Requirements, plans, projects and proposals
General
The pages and documents in this section are a mix of resource or design requirement documents, proposal, planning and assessment. Links to other documents may be made (like meeting, evaluation, reviews) making the pages here a single point shopping to the S&C project resource requirement design.
Computing requirements
- 2008
- 2007
- Computing 2003
- RCF 2002
- Software & Computing requirements : initial design
- SN0382 : STAR Offline Computing Requirements for the First Year of RHIC Running
- Task force on STAR Computing Requirements, Fall 97
- Offline software design document, 1/97 ( PS HTML)
2002
Every year, the 4 RHIC experiments along with the RCF assemble a a task force to discuss and plan for the Computing resource allocation. In STAR, FY03/FY04 was lead by Jérôme Lauret with help from Jeff Porter. We meant for this work to be publically available.
- FY03/FY04 STAR Projection's Statement
- RCF Requirements task force Report June 2002
- RCF Computing Requirements (final) Dec 18th 2002
- RCF Procurement plan Dec 20th 2002
- STAR Capital equipment request
Most documents are from 2002 but are in effect in 2003.
2003
- CPU requirements
Calculated & Projections
Talk at the Collaboration meeting August 2003
Cumulative Data Volume and Projections (Email to Peter Jacobs)
- RHIC Computing Facility
RCF Computing Requirements September 2003
- Remote site & facilities
- Grid plans.
STAR PPDG Grid Plans -- July 31st 2003
This document will be used to shape the PPDG DOE work plan for year 3. A later proposal will be drafted for the Year4/Year5 funding.
Draft 1 (Year3 plan)
Final (Year3 plans)
STAR PPDG extension proposal -- January 28th 2004
BNL Program of Work
PPDG Proposal (latest version)
Jlab/STAR project -- July 31st 2003
This additional document drafts the scope of a JLab/STAR collaboration.
Job Scheduling STAR/Jlab V1
Job Scheduling STAR/Jlab V2
Phenix plans
The Phenix PPDG approach plan include participation and collaboration with STAR.
Phenix PPDG (for the last year of the SciDac PPDG program)
Other Grid Projects
Open Science Grid V1.9
OSG Meeting at FermiLab, STAR Statement of interest -- January 12th 2004
iVDGL statement of intent
2005
This page is a placeholder to import the projects launched in 2005.
Content Management system in STAR
Introduction
This project started in 2005 as a service task aimed to provide a seamless port of the online Web server for document self-maintenance and easy access. The initial description follows. It was motivated by the poor maintenance and log term support of the pages available online and the need for quick page creation for keeping help, instructions and procedures up to date in a multiple user and group environment context. Also, we imagined that shift crew could drop comments on existing pages and hoped for the documentation of our operation to be more interactive and iterative with immediate feedback process. Plone was envisioned at the time but the task was opened to an evaluation based on requirements provided below.
Initial service task
This task would include the evaluation and deployment of the a content management system (CMS) on the online Web server. While most CMS uses a virtual file system, its ability to manage web content through a database is of particular interest. Especially, the approach would allow for a Web automatic mirroring and recovery. We propose the task to include
- A smooth port of the main page available at http://online.star.bnl.gov/ to the CMS base system. This may include look and feel, color scheme etc ... at minimum, content. For example, the main tools should appear as left menu for easy navigation as a general web template.
- The evaluation of the database approach should be made and in place before a transition from the old style to a CMS based online web server.
- The CMS system layout should provide accessible branches for detector sub-systems, each sub-system may manage their branch separately. The branches will be most helpful to keep documentation on the diverse subsystem and provide a remote editable mechanism allowing easy management and modification.
- Depending on time and experience, the development could be applied to the offline Web server to some extend. An area where it could benefit best is the tutorial area and the QA area. Within the plone system, users would be able to leave comments, add new tutorials etc ... a manager would then organize or make available to the public (flexibility of access to be discussed).
Project timelines and project facts
Facts:
- We wanted a framework rather than a tool
- There were more than 762 main stream CMS at the start of the project
- "best" of today is not the best tomorrow
- We therefore decided to start the project with a focus on requirements rather than a specific solutions
Timelines:
- 2005 – Dmitry Arkhipkin took this & Communicated with Dan Magestro from the beginning
- The project evolved toward a offline Web server scope rather than a online Web server. The goal was to similarly address the obsolescence of the offline Web server
- more than 1/2 of the links were dead (65%)
- most documents were obsolete
- AFS tree became inextricable and not scaling (strategy to "hold" it together included the creation of separate (AFS volumes for load balancing reasons / ACL became had to maintain)
- The project evolved toward a offline Web server scope rather than a online Web server. The goal was to similarly address the obsolescence of the offline Web server
- 2006 – Beta (was rapidly used by STAR users) – Version 4.6
- 2007 – Zbigniew Chajecki (development & integration)
Project requirements
The following requirements were set for the project:
Technical requirements
- ¡Database storage support
- Preferably MySQL or Postgres
- Any other with a ”driver”
- Replication
- Flexible
- Can be extended by modules or plug-in
- Programmatic language
- Modul(ar) design
- Can reshape look-and-feel Granularity
- Layout
- Trees, collaborative work
- Individual accounts
- Authorization
- Privileges and/or ACLs based system
- Group management (virtual or group based privs)
- Self-maintained
- Layouts by sections
- Link auto-update (page move should auto-update cross-reference)
STAR requirements
- Easy page creation
- Web based editor – accessibility from anywhere
- WYSIWYG editor, What You See Is What You Get - help novice and advanced users. Feature not a mandate (plain HTML allowed)
- Assisted Help to layout & design
- i.e. no special html, xhtml, xml knowledge required
- Support for
- Attachments, images, …
- Auto-update search (i.e. search index and is self maintained withoit the need for external scripts or program)
- Community (popular) tools supported - may trends corresond to real modern world needs
- Blogs, Comments
- Polls, Calendar, Conferences, Meetings …
- ... many more via modules (a-la-perl extension)
- Group management
- PWG, Sub-systems, Activities, …
- Powerful search (feature rich selector as far as possible)
- Common visual theme for all pages (auto)
- Community support (leverage development from a wider base support)
Functional requirements
The following functional requirements were either requested or desired for a smooth (sup)port of previous deployment.
- Page content must be allowed to be public or require an authentication
- Meetings/agenda should allow for a non-public sections. Public content should remain to the strict minimal "advertisement" level and not reveal information internal to STAR.
- (comments? summary? section support?)
- Talks provided as attachments should not be public (PWG requested)
- Groups should extent beyond sub-systems and PWG (technical groups, sub-groups)
Related presentation
- You do not have access to view this node
2006
To be transfered from the old site
2007
.
Inner Silicon Tracking
| ID | Task Name | Duration | Start | Finish | Resource Names | |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | TPC checks | 7 days | Fri 2/9/07 | Mon 2/19/07 | ||
| 3 | Laser drift+T0 | 7 days | Fri 2/9/07 | Mon 2/19/07 | Yuri[50%] | |
| 4 | SSD shift + East/West TPC tracks | 3 days | Fri 2/9/07 | Tue 2/13/07 | Spiros[25%] | |
| 5 | SVT aligment | 7 days? | Tue 2/20/07 | Wed 2/28/07 | ||
| 6 | SVT+SSD (cone) for each wafer | 1 wk | Tue 2/20/07 | Mon 2/26/07 | Ivan,Richard | |
| 7 | Shell/Sector for each magnetic field settings | 1 day? | Tue 2/27/07 | Tue 2/27/07 | ||
| 8 | Ladder by Ladder | 1 day? | Wed 2/28/07 | Wed 2/28/07 | ||
| 9 | Using TPC+SSD, Determining the SVT Drift velocity | 7 days | Fri 2/9/07 | Mon 2/19/07 | Ivan | |
| 10 | Drift velocity | 12 days | Fri 2/9/07 | Mon 2/26/07 | ||
| 11 | High stat sample processing preview | 7 days | Fri 2/9/07 | Mon 2/19/07 | Vladimir | |
| 12 | Final evaluation | 5 days | Tue 2/20/07 | Mon 2/26/07 | Vladimir | |
| 13 | ||||||
| 14 | Online QA (offline QA) | 7 days | Fri 2/9/07 | Mon 2/19/07 | Ivan,Helen | |
| 15 | ||||||
| 16 | Hit error calculation final pass | 1 wk | Fri 2/9/07 | Thu 2/15/07 | Victor | |
| 17 | Self-Alignement | 3 wks | Fri 2/16/07 | Thu 3/8/07 | Victor | |
| 18 | Code in place for library - aligement related | 1 wk | Fri 2/9/07 | Thu 2/15/07 | Yuri[10%],Victor[10%] | |
| 19 | ||||||
| 20 | Tasks without immediate dependencies | 60 days | Fri 2/9/07 | Thu 5/3/07 | ||
| 21 | Cluster (SVT+SSD) and efficiency studies | 1.5 mons | Fri 2/9/07 | Thu 3/22/07 | Artemios,Jonathan | |
| 22 | Slow/Fast simulators reshape | 3 mons | Fri 2/9/07 | Thu 5/3/07 | Jonathan,Polish students x2,Stephen | |
| 23 | ||||||
| 24 | ||||||
| 25 | Cu+Cu re-production | 87.5 days | Fri 3/9/07 | Tue 7/10/07 | ||
| 26 | Cu+Cu 62 GeV production | 3 wks | Fri 3/9/07 | Thu 3/29/07 | ||
| 27 | Cu+Cu 200 GeV production | 72.5 days | Fri 3/30/07 | Tue 7/10/07 | ||
| 28 | cuProdcutionMinBias (30 M) | 8.5 wks | Fri 3/30/07 | Tue 5/29/07 | ||
| 29 | cuProductionHighTower (17 M) | 6 wks | Tue 5/29/07 | Tue 7/10/07 |
Multi-core CPU era task force
Introduction
On 7/12/2007 23:42, a task force was assembled to evaluate the future of the STAR software
and its evolution in the un-avoidable multi-core era of hardware realities.
