TPC QA 2024
auau run 2024 summary
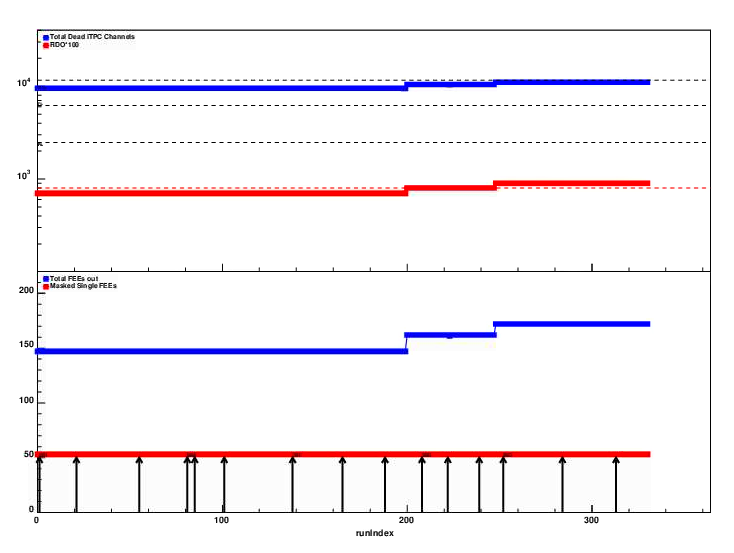
A couple of more RDO's in itpc was lost. Total channels dead is about 15% (upper dashed line)
The number of TPX (outer sector ) dead at end of run is summarized in this screenshot. Total of 8 RDO masked out
due to the fact that 2RDOs are power by same PS, and gets masked out in pairs.
In addition a few single FEEs were masked out.

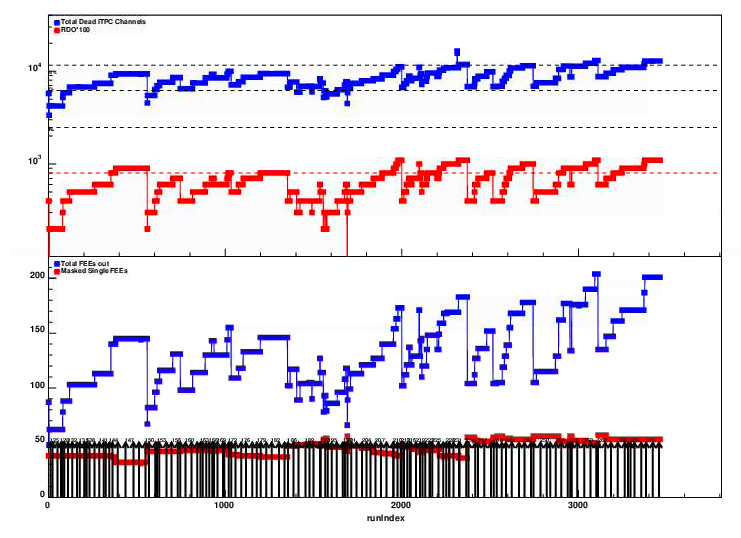
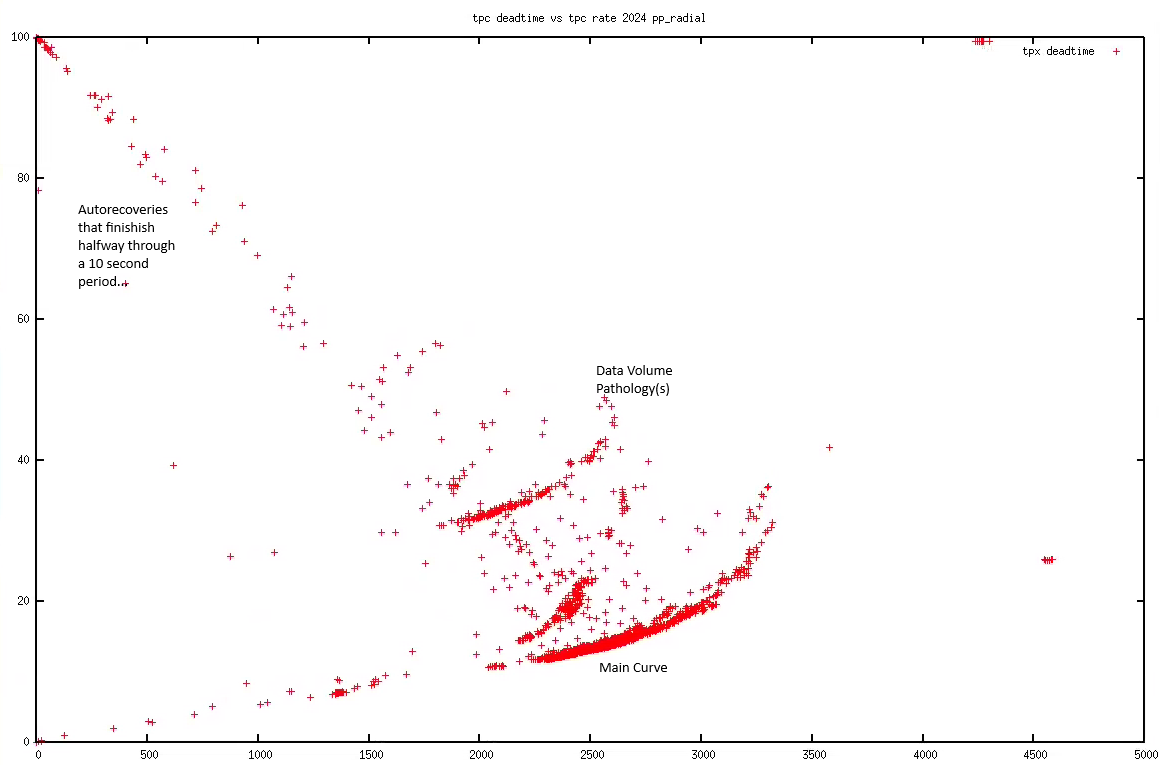
pp Run 2024 Summary
This is for the whole run period up to and including day 274 (September 30)
The last 50 days (since 220) is the next plot
.png)
Archive
The qa histograms for run 23 and 24 has been saved by Gene at
/home/starqa/tpcQA/Run23.tar (~6 GB)
/home/starqa/tpcQA/Run24.tar (~19 GB)
The are also being kept for a while in the file system at
/star/data10/qa/tpc/archive23 ...
Goals and to do
Aim is to make QA more automatic at the FF and bad pad level.
The procedures to run ADC files last year seem good. Improvements are needed in the following area's
Update the AnaQA.C and associates cron job to execute task for both dead channels (FEEs, RDO and singles onesI include TPX too
and for hot channels to produce time sequence of changes.
The hots channel task was tweaked and looks fine.
Hot channels for cosmics April 2024
It is difficult to get enough statistics for cosmic data run. Two sets of run with plenty of ADC data was done thanks to Jeff.
104032-034 for FF field settting and
107059 for RFF setting
The analysis result for channels to be masked permanently is
Sector, row pad
4 72 110
6 61 58
11 3 25
22 56 71
23 21 15
April 18 2024
Shift crew notice in run 109020 , cosmic, higher yield area. It looks like part of a FEE is misbehaving, could be
one event or few. Unlikely for all events. Sector 7, not in following run.
