but didn’t know how to do it. Oleg may know how to do it if Will doesn’t respond. Corruption means stale data. Update: the DO from today’s morning shift was able to fix the problem by following the manual’s instructions for power cycling before the load write and read. They think the instructions could be updated to be a bit clearer.
Other items:
Another DO trainee had a health problem and needed to stay home from this owl shift. Will update with any developments. DO trainee from evening shift is back from the hospital resting for a few days. Hopefully will be able to take her DO shift next week as normal. Need to verify their capabilities before they would start as DOs next week.
Jim suggests a “Weather Standdown [w]hen a thunderstorm is reported to be approaching BNL”. Will be implemented.
From this shift: “l2new.c:#2278 Most timed out nodes : EQ3_QTD::qt32d-8 (2000)” ”We were not able to bring back EQ3_QTD, restarted the EQ3 crate multiple times and rebooted the triggers. When I try to start the run after the reboot, error message says Check detector FEEs. Contacted Mike Lisa, he will bring it up at 10 o'clock meeting. Right now we started run without eq3_qtd.” David Tlusty has been contacted about a button not working for restarting the crate (#64). Alternative with network power switches? Not just QTD affected, but entire crate. VME board not coming back up. May need access. Update: now can turn it on in slow controls, but STP2 monitor says it’s off. Akio couldn’t be reached about this, and eq3_qtd remains out.
Alexei made an access for the laser (laser run was taken and drift velocity and other plots look good, but west laser is not working and will require longer access on Wednesday), but DOs have been informed and will pass on that only east camera should be used. Alexei also looked at EQ3: not responding. Will send Hank an email after trying a hard power cycle. Seems to still be on but not communicating.
Primary RHIC issues: power supplies; power dip on Thursday; magnet in ATR line is down. Weather looks better for the next week.
New procedure: “After rebooting eTOF trigger (or rebooting all triggers)[,] in etofin001 console (eTOF computer) command "etof_daq_reset". It should be typed after bash.” This is now written on a sticky note by the ETOF computer and Norbert is contacting Geary about adding it to the ETOF manual.
July 29, 2023
RHIC Plan:
Saturday—Monday: Physics
Notable items/recap from past 24 hours:
Day shift: Cosmics
Tim: “replaced compressor contactor for STGC air handler. Compressor now runs SAT.”
“Only subsystem which is not working now is the laser”
Evening shift: Cosmics
“one of the main magnet @ AGS has tripped and they are going to replace it”
“MCR changed the plan as they have a problem with one of the booster magnet”
“Alexei came around 8:00 pm and he fixed the east side camera, but not the west as he needs an access in order to fix it.” (not during night shift, after Saturday 20:00)
“…event display…shows the cosmic rays but not the laser tracks."
Owl shift: Cosmics
“Laser run at 7:15 AM, the drift velocity plot is empty” (leave it out for now)
Other items:
Related to SGIS trip: Removed Prashanth’s office number from expert call list. JH printed signs now posted in the control room with an instruction of what to do in the case of an alarm. Shift leaders have been briefed on the procedure.
“Noticed that EVB[6] is put back, there is no info about it in the log.” — since it seems to be working, leave it in.
DO trainee from evening shift had medical emergency. Shift crew from this current shift is with her at hospital. For this week, can operate without DO trainee, but she has two DO weeks (Aug 1, Aug 15). Will hopefully get an update on her condition today and plan accordingly.
July 28, 2023
RHIC Plan:
Friday—Monday: Physics
Notable items/recap from past 24 hours:
Day shift: Mostly smooth physics runs + Cosmics
“EVB1 stopped the run, was taken out for further runs, Jeff was notified.” (Can put it back in the run; was actually a small file building problem) “Temperature in the DAQ room was high in the morning, experts went to the roof and half-fixed the problem. They need access for longer time. Prashanth brought another portable fan and the temperature is now ok.”
Evening shift: Cosmics
“6:41 pm at flattop; then unexpected beam abort…problem with the power supply”
“magnet trips and the TPC water alarm fires…Few mintues later the Water alarm system fires at the control room…MCR informed us they are a general power issue and there are many systems tripped…slow control systems are down”
Owl shift: No physics
“We tried to bring back all the subsystems over the night.” Ongoing problems: “Laser: No, called Alexei…TOF: No, cannot reset CANBUS need to call Geary, already called Chenliang and Rongrong…MTD: same as TOF…ETOF: No…sTGC: No, air blower problem, Prashanth is aware” (Tim is currently checking on it; will let Prashanth, David know when it’s done)
“MCR is also having multiple issues with bringing back the beam"
Other items:
Thanks to experts (Jim, Oleg, Prashanth, Chengliang, Rongrong, Chris, anyone else I missed) for help during the disastrous night
Clear instructions for shift leaders: call global interlock experts on call list, turn off everything water cooled on platform. Written, and PC (or outgoing SL) talking to each shift leader and walking them through logging in and doing it.
Bring back TOF first (Geary will look at it after this meeting), laser second, …
Experts: if your device is on network power switch, send David email with the information so he can upload list to Drupal
July 27, 2023
RHIC Plan:
Thursday—Monday: Physics
Notable items/recap from past 24 hours:
Day shift: Cosmics
“Run restarted ETOF>100 errors” (multiple times) + “Tried eTOF in pedAsPhys_tcd_only - failed, excluded eTOF”
“Temperature in DAQ room still slightly rising, needs to be monitored.” (as of 9:30: room around 84 F; high for next 3 days: 89, 91, 90). 90+ is danger zone => shutdown
Evening shift: Cosmics + mostly smooth physics running
“I got to stop this run due to a critical message from evb01 of daqReader.cxx line 109 states "Can't stat '/d/mergedFile/SMALLFILE_st_zerobias_adc_24207054_raw_2400013.daq' [No such file or directory]”” (also happened this morning; Jeff is looking into it.)
“When the beam is dumped a pedAsPhys_tcd_only with TOF, MTD, ETOF, 1 M events and HV at standby, and the run to be marked as bad, per Geary request via star-ops list.. If there is no ETOF EVB errs and no trigger deadtime, then the ETOF can be included in the run when the beam is back again.”
Owl shift: Mostly smooth physics running
“The run was stopped due to unexpected beam abort and FST HV problem (error 2).”
ETOF check mentioned above was attempted; not enough time to complete before beam returned.
“itpc 9, RDO2 was masked out"
Other items:
Roof access scheduled for next Wednesday, with no beam, for AC servicing. Prashanth will ask an expert to come look at it before Wednesday (today?) to determine if a half-hour access (at end of this fill, ~ 11:00) is needed or not. [UPDATE: AC techs are going to do a roof access after the fill.] Reflective covers for windows in the assembly hall could also be used. If it gets too hot might need to do an unscheduled stop.
Longer term: is there any computing that doesn’t need to be done there? Could maybe take some of L4 offline.
July 26, 2023
RHIC Plan:
Today: APEX “Plan A” = 7:00 - 23:00. Affected by power supply failure — decision by 12:00. Thursday—Monday: Physics
Notable items/recap from past 24 hours:
Day shift: Mostly smooth physics runs
“Lost beam around 3:20 PM, and had a bunch of trips on TPC, FST, TOF.”
“The DAQ room temp. kept going up. Prasanth put a blower in the room, but the temperature needs to be monitored.”
Evening shift: No beam
“Only a cosmic run with the field on during the entire shift…A machine issue, namely the power supply failure, is still under investigations”
Owl shift: Cosmics
“The JEVP server seems to have a problem and stuck at run 24207007” — “Jeff fixed the online plots viewer.”
Other items:
“Controlled access started around 8:40 AM. C-AD electricians went in to reset the fuses on a faulty AC.”
July 25, 2023
Notes from RHIC plan:
• Today: Physics run
• Wed: APEX
• Thu-Mon: Physics runs
Notable items/recap from past 24 hours:
Day shift: Smooth physics runs before noon + 1 beam for sPHENIX BG test (2 hrs)
• Jeff: Updated production_AuAu_2023 and test_HiLumi_2023 configuration files:
production: increased UPC-JPsi & UPC-JPsi-mon from 50->100hz (nominal rates 100->200)
test_HiLumi: 1. set phnW/E to low rates; 2. removed BHT1-vpd100; 3. remove forward detectors from dimuon trigger; 4. set upc-main to rate of 100hz; 5. set upc-JPsi and UPC-JPsi-mon to ps=1
• Jim: PI-14 Methane alarm (Yellow); switched Methane 6 packs on the gas pad; added Alexei's magic crystals to TPC gas system which help enhance the Laser tracks
• Magnet down (2:00pm)
Evening shift: Smooth physics runs
• Owl shift: Smooth Physics runs
• EEMCHV GUI shows one red (chn 7TA) and two yellow (4S3, 3TD) channels.
MAPMT FEE GUI is all blue in the small one, and all red in the detailed view.
However, no apparent problem seen in the online monitoring plots
• EPD PP11 TILE 2345 had low ADC values. reboot EQ3, TRG and DAQ, and took trigger pedestals. issue was fixed
Other items:
• Outgoing PC: Zaochen Ye --> Incoming PC: Isaac Mooney
• Ordered for gas methane 6 packs at beginning of run, but will discuss offline
• Water bottles are empty, get some from other trailer room
July 24, 2023
Notes from RHIC plan:
• Today: Physics run + single beam experiment (for sPHENIX BG test) around noon (~1 hour)
Notable items/recap from past 24 hours:
Day shift: Smooth physics runs
• BTOW-HT plots have missing channels near triggerpatch ~ 200, Oleg suggested to reboot trigger, rebooted but the problem persists, Hank called and suggested that we powercycle BCE crate, We powercycled BCE crate but the problem persists.
• TOF Gas switched PT1 Freon line B to line A
Evening shift: Smooth physics runs
• Jeff Called in and helped us fix the L4Evp:.
• It was not working because:
1. l4evp was not included in the run. It was not clearing from the "waiting" state because it had been disabled from the run, so when L4 was rebooted it was NOT rebooted. Putting it back in the run fixed this.
2. xinetd is used in the communication between the Jevp and the DAQ server. It was in an inconsistent state, so I restarted xinetd.
Owl shift: Physics runs with a few issues
• Beam dumped around 2:20am due to power dip issue
• Magnet went down, VME crates went down as well
• TPC cathode was unresponsive, powercycle VME create associated with cathode (57) fixed the issue
• LeCroy that goes to BBC/ZDC/upVPD. DOs restarted the LeCroy, and BBC and upVPD got back. ZDC IOC still not good. There were 2 screens running LeCroy. Killed both and started IOCs fixed the issue.
• Back to physics around 5am.
Other items:
• Gene: “Distortions from Abort Gap Cleaning on 2023-07-21”
• MB DAQ rate dropped from 41k to 37k (due to TPC deadtime), now back to 41k
• High-lumi test, next week?
July 23, 2023
Notes from RHIC plan
• Today-Monday: Physics run
Notable items/recap from past 24 hours:
Day shift: Smooth physics runs
• Empty areas in eTOF digidensity plot, Geary suggests full eTOF LV/FEE power cycle + noise run during 2 hours access.
Evening shift: 3 physics runs + a few issues
• MTD HV trip for BL4,5,6,7 before flattop. DO powercycled HV block 4-7 following the manual and fixed the issue
• Online QA plots were not updating, restarted Jevp server from the terminal from the desktop near window, fixed it
• L4 has an error: l4Cal, l4Evp, L4Disp are not responding, and prevent starting the run. tried reboot L4, but it is not working. Jeff Landgraf helped work on issue. On the meantime, L4 was moved out and restarted the data taking.
• After l4Evp get solved by Jeff, the issue will be finally solved.
• BBQ from L2 Trigger had problem: Most timed out nodes : BBQ (2000). DO could not powercycle it because the GUI was not responding. Jeff powercycled it. DO contacted expert David and he restarted the canbus to fix the GUI
Owl shift: Smooth physics runs when beam is on
• Beam lost twice (2:27-4:00am, 7:25-9:15am)
Other items:
• MB rate drop (from previous normal 4100à current 3700 Hz), Jeff should check on the prescale, affected by UPC trigger? Dead time from TPC?
• Oleg: need to replace a DSM board? Hank: no need to do it. Oleg and Hank will follow up offline.
• BG level at the beginning of run is too high, triggered lots of trips/spike current from different detectors (sTGC, MTD, TOF,eTOF…). Solution: wait for “physics” (not “flattop”) to bring up detectors.
• Geary: to minimize eTOF effects on the data taking for physics runs (rest of eTOF for a while, Geary will talk to eTOF experts to get a solution on this), tem. Solution: leave eTOF out when it has issue and wait for eTOF expert notice to include it into run.
July 22, 2023
Notes from RHIC plan
•Today-Monday: Physics run
Notable items/recap from past 24 hours:
Day shift: Smooth physics runs
•Loss of EPD connection (but did not affect EPD data taking). Later the connection is back.
•TOF gas is close to low, change of gas would be this Sunday. Shifts should pay special attention.
•DAQ room AC stopped working. Experts replaced the problematic unit.
Evening shift: Smooth physics runs
•Alexei came, worked with the TOF gas (isobutane)
Owl shift: Smooth physics runs
Other items:
•A shift leader of July 25 day shift is filled
July 21, 2023
RHIC plan:
Today-Monday: Physics run
Notable items/recap from past 24 hours:
Day shift: Smooth physics runs
Evening shift: Smooth physics runs
FST: HV alarm (Failure code 2). DO followed procedure of powercycle and fixed it.
mask evb01 out
DAQ dead time was found 20m later than it should be, shifts need to pay more attention on it.
Owl shift: Smooth physics runs
Other items:
eTOF operation should not cost any physics run time, Geary share new instructions
Operation at continuous gap (maybe every hour) cleaning, we should have a plan for the data taking during this condition.
A shift leader is missing for the week of July 25
Bill can help a few days and Dan will get a solution today
Run log is not working well
More attention on the deadtime from DAQ
Run log not work well
July 20, 2023
RHIC plan:
Today-Monday: Physics run
Notable items/recap from past 24 hours:
Day shift: Maintenance
Jeff fixed the issue of Run Control GUI by rebooting X server
sTGC gas, re-adjust the pressure
Eleanor performed CosmicRhicClock test run 24200043
Evening shift: No beam due to (sPHENIX TPC laser work + power supply issue)
Owl shift: Smooth physics runs from 3am
Other items:
DAQ rate at high-lumi runs ~2-3k Hz, we can reach 5k for MB trigger, Gene want special runs a few minutes (DAQ: 5-4-2-4-5 k), sometime next week.
eTOF operation should not cost any physics run time:
Remove it from run if ETOF has issue, try to run a pedestal test after the beam dumped and before the next fill, if ETOF is running good with the test run then it can be included in next physics run, otherwise keep it out of run.
July 19, 2023
RHIC plan:
Today: Maintenance (7:00-17:00)
Thu-Mon: Physics run
Notable items/recap from past 24 hours:
Day shift: Smooth physics runs + Hi-Lumi Test runs (90m)
Slow response/refresh of Run Control GUI, can be improved by moving the GUI window, but not completely solved.
Evening shift: Smooth Physics runs
Owl shift: Smooth physics runs
Maintain:
hours are need in the morning from 10:30am, TPC water will be out (TPC fees should be off)
sTGC gas, re-adjust pressure, reducing valve
tour for summer students
July 18, 2023
RHIC plan:
Today: Physics run
Wed: Maintenance (7:00-17:00)
Thu-Mon: Physics run
Notable items/recap from past 24 hours:
Day shift: Smooth physics runs before 11am
Wayne replaced a disk in EEMC-SC
MCR: power supply issue
Jeff: 1. Removed zdc_fast 2. Put zdc_fast rate into the UPC-mb trigger 3. Added contamination protection to UPC-mb 4. updated production ID for UPC-mb; 5. Added monitor trigger for zdc-tof0; 6. added test configurations: CosmicRhicClock & test_HighLumi_2023
Evening shift: Smooth Physics runs since 6:30 pm
Owl shift: Smooth physics runs
Other items:
remind shifts about eTOF instructions for this year run
Plan for Wed's maintain:
hours are need in the morning from 10:30am, TPC water will be out (TPC fees should be off)
sTGC gas, re-adjust pressure, reducing valve
tour for summer students
July 17, 2023
RHIC plan:
Today: Physics run
Notable items/recap from past 24 hours:
Day shift: physics runs
“Error writing file st_X*.daq: No space left on device”. masked out EvB[5]
Evening shift: Physics runs
sTGC cable 4, 27, 28 were dead. DO powercycled LV and fixed the issuE
eTOF 100% dead. DO powercycled eTOF LV
EVB[24] [0xF118] died/rebooted, After two times, masked EVB[24] out (Once it happen, try reboot it only 1 time, if not work, directly mask it out.)
Owl shift: Smooth physics runs when beam was on
magnet tripped at 3:40am, CAS fixed it, back to normal run after 1 hour (reason of magnet tripped is still not clear)
Other items:
Plan for Wed's maintain:
* hours are need in the morning, TPC water will be out (TPC fees should be off)
* sTGC gas, re-adjust pressure, reducing valve
July 16, 2023
RHIC plan:
Today-Monday: Physics run
Notable items/recap from past 24 hours:
Day shift: 3 physics runs, mostly no beam
Tonko: Reburned failing PROM in iS02-4; Brand new iTPC gain file installed. Should fix issues with S20, row 35; Added code to automatically powercycle TPX RDOs if required
Jeff: L0 software update to make prescale determination (and run log scaler rate logging) to use the proper contamination definition adjusted scaler rate, Jeff will follow up on this issue.
magnet tripped at 1:47pm till the end of this shift (reason of this trip is unclear, need to follow up)
Evening shift: Physics run started at 7pm
BTOW ADC empty entry
eTOF 100% dead
TPX and iTPC both had high deadtime ~ 70%
Owl shift: Smooth physics run except beam dump (2:50-4:45am)
2:35 AM, sTGC gas pentane counter yellow alarm, Prashanth reset counter in sTGC gas system pannel to fix it
MTD gas changed the bottle from Line A to Line B (Operators need to pay closer attention on the gas status)
Other items:
Geary added instruction of ETOF DAQ issue into the ETOF manual
July 15, 2023
RHIC plan:
Today-Monday: Physics run
Now, CAD is working on AC issue, will call STAR when they are ready to deliver beam
Notable items/recap from past 24 hours:
Day shift: Smooth physics runs
ZDC_MB_Fast was tested, need further tunning
Evening shift: Smooth physics run
VME lost communication at 5pm, David reboot main canbus
sTGC fan temperature is higher than threshold, expert fixed it
Owl shift: Smooth physics run till beam dump
Other items:
eTOF DAQ issue was solved by Norbert, can join the run
July 14, 2023
RHIC plan:
Today: Physics run
~ 1 hour CeC access around noon
Friday-Monday: Physics run
Notable items/recap from past 24 hours:
Day shift: no beam
Prashanth changed the sTGC gas.
Evening shift: Physics run
7pm, sTGC gas had an alarm. Expert came over to fix it.
iTPC and TPX high dead ratio issue, problematic RDO of iTPC 18(3), lost ~1 hour
Oleg came over and helped DO to fix the BTOW
Owl shift: Smooth physics run, except 2 hours no beam
Other items:
zdc_mb_fast, Jeff will monitor and stay tunning
eTOF, keep out of run due to it cause high trigger rate
Leaking in control room, from AC, close to eTOF but no harm at this moment, people are working on it.
July 13, 2023
RHIC plan:
Today: 2 hours control access, may have beam early afternoon
Friday-Monday: Physics run
Notable items/recap from past 24 hours:
Day shift: APEX
1 EPD ADC was missing since night shift, EPD exert called, solved by powercycling EQ1 and took rhickclodk_clean run. Shift crew should be more careful on the online plots, compare to the reference plots more frequently.
Evening shift: APEX
Jeff added inverse prescale for ZDC_MB_FAST (not tested, if shiftcrew see problems, deadtime~100%, please inform Jeff. Aim for taking data 4k at very beginning of fill, try to get uniform DAQ rate. Jeff will also watch it)
Owl shift: Cosmics
Ingo fixed eTOF DAQ issue
12 July 2023
RHIC plan:
Today: APEX starting 7:30 am (~16 hours)
Thu - Mon: Physics run
sPHENIX requested no beam for Laser test(5 hours) either on Thu or Fri
Notable items/recap from past 24 hours:
Day shift: no much good beam, pedestal runs, 3 good runs
Evening shift: TRG issue, Beam dump due to power failure, pedestal runs
TRG experts power-cycled triggers and notes, got the TRG back after 3 hours work
OWL shift: Smooth Physics runs 2:20-6:45 am
3 July 2023
RHIC/STAR Schedule
Running AuAu until maintenance day on Wednesday
sPHENIX requested 5-6 hours of no beam after the maintenance.
Students from Texas are visiting STAR. It would be good to arrange a STAR tour for them.
Tally: 3.43 B ZDC minbias events.
Summary
· Continue AuAu200 datataking.
· Yesterday morning beam loss after about 20 minutes at flattop. Some FST HV tripped.
· Beam back at flattop around 10:50 but PHYSICS ON declared half an hour after that.
· Smooth datataking after that with a TPC caveat (see below)
· This morning beam loss that will take few hours to bring back.
· 107x107 bunches last couple of days to address the yellow beam problems.
Trigger/DAQ
TPC/iTPC
· Tonko worked on iTPC RDOs. Most have been unmasked.
· At some point the problems with a 100% deadtime started. Restarting run and/or FEEs did not always solve the problem. Tonko was working with the shift crew.
· Three RDOs are down (iTPC). Two may come back after the access.
BEMC
· Two red strips around phi bin 1.2 in run 24184004, normal otherwise
EPD
· West tiles did not show up in one run, but were back again in the next one.
FST
· On-call expert change
Hanseul will take over as a period coordinator starting tomorrow.
2 July 2023
RHIC/STAR Schedule [calendar]
Running AuAu until maintenance day on Wednesday
sPHENIX requested 5-6 hours of no beam after the maintenance.
Air quality is has substantially improved for today, but this very much depends on the winds, thus may worsen again.
Tally: 3.23 B ZDC minbias events.
Summary
· Continue AuAu200 datataking.
· Beam loss around 17:45, TPC anodes tripped.
· Ran some cosmics until we got beam back around 22:00
· Smooth running after.
· EPD and sTGC computers were moved away from the dripping area.
EPD
West tiles did not show up in one run, but were back again in the next one.
eTOF
· EVB errors once. Was in and out of runs. Some new empty areas reported.
· ETOF Board 3:16 Current(A) is 3A (normally it is ~2A). Shift crew says there was no alarm. Incident was reported to Geary.
1 July 2023
RHIC/STAR Schedule [calendar]
Running AuAu until maintenance day on Wednesday
sPHENIX requested 5-6 hours of no beam after the maintenance.
AIR QUALITY!!!
AQI is not great but nowhere near the HSSD trip levels. The document is growing, but need more input if it is to become a procedure.
https://docs.google.com/document/d/1-NhZJmS9MjIotvHUd9bPRVwObS-Uo7pWdjML36DjgeI/edit?usp=sharing
Tally: 3.02 B ZDC minbias events.
Summary
· Continue AuAu200 datataking.
· sPHENIX requestion access yesterday morning.
· Tim swapped out the troubled BE005 DSM board with a spare. It was tested and Oleg ran bemc-HT configuration and verified that the problem that BTOW was having is fixed.
· Beam back (after the access) around 13:40.
· Beam loss around 20:40 causing anode trips
· Problems with injection. Beam back around half after midnight
· Very smooth running after that.
Trigger/DAQ
· Jeff made agreed modifications to a zdc_fast trigger and added it back
· Also put DAQ5k mods into the cosmic trigger and improved scaler rate warning color thresholds
TOF/MTD
· Gas switched from A to B.
eTOF
· new module missing.
30 June 2023
RHIC/STAR Schedule [calendar]
F: STAR/sPHENX running
sPHENIX requested 2 hour RA from 9 to 11.
Running until maintenance day on Wednesday
sPHENIX requested 5-6 hours of no beam after the maintenance.
AIR QUALITY!!!
AQI is not great but nowhere near the HSSD trip levels. The document is growing, but need more input if it is to become a procedure.
https://docs.google.com/document/d/1-NhZJmS9MjIotvHUd9bPRVwObS-Uo7pWdjML36DjgeI/edit?usp=sharing
Tally: 2.86 B ZDC minbias events.
Summary
· Continue AuAu200 datataking.
· Around 12:50 one beam was dumped for the sPHENIX background studies
· 12x12 bunches beam around 16:40. This was to test the blue beam background. MCR was step by step (stepping in radii) kicking the Au 78 away from beam pipe. This resulted in a much cleaner beam and yellow and blue showing the same rates. Now they are confident in the cause of the background but creating the lattice for this problem is a challenge.
· New beam around 2:20
Trigger/DAQ
· BHT3 high rates happened overnight
· Geary was able to remove the stuck TOF trigger bit.
· Tonko suggested leveling at 20 kHz, based on last nights beam and rates/deadtime.
TOF/MTD
· Lost connection to the TOF and ETOF HV GUIs. David suggested that it could be a power supply connection problem. The problem restored itself.
sTGC
· STGC pT2(2) pressure frequent alarms in the evening. SL suggested to change the pressure threshold from 16 psi to 15.5 psi. I do not know if it was changed. David will have a look at it and decide weather to lower the alarm or to increase the pressure a little.
Discussion
· For the moment keep the leveling 13 kHz and discuss the adjustment of triggers during the next trigger board meeting.
· Tim will replace the DSM1 board and Jack will test it.
· During next maintenance day magnet will be brought down to fix the leak in the heat exchanger that occurred after last maintenance.
29 June 2023
RHIC/STAR Schedule
Th: STAR/sPHENX running
F: STAR/sPHENX running
AIR QUALITY!!!
We were warned about air quality index reaching 200 today, which means the HSSD’s will go crazy and therefore fire department would like them off, which means turning the STAR detector off, as we did a couple of weeks ago.
Experts please be ready and please contribute to this document so we have a written procedure in case this happens again.
https://docs.google.com/document/d/1-NhZJmS9MjIotvHUd9bPRVwObS-Uo7pWdjML36DjgeI/edit?usp=sharing
Tally: 2.65 B ZDC minbias events.
Summary
· Continue AuAu200 datataking.
Beam back around 22:10
· Pretty smooth running except stuck TOF bit starting around 2:00. Geary is working on it.
Trigger/DAQ
· Jeff added tcucheck into the logs, so that does not need to be done manually anymore.
TPC/iTPC
· TPC anode trip in sector 11.
· Tonko worked on the problematic RDOs on the outer sectors that were masked in recent days. It seems that some FEEs have problems with DAQ5k, he masked them and RDOs are back to runs.
· Plan for inner RDOs is to take a look today or at the next opportune moment.
eTOF
· One more empty fee
Discussion
· Power cycle MIX crate to try to fix the stuck TOF bit. Shift crew did it, but did not seem to help.
· If the board for the TOF stuck bit problem needs to be replaced we will need an access.
· 8 o’clock run seems to have proper rate.
06/28/2023
RHIC/STAR Schedule
W: APEX 16 hours
It will most probably be over around 19:00.
Th: STAR/sPHENX running
F: STAR/sPHENX running
Tally: 2.53 B ZDC minbias events.
Summary
· Continue AuAu200 datataking. 45-minute runs. Detectors ON at FLATTOP.
· Beam was extended way beyond its dump time due to the problems with injectors. Dumped around 19:00
· sPHENEX requested short controlled access (30 min) after which beam was back around 20:50
· First run was taken no leveling for tests after this we are running with leveling at 13 kHz.
· There is water dripping in the control room over the sTGC station.
Trigger/DAQ
· Tonko changed DAQ_FCS_n_sigma_hcal threshold from 2 to 5.
TPC/iTPC
· TPC anode sector 13 channel 7 tripped three times.
BEMC
· Overnight high rates of BHT3 and BHT3-L2Gamma.
· Oleg was contacted. Trigger reboot if run restart does not help seems to be helping.
· Oleg: DSM boards need to be replaced otherwise we see it picking up masked trigger pages.
EPD
eTOF
· Geary worked on eTOF and it was included in the runs. It worked without major problems.
· Lost a couple of fees and then the entire module was gone.
06/27/2023
RHIC/STAR Schedule [calendar]
T: STAR/sPHENX running
sPHENIX wants to run some steering tests to the beam will be dumped 2 hours earlier
W: APEX 16 hours
Th: STAR/sPHENX running
F: STAR/sPHENX running
Tally: 2.28 B ZDC minbias events.
Summary
• Continue AuAu200 datataking.
• Beam dumped around 12:45 and we went to controlled access asked by the sPHENIX
• Beam back around 19:00 but lost and then back in about 45 minutes.
• A/C in the control room is fixed.
• We asked MCR to level at 13 kHz zdc rate to take advantage of the DAQ5k. With the new beam we got 4.2 kHz DAQ rate, TPC deadtime around 40%.
• This morning we requested MCR tore remove leveling. Without leveling DAQ rates are ~4.2 kHz. zdc_mb dead times around 51-56%.
• Around 23:00 DAQ monitoring page had some problems but was restored to normal in an hour or so. Perhaps it is related to a single corrupt message which the DAQ monitoring cannot display. It will restore itself.
• There was also an intermittent problem loading the shiftLog page in the evening.
• Vertex looks well under control.
Trigger
• Jeff made bunch of changes to the trigger setup as agreed at the trigger board meeting. Some low rate triggers were implemented (~ 2Hz and ~50Hz).
TPC/iTPC
• Alexei checked the laser system during the access.
• Couple of additional RDOs could not be recovered and were masked out.
• Tonko will look at the masked RDO status tomorrow during the APEX.
BEMC
• Oleg has masked out Crate 0x0F.
• Tonko suppressed BTOW CAUTION message for Crate 4, Board 4.
• The high DHT3 trigger rate showed up but was resolved by restarting the run.
eTOF
• Geary worked on eTOF. It was briefly included in the runs, but the problems persisted. So, it is out again.
In progress / to do
• Increasing run duration.
o Currently we are running 30-minute runs.
o Perhaps we can increase the run duration to 45 minutes?
o AGREED: switch to 45 minute long runs.
• Bringing detectors up at flattop.
o Currently detectors are brought up after PHYSICS ON is declared.
If experts agree that the beams at FLATTOP are stable enough to bring up detectors, we could opt for this.
o AGREED: to bring up detectors at FLATTOP.
Discussion
• Tonko mentioned that sometimes FCS04 is starting to record data at a very high rate that causing deadtime. Perhaps a better adc (nSigma) cut should be applied to remove the noise, which it most likely is at those high data rates.
06/26/2023
RHIC/STAR Schedule
T: STAR/sPHENIX commissioning
sPHENIX will need 4 hour access today. Time TBD around 10:30.
Tally: 2.12 B ZDC minbias events.
Summary
• Continue AuAu200 datataking.
• Fills around 10:00, 18:00, and 4:40 this morning.
• Many eTOF EVB errors. Much more than usual.
• Many BHT3 high trigger rate issues.
• Temperature in the control room was in low 80s and could not be adjusted using thermostat. The fan is blowing constantly because thermostat is set to low but there air it blow is not cold.
• MCR is periodically correcting the vertex position.
• They are monitoring it and will be triggering correction at 10 cm. They also said they are working on automated procedure of vertex correction.
TPC/iTPC
• Tonko updated sectors 1-12 (both inner and outer) to DAQ5k.
• TPX RDOs S11-5 and S08-6 masked as Tonko sees some problem with them.
• ITPC: RDO S24:1 masked later (FEE PROM problem)
• iTPC RDO S18:3 early this morning
• Gas alarm briefly chirped twice this morning.
• This morning Tonko finished updating the entire TPC to DAQ5k
• 24177033 first run with DAQ5k configuration
BEMC
• A lot of BHT3 high rate trigger issues
• Oleg masked out BTOW TP 192, 193 and 159 from trigger.
• Issue with high rate of triggers still persisted.
• Oleg: some crates lose configuration mid-run. Symptoms similar to radiation damage, which is strange with the AuAu beam.
• Constant power cycling of BTOW power supply should not be used so often.
• Oleg will mask the problematic boards to eliminate the problem.
eTOF
• Many EVB errors. eTOF was mostly out of runs overnight and this morning.
• After many attempts to fix and bring back to runs it was decided to keep it out.
Discussion
• J.H will let CAD know that we would like to level ZDC rate at 13 kHz to accommodate DAQ5k rates.
06/25/2023
RHIC/STAR Schedule [calendar]
Su: STAR/sPHENIX commissioning
Tally: 2.01 B ZDC minbias events.
Summary
• Continue AuAu200 datataking.
• Shift leaders were in contact with MCR to have z vertex steered back to center
• Smooth running otherwise.
• MCR was checking on their injectors this morning.
Trigger
• Jeff moved triggers to the recovered bits UPC-JPSI-NS slot 9->15, UPC-MB slot 14->31, fcsJPSI slot 12->34
TPC/iTPC
• jevp plots updated and show the missing RDO data in sectors 4, 5
• PT1 and PT2 alarm threshold lowered to 15.5 PSI, alarms sounded when they dropped below 16 PSI.
• With the new fill around 18:00 shift crew notices higher deadtime and lower rates (1.8 kHz). Tonko was able to fix the problem by power-cycling TPX Sector 8 FEEs, which seems to have be causing this issue.
• Tonko continued working on updating sectors.
• TPC parameters used by the HLT using drift velocity were just changed. This should properly account for the changing drift velocity to reconstruct the z vertex
BEMC
• Issue with BHT3 trigger firing with very high rate reappeared. Oleg was contacted and suggested to power cycle BEMC PS 12 ST when simple run restart does not help.
FST
• Settings/configuration reverted back to pre-timebin-9-diognosis setup.
Discussion
in case of dew point alarm contact Prashanth
06/24/2023
RHIC/STAR Schedule
Sat: STAR/sPHENIX commissioning
Su: STAR/sPHENIX commissioning
Tally: 1.89 B ZDC minbias events.
Summary
• Continue AuAu200 datataking.
• MCR Computer at the SL desk pops a message about needing to update something.
• We had about 2 hours with just one beam circulating as requested by the sPHENIX
• Z vertex is drifting away during the fill
• Unexpected beam dump around 1am. TPC anodes tripped.
• Took cosmic data until beam returned around 6:40 this morning.
• LV1 crate lost communication which caused FCS and sTGC alarms. Back after quick recovery.
• Smooth running since.
Trigger
• Jeff worked on trigger configuration
• Set pre/post = 1 for fcsJPsi, UPC-mb, UPC-Jpsi-NS triggers. (Bits 9,12,14). In order to debug issue with lastdsm data not matching trigger requirements.
• Jeff also changed the scalers that we send to CAD, which had been zdc-mb-fst and not it is changed back to zdc-mb.
• This morning Jeff moved these bits again to the slots that were previously considered “bad” and proved to be usable.
TPC/iTPC
• Methane gas has been delivered.
• Tonko checked problematic RDOs in iTPC sectors 3, 4, 5. The problem is now fixed and needs the jevp code to pick up the changes and be recompiled.
• Drift velocity continues to go down but shows signs plateauing.
TOF/MTD
• TOF gas bottle switched from B to A - 14:20
• TOF LV needed to be power cycled
FST
• Some progress update was distributed by email and experts will discuss it to make conclusion.
