- jwebb's home page
- Posts
- 2019
- 2018
- 2017
- 2016
- 2015
- 2014
- 2013
- November (1)
- October (1)
- September (1)
- July (1)
- June (1)
- April (1)
- March (3)
- February (1)
- January (1)
- 2012
- 2011
- December (2)
- September (3)
- August (5)
- July (6)
- June (6)
- May (1)
- April (5)
- March (5)
- February (2)
- January (2)
- 2010
- December (3)
- October (3)
- September (2)
- August (2)
- June (2)
- May (4)
- April (4)
- March (2)
- February (4)
- January (10)
- 2009
- 2008
- 2007
- 2006
- July (1)
- My blog
- Post new blog entry
- All blogs
STAR Event Generator Framework Review
Specific Issues raised by reviewers
1.0 ID Truth Mismatch [Resolution] [Verify in Pileup]
2.0 I/O Error on Last Event [Workaround][Resolution]
4.0 StarGenPPEvent, StarGenAAEvent, StarGenEPEvent, StarGenEAEvent [Feedback Implemented]
5.0 StarPrimaryGenerator [Resolved]
6.0 StarGenerator [Resolved]
7.0 StarGenParticle [Resolved]
8.0 StarParticleData [Concerns Addressed]
9.0 StarParticleStack [Concerns Addressed]
10.0 StarRandom [Concerns Addressed]
11.0 St_geant_Maker mods [Resolved]
12.0 Organization [Resolution]
General:
Compilation warnings in the framework have been dealt with. Compilation warnings in external packages (i.e. the concrete event generators) will not be corrected. Our policy should be to not change the concrete event generator code unless necessary, e.g. in HIJING where they do not record the location of the production vertex.
ClassImp statements can be removed. Low priority.
There are a few TODO comments scattered throughout the code. These denote areas where I think the code can be improved and / or extended at a future point.
using namespace has been moved from the header to the implementation file in all cases.
Code cleanup:
Mixed case -- I am cleaning up the mixed case issue. There are a few instances where I will keep mixed case for accessor methods, specifically where the intent is to return a kinematic variable, e.g. pt(), eta(), phi(), momentum(), etc...
Unused methods, such as StarGenEvent::Merge(), removed.
Memory management issues largely resolved. The exception is the TTree in StarPrimaryMaker (ex StarPrimaryGenerator). If it's deleted in the class destructor, we get a segmentation violation... I suspect this is due to branches being created / added in the child generators. Will need further investigation to handle properly. For now, leave it.
Naming conventions:
Some work has been performed to cleanup naming conventions. StarPrimaryGenerator --> StarPrimaryMaker, for instance. Also better adherence to naming conventions, i.e. GetMethod() vs method(). There are a few exceptions as noted above and in the detailed comments below.
Warnings and/or Errors are now issued in place of (or just prior to) assert statements.
Reviewer: Ming Shao
Status: Under investigation
Looking at printouts of individual events, there are a large fraction of events where the kinematics between the generated and reconstructed global track do not match, where the generated track is identified using idtruth.
To quantify this, I look at a sample of 10 events (higher statistics forthcoming). I select reconstructed global tracks with an idtruth value pointing to a track in the event generator. (Pythia 8). I require 10 hits on the reconstructed track to make the comparison. Plots below show the correlation between thrown and reconstructed events, and the resolution between thrown and reconstructed.
Figure 1.1 -- Correlation (left) and resolution (right) in eta between the reconstructed and generated tracks.
.png)
.png)
Figure 1.2 -- Correlation (left) and resolution (right) in phi between the reconstructed and generated tracks.
.png)
Figure 1.3 -- Correlation (left) and resolution (right) in 1/pT between the reconstructed and generated tracks.
.png)
.png)
I consider a track mismatched (idtruth points to the wrong generated track) if the difference in eta, phi and pT are > 3sigma from zero.
Plotting the number of mismatched tracks / event...
Figure 1.3 -- Number of mismatched tracks / even (left) and percentage of mismatched tracks / event (right).
.png)
.png)
We see that there is a failure rate where ID truth is not matching the correct generated particle (as determined by a correlation of the kinematics of the track). The failure rate is that about 20% of events have up to ~20% of tracks mismatched.
Reviewers: Ming, Thomas
Status: Workaround available, will debug
There is an I/O error reported on the last event. It is not clear why, but my suspicion is that St_geant_Maker does not make the necessary calls on the FORtran side to properly flush the data to the FZD file at the end of the run. The simple workaround is to generate N+1 events when N are requested.
