Possible impact of STAR Run 2006 inclusive jet data on PDF uncertainties.
Updated on Tue, 2022-06-07 18:14. Originally created by veprbl on 2015-03-22 15:41.
The maximal possible impact of STAR Run 2006 inclusive jet data on PDF uncertainties is studied using HeraFitter+FastNLO(NLOjet++).
HeraFitter takes input of four different kinds:
Second, I used that LHAPDF file with my FastNLO table to produce pseudo-data points, which I combined with relative uncertainties of the real dataset to construct my datafile.
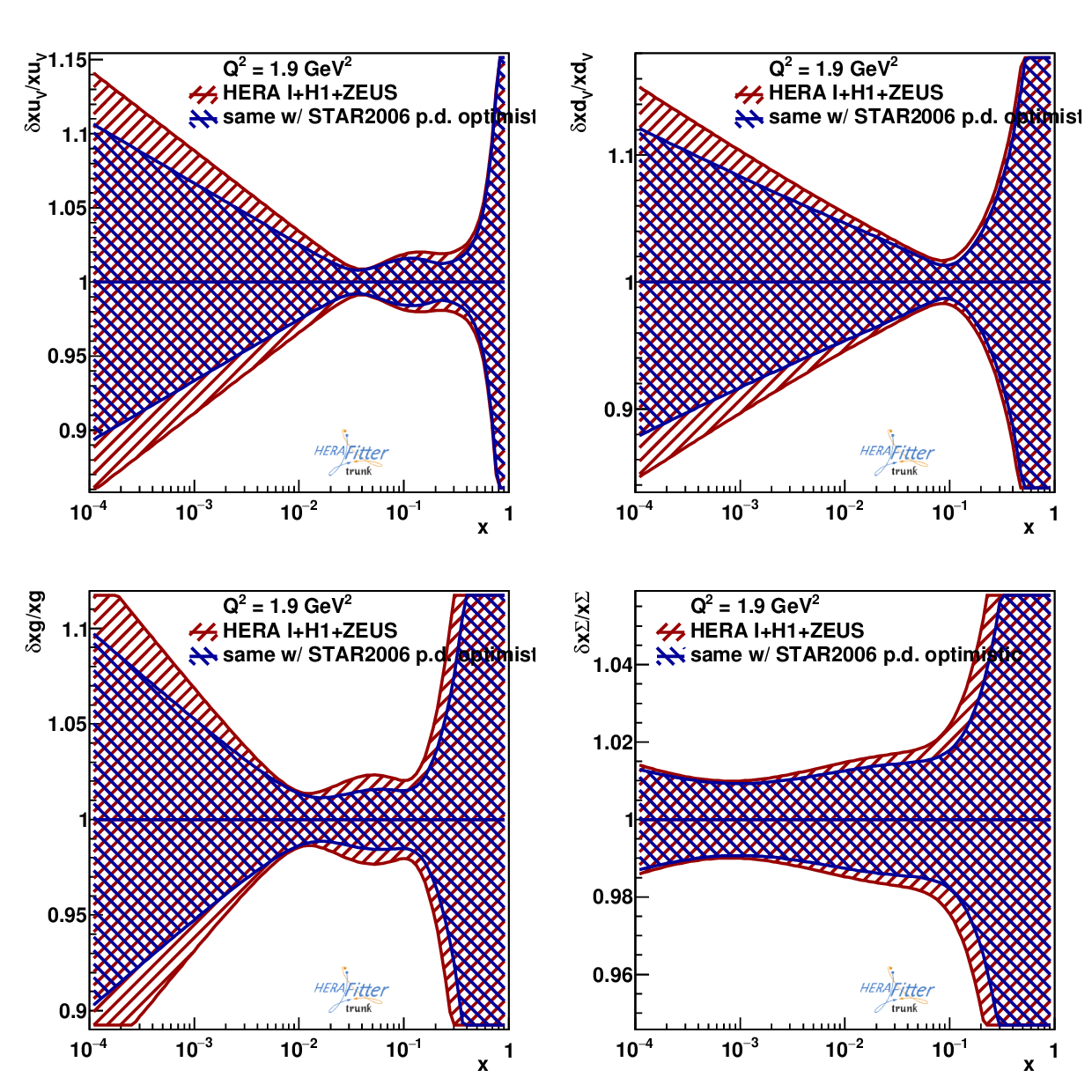
Next, I added my pseudo-data file to the steering file and rerun HeraFitter to obtain new error estimate (again, without doing a fit). The resulting ratio of PDF errors looked like this:
.png)
Next logical step was to see if there can be any impact at all. For that check, the errors were scaled by a factor of 0.1. The resulting error estimate comparison looked like:
My other idea was that many of our dominating errors are actually correlated. For this estimation I took 0.1 of errors as statistical and the rest as correlated:

My conclusion here is that putting effort into separating errors into correlated and uncorrelated can pay off.
I also noticed that HeraFitter seems to support specification of the cross-dataset error correlation what can can be useful for W's.
HeraFitter takes input of four different kinds:
- steering.txt file: determines dataset used for the processing as well as general options like where to output the results and whether error bands should be calculated
- minuit.in.txt file: determines initial starting conditions for coefficients of the PDF parametrization, also contains the scenario for minuit (default setting is "call fcn 3" that essentially doesn't do anything, user should uncomment at least some other lines to perform the fit)
- datafiles: .dat file that specifies basic information about the measurement such as name, type of the "theory", data column meanings, plot settings, and data points with errors.
- theoryfiles: determines how to convert PDF into cross section to be compared with the data points. In my case I had a FastNLO table that I've previously generated
Second, I used that LHAPDF file with my FastNLO table to produce pseudo-data points, which I combined with relative uncertainties of the real dataset to construct my datafile.
Next, I added my pseudo-data file to the steering file and rerun HeraFitter to obtain new error estimate (again, without doing a fit). The resulting ratio of PDF errors looked like this:
Next logical step was to see if there can be any impact at all. For that check, the errors were scaled by a factor of 0.1. The resulting error estimate comparison looked like:
My other idea was that many of our dominating errors are actually correlated. For this estimation I took 0.1 of errors as statistical and the rest as correlated:
My conclusion here is that putting effort into separating errors into correlated and uncorrelated can pay off.
I also noticed that HeraFitter seems to support specification of the cross-dataset error correlation what can can be useful for W's.
»
- veprbl's blog
- Login or register to post comments