Run 2 (200 GeV pp)
Finding primary vertex seeds
What is done to find the seeds
Pass 1
In this pass, the seed finding was done on a per-run basis. Only one file sequence per run was chosen. Here are the results of the preliminiary aggregate fits:
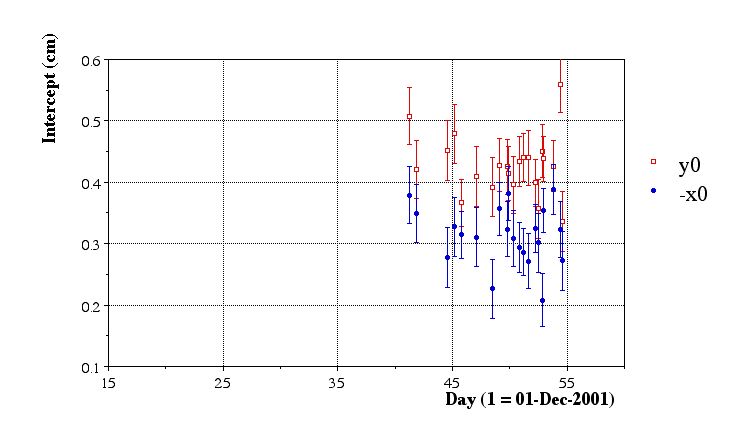
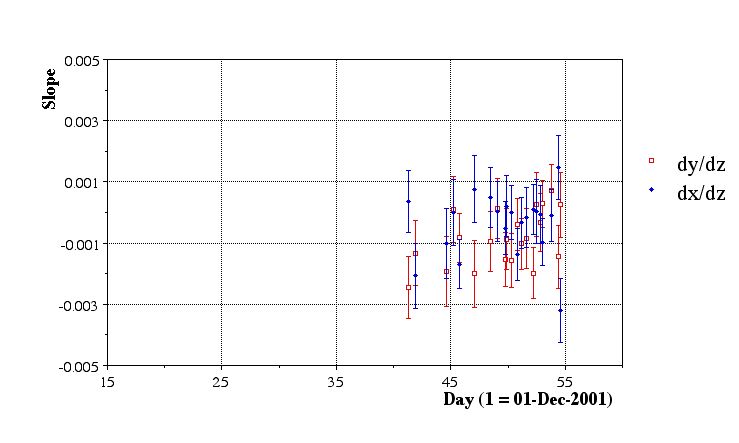
Issues:
- Statistics are insufficient
- Variations are large, but likely due to poor statistics
Pass 2
For the second pass, it was clear that the main issue was to improve statistics. In order to achieve this, several file sequences per run must be done. To take this even further, one calibration per fill of the accelerator would allow for the aggregation of many file sequences with the minimal segmentation of calibration periods. So a method was developed to perform this aggregation on a per-fill basis.
- Preliminary pass
- Here are the results of the preliminiary aggregate fits:
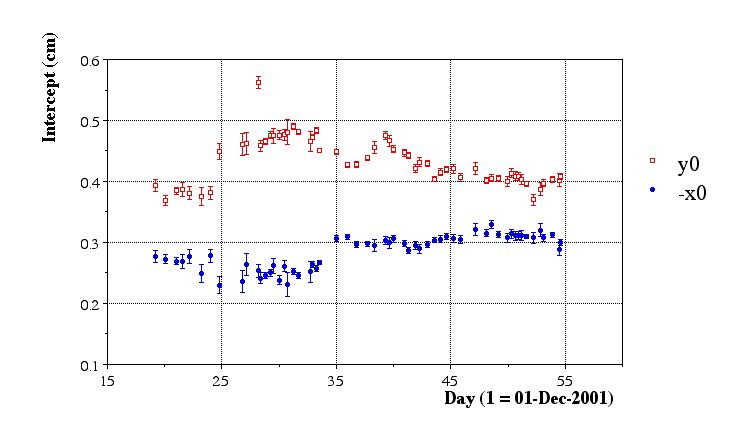
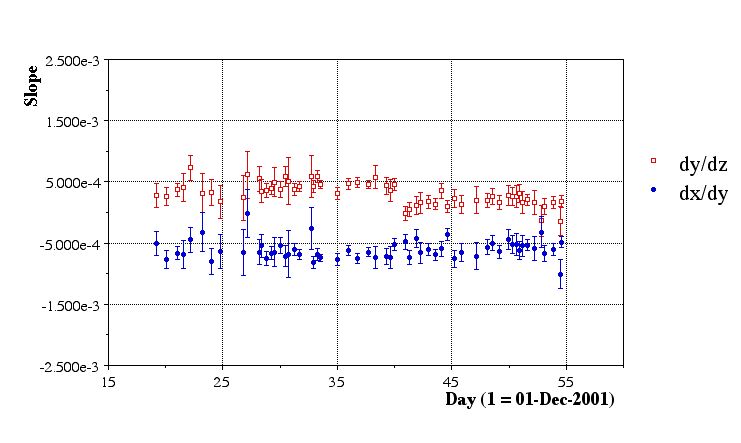
Issues:
- Fill 2075 (20011224.051426) has only one run (2358013), which in turn has only 18 files. All file sequences from this run need to be done to get a good calibration.
