BTOW Gain Calibration -- The effect of the HT trigger
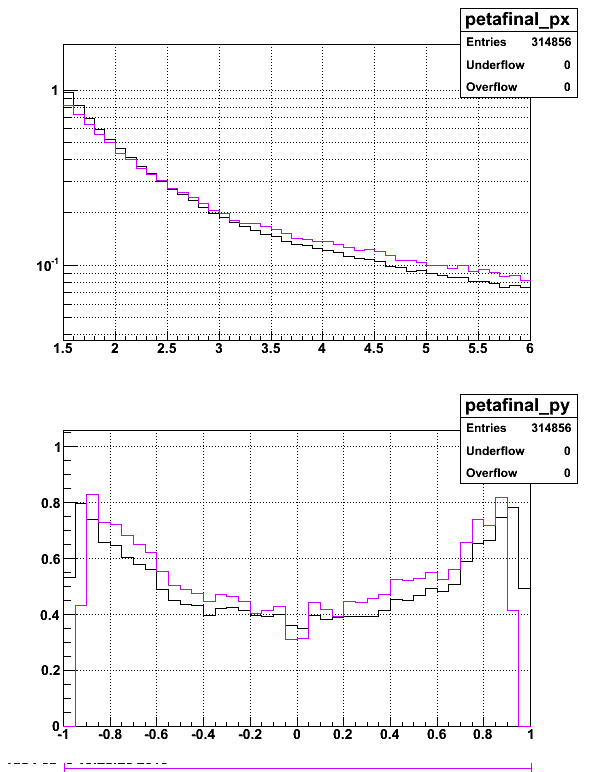
I discovered that the code that should have been rejecting electrons that pointed towards a HT trigger tower was not working properly. I fixed the problem and re-ran the code. Now the momentum distributions look much better (there is no peak around 5-6 GeV). The two plots below show the p and eta distributions of electrons, when TOF information is required (purple) and not required (black).
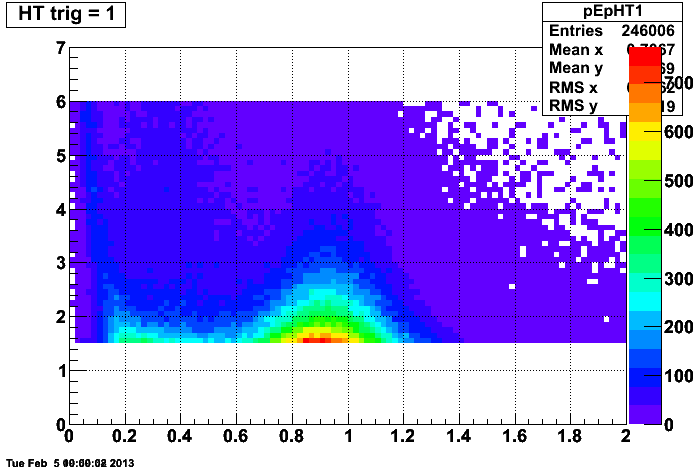
It is necessary to remove electrons that trigger the HT trigger because they have an odd E/p signature. Compare a plot of E/p (horizontal axis) vs p (vertical axis) in MB events:

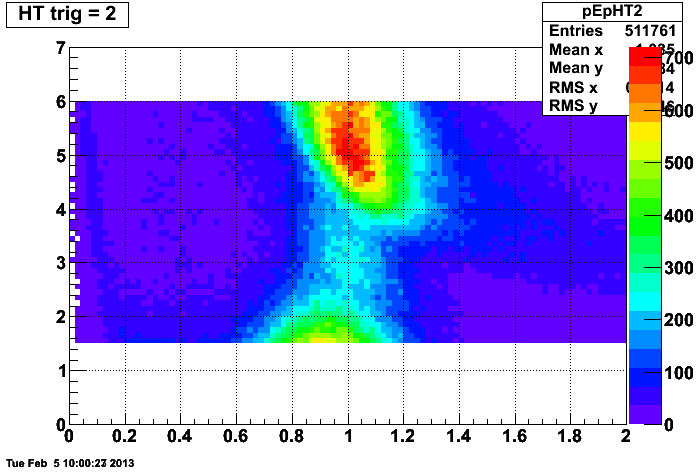
with the same distribution for electrons which trigger the HT:
We can keep electrons from HT triggered events so long as they do not point in the direction of the tower that fired the trigger. Their distribution looks normal:
Note that these plots can be compared with Fig. 3 (page 5) in the 2006 Calibration Report: drupal.star.bnl.gov/STAR/system/files/2006-Calibration-Report_3.pdf
I find that when I exclude HT electrons, the gains go down by ~10%, as may be expected from the above plots.
