Update 07.10.2019 -- Run 9 pp: Comparing Data Unfolded With Pythia8 Priors Vs. Pythia6 Priors
This is a follow-up to this post:
https://drupal.star.bnl.gov/STAR/blog/dmawxc/update-07012019-run-9-pp-comparing-data-unfolded-embedding-response-vs-data-unfolded-pyt
After seeing the difference between the data unfolded with Pythia8 response (i.e. our parameterized response) and the data unfolded with the Pythia6 response (i.e. the response obtained from the embedding process), my first thought was that it could be due to the priors I fed to RooUnfold and/or due to a difference in the jet-matching algorithms used in each case. So the plots below compare different combinations of pythia8 and pythia6 priors and responses. First, I compared the data unfolded using the same response but with different priors.
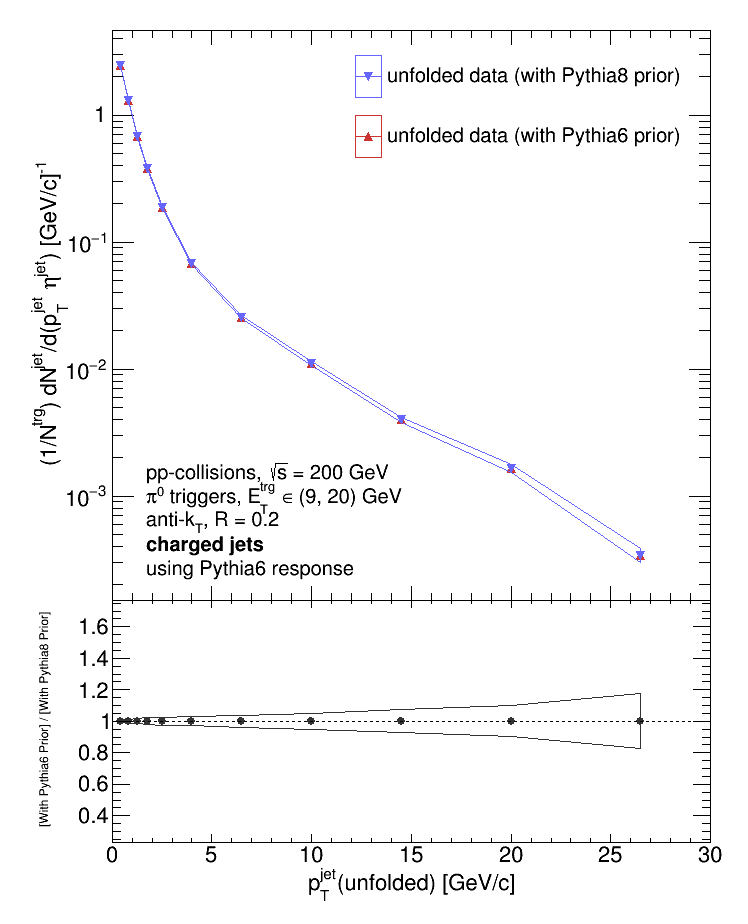
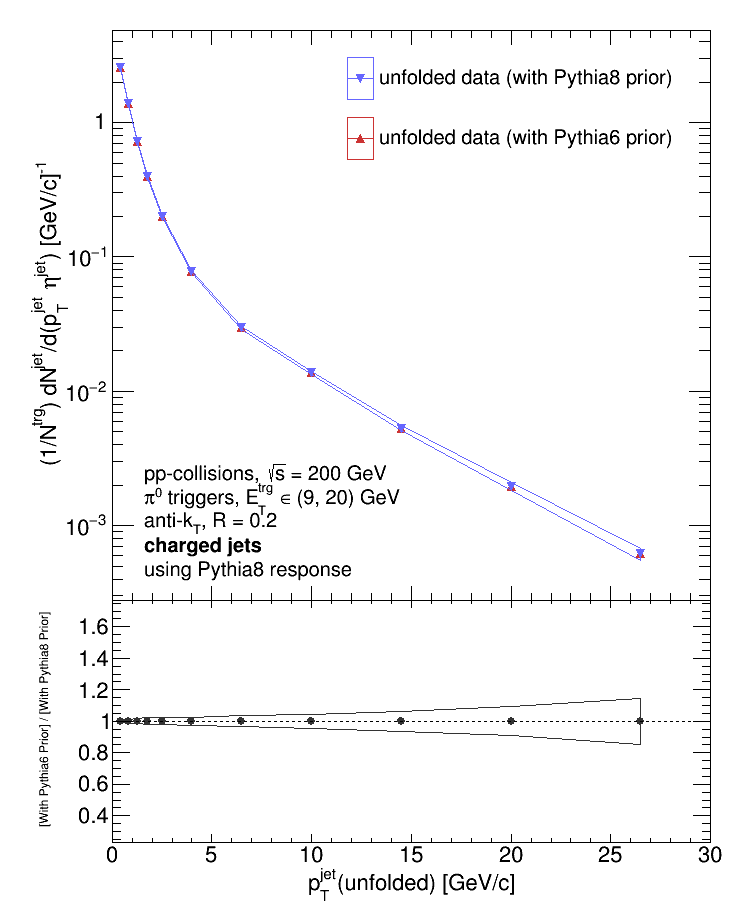
Varying the prior while keeping the response fixed makes no difference. So what happens when I keep the prior fixed and vary the response?