• Inclination seems to be switched the time bin back
• The switch will happen at the end of the current fill.
06/23/2023
RHIC/STAR Schedule
F: STAR/sPHENIX commissioning
Sat: STAR/sPHENIX commissioning
Su: STAR/sPHENIX commissioning
Tally: 1.79 B ZDC minbias events.
Summary
· From the 9 o’clock coordination meeting
o CAD has a plan to go back to the blue background issue and try to eliminate it.
o They will also work on tuning the beam to get our vertex centered.
o sPHENIX requested an hour long tests with single beam configuration (one hour for each). At the end of the fill one beam will be dumped and another one at the end of the next fill.
· Yesterday beam back around 13:15 after a short access that we requested.
· sPHENIX requested a short access around 17:00
· Beam back around 18:30 but without sPHENIX crossing angle. It was put in around 19:30 and that seemingly improved our background
· Smooth running after that.
· This morning PSE&G did some work. There was just a split second light flicker in the control room, but nothing else was affected.
Trigger
· Jeff updated MTD-VPD-TACdiff window: MTD-VPD-TACDIF_min 1024->1026. The TACDIF_Max stays the same at 1089DAQ
TPC/iTPC
· About 11 days of methane gas supply is available.
· Expectation to deliver 2 six-packs today.
· Drift velocity continues to decline
BEMC
· Oleg took new pedestals for the BEMC and noise problem has vanished. Must have had bad pedestals.
EPD
· Tim used access time to check on EPD problem.
· The East TUFF box CAT5 cable was disconnected. After reconnecting it everything seem back to normal.
FST
· Gene: FST crushes the reconstruction chain so it is out until fixed
Discussion
Jeff: added monitoring to trigger bits and noticed that some triggers are not behaving as expected. There are some slots marked “bad” that could be used for the newly noticed “corrupted” triggers after checking that they are actually “bad” or not.
06/22/2023
RHIC/STAR Schedule
Th: STAR/sPHENIX commissioning
12 x 12 bump test @ 8:00
F: STAR/sPHENIX commissioning
About 1.69 B ZDC minbias events collected.
Summary
• Magnet was down for the cooling maintenance (heat exchange cleaning)
• Maintenance team was not able to wrap up early, so we kept magnet down overnight.
• Took zero field cosmics during the RHIC maintenance day.
• Beam back around 1:00 am with 56 x 56 bunches.
• We took data with production_AuAu_ZeroField_2023 configuration.
• Gene reported the DEV environment on the online machines to be back to normal operations. Problems are reported to be gone.
Trigger
• Tonko corrected the deadtime setting. Now it is set to the requested 720. This fixed the FST problems seen in the beginning of this fill.
TPC/iTPC
• About 12 days of methane gas supply is available. Suppliers are being pressed to deliver more ASAP.
• Tonko worked on moving more sectors to DAQ5k configuration. Came across problems with sector 6.
• iTPC iS06-1 masked
• Some empty areas in sectors 4,5,6
• Tonko will look once the beam is back. The cluster seem to be there but not seen on the plots (sec. 4 and 5)
BEMC
Oleg asked to power cycle crate 60 to address noise issues in BEMC. It did not help. Access is needed to attempt to fi this issue. The problem seems to have started on Saturday. Only few minutes access needed to the platform.
It was suggested to power cycle DSM as an initial measure to see if it helps, but this problem might also be coupled with the EPD problem we are seeing.
EPD
• EPD ADC east empty, EPD ADC west has limited number of entries.
• Experts are looking into this problem. It may be due to problem in QA plot making.
• Some sections were also reported to have problems.
• Might be the problem with the FEE.
• To check this issue access will be needed as well – up to an hour.
FST
• FST experts made changes for the time-bin diagnostics.
• It was having problems in the beginning of the fill but was settled after Tonko corrected the deadtime settings.
• Experts are looking at the data after the change.
• The timebin distribution might be indicating an out of time trigger presence. Jeff will also investigate this.
06/21/2023
RHIC/STAR Schedule
W: maintenance day: 7:00 – 20:00
sPHENIX TPC commissioning 5 hours after maintenance – no beam
Th: STAR/sPHENIX commissioning
12 x 12 bump test @ 8:00
F: STAR/sPHENIX commissioning
Summary
• AuAu 200 GeV continues.
• Around 11:00 sPHENIX asked for a one hour access. Took a few cosmic runs.
• Beam back around 12:45 with 50 x 50 bunches
• 111 x 111 bunch beam around 19:45, although the MCR monitor showed 110 x 111
• About 1.69 B ZDC minbias events collected.
• Dumped this morning around 6:30. Prepared for magnet ramp and brought the magnet down (and disabled). Around 7:00 David Chan confirmed that magnet was down and said they work on heat exchanger cleaning will start and we will be kept updated throughout the day.
• Depending how it goes we may or may not keep magnet down overnight.
Trigger
Jeff made some changes to the production trigger and L0 code
DAQ
• BHT3 trigger high-rate issue that causes deadtime has reappeared yesterday. Run restart did not help and neither all the other superstitious attempts. Coincidently beam was dumped and refilled around that time. Once we came back with a new beam the problem was gone.
• Oleg: looked and saw no error messages when this is happening. If it happens again suggestion is to power cycle the LV of this crate [4 crates affected by power cycle].
TPC/iTPC
• Needed some attention time to time (power cycling FEEs).
• Multiple peaks in drift velocity in a couple of laser runs (not all)
• Drift velocity keeps falling after the gas change
• Tonko will update about 6 sectors probably once beam is back
TOF/MTD
EEMC
• Brian noted that EEMC tube base 7TA5 seems dead and can be masked
eTOF
• DAQ restarted and kept out for one run because of additional empty strip (13) noticed by the shift crew.
FST
• Time bin diagnostics plan? Doing the time bin change diagnosis in parallel of the offline analysis might be prudent.
• Ziyue will distribute the summary of the plan for this 9 time bin diagnosis.
• Jeff: there has to be changes made in trigger setup associated to the FST time bin change for us to run properly.
Discussion
• Zhangbu: MCR were using the ZDC rate without killer bit for their beam tuning. It seems now they are using the right rate (with killer bit). We might require to redo the vernier scan.
• Maria: EPD QA monitoring plots are lost since day 166. Akio had the same problem. Gene had been working on the DEV environment on online machines. There is some improvement but automatic running of jobs are failing.
06/20/2023
RHIC/STAR Schedule
T: STAR/sPHENIX
W: Maintenance day : 7 :00 – 20 :00
sPHENIX TPC commissioning 5 hours after maintenance – no beam
Th: STAR/sPHENIX commissioning
12 x 12 bump test @ 8:00
F: STAR/sPHENIX commissioning
Summary [last 24 hrs]
· AuAu 200 GeV continues.
· Over 1.56 B ZDC minbias events collected thus far.
· Beam extended past the scheduled dump time due to the issues at CAD. Unexpected beam dump around 2:20 this morning. Back around 6:50 and a quick loss. Back for physics around 7:30 again. Running since.
DAQ
· Yesterday afternoon: TPC showing 100%. Power cycling TPC fees did not help. Many things were tried, but only after PefAsPhys it was fixed, although the culprit was not clear to the crew. Problem was caused by BHT3. It was firing at a very high rate. If this happens restarting the run should fix the issue, if not call to Oleg should help.
TPC/iTPC
· Tonko: updated TPX 3 and 4 updated – ongoing process. Waiting for Jeff to discuss a couple of ideas about token issues in iTPC. iTPC 2 sectors updated so far.
FST
· From the discussion at the FST meeting: Test setting 9 time bin running for diagnostics. To test timing shift. This will slow down the datataking.
· Experts will discuss it further to come up with the action plan for this test.
· Tonko: the plan is to split forward triggers in DAQ5k. So after that slow FST will only affect forward triggers and thus less of a problem. Perhaps it is a good idea to wait for that to happen before these test.
Discussion
· Alexei: changed the gas. Old one was affecting the drift velocity because of a contamination. This change should stabilize changed the gas drift velocity. It has already started to drop.
06/19/2023
(Weather: 59-76F, humidity: 74%, air quality 22)
§ RHIC Schedule
This week transverse stochastic cooling (one plane each for both blue and yellow).
toward 2x10^9 per bunch, 56x56 will be regular.
Physics this week,
· 56x56 nominal store yesterday.
· 111x111 store since last night 10:30pm.
§ STAR status
· Full field: zdc_mb = 1.45B, 280 hours of running.
· DAQ5k tested two sectors, ran at 5.2 kHz with 37% deadtime. See star-ops email from Tonko for details. Tonko: we should produce the FastOffline for this run, 24170017, to analyze the output.
Gene: /star/data09/reco/production_AuAu_2023/ReversedFullField/dev/2023/170/24170017
§ Plans
· Continue to take data thru the long weekend.
· Tonko, slowly ramp up the DAQ5k next week, 1hour/day ~ each day.
· FastOffline production for DAQ5k test runs.
· Reminder:
1) Trigger-board meeting tomorrow at 11:30am, see Akio’s email. To discuss trigger bandwidth.
2) RHIC scheduling meeting at 9:30am (was 3pm Monday).
3) Irakli will be Period Coordinator starting tomorrow, running 10am meeting. I will be giving the STAR update for the Time meeting at 1:30pm.
06/18/2023
(Weather: 59-78F, humidity: 66%, air quality 72)
§ RHIC Schedule
This week transverse stochastic cooling (one plane each for both blue and yellow).
toward 2x10^9 per bunch, 56x56 will be regular.
Physics this week,
· 56x56 nominal store until Tuesday.
§ STAR status
· Full field: zdc_mb = 1.29B, 259 hours of running (+120M events since yesterday 2pm)
· Half field: zdc_mb = 247M, 38 hours of running.
· 500A field: zdc_mb = 68M, 11 hours of running
· Zero field: zdc_mb = 168M, 30 hours of running
· Smooth running and data taking since 2pm yesterday. Magnet, PS, cooling, all worked.
· Carl: lowered TOFmult5 threshold from 100 to 20 for the FCS monitoring trigger.
· GMT gas bottle switched. Shift crew should silence the alarm for the empty bottle.
§ Plans
· Continue to take data thru the long weekend.
06/17/2023
(Weather: 59-76F, humidity: 86%, air quality 29)
§ RHIC Schedule
This week transverse stochastic cooling (one plane each for both blue and yellow).
toward 2x10^9 per bunch, 56x56 will be regular.
Physics this week,
· 56x56 nominal store until Tuesday.
§ STAR status
· Full field: zdc_mb = 1.17B, 241 hours of running.
· Half field: zdc_mb = 247M, 38 hours of running.
· 500A field: zdc_mb = 68M, 11 hours of running
· Zero field: zdc_mb = 168M, 30 hours of running
· STAR magnet is down, and we are doing PS cooling system work (heat exchanger cleaning)
Many junks accumulated on the tower side, while the PS side is clean as expected.
· Blue beam background seems to be only a factor of 5 higher than yellow.
· Shift overlap issue: Evening shift DO trainee owl shift DO. My proposal is to dismiss him early to be prepared for owl shift. Carl: ask him not to come in for evening shift.
· David: MCW temperature changed from 67F to 65F. David proposes to put it to 63F, given the dew point ~ 51-54F. Prashanth will set it to 63F.
06/16/2023
(Weather: 58-79F, humidity: 61%, air quality 28)
§ RHIC Schedule
This week transverse stochastic cooling (one plane each for both blue and yellow).
toward 2x10^9 per bunch, 56x56 will be regular.
Physics this week,
· Today will be 6x6 from now to ~1pm, and 12x12 in the afternoon.
· 111x111 nominal store starting this evening until Tuesday.
§ STAR status
· Full field: zdc_mb = 1.08B, 226 hours of running.
· Half field: zdc_mb = 247M, 38 hours of running.
· 500A field: zdc_mb = 68M, 11 hours of running
· Zero field: zdc_mb = 160M, 28 hours of running
· STAR magnet is at full field!
· TOF: pressure alarm from Freon, shift crew missed it.
· Tonko: DAQ5K, some tests were interrupted due to the magnet ramping.
· Blue beam background: now it seems the mystery is understood but not yet confirmed:
- Au78 is the source of the background. CAD did some calculations (can remain in RHIC for ~ 3 turns?, big spikes on Q3 magnet)
- 2016 didn’t have it because we had the “pre fire protection bump”.
JH: CAD will come up with a new lattice or plan to remove the background.
§ Plans
· Ready to take data!!!
· Tonko will finish the tests that were left unfinished.
· David: VME crates temperature sensor, what should we do with the alarm?
· FST: no more adjustment until next Tuesday.
· Lijuan: talked with David Chan, preparation work, e.g., chiller, heat exchanger, cooling system, etc. should be done during the shutdown and well in advance before the run.
Communication with the support group should be done thru 1 person, e.g., Prashanth, instead of thru multiple people and potentially cause miscommunications.
06/15/2023
(Weather: 58-77F, humidity: 67%, air quality 29)
§ RHIC Schedule
This week transverse stochastic cooling (one plane each for both blue and yellow).
toward 2x10^9 per bunch, 56x56 will be regular.
Physics this week,
· Thursday: PSEGLI work at Booster cancelled. Moved to next Wednesday.
12x12 bunches 6:00-13:00, no beam 13:00-18:00.
· Physics for the rest of the week.
§ STAR status
· Full field: zdc_mb = 1.08B, 226 hours of running.
· Half field: zdc_mb = 247M, 38 hours of running.
· Zero field: zdc_mb = 159M, 28 hours of running
· STAR magnet tripped due to the water supply issue. A few SCR fuses blown. CAS is still working on it. The current estimate is it can be back online this afternoon.
· Tonko: DAQ5K will be tested with real data, zero or half field.
§ Plans
· Magnet will be ramped up from half to full field in small steps.
· FST: APB timing, experts will look into it.
· FST running with DAQ5K. Jeff provided possible trigger setups for PWG to choose from, Carl made some suggestions. Jeff provided codes to Gene for the FastOffline production.
06/14/2023
(Weather: 60-74F, humidity: 77%, air quality 28)
§ RHIC Schedule
This week transverse stochastic cooling (one plane each for both blue and yellow).
toward 2x10^9 per bunch, 56x56 will be regular.
Physics this week,
· Wednesday APEX. (07:00-17:00) Overnight Physics.
· Thursday: PSEGLI work at Booster for 12-16 hours. Only one store during the day, if STAR has magnet.
12X12 bunches for morning, no beam for the afternoon.
· Physics for the rest of the week.
§ STAR status
· Full field: zdc_mb = 1.08B, 226 hours of running.
· Half field: zdc_mb = 247M, 38 hours of running.
· Zero field: zdc_mb = 124M, 21 hours of running
· STAR chiller is still being fixed. See Prashanth’s photos.
· David rebooted the main Canbus, the VME crate issues resolved.
· Tonko did some DAQ tests during the morning shift, including Elke’s request for sTGC. See shift log for details.
· Tonko: Data format is different for the DAQ5k, and online-found clusters are there but not the ADC plot.
· Shift Crew reported that the online QA plot doesn’t have many entries for laser runs, where the events did not get “abort”. JEVP plot issue? Alexi: need to train the DO to tune lasers better.
· Zhen Wang had some issues recovering daq files from HPSS, should contact star-ops (expert: Jeff). Ziyue had similar issues (FST).
· Shift: one DO trainee came to shift for all day without taking RHIC Collider Training.
This is not acceptable, and each institute council representative needs to be responsible!
One possible solution is that: Period Coordinator checks ALL shift crew’s status online each week, e.g., Friday.
§ Plans
· Shift: Email reminder to the entire Collaboration. Bill: talk to CAD about training/schedule.
· Elke: some updates are needed on sTGC. Elke will send it to star-ops.[1]
· DAQ5k hope to be working before next week…
· sTGC group needs to come up with a plan. QA team needs to look into forward detectors.
· FST: APB timing, experts will look into it.
· FST running with DAQ5K. How to make the trigger? FST limit is at 3k. (prescale for the time being). Also follow up with PAC, PWGC, and trigger board.
Jeff will provide possible trigger setup for PWG to choose from.
[1] summary from todays sTGC meeting.
So Tonko uploaded the correct software to the one RDO which was replaced before the RUN, this definitely improves the time bin plot on page 144 for the online plots.
Based on the recent runs we will keep the time window at -200 to 600 so we do not cut in the distribution and also if the luminosity goes up we will need it.
The Multiplicity plot has not improved yet, first becuase the online plots have a cut on it so can we please remove the time-window cut on the multiplicity plot, page 142.
But of course one still needs to check the multiplicity plots per trigger, to explain the shape offline.
Additional observations, page 139 plane 4 quadrant C VMM 10 to 12 are hot, this most likely is FOB 87 which looks strange on page 148.
Should we disable it or live with it, or can we wiggle a cable during an access.
06/13/2023
(Weather: 63-77F, humidity: 74%, air quality 28)
§ RHIC Schedule
This week transverse stochastic cooling (one plane each for both blue and yellow).
toward 2x10^9 per bunch, 56x56 will be regular.
Currently 111x111 bunches, started the store from yesterday.
12x12 bunches after this store for sPHENIX.
Physics this week,
· Tuesday: 100 Hz leveling at sPHENIX. ~ No leveling at STAR.
· Wednesday APEX.
· Physics for the rest of the week.
§ STAR status
· Full field: zdc_mb = 1.08B.
· Half field: zdc_mb = 235M, 34 hours of running.
· Shift changeover went smoothly.
· STAR chiller is being installed now.
· VME crate 77: Tim went in yesterday during the access and checked the voltage on those crates. They were fine. Issues are the Slow Control or monitoring?
David: Reboot the main Canbus.
· Tonko did some DAQ tests.
· FST running with DAQ5K. How to make the trigger? FST limit is at 3k. (prescale for the time being). Also follow up with PAC, PWGC, and trigger board.
Elke: we should think of which trigger needs FST first, e.g., how much data needed.
§ Plans
· For the VME crate 77, David is going to reboot the main Canbus today.
· sTGC group needs to come up with a plan. QA team needs to look into forward detectors.
Tonko suggests: look at some low event activity events, e.g., upc triggers.
FST: APB timing, experts will look into it.
06/12/2023
(Weather: 65-74F, humidity: 79%, air quality 61)
§ RHIC Schedule
This week transverse stochastic cooling (one plane each for both blue and yellow).
toward 2x10^9 per bunch, 56x56 will be regular.
After the current store (dump time @ 12pm), it will be 111x111 for one store until 9pm.
· Controlled access 45mins after this store.
· Machine testing next store.
Physics this week,
· Mon: 1kHz, Tu: 3kHz, leveling at sPHENIX, but normal rate at STAR.
· Wednesday APEX.
Monday 3-5pm, tour at STAR control room, guided by Lijuan and Jamie.
§ STAR status
· Full field: zdc_mb = 1.08B.
· Half field: zdc_mb = 99M, 15 hours of running.
· TOF issue resolved. NW THUB is now running on the external clock.
· Magnet tripped again when ramping up at midnight. Outdoor temperature was ~65F.
· STAR chiller ready on Tuesday. JH: first thing in the morning, confirmed, a few hours expected. Tonko: use this time to run tests on the TPC with zero field.
· Many “Didn’t build token because of ..abort” error messages. Remind the shift crew for next week. Jeff will take this caution message out.
· VME crate 77 (BBQ) LV PS seems to have problems. Akio looked thru the QA plots and found nothing is wrong. Trigger group should investigate it, and Tim can be ready around 9am to go in, if we request controlled access.
· Jamie mentioned the drift velocity isn’t great? [1] (run 24163024), HLT people look into it. Tonko: could be half field effect?
§ Plans
· Hank will look at the problem of crate 77 (BBQ) LV ps, and Tim will go in during the Control Access.
· Diyu will grab new drift velocity from this year.
· Tonko: going to test the DAQ5K, mask RDO 6, Sector 1 in the code. DON’T mask it in Run control.
· Jeff will update ALL the trigger ids after the fix of TOF issue.
· sTGC group needs to come up with a plan. QA team needs to look into forward detectors.
06/11/2023
(Weather: 60-78F, humidity: 73%, air quality 58)
§ RHIC Schedule
This week transverse stochastic cooling (one plane each for both blue and yellow).
toward 2x10^9 per bunch, 56x56 will be regular.
Physics all week until Monday, however,
· No beam: Fri-Sun, 9pm-2am
· Next week, Mon: 1kHz, Tu: 3kHz, Wed: 5kHz leveling at sPHENIX, but normal rate at STAR.
Monday 3-5pm, tour at STAR control room, guided by Lijuan and Jamie.
06/14 APEX.
§ STAR status
· zdc_mb = 1.08B, 226 hours of running time. (~+90M since yesterday)
· Three magnet tripped over the last ~16 hours!
· STAR chiller ready on Tuesday.
§ Plans
· Will be running half-field now.
· TOF: change or swap a cable to a different port. Tim can go in Sunday night 9pm-2am during no beam downtime. Geary will be monitor/check.
Tim: check NW THUB if it is on local clock mode.
· David: if half-field running, will look into the alarm handler.
· sTGC group needs to come up with a plan. QA team needs to look into forward detectors.
06/10/2023
(Weather: 54-75F, humidity: 69%, air quality 20)
§ RHIC Schedule
This week transverse stochastic cooling (one plane each for both blue and yellow).
toward 2x10^9 per bunch, 56x56 will be regular.
Physics all week until Monday, however,
· No beam: Fri-Sun, 9pm-2am
· Next week, Mon: 1kHz, Tu: 3kHz, Wed: 5kHz leveling at sPHENIX, but normal rate at STAR.
Monday 3-5pm, tour at STAR control room, guided by Lijuan and Jamie.
06/14 APEX.
§ STAR status
· zdc_mb = 994M, 212 hours of running time. (~+60M since yesterday)
· Vernier scan finally happened last night. (background seems to be different when vernier scan happened at IP8)
· TOF investigation. Tim went in to move the NW-THUB TCD cable to a spare fanout port. Problem persists.
· RHIC seems to have problems inject yesterday, and 9am just lost the beam.
· STAR magnet chiller status: Tuesday will be ready.
· sTGC timing is off. RDO changed, did Tonko look into this?
§ Plans
· TOF: change or swap a cable to a different port. Tim can go in Sunday night 9pm-2am during no beam downtime. Geary will be monitor/check.
· sTGC group needs to come up with a plan. QA team needs to look into forward detectors.
06/09/2023
(Weather: 53-70F, humidity: 71%, air quality 59)
§ RHIC Schedule
HSSDs enabled in STAR Thursday, and resumed operation.
This week transverse stochastic cooling (one plane each for both blue and yellow).
toward 2x10^9 per bunch, 56x56 will be regular.
Physics all week until Monday, however,
· Today: sPHENIX requests 20 mins access after this store. first 6x6 bunches for MVTX. vernier scan with 56x56 without crossing angle.
· No beam: Fri-Sun, 9pm-2am
· Next week, Mon: 1kHz, Tu: 3kHz, Wed: 5kHz leveling at sPHENIX, but normal rate at STAR.
Monday 3-5pm, tour at STAR control room, guided by Lijuan and Jamie.
06/14 APEX.
§ STAR status
· STAR is back on running. zdc_mb = 933M, 202 hours of running time. (~10% of goal)
· Yesterday, first fill was 6x6 bunches and 56x56 afterwards.
· We followed procedure of turning all systems back on, with help of experts. Everything was brought back within 1h 5mins, except TPC. Total was about 3 hours. TPC cathodes power supply (Glassman) and two control/monitor cards (4116 and 3122) were replaced. Alexei: contacted sPHENIX (Tom Hemmick), and need to build a spare for the HV system for cathode. David: buy a new power supply, but Tom also has some spares in the lab.
· TOF: Since beginning of Run 23, ¼ of TOF was lost, only ¾ of TOF work (?). Not sure what the cause is. Offline QA should look at TOF trays. Bunch IDs were not right, and data was not right. More investigations are needed.
· UPC-jet triggers rates were much higher after STAR restarted, regardless ETOW had problems or not. Other triggers, please also pay attention to the difference if any. (W. Jacobs just fixed/masked one of the trouble bits, rates seem ok)
· DAQ: Event abort errors happened a few times. Look out online QA plots to see if they are empty. Jeff will remove that caution message.
§ Plans
· TOF experts should provide instructions to star-ops and/or offline QA team.
· We need to update the procedure after the Power dip to bring back STAR (2021 version missed EEMC, all forward detectors, MTD, RICH scaler). Experts should provide short instructions.
· Reference plots are more or less updated. Subsystems that did not respond/provide feedbacks are: sTGC, EPD. (These experts were busy the past few days in the control room). https://drupal.star.bnl.gov/STAR/content/reference-plots-and-instructions-shift-crew-current-official-version
06/08/2023
(Weather: 48-70F, humidity: 64%, air quality 162)
§ RHIC Schedule
This week stochastic cooling transverse.
toward 2x10^9 per bunch, 56x56 will be regular.
Physics all week until Monday but NOT at STAR until further notice.
and 06/14 APEX
§ STAR status
· STAR at full field; Field on to ensure RHIC running.
· No physics was taken after access Wednesday. STAR is shut down due to the poor air quality.
Lab decided to turn off HSSDs lab wide -> No HSSD in STAR -> No STAR running.
Details:
The reason to shut down STAR is because they needed to turn off HSSD (high-sensitive-smoke-detector). They worry the air quality would get worse, and all the HSSD might go off, and the fire department would not know what to do and if there is a real fire. Since HSSD is within our safety envelope for operation, we cannot operate STAR if we turn off the HSSD. (sPHENIX is different, so they have been running)
· Since last night, 2-person gas-watch shift started. See Kong’s email on star-ops.
§ Plans
· MCR just called to ask us to prepare to ramp up! (09:58am)
· We need to come up with a procedure to shut down STAR safely and quickly. (Note: The process to shut down STAR yesterday was not as smooth as expected. Clearly, we do not do this every day.)
· We can use the procedure after the Power dip to bring back STAR.
· Jeff needs time to investigate DAQ.
06/07/2023
(Weather: 51-73F, humidity: 63%)
§ RHIC Schedule
This week stochastic cooling transverse.
VDM scan Wednesday after access (postponed from yesterday)
no cooling and no crossing angle (1h for physics), then add the angle back.
toward 2x10^9 per bunch, 56x56 will be regular.
Access today (07:00-18:00), then physics;
and 06/14 APEX
§ STAR status
· STAR at full field;
· zdc_mb = 854M over 190 hours; (~104M+ since yesterday)
· MCW work is being done right now.
· STAR chiller for magnet update. Parts are here, the work will be finished today, but won’t switch over. The switch over does NOT need access.
· Blue Beam Background:
Akio: performed BBC test yesterday and confirmed the blue beam background. Run number: 24157039 was taken with bbcBackgroundTest. (Offline analysis on the background events would be helpful, but not easy without modifying the vertex reco code.)
During the 5 mins store yesterday, supposed to be the Vernier scan, background was still present without crossing angle.
· Akio instructed the shift crew to perform a localClock and rhicClock test to understand the rate jump issue. Changed DetectorReadinessChecklist [1]
Jeff: run “setRHICClock” after cosmic runs, which is already updated in DetectorReadinessChecklist.
· One daughter card on EQ3, will be done by Christian.
· Overnight shift observed a few blue tiles in EPD adc. Experts? Mike: two SiPMs died, two are the database issue. Will make a note to the shift crew. (Mike: Going in today to look at the tiles)
· asymmetric vertex distribution for satellite bunch, but not the main peak.
· pedestals
L2 waits for 2 minutes before stop run;
MXQ rms>50, very large; take another pedestal right after the fill;
EQ1,2,3,4 pedestals; mean>200; check daughter card (will be discussed at the Trigger Meeting today).
§ Plans
· Update the DetectorReadinessChecklist for Vernier scan. (a copy of the production config. Bring up detectors at flattop, don’t stop the run regardless of detector conditions.)
· MCW fixes for the electronics, 9am Wednesday, 3 hours expected. But likely needs longer.
for the MCW fix: TOF LV needs to be off and the full list of subsystems will be sent on star-ops by Prashanth. (DONE)
· TCU bits; Jeff/trigger plan for Wednesday down time with delay tests;
Jeff: will take 4-5 runs and 1h after the water work is done.
· ETOW Crate #4 (W. Jaccob/Tim) on Wednesday (Tim is working on the fix now)
· Spare QTD tests; Chris continues to work on it;
· DAQ5K, outer sectors; Tonko will do this on Thursday with beam.
Tonko: mask RDO6 sector 1, and perform tests.
· After water work is done, who needs to be called. Email star-ops first, and make a call list.
· Passwords update (Wayne Betts)
· Reference plots for online shift; experts of subsystems provide reference for a good run.
FST: run22 is the reference, no update needed.
EPD: will get to us.
GMT: will provide after the meeting.
MTD: ask Rongrong
sTGC: will get back to us
06/06/2023
RHIC Schedule
This week stochastic cooling transverse, (yellow done, but not blue)
toward 2x10^9 per bunch, 56x56 will be regular.
06/07 APEX cancelled, sPHENIX access (07:00-18:00), then physics;
and 06/14 APEX
§ STAR status
· STAR at full field;
· zdc_mb = 750M over 176 hours; (~100M+ since yesterday)
· asymmetric vertex distribution for satellite bunch, but not the main peak.
(could test without the crossing angle, 0.5mrad each, to see if the structure disappears)
· Blue Beam Background, due to fixed target we installed? The investigation indicated not related to the fixed target. FXT data yesterday, only see background at positive x horizontal plane;
Akio: perform BBC test today.
· Overnight shift observed a few blue tiles in EPD adc. Experts? Mike: two SiPMs died, two are the database issue. Will make a note to the shift crew.
· Triggers: 2 upc-jet triggers (3,17) should be promoted (back) to physics;
(From yesterday)
· pedestals
L2 waits for 2 minutes before stop run;
MXQ rms>50, very large; take another pedestal right after the fill;
EQ1,2,3,4 pedestals; mean>200; check daughter card (will be discussed at the Trigger Meeting today).
§ Plans
· Magnet will be ramped down tomorrow 8:30am by shift leader, and Prashanth will take out the key.
· Magnet: chill water pump issues, prepare to be fixed on Wednesday morning.
JH: Oil line of the chiller is the problem. A few hours expected and hopefully fix the issue.
· MCW fixes for the electronics, 9am Wednesday, 3 hours expected.
for the MCW fix: TOF LV needs to be off and the full list of subsystems will be sent on star-ops by Prashanth.
· TCU bits; Jeff/trigger plan for Wednesday down time with delay tests; (plan for the afternoon after the water work done, and will be discussed at the Trigger Meeting Tuesday June 06 noon)
· ETOW Crate #4 (W. Jaccob/Tim) on Wednesday? (Tim plans to fix this tomorrow, may need to replace a card in this crate)
· Spare QTD tests; Chris continues to work on it;
· DAQ5K, outer sectors; Tonko will do this on Thursday with beam
· Reference plots for online shift; experts of subsystems provide reference for a good run.
06/05/2023
1. RHIC Schedule
This week stochastic cooling transverse,
toward 2x10^9 per bunch, 56x56 will be regular;
chill water pump issues, prepare to be fixed in next few days, but STAR at full field;
06/07 APEX cancelled, sPHENIX 8 hours access;
and 06/14 APEX
2. STAR status
a. zdc_mb = 645M over 159 hours;
zero field: zdc_mb = 45M
half field: zdc_mb = 17M
b. bunch crossing and vertex fingers;
maybe transverse SC will fix everything;
move beam 0.6mm and 0.3mm both directions;
still investigating;
c. STAR chill water pump issues,
shift leader can ramp STAR magnet while beam is ON, but need to coordinate with MCR ahead of time; run well so far;
clean water tank on Wednesday; still searching for parts;
d. Blue Beam Background, due to fixed target we installed?
FXT data yesterday, only see background at positive x horizontal plane;
e. ZDCSMD ADC issues;
Chris reported gain file issue; understood and will be fixed; remove pxy_tac.dat file
f. pedestals
L2 waits for 2 minutes before stop run;
MXQ rms>50, very large; take another pedestal right after the fill;
EQ1,2,3,4 pedestals; mean>200; check daughter card
g. dimuon trigger:
MXQ calibration is good; loose trigger time window than used to be;
3. Plans
a. Kong Tu is going to the period coordinator for next two weeks;
b. TCU bits; Jeff/trigger plan for Wednesday down time with delay tests;
c. Spare QTD tests; Chris works on it;
d. DAQ5K, outer sectors; Wednesday test during down time;
10 days on low luminosity; another week for high luminosity;
e. Reference plots for online shift;
f. Water group (coordination) starts in Wednesday morning, 3+ hours;
06/04/2023
1. RHIC Schedule
Thursday stochastic cooling longitudinal done, transverse next week,
1.3x10^9 per bunch, 56x56 will be regular;
chill water pump issues, prepare to be fixed in next few days, but STAR at full field;
9PM-2AM no beam both Saturday and Sunday, sPHENIX TPC conditioning;
06/07 APEX cancelled, sPHENIX 8 hours access;
and 06/14 APEX
2. STAR status
a. zdc_mb = 450M over 143 hours;
zero field: zdc_mb = 45M
half field: zdc_mb = 17M
b. bunch crossing and vertex fingers;
storage cavity not fully functional, asymmetric?
Yellow (WEST) second satellite bunch colliding with blue main bunch;
keep it as is;
c. STAR chill water pump issues,
shift leader can ramp STAR magnet while beam is ON, but need to coordinate with MCR ahead of time; run well overnight so far
d. ZDCSMD ADC issues;
Hank confirmed the issues (potentially internal timing issue)?
all channels; NOT in EPD QTD; some features need further investigation;
work with Chris on this
e. Blue Beam Background, due to fixed target we installed?
a FXT test?
FXT configuration flip east vs west; DONE;
HLT needs to change to FXT mode, DONE;
J.H. coordinates the fast offline (~0.5—1 hours);
f. eTOW out quite frequently (one crate is out);
g. pedestals
L2 waits for 2 minutes before stop run;
MXQ rms>50, very large; take another pedestal right after the fill;
EQ1,2,3,4 pedestals; mean>200; discuss it tomorrow?
Or give shift leader specific instruction to ignore specific boards;
3. Plans
a. TCU bits;
b. Spare QTD tests;
c. Blue beam background FXT test right after the meeting;
d. DAQ5K, outer sectors; Wednesday test during down time;
10 days on low luminosity; another week for high luminosity;
e. FCS monitoring trigger (discuss at triggerboard);
06/03/2023
1. RHIC Schedule
Thursday stochastic cooling longitudinal done, transverse next week,
56x56 will be regular;
chill water pump issues, no full field until 8PM last night, tripped at 11PM.
sPHENIX magnet quench yesterday, ramp up successfully;
9PM-2AM no beam both Saturday and Sunday, sPHENIX TPC conditioning
06/07 APEX cancelled, sPHENIX 8 hours access;
and 06/14 APEX
2. STAR status
a. zdc_mb = 452M over 127 hours;
zero field: zdc_mb = 45M
half field: zdc_mb = 17M
b. STAR chill water pump issues, magnet trip at around 11PM last night
shift leader can ramp STAR magnet while beam is ON, but need to coordinate with MCR ahead of time; run well overnight so far
c. ZDCSMD ADC issues;
Han-sheng found and reported to QA board.
