- videbaks's home page
- Posts
- 2025
- 2024
- 2023
- 2022
- 2021
- 2020
- 2019
- 2018
- December (1)
- November (2)
- October (1)
- September (1)
- August (1)
- July (4)
- April (3)
- March (1)
- February (2)
- January (1)
- 2017
- 2016
- November (1)
- September (2)
- August (2)
- July (1)
- June (1)
- May (1)
- April (1)
- March (1)
- February (1)
- January (1)
- 2015
- 2014
- 2013
- 2012
- 2011
- 2010
- November (3)
- 2009
- My blog
- Post new blog entry
- All blogs
iTPC QA run 19
History of bad/DEAD FEEs and channels. Will be updated as run goes along (last July 15, 2019). Updated plot with corrected sinngle FEEs Jan 2022
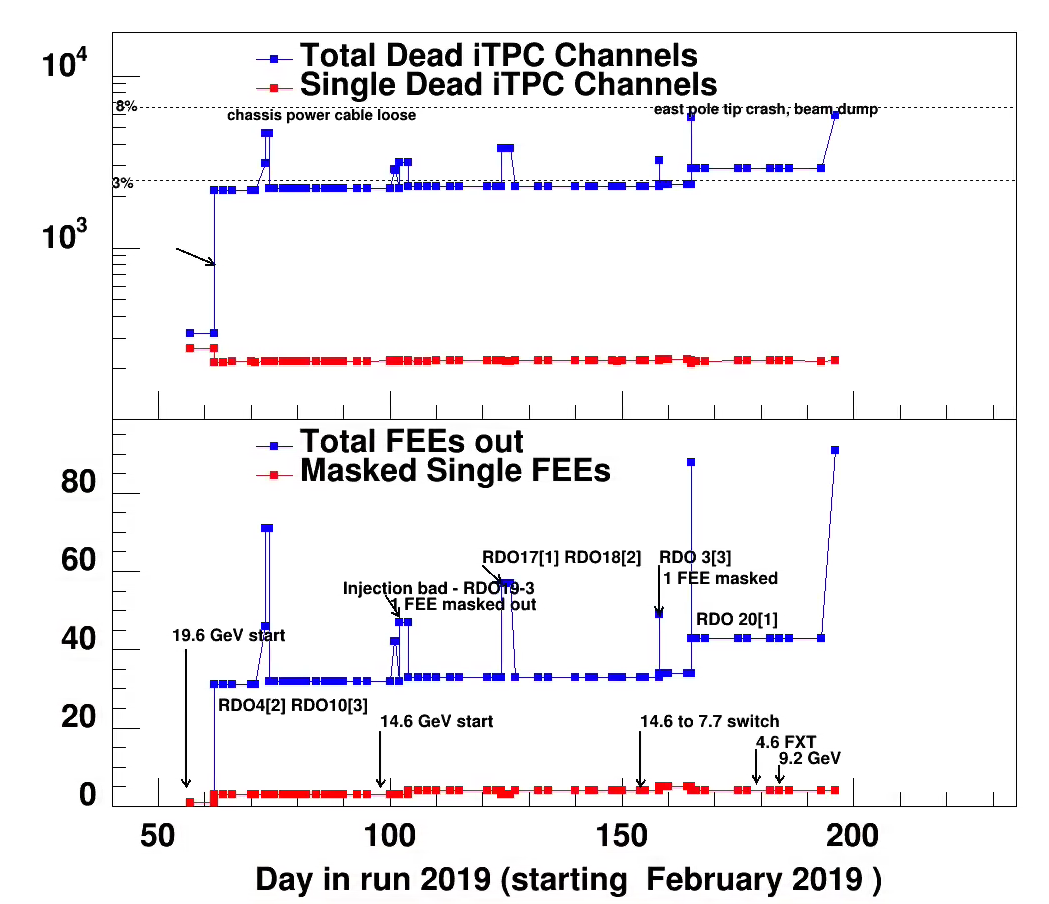
Check of status
A spreadsheet with dates for changes in RDOs and FEEs was uploaded in Jan 2022
As part of check FEE status for embedding of 2019 data.