The task force was composed of: Claude Pruneau (Chair), Andrew Rose, Jeff Landgraf, Victor Perevozchikov, Adam Kocolosk. The task force was later joined by Alex Wither from the RCF as the local support personnel were interested in this activity.
The charges and background information are attached at the bottom of this page.
The initial Email announcement launching the task force follows:
Startup Email (7/12/2007 23:42)
Date: Thu, 12 Jul 2007 23:42:40 -0400 From: Jerome LAURET <jlauret@bnl.gov> To: pruneau claude <aa7526@wayne.edu>, Andrew Rose <AARose@lbl.gov>, Jeff Landgraf <jml@bnl.gov>, Victor Perevozchikov <perev@bnl.gov>, Adam Kocoloski <kocolosk@MIT.EDU> Subject: Multi-core CPU era task force Dear Claude, Adam, Victor, Jeff and Andrew, Thank you once again for volunteering to participate to serve on a task force aimed to evaluate the future of our software and work habits in the un-avoidable multi-core era which is upon us. While I do not want to sound too dire, I believe the emergence of this new direction in the market has potentials to fundamentally steer code developers and facility personnel into directions they would not have otherwise taken. The work and feedback you would provide on this task force would surely be important to the S&C project as depending on your findings, we may have to change the course of our "single-thread" software development. Of course, I am thinking of the fundamental question in my mind: where and how could we make use of threading if at all possible or are we "fine" as it is and should instead rely on the developments made in areas such as ROOT libraries. In all cases, out of your work, I am seeking either guidance and recommendation as per possible improvements and/or project development we would need to start soon to address the identified issues or at least, a quantification of the "acceptable loss" based on cost/performance studies. As a side note, I have also been in discussion with the facility personnel and they may be interested in participating to this task force (TBC) so, we may add additional members later. To guide this review, I include a background historical document and initial charges. I would have liked to work more on the charges (including adding my expectations of this review as stated in this Email) but I also wanted to get them out of the door before leaving for the V-days. Would would be great would be that, during my absence, you start discussing the topic and upon my return, I would like to discuss with you on whether or not you have identified key questions which are not in the charges but need addressing. I would also like by then to identify a chair for this task force - the chair would be calling for meetings, coordinate the discussions and organize the writing of a report which ultimately, will be the result of this task force. Hope this will go well, Thank you again for being on board and my apologies for dropping this and leaving at the same time. -- ,,,,, ( o o ) --m---U---m-- Jerome -
Follow up EMail (8/3/2007 15:34)
Date: Fri, 03 Aug 2007 15:34:56 -0400 From: Jerome LAURET <jlauret@bnl.gov> CC: pruneau claude <aa7526@wayne.edu>, Andrew Rose <AARose@lbl.gov>, Jeff Landgraf <jml@bnl.gov>, Victor Perevozchikov <perev@bnl.gov>, Adam Kocoloski <kocolosk@MIT.EDU>, Alexander Withers <alexw@bnl.gov> BCC: Tim Hallman <hallman@bnl.gov> Subject: Multi-core CPU era task force Dear all, First of all, I would like to mention that I am very pleased that Claude came forward and offered to be the chair of this task force. Claude's experience will certainly be an asset in this process. Thank you. Second news: after consulting with Micheal Ernst (Facility director for the RACF) and Tony Chan (Linux group manager) as well as Alex Withers from the Linux group, I am pleased to mention that Alex has kindly accepted to serve on this task force. Alex's experience in the facility planing and work on batch system as well as aspects of how to make use of the multi-core trends in the parallel nascent era of virtualization may shade some lights on issues to identify and bring additional concepts and recommendations as per adapting our framework and/or software to take best advantage of the multi-core machines. I further discussed today with Micheal Ernst of the possibility to have dedicated hardware shall testing be needed for this task force to complete their work - the answer was positive (and Alex may help with the communication in that regard). Finally, as Claude has mentioned, I would very much like for this group to converge so a report could be provided by the end of October at the latest (mid-October best). This time frame is not arbitrary but is at the beginning of the fiscal year and at the beginning of the agency solicitations for new ideas. A report by then would allow shaping development we may possibly need for our future. With all the best for your work,
Background work
The following documents were produced by the task-force members and archived here for historical purpose (and possibly providing a starting point in future).
- First meeting notes - Claude Pruneau
- CPU benchmarking (plenty of memeory context) - Andrew Rose
- Concurrent Computing for C++ Applications
CPU and memeory usage on the the farm - Alex Wither
Opteron (CPU / memory)
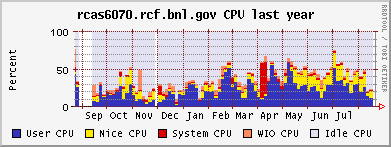
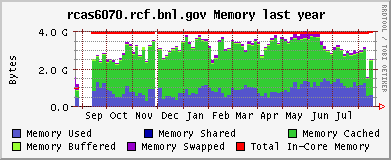
Xeon (CPU / memory)
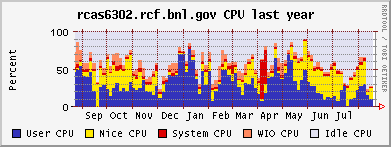
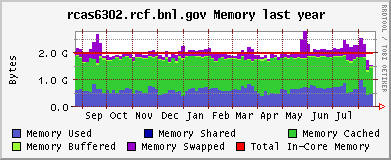
CAS & CRS CPU usage, month and year
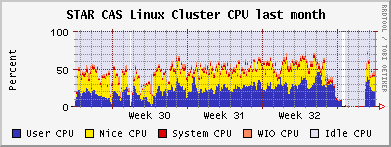
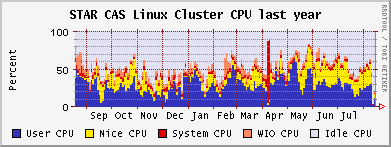

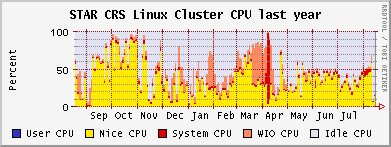
Outcome & Summary
A reminder as per the need for a reoprt was sent on 10/3/2007 to the chair (with a side track discussion on other issues which seemed to have taken attention). To accomodate for the busy times, a second reminder was sent on 11/19/2007 with a new due date for the end of november. Sub-sequent reminders were sent on the 12/10/2007 and 1/10/2008.
The task force has not deliverred the report as requested. A summary was sent in an Email as follow:
... a summary of the activities/conclusions of the committee. ... during the first meeting, all participants agreed that if there was anything to be done, it would be on reconstruction. Members of the committee felt that GEANT related activities are not in the perview of STAR and should not be STAR's responsibility. In view also of what we did next it also appears that not much would actually be gained. We also discussed (1st meeting) the possibility of multi-treading some aspects of user analysis. e.g. io, and perhaps some aspects of processing. Here people argued that there is too much variability in type of analyses carried by STAR users. And it is not clear that multi-treading would be in anyway faster - while adding much complexity to infrastructure - if not to the user code. Members of the committee thus decided to consider reconstruction processes only. In subsequent meetings, we realized (based on some references test conducted in the Industry) that perhaps not much would be gained if a given node (say 4 cores) can be loaded with 4 or 5 jobs simultaneously and provided sufficient RAM is available to avoid memory swapping to disk. Alex, and Andrew carried some tests. Alex's test were not really conclusive because of various problems with RCF. Andrew's test however clearly demonstrated that the wall clock time essentially does not change if you execute 1 or 4 jobs on a 4-core node. So the effective throughput of a multicore node scales essentially with the number of cores. No need for complexity involving multithreading. Instant benefits. Cost: PDSF and RCF are already committed according to Alex and Andrew to the purchase of multicore machines. This decision is driven in part by cost effectiveness and by power requirements. 1 four core machine consumes less power, and is less expensive than 4 1-core machine. Additionally, that's where the whole computing industry is going... So it is clear the benefits of multicore technology are real and immediate without invocation of multitreading. Possible exceptions to this conclusion would be for online processing of data for trigger purposes or perhaps for fast diagnostic of the quality of the data. Diagnostics (in STAR) are usually based on a fairly large dataset so the advantage of multi-threading are dubious at best in this case because the througput for one event is then irrelevant - and it is the aggregate throuput that matters. Online triggering is then the only justifiable case for use of multithreading. Multithreading would in principle enable faster throughput for each event thereby enabling sophisticated algorithms. This is however a very special case and it is not clear that adapting the whole star software for this purpose is a worthy endeavor - that's your call. I should say in closing that the mood of the committee was overall quite pessimistic from the onset. Perhaps a different group of people could provide a slightly different point of view - but I really doubt it.