Does EPD see this feature in QTD?
fencing feature with one ADC count per bin;
d. Blue Beam Background, due to fixed target we installed?
a FXT test?
FXT configuration flip east vs west; TODAY;
HLT needs to change to FXT mode (Dayi)?
J.H. coordinates the fast offline?
e. Shift leader found a (significant size) snake in the assembly hall, moved it to RHIC inner ring area. If you spot one, can call police.
3. Plans
a. TCU bits
b. Spare QTD tests
c. Blue beam background FXT test
06/02/2023
1. RHIC Schedule
Thursday stochastic cooling longitudinal done, transverse next week,
56x56 will be regular;
STAR magnet tripped yesterday morning, has not been at full power since;
chill water pump issues, no full field until 5PM tonight.
sPHENIX first cosmic ray track in TPC;
9PM-2AM no beam both Saturday and Sunday, sPHENIX TPC conditioning
06/07 APEX cancelled, PHYSICS data?
and 06/14 APEX
2. STAR status
a. zdc_mb = 405M over 117 hours;
zero field: zdc_mb = 40M
half field? zdc_mb and upc_main
b. a few changes in trigger conditions:
zdc killer bit applied on coincidence condition;
UPC-JPSI and UPC-jets requires eTOW in;
c. MTD QT noise is back, need to retake pedestal;
d. Cannot start chill water pump, start 5PM,
next few days, temperature low, should be able to run
e. BBC route to RHIC, blue background high
3. Plan
a. TCU bit work on-going
b. High luminosity configuration;
06/01/2023
1. RHIC Schedule
no beam from Tuesday 7:30 to Wednesday evening 8PM.
Sweep experiment areas at 6PM Wednesday; physics data at 8:30PM;
1.3x10^9 per bunch, leveling at STAR;
sPHENIX magnet has been ON;
Thursday stochastic cooling after this current store (56x56),
06/07 and 06/14 APEX
2. STAR status
a. zdc_mb = 385M
b. Access task completion:
BEMC done, MTD BL-19 sealant to gas connector for minor gas leak;
BBC scaler, fixed a dead channel (move from #16 to different label),
need to route from DAQ room to RHIC scaler;
ZDC TCIM: fixed a broken pin and dead processor,
setting deadtime for scaler output (was 20us, set to 1us)
gain to sum output set to 1:1 (was 1:0.5)
Pulser to TCU: 3 TCU bits out of time, need look into this;
sTGC 4 FEEs did not improved (still dead)
EPD 2 channels remap done; QTD into spare slot;
VPD MXQ calibration does not look correct; contact Isaac/Daniel
c. Trigger condition updates, and production IDs
all physics triggers are promoted to production ID;
EJP trigger 10x higher; hot towers?
UPC-JPSI trigger too high after access; ETOW was out while related triggers are IN;
set up reasonable range expected with color scheme for DAQ monitoring;
Jeff and the specific trigger ID owners
reference plots, still run22 plots for online shift crew; need to work on this once the beam and STAR operation are stable (next few days)
d. Magnet trip this morning at 9:29AM
bringing back the magnet in progress;
no errors on our detector; beam loss 3 minutes later;
magnet is back up;
magnet temperature is high; work in progress; down to 0 and
call chill water group;
3. On-going tasks and plans
a. BBC scaler need to route from DAQ room to RHIC scaler;
b. ETOW readout is out but trigger is ON;
Jeff need to set up a scheme for eTOW related trigger when ETOW is out;
c. TCU bits, trigger group continues the work on bit issues using the pulser
d. QTD, chris will look into the one we just put back into EQ4
e. MXQ VPD need further work on calibration
JEVP online plot of BBQ VPD vertex distribution missing;
05/31/2023
1. RHIC Schedule
no beam from Tuesday 7:30 to Wednesday evening 8PM (access could be up to 6PM).
Sweep experiment areas at 3PM Wednesday;
1.3x10^9 per bunch, leveling at STAR;
Thursday stochastic cooling first,
then sPHENIX magnet ON exercise, we should probably put STAR detector on safe status for the first fill.
06/07 and 06/14 APEX
2. STAR status
a. Trigger condition updates, and production IDs
promote everything from BTH, UPC, UPC-JPsi (prescale not decided);
dimuon-MTD;
UPC-jets, UPC-photo;
zdc_mb_counter no production ID, zdc_mb_y and zdc_mb_ny removed
b. Another two incidents of DO and shift crew did not show up
DO from SBU started Wednesday owl shift
c. Water tower work plan in a couple of weeks
1. Access plans for Tuesday and Wednesday
a. Magnet OFF Wednesday
BEMC and MTD BL8 (done) work
MTD gas leak BL19 (11:30) Rongrong/Bill
b. Pulser for TCU bit checking Christian/Tim 107ns pulse; connected, waiting for jeff test
c. Laser in progress
d. MTD/VPD splitters (swap out with a spare) not done yet, 3 dead channels, Christian/Tim
e. EPD QTC remapping two QTC channels happens today;
QTD put into the crate to EQ4 spare slot?
f. sTGC 4 FEEs no signals, reseat cables (magnet OFF) on-going
g. BBC B&Y background signals, single and coincidence issues to RHIC Blue background;
h. BCE crate errors; fixed by Power cycle
i. Measurement of dimensions of rails for EIC (Rahul/Elke, 12-1PM)
05/30/2023
1. RHIC Schedule
no beam from Tuesday 7:30 to Wednesday evening.
Sweep experiment areas at 3PM Wednesday;
1.3x10^9 per bunch, leveling at STAR;
Vacuum issues with store cavity in both yellow and blue, BPM issues, debunch issues on Monday 1 hour store;
Thursday stochastic cooling first,
then sPHENIX magnet ON exercise, we should probably put STAR detector on safe status for the first fill.
06/07 and 06/14 APEX
2. STAR status
a. Trigger condition updates, and production IDs
promote everything from BTH, UPC, UPC-JPsi (prescale not decided);
dimuon-MTD;
Not promoted on UPC-jets, UPC-photo;
b. TPC Cathode trips during beam dump;
change procedure on TPC Cathode turn OFF before beam dump and right after beam dump, turn cathode back ON;
eTOF standby with high current a few days ago;
c. Air conditioners in trailer (Bill will check on this)
d. Trigger BCE crate, dsm1 STP error, took out BCE crate;
update outdated document (on removing BBC crate);
e. Arrange for sTGC/MTD HV crate repairs
f. FST refill coolant
1. Access plans for Tuesday and Wednesday
a. Magnet OFF Wednesday
BEMC and MTD BL8 work
MTD gas leak BL19 (maybe) Rongrong/Bill
b. Pulser for TCU bit checking
Christian/Tim 107ns pulse;
c. Laser
d. MTD/VPD splitters (swap out with a spare)
e. EPD QTC remapping two QTC channels
f. sTGC 4 FEEs no signals, reseat cables (magnet OFF)
g. BBC B&Y background signals, single and coincidence issues to RHIC
h. BCE crate errors
i. Measurement of dimensions of rails for EIC (Rahul/Elke, 12-1PM)
05/29/2023
1. RHIC Schedule
Beam for physics over the long weekend, (56 bunches);
No 9AM meeting over long weekend, no beam from Tuesday 7:30 to Wednesday evening.
Sweep experiment areas at 3PM Wednesday;
1x10^9 per bunch (+20%); 16KHz zdc rate; STAR request leveling at 10KHz for about 10-20minutes;
automatic script does not work yet.
No stochastic cooling now; one of the five storage cavities in Yellow failed; store length is about 1.5 hours;
1.3x10^9 per bunch, leveling at STAR;
2. STAR status
a. Trigger condition updates, and production IDs
promote everything from BTH, UPC, UPC-JPsi (prescale not decided);
nothing from UPC-jets, UPC-photo, dimuon-MTD;
b. MTD calibration is done; tables uploaded,
need to apply the TAC cuts, and then production ID:
MXQ VPD maybe minor issues need to address
c. Water out of the cooling tower, this is by design for more efficient cooling; small AC unit to cool down the chill water
d. Replaced MTD PS crate (Dave), was successful;
need to ship the spare for repair; currently use sTGC spare for operation
Tuesday access to check HV mapping
e. FST additional latency adjustment;
FST in pedestal runs
f. Add eTOF into TOF+MTD noise run if eTOF is operational
3. Access plans for Tuesday and Wednesday
a. Magnet OFF Wednesday
BEMC and MTD BL8 work
b. Pulser for TCU bit checking
c. Laser
d. MTD/VPD splitters
e. EPD QTC west daughter card need to swap out?
performance seems to be OK, need further check before swap;
Christian/Tim swap whole module?
f. sTGC 4 FEEs no signals, reseat cables
g. BBC B&Y background signals, single and coincidence issues to RHIC
05/28/2023
1. RHIC Schedule
Beam for physics over the long weekend, (56 bunches);
No 9AM meeting over long weekend, no beam from Tuesday 7:30 to Wednesday evening.
Sweep experiment areas at 3PM Wednesday;
1x10^9 per bunch (+20%); 16KHz zdc rate; STAR request leveling at 10KHz for about 10-20minutes;
automatic script does not work yet.
No stochastic cooling now
2. STAR status
a. Trigger condition updates, and production IDs
promote everything from BTH, UPC,
nothing from UPC-jets, UPC-photo,
elevate on UPC-JPSI triggers
b. Trigger event too large, some crashed L2,
zdc_mb_prepost prepost set to +-1 (was -1,+5)
c. tune_2023 for calibration and test;
Production should be for production ONLY
d. RHIC leveling STAR luminosity at 10KHz ZDC rate, STAR request this.
e. Event counts: zdc_mb = 218M
f. FST latency adjustment is done;
4 APV changed by 1 time bin
3. On-going tasks and plans
a. EPD bias scan done;
a couple of channels have been adjusted;
higher threshold for zero suppresson; Need to implement;
gate on C adjusted; TAC offset and slewing corrections
b. MTD calibration
c. Fast Offline st_physics events not coming out today
d. TOF noise rate does not need to be taken daily if there is
continuous beam injection and Physics
4. Access plans for Tuesday and Wednesday
a. Magnet OFF Wednesday
BEMC and MTD BL8 work
b. Pulser for TCU bit checking
c. Laser
d. MTD/VPD splitters
e. QTC west daughter card need to swap out?
Christian/Tim swap whole module?
f. sGTC 9 FEEs no signals, reseat cables
g. BBC B&Y background signals, single and coincidence issues to RHIC
05/27/2023
1. RHIC Schedule
Beam for physics over the long weekend, (56 bunches);
No 9AM meeting over long weekend, no beam from Tuesday 7:30 to Wednesday evening.
Sweep experiment areas at 3PM Wednesday;
ZDC_MB =~ 5KHz
no stochastic cooling; landau cavity for blue tripped yesterday,
rebucket vs landau cavity RF 56 bunches every other bunches in phase,
changed fill pattern, solved the trip issue. Leveling works at 10KHz, automatic script does not work yet.
2. STAR status
a. Trigger condition updates, and production IDs
UPC_JPsi, ZDC HV and production ID;
UPC_JET; UPC_photo no in Production ID;
FCS bit labels not changed yet; and new tier1 files are in effective;
need clarification today.
b. Any remaining trigger issues? (-1,+5)? zdc_mb_prepost
RCC plot no updating;
c. EPD scans
timing scan done; 4 channel stuck bit;
bias scan next; onl11,12,13 for online plotting cron servers;
zero suppression 30-40% occupancy 0.3MIP (~50)
d. MXQ VPD calibration done, MTD calibration next
e. BBC B&Y background scalers not working
Christian has a pulser; order a few more?
f. Confusion about FST off status and message
DO need to make sure FST OFF
g. Jamie’s goal tracking plots? zdc_mb, BHT3?
h. eTOF ran for 6 hours, and failed,
If failed, take out of run control;
eTOF follows HV detector states as TOF for beam operation;
i. TPC, drift velocity changes rapidly; new gas?
new vender, old manufactory; online shows stable
3. On-going tasks and plans
a. Pulser for TCU, MTD BL8 and BEMC work on Wednesday
b. sTGC FEE reseat the cable on Wednesday; Magnet OFF
c. ESMD overheating; inspect on Wednesday, talk to Will Jacobs
d. East laser tuning Tuesday
05/26/2023
1. RHIC Schedule
Beam for physics over the long weekend, (56 bunches);
No 9AM meeting over long weekend, no beam from Tuesday 7:30 to Wednesday evening.
Sweep experiment areas at 3PM Wednesday;
Blue beam Landau cavity tripped, beam loss ½ at beginning and see to light up iTPC;
Stochastic cooling will setup hopefully today; no expert available today, over the weekend;
three-hour fill with Landau cavity on (or without if it does not work)
2. STAR status
a. We had a couple of incidents that shift crew and shift leader did not show up; please set your alarm, it is an 8-hour job, try to rest/sleep in the remaining of the day
b. Laser, DO always need to continue the intensity
need to pass the experience to evening shifts
c. zdc_mb = 65M
d. VPD calibration; BBQ done, MXQ not done, dataset done
e. MTD dimuon_vpd100 out until expert calls
f. L4 plots are not updating; online plot server is not available;
g. FST fining tuning on latency setting; update online plot;
beam with updated online plot;
h. New production ID; vpd100, BHT#? BHT3?
3. On-going tasks and plans
a. Pulser for TCU monitoring;
b. sTGC 4 FEE not working;
HV scan, gain matching; (Prashanth/Dave instructions)
c. L2ana for BEMC
The l2BtowGamma algorithm has been running. L2peds have not been, Jeff just restored them.
d. QTD
Chris fixed the issue, EPD looks good;
QTC looks good;
pedestals width large when EPD ON
ON for the mean, MIP shift correlated with noise rate?
gain QTD>QTC>QTB
Eleanor new tier1 file?
afterward, EPC Time, gain, offset, slewing, zero-suppression items
QTB->QTD swap back? Wait for trigger group?
leave it alone as default
ZDC SMD ADC noisier, but it is OK.
05/25/2023
1. RHIC Schedule
another PS issue, and storage cavity problem,
Stores will be back to 56 bunches after stochastic cooling commissioning first with 12 bunches and sPHENIX requested 6 bunches
2. STAR status
a. No beam yesterday and this morning
b. Laser, DO always need to continue the intensity
c. zdc_mb = 50M
d. VPD slewing waiting for beam
3. On-going tasks
a. QTD issues,
LV off taking pedestal file
threshold and readout speed
Chris confirmed by email that indeed 0-3 channels in QTD
are off by 1 bunch crossing on bench test;
Chris and Hank are going to discuss after the meeting
and send out a summary and action items later today.
I feel that we may have a resolution here
05/24/2023
1. RHIC Schedule
Abort kicker power supply issue (blue beam), no physics collisions since yesterday.
They may do APEX with just one beam;
Stores will be back to 56 bunches after stochastic cooling commissioning first with 12 bunches
2. STAR status
a. zdc_mb = 50M
b. VPD slewing and BBQ upload done,
NEXT MXQ
c. sTGC sector#14 holds HV;
a few FEEs do not show any hits;
d. sTGC+FCS in physics mode
FST still offline, need online data QA to confirm
Latence adjustment,
e. eTOF HV on, included in run
OFF during APEX
3. On-going tasks
a. TCU pulser another test during APEX
4. Plans for the week and two-day access next week
a. MTD calibration and dimuon trigger after VPD done
b. EPD bias scan and TAC offset and slew correction
c. Next week, electronics for pulser in the hall (Christian)
d. Wednesday BEMC crate ontop of magnet PS fix (Bill/Oleg)
e. Wednesday MTD BL-8 THUB changed channel (Tim)
f. Plan for resolving QTD issues:
before Sunday,
taking data with zdc_mb_prepost (-1,+2) in production;
Aihong observed changes in ZDC SMD signals when BEMC time scan;
Jeff will follow up on what time delays in TCD on those scans;
After Sunday, Chris will do time scan or other tricks to figure out what
the issues with QTD; We need a clean understanding of the issues and solutions; If this is NOT successful,
Wednesday replace all QTD by QTB and derive a scheme to selective readout QTB for DAQ5K for both BBQ,MXQ (EPD and ZDCSMD).
Mike sent out a scheme for EPD
05/23/2023
1. RHIC Schedule
MCR working on stochastic cooling, longitudinal cooling first, will reduce the background seen at STAR and sPHENIX.
Stores will be back to 56 bunches after stochastic cooling commissioning first with 12 bunches
2. STAR status
a. TPC in production, DAQ 5K tested this morning with iTPC sector, TPC current looks good;
Deadtime rate dependent, outer sector RDO optimization for rate (Gating Grid); 15KHz to saturate the bandwidth; Tonko would like to keep ZDC rate to be high (~5KHz)
b. EPD gain and time scan
Timing scan last night and set for 1-3 crates, EQ4 very different timing,
need update on individual label for setting; need this for next step bias scan; QTD first 4 channels signals low (1/20); same observed in ZDC SMD; Eleanor needs to change the label in tier1 file, tune file, and Jeff moves it over. QTD->QTB replacement works.
c. VPD scan
Daniel and Isaac BBQ data using HLT files for fast calibration;
VPD_slew_test from last year (BBC-HLT trigger)
MXQ board address change? Noon:30 trigger meeting;
d. BSMD time scan; scan this morning, will set the time offset today
3. On-going tasks
a. ZDC SMD QTD board issues
ZDC SMD QTD shows same issues with first 4 channels
MXQ power cycled, SMD readout is back
pre-post +-2 zdc_mb trigger data taking after the meeting
b. TCU bit test with the pulser RCC->NIM Dis->Level->TTL->RET
bit to TCU 12,15
c. Some triggers are being actively updated, BHT4 UPCjet at 13
d. Adding more monitoring trigger (ZDC killer bits)
plan: discuss at trigger meeting; pulser 100ns
4. Plans for the days
a. FCS close today?
coordinate with MCR for a short controlled access today
b. BSMD helper from TAMU
BSMD only operates at high luminosity
ESMD only operates at high luminosity
Will discuss action items at later time
05/22/2023
1. RHIC Schedule
access at 10AM 2 hours of controlled access.
Stores will be back to 56 bunches after stochastic cooling commissioning first with 12 bunches
2. STAR status
a. TPC in production, DAQ 5K is NOT ready yet,
outer sectors firmware optimization, need about 3 weeks,
rate at about 3KHz,
laser runs well,
b. sTGC sector 14, masked out, you will do the checking behind scene,
sTGC and FST will be in production
c. FCC, watch the luminosity and background for the next few days, decide whether we close the calorimetry
d. Trigger system, tcu bit slot#21-35 BAD, BHT1, dimuon, zdc_mb_gmt
a few other triggers with high scaler deadtime, zdc_killer should discuss at triggerboard meeting,
TCU spare daughter card good, two spare motherboards,
highest priority,
e. TOF
no issues in production
f. VPD
working on slewing correction, an issue with TAC offset with MXQ
VPD MXQ one and BBQ two channels (Christian is going to check them next access)
g. ZDC and ZDC SMD
SMD timed correctly, need Aihong to check again
SMD no signal at QT
h. EPD
replace EQ4 QTD now
EPC time scan and LV bias scan tonight,
Need to do time and offset matching among tiles, need more time,
i. BEMC is timed, one crate on top of magnet stopped sending data, never seen such failure (coincide with the beam dump), 3% of total channels
j. BSMD in middle of time scan BSMD02 failed,
need pedestal online monitoring helper (star management follows up)
k. FCC need to close position, LED run procedure, trigger not commissioned, stuck bit need to re-routed, thresholds need to be discussed, a week from today
l. MTD, Tim THUB push in, trigger needed VPD and MTD timing calibration
m. Slow control
fully commissioned, MCU unit for sTGC, more resilent against radiation,
HV IOC updated, trip level set according to luminosity
TOF and MTD IOC updated (fixed connection issues)
need update instruction procedure
SC general manual updates.
n. Fast Offline
started on Friday, and processing st_physics and request to process st_upc streams, st_4photo?
QA shift fast offline in China, google issues, alternative path to fill histograms and reports
o. FST, commissioning,
Field OFF beam special request after everything ready
05/21/2023
1. RHIC Schedule
No 9AM CAD meeting. Stores with 56 bunches, will continue over the weekend,
Potential access Monday for RHIC work, sPHENIX and STAR
2. STAR status
a. production_AuAu_2023 TRG+DAQ+ITPC+BTOW+ETOW+TOF+GMT+MTD+L4+FCS
Fixed a few issues yesterday, zdc_mb promoted to production ID.
TCU hardware issue, avoid tcu slot#21-25
Need to check whether same issue occurs with other tcu slots: external pulse (Christian)
b. Fix blue beam sync bit
c. Fix L4 nhits
d. ESMD time scan done
e. TPX/iTPC done
f. UPS battery and the magnet computer dead, need replacement by CAS
3. Ongoing tasks
a. VPD scan for slew correction, update to “final”, QTC in BBQ and MXQ
pedestal run needed to apply the slewing and offset corrections
L4 needs new VPD calibration file.
VPD TAC look good now after pedestal run, last iteration will be done.
VPD on BBQ is fine, but need to check MXQ
b. Minor issues need work on TPC
c. Fast offline production comes (contact Gene)
d. BSMD one of two PCs has memory errors,need to swap out in DAQ room
e. EPD time and bias scan after QTD replacement
f. MTD one backleg need work (canbus card need push-in, magnet off, need VPD calibration done)
g. Beam loss at 10:30 chromo measurement, beam abort unexpectedly, MCR called STAR informing about the measurements, But the CAD system puts “PHYSICS ON” and STAR shift turned on the detector, thought that MCR was done with the measurement and PHYSICS is ON. Mitigation is to make sure that the information (calls and instructions) from MCR should overwrite the BERT system.
4. Plan of the day/Outlook
a. Collision stores over the weekend
b. Access Monday
c. FCS position, wait until we get more information about the abort, takes 15 minutes to close.
d. sTGC status and plan?
e. FST is good status, will check if further calibration is needed
f. Monday magnet OFF during access? Shift leader
Confirm with Christian about access Monday
05/20/23
I. RHIC Schedule
Stores with 56 bunches since yesterday evening, will continue over the weekend
II. STAR status
production_AuAu_2023 TRG+DAQ+ITPC+BTOW+ETOW+TOF+GMT+MTD+L4+FCS+STGC+FST
III. Ongoing tasks
Production configuration, trigger rates, BBC tac incorrect
Autorecovery for TPX not available, crews powercycle the relevant FEE
EPD bias scan to resume today, timing scan for QTD
VPD tac offsets taken overnight, slew correction to take
Series of sTGC HV trips after beam loss yesterday evening, keep off over weekend
BSMD, ESMD need timing scan
zdc-mb production id
Access requirements, list of the needs
IV. Plan of the day/Outlook
Collision stores over the weekend
05/19/23
I. RHIC Schedule
We had stores with 56 bunches till this morning.
Possible access till 11am, beam development during the day
Collisions overnight
II. STAR status
tune_2023 TRG+DAQ+ITPC+BTOW+ETOW+TOF+GMT+MTD+L4+FCS+STGC+FST running overnight
ZDC HV calibration done
III. Ongoing tasks
TPX prevented starting the run, Tonko working on it, ok now
EEMC air blower is on, chill water not yet
BSMD had corrupt data in bsmd02 in cal scan
EPD calibrations ongoing, work on QTD, ok for physics
eTOF worked on by experts
VPD HV updated, will do TAC offsets
sTGC plane 2 is empty in some place
Production trigger configuration by Jeff today
IV. Plan of the day/Outlook
Possible access till 11am
Beam development during the day
Collision stores overnight and during the weekend
05/18/23
I. RHIC Schedule
We had store with 56 bunches till this morning.
1 - 3 stores are scheduled today overnight
Beam development during the day, opportunity for controlled access
II. STAR status
Runs with tune_2023 TRG+DAQ+ITPC+TPX+BTOW+TOF+GMT+MTD+L4+FCS+STGC overnight
Done with BBC gain scan, and EPD scan without EQ4, BTOW timing scan without ETOW
III. Ongoing tasks
EEMC turn on (email by Will J.), BTOW + ETOW timing scan in upcoming store
VPD-W, cat-6 to be connected, VPD data from this morning ok, VPD should be off till then, controlled access needed with magnet off
sTGC ROB #13 has TCD cable disconnected, needs fixed or masked out, access with magnet off
EQ4 does not run for EPD, 25% of the detector not available, ongoing with trigger group
Trigger FPGA issues in the beginning of the store, could not get past 15 events, started to take data when different part of the FPGA was used (temporary workaround)
TOF LV yellow alarms
BSMD timing scan (Oleg, tonight) + endcap shower max
IV. Plan of the day/Outlook
Beam development during the day for rebucketing
Opportunity for controlled access after rebucketing is done (work on collimators)
Collision stores (1 - 3 stores) overnight, no crossing angle
05/17/23
I. RHIC Schedule
Restricted access till 6pm (scheduled)
First collisions today early overnight
II. Ongoing tasks
Access ongoing for poletip (scheduled till 6pm), reinsertion in progress
All TPC RDOs were replaced yesterday and tested
FST tested ok, water leak is fixed
TPC lasers, work in progress on control computer, waiting for new repeater, for now works only on the platform
III. Plan of the day/Outlook
Access till 6pm, poletip insertion, will finish earlier (before 4pm)
Collisions early overnight, could be in 2 hours after the access is done, lower intensity because of no stochastic cooling for now
Cosmics + lasers after poletip closed and magnet on
05/16/23
I. RHIC Schedule
Restricted access till 10pm.
Beam ramps overnight, both beams
First collisions as early as Wednesday night, likely on Thursday
II. Ongoing tasks
Poletip removal in progress, access till 10pm today + access tomorrow till 6pm
TOF LV for tray 18 west 2 was too low, the channel was swapped to a spare (ok), work in progress on GUI update
III. Plan of the day/Outlook
Access till 10pm, beam development overnight
Collisions on Thursday
05/15/23
I. RHIC Schedule
Restricted access ongoing till 2:30pm to prepare for poletip removal
Beam development overnight, blue and yellow ramps
First collisions on Wednesday night, 6 bunches
II. Ongoing tasks
Preparation for poletip removal (BBC, EPD, sTGC), access today till 2:30pm
ETOW and ESMD off (FEE LV and cooling water)
TOF LV is too low for tray 18 west 2, caused high trigger rate, taken out of the run, call to Geary, mask it off now
MTD THUB-N new firmware (Tim today, behind the barrier)
Tier-1 for timing on Wed (Jeff+Hank)
Inform SL over zoom of any work from remote, like ramping up/down HV/LV
sTGC LV to standard operation in the manual (David)
III. Plan of the day/Outlook
Access till 2:30, likely done earlier, beam development overnight
Collisions on Wednesday night, 56 bunches (10 kHz) + then 6 bunches for sPHENIX
2022 ops meeting notes
04/18/2022
- Forward system 107% goal reached, 98% goal for central (BHT3) program reached - congratulations to all!
- Smooth data taking
- 6 hrs CeC after 17:30
- sTGC gas alarm due to malfunction in HSSD, which was checked and fixed during CeC
- Today
- Shutdown activities Shift leader and a DO shall be present in the CR
- Day Shift
- Physics data taking with minor problems
- Evening Shift
- Cosmics during CeC
- sTGC gas alarm due
- Overnight Shift
- Continue data taking with few issues
- Beam dumped at about 8 as planned
- Gas purge
- Other shutdown activities
- Shift leader and one DO in the CR as long as the purge is going on, certainly during the day
- Do we need eve. shift if the purge is complete?
- DAQ shut down…
04/17/2022
- Smooth data taking
- 4 hrs CeC after 16:30 -22:00
- Three occurrences of DAQ control window crashing - restored by Shift Leader, no data los
- CeC can take time “at will” between now and the end of the run
- Today
- Physics for STAR
- Possible CeC
- Tomorrow
- End of run at 8:00
- TPC purge after beam dump at 8 am- Shift leader and a DO shall be present in the CR
- Day Shift
- Physics data taking with minor problems
- Evening Shift
- Cosmics during CeC
- Problem with ETOW FEE crates taken care of with Scott’s help
- Data taking after 22:30
- Overnight Shift
- Continue data taking with few issues
- Beam dumped at 7:05
- Efforts to include ETOF in data taking shall continue
- Watch QA plots for EEMC because of eemc-dc error message
- Follow instructions and contact EEMC expert in case of problems, contact person Scott Wissink
- TPC purge - requires Shift Leader and DO present
- Hank to contact Jack about STP and shall email starops the recommendations
04/16/2022
- pCarbon 2hrs done, 10 min zdc polarimetry runs taken during that period
- CeC after pCarbon in the evening
- Beams back at about 22:45
- CeC can take time “at will” between now and the end of the run
- Damper test at injection sometime this weekend
- Messages can't connect to eemc-dc -- data corruption possible
- Wayne came a checked the communications, nothing was found, no access during CeC was needed
- EEMC online QA shows no problems
- TPC sector 12 has one hot pixel (intermittently), experts know about it
- Today
- Physics for STAR
- Possible CeC
- Tomorrow
- Physics for STAR
- Possible Cec
- Day Shift
- Physics data taking with minor problems
- Evening Shift
- pCarbon polarimetry
- Daily calibration runs
- Cosmics during CeC
- Data taking after 22:45
- Overnight Shift
- Continue data taking with few issues
- Beam dumped at 6:45
- Some issues with FCS triggers but online QA ok, reboot trigger and/or reboot all fixed the issue
- Efforts to include ETOF in data taking shall continue
- Watch QA plots for EEMC because of eemc-dc error message
- Follow instructions and contact EEMC expert in case of problems, contact person Scott Wissink
04/15/2022
- Access to fix communications 9 - 11:30, during which:
- Alexei checked the water leaks.
- Wayne and Tim helped us bring the sTGC LV, FCS connections back. Also cleared the EEMC crate booting issues.
- Wayne and Tim noticed the EEMC HVSys A module was dead. Tim replaced the module, restored HV branches. EEMC are now all back up.
- pCarbon 2hrs on not done yet, TBC
- CeC in the evening 6:30 - 11 pm
- Vernier scans done
- Beam lost at about 4 am
- CeC can take time “at will” between now and the end of the run
- Damper test at injection sometime this weekend
- Today
- Physics for STAR
- pCarbon session at the end of this current store
- Detectors in ready to dump state during pCarbon, run ZDC polarimetry only
- Tomorrow
- Physics for STAR
- Day Shift
- Access, fixed number of problems, see above
- Physics data
- Evening Shift
- Physics data till 18:30
- Daily calibration run
- Cosmics during CeC
- Overnight Shift
- Data taking quite smoothly started at ~ 0:45
- Beam loss
- Data taking resumed at the end of the shift ~ 7:10
- Efforts to include ETOF in data taking shall continue
- Use 10 min ZDC polarimetry runs during pCarbon and reconcile the time stamps after the fact
04/14/2022
- APEX started 8:00 - 24:00 yesterday
- pCarbon 2hrs on Thursday 4/14 at the end of a store, TBC
- Expect CeC requesting time intermittently
- Two more vernier scans back to back this week
- EEMC problem diagnosed - fixing requires access - fixed during morning access
- sTGS LV and FCS control communications problem developed during owl shift - fixed during morning access
- Today
- Access 9 am - done, very successful. All known and new found problems were fixed. See shift log for details
- Physics for STAR
- pCarbon session at the end of a store - the upcoming store
- Vernier scans, two in one store - also the upcoming store
- Tomorrow
- Physics for STAR
- Day Shift
- APEX
- Evening Shift
- APEX
- Overnight Shift
- Data taking quite smoothly
- sTGC LV and FCS communications problem developed, data seem OK
- Efforts to include ETOF in data taking shall continue
- Access to fix EEMC and communication problems as described above - all fixed during acces
04/13/2022
- Smooth data taking until 1 pm
- CeC dedicated 4 hrs
- Beam resumed about 18:00 data taking continued
- APEX started at 8:00 today
- There was an attempt to include ETOF in data taking, but not successful
- pCarbon 2hrs on Thursday 4/14 at the end of a store, TBC
- Expect CeC requesting time intermittently
- Two more vernier scans back to back this week
- Today
- APEX 8:00 - 24:00, possibly till 19:00 only…
- Physics for STAR if possible
- No cosmic ray data because of beam at RHIC
- Tomorrow
- Physics for STAR
- pCarbon session at the end of a store
- Vernier scans, two in one store
- Day Shift
- Cosmic ray data during CeC
- Daily tasks done
- Geary and Norbert worked on ETOF
- Evening Shift
- Data taking after CeC
- Usual issues like RDOs, etc.
- Overnight Shift
- Data taking quite smoothly
- Power cycle sTGC
- Few issues with ETOW, ESMD, experts were contacted still working, see email from Will
- Efforts to include ETOF in data taking shall continue
- Tonko is recovering RDOs - done
- EEMC problems - help from slow controls/network experts is needed
04/12/2022
- Recovery from morning QLI took a long time, started taking data again at 18:30
- Taking data smoothly after the recovery
- Controlled access was used to power cycle the FST cooling crate, issue fixed.
- Run list does not show in ShiftLog in the shift report for the last two shifts
- APEX on Wednesday 4/13, 8:00- 24:00
- Possible pCarbon 2hrs on Thursday 4/14 between store
- Expect CeC requesting time intermittently
- Two more vernier scans back to back this week
- Today
- Physics for STAR
- Tomorrow (rest of the week, until further notice)
- APEX 8:00 - 24:00
- Physics for STAR
- Day Shift
- QLI recovery till 18:30
- Daily tasks done
- Took cosmic ray data
- Evening Shift
- QLI recovery till 18:30
- Took cosmic ray data
- Data taking continued quite smoothly, with few issues
- Overnight Shift
- Data taking with few issues
- Efforts to include ETOF in data taking shall continue
04/11/2022 – Monday
- Taking data with usual problems at STAR
- STAR reached 90% of figure of merit goal
- Yesterday power dip caused RHIC and STAR magnet trip,
- Two QLI (magnet quenches) at RHIC: 3:26 and 8:26 am
- Data taking resumed at about 7 am after the first QLI
- CeC access now behind recovery from QLI
- Controlled access opportunity now till about 11 am
- No CeC on Sunday
- Number of RDOs needed to be masked out
- David reduced trip limit in sTGC to 80 microamps
- Kolja and shift leaders suggest to reevaluate need for the emc check before the first run in a new fill: MCR ramps from flattop after only a brief period (with negligible ZDC AND). By the time emc-check is possible, physics is already declared. Is the emc-check needed/helpful under these conditions? We don’t change anything
- Two more vernier scans this week back to back
- II. RHIC Schedule:
- Today
- CeC access during recovery
- Physics for STAR
- Tomorrow (rest of the week, until further notice)
- Physics for STAR
- Day Shift
- Power dip caused STAR magnet trip
- Quite smooth data taking with few minor issues
- Tonko brought four RDO's back to life, iS5-1, iS9-3, iS10-2, iS10-3
- Another trip in sTGC plane 1 cable 6.
