- videbaks's home page
- Posts
- 2024
- 2023
- 2022
- 2021
- 2020
- 2019
- 2018
- December (1)
- November (2)
- October (1)
- September (1)
- August (1)
- July (4)
- April (3)
- March (1)
- February (2)
- January (1)
- 2017
- 2016
- November (1)
- September (2)
- August (2)
- July (1)
- June (1)
- May (1)
- April (1)
- March (1)
- February (1)
- January (1)
- 2015
- 2014
- 2013
- 2012
- 2011
- 2010
- November (3)
- 2009
- My blog
- Post new blog entry
- All blogs
TPC QA 2021
This blog is intended to maintain a log of issues that will be identified as the
run progresses. For initial start the process will be as for run20 and 19. See earlier QA blog page
The run is planned to be from Jan 26, 2021 to July14, 2021, and primarely low energy &.7 collider data
Status of iTPCs FEEs and dead channels
Run ended on July 8 (dAu). There was 24 hours of cosmic with Forward Field setting
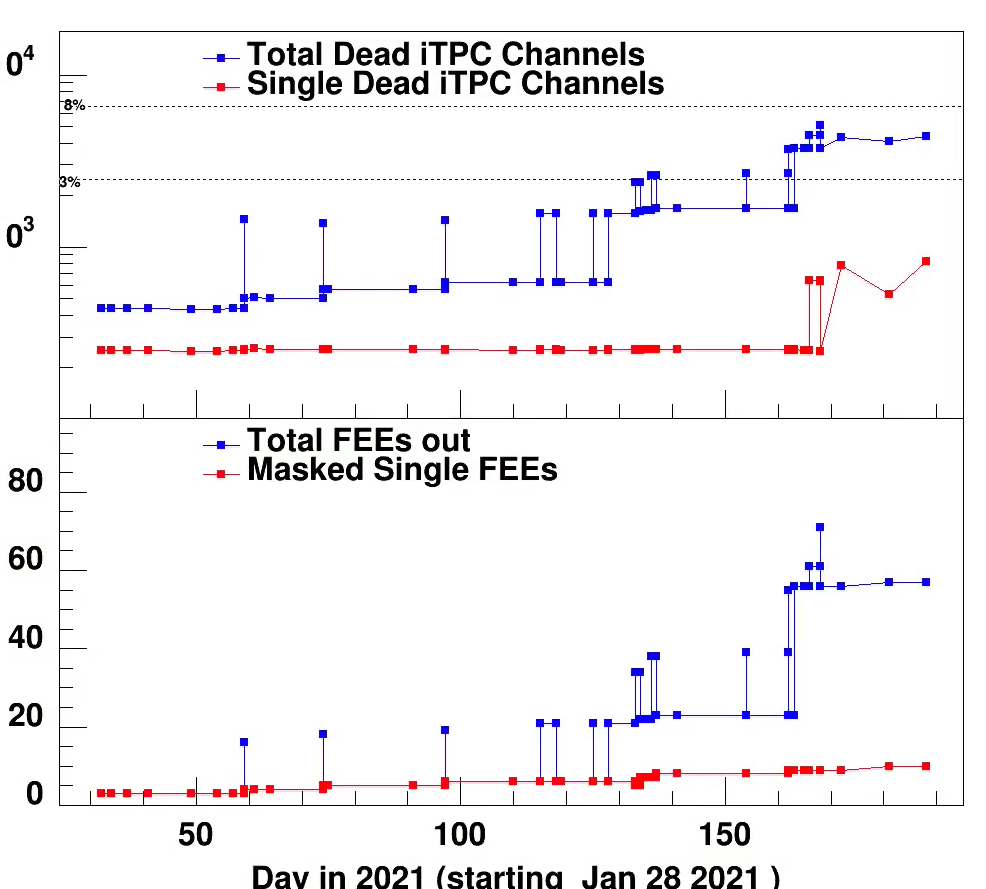
Lifteed from Tonko's google doc indicating the issues, all in the iTPC
-
iTPC
-
iRDOs
-
iS04-4
-
wasn’t masked but flaky trigger iface. Tonko needs to test first.
-
-
iS08-2 -- remove to lab
-
2 FEEs failed with not-POK on ports #2 and #14
-
-
iS11-4 -- remove to lab
-
1 FEE with not-POK on port #13
-
-
iS13-2 -- remove to lab
-
bad POK on port #13
-
-
iS18-1 -- remove to lab
-
pad POK on port #15
-
-
iS20-3
-
flaky trigger interface. TL needs to test first.
