- jeromel's home page
- Posts
- 2025
- 2020
- 2019
- 2018
- 2017
- 2016
- 2015
- December (1)
- November (1)
- October (2)
- September (1)
- July (2)
- June (1)
- March (3)
- February (1)
- January (1)
- 2014
- 2013
- 2012
- 2011
- 2010
- December (2)
- November (1)
- October (4)
- August (3)
- July (3)
- June (2)
- May (1)
- April (4)
- March (1)
- February (1)
- January (2)
- 2009
- December (3)
- October (1)
- September (1)
- July (1)
- June (1)
- April (1)
- March (4)
- February (6)
- January (1)
- 2008
- My blog
- Post new blog entry
- All blogs
DataCarousel behavior, efficiency issue
General
In this Hypernews post, it was noted that we have a large amount of user based requests for the Carousel (at least 5-7 people on a daily basis and up to 15 different users as one could infer from looking at the list of users in the accounting CGI).The purpose of this blog is to evaluate the impact of such large user based usage on the general restore efficiency of bulk restores (done by starlib) and the related impact on users themselves. Bulk restores are at the heart of populating the distributed disks (or Xrootd space). Whenever slow dowsn occur, the availability of datasets is questionable (can be incomplete) and/or the NFS storage can no longer serve as a "cache" for data production and production has to stop.
Carousel general configuration and possible optimization parameters
Let us first re-explain how the carousel is currently tuned.- The carousel allows for applying many restore policies controlled by a few parameters and namely, ORDER and SHARE (and TSORT). Those policies are aimed to porvide fairshare to users in a muli-user environment (similar to what a batch system does). In essence, imagine the Data Carousel Quick Start/Tutorial serving the same purpose for data restore than what a batch system does for scheduling jobs: you ay have to wait your turn ... but we can all work together and shar ethe resources in a reasonable manner.
The policies used in STAR are- SHARE=GRPW which indicates to the Carousel that restores will be shared amongst users belonging to groups. Each group has to share a fraction of the total bandwidth NUMSBMT. Imagine you belong to group X with a share of 2 and other users belong to a group with a share of 1. Group X will get a 2/(2+1)*NUMSBMT requests submitted by cycle and the other group will get 1/(2+1)*NUMSBMT. In case all users belong to the same "group", the share policy will revert to EQUAL (all users have equal shares).
A note that the Carousel submits a "batch" of NUMSBMT files every TIMEDEL minutes up to a maximum number of jobs controlled by the parameter MAXJOBS. - ORDER=TAPEID indicates that for each pass submitting NUMSBMT files to the data restore queue, the requests will be re-ordered as they appear on tape and by tapeID. In other words, if you requests 50 files but the first 5, the middle 10 and the last 5 are on the same tape A and the rest on a tape B, the files will NOT be restored in the order you requested but regrouped as one bundle of requests from tape A and one bundle of requests from tape B. Additionally, the files requested from both tape A and tape B will retored in the order they appear on tape (so the tape is read sequentially from start to end once with no rewind).
- TSORT is an option which is valid ONLY for ORDER=TAPEID. Most sub-options in this category are not adequate for fair-shareness and TSLIDER is the only practical option (the other are for testing purposes at this stage). TSLIDER indicates to the Carousel to regroup all files within the same TapeID BUT with a variance ... i.e. the re-grouping will happen as the requests appeared within a time frame of TSLIDE width in time. For example, TSLIDE=45 mnts (or 2,700 seconds) would regroup files from the same tape A as far as they were requested and appear in the system within the same 45 mnts time slice (or slider). If file requests appeared from the same tape but at a later time, they will have to wait if there are other requests to satisfy. TSLIDER prevents resource starvation issues associated with situations where new requests constantly come for files from the same tape A ... and you have a hard time to get your files from tape B with any reasonable time.
- SHARE=GRPW which indicates to the Carousel that restores will be shared amongst users belonging to groups. Each group has to share a fraction of the total bandwidth NUMSBMT. Imagine you belong to group X with a share of 2 and other users belong to a group with a share of 1. Group X will get a 2/(2+1)*NUMSBMT requests submitted by cycle and the other group will get 1/(2+1)*NUMSBMT. In case all users belong to the same "group", the share policy will revert to EQUAL (all users have equal shares).
