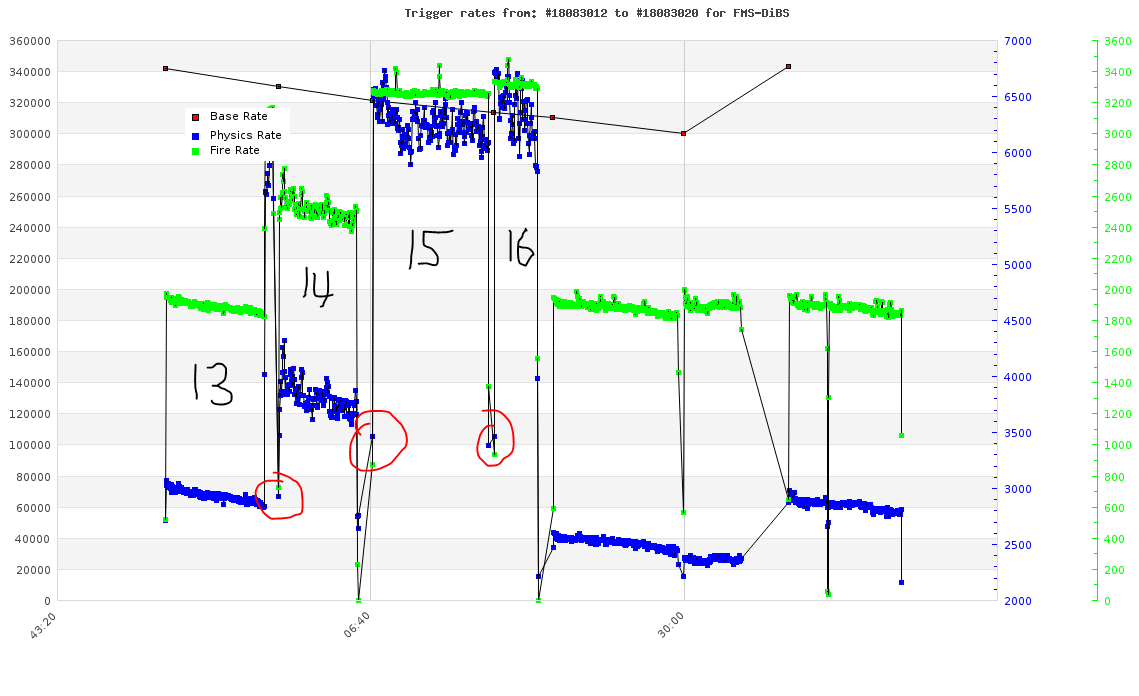
FMS Trigger Ran away at 5am, March 24th. Why? Resulting corrupution in FPS/QT
At about 5am March 24th the FMS-DiBS trigger started to run away resulting in ~6khz daq rates...
This happened at the end of run 18083013 and lasted through 18083016. The problem occured during run 13, so obviously the trigger rates went out of control at the end. The run control measures the scaler rate at the beginning of each run, and which should have controlled the actual trigger rates, despite the glitch in the FMS trigger. The reason it did't was that each time the run was started the rates came down again for a short time (See the red circled measurements). But soon the glitch reasserted itself each time.