-
13-Jul seems OK on TCD-clock. Continue checking...
-
-
iS21-4 -- remove to lab
-
RXbad+ERRs
-
FEEs are shorting? So probably the RDO is OK but I need
to reprogram it in the lab.
-
-
iS24-4
-
flaky trigger interface? TL needs to test.
-
13-Jul seems OK on TCD-clock. Continue checking…
-
set RHICx5 phase to 0 for entire Sector
-
also holds for super-fast pedestal run -- thus BUSY holds
-
-
-
iFEEs
-
iS3-1-3
-
flaky?
-
-
iS3-2-14
-
loads but doesn’t sync -- cable? Or FEE?
-
-
iS3-4-7
-
flaky?
-
-
iS4-3-10
-
flaky?
-
-
iS8-2-2
-
no POK -- fuse on RDO?
-
-
iS8-2-14
-
no POK -- fuse on RDO?
-
-
iS9-4-4
-
loads but doesn’t sync -- cable? Or FEE?
-
-
iS11-4-13
-
no POK -- fuse on RDO?
-
-
iS13-2-12
-
no POK -- fuse on RDO?
-
-
iS18-1-15
-
no POK -- fuse on RDO?
-
-
-
July 8
Runs ended. The dAu was bad in the beginninh withbthe crossing angle
une 21 Update of 15-3 HV section
From Alexei in elog
I checked TPC anode bad channel 15-3. I disconnected cable from CAEN crate and able to run this channel up to 1390V(outer sector nominal voltage) without any trips. i connected cable again and this section tripped at 1070 in 5 min. Could be problem with cable or sector itself. We need to keep this channel at say 500 V.
Lasers also been checked and tuned.
The HV section causes some cluster to be created so # masked pad jumps around due to the 10 rows with reduced efficiency.
June 17
RDO masked out from 2216811 fixed for 2216820 by Tonko. Only one data run was affected.
Re-checked masked out RDO iS5-3. Dead FEE PROM prevented any of the FEEs to start. Re-flashed PROM, checked and all OK
June 15
starting run 166023. Sector 15 HV section 3 could not hold volatge lowered over several runs
from 1070 to100 and finally to 0 and then 500 V. Still not fixed.
Hopefully the tracking code knows about masking out dead HV sections??
for two runs 039 and 010 by op mistake RDO TPX 3 (2,3,4,5) was masked out as they though this corresponded to HV section 3.
June 12
sector 24-4 was masked out for the rest of the run. hardware error
June 11
There are many issues with the 3.85 GeV beam, many autorecovery
In particular Tonko found
"1) Please unmask (by selecting, clicking, enabling) the
iTPC Sector 3, RDO 4.
There's a bad FEE which I masked out.
2) iTPC Sector 21, RDO 4 will need to stay masked.
It has power problems, probably a component is shorted."
Some more information on the background causing the many autorecoveries
msg to ops list
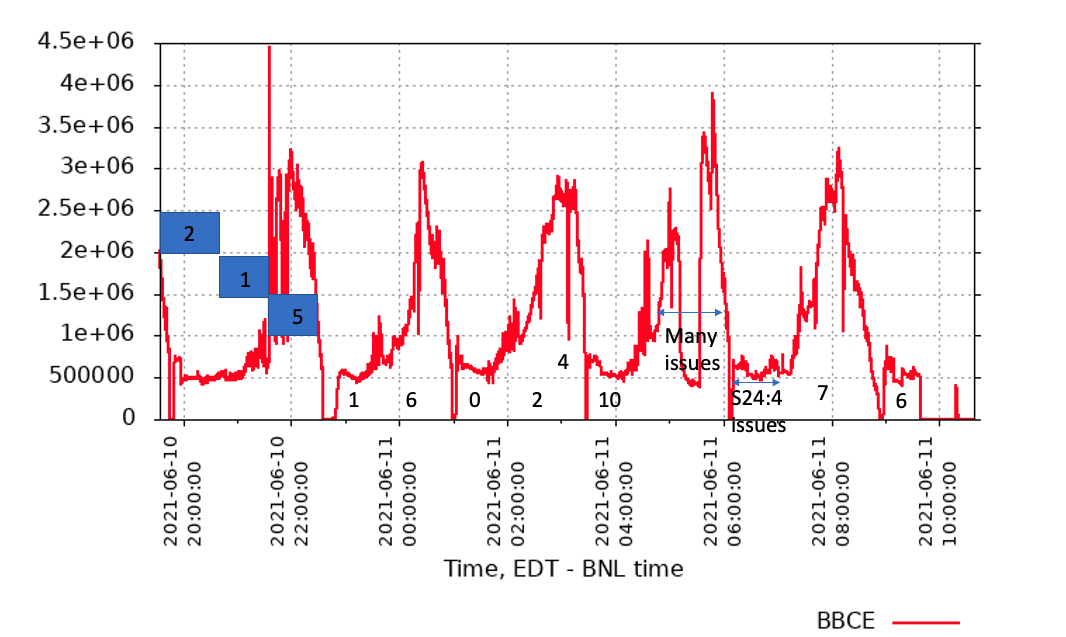
Following the discussion this morning I reviewed the number of auto recoveries for 5 fills
last night starting ~20:00 yesterday and ending this morning.
