Detector Sub-systems
Welcome to the STAR sub-system page. The menu displays all major sub-systems in the STAR setup.
Those pages are used for keeping documentation and information about the subsystems as well as some operational procedures, drawing, pictures and for detector sub-systems calibration procedures and result of studies as well.
Also consult the STAR internal reviews for more information.
- 2009/09 - 01 CPSN0510 : STAR FMS Review report, Summer 2009
- 2008/11 - 17 PSN0467 : TOF software review report, Fall 2008
- 2008/11 - 12 PSN0465 : EMC Calibrations Workshop report, fall 2008
- 2008/03 - 14 CPSN0455 : FTPC sub-system review, 2008
- 2007/01 - 11 You do not have access to view this node
- 2006/12 - 07-08 Review of STAR Tracking Upgrades and the You do not have access to view this node
See also Preview of the 2006/12 review findings for a summary of suggested configurations. - 2006/10 - 06-07 STAR TPC Review and the You do not have access to view this node
- 2006/07 - 07-08 STAR Inner Silicon tracking detector review and the You do not have access to view this node
- 2004/07 - 19-20 CPSN0454 : Report of the FTPC Review Committee, 2004
BEMC
The STAR Barrel Electromagnetic Calorimeter

BEMC Detector Operator Manual
Authored by O. Tsai, 04/13/2006 (updated 02/02/2011)
You will be operating three detectors:
| BTOW | Barrel Electromagnetic Calorimeter |
| BSMD | Barrel Shower Maximum Detector |
| BPSD | Barrel Preshower Detector |
All three detectors are delicate instruments and require careful and precise operation.
It is critical to consult and follow the “STAR DETECTOR STATES FOR RUN 11”
and “Detector Readiness Checklist” for instructions.
Rule 1: If you have a concern of what you are going to do with any of these detectors please don’t hesitate to ask people around you in the control room or call experts to get help or explanations.
This manual will tell you:
- how to turn On/Off low and high voltages for all three detectors.
- how to prepare BTOW for “Physics”.
- how to recover from a PMT HV Trip.
- how to deal with common problems.
First, familiarize yourself with the environment of the control room. This is a picture of the four terminal windows which you will be using to operate the BEMC systems. For run 11, Terminal 4 is not in use. Terminal 0 (not shown) is on the left side of terminal 1/

(clicking on a link will take you directly to that section in the manual)
0 - (on beatrice.starp.bnl.gov)
1 - (on emc02.starp.bnl.gov)
BEMC PMT Low Voltage Power Supply Slow Control
2 - (on emcsc.starp.bnl.gov)
BTOW HV Control
3 - (on hoosier.starp.bnl.gov)
BSMD HV Control
0 - (on emc01.starp.bnl.gov)
BPSD HV Control
To login on any of these computers use the emc account with password (check the control room copy of the manual).
Terminal 0 “BEMC Main Control Window”
Usually this terminal is logged on to beatrice.starp.bnl.gov
The list of tasks which you will be doing from this terminal is:
- Prepare BEMC detectors for Physics.
- Turning On/Off low voltages on FEEs.
- Turning On/Off BEMC crates.
- Resetting Radstone Boards (HDLC).
- Explain to experts during phone calls what you see on some of the terminals.
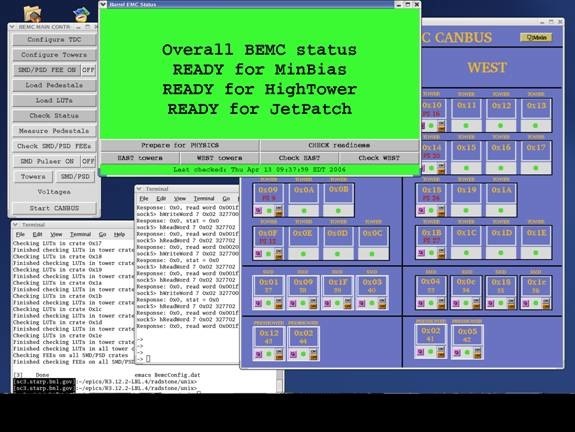
The screenshot above shows how the display on emc02.starp.bnl.gov usually looks during the run. There are five windows open all the time. They are:
- “Barrel EMC Status” - green.
- “BEMC MAIN CONTROL” – gray.
- “BARREL EMC CANBUS” – blue.
- Terminal on sc5.starp.bnl.gov (referred to as the ‘sc5 window’)
- Terminal from telnet scserv 9039 (referred to as ‘HDLC window’)
Prepare BEMC detectors for PHYSICS.
In normal operation this is a one click operation.
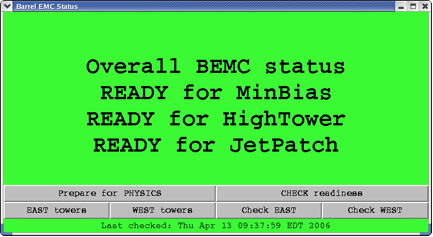
Click “Prepare for PHYSICS” button and in about 10 minutes “Barrel EMC Status” window will turn green and tell you that you are ready to run. This window may look a little bit different from year to year depending trigger requirements for BTOW.
However if this window turns red, then you will be requested to follow the suggested procedures which will popup on this window: simply click on these procedures to perform them.
During “prepare for physics” you can monitor the messages on the sc5 window. This will tell you what the program is actually doing. For example, when you click “Prepare for Physics” you will start a multi-step process which includes:
- Turning OFF FEEs on all SMD/PSD crates
- Programming TDC (Tower Data Collector, Crate 80)
- Reprogramming FPGAs on all BTOW crates
- Configuring all BTOW crates
- Configuring all SMD/PSD FEEs
- Loading pedestals on all BTOW crates
- Loading LUTs on all BTOW crates (only for pp running)
- Checking BTOW crate configuration
- Checking SMD/PSD configuration
- Checking that pedestals were loaded correctly (optional)
- Checking that LUTs were loaded correctly (only for pp running)
Usually, you will not be asked to use any other buttons shown on this window.
BEMC MAIN CONTROL
You can initiate all steps outlined above manually from the BEMC MAIN CONTROL window shown below, and do much more with the BEMC system. However, during normal operation you will not be asked to do that, except in cases when an expert on the phone might ask you to open some additional window from this panel and read back some parameters to diagnose a problem.
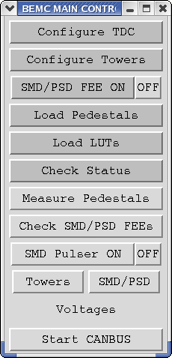
You might be asked to:
- Turn OFF or ON SMD/PSD FEE
- Open SMD/PSD panel and read voltages and currents on different SMD/PSD FEEs
- Open East or West panels to read voltages on some BTOW crates. (Click on Voltages)
That will help experts to diagnose problems you are calling about.
BARREL EMC CANBUS
From this window you can turn Off and On BEMC crates, read parameters of VME crates. This screenshot shows you this window during normal operation with all BEMC crates being ON.
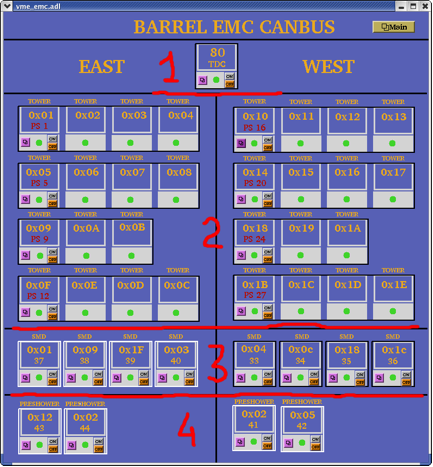
- Crate 80 TDC (Tower Data Collector and “Radstone boards”)
- Thirty crates for BTOW
- Eight crates for BSMD
- Four crates for BPSD
The BTOW crates are powered in groups of three or four from a single power supply (PS) units. The fragment below explains what you see.
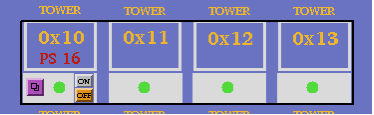
Tower crates 0x10, 0x11, 0x12, 0x13 are all powered from a single power supply: PS 16.
Thus, by clicking the On and Off buttons you will be switching On/Off all four crates and the communication with PMT boxes which are associated with them. (see details in Tower HV Control GUI description).
Sc5 and HDLC windows.
Two other terminal windows on “Terminal 0” are the so-called sc5, and HDLC windows.
These need to be open at all times. To open the sc3 terminal you will need to login as sysuser on sc5.starp.bnl.gov with password (check the control room copy of the manual).
From this sc5 terminal you run two programs. The first program is emc.tcl. If you need for some reason to restart “BEMC MAIN CONTROL” or “Barrel EMC Status” GUI you need to start emc.tcl: the alias for this is emc. To kill this program use alias kill_emc.
To open “Barrel EMC Canbus” GUI use alias emc_canbus_noscale.
If you need to reboot canbus then:
- open sc5 window
- telnet scserv 9040
- press “Ctrl” and “x” keys
- wait while canbus reboots (~5 minutes or so)
- press “Ctrl” and “]” keys
- quit telnet session
- close sc5 window
To open an HDLC window, first you need to open an sc3 window and then telnet scserv 9039.
To close telnet session you need to press “Ctrl” and “]”, and then quit from telnet.
You may be asked by experts on the phone to reset the radstone boards. This is why you need this window open. There are two radstone boards and to reset them type:
radstoneReset 0
and
radstoneReset 1
Terminal 1. “BEMC PMT Low Voltage Power Supply Slow Control”
There is a change in operation procedures for Run7 for PMT HV Low Voltage power supplies.
There are two low voltage power supply PL512 units which powers PMT bases.
PL512 with IP address 130.199.60.79 powers West side and PL512 with IP address 130.199.60.81 powers East side of the detector. A single power supply feeds thirty PMT boxes. The GUI for both PL512 should be open all time on one of the workspace on Terminal1. A screenshot below shows GUI at normal conditions. Both PL512 should be ON all the time, except the case when power cycling of the PMT bases is required.
There are two buttons to turn power On and Off, as usual, wait 30 sec. after turning power supply Off before you will turn it On again. To start GUI use aliases bemc_west and bemc_east on sc5.starp.bnl.gov

Terminal 2. “BTOW HV Control”

This is typical screen shot of the BTOW HV GUI during “Physics” running.

What is shown on this screen?
The top portion of the screen shows the status of the sixty BTOW PMT boxes. In this color scheme green means OK, yellow means bad, gray means masked out.
Buttons marked “PS1 ON” etc. allows to ramp slowly HV on the groups of the boxes. (PS1 ON will bring only boxes 32-39)
Buttons “EAST ON” and “WEST ON” allows to ramp up slowly entire east or west sides.
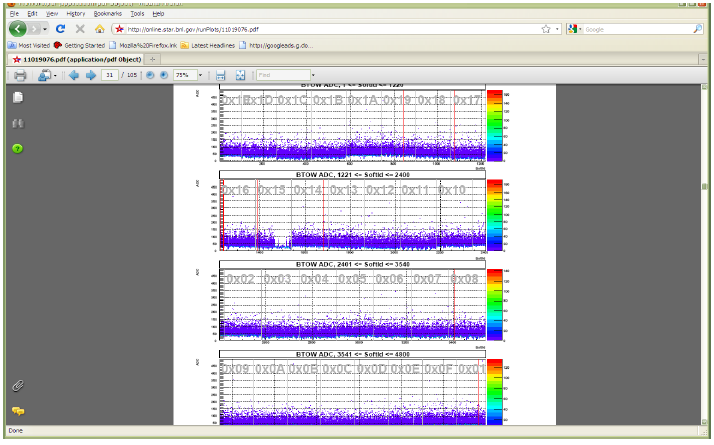
The fragment below explains what the numbers on this screen means.
![]()
Each green dot represent a single PMT box. Label 0x10 tells you that signals from PMTs in boxes 1 and 2 feed to BTOW crate 0x10, boxes 3 and 4 feed crate 0x11 etc. You will need to know this correspondence to quickly recover from HV trips.
Turning ON HV on BTOW from scratch.
1. BEMC PMT LV East and West should be ON.
2. EMC_HighVoltage.vi should be running.
3. Made a slow ramp on the West Side by pressing button “WEST ON”
4. Made a slow ramp on the East Side by pressing button “EAST ON”
Both steps 3 and 4 takes time, there is no audio or visual alarm to tell operators that HV was ramped – operators should observed progress in the window in the “Main Control” subpanel (see below).
Subpanel “Main Control”
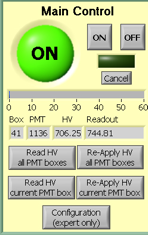
The HV on PMTs is usually ON during the Run. The two buttons on top are for turning the HV On and OFF on all PMT boxes. The most frequently used button on this subpanel is “Re-Apply HV all PMT Boxes” which is usually used to recover after HV trip. Sometimes you will need to “Re-Apply HV current PMT box” if the system does not set the HV on all boxes cleanly.
The scale 0-60 shows you a progress report. The small icons below this scale tells you what PMT box and PMT were addressed or readout.
Once you recover from a HV trip please pay attention to the small boxes labeled “Box”, “PMT”, and the speed at which the program reads the voltages on the PMTs. This will tell you which box has “Timeout” problems and which power supply will need to be power cycled.
Subpanel “PMTs In a Selected Box”
This subpanel shows you the status of the PMTs in a given PMT box.

If you want to manually bring a single PMT box to the operational state by clicking on “Re-Apply HV current PMT box” on the Main Control subpanel you will need to specify which Box To Display on the panel first.
Subpanel “Alarm Control”

On the Alarm Control sub-panel the SOUND should be always ON, except for the case when you are recovering from a HV trip and wish to mute this annoying sound.
Shift personnel are asked to report HV trips in the shift log (type of trip, e.g. single box#, with or without timeout, massive trip, etc…)
Please don’t forget to switch this button back to the ON position after recovering from a trip.
The Main Alarm LED will switch color from green to red in case of an alarm.
HV trip with Timeout problem.
Typical situation – you hear a sound alarm indicating a HV trip. The auto-recovery program did not bring all PMT boxes to the operational state, e.g. some boxes will be shown in yellow. First thing to check for the presence of a “Timeout” problem.
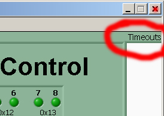
Look at the right upper corner of the GUI. If the field below “Timeouts” is blank then try to recover by re-applying HV to all PMT boxes if the number of bad boxes more then two. If only one or two boxes is yellow then you can try to re-apply HV to the current PMT box.
If only one or two PMT bases timed out and HV tripped try to recover using above procedure. It is possible that one or two PMT bases will timed without causing trips of HV, then just continue running and made a note in the shift log about timed out PMT bases, experts will take care of this problem during the day.
But it is also a chance that a single timed out PMT base will trip lots of other PMT. In this case this bad PMT should be masked out. The procedure to do this is simple and can be found at the end of this manual. However, this is an expert operation and should only be performed after consulting with a BEMC expert.
However, if the field below “Timeouts” is filled with numbers (these are PMTs addresses) then you have a Timeout problem. The procedure to recover is below:
- notify shift leader about this problem and tell him that it will take at least 20 min. to bring back BEMC for Physics running.
- Second, try to identify which PMT box has timeouts (usually it will be first box in yellow counting from 1 to 60). If you are not sure which box has the timeout problem then read all pmt boxes by clicking on corresponding button at the “Main Control” subpanel, and observe which box creates the problem. The box with timeout problem will be responding VERY slowly and will be clearly seen on the “Main Control” subpanel. At the same time, PMTs addresses will be appear in “Timeouts” white space to the right of the green control panel.
- As soon as you find the box with the timeout problem, click “Cancel” on the “Main Control” subpanel and then click “OFF” – you will need to turn HV OFF on all PMTs.
- Wait till HV is shut OFF (all PMT Boxes).
- From Terminal 1, power cycle correspondent PL512 (Off, wait 30 sec., On).
- Now turn ON HV on PMT boxes from the “Main Control” subpanel. It will take about 2 to 3 minutes first to send desired voltages to all PMTs and then read them back – if the HV is set correctly.
It is possible that during step (6) one of the BEMC PMT LV on the East or West side will trip. In this case cancel ramp (press “Cancel” button on the “Main Control” subpanel). Power cycle tripped BEMC PMT LV. Proceed with the slow ramp.
However, if during step (6) you still get a “Timeout” problem then you will need to:
- Call experts
-------------------- Changes for Run10 operation procedures ----------------------------
To reduce the number of HV trips and associated efficiency losses during data taking we changed functionality of the PMT HV program. Namely, the HV read back time interval was changed from 15 minutes to 9999 hours, because it was found that most of the HV trips were self induced during HV read back. As a result efficiency of data taking was improved for the price of “conscious operation”. You can‟t relay anymore on absence of the HV Trip alarm as an indicator that HV on all PMTs is at nominal values. Instead shift crew should monitor associated online plots during data taking to be sure that HV was not tripped. In particular, for Run 10, shift crew should watch two plots “ADC Eta Vs Phi” and “Tower ADC” under the “BEMC Shift” tab. Example of missed HV trip on one of the PMT box during recent data taking is shown below.
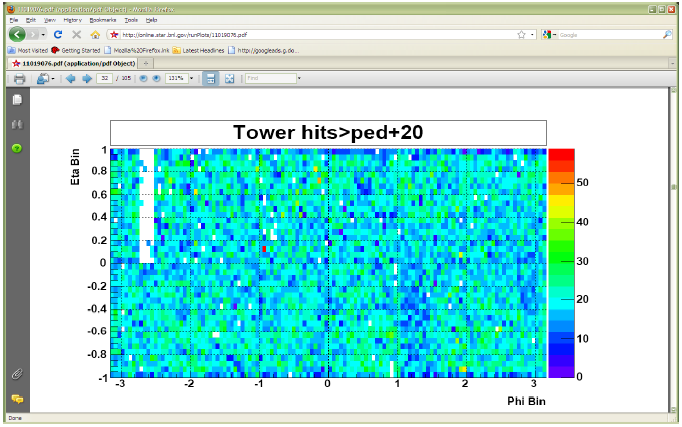
The white gap in the upper left corner shows absence of hits in BTOW due to HV trip in one of the BTOW PMT Box. It is easy to find out which box tripped by looking at second plot.
The gap with missing hits on the second subpanel for crate 0x15 will tell you that one of the PMT box 11 or 12 was tripped (correspondence between BTOW crates ID and PMT boxes is shown in the BTOW HV GUI see the picture at the beginning of this section).
What to do if shift crew will notify you of HV trip?
The fastest way to recover is to identify what box tripped and then try to recover only this PMT box. In some case it will be impossible to do this, because you will be needed to powercycle LV power supply for PMT HV system (timeout problems).
This is typical scenario:
1. Identify which PMT box(es) potentially tripped. (In the example above one PMT box 11 or 12 lost HV) to do that:
1.1 From the BTOW HV GUI form subpanel “PMTs In a Selected Box” select needed box in the “Box To Display” window.
1.2 From the BTOW HV GUI form subpanel “Main Control” press “Read HV current PMT Box”. (In the example above, detector operator found that Box 11 was OK after reading HV, but Box 12 had timeout problems).
1.3 Depending what will be result of (1.2) you may need to simply Re-Apply HV to current PMT box (no timeouts during step (1.2), or you will need to resolve timeout problem.
There are additional duties for detector operators when STAR is not taking data for long period of time for any reasons. We need to keep HV On on all PMTs at all time. This will assure stable gains on PMTs. If for some reasons PMTs will be Off for long time (few hours) then it will be difficult to assure that the PMTs gain will not drift once we turn HV On again. Typical situation is APEX days, when STAR is not taking data for 12 hours or so. To check that HV is on shift will be asked to take a short run 1k events using “bemcHTtest” configuration. TRG+DAQ+BTOW only. Once the data will be taken use a link from the run log browser to “LO Trigger”. Check page 6.
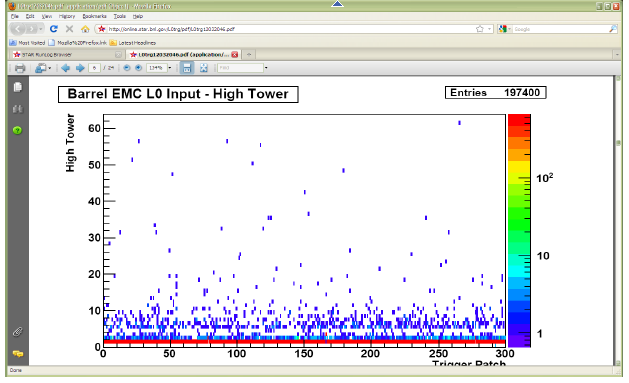
All trigger patches should have some hits. In case of the HV trips you will see blank spots.
Procedure to mask out single timeout PMT base.
Information you will need:
1. In which PMT box timeout PMT base is located
2. PMT (CW Base) to masked out.
In the timeout window the displayed number is CW Base ID this number need to be translated to PMT (CW Base).

From this sub panel you can find out which PMT in the affected PMT box need to be masked out. Scroll thru the
PMT (CW Base) top right small window and read out at the same time CW Base ID in the second from the bottom left window. (As shown, PMT (CW Base) 80 correspond to CW Base ID 1428).
Now, click “Configuration (expert only)” button on the Main Control panel.
Another panel EMC_Configuration.vi will open.
From this panel click “CW Bases Configuration” button on the right bottom.
Another panel EMC_CWBasesConf.vi will open.
On this panel specify PMT BOX Number and then click on desired CW Base to be masked out. The color of the dot will change from bright green to pale green. Then click OK button.
Panel will close after that.
Click OK button on EMC_Configuration.vi panel, this panle will close after that.
To check that you masked out right CW Base, Re-Apply HV to current PMT box. Once HV will be re-applied you will see masked CW base will be in the gray color as shown in the picture above (Bases 50, 59, 65 were masked out in the PMT box 4).
Terminal 3. “BSMD HV Control”
Your login name is emc, your password is __________________________
This screenshot shows how the window on the terminal3 will look when the HV is Off on the BSMD modules. There should be two open windows. One is a LabView GUI and another is a telnet session SY1527 (CAEN HV Main Frame).
In normal operation it is a one click procedure to turn the HV On or OFF on the BSMD.
There is complete description of the BSMD HV program in a separate folder in this document.
Although, operation is very simple, attention should be made for audio alarms.
Do not mute the ALARM. Shift personnel are asked to report all BSMD trips in the shift log.
Terminal 0. “BPSD HV Control”
The BPSD (Barrel PreShower Detector) HV supplies are two Lecroy 1440 HV systems located on the second floor platform, racks 2C5. Each 1440 is commanded by a 1445A controller which communicates via the telnet server on the second floor of the platform (SCSERV [130.199.60.167]). The left supply uses port 9041 and the right supply uses port 9043.
The HV for BPRS should be On at all times.
From Run 10 for BPRS control we will be using new GUI. They will be open on one of the desktop on Terminal 0 (Beatrice.starp.bnl.gov). Usually detector operators no need to take any actions regarding BPRS HV unless specifically requested by experts. The screen shots of of the new GUIs shown below.
To start the GUI use type bemc_lecroy and bemc_lecroy2.


A Green LED indicators tells you that HV is On and at desired level.
You can open subpanel for any slot to read actual values of HV. The screen shot is shown below.

Please Ignore empty current charts – it is normal.
Sometime, BEMC PSD GUI can turn white, due to intermittent problems with LeCroy crate controller. Simply make a log in the shift log and continue normal operation. It is likely HV is still On and at desired level. Experts not need to be called right away in this case.
Easy Troubles:
BEMC Main Control seems to be frozen, e.g. program doesn’t respond to operators requests.
Probable reason: RadStone cards in a “funny state” and needs to be reset
From Terminal 1 try to:
- kill_emc
- soft reboot first “Ctrl” + “x” from HDLC terminal window.
- start emc and see if problem solved
If the problem is still there then:
- kill_emc
- Power Cycle Crate 80
- start emc and see if problem solved
If problem is still there call experts
PL512 Information (Run 11 configuration)
There are two PL512 power supplies which provides power to the BEMC PMT boxes. Both are located in the rack 2C2, second floor.
The top unit (IP address 130.199.60.79) serves West side of the detector. The bottom unit (IP address 130.199.60.81) serves East side of the detector. The connection scheme is shown below
PMT Boxes
West Side East Side
| 1-8 | 9-16 | 17-22 | 23-30 | 32-39 | 40-47 | 48-53 | 54-31 | |
| U 0,4,8 | 1,5,9 | 3,7,11 | 2,6,10 | 0,4,8 | 1,5,9 | 3,7,11 | 2,6,10 | |
| U 0,1,2,3 | +5 V | |||||||
| U 4,5,6,7 | -5 V | |||||||
| U 8,9,10,11 | +12 V |
Note , BEMC PMT Low Voltage Power Supply Slow Control channels enumerated from 1 to 12 in the Labview GUI.
Slow control for PL512 runs on EMC02, login as emc, alias PMT_LV.
You will need to specify IP address.
Configuration (Experts Only) password is ____________.
Log files will be created each time you will start PMT_LV in the directory
/home/emc/logs/
for example
/home/emc/logs/0703121259.txt (March 12, 2007, 12:59)
To restart PL512 epics applications.
Login to softioc1.starp.bnl.gov bemc/star_daq_sc
Look at procIDs
->screen –list
->screen –r xxxx.Bemc-west(east) xxxx is procID
->bemclvps2 > (ctrl A) to detach
exit to kill
->BEMC-West or East to restart
Experts control for PL512
If you need to adjust LV on PL512 you can do this using expert_bemc_west or (east).
These GUI has experts panel. Adjusting LV setting DO NOT try to slide the bars.
Instead click on it then on popup window you can simply type desired value.
Make sure you will close expert GUI and return to normal operational GUI once
you will finish adjustments.
A copy of this manual as a PDF document is available for download below.
Expert Contacts
Steve Trentalange (on site all run) e-mail: trent@physics.ucla.eduPhone: x1038 (BNL) or (323) 610-4724 (cell)
Oleg Tsai (on site all run) e-mail: tsai@physics.ucla.edu
Phone: x1038 (BNL)
SMD High Voltage Operation
Version 1.10 -- 04/25/06, O.D.TsaiOverview
The SMD detectors are a set of 120 proportional wire chambers located inside the EMC modules (one per module). The operating gas is Ar/CO2(90/10). The nominal operating voltage is +1430 V. As for any other gaseous detector, manipulation with high voltage should be performed with great care.A detailed description of the system is given in the Appendix.
SMD HV must be turned OFF before magnet ramp !
Standard Operation includes three steps.
Turn HV ON
Turn HV OFF
Log Defective Modules
To turn SMD HV ON the procedure is:
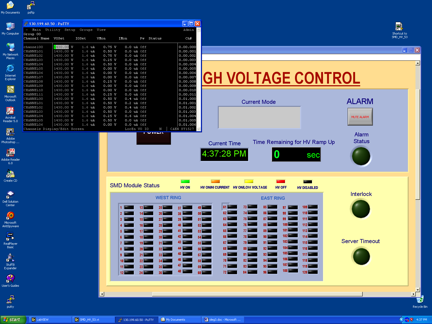
- On HOOSIER.STARP.BNL.GOV computer double click on the SMDHV icon on the Windows desktop. The 'SMD HIGH VOLTAGE CONTROL' window will open.
- On the SMD HIGH VOLTAGE CONTROL window click 'POWER' button.
- 'POWER' button will turn RED
- In no later than 90 + 150 + 300 sec in window 'Current Mode' you will see the message - "Physics Mode"
- All modules with high voltage on them will be shown in GREEN, LIGHT BROWN or YELLOW.
To turn HV OFF on SMD the procedure is:
- Click on the green 'POWER' button. Result:
- 'POWER' button will turn from green to BROWN
- after a 30 sec. or so small window will pop-up telling you that voltages an all channels reached zero.
- Click 'OK' on that small window to stop the program.
To Log Defective Modules
- Scroll down the window -- you will see three tables
- Log contents of the left table called 'Defect Module List' if any modules are presented here.
- Log contents of the right table called 'Modules tripped during Standby' (for example Run XXX #8 - 3 trips, Run XXX #54 - 1 trip)
- Close the 'SMD HIGH VOLTAGE CONTROL' window.
Detailed description of the SMD HV Program and associated hardware settings can be found in Appendix.
-------------------
Indicators to watch:
1. Interlock went RED
In case STAR global interlock went ON
- Interlock led will turn in RED
- the SMD HV program will turn OFF HV on all SMD channels and program will halt.
- Operator should close SMD HV Voltage control window.
Once STAR global interlock will be cleared follow usual procedure to power up SMD.
2. Server Timeout went RED or SMD HV Control program is frozen.
This is an unusual situation and SMD Expert Contacts should be alerted. The lost communication to SY1527 should not lead to immediate damages to the SMD chambers.
In case communication to the SY1527 is lost for some reason the 'SERVER TIMEOUT' led will turn RED. In case SMD HV Control program is frozen the 'Current Time' will not be updated.
Procedure to resolve problem is:
- Open terminal window on EMC01.STARP.BNL.GOV (monitor is on top of SMD HV Control PC)
- ping 130.199.60.50 -- observe that packets transmitted and received.
- If there are no communication with SY1527 (packets lost) -- Call one of the Expert Contacts!
- If communication is OK, then stop ping and type telnet 130.199.60.50 1527 -- You should see 'login window for CAEN SY1527 system'
- Press any key
- Login as 'admin' with password 'admin' -- you will see Main Menu window for SY1527
- From 'Main' chose 'Channels' by pressing 'Enter' -- you will see Channels menu window
- Verify HV is presented on channels (VMon)
Usually second terminal window is open on HOOSIER.STARP.BNL.GOV to monitor SY1527 HV power supply. If this window is not open use “putty” and open SY1527 session.
Now you can operate HV using this window, but if there is no emergency to turn HV OFF you should first try to restart SMD HV Control program.
Basic operations from that window are:
Turn HV OFF
Turn HV ON
Turn HV OFF
- press Tab key
- scroll to 'Groups' menu
- press 'Enter' to chose "Group Mode" --you will see highlighted column
- scroll to "Pw"
- press space bar -- you will see "Pw" will switched from On to Off and VMon will start to decrease.
- press Tab key
- select 'Group' mode
- scroll to IOSet
- type 5.0 (Current limit 5uA)
- scroll to Trip
- type 0.5 sec
- Verify that V0Set is 1430 V
- Scroll to Pw
- press Space bar -- you will see Pw will switch from OFF to ON and Status goes to Up. VMon will start to increase.
- Press Tab key
- reselect 'Group' mode
- Change I0Set and Trip for tripped channels
- Power them up - scroll to Pw, and press Space bar.
Appendix
Before you start:
"Be afraid, even paranoid, and that gives you a chance to catch bad effects in the early stages when they still do not matter"
--J. Va'vra (Wire Aging Conference)
Detailed information regarding SY1527 mainframe and A1733 HV distribution boards can be found at CAEN web page.
The SMD HV is supplied by the CAEN SY1527 HV system. The mainframe is located in rack 2C5 (Second Floor, Third Row, near the center). The HV cables run from modules to the SMD crates (15 cables per each crate). At each crate HV cables re-grounded on patch panels assuring same ground for HV and signals to be read. From SMD crates, the HV lines then run to the SY1527 system. There are 10 HV cards, 12 HV channels each (model A1733) inside the mainframe to supply high voltages to the SMD chambers. The parameters of the high voltage system controlled via Ethernet. The GUI based on LabView and CAEN OPC server.
Hardware settings are:
HV Hardware limit set to +1500 V on each of A1733 cards.
HV Software limit (SVMax) set to +1450 V for each channel.
Communications settings for SY1527 are:
IP 130.199.60.50
Net Mask 255.255.254.0
Gateway 0.0.0.0
User name Admin
Password Admin(from top to bottom, HV is Off)
LED
Chk Pass On
Toggle Switch 'Loc enable' On
Ch Status 'NIM' On
Interlock 'Open'
Master On
+48 V On
+5 V On
+12 V On
-12 V On
Main On
Each A1733 card should have 50 Ohm Lemo 00 terminator to enable HV.
Description of SMD High Voltage Control program.
All SMD HV software is installed on EMCSC.STARP.BNL.GOV in folder C:/SY1527
The SMD HV Control provides one button operation of the HV system for the SMD. There are three main functions Power On, Physics Mode, Power Off. There are two configuration files Conf.txt and Conf2.txt which defines ramp up speed and trip settings for different mode of operation.
The nominal settings for Power On are (C:/SY1527/Conf.txt):
V0 1430 V
I0Set 5 uA
Trip 0.5 s
Ramp Down 50 V/sec
Ramp Up 20 V/sec
All channels are allowed to be ramp up in three consecutive attempts. If the first attempt (90 sec) for given channel lead to trip then ramp up speed will be set to 10 V/sec and second attempt (150 sec) will be performed. If second attempt will lead to trip then ramp up speed will be set to 7 V/sec and third attempt (300 sec) will be made. If all three attempt led to trip the program disconnect that particular channel from HV (corresponding led on main panel will turn in RED).
In no later then 90 + 150 + 300 seconds program will change parameters of I0Set and Trip form 5 uA and 0.5 sec to 1.6 uA and 0.1 sec and will switch to the Physics Mode.
The nominal settings for Physics Mode are (C:/SY1527/Conf2.txt)
V0 1430 V
I0Set 1.6 uA
Trip 0.1 s
Ramp Down 50 V/sec
Ramp Up 20 V/sec
Channels allowed to trip no more then 6 times during the Physics Mode. If channel will trip then I0Set and Trip for that particular channel will be set to 5 uA and 0.5 sec and program will try to bring that channel up. On front panel Alarm Status will turn in RED, corresponded message will pop up in 'Current Mode' window, and corresponded to that channel LED will turn in YELLOW or RED. Once voltage reach 90% of nominal all indicators will turn to normal status. Usually it takes about 15 seconds to bring channel back to normal. At the bottom of the screen the right table with modules that tripped during the Physics Mode will be updated. If some channel will trip more than 6 times that channel will be HV disabled by the program and corresponded led will turn RED. The left table on the bottom of the screen will be updated. Such cases should be treated by experts only later on.
All SMD channels during the Physics Mode is under the monitoring. Each 3 seconds or so, the values of Voltage, Current and time are logged in files XX_YY_ZZ_P.txt in C:/SY1527/Log, where XX - current month, YY - current day, ZZ - current year, and P is V for Voltages and I for Currents. The current time saved in seconds. The macro C:/SY1527/smdhv.C plots bad channels history and fills histograms for all other channels.
Turn Off is trivial and no need explanations.
The meaning of the LED on main panel are:
Green – channel is at nominal HV, current < 1 uA
Brown – channel is at nominal HV, 1 uA < current < 5 uA
Yellow – the HV is < 50% of nominal
Red - channel was disconnected due trips during ramp up or physics modes.
Black - channel disabled by user (Conf.txt, Conf2.txt)
It is important to monitor channels with high current (“Brown”), as well as channels that shows high number of trips during the operation. Note: some channels (54 for example) probably has a leakage on external HV distribution board and believed to be OK in terms of discharges on anode wires as was verified during summer shutdown. The other might develop sparking during the run or might have intermittent problems (#8 for example). If problems with sparking will be detected at early stages then those channels might be cured by experts during the run, without of loss of entire chamber as it was happened during the first two years of operation.
The C:/SY1527/ReadSingleChannel.vi allows to monitor single channel. You may overwrite nominal parameters of HV for any channel using that program (it is not desired to do that). This program can run in parallel with the Main SMD HV Control program. The operation is trivial, specify 'Channel to monitor' and click on 'Update Channel'. If you wish to overwrite some parameters (see above) then fill properly VOSet etc. icons and click on Update Write.
Important! Known bug. Before you start you better to fill all parameters, if you do not do that and stop the program later on the parameters will be overwritten with whatever it was in those windows, i.e. if V0Set was 0 then you will power Off the channel.
In some cases it is easy to monitor channels by looking at front panel of the SY1527 mainframe. The image of this panel can be
obtained by opening telnet session (telnet 130.199.60.50 1527) on EMC01.STARP.BNL.GOV.
All three programs can run in parallel.
-----Experts to be called day or night no matter what---
1. The operation crew lost communication with SY1527
2. Any accidental cases (large number (>5) of SMD channels
suddenly disconnected from HV during the run)
For experts only!
What to do with bad modules?
1. If anode wire were found broken then disable channel by changing 1430 to 0 in both configuration files. That should help to avoid confusions of detector operators.
2. If anode wires are OK, and module trips frequently during first half an hour after power Up then it is advised to set HV on that particular channel to lower value (-100V, -200V from nominal etc…) and observe the behavior of the chamber (ReadSingleChannel.vi). In some cases after a few hours module can be bring back to normal operation.
3. If step 2 did not help, then wait till scheduled access and try to cure chamber by applying reverse polarity HV. Important, you can do that using good HV power supply (fast trip protection, with current limit 5uA), or by using something like ‘Bertran’ with external microammeter and balance resistor of no less then 10 MOhm, only! In any case you need to observe the current while gradually increase HV. In no case ‘Bertarn’ like power supply might be left unattended during the cure procedure. It is not advised to apply more then -1000 V. In some cases curing procedure might be fast (one hour or so). In others it might take much longer (24 hours and more) to bring module back to operation. In any case I would request to talk with me.
4. The SMDHV is also installed on EMCSC.STARP.BNL.GOV and can be run from there, although that will for sure affect BTOW HV, be advised.
LOG:
Version 1.00 was written 11/12/03
Version 1.10 corrected 04/25/06
A copy of this manual as a Word document is available for download below.
Calibrations
Here you'll find links to calibration studies for the BEMC:
BTOW
2006
procedure used to set the HV online
MIP study to check HV values -- note: offline calibrations available at Run 6 BTOW Calibration
2005
final offline
2004
final offline
2003
offline slope calibration
MIPs
electrons
BSMD
2004
Dmitry & Julia - SMD correlation with BTOW for 200 GeV AuAu
BPSD
2005
Rory - CuCu PSD calibration studies
2004
Jaro - first look at PSD MIP calibration for AuAu data
BPRS
This task has been picked up by Rory Clarke from TAMU. His page is here:
Run 8 BPRS Calibration
Parent for Run 8 BPRS Calibration done mostly by Jan
01 DB peds R9069005, 9067013
Pedestal residua for 434 zero-bias events from run 9069005.
The same pedestal for all caps was used - as implemented in the offline DB.
Fig 1.

Fig 2. Run 9067013, excluded caps >120. All 4800 tiles, pedestal residua from 100 st_zeroBias events. Y-axis [-50,+150].

Fig 3. Run 9067013, excluded caps >120. Pedestal corrected spectra for all 4800 tiles, 10K st_physics events. Y-axis [-50,+150].
Dead MAPMT results with 4 patches 4 towers wide.

Fig 4.
Run 9067013, excluded caps >120.
Zoom-in Pedestal corrected spectra, one ped per channel.
Top 10K st_physics events (barrel often triggered)
Bottom pedestal residua 100 st_zeroBias events

Fig 5.
Run 9067013, input =100 events, accept if capID=124 , raw spectra.
There are 4 BPRS crates, so 1200 channels/crate. In terms of softIds it's
PSD1W: 1-300 + 1501-2400
PSD19W: 301-1500
PSD1E: 2401-2900 + 4101-4800
PSD20E: 2901-4100
Why only 2 channels fired in crate PSD20E ?

02 pedestal(capID)
Run 9067013, 30K st_physics events, spectra accumulated separately for every cap.
Top plot pedestal (channel), bottom plot integral of pedestal peak to total spectrum.
Fig 1. CAP=122

Fig 2. CAP=123

Fig 3. CAP=124

Fig 4. CAP=125

Fig 5. CAP=126

Fig 6. CAP=127

Fig 7. Raw spectra for capID=125. Left: typical good pedestal, middle: very wide pedestal, right: stuck lower bit.
For run 9067013 I found: 7 tiles with ADC=0, ~47 tiles with wide ped, ~80 tiles with stuck lower bit.
Total ~130 bad BPRS tiles based on pedestal shape, TABLE w/ bad BPRS tiles

Fig 8. QA of pedestals, R9067013, capID=125. Below is 5 plots A,...,F all have BPRS soft ID on the X-axis.
A: raw spectra (scatter plot) + pedestal from the fit as black cross (with error).
B: my status table based on pedestal spectrum. 0=good, non-zero =sth bad.
C: chi2/DOF from fitting pedestal, values above 10. were flagged as bad
D: sigma of pedestal fit, values aove 2.7 were flagged as bad
E: integral of the found pedestal peak to the total # of entries. On average there was ~230 entries per channel.

Fig 9. BPRS pedestals for 'normal' caps=113,114,115 shown with different colors

Fig 10. BPRS pedestals for caps=100..127 and all softID , white means bad spectrum, typical stats of ~200 events per softID per cap

Fig 11. BPRS:" # of bad caps , only capID=100...127 were examined.

Fig 12. BPRS:" sig(ped)

Fig 13. BPRS:" examples of ped distribution for selected channels. Assuming for sing;e capID sig(ped)=1.5, the degradation of pedestal resolution if capID is not accounted for would be: sqrt(1.5^2 +0.5^2)=1.6 - perhaps it is not worth the effort on average. There still can be outliers.

03 tagging desynchronized capID
BPRS Polygraph detecting corrupted capIDs.
Goal: tag events with desynchronized CAP id, find correct cap ID
Method:
- build ped(capID, softID)
- pick one BPRS crate (19W)
- compute chi2/dof for series capID+/-2
- pick 'best' capID with smallest chi2/dof
- use pedestals for best capID for this crate for this event
- if best capID differs from nominal capID call this event 'desynchronized & fixed'
Input: 23K st_physics events from run 9067013.
For technical reason limited range of nominal capID=[122,126] was used, what reduces data sample to 4% ( 5/128=0.04).
Results:
Fig 1. ADC-ped(capID,softID) vs. softID for crate 1 (i.e. PSD19W) as is'. No capID corruption detection.

Fig 2. ADC-ped(capID,softID) with capID detection & correction enabled. The same events.
Note, all bands are gone - the capID fix works.
Right: ADC-ped spectra: Black: 594 uncorrupted events, red: 30 corrupted & fixed events.
The integral for ADC[10,70] are 2914 and 141 for good and fixed events, respectively.
141/2914=0.048; 30/594=0.051 - close enough to call it the same (within stats).

Fig 3. Auxiliary plots.
TOP left: chi/dof for all events. About 1100 channels is used out of 1200 in served by crate 1. Rejected are bad & outliers.
TOP right: change of chi2/dof for events with corrupted & fixed capID.
BOTTOM: frequency of capID for good & fixed events, respectively.

Conclusions:
- BPRS-Polygraph algo efficiently identifies and corrects BPRS for corrupted capID, could be adopted to used offline .
- there is no evidence ADC integration widow changes for BPRS data with corrupted capID.
Table 1.
shows capIDs for the 4 BPRS crates for subsequent events. Looks like for the same event cap IDs are strongly correlated, but different.
Conclusion: if we discard say capID=125, we will make hole of 1/4 of barrel , different in every event. This holds for BPRS & BSMD.
capID= 83:89:87:90: eve=134 capID= 1:4:11:3: eve=135 capID= 74:74:81:72: eve=136 capID= 108:110:116:110: eve=137 capID= 68:72:73:75: eve=138 capID= 58:55:65:64: eve=139 capID= 104:110:106:101: eve=140 capID= 9:6:8:15: eve=141 capID= 43:37:47:46: eve=142 capID= 120:126:118:122: eve=143 capID= 34:41:41:40: eve=144 capID= 3:0:126:2: eve=145 capID= 28:33:28:30: eve=146 capID= 72:64:70:62: eve=147 capID= 2:6:7:5: eve=148 capID= 22:32:33:24: eve=149 capID= 8:4:5:124: eve=150 capID= 23:17:17:19: eve=151 capID= 62:57:63:61: eve=152 capID= 54:53:45:47: eve=153 capID= 68:75:70:67: eve=154 capID= 73:79:73:72: eve=155 capID= 104:98:103:103: eve=156 capID= 12:5:13:10: eve=157 capID= 5:10:10:2: eve=158 capID= 32:33:27:22: eve=159 capID= 96:102:106:97: eve=160 capID= 79:77:72:77: eve=161
04 BPRS sees beam background?
The pair of plots below demonstrates BPRS pedestal residua are very clean once peds for 128 caps are used and this 5% capID corruption is detected and fixed event by event.
INPUT: run 9067013, st_phys events, stale BPRS data removed, all 38K events .
Fig 0. capID correction was enabled for the bottom plot. Soft ID is on the X-axis; rawAdc-ped(softID, capID) on the Y-axis.

Now you can believe me the BPRS pedestals are reasonable for this run. Look at the width of pedestal vs. softID, shown in Fig 1 below.
There are 2 regions with wider peds, marked by magenta(?) and red circle.
The individual spectra look fine (fig 2b, 2bb).
But the correlation of pedestal width with softID (fig 1a,1b) and phi-location of respective modules (fig 3a, 3b) suggest it could be due to the beam background at
~7 o'clock on the West and at 6-9 o'clock on the East.

05 ---- peds(softID,capID) & status table, ver=2.2, R9067013
INPUT: st_hysics events from run=9067013
Fig 1. Top: pedestal(softID & capID), middle: sigma of pedestal, bottom: status table, Y-axis counts how many capID had bad spectra.
Based on pedestal spectra there are 134 bad BPRS tiles.

Fig 2. Distribution of pedestals for 4 selected softIDs, one per crate.

Fig 3. Zoom-in of ped(soft,cap) spectrum to see there is more pairs of 2 capID which have high/low pedestal vs. average, similar to the known pair (124/125).
Looks like such piar like to repeat every 21 capIDs - is there a deeper meaning it?
(I mean will the World end in 21*pi days?)

