- jeromel's home page
- Posts
- 2025
- 2020
- 2019
- 2018
- 2017
- 2016
- 2015
- December (1)
- November (1)
- October (2)
- September (1)
- July (2)
- June (1)
- March (3)
- February (1)
- January (1)
- 2014
- 2013
- 2012
- 2011
- 2010
- December (2)
- November (1)
- October (4)
- August (3)
- July (3)
- June (2)
- May (1)
- April (4)
- March (1)
- February (1)
- January (2)
- 2009
- December (3)
- October (1)
- September (1)
- July (1)
- June (1)
- April (1)
- March (4)
- February (6)
- January (1)
- 2008
- My blog
- Post new blog entry
- All blogs
Transfer rate study, multi-stream versus parallel send
Updated on Fri, 2010-10-08 06:54. Originally created by jeromel on 2010-10-05 10:01.
1. Base measurements using Iperf
For all measurements, the following nodes were used
PDSF: pdsfgrid4.nersc.bnl.gov
BNL: stargrid03.rhic.bnl.gov
Bulovka: dfpch.ujf.cas.cz
Golias: ui5.farm.particle.cz
Transfer characteritics at the time of measurements are given as caption of the graphs in section 1.2.
1.1 Using a file distribution as input
The graphs below display the bandwidth aggregate for each link as a function of increasing number of threads in a single iperf instance (parameter -P is used to varry the number of threads). The -F option is used in those tests, that is, a sample file is being transferred in multi-stream mode. Each measurements was repeated and were transferring 10 GB of generated files picked from a size distribution where each file has for mean size = 200 MB and a Sigma=50 MB (the consecutive error bars on transfer speed are included and represents the standard deviation calculation sqrt(1/N Sum_i=1,N(xi - <x>)^2)). Data taken on 2010/10/04.