Reviewer: Thomas
What is the reason for not using double precision for mWeights? All other floating point event-wise variables are double. Is the array expected to be very large and the use of float to conserve disk space?
The thinking was to save space. However, weights should only be one or few words per event, so switched to double.
The user is expected to inherit their event from this class (or one of StarGenPPEvent, ...etc) but none of the methods except Clear() are virtual.
StarGenEvent is intended to record the minimal set of properties which are common across diverse event generators. It also establishes part of the interface with the Monte Carlo, e.g. the decision to stack particles for simultion and the order in which they should be stacked. This should not be overridden by the developer.
Is it possible to create events with different particle classes (inheriting from StarGenParticle)? I ask because there are some particle-wise quantities that for example make sense in a DIS event but not in a hadronic event. These would be convenient to have access to in the particle record. Or is the intention that any more complicated particle-wise quantities should always be computed by the end user when analysing the simulated events?
The intent is to keep the particle class as minimal as possible. ID, kinematics, mother/daughter relationships and generator bookkeeping. If we need to store additional particle-wise information, we should do this in a parallel data structure. Perhaps an array of an "attribute" class.
Reviewers: Thomas
Status: pp, AA and ep event records implemented. (EP is a draft, would appreciate feedback). eA record will wait until first concrete eA event generator is incorporated.
• Is the omission of a leading “m” to field names a deliberate omission, to make TTree::Draw() statements simpler? Yes • Accessor/setter methods are absent. Intentional. This is really more of a "struct" than a "class" here. • Comments describing the last few fields would be useful (and make comments Doxygen style). Comments doxigenated • Add comment lines noting use of the default copy constructor/assignment operator. • What is the distinction between process and subprocess? Depends on the event generator, and should be specified by the developer. In pythia 6, I set process = pysubs.msel and subprocess = pypars.msti(1) (a.k.a. the ISUB corresponding to the exact parton+parton interaction involved.)
Reviewers: Thomas, Yuri
Status: Resolved
StarGenerator ? Names StarGenerator and StarPrimaryGenerator suppose they have the same functionality but is not the case.
StarPrimaryGenerator is maker. All others
I proposed to split Maker in name and to move 000README and HOWTO* there.
StarPrimaryGenerator --> StarPrimaryMaker
pdg() returns the TParticlePDG information from TDatabasePDG. There is a StarParticleData class with modified entries - should it not return it from here to be STAR-specific?
I have modified StarPrimaryMaker (and other places in the framework where appropriate) to use StarParticleData.
OOC, why can there only be one primary generator? ...
We need a single maker to be in charge of pushing tracks out to the GEANT stack. This is it.
If a developer wants to have a generator which is a tree of generators, this can be achieved. StarGenerator is really a maker, so one can add makers to it, and iterate over them. So there's no functionality lost by making StarPrimaryMaker a singleton.
We don't use the singleton patten here because that violates the spirit of the Maker/Chain approach, whereby makers are available to other makers in the chain through a call to GetMaker("/path/to/maker").
I believe the ROOT folks recommend using TTree::Branch() not TTree::Branch(). http://root.cern.ch/phpBB3/viewtopic.php?f=10&t=10142
Fixed, and request made to ROOT team to fix their documentation (class reference) for TTree.
Init() returns the result of StMaker::Init(), but potential problems in Init() itself (e.g. failure to open output file) are not handled.
kStWarn will be returned on file open failure.
Make() and Finish() should presumably call/return StMaker::Make() and StMaker::Finish(), assuming the other operations in those methods are successful.
No. StMaker::Make() would loop over all sub makers and call Make() on them, as well as other bookkeeping tasks. This is not needed. Likewise with Finish().
In Finalize(), printing an error and returning kStFatal may be more useful than assert().
Error returned.
Reviewers: Thomas, Yuri
Status: Resolved
StarGenerator ? Names StarGenerator and StarPrimaryGenerator suppose they have the same functionality but is not the case.
StarPrimaryGenerator is maker. All others
I proposed to split Maker in name and to move 000README and HOWTO* there.
Why does it inherit from StMaker? The user is prevented from calling Make(), and
a maker than canʼt make seems like and odd design.
The inheritence from StMaker is to leverage all of the other facilities of the maker class, e.g. hierarchical data structure, list of sub makers over which we can iterate, etc...
Make mm and cm private/protected (are they even used?).
They should be used by developers in order to specify the units used by the concrete event generators, so that the simulation package recieves events with the correct spacial dimensions.
If impact parameter is heavy-ion specific, why is SetImpact() in the base class?