The plot enclosed shows the BBCE singles rates v.s time with the largets background typical at the end of the stored. Most runs were around 1 hour. The number of auto-recoveries for each run are indicated by the numbers.
There is some correlation with recoveries being smaller at beginning of store and larger later, but there are expectations
- at store ~3:30 there was 10 in the first run in the store.
- the store starting ~6 has many recoveries but only for s24:4 so this is likely the hardware issue we see on occasions
Shortening the store the store length should reduce the number of autorecoveries, but will not eliminate them.`
June 3
from e-log:
"Issues on starting first run with iTPC 21:4 that weren't solved by power cycling so masked it out. Tonko called in and found the power cables flipped between 21:3 and 21:4, suggested power cycling whole sector if there are persistent problems in the future. iTPC 21:4 masked out in runs 22154004 - 21154010, back starting with 22154011.
Had "ITPC[2] [0xBF82] died/rebooted -- try restarting the Run" error which stopped run 22154009 but this may be to do with the other iTPC problem? Four restarts in a row from iTPC 24:4 in first run, restarted between fills and no problems since. TPX 14:4, 22:5, then 17:6 stopped three consecutive run starts, power cycling fixed each time."
May 24
There had by many autorecovery for S24-RDO4.in the last week.
Today Tonko reported
Re-flashed Sector 24, RDO 4 PROM and also re-flashed the corresponding FEE PROM. Checked and it works OK. So let's see if this RDO continues to have issues.
May 24 (or so)
There were many reboot os 24.4 (autorecover that created inefficient sector response)
see the blog on 24-- runs 142077-144006
May 17
Sector 11:4 was masked out for runs 136030-run 137003.
Tonko masked in out w/o leaving i note in shiftlog, but in the TPC log.
-
iS11-4-#13 FEE dead [May 17]
-
masked
-
May 14;
During previous night sector 8 -2 was masked out. Tonko disabled 1 FEE and it was brought back at ~1am.
It was out in runs133037 to 134002
May 8
Sector 20-3 was masked out since run 128008
May 6
On May 5 sector 20-3 started making trouble; It was masked out, but crew forgot to reboot iTPC.
On eve of May5 Alexei included it for a test with TPC ; It was left included and ran through the night.
May 1, 2021
When starting the FXT 3.85GeV run RDO 10:5 (TPX) started making trouble.
i) It seems to happens every ~ 4.5-5 minutes very regulary
ii) If you look at errors for TPX machine 29, which serves sector 9 and 10. You will see
many token errors and some evnts errors.
iii) Not so sure it recovers successfully 4 times but seems on the 5'th attemps.
It was masked out starting run 121046; It was fixed on 5/3 from 123020
2 ALTRO channels went bad with corruption in the headers
so this causes auto-recoveries after some amount of errors.
I masked those 2 channels out in Sector 10:
row 32, pad 65
row 33, pad 65
April 30
The sector 20 itpc RDO 3 was out for runs 115046 to 118004. Almost 3 days
Tonko did not find anything wrong but it needed reburned the PROM, and it seems to have worked since.
April 23
Tonko has masked out sector 6 row 1, pad 10. 8:30 am.
April 20
Came across run 22110017 where sector 6 row 1 pad 10 again misbehaved. There was a time peak at ~225, just a usual. Also it happens for about 10% of events analyzed in one file.
