- genevb's home page
- Posts
- 2025
- 2024
- 2023
- 2022
- September (1)
- 2021
- 2020
- 2019
- 2018
- 2017
- December (1)
- October (3)
- September (1)
- August (1)
- July (2)
- June (2)
- April (2)
- March (2)
- February (1)
- 2016
- November (2)
- September (1)
- August (2)
- July (1)
- June (2)
- May (2)
- April (1)
- March (5)
- February (2)
- January (1)
- 2015
- December (1)
- October (1)
- September (2)
- June (1)
- May (2)
- April (2)
- March (3)
- February (1)
- January (3)
- 2014
- 2013
- 2012
- 2011
- January (3)
- 2010
- February (4)
- 2009
- 2008
- 2005
- October (1)
- My blog
- Post new blog entry
- All blogs
Run 22 pp500 production estimates
Updated on Tue, 2023-09-05 10:58. Originally created by genevb on 2023-09-01 23:15.
I used FileCatalog queries for number of events in the st_physics files (random samplied showed that st_fwd files appear not to have TPC present in the most common triggers that go there). I did this for two trigger setups: production_pp500_2022, and forwardCrossSection_2022. I then used my RICH scalers ntuple to correlate with the BBC coincidence rate ("bbcx"), figuring that to be the best proxy for luminosity relevant for scaling reconstruction time (this is merely a guess and hasn't been shown). This way I had a text file I could use as an ntuple with x=number of events in the files, y=run number, z=bbcx.
From the FWD test production I ran in DEV in August, I found that 20% of the chain time was spent on FWD subsystems (ftt and fcs). This implies a factor of (5/4) speed scaling from any productions that don't include FWD subsystems.
From the nightly test that we perform on 500 events from run 23010027 (bbcx = 3.178e6 Hz), we have:
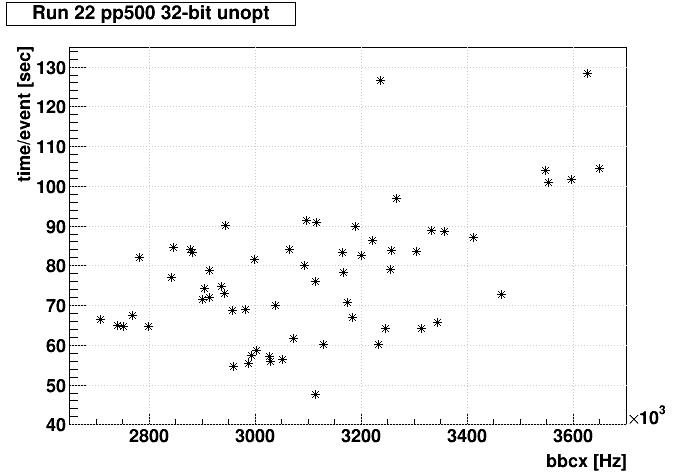
Next, I used Richard Thrutchly's SpaceCharge work to investigate the luminosity (bbcx) dependence. Richard ran in 32-bit unoptimized. In general, bbcx didn't really vary that much over the course of Run 23, which would imply that we don't really need to know the dependence that well. However, the forwardCrossSection_2022 dataset definitely had some low luminosity files with up to 50k events in them that definitely exceeded 3 days when running 64-bit optimized in the DEV FWD test production. So even though there isn't much lever arm to get the scaling accurate, we can try to find a fit result that gives us something close to perhaps 10 seconds/event at the very lowest luminosities (64-bit opt with FWD was doing ~6 seconds per event at low lumi, but this should be a little slower for 32-bit unoptimized).