It is there to define a consistent method across all heavy ion generators.
Why is StarPrimaryGenerator a friend of StarGenerator? What private information is being accessed? All I saw looking through StarPrimaryGenerator was use of public StarGenerator methods.
StarGenerator::mId should only be assigned by the primary generator.
StarPrimaryGenerator - in StarPrimaryGenerator::Init() it is supposed that all makers from GetMakeList() are inherited from StarGenerator. If this is not true then you are looking for seg. fault. You need to use dynamical cast.
Resolved.
Reviewers: Yuri, Thomas
Status: Resolved
StarGenParticle ? Why do you need to duplicate TMCParticle.h ?
TMCParticle is an emulation of the LUJETS/PYJETS particle record. TParticle would be a better choice over TMCParticle, but it would still lack bookeeping information needed to keep track of (a) which event generator created the particle, (b) the unique ID of the particle in the event generator's record, (c) the unique ID of the particle in the aggregated event record and (d) the position of the particle on the starsim event stack (--> id truth).
Additionally, we layout the memory structure such that we can easily add the data to the g2t table for backwards compatability with the current framework.
Enumerations are added which specify the status of the particle, so that developers can follow a consistent standard. A method is also established to determine whether the particle should be sent out to GEANT for simulation.
The documentation here is very good. One thing to add would be whether array indices are in the range [0, N) or [1, N].
Done.
Why is StarPrimaryGenerator a friend of StarGenerator? What private information is being accessed?
get_hepevt_address() is accessed by StarPrimaryGenerator to add the particle to the g2t tables.
SetId() could be inlined.
SetId() now looks up the particle in the StarParticleData class and sets mass accordingly.
Reviewer: Thomas
Status: Resolved
What is the reason for inheriting from TObjectSet? Is that where the particles added to the list are deleted?
Permits us to add StarParticleData to the primary maker so that it is browsable and accessible to makers through the normal chain mechanism. (Low priority: We should eliminate the singleton pattern here in favor of this access method).
sInstance doesnʼt follow naming convention.
True. I prefer to singleout the singleton instance with this convention.
My anti-macro-bias strikes again...
Noted. Function implemented.
Reviewer: Thomas
Status: Resolved
I donʼt understand PopPrimaryForTracking()...
This class follows the Alice implementation of the VMC particle stack. I think they chose the name poorly, because it doesn't really "pop" anything from a stack. But we're stuck with the name of the method.
Reviewers: Yuri, Thomas
Status: Resolved, but additional functionality may be implemented in the future.
StarRandom - Why do you to remap ROOT's TRandom generators to StarRandom ?
I would like to ensure that there is a sinlge-source for random numbers in simulations. There was some discussion in yesterday's (9/6) VMC meeting about providing a single source RNG, but allowing different seeds (or algos) on a per-maker basis.
I would make _Random a nested class of StarRandom and move the forward declaration inside the class (no need to expose its existence to the user).
Done. (Slightly different approach, but same result. _Random is hidden from the developer.)
Is use of the common random generator encouraged for users? Does the rest of the package expect it, or is it just there for convenience in case users want it?
Yes. This is a matter of being able to (a) reproduce results for a given seed, and (b) replace poor-quality FORtran-era random number generators with more robust modern RNGs (higher periodicity, and better randomization).
Reviewer: Yuri
Status: Resolved
StRoot/St_geant_Maker/St_geant_Maker.cxx
remove all xgeometry. All other modifications are o.k.
Done. xgeometry can be selected by loading the xgeometry.so library instead of the geometry.so library at run time.
Reviewers: Yuri
Status: Current version of the code uses Yuri's suggestions, but next version will revert to pool, as we will have too many event generators to keep in one directory / generator.
Keep flat structure of packages, i.e. remove level StarGeneratorPool which generate extra complexity.
No extra complexity is generated. This is exactly the same organization which is currently implemented in pams/gen.
Reviewers: Yuri
Status: Resolved.
I need justification for StarDb/Generators, StarDb/Pythia8
Will move data files required by event generators into the same directory as the event generators.
Round 2
After some investigation, it was determined that two issues were causing the ID truth mismatch.
(1) Somewhere in starsim (either in geant or the starsim codes), neutrinos are being removed before being added to the geant stack. So they never make it into the g2t tables. This results in an offset between ID truth (i.e. position on the geant stack) and the event generator record's accounting of ID truth.
(2) There was an interesting feature using TRefArray to store particles. When reading back events from a TTree, the TRefArray was not being properly cleared, and we were seeing tracks from previous events being associated with reconstructed tracks in the current event. Switched to TObjArray for storing the list of particles sent to the geant stack.