However, it seems that this difference worsens the agreement between my calculated Run 11 gains and the Run 9 gains. For example, if I plot the difference (Run 9 gain) - (Run 11 gain) for all good towers when HT events are excluded (in Run 11):
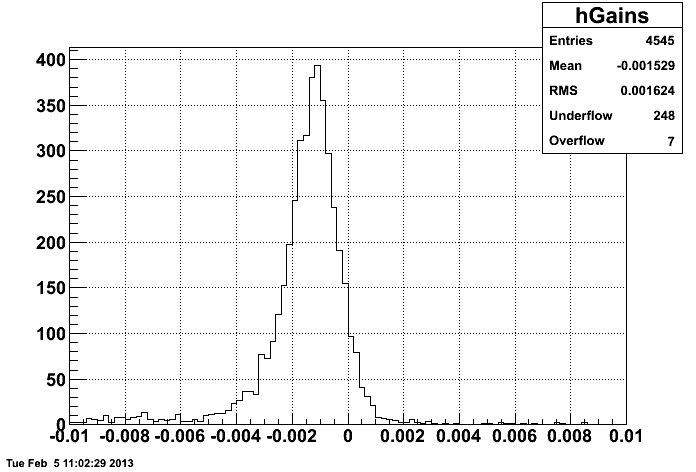
compared to when HT events are not excluded (in Run 11):

I did the similar exercise with the Run 6 gains. Here is the plot of (Run 6 gain)-(Run 11 gain) for all good towers when HT events are excluded (in Run 11):
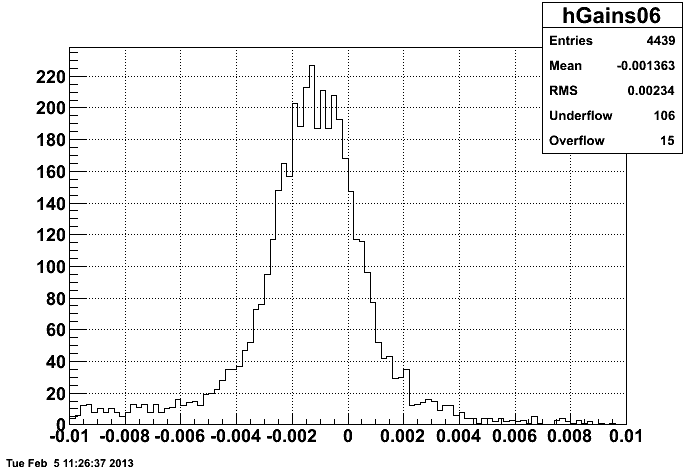
and here is the plot of (Run 6 gain)-(Run 11 gain) when HT events are not excluded (in Run 11):
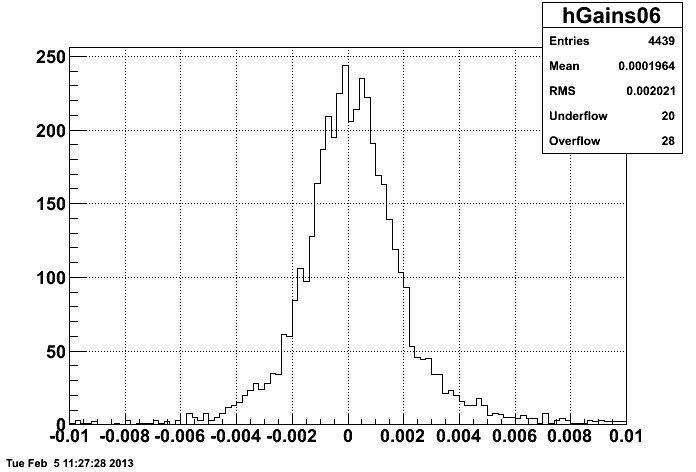
This seems to be consistent with the discrepancy between my Run 11 plots and Fig. 3 in drupal.star.bnl.gov/STAR/system/files/2006-Calibration-Report_3.pdf
From looking at the figure in the 2006 report, the E/p distribution seems centered at ~1, while my figures show it centered around ~0.9. So including the HT electrons was masking another possible problem. I think the next step is to remake the Run 9 trees (will take a few days) to see if this 10% difference is caused by differences in the analysis or is truly a difference in the calibration.
- aohlson's blog
- Login or register to post comments