- Fill 1982 (2001??) and Fill 1997 consisted of very short runs (2350028, 2350036, and 2352018) which were BBC triggers anyhow. Best ignored.
- Fill ? (20020105.194730) had several bad runs (few reconstructed vertices in runs 3005020, 3005021, 3005022), but the runlog says that the inner field cage was off. Run 3005023 looked OK, but this fill is best ignored.
Final Pass
- Here are the results of the final aggregate fits:
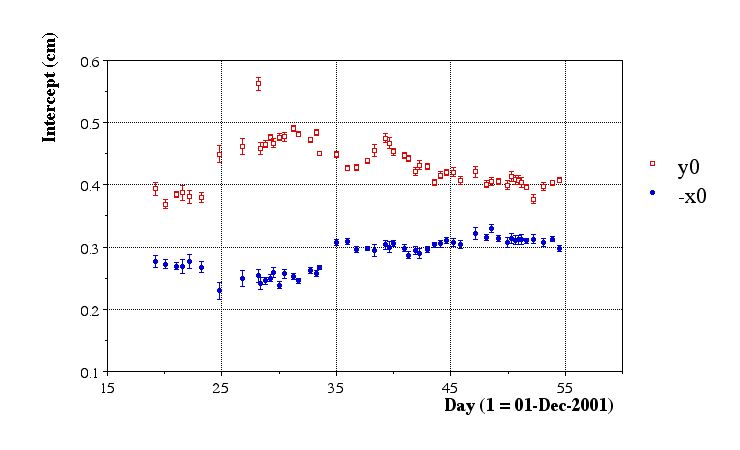
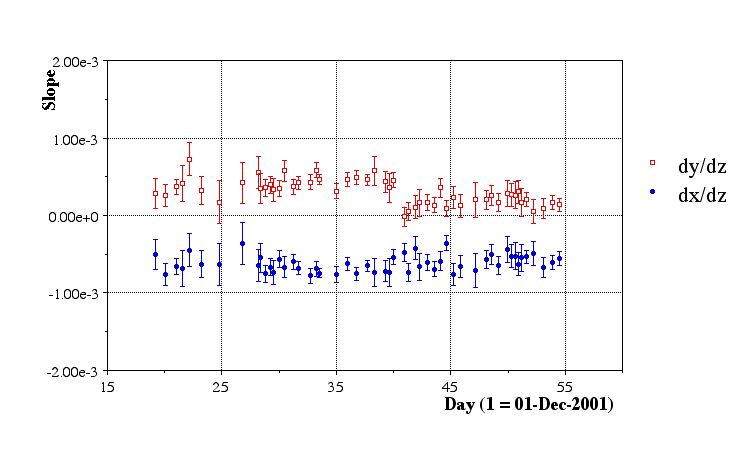
Issues:
- Fill 2102 (20011228.085448, runs 236062-2362078) appears to be legitimately offset in y. Stastistics are high, errors are reasonable, and chisq/dof is close to 1.
- There are some clear systematics of the beam line moving around. We should compare to what information the RHIC people have.
Groups:
- Printer-friendly version
- Login or register to post comments