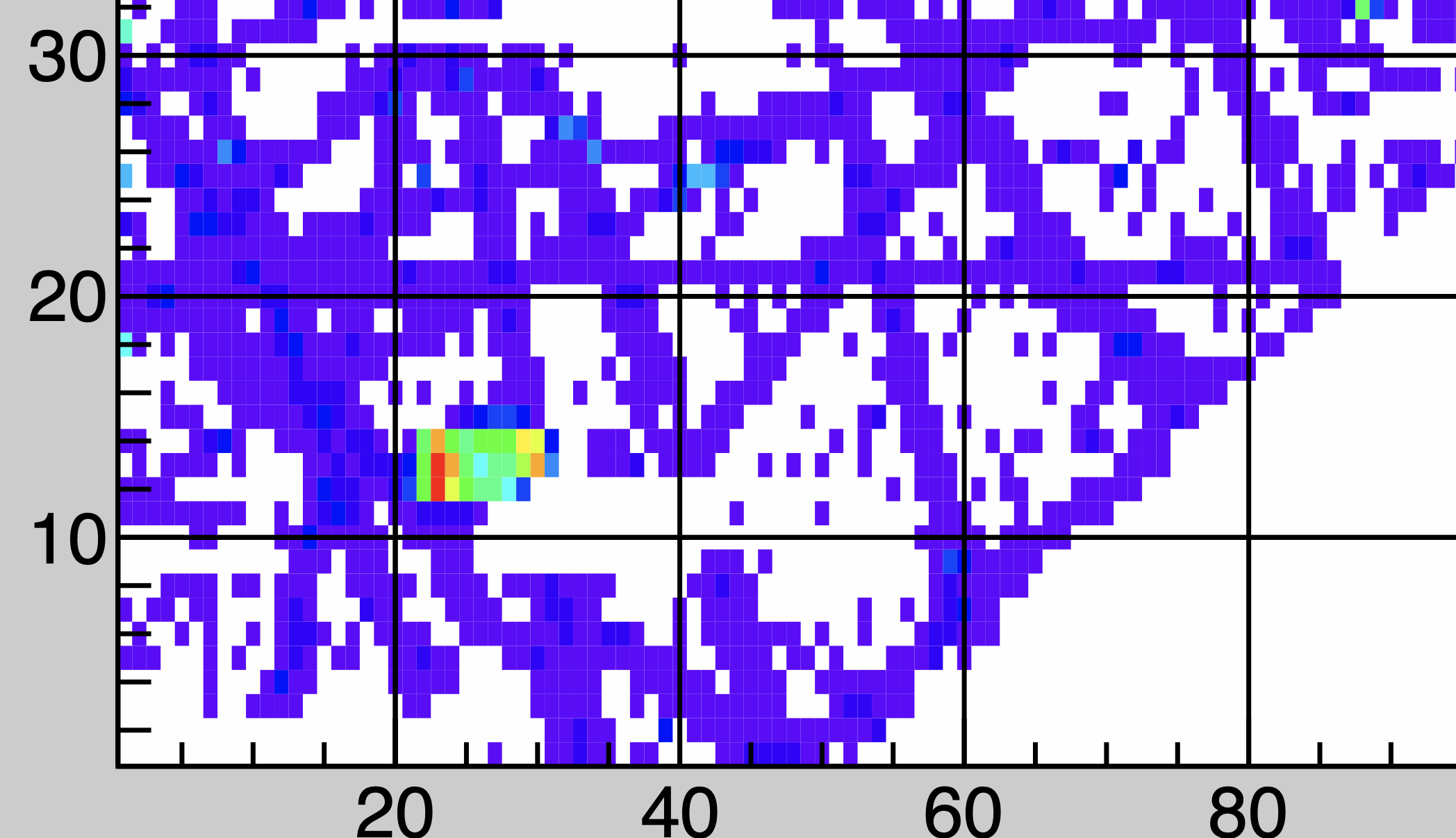
April 28
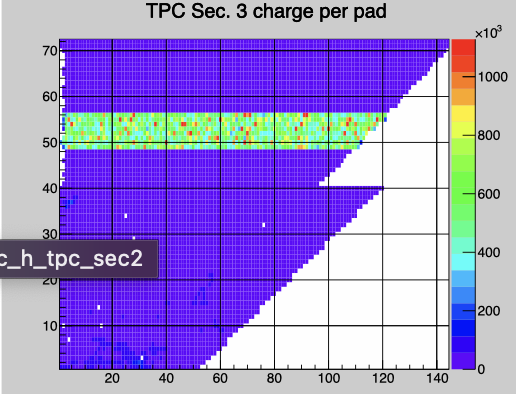
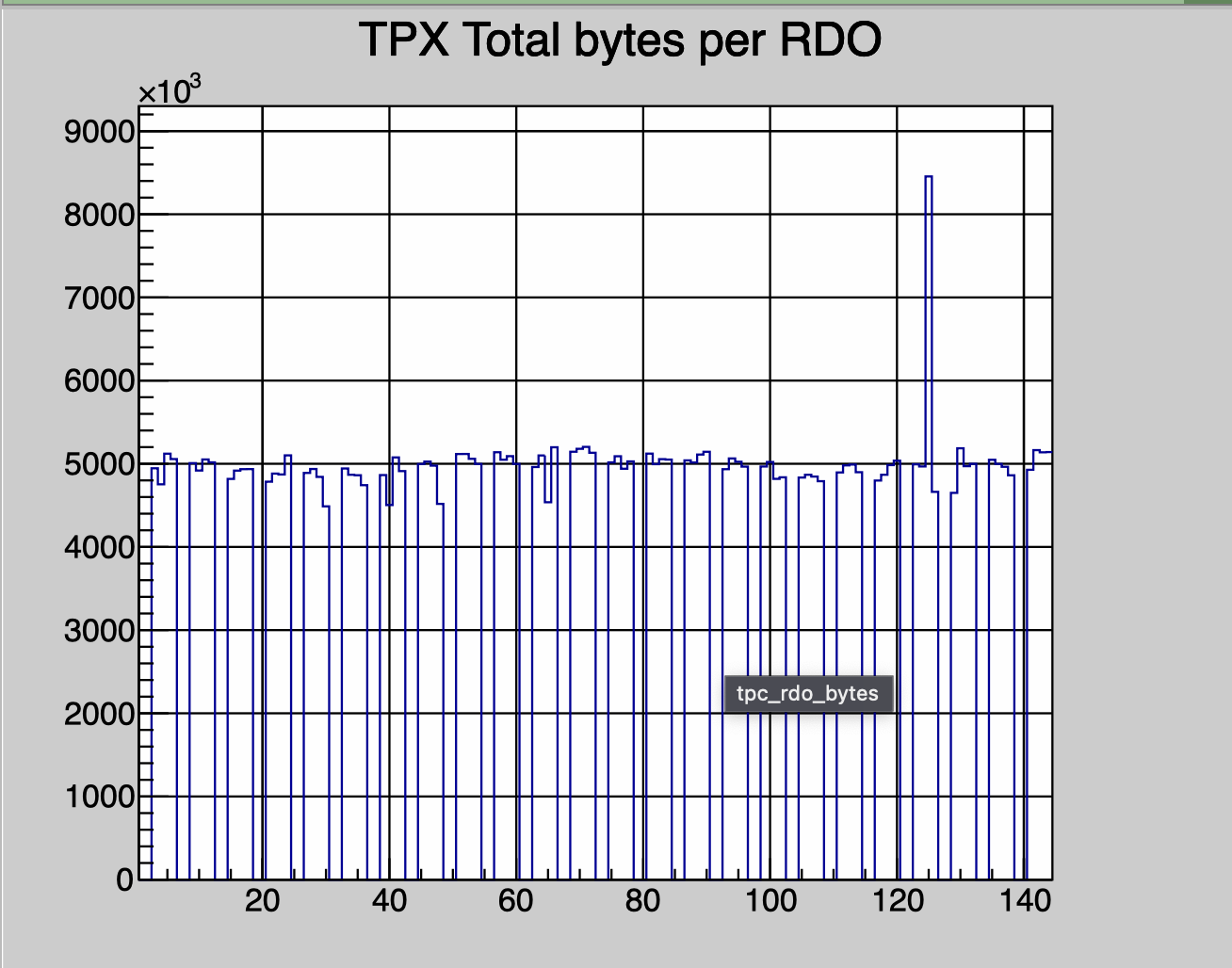
Something is not right in TPX Sector 3, RDO 4. Way too much data causing deadtime. One can see bad data in the online plots.
I powercycled it just now so let's see.
------------------------------------
Tonko: There seem to have been some electronics issues with the TPX03:4 RDO. This in turn caused a lot of data for that RDO which in turn caused the TPC to dominate the deadtime.
After powercycling the TPC deadtime is fine: 17% at 3.5 kHz.
I need to take a better look to figure out why the checking software didn't cause an auto-recovery. TBD.
------------------------------------
Tonko: The first errors started in run 25119018.
Run 25119017 was still fine.
And now run 25119024 is fine again.
Summary of such bad runs
day 133 sector 1 rdo 5 133026-133032 -- reported by Lanny in QA meeting
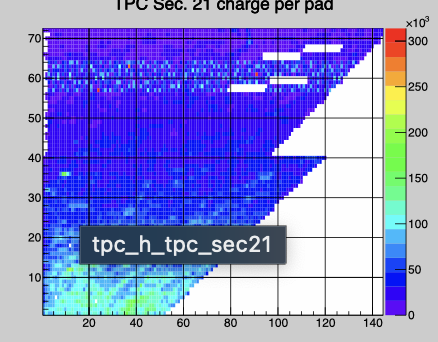
day 150 sector 21 RDO 5 150009-150014 -- should be masked. sector 21 TPX RDO5
day 150 sector 2 RDO 6 150052-150053
May 3, 05
Tonko in shiftlog - next good run is 25124008 (pedestal run)
Looked at various masked RDOs and unmasked all apart from iS12-1 which looks bad and won't be enabled in this run.