2008
Background information
Projects and proposals
This page will either have requirements document or project description for R&D related activity in S&C (or defined activities hopefully in progress).
- We proposed an R&D development within the ROOT framework to support full schema evolution as described in the project description
- We worked on the elaboration of the KISTI proposal to join STAR
- We supported a network upgrade for the RCF backbone (sent via Micheal Ernst to Tom Ludlam Physics departement chair at BNL on April 16th 2008, discussed at the Spokesperson meeting on April 4th 2008)
- For 2008 Network Requirements Workshop for the DOE/SC Nuclear Physics Program Office, we provided background material as below (STAR sections and summary, the Phenix portion was taken verbatim from their contribution)
- Trigger emulation / simualtion framework: discussions from 20070528 and following Emails.
Ongoing activities
Internal projects and sub-systems task lists
- The TPC sub-system task list
Status: sent to the advisory board and spokesperson office on April 11th 2008 - Computing operation and support: IO performance measurements
- Opened project and activities listing
Tasks and projects
Computing operation: IO performance measurements
Goals:
- Provide a documented reference of IO performance tests made toward several configuration sin both disk formatting and RAID level space under non-constrained hardware considerations.
- The base line would help making future configuration choices when it comes to hardware provisioning of servers (services) such as database servers, grid gatekeepers, network IO doors, etc...
Steps and tasks:
- Survey community work on the topic of IO performance of drives especially topics concerning
- Effect of disk format on performance
- Effect of parallelism on performance
- Effect of software raid (Linux) performance and responsiveness (load impact on node under stress)
- Software RAID level and performance impacts
- Kernel parameter tweaks impacting IO performance (good examples are efforts of DAQ group, review consequence)
- Prepare a baseline IO test suite for measuring IO performance (read and write) under two mode Possible test suite could follow what was used in the IO performance page . Other tools welcomed based upon survey recommendations.
- single stream IO
- multi stream IO (parallel IO)
- Use a test node and measure IO performance under the diverse reviewed configurations. A few constraints on choice of hardware are needed to avoid biasing the performance results
- The node should have sufficient memory to accommodate for the tests (2 GB of memory or more is assumed to be large sufficient to accommodate for any tests)
- OS must support software RAID
- Disks used for the test should be isolated from system drive to avoid performance degradation
- Node should have more than two drives (including system disk) and ideally, at least 4 (3+1)
- Present result as a function of disk formatting, RAID level and/or number of drives added in both absolute values (values for each configuration) and differentials (gain when moving from one configuration to another).
Status: See results on Disk IO testing, comparative study 2008.
Opened project and activities listing
A summary of ongoing and incoming projects was sent to the software coordinators for feedback. The document refers to projects listed in this section under Projects and proposals.
The list below does NOT include general tasks such as the one described as part of the S&C core team roles as defined in the Organization job descriptions documents . Examples of which would be global tracking with Silicon including HFT, geometry maintenance and updates or otherwise calibration or production tasks as typically carried for the past few years. Neither does this list include improvements we need for areas such as online computing (many infrastructure issues, including networking an area of responsibility which has been unclear at best) nor activities such as the development and enhancement of the Drupal project (requirements and plans sent here).
The list includes:
- Closer look at Calorimetry issues if any (2007 operation workshop feedback follow-up related to calibration being too"TPC centric" and not addressing Physics qualities). Proposed a workshop with goals to:
- gather requirements from the PWG (statements from the operation workshop in 2007 seemed to have taken the EMC coordinators by surprised as per what resolution was needed to achieve Physics goals)
- discuss with experts technical details and implementation, unrolling / deployment and timing
Status: Underway, see report from a review as PSN0465 : EMC Calibrations Workshop report, fall 2008 - Db related: load balancing improvements, monitoring and performance measurements, resource discovery, distributed database
Status: underway.
References: You do not have access to view this node
- Trigger simulations - (some fleshed out on May 2007 as mentioned in this S&C meeting and attached below). The general idea was to provide a framework to allow trigger emulation / simulation offline for studying rejection/selection effects either applying trigger algorithms on real data (minimum bias) or via true simulation or allow re-applying trigger algorithm to triggered sample (higher threshold for example)
Status: nowhere close to where it should be
References: trigger simulation discussions meeting notes and Email communications.
- Embedding framework reshape.
Status: underway (need full eval with SVT and SSD integrated)
- Unified online/offline framework including integration of online reader offline and offline tools online (leveraging knowledge, minimizing work). This task would address comments and concerns that whenever code is developed online (for PPlot purposes for example), it also needs to be developed offline within separate and very different reader approaches. At a higher level, dramatic memory overwrite offline occurred in early 2007 due to the lack of synchronization between structure sizes (information did NOT propagate and was not adjusted offline by the software sub-system coordinator of interest; an entire production had to be re-run).
Status: tasked and underway, first version delivered in 2008, usage of "cons" and regression testing in principle in place (TBC in 2009 run)
- EventDisplay revisited
Status: underway (are we done? need new review follow-up after the pre-review meeting made in 2007)
- VMC - realistic geometry / geometry description
Status: Project on hold due to reconstruction issues, resumed July 2008.
- Forward tracking (radial field issue). May have importance for FGT project upon schedule understanding.
Status: depend on previous item and would be tasked whenever forward tracking need would be better defined.
- Old framework cleanup, table cleanup, drop old formats and historical baggage. In principle a framework tasks, this is bound to introduce instabilities during which assembling a production library would be challenging. This need to be tasked outside major development projects.
Status: only depend on production of Year 7/8 start-up
- Multi-core CPU era - Task force assembled in 2007 (Multi-core CPU era task force) had an unfortunate conclusion that the work would be too hard hence not necessary. Unfortunately, market development and aggressive company progression toward even more packed CPU and core indicates the future must integrate this new paradigm. First attempts should target the "obvious".
Status: First status and proposal made at ACAT08 (changing chains to accommodate for possible parallelism). Investigated possibility of parallelism at library level and core algorithm (tracking). Talks at ACAT08 very informative.
- Automated QA (project draft available, Kolmogorov etc... discussed and summarized here)
Status: no project drafted yet, only live discussions and Email communications.
- Automated calibration. The main project objective is to move toward a more automated calibration framework whereas migration from one chain to another chain (distortion correction) would be triggered by a criteria (resolution, convergence) rather than a manual change. This work may leverage the FastOffline framework (which was a first attempt to make automated calibration a reality; currently modified by hand and the trigger mechanism is not present / implemented)
Status: Project description available . Summer 08 service task.
- IO schema evolution (reduction of file size by dropping redundant variables but with full transparency to users)
Status: Project started as planned on July 16th with goals drafted on page Projects and proposals. Project deliverables were achieved (tested from a custom ROOT version now in the ROOT main CVS). Future release will include a fully functional schema evolution as specified in our document. Integration will be needed.
Project team: Jerome Lauret (coordination), Valeri Fine (STAR tetsing), Philippe Canal (ROOT team)
- Distributed storage improvement (Efficient dynamic disk population). This project would aim to restore the dynamic disk population of datasets on distributed disk as well as a prioritization mechanism (and possibly bandwidth throttling) so user cannot over-subscribe storage, causing past observed massive delete/restore dropping efficiency.
Status: under-graduate thesis done ; model to improve IO in/out of HPSS is defined and need implementation.
- Efficient multi-site data transfer (coordination of data movement), this project aims to address multi-Tier2 data transfer support and help organize / best utilize the bandwidth out of BNL. A second part of this project aims at data placement on Grid whereas a "task" working on a dataset is to be scheduled with use of existing staged files at sites or possible pre-staging or migration of files from any site to any site (a bit ambitious).
Status: Project started as a computer science PhD program (thesis submitted). Work scheduled over a 3 years period and deliverable would need to be put in perspectives of Grid project deliverables.
- Distributed production and monitoring system, job monitoring, centralized production requests interface
Status: work tasked within the production team.
- FileCatalg improvement. The FileCatalog in STAR was developed from in-house knowledge and support (starting from service work). The catalog now hold 15 Million records (scalability beyond is a concern) and its access possibly inefficient. An initial design diverging from Meta-Data catalog, File Catalog, Replica Catalog has allowed for a quick start and the development of additional infrastructure but has also lead to the replication of the Meta Data information, making hard to maintain consistency of the Catalogs across sites. Federating the Catalogs and using all site's information simultaneously has been marginal to not possible, making a global namespace (replicas) not possible. The lack of this component will directly affect grid realities.
Status: Ongoing (see Catalog centralized load management, resolving slow querries).