- The requests for file restores are sent to HPSS - once sent to HPSS, they cannot be cancelled. Imagine this part being IO equivalent of what a batch system does when scheduling CPU process jobs on machines with n CPUs with a few more options and finess.
Only three strategies for restores exists at this stage however.- HighToLow - We can instruct HPSS to restore all files from the most requested tapes first.
In this mode, the tape with most files is taken and loaded with the highest priority and all files restored from that single tape. In conjunction with ORDER=TAPEID and TSORT, this implies a single mount, a single dismount and a limited time to locate files on a tape (the tape is read sequentially with no rewind as already noted).
It is the most efficient way (i.e. highest number of files / hour) to restore files BUT this is not always the best way depending on expectations ... as it leads to a well-know "resource starvation". The starvation scenario in this case is especially true when requests comes as a constant stream - the chances to then restore the "one file one tape" requests is near null if there is always requests in the system leading to a tape with even 2 files to have a higher priority ... - NoPreference or ~ FIFO
In this mode, the requests are treated more or less in the order they came as. There is a slight "twist" to this theme as file requests submitted within the same bundle (NUMSBMT parameter of the Carousel) would still be ordered. This policy would avoid the starvation described in the explaination of the HighToLow strategy but it would also destroys efficiencies as it is best to wait a while before decidiing to load the "one file / one tape" assymptotic worst-case-scenario. But this policy prevoids opportunity to everyone to have his/her files restored in a reasonable time. - LowToHigh - in this mode, we actually load the tape with the least amount of requested files first. This mode is rarely used and only switched to whenever a starvation is ongoing and an administrator would like to clear it OR whenever we have a long queue of pending requests within the "one file one tape" scenario and want it to be cleared.
- HighToLow - We can instruct HPSS to restore all files from the most requested tapes first.
- The Carousel currently applies GRPW/TAPEID (TSLIDER) policy but alternates between HPSS restore strategies. THis allows to create a balance between efficiency and opportunity to have files restored ina timely manner.
- Whenever we have one user in the queue, HighToLow strategy is used
- Whenever the Carousel detects that mutliple users are requesting files, the strategy is switched back to NoPreference.
- Before changing policy, a time delay is applied.
This is done because if a user A requests files on a tape already loaded by user B (but after user B), there would be no reason to change restore strategies all requests will happen expeditiously from the same tape and be regrouped together (a rewind may occur if the new files requested arrive after the tapeis read beyond the location where they are but again, the rewind will be minimized).
Time delays T0 and T1 (PLCYDELTA0 and PLCYDELTA1 parameters to be exact) are applied for respectively changing from multi-user to one-user strategy (NoPreference to HighToLow) and from one user to a multi-user strategy.
So, what is the problem?
In the case where/when many independent users request files from different tapes and diverse time in the day, the optimizations above will not do any good to efficiency because the Carousel will see mostly multi-users and hence, always (or mostly) use the FIFO restore strategy which is not beneficial to optimal speed of restores. Of course, if user requests are perfectly ordered by tape ID, this would not be a problem but users do not know where the files are located.We speculated that user requests span all over many tapes and close to the "one file / one tape scenario" than anything else.
An illustration (proof) of this assumption (extracted from a submission made on 2014/04/21) follows.
The first panel is the view from the Carousel side while the second is the view from HPSS restore side (tape ID are then known).
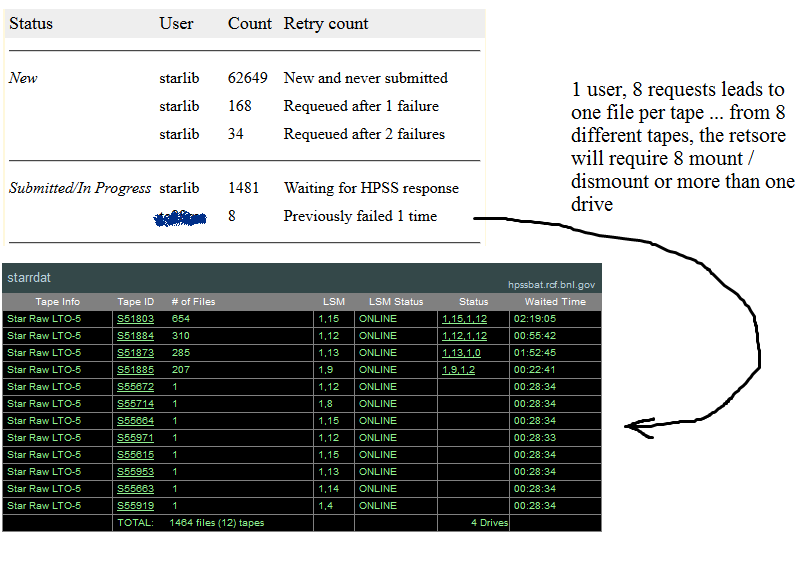
The user's name is anonymized but the point is made: the user had 8 files requested and those 8 requests did span over 8 different tapes.
