- jeromel's home page
- Posts
- 2025
- 2020
- 2019
- 2018
- 2017
- 2016
- 2015
- December (1)
- November (1)
- October (2)
- September (1)
- July (2)
- June (1)
- March (3)
- February (1)
- January (1)
- 2014
- 2013
- 2012
- 2011
- 2010
- December (2)
- November (1)
- October (4)
- August (3)
- July (3)
- June (2)
- May (1)
- April (4)
- March (1)
- February (1)
- January (2)
- 2009
- December (3)
- October (1)
- September (1)
- July (1)
- June (1)
- April (1)
- March (4)
- February (6)
- January (1)
- 2008
- My blog
- Post new blog entry
- All blogs
Year 10, 11W02 production status
- Previous status was given Year 10, W52 production status
- Job Efficiency
- Projections
- Other issues
Job efficiency
Stream ratio - only one peak observed (not significant) ...
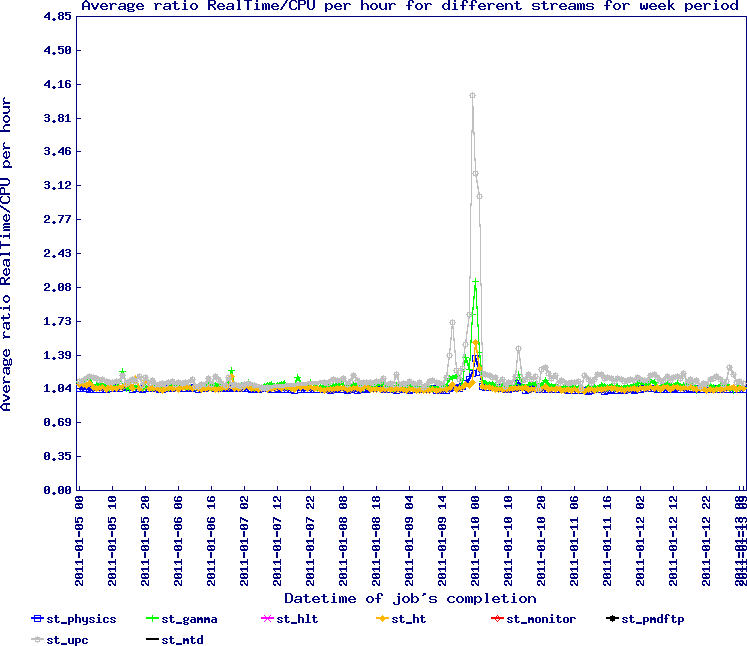
... corresponding to a burst of st_ht: it happens but rather rarely (we seem to handle rather well the mix of streams).
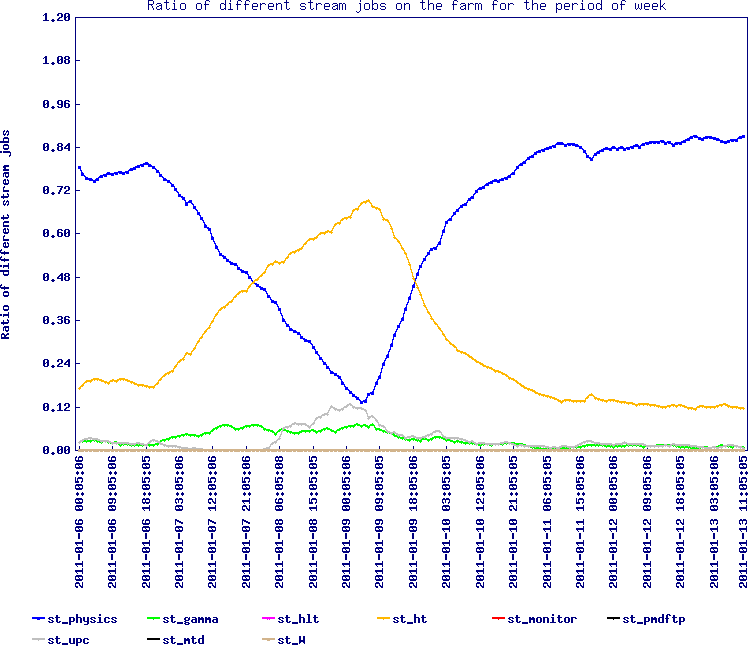
Still fine.
Projections
Projections were given by Lidia at You do not have access to view this node. According to her estimates, she projected another 25 days.
A review of the statistical table give previously (as well as review of the accounting) however shows the following:
Number of events rate graph
As a first note, the event production rate is back to its maximum. The issue detected a few weeks back is hence resolved - however, the bug in our code remains somewhere in "dev" and still under investigation (see RT # 2058 for more information).