The data file for the graphs are here
A summary of recent observations:
July 15, 2019
Before the final short LEReC run and test with STAR, 3 RDO has to bemasekd out after issue with DAQ room over heatiing (?) Beam condition during weeks LEReC test were normal and acceptable. Possible computer problems or real issie
The iTPC RDO in question are S1[4] S15[4] S24[4]. In total 6 RDO masked out at end of run.
The iTPC RDO in question are S1[4] S15[4] S24[4]. In total 6 RDO masked out at end of run.
July 12, 2019
The sector 1 RDO 1 went into the same repeated power cycling overnight was fixed by Tonko. Had a problem with iTPC iS1-1 overnight. Excessive auto-recoveries. Re-burned flash and now seems OK.
iTPC: Sector 1, RDO1 had some issues. Excessive auto-recoveries. Tonko fixed the issue
iTPC: Sector 1, RDO1 had some issues. Excessive auto-recoveries. Tonko fixed the issue
July 9, 2019
For run 190006, the first production run of 31 GeV FXT ll of sector 15 (inner) is not present (masked out?).
Sector 15 RDO2 had many power cycles during runs, but so do several other. Rate of power cycles during run about 1 per 6 minutes for itpc.
This energy may have the highest particle density in the forward direction.
The PROM was re-flashed afeter the end of 31 GeV FXT. was
Sector 15 RDO2 had many power cycles during runs, but so do several other. Rate of power cycles during run about 1 per 6 minutes for itpc.
This energy may have the highest particle density in the forward direction.
The PROM was re-flashed afeter the end of 31 GeV FXT. was
July 3
Observed for first time an increase of single bad channels by 3(2?) run 184010. These are for sector 4 FEE28 18->20
sector 19 FEE26 6-7. Day 182 had the usual 221 single bad channels. Day 175 had 19 bad in FEE26 rather than 18 so it's probably not a real change
June 14
-itpc RDO1 in sector 20
At end of run 165041 there was a eastpole tip trip. itpc[20] was masked off for runs 165057 where it was realized
that it was only rdo[1] that should be masked off. Not fixed as of run 166021. Note from Tonko June 17
I looked inI looked in detail just now and the RDO seems dead so leave it masked.detail just now and the RDO seems dead so leave it masked.
Note that this happened immediately after a magnet crash [east pole tip]
same as the previous 2. It will be interesting to see what exactly happened once we gain access in July.
same as the previous 2. It will be interesting to see what exactly happened once we gain access in July.
- last run not affected 165041
- 165046 -165055 itpc[20] full sector masked
- 165057 - itpc[20][1] masked out
June 8 - RDO3 in sector 3 was masked out for one run 158036 (4k events). A single FEE #13
was masked out.
Fill was lost see elog https://online.star.bnl.gov/apps/shiftLog/logForDay.jsp?day=6/7/2019
June 3 day 154 - end of 14.6 GeV.
Very stable performance apart from ~4 days of RDO outages
May 6, 2019
Tonko fixed the two RDOs . Rather intricate fix of eprom images.
Back to same config s before masking off.
May 4, 2019
After run 124045 RDO sector 17[1] and 18[2] could not reboot, and was masked out. There is no 'extraordinary beam activity to be seen, and the run45 was a laser run stopped due to eTOF;
3766 bad channels overall i.e. 4.6%
Tonko checked later and reported:
I took a look and nothing I can do right now. We keep running with those
2 RDOs masked.
However, I can get the RDOs to respond after a number of powercycles
so it might be fixable. We'll take a longer look during the next access
on Wednesday. Could be the power supply. Odd that both died at the
same time.
Summary from report recent.
Masked out singles FEEs (since April 12)
sector17 FEE 13
sector19 FEE 40
sector19 FEE 17
sector20 FEE 3
In addition sector 10-FEE 36 has 37 bad pads.
April 20, 2019
The code to identify bad channels now removes to hot channels sector 12 (26,41) and sector 14 (38,41) therefore bad count increases by 2; otherwise not change
The reports now print RDO-cable # in additiion to FEE#.
April 12, 2019
After the beam change to 14.6 and in particular after beat squeeze on 4/8 some RDO eprom has been hit by large radiation damage
we were lucky, was in part that could be reloaded. See messega from tonko
1) We had RDO 4-1 fail. I looked at it and considered it dead.