Fig 4. Example of MIP spectra (bottom). MIP peak is very close to pedestal, there are worse cases than the one below. 
06 MIP algo ver 1.1
TPC based MIP algo was devised to calibrate BPRS tiles.
Details of the algo are in 1st PDF,
example of MIP spectra for 40 tails with ID [1461,1540] are in subsequent 5 PDF files, sorted by MAPMT
Fig 1 shows collapsed ADC-ped response for all 4800 BPRS tiles. The average MIP response is only 10 ADC counts above ped wich has sigma of 1.5 ADC. The average BPRS gain is very is very low. 
07 BPRS peds vs. time
Fig 1. Change of BPRS pedestal over ... within the same fill, see softID~1000
Pedestal residua (Y-axis) vs. softID (X-axis), same reference pedestals used from day 67 (so some peds are wrong for both runs) were used both plots.
Only fmsslow events, no further filtering, capID corruption fixed in fly.
Top run 9066001, start 0:11 am, fill 9989
Bottom run 9066012, start 2:02 am, fill 9989

Fig 2. Run list. system config was changed between those 2 runs marked in blue.

Fig 3. zoom in of run 9066001

Fig 4. another example of BPRS ped jump between runs: 9068022 & 9068032, both in the same fill.

08 BPRS ped calculation using average
Comparison of accuracy of pedestal calculation using Gauss fit & plain average of all data.
The plain average method is our current scheme for ZS for BPRS & BSMD for 2009 data taking.
Fig 2. TOP: RMS of the plain average, using 13K of fmsslow-triggered events which are reasonable surrogate of minBias data for BPRS.
Middle: sigma of pedestal fit using Gauss shape
Bottom: ratio of pedestals from this 2 method. The typical pedestal value is of 170 ADC. I could not make root to display the difference, sorry.

09 BPRS swaps, IGNORING Rory's finding from 2007, take 1
This page is kept only for the record- information here is obsolete.
This analysis does not accounts for BPRS swaps discovered by Rory's in 2007, default a2e maker did not worked properly
- INPUT: ~4 days of fmsslow-triggered events, days 65-69
- DATA CORRECTIONS:
- private BPRS peds(cap,softID) for every run,
- private status table, the same , based on one run from day 67
- event-by-event capID corruption detection and correction
- use vertex with min{|Z|}, ignore ranking to compensate for PPV problem
- TRACKING:
- select prim tracks with pr>0.4 GeV, dEdX in [1.5,3.7] keV, |eta|<1.2
- require track enters tower 1cm from the edge and exists tower at any distance to the edge
- tower ADC is NOT used (yet)
- 2 histograms of rawADC-ped were accumulated: for all events (top plot) and for BPRS tiles pointed by TPC track (middle plot w/ my mapping & lower plot with default mapping)
There are large section of 'miples' BPRS tiles if default mapping is used: 3x80 tiles + 2x40 tiles=320 tiles, plus there is a lot of small mapping problems. Plots below are divided according to 4 BPRS crates - I assumed the bulk of mapping problems should be contained within single crate.
Fig 1, crate=0, Middle plot is after swap - was cured for soft id [1861-1900]
if(softID>=1861 && softID<=1880) softID+=20;
else if(softID>=1881 && softID<=1900) softID-=20;

Fig2, crate=1, Middle plot is after swap - was cured for soft id [661-740]
if(softID>=661 && softID<=700) softID+=40;
else if(softID>=701 && softID<=740) softID-=40;

Fig3, crate=2, Middle plot is after swap - was cured for soft id [4181-4220].
But swap in [2821-2900] is not that trivial - suggestions are welcome?
if(softID>=4181 && softID<=4220) softID+=40;
else if(softID>=4221 && softID<=4260) softID-=40;

Fig4, crate=3, swap in [3781-3800] is not that trivial - suggestions are welcome?

10 -------- BPRS swaps take2, _AFTER_ applying Rory's swaps
2nd Correction of BPRS mapping (after Rory's corrections are applied).
- INPUT: ~7 days of fmsslow-triggered events, days 64-70, 120 runs
- DATA CORRECTIONS:
- private BPRS peds(cap,softID) for every run,
- private status table, excluded only 7 strips with ADC=0
- event-by-event capID corruption detection and correction
- use vertex with min{|Z|}, ignore PPV ranking, to compensate for PPV problem
- BPRS swaps detected by Rory in 2007 data have been applied
- TRACKING:
- select prim tracks with pr>0.4 GeV, dEdX in [1.5,3.7] keV, |eta|<1.2, zVertex <50 cm
- require track enters tower 1cm from the edge and exist the same tower at any distance to the edge (0 cm)
- tower ADC is NOT used (yet)
- 3 2D histograms of were accumulated:
- rawADC-ped (softID) for all events
- the same but only for BPRS tiles pointed by QAed MIP TPC track
- frequency of correlation BPRS tiles with MIP-like ADC=[7,30] with towers pointed by TPC MIP track
Based on correlation plot (shown as attachment 6) I found ~230 miss-mapped BPRS tiles (after Rory's correction were applied).
Once additional swaps were added ( listed in table 1, and in more logical for in attachment 3) the correlation plot is almost diagonal, shown in attachment 1.
Few examples of discovered swaps are in fig1. The most important are 2 series of 80 strips, each shifted by 1 software ID.
Fig 2 shows MIP signal shows up after shit by 1 softID is implemented.
The ADC spectra for all 4800 strips are shown in attachment 2. Attachment 5 & 6 list basic QA of 4800 BRS tiles for 2 cases: only Rory's swaps and Rory+Jan swaps.
Fig 1. Examples of swaps, dotted line marks the diagonal. Vertical axis shows towers pointed by TPC MIP track. X-axis shows BPRS soft ID if given ADC was in the range [7,30] - the expected MIP response. Every BPRS tile was examined for every track, multiple times per event if more than 1 MIP track was found.
Left: 4 sets of 4 strips needs to be rotated. Right: shift by 1 of 80 strips overlaps with rotation of 6 strips.

Fig 2. Example of recovered 80 tiles for softID~2850-2900. Fix: softID was shifted by 1.

Fig 3. Summary of proposed here corrections to existing BPRS mapping

Table 1. List of all BPRS swaps , ver 1.0, found after Rory's corrections were applied, based on 2008 pp data from days 64-70.
The same list in human readable from is here
Identified BPRS 233 swaps. Convention: old_softID --> new_softID
389 --> 412 , 390 --> 411 , 391 --> 410 , 392 --> 409 , 409 --> 392 ,
410 --> 391 , 411 --> 390 , 412 --> 389 , 681 --> 682 , 682 --> 681 ,
685 --> 686 , 686 --> 685 ,1074 -->1094 ,1094 -->1074 ,1200 -->1240 ,
1220 -->1200 ,1240 -->1260 ,1260 -->1220 ,1301 -->1321 ,1303 -->1323 ,
1313 -->1333 ,1321 -->1301 ,1323 -->1303 ,1333 -->1313 ,1878 -->1879 ,
1879 -->1878 ,1898 -->1899 ,1899 -->1898 ,2199 -->2200 ,2200 -->2199 ,
2308 -->2326 ,2326 -->2308 ,2639 -->2640 ,2640 -->2639 ,2773 -->2793 ,
2793 -->2773 ,2821 -->2900 ,2822 -->2821 ,2823 -->2822 ,2824 -->2823 ,
2825 -->2824 ,2826 -->2825 ,2827 -->2826 ,2828 -->2827 ,2829 -->2828 ,
2830 -->2829 ,2831 -->2830 ,2832 -->2831 ,2833 -->2832 ,2834 -->2833 ,
2835 -->2834 ,2836 -->2835 ,2837 -->2836 ,2838 -->2837 ,2839 -->2838 ,
2840 -->2839 ,2841 -->2840 ,2842 -->2841 ,2843 -->2842 ,2844 -->2843 ,
2845 -->2844 ,2846 -->2845 ,2847 -->2846 ,2848 -->2847 ,2849 -->2848 ,
2850 -->2849 ,2851 -->2850 ,2852 -->2851 ,2853 -->2852 ,2854 -->2853 ,
2855 -->2854 ,2856 -->2855 ,2857 -->2856 ,2858 -->2857 ,2859 -->2858 ,
2860 -->2859 ,2861 -->2860 ,2862 -->2861 ,2863 -->2862 ,2864 -->2863 ,
2865 -->2864 ,2866 -->2865 ,2867 -->2866 ,2868 -->2867 ,2869 -->2868 ,
2870 -->2869 ,2871 -->2870 ,2872 -->2871 ,2873 -->2872 ,2874 -->2873 ,
2875 -->2874 ,2876 -->2875 ,2877 -->2876 ,2878 -->2877 ,2879 -->2878 ,
2880 -->2879 ,2881 -->2880 ,2882 -->2881 ,2883 -->2882 ,2884 -->2883 ,
2885 -->2884 ,2886 -->2885 ,2887 -->2886 ,2888 -->2887 ,2889 -->2888 ,
2890 -->2889 ,2891 -->2890 ,2892 -->2891 ,2893 -->2892 ,2894 -->2893 ,
2895 -->2894 ,2896 -->2895 ,2897 -->2896 ,2898 -->2897 ,2899 -->2898 ,
2900 -->2899 ,3121 -->3141 ,3141 -->3121 ,3309 -->3310 ,3310 -->3309 ,
3717 -->3777 ,3718 -->3778 ,3719 -->3779 ,3720 -->3780 ,3737 -->3757 ,
3738 -->3758 ,3739 -->3759 ,3740 -->3760 ,3757 -->3717 ,3758 -->3718 ,
3759 -->3719 ,3760 -->3720 ,3777 -->3737 ,3778 -->3738 ,3779 -->3739 ,
3780 -->3740 ,3781 -->3861 ,3782 -->3781 ,3783 -->3782 ,3784 -->3783 ,
3785 -->3784 ,3786 -->3785 ,3787 -->3786 ,3788 -->3787 ,3789 -->3788 ,
3790 -->3789 ,3791 -->3790 ,3792 -->3791 ,3793 -->3792 ,3794 -->3793 ,
3795 -->3794 ,3796 -->3835 ,3797 -->3836 ,3798 -->3797 ,3799 -->3798 ,
3800 -->3799 ,3801 -->3840 ,3802 -->3801 ,3803 -->3802 ,3804 -->3803 ,
3805 -->3804 ,3806 -->3805 ,3807 -->3806 ,3808 -->3807 ,3809 -->3808 ,
3810 -->3809 ,3811 -->3810 ,3812 -->3811 ,3813 -->3812 ,3814 -->3813 ,
3815 -->3814 ,3816 -->3855 ,3817 -->3856 ,3818 -->3817 ,3819 -->3818 ,
3820 -->3819 ,3821 -->3860 ,3822 -->3821 ,3823 -->3822 ,3824 -->3823 ,
3825 -->3824 ,3826 -->3825 ,3827 -->3826 ,3828 -->3827 ,3829 -->3828 ,
3830 -->3829 ,3831 -->3830 ,3832 -->3831 ,3833 -->3832 ,3834 -->3833 ,
3835 -->3834 ,3836 -->3795 ,3837 -->3796 ,3838 -->3837 ,3839 -->3838 ,
3840 -->3839 ,3841 -->3800 ,3842 -->3841 ,3843 -->3842 ,3844 -->3843 ,
3845 -->3844 ,3846 -->3845 ,3847 -->3846 ,3848 -->3847 ,3849 -->3848 ,
3850 -->3849 ,3851 -->3850 ,3852 -->3851 ,3853 -->3852 ,3854 -->3853 ,
3855 -->3854 ,3856 -->3815 ,3857 -->3816 ,3858 -->3857 ,3859 -->3858 ,
3860 -->3859 ,3861 -->3820 ,4015 -->4055 ,4016 -->4056 ,4017 -->4057 ,
4018 -->4058 ,4055 -->4015 ,4056 -->4016 ,4057 -->4017 ,4058 -->4018 ,
4545 -->4565 ,4546 -->4566 ,4549 -->4569 ,4550 -->4570 ,4565 -->4545 ,
4566 -->4546 ,4569 -->4549 ,4570 -->4550 ,
For the reference:
- mapping of BPRS softID to MAPMT made by Will J. in 2007 is shown here: http://www.star.bnl.gov/protected/emc/wwjacobs/tmp/bprs_tubehookup_run7.pdf
Identified BPRS hardware problems:
Tiles w/ ADC=0 for all events:
* 3301-4, 3322-4 - all belong to PMB44-pmt1, dead Fee in 2007
belonging to the same pmt:
3321 has pedestal only
3305-8 and 33205-8 have nice MIP peaks, work well
* 2821, 3781 , both at the end of 80-chanel shift in mapping
neighbours of 2821: 2822,... have nice MIP
similar for neighbours of 3781
* 4525, 4526 FOUND! should be readout from cr=2 position 487 & 507, respectively
I suspect all those case we are reading wrong 'positon' from the DAQ file
Pair of consecutive tiles with close 100% cross talk, see Fig 4.
35+6, 555+6, 655+6, 759+60, 1131+2, 1375+6, 1557+8,
2063+4, 2163+4, 2749+50, 3657+8,
3739 & 3740 copy value of 3738 - similar case but with 3 channels.
4174+5
Hot pixels, fire at random
1514, 1533, 1557,
block: 3621-32, 3635,3641-52 have broken fee, possible mapping problem
block: 3941-3976 have broken fee
Almost copy-cat total 21 strips in sections of 12+8+1
3021..32, 3041..48, 3052
All have very bread pedestal. 3052 may show MIP peak if its gain is low.
Fig 4. Example of pairs of correlated channels.

11 BPRS absolute gains from MIP, ver1.0 ( example of towers)
BPRS absolute gains from MIP, ver 1.0
Fig 1 Typical MIP signal seen by BPRS(left) & BTOW (right) for soft ID=??, BPM16.2.x (see attachment 1 for more)
Magenta line is at MIP MPV-1*sigma -> 15% false positives

Fig 2 Typical MIP signal seen by BPRS, pmt=BPM16.2
Average gain of this PMT is on the top left plot, MIP is seen in ADC=4.9, sig=2.6

Fig 3 Most desired MIP signal (ADC=16) seen by BPRS(left) & BTOW (right) for soft ID=1388, BPM12.1.8
Magenta line is at MIP MPV-1*sigma -> 15% false positives, (see attachment 2 for more)

Fig 4 Reasonable BPRS, pmt=BPM11.3, pixel to pixel gain variations is small

Fig 5 High MIP signal (ADC=28) seen by BPRS(left) & BTOW (right) , BPM11.5.14
Magenta line is at MIP MPV-1*sigma -> 15% false positives, (see attachment 3 for more)

Fig 6 High gain BPRS, pmt=BPM11.5

12 MIP gains ver1.0 (all tiles, also BTOW)
This is still work in progress, same algo as on previous post.
Now I run on 12M events (was 6 M) and do rudimentary QA on MIP spectra, which results with ~10% channel loss (the bottom figure). However, the average MIP response per tile is close to the final value.
Conclusion: only green & light yellow tiles have reasonable MIP response of ~15 ADC. For blue we need to rise HV, for red we can lower it (to reduce after pulsing). White area are masked/dead pixels.
Fig 1: BPRS MIP gains= gauss fit to MIP peak.
A) gains vs. eta & phi to see BPM pattern. B) gains with errors vs. softID, C) sigma MIP shape, D) tiles killed in QA

Fig 2: BTOW MIP gains= gauss fit to MIP peak. Content of this plot may change in next iteration.
A) gains vs. eta & phi. "ideal" MIP is at ADC=18, all towers. Yellow& red have significantly to high HV, light blue & blue have too low HV.
B) gains with errors vs. softID, C) sigma MIP shape, D) towers killed in QA

13 MIP algo, ver=1.1 (example of towers)
This is an illustration of improvement of MIP finding efficiency if ADC gates are set on BPRS & BTOW at the places matched to actual gains instead of fixed 'ideal' location.
Fig 1 is from previous iteration (item 11) with fixed location MIP gates. Note low MIP yield in BPRS (red histo) due to mismatched BTOW ADC gate (blue bar below green histo).

Fig 2 New iteration with adjusted MIP gates. (marked by blue dashed lines).
MIP ADC gate is defined (based on iteration 1) by mean value of the gauss fit +/- 1 sigma of the gauss width, but not lower than ADC=3.5 and not higher than 2* mean ADC
Note similar MIP yield in BPRS & BTOW. Also new MIP peak position from Gauss fit did not changed, meaning algo is robust. The 'ideal' MIP ADC range for BTOW is marked by magenta bar (bottom right) - is visibly too low.

Attached PDF shows similar plots for 16 towers. Have a look at page 7 & 14
14 ---- MIP gains ver=1.6 , 90% of 4800 tiles ----
BPRS absolute gains using TPC MIPs & BTOW MIP cut, ver 1.6 , 2008 pp data
- INPUT: fmsslow-triggered events, days 43-70, 525 runs, 16M events (see attachment 1)
- BTOW peds & ped-status from offline DB
- DATA CORRECTIONS (not avaliable using official STAR software)
- discard stale events
- private BPRS peds(cap,softID) for every run,
- private status table
- event-by-event capID corruption detection and correction
- use vertex with min{|Z|}, ignore PPV ranking, to compensate for PPV problem
- BPRS swaps detected by Rory in 2007 data have been applied
- additional ~240 BPRS swaps detected & applied
- BTOW ~50 swaps detected & applied
- BTOW MIP position determine independently (offline DB gains not used)
- TRACKING:
- select prim tracks with pr>0.35 GeV, dEdX in [1.5,3.3] keV, |eta|<1.3, zVertex <60 cm, last point on track Rxy>180cm
- require track enters & exits a tower 1cm from the edge, except for etaBin=20 - only 0.5cm is required (did not helped)
- triple MIP coincidence, requires the following (restrictive) cuts:
- to see BPRS MIP ADC : TPC MIP track and in the same BTOW tower ADC in MIP peak +/- 1 sigma , but above 5 ADC
- to see BTOW MIP ADC : TPC MIP track and in the same BPRS tile ADC in MIP peak +/- 1 sigma , but above 3.5 ADC
Fig 1. Example of typical BPRS & BTOW MIP peak determine in this analysis.
MIP ADC gate (blue vertical lines) is defined (based on iteration 1.0) by the mean value of the gauss fit +/- 1 sigma of the gauss width, but not lower than ADC=3.5 (BPRS) or 5 (BTOW) and not higher than 2* mean ADC.
FYI, the nominal MIP ADC range for BTOW (ADC=4096 @ ET=60 GeV/c) is marked by magenta bar (bottom right).
- Attachment 6 contains 4800 plots of BPRS & BTOW like this one below ( large 53MB !!)
- Numerical values of MIP peak position,width, yield for all 4800 BPRS tiles are in attachment 4.

Fig 2. ADC of MIP peak for 4800 BPRS tiles.
Top plot: mean, X-axis follows eta bin , first West then East. Y-axis follows |eta| bin, 20 is at physical eta=+/- 1.0.Large white areas are due to bad BPRS MAPMT (4x4 or 2x8 channels), single white rectangles are due to bad BPRS tile or bad BTOW tower.
Middle plot: mean +/- error of mean, X-axis =soft ID. One would wish mean MIP value is above 15 ADC to place MIP cut comfortable above the pedestal (sig=1.5-1.8 ADC counts).
Bottom plot: width of MIP distribution. Shows the width of MIP shape is comparable to the mean and we want to put MIP cut well below the mean to not loose half of discrimination power.
Note, the large # 452 of not calibrated BPRS tiles does not mean that many are broken. There are 14 known bad PMTs and e 'halves' , total=15*16=240 (see attachment 2). There rest are due broken towers (required by MIP coincidence) and isolated broken fibers, FEE channels.

Fig 3. Example of PMT with fully working 16 channels.
Top left plot shows average MIP ADC from 16 pixels. Top middle: correlation between MIP peak ADC and raw slope - can be used for relative gain change in 2009. Top right shows BTOW average MIP response.
Middle: MIP spectra for 16 pixels.
Bottom: raw spectra fro the same 16 pixels.
300 plots like this is in attachment 3.

Fig 4. Top plot: average over 16 pixels MIP ADC for 286 BPRS pmts. X axis = PMB# [1-30] + pmt #[1-5]/10. Error bars represent RMS of distribution (not error of the mean).
Middle plot : ID of 14 not calibrated PMTs. For detailed location of broken PMTs see attachment 2, the red computer-generated ovals on the top of 2007 Will's scribbles mark broken PMTs (blue ovals are repaired PMTs) found in this 2008 analysis.
Bottom plot shows # of pixels in given PMT with reasonable MIP signal (used in the top figure).
- Numerical values of MIP peak per PMT are in attachment 5.

Fig 5. ADC of MIP peak for 4800 BTOW tower. Top lot: mean, middle plot: mean +/- error of mean, bottom plot: width of MIP
- Numerical values of MIP peak position,width, yield for all 4800 BTOW towers are in attachment 4.
Note, probably 1/2 of not calibrated BTOW towers are broken, the other half is due to bad BPRS tiles, required to work by this particular algo.

Koniec !!!
15 Broken BPRS channels ver=1.6, based on data from March of 2008
The following BPRS pmts/tiles have been found broken or partially not functioning, based on reco MIP response from pp 2008 data.
Based on PMT-sorted spectra available HERE (300 pages , 3.6MB)
Table 1. Simply dead PMT's. Raw spectra contain 16 nice pedestals, no energy above, see Fig 2.
PMB,pmt, PDF page # , 16 mapped softIDs 2,3 8, 2185 2186 2187 2188 2205 2206 2207 2208 2225 2226 2227 2228 2245 2246 2247 2248 2,4, 9, 2189 2190 2191 2192 2209 2210 2211 2212 2229 2230 2231 2232 2249 2250 2251 2252 4,5, 20, 2033 2034 2035 2036 2053 2054 2055 2056 2073 2074 2075 2076 2093 2094 2095 2096 5,1, 21, 1957 1958 1959 1960 1977 1978 1979 1980 1997 1998 1999 2000 2017 2018 2019 2020 12,2, 57, 1421 1422 1423 1424 1425 1426 1427 1428 1441 1442 1443 1444 1445 1446 1447 1448 14,1, 66, 1221 1222 1223 1224 1225 1226 1227 1228 1241 1242 1243 1244 1245 1246 1247 1248 24,4, 119, 433 434 435 436 453 454 455 456 473 474 475 476 493 494 495 496 25,4, 124, 353 354 355 356 373 374 375 376 393 394 395 396 413 414 415 416 26,4, 129, 269 270 271 272 289 290 291 292 309 310 311 312 329 330 331 332 32,3, 158, 2409 2410 2411 2412 4749 4750 4751 4752 4769 4770 4771 4772 4789 4790 4791 4792 44,5, 220, 3317 3318 3319 3320 3337 3338 3339 3340 3357 3358 3359 3360 3377 3378 3379 3380 39,2, 192, 2905 2906 2907 2908 2925 2926 2927 2928 2945 2946 2947 2948 2965 2966 2967 2968
Table 2. FEE is broken (or 8-connector has a black tape), disabling 1/2 of PMT, see Fig 3.
PMB,pmt, nUsedPix, avrMIP (adc), rmsMIP (adc),PDF page # , all mapped softIDs 7,1, 7, 19.14, 4.36, 31, 1797 1798 1799 1800 1817 1818 1819 1820 1837 1838 1839 1840 1857 1858 1859 1860 40,1, 8, 5.16, 0.53, 196, 2981 2982 2983 2984 3001 3002 3003 3004 3021 3022 3023 3024 3041 3042 3043 3044 40,2, 6, 5.44, 0.80, 197, 2985 2986 2987 2988 3005 3006 3007 3008 3025 3026 3027 3028 3045 3046 3047 3048 40,3, 12, 8.50, 1.05, 198, 2989 2990 2991 2992 3009 3010 3011 3012 3029 3030 3031 3032 3049 3050 3051 3052 44,1, 10, 13.72, 8.24, 216, 3301 3302 3303 3304 3305 3306 3307 3308 3321 3322 3323 3324 3325 3326 3327 3328 45,2, 8, 5.04, 1.55, 222, 3421 3422 3423 3424 3425 3426 3427 3428 3441 3442 3443 3444 3445 3446 3447 3448 51,5, 7, 11.37, 2.15, 255, 3877 3878 3879 3880 3897 3898 3899 3900 3917 3918 3919 3920 3937 3938 3939 3940 52,5, 8, 15.84, 4.80, 260, 3957 3958 3959 3960 3977 3978 3979 3980 3997 3998 3999 4000 4017 4018 4019 4020 60,1, 8, 15.12, 3.41, 296, 4581 4582 4583 4584 4601 4602 4603 4604 4621 4622 4623 4624 4641 4642 4643 4644
Table 3. Very low yield of MIPs (1/5 of typical), may de due to badly sitting optical connector, see Fig 4
PMB,pmt, QAflag, nUsedPix, avrMIP (adc), rmsMIP (adc),PDF page # , all mapped softIDs
10,5, 14, 0, 0.00, 0.00, 50, 1553 1554 1555 1556 1573 1574 1575 1576 1593 1594 1595 1596 1613 1614 1615 1616
31,5, 14, 0, 0.00, 0.00, 155, 4677 4678 4679 4680 4697 4698 4699 4700 4717 4718 4719 4720 4737 4738 4739 4740
37,2, 0, 10, 12.90, 7.41, 182, 2745 2746 2747 2748 2765 2766 2767 2768 2785 2786 2787 2788 2805 2806 2807 2808
49,1, 0, 16, 9.36, 3.55, 241, 3701 3702 3703 3704 3705 3706 3707 3708 3721 3722 3723 3724 3725 3726 3727 3728
Table 4. Stuck LSB in FEE, we can live with this. (do NOT mask those tiles)
PMB,pmt, QAflag, nUsedPix, avrMIP (adc), rmsMIP (adc),PDF page # , all mapped softIDs 51,1,0, 15, 8.37, 1.30, 251, 3861 3862 3863 3864 3881 3882 3883 3884 3901 3902 3903 3904 3921 3922 3923 3924 51,2,0, 16, 8.66, 1.06, 252, 3865 3866 3867 3868 3885 3886 3887 3888 3905 3906 3907 3908 3925 3926 3927 3928 51,3,0, 16, 11.08, 1.28, 253, 3869 3870 3871 3872 3889 3890 3891 3892 3909 3910 3911 3912 3929 3930 3931 3932 51,4,0, 16, 17.16, 2.70, 254, 3873 3874 3875 3876 3893 3894 3895 3896 3913 3914 3915 3916 3933 3934 3935 3936
Table 5. Other problems:
PMB,pmt, QAflag, nUsedPix, avrMIP (adc), rmsMIP (adc),PDF page # , all mapped softIDs 31,2,0, 16, 12.32, 3.73, 152,4665 4666 4667 4668 4685 4686 4687 4688 4705 4706 4707 4708 4725 4726 4727 4728
Fig 1. Example of fully functioning PMT (BPM=4, pmt=5). 16 softID are listed at the bottom o fthe X-axis.
Top plot: ADC spectra after MIP condition is imposed based on TPC track & BTOW response.
Bottom plot: raw ADC spectra for the same channels.

Fig 2. Example of dead PMT with functioning FEE.

Fig 3. Example of half-dead PMT, comes in pack, most likely broken FEE.

Fig 4. Example of weak raw ADC, perhaps optical connector got loose.

Fig 5. Example of stuck LSB, We can live with this, but gain hardware must be ~10% higher (ADC--> 18)

16 correlation of MIP ADC vs. raw slopes
Scott asked for crate based comparison of MIP peak position vs. raw slopes .
I selected 100 consecutive BPRS tiles, in 2 groups, from each of the 4 crates. The crate with systematic lower gain is the 4th (PSD-20E).
The same spectra from pp 2008 fmsslow events are used as for all items in the Drupal page.
Fig 1. BPRS carte=PSD-1W

Fig 2. BPRS carte=PSD-19W

Fig 3. BPRS carte=PSD-1E

Fig 4. BPRS carte=PSD-20E This one has lower MIP peak

Run 9 BPRS Calibration
Parent for Run 9 BPRS Calibration
01 BPRS live channels on day 82, pp 500 data
Status of BPRS live channels on March 23, 2009, pp 500 data.
Input: 32K events accepted by L2W algo, from 31 runs taken on day 81 & 82.
Top fig shows high energy region for 4800 BPRS tiles
Middle fig shows pedestal region, note we have ZS & ped subtracted data in daq - plots is consistent. White area are not functioning tiles.
Bottom fig: projection of all tiles. Bad channels included. Peak at ADC~190 is from corrupted channels softID~3720. Peak at the end comes most likely form saturation of BPRS if large energy is deposited. It is OK - BPRS main use is as a MIP counter.
Attached PDF contains more detailed spectra so one can see every tile.

BSMD
Collected here is information about BSMD Calibrations.
There are 36,000 BSMD channels, divided into 18,000 strips in eta and 18,000 strips in phi. They are located 5.6 radiation lengths deep in the Barrel Electromagnetic Calorimeter (BEMC).
1) DATA: 2008 BSMD Calibration
Information about the 2008 BSMD Calibration effort will be posted below as sub-pages.
Fig 1. BSMD-E 2D mapping of soft ID. (plot for reverse mapping is attached)

01) raw spectra
Goals:
- verify pedestals loaded to DB are reasonable for 2008 pp data
- estimate stats needed to find slopes of individual strips for minB events
Method:
- look at pedestal residua for individual strips, exclude caps 1 & 2, use only status==1
- fit gauss & compare with histo mean
- find integrals of individual strips, sum over 20 ADC channels starting from ped+5*sig
To obtain muDst w/o zero suppression I run privately the following production chain:
chain="DbV20080703 B2008a ITTF IAna ppOpt VFPPV l3onl emcDY2 fpd ftpc trgd ZDCvtx NosvtIT NossdIT analysis Corr4 OSpaceZ2 OGridLeak3D beamLine BEmcDebug"
Fig 1
Examples of single strip pedestal residua, based on ~80K minB events from days 47-65, 30 runs. (1223 is # of bins, ignore it).
Left is typical good spectrum, see Fig2.3. Middle is also reasonable, but peds is 8 channels wide vs. typical 4 channels.
The strip shown on the right plot is probably broken.

Fig 2
Detailed view on first 500 strips. X=stripID for all plots.
- Y=mean of the gauss fit to pedestal residuum, in ADC channels, error=sigma of the gauss.
- Y=integral of over 20 ADC channels starting from ped+5*sig.
- Raw spectra, Y=ADC-ped, exclude caps 1 & 2, use only status==1

Fig 3
Broader view of ... problems in BSMD-E plane. Note, status flag was taken in to account.
Top plot is sum of 30 runs from days 47-65, 80K events. Bottom plot is just 1 run, 3K events. You can't distinguish individual channels, but scatter plot works like a sum of channels, so it is clear the slopes are there, we need just more data.

Conclusions:
- DB peds for BSMDE look good on average.
- with 1M eve we will start to see gains for individual strip relativewith ~20% error. Production will finish tomorrow.
- there are portions of SMDE masked out (empty area in fig 3.2, id=1000) - do why know what broke? Will it be fixed in 2009 run
- there are portions of SMDE not masked but dead (solid line in fig 3.2, id=1400) - worth to go after those
- there are portions of SMDE not masked with unstable (or wrong) pedestal, (fig 3.1 id=15000)
- for most channels there is one or more caps with different ped not accounted for in DB ( thin line below pedestal in fig 2.3)
- One gets a taste of gain variation from fig 2.2
- Question: what width of pedestal is tolerable. Fig 2.1 shows width as error bars. Should I kill channel ID=152?
02) relative BSMD-E gains from 1M dAu events
Glimpse of relative calibration of BSMDE from 2008 d+Au data
Input: 1M dAu minb events from runs: 8335112+8336019
Method : fit slopes to individual strips, as discussed 01) raw spectra
Fig 1
Examples of raw pedestal corrected spectra for first 9 strips, 1M dAu events

Fig 2
Detailed view on first 500 strips. X=stripID for all plots.
- Y=mean of the gauss fit to pedestal residuum, in ADC channels, error=sigma of the gauss.
- Y=integral of over 20 ADC channels starting from ped+5*sig. Raw spectra,
- Y=gain defined as "-slope" from the exponential fit over ADC range 20-40 channels, errors from expo fit. Blue line is constant fit to gains.

Fig 3
BSMDE strips cover the whole barrel and eta-phi representation is better suited to present 18K strips in one plot.
- Mapping of BSMDE-softID (Z-axis) in to eta-phi space. Eta bin 0 is eta=-1.0, eta bin 299 is eta=+1.0. Phi bin 0 starts at 12:30 and advances as phi angle.
- gains for majority of 18K BSMDE strips. White means no data or discarded by rudimentary QA of peds, yields or slope.

Fig 4
For reference spectra from 1M pp events from ~12 EmcCheck runs from days 47-51. It proves I did it and it was naive on my side to expect 1M pp events is enough.

Fig 5
More pp events spectra - lot of problems with DB content.

03) more details , answering Will
This page provides more details addressing some of Will's questions.
2) fig 2: well, 500 chns is not a very "natural" unit, but I wonder
what corresponds to 50 chns (e.g., the region of fluctuation
250-300) ... I need to check my electronics readout diagrams
again, or maybe folks more expert will comment
Fig 1.
Zoom-in of the god-to-bad region of BSMDE

Fig 2.
'Good' strips belong to barrel module 2, crate 2, sitting at ~1 o'cloCk on the WEST

Fig 3.
'BAD' strips belong also to barrel module 2, crate 2, sitting at ~1 o'cloCk on the WEST

04) bad CAP 123
Study of pedestal correlation for BSMDE
Goal: identify source of the band below main pedestals.
Figs 1,2 show pedestals 'breathe' in correlated way for channels in the same crate, but this mode is decoupled between crates. It may be enough to use individual peds for all CAPS to reduce this correlation.
Fig3 shows CAP=123 has bi-modal pedestals. FYI, CAPS 124,125 were excluded because they also are different.
Based on Fig1 & 3 one could write an algo identifying event by event in which mode CAP=123 settled, but for now I'll discard CAP123 as well.
All plots are made based on 500K d-Au events from the run 8336052.
Fig 0
Example of pedestal residua for BSMDE strips 1-500, after CAPS 124 and 125 were excluded.

Fig 1
Correlation between pedestal residua for neighbor strips. Strip 100 is used on all plots on the X-axis

Fig 2
Correlation between pedestal residua for strips in different crates. Strip 100 is used on all plots on the X-axis

Fig 3
Squared pedestal residua for strips [1,150] were summed for every event and plotted as function of CAP ID (Y-axis).
Those strips belong to the same module #1 . X-axis shoes SQRT(sum) for convenience. CAP=123 has double pedestal.

05) BSMDE saturation, dAu, 500K minB eve
Input: 500K d-Au events from run 8336052,
Method : drop CAPS 123,124,125, subtract single ped for all other CAPS.
Fig 1 full resolution, only 6 modules , every module contains 150 strips.
Fig 2 All 18K strips (120 modules), every module contain only 6 bins, every bin is sum of 25 strips.
h->RebinX(25), h->SetMinimum(2), h->SetMaximum(1e5)

06) QAed relative gains BSMDE, 3M d-Au events , ver1.0
Version 1 of relative gains for BSMDE, d-AU 2008.
INPUT: 3M d-AU events from day ~336 of 2007.
Method: fit slopes to ADC =ped+30,ped+100.
The spectra, fits of pedestal residuum, and slopes were QAed.
Results: slopes were found for 16,577 of 18,000 strips of BSMDE.
Fig1 Good spectrum for strip ID=1. X-axis ADC-ped, CAPs=123,124,124 excluded.

Fig2 TOP: slopes distribution (Y-axis) vs. stripID within given module ( X-axis). Physical eta=0.0 is at X=0, eta=1.0 is at X=150.
BOTTOM: status tables with marked eta-phi location excluded 1423 strips of BSMDE by multi-stage QA of the spectra. Different colors denote various failed tests.

Fig3 Mapping of known BSMDE topology on chosen by us eta-phi 2D localization. Official stripID is shown in color.
07) QA method for SMD-E, slopes , ver1.1
Automatic QA of BSMDE minB spectra.
Content
- example of good spectra (fig 0)
- QA cuts definition (table 1) + spectra (figs 1-7)
- Result:
- # of bad strips per module. BSMDE modules 10,31,68 are damaged above 50%+. (modules 16-30 served by crate 4 were not QAed).
- eta-phi distributions of: slopes, slope error (fig 9) , pedestal, pedestal (fig 10) width _after_ QA
- sample of good and bad plots from every module, including modules 16-30 (PDF at the end)
The automatic procedure doing QA of spectra was set up in order to preserve only good looking spectra as shown in the fig 0 below.
Fig 0 Good spectra for random strips in module=2. X-axis shows pedestal residua. It is shown to set a scale for the bad strips shown below.

INPUT: 3M d-AU events from day ~336 of 2007.
All spectra were pedestals subtracted, using one value per strip, CAPS=123,124,125 were excluded. Below I'll use term 'ped' instead of more accurate pedestal residuum.
Method: fit slopes to ADC =ped+40,ped+90 or 5*sig(ped) if too low.
The spectra, fits of pedestal residuum, and slopes were QAed.
QA method was set up as sequential series of cuts, upon failure later cuts were not checked.
Note, BSMD rate 4 had old resistors in day 366 of 2007 and was excluded from this analysis.
This reduces # of strips from 18,000 to 15,750 .
| cut# | cut code | description | # of discarded strips | figure |
| 1 | 1 | at least 10,000 entries in the MPV bin | 4 | - |
| 2 | 2 | MPV position within +/-5 ADC channels | 57 | Fig 1 |
| 3 | 4 | sig(ped) of gauss fit in [1.6,8] ADC ch | 335 | Fig 2 |
| 4 | 8 | position of mean gauss within +/- 4 ADC | 11 | Fig 3 |
| 5 | 16 | yield from [ped+40,ped+90] out of range | 441 | Fig 4 |
| 6 | 32 | chi2/dof from slop fit in [0.6,2.5] | 62 | Fig 5 |
| 7 | 64 | slopeError/slop >16% | 4 | Fig 6 |
| 8 | 128 | slop within [-0.015, -0.05] | 23 | Fig 7 |
| - | sum | out of processed 15,750 strips discarded | 937 ==> 5.9% |
Fig 1 Example of strips failing QA cut #2, MPV position out of range , random strip selection

Fig 2a Distribution of width of pedestal vs. eta-bin

Fig 2b Example of strips failing QA cut #3, width of pedestal out of range , random strip selection

Fig 3a Distribution of pedestal position vs. eta-bin

Fig 3b Example of strips failing QA cut #4, pedestal position out of range , random strip selection

Fig 4a Distribution of yield from the slope fit range vs. eta-bin

Fig 4b Example of strips failing QA cut #5, yield from the slope fit range out of range , random strip selection

Fig 5a Distribution of chi2/DOF from the slope fit vs. eta-bin

Fig 5b Example of strips failing QA cut #6, chi2/DOF from the slope fit out of range , random strip selection

Fig 6a Distribution of err/slope vs. eta-bin

Fig 6b Example of strips failing QA cut #7, err/slope out of range , random strip selection

Fig 7a Distribution of slope vs. eta-bin

Fig 7b Example of strips failing QA cut #8, slope out of range , random strip selection

Results
Fig 8a Distribution of # of bad strips per module.
BSMDE modules 10,31,68 are damaged above 50%+. Ymax was set to 150, i.e. to the # of eat strips per module. Modules 16-30 served by crate 4 were not QAed.

Fig 8b 2D Distribution of # of bad strips indexed by eta & phi strip location. Z-scale denotes error code from the 2nd column from table 1.

Fig 9 2D Distribution of slope indexed by eta & phi strip location.
TOP: slopes. There is room for gain improvement in the offline analysis. At fixed eta (vertical line) there should be no color variation.
BOTTOM error of slope/slope.

Fig 10 2D Distribution of pedestal and pedestal width indexed by eta & phi strip location.
TOP: pedestal
BOTTOM: pedestal width.

08) SMD-E gain equalization , ver 1.1
Goal : predict BSMD-E relative gain corrections for every eta bin
Method : find average slope per eta slice, fit gauss, determine average slope : avrSlope(iEta)
Gain correction formula is used only for extreme deviations:
- gainCorr_i = slope_i/avrSlope(iEta), i =1,..,18,000
- if( fabs(1-gainCorr)<0.15) gainCor=1.0 // do not correct
Fig 1 Example of 2 eta slices
 |  |
Fig 2 TOP: Slope distribution vs. eta-bin, average marked by crosses
BOTTOM: predicted gain correction. Correction=1 for strips w/ undetermined gains.

Fig 3 Predicted gain correction. Correction=1 for ~14K of 18K strips.

Fig 4 The same predicted gain correction vs. stripID.

09) QA of SMD-P slopes, ver1.1
Automatic QA of BSMD-P minB spectra.
Content
- example of good spectra (fig 0)
- QA cuts definition (table 1) + spectra (figs 1-7)
- Result:
- # of bad strips per module. BSMD-P modules 1,4,59,75,85 are damaged above 50%+. (modules 16-30 served by crate 4 were not QAed).
- eta-phi distributions of: slopes, slope error (fig 9) , pedestal, pedestal (fig 10) width _after_ QA
- sample of good and bad plots from every module, including modules 16-30 (PDF at the end)
The automatic procedure doing QA of spectra was set up in order to preserve only good looking spectra as shown in the fig 0 below.
Fig 0 Good spectra for random strips in module=2. X-axis shows pedestal residua. It is shown to set a scale for the bad strips shown below.

INPUT: 3M d-AU events from day ~336 of 2007.
All spectra were pedestals subtracted, using one value per strip, CAPS=123,124,125 were excluded. Below I'll use term 'ped' instead of more accurate pedestal residuum.
Method: fit slopes to ADC =ped+40,ped+90 or 5*sig(ped) if too low.
The spectra, fits of pedestal residuum, and slopes were QAed.
QA method was set up as sequential series of cuts, upon failure later cuts were not checked.
Note, BSMD rate 4 had old resistors in day 366 of 2007 and was excluded from this analysis.
This reduces # of strips from 18,000 to 15,750 .
| cut# | cut code | description | # of discarded strips | figure |
| 1 | 1 | at least 10,000 entries in the MPV bin | 2 | - |
| 2 | 2 | MPV position within +/-5 ADC channels | 10 | Fig 1 |
| 3 | 4 | sig(ped) of gauss fit in [0.75,8] ADC ch | 32 | Fig 2 |
| 4 | 8 | position of mean gauss within +/- 4 ADC | 0 | Fig 3 |
| 5 | 16 | yield from [ped+40,ped+90] out of range | 758 | Fig 4 |
| 6 | 32 | chi2/dof from slop fit in [0.55,2.5] | 23 | Fig 5 |
| 7 | 64 | slopeError/slop >10% | 1 | Fig 6 |
| 8 | 128 | slop within [-0.025, -0.055] | 6 | Fig 7 |
| - | sum | out of processed 15,750 strips discarded | 831 ==> 5.2% |
Fig 1 Example of strips failing QA cut #2, MPV position out of range , random strip selection

Fig 2a Distribution of width of pedestal vs. strip # inside the module. For the East side I cout strips as -1,-2, ...,-150.

Fig 2b Example of strips failing QA cut #3, width of pedestal out of range , random strip selection

Fig 3 Distribution of pedestal position vs. strip # inside the module

Fig 4a Distribution of yield from the slope fit range vs. eta-bin

Fig 4b Example of strips failing QA cut #5, yield from the slope fit range out of range , random strip selection

Fig 5a Distribution of chi2/DOF from the slope fit vs. eta-bin

Fig 5b Example of strips failing QA cut #6, chi2/DOF from the slope fit out of range , random strip selection

Fig 6 Distribution of err/slope vs. eta-bin

Fig 7a Distribution of slope vs. eta-bin

Fig 7b Example of strips failing QA cut #8, slope out of range , random strip selection

Results
Fig 8a Distribution of # of bad strips per module.
BSMD-P modules 1,4,59,75,85 are damaged above 50%+. Ymax was set to 150, i.e. to the # of eat strips per module. Modules 16-30 served by crate 4 were not QAed.

Fig 8b 2D Distribution of # of bad strips indexed by eta & phi strip location. Z-scale denotes error code from the 2nd column from table 1.

Fig 9 2D Distribution of slope indexed by eta & phi strip location.
TOP: slopes. At fixed eta (horizontal line) there should be no color variation. red=dead strips
BOTTOM error of slope/slope. white=dead strip

Fig 10 2D Distribution of pedestal and pedestal width indexed by eta & phi strip location.
TOP: pedestal. dead strip have 0 residuum.
BOTTOM: pedestal width. white marks dead strips

10) SMD-P gain equalization , ver 1.1
Goal : predict BSMD-P relative gain corrections for every eta bin
Method : find average slope per eta slice, fit gauss, determine average slope : avrSlope(iEta)
Gain correction formula is used only for extreme deviations:
- gainCorr_i = slope_i/avrSlope(iEta), i =1,..,18,000
- if( fabs(1-gainCorr)<0.10) gainCor=1.0 // do not correct
Fig 1 Example of 2 eta slices
 |  |
Fig 2 LEFT: Slope distribution vs. eta-bin, average marked by crosses
RIGHT: predicted gain correction. Correction=1 for strips w/ undetermined gains.

Fig 3 Predicted gain correction. Correction=1 for ~14K of 18K strips.

Fig 4 The same predicted gain correction vs. stripID.