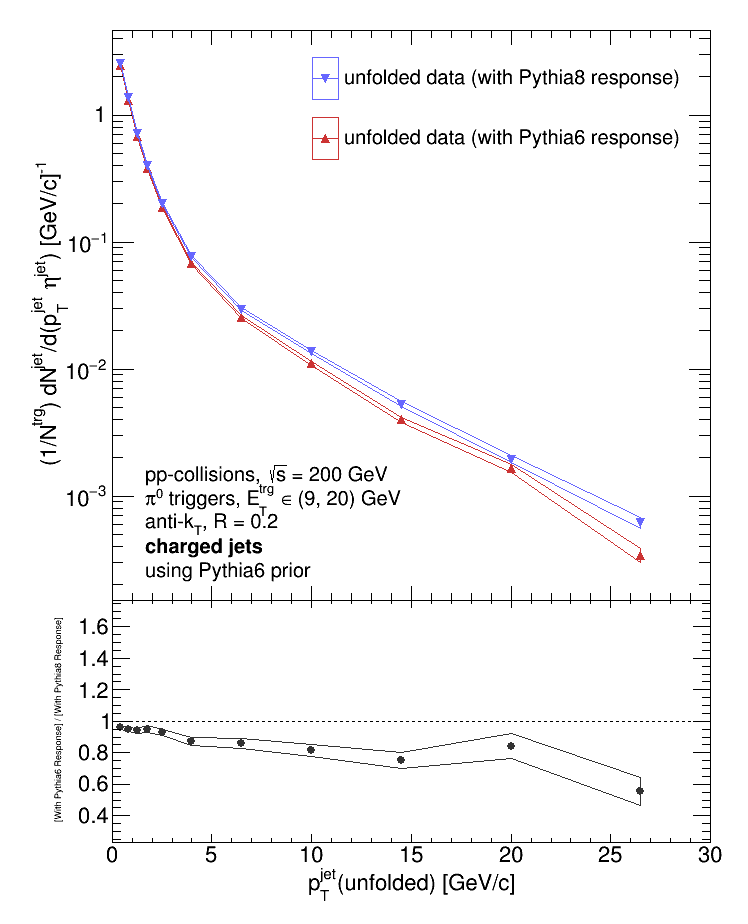
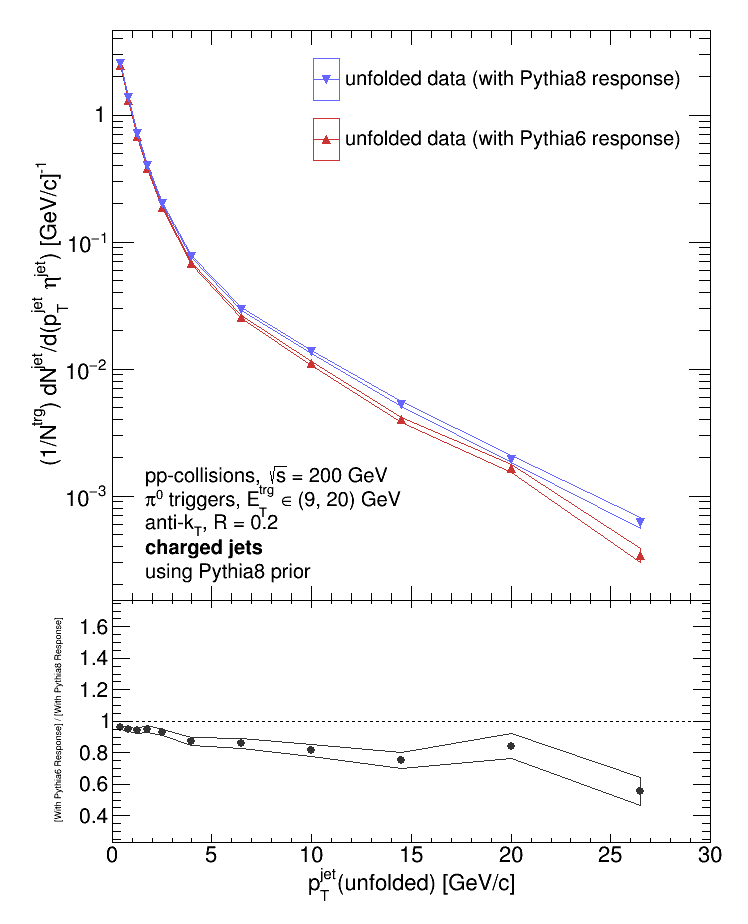
And there is a difference! So it is the response that's making the difference. I should've expected this from the outset; the priors are varied by (1) randomly sampling the provided prior, (2) smearing the randomly selected pT with a randomly selected correction from the response matrix, (3) applying the provided efficiency to the randomly generated smeared prior, and finally (4) using the "new" response + efficiency obtained from steps (1) - (3) to do the unfolding. Unless I've set the code to do that, the provided priors aren't used in the unfolding. For reference, here are all 4 distributions plotted on top of each other:

So the next step is to take a deep dive into my matching algorithms...
- dmawxc's blog
- Login or register to post comments