After making fixes for the above, we have much improved ID truth matching--
Figure 1.1 -- Correlation (left) and resolution (right) in eta between the reconstructed and generated tracks.
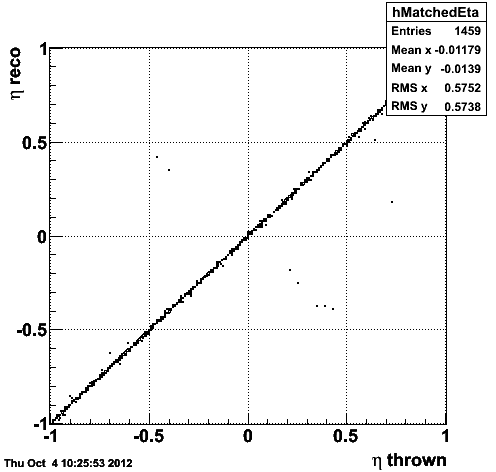
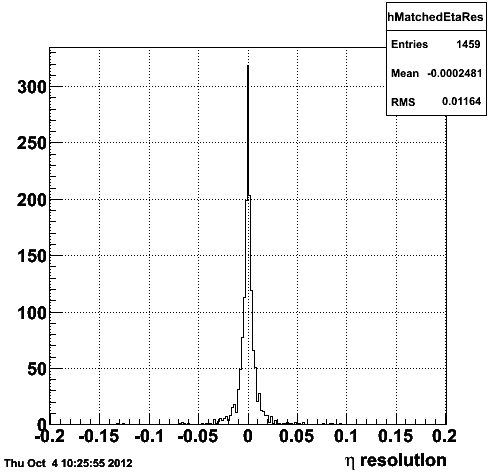
Figure 1.2 -- Correlation (left) and resolution (right) in phi between the reconstructed and generated tracks.
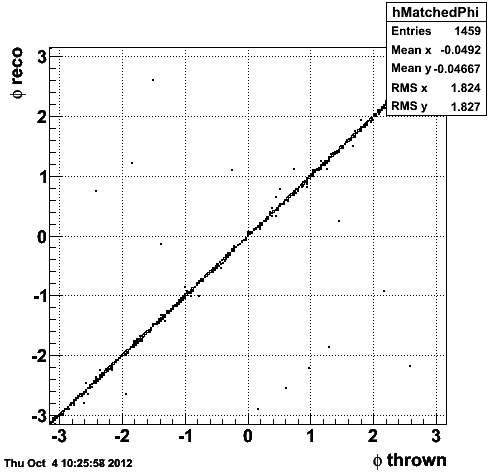
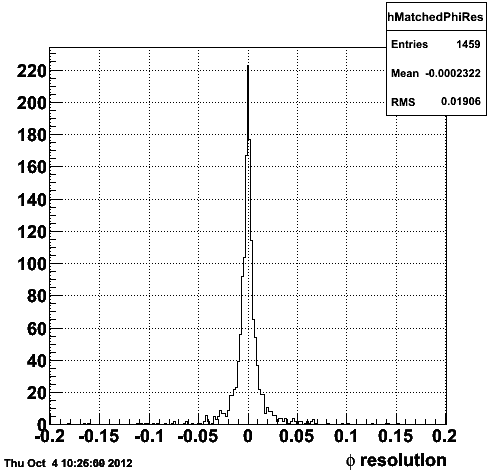
Figure 1.3 -- Correlation (left) and resolution (right) in 1/pt between the reconstructed and generated tracks.
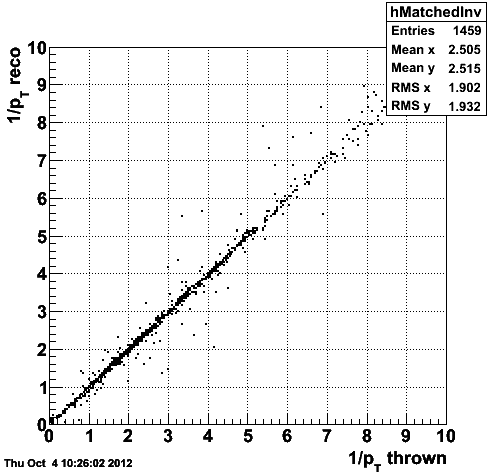
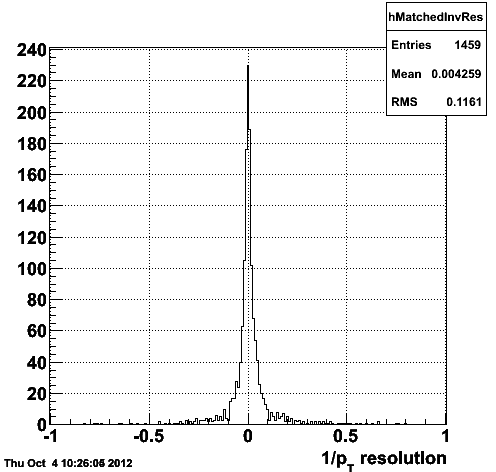
I consider a track mismatched (idtruth points to the wrong generated track) if the difference in eta, phi and pT are > 3sigma from zero.
