Production priorities for Run 14 and beyond - revisit 2015/03
Updated on Wed, 2015-09-30 09:54. Originally created by jeromel on 2015-03-17 13:52.
Following the discussion with the PWG, a production plan was made and advertized (this note was sent back to the PWGC list for comments). The general guidances were
Well in general.
2015/03/20 We explained the farm ramp up is about a day - jobs also take from 5-6 days to finish. We can see this in the below plot as most job which ended so far were files with a low number of events. In steady mode, we should be producing 20 M events / day (but have not reached that stage). This slow ramp up stresses the need to NOT stop and restart production but QA the preview thoroughly ... then run non-stop.
We are seeing the first signs of a slope inflexion. ETA for steady mode: sometimes between Saturday-Sunday.

Now that the high priority Au+Au is out of the way, calibration will resume next week for Cu+Au.
Updates will be provided in this blog as we proceed forward.
More news later.
Targetted re-production was announced done on 2015/06/28.
- run 14 production - 200 GeV
- How is the production going?
- Production event rates.
- Snapshots (production evolution) and latest snapshot.
- He3+Au or Cu+Au
- Opened issues and summaries
Run 14 Au+Au 200 GeV
Following the discussion with the PWG, a production plan was made and advertized (this note was sent back to the PWGC list for comments). The general guidances were
- st_physics - all data in this category considered
- st_hlt (16 M) - (note: st_hltgood only in BES data, 200 GeV only has st_hlt - catalog has 14 M events st_hlt only TBC)
- st_mtd - S&C note: this would be pending a two pass filtering code under review + chain updates
- st_hcal & st_hcaljet (324 M, mostly fast events) - A sample of st_hcal was produced as noted here. Unless further feedback, we would not consider this sample for further processing.
- st_upc (200 M) - st_upc sample would require to proceed with a beamLine constraint calibration (not yet done) - its priority is assumed to be "at the end and after QM"
- st_WB (21 M) - we did not get any feedback on this one ...
- st_sst - We discussed we would not produce the st_sst due to an already complicated tracking / efficiency problem when we have the sst in or not - this dataset would be used for further work with the SST
- st_zerobias (30 M) - unless otherwise noted, we would not produce the zerobias data (used typically for some embedding)
How is the production going?
Well in general.
- We have ~ 1% of the slots down due to miscellaneous problems (RCF side) - slot efficiency cap at 99% is a theoretical maximum (but still tracking them down).