12) investigating status of P-strips
Fig 1. West BSMD-P

Fig 2. East BSMD-P
p>
13) ver 1.2 : SMD-E, -P, status & relative gains, no Crate4
Automatic BSMD-E, -P relative calibration and status tables.
The second pass through both SMDE, SMDP was performed, learning from previous mistakes.
Main changes:
- relax most of the QA cuts
- smooth raw spectra to reduce significance 1-2 channels wide of spikes and deeps in raw spectra
- extend slop fit range to ped +[30,100]
- still do not use crate 4 - it has to many problems
- reduce margin for gain correction - now 10%+ deviation is corrected.
INPUT: 3M d-AU events from day ~336 of 2007.
All spectra were pedestals subtracted, using one value per strip, CAPS=123,124,125 were excluded. Below I'll use term 'ped' instead of more accurate pedestal residuum.
Method: fit slopes to ADC =ped+30,ped+100 or 5*sig(ped) if too low.
The spectra, fits of pedestal residuum, and slopes were QAed.
Note, BSMD rate 4 had old resistors in day 366 of 2007 and was excluded from this analysis.
This reduces # of strips from 18,000 to 15,750 .
| cut# | cut code | description | # of discarded E strips | # of discarded P strips | figure in PDF1 |
| 1 | 1 | at least 10,000 entries in the MPV bin | 4 | ? | - |
| 2 | 2 | sig(ped) of gauss fit <~13 ADC ch | 13 | 11 | Fig 1 |
| 3 | 4 | position of mean gauss within +/- 4 ADC | 10 | 8 | Fig 2 |
| 4 | 8 | yield from [ped+30,ped+100] out of range | 513 | 766 | Fig 3 |
| 5 | 16 | chi2/dof<2.3 from slop fit | 6 | 1 | Fig 4 |
| 6 | 32 | slopeError/slop >10% | 5 | 0 | Fig 5 |
| 7 | 64 | slope in range | 19 | 6 | Fig 6 |
| - | sum | out of processed 15,750 strips discarded | 635 ==> 4.0% | 789 ==> 5.0% |
Relative gain corrections for every eta bin
Method : find average slope per eta slice, fit gauss, determine average slope : avrSlope(iEta)
Gain correction formula is used only for extreme deviations:
- gainCorr_i = slope_i/avrSlope(iEta), i =1,..,18,000
- if( fabs(1-gainCorr)<0.10) gainCor=1.0 // do not correct
- Fig 1 SMDE status table, distribution per module
- Fig 2 SMDP status table, distribution per module
- Fig 3 SMDE gain corrections, changed 3408 strips=22%
- Fig 4 SMDP gain corrections, changed 2067 strips=13%
Summary of BSMDE,P status tales and gains , ver 1.2

14 Eval of BSMDE status tables for pp 2008, day 49,50
Method:
from _private_ production w/o zero BSMD suppression we look at pedestal residua for raw spectra for minb events.
chain="DbV20080703 B2008a ITTF IAna ppOpt VFPPV l3onl emcDY2 fpd ftpc trgd ZDCvtx NosvtIT NossdIT analysis Corr4 OSpaceZ2 OGridLeak3D beamLine BEmcDebug"
The only QA was to require MPV of the spectrum is below 100, one run contains ~80K events.
Fig 1
Good spectra look like this:

Fig 2. Run 9049053, 80K events,
9,292 strips out of 15,750 tested were discarded by condition MPV>100 eve
TOP: MPV value from all strips. White means 0 (zero) counts. Crate 4 was not evaluated.
BOTTOM: status table: red=bad, white means MPV>100 events

Fig 3. Run 9050022, 80K events,
9,335 strips out of 15,750 tested were discarded by condition MPV>100 eve
TOP: MPV value from all strips. White means 0 (zero) counts
BOTTOM: status table: red=bad, white means MPV>100 events

Fig 4. Run 9050088, 80K events,
9,169 strips out of 15,750 tested were discarded by condition MPV>100 eve
TOP: MPV value from all strips. White means 0 (zero) counts
BOTTOM: status table: red=bad, white means MPV>100 events

15 stability of BSDM peds, day 47 is good
Peds from run minB 17 were used as reference
Fig1 . pedestal residua for runs 17,29,31

Fig2 . pedestal residua for run 31, full P-plane

Fig3 . pedestal residua for run 31, full E-plane

Fig4 . pedestal residua for run 31, zoom in E-plane

Fig5 . pedestal residua for run 29, West, E-plane red, P-plane black, error=ped error

15a ped stability day 47, take 2
On August 8, BSMD peds in the offline DB where corrected for day 47.
Runs minb 34 & 74 were used to determine and upload DB peds.
Below I evaluated pedestal residua for 2 runs : 37 & 70, both belonging to the same RHIC fill.
I have used 500 zero-bias events from runs 37 & 70, for the official production w/o zero suppression.
All strips for which mTables->getStatus(iEP, id, statPed,"pedestal"); returns !=1 and all events using CAP123,124,125 were dropped.
Fig 1,2 show big picture: all 38,000 strips.
Fig 3 is zoom in on some small & big problems.
Fig 4 & 5 illustrates improvement if run-by-run pedestal is used.
Fig 1, run=9047037

Fig 2, run=9047070

Fig 3, run=9047070, zoom in

Private peds were determine for 16 runs for day 47 and used appropriately. Below is sum of ped residua from all 16 runs, from zero bias events.
Fig 4, run=9047001,...,83 zoom in

Fig 5, run=9047001,...,83 full range

16) Time stability by fill of BSMD pedestals
I calculated the pedestals for every PP fill for 2008. This plot shows the pedestal per stripID and fill index. The Z-axis is the value of the pedestal. Only module 13 is shown here, but the full 2D histogram (and others) are in the attached root files.

17) Absolute gains , take1
Goal: reco isolated gammas from bht0,1,2 -triggered events
Method: identify isolated EM shower and match BSMD cluster energy to tower energy, as exercised earlier on 4) demonstration of absolute calib algo on single particle M-C
INPUT events: 7,574 events triggered by barrel HT0,1,2 (id 220500 or 220510 or 220520) from run 9047029.
Cluster finder algo (sliding window, 1+3+1 strips), smd cluster threshold set at 5 keV, use only barrel West.
Tower cluster is defined as 3x3 patch centered on the tower pointed by the SMD peak.
Assumed BSMD calibration:
- ene(GeV)= (adc-ped)*1e-7, one constant for all barrel
- pedestals, status tables hand tuned, some modules are disabled, but crate 4 is on
Results for ~3,8K barrel triggered events (half of 7,6K was not used)
Fig 1, Any Eta-cluster
TOP: a) Cluster (Geant) energy;
b) Cluster RMS, peak at 0.5 is from low energy pair of isolated strips with almost equal energy
c) # of cluster per event,
BOTTOM: X-axis is eta location, 20 bins span eta [-1,+1]. d) cluster ene vs. eta, e) cluster RMS vs. eta,
f) cluster yield vs. eta & phi, white bands are masked modules.

Fig 2, Any Phi-cluster
see Fig 1 for details

Fig 3, Isolated EM shower
TOP: a) cluster loss on subsequent cuts, b) # of accepted EM cluster vs. eta location,
c) ADC distribution of 3x3 tower cluster centered at SMD cluster. In principle you should see there 3 edges from bht0, bht1, and bht2 trigger.
BOTTOM: X-axis is eta location, 20 bins span eta [-1,+1].d) Eta-cluster , e) phi-cluster energy, f) hit tower ADC .

Fig 4a,b, Calibration plots
TOP: BSMD Eta vs. Phi as function of pseudorapidity. BOTTOM: BSMD vs. BTOW as function of pseudorapidity.2 eta location of 0.1, 0.5 of reco EM cluster are shown in 3 panels (2x2)
1D plots are ratios of the respective 2D plots.
The mean values of 1D fits are relative gains of BSMDP/BSMDP and BSMD/BTOW .

Fig 4c, Same as above, eta=0.9

18 Absolute gains, take 2
Goal: reco isolated gammas from bht0,1,2 -triggered events
Method: identify isolated EM shower and match BSMD cluster energy to tower energy, as exercised earlier on 4) demonstration of absolute calib algo on single particle M-C
INPUT events: 100K events triggered by barrel HT0,1,2 (id 220500 or 220510 or 220520) from day 47, runs 1..83
Cluster finder algo (sliding window, 1+4+1 strips), smd cluster threshold set at 10 keV, use only barrel West, BSMD CR=4 masked out.
Tower cluster is defined as 3x3 patch centered on the tower pointed by the SMD peak, must contain 90% of energy from 5x5 cluster.
Default pedestals from offline DB used.
Assumed BSMD calibration: see table 1 column J+K
Results for ~25K barrel triggered events (7/8 of 100K was not used)

Fig 1 is above
Fig 2, Eta strips, any cluster

Fig 3 Phi strips, any cluster

Fig 4 isolated cluster (different sort). Plot c has huge peak at 0 - X-axis is chopped. Similar but smaller peak is in fig d. Magenta are event with bht0 and bht2 trigger.

Fig 5 isolated cluster :
Left: eta & phi plane coincidence--> works,
Right: eta & phi & tower 3x3>150 fials for modules 30-60, I have mapping problem??

Fig 6 Example of Eta vs. Phi and SMD vs. Tower calibrations for eta bins 0.15, 0.5, and 0.85.

19) Absolute BSMD Calibration, table ver2.0, Isolated Gamma Algo description
BSMD calibration algo has been developed based on M-C response of BSMD & towers to single gammas.
Executive summary:
The purpose of BSMD absolute calibration summarized at this drupal page is to reconstruct integrated energy deposit (dE) in BSMD based on measured ADC.
By integrated dE in BSMD I mean sum over few strips forming EM cluster, no matter what is the cluster shape.
This calibration method accounts for the varying absorber in front of BSMD and between eta & phi planes.
This calibration will NOT help in reconstruction:
- full energy of EM particle which gets absorbed in BEMC ( shower development after BSMD layer does not matter for this calibration).
- partial energy of hadrons passing or showering in BEMC
- correct for the incident angle of the particle passing through detector
- saturation of BSMD readout. I only state up to which loss (DE) the formula used in reconstruction:
dE/GeV= (rawAdc-ped) * C0 * (1 +/- C1etaBin)
- determine sampling fraction (SF) of BSMD with high accuracy
Below you will find brief description of the algo, side by side comparison of selected plots for M-C and real data, finally PDF with many more plots.
Proposed absolute calibration coefficients are show in table 2.
Part 1
Description of algorithm finding isolated gammas in the Barrel.

Input events
- M-C : single gamma per event, 6 GeV ET, flat in eta, phi covers 3 barrel modules 12,13,14, geometry=y2006
- DATA: BHT0,1,2 triggered pp 2008 events from day 47, total 100K, individual triggers: 44K, 33K, 40K, respectively
events were privately produced w/ zero suppression.
Raw data processing based on muDst
- M-C : BSMD - take geant energy deposit ~100 keV range, towers - take ADC*0.493 to have nominal calibration of 4070 ADC=60 GeV ET.
- Data : BSMD - use private pedestals & status tables for day 47, use custom calibration
use BSMD calibration dE/GeV= (rawAdc-ped) * C0 * (1 +/- C1etaBin), where '+' is for Phi-plane and '-' for eta plane, see table below
skip strips 4 sigma above ped or with energy below 1keV, strip to strip relative gains NOT used , data from CAPs=123,124,125 were not used
towers- take ADC as is, no offline gains correction.
Cluster finder algo (seed is sliding fixed window), tuned on M-C gamma events
- work with 150 Eta-strips per module or 900 Phi-strips at fixed eta
- all strips are marked as 'unused'
- sum dE in fixed window of 4 unused strips, snap at location which maximizes the energy
- if sum below 10 keV STOP searching for clusters in this band
- add energy from one strip on each side, mark all 1+4+1 strips as 'used'
- compute energy weighted cluster position and RMS
- goto 1
This cluster finder process full Barrel West, more details about clustering is in one cluster topology , definition of 'barrel cell'
Isolated EM shower has been selected as follows, tuned on gamma events,
- select isolated eta-cluster in every segment of 15 eta strips.
- require cluster center is at least 3 strips away from edges of this segment (defined by eta values of 0.0, 0.1, 0.2,....0.9, 1.0)
- require there is only one phi-cluster in the same 0.1x0.1 eta.phi cell
- require phi-cluster center is at least 3 strips from the edges
- find hit tower matching to the cross of eta & phi cluster
- sum tower energy from 3x3 patch centered on hit tower
- require 3x3 tower ADC sum >150 ADC (equivalent to 2.2 GeV ET, EM)
- sum tower energy from 5x5 patch centered on hit tower
- require 3x3 sum/ 5x5 sum >0.9
- require RMS of Phi & Eta-cluster is above 0.2 strips
Below is listing of all cuts used by this algo:
useDbPed=1; // 0= use my private peds par_skipSpecCAP=1; // 0 means use all BSMD caps par_strWinLen=4; (3) // length of integration window, total 1+4+1, in strips par_strEneThr=1.e-6; (0.5e-6) // GeV, energy threshold for strip to start cluster search par_cluEneThr=10.0e-6; (2.0e-6) // GeV, energy threshold for cluster in window par_kSigPed=4.; (3) // ADC threshold par_isoRms=0.2; (0.11) // minimal smd 1D cluster RMS par_isoMinT3x3adc=150; //cut off for low tower response par_isoTowerEneR=0.9; // ratio of 3x3/5x4 cluster (in red are adjusted values for MIP or ET=1GeV cluster selection)
Table 1 Tower cluster cut defines energy of isolated gammas.
| 3x3 tower ET (GeV), trigger used | MIP, BHT0,1,2 | 1.0, BHT0,1,2 |
3.4, BHT0 |
4.7, BHT1 |
5.5, BHT2 |
7, BHT2 |
| 3x3 tower ADC sum range | 15-30 ADC | 50-75 ADC | 170-250 ADC | 250-300 ADC | 300-380 ADC | 400-500 ADC |
| 3x3 energy & RMS (GeV) @ eta=[0.1,0.2] | 0.34 +/- 0.06 | 0.92 +/- 0.11 | 3.1 +/- 0.3 | 4.1 +/- 0.2 | 5.1 +/- 0.3 | 6.6 +/- 0.4 |
| 3x3 energy & RMS (GeV) @ eta=[0.4,0.5] | 0.37 +/- 0.07 | 1.0 +/- 0.11 | 3.4 +/- 0.4 | 4.6 +/- 0.3 | 5.6 +/- 0.4 | 7.3 +/- 0.5 |
| 3x3 energy & RMS (GeV) @ eta=[0.8,0.9] | 0.47 +/- 0.09 | 1.3 +/- 0.16 | 4.3 +/- 0.4 | 5.7 +/- 0.3 | 7.1 +/- 0.5 | 9.3 +/- 0.6 |
Table 2 shows assumed calibration.
Contains relative calibration of eta vs. phi plane, different for M-C vs. data,
and single absolute DATA normalization of the ratio of SMD (Eta+Phi) cluster energy vs. 3x3 tower cluster at eta=0.5 .
Table 3 shows what comes from data & M-C analysis using calibration from table 2.

Part 2
Side by side comparison of M-C and real data.
Fig 2.1 BSMD "Any cluster" properties
TOP : RMS vs. energy, only Eta-plane shown, Phi-plane looks similar
BOTTOM: eta -phi distribution of found clusters. Left is M-C - only 3 modules were 'populated'. Right is data, white bands are masked modules or whole BSMD crate 4

Fig 2.2 Crucial cuts after coincidence & isolation was required for a pair BSMD Eta & Phi clusters
TOP : 3x3 tower energy (black), hit-tower energy (green) , if 3x3 energy below 150 ADC cluster is discarded
BOTTOM: eta dependence of 3x3 cluster energy. M-C has 'funny' calibration - there is no reason for U-shape, Y-value at eta=0.5 is correct by construction.

Fig 2.3 None-essential cuts, left by inertia
TOP : ratio of 3x3 tower energy to 5x5 tower energy , rejected if below 0.9
BOTTOM: RMS of Eta & Phi cluster must be above 0.2, to exclude single strip clusters

Part 3
Examples of relative response of BSMD Eta vs. Phi AFTER calibration above is applied.
I'm showing examples for 3 eta slices of 0.15, 0.55, 0.85 - plots for all eta bins are available as PDF, posted in Table 2 at the end.
The red vertical line marks the target calibration, first 2 columns are aligned by definition, 3rd column is independent measurement confirming calibration for data holds for ~40% lower gamma energy.
Fig 3.1 Phi-cluster vs. Eta cluster for eta range [0.1,0.2]. M-C on the left, data in the middle, right.

Fig 3.2 Phi-cluster vs. Eta cluster for eta range [0.4,0.5]. M-C on the left, data in the middle, right.

Fig 3.3 Phi-cluster vs. Eta cluster for eta range [0.8,0.9]. M-C on the left, data in the middle, right.

Fig 3.4 Phi-cluster vs. Eta cluster for eta range [0.9,1.0]. M-C on the left, data in remaining columns.

Part 4
Absolute response of BSMD (Eta + Phi) vs. 3x3 tower cluster, AFTER calibration above is applied.
I'm showing eta slices [0.4,0.5] used to set absolute scale. The red vertical line marks the target calibration, first 2 columns are aligned by definition, 3rd column is independent measurement for gammas with ~40% lower --> BSMD response is NOT proportional to gamma energy.
Fig 4.1 Phi-cluster vs. Eta cluster for eta range [0.4,0.5]. Only data are shown.

Fig 4.2 Absolute BSMD calibration for eta range [0.0,0.1] (top) and eta range [0.1,0.2] (bottom) . Only data are shown.
Left: Y-axis is BSMD(E+P) cluster energy, y-error is error of the mean; X-axis 3x3 tower cluster energy, x-error is RMS of distribution . Fit (magenta thick) is using only to 4 middle points - I trust them more. The MIP point is too high due to necessary SMD cluster threshold, the 7GeV point has very low stat. There is no artificial point at 0,0. Dashed line is extrapolation of the fit.
Right: only slope param (P1) from the left is used to compute full BSMD Phi & Eta-plane calibration using formulas:
slope P1_Eta=P1/2./(1-C1[xCell])/C0
slope P1_Phi=P1/2./(1+C1[xCell])/C0
Using C1[xCell],C0 from table 2.

Fig 4.3 Absolute BSMD calibration for eta range [0.2,0.3] (top) and eta range [0.3,0.4] (bottom) . Only data are shown, description as above.

Fig 4.4 Absolute BSMD calibration for eta range [0.4,0.5] (top) and eta range [0.5,0.6] (bottom) . Only data are shown, description as above.

Fig 4.5 Absolute BSMD calibration for eta range [0.6,0.7] (top) and eta range [0.7,0.8] (bottom) . Only data are shown, description as above.

Fig 4.6 Absolute BSMD calibration for eta range [0.8,0.9] (top) and eta range [0.9,0.95] (bottom) . Only data are shown, description as above.
I'm showing the last eta bin because it is completely different - I do not understand it at all. It was different on all plots above - just reporting here.

Fig 4.7 Expected BSMD gain dependence on HV, from Oleg document The 2008 working HV=1430 V (same for eta & phi planes) - in the middle of the measured gain curve.

Part 5
Possible extensions of this algo.
- cover also East barrel (for the cross check)
- include vertex correction in projecting SMD cluster to tower (perhaps)
- study energy resolution of eta & phi plane - now I just compensated relative gains but the total BSMD energy is simply sum of both planes
- last eta bin [0.9,1.0] is completely different, e.g. there is no MIP peak in the 2D fig 2.2 - BTOW gain (HV) is factor 2 or more way too high in this 2 bins
Justification: Inspect right plot on figures 4.2,...,4.6, in particular note at what gamma energy the blue line reaches ADC of 1000 counts. Look at this pattern vs. eta bin. On the last plot it should happen at gamma energy of ~5 GeV but in reality it is at ~10 GeV. - crate 4 (unmodified) would have different gains - excluded in this analysis
- Speculation: those multiple peaks in raws BSMD spectra (seen by others) could be correlated with BHT0,1,2 triggers
- Scott suggestion: more detailed study of BSMD saturation could use BSMD cluster location for fiducial cut forcing gamma to be in the tower center and use just the hit tower. This needs more stats. This analysis uses 1 day of data and ends up with just ~100 entries per energy point.
- non-linear BSMD response does not mean we can reco cluster position with accuracy better than 1 strip.
Fig 5.1 BSMD cluster energy vs. eta of the cluster.

Fig 5.2 hit tower to 3x3 cluster energy for accepted clusters. DATA, trigger BHT2, gamma ET~5.5 GeV.

Fig 5.3 hit tower to 3x3 cluster energy for accepted clusters. M-C, single gamma ET=6 GeV, flat in eta .

20 BSMD saturation
The isolated BSMD cluster algo allows to select different range of tower energy cluster as shown in Fig.1
Fig 1. Tower energy spectrum, marked range [1.2,1.8] GeV.

In the analysis 5 energy tower slices were selected: MIP, 1.5 GeV, and around BHT0,1,2 thresholds.
Plots below show example of calibrated BSMD (eta+phi) cluster energy vs. tower cluster energy. (I added point at zero with error as for next point to constrain the fit)
Fig 2. BSMD vs. tower energy for eta of 0.15, 0.55, and 0.85.

I'm concern we are beyond the middle of BSMD dynamic range for ~6 GeV (energy) gammas at eta 0.5. Also one may argue we se already saturation.
If we want BSMD to work up to 40 GeV ET we need to think a lot how to accomplish that.
Below is dump of one event contributing to the last dot on the middle plot. It always help me to think if I see real raw event.
BSMDE i=526, smdE-id=6085 rawADC=87.0 ped=71.4 adc=15.6 ene/keV=0.9 i=527, smdE-id=6086 rawADC=427.0 ped=65.0 adc=362.0 ene/keV=20.0 i=528, smdE-id=6087 rawADC=814.0 ped=71.8 adc=742.2 ene/keV=41.0 i=529, smdE-id=6088 rawADC=92.0 ped=66.4 adc=25.6 ene/keV=1.4 BSMDP i=422, smdP-id=6086 rawADC=204.0 ped=99.3 adc=104.7 ene/keV=7.8 i=423, smdP-id=6096 rawADC=375.0 ped=98.5 adc=276.5 ene/keV=20.3 i=424, smdP-id=6106 rawADC=692.0 ped=100.1 adc=591.9 ene/keV=47.3 2D cluster bsmdE CL meanId=6086 rms=0.80 ene/keV=66.80 inTw 1632.or.1612 bsmdP CL meanId=6106 rms=0.68 ene/keV=75.45 inTw 1631.or.1632 BTOW id=1631 rawADC=43.0 ene=0.2 ped=30.0, adc=13.0 id=1632 rawADC=401.0 ene=6.9 ped=32.4 adc=368.6 id=1633 rawADC=43.0 ene=0.1 ped=35.5 adc=7.5 gotTwId=1632 gotTwAdc=368.6 tow3x3 sum=405.7 ADC 3x3Tene=7.3GeV
1) M-C : response of BSMD , single particles (Jan)
Below are studies of BSMD response and calibration algo based on BMSD response to single particle M-C
1) BSMD-E clusters, sliding max, fixed width
Goal: study SMDE energy resolution and cluster shape for single particles M-C
Input: single particle per event, fixed ET=6 GeV, flat eta [-0.1,1.1], flat |phi| <5 deg, 500 eve per sample, Geant geometry y2006
Cluster finder algo (sliding fixed window), tuned on electron events
- work with 150 Eta-strips per module
- sum geant dE in fixed window of 4 strips
- maximize the sum, compute energy weighted cluster position and RMS inside the window
- algo quits after first cluster found in given module
Example of BSMDE response for electon:
McEve BSMD-E dump, dE is Geant energy sum from given strip, in GeV
dE=1.61e-06 m=104 e=12 s=1 stripID=15462
dE=2.87e-05 m=104 e=13 s=1 stripID=15463
dE=8.35e-06 m=104 e=14 s=1 stripID=15464
dE=1.4e-06 m=104 e=15 s=1 stripID=15465
ALL plots below have energy in keV , not MeV - I'll not change plots.
Results:
Fig 1. gamma - later, job crashed.
Fig 2. electron

Fig 3. pi0

Fig 4. eta

Fig 5. pi minus

Fig 6. mu minus

2) BSMDE , 1+3+1 sliding cluster finder
Goal: test SMDE cluster finder on single particles M-C
Input: single particle per event, fixed ET=6 GeV, flat eta [-0.1,1.1], flat |phi| <5 deg, 5k eve per sample, Geant geometry y2006
Cluster finder algo (seed is sliding fixed window), tuned on pi0 events
- work with 150 Eta-strips per module
- all strips are marked as 'unused'
- use only module 13, covering ~1/3 of probed phase space
- sum geant dE in fixed window of 3 unused strips, snap at location which maximizes the energy
- if sum below 5 keV STOP searching for clusters in this module
- add energy from one strip on each side, mark all 1+3+1 strips as 'used'
- compute energy weighted cluster position and RMS
- goto 1
Example of BSMDE response for pi0:
... strID=1932 u=0 ene/keV=0 strID=1933 u=1 ene/keV=0 + strID=1934 u=1 ene/keV=2.0 * strID=1935 u=1 ene/keV=48.2 *X strID=1936 u=1 ene/keV=3.9 * strID=1937 u=1 ene/keV=0.8 + strID=1937 u=0 ene/keV=0 strID=1938 u=0 ene/keV=0 strID=1939 u=2 ene/keV=1.5 + strID=1940 u=2 ene/keV=8.2 * strID=1941 u=2 ene/keV=28.1 *X strID=1942 u=2 ene/keV=13.8 * strID=1943 u=2 ene/keV=4.0 + strID=1944 u=0 ene/keV=5.6 strID=1945 u=0 ene/keV=0.5 strID=1946 u=0 ene/keV=0 strID=1947 u=0 ene/keV=0 ...
| particle | any cluster found in the module, all eventsFig 1a | only events with exactly 2 found clustersFig 1b |
e- |  |  |
| . | Fig 2a | Fig 2b |
pi0 |  |  |
| . | Fig 3a | Fig 3b |
eta |  |  |
3) same algo applied to full East BSMDE,P
Smd cluster finder with sliding window of 3 strips + one strip on each end (total 5 strips) applied to all 9000 BSMDE,P strips, one gamma per event
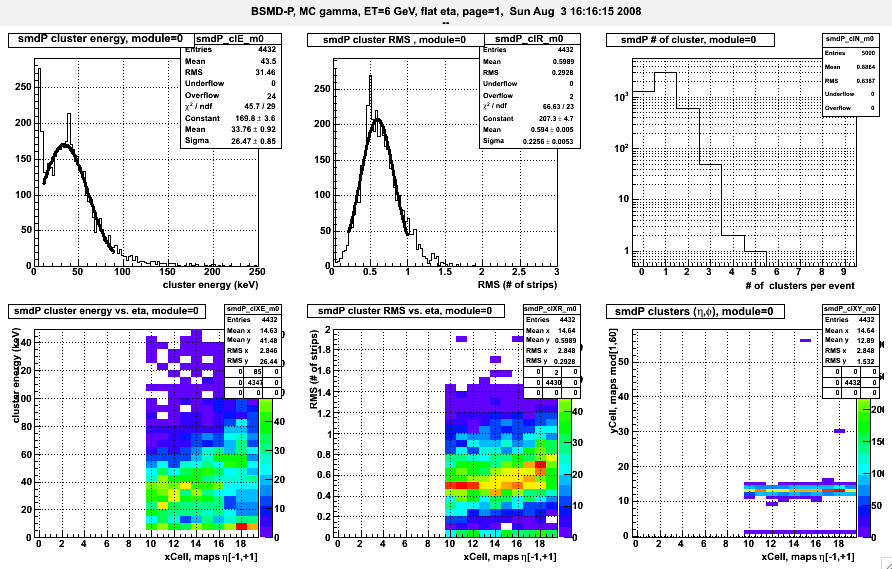
4) demonstration of absolute calib algo on single particle M-C
Goal: determine absolute calibration of BSMDE,P planes
Method: identify isolated EM shower and match BSMD cluster energy to tower energy
INPUT events: single particle per event, fixed ET=6 GeV, flat eta [-0.1,1.1], flat |phi| <5 deg, 5k eve per sample, Geant geometry y2006
Cluster finder algo (seed is sliding fixed window), tuned on pi0 events
- work with 150 Eta-strips per module or 900 Phi-strips at fixed eta
- all strips are marked as 'unused'
- use only module 13, covering ~1/3 of probed phase space
- sum geant dE in fixed window of 3 unused strips, snap at location which maximizes the energy
- if sum below 5 keV STOP searching for clusters in this module
- add energy from one strip on each side, mark all 1+3+1 strips as 'used'
- compute energy weighted cluster position and RMS
- goto 1
This cluster finder process full Barrel West, more details about clustering is in one cluster topology , definition of 'barrel cell'
Isolated EM shower has been selected as follows, tuned on gamma events,
- select isolated eta-cluster in every segment of 15 eta strips.
- require cluster center is at least 3 strips away from edges of this segment (defined by eta values of 0.0, 0.1, 0.2,....0.9, 1.0)
- require there is only one phi-cluster in the same 0.1x0.1 eta.phi cell
- require phi-cluster center is at least 3 strips from the edges
- find tower matching to the cross of eta & phi cluster
- require this tower has ADC>100
Example of EM cluster passing all those criteria is below:
smdE: ene/keV= 40.6 inTw 451.or.471 cell(15,12), jStr=7 in xCell=15 ... id=1731 ene/keV=4.9 * id=1732 ene/keV=34.3 X * id=1733 ene/keV=1.5 * ... ---- end of SMDE dump smdP: ene/keV= 28.5 inTw 471.or.472 cell(15,12), jStr=7 in xCell=15 ... id=1746 ene/keV=2.7 * id=1756 ene/keV=22.0 X * id=1766 ene/keV=3.7 * ... ---- end of SMDE dump muDst BTOW id=451, m=12 rawADC=12.0 * id=471, m=12 rawADC=643.0 id=472, m=12 rawADC=90.0 id=473, m=12 rawADC=10.0
Results for gamma events
will be show with more details. The following PDF files contain full set of plots for all other particles.
particle | # of eve | plots |
| gamma | 25K | |
| e- | 50K | |
| pi0 | 50K | |
| eta | 50K | |
| pi- | 50K |
Fig 1, Any Eta-cluster, single gamma, 25K events
TOP: a) Cluster (Geant) energy; b) Cluster RMS, c) # of cluster per event,
BOTTOM: X-axis is eta location, 20 bins span eta [-1,+1]. d) cluster ene vs. eta, e) cluster RMS vs. eta, f) cluster yield vs. eta & phi.

Fig 2, Any Phi-cluster, single gamma, 25K events
see Fig 1 for details

Fig 3, Isolated EM shower, single gamma, 90K events
TOP: a) cluster loss on subsequent cuts, b) # of accepted EM cluster vs. eta location, c) ADC distribution of hit tower (some wired gains are in default M-C), tower ADC is in ET
BOTTOM: X-axis is eta location, 20 bins span eta [-1,+1]. d) Eta-cluster , e) phi-cluster energy, f) hit tower ADC .

Fig 4, Calibration plots, single gamma, 90K events.
TOP: BSMD Eta vs. Phi as function of pseudorapidity. BOTTOM: BSMD vs. BTOW as function of pseudorapidity.3 eta location of 0.1, 0.5, 0.9 of reco EM cluster are shown in 3 panels (2x2)
1D plots are ratios of the respective 2D plots.
The mean values of 1D fits are relative gains of BSMDP/BSMDP and BSMD/BTOW , determine for 10 slice in pseudorapidity. Game is over :).

Fig 5, Same as above, eta=0.1, single pi0, 50K events.

Fig 6, Same as above, eta=0.1, single pi minus, 50K events.

Below are PDF plots for all particles:
Correction - label on the X-axis for 1D plots is not correct. I did not apply log10() - a regular ratio is shown, sorry.
5) Evaluation of BSMD dynamic range needed for the W program at STAR, ver 1.0
M-C study of BSMD response to high energy electrons

Attachment 1:
Fig 1 & 2 reminds actual (pp data based) calibration for 2 eta location of 0.1 and 0.8, presented earlier.
Table 1 shows M-C simulation of average cluster energy (deposit in BSMD plane), its spread, and width as function of electron ET, separately for eta- & phi-planes of BSMD.
As expected, BSMD sampling fraction (SF, red column) is not constant but drops with energy of electron.
The BSMD SF(ET) deviates from constant by less then 20% - it is a small effect.
Fig 3,4,5 show expected BSMD response to M-C electrons with ET of 6,20, and 40 GeV. Only for the lowest energy the majority of EM showers fit in to the dynamic range of BSMD, which ends for energy deposit of about 60 keV per plane.
I was trying to be generous and draw the red line at DE~90 keV .
The rms of BSMD cluster is about 0.5 strips, so majority of energy is measured by just 2 strips (amplifiers). Such narrow cluster lowers saturation threshold.
Fig 6, shows BSMD cluster energy for PYTHIA W-events.
Fig 7 shows similar response to PYTHIA QCD events.
Compare area marked with red oval - there is strong correlation between BSMD energy and electron energy and would be not wise to forgo it in the e/h algo.
Conclusion:
The attached slides show 2008 HV setting of BSMD would lead to full saturation of BSMD response for electrons from W decay with ET as low as 20 GeV , i.e. would reduce BSDM dynamic range to 1 bit.0
For the reference:
* absolute BSMD calibration based on 2008 pp data.
http://drupal.star.bnl.gov/STAR/subsys/bemc/calibrations/bsmd/2008-bsmd-calibration/19-isolated-gamma-algo-description-set-2-0
* current BSMD HV are set very high , leading to saturation of BSMD at gamma energy of 7-10 GeV, depending on eta and plane. (Lets ignore difference between E & ET for this discussion, for now).
http://drupal.star.bnl.gov/STAR/subsys/bemc/calibrations/bsmd/2008-bsmd-calibration/20-bsmd-saturation
* STAR priorities for 2009 pp run presented at Apex: http://www.c-ad.bnl.gov/APEX/APEXWorkshop2008/talks/Dunlop_Star_Apex_2008.pdf
* Attachment 2,3 show BSMD-E, -P response for electrons with ET: 4,6,8,10,20,30,40,50 GeV and to Pythia W, QCD events (in this order)
BSMD 2005 energy scale uncertainty
STAR/blog/ogrebeny/2009/jun/08/bsmd-energy-scale-uncertainty
Definition of absolute BSMD calibration
NOT FINISHED
Definitions of quantities used for empirical calibration of BSMD.
Revised January, 26, 2009
A) Model of the physics process (defines quantities: E, eta, smdE, smdEp, smdEe, C0, C1)
- gamma particle with fixed energy E enters projectively EMC at fixed pseudo-rapidity eta. Eta is defined in detector ref. frame.
- EM showers develops and BSMD (consisting of 2 planes) captures smdEtot of shower energy. Single plane captures smdE=0.5*smdEtot. The SMD cluster energy from single plane is denoted as smdE.
- SMD consist of 2 planes : eta-plane closer to IP and the outer phi-plane. Each plane captures non-equal fraction ofenergy deposited in BSMD: smdEp, smdEe, respectively.
 The following relation holds:
The following relation holds:
smdEp(E,eta) =smdE(E) * [1-C1(eta)]
smdEe(E,eta) =smdE(E) * [1+C1(eta)]
where theta-dependent coefficient C1 accounts for all physical processes differentiating fraction of captured shower energy by eta vs. phi-planes along Z-direction.
allows reconstruction of full BSMD energy deposit independent on gamma angle theta if cluster energy in both plane is measured - BSMD Cluster energy is measured in each plane by few consecutive strips which:
- response is linear and
- strip-to-strip local hardware gain variation is negligible (the "long-wave" is accounted for in C1(theta))
Note, there are 4 low gain strip (id=50,100) in the eta-plane , seen in fig 2 of 08) SMD-E gain equalization , ver 1.1, which require ADC to be rescaled appropriately.

- The overall conversion constant C0=6.5e-8 (GeV/ADC chan) allows reconstruction of BSMD cluster energy in given plane based on the sum of ADCs from all strips participating in the cluster
smdEp(E,eta)=C0* sum{ ADC_i - ped_i}, over cluster of few strips , similar formula for smdEp(E,eta)=....
The value of C0 was determined based on 19) Absolute BSMD Calibration, table ver2.0, Isolated Gamma Algo description, table 2. Gammas with ET=6 GeV were thrown at EMC and resulting SMD cluster ADC sum was matched to the average value seen for 2008 pp data.
To summarize
The reconstructed cluster energy in each plane with use of C0 & C1 should have eta dependence
smdE(E) =C0* sum{ ADC_i - ped_i}/[1-C1(eta)] for phi-plane cluster
smdE(E) =C0* sum{ ADC_j - ped_j}/[1+C1(eta)] for eta-plane clusterThose 2 quantities are well suited to place cuts.
B) Determination of C1(eta) was based on 19) Absolute BSMD Calibration, table ver2.0, Isolated Gamma Algo description, from crates 1,2,and 4.
Data analysis was done for 10 pseudo-rapidity ranges [0,0.1], [0.1,0.2] ,..., as shown in table 2, row labeled 'DATA'.
For practical application analytical approximation is provided
C1(eta)= C1_0 + C1_1*|eta| + C1_2*eta*eta
symmetric versus positive/negative pseudo-rapidity.
The numerical values of expansion coefficients are: C1_0=0.014, C1_1=0.015, C1_2=0.333
C) Modeling of BSMD response in STAR M-C
- find geantDE geant energy deposit for given BSMD strip
- undo simulated by GEANT +/-7% difference between eta/phi planes (see 19) Absolute BSMD Calibration, table ver2.0, Isolated Gamma Algo description, row 'M-C')
geantDEp=geantDE*0.93
geantDEe=geantDE*1.07 - compute ADC for every i-th strip & plane
ADCp_i= geantDEp/[1-C1(eta)]/C0
ADCe_i= geantDEe/[1+C1(eta)]/C0- If NO saturation is assumed that is all - use ADC-values in reconstruction.
- To simulate full ADC saturation at 1024 assume pedestal is at ADC=100 and saturate values of ADCp_i, ADCe_i at 924. Then proceed to reconstruction.
Mapping, strip to tower distance
For every strip we find the closest tower and determine the distance between tower center and strip center.
Both plots show strip ID on the X-axis, and tower ID on the Y-axis. Error in Y is distance between centers in CM.
It is not true 15 eta strips covers every 2 towers! It is only approximate since strip pitch is constant bimodal and tower width changes continuously.
There is still small problem, namely strip Z is calculated at R_smd and tower Z is calculated at the entrance of the tower
leading to clear paralax error - we are working on this.
Fig 1.
Top plots is for SMDE for module 1. Note E-strip always spans 2 towers and we used tower IDs in one module.
Bottom plots shows phi strips for module 1.

Fig 2.
Top plots is for SMDE for modules 1-4.
Bottom plots shows phi strips for modules 1-4.


Run 10 BSMD Calibrations
Parent page for BSMD Run 10 Calibration
BSMD Status Table in run10 AuAu200GeV runs
==========
We started this task by looking at BSMD in Run 10 with some MuDst files, and found the pedestals probably need to be QA-ed as well.
http://www.star.bnl.gov/HyperNews-star/get/emc2/3500.html
and
http://www.star.bnl.gov/HyperNews-star/get/emc2/3515.html
==========
Then we started to look for Non-zero-suppressed BSMD data, and found that we have to run through the daq files to produce the NZS data files to produce the NZS data. The daq files are stored on HPSS, and we have to transfer them onto RCF. The transferred daq files were then made into root files with Willim's BSMD online monitering codes.
http://www.star.bnl.gov/HyperNews-star/get/emc2/3533.html
==========
We decided to use same critiria and status codes as Willim used for run09 pp500GeV.
http://drupal.star.bnl.gov/STAR/blog-entry/wleight/2009/may/13/bsmd-status-cuts-and-parameters
==========
We discovered that a modification is needed to the critiria of code bit 3 (the ratio of the integral over a window to the integral over all, i.e. the pedestal integral ratio) We found about half of the BSMD strips fail the criteria of this ratio > 0.95, but nearly most of them satisfy ratio > 0.90, so the critiria is loosed to 0.90. We think this is a reasonable difference between run09 pp and run10 AuAu collisions.
http://www.star.bnl.gov/HyperNews-star/get/emc2/3546/1/1.html
==========
The daq files are huge in size, on the order of TB for one day. In order to not disturb the run10 data production, we had to only copy 1/10~1/20 of the daq files.
http://www.star.bnl.gov/HyperNews-star/get/emc2/3589/2.html
==========
After a long period of transffering and root files making, almost all the days between Jan/02/2010 and Mar/17/2010 are done.
http://www.star.bnl.gov/HyperNews-star/get/emc2/3601.html
We found that another criteria has to be modified, because we use NZS data for the QA of the tail of ADC spectrum. The definition of the tail ranges and the limits are adjusted. Three ranges of the tail part of ADC are defined,
Range 1:peak+6*rms to peak+6*rms+50 channels
Range 2:6*rms+50 channels to 6*rms+150 channels
Range 3:6*rms+150 channels to 6*rms+350 channels
The entries (hits) in these three ranges are counted, and the ratios to all the entries in the whole spectrum are calculated. The limits for good ratios are selected based on the ratios distribution trough out all the days. They are
@font-face {
font-family: "Cambria";
}p.MsoNormal, li.MsoNormal, div.MsoNormal { margin: 0in 0in 0.0001pt; font-size: 12pt; font-family: "Times New Roman"; }div.Section1 { page: Section1; }
Range 1: 3.35~80 x0.001
Range 2: 0.95~40 x0.001
Range 3: 0.25 ~ 20 x0.001
See the attached newlimits.docx for more details and plots.
Also, bit 0 of the status code is supposed to indicate whether a channel is bad or not. Not every problem is fatal, i.e cause the channel to be regarded as bad.
Originally, only if all the 3 ratios are beyond the limits, a fetal condition is met; we addjusted this to be if more than one, i.e. >=2, out of the 3 ratios are beyond the limits, a fetal condition is met. One can also treat any channel with a code not equal to 1 as bad, regardless what the bit 0 is.
==========
A final report with sample codes in one day was presented to and approved by EMC2 group.
http://www.star.bnl.gov/HyperNews-star/get/emc2/3637/1.html
==========
Note: The map file used in bsmd montoring in run10 was with some inconsistence with the acctual hardware. An after-burn map correction was done by the EMC software coordinator, Justin.
Note: Up to now, no corrections are made to pedestals. The bad strips caused by bad pedestals are rouphly 1/3~1/4 of all the bad strips.
Wenqin Xu
16Feb2011
Run 9 BSMD Calibration
Parent page for BSMD Run 9 Calibration
01 Status of BSMDE,P at the end of pp 500 GeV run, April of 2009
Summary of BSMD performance on April 6. Input : 200K events tagged by L2W clust ET>13 GeV, days 85-94, ~all events, only ZS data are shown.


Attached PDFs shows zoom in spectra for individual modules. 1st page is summary, next I show 3 modules per row, 5 rows per page. Even pages shows zoom-in for low ADC<100, odd pages shows full ADC scale. Common maxZ=1000 is used for all plots , except page 1.
02 offline QA of BSMD pp 500, ver1 (Willie+Jan)
BSMD QA algorithm and results for pp 500, tune optimized for high energy energy response
- QA method, details are given in Willie's blog
Fig 1. Typical good/bad strips from the E-plane and with wide pedestals.

- Input: all available events from fills 10399, 10402, 10403, 10404, 10407, 10412, 10415 added together
- evaluate shape of pedestal residua for NZS data captured on-line by Willie's daq reader (Blue filled histo)
- evaluate yield in high energy range (ADC ~300,500,800) using ZS data from L2W triggered events (Magenta line-only)
- ignored: satellite spikes around pedestal at ADC ~32, those come from correlated noise and (most likely) such events will be discarded.
- Example of such spectra for few strips is shown in fig 1.
- Encoding of BSMD status bits extends existing convention to use LSB=1 for good strips and LSB=0 for bad strips. We used bits 1,2,3 to tag pedestal problems and bits 5,6,7 to tag yield problems.
- More plots with individual strips is in attachment A,B,C,D.
- Bad strip is defined as having : bad pedestal or god pedestal but no yield above it.
Fig 2. Distribution of bad strips from both planes, details about each plane separately is in attachment E.

- The remaining issues:
- of tagging 'spiked' events (or modules?) needs to be investigated.
- study time dependence
- For the reference this directory contains PDF files with plots from all 120 BSMD modules.
Fig 3. # of bad strips per module.

03 correlated, small ADC spikes in BSMD (Jan)
Study of small ADC spikes in BSMD
Input:
The following plots support those observation:
- spikes are symmetric on both sides of pedestals peak, separated by 2^N ADC counts, narrower than pedestal peak, (Fig1)
- spikes are correlated in even ID (or odd) strips the same plane, correlation is local, Fig 2
- spikes are correlated between P-plane & E-plane strips, Fig 3
- energy deposit in BSMD increases probability of spikes, see peak/valley for blue vs. magenta in fig 1b.
- bands are visible at larger ADC, as shown by Oleg, not sure what data and how many events, fig 4
- perhaps fig 1c shows yet another pathology, because it does not obey odd/even rule in fig 1a & 1b.
Fig 1a. Example of spikes delADC=16, in the vicinity of strip 1525-P, all strips from module 11 are shown in attachment A.

Fig 1b. Example of spikes delADC=32, in the vicinity of strip 1977-P, all strips from module 14 are shown in attachment B, module 22 looks similar.

Fig 1c. Example of spikes delADC=128, in the vicinity of strip 4562-P, all strips from module 31 are shown in attachment C, modules 51,52,57 look similar

Fig 2. Phi-Phi plane correlation of P-strip 1979 with (odd) P-strips: 1977..1994. Attachment D contains correlation of P-strips [1977-80] with 24 strips in proximity.

Fig 3. Phi-Eta plane correlation of P-strip 1979 with (odd) E-strips: 1977..1994. Attachment E contains correlation of P-strips [1977-80] with 24 strips in proximity.