All other requests were for populating the distributed disks (Xrootd namespace disk population). Since the Carousel has only a resource allocation of 4 tape drives to restore files, the HighToLow restores would have to cease to leave some bandwidth to those users requests. Restore efficiencies would be immediately destroyed.
In fact, the restore speed is also monitored. Here is a graph of what we had ... Let us look at only zone A and B only for now.
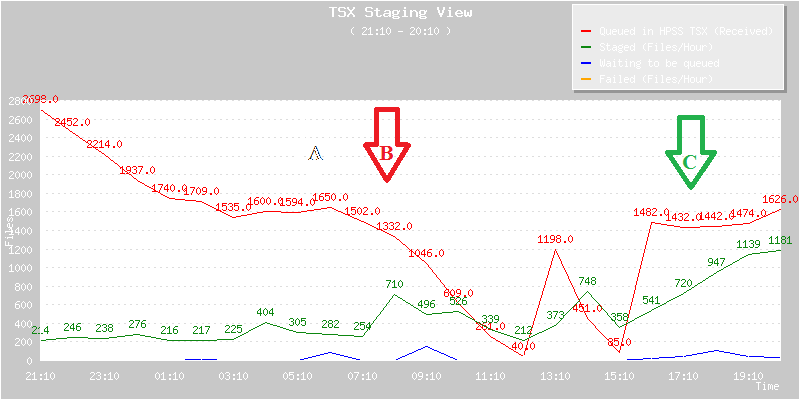
The file restores were monitored over the week-end of 14W15. The restore rate was below 300 files/hour all over the entire period from Saturday to Monday 7:00 AM (there is a small peak at 400 files /hour once). This means that if you had submitted requests but several 1,000 files were ahead of you (like in this post from Jonathan), your expected minimal wait time would be at least (in his case 2,494 files before) a good 8 hours and 20 mnts wait time. This is if all goes well, a heavy price to pay for restoring opportunity at the sacrifice of efficiency.
Zone B on the contrary is where, under the same file requests queue, the strategy was switched back to HighToLow. The file restore rate bumped to 710 files / hour or a good x2.4 the file restore rate observed before in the most optimistic case of a 300 files/hour (observed averages are less than that).
Solutions
Yeah yeah! The effect of one solution is seen already around the marker C zone. But let us be more systematic.To increase the file restore rate we have a few solutions
- The obvious solution: at the limit of an infinite number of drives, we would not have any issues. Increasing the number of drives would help. This is cost ineffective (HPSS drives are costly).
Note 0: Off run period, this is what we do - we move the drives typically allocated to data taking to the Carousel and hence we have an "off run period" of peak efficiency and no trouble to satisfy standard demands ... a "during the run" drive re-allocation slows restores (as the number of drive available for the Carousel dramatically decrease as resources need to be shared).
- Decrease the number of simultaneous users requesting files. This would essentially allow submitting more (user) files together, increasing the chance to avoid the "one file / one tape" scenario.
Note 1: the HFT team (4 users at least requesting files at any point in time) was asked to coordinate such request but ignored it (I will assume that organization is not practical and will drop this as a solution in STAR).
Note 2: starlib, with ultra-optimized restores, could be isolated to its own Carousel service which would always be set to HighToLow but this would not make us gain much as the drives would STILL need to be shared between two services. The second service set to LowToHigh would interfere with optimization.
- Make sure the requests happen at the same time for maximal optimization. If all users would submit at about the same time of the day, the amount of time the restore strategy would be switched to the non-optimal FIFO strategy would be minimum. Hence in average, we would gain speed (and again, increase the chances for a higher restore rate by bundling restores together). New requests submitted at noon for example could be made.
