- jeromel's home page
- Posts
- 2025
- 2020
- 2019
- 2018
- 2017
- 2016
- 2015
- December (1)
- November (1)
- October (2)
- September (1)
- July (2)
- June (1)
- March (3)
- February (1)
- January (1)
- 2014
- 2013
- 2012
- 2011
- 2010
- December (2)
- November (1)
- October (4)
- August (3)
- July (3)
- June (2)
- May (1)
- April (4)
- March (1)
- February (1)
- January (2)
- 2009
- December (3)
- October (1)
- September (1)
- July (1)
- June (1)
- April (1)
- March (4)
- February (6)
- January (1)
- 2008
- My blog
- Post new blog entry
- All blogs
Weighted Water mark file deletion
Problem statement
This blog documents the issue of cleaning of our public disks (like data05) using a new water-marking algorithm.
The basic issue is that our publicly available disks are cleaned up based on a retention time as documented on the disk overview / overall page. Starting at 60 days, data05 was dropped to a 40 days threshold due to constant "data05 is full" syndrome, causing all other users to have their job fail.
A new mechanism was discussed and proposed, involving water marking techniques: when the space reaches a High Water mark (HWM), a deletion process starts and delete files until a Low Water Mark (LWM) is reached. STAR users voted for a weighted water mark i.e. that deletion happen more severely for users with the largest usage with concerns that
- a high usage user may push the usage to the extreme (run-away jobs may fill the disk faster than what we can delete, squashing other users out)
- good citizens may be penalized by a too strict water marking mechanism (it would be good to define two classes)
Verification of assumptions, derived functionality
To verify the assumptions, a snapshot usage was made on 2012/05/03. It is represented by the graph below; the x axis is simply a user name and Y the usage in KBytes as shows on the DiskUsage.cgi script (data05 was selected).
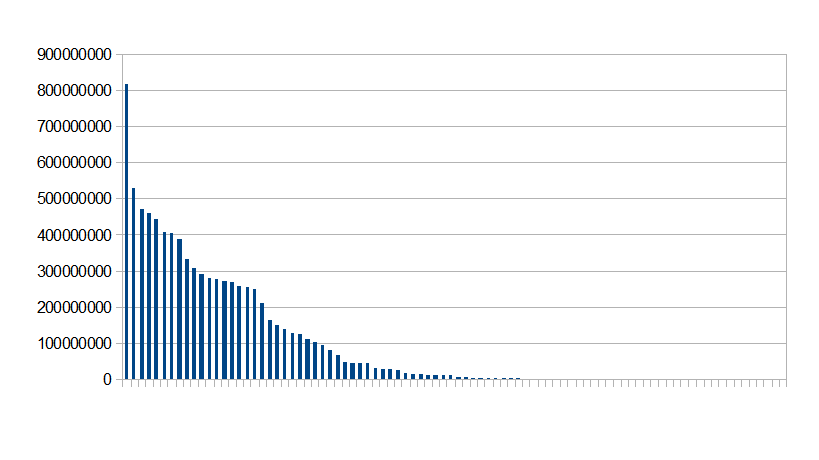
A few observations can be made:
- Apart from the very first top user, the rest of the distribution tend to follow a linear decrease of space usage
- The top user has near x2 the usage than the second user
- The distribution has long tails (empty directories and some left overs keep a large number of users on disk, this may bias the average)
Consider the previous section and the observations herein, the general functional requirements should then be:
- Aggressive cleaning of empty files and directories should be made to avoid long tails in the distribution (this was checked to be the reason for the tail)
- An average can be computed but may be meaningful only if the tail-end is removed
- A linear weight water marking algorithm would be valid BUT for the top heaviest user - if the current pattern stands, a linear fit and a deletion weight based on the usage AND the deviation to to the fit may be beneficial (in the case illustrated above, we would proportionally delete files from heaviest to lowest usage linearly BUT the first user who diverges from a linear decrease fit of the user/usage pattern)
To implement a Weighted Water Mark mechanism (WWM), quota usage would be needed. This is not always possible as SAN/NAS are often managed by proprietary appliance or dedicated storage-manager nodes disconnected from the management node (where the cron / cleanup scripts run) and quota information are only possible from those storage-manager nodes. A mechanism, leveraging what was already done for the DiskUsage script, was devised on 2012/04/03 - the quota information will be as frequently updated as once every hour.
Proposed algorithm
Proposition 1
A first simplistic algorithm was proposed to users on 2012/05/03.
- A disk will be inspected for usage. Each disk will have a HWM and LWM. If the disk space available is > HWM, the algorithm kicks in ... otherwise, no action is made.