 |
 |
 |
|
1.1.a |
1.1.b |
1.1.c |
Comparing to a typical transfer pattern as a function of stream previously seen, such as the plot below, this is most un-expected.
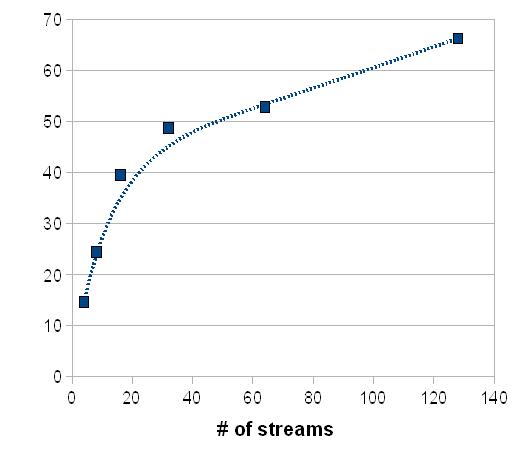
As it stands, even on short distance and for all purpose, no RTT to deal with, the performance drops abruptly with the number of thread possibly indicating a IO clash when a file is used as input for transfer speed measurement (it is possible that a thread lock and synchronization issue appear while reading file blocks to be transferred by multiple threads).
1.2 Using standard options (no file as input)
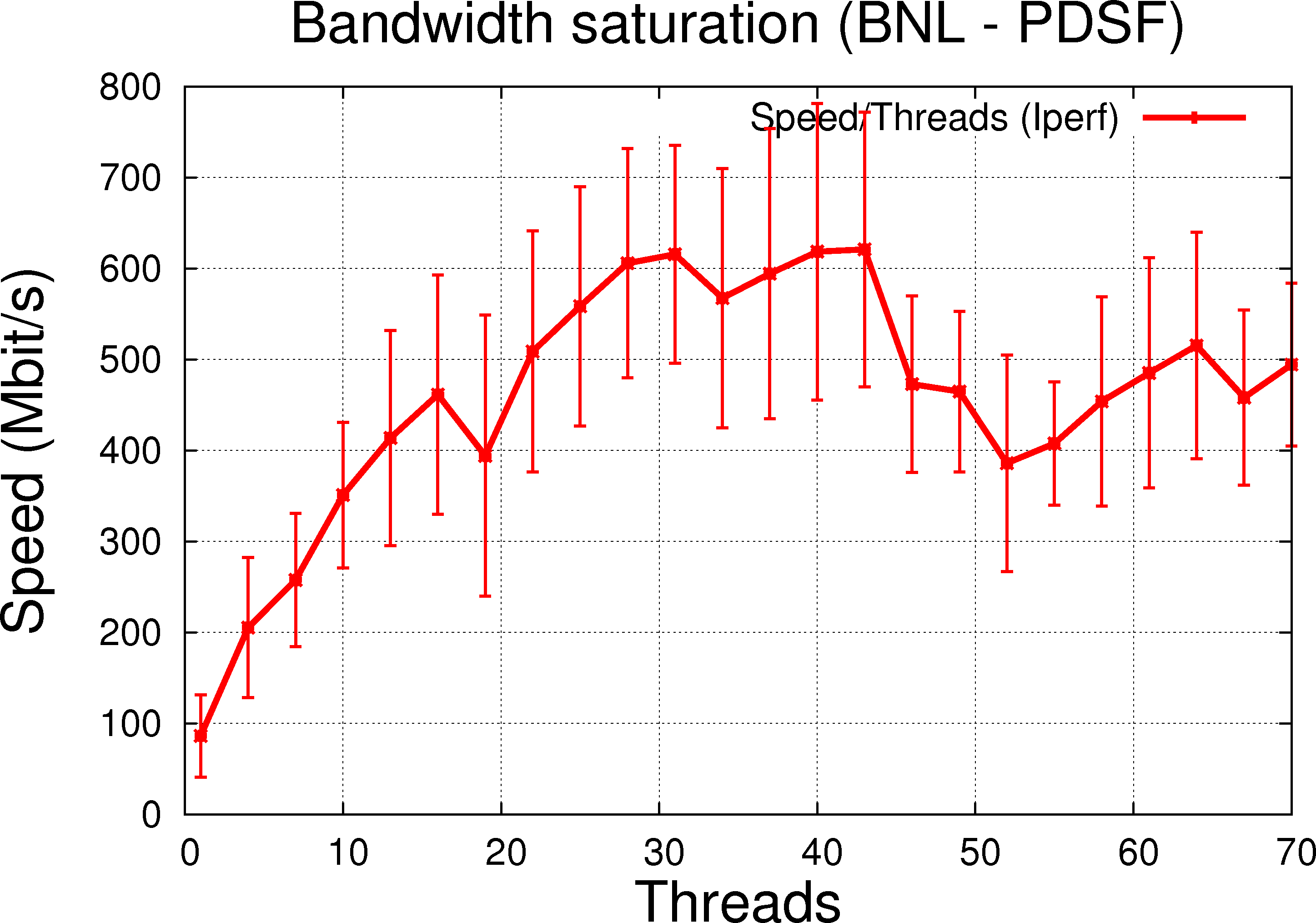
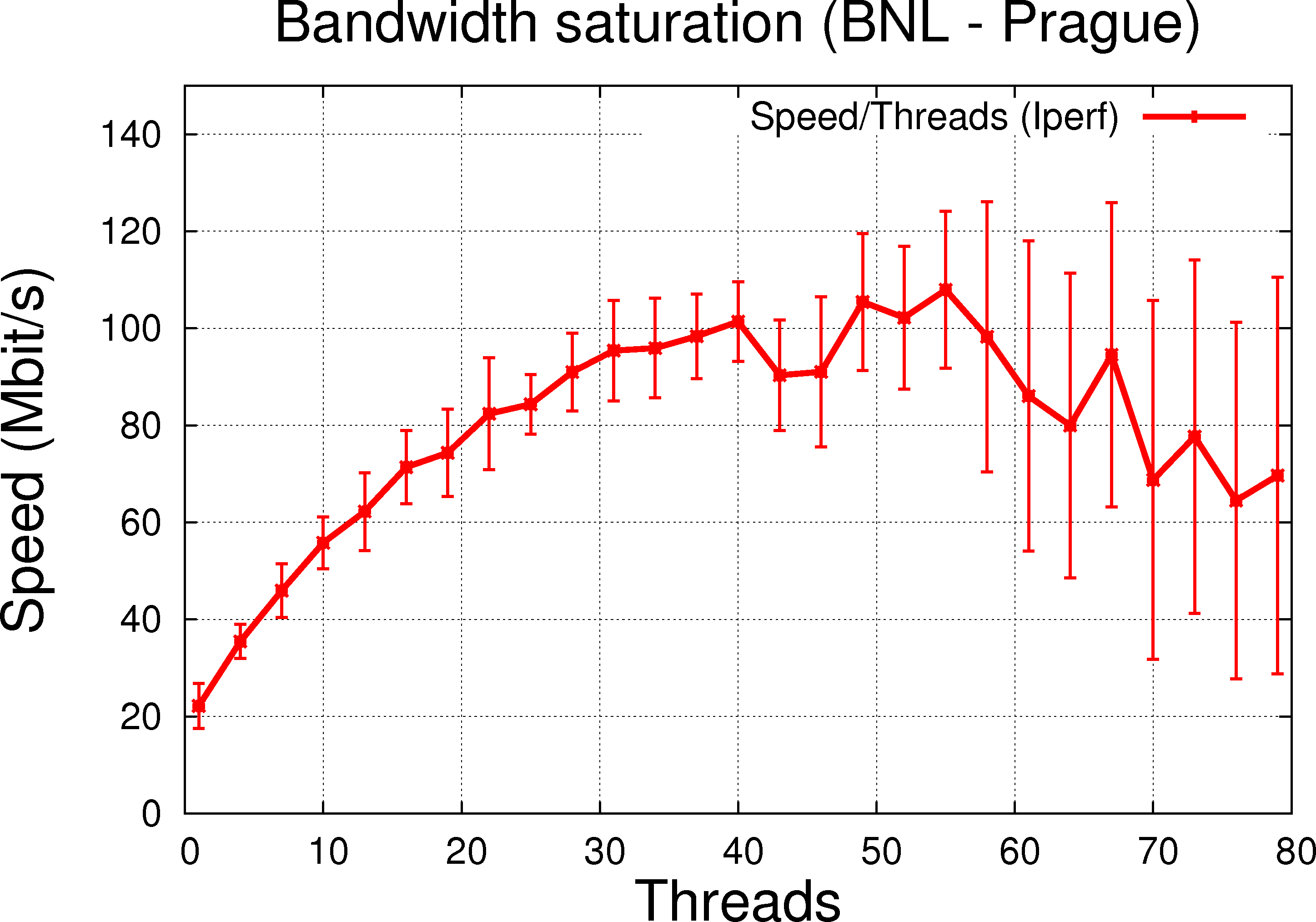
