- General information
- Data readiness
- Grid and Cloud
- Infrastructure
- Online Computing
- Software Infrastructure
- Batch system, resource management system
- Computing Environment
- Facility Access
- FileCatalog
- HPSS services
- Home directories and other areas backups
- Hypernews
- Installing the STAR software stack
- Provision CVMFS and mount BNL/STAR repo
- RCF Contributions
- Software and Libraries
- Storage
- Tools
- Video Conferencing
- Web Access
- Machine Learning
- Offline Software
- Production
- Test tree
HPSS Performance study
Updated on Mon, 2006-10-30 18:39. Originally created by jeromel on 2006-10-29 07:48.
Under:
File size effects on IO performance
In this paper (CERN/IT 2005), the author measured the IO performance as a function of file size and number of files requested per tape. The figure of relevance is added here for illustration.
 This graph has been extracted for an optimal 30 MB/s capable drive (9940B like). Both file size and number of files per cartriges have been evaluated. The conclusions are immediate and confirms the advertized behavior observed by all HPSS deployment (see references below). Smal file size is detrimental to HPSS IO performance and this size highly depends on the tape technology.
This graph has been extracted for an optimal 30 MB/s capable drive (9940B like). Both file size and number of files per cartriges have been evaluated. The conclusions are immediate and confirms the advertized behavior observed by all HPSS deployment (see references below). Smal file size is detrimental to HPSS IO performance and this size highly depends on the tape technology.
In STAR, we use the 9940B (read only as per 2006) and LT0-3 drives (read and write /all new files would go to LTO-3). The finding would not be altered but we have little marging of flexibility as per the "old" tape drive.
Below, we show the average file size per file type in STAR as a 2006 snapthot.
Note that the average size for an event file is 284MB while for a MicroDST, the size average is 84 MB so a ratio of 3. The number of files per catriges is at best 1.2 files per cartriges with peaks at 10 or more. THis is mostly due to a request profile dominated by Xrootd "random" pattern and a few user's requests. According to the previous study, the IO efficiency should be around 8% for 84 MB file and reaching perhaps 20-25% efficiency for a 284 MB average file class. Cosndiering we have not studied the drive access pattern beyond a simple scaling (i.e. we will ignore to first order the fcat we have many drives at our disposal), we should see a performance change change from 8 to 20 so an improvement of x2.5-3 shall the file size argument stand.
In order to observe the IO performance when small or big files are being requested, we requested event files to the DataCarousel and produced the below two graphs for the dates ranging between 2006/10/26 and 2006/10/29. The first graph represents the IO "before" the massive submission of event file dominated requests, the second the graph "after" the event. The graphs are preliminary (work in progress).
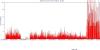
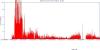 We observe an average transfer rate at best saturating at 15 MB/sec for MuDST
dominated files and an average close to 50 MB/sec for event files. The ratio is
~ 3 which remains consistent with the results on HPSS IO efficiency per file size and per and
our initial rough estimate.
We observe an average transfer rate at best saturating at 15 MB/sec for MuDST
dominated files and an average close to 50 MB/sec for event files. The ratio is
~ 3 which remains consistent with the results on HPSS IO efficiency per file size and per and
our initial rough estimate.
Note: It is interresting to note that a significant mix of very small files (below 12 MB average) would bring the performance to a sub 1% efficiency. The net result for 9 drives (as we have in STAR) would be an aggregate performance no better than 3MB/sec for a 9940B x 9 drive configuration . We observe periods with such poor performance. The second observation is that even with MuDST dominated files only, we would not be able to exceed in speed 70% of the performance of one drive so at best, 21 MB/sec (this correspond to our current "best hour"). The results are coherent to first order.
 While there are errors at the early stage of this graph, reminissent of previous
failures, problems during the focused time period starts around 9 AM with a MetaData
lookup failure (cannot get lock after 5 retries). Subsequentely, there is an immediate
appearance of files failing to be restored for more than an hour and this continues
up to around 10:30 to 11:00 at ehich point, more errors occur from the Mass Storage
system (a mix of MetaData lookup failure and massive authentication failures). The
authentication failures are related to the DCE component failure, causing periodic
problems. In our case, we immediately the light blue band continuing for up to 15:00
(3 PM) followed but yet again a massive meta data failure. All of those cacading
failures would, for a period of no less that 6 hours long, affect users requesting
files from Xrootd which would needto be restored from MSS.
While there are errors at the early stage of this graph, reminissent of previous
failures, problems during the focused time period starts around 9 AM with a MetaData
lookup failure (cannot get lock after 5 retries). Subsequentely, there is an immediate
appearance of files failing to be restored for more than an hour and this continues
up to around 10:30 to 11:00 at ehich point, more errors occur from the Mass Storage
system (a mix of MetaData lookup failure and massive authentication failures). The
authentication failures are related to the DCE component failure, causing periodic
problems. In our case, we immediately the light blue band continuing for up to 15:00
(3 PM) followed but yet again a massive meta data failure. All of those cacading
failures would, for a period of no less that 6 hours long, affect users requesting
files from Xrootd which would needto be restored from MSS.