Fig 4.Oleg observed this stripes in raw BSMD ADC spectrum, not sure what data.

2009 BSMD Relative Gains Information
The pdf posted here has a good overview of the computation of the slope for each strip, discussing the method and the various ways in which strips were marked as bad. This page discusses the computation of the actual relative gains and statuses that went into the database.
The code used to compute the relative gains is archived at /star/institutions/mit/wleight/archive/bsmdRelGains2009/.
DELETE - Run 9 BSMD Status Update 3 (4/24)
After looking more closely at the crate 1 channels I was forced to make serious revisions to status bit 2 from the previous update. The new status bit 2 test is as follows:
First, I scan through the strip ADC distribution looking for peaks. A peak is defined as a channel that is greater than or equal to the four or two channels to either side (if the sigma of the fit to the strip ADC distribution is greater than or less than six, respectively), has a content that is greater than 5% of the maximum of the strip ADC distribution, and has a depth greater than 5% of the maximum of the strip ADC distribution. The depth is calculated by first calculating the difference between the peak content and the channel content for each of the four or two channels on either side of the peak. The maximum of these differences is obtained for the left and right sides separately, and the depth is then equal to the lesser of these two maxima.
If the strip has more than one peak and the maximum of the depths is greater than 20% of the maximum of the strip ADC distribution, then the strip is given bad status 2. If the strip has only one peak (which is then necessarily the maximum of the entire distribution) but the distance between that peak and the peak obtained from the gaussian fit is greater than 75% of the sigma from the gaussian fit, the strip is given bad status 2 as well. Attached is a pdf that has only the pedestal plots for all channels from crate 1.
Edit: I forgot that the BSMD crates don't increase with module number: what is labeled as crate 1 is actually crate 2, as that is the crate that has the first 15 modules, and the attachment labeled as crate 2 is the 2nd 15 modules and so actually crate 1.
2nd edit: This is now out of date, please see the new update.
DELETE - Run 9 BSMD Status Update 4 (4/27)
After further investigations -- specifically looking at strips that had a significant secondary peak, entirely separated from the main peak, with a max of ~40, which were not being caught by my cuts -- I have again revised my criteria for status bit 2. Again, I begin by looking for peaks. If a peak candidate is less than three sigma from the peak of the strip ADC distribution (strip and peak both taken from the gaussian fit), the same cuts are imposed: the candidate must be greater than the four (if sigma>6) or two (if sigma<6) channels on on either side of it, it's content must be greater than 5% of the maximum of the strip ADC distribution, and the depth must be at least 5% of the maximum of the strip ADC distribution. If the strip has two such peaks with the maximum of the depths greater than 20% of the maximum of the strip ADC distribution, or has only one peak but that peak is at least one sigma away from gaussian fit peak, it is given bad status 2. Note the only change here is that the previously a strip with only one peak could be marked bad if it was 75% of sigma away from the gaussian fit peak.
Most of the changes have to do with candidates that are at least three sigma from the gaussian fit peak. In this case the cuts are relaxed: the bin content need only be .5% of the max, not 5%, though it still must be at least 10, and the peak depth is required to only be at least 5% of the peak itself, not of the max. A more than three-sigma peak has the same requirements for the number of channels it must be greater than: however, none of those channels can have value 0. Any strip with a candidate that passes these criteria is automatically given bad status 2.
Pdfs for crates 1 and 2 are attached (but note that the crate 1 and crate 2 pdfs contain the first and second 15 modules, respectively, and therefore crate 1 should actually be labeled crate 2 and crate 2 is really crate 4).
DELETE - Run 9 BSMD Status Update 5 (4/30)
Edited on 5/1 to reflecte new status bit assigments for bits 3 and 4.
The current BSMD status bits are as follows:
Bit 2: Bad pedestal peak/multiple pedestal peaks. This is described in more detail here. Examples can be found in crate2_ped.pdf pp 207 and 314 and crate4_ped.pdf p 133.
Bit 3: Pedestal peak has bad sigma, sigma<1 or sigma >15
Bit 4: Chi squared value from gaussian fit is greater than 1000 (i.e., pedestal has a funny shape)
Bit 5: Strip is exactly identical to the previous strip
Bit 6: The ratio of the integral of channels 300-500 to the total integral does not fall between .0001 and .02
Bit 7: The ratio of the integral of channels 500-800 to the total integral does not fall between .00004 and .02
Bit 8: The ratio of the integral of channels greater than 800 to the total integral does not fall between .00005 and .02
Note that this means that dead channels have status 111xxxx0->448 (or greater).
The attached pdfs crate2 and crate4.pdf have the pedestal distributions, taken from NZS data, and the overall distributions, taken from ZS L2W data, overlayed; crate2_ped and crate4_ped.pdf have only the pedestal distributions. The NZS data used was taken from my monitoring for fills 10415-10489. The L2W data came from fills 10383-10507. Additionally, at the beginning of each module is a summary page that has plotted the distributions for the ratios used to determine bad status bits 6, 7, and 8, and the overal distribution of status vs. strip for eta and phi.
Finally, there are a couple of possible new problems. Page 18 in crate4_ped.pdf has several examples of pedestal distributions that have shoulders. Page 20 has a few examples of pedestal distributions with a small, skinny peak perched on top of a large, broad distribution. At the moment I have no bad status bit for either of these, and any peak with either of these features would almost certainly not be marked bad (even though I did manage to catch one of the ones on page 20).
Edit: Scott suggested during the phone meeting today that perhaps the problem of a small peak on a broad distribution was due to time variation of the pedestal width, and in the plot below you can see that he was correct: the strip initially has an extremely wide pedestal which then shrinks down suddenly. Futhermore, looking at one of the strips that had a sort of shoulder to it, you can see that this is just a less-pronounced version of the double peak problem seen before: the pedestal goes up by 10 for a much shorter time frame, thus producing a shoulder rather than a second peak. This suggests that, as Scott said, these channels should still be usable, and that once we begin breaking status down by time these funny shapes should be less of a problem.


DELETE - Run 9 BSMD Status Update 6 (5/4)
As Matt says that the maximum status is 255, I have dropped the old status bit 5 as (it was unused). Also, I have loosened the dead strip cuts based on looking at module 55 (see pages 203 or 205 in the attached crate1.pdf, for instance). The status bits are now as follows:
Bit 2: Bad pedestal peak/multiple pedestal peaks.
Bit 3: Pedestal peak has bad sigma, sigma<1 or sigma >15
Bit 4: Chi squared value from gaussian fit is greater than 1000 (this applies only for strips that do not have bad status 2 already)
Bit 5: The ratio of the integral of channels 300-500 to the total integral does not fall between .0005 and .02
Bit 6: The ratio of the integral of channels 500-800 to the total integral does not fall between .0002 and .02
Bit 7: The ratio of the integral of channels greater than 800 to the total integral does not fall between .0002 and .02
Below is a plot of status vs. eta and phi for BSMDE and BSMDP strips. Note that strips with all three of bits 5, 6, 7 bad (generally, dead strips) are given the value 8 in this plot to distinguish them from strips that may have just one of those bits bad. As some strips may have more than one bad status bit, for clarity I ranked the potential bad statuses in the order 2, 8, 7, 6, 5, 4, 3 (i.e., approximately in order of importance) and plotted for each strip only the highest-ranked status.

Additionally, I found a problem I had not seen before. On page 207 of the attached crate1.pdf you can see that in the L2W data some strips have a large peak out in the tail of the ADC distribution. However, as all these strips are caught by my code it's not a serious problem.
Final Run 9 200 GeV BSMD Status
In essence, the 200 GeV status tables were calculated the same way as the 500 GeV tables were. Please see here for details.
Final Run 9 500 GeV BSMD Status - Willie Leight
BSMD Pedestals and Status for Run 9 pp 500 Data (June 2009, uploaded to offline DB)
The BSMD status analysis for the 500 GeV data proceeds as follows:
- Each strip is assigned a status for the whole run from an analysis of fills 10399, 10402, 10403, 10404, 10407, 10412, and 10415. Pedestals are analyzed using NZS data taken by the BSMD online monitoring, which reads NZS data from evp and subtracts off pedestals which are updated each time a new BSMD pedestal run is taken. Because NZS data is essentially minbias, high energy tails are analyzed using L2W-triggered data. Status bits are described in detail here.
- Once each strip has an assigned status, those strips that are not marked as bad move on to the second step. Here the strips are examined fill-by-fill: for each fill the strip pedestal is QAed by re-applying the pedestal cuts (but not the tail cuts due to lack of statistics), and a new status for that fill is determined.
- Next, a pedestal correction is calculated. The pedestal correction is just the MPV of the pedestal residua if the MPV is greater than the RMS of the pedestal residua.
- Finally, we upload a number of tables to the database: for each BSMD plane there is one that contains a universal status for every strip, one for each fill containing a status for every strip, and one for each fill containing the RMS and pedestal correction for every strip.
Attached is a pdf that presents the results of this study, including examples.
All code and root files are archived at /star/institutions/mit/wleight/archive/2009-pp500-bsmdStatus/.
Table 1: Pedestal correction, RMS, and status vs. fill for each module (Crates 1-4 are the West Barrel)
Table 2: BSMD spectra for 150 eta and 150 phi strips used for status determination for each module (for fills listed above). Bad strips are identified with the status (in hex): strips with red status are marked bad, strips with green failed a cut but are not necessarily bad. Note that these spectra are shifted up by 100 on the X-axis so that the pedestal is centered around 100 rather than 0.
Table 3: Fills used in this study.
# Fill Date Begin run End run LT/pb
1 F10383 2009-03-18 R10076134 R10076161 0.00
2 F10398 2009-03-20 R10078076 R10079017 0.08
3 F10399 2009-03-20 R10079027 R10079086 0.22
4 F10402 2009-03-21 R10079129 R10079139 0.04
5 F10403 2009-03-21 R10080019 R10080022 0.01
6 F10404 2009-03-22 R10080039 R10080081 0.09
7 F10407 2009-03-22 R10081007 R10081056 0.05
8 F10412 2009-03-23 R10081096 R10082095 0.23
9 F10415 2009-03-24 R10083013 R10083058 0.24
10 F10426 2009-03-25 R10084005 R10084024 0.11
11 F10434 2009-03-26 R10085016 R10085039 0.18
12 F10439 2009-03-27 R10085096 R10086046 0.26
13 F10448 2009-03-28 R10087001 R10087041 0.29
14 F10449 2009-03-28 R10087051 R10087097 0.32
15 F10450 2009-03-29 R10087110 R10088036 0.29*
16 F10454 2009-03-29 R10088058 R10088085 0.15*
17 F10455 2009-03-30 R10088096 R10089023 0.29*
18 F10463 2009-03-31 R10089079 R10090027 0.20*
19 F10464 2009-03-31 R10090037 R10090047 0.08*
20 F10465 2009-03-31 R10090071 R10090112 0.13*
21 F10471 2009-04-02 R10091089 R10092050 0.30
22 F10476 2009-04-03 R10092084 R10093036 0.28
23 F10478 2009-04-03 R10093057 R10093085 0.08
24 F10482 2009-04-04 R10093110 R10094024 0.55
25 F10486 2009-04-05 R10094063 R10094099 0.52
26 F10490 2009-04-05 R10095019 R10095057 0.40
27 F10494 2009-04-06 R10095120 R10096027 0.61
28 F10505 2009-04-07 R10096139 R10097045 0.39
29 F10507 2009-04-08 R10097086 R10097153 0.29
30 F10508 2009-04-08 R10098029 R10098046 0.17
31 F10517 2009-04-09 R10099020 R10099078 0.32**
32 F10525 2009-04-10 R10099185 R10100032 0.68
33 F10526 2009-04-10 R10100049 R10100098 0.37
34 F10527 2009-04-11 R10100164 R10101020 0.82
35 F10528 2009-04-11 R10101028 R10101040 0.31
36 F10531 2009-04-12 R10101059 R10102003 0.86
37 F10532 2009-04-12 R10102031 R10102070 0.76
38 F10535 2009-04-13 R10102094 R10103018 0.86
39 F10536 2009-04-13 R10103027 R10103046 0.43
* Crate 2 was off for this fill
** This fill had no BSMD data
Final Run 9 BSMD Absolute Calibration
The Run 9 BSMD absolute calibration was made using few-GeV TPC-identified electrons from pp500 running, and has two pieces. The first is a new CALIBRATION table in the database which will be used in the EMC slow simulator to improve the agreement of of MC ADC with data. This table starts by combining the previously-determined strip-by-strip relative gains with the existing values in the table. This is then multiplied by the ratio of the slope of a linear fit to the mean cluster ADC distribution from few-GeV isolated data electrons to the same slope in simulated electrons, where the slope is calculated in four different eta bins. The second piece is a new GAIN table in the database which allows ADC values to be converted to energy deposited in the BSMD. This table was determined by combining the strip-by-strip relative gains with a similar ratio as above, but using mean cluster energy deposited in the BSMD instead of reconstructed ADC values (the electron samples used for data and MC were the same) and it is calculated in ten eta bins instead of four. Both tables are currently in the database with flavor "Wbose2": it is hoped that eventually the CALIBRATION table will migrate to flavor "ofl", but the GAIN table will have to remain "Wbose2" because it is currently used (with values all equal to 1) in some codes to determine the change in the BSMD calibration over time. While producing two tables which are in some ways overlapping and one of which can never be flavor "ofl" is not an ideal solution, it allows us to avoid making any modifications to currently existing code (in particular the StEmcSimulator) and allows people who prefer to think of reconstructed energy from BSMD ADCs as being the full particle energy instead of the energy deposited in the BSMD to continue as they were with no change. For more details, please see:
2. Final cut list and data-MC comparison
Additionally, a link to the 2009 BSMD Calibration note will be added here once it is completed.
See also a brief presentation on why we chose not to include the BSMD gas pressure in our analysis.
Run 9 BSMD Status Update 1 (4/19)
I use two datasets to QA BSMD channels: zero-suppressed data from L2W events (fills 10383-10507) and non-zero-suppressed data from online monitoring (fills 10436-10507) (note that at the moment I am not examining the time dependence of BSMD status). NZS data is used to QA the pedestal peak of a channel, while high-energy ZS data is used to QA the tail.
Next, the ZS data are compared to the ZS data from the previous channel to check for copycat channels. Then three quantities are calculated: the ratios of the integrals from 300-500, 500-800, and 800-the end of the spectrum to the total integral of the channel. Each of these quantities must then fall within the following cuts: .0001-.02, .00004-.02, and .00005-.02 respectively. Here is a sample distribution:

Also, the spectra for the strips in module 3, with status, are attached. I have not had a chance to look closely at any other modules yet.
details about known hardware problems
Attached file 'SMD_07.xls' contain my notes from run 7, the only things that might be useful for
you is in the red color, permanently disconnected anode wires and affected
strips (again this is not SoftIds). I think that I cut out one more wire
before Run8 started, but for that I need to check logbook.
Oleg
-----------------------
BSMD Wire Support Effects on GAIN
Here is a note from Oleg Tsai (and attached file "wiresup.pdf" below) concerning source
measurements of the BSMD gain behavior near the nylon wire supports:
On Fri, 18 Jul 2008, tsai@physics.ucla.edu wrote:
> Attached plot will help you to understand what you see close to
> strips 58 and 105. There are two nylon wire supports in the chamber
> at distances 34.882" and 69.213" from the (eta=0 end of the chamber,
> not from the real eta 0). Gain drops near these supports. You can
> see this in your plots also. The attached plot shows counting rate vs
> strip id for a typical chamber. Don't pay attention to channels
> near 0 and 150 - these effects are due to particular way co60 source
> was collimated (counting profile was close to 0.1/0.2/0.4/0.2/0.1)
> 0.4 in central strip. From that I estimated that eta strips
> 56-60 and 104-107 should have calib. coefficients
> (.95,.813,.875,.971,.984) (.99,.89,.84,.970.), I don't remember
> if I was using counting rate vs HV to derive these numbers...
> (this is my third and final attempt :-))
>
details of SMD simulator, simu shower zoom-in
Fig 1. Geant simu of EM shower of one electron with ET=10 GeV at eta=0.
Note,
- one phi-strip is parallel to cavities, extends over 1/10 of the cavity length, and integrates over 2 consecutive cavities.
- one eta-strip is perpendicular to cavities, extends over 1/150 of the cavity length, and integrates over all 30 cavities in the module.

Hi Jan,
the only documentation I know of is the code itself --
hopefully you'll consider it human-readable. Look at
StEmcSimpleSimulator::makeRawHit() in StEmcSimulatorMaker. We use the
kSimpleMode case. The GEANT energy deposition is multiplied by a
sampling fraction that's a second-order polynomial in pseudorapidity,
and then we take pedestals, calibration jitter, etc. into account.
The exact parameters of the sampling fraction are defined in the
constructor for StEmcSimpleSimulator. I don't remember how they were
determined.
also meant to add that the width broadening is OFF by
default. To turn it on one needs to do
emcSim->setMaxCrossTalkPercentage(kBarrelEtaStripId, aNumber);
The "width broadening" only occurs
for eta strips and was implemented by Mike Betancourt in
StEmcSimulatorMaker::makeCrossTalk(). He wrote a blog post about it:
http://drupal.star.bnl.gov/STAR/blog-entry/betan/2007/nov/19/cross-talk-bsmd
Adam
Maybe I should note that the cross talk I implemented was to account
for the capacitive cross talk between the cables carrying the eta
strip signals to the readout, and not for any effects related to the
energy deposition.
-Mike
Hi Jan,
Well, Oleg should probably make the definitive reply, but I think it is like this:
The amplification happens only at the wire, it is independent of the positions of the primary ionization. Of course, there is a little effect from a small amount of recombination or capture of the charge on impurities, and there must be a (hopefully small) effect from the dependence of the mean pulse shape on the position of the ionization and the dependence of the effective gain of the electronics on the mean pulse shape. But these things can't amount to much, I would think. (Of course, I don't want to discourage you from looking in the data to confirm it!)
Gerard
These are all quite true, small effects which will be difficult
to see. The bigger effect is reading out one time bucket.
I have made some estimates before test run 98 (?) or so, see this PS
if you look at numbers still very small effect which is unpractical
to measure.
Oleg
Hi, Yes indeed, I don't know why I neglected to think of the simple effect of drift time, but it is certainly going to be a much bigger effect (~10% if I read your fig.3 correctly?) than the other two. (Perhaps still too small to see in the data, I don't know...). Anyway, given the data volume and already limited readout speed of the BSMD I am pretty sure there is no prospect to ever read more than the one fixed time sample from BSMD; this is probably something to live with. [But it is not impossible to have 2 or 3 point readout, and if we want to seriously consider it it should be brought up ~now, well that is in case we are given the green light to work on BSMD readout "mini-upgrade". If not, well it will just wait until then. But keep in mind, more points readout would offer slightly better gain accuracy but will complicate offline and calibrations too, probably you really don't want it anyway!]
Gerard
p.s. Jan I don't know if it adds anything to the wider discussion on BSMD gain/cal but if you feel so you may surely post to hn.
p.p.s. Oleg, an important question - in your note you don't specify exactly how you obtain the drift time... I mean, yes you show a drift velocity curve, but really of course you must mean there was a calculation such as with garfield to get a drift time out of this... _So_, was that calculation done with the magnetic field on? [The wires are parallel to the magnetic field, right? So it will make possibly a very big difference in drift times.] Jan, do you/others realize the BSMD gain will probably have some systematic dependence on the magnetic field, including the sign thereof? So if you care about gain calibration it should be separated out according to the state of STAR magnet, fortunately there are only a few running states, right?
Gerard
one cluster topology , definition of 'barrel cell'
One dimensional BSMD cluster finder is insensitive to single dead strips and module boundaries for the phi strip.
However certain class of Phi-strip clusters (marked as red) are artificial split and reco as 2 phi-clusters.
One could use the Eta-strip cluster to recover from such phi-plane split if occupancy is low and relative scale of eta & phi cluster energy known.
Plots below also introduce a concept of 'barrel cell' which has approximate size of 0.1 in eta & phi physical units and is aligned with barrel modules. 'barrel cell' is the smallest common unit in eta-phi space for SMD and BTOW tower topologies.
'Barrel cell' has 2 coordinates : x[0,19] and y[0,59] . If such object is already defined for the Barrel, uniform for East & West let me know and I'll adjust numbering scheme.
Back to recovery of split phi cluster, shown below as red oval. Green clusters are shown to 'calibrate' yourself to this type of representation.
Fig 1.
Fig 2.
BTOW - Calibration Procedure
Here you will find the calibration procedure for the BTOW (as of 2013).
Additional documentation about BTOW gain calibrations in previous years can be found here:
Report from the STAR EMC Calibrations Workshop (2008)
2006 BEMC Tower Calibration Report
2009 BEMC Tower Calibration Report
As well as in BEMC > Calibrations section on Drupal here.
1) Generating Pedestal/Status Tables
Getting Started
The files which are used for this are from L2 and they're stored on the online "starp" network. You will need to request an account on those machines. Following the instructions here, you should request an account on the "onlldap.starp.bnl.gov" host with the "onlmon" username (you should also request an account with your username if you can). After your request is approved you can log in with the commands shown here:
ssh-agent > agent.sh
source agent.sh
ssh-add
ssh -X -A aohlson@rssh.rhic.bnl.gov % using your own username, of course
ssh -X -A stargw.starp.bnl.gov
ssh -X -A onlmon@onl05.starp.bnl.govIt is also necessary to set up the proper directory structure and files.
% after logging in you should be in /ldaphome/onlmon/
mkdir emcstatus2013 % make a directory for the appropriate year
cd emcstatus2013
mkdir pp500 % make a directory for the species/energy
cd pp500
cp ../../emcstatus2012/pp500/l2status.py ./ % copy files from a previous year
cp ../../emcstatus2012/pp500/indexWrite.py ./
cp ../../emcstatus2012/pp500/l2status2012.sqlite3 ./l2status2013.sqlite3
cp ../../emcstatus2012/pp500/empty.sqlite3 ./
cp ../../emcstatus2012/pp500/mapping.sqlite3 ./
cp ../../emcstatus2012/pp500/star_env ./
mkdir db
mkdir db/bemc
mkdir db/eemc
mkdir histoFiles
mkdir /onlineweb/www/emcStatus2013 % make the directories where the online files will be written by indexWrite.py
mkdir /onlineweb/www/emcStatus2013/pp500
mkdir /onlineweb/www/emcStatus2013/pp500/pdf
mkdir /onlineweb/www/emcStatus2013/pp500/details
cd /onlineweb/www
ln -s emcStatus2013 emcStatus % make a softlink from emcStatus to the current year's directory
cd -
Now you should go through l2status.py and indexWrite.py and change each instance of the year and species/energy to the current ones. Also there are some lines in l2status.py which refer to runnumbers, these should be changed as well. I also like to start fresh with the QA every year, and comment out the lines which hard-code bad channels. The variable "minimumMedianCounts" should be changed to a value appropriate for the species/energy that is being run.
Generating Status/Pedestal Tables with L2
In each run, as part of the L2 algorithm, a 2D histogram is filled with (channel# + 160*crate#) vs. (ADC-l2ped+20). This histogram is named "h22" and is contained within the root files located here: /ldaphome/onlmon/L2algo2013/l2ped/output/ The python macro named "l2status.py" takes this histogram as an input, and generates individual 1D histograms of the ADC spectra for every tower. These histograms are analyzed to determine the tower status, the ADC value of the pedestal peak, and the sigma of the pedestal peak. See below for the status code definitions and examples.
To execute the code do:
source star_env
python l2status.pyYou can monitor the progress of the script by looking at l2status.log (for example, by opening another terminal and doing 'tail l2status.log -n50' periodically). As the script progresses you will see the summary pdf files posted to the webpage http://online.star.bnl.gov/emcStatus/pp500/ (for the relevant species/energy), the status and pedestal tables will be written as text files into db/bemc and db/eemc, the actual root histograms will be written into the histoFiles directory, and the results will be written into the database file l2status2013.sqlite3. The statuses and pedestals should be generated once for every good fill.
In a perfect world you would run over the code over the entire dataset once and you would have the status tables which are then uploaded to the STAR database. However, its usually not that simple. There are often problems with a handful of channels that aren't caught by the status checking code, or some that are flagged as bad, but shouldn't be. My suggestion would be to run the code over all the files first and then then we can use the information in the pdfs and in l2status2013.sqlite3 to isolate problem channels. Some of the parameters in the code you may need to tweak to improve the status tables, and some channels you may have to hard code as a bad status for a period of time.
If you want to clear everything and start fresh, you can do this: clean out the folders db/bemc/ and db/eemc/, remove the log file, remove runList.list, and do 'cp empty.sqlite3 l2status2013.sqlite3'
So as a first step, let l2status.py run for a while (it will take time, I often run it in screen so that I don't have to keep a terminal open). You should kill it manually (ctrl+c) when it reaches the end of the runs that you want to look at. When you start it running again it should just pick up (approximately) where it left off.
The code only computes status/pedestal tables if there are enough hits to get good-quality calibrations. The median number of hits above the pedestal must surpass some threshold (minimumMedianHits) in a given fill; this parameter should be set to an appropriate value in l2status.py (not too high that we miss a lot of fills, and not too low that we don't get good calibrations -- there are some examples for appropriate values given in the code). When the threshold is reached you will see some messages in the log file like
2012-06-07 00:26:36 PID: 21394 INFO medianHits = 635
2012-06-07 00:26:36 PID: 21394 INFO begin status computation
2012-06-07 00:28:05 PID: 21394 INFO end status computation -- found 122 bad channels
2012-06-07 00:28:05 PID: 21394 INFO begin endcap status computation
2012-06-07 00:28:05 PID: 21394 INFO 04TB07 status=136 nonzerohists=22
2012-06-07 00:28:05 PID: 21394 INFO 06TA07 status=136 nonzerohists=18
2012-06-07 00:28:05 PID: 21394 INFO 08TB07 status=136 nonzerohists=21
2012-06-07 00:28:06 PID: 21394 INFO 11TA12 status=0 nonzerohists=60
2012-06-07 00:28:06 PID: 21394 INFO end status computation -- found 11 bad endcap channels
2012-06-07 00:28:10 PID: 21394 INFO current state has been saved to disk
2012-06-07 00:28:10 PID: 21394 INFO creating PostScript file
2012-06-07 00:29:09 PID: 21394 INFO calling pstopdf
2012-06-07 00:29:42 PID: 21394 INFO removing ps file
2012-06-07 00:29:43 PID: 21394 INFO creating endcap PostScript file
2012-06-07 00:29:52 PID: 21394 INFO calling pstopdf
2012-06-07 00:29:57 PID: 21394 INFO removing ps file
2012-06-07 00:29:58 PID: 21394 INFO Finished writing details webpage for F16732_R13108069_R13108080
2012-06-07 00:30:00 PID: 21394 INFO goodnight -- going to sleep nowTo evaluate the status of each BEMC tower, its ADC spectrum is tested for various features. If a test fails, then a bit (or multiple bits) is flipped to indicate the nature of the problem with the tower. It is possible for a tower to fail multiple tests and therefore have a status code which indicates multiple problems. I show examples of towers which fail each of the basic tests and are therefore assigned specific status codes.
Status Code Definitions
000 == channel does not exist or is masked in L2ped
001 == channel is good
002 == channel is either hot or cold (see bit 16)
004 == channel has a weird pedestal (see bit 32)
008 == channel has a stuck bit (see bits 64 and 128)
016 == if off, hot (10x as many hits); if on, cold tower (10x fewer hits)
032 == if off, pedestal mean is out of bounds; if on, pedestal width is too large/small
064 == bit stuck on
128 == bit stuck off
254 == identical channel
These codes can be seen by going to the EMC Status webpage and clicking on any of the Details pages.
I show examples from a heavy ion (U+U) run where the numbers of counts in the histograms are higher than in p+p, for clarity. All these plots come from the pdf here.
status = 1 (normal ADC spectrum)
status = 0 (channel is masked out)
Note: MOST of the channels marked with a zero status are (or were) hot channels that were caught and masked out.
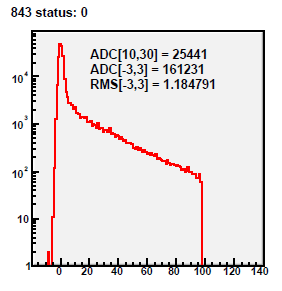
status = 2 (hot channel)
Hot channels look like the above plot, and most of them are caught in realtime and masked out, and thus assigned a status of zero. It is unusual to actually catch a really hot channel after the fact.
status = 18 = 2+16 (cold channel)
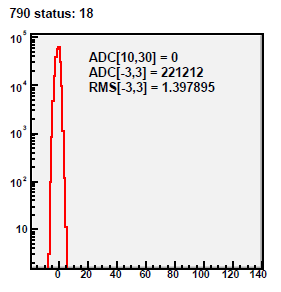
status = 4 or 36 (bad pedestal)
This status catches a range of problems, from weird-looking spectra (like shown here), to wide pedestals, etc.
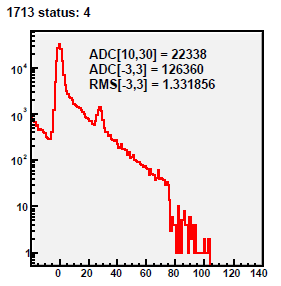
status = 72 = 8+64 (stuck bit - on)
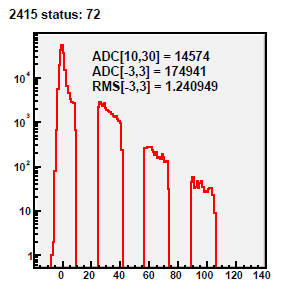
status = 136 = 8+128 (stuck bit - off)
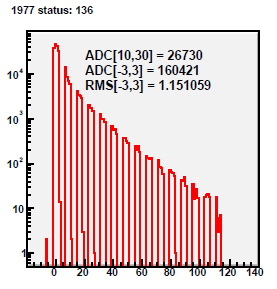
status = 254 (identical channels)
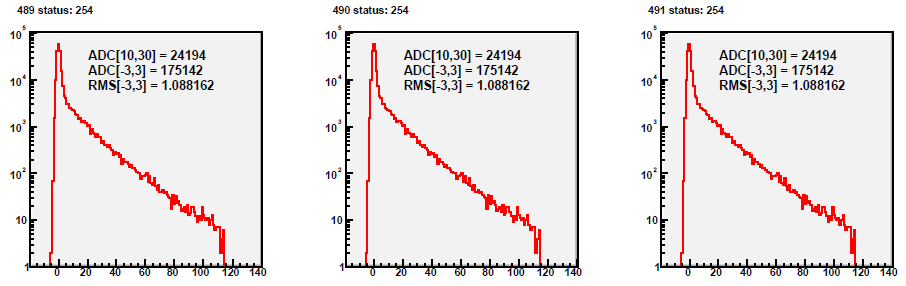
2) QAing the Pedestal/Status Tables
Once the ped/stat tables have been generated, they must be QAed. I do the QA in two parts:
1) I spot check the pdf files by eye. I pick about 5 or 6 fills evenly spaced throughout the run and go through each page of the pdf files looking for any strange-looking towers (for example, towers with stuck bits are pretty easy to see, and they don't always get caught by the algorithm). Yes, this takes a while, but we don't have to look at the pdfs for every fill!
For examples of the bad channels you are looking for, have a look at Suvarna's nice QA of the tables last year:
https://drupal.star.bnl.gov/STAR/blog/sra233/2012/dec/05/bemc-statuscuau200hard-coded-towers
https://drupal.star.bnl.gov/STAR/blog/sra233/2012/aug/15/bemc-statuspp200towers-with-status-marked-oscillating
2) The status and pedestal information is stored in the sqlite database file, and we can spin over this quickly in order to look at the data over many runs/fills. I have attached a script which is used to analyze the database file l2status2013.sqlite3. The first step is to download l2status2013.sqlite3 somewhere *locally* where you can look at it, and save statusCheckfill2.py in the same place. In statusCheckfill2.py you should change line 27 to the appropriate run range that you are analyzing, and change 2012-->2013 if necessary. Then all you need to do to run the code is something like:
setenv PYTHONPATH $ROOTSYS/lib
python statusCheckfill2.py
This python code allows you to look at the statuses and pedestals from run to run. At the moment I make lists of the statuses and pedestals for each tower (in the variables u and y -- sorry for my horrible naming scheme!), and then I can print these lists to the screen or graph them. At the moment I have the code so that it prints the statuses for any tower that has status 1 some, but not all, of the time (line 138). This script can be used to find channels which change status frequently over the course of the run... for example, sometimes there are channels which are right on the edge of satisfying the criteria for being marked as "cold" and therefore their status alternates 1 18 1 1 18 18 1 1 18 1 18 etc. Then we can look at the pdf files to see if the tower always looks cold, or if its behavior really changes frequently. If it is truly cold, then at that point we can either adjust the criteria for being marked as cold, or hard-code the channel as status 18 (I typically just hard-code it).
Also I can look at the histograms histoPedRatio and histoPedRatioGood (which are saved out in histogramBEMCfill.root), which are plots of the ratio of the pedestal for a given run to the pedestal of the first run as a function of tower id. histoPedRatio is filled for every tower for every run (unless the pedestal for that tower in the first run is zero), and histoPedRatioGood is only filled if the tower's status is 1. I haven't needed to cut out any towers based on these plots, but I think they would be a good way to find any towers whose pedestals are fluctuating wildly over time (or maybe you might want want to plot the difference, not the ratio).
So you can take a look at the code and play around with it so that it allows you to do the QA that you think is best.
If you look at l2status.py, you can see where I've hard-coded a bunch of channels I thought were bad (the lines which hard-code bad channels are commented out right now because I prefer to start from scratch each year). I've pasted the code here too:
## hard code few bad/hot channels
#if int(tower.softId)==939 : ##hard code hot channel
# tower.status |= 2
#if (int(tower.softId)==3481 or int(tower.softId)==3737) : ##hard code wide ped
# tower.status |= 36
#if (int(tower.softId)==220 or int(tower.softId)==2415 or int(tower.softId)==1612 or int(tower.softId)==4059): ##hard code stuck bit
# tower.status |= 72
if (int(tower.softId)==671 or int(tower.softId)==1612 or int(tower.softId)==2415 or int(tower.softId)==4059) : ##hard code stuck bit (not sure which bit, or stuck on/off)
tower.status |= 8
if (int(self.currentFill) > 16664 and (int(tower.softId)==1957 or int(tower.softId)==1958 or int(tower.softId)==1977 or int(tower.softId)==1978 or int(tower.softId)==1979 or int(tower.softId)==1980 or int(tower.softId)==1997 or int(tower.softId)==1998 or int(tower.softId)==1999 or int(tower.softId)==2000 or int(tower.softId)==2017 or int(tower.softId)==2018 or int(tower.softId)==2019 or int(tower.softId)==2020)) : ##hard code stuck bit
tower.status |= 8
if (int(tower.softId)==410 or int(tower.softId)==504 or int(tower.softId)==939 or int(tower.softId)==1221 or int(tower.softId)==1409 or int(tower.softId)==1567 or int(tower.softId)==2092) : ##hard code cold channel
tower.status |= 18
if (int(tower.softId)==875 or int(tower.softId)==2305 or int(tower.softId)==2822 or int(tower.softId)==3668 or int(tower.softId)==629 or int(tower.softId)==2969 or int(tower.softId)==4006) : ##either cold or otherwise looks weird
tower.status |= 18
Some of these channels are persistently problematic, so I expect that your list of bad channels will look similar to mine from previous years.
It may take a few iterations of generating the tables, finding bad towers, tweaking the code or hard-coding the bad channels, regenerating the tables, etc before you are satisfied with the quality of the tables. Once you have run l2status.py one last time and are satisfied with the quality of the tables you have generated, they are ready to be uploaded to the database by the software coordinator.
3) Uploading Pedestal/Status Tables to the Database
Once the ped/stat tables have been QAed satisfactorily, the values need to be uploaded to the database.
First, the files in /db/bemc/ need to be moved to RCF, where the upload will take place. This can be done with the following commands:
ssh-agent > agent.sh
source agent.sh
ssh-add
ssh -X -A aohlson@rssh.rhic.bnl.gov % using your own username
rterm -i
mkdir bemcUpload2013 % make a directory to work in
mkdir bemcUpload2013/tables
cd bemcUpload2013/tables/
scp onlmon@onl05.starp.bnl.gov:'/ldaphome/onlmon/emcstatus2013/pp500/db/bemc/*.txt' ./
cd ../
The scripts bemcPedTxtUpload.C and bemcStatTxtUpload.C are used to perform the upload. They take as input the name of a file which contains a list of the files to be uploaded. To create the file lists:
% in bemcUpload2013/
mkdir lists
cd tables
ls bemcStatus*.txt > ../lists/bemcStatus.list
ls bemcPed*.txt > ../lists/bemcPed.list
cd ../Once the file lists have been created, the scripts can be run with:
stardev
setenv DB_ACCESS_MODE write
root4star bemcStatTxtUpload.C
root4star bemcPedTxtUpload.C
Important!
1) The upload scripts (bemc*TxtUpload.C) contain return statements to prevent accidental uploads. Make sure everything is working properly by running the scripts with the return statements included (nothing will be uploaded to the db) first. When you are sure that you're ready to upload, then comment out the return statements. After uploading, don't forget to uncomment the return statements!
2) Try uploading one table first, and then check that it is uploaded correctly (see below), before uploading all the tables for the whole run. If a table is uploaded wrongly, it can be disactivated by the software team, but this is not something we want to do often. (In the case of a single table, it may be more efficient to just upload the correct table with a timestamp one second after the incorrect table.)
3) Reminder: this is not a task many people should need to do but should be limited to one or two "experts", who will be given special DB writing priviledges by Dmitry Arkhipkin (arkhipkin@bnl.gov).
Uploaded tables can be viewed with the online BEMC DB browser. I find it helpful to spot-check some tables to make sure they have been uploaded correctly. I find a table with the browser, copy it into an text file, and compare it to the text file I uploaded (in tables/). For the status tables, this can be done with a simple diff command. For the pedestal tables, the script checkPeds.C can be used.
At the beginning of the run (after physics has been declared, L2 is running, etc), it is good to generate a set of ped/stat tables and upload them to the database one second after the initialized values (for example, at 20131220.000001). (Reminder: The procedure for initializing the timeline with ideal values can be found here.) This can be done with the bemc*TxtUpload.C scripts; you will see a commented-out line that shows how to set the timestamp manually. It is good to do this periodically throughout the run, especially if something changes with the detector or beam configuration, so that FastOffline reconstruction can pick up decent DB values. Each time, the tables should be uploaded one second after the previous tables, so that when we upload the fully-QAed tables at the end of the run, the temporary ones will no longer be picked up.
4) Relative Gain Calibration with MIPs
Getting Started
1) The code needed to perform the gain calibrations can be checked out from CVS and compiled. In your working directory, do:
cvs co StRoot/StEmcPool/StEmcOfflineCalibrationMaker/
cons
You can move the required files to your working directory, or make soft links. You need the following files, which are in the macros/ directory:
-- bemcCalibMacro.C
-- btow_mapping.20030401.0.txt
-- CalibrationHelperFunctions.cxx
-- CalibrationHelperFunctions.h
-- electron_drawfits.C
-- electron_histogram_maker.C
-- electron_master.C
-- electron_master_alt.C
-- electron_tree_maker.C
-- geant_fits.root
-- mip_histogram_fitter.C
-- mip_histogram_maker.C
-- SubmitCalibJobs.pl
-- runMIPjobs.sh
-- runElecJobs.sh
-- runFinalElecJobs.sh
Some of the files have lists of triggers which need to be hard-coded in for each year. In particular, in bemcCalibrationMacro.C you should ensure that the correct trigger list is present, and the trigger IDs for the HT triggers need to be written in StEmcOfflineCalibrationMaker.cxx. (In most cases I have already typed in the values for Run 11, but they are commented out while the Run 9 values are commented in.) If you want to use the TOF information (in Run 11 and beyond), there are some lines of code that need to be commented in in StEmcOfflineCalibrationMaker.cxx.
Generating Trees
2) Generate the list of runs with the following command (for Run 9)
get_file_list.pl -keys "runnumber" -distinct -cond "production=P11id,filetype=daq_reco_MuDst,sanity=1,trgsetupname=production2009_200GeV_Single,filename~st_physics,tpx=1,emc=1,storage!=HPSS" -limit 0 | sort -u > runlist.txt
or similar for other years.
3) Run SubmitCalibJobs.pl, which will execute the bemcCalibMacro.C macro. Make sure that the correct catalog query lines are commented in/out in the submit script. Also ensure that the appropriate directories exist ($workingDir, $schedDir, $outDir, $logDir, $scriptDir) as specified at the top of the submit script.
This macro creates trees which store primary tracks which will be further analyzed for the calibration. For each primary track we write out the track information from the TPC, the EMC information for the 3x3 tower cluster around the track, the TOF information (in Run 11 and beyond), and the trigger information.
The trees created by this step are stored on HPSS here:
Run 9: /home/aohlson/bemcCalib2009_x.tar where x=0,...,9
Run 11: /home/aohlson/bemcCalib2011_05_x.tar where x=0,...,14 and /home/aohlson/bemcCalib2011_07_x.tar where x=0,...,18
MIP calibration
The relative gain calibration is obtained by finding the MIP peak in each of the 4800 BEMC towers.
The MIP energy deposit has the following functional form, which was determined from test beam data and simulations:
MIP = (264 MeV)×(1+0.056η2)/sin(θ)
From this expression we can calculate a calibration constant
C = 0.264×(1+0.056η2)/(ADCMIP×sin(θ))
where ADCMIP is the location of the MIP peak in the ADC spectrum. This allows us to combine towers at the same η and thus find the absolute gain calibration in each crate-slice using electrons (see next section).
The procedure for obtaining the MIP calibration is as follows...
4) Make the MIP histograms with runMIPjobs.sh which executes mip_histogram_maker.C Ensure that the correct output filenames are specified in the submit script.
Events with |vz| < 30 cm are selected, and any towers that have multiple tracks associated with them are excluded. We select tracks with p > 1 GeV/c, and require that they enter and exit the same tower. We require that the towers surrounding the central tower do not contain a large energy deposition. We require that ADC-ped > 1.5*pedRMS. After these track quality cuts we fill histograms with the ADC-ped values for each tower.
5) Make a list of the output files from step (4) called mips.list. Run mip_histogram_fitter.C
We fit each histogram with a gaussian on a pedestal; the histograms and fits are shown in mip.pdf. If the fit values fail basic quality cuts (such as if the mean is < 5), then the tower is assigned a bad status (!=1). These fits are marked as red in mip.pdf. For each tower we record the mean and sigma of the gaussian fit, and the status.
6) Check mip.pdf by eye to look for any other towers which were obviously bad. Write a function like isBadTower2009(int id) (see examples in the code) which identifies these bad towers so that they can be assigned a bad status. You can either put this function in mip_histogram_fitter and re-run it, or you can put it in the electron codes. Note that most of the towers with bad MIP peaks were marked as bad (cold/hot/stuck bit) towers when the status/pedestal tables were originally computed.
5) Absolute Gain Calibration with Electrons
Electron calibration
The absolute gain calibration is done by identifying electrons and finding the E/p peak for small groupings of towers. It is desirable to find the E/p peak for as small groupings as possible. In 2006 the calibration was done in rings in η, while in 2009 it was done for "crate-slices", which are groups of 8 towers in the same crate in the same η ring.
The procedure is as follows...
7) Make the electron trees with runElecJobs.sh which will execute electron_tree_maker.C Ensure that the correct output filenames are specified in the submit script.
The macro electron_tree_maker.C makes slimmer trees of electron candidates which satisfy the following criteria:
-- event vertex |vz| < 60
-- track must come from reconstructed vertex (ranking >= 0)
-- 1.5 < p < 20 GeV/c
-- nhits >= 10
-- matched tower status = 1
-- dE/dx > 3e-6
-- ADC-ped > 1.5*pedRMS
In this macro, if the electron track points towards a HT trigger tower then it is assigned htTrig = 2
8)
In the old calibration: Make a list of the output files from step (5) called electrons.list. Run electron_master.C.
---- OR ----
In the new calibration: Run runFinalElec.sh, which executes electron_master_alt.C (make sure that the input/output filenames and directories are correct). Hadd the resulting output files, and use this file as the input to electron_drawfits.C
In this macro even more stringent cuts are placed on the electron candidates:
-- ADC-ped > 2.5*pedRMS
-- track must enter and exit the same tower
-- p < 6 GeV/c
-- track does not point towards a tower which fired the HT trigger (htTrig != 2)
-- dR < 0.025 (distance from the center of the tower)
-- dE/dx > 3.4e-6
-- the maximum Et in the 3x3 cluster of towers must be in the central tower
-- there are no other tracks pointing to the central tower
The resulting histograms of E/p in each crate-slice are drawn and fit with a Gaussian plus a first-order polynomial. If the calibration is already correct, then the E/p peak should be at 1. The deviation from unity establishes the absolute gain calibration which, combined with the relative gain calibration from the MIP procedure, defines the overall BEMC gain calibration.
Run 12 BTOW Calibration
This is parent page that will hold all informationa about the run12 BEMC gain calibration
200 GeV Calibration
This calibration was done with the 200 GeV proton-proton data collected in 2012. The calibration trees are backed up on HPSS and can be found here:
/home/jkadkins/bemcCalibrations/2012/pp200/bemcCaibTrees2012-0XX.tar
where XX = 0, 1, 2, .... , 34
Run 3 BTOW Calibration
I plan on "Drupalizing" these pages soon, but for now here are links to Marco's slope calibration and Alex's MIP and Electron calibrations for the 2003 run:
Marco's tower slope calibrationAlex's MIP calibration
Alex's electron normalization
Run 4 BTOW Calibration
Introduction:
The recalibration of the BEMC towers for Run 4 includes the following improvements:
- recovery of 158 swapped towers
- identification and removal of 38 towers with possible light leakage / electronics problems
- identification and removal of 24 towers with bad p/E distributions
- MIP calibration restricted to low-multiplicity events from minimum-bias data
- isolation requirement imposed on MIP candidates
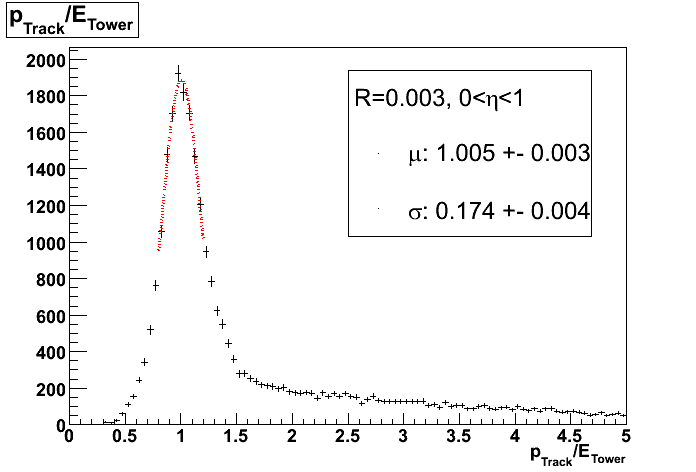
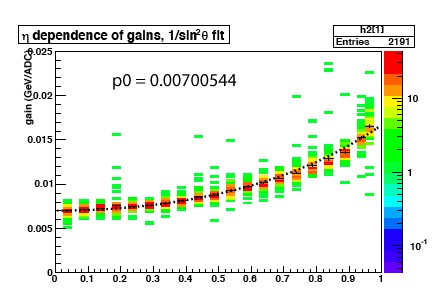
Notes:
- p0 * 4066 = 28.5 GeV full-scale at zero rapidity (assuming pedestal~30).
- 2191/2400 = 91.3% of the towers have nonzero gains.
- Despite the differences in the cuts used, the final gains are similar to the ones currently found in the DB; a histogram of (newgain-dbgain)/newgain for the towers present in both calibrations yields a mean of 0.019 and an rms of 0.03896.
Procedure:
The offline calibration of the BEMC towers for Run 4 is accomplished in three steps. In the first step, MIPs are collected for each tower and their pedestal-subtracted ADC spectra are plotted. The MPV of the distribution for each tower is translated into a gain using an equation originally established by test-beam data (SN 0433). In the second step, electrons are collected for each eta-ring and the ratio of their momentum and energy (with the energy calculated using the MIP gains from step 1) is plotted as a function of the distance between the track and the center of the tower. The calculated curve is fit to a GEANT simulation curve, allowing extraction of scale factors for the MIP gains in each eta ring. Finally, all electrons in all eta-rings are grouped together and the ratio of their energy and momentum (E/p) is plotted, with the energy calculated from the rescaled gains in the second step. The distribution is fit with a Gaussian and a scale factor is applied so that this Gaussian is centered exactly on 1.000.
Catalog query:
<inputURL="catalog:star.bnl.gov?production=P05ia||P05ib||P05ic,sanity=1,tpc=1,emc=1, trgsetupname=ProductionMinBias||productionLow||productionMid||productionHigh,filename~physics, filetype=daq_reco_mudst,magscale~FullField,storage!~HPSS,runnumber>=5028057" nFiles="all" />
Working directories:
/star/u/kocolosk/emc/offline_tower_calibration/2004/jan25_2004mip/
/star/u/kocolosk/emc/offline_tower_calibration/2004/jan30_2004electron/
MIP Cuts:
- track momentum > 1
- track enters, exits same tower
- 1 track / tower
- (ADC - ped) > 2*pedRMS
- trigger == 15007 (mb data)
- abs(z-vertex) < 30
- reference multiplicity < 57 (60-100% centrality)
- isolation cut (all neighboring towers satisfy (ADC-ped) < 2*pedRMS)
Electron Cuts:
- 1.5 < track momentum < 20
- track enters, exits same tower
- 1 track / tower
- # track points > 25
- 3.5 < dEdx < 4.5 keV/cm
- (ADC - ped) > 2*pedRMS
- trigger != 15203 (excludes most ht-triggered electrons; should have been trigger == 15007 to get mb-only data)
Adam Kocoloski, 14 Feb 2006
Run 5 BTOW Calibration
Introduction
The final BTOW calibration for Run 5 offers the following improvements over previous database calibrations:
- recovery of 194 swapped towers
- identification and exclusion of 51 towers with correlated firing problems
- identification and exclusion of 33 towers with p/E~0.6
- exclusion of 58 towers with PMTs replaced by Stephen and Oleg during the shutdown
- isolation cut removes background from MIP spectra, identifies correlated towers
- 30 cm vertex cut introduced to reduce path length differences among MIPs
- uniform scale factor (1.04613) introduced after eta ring electron normalization to set E/p==1 when integrated over all towers