- Evening Shift
- Data taking continued quite smoothly, with few issues
- Overnight Shift
- Data taking until magnet quench at RHIC at about 3:30 am
- Taking cosmics after that
- Data taking resumed at about 7 am
- Efforts to include ETOF in data taking shall continue
04/10/2022 – Sunday
- Taking data continuously with few bumps
- New note by Jeff and Hank on how to handle Trigger DAQ problems with dead times / crate failures DURING PHYSICS RUNS was distributed to the shift leaders and uploaded on STAR operations Drupal page
- CeC 4 hrs
- Attempt to put ETOF in cosmic ray run was not successful
- Access at STAR by Tim to do cable swap, which was a success
- This morningTOF issue was very efficiently recognized by shift crew. Rongrong identified offending tray #32 in TOF, which was giving multiplicity 15 and above. The tray was masked out.
- Intensity reduced by 5%
- Number of RDO failures is reduced, most likely because of the above
- Today
- Physics for STAR
- CeC 16:00 - 20:00, flexible with the store end, dedicated?
- Tomorrow (rest of the week, until further notice)
- Physics for STAR
- Day Shift
- Quite smooth data taking with few minor issues
- Tonko brought four RDO's back to life, iS5-1, iS9-3, iS10-2, iS10-3
- Another trip in sTGC plane 1 cable 6.
- Evening Shift
- Data taking continued quite smoothly, with few issues
- Beam lost at ~ 23:30
- Overnight Shift
- Very smooth running all night. No interruptions except for beta squeezes.
- Check if CeC intends to use their four hours, if so make sure that it matches beam dump and fill
- Efforts to include ETOF in data taking shall continue
- David to reduce trip limit in sTGC to 80 microamps after this meeting
04/09/2022 – Saturday
- Taking data continuously with few bumps
- New note by Jeff and Hank on how to handle Trigger DAQ problems with dead times / crate failures DURING PHYSICS RUNS was distributed to the shift leaders and uploaded on STAR operations Drupal page
- CeC on Friday was cancelled
- Attempt to put ETOF in the run was not successful
- Lost beam due to problem Beam Loss Monitor
- Sat, Sun CeC 16:00 - 20:00 possible dedicated, flexible depending on the store end, can be used for access at STAR
- Today
- Physics for STAR
- CeC 16:00 - 20:00, flexible with the store end, dedicated
- Tomorrow (rest of the week, until further notice)
- Physics for STAR
- CeC 16:00 - 20:00, flexible with the store end, dedicated
- Day Shift
- Quite smooth data taking with few issues
- Two subsequent incidences of daqman CRITICAL scDeamon.C:#1364 EQ1[trg] [0x8019] died/rebooted -
fixed with eq1 power cycle and Reboot Trigger. - Two subsequent incidences ETOW: Errors in Crate IDs: 2
Recovered with Will's instructions: powercycle VME-94, reconfigure crates 1 and 2 - sTGVC HV trip
- Evening Shift
- Data taking continued quite smoothly, with few issues
- Issue on startup iTPC sector 20 was dead in DAQ and we could not get it back either by rebooting in DAQ or by powercycling the RDOs in the sector. It was resolved by powercycling the crate in the DAQ room
- eTOF was put back in towards the start of the fill, but would give the error: "ETOF has 1096>100 EVB errors. Asserting BUSY. Reconfigure detector!” It was taken out of the running.
- Couple of trips in sTGC; both were cleared by DO hitting "clear trips" and then "full" on sTGC slow controls. This is now the correct procedure and is supposed to be included in the official instructions soon.
- New iTPC masks: Sector 9, RDO 3, Sector 10, RDO 2
- Overnight Shift
- Mostly smooth data taking with few issues
- Problem with ESMD Communications. ESMD 03U. Fixed by power cycling Crate 91 and rebooting
between runs. - Had to mask iTPC Sectors S5-1 and S10-3, all fixed
- Access today during CeC? - fix of the trigger problems Tim, Christian on standby, controlled access, call Chris Perkins
- Check if CeC intends to use their four hours, if so make sure that it matches beam dump and fill
- Efforts to include ETOF in data taking shall continue.
- Print new manual for sTGC procedure - Prashanth
- JH to request C-AD to reduce intensity in order to minimize backgrounds
04/08/2022 - Friday
- Taking data continuously with few bumps
- Problem with 100% dead during the day shift, which cascaded because cycling power on trigger crates
-
See recommendations how to handle it: Simple stop/start new run should be sufficient,Call expert before cycling power, which is the last resort
- FCS EMcal problems diagnosed through online QA, two run delay in diagnosing. Fixed by Oleg by power cycling the HV
- Problem with sTCG Plane 1 Cable 6 tripped. Why did it take 13 minutes? Continuing to run while we fix this HV problem.
Fixed by Prashanth during the run by manually setting the Set Point to 2900 V - Fri, Sat, Sun CeC 16:00 - 20:00 dedicated, flexible depending on the store end, can be used for access at STAR
- Today
- Physics for STAR
- CeC 16:00 - 20:00, flexible with the store end, dedicated
- Tomorrow (rest of the week, until further notice)
- Physics for STAR
- CeC 16:00 - 20:00, flexible with the store end, dedicated
- Day Shift
- Smooth running until 100% busy cascaded into a bigger problem by cycling power on trigger crates
- TPX, iTPC 98% dead was a red herring. We power cycled FEEs before initially realizing BTOW was running hot and BHT3 was firing at 80 kHz and swamped everything else. Prepare for physics ended up being the resolution.
- Evening Shift
- Data taking continued quite smoothly, with few issues
- Lost sTGC LV IOC at one point, recovered during TPC recovering from anode trip. .
- Dave was called about MTD HV crate, which shut down and recovered by itself
- Several runs ended early due to 100% dead trigger.
- Overnight Shift
- Mostly smooth data taking - there were small issues, see shift report from Steve
- FCS EMcal problems diagnosed through online QA, two run delay in diagnosing. Fixed by Oleg
- Delayed beam dump because of injector problems
- Kolja recommends power cycling stgc rob#2 (caution message it will stay, goes away with power cycling) after the second warning about it.
- David’s recommendation: DOs no longer have to manually turn off sTGC LV ROB5, sections 3, 5, and 7 on slow controls.
- New trigger 100% dead handling procedure from Hank and Jeff
- Access today during CeC - fix of the trigger problems Tim, Christian on standby, controlled access, call Chris Perkins
- No more low luminosity run
- New trip limit for sTGC to be established
- Shift leader’s computer needs to be upgraded after this run
04/07/2022 -Thursday
- Big power dip, which caused down time about 5 hrs 13:30 - 18:30
- Polarization Blue 0.54, Yellow 0.47
- One target in Blue lost and new one inserted, being conditioned
- New mask rule in the STAR CR announced by JH and implemented
- Shift leaders requested to make sure that ID badges are worn and those on shift have RHIC access cards
- New L4 expert, update the expert list now Diyu Shen, see details below
04/06/2022 - Wednesday
~ Update expert on call to be Jeff
04/05/2022 - Tuesday
I. Summary of Operations:
- Reduced AGS extraction currents, as requested by STAR, going well
- CeC studies continue but their schedule may change, be flexible
II. RHIC Schedule
- Today
- Physics for STAR (Note change of schedule, next line)
- CeC studies 16:35 – 00:35 (no beam, access is possible)
- Tomorrow (Wednesday)
- Physics for STAR
- No scheduled access. Jet needs work but risk analysis suggests don’t touch it.
- p-Carbon spin direction measurements – 2 hours at end of a fill, time TBD.
- Future
- Thursday & Friday CeC (Au Beam, 48 hours) May be reduced to 2 shifts of 8 hrs, TBD, be flexible.
III. Items from Shifts:
- Day Shift
- Smooth running (except unexpected beam abort at 12:30)
- FCS HCal, Trigger 100% dead, EVB-08, Run Control, Tonko@work - fixed
- Multiple sTGC problems. Now missing two sectors of plane 3
- Evening Shift
- Smooth running till ~6 PM. Beam dumped for CeC until 2:00 AM
- STAR Access
- TOF maintenance: replaced THUB-NW, CANBUS not working, replace microcontroller next access (today)
- Prashanth & David checked sTGC reverse burn, no luck. Stopped.
- Akio loaded new HV file for FCS
- Cosmics after 10 PM
- Overnight Shift
- New shift crew, overlap day
- Cosmics till 2:00 AM, Smooth production running after 02:00
- ETOW, JEVP restart, Tonko@work
- MTD and TOF, and sTGC are not happy
IV. To Do:
- Access on Tuesday afternoon (today); report to SL before entry
- Access to start at 16:35 (Note change of schedule)
- No maintenance access on Wednesday. Develop plan to accommodate this
- Shift CeC studies to 4:35 PM, JH to negotiate, notify Ops list – Done
- Quick entry to unplug TOF cable (?)… recommend wait till CeC access
- TOF gas, Alexei and Geary to discuss
- Shift Leaders, please call Prashanth if sTGC trips
- Change sTGC HV and trip current … can be done between runs
04/04/2022 - Monday
I. Summary of Operations:
- RHIC performance ‘pretty good’ over the weekend, some AGS injection issues
- AGS injection current lowered in response to lower effective cross-section used by STAR, generally good results
- Jet polarization avg of 54% - not in full agreement with AGS numbers, experts reviewing the numbers
- STAR took 18.5 hours of data on Saturday. A new record for Run 22! Sunday took 15 hours.
- CAD plans to work on AGS issues behind CeC activity
II. RHIC Schedule
- Today
- Physics for STAR
- CeC studies 16:00 – 00:00 (no beam, access is possible)
- Tomorrow
- Physics for STAR
- CeC studies 16:00 – 00:00 (no beam, access is possible)
III. Items from Shifts:
- Day Shift
- Smooth running
- Trigger 100% dead, VME crate 63 (MXQ), Tonko@work, sTGC, FCS, EQ2
- Removed a few FCS triggers at 10:30 till end of fill
- Access ~15:30, replaced LV power for splitter, TPC field cage currents - fixed
- Evening Shift
- Smooth running
- David T. tuned a few issues around the control room
- VME crate 75 (with scaler board) fan failure at ~20:45, Christian access – fixed
- L2 pedestals shifted at 20:00, expert analysis needed
- Overnight Shift
- Smooth running
- iTPC, TPX, Trigger 100% dead, Run Control, restart JEVP online plots
IV. To Do:
- Access possible Monday afternoon (today); report to SL before entry
- TOF maintenance: Replace THUB-NW. Magnet barrier to come down.
- Ramp TOF LV down. Tune TOF gas. Estimate two hours to replace THUB.
- Prashanth to cycle sTGC – check reverse burn, check HV cables
- Another access possible on Tuesday afternoon.
- Work with RHIC to give ~2 hours of overlap on Tues. afternon shift
- Likely reduced access to STAR on Wednesday … develop maintenance plans accordingly
- Experts to review L2 pedestal shifts
04/03/2022 - Sunday
I. Summary of Operations:
- Access today (Sunday) at 3:00 PM
- CeC on Monday has been reduced to 8 hours, schedule TBD
- Polarization mixed; Hi 40’s – Lo 50’s depending on when you look
II. Yesterday's News
- Lower effective pp cross-section (as seen by ZDCs) has been adopted across all platforms (2.06 => 1.86)
- As a result, the Figure of Merit plots will look 10% higher than previous editions of these plots
- ZDC rates from MCR now to be 10% lower ( 420 ± 100ish Avg => 380 ± 100ish Avg )
III. RHIC Schedule
- Today
- Access at 3:00 PM to fix FCS
- Physics for STAR
- Tomorrow
- Monday April 4th CeC for 8 hours (no beams, access is possible)
- Physics for STAR
IV. Items from Shifts:
- Day Shift
- Smooth running
- TPX, sTGC, Run Control Froze, TOF gas, FCS, Tonko@Work - fixed
- Evening Shift
- Smooth running
- Online plots died, JPlots restarted
- TOF LV and TPC FC IOCs, David@Work, BBC & BBQ – fixed
- FCS needs work (lost Drell Yan and J/Psi triggers as a result)
- Overnight Shift
- Smooth running
- FST, sTGC Plane 4 Prashanth@work, TOF – fixed
- EMC check at begining of fill – no FCS events (?)
- [This is a configuration error, take FCS out or fix configuration; Tonko and Jeff to talk and determine best shift leader actions.]
- Event building 3 left in a few runs early in the shift (?)
- [If it runs, its OK. It ran so it seems it was OK.]
V. To Do:
- Access at 3:00 PM today to fix FCS; fix Field Cage Currents
- FCS pre-shower board needs work during the Sunday access
- Shift Leader Contact Oleg – Alexei – David – Tim & Prashanth for Sunday access
- Shift Leaders - take Drell Yan and J/Psi triggers out of the run until FCS is fixed
- Another access is possible on Monday
- TOF maintenance: repair or replace THUB-NW. Magnet barrier needs to come down.
- Prashanth to cycle sTGC on Sunday and/or Monday
- Please report to the shift leader before entering the STAR hall.
04/02/2022 - Saturday
I. Summary of Operations:
- CeC on Monday has been reduced from 48 hours to 8 hours (no beams on Monday, access is possible)
- More CeC in our future, TBD
- Polarization is good, overnight Hi 40’s, today Lo 50’s
II. Other News
- Lower pp cross-section has been adopted across all platforms (2.06 => 1.86)
- Figure of Merit plots will look 10% higher than previous editions of these plots
- ZDC rates from MCR now to be 10% lower ( 420 ± 100ish Avg => 380 ± 100ish Avg )
III. RHIC Schedule
- Today
- Physics for STAR
- Tomorrow
- Physics for STAR
- Future
- Monday April 4th CeC for 8 hours (schedule TBD, no beams, acesss is possible)
IV. Items from Shifts:
- Day Shift
- Smooth running till Noon, CeC till 8 PM, some cosmics taken
- Polarization high 40’s low 50’s
- MTD, sTGC & gas, Tim&Christian@Work on THUB-complete
- TOF out most of the day
- Shift log stopped recording, disks full, Jeff@work - repaired
- Evening Shift
- Smooth running after 20:00
- Polarization above 50%
- iTPC RDOs, TOF trays, THUB masked/ quarter of detector out
- TPC laser data taken with and without compensating resistor (for TPC Calibrations in coordination with GVB)
- Overnight Shift
- Smooth running
- Polarization Hi 40’s – Lo 50’s, mid 50’s most recent fill
- sTGC, BTOW, DAQ watch program, Tonko@work
V. To Do:
- TOF maintenance: repair or replace THUB-NW. The Magnet barrier will need to come down.
04/01/2022 - Friday
I. Summary of Operations:
- Many strange phenomena at RHIC yesterday, odd day.
- Ramp 33262 stopped ramp, many unusual issues, Vtx wide (JH says good enough)
- OPPIS work overnight & behind CeC – successful after a few false starts
- Polarization in RHIC seems good, not sure if AGS numbers agree
II. RHIC Schedule
- Today
- Physics for STAR 00:00 – 12:00
- CeC no beam 12:00 – 20:00 (access to STAR possible)
- Physics for STAR after ~21:00
- Tomorrow
- Physics for STAR
- Future
- Monday April 4th CeC for 48 hours (CeC with Au beams, no access to STAR)
III. Items from Shifts:
- Day Shift
- Beam dumped at ~08:30 for CeC
- TOF, sTGC, Tonko@work, Christian-Prashanth-Oleg@work
- CeC done at ~16:00 but start of odd problems in AGS & RHIC
- Evening Shift
- Vacuum Valve failure and other unusual issues @ RHIC
- RHIC ready ~22:00 …Ramp delayed…steering for beam…long wait
- Minor TOF LV issues in last run of the evening
- Polarization numbers in the low-mid 50’s
- Overnight Shift
- Smooth running
- TOF THUB, other TOF issues, Rongrong@work, TOF out of run
- TPX, sTGC, EEMC, Polarimetry page & RunLog not updating
- Reminder … Dump at Noon (4/1/2022)
IV. To Do:
- Call Jeff if Run Logs aren’t updating … even late at night
- Additional details entered into the Shift Log would be useful as we come to the end of the run
- Update shift procedures, TPC Short Ops manual w/GG & Laser coming soon
- sTGC statistics for summer shutdown maintenance
- reflash TOF THUB micro-controller, suggest mask off RDO-1 and run TOF today
- ZDC cross-section discussion – JH to consider further. Updates to CAD, Jamie & Vincent.
03/31/2022 - Thursday
I. Summary of Operations:
- OPPIS source work overnight & behind CeC
- Beam dumped at ~08:30 for CeC
- Strong geomagnetic storm today; may affect electric grid.
II. RHIC Schedule
- Today
- Physics for STAR 00:00 – 08:00
- CeC no beam 08:00 – 16:00 (access to STAR possible)
- Physics for STAR after ~17:00
- Tomorrow
- Physics for STAR 00:00 – 08:00
- CeC no RHIC beams 08:00 – 16:00 (access to STAR possible)
- Physics for STAR after ~17:00
- Future
- Monday April 4th CeC for 48 hours (note impact on training shift crews)
III. Items from Shifts:
- Day Shift
- Beam dumped for APEX (w/protons) early in shift
- sTGC, access to online, Magnet trip, MXQ[trg] – fixed
- Alexei and David accessed the hall, power cycled TPC Field Cage Current monitor
- Evening Shift
- APEX till ~22:45
- iTPC & minor Trigger issue - fixed
- new sTGC reference plot available
- Overnight Shift
- Smooth running
- Polarization > 50%, only Blue shows up on web page
- BTOW, Jevp plots, EMC, EEMC, FCS, sTGC, Laser GUI - fixed
- Trigger 100% dead
IV. To Do:
- Christian & team to make access
- Additional detail in the eLog would be useful as we come to the end of the run
- As always, try to maintain high shift efficiency – especially at the start of a fill
- ZDC cross-section discussion – JH to consider further
03/30/2022 - Wednesday
I. Summary of Operations:
- Short stores, Blue lifetime low, AGS emittance high
- Polarization still a bit low (high 40s), injectors?
- Yellow abort kicker access & maintenance
- Strong geomagnetic storm on Thursday may affect electric grid. (minor W & F)
II. RHIC Schedule
- Today
- Physics for STAR 00:00 – 08:00
- APEX studies w/proton 08:00 – 23:00
- Physics for STAR after ~23:00
- Tomorrow
- Physics for STAR 00:00 – 08:00
- CeC no RHIC beams 08:00 – 16:00 (access to STAR possible)
- Physics for STAR after ~17:00
- Future
- Friday – CeC no beam 08:00-16:00 (access to STAR possible)
- Monday April 4th CeC for 48 hours (note impact on training shift crews)
III. Items from Shifts:
- Day Shift
- Smooth running till end-of-shift (Pol high 40’s)
- FCS, TPX, BTOW, iTPC, TOF – ordinary issues
- Trigger 100% dead
- Evening Shift
- Yellow abort kicker maintenance – no beam till ~20:00
- TOF LV – disable and turn off tray 2, masked off
- Relatively smooth running (Pol high 40’s)
- iTPC masked off 9-1, 16-3; other minor issues – fixed
- Question – should we turn off FEE after masking off RDO’s?
- Overnight Shift
- Smooth running
- Polarimetry page not updating
- sTGC, FST, BTOW, TOF, TPC Field Cage lost comms, Tonko@work
- Trigger 100% dead
IV. To Do:
- Shift crews please add more detail regarding shift to eLog, also record significant comms with MCR
- Access required to fix TPC field cage current logger
- Do not turn off FEE unless specifically asked to turn it off; update to shift crew instructions needed
- Take IV scan on day shift – Akio to call STAR Control Room
03/29/2022 - Tuesday
I. Summary of Operations:
- Yellow abort kicker, sextupole PS failure
- Polarization dropping overnight (50's to 40's)
II. RHIC Schedule
- Today
- Physics for STAR
- Tomorrow
- Physics for STAR 00:00 - 08:00
- APEX studies 08:00 - 23:00
- Physics for STAR after 23:00
- Future
- Thursday - CeC 08:00-16:00 (no RHIC beams)
- Friday - CeC 08:00-16:00 (no RHIC beams)
- Monday April 4th – 48 hours for CeC (note impact on training shift crews)
III. Items from Shifts:
- Day Shift
- CeC Development & end effects 08:00-17:30
- Cosmics most of the day, eTOF work, FCS, Tonko@work, HLT code rolled back
- Access by experts: Laser, sTGC HV reverse burn continues
- Evening Shift
- Smooth running after 17:30
- TPX, BTOW, VME CPU Creighton5 (takes 3 minutes to boot, wait till complete)
- Yellow abort kicker failure ~22:00, Sextupole PS failure same time, MCR access required
- Overnight Shift
- Cosmics till ~ 03:00, then regular running
- TOF lv/fixed, BEMC hv/fixed, Jeff magic@midnight, Tonko@work
- Trigger 100% dead
IV. To Do:
- Can MCR work on pre-injectors during CeC?
03/28/2022 - Monday
I. Summary of Operations:
- Today: Booster access 07:00-Noon; CeC development 08:00-16:00 work on injectors
- Booster cavity E6 repaired => 3 fills with low Pol, poor emittance, transverse position error, etc.
II. RHIC Schedule
- Today
- CeC development 08:00-16:00 (Magnets at flattop, no ion beam)
- Restricted Access to STAR Hall possible until 15:30 (no access to tunnels)
- STAR will take cosmics during CeC work
- Physics for STAR evening and overnight
- Tomorrow
- Physics for STAR
- Future
- 16 hours of APEX on Wednesday (no access at STAR)
III. Items from Shifts:
- Day Shift
- Smooth running, Pol low ~45%, beam position not ideal
- Trigger 100% dead
- JEVP server restart, TOF tray, power cycled scaler board 6 - fixed
- Evening Shift
- Smooth running, Pol ~50%
- sTGC FEEs power cycled, EEMC crate power cycled
- L4 calib table errors, L4 rebooted ~22:00, VTX distributions improved, diagnostics improved
- Overnight Shift
- Smooth running, Pol ~52%, beam position good
- L4 error, TPX issues, FCS errors, RHIC monitors frozen/fixed, Tonko@work
- sTGC chamber tripped, additional work today
- ZDC rates ~550kHz new fill, L4 Vz histograms look good
IV. To Do:
- Alexei to make access, Prashanth to make access, Reverse polarity burn – update?
- Bill to walk through at Noon for property inventory
- Akio to load new voltage tables (not an access)
- RMS distributions on L4 undergoing review by experts
03/27/2022 - Sunday
I. Summary of Operations:
- Booster rf problem, no estimate, trouble shooting continues
- Deer Management activities Evening and Overnight – call MCR if you have questions
II. RHIC Schedule
- Today - Sunday
- Physics for STAR
- Tomorrow - Monday
- CeC Development 08:00-16:00 (TBD)
- Physics for STAR
- Future
- TBD on Monday Morning
III. Items from Shifts:
- Day Shift- Saturday
- Boooster RF problem. Held midnight fill till ~14:30, new fill ~16:30
- Trigger 100% dead, screenshots saved
- BBC crashed, lost comms to VME crates, SC3 crashed, etc.
- Many good runs
- Evening Shift- Saturday
- Trigger 100% dead
- EEMC Radstone board problem/fixed
- Smooth running (but beam quality not so good)
- Overnight Shift - Sunday
- Trigger 100% dead, screen shots saved
- Smooth running, but beam quality not ideal overnight, also current fill not ideal
- Etow, sTGC, TRG, comms issues with MCR etc.
- Discussion with MCR about when to dump beam due to issues at RHIC. Held beam till 06:30, new fill ~07:30, JH suggests dump < 350 kHz
IV. To Do:
- Consider low luminosity fill if low quality beam continues - beam shifted low - poor polarization
- Scaler board 6 network issues - (last run day 83 run 61). This impacts Lumi counting but board 5 is backup and should allow analysis to proceed.
03/26/2022 - Saturday
I. Summary of Operations:
- Deer Management activities Evening and Overnight – call MCR if you have questions
- There still be daemons in RHIC ...
II. RHIC Schedule
- Today - Saturday
- Physics for STAR
- Tomorrow - Sunday
- Physics for STAR
- Future
- Monday: CeC development 08:00-16:00 (to be confirmed)
- Deer Management activities Evening and Overnight till Monday morning
III. Items from Shifts:
- Day Shift- Friday
- No beam all day
- Tim worked on sTGC Blower. Better? (yes, so far)
- Christian tuned RDO power, Tonko burned Proms, etc.
- Evening Shift- Friday
- Beams in RHIC after 10:00 PM
- Smooth running
- Overnight Shift - Saturday
- Smooth running from RHIC
- TPX & BTOW & TOF issues, EMC manual needs update re: alias for GUI
- RF injector problem - not yet solved, no AGS beam, keep current beam till ~Noon
IV. To Do:
- Summer activity: check sTGC blower
03/25/2022 - Friday
I. Summary of Operations:
- Deer Management activities Evening and Overnight – call MCR if you have questions
- CAD worked on Yellow abort kicker
- AGS calibrate pulse was found to be incorrect … explains (false) extraction losses
- Polarization has slipped slightly in both rings (< 55%), work on injectors proposed
- Last 3 fills for STAR were above Lumi target, but keep at this rate, tune later if necessary
II. RHIC Schedule
- Today - Friday
- p-Carbon spin studies 09:00-14:00 during Day shift (no beam for STAR)
- Physics for STAR remainder of evening and night
- Tomorrow - Saturday
- Physics for STAR
- Future
- Monday: CeC development 08:00-16:00 (to be confirmed)
- Deer Management activities Evening and Overnight till Monday morning
III. Items from Shifts:
- Day Shift- Thursday
- Smooth running
- TOF gas changed, TOF QA Plots funny/fixed, power cycle sTGC, etc.
- Trigger 100% dead, screen shots taken and put in eLog
- Evening Shift- Thursday
- Smooth running
- Trigger 100% dead, Hank took some screen shots
- L2 died, TOF, EPD, BTOW online plots not working, L2 was out of run - fixed
- Overnight Shift - Friday
- Smooth running but ended with a double quench in yellow at 6:20 AM
- sTGC minor issues/fixed, BEMC confusion/fixed, Tonko@work on RDOs, etc.
- Trigger 100% dead, mystery continues, screen shots taken and put in eLog
IV. To Do:
- Experts, please double check health of systems in preparation for a good weekend
- Oleg to power up FCS radiation monitors
03/24/2022 - Thursday
I. Summary of Operations:
- CANCELLED: CeC e-beam development (no RHIC beam) 08:00 – 16:00
- Otherwise - no news is good news
II. RHIC Schedule
- Today
- Physics for STAR
- Tomorrow
- Friday: p-Carbon spin studies 09:00-13:00 during Day shift (no beam for STAR)
- Physics for STAR remainder of Evening and Night
- Future
- Monday: CeC development 08:00-16:00 (to be confirmed)
III. Items from Shifts:
- Day Shift
- STAR cooling tower was cleaned and put back into operations
- Long access – many experts at work (e.g. TOF new HV board, sTGC blower bad sensor)
- TOF HV glitch, repaired. Some issues with default config needing update by DO
- sTGC communications issues … alarm handler will have to be rebooted to fix the problem. Shift crew can do this.
- Evening Shift
- Late start ... but no major issues
- Will Jacobs worked on ETOW hot tower issue; crate masked but still shows as hot channel in QA plots
- Smooth running after 10:45 PM, minor issues. (e.g. Frozen online histograms fixed)
- Overnight Shift
- Smooth running most of shift
- Shift Leader computer was erratic, fixed itself.
- Lost communications with alarm handler, fixed itself.
- BTOW PMT 10 empty bins, required cycling HV.
- FCS issues, power cycle MPOD crate by expert
- MTD had multiple errors on several occasions (54)
- Trigger 100% dead a few times
IV. To Do:
- sTGC blower sensor – action plan?
- Work will continue on Trigger 100% dead issue; suggest reboot trigger whenever it happens
- Continue with negative voltage burn-in
03/23/2022 - Wednesday
I. Summary of Operations:
- Relatively smooth data taking since yesterday; last 5 fills have lasted natural lifetime
- Siemens performance has been good for past 2 weeks, so confidence is growing that OK
- Luminosity a bit low, RHIC Ops hopes this will improve after today’s access (e.g. they will work on chromaticity tuning)
II. RHIC Schedule
- Today
- AGS Access started at 07:00, RHIC Beam dumped 09:00 (on schedule)
- AGS Access scheduled to complete by 14:00 so RHIC Beams by 15:00
- This may slip but hopefully no later that 17:00 for RHIC beams
- Physics for STAR remainder of Evening and Night
- Tomorrow
- CANCELLED: CeC e-beam development (no RHIC beam) 08:00 – 16:00
- Physics for STAR remainder of Evening and Night
- Future
- Friday: p-Carbon spin studies 09:00-13:00 during Day shift (no beam for STAR)
- Monday: CeC development 08:00-16:00 (To be confirmed)
III. Items from Shifts:
- Day Shift
- BEMC glitches
- High bin at 97 in cr2Hot QA Plot for EEMC
- STGC air blower temp not stable – sets off annoying alarm. (SlowC or STGC?)
- Scaler rate for J/Psi were high in the middle of the day (not a continuing problem)
- Evening Shift
- Smooth running
- Overnight Shift
- High bin at 97 in cr2Hot QA Plot for EEMC – hot channel? (Will@work)
- Long list of iTPC & TPX RDOs masked off (~dozen), could not unmask.
(consultation with Tonko suggested before unmasking RDOs) - iTPC[9] prevented Run Stop. Powered Down node in DAQ room & restart.