What is note worthy is that the time distribution is not the same a before, so appearently the value subtracted is the same for each event in this file with the bad data
but can vary from instance to instance !!! I have asked tonko to mask this pad (1,10) in sector 6 .
from shiftlog that day
TPC
- A peak shows up around 220 in charge step plot for sector 6 in run 017, 018, 021, and for sector 21 in run 028
In sector 21 it is row 20 pad 50 and also row 21, pad 46 . First time have seen more than a single pad with issues.
All these runs have the same 'adc height..
April 12
sector6 row 1 pad 10 showed up again as hot and with strange peaks.
This is (at least) second time it showed up. I looked in some more detail on this , and also on the prev sector21 just below.
It is clear that the pedestal is not subtracted for the events that cause this effect. The first plot shows the adc vs. time bin distribution
for all events of row 1 pad 10. This is dat w/o pedestal subtracted. TTwo curious things are observed
a) these are converted by the clusterfinder to a cluster with '30 timebins" and a time that is basically the center of the time distribution (~ channel 225)
b) it does not occur for all events for the tow cases it was ~68/400 and 17/350 i.e a few %. The second plot shows the event dist of events that hav these peculiar distributions.
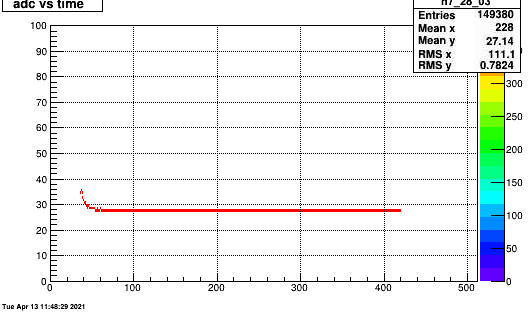
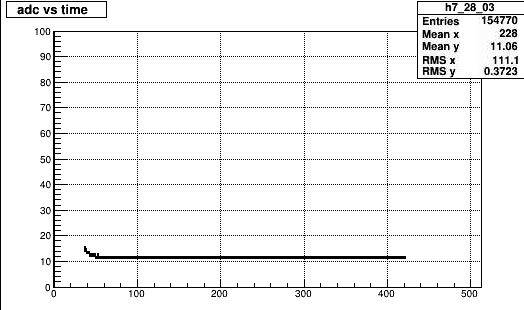
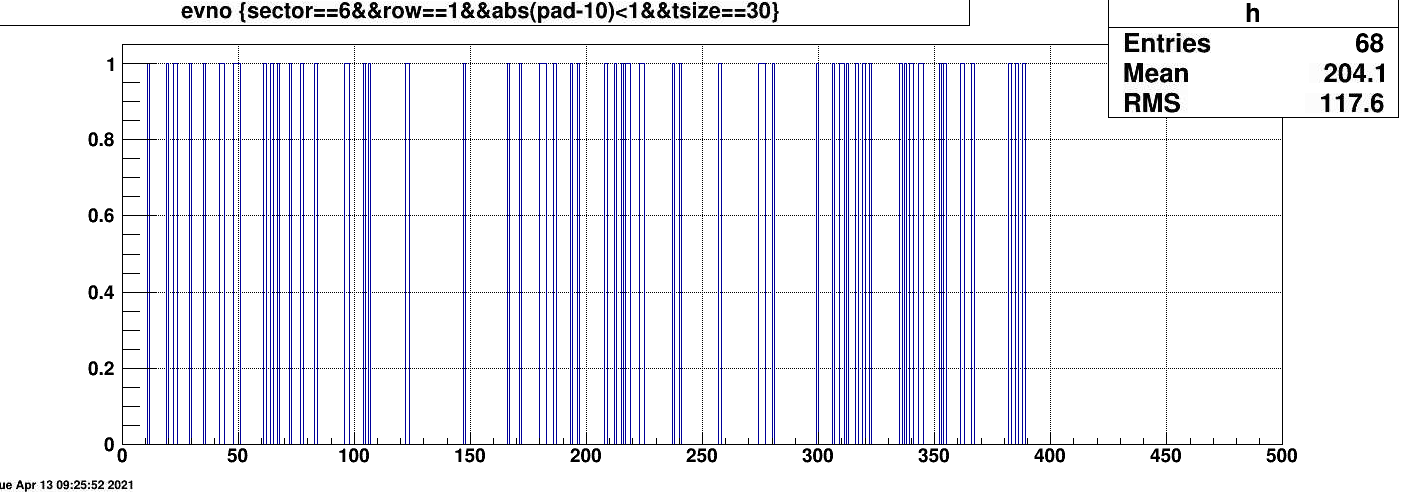
April 11
run 22101008
sector 21 row 11 pad ~51) seems hot and gives rise to peak in chargestep distributions run 22102043.