p0 = 0.00696912 for the fit parameter implies an <ET> = 28.3 GeV on the west side, but the gains do not seem to be well described by the 1/sin(theta) fit
3997/4240 = 94.3% of commissioned towers have nonzero gains
Procedure
The offline calibration of the BEMC towers for Run 5 is accomplished in three steps. In the first step, MIPs are collected for each tower and their pedestal-subtracted ADC spectra are plotted. The MPV of the distribution for each tower is translated into a gain using an equation originally established by test-beam data (SN 0433). In the second step, electrons are collected for each eta-ring and the ratio of their momentum and energy (with the energy calculated using the MIP gains from step 1) is plotted as a function of the distance between the track and the center of the tower. The calculated curve is fit to a GEANT simulation curve, allowing extraction of scale factors for the MIP gains in each eta ring. Finally, electrons in all eta-rings that pass through the center of a tower are grouped together and the ratio of their energy and momentum (E/p) is plotted, using the energy calculated from the rescaled gains in the second step. The ditribution is fit with a Gaussian and a scale factor is applied so that this Gaussian is centered exactly on 1.000.
Catalog query:
<input URL="catalog:star.bnl.gov?production=P05if,tpc=1,emc=1, trgsetupname=ppProduction||ppTransProduction||ppProductionMinBias, filename~st_physics,filetype=daq_reco_mudst,storage!~HPSS" nFiles="all" />Working directories:
/star/u/kocolosk/emc/offline_tower_calibration/2005/feb08_2005/
/star/u/kocolosk/emc/offline_tower_calibration/2005/feb08_earlyfiles/The 2005 directory contains jobs run using Dave Relyea's offline pedestals (the bulk of the data), while the earlyfiles directory uses online pedestals for runs before April 26th that are not included in the offline pedestal calculations.
MIP Cuts:
- track momentum > 1
- track enters, exits same tower
- 1 track / tower
- (ADC - ped) > 2*pedRMS
- abs(z-vertex) < 30
- isolation cut (all neighboring towers satisfy (ADC-ped) < 2*pedRMS)
- no trigger selection (previous statement of mb-only triggers was in error)
Electron Cuts:
- 1.5 < track momentum < 20
- track enters, exits same tower
- 1 track / tower
- # track points > 25
- 3.5 < dEdx < 4.5 keV/cm
- (ADC - ped) > 2*pedRMS
- no trigger selection
For More Information:
Detailed information on this and other BTOW calibrations, including tower-by-tower MIP and p/E spectra and a summary of outstanding issues, is available at
http://www.star.bnl.gov/protected/spin/kocolosk/barrel_calibration/saved_tables/
The calibration summarized here has the timestamp 20050101.000001.
First Calibration using CuCu data
Runs used: 6013134 (13 Jan) - 6081062 (22 Mar)
The procedure for performing the relative calibration can be divided into 3 steps:
- Create a histogram of the pedestal-subtracted ADC values for minimum-ionizing particles in each tower
- Identify the working towers (those with a clearly identifiable MIP-peak)
- Use the peak of each histogram together with the location of the tower in eta to calculate a new gain
- Create new gain tables and rerun the data, this time looking for electrons
- Use the electrons to establish an absolute energy scale for each eta-ring
Using Mike's code from the calibration of the 2004 data, an executable was created to run over the 62GeV CuCu data from Run 5, produce the 2400 histograms, and calculate a new gain for each tower. It was necessary to check these histograms by hand to identify the working towers. The output of the executable is available as a 200 page PDF file:
2005_mip_spec.pdf (2400 towers - 21.6 MB)
Towers marked red or yellow are excluded from the calibration. Condensed PDFs of the excluded towers are available at the bottom of the page ("bad" and "weird"). In all, we have included 2212 / 2400 = 92% of the towers in the calibration.
Systematic Behavior of the Gains
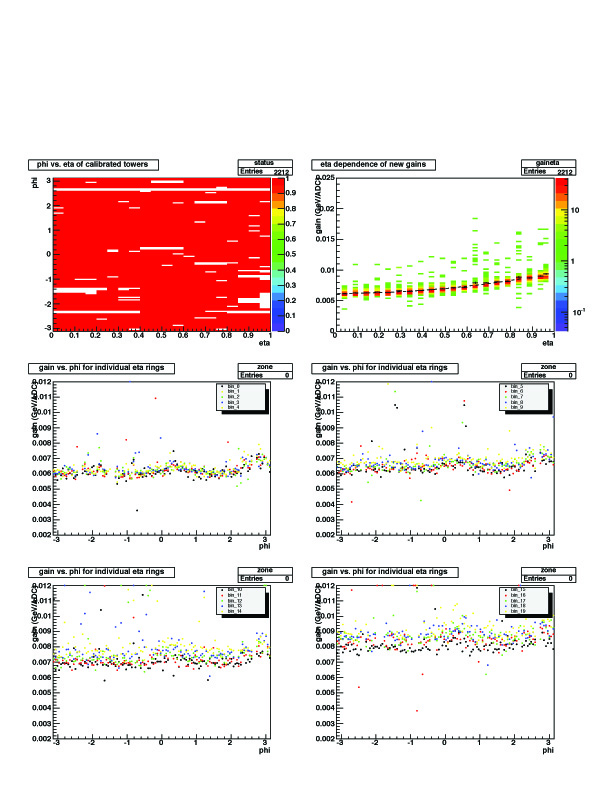
The first plot in the top left shows the excluded towers (white blocks) in eta_phi space
In the second plot we collect the towers into 20 eta-rings (delta-eta = 0.05) and look at the change in gain as we move out in eta. This plot shows the expected increase in gain as we move into the forward region (except for eta-rings 19 and 20).
Finally we look at each individual eta-ring for for systematic variations in azimuth. There appears to be some structure around phi=0.2 and phi=3.
Electron Calibration Status
We have made an attempt to realize the absolute energy scales using electrons. Unfortunately, there does not appear to be a sufficient number of electrons in the processed 62GeV data to do this for each eta-ring. We will revisit this later when more statistics are available, but in the meantime we have established the following workaround:
- Fit the average gains of the first 17 eta-rings with a function that goes as 1/sin(theta)
- Caclulate the expected gains for eta-rings 18, 19, and 20 from this function
- Scale the forward eta-rings accordingly
The results of this procedure are seen in an updated plot of gain vs. eta:
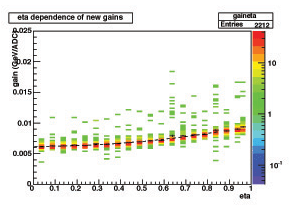
Here are new bemcCalib and bemcStatus .root files created using these rescaled gains:
bemcCalib.20050113.053235.root
bemcStatus.20050113.053235.root
The text file is a list of tower-gain pairs. A gain of zero indicates a tower that has been masked out. Finally, we have a plot of p/E summed over all eta:

Update: Addition of the East BEMC Towers
We have calculated new gains for the 1200 towers in the east half of the barrel that were turned on by March 22. Only data from March 22 were used in this calibration. The results can be found in 2005_mip_spec_newtowers.pdf
bemcCalib.20050322.000000.root
bemcStatus.20050322.000000.root
The gains for towers 1-2400 are the same as before. These files include those entries, as well as new gains for towers 2401-4800. No attempt has been made to get an absolute energy scale for the east towers, so we still see the drop in gain for large eta:

Implementation of Tower Isolation Cut
Originally posted 11 October 2005
Previously we had calibrated the BEMC using data from all triggers. We now have enough data to restrict ourselves to minimum-bias triggers. Additionally, we have implemented a cut that requires the pedestal-subtracted ADC value of neighboring towers to be less than twice the width of the pedestal. This cut does an excellent job of removing background, especially in the high-eta region:
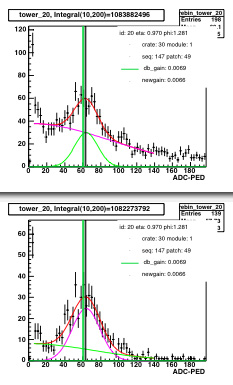
The cut is used in the bottom plot. Unfortunately there is also a small subset of towers where the isolation cut breaks the calibration:
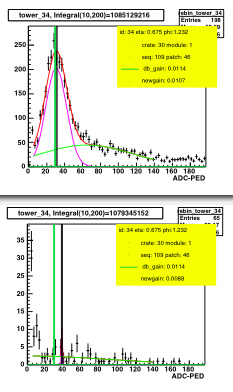
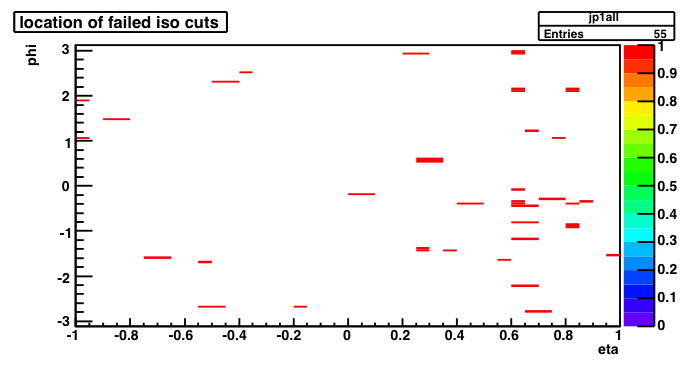
Again the cut is used in the bottom plot. We have decided to use the isolation cut when possible, and use the full minimum-bias data in the case of the (55) towers for which the cut breaks the calibration. This new calibration is able to recover ~30 towers that were previously too noisy to calibrate. We are in the process of reviewing the remaining bad towers found in 2005_MinBiasBadTowers.pdf. Towers 671,1612, and 4672 appear to have problems with stuck bits in the electronics, and there are a few other strange towers, but the majority of these towers just seem to have gains that are far too high. We plan on reviewing the HV settings for these towers. An ASCII file of the bad towers is attached below.
Recalibration Using pp data
Originally posted 26 September 2005
Catalog query:
input URL="catalog:star.bnl.gov?production=P05if,tpc=1,emc=1,trgsetupname=ppProduction,filename~st_physics,filetype=daq_reco_mudst,storage=NFS" nFiles="all"
note: 3915/4240 = 92.3% of the available towers were able to be used in the calibration. Lists of bad/weird towers in the pp run are available by tower id:
bad_towers_20050914.txt
weirdtowers_20050914.txt
The relative calibration procedure for pp data is identical to the procedure we used to calibrate the barrel with CuCu data (described below). The difference between pp and CuCu lies in the electron calibration. In the pp data we were able to collect enough electrons on the west side to get an absolute calibration. On the east side we used the procedure that we had done for the west side in CuCu. We used a function that goes like 1/sin(theta) to fit the first 17 eta rings, extrapolated this function to the last three eta rings, and calculated the scale factors that we should get in that region. Here is a summary plot comparing the cucu and pp calibrations for the 2005 run:

Comparing the first two plots, one notices immediately that many of the pp gains on the east (eta < 0) side are quite high. A glance at the last plot on the summary canvas reveals a collection of towers with phi < -pi/2 that have unusually high gains. These towers were added during the pp run and hence their gains are based on nominal HV values without any iteration (thanks Mike, Stephen). If we mask out those towers in the summary plot, the plots look much more balanced:

The bottom plot clearly shows that the final pp gains are ~10% higher than the gains established from the mip calibration using the cucu data. Moreover, the cucu data closely follows a 1/sin(theta) curve, while the curve through the pp data is flatter. This is revealed in the shape of the bottom plot. Note that we never scaled the gains near eta=-1 for the cucu data, which is why there is still a significant drop-off in the ratio of the mean gains in that region.
New calibration and status tables (including the gains for the new towers that were turned on during pp running) are available at
bemcCalib.20050322.000001.root
bemcStatus.20050322.000001.root
It should be noted that the scale factors we used to get the final gains near eta=-1 on the east side were calculated without the new towers since they were throwing off the fit function. However, those new towers still had their final gains scaled before we produced the calibration and status tables.
Systematic Uncertainty Studies
In the 2003+2004 jet cross section and A_LL paper we quoted a 5% systematic uncertainty on the absolute BTOW calibration. For the 2005 jet A_LL paper there is some interest in reducing the size of this systematic.I went back to the electron ntuple used to set the absolute gains and started making some additional plots. Here's an investigation of E_{tower} / p_{track} versus track momentum. I only included tracks passing directly through the center of the tower (R<0.003) where the correction from shower leakage is effectively zero.
Full set of electron cuts (overall momentum acceptance 1.5 < p < 20.):
dedx>3.5 && dedx<4.5 && status==1 && np>25 && adc>2*rms && r<0.003 && id<2401
I forgot to impose a vertex constraint on these posted plots, but when I did require |vz| < 30 the central values didn't really move at all.
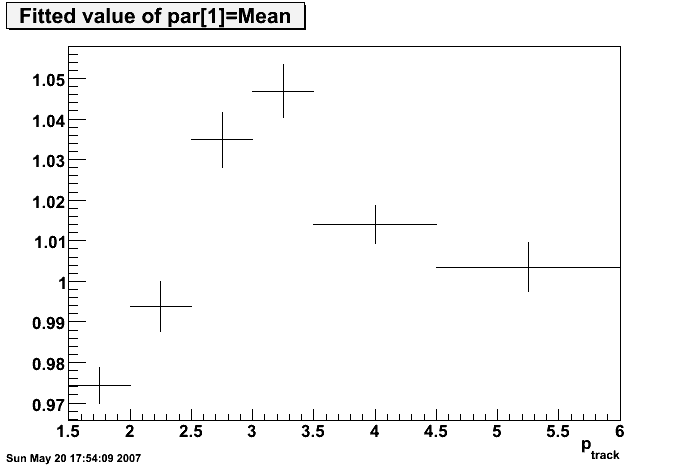
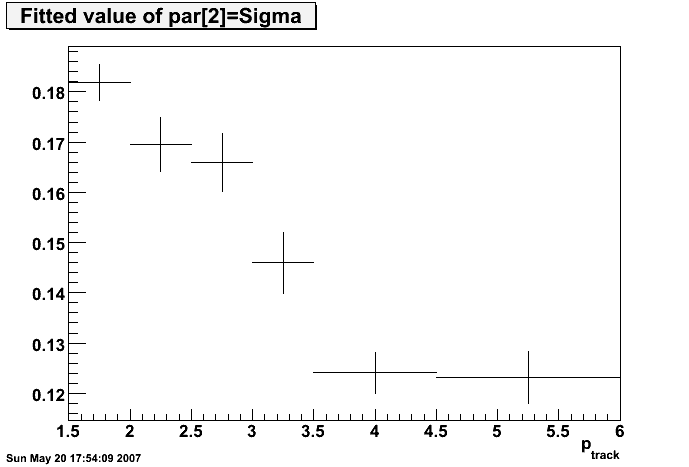
Here are the individual slices in track momentum used to obtain the points on that plot:

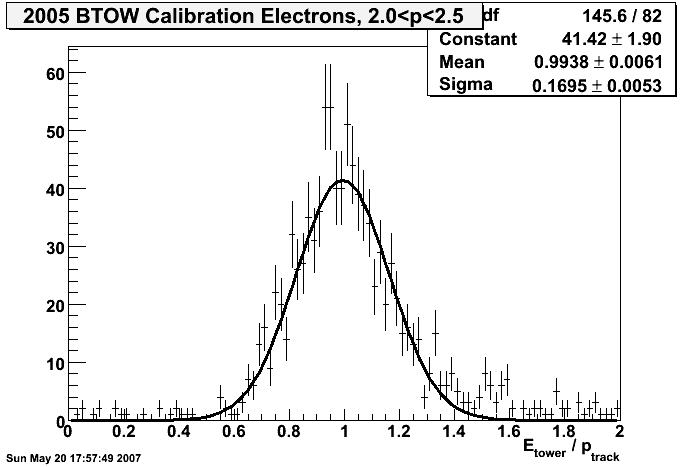
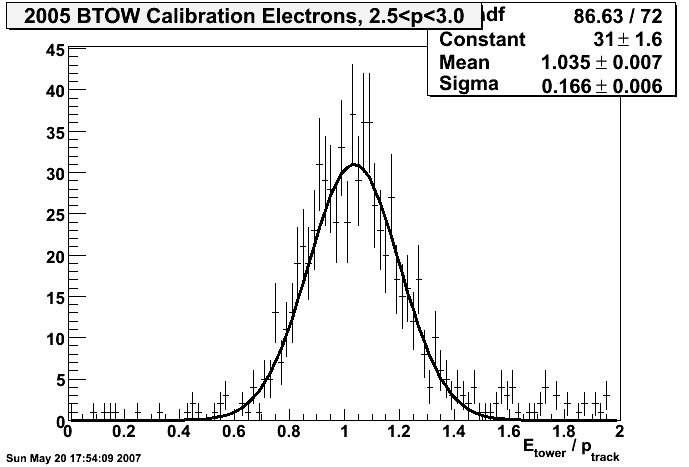
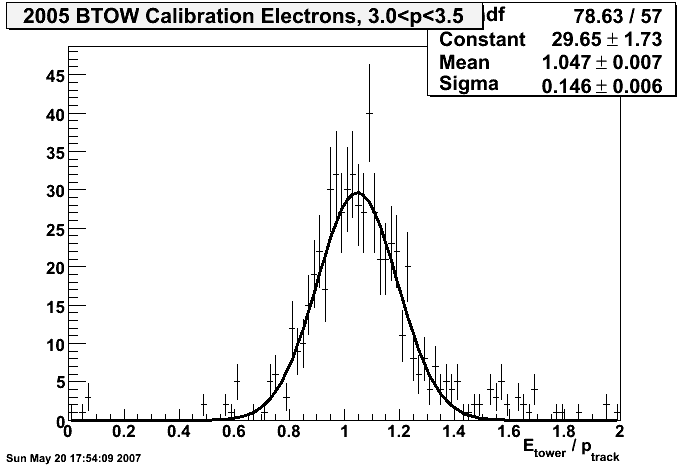
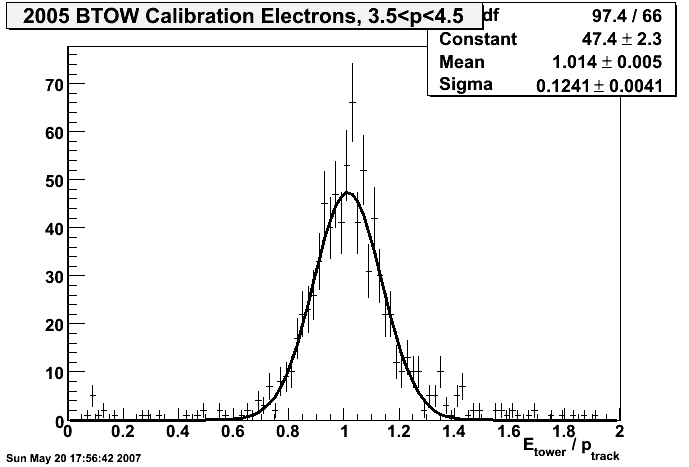
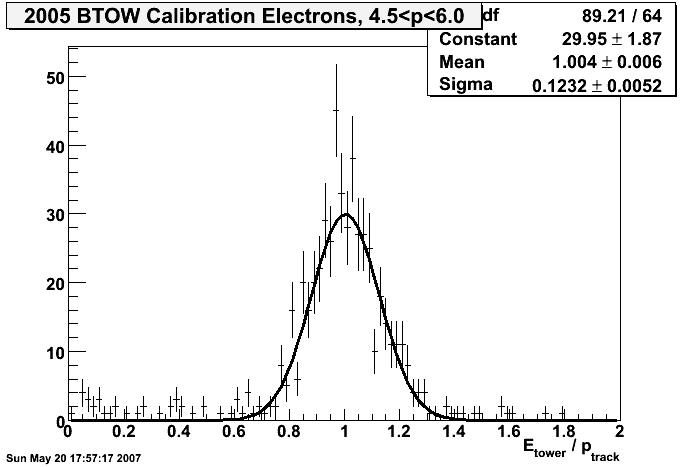
Electrons with momentum up to 20 GeV were accepted in the original sample, but there are only ~300 of them above 6 GeV and the distribution is actually rather ugly. Integrating over the full momentum range yields a E/p measurement of 0.9978 +- 0.0023, but as you can see the contributions from invididual momentum slices scatter around 1.0 by as much as 4.5%
Next Steps? -- I'm thinking of slicing versus eta and maybe R (distance from center of tower).
Run 6 BTOW Calibration
Introduction
This is not the final calibration for the 2006 data, but it's a big improvement over what's currently in the DB. It uses MIPs to set relative gains for the towers in an eta ring, and then the absolute scale is set by electron E/p.
Isolation Cut Failures
This is a problem that we encountered in 2005, where several pairs of towers had good-looking spectra until the isolation cut was applied, and then quickly lost all their counts. Well, all of the towers that I had tagged with this problem in 2005 still have it in 2006, with one exception. Towers 1897 and 1898 seem to have miraculously recovered, and now towers 1877 and 1878 appear to have isolation failures. Perhaps this is a clue to the source of the isolation failures?
Dataset:
everything I could find on nov07:
<input URL="catalog:star.bnl.gov?production=P06ie,sanity=1,tpc=1,emc=1,trgsetupname= ppProduction||ppProductionTrans||ppProductionLong||pp2006MinBias||ppProductionJPsi||ppProduction62||ppProductionMB62, filename~st_physics,filetype=daq_reco_mudst" nFiles="all" />
Cuts:
Same as 2005. All MIP fits are basic Gaussians over the range 5..250 ADC-PED. Electron fits are Gaussian + linear in a very crude attempt to estimate hadronic background.
Working Directory:
/star/u/kocolosk/emc/offline_tower_calibration/2006/nov07/
Plots:
The gains look pretty balanced on the east side and west side. Note that I didn't multiply by sin(theta), so we expect an eta-dependence here. The widths plot is interesting because it picks out one very badly behaved crate on the east side at phi=0. I believe it is 0x0C, EC24E (towers 4020-4180). The tower fits are attached below if you're interested. Bad towers are marked in red.

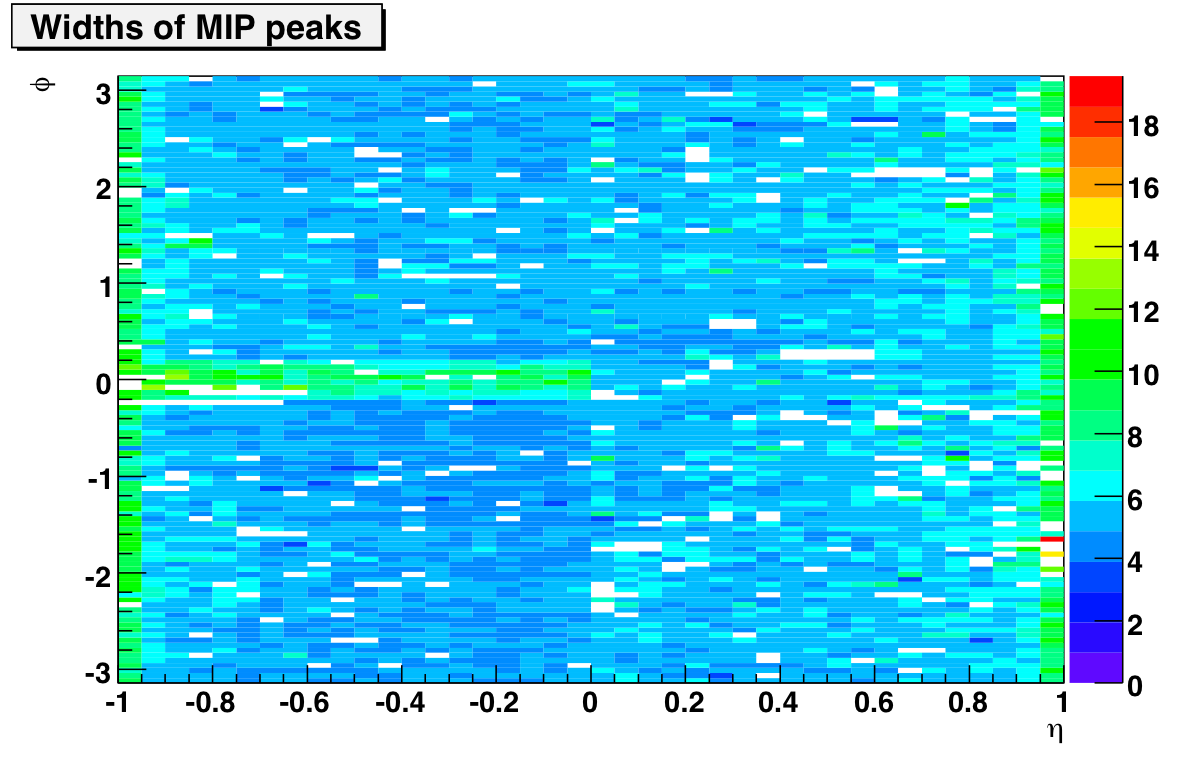
Electron Normalization:
E/p plots for all 40 eta-rings (first 20 on west side, 21-40 on east side) are attached below. In general, the electrons indicate a 9-10% increase in the MIP gains is appropriate. In the last two eta rings on each side, that number jumps to 20% and 40%. This is more or less consistent with the scale factors found in the 2003 calibration (the last time we used a full-scale energy of 60 GeV. If I scale the MIP gains and plot the full-scale E_T I get the plot on the left. Fitting the eta dependence with a pol0 over the middle 36 eta rings results in a ~62 GeV scale and a nasty chi2.
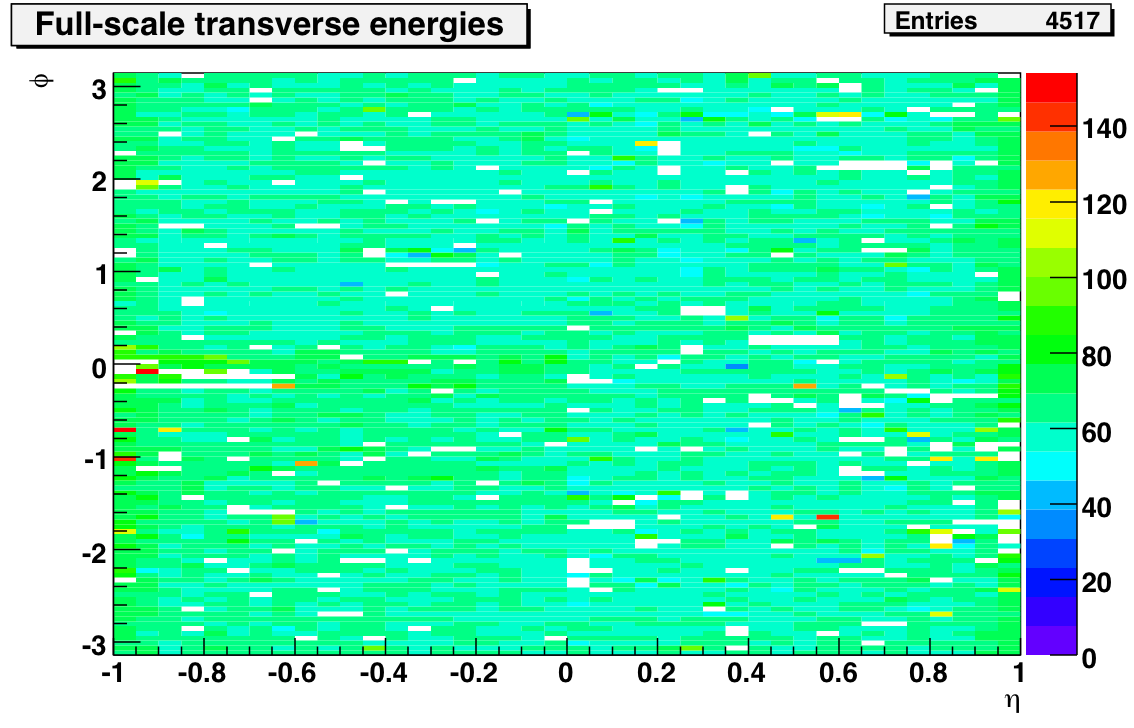
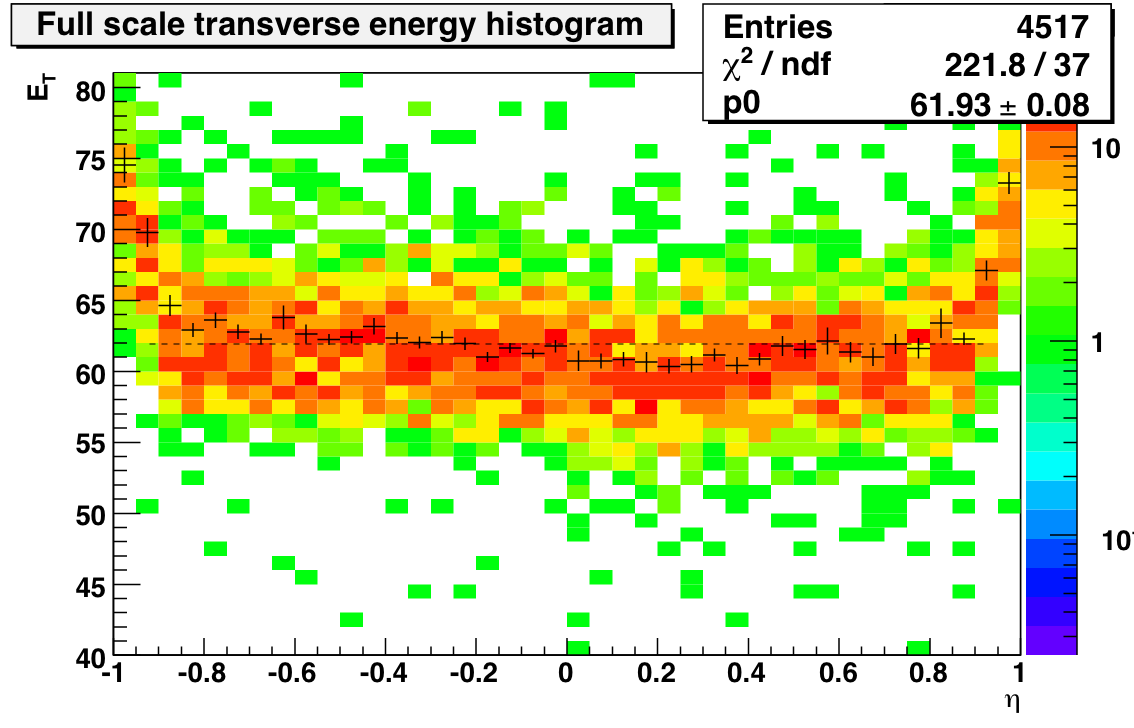
So after scaling with the electrons it looks like we are actually a couple of GeV high on the absolute scale. I'll see if this holds up once I've made the background treatment a little more sophisticated there. I also have to figure out what went wrong with the electrons out at the edges. I didn't E/p would be that sensitive to the extra material out there, but for some reason the normalization factors out there are far too large. Next step will be to comapre this calibration to one using electrons exclusively.
Calibration Uncertainty:
Here are some links that address different parts of the calibration uncertainty that are not linked from this page:
drupal.star.bnl.gov/STAR/subsys/bemc/calibrations/run6/btow/calibration-uncertainty-calculation
drupal.star.bnl.gov/STAR/blog-entry/mattheww/2009/apr/09/2006-calibration-uncertainty
drupal.star.bnl.gov/STAR/blog-entry/mattheww/2009/apr/27/crate-systematic-2006
Online Work
Steve's caiibrations page contains most of the details:http://www.star.bnl.gov/protected/spin/trent/calibration/calibration.html
Some files of slopes, etc. that I produced are currently stored at
http://web.mit.edu/kocolosk/www/slopes/
MIP check on 2006 Slope Calibration
~300k events processed using fastOffline:
Run 7079034 ~189K
Run 7079035 ~115K
Number of events with nonzero primary tracks = 109k / 309k = 35%
Still a few problems with pedestal widths in the database, although now they appear to be restricted to id > 4200. If I don't cut on adc>2*rms, the software id distribution of MIPs looks pretty isotropic:
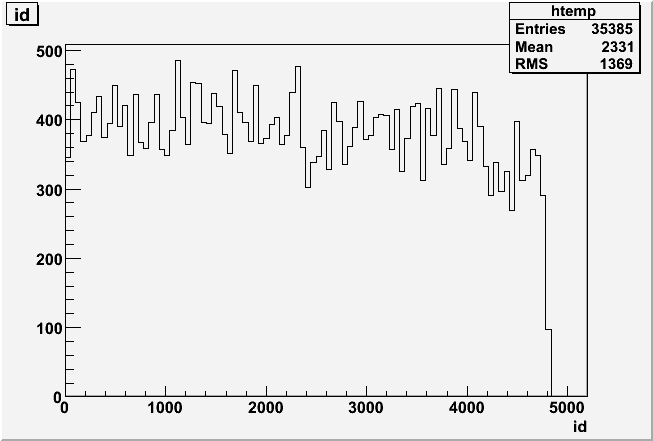
The distribution of primary tracks also looks a lot better:
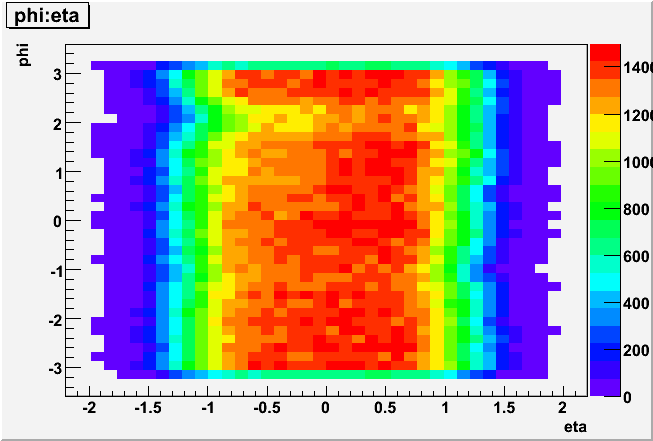
I was able to calculate MIP gains for each of the 40 eta-rings. The plot at the top fits a line to the full-scale transverse energies extracted from the gains (excluding the outer two eta-rings on each side). For the error calculations I used the error on the extraction of the mean of the MIP ADC peak and propagated this through the calculation. This is not exactly correct, but it's a pretty close approximation. In a couple of cases the error was exceedingly small (10^-5 ADC counts), so I forced it to an error of 1 GeV (the fit failed if I didn't).
As you can see in the text file, an error of 1 ADC in the MIP peak leads to an error of 3 GeV in the full-scale transverse energy. Therefore I would say that pedestal fluctuations (1-2 ADCs) give an additional error of 5 GeV to my calculations, which means that the majority of these eta-rings are consistent with a 60 GeV full-scale.
Conclusions:
- A straight-line fit yields 56 GeV as the average full-scale transverse energy of the towers
- We have enough stats; errors are dominated by pedestal fluctuations leading to a 5 GeV uncertainty
- Tower response is flat in E_t across eta-rings (excluding last two rings where MIPs fail)
- Good job Stephen and Oleg!
The First Attempt
Note: The first attempt at this analysis was plagued by poor TPC tracking and also problems with corrupted BTOW pedestal widths in the database. I'm including the content of the original page here just to document those problems.
250k events processed using fastOffline:
Run 7069023 100K
Run 7069024 100K
Run 7069025 50K
Number of events with nGlobalTracks > 0 = 30166 (12%)
On the left you see the software id distribution of slope candidates (adc-ped>3*rms, no tracking cuts). There's a sharp cutoff at id==1800. But before you go blaming the BEMC for the missing MIPs, the plot on the right shows eta-phi distribution of global tracks without any EMC coincidence. The hot region in red corresponds to 0<id<1800:
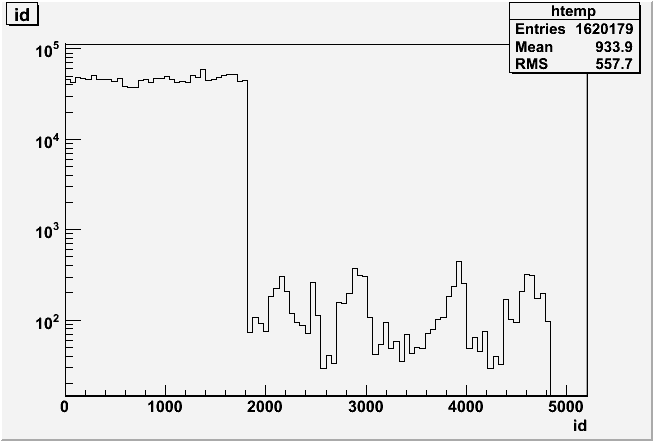
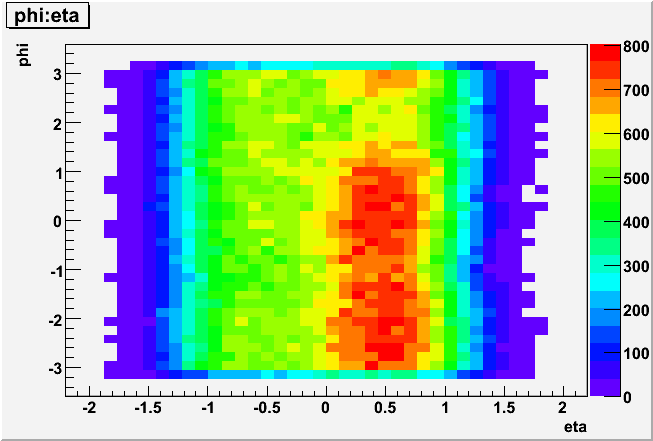
As it turns out, the missing slope candidates are likely due to wide pedestals. The pedestal values look fine, but if I plot pedrms for id<1800 and id>1800 using the slope candidates that did survive:
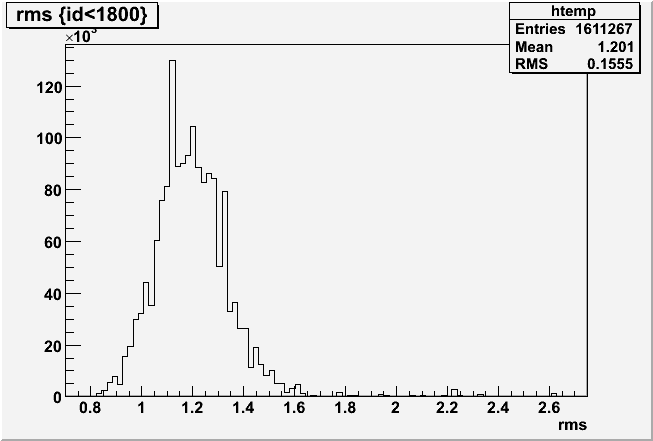
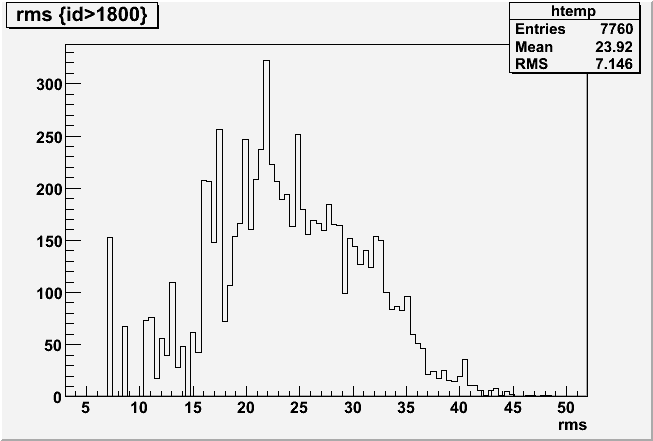
Is it possible that the TPC track distribution is connected to this problem?
2006 Gain uniformity
Using the gains we calculated for 2006 tower by tower from the MIPs and then corrected with the electron eta rings, I calculated how it differed from the ideal gain assuming containment of an EM shower with 60 GeV ET. After removing bad towers, we can fit the distribution of this ratio to a gaussian and we find there is approximately a 6% variation in the gains.


