- jeromel's home page
- Posts
- 2025
- 2020
- 2019
- 2018
- 2017
- 2016
- 2015
- December (1)
- November (1)
- October (2)
- September (1)
- July (2)
- June (1)
- March (3)
- February (1)
- January (1)
- 2014
- 2013
- 2012
- 2011
- 2010
- December (2)
- November (1)
- October (4)
- August (3)
- July (3)
- June (2)
- May (1)
- April (4)
- March (1)
- February (1)
- January (2)
- 2009
- December (3)
- October (1)
- September (1)
- July (1)
- June (1)
- April (1)
- March (4)
- February (6)
- January (1)
- 2008
- My blog
- Post new blog entry
- All blogs
Catalog centralized load management, resolving slow querries
General problem
The FileCatalog management from an administrator stand point (i.e. connection made with the FileCatalog API with intent=Admin) has been slow and suffering delays, hangs and race conditions.
A typical view of the server's load is showed in the graph below:
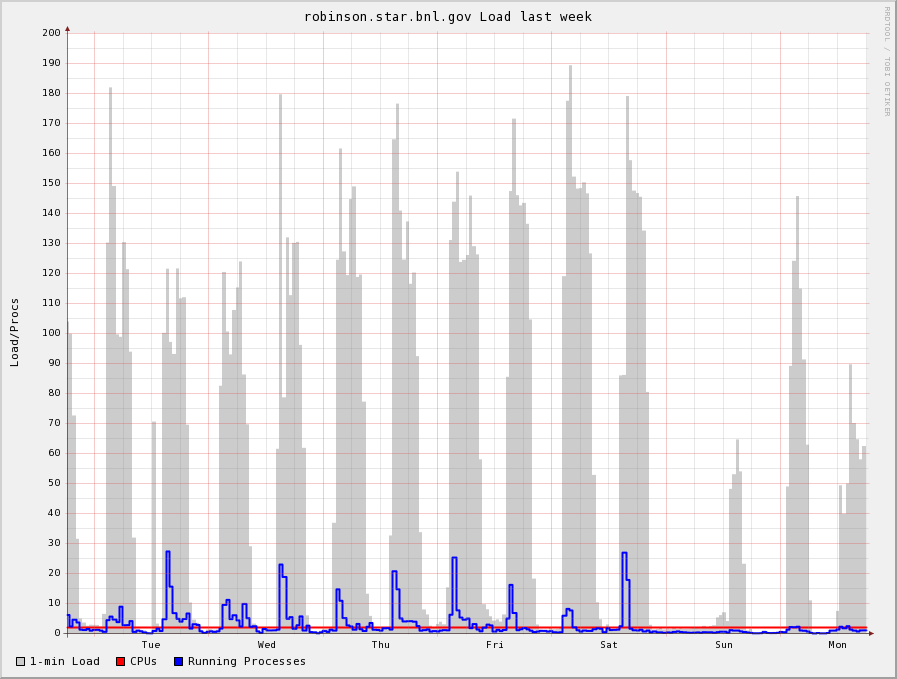
Each pick could go as high as load=180 which, at this value the server is blocking i.e. querries are not resolved for multiple hours. Race conditions have been observed as well. The rapid start of many access could result in queries coming into clash and we have seen MySQL not able to decide which one to do first (typically, one need to kill one of the top longest query and all moves again).
This profile is dominated by two factors:
- Because spiders are running from each node and we have CAS=343 nodes and CRS=92 nodes, we can have as many as 435 processes making almost simultaneous connections. The spike are caused by spiders and indexers looking at local files (Xrootd related namespace and access to storage=local)
- NB: removing storage=local would resolve the issue altogether for now but would delay the issue rather than solving it (soon enough, out total central disk space could also exceed a threshold value creating race conditions again)
- The way the processes are started is via a loosely coupled many-client socket architecture (leveraging nova) whereas a command is sent (with no guarantees) to a list of clients then performing the operation. The load would be expected to rise suddenly to as high as 400+ but this is not the case since we introduced a random delay in start-up of spawned processes.
- NB: However, such delay would have to be constantly adjusted depending on the number of nodes and length of the operation (which itself, depend on the size of local storage, number of files, and so on ...). In other words, it is not the solution.
- The root cause and problem: how to control and maintain load below a threshold at all times, allowing a few active clients to perform their operations (rather than many clashing with each other). This is classic "coordinator" problem.
Solution - load control and connection throttling?