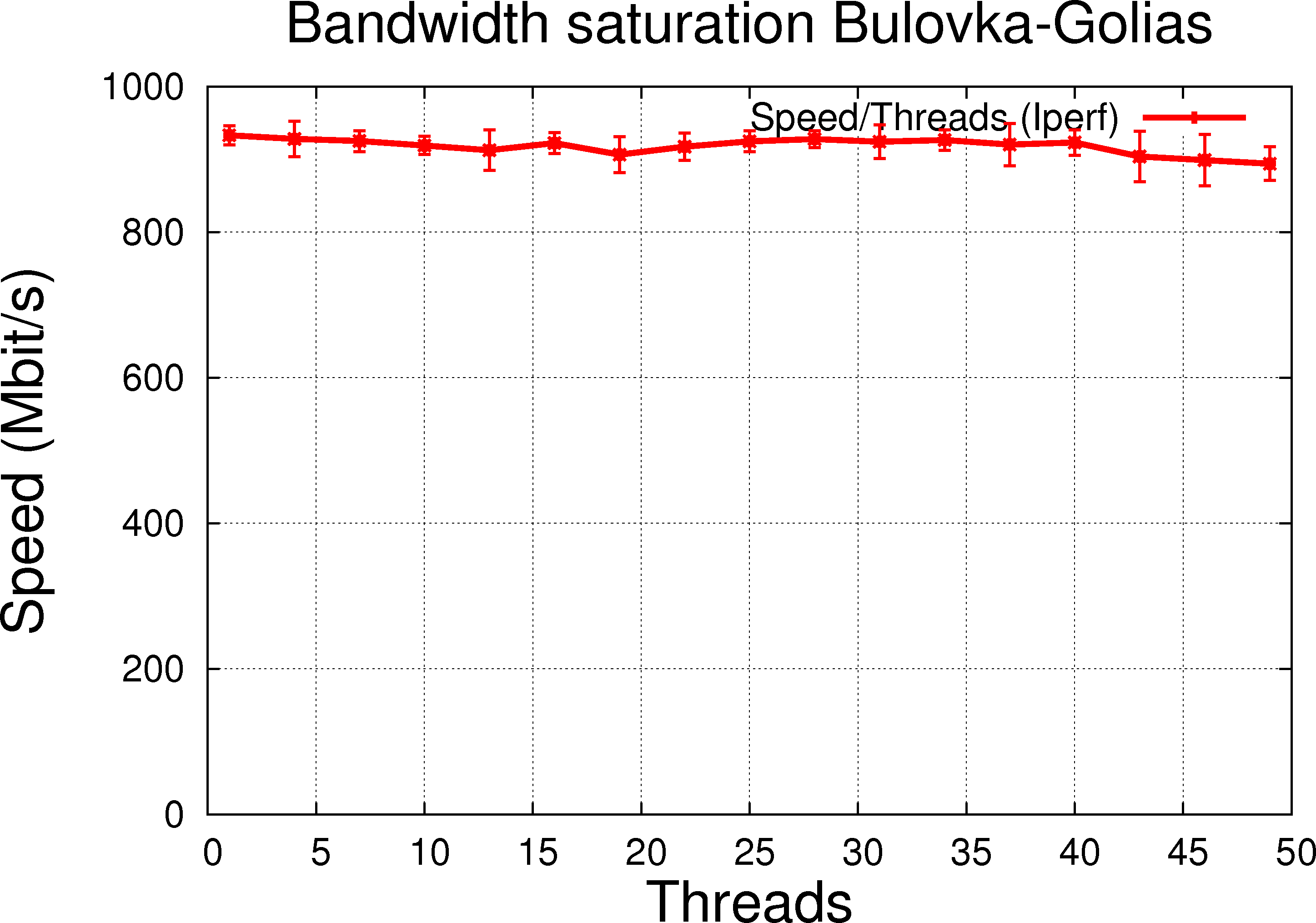
Modulo error bars currently large, results from Iperf ( similar to % iperf -c pdsfgrid4.nersc.gov -p 40000 -P $THREADS -f m -x C) without using a file as input are shown below (data taken on 2010/10/05):
 |
 |
 |
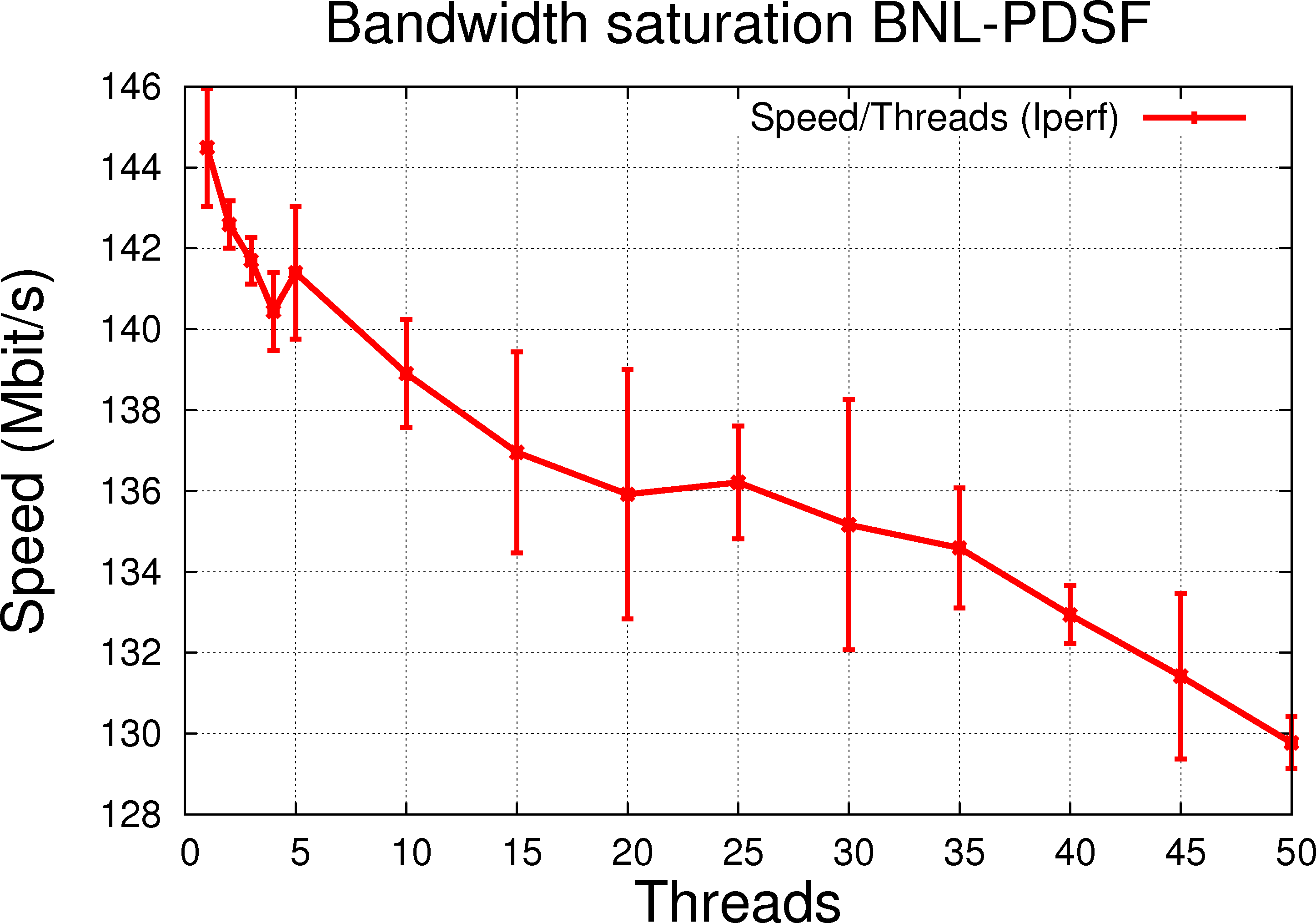
| 1.2.a BNL to PDSF (Esnet, RTT @ 83.360ms) |
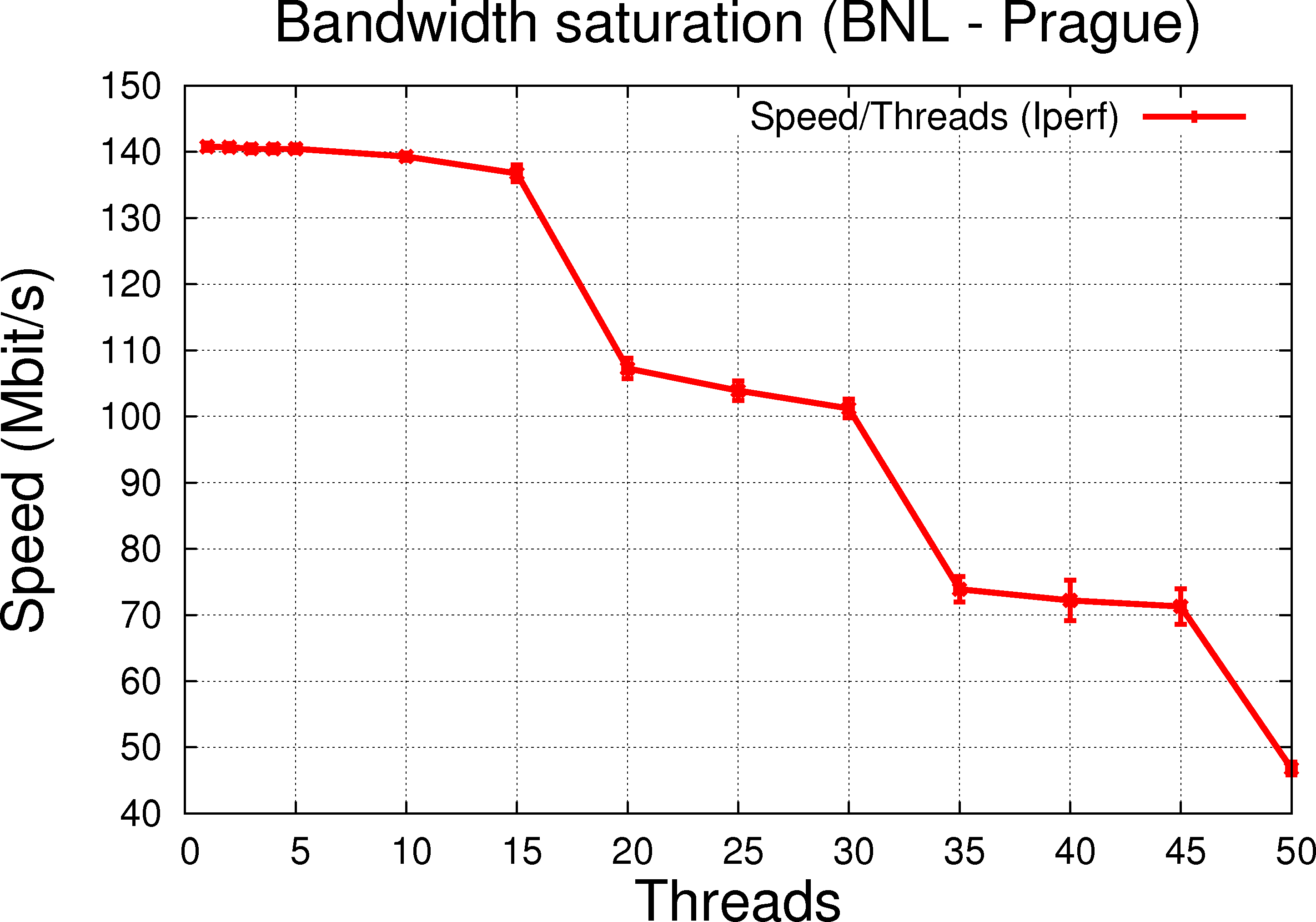
1.2.b BNL to Bulovka (dedicated link, reasonable RTT @ 93.428ms, limited to 150MBit/s) |
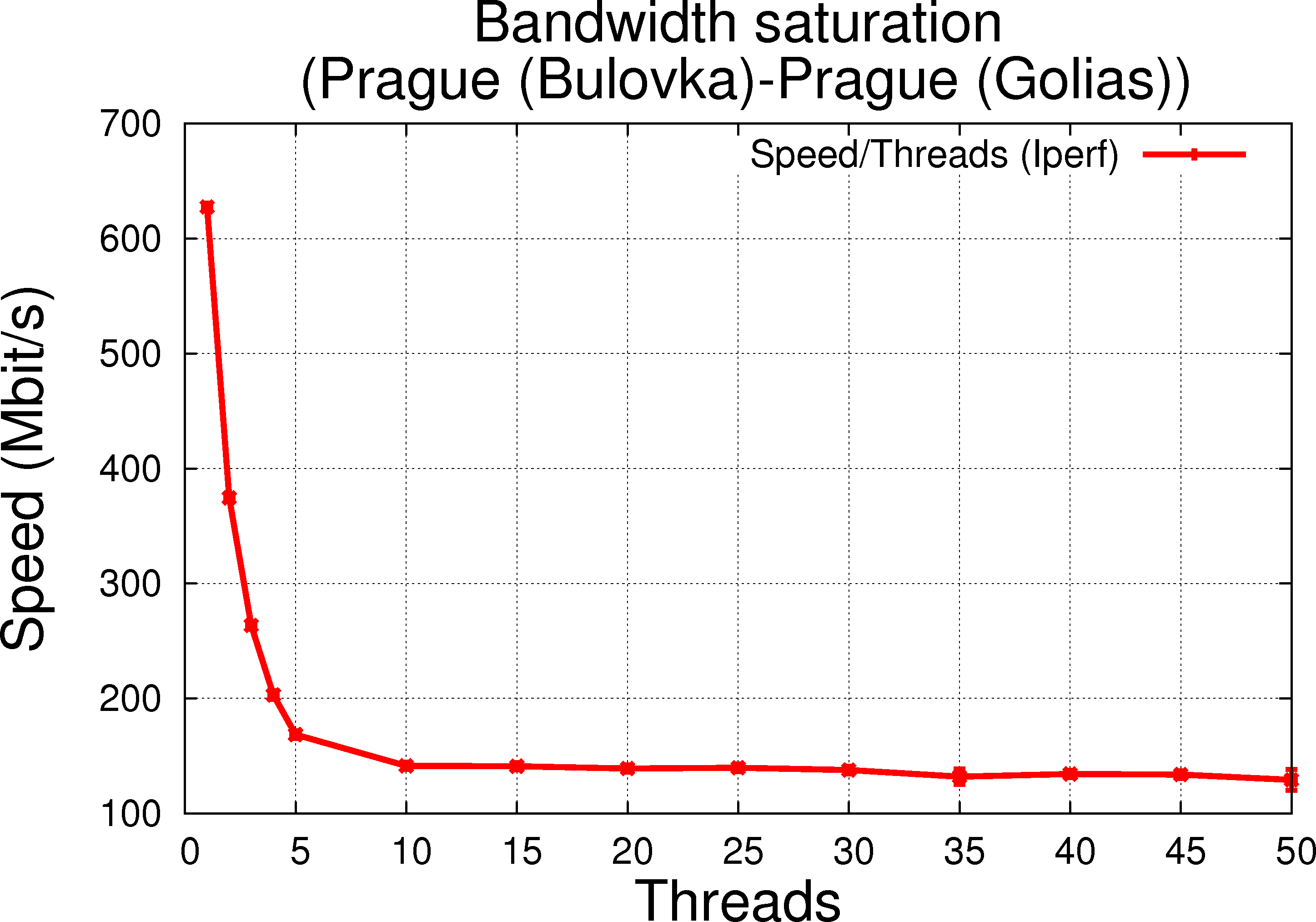
1.2.c Bulovka to Golias (dedicated link, low RTT reported to be 0, full 1GB/s LAN link) |
In general, the features are as expected for the link speed expected maximum. As we increase the number of threads, the transfer rate and performance increase as the network bandwidth saturates.