- Occupancy of the current production on 2015/03/20 is 13111 over 15600 slots available (84%) - this is confirmed by an independent monitoring (process occupancy reported by nova monitoring is 84.08%).
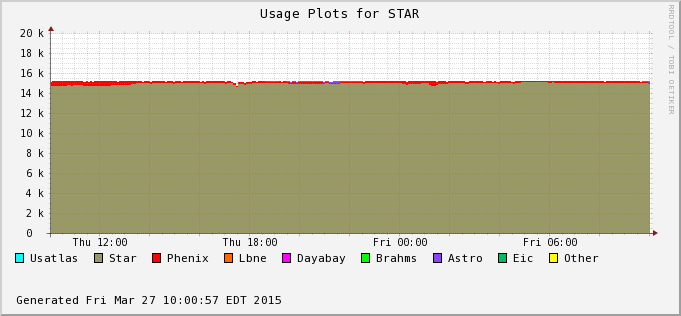
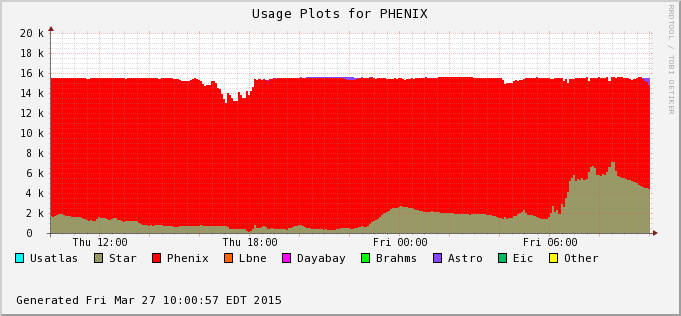
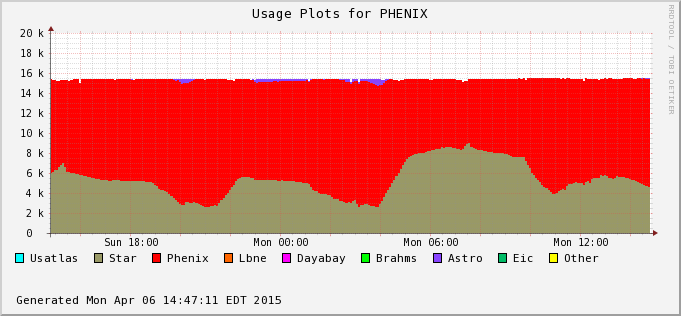
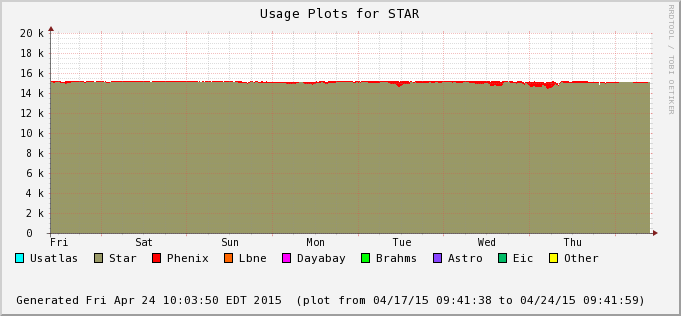
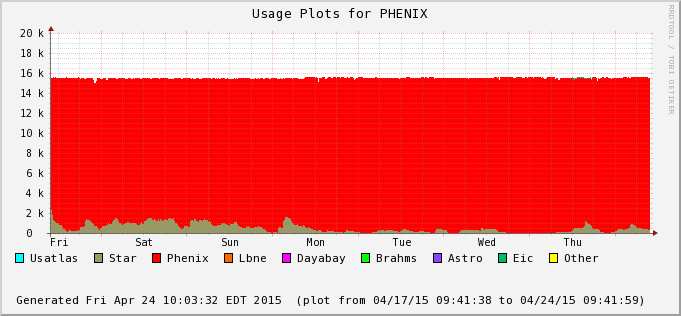
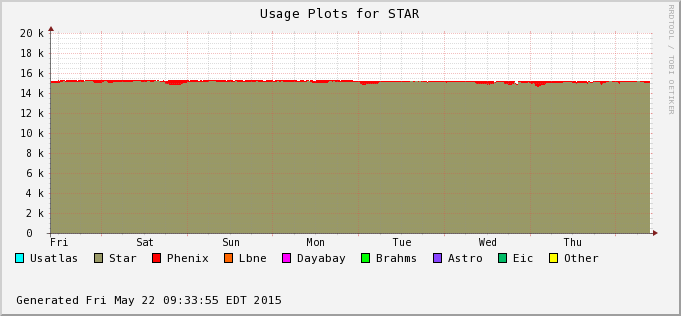
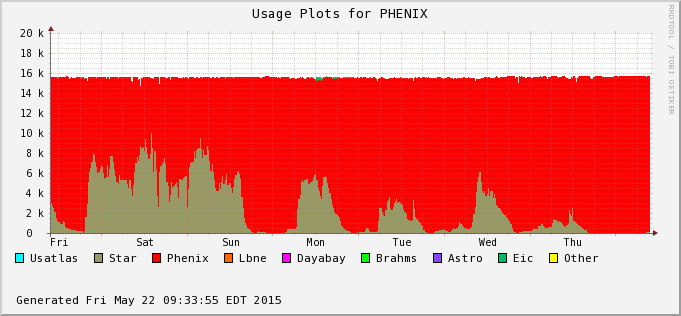
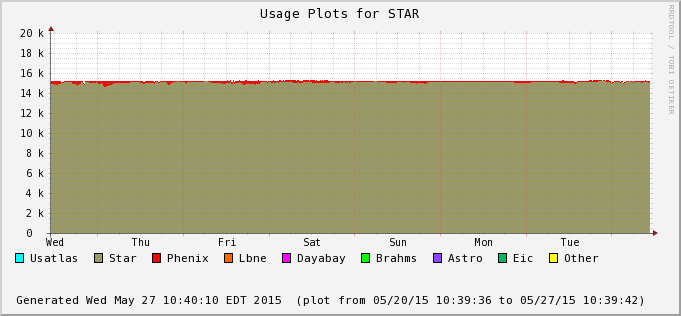
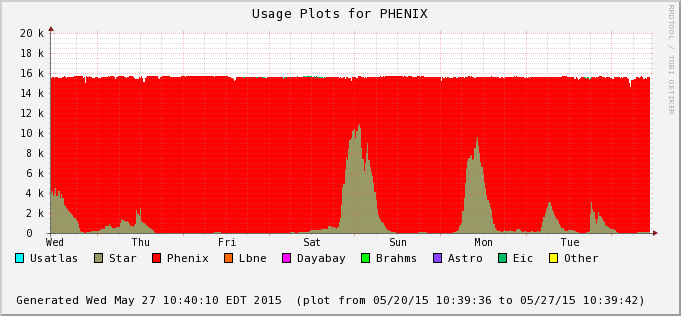
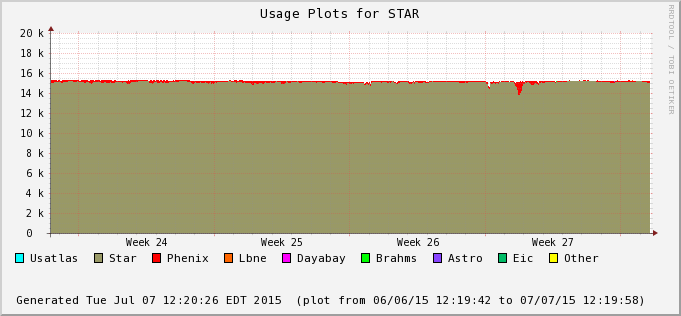
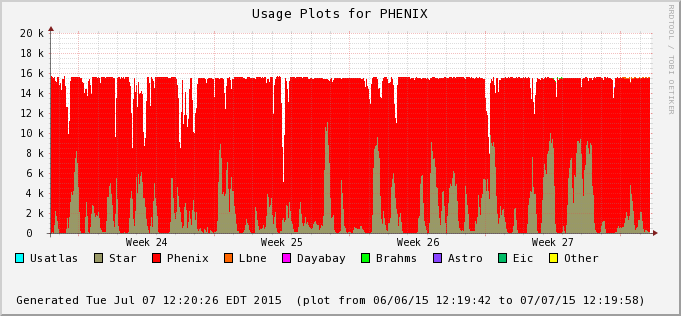
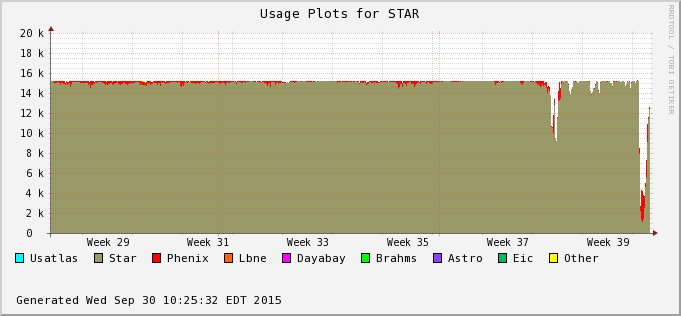
The difference is accounted by user jobs not pushed to the PHENIX nodes - PHENIX is running too at the moment (bummer!). We can see this in the next two plots - Bothe farms utilizes all of their CPU slots and STAR cannot take much of PHENIX's (second plot) at the moment. In average, we still hope to recover 30% or so of raw processing power.
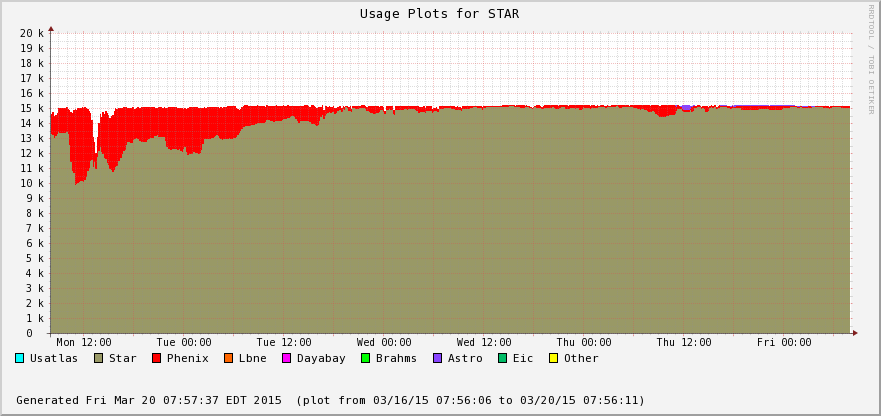
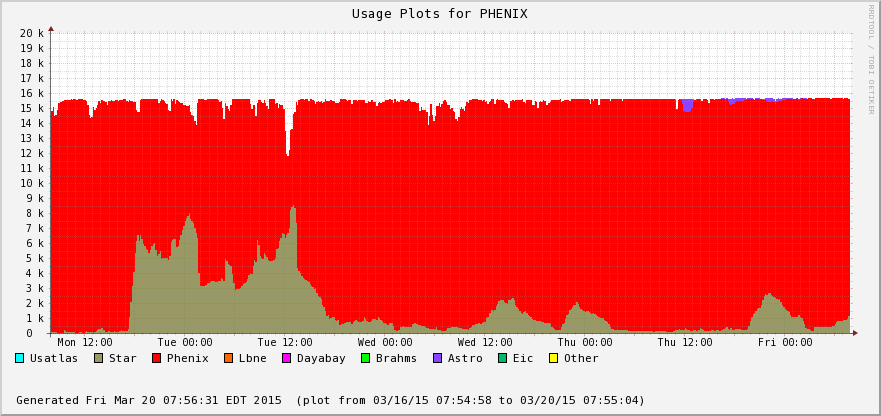
- Job success rate is 99.64% so far - the 14 jobs that have crashed were all running on a farm node having a disk problem (nothing to do with STAR inefficiency but an additional RCF issue now solved).