Calibration Uncertainty Calculation
Summary:
The uncertainty on the 2006 BTOW Calibration is 1.6%. This value is the combination of a 1.3% overall uncertainty and a 0.9% uncertainty caused by variations in the different crates. This uncertainty should be treated as a measure of the bias in the 2006 Calibration.
Plan:
Attached is a document how the calibration uncertainty for 2006 will be calculated:
- Eliminate dependence on simulations through tighter fiducial volume cuts
- Reduce trigger bias by explicitly avoiding electrons matched to trigger HTs or TPs
- Validate modeling of E/p backgrounds. Confirm that the fit is unbiased by checking
consistency of low-background and high-background samples. - Confirm that crate timing does not systematically bias the energy reconstruction.
The uncertainty on the calibration will be assigned as the maximum between |E/p −1.0| and the uncertainty on the peak position.
Method:
We did some initial studies to determine the magnitude of each of these effects, and then we generated calibration trees covering the entire 200 GeV pp run from 2006. The code used to generate these trees is available in StRoot/StEmcPool/StEmcOfflineCalibrationMaker.
We made the following cuts on the tracks to select good electrons and an unbiased sample.
List 1:
- 3.5 < dEdx < 4.5
- abs(vertexZ) < 30
- 1.5 < p < 15 GeV
- dR (from tower center to track projection) < 0.004 (in units of deta,dphi)
- tower_id == tower_id_exit of projection
- Energy of highest neighbor < 0.5 * track energy
After making these cuts, we fit the remaining sample to a gaussian plus a first order polynomial, based on a study of how to fit the background best.
Figure 1 uses an isolation cut to find a background rich sample to fit:

Figure 2 shows the stability of the E/p location (on the y-axis) between our fit and just a gaussian for different windows in dEdx (x-axis)
Figure 3 shows the E/p location (y-axis) for different annuli in dR (x-axis/1000), which motivated our dR cut to stay in a flat region:
.png)
After making all of these cuts, we fit E/p to the entire sample of all our electrons. We then add different cuts based on the trigger information to see how that might affect the bias. We looked at four scenarios:
List 2:
- All electrons after stringent cuts
- Electrons from events that were NOT HT/HTTP triggered
- Electrons from events that were only HT/HTTP triggered
- Electrons from HT/HTTP events with trigger turnon tracks (4.5 < p < 6.5 GeV) removed
From these scenarios we chose the largest deviation from E/p = 1.0 as the overall uncertainty on the calibration. This happens to be scenario 3, working out to 1.3%.
Figure 4: E/p for different scenarios
.png)
We also observed a possible crate systematic by fitting E/p for each crate separately.
Figure 5 E/p for each crate:
.png)
According to the chi^2, there is a non statistical fluctuation. To figure out how much that is, we compared the RMS of these points to that when the data is randomly put into 30 partitions. It turns out that all of it is due to that one outlier, crate 12. Since crate 12 contributes 1/15 to each eta ring that it touches, the deviation of this point from the fit causes an uncertainty of 0.9%. This additional uncertainty increases the total uncertainty to 1.6%.
Side Note - Linearity:
After removing HT/HTTP events, we took a look at this plot of p (y-axis) vs E/p (x-axis). By eye, it looks pretty flat, which we verified by splitting into p bins.
Figure 6 p vs E/p
.png)
Figure 7 E/p vs p
Eta Dependence:
There was some question about whether there was eta dependence. This was investigated and found to be inconsequential: http://drupal.star.bnl.gov/STAR/node/14147/
Figure 8: Divided the sample into 3 separate time periods. Period 1 goes is before run 7110000. Period 2 is between runs 7110000 and 7130000. Period 3 is after run 7130000. The deviations are below 1.6%.
.png)
Figure 9: Agreement between east and west barrel:
.png)
Figure 10: ZDC Rate vs. energy/p
.png)
Figure 11: E/p fits for three different regions in ZDC rate: 0 - 8000, 8000-10000, 10000-20000 Hz.
.png)
Comparison of Electron and MIP Calibrations
This page compares the new tower calibration performed using only electron E/p to the calibration using last year's algorithm. The two calibrations are found to be consistent within 120 MeV in E_T.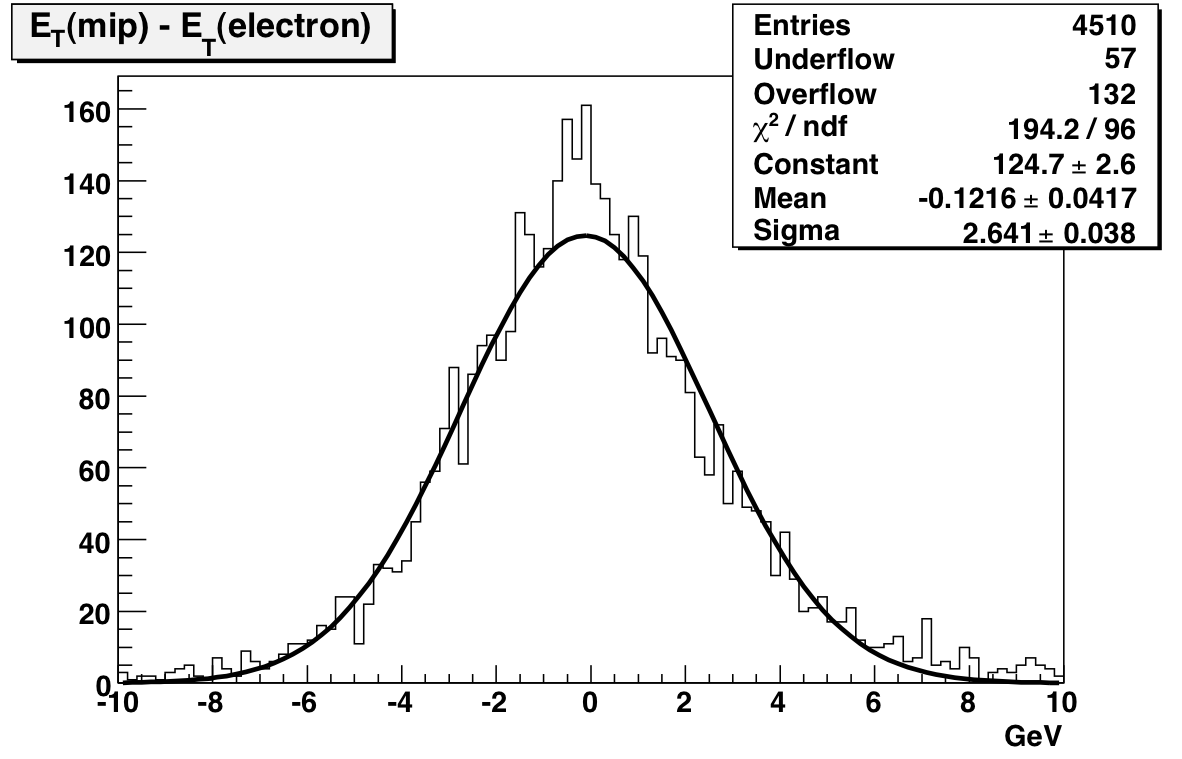
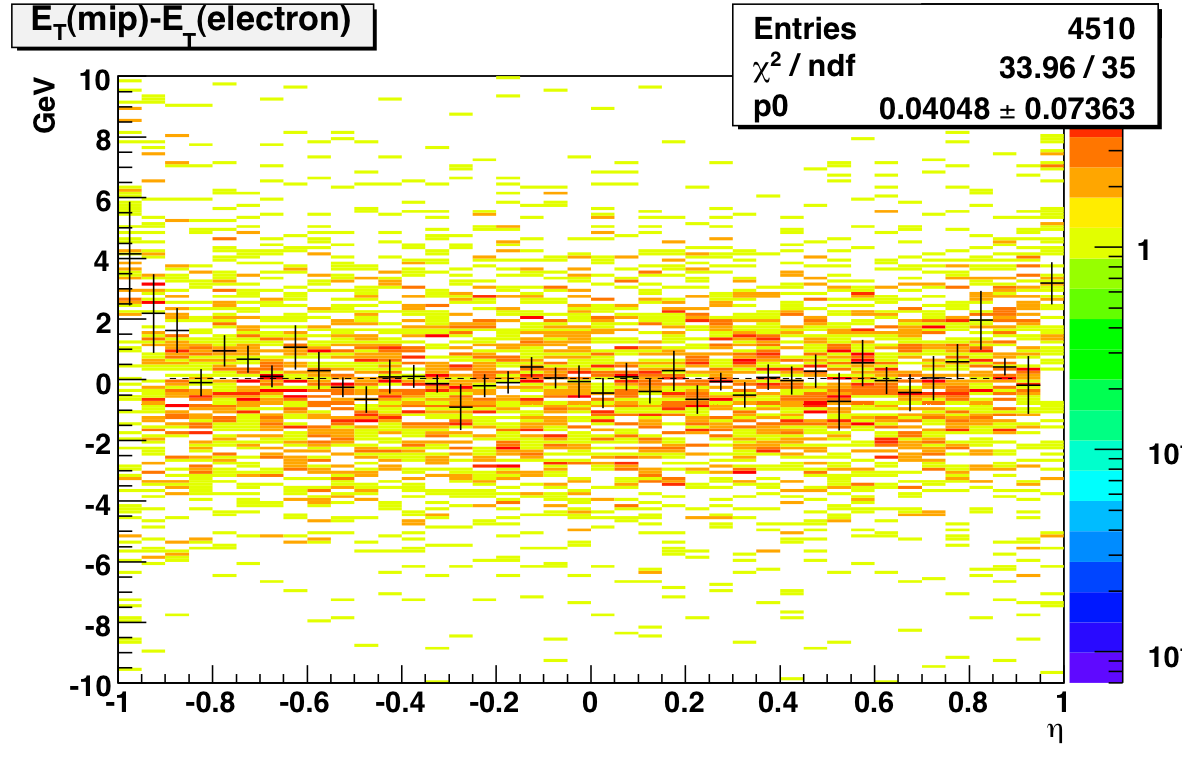
I've also attached the tower-by-tower plots of electron E/p so you can see the results for yourself. I'll write up a more complete description of the calibration algorithm shortly.
Comparison of Online and Offline Calibrations
Introduction:
This page compares the online and first offline calibrations. The online calibration table was generated during data-taking using a single long run processed through fastOffline production and uploaded on March 30th. It uses slopes to set the relative gains in an eta-ring and then normalizes the eta-rings using MIPs. The first offline calibration uses a significant fraction of the produced transverse and late longitudinal runs. It sets the relative gains using MIP peaks and then uses electron E/p to set the absolute scale. It was uploaded on December 7th.Body Counts:
138 additonal towers are masked in this first offline calibration, leaving 4517 good towers. 1 tower (2916) was masked before but is now listed as OK. To be honest, I have no idea why it was masked in the online calib; its slope looks fine to me.Plots:
The electron E/p scaling in the offline calibration increased the gains by an approximately uniform 10 percent (more at the edges). This effect is seen in the following plot of offline E_T - online E_T, integrated over all towers that were good in both calibrations: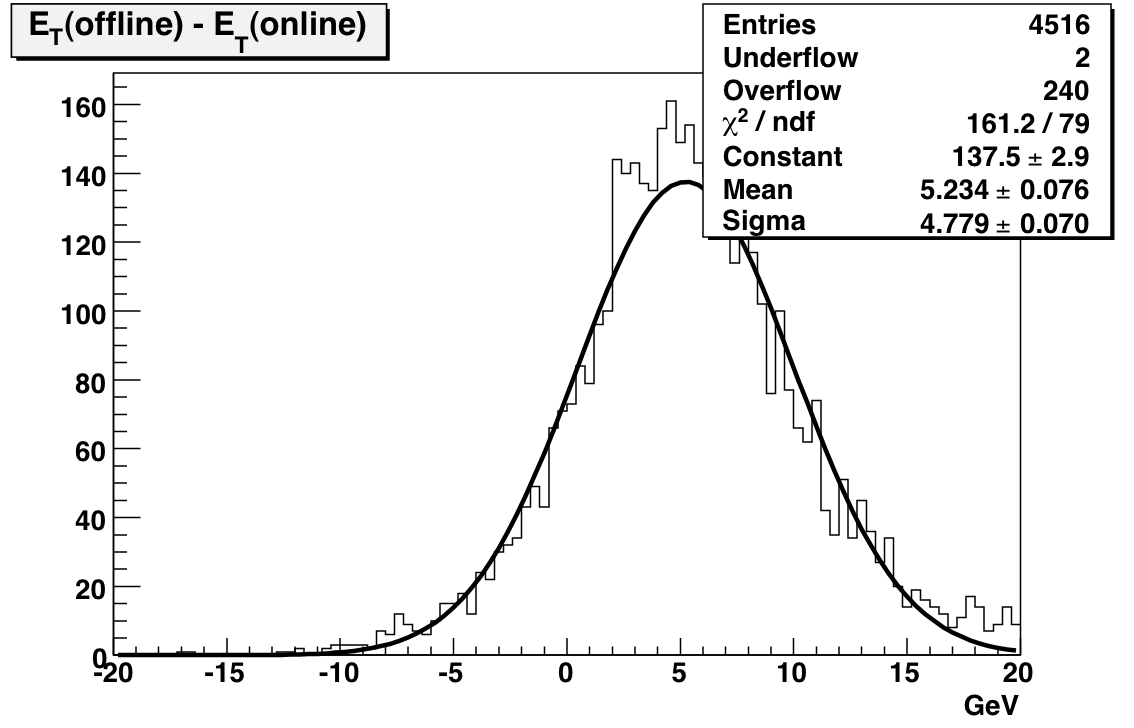
Now, the interesting thing is the relative changes of offline-online for the east side and the west side. If I only plot the location of towers whose gains increased by more than 20% I get
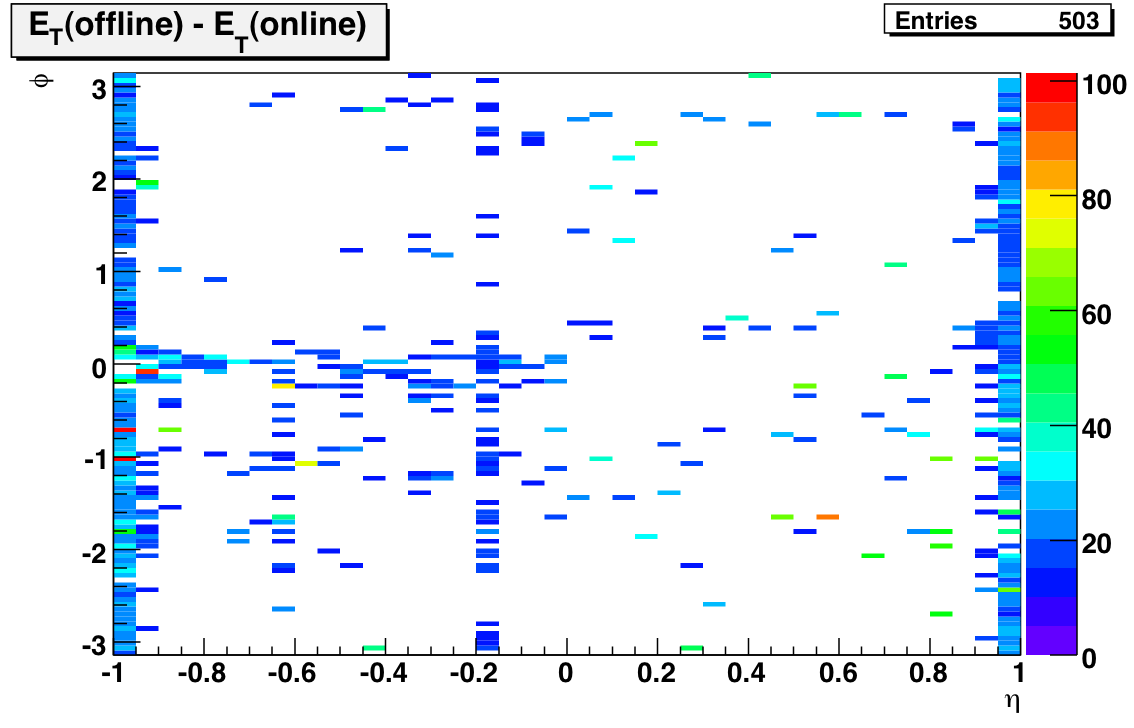
There were only 12 towers whose gains decreased by 20%; all of them were on the west side. Finally here's a plot of the E_T change of the remaining towers:
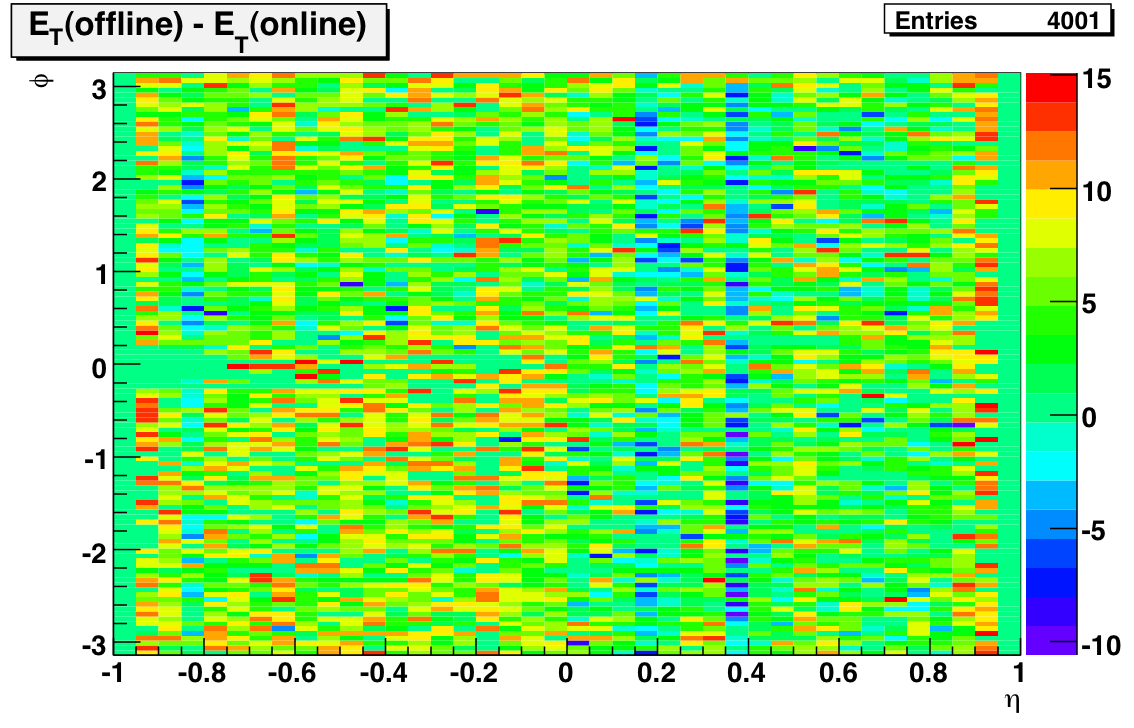
I think the message here is clear: the gains on the east side have increased more than the gains on the west side! It's possible that the use of the online calibration in previous Run 6 jet studies is at least partially responsible for the obsereved east-west jet asymmetry.
To get quantitative about this effect we have to go to 1D. I've attached a PDF of eta-ring by eta-ring histograms like the first one on this page. The first two pages are the east side; the next two are the west side. I've found it easiest to analyze if you set your Reader to view two pages at a time; then you'll be comparing towers with the same absolute value of pseudorapidity when you flip. The conclusion is pretty clear: at midrapidity the difference in offline - online E_T floats around 5 - 8 GeV on the east side, but it's only about 2 - 5 GeV on the west side.
Gain Stability Check
I've updated my codes to do a more systematic investigation of the stability of the gains. Instead of trying to get sufficient tower-by-tower statistics for different time periods, I'm looking at MIP peaks for single runs integrated over all towers. Here's the plot:
Features of note include the bump covering the first couple of days after the shutdown, the bunch of runs on day 123/4 with very low average peaks, and the general decreasing slope (consistent with towers losing high voltage). I also ran this plot for west and east separately:
I'm running jobs now to do electron selection instead of MIPs. I think that I can probably still do this as a function of run, but certainly I'll have sufficient stats to plot vs. fill if necessary.
Goal: Compare the tower slopes and MIP peaks from the following three periods to check for stability.
- Day < 104 (97-99)
- 104 < Day < 134 (114-119)
- Day > 134 (134-139)
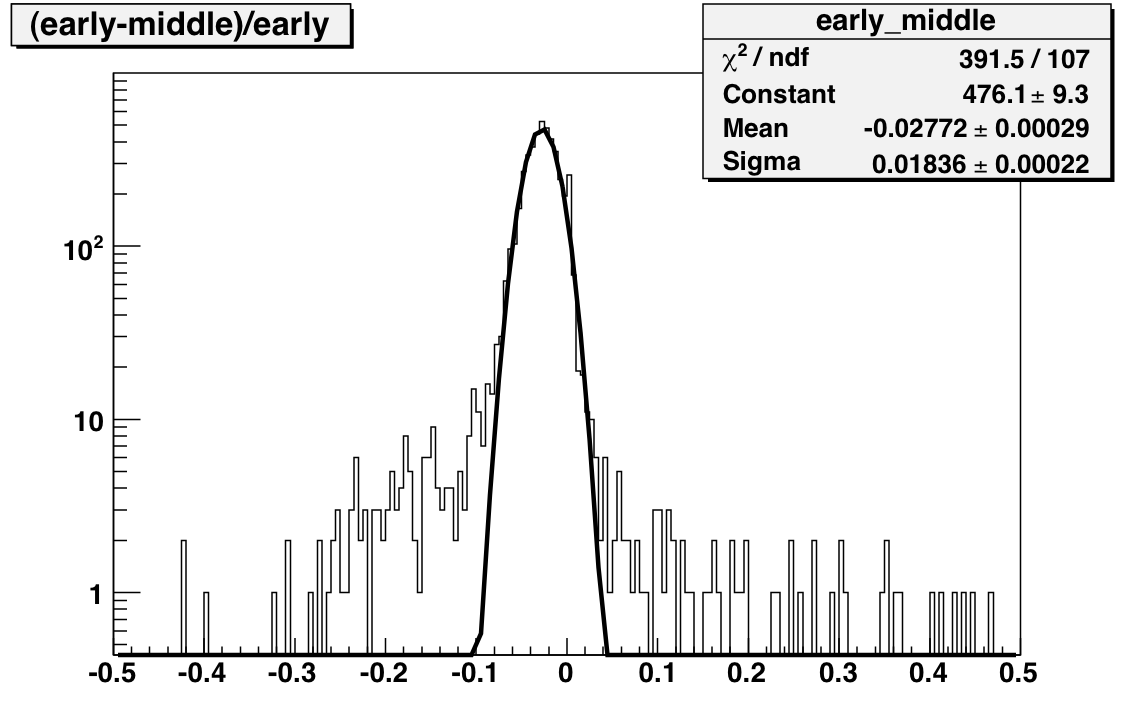
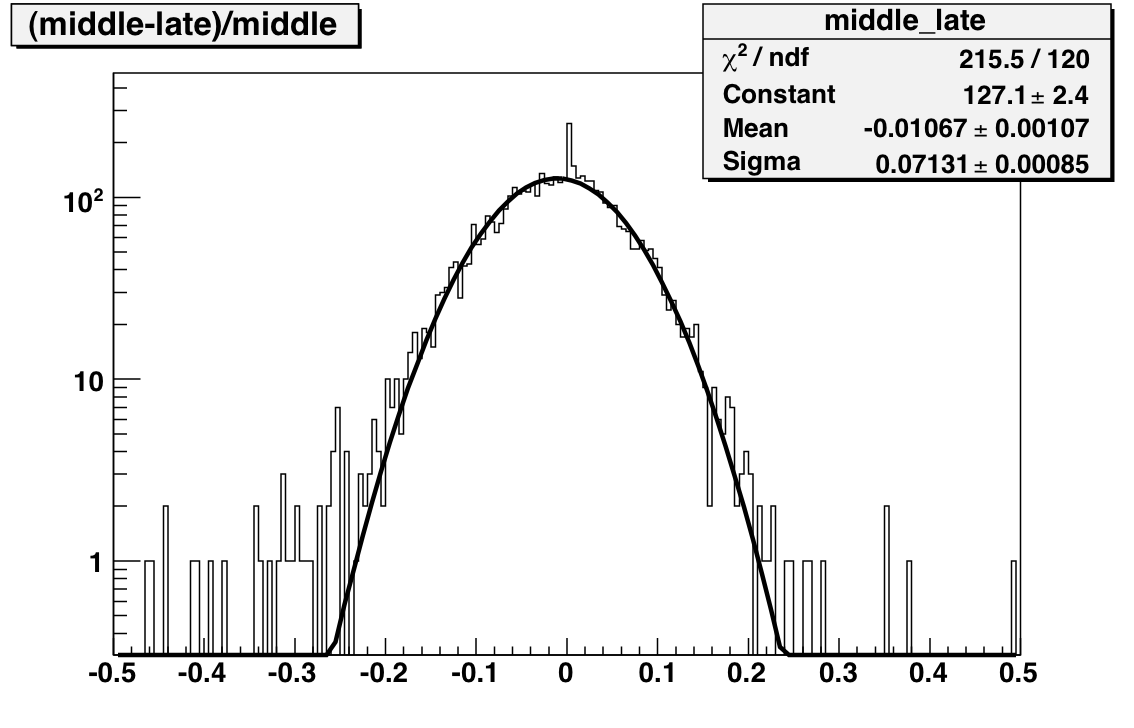
The next set of plots compare gains extracted from MIP peak positions where the MIP peaks are generated using subsets of the Run. Comparing before and after the shutdown yields a mean difference of 110 MeV with a width of 3 GeV. This difference is significantly less than 1 percent. The comparison between middle and late (essentially a comparison between transverse and late longitudinal running) indicates a 1.5 percent drop in the gains with a 2.3 GeV sigma.
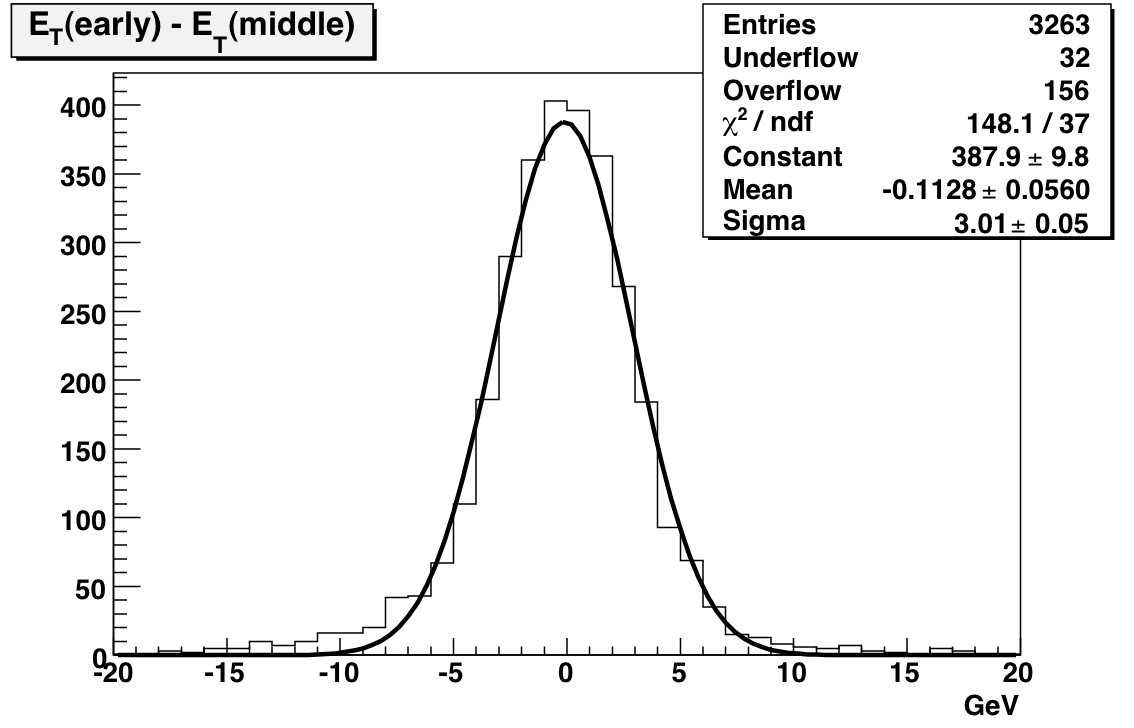
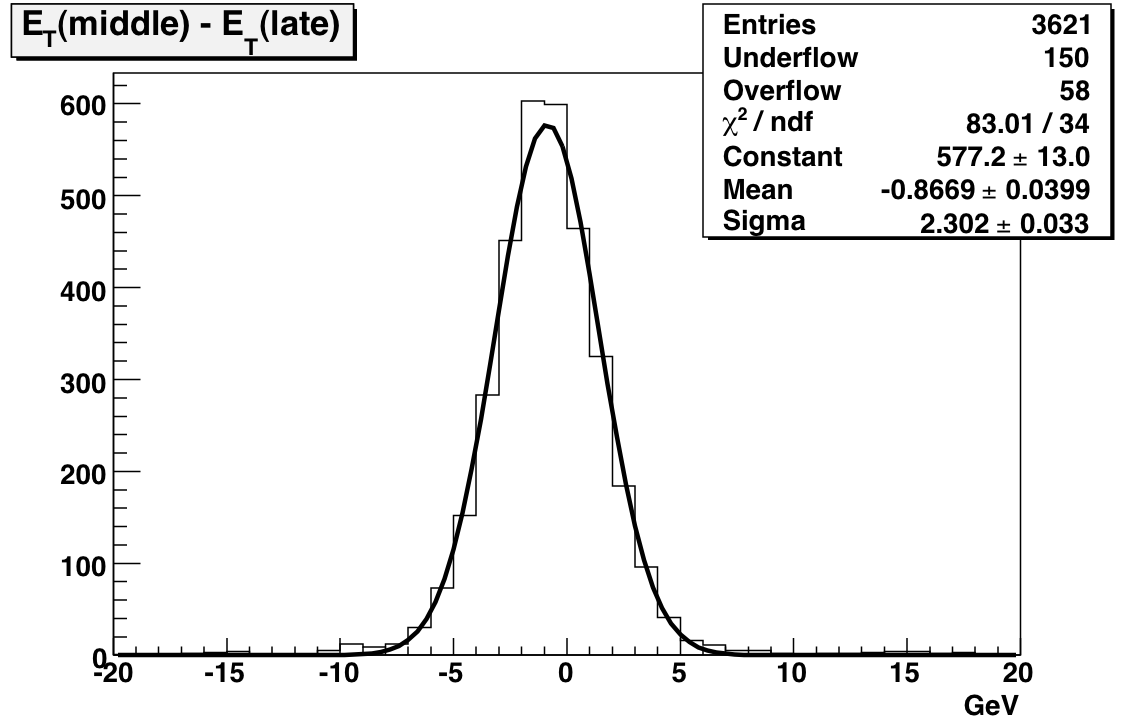
Run 7 BTOW Calibration
Online Work
Steve T's page:http://orion.star.bnl.gov/protected/spin/trent/calibration/calibration.html
First Iteration
March 27, 2007Steve and Oleg took 600k fast events in runs 8086057, 8086058, and 8086060 to calculate the tower slopes. Here's a summary plot of tower slopes vs. eta:
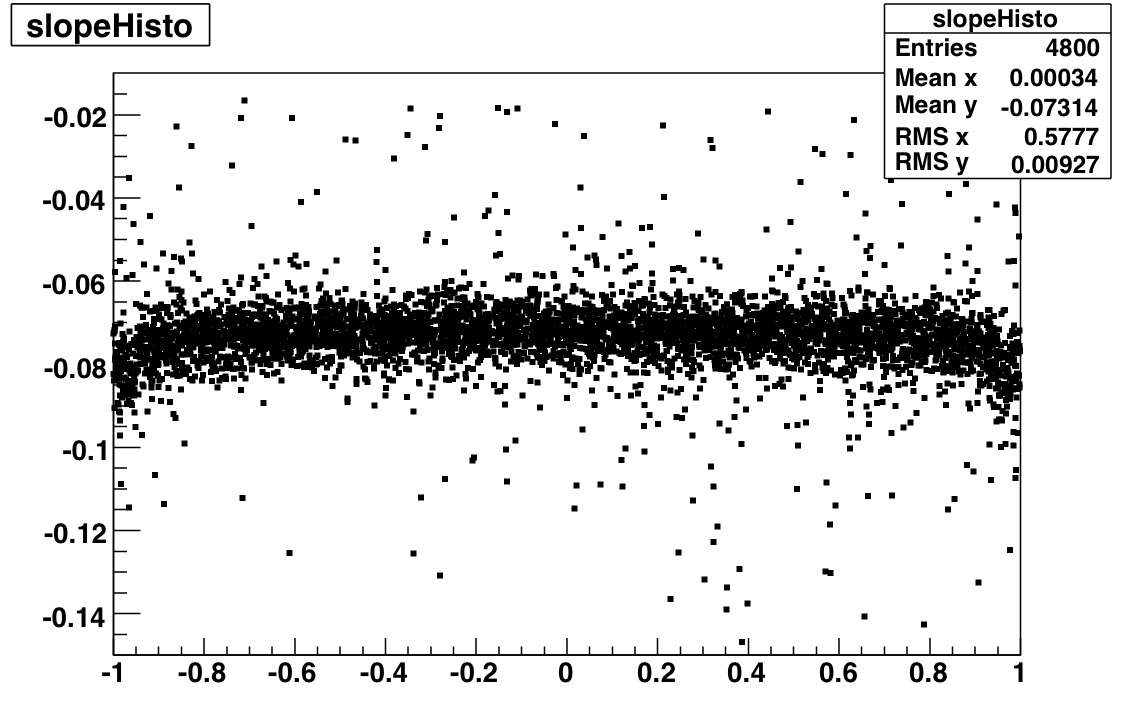
I've attached two list of slopes for each tower at the bottom of the page. The columns are
id -- flag -- slope -- error -- chi2 -- ndf
where the flag is determined by
if(ndf < 30) x //empty, stuck bit
else if(chi2 > 200.) ? //worth a closer look
else if(slope outside 4*RMS) * //probably needs HV adjustment
else blank //channel OK at 4*RMS level
The file slopes_noflags.txt has the same data as the first file, but it omits all the flag information so that it can be read into a macro easily. Flagged channels are also listed in red in the mega-PDF
Second Iteration
Same procedure as First Iteration. Took 600k events in runs 8089017, 8089019, 8089021. This time the processing went smoothly and I was able to analyze ~all the events that were taken. Here's the summary of slopes vs. eta: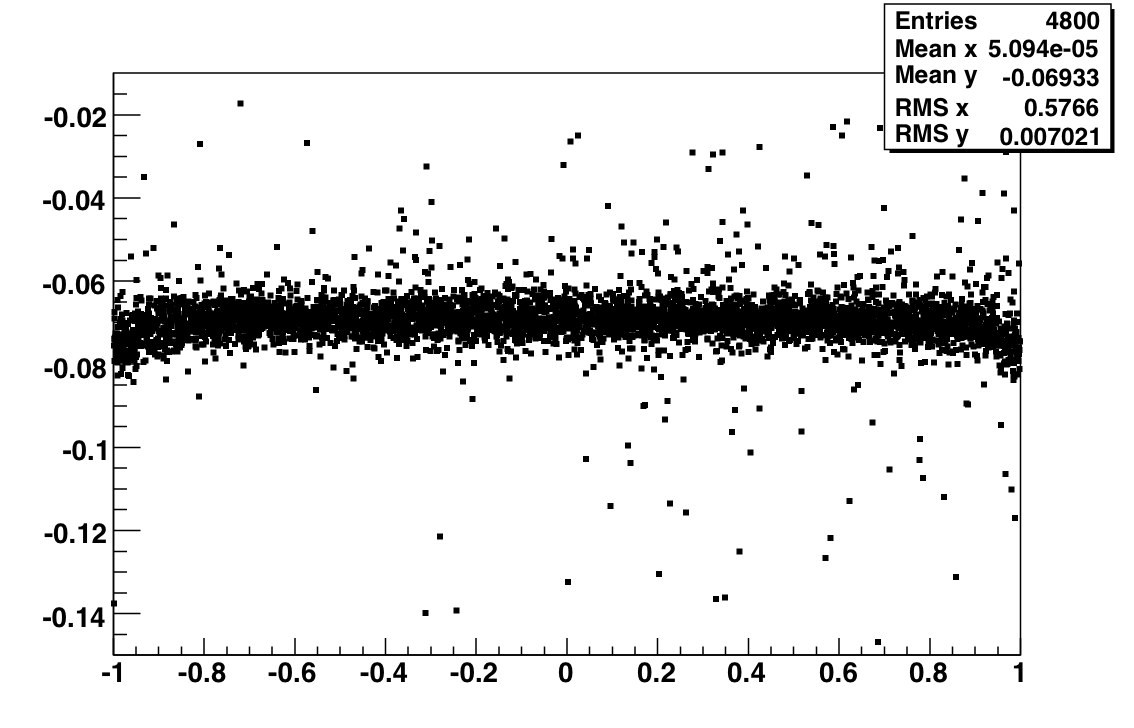
I've attached at the bottom of the page lists of slopes for individual towers. The format is the same as before, although I've adjusted the chi2 cut to 300 because of the additional statistics and I've also adjusted the 4*RMS slope cut to take into account the updated mean and RMS values from the plot above.
Third Iteration
Data gathered from runs 8090021, 8090022, 8090023. The only change I made to the code was to tweak the parameters of the pedestal fit a little bit, since I noticed a couple of towers where it failed.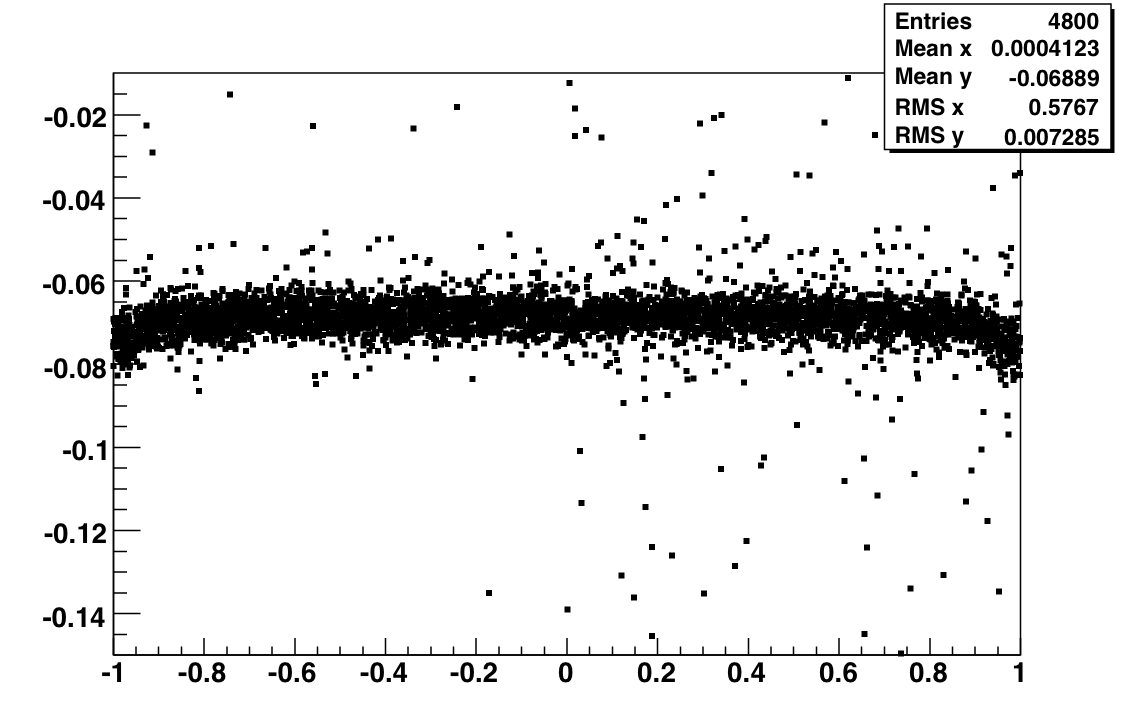
Fourth Iteration
Data gathered from Runs 8091003, 8091005, 8091007. Same analysis codes as in Third Iteration.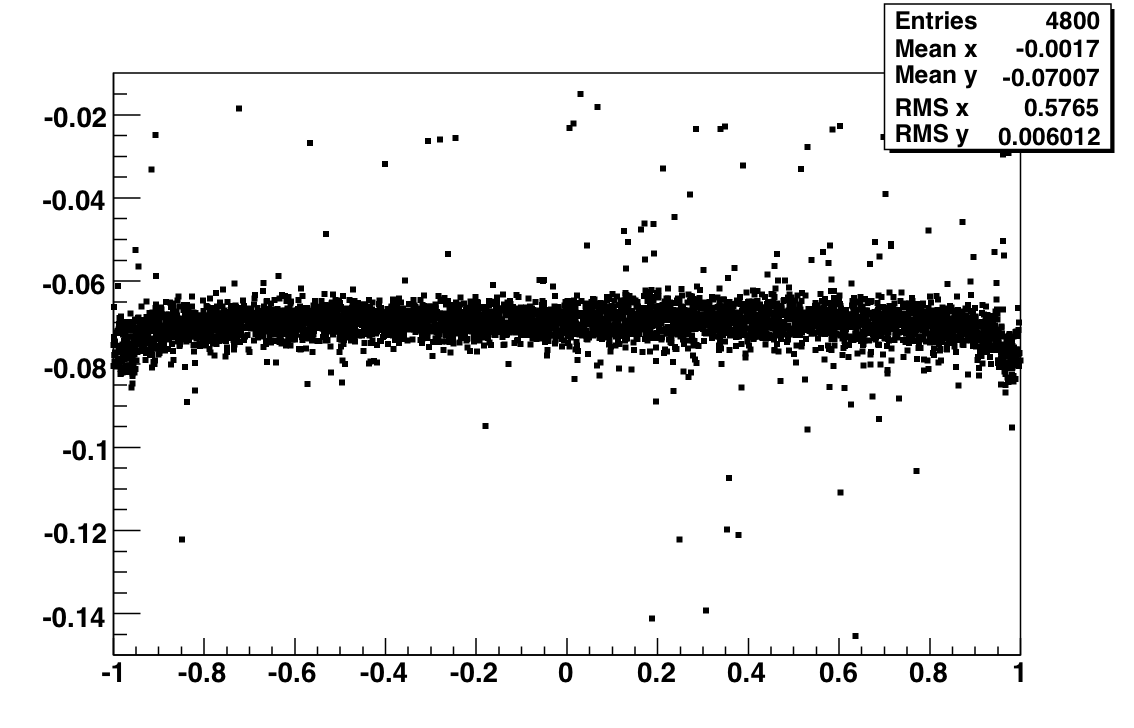
Fifth Iteration
Runs: 8092080, 8092081, 8092083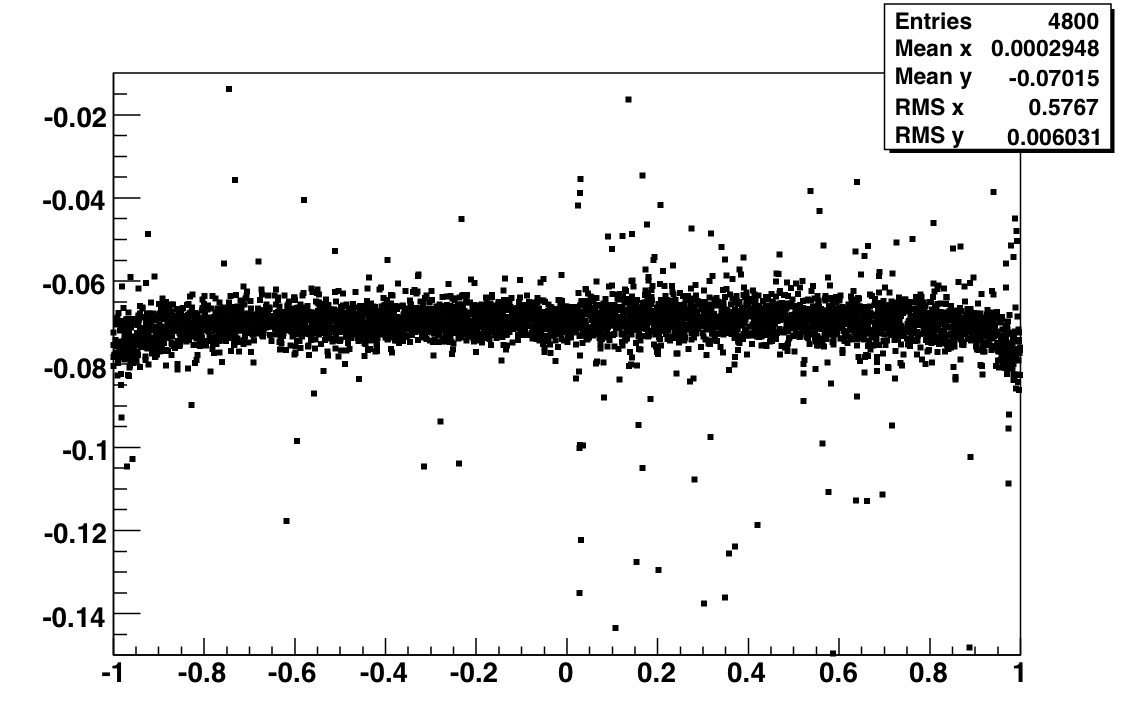
Seventh Iteration
Run 8095073, 600k events.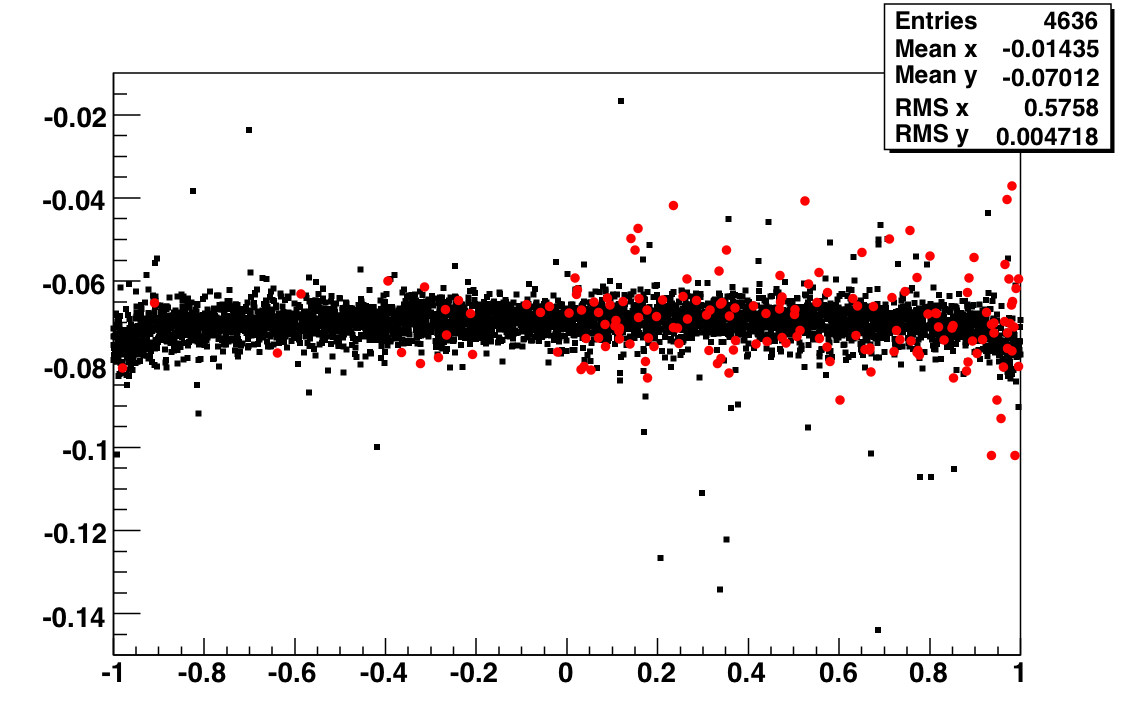
This summary plot highlights swapped towers in red. As Steve pointed out, we weren't adjusting the HV of these tubes correctly in most of the previous iterations.
Run 8 BTOW Calibration (2008)
2008 BTOW calibrations
- BTOW HV used in 2008 are in the file 2008_i2a.csv, this file will contain a few towers
(<50)which might have been set to zero at a later date
01 statistical analysis of 2008 HV
Goal: study eta dependence of 2008 BTOW HV
Fig 1 Eta-phi distribution of HV