For the LAN transfer, increasing the number of threads would not change the speed since at one thread, a dedicated transfer already takes the full link speed. But moreover, it is clear figure 1.2.c that the thread handling does not decrease performance over single thread usage, an observation which gives confidence that we do not suffer from any other second order effects due to thread handling.
Note:
- In High performance data transfer and monitoring for RHIC and USATLAS (J Packard, D Katramatos, J Lauret et al 2010 J. Phys.: Conf. Ser. 219 06206 doi: 10.1088/1742-6596/219/6/062062) we explained in section 3 how the TCP window size tcp_window_size = RTT * desired_bandwidth should be adjusted for better performance. This is consistent with the TCP tuning guide from ESNet and example also in this article is nearly quoted as-is below (small correction in the calculation of the actual buffer size):
You can calculate the maximum theoretical window size by multiplying the lowest link bandwidth by the round trip time of an ICMP packet. For example, let's assume we're sending a large file from Duke University in North Carolina to MIT in Massachusetts. If the lowest link bandwidth is 45Mbps, and the round trip time is 23 milliseconds, the bandwidth delay product would be:
45Mbps * 23ms (45*1024/8 * 0.023) = 132.5KBytes
- Currently, Iperf reports a 64 KByte window size, likely on the low side for maximal performance. However, since we are interested in comparing multi-stream versus multi-file transfer, the environment will be consistent for the comparison [we could later optimize one of the three links and bootstrap the results to convince ourselves the Window Size plays no role in the cross-comparison]. RTT measured and possible Window size calculations below:
RTT for BNL->PDSF: 83.360ms @ 600 Mbps (likely a 1 Gbps line) - 6.252 MBytes
RTT for BNL->Prg: 93.428ms @ 150 Mbps - 1.75 MBytes
RTT for Bulovka->Golias: 0ms @ 1 Gbps - N/A
2. Comparison with multiple-send of one file (one thread) each
To demonstrate whether or not the network links act as unary resources (implementation neglected), one has to compare transfers done one file at a time (multiple threads or not) with transfers of multiple-files in parralele. Ideally, they should be equivalent if no overhead is expected by creating multiple instances of a transfer protocol tool (starting multiple Iperf for example) and likely, multiple iperf instances would be less efficient from a performance issue stand point as each consumes reources making it less available to the other instances.