Wish list (for now):
- Online tracking & High Level trigger. This may depend on a trigger simulation framework (it would have benefited from it for sure) or may be an opportunity to revive the issue and shape anew focused (and reduced in scope) project.
Status: How to fit this additional activity is under debate. First discussion held at BNL on 2008/07/10 and followed later by additional meetings. This activity moved to the "upgrade" activity.
STAR/RCF resource plans
- General fund
- External fund summary
- 2008 requirements
- Post plan adjustements
- BlueArc layout within Physical stores, BA, ...
- Proposal for reshape
General fund
The level of funding planned for 2008 was:
- According to the RHIC mid-term strategic planning for 2006-2011 document, the budget for 2008 was projected to be 2140 k$ (table 7-2) with a note that and additional 2 M $ additional would be needed between FY08 and FY10 (to accommodate for network infrastructure, storage robotics and silo expansion and general infrastructure changes)
- The budget planned for FY08 in FY07 was 2.5 M$, accounting for recovering by 0.5 M$ already present past years shortfalls
- The current budget available is 1.7 M$ with a 1.5 M$ usable base fund.
External funds
Following previous years "outsourcing" of funds approach, an note was sent to the STAR collaboration (Subject: RCF requirements & purchase) on 3/31/2008 12:18. The pricing offered was 4.2 $/GB i.e. 4.3 k$/TB of usable space. Based on the 2007 RCF requirement learning experience (pricing was based on vendor's total space rather than usable), the price was firmed, fixed and guaranteed as "not higher than 4.2 $/GB" by the facility director Micheal Ernst at the March 27th liaison meeting.
The institutions external fund profile for 2008 is as follows:
| STAR external funds | |||
| Institution | Paying account | TB requested | Price |
| UCLA | UCLA | 1 | 4300.8 |
| rice | rice | 1 | 4300.8 |
| LBNL | LBNL | 4 | 17203.2 |
| VECC | BNL | 1 | 4300.8 |
| UKY | UKY | 1 | 4300.8 |
| Totals | 8 | 34406.4 | |
Penn State university provided (late) funds for 1 TB worth.
*** WORK IN PROGRESS ***
Requirements
The requirements for FY08 are determined based on
The initial STAR requirements provided for the RHIC mid-term strategic plan can be found here
The initial raw data projected was 870 TB (+310 TB).
The RAW data volume taken by STAR in FY08 (shorter run) is given by the HPSS usage (RAW COS) as showed below:

A total of 165 TB was accumulated far below expected data projections by a factor of 2. The run was however declared as meeting (to exceeding) goals comparing to the STAR initial BUR.
Some notes:
- STAR made extensive use this year of fast triggers
- Based on those numbers, we assumed that
- The CPU requirements of 1532 kSI2k (+1071 kSI2k) would equally scale, hence a minimal requirement of +215 kSI2K should be accounted for
- A bigger pool of distributed storage would allow for more flexibility: it would allow for re-considering multiple (if not most of) the datasets to be placed on disk in Xrootd pool + it would allow (modulo expanding beyond the 1.2 replication baseline) to better load balance the resources.
- The distributed disk planing accounted for 365 TB of storage (1 pass production, small fraction of past results on disk). We targeted 800 TB of disk space (about twice the initial amount).
Allocations within total budgets
scenario B = scenario A + external funds
| Experiment Parameters | STAR | STAR |
| Senario A | Senario B. | |
| Sustained d-Au Data Rate (MB/sec) | 70 | 70 |
| Sustained p-p Data Rate (MB/sec) | 50 | 50 |
| Experiment Efficiency (d-Au) | 90% | 90% |
| Experiment Efficiency (p-p) | 90% | 90% |
| Estimated d-Au Raw Data Volume (TB) | 130.8 | 130.8 |
| Estimated p-p Raw Data Volume (TB) | 41.5 | 41.5 |
| Estimated Raw Data Volume (TB) | 172.3 | 172.3 |
| <d-AU Event Size> (MB) | 1 | 1 |
| <p-p Event Size> (MB) | 0.4 | 0.4 |
| Estimated Number of Raw d-Au Events | 137,168,640 | 137,168,640 |
| Estimated Number of Raw p-p Events | 108,864,000 | 108,864,000 |
| d-AU Event Reconstruction Time (sec) | 9 | 9 |
| p-p Event Reconstruction Time (sec) | 16 | 16 |
| SI2000-sec/event d-Au | 5202 | 5202 |
| SI2000-sec/event p-p | 9248 | 9248 |
| CPU Required (kSI2000-sec) | 1.7E+9 | 1.7E+9 |
| CRS Farm Size if take 1 Yr. (kSI2k) | 54.6 | 54.6 |
| CRS Farm Size if take 6 Mo. (kSI2k) | 109.1 | 109.1 |
| Estimated Derived Data Vlume (TB) | 200.0 | 200.0 |
| Estimated CAS Farm Size (kSI2k) | 400.0 | 400.0 |
| Total Farm Size (1 Yr. CRS) (kSI2k) | 454.6 | 454.6 |
| Total Farm Size (6 Mo. CRS) (kSI2k) | 509.1 | 509.1 |
| Current Central Disk (TB) | 82 | 82 |
| Current Distributed Disk (TB) | 527.5 | 527.5 |
| Current kSI2000 | 1819.4 | 1819.4 |
| Central Disk to retire (TB) | 0 | 0 |
| # machines to retire form CAS | 0 | 0 |
| # machines to retire from CRS | 128 | 128 |
| Distributed disk to retire (TB) | 27.00 | 27.00 |
| CPU to retire (kSI2k) | 120.00 | 120.00 |
| Central Disk (TB) | 49.00 | 57.00 |
| Cost of Central Disk | $205,721.60 | $239,308.80 |
| Cost of Servers to support Central Disk | ||
| Compensation Disk entitled (TB) | 0.00 | 0.00 |
| Amount (up to entitlement) (TB) | 0.00 | 0.00 |
| Cost of Compensation Disk | $0 | $0 |
| Remaining Funds | $0 | $0 |
| Compensation count (1U, 4 GB below) | 5 | 5 |
| Compensation count (1U, 8 GB below) | 0 | 0 |
| CPU Cost | $27,500 | $27,500 |
| Distributed Disk | 27.8 | 27.8 |
| kSI2k | 114.5 | 114.5 |
| # 2U, 8 cores, 5900 GB disk, 8 GB RAM | 27 | 27 |
| # 2U, 8 cores, 5900 GB disk, 16 GB RAM | 0 | 0 |
| CPU Cost | $148,500 | $148,500 |
| Distrib. Disk on new machines (TB) | 153.9 | 153.9 |
| kSI2k new | 618.2 | 618.2 |
| Total Disk (TB) | 813.2 | 821.2 |
| Total CPU (kSI2000) | 2432.1 | 2432.1 |
| Total Cost | $354,222 | $387,809 |
| Outside Funds Available | $0 | $34,406 |
| Funds Available | $355,000 | $355,000 |
Post purchase actions
BlueArc disk layout before the new storage commissioning
Name | File System | Path | Hard Quota | Space allocated | Available Space | BlueArc Physical storage | |
star_institutions_bnl | STAR-FS01 | /star_institution/bnl | 3.50 | 16.50 | 19.00 | BA01 | |
star_institutions_emn | STAR-FS01 | /star_institution/emn | 1.60 | ||||
star_institutions_iucf | STAR-FS01 | /star_institution/iucf | 0.80 | ||||
star_institutions_ksu | STAR-FS01 | /star_institution/ksu | 0.80 | ||||
star_institutions_lbl | STAR-FS01 | /star_institution/lbl | 9.80 | ||||
star_data03 | STAR-FS02 | /star_data03 | 1.80 | 17.22 | 19.75 | ||
star_data04 | STAR-FS02 | /star_data04 | 1.00 | ||||
star_data08 | STAR-FS02 | /star_data08 | 1.00 | ||||
star_data09 | STAR-FS02 | /star_data09 | 1.00 | ||||
star_data16 | STAR-FS02 | /star_data16 | 1.66 | ||||
star_data25 | STAR-FS02 | /star_data25 | 0.83 | ||||
star_data26 | STAR-FS02 | /star_data26 | 0.84 | ||||
star_data31 | STAR-FS02 | /star_data31 | 0.83 | ||||
star_data36 | STAR-FS02 | /star_data36 | 1.66 | ||||