- CPUTime/RealTime ratio is high (>99%) - we are running without slow downs (no IO or database access problem).
- Global efficiency: 98.65% counting run-time efficiency and job success or 97.66% if we consider the farm nodes currently down (and quote an global efficiency over all available hardware). This is a very high number.
Production event rate
2015/03/20 We explained the farm ramp up is about a day - jobs also take from 5-6 days to finish. We can see this in the below plot as most job which ended so far were files with a low number of events. In steady mode, we should be producing 20 M events / day (but have not reached that stage). This slow ramp up stresses the need to NOT stop and restart production but QA the preview thoroughly ... then run non-stop.
We are seeing the first signs of a slope inflexion. ETA for steady mode: sometimes between Saturday-Sunday.
Other snapshots
| Date | # Event so far | STAR farm occupancy | PHENIX farm occupancy |
| 2015/03/23 | 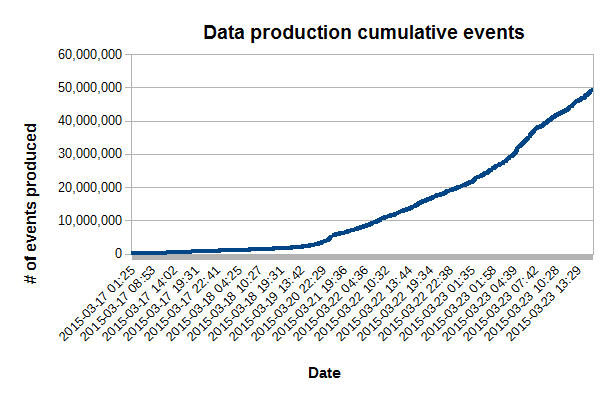 |
 Reco slot %tage: 81.2% Process %tage : 81.5% |
 |
| 2015/03/27 | 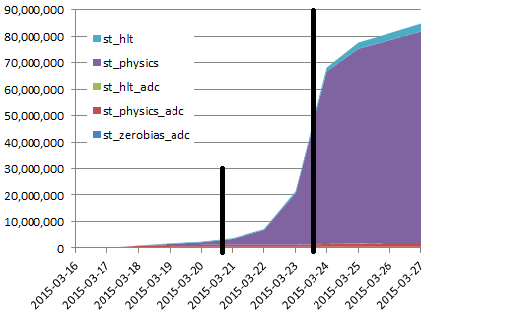 The change of slope is understood as an effect of a depletion of the farm from the first wave following a gaussian distribution. This, coupled with an inefficient farm ramp-up, causes waves for a while until all jobs get de-synchronized. |
 Reco slot %tage: 81.7% Process %tage : 81.5% |