(in general, contact Tonko or Jeff before power cycle nodes). - STGC air blower temp still unstable
Period coordinator change: Sooraj Radhakrishnan --> Jim Thomas
03/22/2022
I. Summary of operations:
- Good stable fills all through yesterday
- Vernier scans taken ~4.00 pm
- Updates on Trigger 100% dead issue ---- Experts looking into, some cases issue is from tokens lost, but not from busy detectors
- Maintenance day tomorrow. STAR Magnet off ~10.00 am
- Please inform on tasks/to do/plans. So far:
- Cleaning of magnet cooling tower
- Time for Tonko to work on TPC
- Access for Prashanth+David (stgc cable reconnection)
- Access for Xu (~hr) coolant for FST
- Access for Alexei for TPC survey
- Access for Oleg/Akio install radiation censors in front of FCS
- TOF Rack 1C1 need to checked if cooling fans are working correctly (Alexei)
II. RHIC Schedule:
- Today:
- STAR Physics
- Tomorrow:
- 07.00 - 17.00 :: Maintenance (RHIC from 9:00, Access at AGS behind store from 07.00), IP2 close at 14:00
III. Items from shifts:
- Evening shift:
- Masked out iTPC Sector 5 RDO 1
- New voltage files are loaded for both FCS Ecal and Hcal. Rates looks good. Production Ids for all FCS production triggers were incremented AFTER this run
- For first time TOF noise seems to have shown up in production running. Also seems to be on BTOW TP in the same region (fuzzy TP pedestals and enhanced response around TP = 100) ---- origin of issue not clear. Jeff will look for large events in cosmic runs and if so could reconstruct and look into further
- Overnight shift:
- Issue with FST and ETOW. FST Critical Recovery failed for RDO(s): 4. EEMC lost communication
- DOs turned the FST off and back on that fixed FST, back in next run. ETOW out for a few runs. DOs recovered ETOW following manual. Details on shift log
- Jpsi*HTTP Sca Hz, upcJpsiSN Sca Hz was a little to moderately high, noted from Run 23081008 ---- Do 'Prepare for Physics' on BEMC computer if this happens
- STGC computer in control room has completely frozen. Switched to a different tty (using Ctrl+Alt+F3) and came back into the original tty (using Ctrl+Alt+F1) to fix ---- David will follow up
- Because the STGC wasn't in a safe state before beam dump, missed the opprotunity to take the zdcPolarimetry_2022 run
- Gas alarm for STGC for PT-1. It is rising and is now at 24
- TOF LV East Sec 5 U5 temperature alarm of 42 (orange)
03/21/2022
I. Summary of operations:
- Unexpected beam loss 3 times. Some downtime bcos of this. Apparently still Yellow abort kicker issues
- Trigger going 100% dead a few times and needing to restart runs ---- Trigger experts are looking into the issue
- 8 hr maintenance day on Wednesday. Please inform on plans/tasks to do/requirements
II. RHIC Schedule:
- Today:
- STAR Physics. Access for CeC taken, back to STAR
- Vernier scans possibly today
- Tomorrow:
- STAR Physics
III. Items from shifts:
- Day shift:
- FCS "FEE count 44, expected 55 -- restart run for two runs in a row. Contacted Akio
- Shift crew pointed out extra spikes in FST Non-ZS noise vs channel for disk
- Node 0xf001Is forcing the run to stop because: 494|rc_handler.c|L2 stopping run. Looks like BCW was the problem. Rebooted trigger after run stopped and starting a new run
- Evening shift:
- Under ETOW cr2Hot shows hot tower at ~97. Earlier this week (day 77) this hot tower was gone
- TPX and iTPC are regularly go 100% dead - probably 5-10x a run. Auto-recovery and auto powercylcing works 99.99% of the time, but it still seems like a lot of autorecoveries(?) ---- Tonko informs the occurrence is in fact less frequent for the past 5 days
- Overnight shift:
- New spike in ETOW->Hot_Tower cr2, right next to the other spike
- stgc pt-1 pressure just went above minor threshold. From online plot looks like a slow but steady trend upwards over last day or two
- TOF HV was ramped to standby after unexpected beam abort, but DO noticed voltages stayed at full values (7k). Online status viewer confirms that TOF HV still at full. DOs working through restart TOF HV IOC procedure. ---- Call experts if happens
03/20/2022
I. Summary of operations:
- Got beams for STAR all yesterday. A few unexpected beam losses. Might be an access to work on some problems related to it at end of this fill
- No vernier scans taken
- Some recurring issues with ETOW during the shifts
- Trigger goes dead 100% several times. Dylan has put in a Python script on the SL computer to monitor to watch DAQ Monitor webpage and play sound if trigger is dead
II. RHIC Schedule:
- Today:
- STAR Physics
- Tomorrow:
- STAR Physics
III. Items from shifts:
- Day shift:
- EEMC crate issues, dont know the cause yet. Happened a few times, see below for other instances in all the shifts. Taken out of run and powercycled relevant crates and vme crates to fix
- Caution message: "ETOW: failed crate Ids: 4". QA plot ETOW Hot_Tower cr4Hot mostly empty. EEMC GUI Tower FEE Crate 4 showed "Ready" light red. Most FEE crate voltages were in red. Monitoring plots related to that crate were nearly empty. After consulting the expert power cycled the corresponding CANBUS crate which restored the FEE crate voltages. After a master reload everything seems back to normal
- Run would not start due to TPX 23-4 and 23-5 failed configuration. Masked out TPX 23-5
- New sTGC caution messages:"2: FOB 0 (R#10:F#55) NOT found" and "2: FOB 5 (R#10:F#60) NOT found" (since changes David made yesterday, we always get "1: FOB 5 (R#05:F#30) NOT found", but these two are new). QA plots look fine ---- Prashanth will look into and ask Tonko to suppress these messages
- FCS[1] stuck configuring and run could not start, power cycled fees twice to fix
- Evening shift:
- ETOW: configuration failed -- watch ETOW triggers or restart run. Crates 3 and 4 are off and no tower response. Tried powercycling crates and following instructions for reconfigure but that didn't work. Cycled Crate 90 and started over and that worked
- EEMC Crates 1&2 and MAPMT sectors 12-3 are bad. Monitoring plots show missing data. Problem with EEMC in last run was somehow HV was not applied to the cycled crates, even though they were all green and looked ok. Will fixed it but noticed there was an error with Crate 3 configuration
- Monitoring plots interface not updating, restarted servers
- Overnight shift:
- ETOW Hot_Tower spike in cr2 appears to be back, also new spike in cr4Critical_Shift_Plots->ETOW->Tower_ADC for cr2. We power cycled tower FEE cr1&cr2. Problem is resolved
- Many fcs trigger rates are high (red). Stopped run and rebooted fcs from run control. Fixed
- prom_check: trg + daq + itpc: “Incorrect Trigger clock 10.000 MHz -- restart run" --- not important, can be ignore. Also, prom_check can be taken with beam
03/19/2022
I. Summary of operations:
- Back from APEX around 12.00, but unexpected beam loss. Long downtime, beam back around 12.30 am. Did cosmic runs during downtime
- No vernier scan last night, might do later today
II. RHIC Schedule:
- Today:
- STAR Physics, Vernier scan
- Tomorrow:
- STAR Physics
III. Items from shifts:
- Day shift:
- West laser failed. Short access for Alexei to fix
- Prashanth increased pressue PT1 as we were getting low alarms
- David took out sTGC ROB #5 channels 3, 5, and 7. These should be manually removed when ramping up LV
- Updated run control handler for support for new prom_burn and fcs_ivscan runs (Jeff)
- Evening shift:
- Cosmic run: Noise in TOF and BEMC JP is back
- Overnight shift:
- ETOW Hot_Tower spike in cr2 appears to be back, also new spike in cr4
03/18/2022
I. Summary of operations:
- Got one fill overnight. Unexpected beam loss just after fill after that. Yellow abort kicker issues during injection. MCR decided to go into pC spin direction measurements early, ~6.00 am
- Shift was smooth, no major issues
II. RHIC Schedule:
- Today:
- 08.00 - 12.00 :: pC spin direction measurements. STAR Physics otherwise
- Vernier scan during store after pC spin measurements
- Tomorrow:
- STAR Physics
III. Items from shifts:
- Evening shift:
- FST error code during pedestal. Disk1 module 12 alternate sensor current was fluctuating called Xu and he fixed. He will raise limit on this module so it doesn't happen again
- Masked out iTPC S13:2
- iTPC and TPX 100% dead during start of run, power cycled FEEs to fix. ---- likely from masked out RDO S13:2 in error state, power cycling fees was right way to fix
- Overnight shift:
- Unmasked itpc S13-2 after instructions from Tonko
03/17/2022
I. Summary of operations:
- Dedicated time for APEX and CeC. Not much activity at STAR. Took btow_ht: trg + daq + btow every two hours
II. RHIC Schedule:
- Today:
- CeC till 16.00, STAR Physics afterwards
- Tomorrow:
- 08.00 - 12.00 :: pC spin direction measurements. STAR Physics otherwise
III. Items from shifts:
- Day shift:
- TOF HV was turned to standby, but voltages not ramping down. DOs going through HVIOC restart procedure. Connection appears to be back, but gui does not seem to be responding still (voltages will not ramp up when HV turned on). David power cycled TOF HV crate, which fixed issue
- Unmasked iTPC S13-2 and S20-4 following Tonko's instructions
- Some delay in ramping up the magnet, was unable to turn on the main power supply
03/16/2022
I. Summary of operations:
- Access till ~12.00 to fix sextupole issues. Beam back around 1.00 pm
- Power dip and magnet trip at STAR ~4.00 pm. Lost connection with trigger detectors, TPC FEE GUI went completely white. Fixed by David. Run could not be stopped in run control. Needed to turn power back on to MIX, BE, EQ2, and LOL2 VMEs following instructions from Jeff. STAR back ~5.00 pm. Got next fill at 1.00 am
II. RHIC Schedule:
- Today:
- APEX till 16.00 (STAR Magnet is off, Power supply repair behind APEX); CeC afterwards
- Tomorrow:
- CeC till 16.00, STAR Physics afterwards
III. Items from shifts:
- Day shift:
- Unmasked iTPC S2-3, 10-4, and 6-4 at Tonko's request
- Updated fcs offline trigger ids to match fast offlines organization scheme (Jeff)
- In shift critical plots, observe peaks in TOF ADC plots that were not present in previous cosmic data. Experts notified, but they don’t know the reason
- Spike in BEMC DSM L0 Input - PatchSum plot. Oleg asked us to take a btow_ht run to debug, all looks ok
- Online shift plots not updating so restarted JEVP server
- Evening shift:
- pedestal_rhicclock_clean: trg + daq + fcs runs correctly but DAQ monitor but BCE gives errors. CRC Error on STP Build header. Event 1000, Token 1000, nPre 0, nPost 0
- Cosmic runs: The unusual activity is back in the TOF and BEMC
- Overnight shift:
- TOF THUBNW now staying at yellow alarm with terminal voltage 5.9, should be fine
03/15/2022
I. Summary of operations:
- Much smoother fills and shifts than yesterday
- Faster loss of intensity in the last fill, yellow beam has issues. Yellow sextupole issue
- Possible access for 2 hours from 10.00 am (work on sextupole)
II. RHIC Schedule:
- Today:
- 09.00 - :: Fix RF (2 hrs behind the store)
- STAR Physics afterwards
- Tomorrow:
- 08.00 - 16.00 :: APEX
- 16.00 - :: CeC dedicated time
III. Items from shifts:
- Day shift:
- GMT was checked to be ok after the gas bottle change yesterday
- "Reboot" Button for LV on sTGC sometimes does not complete correctly. Got the same error last week. It says "starting socket... / sudu: command not found” --- David will look into
- High Sca Hz rates for BHT2*BBCTAC and BHT3 and JP2. iTPC and TPX at 100% dead and would not recover. If the Sca Hz for BHT2*BBCTAC and BHT3 are high, causing the iTPC and TPX to be 100% dead, click "perpare for physics" on the BEMC computer. Wait for terminal to say "Finished checking FEEs on all SMD Crates" ---- would be good idea to do "perpare for physics" on the BEMC computer between the fills
- Masked out iTPC S2-3
- The TOF PT-1 gas ran out, so we switched the valves
- Evening shift:
- ETOW lost communication. Took out of run. Power cycled crate 90 (controls) and reconfigure all (from Will)
- iTPC RDO 10-4 was masked out
- Overnight shift:
- Shift crew noticed hole in BTOW ADC plot from runs 19 and 21. DOs determined it to be from crate 0x14 and the run was stopped. DOs reapplied HV
03/14/2022
I. Summary of operations:
- Unexpected beam loss 3 times, TOF and MTD HV alarms during beam loss
- Faster loss of intensity after beta squeeze during last night’s run. Yellow sextupole failure, fixed now, should be better from the current fill
- A few issues with MTD, EEMC, Trigger during the shifts
II. RHIC Schedule:
- Today:
- STAR Physics
- Tomorrow:
- STAR Physics
III. Items from shifts:
- Day shift:
- High Err numbers in many of the triggers on DAQ monitoring web page during one run (Run 23072031), stopped and restarted
- dimuon trigger Sca Hz is red and sitting around 900 Hz with a Sca Dead of 18%,.The Daq Hz is low, (during Run 23072035)
- EHT0*BBCTAC trigger had a high Sca Hz rate of 2500. EHT1 trigger had a high Sca Hz rate of 140 (during Run 23072044) --- could be from beam issues
- Evening shift:
- While updating L2 pedestal reference for run23072042, L2 trigger crashed. Jeff asked Navagyan to restart L2 trigger and update the L2 pedestal reference for run23072043
- Sudden beam loss and saw MTD low HV red alarms (value ~4600) on some sectors
- Overnight shift:
- dimuon trigger Sca Hz is red and sitting around 1600 with a Sca Dead of 25%. Shift crew observed hot spot in MTD critical strips vs BL plot between 100-120 and 4-8 (Run 23073002+)
- got TOF LV error (NW THUB current is red) so power cycling LV. Also itpc[19] preventing run from starting. Contacted Tonko for assistance ---- needed powercycling of one FEE causing issues
- GMT gas bottle changed, but adjusted to have pressure at 14 psi. Expert might want to look. ---- Alexei will take a look. Shift crew are not supposed to alter anything than change the bottles
- Unexpected beam loss and got TOF and MTD HV alarm
- Temperature for crate 1 is at 0 on ETOW GUI. ETOW QA plots monitored closely but no issues seen. Continued runs with this caution messages. Expert instructed same and power cycle the crate and then issue a master reload at next beam dump
- Day shift (Today):
- TPC high dead times, Powercycling fees didn’t help. From last pedestal run not completing ---- If the pedestal run doesnt complete and keep requesting more events, call the expert
03/13/2022
I. Summary of operations:
- Magnet trip around 5.30 pm, same issue as last Thursday. Couldn’t be ramped back till today morning
- Took zero field alignment runs with low luminosity beams
- Magnet ramped back around 8.00 am. At next opportune time possible, a more permanent fix to the circuit causing the issue will be done
- Online status viewer not loading ---- Dimitri was called to fix
II. RHIC Schedule:
- Today:
- STAR Physics
- Tomorrow:
- STAR Physics
III. Items from shifts:
- Day shift:
- BERT was saying we had Physics On for 5min after a beam dump ---- Communication issue, didnt repeat in later shifts
- Took access for laser and interlock communication issue
- Piezodrive froze and I came to WAH and restarted by AC power flipping — Alexei
- Corrupt Trigger Data Event : Token 2213, Node qt32d-3 (Crate=5, Slot=6) (TCU Event Ctr 0x7f8b3343, Node Readout Ctr 0x7eb4aff2), similar msg in the next run also ---- not an issue
- Noticed the Sca Hz associated with the FCS were high. Stoped Run. Rebooted FCS from run control
- Evening shift:
- Made a controlled access and power cycled the crate #52 manually and interlock monitoring is working again — David
- Overnight shift:
- "TOF: too many trays (111>5) require power cycle -- consider TOF/MTD CANBUS reset!" so will restart CANBUS
- Unknown alarm at ~4 AM heard by entire shift crew, lasted only about 1 second. High-pitched train whistle like sound (not very loud) from area of gas/interlock alarm
03/12/2022
I. Summary of operations:
- Beam conditions are very good, peak luminosity touching around 600 KHz. ---- will keep watching, and will ask MCR to trim down a bit if needed
- Issue with the abort kicker, few hours till next fill during day shift
- Shifts were smooth, no major issues
II. RHIC Schedule:
- Today:
- STAR Physics
- Tomorrow:
- STAR Physics
- Run officially extended by 2 weeks!
III. Items from shifts:
- Day shift:
- Regained communication with FCS with help from David
- Shift crew noted that the wide sTGC Diagonal Strips Plane 3 QA plot has been varying in intensity since run 23070017. STGC HV looks okay on GUI for Plane 3 ----- Powercycle LV to fix
- Jeff made an update to the JEVP plots attempting to stop the crashes that have been happening periodically
- Evening shift:
- iTPC: RDO S13:2 was masked out
- The interlock alarm handler appeared white. Expert said that there seems to be some issues with Canbus 52, he was unable to bring the power back up, and suspects that it is a fan failure. Ignore and keep running for now, the electronics expert will try to go in and fix it at the next access ----- short access expected, so will take access at the end of this fill
- Overnight shift:
- Gaps in sTGC hits/VMM, powercycled LV to fix
- The laser cameras do not change when steering buttons are pressed. The laser is very poor for this run. ----- Alexei will check after the meeting
03/11/2022
I. Summary of operations:
- Beam conditions are very good after the switch to Siemens MG. Better luminosity, peak for last fill at 600 KHz, may want to reduce depending on STAR's preference. Better beam polarization (55% for both beams as per 9 am meeting)
- Downtimes due to STAR Magnet trip and Yellow abort kicker issues
- Magnet ramped back ~3.30 pm. Beam back around 4.00 pm, unexpected beam loss around 11.00 pm
- Shifts were smooth, some issues for FCS and ETOW
II. RHIC Schedule:
- Today:
- STAR Physics (after the magnet is ramped back)
- Tomorrow:
- STAR Physics
- CeC scheduled to have dedicated 4 days (not continuous) for run till April 4, starting March 21
III. Items from shifts:
- Day shift:
- Oleg and Bill put ecal block on the east side
- FST had a failure code 2, out of runs. FST Disk3 Module1 inner sensor shows a significantly higher current than other channels. seems like the inner HV cable of D3M1 broke. A 1 hour access is needed to investigate the cable issue. Currently running D3M1 with 120V and the current is around ~25muA. ---- Expert wanta an access, but not urgent, when available
- Evening shift:
- iTPC RDO 14-4 masked out
- ETOW out of 3 runs bcos of lost connection. Took a while with help from expert to bring back
- Overnight shift:
- L3 event display only shows lasers on north side and none on south. During evening shift: laser was left on for longer than usual (>20min). Laser power was suddenly lost and the run was stopped ---- Likely from DOs not tuning correctly
- Unmasked iTPC S4-2 and S16-4
- There is a silenced IOC error for FCS LV (IOC_Monitor->forward-cr->FCS,FCS_LV). Online plots for FCS are normal. ---- Jarda will look into
03/10/2022
I. Summary of operations:
- Beams through all shifts for STAR physics
- Three vernier scans during day shift, took data
- Luminosity comparable to before, above 400 KHz for ZDCAnd_nokiller. Unexpected beam loss around 7.00 am today
- STAR magnet trip ~6.45 am. CAS tried to bring the magnet up three times without success. Trying to ramp again now.
II. RHIC Schedule:
- Today:
- STAR Physics (after the magnet is ramped back)
- Tomorrow:
- STAR Physics
III. Items from shifts:
- Day shift:
- Lost a HV board in the STGC. STGC and MTD out of run on expert recommendation. Back in after two runs
- Stopped the run due to high rates in triggers associated with FCS. Called Akio and DO power cycled the LV
- BTOW Pmt Box 10 had empty histogram entries. Cycled the HV of PMT box 10 after run stop. Looking back at the QA histograms, that PMT box had missing entries since run 27 today
- Needed to reboot L4 to stop run for few runs --- likely from scheduled disc checks on Wednesday, shouldnt happen again
- Evening shift:
- Laser run: The QA plot of TPC drift velocity is empty ---- from QA plots not updating and needing to reboot jevp servers
- ITPC: Sector 4, RDO 2 masked out
- QA plots were not updating; read through the manual for it, and followed the instructions for both the "SHIFT" and "L4" server restart processes
- Overnight shift:
- Couple of time stgc QA plots showed missing hits, power cycled LV to bring back
- Jeff adjusted trigger rates to minimize deadtime
03/09/2022
I. Summary of operations:
- MCR did switch from Westinghouse to Siemens MG. Went well. RHIC injection polarization ~61%
- Extended the store from morning till 6.00 pm. Yellow abort kicker issues after the beam dump, fixed and beam back around 3 am
- Luminosity comparable to before, unexpected beam loss around 7.00 am today
- Very smooth shifts. No major issues
II. RHIC Schedule:
- Today:
- STAR Physics
- Tomorrow:
- STAR Physics
III. Items from shifts:
- Day shift:
- Persistent FST failure with error code 2. Taken out of runs. Included back in runs after expert changing FST current trip limit and alarm limit from 20 to 30 muA
- Jeff made rebalancing of trigger rates in production_pp500_2022 ---- Jeff will watch data rates and adjust if there is much deadtime
- Overnight shift:
- Vernier scan at start of store ---- MCR will be asked to let STAR know in advance of Vernier scan plans/schedule
- Multiple emcvme1_u5val low alarms, looked at GUI and everything turned white. Called Oleg who fixed the issue
03/08/2022
I. Summary of operations:
- Beams for STAR physics all day without much downtime
- Extended the last store yesterday till today morning to start a new fill ~7.00 am
- A few issues with BTOW, L2 error, but overall smooth runs
II. RHIC Schedule:
- Today:
- Siemens MG Changeover (behind long store for STAR): Change to Siemens (7-11), Hold store until ready to re-inject (~19:00)
- Tomorrow:
- STAR Physics
III. Items from shifts:
- Day shift:
- Trigger went 100% dead - due to high rates for FCS triggers. Couldn’t start runs due to FCS error "FEE count xx, expected 55”. DOs powercycled FEEs with help from Oleg
- Got BTOW crate 15 failed to configure a few times at start of run. BTOW so that crate 15 changed to manual configuration by Oleg
- Akio loaded new FCS tower gains, took test run near end of fill
- Evening shift:
- iTPC S12:1 masked out
- Much of BTOW is missing in critical plots. DOs called the expert: take it out of the run and power cycle LV, reapplied HV
- Stopped the run: BERT unexpectedly says "Physics OFF" but there's still beam in RHIC. Seems a connection issue
- Overnight shift:
- New missing hits in sTGC (hits/VMM) and sTGC (hits/Fob). Back in the new fill today morning ---- If the power cycling ROB didn't help, please ask the crew to power cycle entire LV. It seems crew power cycled wrong ROB (from Prasanth)
- Error message mid run 23067012 that BC1 timed out, "L2 stopping run”. On trigger component tree BC1 was red, TCD flashing red. TCD sys-reset and powercycling TCD VME crate didn’t help. Tonko fixed remotely ---- Separate issues from BC1 and TCD. TCD issue from Tonko updating the codes. For BC1 issue, powercycle the BC1 crate
- iTPC s12-1 unmasked
03/07/2022
I. Summary of operations:
- Got beams for STAR physics all day without much downtime
- Unexpected beam abort two out of three times
- Some issues with TPC, BTOW, ETOW, but nothing major during shifts
II. RHIC Schedule:
- Today:
- STAR Physics
- Tomorrow:
- STAR Physics, Change to Siemens MG behind a long RHIC store
III. Items from shifts:
- Day shift:
- ETOW and ESMD out for 2 runs due to configuration problem with ETOW crate 2. Back after powercycling of all crates and reconfigure
- iTPC sector 9, RDO 1 masked after three failures
- BTOW crate 15 required restart of run couple of times, also twice during evening shift ---- for crate 15, just restart the run
- Evening shift:
- Several runs had to be stopped due to various iTPC RDOs, not necessarily consecutively: S14:1(x2), S13:2(x3), S12:1(x2), S12:3
- iTPC RDO S13:2 is masked out
- Overnight shift:
- iTPC: sector 12, RDO 1 masked
- FCS started to show this error: FEE count 13, expected 26. This was fixed by Oleg after powercycling FEEs
- Critical plots for SHIFT not being updated, JEVP server needed to be restarted
- ETOW: configuration failed, DOs found that crates 5 and 6 were red, out of one run. Rebooted and reconfigured and back in run
- BTOW: configuration failed -- watch BTOW triggers or restart run. We restarted the run and BTOW trigger were firing at a too high rate. Reconfigured
03/06/2022
I. Summary of operations:
- STAR Physics through yesterday, not much interruptions
- FCS: DEP10:2 failed, was taken off runs from ~8.30 pm. Fixed and back in ~6.00 am
II. RHIC Schedule:
- Today:
- STAR Physics
- Tomorrow:
- STAR Physics
III. Items from shifts:
- Day shift:
- Overall smooth shift, with a power-cycle of an iTPC RDO, and a few ROB's (often #15) in the sTGC every once and a while
- iTPC sector 3, RDO 3 masked
- Incorrect number of events shown on RunMarker for several runs. Issue of monitoring programs not updating properly, but files were sent to sdcc fine
- Evening shift:
- btow crate 23 removed from automatic configuration, it is on manual control now (Oleg)
- Overnight shift:
- sTGC (hits/VMM) plot shows a line that appeared from run# 23065006 (see shift log)
- FCS fixed and included back in run. Masked RDOs iTPC sector 3, RDO 3 and iTPC sector 4 and RDO 2) also fixed by Tonko ---- Akio will follow up with Tonko so that there is more than one expert who can be contacted to fix the FCS issue
03/05/2022
I. Summary of operations:
- 56 x 56 bunches low luminosity run for alignment yesterday. STAR magnet was OFF. Got 6 hrs, till 8 pm
- CeC took access for 2 hrs. Back to high luminosity run ~11.30 pm
- Lost beam due to Quench Link Interlock around 3.00 am. MCR just got back a new fill
- Shifts were smooth, no major issues
II. RHIC Schedule:
- Today:
- STAR Physics
- Tomorrow:
- STAR Physics
III. Items from shifts:
- Overnight shift:
- Masked TPC: Sector 4, RDO 2 ----- Tonko will look into
- Day shift (Today):
- At start of run, got Caution messages about BTOW crate 23 (crate failed, config failed). Trigger scaler rates all look okay, except for Jpsi*HTTP which is ~400 Hz (expect 50) ------- Indicates misconfiguration of the crate, not to be ignored. Oleg will put this crate under manual configuration
03/04/2022
I. Summary of operations:
- AGS chiller work not finished yesterday. So was decided to provide fill for STAR and work behind it today
- Got beam around 04.00 am today (lost around 09.30 am), high intensity fill
- Shifts were smooth, no major issues
II. RHIC Schedule:
- Today:
- No APEX today. 56 x 56 bunches low lumi fill for alignment run. STAR magnet off. 6 hr fill expected
- Tomorrow:
- STAR Physics
III. Items from shifts:
- Overnight shift:
- sTGC out of one run due to communication loss. DOs fixed the problem by powercycling the crate 1 and bringing back the LV modules. Happened once also on todays Day shift ----- No need to take sTGC out of run, fix and include back in the run
- Getting messages ‘TPX TDBm: error setting up -- TPX might not work! ’. Been happening for all runs since ~05.30 am. DAQ and online plots for TPC looks ok ------- likely communication issue, need to powercycle TDM board. Tonko will follow up with shift
03/03/2022
I. Summary of operations:
- Low luminosity run yesterday night with vernier scans at beginning and end of fill
- MCR has injector issues, working on fixing those now. STAR is open for access. MCR expects at least 6 hour down time, possibly longer
- Shifts were smooth, no major issues
II. RHIC Schedule:
- Today:
- STAR Physics (after beam is back)
- Tomorrow:
- 08:00-14:00 APEX
- 14:00-16:00 CeC Access
- 16:00 - STAR Physics
III. Items from shifts:
- Smooth shifts, no major issues
03/02/2022
I. Summary of operations:
- Generally smooth data taking, but some issues with TPC
- Fills are lower luminosity (peak 400 kHz), mostly correlated with blue intensity
- Took runs with modified DX angle and low luminosity run with missteered beam at end of fill last night
II. RHIC Schedule:
- Today:
- 7:00-11:30 CeC access
- 12:00-17:00 APEX
- 17:00 - STAR low lumi. fill
- Tomorrow:
- STAR Physics
III. Items from shifts:
- Day shift: Got beam around 1.15 pm. Smooth shift
- Had a problem with TPX[4] died/rebooted, was taken out for one run
- Evening shift: Smooth Physics runs, some TPC issues (19:00-)
- The itpc20 node died. iTPC rdo S20:4 masked out
- tpx and itpc were going 100% persistently dead, masked out iTPC: RDO S13:3 ----- Both channels to remain masked out. Tonko looking into it, suspects a hardware issue
- Owl shift: Smooth Physics runs
- Issue with laser and cathode HV GUI, David restarted VME crate to bring back
- Lost laser in the middle of the run (~06.00 am) ---- Alexei checked laser today morning, works fine
03/01/2022
Period coordinator change: Zaochen Ye ==> Sooraj Krishnan
I. RHIC Schedule
- Today: Collision for Physics
- Local pol test with DX angle (any opportune end of store)
- Tomorrow: 7:00--
- 7:00-11:30 CeC access
- 12:00-17:00 APEX
- 17:00 - STAR low lumi. fill
II. Notable items/recap from past 24 hours: Smooth Physics
III. Items from shifts:
- Day shift: Smooth Physics runs (ended ~11:15am) + Cosmic runs
- Masked out iTPC sector 13 RDO 3
- Alexei restarted Laser PC, fixed laser GUI no-response issue
- Akio uploaded a new electronic gain file for FCS ECal, Jeff updated associated production ids
- Evening shift: Smooth Physics runs (19:00-)
- sTGC lost communication, and both crates had to be rebooted and powercycled
- BEMC sector 10 had hits missing for half a run. Had to be powercycled
- Owl shift: Smooth Physics runs
IV. Other items: may request to reduce CeC and APEX time to get more physics runs
02/28/2022I. RHIC Schedule
- Today: Collision for Physics
- will have a local pol test with DX angle 14:00, nominal end of store 14:25
- Tomorrow: Collision for Physics
II. Notable items/recap from past 24 hours: Cosmics + Smooth Physics
III. Items from shifts:
- Day shift: (first a few hours) Cosmic runs + (11:15) Smooth Physics runs
- many auto-recoveries in TPX, iTPC, TOF
- sTGC error "ROB #01 bad FEB.”, powercycle ROB #1
- FST 100% dead, no errors in scrolling DAQ messages. Power cycled FST.
- Evening shift: Smooth Physics runs when beam available (no beam: 19:00-21:00)
- TPC Anode Trip, GMT HV needed powercycling
- Owl shift: Smooth Physics runs
- missing bins in EEMC Tower ADC plots, expert power cycled crate 92, and performed master reload
- laser control GUI (where the camera is controlled) froze, Alexei will investigate during day shift
- ITPC: Sector 23, RDO 4 -- powercycle then restart run (several times)
Other discussions: request low lumi runs (Wed or Thu ?)
02/27/2022
I. RHIC Schedule
- Today: Collision for Physics till Monday morning, exchange the cathodes (~ 2 hours)
II. Notable items/recap from past 24 hours: Cosmics + Physics + Cosmics
III. Items from shifts:
- Day shift: Cosmic runs + 3 Physics runs
- node TPX[19] removed / masked from run configuration
- Evening shift: 13 Physics runs
- node TPX[19] removed / masked from run configuration
- Owl shift: 5 Physics runs + Cosmic runs
- TPX: RDO S01:6, TPX: RDO S01:3, ITPC: Sector 1, RDO 4, ITPC: Sector 10, RDO 3
- partial trip of BTOW PMT 10
- Beam lost ~2:40 (failure of a Yellow Abort Kicker, requires a Thyratron replacement)
Other discussions: CAD should do a better job to deliver beam
02/26/2022
I. RHIC Schedule
- Today: Collision for Physics till Monday morning, exchange the cathodes (~ 2 hours)
II. Notable items/recap from past 24 hours: Cosmic runs
III. Items from shifts:
- Day shift: Cosmic runs
- Alexei changed a burned mirror for East laser (camera 3), more laser tracks on East part of TPC
- 12:37 Tonko fixed a bug in the ROB firmware which caused odd behavior under sparse data taking conditions (cosmics, low lumi runs). The new code version is 0x126 (old, up to now, was 0x124)
- Evening shift: Cosmic runs
- Owl shift: Cosmic runs
- sTGC air flow alarm went off, slow control issue
- Tonko: “Now all STGC RDOs have the newest firmware version (0x126).” 4:40am
02/25/2022I. RHIC Schedule
- Today: 7:30 access to exchange garages, start bake load-lock chamber (~ 8 hours)
- Collision for Physics till Monday morning, exchange the cathodes (~ 2 hours)
II. Notable items/recap from past 24 hours: Access + Low lumi + Smooth Physics
III. Items from shifts:
- Day shift: Smooth physics till 13:30 + CeC Access
- A few powercycles of iTPC RDO, sTGC ROB, BTOF, DAQ
- Evening shift: Low lumi runs till 21:13 + normal physics runs started 23:59
- testVernierScaler, forwardCrossSection, zdc_Polarimetry_2022
- trigger was 100% dead. sTGC plots looked abnormal, and had missing tiles, stgc_n_sigma reset to 12 and 8, taking a production run to check what the issue is with sTGC, still open issue (days to solve) will request another low lumi runs after figure out sTGC issue
- MXQ crate had to be powercycled
- Owl shift: Smooth Physics runs till 5:30 am (beam lost)
- False magnet trip alarm, apparently due to communication or slow control glitch
- BEMC PMT box 10 west partially tripped, solved by reapplied HV
Others: if plan to make use of the access time, please bring up
02/24/2022
I. RHIC Schedule
- Today: 14:00-24:00 STAR Low lumi. Fill with Field on (Forward experts should watch the online plots to make sure detectors are running good)
- Friday: Aperture scan and crossing angle for local pol. measurement
II. Notable items/recap from past 24 hours: Access + Smooth Physics
III. Items from shifts:
- Day shift: Access
- Evening shift: Smooth Physics started from 18:33
- Owl shift: Smooth Physics
- FCS: persisting errors “FEE count 44, expected 5”. FCS GUI no responding, Oleg power cycled FEEs manually cleared error message, however the GUI is still frozen, solved by restart IOCs
- iTPC node 13 died at end of the evening fill, back online after powercycle corresponding computer
02/23/2022I. RHIC Schedule
- Wed: 7:00-13:00 Maintenance
- Thu: 16:00-24:00 STAR Low lumi. Fill with Field on
II. Notable items/recap from past 24 hours: Smooth Physics
III. Items from shifts:
- Day shift: CeC access + Smooth physics + AGS Snake issue
- TPC gating grid lost communication, solved by reboot software
- Evening shift: Smooth Physics + a few issues
- Dimuon triggers were not included in time
- "Incorrect Trigger Clock 76 MHz" error due to stuck in PLL. Had to powercycle TCD and turn MXQ on
- FCS PS channel U302 got stuck. Power cycling MPOD crate recovered that channel
- Owl shift: Smooth Physics
IV. Access today:
- Tonko: DAQ tests with TPX and iTPC, don't need access but no runs with Run Control, finished 10:15.
- MTD group: 2.5 hrs with field cosmics after Tonko’s test. MTD HV 13.2 kV to check eff. Vs. 13 kV
- Wayne:
- replace a disk in the computer named deneb, on the 2nd floor of the South Platform
- apply some routine software and OS updates to the shift-leader PC in the Control Room
02/22/2022
I. RHIC Schedule- Today: 10:00-12:00 CeC access, after will be Collision for physics
- Wed: 8:00-16:00 Maintenance
- Thu: 16:00-24:00 STAR Low lumi. Fill with Field on
II. Notable items/recap from past 24 hours: Smooth Physics
III. Items from shifts:
- Day shift: Smooth physics
- BTOW: PMT box 10 west partially tripped. Solved by reapply HV
- Evening shift: Smooth Physics
- MTD HV BL 24-30 HV cannot be set to full from standby at first try, second try succeed
- ETOW crate Id 5 configuration failure, solved with expert’s help
- Owl shift: Smooth Physics
- BTOW: PMT box 10 west partially tripped. Solved by reapply HV
- sTGC error: 1: FOB 4 (R#13:F#77) NOT found, power-cycle ROB #13
02/21/2022
I. RHIC Schedule- Today-Tuesday morning: Collision for physics
II. Notable items/recap from past 24 hours: Smooth Physics + a few issues
III. Items from shifts:
- Day shift: Smooth physics
- GMT -> APV -> pedestals_APV_0-3 pulse height for all channels in ARM:0, APV0 shows a second band and scattered values all throughout
- BTOW Crate Id 1: Oleg put under manual control -> Watch trigger rates and reconfigure if needed
- Evening shift: Smooth Physics
- Global communication problem, fixed by David
- "too many recoveries - powercycle TOF LV”, Tray 67 (dead, masked out) was accidentally enabled by DO, which caused the failure of auto recovery. Zaochen updated instruction to reduce the mistake
- Owl shift: Physics run + issues
- DAQ issue: EVB[3] [0xF103] died/rebooted) EVB3 is suggested to be out of run for now. writing data issue (No space left on device)
- error " Incorrect Trigger clock 10.000 MHz”, solved by powercycle TCD and turn on MXQ from off. Tonko:”One TCD board was stuck and couldn’t lock its PLL, it happens after too many Trigger reboots”
- high rates of JetPatch triggers, solved by reconfigure BEMC. Related to TCD powercycle.
- 6:17am, TPC Gating-grid monitor lost connection, need access to powercycle hardware (8:50am, Tim cycled crate 50, gating grid control is back now)
- IOC for sTGV LV lost connection, solved by David
- Laser brightness has no response to control, drift velocity looks normal. Alexei fixed this.
02/20/2022
I. RHIC Schedule- Today-Tuesday morning: Collision for physics
II. Notable items/recap from past 24 hours: Smooth Physics
Main discussions: Carl: "correct" bunch crossing has barely more hits than any of the visible out of time bunches. In this environment, it’s impossible to see if 2-5% of the triggers are late by a RHIC tick. We’re going to need a 28 or 56 bunch fill to answer this question. ZDC_Polarimetry runs can go back to “TRG + DAQ only”, Will try “TRG + DAQ + FCS” on sometime in middle of next week (Wed-Fri, decide in schedule meeting?)III. More items from shifts:
- Day shift: Smooth physics
- FST plots were empty during run, but filled after run stops.
- JP triggers hot, solved by restart run
- Run stopped by EQ crate, solved by power cycle and reboot trigger then restarted run
- Evening shift: Smooth Physics
- PMT box 10 west partially tripped, solved by reapplied HV
- from run 23050064: "dimuon" and "hit_dimuon_mon" are on Enabled list
- Owl shift: Smooth physics run
- BTOW Configuration failed for crate 1 (will mask out from auto configuration, do similar thing as crate 8)
02/19/2022
I. RHIC Schedule- Today-Tuesday morning: Collision for physics
II. Notable items/recap from past 24 hours: Smooth Physics when beam available
- GMT HV alarm went off, HV has no response to “Physics” or “Standby” mode in GUI, Nikolai fixed the GMT. It had lost connection. Fixed by rebooting the crate and restarting the controls
III. More items from shifts:
- Day shift: Physics started 10 am
- sTGC air blower, solved and discussed yesterday 10 am
- Alexei fixed TPC air blower
- Evening shift: Smooth Physics
- Owl shifts: Smooth Physics run (till 5:30, injection issue, solved 7am)
- FCS FEE LV caused missing hits in FCS ECal's North 18~24 and high rates of FCS ECAL triggers. Resolved by powercycling FCS FEE LV
- BTOW Configuration failed for crate 1 (23050011, 23050013) and L2 issues (23050016)
- iTPC errors (S2, RDO 1; S16 RDO 1). Tonko fixed
IV. other items:
- zdc_polarimetry runs please do with (TRG+DQA+FCS)
02/18/2022
I. RHIC Schedule- Today-Tuesday morning: Collision for physics
II. Notable items/recap from past 24 hours: Snake scan + Physics + IssueMain issues:
- TPC gas alarm at 03:35 and called Prashanth and Alexei.
- 4:20 there was a power dip, which caused magnet trip, problems with water system and sTGC blower trip.
- Alexei and Prashanth fixed the TPC gas and water issues, CAS brought back the magnet
- 7:10 Tim and Mike access to fix issue with sTGC air blower (6:00, MCR: a spark in ion source). Compressor not running, after replaced compressor contractor, Compressor is now running. Replaced LV relay for preventative maintenance. Mike connected aux contacts from compressor relay to monitor contractor state. Tim replaced sTGC AHU Contactor, Capotosto added remote monitoring for contactor state to sTGC interlock cabinet. Just fixed all issues, sTGC can be added in the run now.
