- genevb's home page
- Posts
- 2025
- 2024
- 2023
- 2022
- September (1)
- 2021
- 2020
- 2019
- December (1)
- October (4)
- September (2)
- August (6)
- July (1)
- June (2)
- May (4)
- April (2)
- March (3)
- February (3)
- 2018
- 2017
- December (1)
- October (3)
- September (1)
- August (1)
- July (2)
- June (2)
- April (2)
- March (2)
- February (1)
- 2016
- November (2)
- September (1)
- August (2)
- July (1)
- June (2)
- May (2)
- April (1)
- March (5)
- February (2)
- January (1)
- 2015
- December (1)
- October (1)
- September (2)
- June (1)
- May (2)
- April (2)
- March (3)
- February (1)
- January (3)
- 2014
- December (2)
- October (2)
- September (2)
- August (3)
- July (2)
- June (2)
- May (2)
- April (9)
- March (2)
- February (2)
- January (1)
- 2013
- December (5)
- October (3)
- September (3)
- August (1)
- July (1)
- May (4)
- April (4)
- March (7)
- February (1)
- January (2)
- 2012
- December (2)
- November (6)
- October (2)
- September (3)
- August (7)
- July (2)
- June (1)
- May (3)
- April (1)
- March (2)
- February (1)
- 2011
- November (1)
- October (1)
- September (4)
- August (2)
- July (4)
- June (3)
- May (4)
- April (9)
- March (5)
- February (6)
- January (3)
- 2010
- December (3)
- November (6)
- October (3)
- September (1)
- August (5)
- July (1)
- June (4)
- May (1)
- April (2)
- March (2)
- February (4)
- January (2)
- 2009
- November (1)
- October (2)
- September (6)
- August (4)
- July (4)
- June (3)
- May (5)
- April (5)
- March (3)
- February (1)
- 2008
- 2005
- October (1)
- My blog
- Post new blog entry
- All blogs
Track-by-track comparisons using the TrackInfo mode of SpaceCharge code
This process involves 3 steps:
Other relevant notes:
-Gene
- Process the same data twice, with some alteration affecting tracking between the two.
- Create ntuples of comparable track-wise quantities.
- Using the ntuples to make comparisons.
- TrackInfo mode of the SpaceCharge code is turned on when using the BFC chain to process data via the chain options: SCScalerCal,goptSCE100051
An example BFC reconstruction chain might look like this:
bfc.C(1000,"P2014a,btof,BEmcChkStat,Corr4,OSpaceZ2,OGridLeak3D,SCScalerCal,goptSCE100051,-hitfilt", "/star/data03/daq/2014/047/15047100/st_physics_15047100_raw_2500001.daq")
The SpaceCharge code uses global tracks from StEvent, so as long as reconstructed global tracks exist in StEvent, this can be used. You can also process event.root files which have StEvent and global tracks, as long as the SpaceCharge code is run with the mode properly set. I will not explain this level of detail here.
Note that goptSCE100051 (mode 51) accepts all global tracks with at least 25 TPC hits that point within 2 cm of the z axis (x=0,y=0), which may have significant pile-up contributions. This may not be a concern if the TPC portion of the tracks is not relevant to whatever is being studied. If it is a concern, using goptSCE100050 (mode 50) instead activates tight cuts to remove pile-up tracks, which can lead to significant statistics reductions. [You can go to even looser cuts and accept TPC tracks without a cut on number of hits using goptSCE100052 (mode 52).]
With TrackInfo mode turned on, the output will contain lines like the following:
StSpaceChargeEbyEMaker:INFO - GOODTRACK 15047100 13 56.57 3.6778 -1.158 -2.3853 -1.7136 0.1962 0.3263 33
StSpaceChargeEbyEMaker:INFO - GOODTRACK 15047100 13 51.15 -2.1086 -0.284 1.0825 -0.2622 0.0834 0.3263 32These 10 columns of track-wise information are:- Run number
- Event number
- z of track at DCA to the z-axis (mode 51), or zvtx (mode 50)
- q/pT (essentially what the TPC really measures)
- η, pseudorapidity of track
- φ, angle of track momentum vector in the x-y plane at DCA to either the z-axis (mode 51) or primary vertex (mode 50)
- sDCA, the geometric-signed 2D DCA of the track to either the z-axis (mode 51) or primary vertex (mode 50)
- error on sDCA
- error on the transverse position of the primary vertex (mode 50), or [0,1] for tracks which do/do not have a "DCA geometry" (mode 51)
- Nhits
- These quantities can then be used in the following manner to do track-by-track comparisons from two output log files (e.g. logA & logB) as follows:
cvs co -d . offline/users/genevb/prepMatchNtuple.csh ./prepMatchNtuple.csh logA logB myntup.root root -l myntup.root
The generated ROOT file will contain a TNtupleD which has the above 10 variables twice (i.e. 20 total variables), with the first 10 having a suffix "A" and the second 10 having "B" for the quantities from the first and second input files respectively.
