- genevb's home page
- Posts
- 2025
- 2024
- 2023
- 2022
- September (1)
- 2021
- 2020
- 2019
- 2018
- 2017
- December (1)
- October (3)
- September (1)
- August (1)
- July (2)
- June (2)
- April (2)
- March (2)
- February (1)
- 2016
- November (2)
- September (1)
- August (2)
- July (1)
- June (2)
- May (2)
- April (1)
- March (5)
- February (2)
- January (1)
- 2015
- December (1)
- October (1)
- September (2)
- June (1)
- May (2)
- April (2)
- March (3)
- February (1)
- January (3)
- 2014
- 2013
- 2012
- 2011
- January (3)
- 2010
- February (4)
- 2009
- 2008
- 2005
- October (1)
- My blog
- Post new blog entry
- All blogs
Missing RICH scalers for Run 19
Updated on Wed, 2019-05-22 23:10. Originally created by genevb on 2019-05-22 13:04.
Due to problems on slow controls computers, RICH scalers were not being properly delivered to databases as well as DAQ for portions of time on days 138-139 (May 18-19, 2019). It is believed that the delivery to DAQ suffered the least and is a subset of the database absences. Since we rely on the DAQ stream for RICH scalers as our primary source, we need only understand the data for which it was missing.
Tonko records the absence of the RICH scaler feed in the DAQ logs, and posted his observations of missing data from his logs in this table (times are EDT):
Using these times, I scanned the start and stop times of runs and found the impacted runs shown in the right-most column above (added by me, if any). Example query to the RunLog database:
Looking through files produced for those 5 runs from FastOffline, all but one successfully processed only data outside the affected time windows. Run 20138036 included the affected data. I show here some plots of some BBC coincidence and singles scalers seen in the resulting PicoDsts, where red lines indicate the 81-second gap in recordings as reported by DAQ, and time [sec] = 0 is defined as the time that the RICH scaler gap started (2019-05-18 19:06:21 EDT = 2019-05-18 23:06:21 GMT):
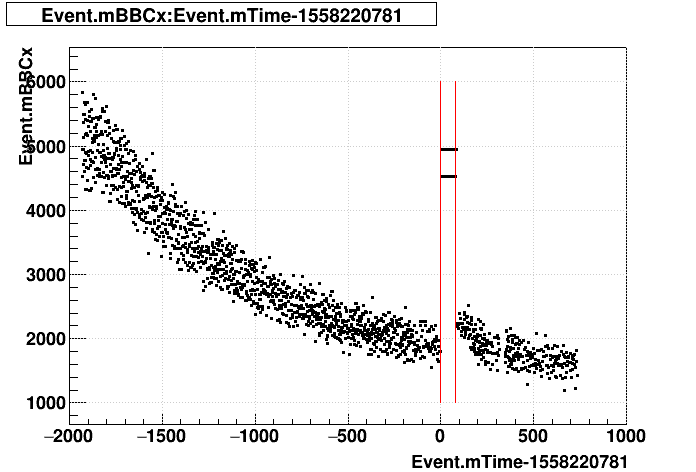
Zooming in:
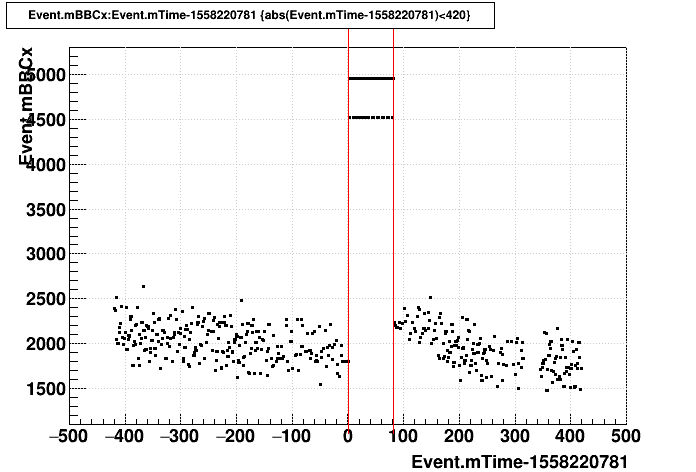
Taking a profile with 30-second-wide bins:
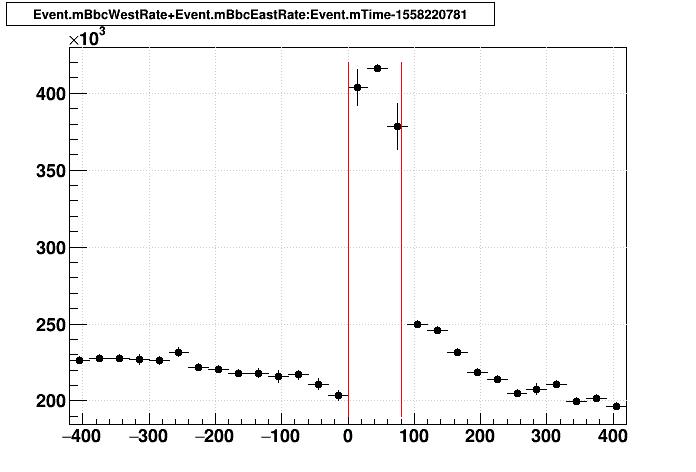
While the outage period appears to be accurate with data seen after processing, it also appears that some readings after the outage are affected. Perhaps even before the outage is affected as well. My inclination would be to set the TPC status to be dead for a period from 1 minute before the outage through 2 minutes past the outage. I checked whether this expansion of the exclusion windows allowed any additional runs to be affected and found the answer to be no - just the same runs.