April 7 sector 8 RDO-2 masked out for runs 22097016-22097019
FEE#14 masked out by Tonko.
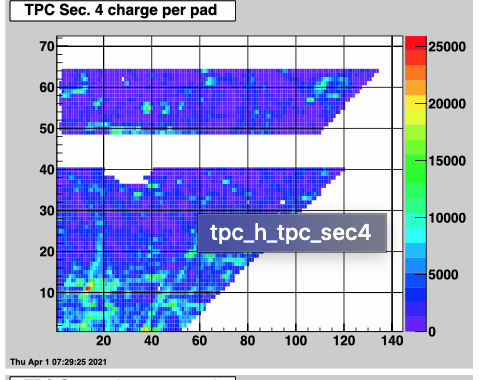
April 1
Run22091020-021 21 completely blank. 20 must have had partial voltage on.
This run had issue with sector 11 HV5 partial and fully off. Crew ignored the communication error.
.png)
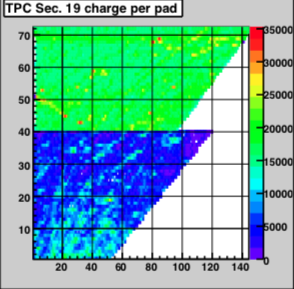
Run 091011
The crew masked out TPX-4 3+6 . Errors. Powered off. Bus issue on RDO
1) 1 entire so-called bus of the TPX S4-6 RDO is dead. This happens
because of metallic particles that get lodged between pins
thus shorting them out.
I masked those 12 FEEs (which is 1/3 of the RDO) and asked
the Shifcrew to unmask the RDO (and the TPX S4-3 part of the
pair as well).
Better 1/3 than 2 :-) And who knows, it might recover after the next
magnet up/down motion.
2) There's a hole in Sector 11 at anode section 5.
This is not a pedestal issue. It's an anode issue.
And that particular anode channel seems to be flaky
and tripping anyway.
Mar21
Sector 6 row 1 pad 10 shows the hot pad and a time bin around 225. It was not very dominant in the qa plts.
Just watching
Mar13/17
This appeared again in run22075043. Asked Tonko to mask out.
Masked out on 6/19 6:50am i.e. sec 1 row 11 pad 51 -
sector 1
Run 22072052 - production_7p7GeV_2021 TRG+DAQ+TPX+iTPC+BTOW+ETOF+TOF+GMT+FCS+L4
275K events, 28K minbias-hlt70
spike in the middle of iTPC adc vs time sector#1
(was also in previous runs)
------------------------------------
videbaks:
thus 3rd time it appeared. Previous run was 053. As it does not effect tracking (single pad11,52) willl leave as is unless it shows up again.
Mar 8
Notified by fast-offline (Gene) about a issue with outer sector 19, that show excessive hits in run 22062016
The Offline QA shift crew spotted what appears to be a repeat of this issue with Sector 19 today. Originally seen in run 22038014, now seen today in run 22066016.
The fast-offline ticket is at https://www.star.bnl.gov/devcgi/qa/QAShiftReport/issueEditor.php?iid=17020
I checked that the issue was the same in 22066016 and in 22038014.
This is different than the issue found in inner sectors where a single pad did note subtract pedestals and in most cases masked out.
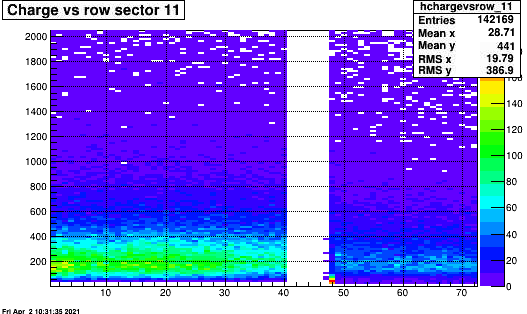
In this case it shows that all pads in the outer sector was affected, and concentrated in the first several hundred of time buckets. This is demonstrated in in following plot that analyzed the zero-bias data. It shows the excess ADC starting at the gating grid turn on. The fact that it appears for all section and RDO in the outer sector point to the Gating grid. Why it is only for a single run is not clear. Could it be the startup of a run that just happened to introduce oscillations? The fact you can see tracks at large time bins show its not the related to pedestal subtraction.