If the matching macro is not working well, you may instead try this alternative, which may be slower but more accurate (it separates tracks by events before trying to match them):
cvs co -d . offline/users/genevb/prepMatchNtupleEbyE.csh ./prepMatchNtupleEbyE.csh logA logB myntup.root root -l myntup.root
- In ROOT you can then make plots of interest, such as:
TCut& cut1 = *CUT1; matches->Draw("zB>>hist1(100,-200,200)"); gPad->SetLogz(); matches->Draw("Dmetric:zB>>hist2(100,-200,200,100,-5,5)",cut1,"zcol"); h1 = hist1; h2 = hist2; for (int ii=1;ii<=100;ii++) for (int jj=1;jj<=100;jj++) \ h2->SetBinContent(ii,jj,h2->GetBinContent(ii,jj)/h1->GetBinContent(ii)); h2->SetMinimum(0.001); h2->Draw("zcol");This generates plots as seen Sti embedded and overlapped materials tests and Correcting an error in the PXL material in Sti, or for an immediate visual example (click for larger version):
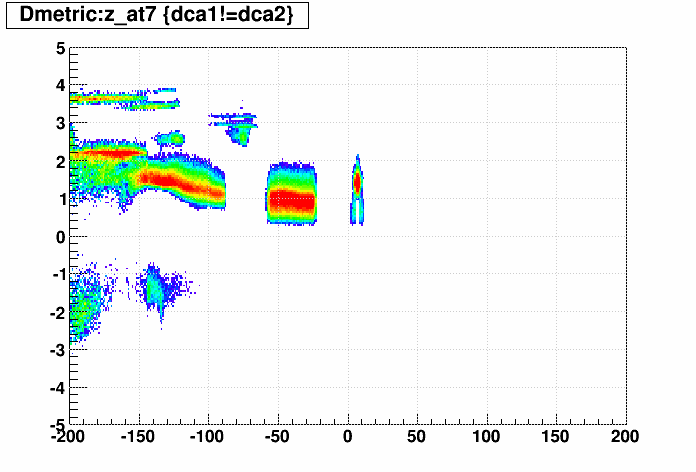
One can see the list of ntuple variables, pre-defined cuts and aliases I have provided as follows:
matches->Print(); cut1.Print(); matches->GetListOfAliases()->Print();
which, for the latter two as of this writing, are:OBJ: TCut CUT1 dcaB!=dcaA OBJ: TNamed deltaQPt (1/qinvptB)-(1/qinvptA) OBJ: TNamed deltaQInvPt qinvptB-qinvptA OBJ: TNamed scaledDeltaQPt -deltaQInvPt OBJ: TNamed deltaDca dcaB-dcaA OBJ: TNamed scaledDeltaDca deltaDca/(abs(qinvptB)*qinvptB) OBJ: TNamed Dmetric sign(scaledDeltaDca)*max(0,6+log10(abs(scaledDeltaDca))) OBJ: TNamed z_at7 zB+7*etaB/0.88 OBJ: TNamed z_at15 zB+15*etaB/0.88 OBJ: TNamed z_at23 zB+23*etaB/0.88 OBJ: TNamed phi_at23 phiB+0.02*qinvptB
(note: my first version of Dmetric did not use max() and was susceptible to getting the wrong sign for very small shifts)
Other relevant notes:
- If you want more statistics than are yielded by a single file, the ntuple ROOT files can be combined using hadd before step III.
- You will also see additional ROOT files produced from prepMatchNtuple.csh (or prepMatchNtupleEbyE.csh) which have a "U_" prefix. Such files contain the un-matched track information, which may be useful in understanding either why tracks are not passing the matching cuts (e.g. a distribution for true matches extends beyond a cut range), or which tracks (dis)appear from TrackInfo mode after some modification that affects tracking. The TNtupleD inside these files has the original 10 variables + 1 "INPUT" variable whose value (1 or 2) corresponds to the input log (first or second) from which each track came.
-Gene
Groups:
- genevb's blog
- Login or register to post comments