- GMT HV alarm went off, HV has no response to “Physics” or “Standby” mode in GUI, issue is still open
III. More items from shifts:
- Day shift: snake scan for spin direction
- BTOW is flashing blue (W) for >30 minutes
- Evening shift: Smooth Physics while beam is available
- Beam came at 19:35, beam lost at 21:12, beam back at 23:20
- Owl Shift: Smooth physics run
- Trigger: BBQ and EQ2 VME crates tripped, then L2 was stopping the run. Powercycling BBC and EQ2 crate and rebooting the trigger solved the problem.
- Online plots issues of TPC, MTD and ESMD.
IV. other items:
- Request for 2 polarimetry runs at the end the fill
02/17/2022
I. RHIC Schedule- Today: 8:00-14:00 Snake scan for spin direction
- Tomorrow: Collision for physics
II. Notable items/recap from past 24 hours: General: APEX + Smooth physics
- Main issues: A mistake to assign channel 1 of the 2nd board to channel 1 of the 1st board. So the channel was not turned on when controlled by the GUI. David fixed it and HV is back on that sTGC chamber. Online plots back to normal.
III. More items from shifts:
- Day shift: APEX
- Alexei replaced GMT tank-1
- David found HV channel was mis-mapped, online plots shows normal
- Evening shift: Smooth Physics started 21:40
- JP1 was high due to hot trigger patches on crates 0E, 0D, 05, solved by power cycle. However, crates 0C, 07, 0F was not get configurated at start of next run. Oleg Tsai helped manually configure these crates.
- Owl Shift: Smooth physics run
- high JetPatch trigger rates, Oleg manually configured BTOW crate 1E. Restarted run, JP rates are normal.
- Twice problems when stopping run (EVB[5] [0xF105] died/rebooted; ITPC[23] [0xBF97] died/rebooted)
IV. other items:
- Remind shiftcrew to check more frequently on the critical plots
02/16/2022
I. RHIC Schedule- Today: 9:00-19:00 APEX (Au, 3.85 GeV/n)
- Tomorrow: 8:00-19:30 Siemens test and Rotator scan?
II. Notable items/recap from past 24 hours: General: Access + Smooth physics (Owl)
- Main issues: David, Prashant, Mike, Tim installed sTGC HV boards to MTD CAEN HV crate, rerouted and reconnected HV and interlock cables. However, sTGC still looks strange in test pedestals and cosmic runs. Experts will check on RDO and others
III. More items from shifts:
- Day shift: Access
- David, Prashant, Mike, Tim installed sTGC HV boards to MTD CAEN HV crate, rerouted and reconnected HV and interlock cables. However, sTGC still looks strange in test pedestals and cosmic runs
- Jeff cleaned up and changed some cables for iTPC DAQ machines
- Evening shift: Physics run started 23:50
- Owl shift: smooth physics run
- 2B quadrant was empty in sTGC (hits/Quadrant) online plots.
- Masked ITPC: Sector 11, RDO 4
IV. Other items?
02/15/2022
I. RHIC Schedule- Today: 7:00-15:30 maintenance, then collisions for physics
- Tomorrow: 9:00-19:00 APEX (Au, 3.85 GeV/n)
II. Notable items/recap from past 24 hours: General: Access + Smooth physics run
- Main issues:
- sTGC HV GUI lost connection, David and Tim checked sTGC CAEN HV crate, no solution, run without sTGC
- Partial trip of BTOW PMT box 10 West, solved by reapplying HV to this PMT box
III. More items from shifts:
- Day shift: Access
- sTGC bad chamber was checked by Prashanth and Tim, will order parts and replace later
- FST coolant refilled by Xu and Yu
- Wayne fixed issue with BBC_DSM2 and BCW_DSM2, if same problem happens, call trigger experts first, may call Wayne later.
- Evening shift: Access + Smooth physics run
- sTGC HV GUI lost connection, David and Tim checked sTGC CAEN HV crate, no solution, run without sTGC
- Owl shift: smooth physics run
- no sTGC in the run
IV. Other items?
02/14/2022
I. RHIC Schedule- Today: 7:00-15:30 maintenance, then collisions for physics
- Tomorrow: 7:00-15:30 maintenance, then collisions for physics
II. Notable items/recap from past 24 hours:
- General: Smooth physics run
- Main issues:
- Error configuring BBC_DSM2 Node and Error configuring BCW_DSM2 Node. Reboot all did not help. Powercycling the corresponding VME crates and reboot all did not help either. Had to take out BBC_DSM2 and BCW_DSM2 from the Component tree (experts are working on it)
- Tonko masked Crate Id 8 from _any_ configuration, Oleg shows how to manually reconfigure BTOW crate 8, will need to keep watching the performance
III. More items from shifts:
- Day shift: smooth physics run
- BTOW crate 8 config. Err., Tonko: disable à rates too high à keep old procedure
- Online QA plots lost, solved by reset jevp server
- Lost connection of sTGC LV, solved by David T.
- Evening shift: smooth physics run
- iTPC: Sector 4, RDO 3 powercycled
- sTGC LV errors, solved by power-cycle
- BTOW: PMT box 10 west partially tripped, solved by reapply HV
- Owl shift: smooth physics run
- Error configuring BBC_DSM2 Node and Error configuring BCW_DSM2 Node, moved out from the Component tree
IV. Other items?
- Access plan on Monday-Tuesday (8 hrs each day)
- Magnet maintenance: Water Supply Group will be cleaning the strainers in the STAR magnet power supplies during the maintenance on Monday. This involves de-energizing STAR magnets.
- FST: Refill the coolant for FST, need about 30 mins for the fill then 20~30 mins cosmic runs to verify
- others?
02/13/2022
I. RHIC Schedule- physics run
II. Notable items/recap from past 24 hours:
- General: Smooth physics run
- Main issues:
- DO had difficulty to reboot CANBUS to solve BTOF LV errors, due to the mistake in password list
- Several EVB errors
- BTOW configuration errors happen many times from crate 8 (Oleg will provide solutions for the shifts to help reduce the down time for the data taking)
III. More items from shifts:
- Day shift: smooth physics run
- BTOW configuration issues solved by restarting run while waste a lot of beam time (experts will provide better solution)
- 2: FOB 2 (R#14:F#81) NOT found -- power-cycle ROB #14
- 2: FOB 2 (R#14:F#81) NOT found -- power-cycle ROB #14
- Evening shift: smooth physics run
- Power-cycle BTOF LV
- sTGC "3: FOB 0 (R#07:F#37) NOT found" errors, and we power-cycled ROB #07
- sTGC "4: FOB 3 (R#16:F#94) NOT found" errors, and we power-cycled ROB #16
- "EVB[3] [0xF103] died/rebooted"
- "BTOW: failed crate Ids: 1; BTOW: configuration failed - watch BTOW triggers or restart run."
- Owl shift: smooth physics run
- l4 got stuck at the end of several runs, “EVB[3] [0xF103] died/rebooted”, “EVB[4] [0xF104] died/rebooted
- BTOF LV errors, get difficulty to reboot the CANBUS due to the mistake in password list
- a few BTOW Configuration failed for crate Id 8 and once for crate Id 1
- iTPC RDO S20:1 was masked
Other items?
- Access plan on Monday-Tuesday (8 hrs each day)
- Magnet maintenance: Water Supply Group will be cleaning the strainers in the STAR magnet power supplies during the maintenance on Monday. This involves de-energizing STAR magnets.
- FST: Refill the coolant for FST, need about 30 mins for the fill then 20~30 mins cosmic runs to verify
- others?
02/12/2022
I. RHIC Schedule- physics run
II. Notable items/recap from past 24 hours:
- General: smooth physics run
- Main issues:
- Lasers had no respond to controls well. Brightness does not change when pressing control button. Called Alexei.
- East laser was fine for two laser runs, West laser was far from normal brightness
III. More items from shifts:
- Day shift: physics run, short access, physics run
- Issue with L2, solved by reboot trigger
- Jeff fixed the TOF+MTD noise run rate, runs ~14 kHz now.
- 13:00-14:30: David and Prashanth refilled the sTGC n-Pentane
- Evening shift: smooth physics run
- Power-cycle iTPC sector 14, RDO 3 (twice)
- BTOW configuration failed, restarted the run
- "tpc_caen_alive" alarm went off, fixed by following manual
- sTGC “3: FOB 2 (R#11:F63) NOT found”, fixed by power-cycle sTGC LV ROB #11
- Owl shift: smooth physics run
- iTPC RDO S14:3 and S16:3 were masked out, (had error in 2 consequent runs
- FCS error in DAQ, solved by restarted the run twice
- sTGC LV: 2: FOB 3 (R#10:F#58) NOT found -- power-cycle ROB #10 if the problem persists.
Other items?
- Lumi was a little too high than usual during Owl
- sTGC cable(chamber) 9
- Access plan for Monday-Tuesday
02/11/2022
I. RHIC Schedule- Plan from RHIC
- Collisions for physics now to Sunday
II. Notable items/recap from past 24 hours:
- General: APEX and smooth run
- Main issues:
- - sTGC: HV cable 9 trip
III. More items from shifts:
- Day shift: physics run at the beginning, then APEX
- - 10:00, Power dip, magnet tripped, lost slow control. Experts solved the problem.
- Evening shift: APEX ended around 22:00, Physics from 22:30
- - sTGC HV cable 9 tripped, ran without this channel
- Owl shift: very smooth physics run
- - TPX 36 config error, solved by powercyle TPC FEEs and Reboot All (Comments: Reboot All is not necessary but no any harm)
IV. Other items?
-
02/10/2022
I. RHIC Schedule- Plan from RHIC
- 8:00-16:00: LEReC APEX: 3:85 GeV/n Au
- Today 16:00-Tomorrow 16:00: Collision for physics
II. Recap
- General: Rotator study, low lumi run (18:00-4:15am), 7:00 am normal physics run, smooth
- Main issues:
- sTGC: LV unresponsive, solved by short access (18:55).
- sTGC HV cable 9 trip, experts will discuss for a solution today
- Timing during alignment fill, “extra” peak in preshower, ECal and HCal 8 time bins before “right” peak… (Carl Gagliardi), experts will follow up later.
III. More items from shifts
- Day shift: Rotator study
- 12:43: Wayne replaced the monitor for EPD-CR
- Evening shift: low lumi run
- sTGC: LV1 is unresponsive, after a short access, run smoothly for the rest of the shift.
- Owl shift: low lumi run till 4:15am, then normal physics 7:00am
- sTGC HV Cable 9 trip, still open
- BTOW configuration cautions, Rebooting not help but rates and critical plots are good
IV. Others items?
- Battery for the clock replaced
- fast offline data production request for forward detector calibrations with the low lumi runs.
02/09/22
I. RHIC Schedule
- Today's plan:
- 08:00 - 14:00: Rotator study
- 14:00 - 23:59: STAR low luminosity run (for alignment; magnet off, 0.2e11/bunch, 8 hr, 56x56)
- 00:01 -8:00: collision forphysics
- Tomorrow’s plan:
- 8:00-16:00: LEReC APEX: 3.85 GeV/n Au
II. Recap
- Main issue in past 24 hours:
- 14:17: EEMC (ETOW, BTOW) config errors, “GUI is white” seen from SC3 but not seen in control room. (15:12) Dmitry K "Recovery & Restart", turned HV and MAPMT FEEs back on
- sTGC cable 9 HV trip, David fixed it, after 2 hrs run, tripped again, David T. checked on it (see his email). HV current frequent spikes even at a lower voltage may due to the dust in chamber. If this happen again, don’t need to take out sTGC from data taking. Just make a note which channel/cable tripped, i.e. is not at full voltage in the run. Tripped again during OWL, under David T’s control
- 23:44, EPD GUI is saying that the current is too high for most channels, not affect data taking. Rosi pointed out that current values were fine, a problem with GUI, she will follow up with EPD maillist.
- Open issues:
- sTGC cable 9 HV trip, David T. will work on it this after noon, during the low lumi run.
- Day shift: smooth run from the beginning to the end
- Jeff fixed the issue effecting the sTGC critical plots (y-axis range).
- Issues with BTOW and ETOW, Dmitry K worked on it.
- EVB12 was out for a while in a run, back in next run
- sTGC LV issue, fixed by David.
- sTGC cable 9 HV trip. After clearing trip and ramping up the channel tripped again. David advised a temporary solution of manually setting demand voltage to 2K until he fixes it. David fixed the issue. 16:18, same issue came again.
- Evening shift:
- "GUI is white" when trying to access slow controls from SC3. Followed manual section "Recovery & Restart", turned HV and MAPMT FEEs back on – Dmitry Kalinkin
- EPD GUI is saying that the current is too high for most channels, however not affect data taking. Rosi said current values were fine, a problem with GUI, she will follow up with EPD maillist.
- TOF critical errors around 8pm, POWERCYCLE TOF LV. Tried to power cycle at least twice, no luck. Geary instructed us to try one more time as the problematic trays are different.
- Display for EPD computer went off. Michael will work on it in the morning
- Overnight shift: Beam and physics for all time
- Major issues with the sTGC Cable 9 HV supply.
- sTGC cable 9 HV trip, slowly increasing HV by +10V or +5V, reached full, then tripped again, David worked on it.
- BTOW configuration cautions at the start of each run. Rebooting BTOW in Run cotrol or restarting run did not help. Rates and critical plots look OK, keep running.
- TOF ADC critical plot: One run (23040009) had ADC entries at ADC = 15 and ADC = 30 for all channels. Restarting the run helped.
- Relatively many TOF auto-recoveries. Apart from the run mentioned above, no indication of problems in the critical plots.
- Had to powercycle a couple of iTPC RDOs manually which helped.
02/08/22
I. RHIC Schedule
- Collisions for physics today
- Tomorrow’s plan:
08:00 - 14:00 Rotator study
14:00 - 22:00 STAR low luminosity run (for alignment; magnet off)
II. Recap
- Machine development all day yesterday, beam back later in evening shift
- EEMC QA plots having issues during day shift (first note @ 07:54), needed short access after MD (before physics) and replace HVSYS module A
- In overnight shift: ETOW error messages in DAQ for crate 6 -> No success in fixing issue overnight; today’s morning shift advised to power cycle the crate and then issue a master reset; noted: this is the procedure, no need to contact on-call expert for this
- Period coordinator shift changeover Matt -> Zaochen
III. Open issues/status
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-February/006606.html)
02/07/22
I. RHIC Schedule
- Machine development unitl around 17:00, back to physics after
II. Recap
- In terms of sampled luminosity, yesterday was best day so far: 6.1 pb-1 w/ 18.5 DAQ hrs
III. Open issues/status
- Discussed prospects of dedicated aligment/forward cross section runs. Potential to do alignment run Wed and cross section run Fri. Will be discussed during sheduling meeting, etc.
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-February/006594.html)
02/05/22
I. RHIC Schedule- Collisions for physics all weekend
II. Recap
- No beam 6:45 until around ~17:00
- sTGC HV slowly ramped up during shifts; new temporary ramping procedure for cable 9 (see overnight shift log and https://lists.bnl.gov/mailman/private/star-ops-l/2022-February/006575.html)
- Warning from TPC computer (chaplin): running low on GPU memory, usage at 99% (18:01)
- Two TOF FM2 red alarms in overnight shift. FM2 plot shows sudden spikes (04:47)
III. Open issues/status
- Discussed on making the new temporary sTGC HV ramp the same for entire sTGC (i.e., automated)
- BTOW crate 8 error - Noted shifts should just stop and restart run
- Note on various reported high rates in logs, at beginning of fill this is expected, Jeff may change the baseline rate used to determine color-coding in monitor
- Need to follow up with Wayne on TPC computer (chaplin) GPU memory usage warning
- Alexie following up on current laser issue and TOF FM2 alarm
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-February/006577.html)
02/04/22
I. RHIC Schedule- MCR access until 12:00, about 2 hrs to get back to physics
II. Recap
- Physics running started around 22:50 due to long injection tuning
- Lots of errors overnight (see below), however no major downtime
- sTGC HV trip for plane 2 cable 9. Powercycled the HV - Investigation still ongoing
- sTGC LV (23:31) powercycled after getting following error: “ROB-15: FOB 1 (R#15:F#86) NOT found -- power-cycle ROB #15 if the problem persists” - This is also a correction note w.r.t. minutes sent durectly to star-ops
III. Open issues/status
- Tentative plan to do rotator measurements/corrections Monday during day
- When beam comes back today, add BBC back into run for testing
- Investigation of sTGC HV ongoing.
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-February/006569.html)
02/03/22
I. RHIC Schedule- APEX 9:00 - 17:00. Followed by physics.
- Tomorrow: CeC access ~7:00 for 3 or 4 hrs; TBD if machine development with follow, or back to physics
II. Recap
- All contingent activities for APEX running were solved, so APEX will run today ~8hrs (started at 9)
- Tomorrow’s afternoon activities still TBD
- Identified incorrect terminating resistor on injection kicker (40 -> 25 ohm); will fix during tomorrow’s access, should improve performance
- TOF HV turned off during evening shift, values frozen in GUI indicated “on” (fixed with "IOC reset FULL” and ramping HV)
III. Open issues/status
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-February/006560.html)
02/02/22
I. RHIC Schedule- 07:00 to 11:00: RHIC access -- CeC clean room, Booster access for foil, back to physics
- Thur: 09:00-17:00: APEX (if ready). Followed by physics.
- Fri: 07:00-12:00(?): RHIC access injection kicker module replacement + CeC access; imperfection study after(TBD)
II. Recap
- Two (last minute) Vernier scans in day and evening shifts - Will update crew checklist to note what to do if this happens again
- Booster RF power amplifier leak, extended evening shift fill, no beam after 2:55
- Major issue with DAQ starting @ 18:20. Jeff stepped in and was able to eventually pinpoint the problem. Noted computer disc may need to be changed - Done by Tonko
- Alarm for VME crates, lost communication and QA plots. David worked on this for awhile. Decided access is needed (23:43). Accessed today at 9:30 - eveything should be OK now
III. Open issues/status
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-February/006549.html)
02/01/22
I. RHIC Schedule- Collisions for physics
- Tomorrow: likely APEX from 9:00 - 17:00
II. Recap
- No beam from ~7:00 -~19:30 yesterday
- Smooth running once beam returned
- TOF gas changes twice in past 24 hrs
- JH will bring up request for low intensity run for forward x-sec and alignment runs @ RHIC coordination meeting; alignment run will need magnet off, warmer ambient temperatures should be considered when doing this
- David will increase current alarm for sTGC from 200 micro amps to 300
III. Open issues/status
- ETOF HV proceedure has been changed, shifters should change to OFF for all states
- APEX runing for tomorrow contingent on a few ongoing RHIC/AGS activities. If postponed, tomorrow will be physics, and APEX will run Thursday
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-February/006531.html)
01/31/22
I. RHIC Schedule- Collisions for physics
II. Recap
- Luminosity highest in recent fills; improvement in RHIC polarization (~50%)
- Issues at linac, unclear when will be fixed
- Afternoon access requests: CeC 4 hrs, Jet 1/2 hr; may be earlier in morning -> Will hear back from MCR/Vincent et al. shortly on schedule
- Relatively smooth running over past 24 hours
- Sampled luminosity: 5.1 pb-1 w/ 15.5 DAQ hrs; today 1.5 pb-1
- Forward x-sec strawman trigger config test with low lumi in run 23030047 - will request fastoffline production
III. Open issues/status
- Day shift will take a laser run ASAP to see if they can get West laser working; if problems Alexie may go in to make some adjustments
- David will make changes to alarm handler (see FCS HCal PS issue in elog in overnight shift)
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006515.html)
01/30/22
I. RHIC Schedule- Collisions for physics
II. Recap
- Very smooth running over past 24 hours
- Sampled luminosity (note with updated x-sec): 4.6 pb-1 w/ 16.5 DAQ hrs; today 2.2 pb-1
- Forward x-sec strawman trigger config test in Run 23029038; todays test at end of fill should aim to have MCR displace beams to achieve ZDC rate between 10-20k (~10 min); request offline to produce runs ASAP
III. Open issues/status
- Will test forward x-sec strawman trigger config today with low lumi beams at end of next fill
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006495.html)
01/29/22
I. RHIC Schedule- Collisions for phyics over weekend
II. Recap
- Weather conditions very bad due to winter storm. So far no major issues reported
- Sample luminosity: yesterday: ~4 pb-1 w/ 17 DAQ hrs; today: ~1 pb-1
- Updated Vernier scan x-sec: 2.06 mb, all plots will be updated with new value
- Very high JP1, JP2, ETH1, … rates noted in Run 23028049, had to power cycle and reconfigure EEMC (with experts), also next shift noticed high JP1 rates in one run
- Ground fault of substation 6A @ 7:22 (another at 10 AM), addressed promptly by CAS watch
- Forward x-section measurement strawman trigger configuration provided by Jeff, tested in Run 23028062 (in between fills). Test today @ end of fill - 5 min needed (note: another test tomorrow with beam steering for low lumi.)
III. Open issues/status
- Forward x-section measurement strawman trigger configuration will be tested today at end of fill. Should also be tested tomorrow with a lower luminosity
- Shuai: will update dimuon timing window trigger configuration
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006485.html)
01/28/22
I. RHIC Schedule- Collisions for physics over weekend
II. Recap
- ZDC polarimetry done during rotator test
- FCS gain tests after rotator test (some thresholds changed after)
- Smooth running when beam came back during overnight shift
- sTGC settings changed in evening shift, some “spikes” seen in QA plots (02:33)
- New PROM check run added by Tonko to be done before; will update detector readiness checklist
- Vernier scan was performed, preliminary cross section is lower than Run17
- Carl proposed we take out dimuon trigger for first 1.5 hrs of a fill, and agreement was reached. This has to be done manually by shifters. Jeff will conveniently move where the SL can do this on the computer to be right next to laser run trigger.
III. Open issues/status
- We should start planning the low luminosity runs (as early as next week). Jeff is working on the configuration, once ready we will ask MCR to steer the beams to lower rates and take a run with this configuration at the end of a fill
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006475.html)
01/27/22
I. RHIC Schedule- CeC will take 4 hrs of dedicated time
- 1/2 hr coupling test
- Rotator test after CeC/coupling test (STAR will do zdc polarimetry runs as we did last rotator scan, one before and after rotator ramp, we will also do a FCS gain check at the end of store for ~30 min.)
- Back to physics
II. Recap
- Blue injection efficiency is getting worse every fill, reducing luminosit
- AGS polarization also seems to also be decreasing
- Smooth running after maintenance, albeit with lower intensity
- Various maintenance day activities compled yesterday, see elog for details
III. Open issues/status
- Jeff/Tonko: doing a few checks today, but may begin to have a daily PROM check run
- Daniel: sTGC will have SL update configurations for pedestals
- Hank: still investigating BBC crate issue
- Xu: Current in problematic FST module seems to be stabilizing. Will keep an eye on for next 24 hrs, and may start to slowly ramp HV back up
- David: Now has updated manuals ready for sTGC, also compressor monitoring
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006456.html)
01/26/22
I. RHIC Schedule- Maintenance from 7 AM until around 3 (likely till 5 or so) PM, back to collisions for physics
- Tomorrow: 4 hrs for CeC starting after natural end of a fill, some time between 9-12
II. Recap
- 3 good fills yesterday, one fill this morning with reduced luminosity
- Yesterday: sampled lumi 4.1 pb-1 w/ 17 DAQ hrs; Today: 1.2 pb-1
- Crew enable BBC readout on evening shift as requested by Hank
- Overnight L2 timeout error was from MXQ, not BBC. Will work on making this more explicit for shifters
- New items during maintenance time:
Hank/Jeff, will need control system to test new tier 1 file, will convene around 15:00 to start
Akio, work on EPD
III. Open issues/status
- Manual for sTGC will be updated with current procedures
- Explicity logging for L2 timeouts to aid shifte
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006438.html)
01/25/22
I. RHIC Schedule- Collisions for physics today
- Tomorrow maintenance from 7 AM until around 3 PM, likely to extend longer
II. Recap
- Consistent 2+1 ongoing fills since last meeting; Yesterday: 4 pb-1 w/ 15.5 DAQ hrs (best day for int. lumi/hr); today: ~1.5 pb-1
- FCS taken out of run during day shift, put back in during overnight shift
- Unusual fill pattern for sTGC shift crew plots, Jeff and Daniel B we notified, not immediately obvious is anything is wrong but Jeff will followup, and Daniel may change plotting scales
- One more (noted) online plot crash during evening shift
- Several activities planned for tomorrow's maintenance day. See detaIls in star-ops log linked below
- Daniel requested a special ~30 min run for sTGC at end of fill at 3:25 PM today, will coordinate with PC & SL
III. Open issues/status
- FST still tripping, experts changing trip limits and HV, expect to be OK after tomorrow's maintenance
- Manual for sTGC will be updated with current procedures
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006406.html)
01/24/22I. RHIC Schedule
- Collisions for physics
- Maintenance schedule for Wed. (8 hrs?, depends on yellow rotators TBD)
II. Recap
- Consistent stores in terms of luminosity (slight improvement w.r.t. yesterday’s report); two beam dumps with ~3+~6 hr downtimes
- Yesterday: 3.2 pb-1 & 13 DAQ hrs; today: ~1.2 pb-1
- Some continuing FST HV trips in evening shift; Xu adjusted limits and HV again
- Fire department had to check a (false) smoke alarm in the cave at 22:30 (during downtime so no interruptions to data-taking)
- EEMC, TPC/iTPC out for a few runs during overnight shift; in both cases experts were consulted and eventually came back online (fixed with: rebooted crate 90, “reboot all” in run control, respectively)
- GMT bottle B has been replaced (18:14)
- Online plots crashed twice over 24 hrs
- Noted that a full rack of TPC power supplies have browned out a few times over the past week (TPC/iTPC sectors 13,14,15). This is an open issue and Wed. during access we should check it out
III. Open issues/status
- TPC power supply rack experiencing brown-outs. Needs to be investigated during next access
- FST: plan to access Wed to swap boards (see details above and previous 10 am meeting minutes)
- Jeff is looking into the online plot crashes
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006388.html)
01/23/22
I. RHIC Schedule
- Collisions for physics
II. Recap
- Generally good 24 hours of data taking with no major issues. 3.3 pb-1 & 15 DAQ hrs.
- Besides low luminosity fill early yesterday following fills look better (2+1 ongoing fills)
- Already accumulated ~1.5 pb-1 this morning
- FST Disk 1 Module 12 outer sector: ISEG module board trips due to current fluctuation, current limit increased and HV decreased. ABC board needs to be swapped next access - Xu Sun (see entries 8:34 and 09:48 from today, and overnight shift starting from 06:46)
- Online plots crashed again this morning. Shift crew have noted in the log book where to find instructions to restart
- >2000k errors in VC1 in one particular run last evening shift (54). Not noted in log book but assumed shift followed instructions. Was noted during meeting just for information
III. Open issues/status
- Alexie will work on addressing gas alarms
- See FST issue above, will wait till tomorrow to formulate a plan on when to access
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006380.html)
01/22/22I. RHIC Schedule
- Collisions for physics today and tomorrow
II. Recap
- CeC all day starting from 8 AM
- Smooth running overnight when beam came back after CeC (1:30 AM)
- Beam intensity low in first fill of the day
- Few iTPC RDOs masked out during cosmics and overnight runs
- David called and had VME slow controls reset (13:11)
III. Open issues/status
- JH will communicate with accelerator to use a 280k ZDC rate threshold to optimize data taking
- Increased TPC dead time was noticed for an early run by Jeff (fixed by itself next run). SL can check for this under the “Current rates” tab on the DAQ page. If any noticeable changes in rates/dead times during run -> restart run
- Transient alarm from TOF pressure-transmitter tof_gas_PT-2 (yellow warning, low pressure) - Alexie said he will change today
- The online plots may crash and not update to latest run, SL needs to check with shift crew each run early
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006374.html)
01/21/22
I. RHIC Schedule
- Cec Au beam dev. will happen today from 8 AM - 9 AM. End time may shift either way by one or two hours (likely end around 8 PM)
- Collisions for physics after CeC and over the weekend
II. Recap
- Generally last 24 hours have been good, new run procedure and new beam sequence has nicely improved data taking (~17 DAQ hrs and sampled lumi = 4 pb^-1)
- Jeff implemented the new production_pp500 configuration disabling BBC readout during day shift
- Short access in between fills to check sTGC blower (~6 PM). It was running fine and also so was the compressor. Alexie also tuned the laser
- The alarm handler is not connecting to the VME crates. That is something to be checked when there is no beam (see entry at 23:57)
- Beam dump @ 01:13 overnight; no beam for rest of shift
- Slight improvment in polarization and also new beam sequence with imediate first beta* squueze at begginging of fill; second at ~3hrs
- Unclear when Siemens will (and if) come back online; at least another week of investigation
III. Open issues/status
- David/Alexie will try to add more monitors for TPC to aid shifters
- Jeff is working on the error logs to aid shifters remedy the configuration error messages that occurred over last few days; suggest maybe to run pedPhys run at end of extended downtime to preemptively identify any issues instead of during physics run.
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006369.html)
01/20/22I. RHIC Schedule
- Physics running till 8 AM tomorrow then CeC Au beam devellopment until 9 PM tomorrow night
II. Recap
- Beam dump @ 8 AM; nothing for rest of morning shift due to RHIC issues with rotator scan; took calibration runs
- Polarimetry runs start at 19:01, and continue until 22:52 (three 3M runs per setting [3x5])
- Delay in run start due to “l4Disp” in component tree; recovered automatically in 7 min. (00:49) [not critical]
- High temp. in sTGC air blower; sTGC removed from one run; was already in recovery after previous shift notified Prashanth (00:56)
- Few TPC RDOs masked out during shift
III. Open issues/status
- sTGC reference plots now available
- Today: Short access (~5 min.) in between fills to check sTGC air blower; current scheduled beam dump is 6 PM
- Follow-up on BBC crate/L2 timeout discussion. Jeff will set new configuration to not read out BBC to remove this issue
- Missing HV sections from TPC sectors 8,9,10,11 from yesterdays runs, pointed out by Flemming, will have some followup with potential plots/alarms from Flemming/Alexie
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006352.html)
01/19/22
I. RHIC Schedule
- Rotator scan until 4 PM
- Physics evening/overnight and tomorrow
II. Recap
- Beam dumps at 8:00 and 10:55 (beam resumption at 9:40, 16:00)
- L2 error "More than 2000 timeouts... Suppressing further timeout error messages. STOP the run!” (16:15)
- Magnet trip 17:22, followed by alarms in sTGC and TOF; fixed by David and Isaac, respectively (see log entry 18:05). EEMC w/ Radstone problem found by Will (see entry at 20:37); Troubles ramping until filter in magnet cooling tower replaced by CAS (20:20) - Following up on periodicity/consistency of filter cleaning schedule
- In parallel to magnet problem, MCR reports cryo problems. No beam till end of shift
- FST HV RDO issue at end of shift (00:12) ("Failure code 2”) while turning on), procedure followed to restore; fixed by expert
- Problems with FCS ("FCS:DEP09:1 failed”); runs until 2:39 had no FCS until fixed by Tonko (see entry at 2:39); also around 3:53
- Run 23019011 - scalar rate of BBC, VPD, ZDC and EPD are much higher than expected (plot in entry at 2:16) - Jeff looking into this (possible mis-config.)
- TPC GUI computer frozen (5:18); had to restart computer ; Possible solution to be investigated - Wayne
III. Open issues/status
- Optimization of fills/beta squeezes - JH will discuss with Vincent
- TPC GUI computer freezing will be looked at by Wayne
- Large scaler rates for Run 23019011 will be checked by Jeff
- sTGC critical plots for shifters
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006347.html)
01/18/22
I. RHIC Schedule
- Schedule: physics until Wednesday 0800 (https://calendar.google.com/calendar/u/0/embed?src=boaudkh2sbs1lqsqgsjal563k0@group.calendar.google.com&ctz=America/New_York)
- Rotator scan on Wednesday 0800-1600
- Low lumi runs tentatively scheduled Sat 9am - Sun 9am
- Double beta squeeze test was a success, we will start doing this but during a polarization measurement.
II. Recap
- Tim fixed the compressor for the sTGC-FCS air blower after the meeting yesterday (https://online.star.bnl.gov/apps/shiftLog/logForEntry.jsp?ID=63743)
- 19:30 Magnet trip
- DAQ error "Trigger Bits corrupted: (0-5) set=0x00000000 read=0x00000040 addr=0x512114". This is currently unknown. Jeff is looking into it.
- BBC taken out last night. The BBC TAC difference was empty since. Akio contends that this plot is empty whenever the BBC is out, so it's not indicative of a problem. Akio is changing his code so that it might be an indicator in the
- 4 low lumi fills (2*10^10 bunch intensity -- 56 with STAR magnet off and 28 bunches) requested for later this week. Nominal schedule is 9am Saturday to 9am Sunday. Refer to Elke's slides for more detailed and current information
III. Open issues/status
- We need some clarification on the BBC crate issue. I thought this TAC difference plot was important. If not, the instructions need to be updated.
- Short instructions for fixing holes in the BEMC need to be updated. They were proven wrong last night.
- sTGC still has no critical plot instructions.
- AH GUI still mislables the air blowers.
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006317.html)
01/17/22
I. RHIC Schedule
- Schedule: physics until (at least) Wednesday 0800 (https://calendar.google.com/calendar/u/0/embed?src=boaudkh2sbs1lqsqgsjal563k0@group.calendar.google.com&ctz=America/New_York)
- Double beta squeeze test might happen this evening
II. Recap
- sTGC air blower AC compressor needs a fix, whenever there is access next time. (https://online.star.bnl.gov/apps/shiftLog/logForEntry.jsp?ID=63692). Confusingly this is under the eTOF in the AH, but this one is serving the sTGC and FCS. The eTOF shares the TPC blower this year.
- Work on the air blower is happening this morning
- We can probably run without the error blower. The sTGC LV will drop if it hits a limit (currently 80F). Without the compressor we're still generally under this limit, but we're close (~77F).
- Many issues with the trigger, as we discussed yesterday. bbc errors from the daqlog will be suppressed so that the operators should never see those ErrCnt messages. Not all events with BBC errors make it to L2, so not all are counted for the 200-error run stop limit. That's how we've been going beyond 200. Crews do not need to stop runs for this. Hank might get Chris to increase this limit from 200.
- BBC issue might affect analyses that use the earliest TAC information. The TAC difference is from the earliest TAC, so the information is there. This should affect a very small fraction of events, but it might need to be considered by future analyzers (or maybe even the production?)
III. Open issues/status
- air blower status
- sTGC critical plot information
- rotator study (schedule not fixed)
- Detector readiness checklist needs updating with new BEMC instructions and new BBC instructions
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006326.html)
01/16/22
I. RHIC Schedule
- Schedule: physics until Monday 1600 (https://calendar.google.com/calendar/u/0/embed?src=boaudkh2sbs1lqsqgsjal563k0@group.calendar.google.com&ctz=America/New_York)
- Double beta squeeze test might happen Monday evening
II. Recap
- Updates on BBC instructions "Slow DMA error". Runs are going beyond 200 errors, which is a surprise.