 |
| 2015/03/30 | 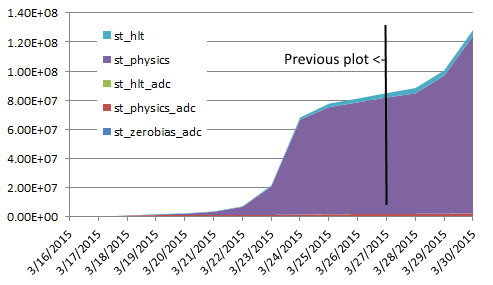 |
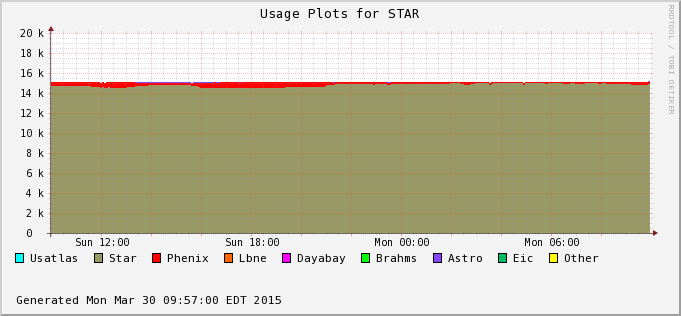 Reco slot %tage: 80.9% Process %tage : 82.3% |
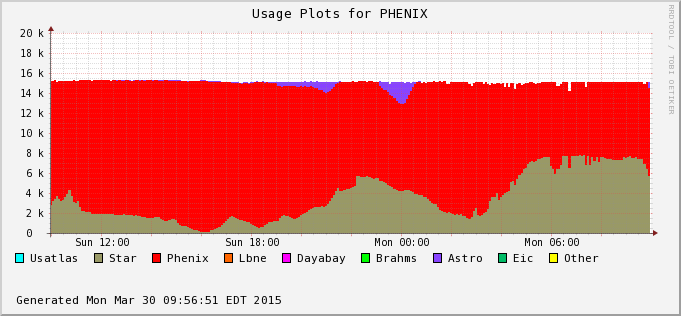 |
On 2015/03/31, J. Lauret took the time to review the CRS production system. The following action were taken to resolve the issues and features noted above (and some not discussed herein)
|
|||
| 2015/04/06 | 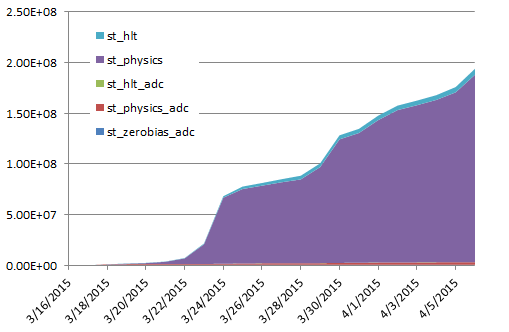 |
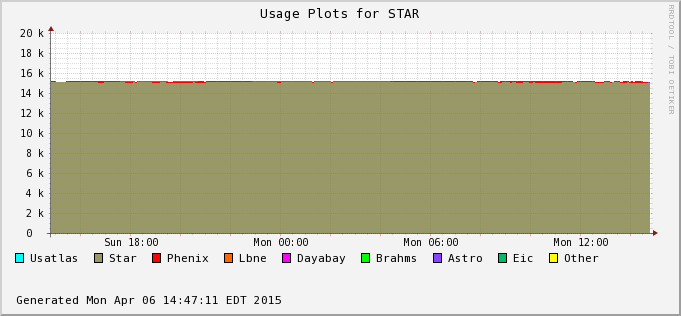 Reco slot %tage: 79.0% Process %tage : 81.8% |
 |
|
|||
| 2015/04/24 |  |
 Process %tage: 81.16% |
 |
| 2015/04/30 | 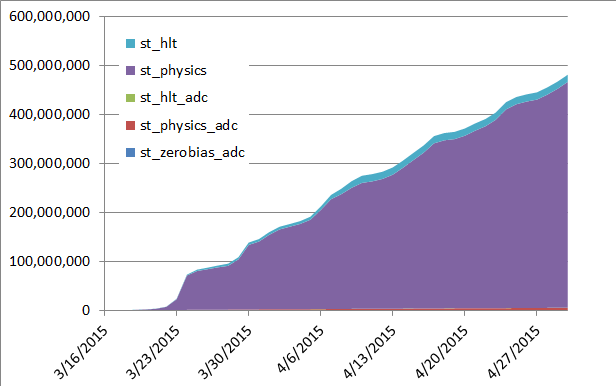 |
 |
|
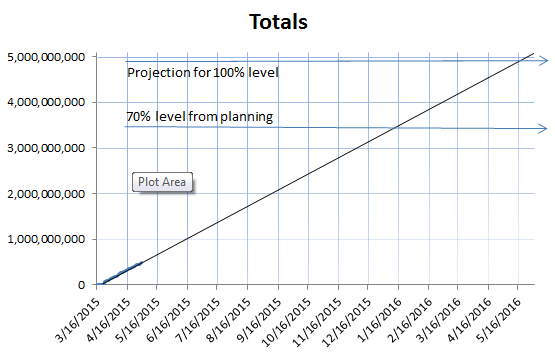
| Since the farm occupancy plots pretty much look the same (STAR is not able to take CPU slots from PHENIX as they are using it), the long term projection plot is showed instead. With no additional resources to the RCF, the ETA is moved to mid-January 2016 for a 70% level data production and mid-May 2016 for a full Run 14 data production. This assumes we do not lose further CPUs (the rate of losses noted here is alarming) and maintain a high efficiency. | |||
| 2015/05/06 | 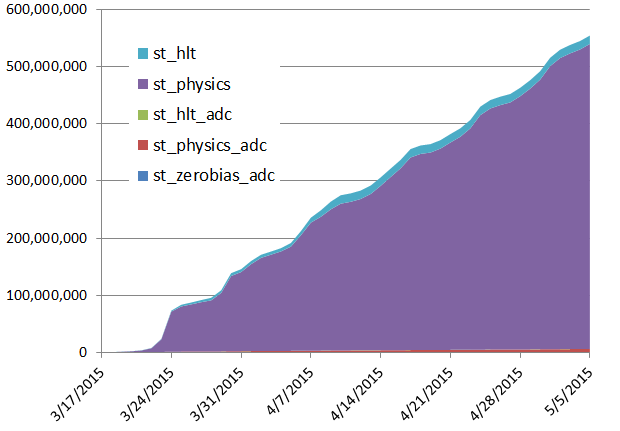 |
 |
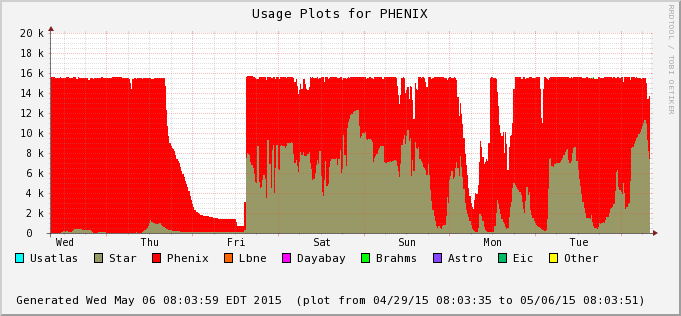 |
