July 22 Clustering Algorithms
So, I finally got the clustering mechanisms to run with the tree. The original clustering was a K Means cluster (each strip is assigned to the nearest cluster, then the cluster was recentered, and the process begins again). The second clustering was a C Means cluster (each strip is shared between the cluster, with the amount of sharing determined by the distance from the center of a cluster), The clusters lead to the two sets of graphs seen below.
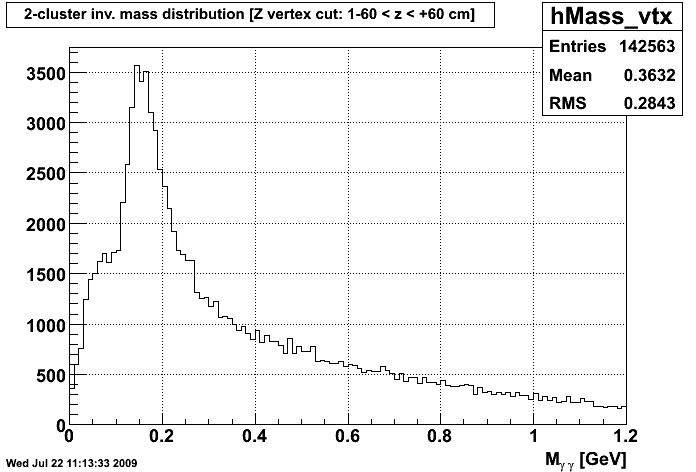
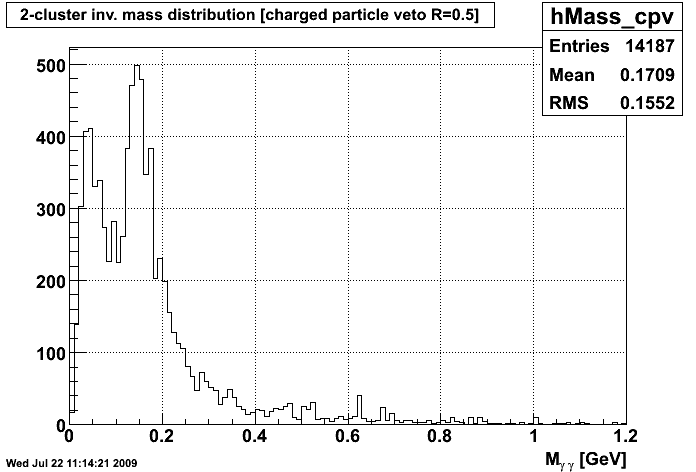
K Means Invariant Mass Distribution after VTX K Means Invariant Mass Distribution after CPV
C Means Invariant Mass Distribution after VTX C Means Invariant Mass Distribution after CPV
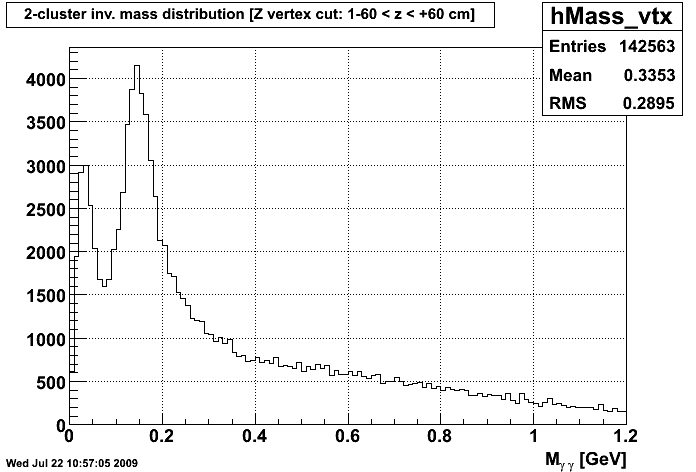
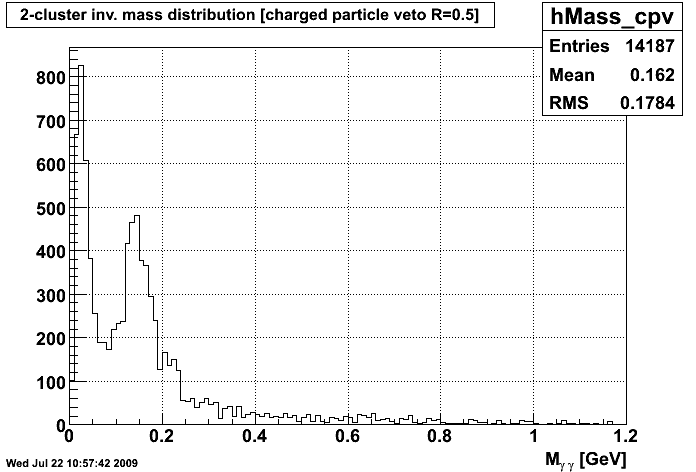
So, I think what this shows is that the C Means algorithm is at the moment reconstructing the pion peak better, and is getting a crisper photon peak, especially after the charged particle veto. Currently, the C Means weights are determined for each strip by the scaling the factors of 1/(Distance2+.1), so that the sum of the two weights equals 1. Tinkering with the power to which distance is raised may yield better or worse clustering, so that's something I will tinker with once we have the method down.