Formulas used to map tower ID in to eta-phi location
int id0=id-1;
int iwe=0; // West/East switch
if(id>2400) iwe=1;
int id0=id0%2400;
int iphi=id0/20;
int ieta=id0%20;
if(iwe==0) ieta=ieta+20;
else ieta=19-ieta;
Fig 2 Batch 1, Eta-phi distribution of HV

eta=0.05 mean HV=821 +/- 5 sigHV=60 eta=0.15 mean HV=820 +/- 5 sigHV=60 eta=0.25 mean HV=815 +/- 5 sigHV=62 eta=0.35 mean HV=811 +/- 5 sigHV=66 eta=0.45 mean HV=817 +/- 5 sigHV=66 eta=0.55 mean HV=820 +/- 5 sigHV=57 eta=0.65 mean HV=820 +/- 5 sigHV=59 eta=0.75 mean HV=806 +/- 5 sigHV=62 eta=0.85 mean HV=807 +/- 5 sigHV=58 eta=0.95 mean HV=829 +/- 5 sigHV=65
Fig 3 Batch 2, Eta-phi distribution of HV

eta=0.05 mean HV=759 +/- 6 sigHV=56 eta=0.15 mean HV=760 +/- 7 sigHV=62 eta=0.25 mean HV=756 +/- 6 sigHV=53 eta=0.35 mean HV=763 +/- 6 sigHV=55 eta=0.45 mean HV=756 +/- 7 sigHV=58 eta=0.55 mean HV=760 +/- 6 sigHV=54 eta=0.65 mean HV=743 +/- 6 sigHV=52 eta=0.75 mean HV=754 +/- 6 sigHV=54 eta=0.85 mean HV=754 +/- 7 sigHV=64 eta=0.95 mean HV=769 +/- 7 sigHV=59
Fig 4 Batch 3, Eta-phi distribution of HV

eta=-0.95 mean HV=730 +/- 4 sigHV=57 eta=-0.85 mean HV=723 +/- 4 sigHV=57 eta=-0.75 mean HV=727 +/- 4 sigHV=59 eta=-0.65 mean HV=718 +/- 4 sigHV=58 eta=-0.55 mean HV=723 +/- 4 sigHV=58 eta=-0.45 mean HV=720 +/- 4 sigHV=56 eta=-0.35 mean HV=727 +/- 4 sigHV=54 eta=-0.25 mean HV=724 +/- 4 sigHV=60 eta=-0.15 mean HV=735 +/- 4 sigHV=59 eta=-0.05 mean HV=729 +/- 4 sigHV=60
02 BTOW swaps ver=1.3
Example of MIP peak for BTOW towers pointed by TPC MIP track:  Spectra for 4800 towers (raw & MIP) are in attachment 1.
Spectra for 4800 towers (raw & MIP) are in attachment 1.
Method of finding MIP signal in towers:

Table 1
BTOW swaps, very likely, ver 1.3, based on 2008 pp data, fmsslow-production 266 --> 286 , 267 --> 287 , 286 --> 266 , 287 --> 267 , 389 --> 412 , 390 --> 411 , 391 --> 410 , 392 --> 409 , 409 --> 392 , 410 --> 391 , 411 --> 390 , 412 --> 389 , 633 --> 653 , 653 --> 633 , 837 --> 857 , 857 --> 837 ,1026 -->1046 ,1028 -->1048 ,1046 -->1026 ,1048 -->1028 , 1080 -->1100 ,1100 -->1080 ,1141 -->1153 ,1142 -->1154 ,1143 -->1155 , 1144 -->1156 ,1153 -->1141 ,1154 -->1142 ,1155 -->1143 ,1156 -->1144 , 1161 -->1173 ,1162 -->1174 ,1163 -->1175 ,1164 -->1176 ,1173 -->1161 , 1174 -->1162 ,1175 -->1163 ,1176 -->1164 ,1753 -->1773 ,1773 -->1753 , 2077 -->2097 ,2097 -->2077 ,3678 -->3679 ,3679 -->3678 ,3745 -->3746 , 3746 -->3745 ,4014 -->4054 ,4015 -->4055 ,4016 -->4056 ,4017 -->4057 , 4054 -->4014 ,4055 -->4015 ,4056 -->4016 ,4057 -->4017 ,4549 -->4569 , 4569 -->4549 ,
Details for all swaps are shown in attached 2.
Other problems found during analysis, not corrected for, FYI

03 MIP peak analysis (TPC tracks, 2008 pp data)
I examined runs from 2008 pp (list attached below) to create calibration trees (using StRoot/StEmcPool/StEmcOfflineCalibrationMaker). The code loops over the primary tracks in the event and selects the global track associated with it, if available. If the track can be associated to a tower and has outermomentum > 1 GeV, it is saved.
I then loop over those tracks and choose ones that fall within a certain criteria:
- p > 1
- adc - ped > 1.5 * ped_rms
- tower_entrance_id = tower_exit_id
- only a single track points to the tower
- neighoring towers have small amounts of energy
We can sum over all runs to produce MIP spectrum in 4445 towers. Of those, 4350 pass current QA requirements. An example MIP spectrum with fit is shown below. All MIP peaks can be seen in the attached PDF. It's important to note that the uncertainty on the MIP peak location with these statistics is on average 5%. This number is a lower limit on the calibration coefficient uncertainty that can only be improved with statistics.
Fig 1. Typical MIP peak. Plots like this for all 4800 towers are in attachment 1.
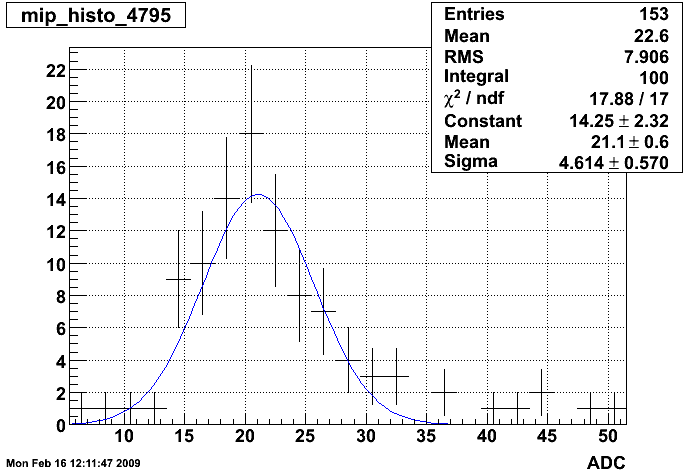
The following plot shows MIP peak location in ADCs (in eta, phi space) of all of towers where such a peak could be found.
Fig 2. MIP Peak (Z-axis) for all towers
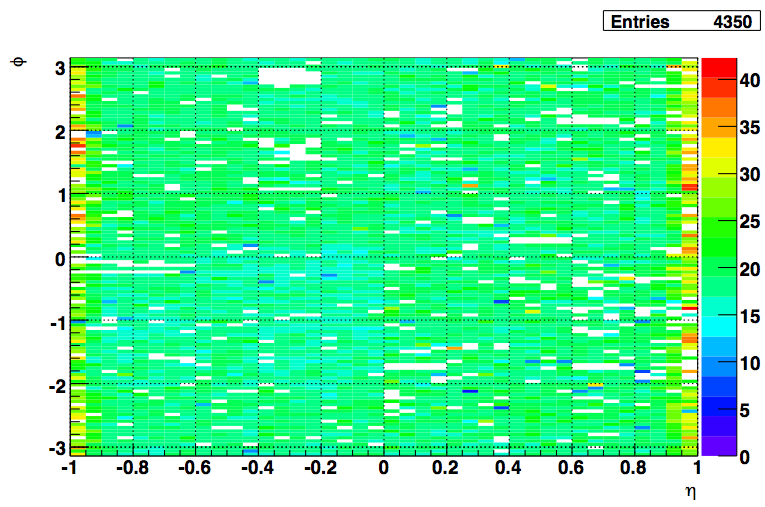
This plot shows the status codes of the towers. White are the towers that had 0 entries in their histograms. Red are the good towers (pushed them off scale to see the rest of the entries). Towers in the outermost eta bin received different treatment. The fit range was between [6,100] for those towers (vs [6,50] for the rest). The cuts applied for QA were slightly loosened. The rest of the codes follow this scheme:
- bit 1: entries in histogram > 0
- bit 2: sigma of fit below threshold (15,20)
- bit 4: mean of fit above 5 ADCs
- bit 8: difference of fit mean and MPV in fit range below threshold (5,10)
Fig 3. status of towers
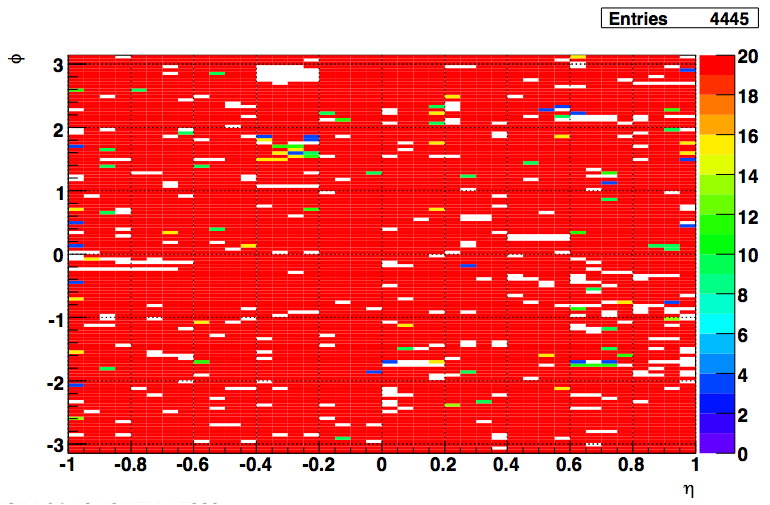
Spectra of towers rejected by rudimentary automatic QA were manually inspected and 91 were found to contain reasonable MIP peak and have bin re-qualified as good. PLots for those towers are in attachment 2.
04 relative tower gains based on MIPs (gain correction 1)
Determination of relative gains BTOW gains based on MIP peak for the purpose of balancing HV for 2009 run
Procedure:
- use fitted 03 MIP peak analysis (TPC tracks, 2008 pp data)
- find average MIP value for 40 eta bins
- West barrel: preserve absolute average MIP peak position in the , compute gain correction to equalize all towers at given eta to the average for this eta
- East barrel: enforce absolute average MIP peak to agree with the West barrel, correct relative gains in the similar way.
In this stage of calibration process 4430 towers with well visible MIP peak were use. The remaining 370 towers will be called 'blank towers' . There are many reasons MIP peak doe snot show up e.g. dead hardware. ~60 of the 'blank towers' are 02 BTOW swaps ver=1.3- as identified earlier and not corrected in this analysis.
Fig 1. Left: MIP peak (Z-axis) was found for 4430 towers shown in color. White means no peak was found - those are "blank towers". Right: eta-phi distribution of blank towers. On both plots East (West) barrel is show on etaBins [1-20], (21,40).

The (iEta, iPhi ) coordinates were computed based on softID as follows:
int jeta= 1+(id-1)%20; // range [1-20]
int jphi= 1+(id-1)/20; // range [1-240]
if(jphi<=120) { // West barrel
keta=jeta+20; kphi=jphi;
} else { // East barrel
keta=-jeta+21; kphi=jphi-120;
}
Fig 2. Average MIP position as function of eta bin. West-barrel gains are higher even of average.

Gain corrections (GC1) were computed as
GC1(iEta,iPhi)= MIP(iEta,iPhi) / avrMip(iEta)
For the East-barrel we used values of avrMip(iEta)from symmetric eta-bins from the West barrel.
If computed correction was between [0.95,1.05] or if towers was "blank" GC1=1.00 was used.
Fig 3. Left distribution of gain corrections GC1(iEta). Right: value of GC1(iEta,iPhi).

Attached spreadsheet contains computed GC1(softID) in column 'D' together with MIP peak parameters (columns H-P) for all 4800 towers. Below is just first 14 towers.

Used .C macro is attached as well.
05 Absolute Calibration from Electrons
We use the MIP ADC location calculated in part 03 to get a preliminary measure of the energy scale for each tower.
The following formula from SN436 provides the calibration coefficient:
C = 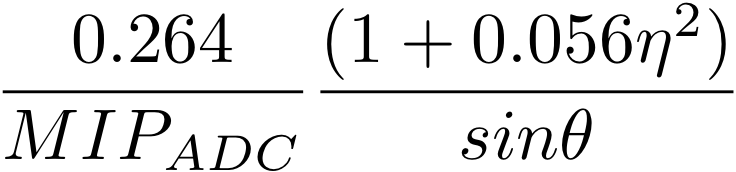
where E = C * (ADC - ped).
For the electron sample I select tracks with:
- 1.5 < p < 6.0 (GeV)
- dR < 0.0125 (from center of face of tower in eta/phi space)
- adc - ped > 2.5 * ped_rms in tower
- nHits > 10
- nSigmaElectron > -1
Here is one of the E/p distributions. Note the error on the mean is about 2%, which is about average.
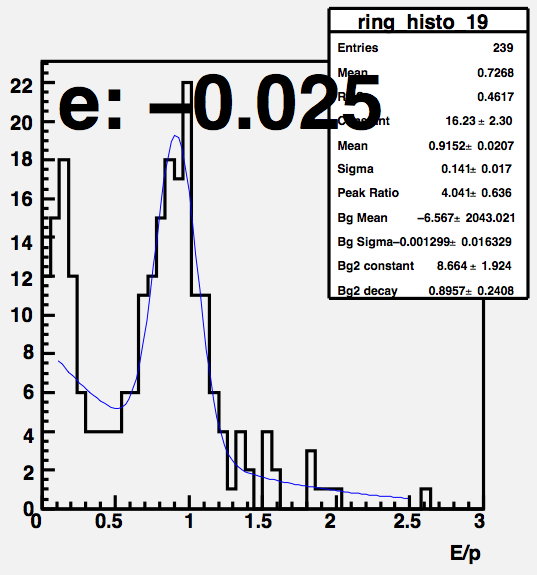
For each electron we calculate E/p and sum over eta rings. Here is the peak of E/p for each eta bin. The error bars show the error on the mean value, and the shaded bar is the sigma. I fit over the range [-0.9,0.0] and [0.0,0.9] separately. The fit for the east reports the mean is 0.9299 +/- 0.0037. For the west, I get 0.9417 +/- 0.0035.
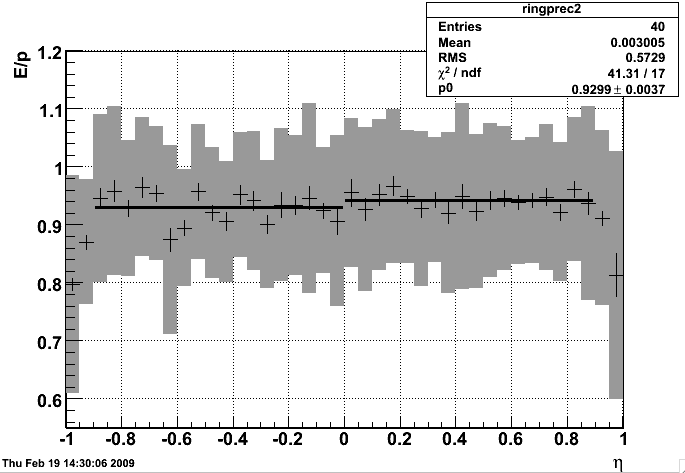
The location of the E/p peak tells us the correction that needs to be applied to the calibration coefficients of towers in each eta ring to get the correct absolute energy.
Reference plot (electron showers):
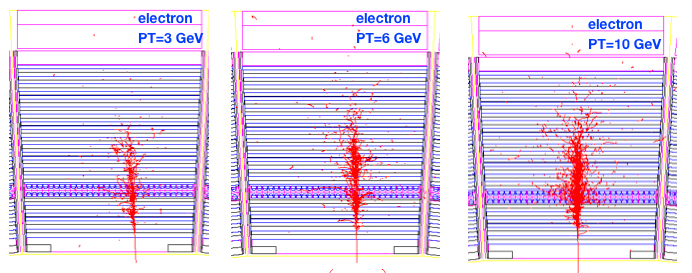
06 Calculating 2009 HV from Electron Calibrations
The ideal gain for each tower satisfies the following relation, where E_T = 60 GeV when ADC is max scale (~4095 - ped):
(1)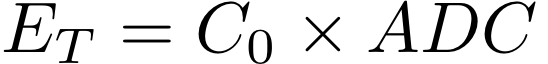
We want to calculate the total energy deposited in a tower, which is the following in the ideal case:
(2)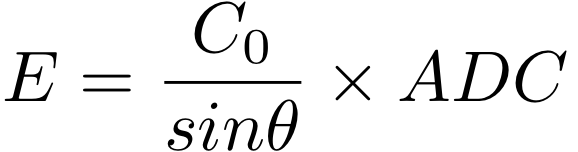
In reality, we calculate the calibration according to the following formula:
(3)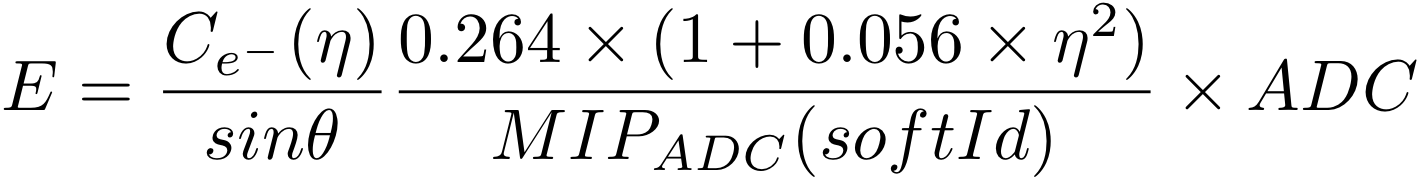
where there is an electron correction for each eta ring, and the MIP location is determined for all towers.
Thus, to have ideal gains, we want the following relation to hold
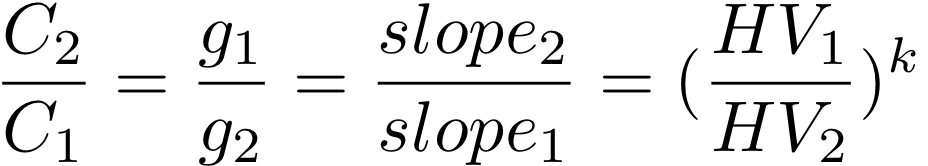 (4)
(4)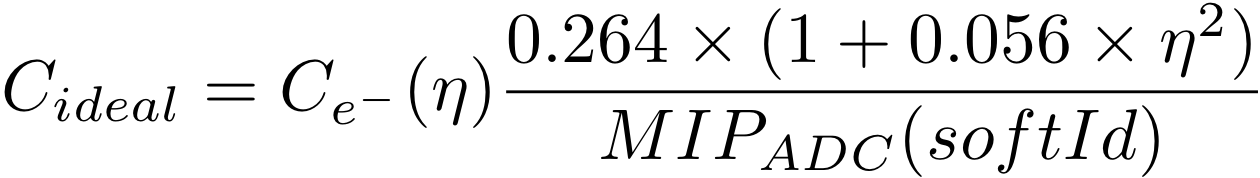
To make this relation true, we need to adjust the high voltage for each tower according to the following relation:
(5)
We can check the changes using slopes.
07 BTOW absolute gains 'ab initio'
Summary of intended BTOW HV change, February 24, 2009
Conclusion:
We will NOT change average gain of West BTOW for eta bins[1,18]. For all other eta bins we will aim at the average West Btow marked as red dashed line.

Full presentation is in attachment 1.
Detailed E/P spectra for 40 eta bins are in attachment 2 & 3.
08 Completed Calibration and Uncertainty
The 2008 Calibraton has been uploaded into the database. I was able to find calibration coefficients for 4420 towers. Of the remaining towers, 353 were MIPless and 27 had spectrums that I could not recover by hand.
This year, differently from previous years, known sources of bias are removed. If an event had a nonHT trigger, the tracks from that event were used for the calibration (even if it had an HT trigger). Most of the triggers were fms slow triggered events. Each eta ring was calibrated separately, and then a correction for each crate was applied. After these corrections, I once again made the cuts on the electrons more stringent. No deviation from E/p =1 was found. With the biases eliminated, we now quote a systematic variance instead of a systematic bias as the uncertainty on the calibration.
The source of this uncertainty are the uncertainties on various fits used for each calibration, namely the MIP peak for each tower, the absolute calibration for each eta ring, and the correction for each crate. These uncertainties are highly correlated. I have completed this calibration by recalculating the calibration table 3,000 times varying the MIP peaks, the eta ring corrrections and the crate corrections each time. Using this method, I was able to determine the correlated uncertainty for each calibrated tower. This uncertainty is, on average, 5%.
This uncertainty is different than the systematic bias quoted for 2005 and 2006. It is a true variance on the calibration. To use this uncertainty, analyzers should recalculated their analysis using test tables generated for this purpose. The variance in the results of these multiple analyses will give a direct measure of the uncertainty due to the calibration scale uncertainty. These tables will be uploaded to the database with the names "sysNN". They should be used before clustering, jet finding, etc.
Run 9 BTOW Calibration
Parent page for BTOW 2009 Calibrations
01 BTOW HV Mapping
We started at the beginning of the run to verify the mapping between the HV cell Id and the softId it corresponds to. To begin, Stephen took 7 runs with all towers at 300V below nominal voltage except for softId % 7 == i, where i was different for each run. Here are the runs that were used:
| softId%7 | Run Number | Events |
| 1 | 10062047 | 31k |
| 2 | 10062048 | 50k |
| 3 | 10062049 | 50k |
| 4 | 10062050 | 50k |
| 5 | 10062051 | 50k |
| 6 | 10062060 | 100k |
| 0 | 10062061 | 100k |
We used the attached file 2009_i0.txt (converted to csv) as the HV file. This file uses the voltages from 2008 and has swaps from 2007 applied. Swaps indentified were not applied and will be used to verify the map check.
File 2009_i0c.txt contains some swaps identified by the analysis of these runs.
File 2009_i1c.txt contains adjusted HV settings based on the electron/mip analysis with same mapping as 2009_i0c.txt.
Final 2009 BTOW HV set on March 14=day=73, Run 10073039 , HV file: 2009_i2d.csv
02 Comparing 2007, 2008 and 2009 BTOW Slopes
We have taken two sets of 1M pp events at sqrt(s)=500 GeV. For future reference, the statistical error on the slopes is typically in the range of 3.7%. I give a plot of the relative errors in the 5th attachment.
plus we have
Comparing the overall uniformity of the gain settings, I give the distribution of slopes divided by the average over the region |ETA|<0.8 for 2007, 2008 and 2009 (First three attachments)
I find that there is little difference in the overall uniformity of the slopes distribution over the detector...about +/-5%. I also give a plot showing the average slopes in each eta ring for the three different voltage settings in each year 2007. 2008 and 2009. (4th attachment) As you can see, the outer eta rings were overcorrected in 2008. They are now back to nearly the same positions as in 2007.
_________________________________________________________________
Here is my measurement of 'kappa' from 2007 data. I get from 7-8, depending on how stringent the cuts are. I think this method of determining kappa is dependent on the ADC fitting range. In theory, we should approach kappa~10.6 as we converge to smaller voltage shifts.
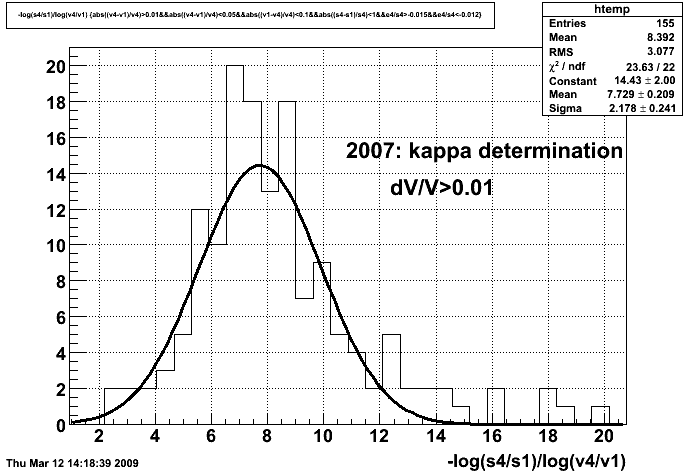
So which ones should we adjust? Here is a fit of the slope distribution to a gaussian.
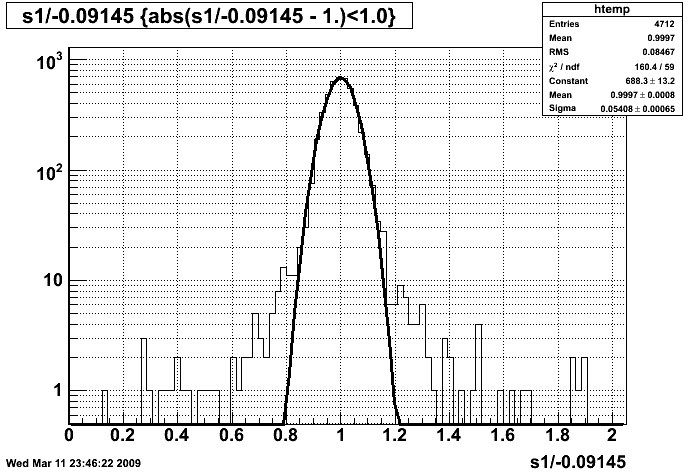
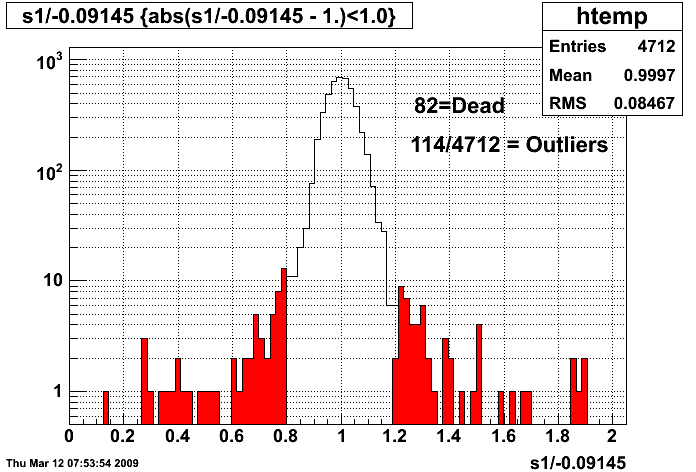
As we can see, the distribution has an excess of towers with slopes >+/-20% from the average. I checked that these problem towers are not overwhelmingly swapped towers (15/114 outliers are swapped towers; 191/4712 are swapped towers). Here is an eta:phi distribution (phi is SoftId/20%120, NOT angle!). The graph on the left gives ALL outliers, the graph on the right gives outliers with high slopes only (low voltage). There are slightly more than expected in the eta~1 ring, indicating that the voltages for this ring are set to accept few particles than the center of the barrel.
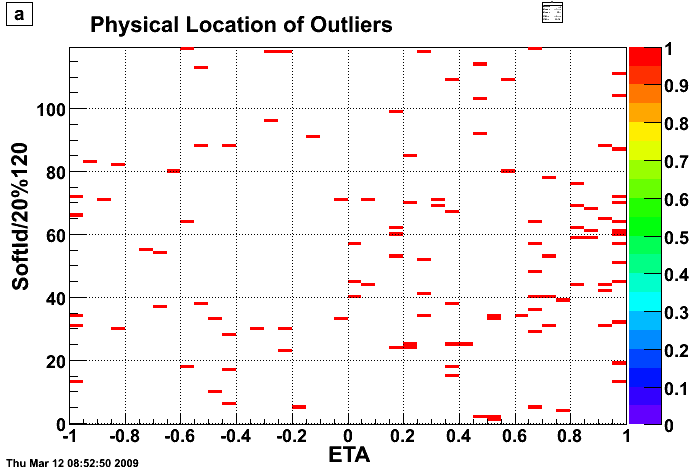
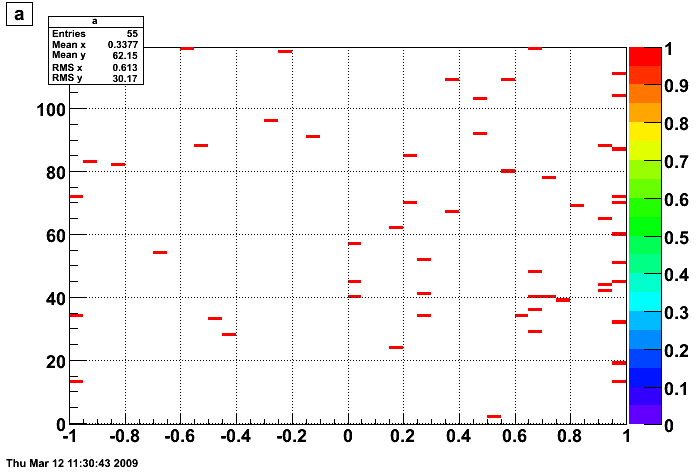
______________________________________________________________________
So Oleg Tsai and I propose to change only those outliers which satisfy the criteria:
|slope/ave_slope - 1|>0.2 && |eta|<0.8. (Total of 84 tubes)
We then looked one-by-one thru the spectra for all these tubes (Run 10066010) and found 12 tubes (not 13 as I stated in my email) with strange spectra:
Bad ADC Channels: Mask HV to Zero
We then calculated the proposed changes to the 2009_i1c.csv HV using the exponent kappa=5. Direct inspection of the spectra made us feel as though the predicted voltage changes were too large, so we recomputed them using kappa=10.48. We give a file containing a summary of these changes:
Proposed HV Changes (SoftId SwappedID Slope(i1c) Ave Slope Voltage(i1c) New Voltage
(We have identified 3 extra tubes with |eta|>0.8 which were masked out of the HT trigger to make it cleaner....we propose to add them to list to make a total of 87-7 = 80 HV changes.)
PS. We would also like to add SoftId-3017 HV800 -> 650. This make 81 HV changes.
_____________________________________________________________________
A word about stability of the PMT High Voltage and these measurements. I compared several pairs of measurements in 2007 taken days apart. Here is an intercomparison of 3 measurements (4,5 and 7) taken in 2007. The slopes have a statistical accuracy of 1.4%, so the distribution of the ratio of the two measurements should have a width of sqrt(2)*1.4 = 2% The comparison of the two measurements is just what we expect from the statistical accuracy of the slope measurements.
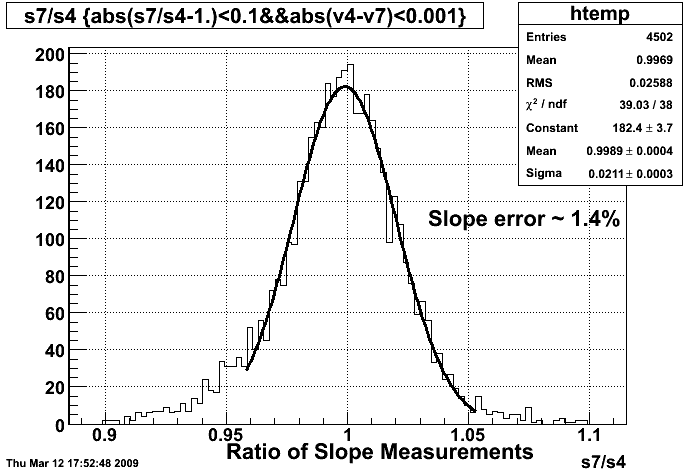
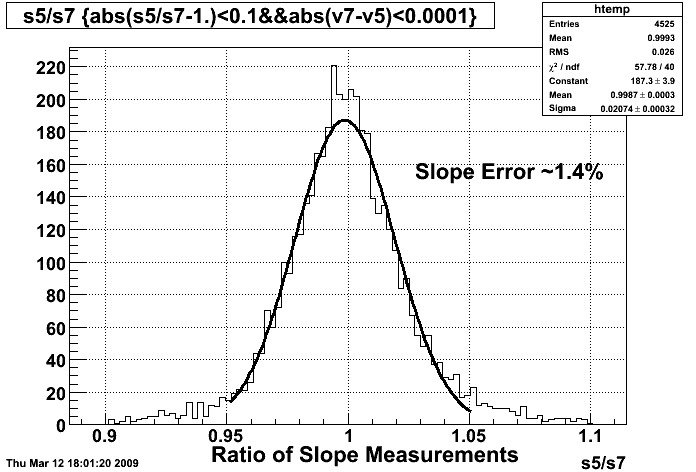
Comparing the two recent measurements in 2009, we have a set of about 600 tubes with a very small voltage change. The slopes were measured with an accuracy of 3.7%, so the width of the slope ratio distribution should be sqrt(2)*3.7% =5.2%. Again, this is exactly what we see. I do not find any evidence that (a large percentage of) the voltages are unstable!
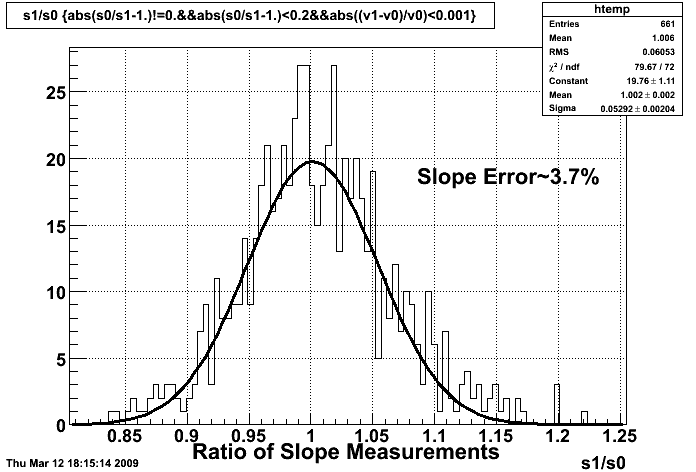
___________________________________________________________________
03 study of 2009 slopes (jan)
Purpose of this study is to evaluate how successful was our firts attempt to compute new 2009 HV for BTOW.
Short answer: we undershoot by a factor of 2 in HV power- see fig 4 left.
Input runs: 10066160 (new HV) and 10066163 (old HV)
Fig 1. Pedestal distribution and difference of peds between runs - perfect. Peds are stable, we can use the same slope fit range (ped+20,ped+60) blindly for old & new HV.

Fig 2. Chosen HV change and resulting ratio of slopes - we got the sign of HV change correctly!

Fig 3. Stability test. Plots as in fig 2, but for a subset of towers we change HV almost nothing (below 2V) but yield was large. One would hope slope stay put. They don't. This means either slopes are not as reliable as we think or HV is not as stable as we think.

Fig 4. Computed 'kappa' : sl2/sl1=g1/g2=V1/V2^kappa for towers with good stats and HV change of at least 10 Volts, i.e. the relative HV change is more than 1%. Right plot shows kappa as function of eta - no trend but the distribution is getting wider - no clue why?

Fig 5. Computed 'kappa' as on fig 4. Now negative, none physical values of kappa are allowed.

04 Spectra from Problem PMT Channels
We set the HV = 800 Volts for all channels which have been masked out, repaired, or otherwise had problems in 2008. I have examined the spectra for these channels and give pdfs with each of these spectra:
drupal.star.bnl.gov/STAR/system/files/2009_800_1_12.pdf
drupal.star.bnl.gov/STAR/system/files/2009_800_13_24.pdf
drupal.star.bnl.gov/STAR/system/files/2009_800_25_36.pdf
drupal.star.bnl.gov/STAR/system/files/2009_800_37_48.pdf
drupal.star.bnl.gov/STAR/system/files/2009_800_49_60.pdf
drupal.star.bnl.gov/STAR/system/files/2009_800_61_72.pdf
drupal.star.bnl.gov/STAR/system/files/2009_800_72_78.pdf
I identify 37 tubes which are dead, 39 tubes which can be adjusted, and 1 with a bit problem. We should pay careful attention to these tubes in the next iteration.
05 Summary of HV Adjustment Procedure
Summary of process used to change the HV for 2009 in BTOW:HV Files: Version indicates interation/mapping (numeral/letter)
1) 2009_i0.csv HV/Mapping as set in 2008. Calibration determined from 2008 data electrons/MIPS.
http://drupal.star.bnl.gov/STAR/subsys/bemc/calibrations/run-8-btow-calibration-2008/05-absolute-calibration-electrons
2) 2009_i0d.csv Map of SoftId/CellId determined by taking 6 data sets with all voltages set to 300 V, except for SoftId%6=0,1,2,3,4,5,6, successively. (link to Joe's pages)
http://drupal.star.bnl.gov/STAR/subsys/bemc/calibrations/run-8-btow-calibration-2008/08-btow-hv-mapping
drupal.star.bnl.gov/STAR/blog-entry/seelej/2009/mar/10/run9-btow-hv-mapping-analysis-summary
drupal.star.bnl.gov/STAR/blog-entry/seelej/2009/mar/05/run9-btow-hv-mapping-analysis
drupal.star.bnl.gov/STAR/blog-entry/seelej/2009/mar/08/run9-btow-hv-mapping-analysis-part-2
3) 2009_i1d.csv HV change determined from 2008 data electrons/MIPS (g1/g2)=(V2/V1)**k, with k=10.6 (determined from LED data).
http://drupal.star.bnl.gov/STAR/subsys/bemc/calibrations/run-8-btow-calibration-2008/06-calculating-2009-hv-electron-calibrations
4) 2009_i2d.csv Slopes measured for all channels. Outliers defined as |slope/<slope> -1|>0.2 (deviation of channel slope from average slope over barrel >20%:Approx 114 channels. Outliers corrected according to (s1/s2)=(V1/V2)**k as above. Hot towers HV reduced by hand. (Approx 10 towers)
http://drupal.star.bnl.gov/STAR/subsys/bemc/calibrations/run-9-btow-calibration-page/02-comparing-2007-2008-and-2009-btow-slopes
06 comparison of BTOW status bits L2ped vs. L2W , pp 500 (jan)
Comparison of BTOW status tables generated based on minB spectra collected by L2ped ( conventional method) vs. analysis of BHT3 triggered , inclusive spectra.
- Details of the method are given at BTOW status table algo, pp 500 run, in short status is decided based on ADC integral [20,80] above pedestal.
- the only adjusted param is 'threshold' for Int[20,80]/Neve*1000. Two used values are 1.0 and 0.2.
- For comparison I selected 2 fills: F10434 (day 85, ~all worked) and F10525 (day99, 2 small 'holes' in BTOW) - both have sufficient stats in minB spectra to produce conventional status table.
- Matt suggested the following assignment of BTOW status bits (value of 2N is given)
- good -->stat=1
- bad, below thres=0.2 --> stat=2+16 (similar to minB cold tower)
- bad, below thres=1.0 --> stat=512 (new bit, stringent cut for dead towers for W analysis)
- stuck low bits --> stat=8 (not fatal for high-energy response expected for Ws)
- broken FEE (the big hole) in some fills, soft ID [581-660] --> stat=0
Fig 1. Fill F10343 thres=1.0 (red line)

There are 108 towers below the red line, tagged as bad. Comparison to minB-based tower QA which tagged 100 towers. There are 4 combinations for tagging bad towers with 2 different algos. Table 1 shows break down, checking every tower. Attachments a, b show bad & good spectra.
|
|
Conclusion 1: some the additional 8 towers tagged as bad based on BHT3 spectra are either very low HV towers, or optical fiber is partially broken. If those towers are kept for W analysis any ADC recorded by them would yield huge energy. I'd like to exclude them from W analysis anyhow.
To preserve similarity to minB-based BTOW status code Matt agreed we tag as bad-for-everybody all towers rejected by BHT3 status code using lower threshold of 0.2. Towers between BHT3 QA-thresholds [0.2,1.0] will be tagged with new bit in the offline DB and I'll reject them from W-analysis if looking for W-signal but not necessary if calculating the away side ET for vetoing of away side jet.
|
|
Spectra are in attachment c). Majority of towers for which this 2 methods do not agree have softID ~500 - where this 2 holes reside (see 3rd page in PDF)
Tower 220 has stuck lower bits, needs special treatment - I'll add detection (and Rebin()) for such cases.
Automated generation of BTOW status tables for fills listed in Table 3 has been done, attachment d) shows summary of all towers and examples of bad towers for all those fills.
Table 3
1 # F10398w nBadTw=112 totEve=12194
2 # F10399w nBadTw=111 totEve=22226
3 # F10403w nBadTw=136 totEve=3380
4 # F10404w nBadTw=115 totEve=9762
5 # F10407w nBadTw=116 totEve=7353
6 # F10412w nBadTw=112 totEve=27518
7 # F10415w nBadTw=185 totEve=19581
8 # F10434w nBadTw=108 totEve=15854
9 # F10439w nBadTw=188 totEve=21358
10 # F10448w nBadTw=190 totEve=18809
11 # F10449w nBadTw=192 totEve=18048
12 # F10450w nBadTw=115 totEve=14129
13 # F10454w nBadTw=121 totEve=6804
14 # F10455w nBadTw=113 totEve=16971
15 # F10463w nBadTw=114 totEve=12214
16 # F10465w nBadTw=112 totEve=8825
17 # F10471w nBadTw=193 totEve=21003
18 # F10476w nBadTw=194 totEve=9067
19 # F10482w nBadTw=114 totEve=39315
20 # F10486w nBadTw=191 totEve=37155
21 # F10490w nBadTw=154 totEve=31083
22 # F10494w nBadTw=149 totEve=40130
23 # F10505w nBadTw=146 totEve=37358
24 # F10507w nBadTw=147 totEve=15814
25 # F10508w nBadTw=150 totEve=16049
26 # F10525w nBadTw=147 totEve=50666
27 # F10526w nBadTw=147 totEve=32340
28 # F10527w nBadTw=149 totEve=27351
29 # F10528w nBadTw=147 totEve=22466
30 # F10531w nBadTw=145 totEve=9210
31 # F10532w nBadTw=150 totEve=11961
32 # F10535w nBadTw=176 totEve=8605
33 # F10536w nBadTw=177 totEve=10434
07 BTOW status tables ver 1, uploaded to DB, pp 500
BTOW status tables for 39 RHIC fills have been determined (see previous entry) and uploaded to DB.
To verify mayor features are masked I process first 5K and last 5K events for every fill , now all is correct. # plots below show example of pedestal residua for not masked BTOW towers, 5K L2W events from the end of the fill. Attachment a) contains 39 such plots (it is large and may crash your machine).
Fig 1, Fill 10398, the first on, most of tower were working