Note: A practical implementation may benefit from more than one instance - it often happens in networking that a given transfer tool stops transferring due to network glitches or due to problem in the TCP protocol handling (thinking of the infamous FIN/ACK as documented in TCP parameters, Linux kernel).
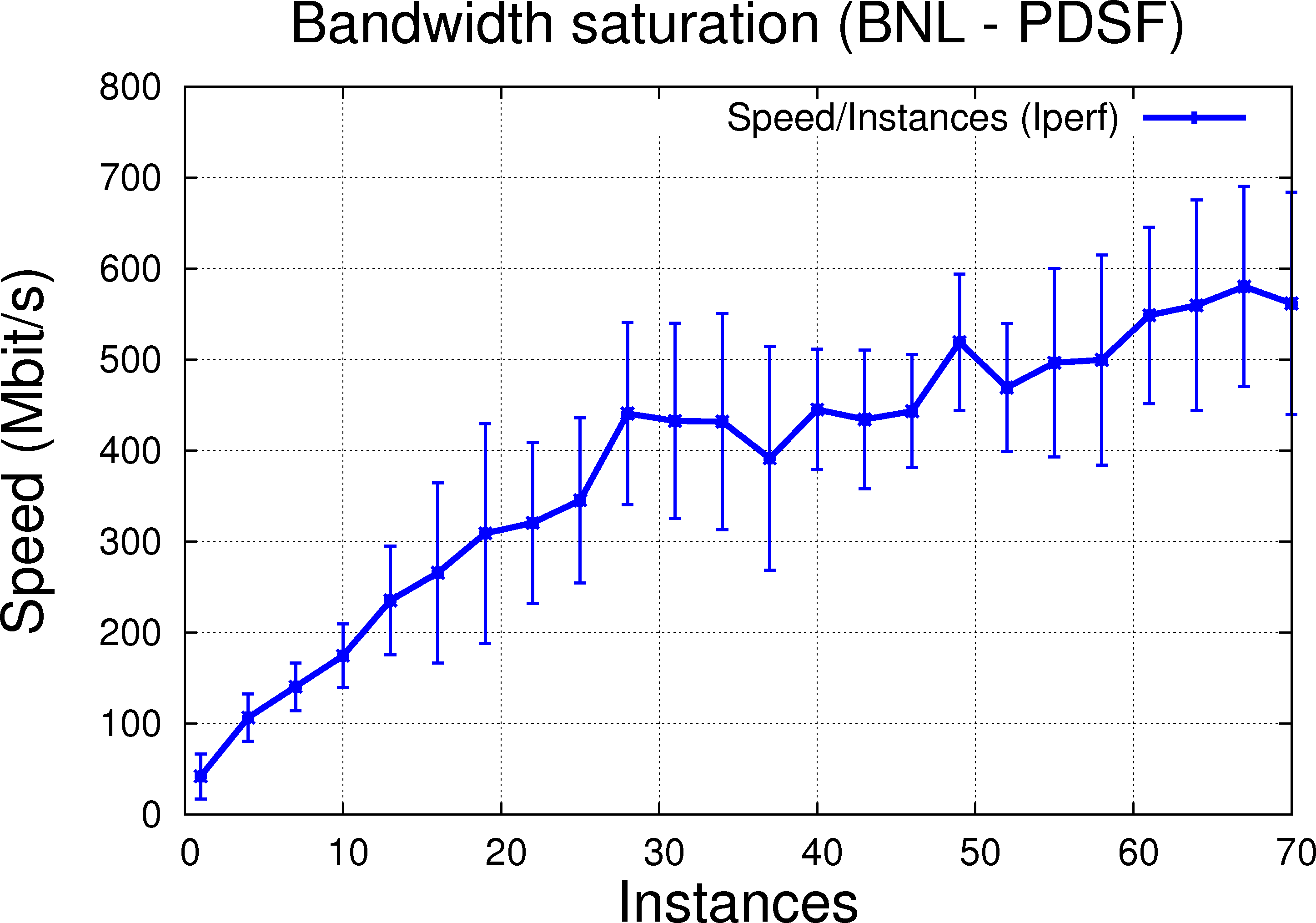
The results below were taken on 2010/10/07:
 |
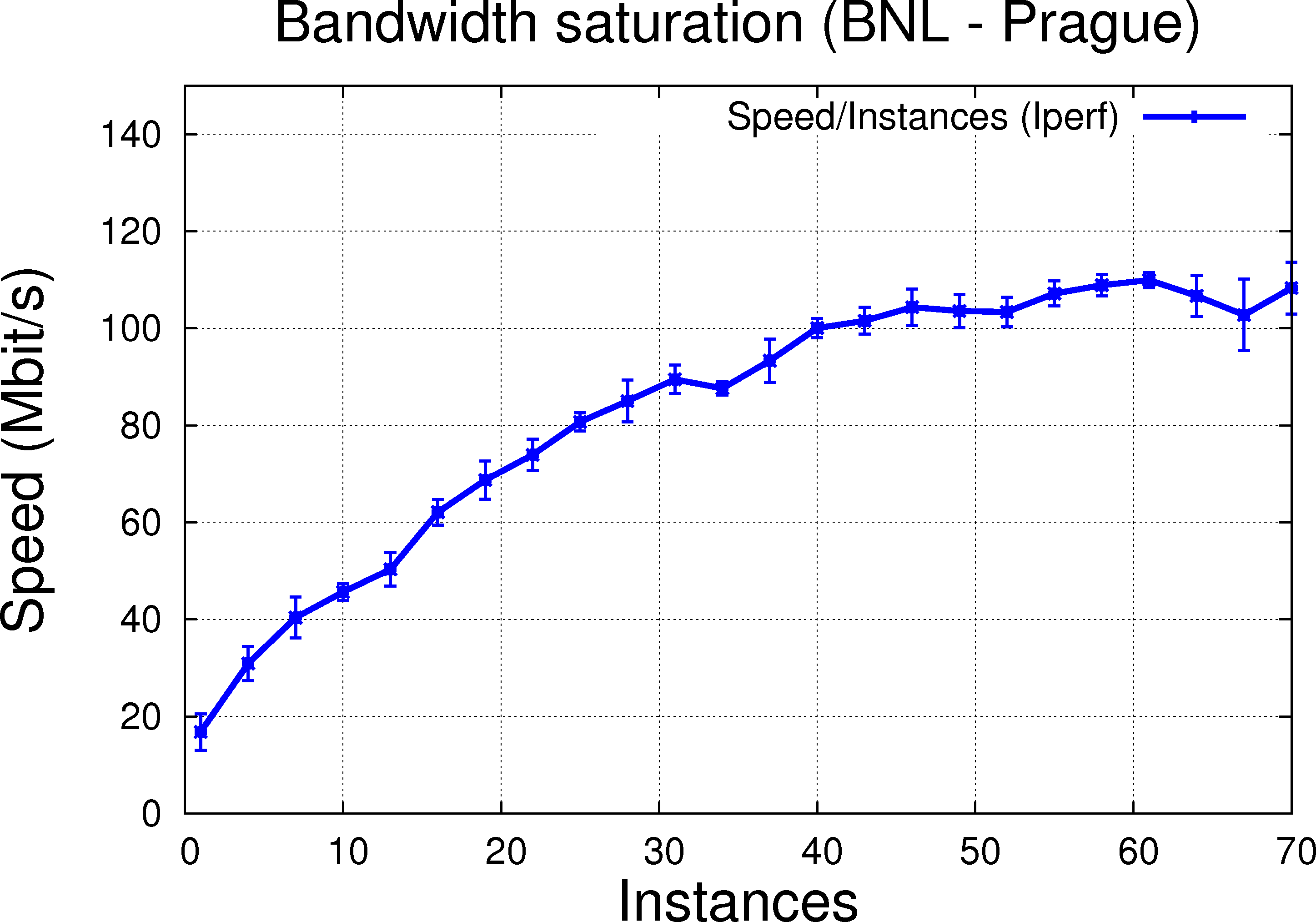 |
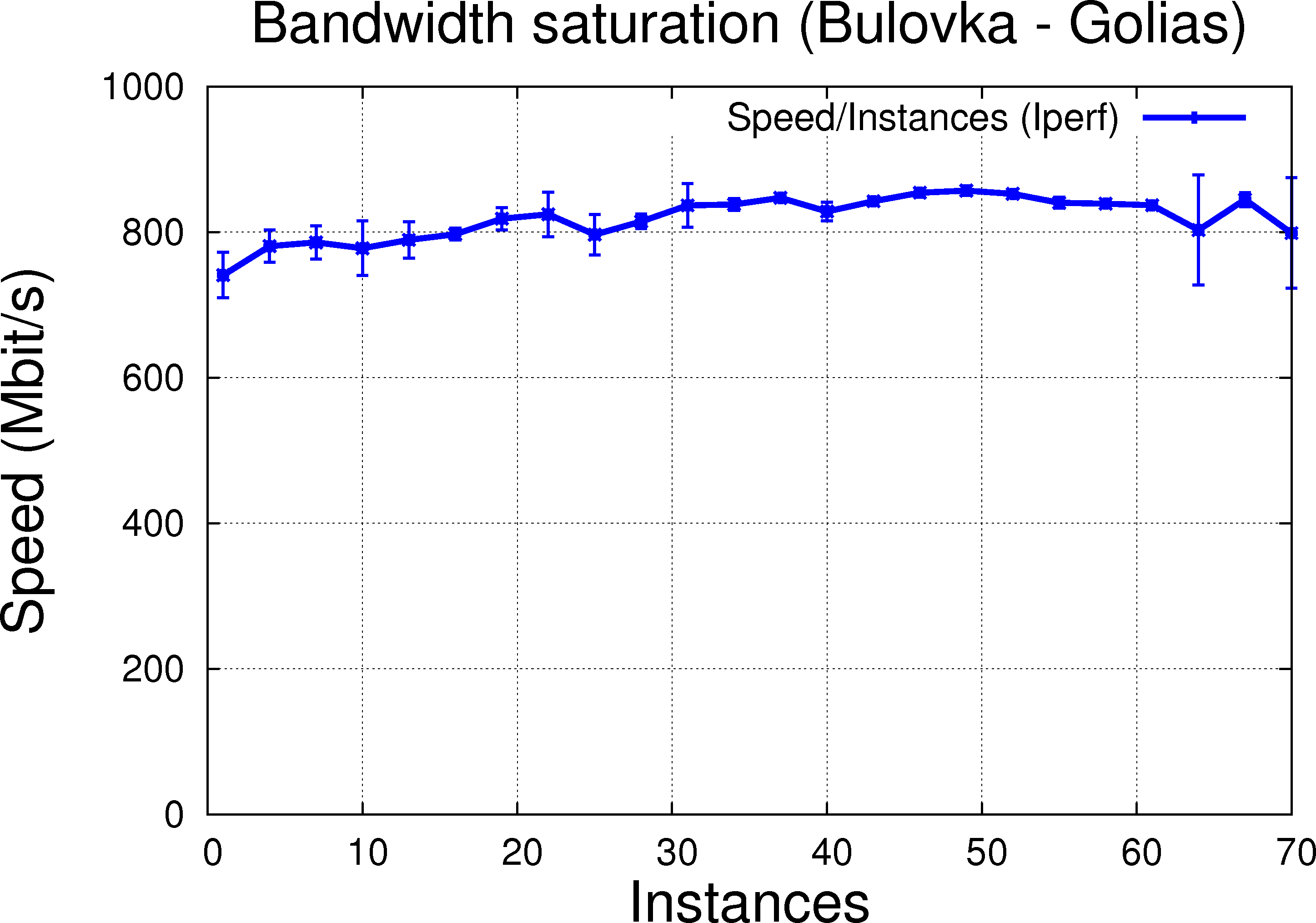 |
The trend is similar to using multiple-thread that is, increasing the number of instances increases as well the througput as noted and expected above. We observe (also as expected) a lower performance comparing to handling it with thread and infer this decrease of performance is due to higher resource consumption and potentially, across process synchronization problems (two instances of Iperf do not know about each other, each making aggressive requests for resources - any operation need to be coordinated by the OS). This is clearer on the LAN connection @ PRG (Bulovka to Golias).
Ratio plots are provided below for guidance (will get with error bars later):