[2009/03/08]
The simple way to resolve this is to define "load" and delay connections whenever load reaches a certain value. In our case, only one Master is considered (hence, we have no need for defining load in a fancy way incorporating for example hardware differences, disk IO, CPU speed and cache speed or network interface performance). A simple measure of load would be in our model:
- number of SELECT, INSERT, UPDATE, ... operations performed at a certain time
With MySQL, this could be trivially obtained by SHOW PROCESSLIST. Several issues then come:
- First, after the load is reached, we do not want to wait indefinitely since slow or stuck queries could still happen. We may want to proceed and see if additional queries would resolve.
- Second, the longer we wait the highest we should get a chance to get "in"
This is a classic fairness issue. Our first implementation was based on the principle "the longer we wait, more chances we have for our request to be satisfied" but we used a linear scaling rule. The result is showed below:

After a rapid rise of the load, the load would linearly build up and later decrease. The total amount of time this would take was five hours. We were looking for a flat profile (or slowly growing profile as a function of time).
Our second try implements a logarithmic rule in load share. As new connections are satisfied, others may be slowed down in a non-linear fashion offering a natural throttling mechanism. The base formula is based on the threshold value and the number of tries.The result over an hour follows:
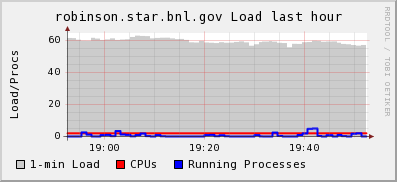
The profile seem to be rather flat and the equilibrium around select threshold (50) +10. The final profile is below:
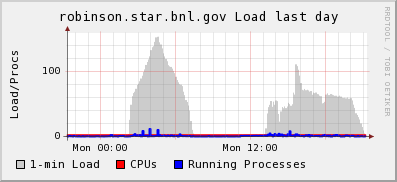
The total amount of time was increased to 7+ hours for a lower load.
Tuning
[2009/03/09]
Third try. This test would need to be done twice (once for a baseline, second to see the caching effect). Changes included
- Using caching in the spider
- Changing a wait tiime from 5*2 to 5*3 seconds (this should change nothing)
- Modifying the random number for startup of the spider (suspicion that the randomization was not good, hence the sharp rise at first)
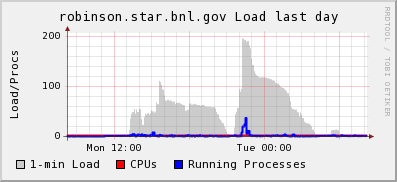
Mixed results. Observations are that
- the rise spanned over an hour as expected (random number throw flat between 0 and 3600 seconds)
- the rise however goes beyond the expected level for unclear reasons [was I playing with the spider script?]
- the little blip after the second bump is the effect of the spiders being triggered again but with caching enabled.
- However, since caching is cyclic (once every N, a full check is made) another development needs tobe introduced i.e. the cycle need to be different per node so we do not get back all at the same time to a large bump.
- Note also that this effect will decrease with time and as node will reboot / start at different times (the cron cycles will no longer be in synch after a while and until a full farm upgrade)
The spidering dameon could be enabled in suhc a way that their startup is probabilsitic. The idea would be to reduce the number of probably starting active dameons while preserving the central-commander / listener model. This is fully iplemented but not enabled at the moment (other tuning shouldbe done prior to reducing the number of simultaneous active daemons).
[2009/03/11]
A spread was introduced in caching cycles. The basics is that not all processes / daemons from our 435 nodes reset their cache (delete it) every N cycles. To introduce an offset, -coff option was added to the DBUpdate.pl script. A value of 0 would trigger a default algorithm extracting the node number and using it as an offset proportional to the base cycle value. To see this effect, we need to increase the daemon execution frequency. Currently set to twice a day with a base cycle of 10, it would take 5 days to see an effect of our implementation. Increasing to four times a day (once every 6 hours) would allow testing the validity of the approach and in the long term, provide faster catalog updates. The increase was done on 2009/03/12 indicating that in three days, some of the nodes would hit the cache cleanup limit. The results are below:
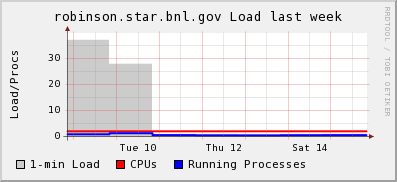
We can see the decrease of load from the Tuesday exercise followed by a no-load zone. A detail on a day range shows the below:

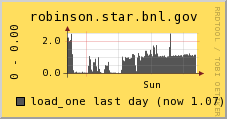
The load overall seem to be maintained below 2.