There were some questions as to how constant the clustering method was. Below are the same invariant mass graphs as above for a different run, where some secondary histograms were weighted wrong.
K Means Invariant Mass Distribution after VTX K Means Invariant Mass Distribution after CPV
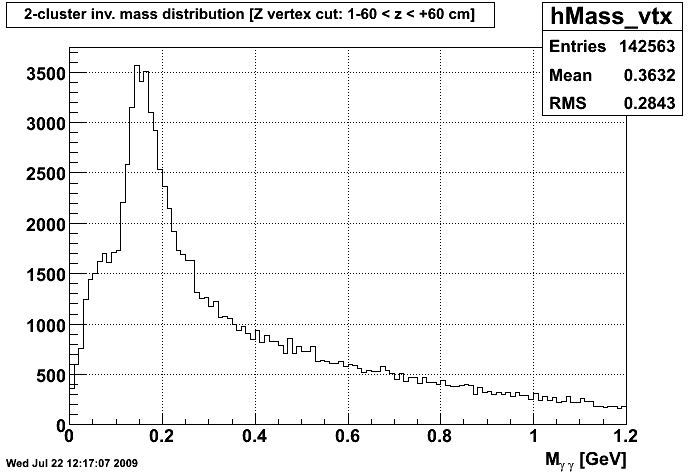
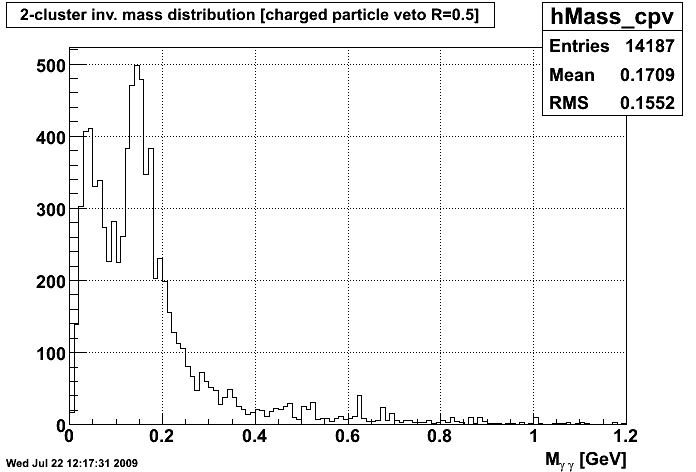
C Means Invariant Mass Distribution after VTX C Means Invariant Mass Distribution after CPV
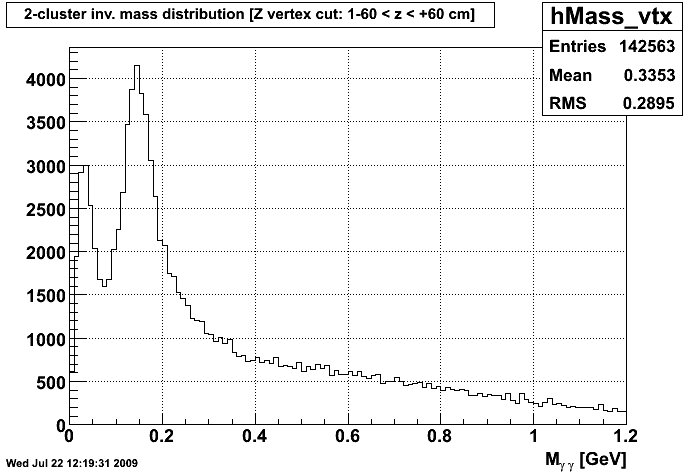
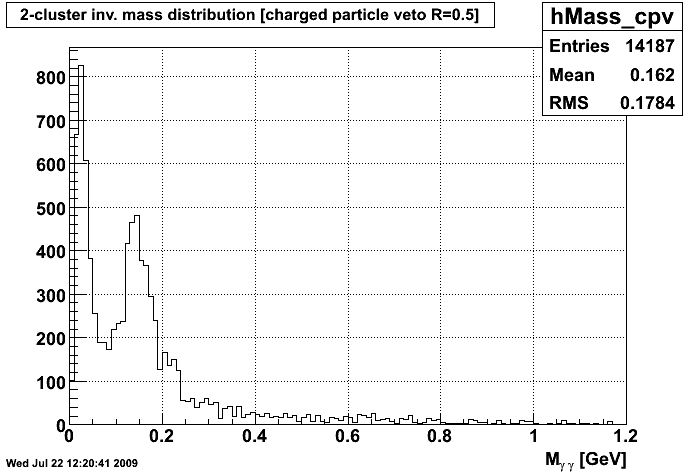
Personally, the only way I could discriminate between the graphs was the file names on my computer. Since these were seperate runs, I would assume that the random seeds for each cluster were different. As you can see, though, when run on the same data, the clustering repeats itself fairly well. So, I don't think we have an issue with repeatility at this point.