The crew did not see any issue with (at least 066016) which has serious problem in online plot
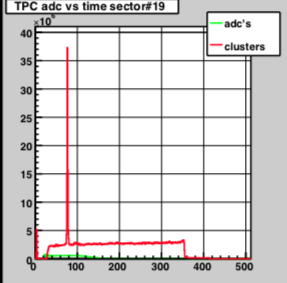
The following plot shows the time distribution for 22066016
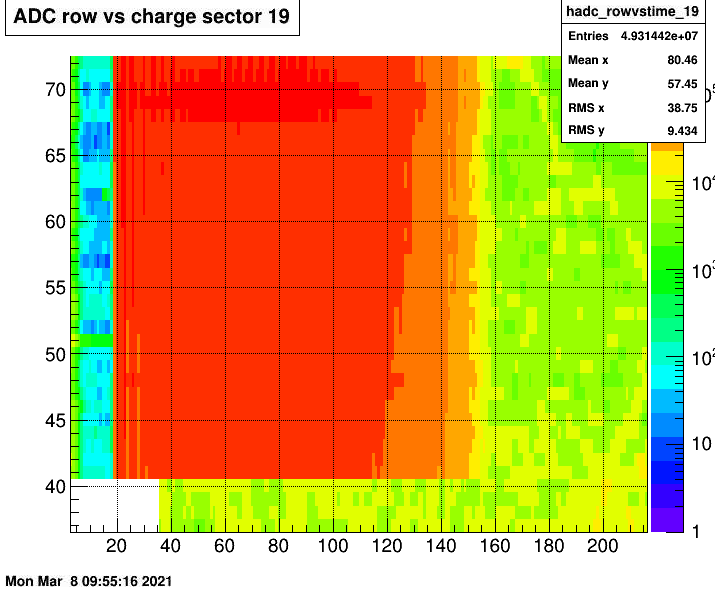
The adc distribution vs time bin. 22066016
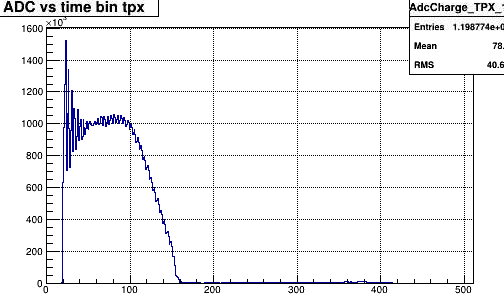
For clusters: (22038014 zero bias with adc)
Note that the cluster algoritm for such a big blob does something strange as it indeed create clusters with 30 tb and thus
distinct peaks. This is an issue - it centainly should not mark such clusters with flag=0,