Unmasked:
iS12-2 -- might still be problematic but I can't capture an error now
iS05-1 -- power issues, had to kill FEEs
iS19-2 -- timeouts, had to kill a few FEEs
iS24-3 -- power issues, had to kill FEEs
Day 129
One iTPC RDO was making problems: iS09:4 in multiple consecutive runs. Had to mask it out.
Failed in run 192010
Day 131
TPX sector 1 RDO 5 failed to load proper pedestal
-- high deadtime due to data volume. Bad pedestal from prev ped run. retake and reload.
.png)
May 28, 2024
First version of easier turnaround on keeping up with TPC,TPX status
First changing scripts to digest the itpc status dead channels
updated anafile.sh - create output in AnaQA.C to generated brief summary file with just run# #failed rdo, faied FEE bad dead itpc channels
These are saved in itpcplot per run. The PoltiTPC.C reads all the files generated based on a runlist.txt file Output in plot is here latest update 7/8/24
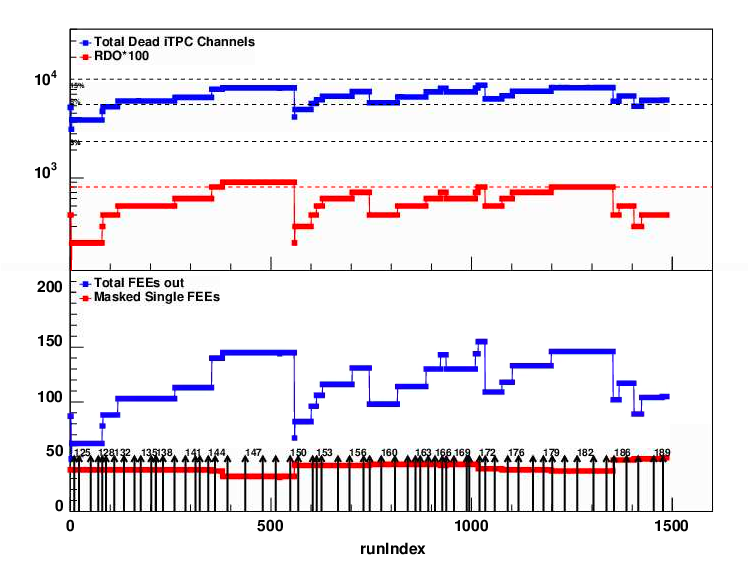
May29/30 from Tonko's google doc
-
iS01-1 masked but looks OK – unmasked 29-May
-
iS08-1 masked but looks OK – unmasked 29-May
-
iS09-4 masked. Disabled 1 FEE – unmasked 29-May
-
hm, still flaky, need a better look [30-May]
-
-
iS12-2 masked, repeatedly but I still can’t find anything wrong(?) – unmasked 29-May
-
will closely monitor its issues in the itpc.log
-
-
iS05-1 PROM – reburned 29-May
-
iS18-1 PROM – reburned 29-May
-
iS10-3 [before 29-May]
-
typical power issues. Had to mask/disable 4 FEEs to get the rest to work.
-
-
iS7-2 [before 29-May]
-
the board has power issues, no FEEs can configure. Similar to iS12-1 before.
-
Will likely stay masked until the end of the run although I’ll check it again.