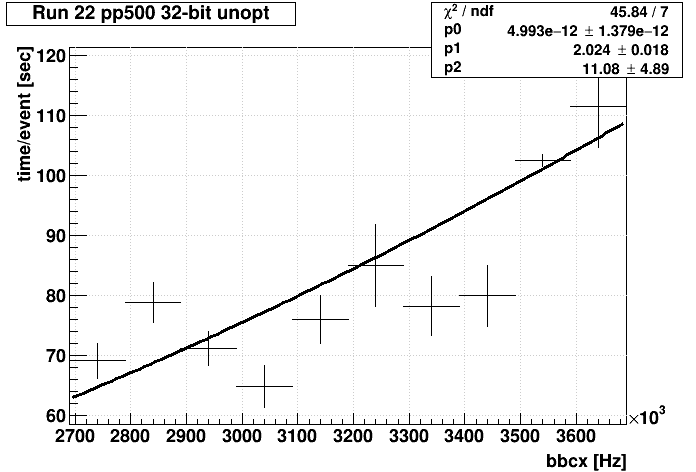
I tried several different initial values for the parameters in the formula below until I found a result with an intercept (parameter [2]) of something positive and close to 10, and got:
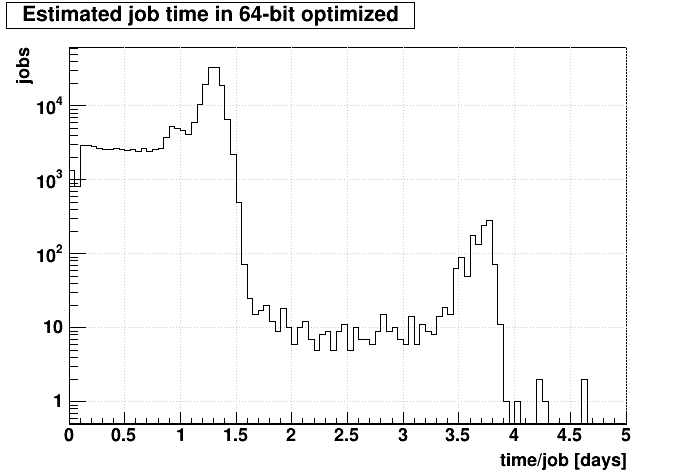
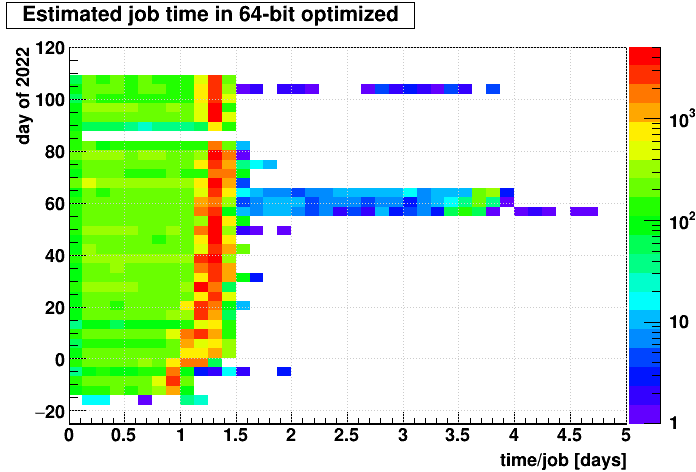
So it does appear to be a specific set of runs (many of which around days 59-62 are the forwardCrossSection_2022 dataset) that account for the slowest jobs. The bulk of the jobs will take less than 2 days, though the 15% variance I mentioned earlier may spread some past 2 days. Nevertheless, the bulk will almost certainly be less than the 3-day limitation currently imposed on our CRS jobs.
I should also add as a final point that the integral of all these ~195k jobs is ~213k CPU-days. This would imply under 2 months on 4000 CPUs, perhaps a little over 2 months if we ran in 32-bit instead of 64-bit. This is surprisingly quick when we remember that the Run 17 pp500 production took more than half a year. I have, however, not included file streams other than st_physics, which could perhaps add several more weeks to the production.
____________
I cut on the jobs that exceeded 2 days and found the following list of 22 runs:
-Gene
From the FWD test production I ran in DEV in August, I found that 20% of the chain time was spent on FWD subsystems (ftt and fcs). This implies a factor of (5/4) speed scaling from any productions that don't include FWD subsystems.