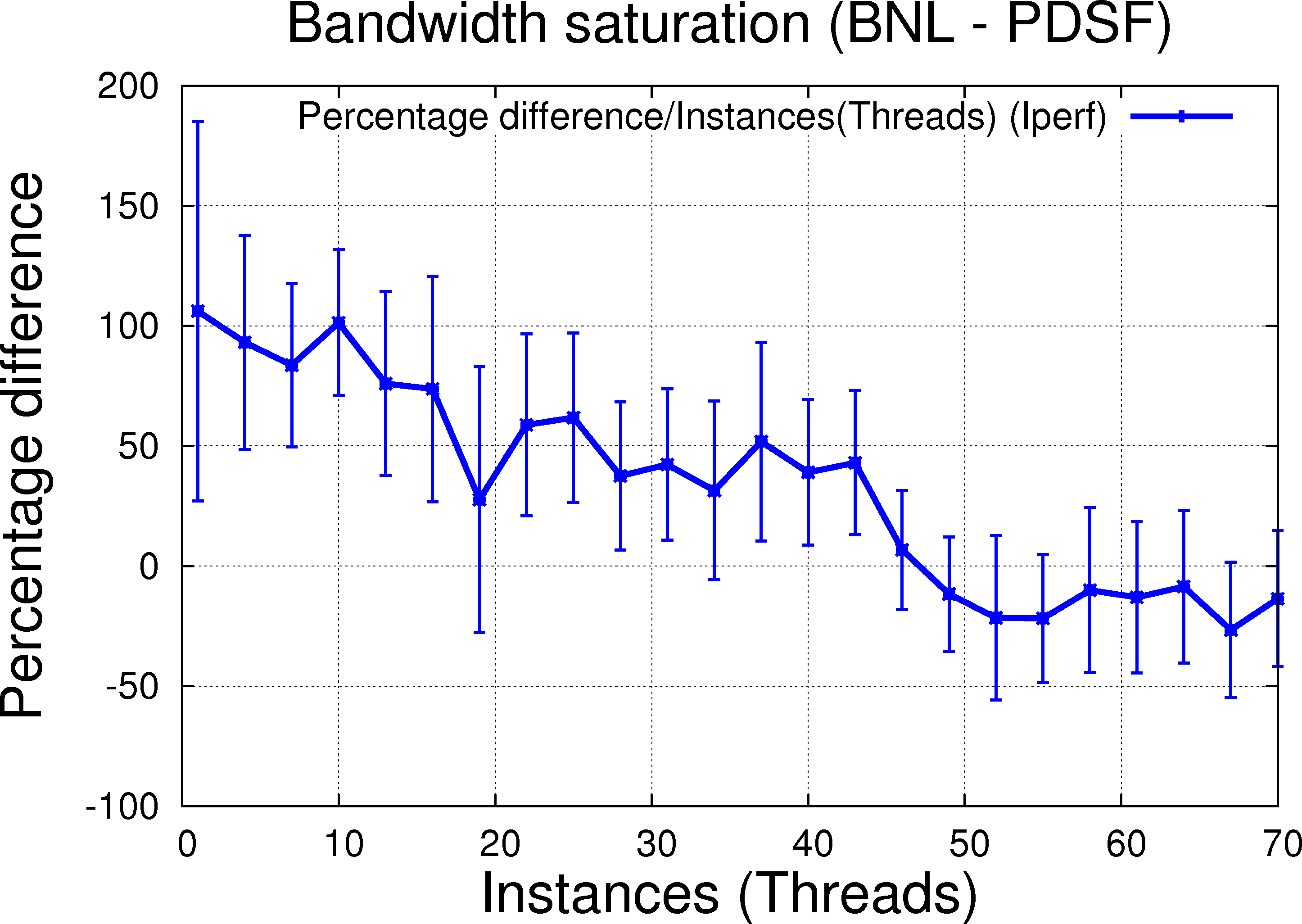 |
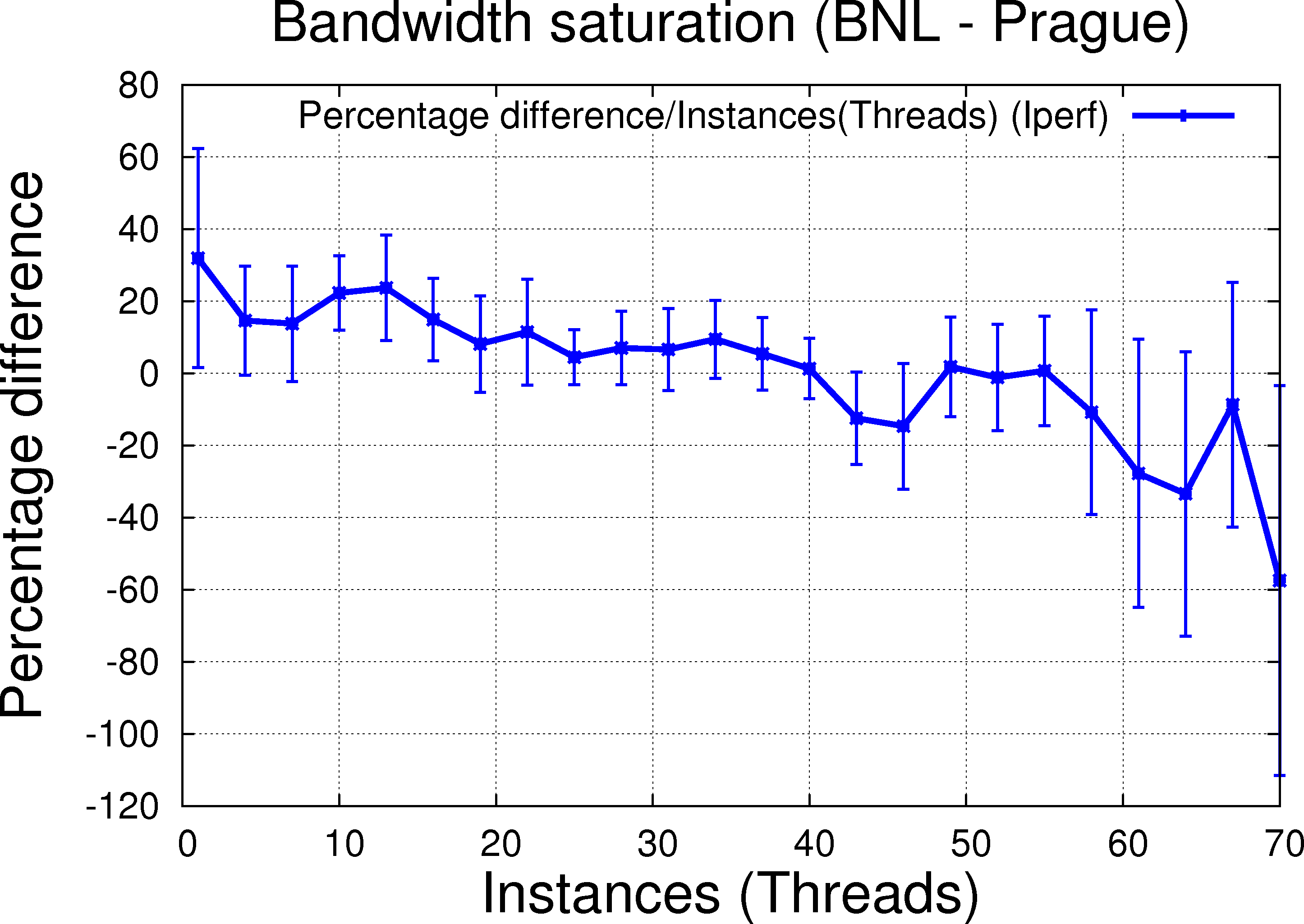 |
.png) |
A few observations:
- BNL-PDSF: clear benefit of thread over instances at lower thread count (let's say up to 30-40 or so), then unclear (error bars touch the 0 value)
- BNL-PRG is a reasonable case and exhibit similar pattern but the benefit of thread is limited to < 20 and not as clear of a cut (due to error bars, the picture is fuzzy).
- The best case is PRG/PRG: on LAN transfer, the case is super-clear - no RTT, error bars and fluctuation are small over short distances alllowing to best estimate the effect of the two mode without interferences or convolution from other effects ...
The PRG/PRG plot is the key plot for debating unary resources. On WAN, things ar emore complicated but the trend is similar hence we can conclude that (a) threads and sending file by file are better than trying to send multiple files in parallele (b) having multiple sender may bring the advantage of redundancy but this can be done from multiple sender nodes rather than multiple instances on one node (c) link can be saturated using threads or instances (no problem either ways as far as resources are available).
»
- jeromel's blog
- Login or register to post comments