- The deletion will first get information on the most recent accounting of usage (done hourly) and an average usage will be computed (in size or in %tage occupancy)
- Note: since the quota cannot be gathered easily, the initial base parameters set in this step will be used again and again for any sub-sequent passes (i.e. if a user was found to be the biggest user at this stage, he will be the highest file loser for each pass as the usage will not and cannot be re-evaluated). This will create a futher incentive for not being above the average.
- Note: since the quota cannot be gathered easily, the initial base parameters set in this step will be used again and again for any sub-sequent passes (i.e. if a user was found to be the biggest user at this stage, he will be the highest file loser for each pass as the usage will not and cannot be re-evaluated). This will create a futher incentive for not being above the average.
- Any user using a space below the average will have the retention time for his/her files set to X days
- Any user using a space above the retention will have their space reduced using an altered retention time as follows:
- From the biggest to the lowest usage above the average, a linear extrapolation will be made
- The user with the heaviest usage will have its file retention time set to be int(X/fct)
- The user with the lowest usage will have its retention time set to X-1
- Note: obviously, a chck will be made so X-1 cannot be null
- Note: obviously, a chck will be made so X-1 cannot be null
- fct will vary and be picked within the ensemble {2,5,10} - at each fct pass the disk space will be computed again and if the space goes below the LWM
- Note: some values of fct in {2,5,10} may not apply depending on the value of X. For example, if X=5 days, the sub-sequent passes would lead to 2, 1, 1 day and only two pass would then be considered (2 and 1).
- If after one fct pass, the space is still not below LWM, the algorithm will go back to stage 3. above and repeat the calculation. The decrease of X will be made based on on a fractional decrease (75% shaving at each pass).
A startup algorithm will consider X=60, HWM=of 95% and LWM=85%.
Tuning
Name removed, here is a new graph
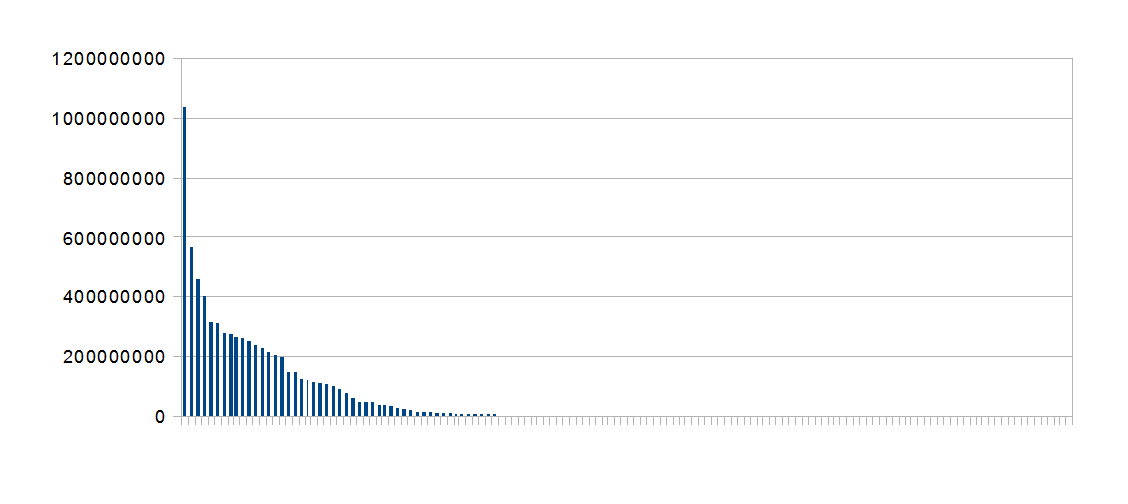
What is happening is that there is a heavy user squashing people out of the disk. Freeing space only gives more room for that single or few users to put more file on. A few observations then:
- More aggressive cleanup factors of {2,7,15,20} were used on 2012/05/18 to cope with this issue and at each addiitonal passes, the pass number serves as multiplier that is:
- pass 1 RET=60, f=(2,7,15,20}
- pass 2 RET=45 (60*0.75), f={4,14,30,40}
- pass 3 RET=33, f={6,21,45,60} ... this already leads to a one day for a heaviest user
- Ultimately, a cleanup which would not be linearly proportional with space (but perhaps a power law) would be more encouraging to users to remain within limits (and manage their space)
- The algorithm based on a median is having a good side effect - the larger use the top users have, the larger the average penalizing more the very top as we go. Though, a future algorithm may also allow for the choice of where the cut begins (for example, <> + 1 sigma would penalize even more the heaviest users)
- There are problems and/or improvements:
- Imagining that one process writes a file and keeps the file open and that file fills the disks, all other user's files would be deleted BUT that file (this is a run-away process scenario). To prevent this, the loop stops when RET < Initial Retention / 2
- For faster gain, the files could be sorted with biggest first (does not matter at the end since all files are scanned but may release more space faster)
Groups:
- jeromel's blog
- Login or register to post comments