From the nightly test that we perform on 500 events from run 23010027 (bbcx = 3.178e6 Hz), we have:
- ~100 sec/evt for 64-bit unoptimized
- ~110 sec/evt for 32-bit unoptimized
- ~45 sec/evt for 64-bit optimized
- ~55 sec/evt for 32-bit optimized
Next, I used Richard Thrutchly's SpaceCharge work to investigate the luminosity (bbcx) dependence. Richard ran in 32-bit unoptimized. In general, bbcx didn't really vary that much over the course of Run 23, which would imply that we don't really need to know the dependence that well. However, the forwardCrossSection_2022 dataset definitely had some low luminosity files with up to 50k events in them that definitely exceeded 3 days when running 64-bit optimized in the DEV FWD test production. So even though there isn't much lever arm to get the scaling accurate, we can try to find a fit result that gives us something close to perhaps 10 seconds/event at the very lowest luminosities (64-bit opt with FWD was doing ~6 seconds per event at low lumi, but this should be a little slower for 32-bit unoptimized).
I tried several different initial values for the parameters in the formula below until I found a result with an intercept (parameter [2]) of something positive and close to 10, and got:
root.exe [9] TF1 ff("ff","[0]*pow(x,[1])+[2]")
...
1 p0 4.99267e-12 1.37927e-12 3.14017e-14 -7.26146e+11
2 p1 2.02413e+00 1.81253e-02 -3.75165e-04 -5.87952e+01
3 p2 1.10813e+01 4.89096e+00 -1.36356e-02 -4.70028e-02
So that's essentially 11 + 5e-12 * bbcx2 (I was surprised the power worked well so close to an integer value!). That's good enough for me for 32-bit non-opt, but it is faster than the nightly test result as this predicts about 83 sec/evt instead of 110 sec/evt at that test job's bbcx rate. Maybe we're doing something in the nightly test chain that Richard isn't? Anyhow, the data points, and the 10-bin profile I fit are shown below. The spread in the data points is also on the order of ±15%, which might perhaps be the same ±15% seen in the nightly test jobs.Final result
We can go with either assuming that 64-bit opt is (83/45) times faster than Richard, or (110/45) times faster than Richard. Conservatively (i.e. for the slower prediction), I will use 83/45. So the reconstruction time in seconds per event in my ntuple should be:(5./4.)*(45./83.)*(11.+5e-12*z*z)and time per day for the files is:
x*(5./4.)*(45./83.)*(11.+5e-12*z*z)/(24.*3600.)This distribution is shown below on the left. And then to see if it is specific data that contributes to this high end, we can look versus "day in 2022" (where days in 2021 are expressed as negative numbers, e.g. 2021-12-31 would be day 0, and 2021-12-20 would be day -1):
y/1000-23000+(1000-365)*(y<23000000):x*1.25*(45.0/83.0)*(11+5e-12*z*z)/(24*3600)
So it does appear to be a specific set of runs (many of which around days 59-62 are the forwardCrossSection_2022 dataset) that account for the slowest jobs. The bulk of the jobs will take less than 2 days, though the 15% variance I mentioned earlier may spread some past 2 days. Nevertheless, the bulk will almost certainly be less than the 3-day limitation currently imposed on our CRS jobs.
I should also add as a final point that the integral of all these ~195k jobs is ~213k CPU-days. This would imply under 2 months on 4000 CPUs, perhaps a little over 2 months if we ran in 32-bit instead of 64-bit. This is surprisingly quick when we remember that the Run 17 pp500 production took more than half a year. I have, however, not included file streams other than st_physics, which could perhaps add several more weeks to the production.
____________
I cut on the jobs that exceeded 2 days and found the following list of 22 runs:
23055059 23055060 23055061 23055062 23055063 23055065 23056025 23060046 23061048 23061051 23061053 23061054 23061055 23062001 23062002 23062004 23062005 23062007 23062008 23062010 23062012 23104052These are all forwardCrossSection_2022 runs except for the last two, which are a Vernier scan (23062012, which we won't produce) and an unusual production_pp500_2022 run (23104052). For the latter the only explanation I can find for the files containing more events than usual is that the run was taken at a lower luminosity (bbcx = 1.87 MHz instead of the usual 2.8-3.4 MHz) and so there are far fewer hits in the TPC...but there seem to be ~5-6x as many events fitting in the usual 5 GB file size for this run while luminosity was still more than half compared to other runs, so this argument doesn't fully explain it.
-Gene
»
- genevb's blog
- Login or register to post comments