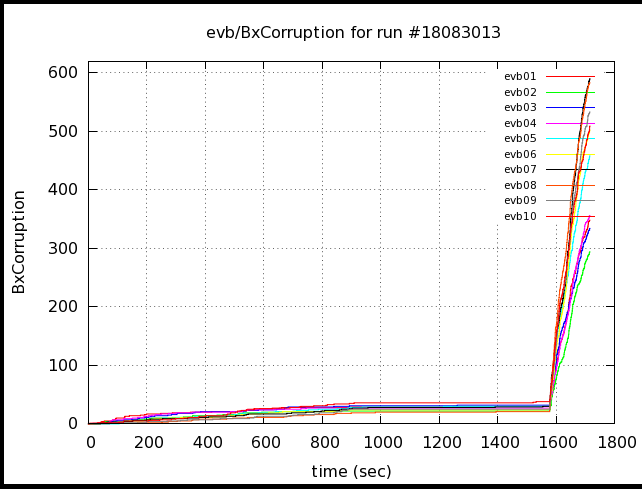
The resulting corruption was almost all in the FPre and FPost... presumably their readout time --> trigger deadtime and prevented the QT's from going past their maximum readout times. Even so, the amount of corruption in each run isn't completely predictable:
Run 13: ~500 events at the end of the run (mostly fpre) (makes sense, this is when the trigger broke)
Run 14: .5% corrupted (mostly fpost). (The rate was only around 5.5khz for this run)
Run 15: 68% corruption (mostly fpost)
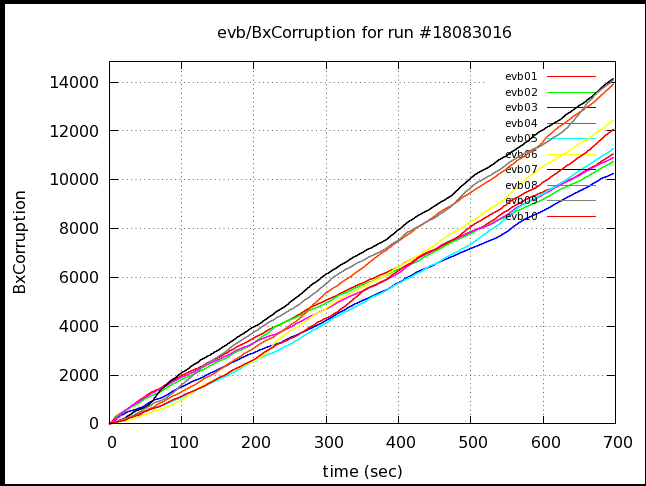
Run 16: 3% corruption (mostly fpost) (same run rate as Run 15 but a shorter run)
Run 18: .004% corruption (normal running at this time)
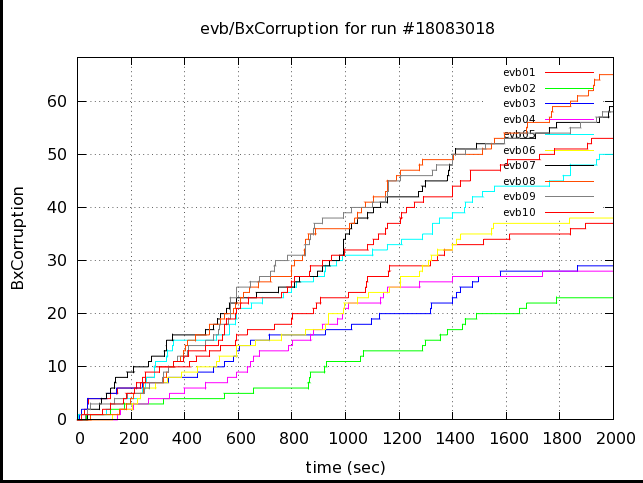
The time the corruption occured is shown below:
.png)
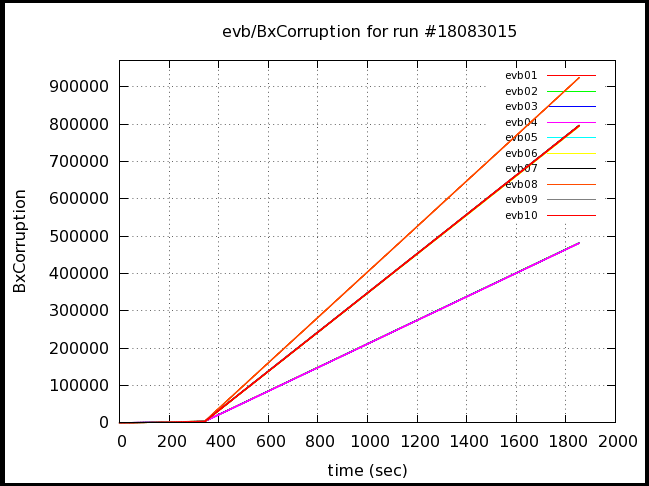
Note that in run 16 has about the same slope as the flat part of run 15, though that slope lasts longer (and for the whole run). This probably reflects a average readout time of just a little longer than 7ms resulting in a slow buildup of the number of processing triggers until the count reaches the max of 30. It's not clear to me why run 15 & 16 are different, though, as the trigger rates were nearly the same.
Normal Run:
- jml's blog
- Login or register to post comments