| A PHENIX NFS reshape intervention on the 1st (Friday on this graph) saw the condor queue closed to all jobs, with a job drain from Thursday onward (announcement was made at 16:46). This explains the first deep in the PHENIX plot. However, a second glitch is unclear (very pronounced in the PHENIX plot, not so in STAR yet visible). | |||
| 2015/05/21 | 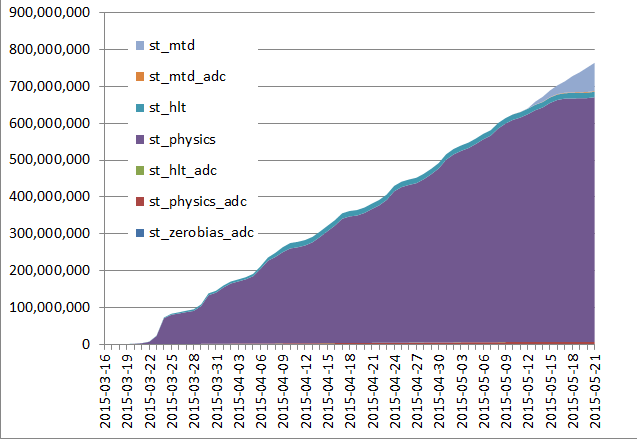 |
 |
 |
| For the past 2 weeks, the farm availability has been 100% (not a single node missing). The MTD production rate (optimistic average) is 11.6 M evets/day at 90% of the job being MTD related data. The process %tage occupancy is 77.27%, lower than usual but both PHENIX and STAR farms have been saturated to the max for the past week. | |||
| 2015/05/26 | 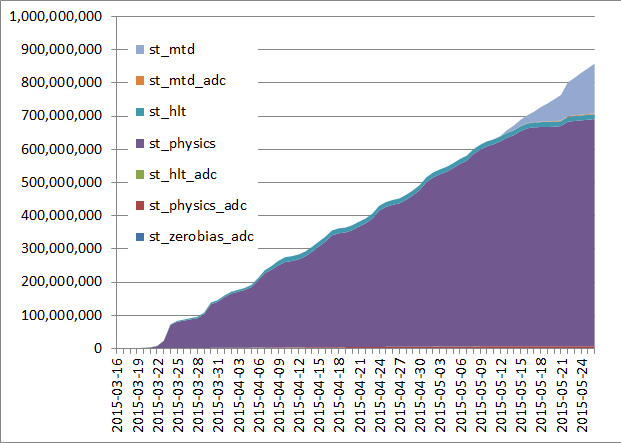 |
 |
 |
| MTD data production at ~ 13 M evets /day at this point. Projections remain stable. ETA for the 70% mark is now in December 2015 (a bit less than what was projected above) and full production ETA between February/March 2016 (assuming the same farm occupancy and efficiency). |
 |
||
| 2015/07/06 | 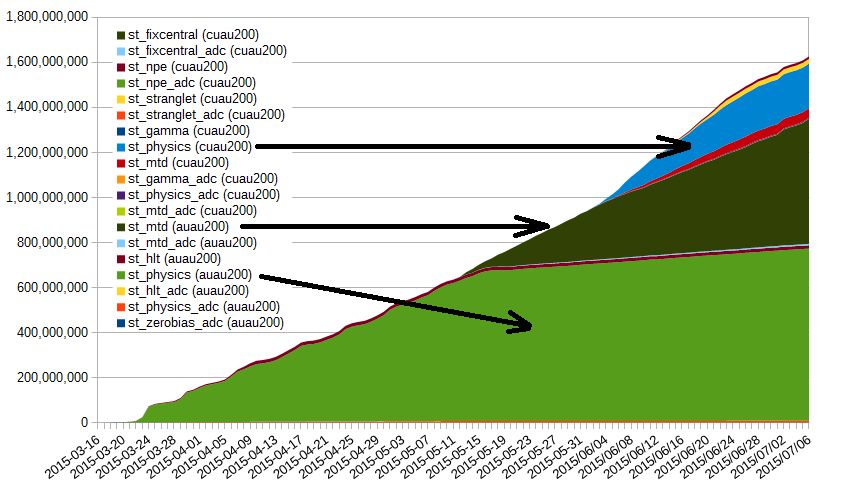 |
 |
 |
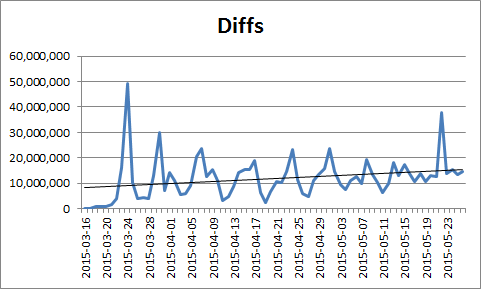
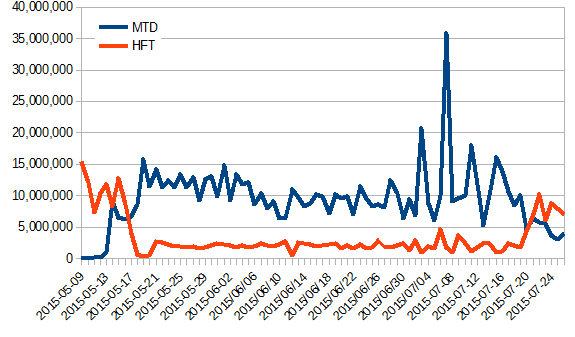
ETA has not fundamently (there is a slight change by a week ahead but this is not to be considered as a time gain at this stage). Occupancy and efficiencies remain super-high. Differential by date for the HFT and MTD data. Only st_physics was plotted for the HFT as the predominent contributor. The slopes can be trivially inferred. |
 |
||