From all failures, the relative proprtion for that day is displayed below
 Only one error in this graph (a DataCarousel connection failue) cna be fixed from a STAR stand point, allother occurances being a facility issue to resolve.
Only one error in this graph (a DataCarousel connection failue) cna be fixed from a STAR stand point, allother occurances being a facility issue to resolve.
Introduction
HPSS is software that manages petabytes of data on disk and robotic tape libraries. We will discuss in this section our observations as per the efficiency of accessing files in STAR as per a snapshot of the 2006 situation. It is clear that IO opptimizations has several components amongst which:- Access pattern optimization (request ordering, ...)
- Optimization based on tape drive and technology capabilities
- Miscellaneous technology considerations
(cards, interface, firmware and driver, RAID, disks, ...) - HPSS disk cache optimizations
- COS and/or PVR optimization
Tape drive and technology capabilities
A starting point would be to discuss the capabilities of the technologies involved and their maximum performance and limitations. In STAR, two technologies remain as per 1006/10:- the 994B drives
- the LTO-3 drives
Access pattern optimization (request ordering, ...)
A first simple and immediate consideration is to minimize tape mount and dismount operations, causing latencies and therefore performance drops. Since we use the DataCarousel for most restore operations, let's summarize its features.
The DataCarousel
The DataCarousel (DC) is an HPSS front end which main purpose is to coordinate requests from many un-correlated client's requests. Its main assumption is that all requests are asynchronous that is, you make a request from one client and it is satisfied “later” (as soon as possible). In other words, the DC aggregates all requests from all clients (many users could be considered as separate clients) and re-order them according policies, and possibly aggregating multiple requests for the same source into one request to the mass storage. The DC system itself is composed of a light client program (script), a plug-and-play policy based server architecture component (script) and a permanent process (compiled code) interfacing with the mass storage using HPSS API calls (this components is known as the “Oakridge Batch” although it current code content has little to do with the original idea from the Oakridge National Laboratory). Client and server interacts via a database component isolating client and server completely from each other (but sharing the same API , a perl module).
Policies may throttle the amount of data by group (quota, bandwidth percentage per user, etc ... i.e. queue request fairshare) but also perform tape access optimization such as grouping requests by tape ID (for equivalent share, all requests from the same tape are grouped together regardless of the time at which this request was performed or position in the request queue). The policy could be anything one can come up with based on the information either historical usage or current pending requests and characteristics of those requests (this could include file type, user, class of service, file size, ...). The DC then submits bundle of requests to the daemon component ; each request is a bundle of N file and known as a “job”. The DC submits K of those jobs before stopping and observing the mass storage behavior: if the jobs go through, more are submitted otherwise, either the server stops or proceed with a recovery procedure and consistency checks (as it will assume that no reaction and no unit of work being performed is a sign of MSS failure). In other words, the DC will also be error resilient and recover from intrinsic HPSS failures (being monitored). Whenever the files are moved from tape to cache in the MSS, a call back to the DC server is made and captive account connection is initiated to pull the file out of mass storage cache to more permanent storage.
Optimizations
While the policy is clearly a source of optimization (as far as the user is concerned), from a DataCarousel “post policy” perspective, N*K files are being requested at minimum at every point in time. In reality, more jobs are being submitted so the consumption of the “overflow”of job are used to monitor if the MSS is alive. The N*K files represents a total amount of files which should match the number of threads allowed by the daemon. The current setting are K=50, N=15 with an overflow allowed up to 25). The daemon itself has the possibility to treat requests simultaneously according to a“depth”. Those calls to HPSS are however only advisory. The depth is set at being 30 deep for the DST COS and 20 deep for the Raw COS. The deepest the request queue will be, more files will be requested simultaneously but this means that the daemon will also have to start more threads as previously noted. Those parameters have been showed to influence the performance to some extent (within 10%) with however a large impact on response time: the larger the request stack, the “less instantaneous” the response from a user's perspective (since the request queue length is longer).
The daemon has the ability of organizing X requests into a sorted list of tape ID and number of requests per tape. There are a few strategies allowing to alter the performance. We chose to enable “start with the tape with the largest number of files requested”. In addition, and since our queue depth is rather small comparing to the ideal number of files (K) per job, we order the files requested by the user by tape ID. Both optimizations are in place and lead to a 20% improvement within a realistic usage (bulk restore, Xrootd, other user activities).
Remaining optimizations
Optimization based on tapeID would need to be better quantified (graph, average restore rate) for several class of files and usage. TBD.
The tape ID program is a first implementation returning partial information. Especially, the MSS failures are not currently handled, leading to setting the tape ID to -1 (since there are now ways to recognize whether or not it is an error or a file missing in HPSS or even a file in the MSS MetaData server but located on a bad tape). Work in progress.