star_data46 | STAR-FS02 | /star_data46 | 6.60 | ||||
star_data05 | STAR-FS03 | /star_data05 | 2.24 | 18.51 | 21.40 | BA02 | |
star_data13 | STAR-FS03 | /star_data13 | 1.79 | ||||
star_data34 | STAR-FS03 | /star_data34 | 1.79 | ||||
star_data35 | STAR-FS03 | /star_data35 | 1.79 | ||||
star_data48 | STAR-FS03 | /star_data48 | 6.40 | ||||
star_data53 | STAR-FS03 | /star_data53 | 1.50 | ||||
star_data54 | STAR-FS03 | /star_data54 | 1.50 | ||||
star_data55 | STAR-FS03 | /star_data55 | 1.50 | ||||
star_data18 | STAR-FS04 | /star_data18 | 1.00 | 16.86 | 19.45 | ||
star_data19 | STAR-FS04 | /star_data19 | 0.80 | ||||
star_data20 | STAR-FS04 | /star_data20 | 0.80 | ||||
star_data21 | STAR-FS04 | /star_data21 | 0.80 | ||||
star_data22 | STAR-FS04 | /star_data22 | 0.80 | ||||
star_data27 | STAR-FS04 | /star_data27 | 0.80 | ||||
star_data47 | STAR-FS04 | /star_data47 | 6.60 | ||||
star_institutions_mit | STAR-FS04 | /star_institutions/mit | 0.96 | ||||
star_institutions_ucla | STAR-FS04 | /star_institutions/ucla | 1.60 | ||||
star_institutions_uta | STAR-FS04 | /star_institutions/uta | 0.80 | ||||
star_institutions_vecc | STAR-FS04 | /star_institutions/vecc | 0.80 | ||||
star_rcf | STAR-FS04 | /star_rcf | 1.10 | ||||
star_emc | STAR-FS05 | /star_emc | ? | 1.042 | 2.05 | BA4 | |
star_grid | STAR-FS05 | /star_grid | 0.05 | ||||
star_scr2a | STAR-FS05 | /star_scr2a | ? | ||||
star_scr2b | STAR-FS05 | /star_scr2b | ? | ||||
star_starlib | STAR-FS05 | /star_starlib | 0.02 | ||||
star_stsg | STAR-FS05 | /star_stsg | ? | ||||
star_svt | STAR-FS05 | /star_svt | ? | ||||
star_timelapse | STAR-FS05 | /star_timelapse | ? | ||||
star_tof | STAR-FS05 | /star_tof | ? | ||||
star_tpc | STAR-FS05 | /star_tpc | ? | ||||
star_tpctest | STAR-FS05 | /star_tpctest | ? | ||||
star_trg | STAR-FS05 | /star_trg | ? | ||||
star_trga | STAR-FS05 | /star_trga | ? | ||||
star_u | STAR-FS05 | /star_u | 0.97 | ||||
star_xtp | STAR-FS05 | /star_xtp | 0.002 | ||||
star_data01 | STAR-FS06 | /star_data01 | 0.83 | 14.94 | 16.90 | ||
star_data02 | STAR-FS06 | /star_data02 | 0.79 | ||||
star_data06 | STAR-FS06 | /star_data06 | 0.79 | ||||
star_data14 | STAR-FS06 | /star_data14 | 0.89 | ||||
star_data15 | STAR-FS06 | /star_data15 | 0.89 | ||||
star_data38 | STAR-FS06 | /star_data38 | 1.79 | ||||
star_data39 | STAR-FS06 | /star_data39 | 1.79 | ||||
star_data40 | STAR-FS06 | /star_data40 | 1.79 | ||||
star_data41 | STAR-FS06 | /star_data41 | 1.79 | ||||
star_data43 | STAR-FS06 | /star_data43 | 1.79 | ||||
star_simu | STAR-FS06 | /star_simu | 1.80 | ||||
star_data07 | STAR-FS07 | /star_data07 | 0.89 | 16.40 | 19.15 | ||
star_data10 | STAR-FS07 | /star_data10 | 0.89 | ||||
star_data12 | STAR-FS07 | /star_data12 | 0.76 | ||||
star_data17 | STAR-FS07 | /star_data17 | 0.89 | ||||
star_data24 | STAR-FS07 | /star_data24 | 0.89 | ||||
star_data28 | STAR-FS07 | /star_data28 | 0.89 | ||||
star_data29 | STAR-FS07 | /star_data29 | 0.89 | ||||
star_data30 | STAR-FS07 | /star_data30 | 0.89 | ||||
star_data32 | STAR-FS07 | /star_data32 | 1.75 | ||||
star_data33 | STAR-FS07 | /star_data33 | 0.89 | ||||
star_data37 | STAR-FS07 | /star_data37 | 1.66 | ||||
star_data42 | STAR-FS07 | /star_data42 | 1.66 | ||||
star_data44 | STAR-FS07 | /star_data44 | 1.79 | ||||
star_data45 | STAR-FS07 | /star_data45 | 1.66 | ||||
Reshape proposal
| Action effect (+/- impact in TB unit) | ||||||||
Action | FS01 | FS02 | FS03 | FS04 | FS05 | FS06 | FS07 | SATA | |
2008/08/15 | Move/backup data25, 26, 31, 36 to SATA |
| 4.56 |
|
|
|
|
| -4.56 |
2008/08/18 | Drop 25, 26, 31, 36 from FS01 and expand on SATA to 5 TB |
|
|
|
|
|
|
| -15.84 |
2008/08/22 | Shrink 46 to 5 TB, move to SATA and make it available at 5 TB |
| 6.60 |
|
|
|
|
| -5.00 |
|
|
|
|
|
|
|
|
| |
2008/08/19 | Move institutions/ksu and institutions/iucf to FS02 | 1.60 | -1.60 |
|
|
|
|
|
|
2008/08/19 | Expand ksu and iucf to 2 TB |
| -0.80 |
|
|
|
|
|
|
2008/08/22 | Move institutions/bnl to FS02 | 3.50 | -3.50 |
|
|
|
|
|
|
Expand bnl to 4 TB |
| -0.50 |
|
|
|
|
|
| |
Expand lbl by 4.2 TB (i.e. 14 TB) | -4.20 |
|
|
|
|
|
|
| |
Expand emn to 2 TB | -0.40 |
|
|
|
|
|
|
| |
Expand data03 to 2.5 TB |
| -0.70 |
|
|
|
|
|
| |
Expand data04 to 2 TB |
| -1.00 |
|
|
|
|
|
| |
Expand data08 to 2 TB |
| -1.00 |
|
|
|
|
|
| |
Expand data16 to 2 TB |
| -0.34 |
|
|
|
|
|
| |
Expand data09 to 2 TB |
| -1.00 |
|
|
|
|
|
| |
Checkpoint |
| 0.50 | 0.72 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | -25.40 |
Action | FS01 | FS02 | FS03 | FS04 | FS05 | FS06 | FS07 | SATA | |
2008/08/22 | Shrink data 48 to 5 TB,move to SATA |
|
| 6.40 |
|
|
|
| -5.00 |
Expand data05 to 3 TB |
|
| -0.76 |
|
|
|
|
| |
Expand 13, 34, 35, 53, 54 and 55 to 2.5 TB |
|
| -5.13 |
|
|
|
|
| |
|
|
|
|
|
|
|
|
| |
2008/08/22 | Shrink and move data47 to SATA |
|
|
| 6.60 |
|
|
| -5.00 |
Move 18,19, 20, 21 to SATA |
|
|
| 3.40 |
|
|
| -3.40 | |
Expand data18, 19, 20, 21 to 2.5 TB |
|
|
|
|
|
|
| -6.60 | |
Add to FS02 a institutions/uky at 1 TB |
|
|
| -1.00 |
|
|
|
| |
Add to FS02 a institutions/psu at 1 TB |
|
|
| -1.00 |
|
|
|
| |
Add to FS02 a institutions/rice at 1 TB |
|
|
| -1.00 |
|
|
|
| |
Expand vecc to 2 TB |
|
|
| -1.20 |
|
|
|
| |
Expand ucla to 3 TB |
|
|
| -1.40 |
|
|
|
| |
Expand 22 and 27 to 1.5 TB |
|
|
| -1.40 |
|
|
|
| |
Expand /star/rcf to 3 TB |
|
|
| -1.90 |
|
|
|
| |
Checkpoint |
| 0.50 | 0.72 | 0.51 | 1.10 | 0.00 | 0.00 | 0.00 | -45.40 |
Action | FS01 | FS02 | FS03 | FS04 | FS05 | FS06 | FS07 | SATA | |
Free (HPSS archive) emc, src2a, src2b, stsg, timelapse, tof |
|
|
|
| 0.00 |
|
|
| |
Free (HPSS archive) tpc, tpctest, trg, trga |
|
|
|
| 0.00 |
|
|
| |
|
|
|
|
|
|
|
|
| |
Move 40, 41, 43 to SATA |
|
|
|
|
| 5.37 |
| -5.37 | |
Expand 01 to 2 TB |
|
|
|
|
| -1.17 |
|
| |
Expand 02 to 2 TB |
|
|
|
|
| -1.21 |
|
| |
Expand star_simu to 3 TB |
|
|
|
|
| -1.20 |
|
| |
Checkpoint |
| 0.50 | 0.72 | 0.51 | 1.10 | 0.00 | 1.79 | 0.00 | -50.77 |
Missing information and progress records:
- 2008/08/14 13:44 - Answer from the RCF as per the above plan being approved (and commented it seemed easy)
- Two caveats: ETA cannot be provided until migration starts (one test example) to get a more accurate estimate
- While virtualmount point are swapped between one storage pool to another, there may be a fluke in access (will need infomring institutions / production disk will be handled by hard-dismount)
- 2008/08/14 13:42 - Sent an Email requesting infomration regarding disk manager and/or policies for PSU, UKY and RICE - Email sent to council rep and/or designated rep on August 14th 2008
- Answer from UKY 2008/08/14 13:56 >> Disk space manager=Renee Fatemi, policy = MIT policy
- Answer from PSU 2008/08/15 16:07 >> Policy is standard
- 2008/08/18
- Achieved actions marked in Italic + date
- Date in Italic are ongoing actions
- If two dates appear, the first is the start of the action and the second the end
2009
Requirements and resource planing for 2009.