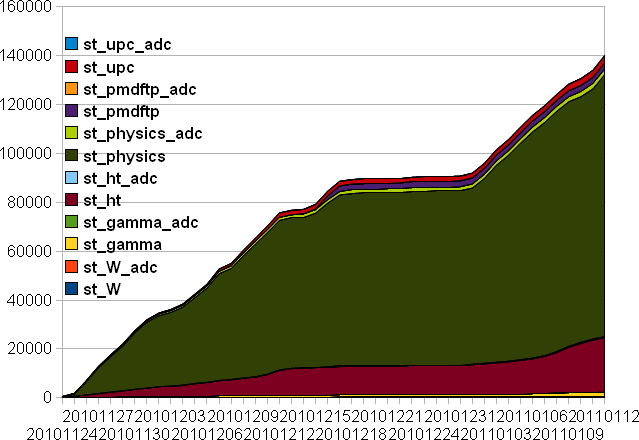
Projections based on goals (re-assessed event time in SL10k)
A similar table as previously shown is below. All processing speeds have been re-assessed based on the log from SL10k (previous estimates were based on SL10j library).
The time adjustements are minimal (you can compare to previous reports) but of the order of 15% still.
| Goals | Done | Left | %left | Real (sec/evt) | CPU (sec/evt) | Real/CPU | Time left (days) | |
| st_gamma [+] | 3,000,000 | 3,006,129 | -6,129 | -0.20% | 45.97 | 38.83 | 1.18 | 0.00 |
| st_ht (all) | 58,752,491 | 35,942,596 | 22,809,895 | 38.82% | 40.77 | 36.31 | 1.12 | 4.44 |
| st_physics | 207,000,000 | 199,983,628 | 7,016,372 | 3.39% | 26.88 | 26.01 | 1.03 | 0.90 |
| st_pmdftp [+] | 5,000,000 | 5,307,771 | -307,771 | -6.16% | 19.05 | 17.68 | 1.08 | -0.03 |
| st_upc | 37,520,000 | 22,401,696 | 15,118,304 | 40.29% | 13.28 | 7.02 | 1.89 | 0.96 |
| Grand totals & avg | 311,272,491 | 266,641,820 | 44,944,571 | 14.44% | 29.19 | 25.17 | 1.16 | 6.30 |
Note that the grand-total does not count negative numbers.
Negative numbers indicate we have exceeded the target goal.
Summary of projections
- We are exceeding our target goal slightly in a few stream - I beleive the discrepency with Lidia's estimates relate to this (whatever number of events she is counting may be more than the target goals above). Will sort this out with her ASAP.
- Current target of "done in ~ 6 days" is more-or-less consistent with the 16.69 days from the Year 10, W52 production status given on December 29 (13 days passed, 17-13 = 4 which would be 5 days with 15% more time it takes now / need to inspect the farm occupancy in more details for the remaining 1 day off but no time now)
Other issues
- Bug 2058 remains and need investigation - we cannot release a new library until understood and fixed
- Service tasks are being collected (see Grant's request and a my reminder to the software coordinators - since the reminder, we got new tasks) for Year11 data processing. When assembled will appear on the usual service page for S&C.
- On the h+/h- status from Grant Webb: The h+/h- issue has been persisent problem since Run 7. Progress has been made to identify the cause as a TPC alignment problem. Tasks have been assigned to resolve this issue and hope that by Run 11 it will be resolved. Some code reshape are being investigated to handle the alignment in a more consistent way (this needs to be demonstrated).
- FMS simulation: on hold still (it is amazing to see how many Email are exchanged on this / the only thing Pibero needs is a chanel/position mapping function). Hopefully, will close this matter this week.
- Farm repair (finishing the CPU replacement) still not done. News on the disk is not good - initial optimism on the possibility that the controller may be deffective went flat after testing on a statistically relevant sample (dozen of nodes) and for some amount of time (same failure rate). Problem still under investigation and Dell helping. The additional duty factor for our production (that is, increasing production time to accout for additional failure) remains in effect.
- New expert list is available on the Web ... initially bumpy road due to incomplete (if nor erroneous) information provided. We are now on our feet.
A few follow-ups:
- Discussing with Lidia as suggested above, several differences could lead to the difference in estimates
- I use a CPUTime and average number of resources (slot) for some period of time; Lidia uses an average number of "job" per day. The former may be affected by farm downtimes if not regulalry re-assessed, the second may be affected by jobs (one job = one file) with a larger number of events as well as the mix used at the time. So far, my estimates have been on target but Lidia is right to stand toward caution.
- There are more events processed comparing to plaining - this should not be a major problem at the end (the table above indicates < 1 day so far of offset)
- What do from the time we exhaust the st_physics was explained in the Year 10, W52 production status (see Summary section). Considering gthe factors below, the avenue of injectin more st_physics will be taken as path forward.
- If the statistics above stand, we are close to finishing our goals including the streams production - since the mix of 80/20 of st_physics/streams seem to prevent slow down, we can infer that maintaing this ratio would allow reaching the st_ht, st_upc goals within the indicated time.
- stream data causes a greater stress on HPSS. Even if we switch to snapshot mode, going for the runNumber ordering and stream mix is a better solution to achieve farm saturation and resource optimization.
- By the afternoon, we were notified that the Farm repairs will be scheduled for Friday/Saturday the 14th/15th - nodes from STAR will be closed to the queue in two waves with an impact of 24 hours per wave.
Groups:
- jeromel's blog
- Login or register to post comments