Projection on the time bucket axis for all outer rows. Single row look the same
Selecting on the peak at 75 tb shows that all pads are effected. (subsequent slide)
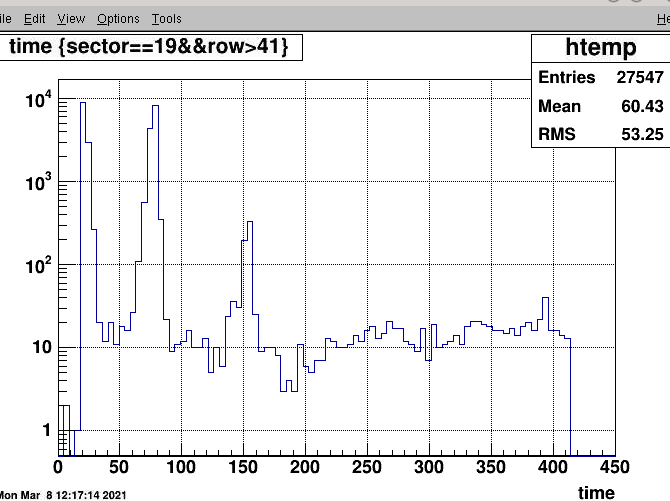
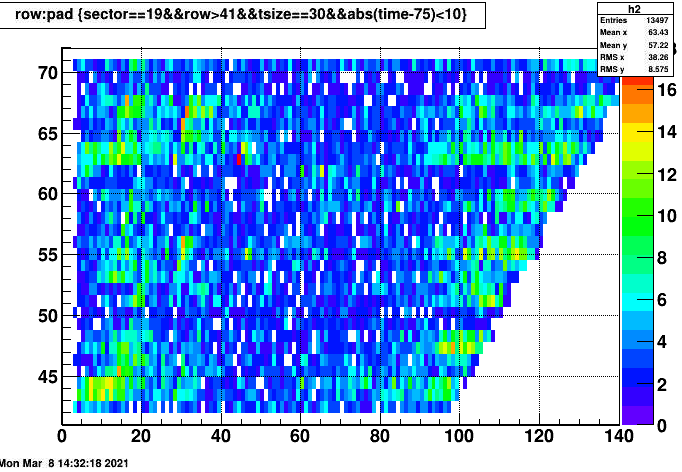
This only apears in the beginning of runs next two plots are from the two bad runs
1: 22038014 (zerobias with adc) 2: 22066016 (phys with adc 2 files out of ) run
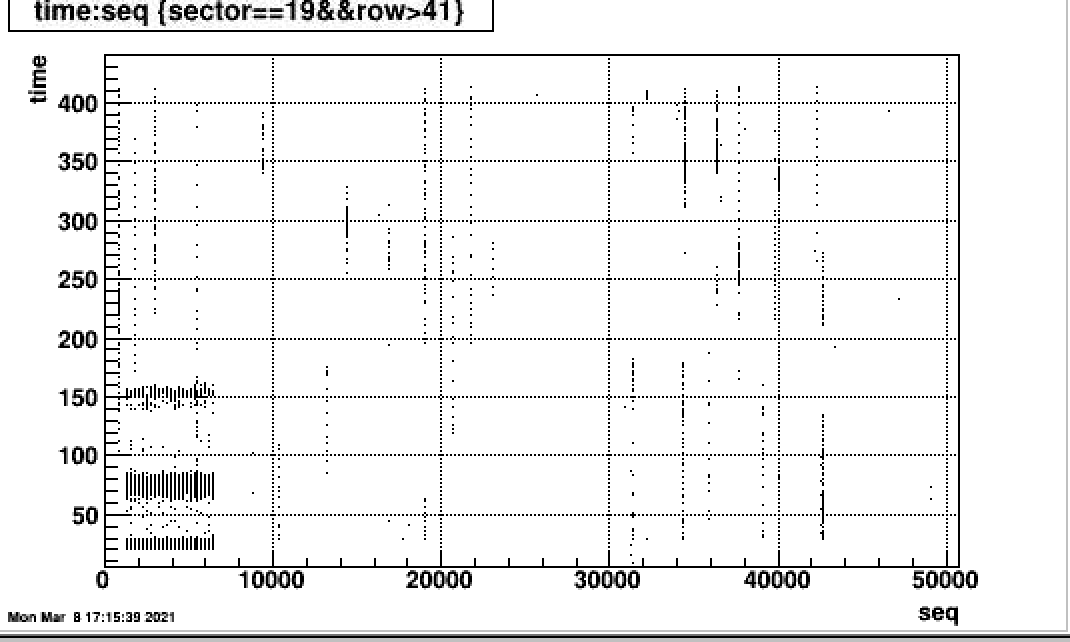
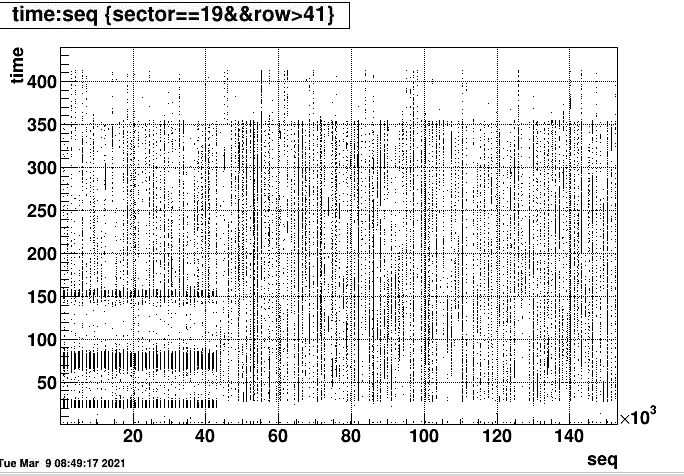
This is 22066016 ...
Mar 5
Plot updated no new issues.