The net impact will be something in the range of 30-40 minutes of physics data lost. Here are the time ranges [GMT] I have uploaded to the database to block out, unifying some overlapping or nearly overlapping windows:
-Gene
Tonko records the absence of the RICH scaler feed in the DAQ logs, and posted his observations of missing data from his logs in this table (times are EDT):
start-of-deadtime day stop-of-deadtime day 19:06:21 138] 19:07:42 138] 20138036 20:39:47 138] 20:41:00 138] 20:44:35 138] 20:45:49 138] 20138038 20:48:38 138] 20:50:43 138] 20138038 21:30:30 138] 21:31:44 138] 23:25:31 138] 23:34:16 138] 23:34:27 138] 23:51:15 138] 20138043 10:43:43 139] 10:44:58 139] 11:37:26 139] 11:39:10 139] 20139018 11:46:16 139] 12:12:17 139] 20139019 14:14:53 139] 14:16:07 139]
Using these times, I scanned the start and stop times of runs and found the impacted runs shown in the right-most column above (added by me, if any). Example query to the RunLog database:
select runNumber from runDescriptor where startRunTime < unix_timestamp("2019-05-19 18:16:07") and endRunTime > unix_timestamp("2019-05-19 18:14:53");
Looking through files produced for those 5 runs from FastOffline, all but one successfully processed only data outside the affected time windows. Run 20138036 included the affected data. I show here some plots of some BBC coincidence and singles scalers seen in the resulting PicoDsts, where red lines indicate the 81-second gap in recordings as reported by DAQ, and time [sec] = 0 is defined as the time that the RICH scaler gap started (2019-05-18 19:06:21 EDT = 2019-05-18 23:06:21 GMT):
Zooming in:
Taking a profile with 30-second-wide bins:
While the outage period appears to be accurate with data seen after processing, it also appears that some readings after the outage are affected. Perhaps even before the outage is affected as well. My inclination would be to set the TPC status to be dead for a period from 1 minute before the outage through 2 minutes past the outage. I checked whether this expansion of the exclusion windows allowed any additional runs to be affected and found the answer to be no - just the same runs.
The net impact will be something in the range of 30-40 minutes of physics data lost. Here are the time ranges [GMT] I have uploaded to the database to block out, unifying some overlapping or nearly overlapping windows:
2019-05-18 23:05:21 - 2019-05-18 23:09:42 2019-05-19 00:38:47 - 2019-05-19 00:52:43 2019-05-19 01:29:30 - 2019-05-19 01:33:44 2019-05-19 03:24:31 - 2019-05-19 03:53:15 2019-05-19 14:42:43 - 2019-05-19 14:46:58 2019-05-19 15:36:26 - 2019-05-19 15:41:10 2019-05-19 15:45:16 - 2019-05-19 16:14:17 2019-05-19 18:13:53 - 2019-05-19 18:18:07
-Gene
»
- genevb's blog
- Login or register to post comments