Day 156 June 4
run156011 part of FEE in sector17 TPX seems not to be initialized properly. Gone in 156012, not in 156010
Only shows as single hotspot in cluster plot
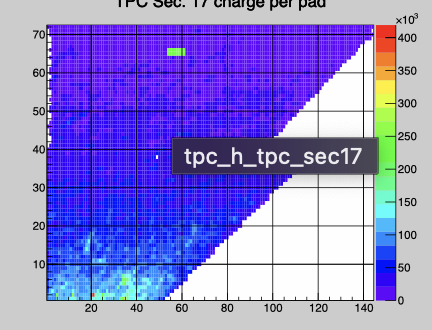
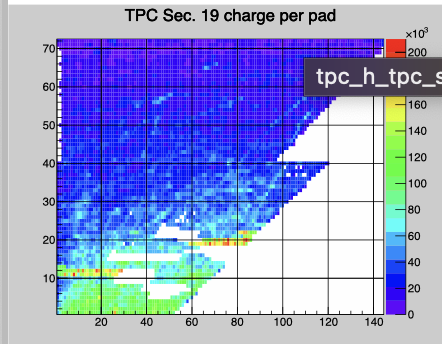
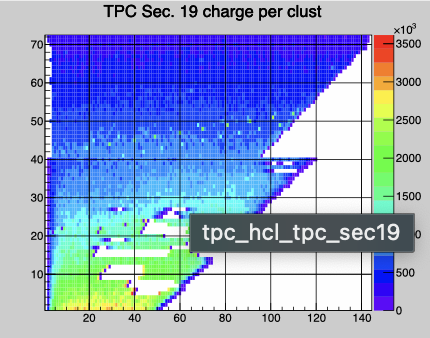
Sector 19 itpc lower rows have noisy FEE response It is in row 11 & 12 pad ~0-7 and in rows 19&20 pad ~60-85. They should probably be masked out. it is quite obvious in the ADC counts but does not seem to give significant to contribution to clusters.
-
05-Jun rom Tonko's googlr doc
TPX-
iTPC
-
iS07-2 old
-
iS09-4 old flaky — masked but will check tomorrow
-
iS11-3 new
-
board doesn’t respond to power, RDO dead, stays masked
-
-
iS12-1 old
-
iS12-2 had power problems earlier – unmasked but will check tomorrow
-
iS14-1 new – PROM – reburning, OK
-
-
-
-
iS15-1 new – PROM – reburning, OK
June 19 2024 Tonko elog
Unmasked RDOs:
iS4-2 -- nothing wrong with it?
iS10-3 -- power problems, had to disable 2 more FEEs but the rest is OK
iS15-2 -- PROM reburned
iS15-4 -- PROM reburned
Also, based upon the prom_check reburned:
iS14-4
iS16-2
iS19-3
iS22-2
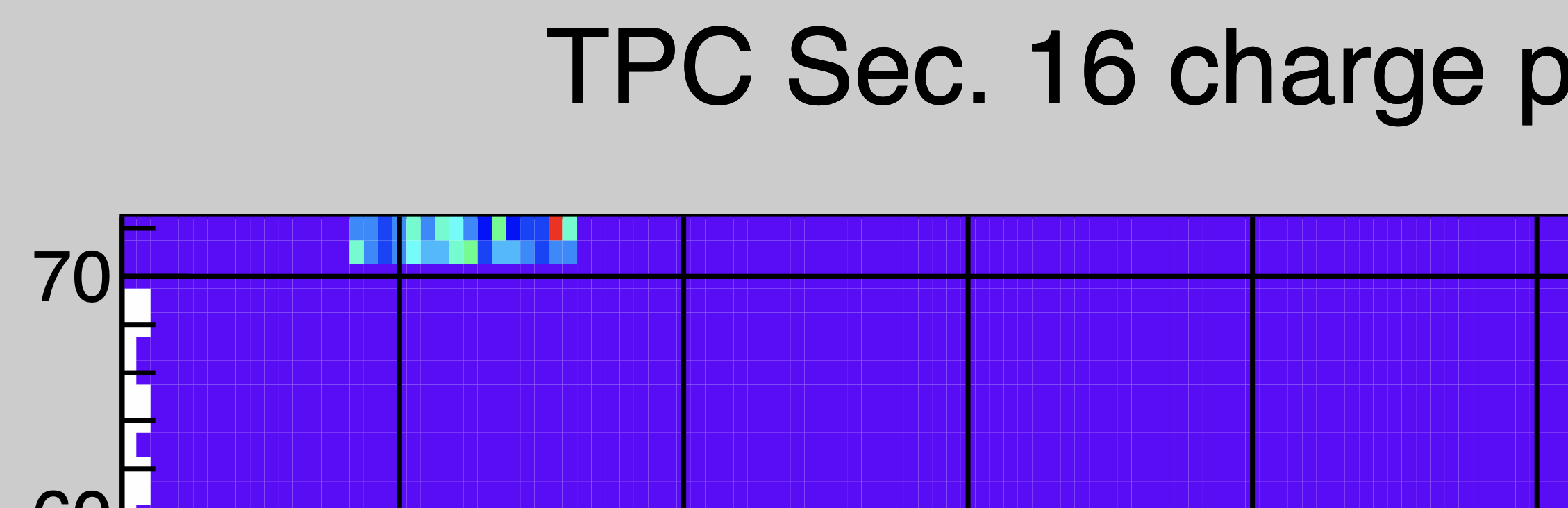
Another case one one flacky FEE for one run
July 2 Tonko
Fixed RDOs.TPX:
S9-4 pedestal data was bad so it was slowing DAQ. Took fresh peds and now OK.
all channels bad pedestal- Tonko suspect some flaw in pedestal software (3rd time it happened, different TPX RDO.