- TPC ran at near 100% dead from about 2200-0030. TThe node causing the problems was TPX35. We tried removing the node and the errors went away. I then tried masking the boards in these run (sector 21 RB 5&6 and sector 22 RB 5&6 respectively). The errors persisted whichever boards were masked. We then rebooted the tpx35 computer and the errors stopped. (Summary Report - Night Shift). We may need mass computer reboots during some down time (only ~10min)
- Scalar board 6 is having unknown issues. It was out from run 29 yesterday to run 44. It's out again today.
- We'll get some more detailed instructions on when to reapply voltage to the BEMC
III. Open issues/status
- sTGC shift crew manual
- Instructions need to be updated for BEMC, BBC crate, and the detector readiness checklist.
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006303.html)
01/15/22
I. RHIC Schedule
- Schedule: physics until Monday 0800 (https://calendar.google.com/calendar/u/0/embed?src=boaudkh2sbs1lqsqgsjal563k0@group.calendar.google.com&ctz=America/New_York)
II. Recap
- Power dip in the afternoon, it took some time to get everything back.
- Several accesses yesterday. Tim had to go in late to work on the TCIM.
- One very-short fill overnight. Poor quality beam. High emittance and low polarization.
- The ZDC scalar rate is not correct, while MCR use ZDC rate to tune the beam. J.H Lee has called MCR to use BBC rate instead of ZDC rate to tune the beam. (https://online.star.bnl.gov/apps/shiftLog/logForEntry.jsp?ID=63575)
- This ZDC problem came from a threshold change on a NIM crate after the power dip that depressed the values ~50% (can be seen by comparing to the BBC values).
- RICH scalars were out after the dip.
- The sTGC crate issue seems to have been solved.
III. Open issues/status
- sTGC shift crew manual
- Still talk of 2 beta squeezes
- Plans for low lumi runs next week (Tuesday?)
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006286.html)
01/14/22
I. RHIC Schedule
- See https://calendar.google.com/calendar/u/0/embed?src=boaudkh2sbs1lqsqgsjal563k0@group.calendar.google.com&ctz=America/New_York
- Injector dead until ~midnight tonight
II. Recap
- Injection plan is tentatively for midnight. Until then zero-field cosmics.
- We're turning off the magnet now (ramping to zero current, no state change). Will be turned on ~midnight.
- Access can be done. Tim went in yesterday to replace a flash card. Today the plan is Tim will replace an sTGC raspberry pi, Christian will replace two failed DEP boards for the FCS, and Prashanth will go in for a quick inspection.
- Oleg will switch the ECal and work on the system after the DEP board replacement.
- Jeff fixed instability with Configuration speedup. There should be a significant speedup for run starts now.
- ^ We will change to 30 minute runs.
- Tonko made a change in the ITPC processing in case of auto-recovery failure:
Before) If the auto-recovery fails 4 times I force-stop the run with an appropriate message.
Now) If the auto-recovery fails 4 times I raise iTPC BUSY with an appropriate message but I DON'T force-stop the run. In this case the forward program continues and it gives the Shiftcrew some time to figure things out.
Crews are not expected to clear this busy. - A brown out this morning seems to have taken out a few sectors in the TPC and nothing else.
- Carl has written detector requirements for the triggers in case, thus no detector -> disabled triggers. This email has been circulated to the trigger board and (will be) to the ops list. If you have expertise or opinions, review this.
- Elke wants detector experts to get ready for the low luminosity runs. This is just a reminder.
III. Open issues/status
- sTGC shift crew manual
- sTGC LV still has some issues
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006275.html)
01/13/22
I. RHIC Schedule
- See https://calendar.google.com/calendar/u/0/embed?src=boaudkh2sbs1lqsqgsjal563k0@group.calendar.google.com&ctz=America/New_York
- Injector dead until late Friday at the earliest due to generator issue. We're holding on to the beam until 2pm.
- CeC will take most of the time until then. Without the injector CeC is just with the electron beam. Thus we can take cosmics and go in for access.
II. Recap
- The collider will switch from the Siemens to the Westinghouse injector, which will reduce the quality of our fills.
- Took out BBC from the triggers, as we always reached 200 BBC errors "Slow DMA error" (https://online.star.bnl.gov/apps/shiftLog/logForEntry.jsp?ID=63341) -- BBC not configured for the next 12 hours
- Multiple problems with the FCS and FST stopping runs
- We need some way to communicate to the shift leaders about what to do after repeated errors.
- Jeff will work on run control during CeC
- We should take advantage of the low luminosity fills from the Westinghouse generator to do some work which should be detailed later.
- Tim will go in to check the LED control box for HCAL after the beam dump
III. Open issues/status
- No injection into RHIC, no beam
- Daniel wants to do a few quick runs for the sTGC (one with and one without beam)
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006267.html)
01/12/22
I. RHIC Schedule
- See https://calendar.google.com/calendar/u/0/embed?src=boaudkh2sbs1lqsqgsjal563k0@group.calendar.google.com&ctz=America/New_York
- Access during meeting -> 5 h CeC -> physics
II. Recap
- Access right now (until 11am) -> 5 hours of CeC (4pm) -> Physics
- BCE had to be power cycled because the 0x1d000000 board failed to configure.
- The BBC hit 200 errors and was out of the trigger for the rest of the night.
- Hongwei reported that he thinks he fixed the issue of l4 hanging run stop requests.
- Jeff is working on making run start faster. Perhaps we'll switch to 30 min runs tomorrow.
- Carl reported that the forward trigger is reading out the MTD and TOF. TOF mult may be useful, but the MTD likely is not. That should be removed.
III. Open issues/status
- Still no sTGC critical plot instructions
- 30-minute runs soon
- We're currently at ~ 80% of requested luminosity from RHIC
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006258.html)
01/11/22I. RHIC Schedule
- See https://calendar.google.com/calendar/u/0/embed?src=boaudkh2sbs1lqsqgsjal563k0@group.calendar.google.com&ctz=America/New_York
- Access planned for 0700-1100 on Wednesday. (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006226.html)
II. Recap
- Jeff: As per trigger board meeting adjusted rates in production_pp500_2022:
Write ADC from every 101 events to every 201 events
JP0 - removed trigger
JP1 - reduce rate from 70 -> 35hz
BT0 - reduce rate from 180 -> 100hz
dimuon - reduce rate from 300 -> 250hz
(https://online.star.bnl.gov/apps/shiftLog/logForEntry.jsp?ID=63133) - Magnet trip at ~6:42pm. Unfortunately the eTOF LV was forgotten again. This is a difficult thing to communicate.
- Jeff added the logscales for the trigger plots, added l4_prim_nDedx/nHits plots to the primary tracks tab, disabled the BES & fixed target tabs in the l4 display, and added sTGC to the 'critical plots' tab.
- EEMC was out all night
- DAQ went 100% dead last night. Tonko came on and helped the crew fix the problem after some confusion (https://online.star.bnl.gov/apps/shiftLog/logForEntry.jsp?ID=63187). JP1 and JP2 were firing at 10 MHz because of the EEMC. Run came back to normal after removing these triggers.
- The EEMC was fixed at ~9am.
- Carl is working on a calorimeter matrix so that clicking out the EEMC will disable these triggers (among other such trigger/subsystem connections)
- Chris implemented a gain correction for the QT boards.
- Tonko proposed a color change for the BBC errors in the DAQ monitor, so that they don't drown out other errors.
- Jeff moved some ethernet cables, increasing the data speed by ~15%. There are a few cables that might still be moved.
III. Open issues/status
- sTGC LV is constantly disconnecting. The solution to this is still not known.
- We need sTGC critical shift plot instructions for the shift crew
- We need higher luminosity
- Daniel's 2 5-minute sTGC runs
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006245.html)
01/10/22
I. RHIC Schedule
- TBD
II. Recap
- production_pp500_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
- zdcPolarimetry_2022: trg+daq
- CosmicLocalClock_FieldOn: trg + daq + itpc + tpx + btow + etow + esmd + tof + gmt + mtd + l4 + fcs + stgc + fst
- Communication with MCR about luminosity should probably be about ZDC and (without killer bit) rates. MCR has more rates to look at, but we want the communication to be clear. Angelika will make something like Jamie's singles-corrected value for them to look at too.
- Daniel wants to do a short sTGC test today - only 5 min run x2
- Tonko recoded the ETOF TCD so that it fires the ETOF whenever TOF is in the run and gets a trigger.
- MTD bias scan: 23009043 (13.1 kV), 23009044 (13.2 kV), 23009045 (13.3 kV), 23009046 (13.4 kV), 23009047 (13.5 kV), 23009048 (13.6 kV), 23009049 (12.8 kV).
- Jeff and Tonko are working on speeding up the DAQ. Jeff will spend a few hours during the CeC today about this.
- We've had a lot of L4 crashes at run stop. The run won't actually stop until L4 is rebooted. Some events might be too big for L4 and the buffer may need an increase. Jeff and Hongwei are working on this.
III. Open issues/status
- sTGC LV is constantly disconnecting. The solution to this is still not known.
- We need to cull some QA plots
- We need sTGC plots in the critical shift plots (this is underway)
- We need sTGC and FST critical shift plot instrucitons for the shift crew
- We need higher luminosity
- l4 crashing at run end
- Daniel's 2 5-minute sTGC runs
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006222.html)
01/09/22
I. RHIC Schedule
- Physics until 0800 Monday.
II. Recap
- production_pp500_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
- zdcPolarimetry_2022: trg+daq
- CosmicLocalClock_FieldOn: trg + daq + itpc + tpx + btow + etow + esmd + tof + gmt + mtd + l4 + fcs + stgc + fst
- Tim replaced a control card for sTGC LV crate #2 during access at the end of a fill. (https://online.star.bnl.gov/apps/shiftLog/logForEntry.jsp?ID=62992)
- MCR had some issues leading to low luminosity fills and they haven't really managed to hit the luminosity they had a few days ago.
- MCR might be able to give us two beta squeezes/fill.
- sTGC LV lost communication frequently. Every time when we need to change the status we will have to restart the sTGC LV IOC and re-build connection. But the communication would be lost again within 5-10 minutes. (https://online.star.bnl.gov/apps/shiftLog/logForEntry.jsp?ID=63042). This seems to be ongoing. It isn't stopping data taking, but it is an inconvenience for the shift crew. Once Tim thinks he understands it the fix will likely require an access.
- Bill has proposed a sort of triangle cut to remove high-rapidity clusters in the TPC to help the DAQ. The number of primary tracks looks reasonable, but the number of globals is huge. He will send out a document on this to be discussed during the triggerboard meeting (Monday 1pm). It may need some additional information from the TPC group and the spin PWG.
- The trigger group has implemented code to skip these problematic BBC issues. This should ease the issues it causes for STAR. They're still working on the source.
- We have a lot of outdated QA plots. If you are/were a subsystem expert please check (see https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006211.html)
- Tuesday will be cold. This might be a concern for the sTGC gas vent.
III. Open issues/status
- sTGC LV is constantly disconnecting
- We need to cull some QA plots
- We need higher luminosity
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006204.html)
01/08/22
I. RHIC Schedule
- Physics until 0800 Monday.
II. Recap
- production_pp500_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
- zdcPolarimetry_2022: trg+daq
- CosmicLocalClock_FieldOn: trg + daq + itpc + tpx + btow + etow + esmd + tof + gmt + mtd + l4 + fcs + stgc + fst
- Yesterday MCR desteered the beams to check how much of our background was coming from single beams. Angelika: "The result from our quick separation test earlier today was that the BBC singles rates came down to 25-25 kHz with full separation (1.8mm). This corresponds to 0.24-0.32% of the singles rates at full overlap. This does not look like background (consistent with it not responding to collimator settings) and appears to be associated with collisions."
- ^ Thus we cannot collimate out the background. There is ongoing discussion why the BBC singles rates are higher than in 2017.
- Special FCS gain calibration runs taken yesterday afternoon (23007067, 68, 69, 75, and 76). We've requested production for these.
- We asked RHIC a few days ago to reduce the luminosity ~20% to ~250k ZDC and rates. After this meeting JH requested we go back up to ~300k. We plan on asking for ~20% higher again in the future.
- We would like 2 beta squeezes/fill. JH will ask about this.
- Jeff set approximate scalar ranges for the DAQ monitoring page. Bright red means the scalar rate for the trigger is too high. Black means the scalar rate for the trigger is about right. Brown means the scalar rate for the trigger is too low. These are only preliminary numbers. (https://online.star.bnl.gov/apps/shiftLog/logForEntry.jsp?ID=62904)
- Geary would like to do an HV scan for the MTD. This would comprise 6 20-min runs. These are normal physics runs, they'll just have different MTD biases.
- It looks like any issues with the TPC automatic restart from Jeff and Tonko were ironed out. This will save the last DAQ restart from clusters of runs that cannot start because of a TPC RDO.
- Hongwei fixed some issues that looked like L4 was stopping the run. Jeff is still working on an issue where a window will pop up saying "configuration not sent" (I think the quote is right) after everything configures and will require a run restart.
III. Open issues/status
- FCS end-of-fill runs
- 2 beta squeezes/fill request
- We will start requesting more luminosity
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006174.html)
01/07/22
I. RHIC Schedule
- Physics until 0800 Monday.
II. Recap
- production_pp500_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
- zdcPolarimetry_2022: trg+daq
- CosmicLocalClock_FieldOn: trg + daq + itpc + tpx + btow + etow + esmd + tof + gmt + mtd + l4 + fcs + stgc + fst
- MCR will do some background tests by unsteering the beam at the end of the current fill
- We will do some FCS gain scans on either side of this desteering
- First fill of the night had about as high luminosity as we have seen this run
- Several problems occurred at once. At flat top the TPC cathode
wouldn't come up, the sTGC had connection errors, and the EEMC GUI went
white. It took a long time (1.5h?) to get the first two back. The EEMC
wasn't back in runs for ~5h. - VPD got new TAC offsets. Jeff updated the trigger IDs (
https://online.star.bnl.gov/apps/shiftLog/logForEntry.jsp?ID=62817 +
https://online.star.bnl.gov/apps/shiftLog/logForEntry.jsp?ID=62820(5am) " - Tonko called in and made us enable all the triggers, more than
half of them were not enabled since previous shifts." -- I suspect this is
from triggers being taken out for VPD TACs - Daniel suggests we change the max TAC for the VPD. There will be an
email about this. There also seems to be an issue with ch14 on the west
VPD. This will be masked out. - Shuai updated the MTD timing window after the VPD was changed. We
should change the trigger ID.
III. Open issues/status
- RHIC desteer beams to check background
- FCS end-of-fill runs
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006174.html)
01/06/22
I. RHIC Schedule
- CeC from now until they finish in the early afternoon. After that there are some beam tests and another hour-long access (~5 or 6pm). Then the focus is on physics until Monday morning.
II. Recap
- production_pp500_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
- zdcPolarimetry_2022: trg+daq
- CosmicLocalClock_FieldOn: trg + daq + itpc + tpx + btow + etow + esmd + tof + gmt + mtd + l4 + fcs + stgc + fst
- No beam since yesterday. Yellow cavity issue overnight -> CeC took over starting around midnight.
- Cosmic data taken around midnight was triggering at an extremely high rate due to TOF sector 3. Hank wonders if this is due to the BBC-MIX CPU swap.
- Jeff and Tonko implemented the TPC autorecovery
- Carl has a proposal for taking four 30-minute FCS runs at the end of a fill. Hopefully we can do this tomorrow.
- We will get a new configuration for Tonko to consistently work on the TPC FEEs during the day
III. Open issues/status
- No beam = no VPD timing, no test of BBC crate, no test of TPC autorecovery, etc.
- After the splitter was taken out and put back in the VPD pedestals look okay, but they continue to be very wide. This is true on both E/W. It's not known why.
- FCS end-of-fill runs + configuration
- no-TPC configuration for Tonko
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006154.html)
01/05/22I. RHIC Schedule
- After access we go into physics until 0800 tomorrow morning. 0800-1600 tomorrow is CeC.
- Long access from 0700-1700 today.
II. Recap
- production_pp500_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
- zdcPolarimetry_2022: trg+daq
- CosmicLocalClock_FieldOn: trg + daq + itpc + tpx + btow + etow + esmd + tof + gmt + mtd + l4 + fcs + stgc + fst
- 11:15 yesterday access. Christian disconnected DSMI boards. Prashanth checked sTGC gas lines. I think we can do a bit better at people who come in for access writing shift entries.
- MCR called and said that they have not received the BBC delayed signals since Sunday. Tim will replace a PS on a nim crate tomorrow. This doesn't need access. I called MCR to let them know that they should get them back then.
- We had issues with the BBC crate not being configured after TRG reboot/reboot all.
- The CPUs for the BBC and MIX crates were swapped. 1M events were taken without error (w/out beam either). If the CPU is the culprit we'll start seeing the same issues with the MIX crate.
- Christian tested the VPD splitter. It was found to be fine. Hopefully just reconnecting solves the problem and we can redo the timing.
- Christian did not have time to look at the eTOF cable while the poletip was open, so this problem is not fixed.
- sTGC HV was not put on an NPS. If there is a parasitic access opportunity Tim can do this quickly, but we won't request an access.
- As a proof of principle Tim was able to reprogram 2 TPC RDOs, so the test discussed yesterday was a success.
- A cable for the TPC gating grid was found to be disconnected. This was reconnected and things can go back to normal in run control.
- The sTGC gas vent on the roof had partly frozen over. Prashanth is working on a solution, but we may see sTGC gas issues in cold weather.
III. Open issues/status
- We're watching the BBC and MIX crates for issues.
- The VPD will need new runs to reset the timing
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006140.html)
01/04/22
I. RHIC Schedule
- Schedule: physics beam until 0700 tomorrow. Access from 0700-1700 (01/05). Physics from 1700(01/05)-0800(01/06). CeC from 0800(01/06)-1600(01/06)
- Long (10h -- 0700-1700) access tomorrow. Check PDF attached to (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006107.html) for the list of tasks.
II. Recap
- production_pp500_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
- zdcPolarimetry_2022: trg+daq
- CosmicLocalClock_FieldOn: trg + daq + itpc + tpx + btow + etow + esmd + tof + gmt + mtd + l4 + fcs + stgc + fst
- Beam energy change from 254.87 to 254.21 yesterday
- Long (10h) access planned tomorrow.
III. Open issues/status
- Today we will have a 15min access for Christian to disconnect the DSMIs from the backplane of the BBC crate and for Prashanth to inspect the sTGC gas lines.
- Jiangyong will cover day shift for the next few days followed (possibly) by Ben Schweid. Next week is unclear.
- Tomorrow's 10am meeting will, instead, be held at 5pm BNL time.
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006107.html)
01/03/22
I. RHIC Schedule
- 0900-1700: CeC
- 1700 (Mon)-1600 (Tues): physics beam
II. Recap
- production_pp500_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
- zdcPolarimetry_2022: trg+daq
- CosmicLocalClock_FieldOn: trg + daq + itpc + tpx + btow + etow + esmd + tof + gmt + mtd + l4 + fcs + stgc + fst
- Beam energy change from 254.87 to 254.21 yesterday
- Long (10h) access planned on Wednesday. This includes opening the East poletip. If you would like to enter please respond to the star-ops message.
III. Open issues/status
- VPD max TAC not changed since yesterday
- The Trigger group needs a 1 hour access for Christian to swap
processors for the BBC and MIX crates. This should happen tomorrow after a
beam dump. - VMEs lost connection (white in GUIs) -- This requires the main CANBUS
to be restarted in the IR. This needs a 10 minute access for Tim to go in
and turn it off and on. We'll wait until right after CeC (maybe 5:30?) or
any other available time today. In the future (Wednesday?) we need an NPS
on this.
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006078.html)
01/02/22
I. RHIC Schedule
- 0800-1600: injector polarization work + physics
- 1600-0800: physics beam
- 0800-1600 (monday 1/3) CeC
- Beam energy change from 254.87 to 254.21 planned today
II. Recap
- production_pp500_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
- zdcPolarimetry_2022: trg+daq
- CosmicLocalClock_FieldOn: trg + daq + itpc + tpx + btow + etow + esmd + tof + gmt + mtd + l4 + fcs + stgc + fst
- Beam energy change from 254.87 to 254.21 planned today
III. Open issues/status
- Access yesterday at noon. sTGC was fixed by a crate powercycle (will be put on NPS in next major access) while DSM 0x17 was replaced
- Lost a lot of time from beam aborts last night
- Clusters of L2 issues happened again. Trigger group is looking into this again.
- TOF gas freon bottle changeover was neglected for several hours.
- Carl noted that the fast offline is just looking at the StPhysics stream (MinBias and HighTower) and not at jet events or the forward stream. I'll contact them.
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006057.html)
01/01/22
I. RHIC Schedule
- 0800-1600: injector polarization work + physics
- 1600-0800: physics beam
II. Recap
- production_pp500_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
- zdcPolarimetry_2022: trg+daq
- CosmicLocalClock_FieldOn: trg + daq + itpc + tpx + btow + etow + esmd + tof + gmt + mtd + l4 + fcs + stgc + fst
- After midnight (year change) the DAQ monitor messages, the JEVP plots, and all of the scalar algorithms went down. The DAQ monitor messages came back with Tonko ~6am and the servers for the plots weren't restarted until ~7:45am. Jamie messaged Jinlong about the scalars.
- BBC DSM board stopped many runs, even after yesterday's access to replace a DSM board.
- sTGC lost connection to a HV board, this needs access.
- Access at 12pm today for both systems
- Typically alarms are masked when detectors are ramping. Given the recent issues of HV going down for both the sTGC and TOF without alarms David has proposed removing these masks.
- Tonko needs a procedure every day to take time to bring back masked RDOs. He also needs accesses periodically to fix ones that cannot be brought back via software.
III. Open issues/status
- Access today at 12pm to replace BBC crate 0x17 board and check sTGC HV board
- Tonko's time to bring back RDOs. In the short term we'll just stop the run for him to do this. In the long term we'll get a special configuration for forward measurements not including TPC.
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2022-January/006066.html)
12/31/21
I. RHIC Schedule
- 0800-1600 - injector polarization work, 1600-0800 collision for physics.
II. Recap
- production_pp500_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
- zdcPolarimetry_2022: trg+daq
- CosmicLocalClock_FieldOn: trg + daq + itpc + tpx + btow + etow + esmd + tof + gmt + mtd + l4 + fcs + stgc + fst
- BBC DSM board issue was a really bad problem starting yesterday
afternoon. We'll plan on a 15-minute access when Akio/Christian are ready
to go in and replace the board. This can be done in the 0800-1600 block. It
looks like it will be 1:15pm. - Many TPC errors hurt running
- L4 had a few issues that Hongwei fixed.
- We're planning a beam energy change (254 GeV beams) for better
polarization perhaps on Tuesday (01/04). - Polarization: B~40% Y ~50% until some time in the overnight shift when
blue suddenly dropped to 11% (
https://online.star.bnl.gov/apps/shiftLog/logForEntry.jsp?ID=62215).
This is primarily due to them changing the fill pattern at the end of the
fill, and was not actually representative of the polarization. Elke has
mentioned that the offline analysis isn't nearly so bad (~40%?)
III. Open issues/status
- Access at 12:30 for the BBC VME crate
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2021-December/006046.html)
12/30/21
I. RHIC Schedule
- Physics beam all day
II. Recap
- production_pp500_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
- zdcPolarimetry_2022: trg+daq
- CosmicLocalClock_FieldOn: trg + daq + itpc + tpx + btow + etow + esmd + tof + gmt + mtd + l4 + fcs + stgc + fst
- iTPC caused many issues last night
- BBC DSM board stopped one run, but not many like before.
- Several hours of sTGC data were lost from confusion on shift.
III. Open issues/status
- Does iTPC need some change so that it doesn't stop so many runs in preparation and doesn't hang the system?
- BBC DSM board issue is hard to understand, but trigger group may replace the board or even the CME CPU
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2021-December/006028.html)
12/29/21I. RHIC Schedule
- Work on polarimetry in the afternoon (~4pm).
- Physics at night (~midnight).
II. Recap
- production_pp500_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
- zdcPolarimetry_2022: trg+daq
- CosmicLocalClock_FieldOn: trg + daq + itpc + tpx + btow + etow + esmd + tof + gmt + mtd + l4 + fcs + stgc + fst
- Switched to 45 min runs
- Laser back to every 4 hours (from 2h cycle) since the TPC methane pressure back to (or slightly higher than) normal.
III. Tasks for commissioning
- sTGC voltage scan planned for tomorrow morning when Daniel and Tonko are both awake
IV. Open issues/status
- L2 (which is really the BBC DSM board) stopped many runs in evening and overnight. Hank + trigger group will look into it.
- sTGC caused many issues in the evening perhaps related to a loss of connection to a raspberry pi
- crate 7, board 4 of the BTOW complains in run control. This can be ignored, but Tonko will stop it to avoid confusion.
- L4 seems to be aborting VPD TACs (https://lists.bnl.gov/mailman/private/star-ops-l/2021-December/006006.html). The rates don't make sense. This is being looked into.
- Polarizations looked to be about B ~ 30, Y ~ 50 last night.
More detailed discussion can be found on the ops list (https://lists.bnl.gov/mailman/private/star-ops-l/2021-December/006016.html)
12/28/21I. RHIC Schedule
Work on blue injection during the day to prevent increase in emittance
Collisions later afternoon and overnight
Maintenance day is rescheduled to Jan 5th, no planned access tomorrowII. Recap
production_pp500_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
zdcPolarimetry_2022: trg+daq
CosmicLocalClock_FieldOn: trg + daq + itpc + tpx + btow + etow + esmd + tof + gmt + mtd + l4 + fcs + stgc + fstIII. Tasks for commissioning
a) Local polarimetry
b) sTGC noise and HV scan and FST HV scan finished yesterday
c) MTD HV scan, after avalanche/streamer analysis
d) VPD splitter board (Christian, maintenance day)
e) MTD dimuon trigger, prod id, trigger patch recovery at maintenance day
IV. Open issues
a) FCS Mpod slot-1 looks dead, no alarm for LV
b) Eemc-pwrs1 NPS has a network interface failure, spare is available with NEMA 5-20 plug (maintenance day, Wayne)
c) Gating grid sector 21 outer disconnected, RDOs masked out, relevant anodes at 0 V, January 4th and 5th
V. Plan of the day/Outlook
a) Work on blue injection during the day
b) Collisions later afternoon and overnight
c) ETOF by expert operation
12/27/21
I. RHIC Schedule
Diagnostic for quench detector and ramp development during the day
Snake settings to compensate for partial snake
Collisions for physics with store-to-store change in emittance in the afternoon and collisions overnightII. Recap
production_pp500_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
zdcPolarimetry_2022: trg+daqIII. Tasks for commissioning
a) Local polarimetry
b) FCS gain calibration, full FastOffline for HCal
c) sTGC noise thresholds, 2-3 hours without beam when possible, HV scan with beam (call Daniel + Prashanth)
d) FST HV scan, sw update without beam, call Xu when physics, together with sTGC, dedicated production configuration
e) MTD HV scan, after avalanche/streamer analysis
f) VPD splitter board (Christian, maintenance day 29th, Daniel to be notified)
g) MTD dimuon trigger, prod id, trigger patch recovery at maintenance day
IV. Open issues
a) Leaking valve replaced for TPC gas, methane concentration from 9% to nominal 10% over these two days, more frequent laser runs (2 hours)
b) TPX automatic power-cycling, ongoing
c) Eemc-pwrs1 NPS has a network interface failure, spare is available with NEMA 5-20 plug (maintenance day 29th, Wayne)
d) Gating grid sector 21 outer disconnected, RDOs masked out, relevant anodes at 0 V, January 4th and 5th
V. Plan of the day/Outlook
a) Ramp development during the day
b) Collisions with emittance changes store-to-store later afternoon and collisions overnight
12/26/21
I. RHIC Schedule
Slower ramp rate (x5) due to problem with quench detectors, work scheduled for tomorrow
Ramp development during the day
Collisions afternoon with intensity steps and overnightII. Recap
production_pp500_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
zdcPolarimetry_2022: trg+daqIII. TPC gas
a) Fluctuations in PI8 and CH4-M4 since yesterday afternoon, interlock overnight
IV. Tasks for commissioning
a) Local polarimetry
b) sTGC noise thresholds, 2-3 hours without beam when possible, HV scan with beam (Daniel + Prashanth)
c) MTD HV scan, after avalanche/streamer analysis
d) VPD splitter board (Christian, maintenance day 29th, Daniel to be notified)
e) MTD dimuon trigger, prod id, trigger patch recovery at maintenance day
V. Open issues
a) Temperature increase in WAH, yellow alarms for several VMEs
b) Gating grid sector 21 outer disconnected, RDOs masked out, relevant anodes at 0 V, January 4th and 5th
VI. Plan of the day/Outlook
a) Ramp development during the day, also stores for physics, MCR will inform
b) Collisions with intensity steps afternoon and overnight
12/25/21
I. RHIC ScheduleCollisions for commissioning
Energy scan shall resume on 12/26II. Recap
production_pp500_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
III. Updates
a) BEMC PMT trips
b) Set of triggers elevated to physics (entry for Run 22359013)
IV. Plan of the day/Outlook
a) Collisions for commissioning
b) Energy scan tomorrow 12/26
12/24/21
I. RHIC Schedule
Energy scan was interrupted by QLI in blue and power dip (2 out of 6 points done), access ongoing for recovery from the quench (~4 hours)
Collisions afternoon, intensity steps, and overnight
Energy scan shall resume on 12/26II. Recap
zdcPolarimetry_2022: trg+daq for part of energy scan
III. Tasks for commissioning
a) Local polarimetry
b) FCS gain calibration, FastOffline finished, ECal ok (pi0), HCal
c) sTGC noise thresholds, 2-3 hours without beam when possible, HV scan with beam (Daniel + Prashanth)
d) MTD HV scan, after avalanche/streamer analysis
e) VPD splitter board (Christian, maintenance day 29th, Daniel to be notified)
f) MTD dimuon trigger, prod id, trigger patch recovery at maintenance day
IV. Open issues
a) Gating grid sector 21 outer disconnected, RDOs masked out, relevant anodes at 0 V, January 4th and 5th
b) TPX automatic power-cycling
c) Readiness and detector states
V. Plan of the day/Outlook
a) Access ongoing
b) Collisions afternoon, intensity steps and overnight
c) Energy scan 12/26, call Ernst
12/23/21
I. RHIC Schedule
Energy scan, low intensity, afternoon: intensity steps, overnight: collisions
II. Recap
Collisions with 111x111 bunches, production_pp200_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
zdcPolarimetry_2022: trg + daqIII. Tasks for commissioning
a) Local polarimetry, scan will start later because of a quench (11:30 EST)
b) Spin direction at STAR, longitudinal in blue is a part of systematic error
c) Scaler bits timing ok now
d) FCS gain calibration
e) sTGC noise thresholds, 2-3 hours without beam when possible, HV scan with beam (Daniel + Prashanth)
f) MTD HV scan, after avalanche/streamer analysis
g) FastOffline, new request for FCS finished
h) VPD splitter board (Christian, maintenance day 29th, Daniel to be notified)
i) MTD dimuon trigger, prod id, trigger patch recovery at maintenance day
IV. Open issues
a) BTOW LV + FCS LV alarm, minor -> major for channel trip
b) sTGC LV
c) Gating grid sector 21 outer disconnected, RDOs masked out, relevant anodes at 0 V, January 4th and 5th
d) TPX automatic power-cycling
e) Mailing lists to inform about any changes + logbook
f) BTOW PMT recovery when opportunity for access, call Oleg (daytime/evening)
g) Readiness and detector states
h) ZDC-SMD pedestal for west horizontal #4
V. Plan of the day/Outlook
a) Energy scans, ZDC polarimetry, all detectors for machine commissioning
b) Collisions overnight
12/22/22
I. RHIC Schedule
Vernier scan, cross section compatible with run 17, energy and squeeze ramps
Local component in blue beam, possibilities include use of existing snakes or phenix rotator, orbit imperfection tuning and energy scanII. Recap
Collisions with 111x111 bunches, production_pp200_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
Polarimetry runs zdcPolarimetry_2022: trg + daqIII. Tasks for commissioning
a) Local polarimetry
b) Scaler bits timing
c) Trigger for Vernier scan
d) FCS gain calibration
e) sTGC data volume
f) sTGC noise thresholds
g) MTD gas, more SF6, HV scan, trigger config
h) FastOffline re-running to include EPD
i) VPD splitter board (Christian, maintenance day 29th, Daniel to be notified)
j) MTD dimuon trigger, prod id, trigger patch recovery at maintenance day
IV. Open issues
a) Temperature in WAH
b) Gating grid sector 21 outer disconnected, RDOs masked out, relevant anodes at 0 V
c) Anode HV for sector 15, channel 3 at 1000 V as default
d) TPC Chaplin frozen (gui available also on sc3 or on alarm handler)
e) Eemc-pwrs1 NPS which has a network interface failure and affects access to eemc-spin, spare is available with NEMA 5-20 plug (Wayne)
f) BEMC critical plots checked by shift crews (holds in general)
g) Reference plots for critical plots
h) SL on star-ops list
V. Plan of the day/Outlook
a) Scans related to longitudinal component and intensity steps during the day
b) Collisions overnight
12/21/21
I. RHIC Schedule
9 MHz RF cavity adjusted, can go to full intensity, alignment for yellow abort kicker, IPMs configured
Snake current increased from 300 to 320 A, blue polarization improved to ~42%
Stores during the day with intensity steps and overnightII. Recap
Collisions with 111x111 bunches, production_pp200_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
Polarimetry runs zdcPolarimetry_2022: trg + daq
Run with 0 V at TPC 21 outer, 400 V after thatIII. Tasks for commissioning
a) FCS rates, x10 - 20 higher, tests runs with change in gain/masks, beam position?
b) sTGC data volume, firmware update
c) Local polarimetry, spin angle
d) FastOffline re-running to include EPD
e) VPD splitter board (Christian, maintenance day 29th, Daniel to be notified)
f) MTD dimuon trigger, prod id, trigger patch recovery at maintenance day
g) BEMC tolerable tripped boxes, 1 out till 29th, DOs follow procedure to recover, run flag as questionable, note in shift log (specific for crate)
h) Vernier scan, low number of bunches
IV. Open issues
a) Gating grid sector 21 outer disconnected, 12h min + risk of need to remove parts in front, maintenance 29th, RDOs masked out, meeting today 3:30pm
b) Eemc-pwrs1 NPS which has a network interface failure and affects access to eemc-spin, spare is available with NEMA 5-20 plug (Wayne)
V. Plan of the day/Outlook
a) Stores during the day with intensity steps
b) Collisions overnight
12/20/21
I. RHIC Schedule
Blue snake re-wired for correct polarity (coil #3)
Timing alignment for abort kicker in yellow beam
Access at 10am for 9 MHz cavity
Ramp development after the access, then collisions after 5pm till tomorrow dayII. Recap
Collisions with 111x111 bunches, production_pp200_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
Polarimetry run zdcPolarimetry_2022: trg + daq
Blue polarization at 30%III. Tasks for commissioning
a) FCS closing
b) ZDC-SMD hot channel, daughter card to be replaced (Christian)
c) Local polarimetry, scaler bits (Hank, Chris)
d) FastOffline completed for previous 3 stores
e) VPD splitter board (Christian, maintenance day 29th, Daniel to be notified)
f) MTD dimuon trigger, prod id, trigger patch recovery at maintenance day
IV. Open issues
a) Increase in magnet current, east ptt, Monday morning
b) Gating grid sector 21 outer disconnected, 12h min + risk of need to remove parts in front, maintenance 29th, RDOs masked out, meeting to determine the risks tomorrow
c) Eemc-pwrs1 NPS which has a network interface failure and affects access to eemc-spin, spare is available with NEMA 5-20 plug (Wayne)
V. BEMC operation
a) Shift crew should star looking at critical plots, they are the same for BTOW as last many years. 2d hit map is main indicator of HV status. There are four boxes tripped since probably Sat., this was not noticed.
b) Det. operator please don't hit wrong button in HV GUI, that can lead to a long recovery of HV, as it was today ~3 hours.
c) For operation instruction:
(a) during long downtime shift should run btow_ht configuration just to check HV was not tripped, looks like during Sat. evening shift no one exercise the system at all.