The queue depth parameters should be studied and adjusted according to the K and N values. However, this would need to respect the machine / hardware capabilities. The beefier the machine would be, the better but this is likely a fine tuning. This needs to be done with great care as the hardware is also shared by multiple experiments. Ideally the compiled daemon should auto-adjust to the DC API settings (and respect command line parameters for queue depth). TBD.
Currently, the daemon number of threads used for handling the HPSS API calls and to handle the call backs are sharing the same pool. This diminishes the number of threads available to communication with the Mass Storage and therefore, causes performance fluctuations (call back threads could get “stuck” or come in “waves” - we observed cosine behavior perhaps related to this issue). TBD.
Optimizations based on drive and technology capabilities
File size effects on IO performance
In this paper (CERN/IT 2005), the author measured the IO performance as a function of file size and number of files requested per tape. The figure of relevance is added here for illustration.
In STAR, we use the 9940B (read only as per 2006) and LT0-3 drives (read and write /all new files would go to LTO-3). The finding would not be altered but we have little marging of flexibility as per the "old" tape drive.
Below, we show the average file size per file type in STAR as a 2006 snapthot.
| Average (bytes) | Average (MB) | File Type |
| 943240627 | 899 | MC_fzd |
| 666227650 | 635 | MC_reco_geant |
| 561162588 | 535 | emb_reco_event |
| 487783881 | 465 | online_daq |
| 334945320 | 319 | daq_reco_laser |
| 326388157 | 311 | MC_reco_dst |
| 310350118 | 295 | emb_reco_dst |
| 298583617 | 284 | daq_reco_event |
| 246230932 | 234 | daq_reco_dst |
| 241519002 | 230 | MC_reco_event |
| 162678332 | 155 | MC_reco_root_save |
| 93111610 | 88 | daq_reco_MuDst |
| 52090140 | 49 | MC_reco_MuDst |
| 17495114 | 16 | MC_reco_minimc |
| 14982825 | 14 | daq_reco_emcEvent |
| 14812257 | 14 | emb_reco_geant |
| 12115661 | 11 | scaler |
| 884333 | 0 | daq_reco_hist |
Note that the average size for an event file is 284MB while for a MicroDST, the size average is 84 MB so a ratio of 3. The number of files per catriges is at best 1.2 files per cartriges with peaks at 10 or more. THis is mostly due to a request profile dominated by Xrootd "random" pattern and a few user's requests. According to the previous study, the IO efficiency should be around 8% for 84 MB file and reaching perhaps 20-25% efficiency for a 284 MB average file class. Cosndiering we have not studied the drive access pattern beyond a simple scaling (i.e. we will ignore to first order the fcat we have many drives at our disposal), we should see a performance change change from 8 to 20 so an improvement of x2.5-3 shall the file size argument stand.
In order to observe the IO performance when small or big files are being requested, we requested event files to the DataCarousel and produced the below two graphs for the dates ranging between 2006/10/26 and 2006/10/29. The first graph represents the IO "before" the massive submission of event file dominated requests, the second the graph "after" the event. The graphs are preliminary (work in progress).
Note: It is interresting to note that a significant mix of very small files (below 12 MB average) would bring the performance to a sub 1% efficiency. The net result for 9 drives (as we have in STAR) would be an aggregate performance no better than 3MB/sec for a 9940B x 9 drive configuration . We observe periods with such poor performance. The second observation is that even with MuDST dominated files only, we would not be able to exceed in speed 70% of the performance of one drive so at best, 21 MB/sec (this correspond to our current "best hour"). The results are coherent to first order.
MSS failures and cascading effects
A poor MSS IO efficiency is one thing, but stability is another. Under poor performance situations, failures are critical to minimize. We have already stated that the DC is error resilient. However, during failure periods, the request queue accumulates requests and whenever the mass storage comes back, all requests are suddenly released, opening the flood gate of IO ... which are not much of a flood than a drip. As a consequence, user's requests or bulk transfer would not suffer much but modes requiring immediate response (such as Xrootd) would become largely impacted. In fact, shall the downtime be long enough, it is likely that all requests occuring while the errors started will fail but subsequent accumulated requests will also cause further delays and spurious Xrootd failures - Xrootd will timeout if the DC has not satisfied its request for 3600 secondes i.e. 1 hour per file. The following graph shows an error sequence:
From all failures, the relative proprtion for that day is displayed below
Miscellaneous technology considerations
All considerations in this sections are beyond our control and a facility work and optmization.HPSS disk cache optimizations
This section seems rather academic considering the previous sections improvement perspectives.
COS and PVR optimizations
In this section, we will discuss optimizing based on file size, perhaps isolated by PVR or COS. This will be possible in future run but would lead to a massive repackaging of files and data for the past years.
Appendix
Further reading:
- Data services tape use optimizations .
- Improving the Access Time of serpentine tape drives.
- Calculations for the sizing of tape performance .
- Ultrium LTO-2 tape drive testing .
- Performance to/from tape and recommended file size in Enstore .
»
- Printer-friendly version
- Login or register to post comments