Feb 28
Run 22059008 stopped by iTPC sector 9 RDO 4 at 05:00:39
Run 59012-59022 has the rdo 4 masked out 1 offending FEE #4 in that sector/RDO;
Back - 1 FEE from run 22059023
59032 looks link sector 1 row 11 (51 or 52) has the pedestal issue? Will look tomorrow (3/1)
Feb 27 morning
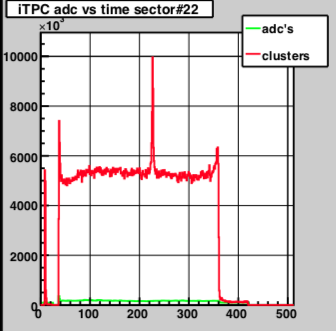
Run 22058012 - Peak in charge iTPC adc vs time sector#16 plot noted.
This only appeared for this one run.
Feb 24
fastoffline report peak for several run near row 22.
The hot pad is row 23 pad 52. It has been requested to be masked
off.
07:47 02/25/21 EST :
videbaek : Tonko masked out the pad on feb 25 4:45AM
Feb 20
Th following hot channel that resulted in bad time cluster at ~225 timebin for runs
2205045- 22051016+ were masked out by Tonko
sector 15 row 34 pad 53
sector 22 row 14 pad 61
Feb 19
Summary:
My macro was not selecting correctly it happens on all events looked at (ADC file). Seems pedestal subtracts nothing
as adc level for all time bins is consistent with pedestal range
Run 49023 sec 1 row 23 pad 52
run 46014 sec 22 row 14 pad 61
run 46004 sec 16 row 31 pad 58
Feb 15
runs 46014 and severaol others around there had a strange time spike in the charge vs. time distribution
It was traced to a few events, It was all events had a coding error in macro. all from a single pad row 14 pad61 that has events with all time bins populated (not all events)
Here is an example for the first event in the adc file with this. This time distribution aperently create a single cluster in the middle of time
with 30 time bins and very large charge. Doe pedestal subtraction fail =After a number of runs the issue disappears.
So how does this create a single adc-cluster, and why flagged as good (0)
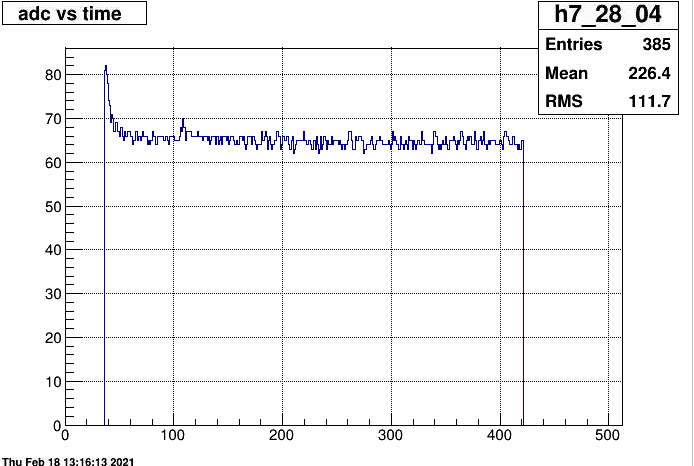
It happens in all event; and the spectrum is nearly identical for each timebin; It appears to look that possible pedestal subtraction fails
Feb 6
TPX04 has errors at rate of a few per 5 sec.
Yes, one RDO has problems with a handful of tokens reminiscent
of last year. But it is only 1 RDO. When there's a bit more time (during regular
access) I can try to burn another PROM image.
If nothing is successful, I will ask Jeff to skip about 6-8 tokens in all.
Not a big deal.
Feb 1.
Physics running with low intensity of 7.7 GeV
RDOs3-1 had to be masked out during the night.
Tonko observed the following
Looking at the bad iTPC RDO #3 in Sector #3 which was masked in the night due to problems:
Looks like a dead SAMPA is causing problems. I can only mask the entire FEE on port #3.
FEE #3 masked, RDO un-masked -- looks good!
Jan 30
The gating grid driver was changed from new to old. Noise disappered
TPC electronics status
Jan 7;
report from Tonko
1) We tested all RDO/FEEs and all look OK after various swaps.
2) We are done with fixing various power cables.
3) The trigger works for all tokens. A bit odd because we
didn't really change anything. Bob had some thoughts that
the problems we had could be related to TCD cables
getting crushed during poletip installation. He put some
protection on the connectors. So TBD.
Next on the list:
1) I haven't done a pulser run yet so this is next in line
but I'm waiting for:
2) The "new" Gating Grid is in place but not yet fully
connected (Alexei said he will do that) and not fully
calibrated (I will do that). Also the monitoring/control
is the same as before (through my web page) --
waiting for David Tlusty to respond.
Groups:
- videbaks's blog
- Login or register to post comments