Plotting the number of mismatched tracks / event...
Figure 1.4 -- The number (left) and fraction (right) of tracks which reconstruct outside of 3 sigma in eta, phi and 1/pt compared with their corresponding ID truth track in the event generator record.
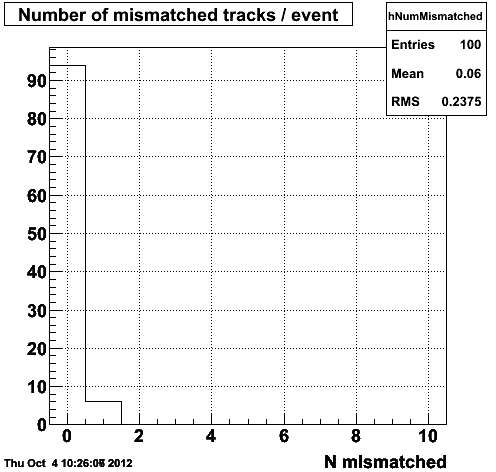
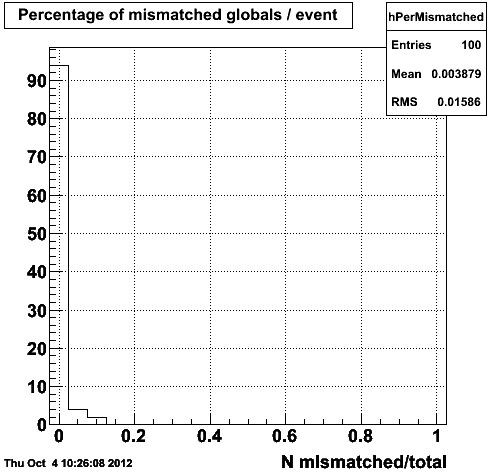
For comparison, we make the above plot using an event sample generated with the old event generator framework and using the g2t tables to determine ID truth tracks.
Figure 1.5 -- Using starsim only -- The number (left) and fraction (right) of tracks which reconstruct outside of 3 sigma in eta, phi and 1/pt compared with their corresponding ID truth track in the event generator record.
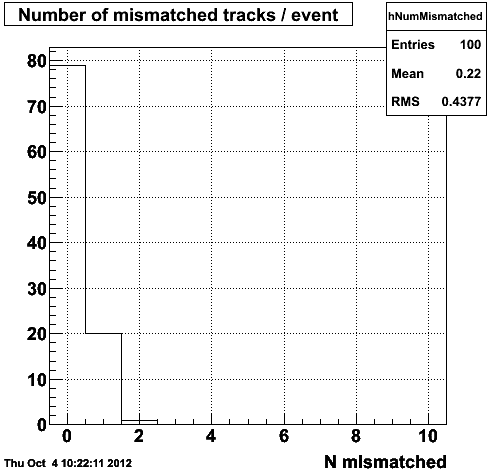
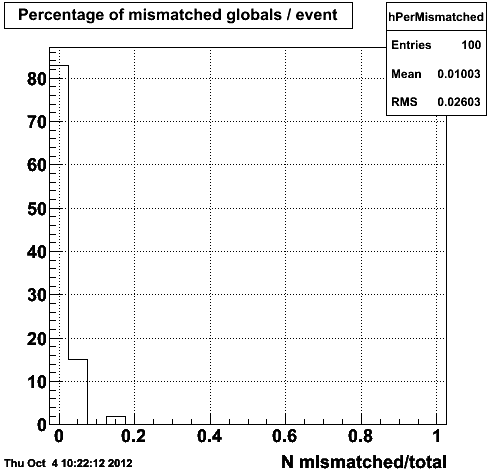
Conclusion: The new framework has similar performance to the old framework in terms of matching tracks from the event record to reconstructed tracks via ID trutrh.
Groups:
- jwebb's blog
- Login or register to post comments