Update 02.27.2019 -- Run 9 pp: efficiency episodes
So, my investigation into the Run 9 efficiency continues, and it's only getting more confusing. Previous studies can be found here:
https://drupal.star.bnl.gov/STAR/blog/dmawxc/update-02192019-run-9-pp-track-efficiency-vs-ettrg
My original intent was to compare the detector-level Pythia8 and Embedding track pT distributions without smearing (ie. after applying the efficiency), take the ratio, and use that ratio to empirically calculate the "correct" efficiency. This depends on a few assumptions:
- The particle-level Pythia8 and Embedding distributions agree if not are identical
- The detector-level Embedding distribution describes the data well
Do those bear out? Here are the detector-level distributions compared to data:
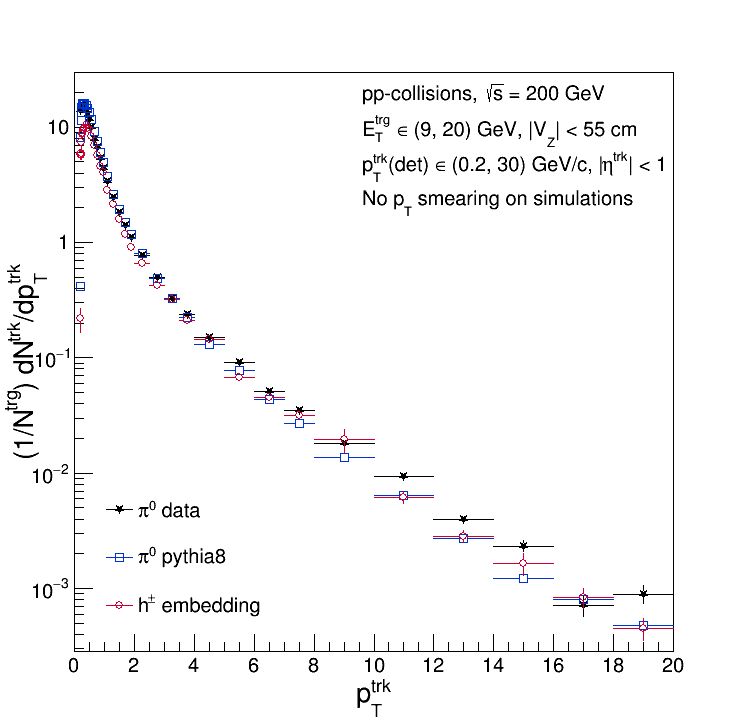

And their ratios:
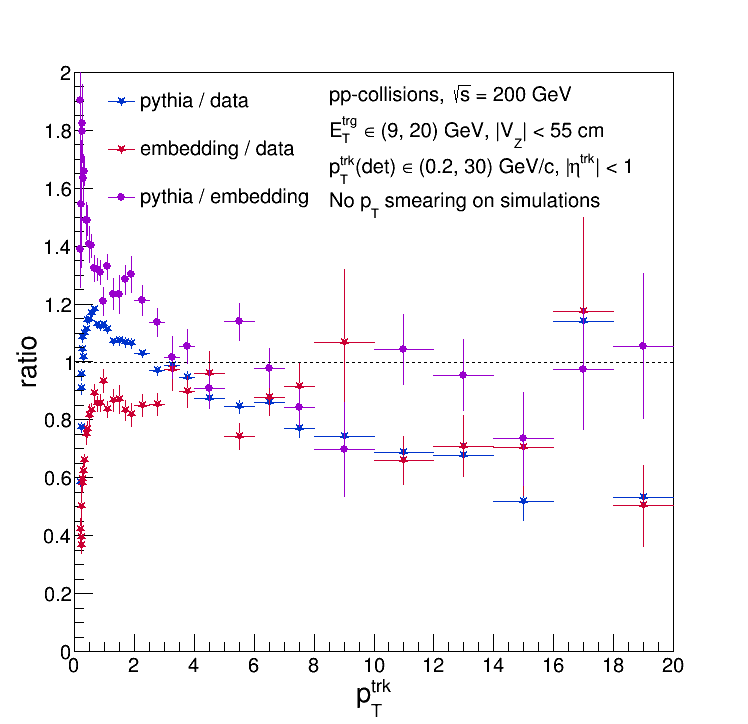
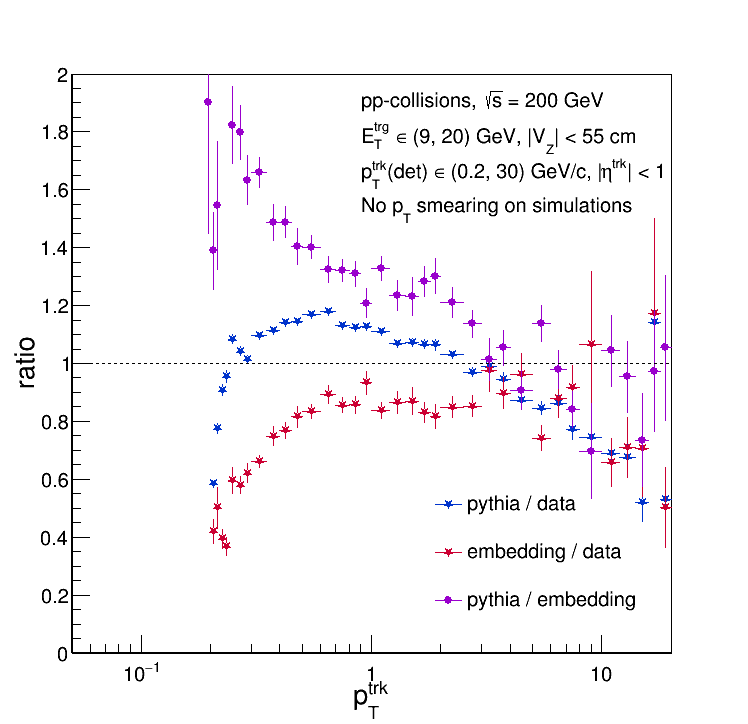
So assumption (2) is bogus. But what about (1)? Here are the particle-level distributions (plotted against data for comparison):