(b) given that recovering one PMT box may lead to trip and then long recovery of entire BEMC HV, we better not to do such thing during overnight shifts for example. Instead, may be, barrel jet triggers should be disabled, and live HT triggers only. Then recover HV between fills?
VI. Plan of the day/Outlook
a) Access 10am, beam development after
b) Collisions after 5pm
12/19/21
I.RHIC Schedule for today-tomorrow
Ramp-up intensity (up to 1.5*10^11) (limited by yellow RF)
(partial) blue snake ramp-up
Collisions with luminosity likely with blue+yellow snakes overnight (111 bunches)
II.Recap
Collisions 111 bunches since 2am, production_pp200_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
Polarimetry run zdcPolarimetry_2022: trg + daq
Abort gap at 2/8
Intensity ~1*10^11
BBC/VPD/ZDC : 0.9 / 0.4 / 0.07M
~55% polarization for yellow ~0% for blue
Access: ZDC scaler / TCMI (Zhangbu,Tim) – fixed
ZDC SMD E-V 2 hot channel (Aihong) - ongoing
III.Tasks for commissioning
a) Detector performance at higher luminosity / issues
b) Any issues with “Beam loss”? (6:43 am)
c) Trigger rates vs beam (ex: BHT3 rate lower ~x2 vs Run17)
d) ZDC SMD hot channel
e) Local polarimetry
f) FCS closing Monday morning?
IV.Open issues
a) Increase in magnet current, east ptt, Monday morning
b) NPS for BC1 for 208V, power cord over two racks (Tim)
c) Gating grid sector 21 outer disconnected, 12h min + risk of need to remove parts in front, maintenance 29th, RDOs masked out
d) Eemc-pwrs1 NPS which has a network interface failure and affects access to eemc-spin, spare is available with NEMA 5-20 plug (Wayne)
V.Plan of the day/Outlook
a) Ramp development (intensity, snake) during the day
b) Collisions (run production) in owl shift
12/18/21
I. RHIC Schedule
Ramps with higher intensity, abort gaps to be aligned, work for UPS for blue RF 9 MHz cavity
Collisions with larger luminosity overnight (111 bunches)
Tomorrow: Snake ramp up, intensity recommissioning, polarized collisions overnightII. Recap
Collisions 56x56 bunches since midnight, production_pp200_2022: trg + daq + tpx + itpc + btow + etow + esmd + tof + mtd + gmt + fcs + stgc + fst + l4
Polarimetry run zdcPolarimetry_2022: trg + daq
60% polarization for yellow from RHICIII. Tasks for commissioning
a) sTGC mapping
b) FST status
c) FastOffline requested for st_fwd
d) ZDC east channel 2 on in QT, no coincidence in RICH scalers after TCIM reboot, incorrect discriminator level, access 2pm - 3pm, SMD to be checked also
e) Local polarimetry
f) VPD splitter board (Christian, maintenance day 29th, Daniel to be notified)
g) FCS closing Monday if blue RF ok
IV. Open issues
a) BBC is ok (no trigger on previous xing on east) after power cycle to BBQ, bit check to be monitored (Akio)
b) Increase in magnet current, east ptt, Monday morning
c) NPS for BC1 for 208V, power cord over two racks (Tim)
d) Gating grid sector 21 outer disconnected, 12h min + risk of need to remove parts in front, maintenance 29th, RDOs masked out
e) Eemc-pwrs1 NPS which has a network interface failure and affects access to eemc-spin, spare is available with NEMA 5-20 plug (Wayne)
V. Plan of the day/Outlook
a) Ramp development during the day, access for ZDC afternoon
b) Collisions in owl shift
12/17/21
I. RHIC Schedule
Potential controlled access till 1pm, ramp development after (squeeze ramp, blue tune kicker, intensity ramp up)
Collisions in owl shiftII. Recap
Collisions 12x12 bunches since 4am, sTGC and FST voltage scans with field ON, tuneVertex_2022: trg + daq + tpx + itpc + fcs + stgc + fst + l4
III. Tasks for commissioning
a) FST (nominal voltages as before) + sTGC voltage scan (sTGC done, 2900 V is default for now)
b) BBC lost earliest TAC on east, EPD was used for voltage scan instead
c) VPD splitter board (Christian, maintenance day 29th, Daniel to be notified)
d) Local polarimetry, results west ZDC only, code issue? (Jinlong), polarimetry runs tonight
e) FCS mapping to be checked after cable swap
IV. Open issues
a) Increase in magnet current, east ptt
b) BC1 fan tray swap, no alarm when ongoing, no on/off via slow controls, NPS? (Tim, David)
c) Gating grid sector 21 outer disconnected, anode at sector 21 outer at 800 V, RDOs are masked, capacitance consistent with cable alone, 12h min + risk of need to remove parts in front, maintenance 29th
d) Eemc-pwrs1 NPS which has a network interface failure and affects access to eemc-spin needs to be replaced (not urgent)
e) sTGC has no data in first run after LV power up, under investigation
f) star-ops mailing list is slow in delivery, also other lists (stgc)
g) AC in control room
V. Plan of the day/Outlook
a) Potential controlled access till 1pm, ramp development after
b) Collisions in owl shift, production configuration (prod ids except mtd), ZDC polarimetry, FCS closing Sat/Sun
c) Forward detectors by experts only, sTGC mapping (Daniel)
d) Saturday: ramp development during the day, collisions in owl shift
12/16/21
I. RHIC Schedule
Blue snake reconfigured for coils #1 and #3, tests for abort kicker UPS
CeC till 8pm, beam development after
Collisions in owl shiftII. Recap
No collisions because of water flow problem at beamstop, caused by incorrect orifice
Cosmics, tune configurationIII. Tasks for commissioning
a) Magnet on/off? -> feedback from FST by 4pm EST
b) FST + sTGC voltage scan, procedure will be set by magnet on or off case
c) MTD, no dedicated commissioning run?
d) VPD slew parameters loaded, TAC windows set, investigation ongoing for splitter board
e) Scalers board, signals ok, more than 6 bunches needed
f) FCS status
g) ZDC status ok
IV. Open issues
a) BC1 multiple power-cycle on crate, SysReset, on/off in slow controls? Fan tray swap when possible (Tim)
b) Gating grid sector 21 outer disconnected, anode at sector 21 outer at 800 V for no gain, fix at maintenance day
c) Eemc-pwrs1 NPS which has a network interface failure and affects access to eemc-spin needs to be replaced (not urgent)
d) sTGC has no data in first run after LV power up, under investigation
e) star-ops mailing list is slow in delivery, also other lists (stgc)
V. Resolved issues
a) EPD mapping at the splitter
b) Magnet monitoring ok after maintenance yesterday, alarm limits ok
VI. Plan of the day/Outlook
a) CeC till 8pm, beam development after
b) Collisions in owl shift
12/15/21
I. RHIC Schedule
Maintenance for CeC and blue snake re-wiring, ramp development after 4pm
Collisions late afternoon / overnightII. Recap
Collisions with 12x12 bunches with forward detectors, production_pp500_2022, tuneVertex_2022
III. Open issues
a) sTGC voltage scan, another scans today (Prashanth + David to be called), in sync with FST
b) FST voltage scan, looks ok from last night, another scans today
c) tuneVertex_2022 for sTGC and FST voltage scans, runs for target number of events + add FCS, use BBC trigger
d) Lists of tasks for collisions from experts passed to SL
e) FCS status, trigger list
f) VPD one channel to be checked for max slew - mask out this one for now, TAC window, need feedback on pedestals while still in access, cabling check (Christian)
g) EPD calibrated now
h) Cal scan, ESMD PMT voltages updated, ETOW phase to be applied
i) ZDC towers check ok (Tomas), signal ok
j) One run with ZDC-SMD HV off, signal cables checked ok on side patch (Aihong)
k) Cabling check today (Christian)
l) Scalers board, SMD counts still at RHIC clock (Jinlong)
m) MTD commissioning (Shuai), VPD trigger and cal needed, instructions for SL by Shuai
n) BC1 power cycled on crate (Tim), booted ok, CAN address 73 will be set (Christian)
o) Gating grid status (Tim), sector 21 timing
p) Laser runs every 4 hours
q) TAC windows for BBC, EPD, ZDC, VPD (Eleanor, Jeff), log affects, delay does not, new tier1 fixed it, readback added
r) Magnet alarm limits
s) Eemc-pwrs1 NPS which has a network interface failure and affects access to eemc-spin needs to be replaced (not urgent)
t) sTGC has no data in first run after LV power up, under investigation
IV. Resolved issues
a) Commissioning done for: BBC, EPD, BTOW, ZDC
V. Updates
a) production_pp500_2022, BBC, BBCTAC, BHT3 and BHT3-L2W elevated (Jeff) + ETOW, VPD (almost)
b) Contact Jeff when a trigger can elevate to physics
VI. Plan of the day/Outlook
a) Restricted access now
b) Cosmics for gating grid, magnet up preferred
c) Beam development after 4pm, detectors in proper safe state
d) Collisions in the evening / overnight
e) SL tasks shift crew based on what we're running
12/14/21
I. RHIC Schedule
Damage in blue snake after power dip on Sunday evening, could use coils #1 and #3, access to rewire for these coils
UPS was disabled for abort kicker
Access now for kicker, snake and CeC, ramp development afternoon, collisions overnightII. Recap
VPD, EPD and Cal scans
Magnet trip yesterday evening
Controlled access now (~4 hours)III. Open issues
a) VPD commissioning (Isaac, Daniel), non-VPD trigger (Jeff), slew test with beam
b) EPD commissioning (Rosi)
c) ZDC SMD bits in scalers fire at RHIC clock (9.38 MHz), test with HV off, pedestal issue, cabling (Jinlong + Hank)
d) ZDC commissioning (Tomas, Zhangbu), signal seen, work for 1n peak
e) Cal scan (Oleg, Will J), BTOW 4ns shift, crate-by-crate scans
f) MTD commissioning (Shuai), VPD trigger and cal needed, instructions for SL by Shuai
g) Local polarimetry (Jinlong)
h) BC1 crate off? fails during boot, spot crash in startup file, power-cycle now (Tim)
i) Spike in 1st gating grid time bin (David), test now with cosmics
j) TAC windows for BBC, EPD, ZDC, VPD (Eleanor, Jeff), test today, log affects, delay not
k) Eemc-pwrs1 NPS which has a network interface failure and affects access to eemc-spin needs to be replaced (not urgent)
l) sTGC has no data in first run after LV power up, under investigation
IV. Resolved issues
a) Commissioning done for: BBC
b) Cards in EQ1, EQ2 and EQ3 replaced yesterday (Christian)
V. Updates
a) Separate trigger configurations for commissioning (Jeff)
b) File stream name for forward detectors: st_fwd
VI. Plan of the day/Outlook
a) Access now, beam development during afternoon, collisions overnight
b) Production configuration with final prescales, start with BBC, BTOW, production_pp500_2022
c) Forward commissioning with low intensity beam, Xu, Prashanth, David, VPD and EPD needed before
d) Magnet work tomorrow
e) Scalers need to run
12/13/21
I. RHIC Schedule
Polarization development and ramp development during the day, collisions with rebucketed beam late afternoon or overnight
Access at IP2
Low intensity now because of mistime abort in both rings at the power dip
Cogging depends on snake availability, needed for correct longitudinal position of vertex
Lossy blue injectionII. Recap
Collisions yesterday after 8pm, BBC HV scan, ended by power dip
Next collisions 5 am, ZDC polarimetry with singles at 2 kHz, VPD HV scan, EPD timing scanIII. Open issues
a) VPD HV 13.01 didn’t turn on, at lower voltage (1627 V) now ok, might need to swap the channel
b) Non-VPD trigger needed (BBC coincidence in L4) for VPD slewing correction, Jeff will make separate configuration file, instructions for SL by Daniel
c) Separate configuration for local polarimetry (Jeff)
d) EPD commissioning (Rosi)
e) ZDC commissioning (Tomas, Zhangbu)
f) Every trigger detector sends a message over star-ops when done with commissioning
g) Cal scan (Oleg)
h) MTD commissioning (Shuai), VPD trigger needed, instructions for SL by Shuai
i) Spike in 1st gating grid time bin, seen as perpendicular planes in event display, should fix after new pedestal, open/close test after beam dump, IOC restart (David)
j) TAC windows for BBC, EPD, ZDC, VPD in investigation (Eleanor, Jeff), monitoring to check the registers
k) L4 was not present because of incorrect R and z vertex cuts, ok now
l) Collision triggers in tune_22 for calibration and tune configuration
m) Dead QT32B daughter card for EPD (daughter A in EQ3 slot 10), also cards in EQ1 and EQ2, access needed to replace (Christian), controlled access (SL), SL calls Rosi after done to check
n) Local polarimetry in progress (Jinlong), not yet from scalers
o) Eemc-pwrs1 NPS which has a network interface failure and affects access to eemc-spin needs to be replaced (not urgent)
p) sTGC has no data in first run after LV power up, under investigation
q) iTPC Sector 13, RB 3 masked out and powered off, keep like this
r) FCS LV was overheating, rack backside was opened (Tim), 1 deg drop, not critical now
s) No ETOF
IV. Resolved issues
a) BBC commissioning done for run 22, Akio not in call list for collisions
V. Updates
a) Call list for collisions, SL informs over star-ops
b) File stream name for forward detectors: st_fwd
VI. Plan of the day/Outlook
a) Potential access
b) Tune configuration with beam development, detectors in proper safe state
c) Could get collisions later afternoon or overnight
12/12/21
I. RHIC Schedule
Collisions later afternoon (4/5pm), likely 6 bunches rebucketed
Magnet quenches were caused by temperature problem at 1010A, not beam induced
Lossy blue injection, work needed on Y2A RF cavity
Rebucketing successful yesterday with 6 bunches
Scans and ramp development till 4pm, stores with collisions after
II. Recaptune_22: trg + daq + btow + etow + esmd + fcs
III. Open issues
a) Global timing with collisions
b) TAC windows for BBC, EPD, ZDC, VPD (Eleanor, Jeff), test with rebucketed collisions
c) Dead QT32B daughter card for EPD (daughter A in EQ3 slot 10), access needed to replace (Chris)
d) Local polarimetry (Jinlong)
e) Eemc-pwrs1 NPS which has a network interface failure and affects access to eemc-spin needs to be replaced (not urgent)
f) First run after LV power up sTGC has no data, under investigation
g) iTPC Sector 13, RB 3 masked out and powered off, keep like this
h) FCS LV was overheating, rack backside was opened (Tim), 1 deg drop, not critical now
i) No ETOF
IV. Resolved issues
a) Phones were out yesterday night due to update, fixed early morning
V. Updates
a) New Readiness checklist, cosmics with 8+ hours without beam
VI. Plan of the day/Outlook
a) Tune configuration with beam development, detectors in proper safe state
b) Could get collisions later afternoon or overnight, call list for shift leaders
12/11/21
I. RHIC Schedule
Polarized scans and rebucketing tests till 8pm, then CeC until tomorrow morning
II. Recap
Collisions at 3am, 28 bunches, both snakes ramped, polarization 44% blue, 54% yellow, beam abort after 20 minutes
Next collisions 8am, ended by blue quench near the snake (but not the snake)
Cosmics, tune_22, trg + daq + btow + etow + esmd + fcsIII. Open issues
a) Global timing with collisions
b) Phones out at STAR and MCR due to update to phone system, fake (?) magnet trip in west trim at the same time, now back (9am)
c) Investigation in DSMs on TAC windows for BBC, EPD, ZDC, VPD (Eleanor, Jeff), affects triggers which use TAC, read from registers is different from write, access will be good to test the VME board-by-board (Jeff)
d) sTGC gas pressure increased after yellow alarm (Prashanth)
e) Timing for scaler board with beam (Chris), expect to be ok, needed for local polarimetry (Jinlong)
f) Eemc-pwrs1 NPS which has a network interface failure and affects access to eemc-spin needs to be replaced (not urgent)
g) First run after LV power up sTGC has no data, under investigation
h) iTPC Sector 13, RB 3 masked out and powered off, keep like this
i) FCS LV was overheating, rack backside was opened (Tim), 1 deg drop, not critical now
j) No ETOF
IV. Resolved issues
a) L4 plots missing from Jevp, fixed (Jeff)
V. Updates
a) New Detector States, 12/10, sTGC for both HV & LV is OFF for PHYSICS and Vernier scan, FST HV is OFF for PHYSICS and vernier scan
b) Output from individual ZDC towers tested (Tomas)
VI. Plan of the day/Outlook
a) Tune configuration with beam development, detectors in proper safe state
b) No collisions overnight (CeC instead)
c) Cosmics only if there will be 8+ hours without beam
12/10/21
I. RHIC Schedule
Blue9 snake ramps today till 4pm, there was shorted diode against spikes from transient current
Recommissioning after that if blue snake is available, or rebucketing and ramp development if not
Stores with collisions during owl shift if ready by 10pm today
II. Recap
Collisions at 4am for short time, ended by multiple beam aborts, access ongoing now
tune_pp500_2022 with collisions, tune_22 or cosmics, field onIII. Open issues
a) Jpsi*HTTP at 1 kHz without beam, hot/warm tower ETOW/BTOW, leave out until calorimeters commissioned
b) Update in TAC min/max for ZDC, EPD, BBC (Jeff)
c) BBC HV adjusted to lower values (initial), need to finish HV scan (Akio)
d) FCS LV overheating, rack backside to be opened (Tim), 1 deg drop, not critical now
e) iTPC Sector 13, RB 3 masked out and powered off, keep like this
f) Timing for scaler board with beam (Chris)
g) Mask from L0 to L1 for a trigger patch
h) Eemc-pwrs1 NPS which has a network interface failure and affects access to eemc-spin needs to be replaced (not urgent)
i) First run after LV power up sTGC has no data, under investigation
j) No ETOF
IV. Resolved issues
a) Remote access to scalers for polarimetry on cdev for Jinlong, was related to 64bit/32bit change, ok now
b) Fan tray for EEMC CANbus, crate #70 replaced (Tim), also reboot to main CANbus, gating grid restored
V. Updates
a) VPD voltages HV changed to 2013 values (Isaac)
VI. Plan of the day/Outlook
a) Schedule from rhic is largely uncertain, could get collisions in owl shift
b) tune_pp500_2022 with collisions, tune_22 or cosmics, field on, safe state when beam development
c) FST keep off until very nice beam, expert present for any operation (Xu)
d) sTGC by expert only (Prashanth)
e) Commissioning starts with collisions on, state of experimental setup now
12/09/21
I. RHIC Schedule
Possible collision setup in upcoming owl shift, progress on collimator, kicker alignment and timing, vertical injection matching
and yellow injection damper, safe state important for detectors during beam development.blue9 snake: beam induced quench without substantial beam loss, question on magnet training or real problem,
access today for a p.s. related to the snakeToday after p.s. access: beam development without blue snake
II. Recap
Cosmic runs with field on, tune_22 with beams, trg + daq + btow + etow + esmd + fcs
III. Open issues
a) EEMC CANbus fan failure, crate #70, few minutes access to replace the tray (Tim)
b) sc5 reboot by mistake by DO when trying to reboot crate #70 caused by incomplete instructions
c) FCS LV overheating, rack backside to be opened (Tim), ½ hour to observe temperatures
d) Level for yellow alarm for sTGC pentane gas, done
e) Online database not visible yesterday ~2pm → ~5pm, Dmitry was called
f) sTGC HV IOC having multiple instances (red alarm), ok now
g) EEMC and EQ2, MXQ, and BBQ in alarm handler (David, input from experts on what to unmask in alarm handler)
h) iTPC Sector 13, RB 3 was asserting busy even masked out, was powered off, Tonko + Jeff will take a look
i) BCE DSM2, new algorithm uploaded, in test yesterday, in trigger, L0 to be checked by Chris
j) Instructions on recovery for BBC/ZDC/VPD HV system (LeCroy1440) communication after power failure, pwd to bermuda needed
k) Remote access to scalers for polarimetry on cdev for Jinlong
l) Add instructions to recover forward detectors after power dip (sTGC call experts), Oleg T will add inst for FSC, FST call experts
m) Eemc-pwrs1 NPS which has a network interface failure and affects access to eemc-spin needs to be replaced (not urgent)
n) sTGC auto-recoveries (is a place-holder for final message), empty plots for a few runs → on hold for commissioning
o) Disk that stores TPC sector 8 pedestals needs to be replaced by Wayne (not urgent)
p) No ETOF
IV. Resolved issues
a) Scaler board replaced during access yesterday (Chris), SCLR48 in trigger since run 22342037
V. Updates
a) Update in sTGC HV and LV GUI (channel numbering), instructions are updated
b) Magnet current limit alarm, Flemming + David for default limits
VI. When collisions are delivered
a) Commissioning plan
b) Time scan for BEMC together with ETOW and ESMD
c) ETOW and ESMD basic QA with collisions to test if its configuration is ok
VII. Plan of the day/Outlook
a) beam development with detectors in correct safe states, tune_22 or tune_pp500_2022, cosmics when possible
b) p.s. access for blue snake, beam work till midnight, possible collisions setup during owl shift
c) ETOF may be turned over to SC for a few weeks during the run
12/08/21
I. RHIC Schedule
Test for blue9 snake ok (partial snake, ongoing work), beam work till 10:00, access 10:00 -> 12:00,
then injection, ramps and rebucketing till tomorrow (12/09 4pm)II. Recap
Cosmic runs with field on, tune_22 with beams, trg + daq + btow + etow + esmd + fcs
III. Open issues
a) Restricted access 10am today, scaler board (Chris, finished), also for EPD (finished)
b) Add instructions to recover forward detectors after power dip
c) EEMC and EQ2, MXQ, and BBQ in alarm handler
d) iTPC Sector 13, RB 3 was asserting busy even masked out, was powered off, Tonko + Jeff will take a look
e) sTGC HV at 2900 V for now
f) sTGC auto-recoveries (is a place-holder for final message), empty plots for a few runs → on hold for commissioning
g) BCE DSM2, new algorithm uploaded, ready to test (during today), not in trigger now
h) Eemc-pwrs1 NPS which has a network interface failure and affects access to eemc-spin needs to be replaced (not urgent)
i) Disk that stores TPC sector 8 pedestals needs to be replaced by Wayne (not urgent)
j) No ETOF
k) Instructions on recovery for BBC/ZDC/VPD HV system (LeCroy1440) communication after power failure, pwd to bermuda needed
l) Access to scalers for polarimetry on cdev for Jinlong
IV. Resolved issues
a) BTOW crate Id 8 failed configuration fixed, (disconnected 0x08 board 1 and put it back)
b) Replaced the problematic DSM1 in BCE crate, hole in trigger patch 250-259 seems gone from btow_ht run, 22340037
V. Updates
a) Two screens for sc3 (VPD/BBC/ZDC HV)
b) 30 new mtd plots to the JevpPlots
c) evb01/evb07 added to the DAQ default
d) New firmware in BE004 DSM2
e) sTGC LV IOC to follow the procedure
f) To power cycle a EEMC follow the operation guide, power off and on not enough, follow manual strictly
g) TPC current calibration should be done once per day
h) Magnet current limit alarm, Flemming + David for default limits, sampling frequency?
VI. When collisions are delivered
a) Global timing, tune_pp500_2022 trigger definition
b) Time scan for BEMC together with ETOW and ESMD, files from DAQ by Tonko, min bias trigger, time interval and steps to be set
c) ETOW and ESMD basic QA with collisions to test if its configuration is ok, first reference plots will be available with collisions
VII. Plan of the day/Outlook
a) beam work till tomorrow afternoon, cosmics when possible
b) no collisions are expected till tomorrow 12/9 4pm at least
c) exercise for BBC/VPD/ZDC lecroy recovery after power failure (David)
d) ETOF may be turned over to SC for a few weeks during the run
11/17/21 to 12/07/21 Zilong Chang
11/16/21
RHIC schedule: no new info: “2-3 weeks” start-up delay (incomplete cryo controls upgrade).
11/15 Blue 4K cool-down, starting 1/2 (12-6), 11/29 < for Yellow
11/15: magnet polarity change RFF -> FF
11/15: Calibration sets taken: Long Laser run, polarity flip, long laser run + laser with resistors in the chain
Currently 1.5MOhm in the chain, How long?
will learn from the analysis (Gene) of the data set on the short in TPC
Magnet stable
All detectors are included and currently running (except ETOF)
gmt trigger is enabled
Issues and resolved:
MTD: issue with LV. RDO masked out (1 out of 2): running / Geary
BTOW: configuration fail. Fix by resetting board / Oleg
Plan for today
new shift crew + period coordinator (Zilong)
NO access 07am-12pm tomorrow (11/17) for access controls test
cosmic with all available detectors with Forward FFrun until Thursday morning with FFF
Flip the polarity back to RFF the polarity on Thursday morning (combined with BBC installation, MTD work)
let crew know the detector is not ready to be included
laser / 4 hours (separate run)
pedestal / shift
TOF,MTD noise run / day
11/15/21RHIC schedule: the same: “2-3 weeks” start-up delay (incomplete cryo controls upgrade).
11/15 Blue 4K cool-down, 11/29 < for Yellow
Short term plan:
11/15: Flipping magnet polarity to RFF -> FF (BBC installation postponed)
11/15: Long Laser run (done), polarity flip (ongoing), long laser run + laser with resistors in the chain (to be done)
11/18: evaluate the short in TPC with data taken with two field settings, and decide on the need to open East pole-tip to fix the if necessary
magnet stable
a trip yesterday 4:30pm with “daily” power dip
TPC GG issue resolved: with correctly reloaded value
Issues, detectors not included:
FST: Error with HV ramping / 7am
STGC running, included but HV off
MTD: too many recoveries.LV control / 3am
Shift procedure
FST, STGC under shifter control?
pedestal after “warm up” time
Plan for today
cosmic with field on with all available detectors with RFF -> FF
long Laser runs
TPC, BTOW, ETOW, ESMD,TOF, FCS, sTGC, FST, MTD
let crew know the detector is not ready to be included
laser / 4 hours (separate run)
pedestal / shift
TOF,MTD noise run / day
11/13/21RHIC schedule: the same: “2-3 weeks” start-up delay (incomplete cryo controls upgrade).
11/15 Blue 4K cool-down, 11/29 < for Yellow
Any beam activities with only Blue cold?
Short term plan:
11/12 - 11/15: continue with cosmic data taking at Reverse Full Field
11/15 Monday morning: Magnet polarity flip, BBC (West) installation
11/15 - cosmic (+laser) data taking at Forward Full Field.
11/18: evaluate the short in TPC with data taken with two field settings, and decide on the need to open East pole-tip to fix the if necessary
magnet stable
trip yesterday likely from power dip
alarm: set value, range to reduce false alarm from fluctuation
ETOW: cable fixed. DAQ error. trigger/hardware/DAQ issue?
FST overheating module 3-11. not resolved. masked-out. Still out of run?
STGC: DAQ 0. Still out
shift QA plots, online QA, event display: lagging
laser run: separate
Plan for today
cosmic with field on with all available detectors
TPC, BTOW, ETOW, ESMD,TOF, FCS, sTGC, FST, (MTD)
let crew know the detector is not ready to be included
laser / 4 hours (separate run)
pedestal / shift
TOF noise run / day
Reference plots and instructions for shift crew (Current, Official Version)
Attached are critical reference plots for every subsystem with description, instructions on what to look for in every plot and finally what action should be taken.0 - Experts should do their best to select plots that are independent of the triggers we are running.
1 - Experts should limit their critical plots to a maximum of 4 plots for every subsystem.
2 - Experts should maintain their plots up to date and inform the period coordinator of any updates.
3 - Period coordinator should make sure that the printed hard copy matches the online copy.
4 - Shift crew should closely monitor all of the corresponding plots online.
------------------------------------------------------
Note:
Experts description for every plot should answer the following questions:
1- What the plot is showing?
2- What aberrations to look for in the plot?
3- What to do if there is a problem?
------------------------------------------------------
I'm going to copy the documents below as links here to group subsystems together:
BTOW critical plots (Run 22 and Run 23)
EEMC critical plots (06/08/23)
EPD
- Good QA plots
- Bad behavior
- Cold tile response (what to do if you see a cold tile) (12/19/19)
eTOF
- Critical plots reference (06/02/2024)
FCS critical plots (Run 22 and Run 23)
FST (05/06/24)
sTGC (03/30/22)
TOF critical plots (08/23/2024)
MTD critical plots (07/23/2024)
VPD critical plots (01/08/20)
TPC plots and comments (09/18/2024)
Misc advise (01/05/22)
- Do not only check plots with references, check the entire set of plots (l4 and shift). Even if you don't understand what a plot means you can observe holes in the plot or a plot not filling when it usually does.
- Check the L0Trg plots (usually) on page 21. If the BBC is not configured the BBC TAC difference plot will be empty. That is: shift > Trigger > Trigger_Detector_Vertex > BBC TAC Difference
- FST MPV plots only fill at the end of a run, so they'll look empty during it.
- The GMT plot Shift > GMT > Timing > Sum is empty for some runs and not others. Nikolai said “QA plots can be sometimes empty because the occupancy / statistics for GMT is rather small one." It does not require contacting the expert.
- Check the TPC drift velocity during laser runs. If it's empty the shift crew/leader likely forgot to check the laser in in run control. A laser which doesn't turn on should be obvious to the DO.
- The statistics in the drift velocity plot are not very indicative of the number of events recorded. It shows a sampling that can vary run-to-run and will always have far fewer entries than events recorded.
- Double peaks in the TPC drift velocity plot may not show anything serious. This comes about from the online code which is not the same code used offline. The expert probably can't do anything, but you can note it in the shift log.
- A hot tower can dramatically change the scale of the BEMC eta phi plot, making almost all channels the same color. This is typical in fact, and not cause for alarm.
WAH Network Switch NPS details
This is NOT a comprehensive list of NPS units in the WAH, only those used with network switches
Note that in some cases the NPS units listed here also supply power to devices other than network switches.
| Network Switch | Location | NPS | Outlet | Model | telnet | SSH1 | HTTP | User Accounts2 |
| splat-s60.starp (130.199.60.118) |
SP 1C4 | netpower1.starp (130.199.60.252) |
3 | APC AP7900B | • | • | staradmin (wbetts) trgexpert (wbetts, ?) device (wbetts) jml tlusty |
|
| splat-s60-2.starp (130.199.60.138) |
SP 1C4 | netpower2.starp (130.199.60.253) |
A1 | WTI NPS-8 | • | staradmin (wbetts (pw or SSH key)) akio crawford cperkins jml tlusty |
||
| east-s60.starp (130.199.60.251) |
east side rack under stairs | eastracks-nps.trg (172.16.128.226) |
8 | APC AP7901 | •3 |
• | apc (wbetts) device (wbetts,?) jml tlusty |
|
| west-s60.starp (130.199.60.174) |
west side rack (EEMC stuff) | westracks-nps.trg (172.16.128.227) |
1 | APC AP7900 | •3 | • | apc (wbetts) device (wbetts) jml tlusty |
|
| nplat-s60.starp (130.199.60.62) |
NP, 1st floor | north-nps1.starp4 (130.199.60.71) |
1 | APC AP7900B | • | • | staradmin (wbetts) apc (wbetts) jml tlusty |
|
| east-trg-sw.trg (172.16.128.223) |
east side rack under stairs |
pxl-nps.starp (130.199.61.2) |
8 | APC AP7901 | • | • | STARpwradm (wbetts) device (wbetts) jml tlusty |
|
| splat-trg2.trg (172.16.128.224) |
SP 1C4 | netpower1.starp (130.199.60.252) |
1 | APC AP7900B | • | • | staradmin (wbetts, ?) trgexpert (wbetts, ?) device (wbetts) jml tlusty |
|
| switch1.trg (172.16.128.201) |
SP 1C4 | netpower1.starp (130.199.60.252) |
2 | APC AP7900B | • | • | staradmin (wbetts, ?) trgexpert (wbetts, ?) device (wbetts) jml tlusty |
|
| switch2.trg (172.16.128.202) |
SP 1C4 | eemc-pwrs1.starp (130.199.60.23) |
4 | APC AP7901 | • | • | apc (wbetts) device (wbetts) eemc (Will Jacobs and the shift crew?) oleg (Oleg Eyser, outlet 8 only) jml tlusty |
|
| switchplat.scaler (10.0.1.150) |
SP 1C4 | netpower2.starp (130.199.60.253) |
A2 | WTI NPS-8 | • | staradmin (wbetts (pw or old SSH key)) akio crawford cperkins jml tlusty |
||
| switchplat2.scaler (10.0.1.149) |
SP 1C4 | netpower2.starp (130.199.60.253) |
A3 | WTI NPS-8 | • | staradmin (wbetts (pw or old SSH key)) akio crawford cperkins jml tlusty |
||
| switchplat3.scaler (10.0.1.154) |
SP 1C4 | netpower1.starp (130.199.60.252) |
4 | APC AP7900B | • | • | staradmin (wbetts) trgexpert (wbetts, ?) device (wbetts) jml tlusty |
1 Establishing an SSH connection to some of these NPS units can take about 20 seconds.
2 In most cases, additional individual user accounts are possible (and advisable!)
3 only older weak encryption is available, use 'ssh -c 3des-cbc' to connect with an older cipher that is used by these NPS units
4 The North Platform NPS uses copper-to-fiber media convertors for its network connections.
Though the media convertors themselves are relatively unlikely to fail, it is possible to power cycle one of them on netpower2.starp, plug A4.
If one is unable to connect to north-nps1 to powercycle nplat-s60.starp, then one could try powercycling this media convertor as a last resort short of entry to the WAH for troubleshooting.
Additional Notes:
".starp" is short for .starp.bnl.gov (130.199.60.0/23)
".trg" is short for .trg.bnl.local (172.16.0.0/16)
"scaler" is short for .scaler.bnl.local (10.0.1.0/24)
In order to access an NPS or test if a given network switch is online (with ping for instance), one must first get to a system that has access to the same subnet as the NPS or switch in question.
Most machines using a 130.199.60.0/23 address (aka "starp") will not have access to .trg or .scaler (and vice versa).
The trgscratch machine has network interfaces on all three networks, so is particularly useful in this regard.
And a final note - DNS resolution is not 100% shared across the three networks. In particular, the scaler network has its own DNS servers which are not configured on all multi-homed hosts. The point being that using the numeric IP address may be necessary instead of the FQDN in some cases.