| 2015/07/26 | 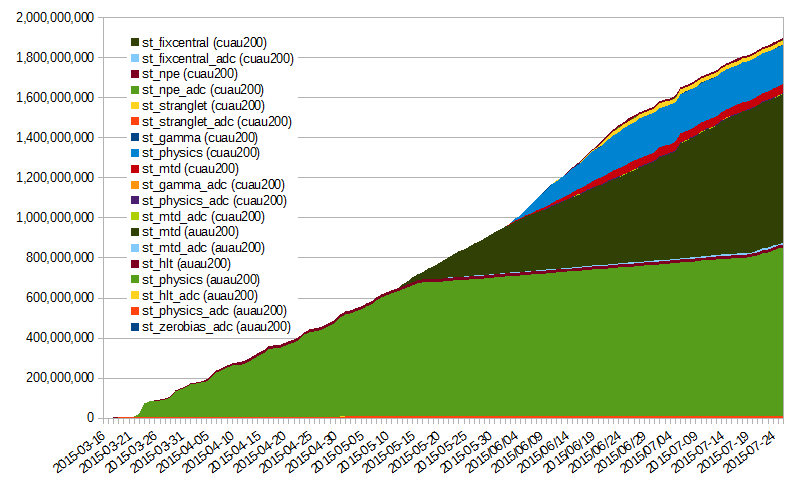 |
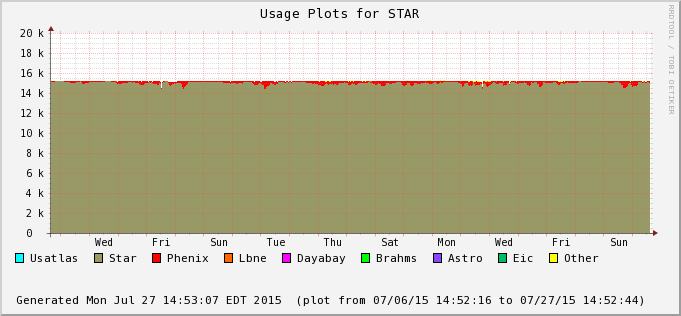 |
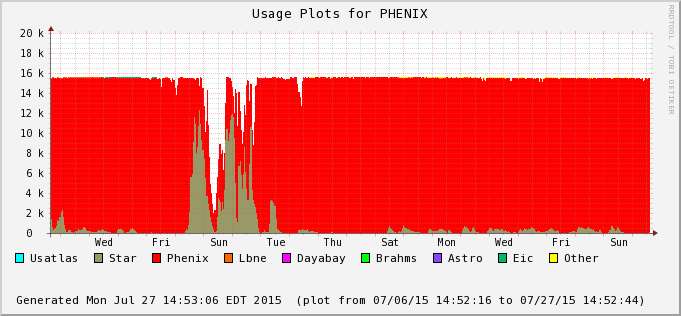 |
 |
|||
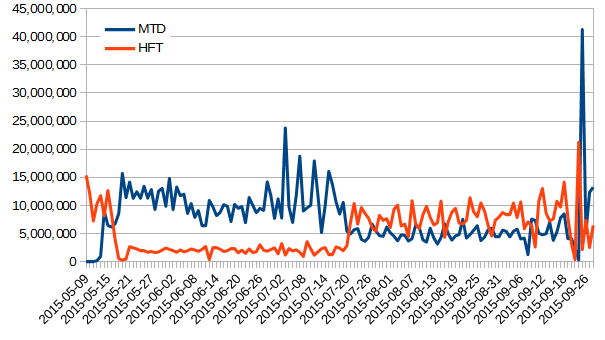
| 2015/09/30 | 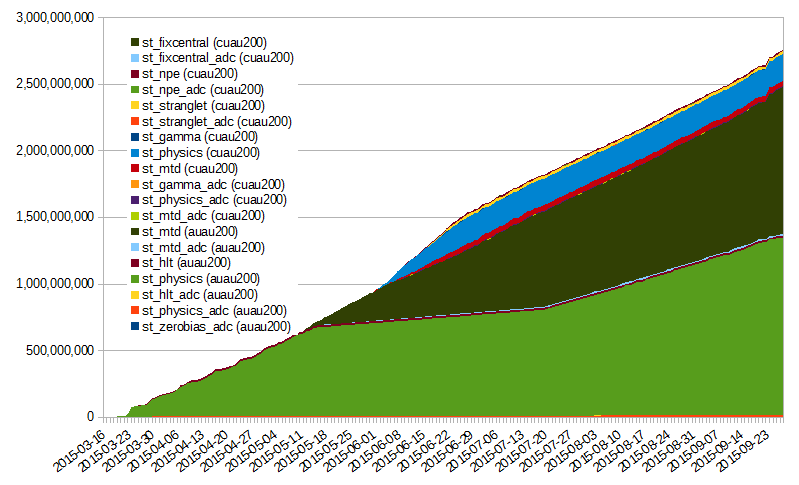 |
 |
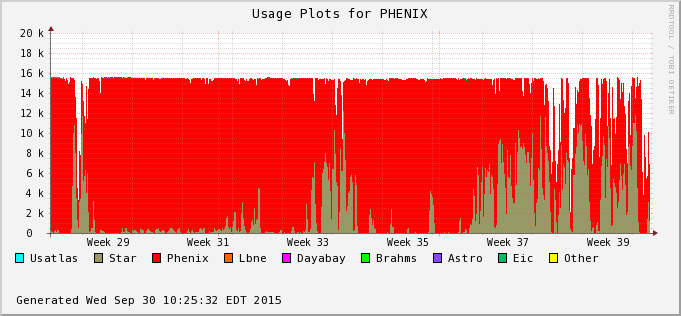 |
| The drop in occupancy toward the end of this graph is due to a hardware failure on the RCF side. Discussion is ongoing to provide a redundant submitter node infrastructure (will require development from the RACF sde). As one can see on the right hand-side plot, the ratio of HFT/MTDwa also switch back to provide a boost to the MTD as the HFT event count for QM was reached. |
 |
||
H3+Au / Cu+Au
The He3+Au sample was next on the priority list with Cu+Au as a possibility. Priorities reshuffled the order as noted here.Now that the high priority Au+Au is out of the way, calibration will resume next week for Cu+Au.
Updates will be provided in this blog as we proceed forward.
More news later.
Cu+Au
Cu+Au production began in the last week of June. The graph showed above have this production on as well.Targetted re-production was announced done on 2015/06/28.
Opened issues and Summaries
The dates below documents the dates the management team discussed the opened questions and agreed/decided on a direction.Issues from 15W11
- The HLT events are not numerous - at 20 M evts/day, we can finish in a day - should we do this?