There was some later confusion with the Shiftcrew but it has
nothing to do with the RDO.
But then I looked at it more closely today and saw that what failed is
the FEE part of the PROM. I re-flashed that part and the
RDO is now functional and back in the run.
2) This night another RDO (13-3) started failing. It was pretty
odd and intermittent.
I also looked at it and determined it must be the
so-called "user" part of the PROM. I re-flashed it and it's
OK again.
The summary is that we see PROM failure presumably due
to beam. If the "boot" part of the image in the PROM gets corrupted
then it's over for that RDO for the run.
Bob & I crafted a way to re-program the PROMs on
the old TPX RDOs but I haven't done it for the iRDOs.
It's pretty involved reverse-engineering of various Xilinx
commands. Possible but unlikely I will have time in this run.
I also see a rise in TPX transient failures in the recent week
so my guess is that this beam is pretty bad, at least during injection.
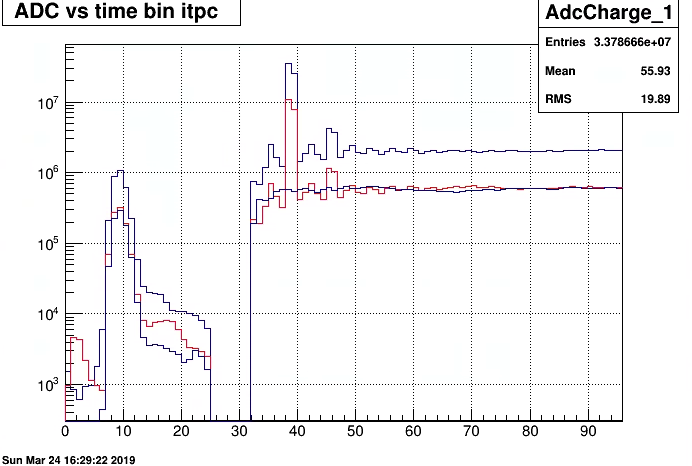
March 24
shift crew noticed a high spike for sector 1 itpc charge -time distribution.
I review and plotted in high resolution the adc charge distribution for for one run where problem was said not to be there and one where it is
(red) . For reference sector 2 distribution is shown a black curve. Statistics (#events) is different in the runs, so just look at the shape.There is clearly a problem with sector 1 (gating grid response) but it has not chan ge with time.
I did also rerun a file (adc) from 4 days ago and it looks the same
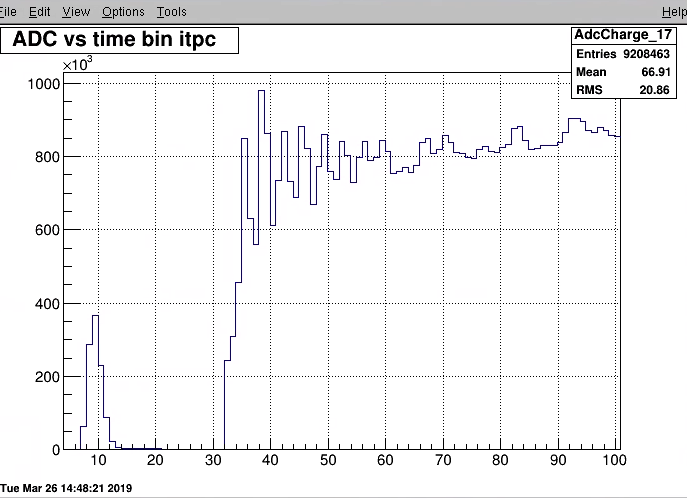
I noted that a couple of other sector do have similar pattern e.g sector 17.
I suspect that sector 1 is excessive; I check if any particular pad-row adds to this but that did not find any evidence.
It should be discussed if we should implement time dependent pedestals, otherwise we do loos the clusters for tb 40 to ~60
for several sectors
-- RDO issue
There was a small power dip on March 3morning (day 62) that caused a west pole tip crash and beam loss. After that event the
RDO 4-2 and RDO 10-3 was completely lost. The PS status was checked on this week and is ok, so the issue is with the
RDOs. As we cannot get to them, they are out for the reminder of the run.