Note 1: As for asking people to regroup and have one user submitting requests instead of 4, I doubt this would happen in STAR with enforcing it.
Note 2: This idea could however be easily enforced by changing the current Carousel policy and run in an optimized manner for at least X hours (never submitting requests from any other users than a few "power users") then, submitting all other users once every X hours and alternating. Improvement of this would be to disfavor (yet not prevent) the "one file / one tape" requests and/or apply wright factors depending on the "N per tape". Such policy does not currently exist.
- Parameter tuning could be done and achieve some of the above ...
- Decreasing the frequency of submission request bundles
Less is better because less frequent submission of a batch of NUMSBMT files would essentially mean increasing the chances to regroup requests from users. Increasing this to a larger number would cause an artificial time delay in the restores (imagine we submit requests for file restores only once an hour). Since the current restore time average for individual files tend to be many hours long, there is some margin.
The previous setting was to submit a new bundle once per mnts. it is now changed to once per 3 mnts.
It could be increased to once every 5 mnts (TBD) - Decreasing the number of simultaneous jobs MAXJOBS while increasing the number of files per submission seem to be a zero sum game to first order (we would have the same number of files / hour submitted to the system) but have drastic different effects - first, the Carousel evaluates its success/failure rate only when MAXJOBS is reached and this helps re-assessing localized inefficiencies (dead nodes, users displaying more restore errors than others, ...) and apply other automatic tuning not discussed here. But more files submitted less often would help increase the efficiency and effect of the ordering of files versus tapes.
The current number of jobs was dropped from 75 to 45 and the number of files per batch was increased from 75 to 150. - Limiting the maximum number of file a single user is able to have queued at a single time would prevent the long time wait when the restore strategy is switched from HighToLow to FIFO. In the example previously givenabove, 2494 files from user A before user B at 300 files/hour implied a wait time of 8 hours+. A limit at 1,500 files would drop this to 5 hours at similar restore rate. Droping too low would again kill optimization as we sould not have enough files to re-group by tapeID.
Note that in the 8 files / 8 tapes example, starlib had up to 600+ files requested from a single tape (so an order of 1,000 per user in the queue at any point in time seem a minimal for optimizing).
The current limit is 1,500 files at any point in time. - TSLIDE time window need to be large enough to regroup files efficienctly. A too large number may lead to starvation but too low would not allow to properly re-group.
This set to 45 mnts but could be increased to hours - this value may be increased. - The time delay between switching restore strategies (between FIFO and HighToLow) would have an effect similar as to privilege optimized user's requests or allow the "one file / one tape" requests to be satisfied. Previous parameters assumed a situation where more drives would be available for restore as more concurrent requests were possible. The switch between the one user strategy (HighToLow) and the multi-user restores (FIFO) was 2 mnts and the reserve was 20 mnts (assuming more user requests would come soon).
The current parameter setting were reversed - the optimized strategy will now be applied within 2 mnts of detecting one user and the change to FIFO will not occur until many users are detected as in the queue for a least 20 mnts.
- Decreasing the frequency of submission request bundles
Result /effects
The new restore rates are seen below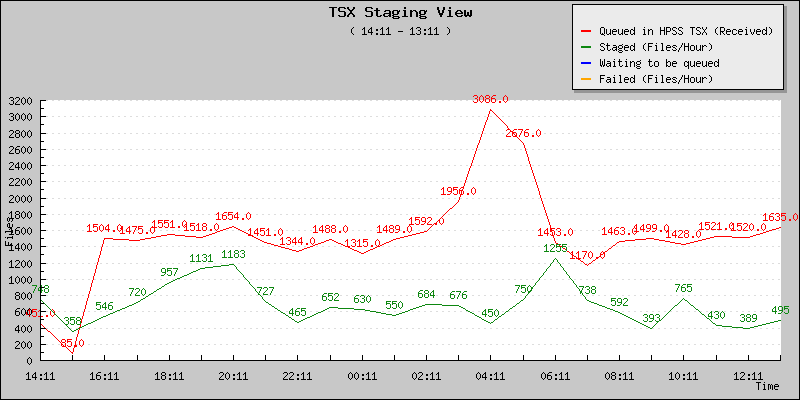
The new number of files average is in now between 600-700 files / hour. This is an increase by at least a factor of 2 to 2.3 comparing to what we had before. Peaks are visible at 1,200 files and beyond, corresponding to periods when single user restores and HighToLow restore strategy is auto-enabled. The low values are correlated to multi-user usage. 1,500 files from user A queued ahead of user B would be a 2 hours delay (instead of 5 to 8).