S11-6 No obvious reason? Either it recovered magically or there was a cockpit error powercycling manually.
iTPC:
iS1-2 bad PROM -- reburned.
iS9-1 bad PROM -- reburned.
iS9-3 I see nothing wrong?
iS10-3 the power of this RDO is slowly failing. Masked 2 more FEEs and now OK.
July 6 !&-5
This rdo has ecessive counts as can be seen in rdo bytes histogram, and also in the adc 2D for sector 17.
This has been the cace for all runs in tghe current fill 042 - 046.
I suspect this is a case of bad pedestals, but since there is been you may try to recycle RDO first, and see if it goes away. If not consult with Oleg on actions to take -
- take pedestal now
- if not mask out for rest of this fill, as data are suspect for this RDO
action: worked after power cycling.
July 10
I scanned the last days run to gather some statistics of what RDO are
autorecovering. (189001-189039(
For itpc there is no pattern, but for TPX
21:6 auto-recovered 11 times in 19 runs whereas only 3 other TPX RDO's
autorec.
I did take a look and also sent an email to star-ops.In short: I can't find any cause which I can fix. I suspectthe power-supply which can potentially be alleviated on thenext longer access if Tim has time to turn it up a notch.
July 17
Tonko after access day
TPX 11-3 and 20-5 remain offline. fuses are open at supply end and will need to investigate during shutdown.
July 31 2024
On July 30, there had been multiple trips on anode for sector 11 ch 8. Shift crew was instructed to lower voltage by45. If it happened again. Instead the following happened: 4-5 only had a single trip so should not have been set.
From run 25212008 to 25213011, the TPC anode sector 11 channel 8 is set to 45V.From run 25212017 to 25213002, the TPC anode sector 4 channel 5 is set to 45V
This was also maintanence day. Tonk fixed the following RDO's
31-Jul
TPX S17-6 masked (tpx33-2)
looks OK (?), retook pedestals
unmask
iS2-1
no FEEs configure, check FEE PROM
FEE PROM reburned
unmask
iS2-4
configures, at least
this is a known flaky RDO – keep an eye
unmask
iS3-1
no FEEs configure – FEE PROM?
reburned
unmask
iS4-1
configures
known flaky
unmask?
iS5-3
no FEEs configure
reburned
unmask
iS8-1
FEEs are ratty, power, damn…
but let’s try reburning…
hm… maybe better?
unmask
iS9-3
looks like PROM
reburning
unmask
iS10-3 OLD
iS11-2
crashes in FEE load – power
try reburning FEEs… nah, no help
power
stays masked
iS12-1 OLD
iS17-2
looks like PROM – nope, not PROM
but now it works?
unmask
iS19-1
no FEEs configure
burning FEE PROM…
unmask
Checksums I0
9-4
20-1
10-2
11-3
Noticed that there are now msg like (run 219058)
Aug 7 2024
Tonko: iTPC iS19-1 is completely dead. No response to power. Masked until the end of the run.
Tue, 06 Aug 2024 22:31:23 -0400 OPERATOR itpc23 itpcMain RDO4: automatically masking FEE #7
Does this mean it is not in subsequnt runs, is it in dead channel maps?? or do we need to take into account on this
follow up with dead fee infor for e.g. this and subsequent runs.
August 21 2024 from shift log
Unmasked iTPC RDOs
iS02-4 had to power-down 2 more FEEs
iS03-2 FEE PROM reburned
iS04-1 powered off 2 more FEEs
iS08-1 can't find anything wrong although this RDO keeps getting masked. Added more logging so let's see.
iS09-4 power off 2 FEEs
iS18-4 reburned PROM
iS23-4 powered down 2 FEEs
- videbaks's blog
- Login or register to post comments