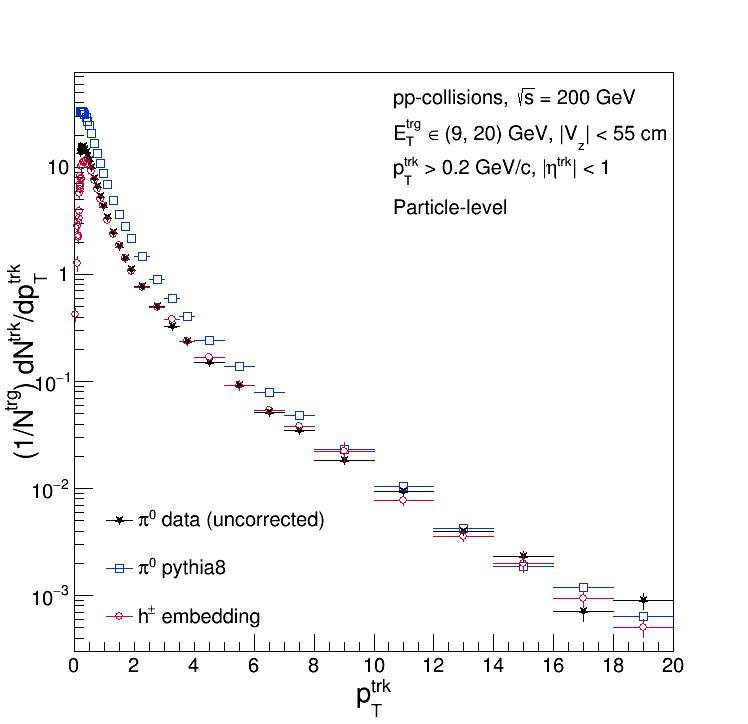
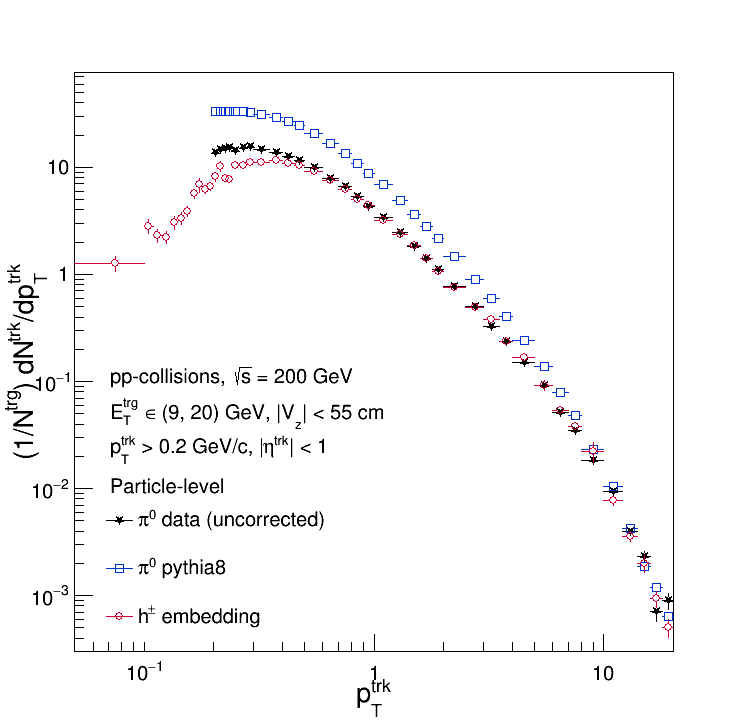
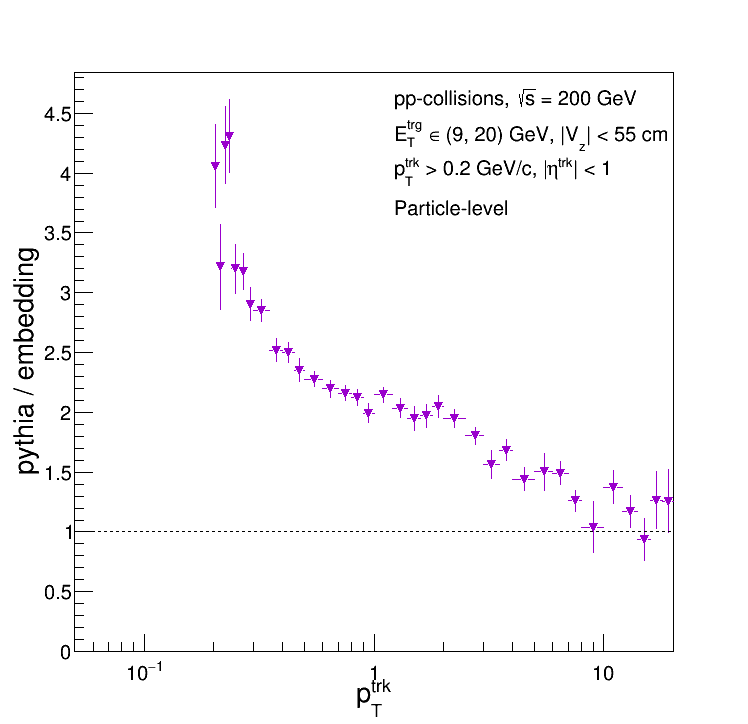
So (1) is also completely unfounded! For completeness, here is the ratio of the particle-level Pythia and Embedding distributions:

And also here's the extracted efficiency for the above embedding distributions:
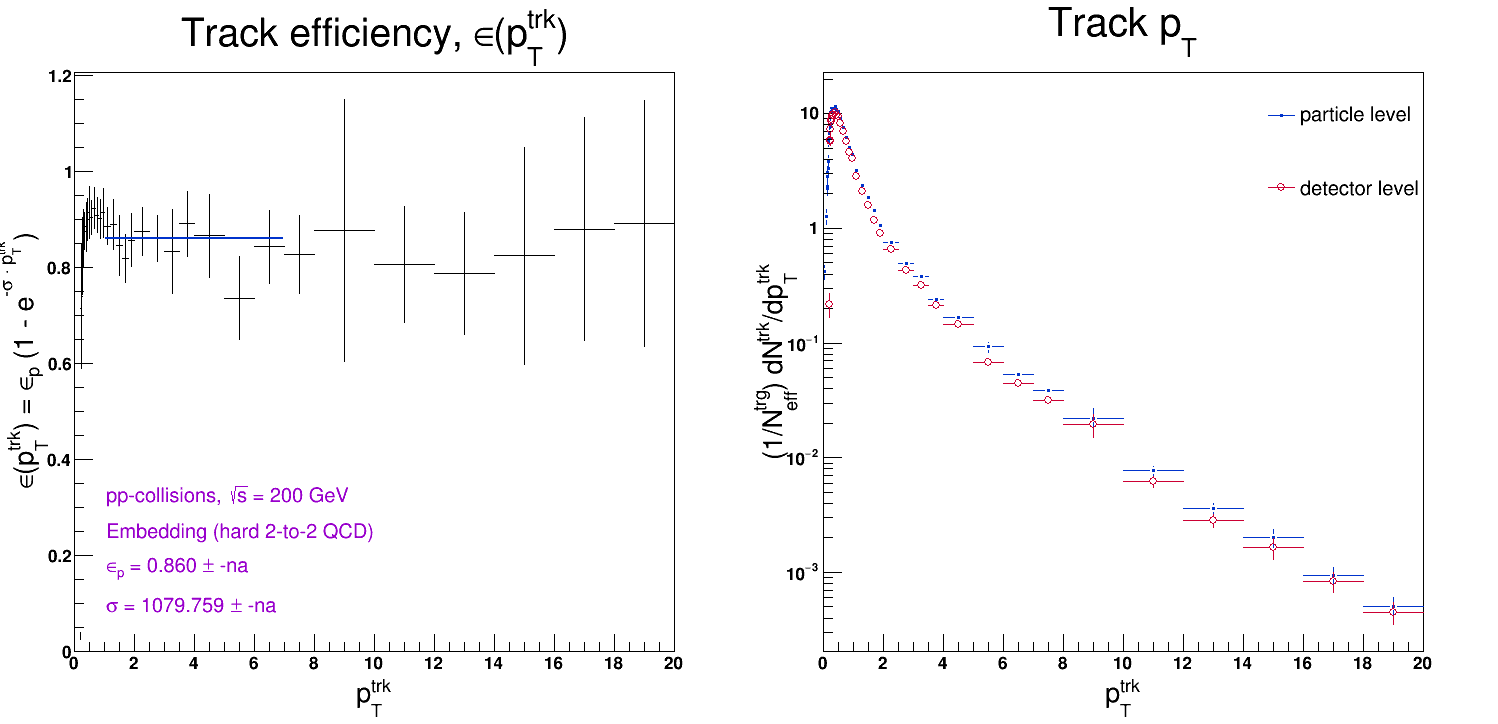