Monitroing below tend to indicate an improvement overall.
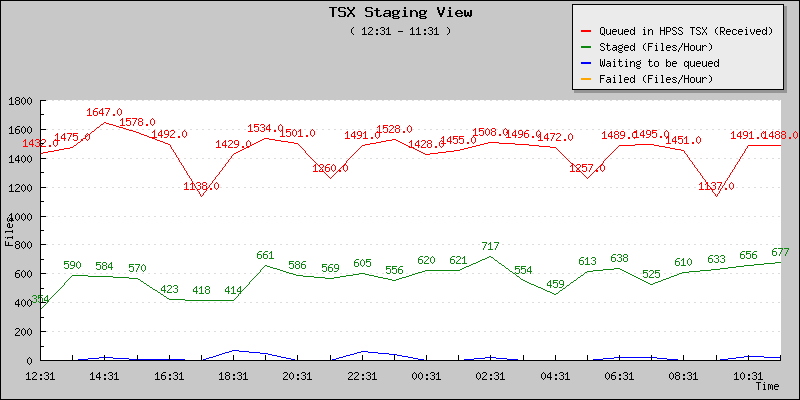 April 23rd - Average ~ 569 files/hour |
 April 24th - Average = 636 files/hour |
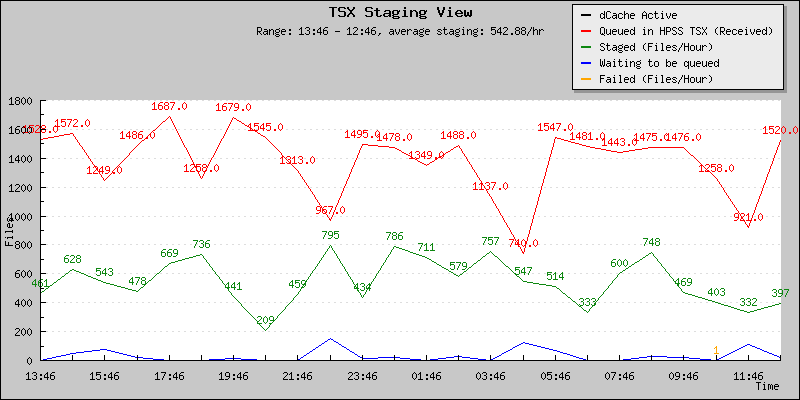 April 25th - Average ~ 543 files/hour |
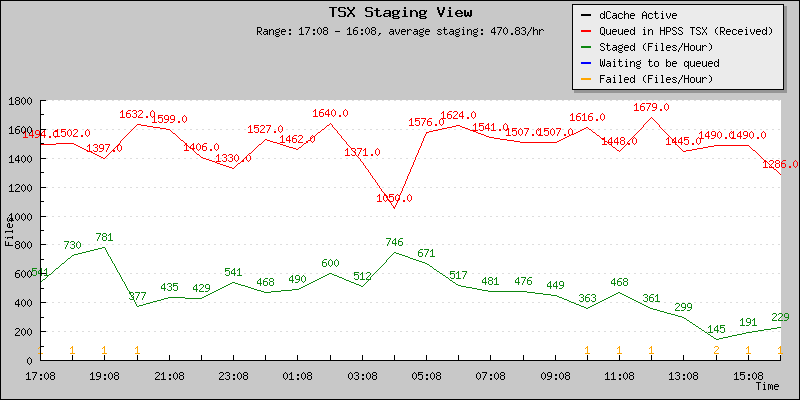 April 26 - Average ~ 471 files/hour |
Remaining problems
During this period, the case of one file / one tape came frequently from a few users as well as the sparse restore for Xrootd purposes in case of a small amount of missing files on distributed disks. The latest is understood, the former less so ... querying users.This blog is closed. While a few parameters could be further tuned, more optimization will be carried through other blogs.
Groups:
- jeromel's blog
- Login or register to post comments