Some people were also curious about how many iterations were required for the clusters to settle down. At the moment, I require that the center of the clusters move less than half a strip in order to stop clustering or that the loop runs 100 times. Below is a graph of the number of iterations required in order for the cluster to settle for the C Means algorithm (this wasn't incorporated yet when I last ran the K Means algorithm on the tree).
Iterations required for all clustered samples Iterations required for all samples passing CPV
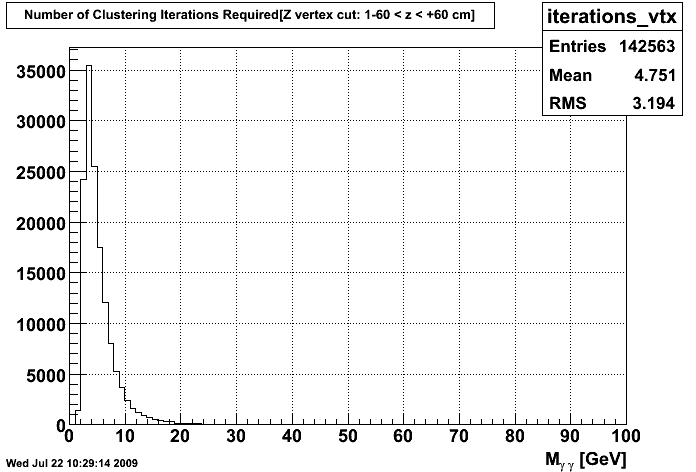
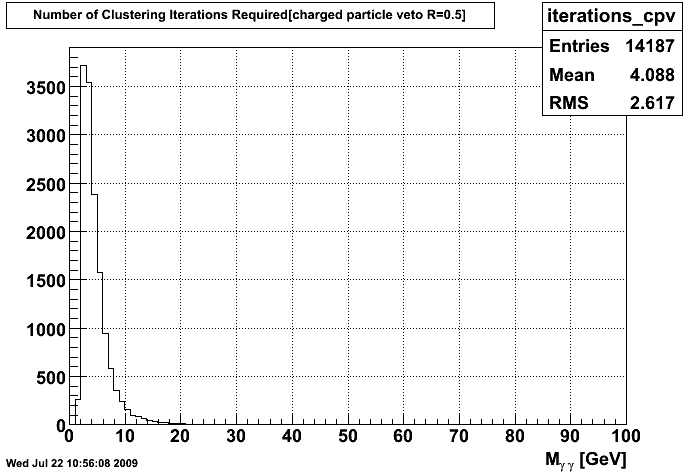
(Ignore the graph axes: I just noticed what the x was. The label should instead be "Iterations Req" and will be that on future graphs)
I think these graphs are justification for dropping the maximum allowed number of iterations, as only a few seem to require more than 24-25 iterations, so dropping the maximum to 30 iterations or so would speed up the program for those few runs which don't wish to converge.
- bbarber's blog
- Login or register to post comments