Note 1: While it is best to restore the files from HPSS in sequence (hence intermix streams), the impact on efficiency may be minimal for this sample.
Note 2: The HLT folks already asked ...
2015/03/20 Recommended to move and submit all jobs now - agreed. - The UPC stream will require a beamLine constraint calibration - a day at most (not the issue).
Q: Can the time when we do this be confirmed? [currently understood as after QM, the UPC folks already asked]
2015/03/20 Confirmed as NOT a production targeted within QM time-frame - There is no guidance for the st_WB stream.
2015/03/20 not to be produced to first order, unclear why we have this stream - The production of the hcal as a calibration request was already noted at the management meeting as a "to follow-up". What's the news?
2015/03/20 no analysis or news surfaced from this - no go for production for QM - He3+Au or Cu+Au
2015/03/20 The management team leans towards Cu+Au as the PWG priorities have changed. - Cu+Au was produced as decided. See section above. The proportion was decided to be set to 10% HFT / 80% MTD / 10% Cu+Au - On 2015/06/17, we changed this to 10% / 60% / 30% as Cu+Au did not seem to be fast enouh to meet the initially noted deadline. After the Cu+Au production was done, the ratio was restored as 10/90.
- 2015/07/XX - discussions ongoing to change the proprotion to 50/50.
»
- jeromel's blog
- Login or register to post comments