-- Loss of channels (pads)
I have noted that we are very slowly loosing a few channels on iTPC kind of randomly distributes. A program and macro to analyze
how many 'dead channels are present was developed. The st_physicsi_adc_... files are read (500-1000 events), and the pad-row-adc histograms
are scanned for very low (~0) response. The macro generates a list for each sector of FEEs affected and the specific (row,pad)
that is marked as bad.
3/12: about 5 of these channels have a tiny respone, but most are really zero
so far following runs has been analyzed
run 057013 327 bad channels
run 064016 2149 bad channels loss of 2 RDO (out from on 062030 and on)
run 066027 2151 bad channels 2 channels lost
run 070020 2154 bad channels 3 channels lost sector 7 FEE 23 (27,94) (29,88). Neighbours to channels already lost?
sector 12 FEE 11 (35,108)
run071038 2152 bad channels!! Channels that came back
sector 14 FEE28 channel (24,4) Many channels 17 out in this FEE
sector 22 FEE-7 (36,1) single channels back.
The detailled reports are attached to this blog.
run 057013 327 bad channels
run 064016 2149 bad channels loss of 2 RDO (out from on 062030 and on)
run 066027 2151 bad channels 2 channels lost
run 070020 2154 bad channels 3 channels lost sector 7 FEE 23 (27,94) (29,88). Neighbours to channels already lost?
sector 12 FEE 11 (35,108)
run071038 2152 bad channels!! Channels that came back
sector 14 FEE28 channel (24,4) Many channels 17 out in this FEE
sector 22 FEE-7 (36,1) single channels back.
Update from Tonko on 3/13/19
I did a quick check of your list vs my list of bad pads.
I didn't include the 2 bad RDOs and 2 bad FEEs so I simply
removed sectors 4,10,19 & 20 from any consideration
for this check.
I am then left with only 8 pads that you flagged as bad but are not
in my list. This doesn't sound so bad to me.
I then looked at pedestals/rms of 2 of them, randomly:
1) One is indeed bad and this started on day 17. Before that it was OK.
The RMS dropped suddenly and this is a tell-tale sign that there is nothing
connected to the input of the SAMPA. So a trace broke either on the FEE
or the padplane connector. This is NOT a signature of a blown preamp.
This is pad "7 27 94".
2) The second one (23 13 19) also died similarly but on day 44.
So yeah, there is a clear sign that this stuff is dying as time goes by
but it doesn't look too critical to me.
On 3/14 early morning sector 17--RDO 3 failed power cycling multiple times
Not clear if Tonko was alerted.
Run 20073002 - iTPC: RDO S17:3 -- auto-recovery happened 6th times during 5minutes so we stopped this run and DO's power cycled it manually.
II know. It's a FEE. I'll get to it a bit later. Once I wrap up some FCS stuff. (3/14/10:30 am
On 3/14 in evening at 22:30 a power to sector 24 (1,2,3) was discovered Likely happened during access Next day at access the AC power cable (loose) was reconnected.
After RDO 24-1-3 was fixed. we are back to ~2210 'dead' or masked out channels this is about 2.6%
For runs 73071 to 74030 there are 4647 masked channel i.e 5.6% suggest to not count those runs.
1) We had RDO 4-1 fail. I looked at it and considered it dead.
There was some later confusion with the Shiftcrew but it has
nothing to do with the RDO.
But then I looked at it more closely today and saw that what failed is
the FEE part of the PROM. I re-flashed that part and the
RDO is now functional and back in the run.
2) This night another RDO (13-3) started failing. It was pretty
odd and intermittent.
I also looked at it and determined it must be the
so-called "user" part of the PROM. I re-flashed it and it's
OK again.
The summary is that we see PROM failure presumably due
to beam. If the "boot" part of the image in the PROM gets corrupted
then it's over for that RDO for the run.
Bob & I crafted a way to re-program the PROMs on
the old TPX RDOs but I haven't done it for the iRDOs.
It's pretty involved reverse-engineering of various Xilinx
commands. Possible but unlikely I will have time in this run.
I also see a rise in TPX transient failures in the recent week
so my guess is that this beam is pretty bad, at least during injection.
Groups:
- videbaks's blog
- Login or register to post comments