CPU and bulk storage purchase 2009
The assumed CPU profile will be:
- 2 GB of memory per core
- Nearly 6 TB of disk space per node
- Several CPU model will be investigated for best price/performance ratio (bulk purchase pricing matters in this purchase hence coordination between STAR/Phenix is likely needed) - currentely being considered are
- Xeon 5550 @ 3350 SI2k (scenario A)
- Xeon 5560 @ 3526 SI2k (scenario B)
The share between space and CPU is as below within the following caveats:
- THe additional massive amount of storage (+170 TB for production) requires a secondary Titan head and the proper network switches. The total cost is projected to be ~ 50k$ and we agreed to leave a ~ 20k$ unspent fund to move in this direction (cost shared with facility budget)
|
Experiment Parameters |
Scenario A |
Scenario B |
|
Central Disk (TB) - Institution |
20.00 |
20.00 |
|
Type Institution (Index from C&C) |
11 |
11 |
|
Cost of Central Disk for Institution |
$62,441.47 |
$62,441.47 |
|
Central Disk (TB) - NexSan-Production |
0.00 |
0.00 |
|
Type NS-Prod (Index from C&C) |
13 |
13 |
|
Cost of NexSan-Production |
$0.00 |
$0.00 |
|
Central Disk (TB) - Production |
170.00 |
170.00 |
|
Type of Production (Index from C&C) |
12 |
12 |
|
Cost of Production Disk |
$136,374.27 |
$136,374.27 |
|
Total Size of new Central Disk (TB) |
190.00 |
190.00 |
|
Total Cost of Central Disk |
$198,815.74 |
$198,815.74 |
|
Cost of Servers to support Central Disk |
|
|
|
|
|
|
|
Compensation Disk entitled (TB) |
0.00 |
0.00 |
|
Amount (up to entitlement) (TB) |
0.00 |
0.00 |
|
Cost of Compensation Disk |
$0 |
$0 |
|
Remaining Funds |
$0 |
$0 |
|
|
|
|
|
Compensation count (1U, 4 GB below) |
0 |
0 |
|
Compensation count (1U, 8 GB below) |
0 |
0 |
|
CPU Cost |
$0 |
$0 |
|
Distributed Disk |
0.0 |
0.0 |
|
kSI2k |
0.0 |
0.0 |
|
|
|
|
|
CPU Type (Index from Constants&Costs) |
2 |
5 |
|
# 2U, 55xx, 5700 GB disk, 24 GB |
74 |
72 |
|
CPU Alternative (not used) |
0 |
0 |
|
CPU Cost |
$429,126 |
$427,680 |
|
Distrib. Disk on new machines (TB) |
421.8 |
410.4 |
|
kSI2k new |
1983.2 |
2031.0 |
|
Total Disk (TB) |
1393.8 |
1382.4 |
|
Total CPU (kSI2000) |
4303.2 |
4351.0 |
|
Total Cost |
$627,942 |
$626,496 |
|
Outside Funds Available |
$62,441 |
$62,441 |
|
Funds Available |
$588,000 |
$588,000 |
|
Unspent Funds |
$22,500 |
$23,946 |
Disk space for FY09
Institution disk space
The below is what was gathered as the call sent to starsoft "Inquiry - institutional disk space for FY09" (with delay, a copy was sent to starmail on the 14th of April 2009). The deadline was provided as the end of Tuesday the 14th 2009, feedback was accepted until Wednesday the 15th (anything afterward could have been ignored).
| Institution | # TB | confirmed |
| LBNL | 5 | April 21st 17:30 |
| BNL hi | 2 | [self] |
| BNL me | 1 | [self] |
| NPI/ASCR | 3 | April 22nd 05:54 |
| UCLA | 1 | |
| Rice | 4 | April 21st 18:47 |
| Purdue | 1 | April 22nd 15:12 |
| Valpo | 1 | April 22nd 17:59 |
| MIT | 2 | April 22nd 15:56 |
| Total | 20 |
The pricing on the table is as initially advertised i.e. a BlueArc Titan 3200 based solution at 4.3 k$/ TB for fiber channel based storage. For a discussion of fiber channel versus SATA, please consult this posting in starsofi. A quick performance overview of the Titan 3200 is showed below:
| Titan 3200 | |
| IOPS | 200,000 |
| Throughput | Up to 20Gbps (2.5 GB/sec) |
| Scalability | Up to 4PB in a single namespace |
| Ethernet Ports | 2 x 10GbE or 6 x GbE |
| Fibre Channel Ports | Eight 4Gb |
| Clustering Ports |
Two 10GbE |
Solution enables over 60,000 user sessions and thousands of compute nodes to be served concurrently.
The first scalability statement is over the top comparing to RHIC/STAR need but the second is by far reached at the RCF environment.
Production space
SATA based solution will be priced at 2.2 k$ / TB. While the price is lower than the fiber channel solution (and may be tempting), this solution is NOT recommended for institutional disk as the scalability for read IO at the level we are accustom to is doubtful (doubtful is probably an under-statement as we know by 5 years ago experience we will have to apply IO throttling).
As a space for production however (and considering resource constrained demanding cheaper solutions coupled with a Xrootd fast IO based aggregation solution which will remain the primary source of data access to users), the bet is that it will work if used as a buffer space (production jobs write locallyto the worker nodes, move files to central disk at the end as an additional copy along an HPSS data migration). There will be minimal guarantees of read performance access for analysis on those "production reserved" storage.
One unit of Thumper at 20k$ / 33 TB usable will be also purchased and tried out in special context. This solution is even less scalable and hence, requires a reduced amount of users and IO. The space targeted for this lower end may include (TBC):
- data06 & data07 (2 TB) - reserved for specific projects and not meant for analysis, performance would not an issue
- data08 (2 TB) - meant for Grid, IO is minimal there but we may need to measure data transfers compatible with KISTI based production
- /star/rcf (5 TB) - production log space (delayed IO, mostly a one time saving and will be fine)
Final breakdown
Post procurement 1 space topology
Following the Disk space for FY09, here is the new space topology and space allocation.
| BlueArc01 | BlueArc02 | BlueArc04 | |||
|---|---|---|---|---|---|
| STAR-FS01 | Space | STAR-FS03 | Space | STAR-FS05 | Space |
| star_institutions_emn | 2.0 | star_data05 | 3.0 | star_grid | 0.5 |
| star_institutions_lbl | 14.0 | star_data13 | 2.5 | star_starlib | 0.25 |
| star_institutions_lbl_prod | 5.0 | star_data34 | 2.5 | star_u | 1.6 |
| star_institutions_mit | 3.0 | star_data35 | 2.5 | ||
| star_institutions_rice | 5.0 | star_data53 | 2.5 | STAR-FS06 | Space |
| star_data54 | 2.5 | star_data01 | 2.2 | ||
| STAR-FS02 | Space | star_data55 | 2.5 | star_data02 | 2.2 |
| star_data03 | 2.5 | star_data06 | 1.0 | ||
| star_data04 | 2.0 | STAR-FS04 | Space | star_data14 | 1.0 |
| star_data08 | 2.0 | star_data22 | 2.0 | star_data15 | 1.0 |
| star_data09 | 2.0 | star_data27 | 1.5 | star_data16 | 2.0 |
| star_institutions_bnl | 6.0 | star_institutions_psu | 1.0 | star_data38 | 2.0 |
| star_institutions_bnl_me | 1.0 | star_institutions_purdue | 1.0 | star_data39 | 2.0 |
| star_institutions_iucf | 1.0 | star_institutions_ucla | 4.0 | star_simu | 3.0 |
| star_institutions_ksu | 1.0 | star_institutions_uky | 1.0 | ||
| star_institutions_npiascr | 3.0 | star_institutions_uta | 1.0 | STAR-FS07 | Space |
| star_institutions_valpo | 1.0 | star_institutions_vecc | 2.0 | star_data07 | 0.89 |
| star_rcf | 3.0 | star_data10 | 0.89 | ||
| star_data12 | 0.76 | ||||
| star_data17 | 0.89 | ||||
| star_data24 | 0.89 | ||||
| star_data28 | 0.89 | ||||
| star_data29 | 0.89 | ||||
| star_data30 | 0.89 | ||||
| star_data32 | 1.75 | ||||
| star_data33 | 0.89 | ||||
| star_data37 | 1.66 | ||||
| star_data42 | 1.66 | ||||
| star_data44 | 1.79 | ||||
| star_data45 | 1.66 |
Projects & proposals
This page is under constructions. Most projects are stil under the Projects and proposals page and not revised.