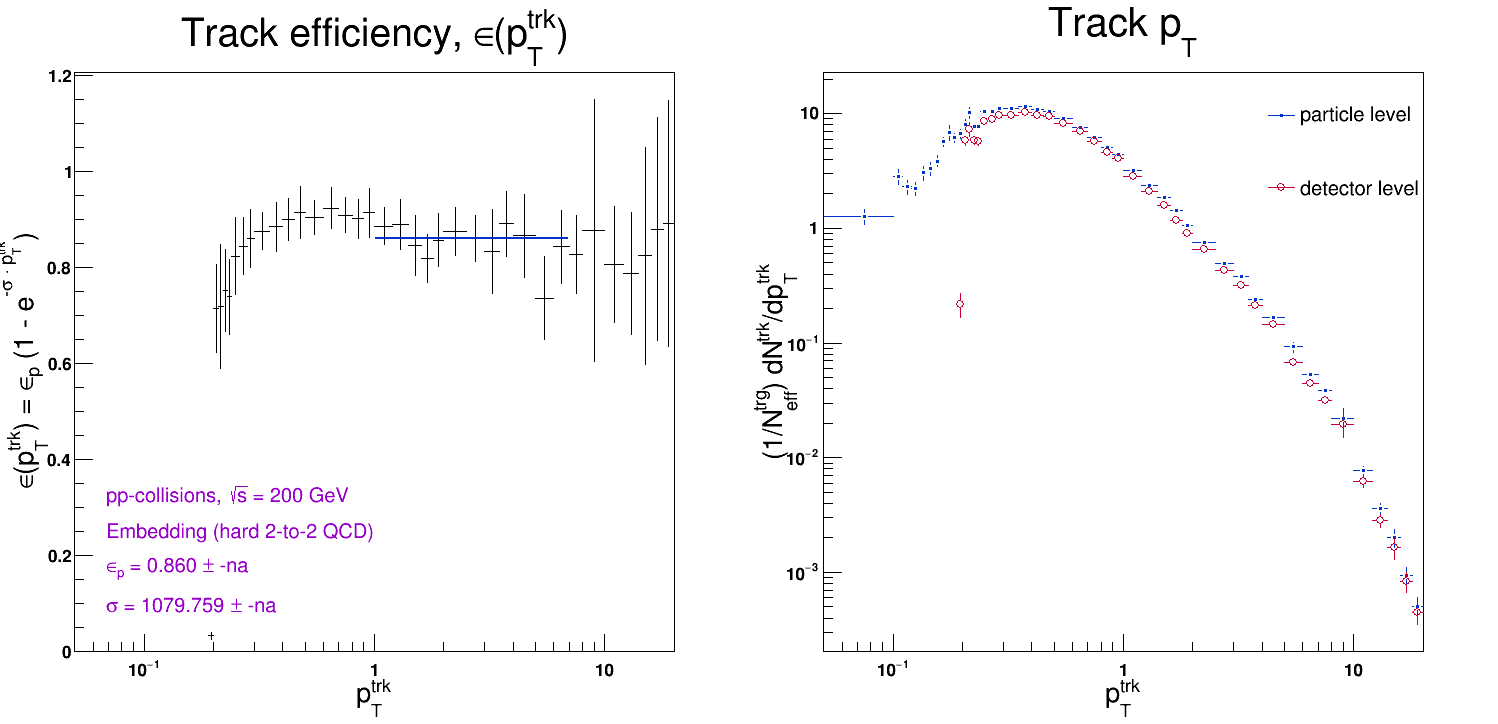 Now I'm back to square one. I don't know what the issue is, and I don't which way to proceed. I'm probably doing something profoundly dumb, but I'm not sure what... The safest route is probably to re-do the efficiency calculation from scratch. However, it might also be that the efficiency is perfectly fine and that issue is at the jet-finding level; ie. I'm just doing something different with the jet-finding in Pythia vs. data and embedding... See this post, for instance:
Now I'm back to square one. I don't know what the issue is, and I don't which way to proceed. I'm probably doing something profoundly dumb, but I'm not sure what... The safest route is probably to re-do the efficiency calculation from scratch. However, it might also be that the efficiency is perfectly fine and that issue is at the jet-finding level; ie. I'm just doing something different with the jet-finding in Pythia vs. data and embedding... See this post, for instance:
But, again, I'm not sure...
- dmawxc's blog
- Login or register to post comments