MORE TODOs
- understanding the rise beyond base load-control threshold
- reduce the length of one operation per node: we can further reducing load from the spiders by introducing caching - DONE
- re-tuning (caching needs to be disabled)
- reduce the number of connections per unit of time:
- first order solution: be sure caching is enabled, make the cache cycle reset random so not all nodes would recycle their cache at the same time [DONE]
- possibly adjust the cache reset offset depending on results []
- IF not sufficient, reducing the number of nodes per cycle by increasing the number of cycles per day but rolling a dice on which node should start and which one should wait [IMPLEMENTED / NOT ENABLED]
- adjusting / tuning the threshold: this should be done within the same conditions; the width of the distribution and the total integral should characterize the efficiency of the process. The real measure would be how long one client would perform its operation.
- Queries on storage!= remain slow since they go back to the huge FileLoation table rather than using the sub-tables FileLocations_x tables. This could be circunvented by instead looping over the diverse storage indexes. Perhaps to first order, a SQL query IN(val1,val2) would also help. This was reported in RT # 1297.
- Revisit of queries making LEFT OUTER JOIN rather than extracting dictionary index values and querying on those as selector.
- This is tricky as the FileCatalog API is based on "can query anything versus anything" requiring a generic logic but detection of queries based on FileData/Filelocations tables could branch the logic to an optimal query.
Recent API Modifications
Preventing long / stuck queries
[2009/02/00]
Upon executing of queries, the API should time out if a query is not satisfied after a long time. THe query may be re-tried (or not). A NULL result should be sent back to caller. This is trivially implemented by setting
$SIG{ALRM} = ...
alarm($FC::TIMEOUT);
$success = $sth->execute();
alarm(0);
and handling the alarm by evaluating the thrown exception. However, aborted inserts in dictionaries could be disastrous and hence, only general relational queries would be caught.
As per 2009/02, the FileCatalog API run_query() internal fully implements a timeout set to be 45 mnts.
Preventing connection failures on slave
TODO: The same timeout mechanism could be introduced. $FC::DBCONTIMEOUT is globally set but this is not yet implemented.
Separating SELECT queries and operation requiring Master / Admin access
[2009/03/07]
One aspect which needs to be investigated is the separation of SELECT statements, which may be performed on a slave naturally load-balanced slave and operations requiring admin privileges. This can be done by separating:
- the detection of new, to be marked, to be modified files
- the actualaction of inserting new files, updating records, altering records
The FileCatalog API allows for the same FileCatalog handler to be re-used for connecting to different servers and service whether connection as intent=User (slave) or intent=Admin (Master). The sequence should be:
$fC = FileCatalog->new();
... perform global settings if needed, then as example ...
@info = $fC->get_connection("User");
$fC->connect(@info);
... perform operation involving selects ...
$fC->destroy(); # close connection to the FileCatalog load balancing DB
@info = $fC->get_connection("Admin");
$fC->connect(@info);
... perform privileged operations ...
This could be done over and over i.e. the privileged connection could be closed again, a intent=User could be re-opened and so on. However, there is a small problem with this approach: depending on how fast updates to the Master propagates to the slaves, operations may be done multiple times. For example, imagine you select a list of files you want to mark available=0. After selecting many records and saving enough information to build a unique and non-ambiguous context, you open the connection to the Master using the approach above, update the records using $fC->update_location("available",0,1); . You do this on a lagher number of records, close the connection to the Master and re-open as user. You may select the same record again if the Master has not sent the update commands to the slave yet and ask the Master to update the record again. As it turns out, the FileCatalog API detects such conditions and will complain.
The message and warning are understood and hence, there should be no need for them as far as you are sure that what is happening is correct. We have introduced a new method $fC->warn_if_duplicates({0|1}) to enable/disable the warning. "duplicates" here hav the meaning of duplicate updates sent multiple times to the API.
Be very careful when using this trick in conjunction with $fC->clone_location(), $fC->update_location(), $fC->update_record(), $fC->delete_records(), $fC->insert_file_location(). All of those function acts on a context and the separation of slave/master operations implies
(a) save the FULL context between slave/Master connections and restore the exact context for each file to operate on
(b) you make appropriate use of $fC->clear_context() between operations and between open/close to protect yourself and your script against interferences or side effects due to previous operation
Also remember that $fC->destroy() destroys the connection not the current handler and, in load balancing mode, you may get different slave when re-connecting to the FileCatalog as intent=user.
The script fC_cleanup.pl fully implements this principle.
Groups:
- jeromel's blog
- Login or register to post comments