- Supplemental funds were requested from DOE to help with infrastructure issues for both STAR & Phenix (and in predicion of a difficult FY10 funding cycle). The document is attached below as Supplemental-justification-v0 7.jl_.pdf
- CloudSpan: Enabling Scientific Computing Across Cloud and Grid Platforms proposal was granted a Phase-I SBIR. This proposal is made in collaboration with Virkaz Tech.
- Customizable Web Service for Efficient Access to Distributed Nuclear Physics Relational Databases proposal was granted a Phase-II award.
2010
.
CPU and bulk storage purchase 2010
Institutional disk space summary
Announcement for institutional disk space was made in starmail on 2010/04/26 12:31.
To date, the following requests were made (either in $ or in TB):
| Institution | Contact | Date | $ (k$) | TB equivalent | Final cost | ||
| LBNL | Hans Georg Ritter | 2010/04/26 15:24 | 20 | 5 | $17,006.00 | ||
| ANL | Harold Spinka | 2010/04/26 16:29 | - | 1 | $3,401.00 | ||
| UCLA | Huan Huang | 2010/04/26 16:29 | - | 1 | $3,401.00 | ||
| UTA | Jerry Hoffmann | 2010/04/27 14:59 | - | 1 | $3,401.00 | ||
| NPI | Michal Sumbera & Jana Bielcikova | 2010/04/20 10:00 | 30 | 8 | $27,210.00 | ||
| PSU | Steven Heppelmann | 2010/04/29 16:00 | - | 1 | $3,401.00 | ||
| BNL | Jamie Dunlop | 2010/04/29 16:45 | - | 5 | $17,006.00 | ||
| IUCF | Will Jacobs | 2010/04/29 20:18 | - | 2 | $6,802.00 | ||
| MIT | Bernd Surrow | 2010/05/08 18:07 | - | 2 |
|
||
| Totals | 24 |
|
The storage cost for 2010 was estimated at 3.4k$ / TB. Detail pricing below.
Central storage cost estimates
Since the past storage stretches on the number of servers and scalability, we would (must) buy a pair of mercury servers which recently cost us $95,937. The storage itself would be based on a recent pricing i.e. a recent configuration quoted it as: (96) 1TB SATA drives, price $85,231 + $2,500 installation yielding to 54 TB usable. STAR's target is 50 TB for production +5+10 TB for institution (it will fit and can be slightly expanded). Total cost is hence:
$95,937 + $85,231 + $2,500 = $183,668 / 54TB = 3401/TB
Detail cost projections may indicate (depending on global volume) a possibly better pricing: the installation price (a haf a day of work for a tech from BlueArc) is fixed and each server pair could hold more than the planned storage (hence the cost for two servers is also fixed). Below a few configurations:
| Service installation | 2500 | 2500 | 2500 | |
| Cost for 54+27 TB | 127846.5 | |||
| Cost per 54 TB | 85231 | |||
| Cost per 27 TB | 42615.5 | |||
| Two servers | 95937 | 95937 | 95937 | |
| Price with servers | 183668 | 141052.5 | 226283.5 | |
| Price per TB | 3401.3 | 5224.2 | 3187.1 | |
| Price per MB | 0.003244 | 0.004982154 | 0.003039447 | |
CPU estimates, choices, checks
Projected / allowed CPU need additional based on funding guidance (see CSN0474 : The STAR Computing Resource Plan, 2009): 7440 kSi2k / 2436 kSi2k - projected to be 43% shortage
Projected distributed storage under the same condition (dd model has hidden assumptions): 417 TB / 495 TB - projected to be at acquired level 130% off optimal solution
The decision was to go for 1U machine, switch to the 2 TB drive Hitachi HUA722020ALA330 SATA 3.0 Gbps drive to compensate from drive space loss (4 slots instead of 6 in a 2U). The number of network ports was verified to be adequate for our below projection. The 1U configuration allows recovering more CPU power / desnity. Also, the goal is to move to a boosted memory configuration and enable hyper-threading growing from 8 Batch slots to a consistent 16 slots per node (so another x2 although the performance scaling will not be x2 due to the nature of hyper-threading). Finally, it was decided NOT to retire the older machines this year but keep them on until next year.
Planned numbers
- Distributed storage additional: 1009.4 TB
- Only 3/4th of this space is usage * 90% for high watermarking hence, we end up with 681 TB of new storage. The assumption is that one of teh 2 TB disk will go to support production and user analysis (the likely proper number is 1 TB, hence a 16% effect and margin TBC).
- The total required space for considering all production passes within a year is 1440 TB.
- The accumulated total usable distributed storage is 277 TB - the total space is hence planned to be 958 TB with the assumptions above (possibly 30% shortfall or only 15% if we recover 1 TB from the OS+TEMP disk).
- Conclusion: distributed storage will remain constrained as planned (not all productions will be available but near all).
- The total centralized disk needed for 2010 was 50 TB. The final number will be a 81 TB unit - 24 TB for institutional support = 57 TB storage.
- Conclusion: The central storage will have a small margin of flexibility allowing expansion of simu space and other similar areas
- The total needed CPU required was projected to be 11634 kSI2k
- Within the current procurement, the total CPU will reach 8191 kSI2k with 1U nodes (would have been 6827 kSI2k for 2U nodes).
- Our shortfall will be ~ 30% off the theoretical projected needs. Initial projection was a fall by 43% (so a 13% gain by balancing cost between storage, memory and CPU).
- Assuming the hyper-threading will allow for at least a gail factor of x1.4 (TBC but evidence through beta-testing indicates this is likely), the shortfall may be as little as 16% shortfall. This number is within reacheable enhanced duty factor.
- Conclusion: the shortfall, if the initial projections remain accurate, is assumed to be from 16 to 30%.
Reality checks:
- Event size estimates DAQ + Event size estimates reco - implicitly done in You do not have access to view this node - the bottom line is that the space is tracking fine but overall, we exceeded our goals not by 50% as initially though but by 79% +/- 2%.
- Processing time estimates (extracted from FastOflfine, final times are unclear due to slow time caused by the so-called Speeding up DB access using SSD or Memory (see also Effect of stream data on database performance, a 2010 study).
Accounting check - post install
Since we had many problems with missmatch of purchased/provided space with the RCF in past years, keeping track of the space accounting is a good idea. Below is an account of where the space went (we should total to 55 TB of production space and 26 TB of institution space).
| Disk | Initial space | Final size | Total |
| lbl_prod | 5 | 5 | 10 |
| lbl | 14 | 0 | 14 |
| anl | 0 | 1 | 1 |
| mit | 3 | 2 | 5 |
| bnl | 6 | 5 | 11 |
| iucf | 1 | 2 | 3 |
| npiascr | 3 | 8 | 11 |
| psu | 1 | 1 | 2 |
| ucla | 4 | 1 | 5 |
| uta | 1 | 1 | 2 |
| Total added | 26 | ||
| data08 | 2 | 2.5 | 4.5 |
| data09 | 2 | 3 | 5 |
| data22 | 2 | 3.5 | 5.5 |
| data23 | 5 | 0.5 | 5.5 |
| data27 | 1.5 | 4 | 5.5 |
| data11 | (gone in 2009) | 5 | 5 |
| data23 | (gone in 2009) | 5 | 5 |
| data85 to 89 | N/A | 5*5 | 25 |
| data90 | N/A | 6 | 6 |
| Total added so far | 54.5 | ||
There should be a 0.5 TB unallocated here and there.
2011
Quick notes - initial purchase cycle process
- Discussion on procurements re-opened on 2011/05/31. Discussed with facility director on of institutional disk space dire need for STAR (following some chat from the last Collaboration Meeting) - general commitment was to try to find a viable payment solution (still unclear how)
- Initial call for institutional disk space need made on 2011/06/01 - only couple days for feedback (requirements total is needed immediately as agreed with the facility director). Provided feedback insofar
- 2011/06/01 12:17: UCLA + 2 TB
- 2011/06/01 12:20: Purdue + 3 TB
- 2011/06/02 11:07: NPI/ASCR + 7 TB
- 2011/06/02 21:16: LBL + 7 TB
- Other note
- 2011/06/02 03:33: Valpo U offered to pay back this year what they owed last year (1 TB equivalent)
- Exceeded deadline (low priority request with even less guarantees):
- 2011/06/06 15:32: IUCF + 2 TB
- 2011/06/06 16:14: BNL + 5 TB
- Exceeded submission of the requirements request
- 2011/06/14 10:54: UTA + 1.5 TB
2011/06 - FY11 procurement Status
- Requirements turn to the RCF on 2011/06/09 - institutions in blue above were included but institution in red was NOT (for obvious date reason)
- Purchase for the Linux farm went out on the 10th
- Requests for storage quotes went out on the 13th
- Any other requests will need to be re-addressed at a later time: 2x 26 TB cabinets were ordered exceeding the storage request from STAR of 36 TB total for FY11
Summary of requests and dues:
| Institution | Space (TB) | Estimated cost * |
Charged & date | Left over due + |
| UCLA | 2 | 4802.47808 | 4,800$ - ????/??/?? | 3$ |
| Purdue | 3 | 7203.71712 | 7,203.72$ - 2013/02/20 | 0$ |
| NPI/ASCR | 7 | 16808.67328 | 15,000$ - 2011/12/09 | 1,809$ |
| LBNL | 7 | 16808.67328 | 14,160$ - 2011/06/15 | 2,649$ |
| IUCF | 2 | 4802.47808 | 6,802$ - 2012/06/11 | (past unpaid due added) |
| BNL | 5 | 12006.1952 | (internal) | 0$ |
| Grand totals | 26 | 62432.21504 |
* ATTENTION: estimated cost based on initial purchase cost estimates. Final price may varry.
+ Unless a number appears in this column, the estimated cost is due in full. Multiple charge may apply to a given institution (until total dues are collected).
Acquired otherwise:
| Additional | Total after purchase | %tage increase | S&C plan 2008 | Deficit * | |
| Central space (prod) | 10.00 | 345.00 | 2.90% | 377.00 | -8.49% |
| Distributed disk space | 430.47 | 1456.47 | 29.56% | 2659.50 | -45.24% |
| kSI2K farm | 3045.00 | 6900.00 | 44.13% | 30115.00 | -77.09% |
* ATTENTION: Note-A: deficit assumes a similar run plan - U+U was suggested for FY11 ; Note-B: increase in number of events is not helping; Note-C: if we are lucky and size / events is smaller than projected, the distributed disk may be fine.
Disk space status on 2011/08/04
Storage
| Mount | Y2010 | Current | Requested | Status / Comment |
|---|---|---|---|---|
| ANL | 1 | 1 | ||
| BNL | 11 | 16 | +5 | Taken care off |
| BNL_ME | 1 | 1 | ||
| EMN | 2 | 2 | ||
| IUCF | 3 | 5 | +2 | Taken care off |
| KSU | 1 | 1 | ||
| LBL | 14 | 14 | +5 | Taken care off |
| LBL_PROD | 10 | 12 | +2 | Taken care off |
| MIT | 5 | 5 | ||
| NPIASCR | 11 | 18 | +7 | Taken care off |
| PSU | 2 | 2 | ||
| PURDUE | 1 | 4 | +3 | Taken care off |
| RICE | 5 | 5 | ||
| UCLA | 5 | 7 | +2 | Taken care off |
| UKY | 1 | 1 | ||
| UTA | 2 | 2 | ||
| VALPO | 1 | 1 | ||
| VECC | 2 | 2 |
2012
The 2012 budget did not allow for flexible choices of hardware or storage. The RHIC experiments were not asked for partitioning (1/2 and 1/2 was done for STAR and PHENIX and essentially coverred for new farm nodes). Storage was handled via a replacement of old storage by newer storage media (and we doubled out space).
Since several institutional disk space bills were pending (unpaid), that possibility did not offer itself either. See the 2011 requirements for where we were.
2013
Requirements and plans for 2013
The RCF budget was minimal - no extranl disk purchase was carried but essentially, "infrastruture" related money (HPSS Silo expansion) too the core budget modulo some left for COU purchases.
Software effort level by sub-systems
Please map in blue with physics program.
N/A indictae constant effort level for duration of the project.
| Sub system | Task description | Aproximate time | Start time needed | Core FTE | Sub-sys FTE |
| HFT | Geometry / alignment studies Includes dev geometry development, developing alignment procedures, infrastructure support for code and alignment, |
12 months | 2012-10-01 | 0.2 | 2*0.5=1.0 |
| HFT | Survey, Db work and maintenance | 12 months | 2012-10-01 | 0.1 | 0.5 |
| HFT | Detector operations. Includes monitoring QA, calibrations, alignment for PXL, IST,SSD | Each Run | 2013-03-01 | 0.1 | 3*0.5=1.5 |
| HFT | Tracking studies, Stv integration and seed finder studies | 12 months | 2012-10-01 | 0.4 | 0.5 |
| HFT | Cluster/Hit reconstruction: DAQ for PXL, SSD, IST and definition of base structures but also development of Fast simulator | 12 months | 2012-10-01 | 0.2 | 1.0 |
| HFT | Decay vertex reconstruction, development of secondary vertex fitting methods and tools | 8 months | 2012-12-01 | 0.1 | 0.3 |
| HFT | General help | N/A | 2012-09-01 | 0.1 | 0.2 |
| FGT | Tracking with Stv including integration of FGT and EEMC, ... ECAL W program requires good charge separation. Requirements for other physics goals like direct photon in the EEMC, delta-G, jets, IFF and x-sections have to be investigated and likely range from crude track reconstruction for vetoing to optimal momentum reconstructions |
8 months | 2012-12-01 | 0.6 | 0.2 |
| FGT | Vertexing for forward physics | 2 months | 2013-04-01 | 0.2 | 0.3 |
| FGT | Alignment study, improvements | 8 months | 2012-12-01 | 0.2 | 0.5 |
| FGT | Improvements and tuning (Cluster finding, ...) | 3 months | 2013-01-01 | 0.0 | 0.3 |
| FGT | Tuning simulation to data, comparison studies using VMC | 10 months | 2012-12-01 | 0.3 | 1.0 |
| FGT | MuDST related work | 1 month | 2012-02-01 | 0.1 | 0.1 |
| FGT | Miscellaneous maintenance | N/A | 0.1 | 0.2 | |
| FMS | Database interface, client and maintenance | N/A | 0.1 | 0.2 | |
| FMS | Better simulation for the FMS, VMC based | 6 months | 0.2 | 0.4 | |
| TPC | Calibration and alignment efforts: space charge and grid leak distortions and calculating correction factors, twist correction work, alignment (sector to sector as well as inner to outer), T0 and gain determinations, and dE/dx calibration | 22 months | 2013-01-01 | 0.5 | 1.5 |
| TPC | Calibration maintenance (methods developed converged, documented and automated) | N/A | 2015-01-01 | 0.3 | 0.7 |
| TPC | Calibration R&D: alignment and distortions | 8 months | 2012-07-01 | 0.2 | 0.3 |
| TPC | Understanding aging effects | 20 months | 2012-07-01 | 0.5 | 0.0 |
| TPC | iTPC upgrade efforts as well as contingency planning for existing TPC. Design and construction of a sector removal tool. | 20 months | 2012-07-01 | 0.5 | 1.5 |
| UPG | Geometry implementation for ETTR, FCS, VFGT | 6 months | 2012-07-01 | 0.2 | 0.5 |
| UPG | Event generator integration and simulator development (initial effort for generator, effort for proposal, longer term efforts as needed) | 12 months | 2012-07-01 | 0.2 | 0.5 |
| EEMC | Calibration support for physics readiness, software adjustements and maintenance | N/A | 2013-01-01 | 0.1 | 0.3 |
| EEMC | SMD calibration related software development | coming year | 2013-01-01 | 0.0 | 0.1 |
| EEMC | EEMC alignement work, development of better methods | 12 months | 2013-01-01 | 0.0 | 0.5 |
| EEMC | Cluster MIPS studies | 6 months | 2013-01-01 | 0.0 | 0.2 |
| TOF | Calibration support, software and database maintenance. Provide final parameters for TOF-based PID, and status tables for BTOF in PPV |
per run | 2013-01-01 | 0.2 | 0.5 |
| TOF | Separate TOF and VPD slow simulators | 2 months | 2013-01-01 | 0.2 | 0.5 |
| TOF | Simulation studies, mixermaker | 6 months | 2013-01-01 | 0.1 | 1.0 |
| TOF | Geometry maintenance | 2 months | 2013-01-01 | 0.2 | 0.2 |
| MTD | Calibration support, software maintenance. Provide final parameters for MTD-based muon ID | per run | 2013-01-01 | 0.1 | 1.0 |
| MTD | Simulation studies & development: simulation maker. | 6 months | 2013-01-01 | 0.2 | 1.0 |
| MTD | Software development: calibration maker | 6 months | 2013-01-01 | 0.2 | 1.0 |
| MTD | Geometry maintenance | 2 months | 2013-01-01 | 0.2 | 0.2 |
| MTD | Database maintenance & development | 2 months | 2013-01-01 | 0.1 | 0.5 |
2014
The base budget was sufficient to purchase network equipment needed to move to 10 GbE, a first wave of HPSS upgrade (disk cache, drive for Run 14 bandwidth requirements), refresh of BlueArc storage (end of warranties) and purchase of the GPFS system (with supplemental funds argued by STAR). The remainder went into purchasing an equal amount of CPU to be shared between STAR and PHENIX (TBC).
2015
Budget initially thought to be allocated for the RCF for equipment growth and refresh was not provided. Only emergency purchases and minor refresh were done (like replacing dying drives on 4-6 years old hardware to keep it alive) from a farm/processing perspective.
The latest computing resource needs is available at PSN0622 : Computing projections revisited 2014-2019. Even under a modest budget, the resources were dimmed insufficient to meet the need for timely scientific throughput. A new projection based on the non-funding profile of FY15 is not available at this time.