Fig 2, Fill 10478, in the middle, the worst one

Fig 3, Fill 10536, the last one, typical for last ~4 days, ~1/3 of acquired LT

08 End or run status
Attached are slopes plotted for run 10171078 which was towards the end of Run 9.
09 MIP peaks calculated using L2W stream
The MIP peaks plotted in the attachment come from the L2W data. 4564 towers had a good MIP peak, 157 towers did not have enough counts in the spectra to fit, and 79 towers had fitting failures. 52 were recovered by hand for inclusion into calibration.
Also attached is a list of the 236 towers with bad or missing peaks.
I compared the 157 empty spectra with towers that did not have good slopes for relative gains calculated by Joe. Of the 157 towers, 52 had good slopes from his calculation. Those are in an attached list.
Fig 1 MIP peak position:
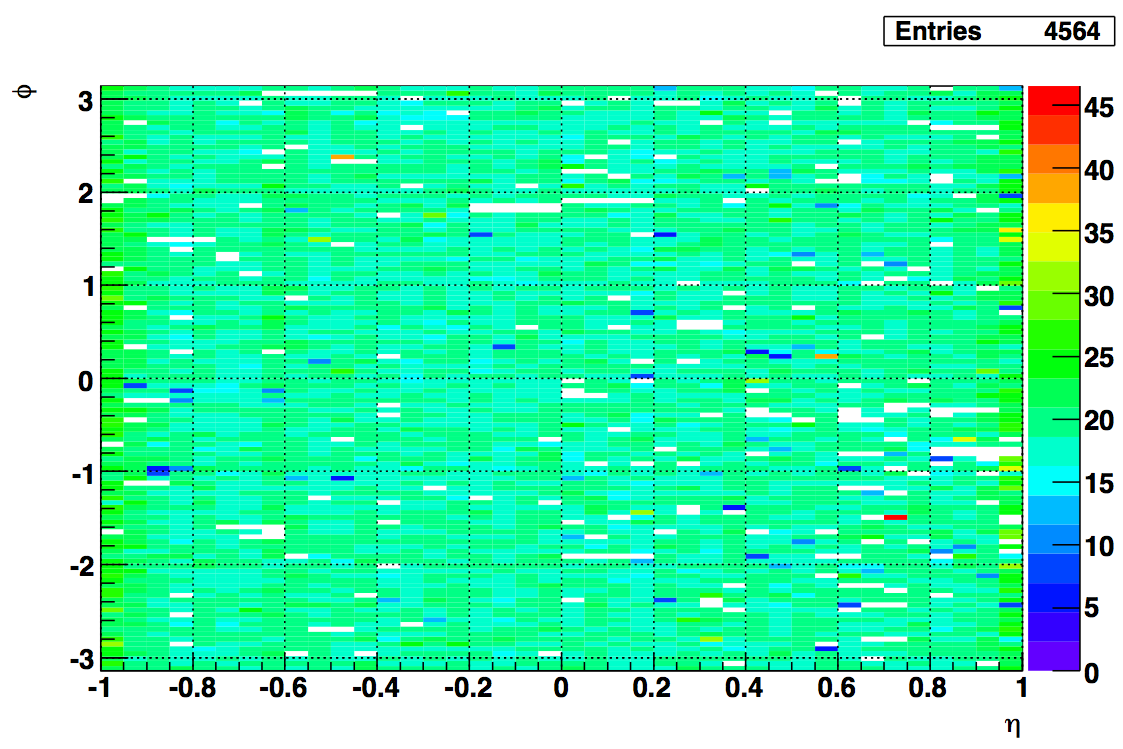
10 Electron E/p from pp500 L2W events
I ran the usual calibration code over the L2W data produced for the W measurement.
To find an enriched electron sample, I applied the following cuts to the tracks, the tower that the track projects to, the 3x3 tower cluster, and the 11 BSMD strips in both planes under the track:
central tower adc - pedestal > 2.5*rms
enter tower = exit tower
track p < 6 and track p > 1.5
dR between track and center of tower < 0.025
track dEdx > 3.4 keV/cm
bsmde or bsmdp adc total > 50 ADC
no other tracks in the 3x3 cluster
highest energy in 3x3 is the central tower
The energies were calculated using ideal gains and relative gains calculated by Joe Seele from tower slopes.
The corrections were calculated for every 2 eta rings and each crate. The corrections for each 2 rings were calculated first and then applied. The analysis was rerun, then the E/p was calculated for each crate.
The calibration constants will be uploaded to a different flavor to be used with the preliminary W analysis.
Fig. 1 E/p spectrum for all electrons
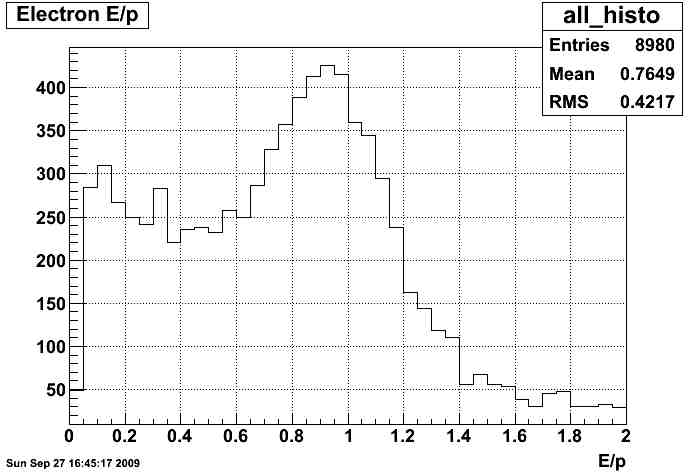
Fig. 2 p vs E/p spectrum for all electrons
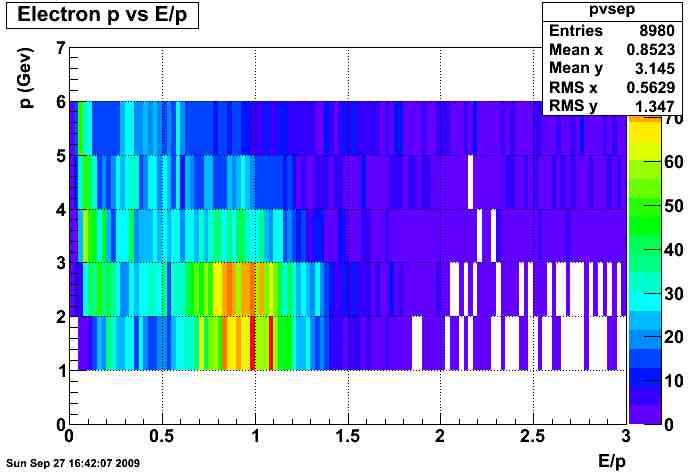
Fig. 3 BSMDP vs BSMDE for all electrons
Fig. 4 corrections by eta ring
Fig. 5 Crate corrections
Fig. 6 difference between positrons (blue) and electrons (red):
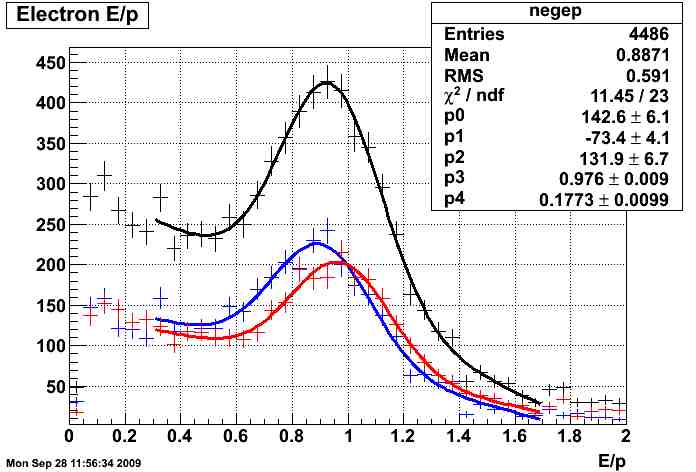
Update: I reran the code but allowed the width of the gaussian to only be in the range 0.17 - 0.175. This region agrees with almost all of the previously found widths within the uncertainties. The goal was to fix a couple fits that misbehaved. The updated corrections as a function of eta are shown below.
Fig. U1
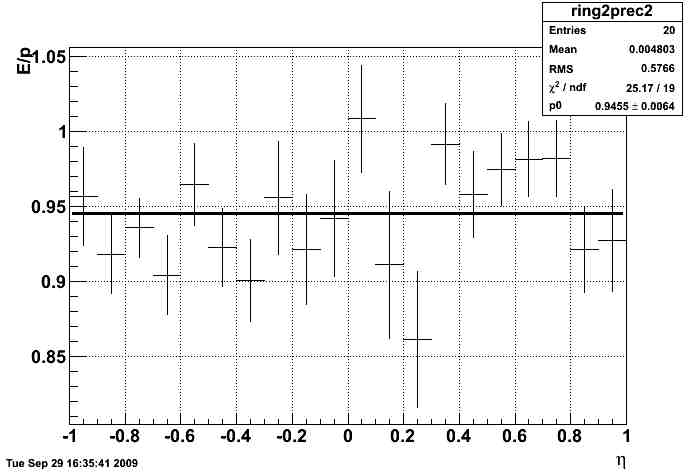
Update 09/30/2009: Added 2 more plots.
Fig. V1 East vs. West (no difference observed)
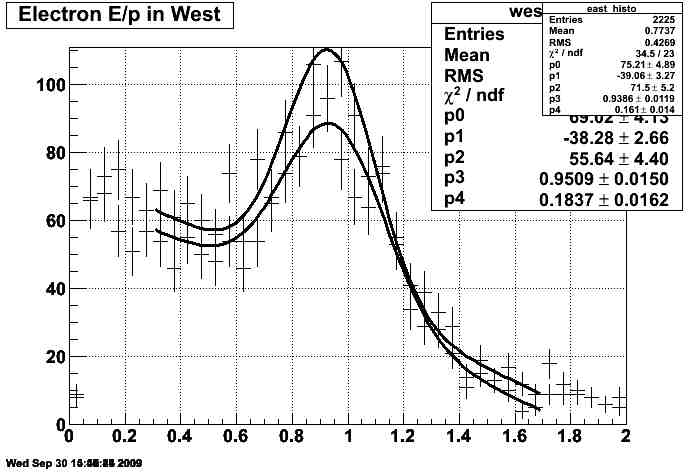
Fig. V2 slices in momentum (not much difference)
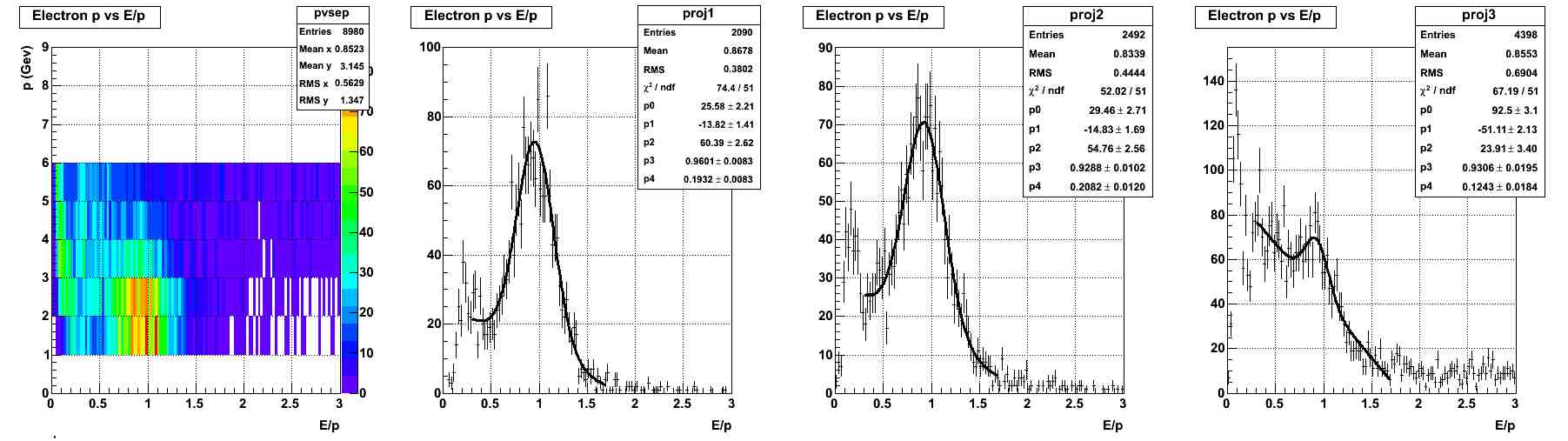
Attached are the histograms for each ring and crate.
12 Correcting Relative gains from 500 GeV L2W
After examining the Z invariant mass peak calculated using the L2W data stream with the offline calibration applied, it seemed like there was a problem. The simplest explanation was that the relative gains were reversed, so that hypothesis was tested by examining the Z peak with the data reversed.
The slopes were also recalculated comparing the original histogram to histograms corrected with the relative gains and the inverse of the relative gains.
In the following two figures, black is the original value of the slopes, red has the relative gain applied, and blue has the inverse of the relative gain applied.
Fig 1 Means of slope by eta ring with RMS
.png)
Fig 2 RMS of slope by eta ring
.png)
The E/p calculation improves after making the change to the inverse of the relative slopes because the effect of outliers is reduced instead of amplified.
Fig 3 E/p by eta ring with corrected relative gains
.png)
Update:
After last week's discussion at the EMC meeting, I recalculated all of the slopes and relative gains.
Fig 4 Update Slope RMS calculation
.png)
I then used these relative gains to recalculate the absolute calibration. Jan used the calibration to rerun the Z analysis.
Fig 5 Updated Z analysis
.png)
The updated calibration constants will now supercede the current calibration constatns.
13 Updating Calibration using the latest L2W production
I recalculated the Barrel calibration using the latest L2W production, which relies on the latest TPC calibration. It is suggested that this calibration be used to update the current calibration.
Fit Details:
Negative Peak location: 0.941
Negative Sigma: 0.14
Positive Peak location: 0.933
Positive Sigma: 0.17
<p> = 3.24 GeV
Fig 1. E/p for all electron (black), positive charged (blue), negative charged (red)
.png)
14 200 GeV Calibration
I selected 634 runs for calibration from the Run 9 production, processing over 300M events. The runs are listed in this list, with their field designation.
The MIP peak for each tower was calculated. 4663 towers had MIP peaks found. 38 were marked as bad. 99 were marked as MIPless. The MIP peak fits are here.
The electrons were selected using the following cuts:
- |vertex Z | < 60 cm
- vertex ranking > 0
- track projection enters and exits same tower
- tower status = 1
- 1.5 < track p < 10.0 GeV/c
- tower adc - pedestal > 2.5 * pedestal RMS
- Scaled dR from center < 0.02
- 3.5 < dE/dx < 5.0
- No other tracks in 3x3 cluster
- No energy in cluster > 0.5 central energy
- Track can only point to HT trigger tower if a non-HT trigger fired in the event
Fig. 1: Here is a comparison of all electrons from RFF (blue) and FF (red):
.png)
The RFF fit mean comes to 0.965 +/- 0.001. The FF fit mean comes to 0.957 +/- 0.001. The total fit is 0.957 +/- 0.0004.
Fig. 2 Comparison of electron (red) positron (blue):
.png)
Positron fit results: 0.951 +/- 0.001. Electron fit results: 0.971 +/- 0.001
Calibration was calculated using MIPs for relative calibration and absolute calibration done for eta slices by crate (30 crates, 20 eta slices per crate).
The outer ring on each side was calibrated using the entire ring.
2 towers were marked bad: 2439 2459 due to a peculiar E/p compared to the other in their crate slice. It is suggested this is due to bad bases.
Fig 3 Crate Slice E/p correction to MIPs (eta on x axis, phi on y axis):
.png)
New GEANT correction
A new geant correction was calculated using new simulation studies done by Mike Betancourt. The energy and pseudorapidity dependence of the correction was studied, and the energy dependence is small over the range of the calibration electron energies.
A PDF of the new corrections are here.
Is it statistical?
From this plot, it can be seen that most of the rings have a nonstatistical distribution of E/p values in the slices. The actual E/p values for each ring (for arbitrary slice value) can be seen here.
Comparison to previous years
Fig 4 Eta/phi of (data calibration)/(ideal calibration)
.png)
Fig 5 Eta ring average of (data calibration)/(ideal calibration)
.png)
Issues:
- FF vs RFF (partially examined)
- positive vs negative (partially examinced)
- eta/phi dependence of geant correction, direction in eta/phi
- dR dependence of calibration
- comparison to previous year
Database
These pages describe how to use the BEMC database. There is a browser-based tool that you can use to view any and all BEMC tables available at:
http://www.star.bnl.gov/Browser/BEMC/
Frequently Asked Questions
How do I use the database as it looked at a particular time?
You might be interested in this tip if e.g. you want to repeat an analysis performed before additional tables were added to the BEMC database. Add the following lines of code to your macro after St_db_Maker is instantiated, and change myDate and myTime as appropriate:
Int_t myDate = 20051231;
Int_t myTime = 235959;
dbMaker->SetMaxEntryTime(myDate,myTime);How do I force St_db_Maker to use the event time I specify?
If you're running over simulation files, where the event timestamp is not a meaningful quantity (at least, it's not meaningful for the BEMC database), you need to choose a particular event timestamp that best represents the state of the BEMC during the data-taking period to which you're comparing the simulations. A list of timestamps is being compiled at Simulation Timestamps. Add the following lines of code to your macro, and change myDate and myTime as appropriate:
Int_t myDate = 20051231;
Int_t myTime = 235959;
dbMaker->SetDateTime(myDate,myTime);Calibrations Database
All calibration information is stored in the STAR database. We have the following tables for BEMC calibrations:- For the BTOW and BPRS detectors:
- St_emcCalib - this table contains absolute gain information for each channel
- St_emcPed - this table contains pedestal values for each channel
- St_emcGain - this table contains a gain correction factor vs. time for each channel (not currently used)
- St_emcStatus - this table contains the final status for each channel
- For the BSMDe and BSMDp detectors:
- St_smdCalib - this table contains absolute gain information for each channel
- St_smdPed - this table contains pedestal values for each channel
- St_smdGain - this table contains a gain correction factor vs. time for each channel (not currently used)
- St_smdStatus - this table contains the final status for each channel
To get a pointer for those tables in an analysis maker do:
TDataSet *DB = GetInputDB("Calibrations/emc/y3bemc"); // for towers
St_emcCalib *table = (St_emcCalib*) DB->Find("bemcCalib");
emcCalib_st *struct = table->GetTable();Important Information About Pedestal Tables
In order to save space and make the download faster, PEDESTALS and RMS are saved as SHORT. So, the real pedestal value is PED/100. Similarly, in order to save tables in the database you have to multiply the real pedestal by 100. The same goes for the RMS.SMD has different pedestals for different capacitors. Only 3 pedestal values are saved:
- Pedestal 0 is the average of 126 capacitors
- Pedestal 1 is the pedestal value for capacitor 124
- Pedestal 2 is the pedestal value for capacitor 125
unsigned char cap = (char) rawHit->calibrationType();
if(cap > 127) mCap[i][did-1]-=128;Status Information
The St_emcStatus and St_smdStatus tables contain final status codes for each tower. The final status is a combination of installation/run status, pedestal status and calibration status. The final status has a bit pattern as follows:- 0 - not installed
- 1 - installed / running
- 2 - calibration problem
- 4 - pedestal problem
- 8 - other problem (channel removed, dead channel, etc.)
To check individual bits of the final status do
- (status&1) == 1 means tower is installed
- (status&2) == 2 means a calibration problem
- (status&4) == 4 means a pedestal problem
- (status&8) == 8 means another problem
Tables Structure
/* emcCalib.idl
*
* Table: emcCalib
*
* description: //: Table which contains all calibration information
*/
struct emcCalib {
octet Status[4800]; /* status of the tower/wire (0=problem, 1=ok) */
float AdcToE[4800][5]; /* ADC to Energy */
};
/* emcPed.idl
*
* Table: emcPed
*
* description: * //: Table which contains pedestal information for emctower ADCs
*/
struct emcPed {
octet Status[4800]; /* status of the emc tower(0=problem, 1=ok) */
short AdcPedestal[4800]; /* ADC pedestal of emc tower x 100 */
short AdcPedestalRMS[4800]; /* ADC pedestal RMS of emc tower x 100 */
float ChiSquare[4800]; /* chi square of Pedestal fit */
};
/* emcGain.idl
*
* Table: emcGain
*
* description: //: Table which contains gain correction information
*/
struct emcGain {
octet Status[4800]; /* status of the tower/wire (0=problem, 1=ok) */
float Gain[4800]; /* Gain Variation */
};
/* emcStatus.idl
*
* Table: emcStatus
*
* description: // which emc towers are up and running
*/
struct emcStatus {
octet Status[4800]; /* */
};
/* smdCalib.idl
*
* Table: smdCalib
*
* description: //: Table which contains all calibration information
*/
struct smdCalib {
octet Status[18000]; /* status of the tower/wire (0=problem, 1=ok) */
float AdcToE[18000][5]; /* ADC to Energy */
};
/* smdPed.idl
*
* Table: smdPed
*
* description: * //: Table which contains pedestal information for shower max ADCs
*/
struct smdPed {
octet Status[18000]; /* status of the smd stripe (0=problem,1=ok) */
short AdcPedestal[18000][3]; /* ADC pedestals of smd strip x 100 */
short AdcPedestalRMS[18000][3]; /* ADC pedestals RMS of smd strip x 100 */
};
/* smdGain.idl
*
* Table: smdGain
*
* description: //: Table which contains gain information
*/
struct smdGain {
octet Status[18000]; /* status of the tower/wire (0=problem, 1=ok) */
float Gain[18000]; /* Gain Variation */
};
/* smdStatus.idl
*
* Table: smdStatus
*
* description: // which smds are up and running
*/
struct smdStatus {
octet Status[18000]; /* */
};Control Room
We use a crontab on emc01.starp.bnl.gov to update the trigger database tables as well as the "offline" pedestals throughout the run. Here's the relevant portion of /etc/crontab:00 4 * * * emc /home/emc/online/emc/pedestal/job
00 * * * * emc /home/emc/online/emc/trigger/job
10 * * * * emc /home/emc/online/emc/trigger/job
20 * * * * emc /home/emc/online/emc/trigger/job
30 * * * * emc /home/emc/online/emc/trigger/job
40 * * * * emc /home/emc/online/emc/trigger/job
50 * * * * emc /home/emc/online/emc/trigger/jobPedestal Job
The job runs every day at 4:00 AM and executes the script$EMCONLINE/pedestal/updateOnlinePed
which in turn calls the root4star macro
$EMCONLINE/pedestal/makeOnlinePed.C
This macro calculates pedestals for all 4 subdetectors and uploads the tables to the STAR database. A local backup copy of each table is stored in
$EMCONLINE/pedestal/tables/tables/
Trigger Job
The job runs $EMCONLINE/trigger/updateTriggerDB every ten minutes. If the file $EMCONLINE/trigger/RUNMODE contains STOP, the job will do nothing. $EMCONLINE/trigger/startTriggerDB and $EMCONLINE/trigger/stopTriggerDB can be used to change the content of RUNMODE. The updateTriggerDB shell script contains some decent documentation which I've reproduced here:# this script checks if ANY of the BEMC trigger
# configuration had changed. If so, it updated the
# database with the new trigger configuration
#
# it runs as a cronjob every 5-10 minutes in the star01
# machine
#
# this script follows the steps bellow
#
# 1. check the file RUNMODE. If content is STOP, exit the
# program. This is done if, for some reason, we
# want to stop the script from updating the DB
#
# 2. SCP the config_crate* and pedestal_crate* files
# from sc3.starp.bnl.gov machine
#
# 3. SCP the trigegr masks from startrg2.starp.bnl.gov machine
#
# 4. Copy these files to the sc3 and startrg2 directories
#
# 5. Compare these files to the files saved in the sc3.saved
# and startrg2.saved directories
#
# 6. If there is no difference, clear the sc3 and startrg2
# directories and exit
#
# 7. If ANY difference was found, copy the contents of the
# sc3 and startrg2 directories to sc3.saved and startrg2.saved
# Also saves the directory with timestamped names in the
# backup directory
#
# 8. runs the root4star macro that create the tables from
# the files in those directories and save them to the DB
# It also creates plain text file bemcStatus.txt with the same information
# for the trigger people and Pplots
#
# 9. clear the sc3 and startrg2 directories and exit
#
# you can also run it by hand with the command
#
# updateTriggerDB TIMESTAMP FORCE
#
# where TIMESTAMP is on the format
#
# YYYYMMDD.hhmmss
#
# if FORCE = yes we force saving the DB
#
# this procedure overwrites the RUNMODE variable
#
# AAPSUAIDE, 12/2004
#Basically the job is always checking for changes to the trigger pedestals, status tables, and LUTs and uploaded a new table if any changes are found.
Mapping DB Proposal
Proposal
We propose to add a new set of tables to the Calibrations_emc database that will track the electronics mapping for the BEMC, BSMD, and BPRS and allow for an alternative implementation of StEmcDecoder.
Motivation
The existing BEMC electronics mapping code (StDaqLib/EMC/StEmcDecoder) has become difficult to maintain. Each time we discover something about the BEMC that requires an update to our lookup tables we have to decipher the algorithms that generate these lookup tables, and more often than not our first guess about how to add the new information is wrong.
StEmcDecoder is also inefficient because it doesn’t track the validity range of the current lookup tables and so it rebuilds the tables every event. Analysis jobs spend a non-neglible amount of CPU time rebuilding these decoder tables.
The information in the decoder is critical for BEMC experts, but the interface to that information is less than ideal. StEmcDecoder does not even have CINT bindings. An SQL interface would allow for much easier debugging.
For the End User
We are preserving the StEmcDecoder interface and reimplementing it to use the DB tables. Offline users should see a seamless transition. StEmcDecoder also plays an important role in the online p-plots. We’ll need to find a solution that allows access to the DB tables in that framework.
For Experts
The new mapping tables will contain a row for each detector element, so we expect that querying the tables using SQL will prove to be a valuable debugging tool. A simplified query might look like:
SELECT elementID,m,e,s FROM bemcMapping WHERE triggerPatch=5 and beginTime='2007-11-01 00:00:00';
which would yield
+-----------+------+------+------+
| elementID | m | e | s |
+-----------+------+------+------+
| 1709 | 43 | 9 | 2 |
| 1710 | 43 | 10 | 2 |
| 1711 | 43 | 11 | 2 |
| 1712 | 43 | 12 | 2 |
| 1729 | 44 | 9 | 1 |
| 1730 | 44 | 10 | 1 |
| 1731 | 44 | 11 | 1 |
| 1732 | 44 | 12 | 1 |
| 1749 | 44 | 9 | 2 |
| 1750 | 44 | 10 | 2 |
| 1751 | 44 | 11 | 2 |
| 1752 | 44 | 12 | 2 |
| 1769 | 45 | 9 | 1 |
| 1770 | 45 | 10 | 1 |
| 1771 | 45 | 11 | 1 |
| 1772 | 45 | 12 | 1 |
+-----------+------+------+------+
16 rows in set (0.12 sec)Previously, we needed to write one-off compiled programs to export this kind of information out of the decoder.
Draft IDLs
struct emcMapping {
octet m; /* module 1-120 */
octet e; /* eta index 1-20 */
octet s; /* sub index 1-2 */
unsigned short daqID; /* ordering of elements in DAQ file 0-4799 */
octet crate; /* electronics crates 1-30 */
octet crateChannel; /* index within a crate 0-159 */
octet TDC; /* index in crate 80, 0-29 */
unsigned short triggerPatch; /* tower belongs to this TP 0-299 */
octet jetPatch; /* tower belongs to this JP 0-11 */
unsigned short DSM; /* just integer div TP/10 0-29 */
float eta; /* physical pseudorapidity of tower center */
float phi; /* physical azimuth of tower center */
char comment[255];
}struct smdMapping {
octet m; /* module 1-120 */
octet e; /* eta index 1-150 (eta), 1-10 (phi) */
octet s; /* sub index 1 (eta), 1-15 (phi) */
octet rdo; /* readout crate 0-7 */
unsigned short rdoChannel; /* index in crate 0-4799 */
octet wire; /* wire number 2-80 */
octet feeA; /* A value for FEE 1-4 */
float eta; /* physical pseudorapidity of strip center */
float phi; /* physical azimuth of strip center */
char comment[255];
}struct prsMapping {
octet m; /* module 1-120 */
octet e; /* eta index 1-20 */
octet s; /* sub index 1-2 */
octet PMTbox; /* PMT box 1-30 (West), 31-60 (East) */
octet MAPMT; /* MAPMT # for this element in PMTbox 1-5 */
octet pixel; /* index inside MAPMT 1-16 */
octet rdo; /* readout crate 0-3 */
unsigned short rdoChannel; /* index in readout crate 0-4799 */
octet wire; /* wire number 1-40 */
octet feeA; /* A value for FEE 1-2 */
octet SCA; /* switched capacitor array 1-2 */
octet SCAChannel; /* index inside SCA 0-15 */
octet powerSupply; /* 1-2 */
octet powerSupplyModule; /* 1-15 */
octet powerSupplyChannel; /* 0-14 */
float eta; /* physical pseudorapidity of tower center */
float phi; /* physical azimuth of tower center */
char comment[255];
}I also proposed MySQL schemata on my blog, but I guess in STAR these IDLs define the schema.
Performance Estimates
I’ve temporarily installed tables on our MIT mirror and filled them with data describing the 2008 BEMC electronics mapping. Here are the stats:
*************************** 1. row ***************************
Name: bemcMapping
Engine: MyISAM
Version: 10
Row_format: Dynamic
Rows: 4800
Avg_row_length: 55
Data_length: 268732
Max_data_length: 281474976710655
Index_length: 163840
Data_free: 0
Auto_increment: 4801
Create_time: 2008-11-14 16:03:51
Update_time: 2008-11-14 16:05:45
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
*************************** 2. row ***************************
Name: bprsMapping
Engine: MyISAM
Version: 10
Row_format: Dynamic
Rows: 4800
Avg_row_length: 70
Data_length: 336036
Max_data_length: 281474976710655
Index_length: 165888
Data_free: 0
Auto_increment: 4801
Create_time: 2008-11-14 17:52:53
Update_time: 2008-11-14 17:59:40
Check_time: 2008-11-14 17:52:53
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
*************************** 3. row ***************************
Name: bsmdeMapping
Engine: MyISAM
Version: 10
Row_format: Dynamic
Rows: 18000
Avg_row_length: 52
Data_length: 936000
Max_data_length: 281474976710655
Index_length: 604160
Data_free: 0
Auto_increment: 18001
Create_time: 2008-11-14 16:03:51
Update_time: 2008-11-18 01:48:36
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
*************************** 4. row ***************************
Name: bsmdpMapping
Engine: MyISAM
Version: 10
Row_format: Dynamic
Rows: 18000
Avg_row_length: 52
Data_length: 936000
Max_data_length: 281474976710655
Index_length: 604160
Data_free: 0
Auto_increment: 18001
Create_time: 2008-11-14 16:03:51
Update_time: 2008-11-18 02:13:36
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
4 rows in set (0.11 sec)This information is supposed to be static, even from year-to-year. In reality, we discover some details about the mapping each year which will require updates to some of these rows. There should certainly be no intra-run changes, so StEmcDecoder will need to retrieve 4800+4800+18000+18000 rows from the DB for each BFC and user job.
The equivalent C++ array sizes (excluding the comment field as I’m not sure how its handled) will be 101 KB (4800*21) for BEMC, 115 KB (4800*24) for BPRS and 288 KB (18000*16) for each SMD plane.
Pedestals / Status Tables
Code for the calculation of the BTOW & BSMD status tables has been made publicly accessible. BTOW status code is in StRoot/StEmcPool/CSMStatusUtils. The following studies of pedestals and status tables have been performed:
BTOW
2006
Dave S. - status
2004
Thorsten - 62 GeV AuAu status tables
Oleksandr - 200 GeV AuAu pedestals
Oleksandr - 62 GeV AuAu pedestals
2003
Oleksandr - dAu status tables
Oleksandr - pp status tables
BSMD & BPSD
2006
Priscilla - SMD pedestals
2005
Frank - SMD status for pp (bug found in code http://rhig.physics.yale.edu/~knospe/cucu200/bsmd_status_bug.htm)
Frank's code used to generate status tables from MuDsts
2004
200 GeV AuAu SMD status - taken by Martijn
Marcia - 200 GeV AuAu SMD pedestals
Subhasis - 62 GeV AuAu SMD & PSD pedestals
2003
Martijn - dAu SMD status
CSMStatusUtils
This is CSMStatusUtils, which outputs the status of either calorimeter to text and root status files. Documentation is by Dave Relyea. The code can be found atStRoot/StEmcPool/CSMStatusUtils
History:
I was given code from both Joanna and Thorsten to figure out the status of the calorimeter towers over all pp production runs. I merged the two sets of code, and and created a package called CSMStatusUtils.
Method:
The first piece of code in CSMSU takes every run and fills a 2-d histogram of ALL channels vs hit number (in ADC counts, from 0 to 150). A second routine then combines these histograms from run subsets into single histograms for each run. From the second routine and on down, the EEMC and BEMC are done entirely separately; the code needs to be run twice, once for each detector.
The code has an algorithm which then takes runs in each fill and combines them until the average number of hits above pedestal for all channels is greater than 100. If runs are left over at the end of a fill, their statistics are added to prior runs in the fill.
For each combined set of runs, the code puts each channel through a series of tests. It finds the pedestal (and writes it out to a file, btw) and determines if the pedestal is abnormally wide, or whether it falls outside acceptable limits (ADC channels 0 to 3, or 147 to 150). It compares all towers' mean number of hits (ten sigma) above pedestal, and then flags towers which have 10x as many hits as the average, or 40x fewer. Finally, it looks for stuck bits (either on or off) in the 1, 2, 4, or 8 position, and flags channels with stuck bits.
The code writes out a table (in text format) for each set of runs with the status of each channel clearly marked. This table is also written in ROOT format, to be read by existing BEMC algorithms. Also written is a hot tower plot, so the hot tower results can be eyeballed. The code can also write out gif files of the spectra of every channel that failed a status test, so long as the number of channels in a given run set that failed the test is less than 25 (**for 2004 pp, gif files were not written out**). Finally, the code creates a nice html file containing links to html subfiles detailing the channel status for each run set, which in turn link to the gif files.
As a final step, the code takes the text files and creates a new series of text status files with the results in differential format, meaning channels whose status didn't change from run set to run set are omitted. However, since some channels fall very near the thresholds of certain status tests (for instance, channels whose pedestals sit at 2.9 ADC counts), I make the requirement that the channel's status must not have changed more than ten percent of the time over all runs sets, excluding runs in which all channels were bad (for nominal production running, this needs to be done, of course!). If it has, it is marked bad once at the beginning, and then does not appear in any of the differential files.
************************************************************************
Running:
To run CSMSU, the first step is to use the FileCatalog to create a list of all the files you wish to analyze. The command I use is typically something like:
get_file_list.pl -keys 'path,filename' -cond 'production=P04ik,tpc=1,emc=1, trgsetupname=productionPP||productionPPnoEndcap||pp||PP,filename~st_physics,filetype=daq_reco_mudst' -onefile -limit 100000 -distinct > allthephysicsfiles
Note that the output format I use is just 'path,filename', and I keep the :: delimiter that the FileCatalog uses. My next step is to call
CSMSU/scripts/analysis0 allthephysicsfiles
(YOU NEED TO CHANGE THE HEADER IN THIS FILE TO YOUR OWN OUTPUT DIRECTORY)
which takes the "allthephysicsfiles" file from FileCatalog, splits it up into groups of 20 miniruns, and submits the entire processing job to batch. Note - if I knew how to use the XML submission scripts, I would, but the online documentation for them doesn't mention how to code up your macro (.C) file such that the XML header file will work. No matter.PLEASE NOTE: Each minirun will generate about a 200k file. This adds up to ENORMOUS disk space for large runs. The 2004 pp run takes up about 1.4 Gig. The 2004 Au-Au run would be even larger. Thus, I really need to learn how to
use the XML submission scripts.
(FROM HERE ON, SCRIPT FILES CALL MACROS IN THE MACROS DIRECTORY. YOU NEED TO CHANGE THE DEFAULT ARGUMENTS OF THE MACROS TO YOUR WORKING DIRECTORY. YOU CAN DO THIS IN THE SCRIPT, OR JUST MAKE YOUR OWN SCRIPT, SINCE THEY'RE ALL TRIVIAL ONE LINE SCRIPTS ANYWAY. SORRY ABOUT THE CAPS.)
After all miniruns have been processed, the next step is to combine them into runs. The script "analysis1" does this.Next, you want to run the actual status code on the files. The script "analysis2" does this. PLEASE NOTE: this macro requires an x window, as root needs to be able to Draw certain things. I don't know how to do this in batch,
so I always run this interactively. It's not a good solution, but for now, it's a solution.
Finally, you want to generate the ".root" status files and the concatenated status files (to alert you to changes in calorimeter tower status). The script "analysis3" does this.
StBSMDStatusMaker
This page gives a brief overview of the code Frank Simon developed to create SMD Status Tables from MuDSTs.
Some features and limitiations of the code:
- Create one status table per fill for each SMD plane (if enough statistics are available)
- all triggers are used to maximize statistics (this can be a potential problem if there are hot trigger towers)
- pedestals are taken from the data base (MuDST SMD data are zero-suppressed)
- db-readable status tables can be created. Currently there are only to status flags implemented: good and bad. Adding more "variety" is straigth forward
- can be used with the STAR scheduler, no specific ordering of the input files required (although some structure in the job submission is recommended, see below)
Basic ideas behind the code:
- based on Daves tower status code, but: there are some very important differences
- One job runs over several MuDST files, when a new fill number is encountered, a new output file is opened. That way, the jobs can be run with the STAR scheduler and they can use files on distributed storage, since no particular ordering of the input files is needed
- for each fill, a file with 18000 channel TH2Fs storing amplitude information for each SMD channel is created (this method of dealing with random file order is a bit disk space hungry, so make sure enough space is available (~ 10 GB for 2005 pp); this can be deleted after the next step), other information such as time stamps and pedestals are stored in text files
- As a next step, the large number of files created by jobs on MuDSTs is consolidated into one file per fill
- Status tables are created from each of those files (one per fill, if statistics are sufficient, otherwise no status table for that fill is created)
- db readable files are produced from these status tables
Running the code
- Copy and compile the code in StRoot/StBSMDStatusMaker
- Copy the macro that runs the code: RunStatus.C
- Create scheduler scripts to submit your jobs. For pp2005, 50 jobs per job seems to give jobs with useful runtimes. In order to not get a totally randomized fill distribution in your jobs, submit them by day. A macro that creates a .csh that you can use to submit jobs by day is CreateSubmitScript.C, a template job describtion (you have to modify tha paths to suit your needs) is pp2005Template.xml
- Submit your jobs
- Once all jobs are done, create a list of all output files via ls * > FileList.list in the directory where your output ended up
- Consolidate data using the file list: run macro DoAdding.C after compiling AddHistograms.C (via .L AddHistograms.C++), this macro takes the directory where the files are located and the file list as arguments. This creates three files per fill: Fill*.root containing the histograms, Fill*.ped containing pedestal db information and Fill*.time containing the (approximate) start time of the fill
- Create a list of root files via ls Fill*.root > FileList.list and convert it into a list of fill numbers using the macro GetListOfFills.C. This maco takes the file list and a file name for the fill number list as argument
- Perform the status table creation. For that, compile the shared library StatusTools.C (via .L StatusTools.C++), then run the macro ProcessList.C, with arguments RunList (created previously) and the directory where the Fill* files are located. The output of this is a number of files per fill (root file, flag file and time stamp file). The flag and the time stamp file are needed to create the db readable status table, the root file contains histograms created during the analysis process.
- Create db readable status tables. This is done by running the macro WriteStatusFiles.C. This takes the directory where the flag and timestamp files are located as an argument. Two important notes:
- This macro needs the full STAR environment (all other steps above except the running of jobs can be done on standalone machines)
- The order in which the flag and time files are written (created) is crucial, since gSystem->GetDirEntry() is used to loop over all files. So care has to be taken if the files are copied from somewhere else
- Copy the db readable files to the database location in StarDb, and test them! Use TestStatusFiles.C for example.
For questions, please don't hesitate to contact me at fsimon@mit.edu!
Simulation Timestamps
All 4800 perfect:dbMaker->SetDateTime(20070101,000001);
Run 5 pp, selected by Spin PWG:
dbMaker->SetDateTime(20050506,214129);
some more info from Frank on detailed SMD status:
if (dbTime == 1) db1->SetDateTime(20050423,042518); //2005 stat1
else if (dbTime == 2) db1->SetDateTime(20050521,100745); //2005 stat2
else if (dbTime == 3) db1->SetDateTime(20050529,210408); //2005stat3
else db1->SetDateTime(20050610,120313); //2005, JumbodbMaker->SetDateTime(20060522,112810);
Table Insertion Timeline
This page keeps a log book of all the BEMC database modifications. Please use this information in order to make sure about the version of the tables you are grabbing from DATABASE. The table is sorted by EntryTime.
If you'd like to run an analysis using the database as it looked at some particular time, use the method
St_db_Maker *dbMaker = new St_db_Maker("StarDb", "MySQL:StarDb");
Int_t myDate = 20051231;
Int_t myTime = 235959;
dbMaker->SetMaxEntryTime(myDate,myTime);You can use the BEMC DB Browser to look at all the tables in the database
| row number |
EntryTime | Tables | Note |
| 1 | 2005-11-03 | pp2005 bemcCalib table with timestamp = 2005-03-22 00:00:01 was uploaded to the database |
Adam's calibration table for pp2005. Click here for details |
| 2 | 2005-12-07 | pp2005 offline bemcStatus with timestamp between 2005-04-19 11:36:11 and 2005-06-24 08:58:25 were uploaded to the database |
Dave's status tables for the pp2005 run |
| 3 | 2006-02-08 | pp2005 online bemcPed with timestamp between 2005-04-19 05:37:10 and 2005-06-10 23:38:20 were deactivated |
Corruption problems reported by Dave |
| 4 | 2006-02-09 | pp2005 offline (Dave's) bemcPed with timestamp between 2005-04-19 05:37:10 and 2005-06-10 23:38:20 were uploaded to the database |
Replacement for pp2005 bemcPed tables |
| 5 | 2006-02-09 | pp2004 online bemcPed with timestamp between 2004-05-05 01:41:40 and 2004-05-14 23:21:19 were deactivated |
Bad tables reported by Joanna with large RMS values and missing channels. Click here for details |
| 6 | 2006-02-09 | pp2004 offline (Dave's) bemcPed with timestamp between 2004-05-05 01:41:40 and 2004-05-14 23:21:19 were uploaded to the database |
Replacement for pp2004 bemcPed tables |
| 7 | 2006-02-22 | AuAu and pp 2004 bemcCalib table with timestamp 2004-01-01 00:04:00 was uploaded to database |
Improvements in calibration by Adam Kocoloski. Click here for details |
| 8 | 2006-02-22 | CuCu 2005 bemcCalib table with timestamp 2005-02-01 00:00:01 was uploaded to database |
Improvements in calibration by Adam Kocoloski. Click here for details |
| 9 | 2006-02-22 | pp 2005 bemcCalib table with timestamp 2005-03-22 00:00:02 was uploaded to database |
Improvements in calibration by Adam Kocoloski. Click here for details This is a copy of the table saved in row number 8. This is necessary because there were calibration tables saved for pp2005 run |
| 10 | 2006-03-07 | Saved perfect status tables (bemc, bsmde, bsmdp and bprs) for run 6 with timestamp 2006-01-01 00:00:00 |
First order status tables necessary for fast production and pp2006 vertex finder |
| 11 | 2006-03-30 | Saved initial BTOW calibration for pp2006 with timestamp 2006-03-11 08:27:00 |
First calibration for pp2006 (online). Based on eta-slices MIP peaks and slopes equalization. Click here for details |
| 12 | 2006-04-19 | A set of perfect status tables (bemc, bsmde, bsmdp and bprs) was saved in DB for the CuCu2005 with timestamp 2005-01-01 00:00:00 |
This makes sure that the 2004 status tables are not picked for any analysis/production done with the 2005 CuCu data while there is no detailed status tables available |
| 13 | 2006-04-20 | A perfect status table for BTOW, including only the west side of the EMC was saved in DB for the CuCu2005 with timestamp 2005-01-01 00:00:01 |
Added to replace previous perfect status table that includes the full detector because the east side was being commissioned |
| 14 | 2006-06-16 | Offline BSMD status tables for 2005 pp running. Event timestamps are between 2005-04-16 06:48:09 and 2005-06-23 19:38:42 |
Tables produced by Frank Simon. Click here for details |
| 15 | 2006-06-21 | Offline BTOW status tables for 2005 pp running. Event timestamps are between 2005-04-19 11:36:11 and 2005-05-14 09:17:59 |
These tables should have been / were uploaded back in row 2. It's not clear what happened to them. |
| 16 | 2006-06-21 | Online BTOW pedestals for 2006 pp running. Event timestamps are between 2005-03-02 08:40:15 and 2005-06-19 04:41:18 |
BTOW pedestals were calculated and saved to the DB automatically during the run. Unfortunately the tables were corrupted during the upload, so we need to upload these tables again with +1 second timestamps. |
| 17 | 2006-08-15 |
BSMD pedestals for Run 6. |
Details |
| 18 | 2006-08-16 |
BTOW status for Run 6. |
~1 table/fill. Should be good enough for vertex finding during production, but not necessarily the final set of tables. Details |
| 19 | 2006-10-17 |
Perfect BPRS status table for 2006 run |
Begin time 2006-01-01 |
| 20 | 2006-11-10 | BTOW status for Run 5 CuCu |
Link needs to be updated with a summary page. Details |
| 21 | 2006-11-21 |
Fixed timestamps for Run 5 pp status |
See starsoft post |
| 22 | 2006-11-30 |
Fixed timestamps for Run 5 pp peds |
See starsoft post |
| 23 | 2006-12-07 | Offline BTOW calibration for Run 6 | Run 6 BTOW Calibration |
| 24 | 2007-01-17 | Final BTOW status tables for trans,long2 | Details |
| 25 | 2007-02-13 | Corrected 3 Run6 tower peds in few runs | Hypernews discussion |
| 26 | 2007-02-26 | Final BSMD Run6 status tables | Details |
Trigger Database
This database stores all BEMC trigger information such as trigger status, masks and pedestals used to obtain the high tower and patch sum information. The database is updated online while taking data. We have the following table formats:- St_emcTriggerStatus - this table contains status/mask information for the trigger
- St_emcTriggerPed - this table contains the pedestal and bit conversion scheme used in the trigger
- St_emcTriggerLUT - this table contains the lookup table information. Because the LUT is very large it is encoded in simple formulae. The FormulaTag entry specifies the formula used for each patch.
TDataSet *DB = GetInputDB("Calibrations/emc/trigger");
St_emcTriggerStatus *table = (St_emcTriggerStatus*) DB->Find("bemcTriggerStatus");
emcTriggerStatus_st *struct = table->GetTable();Important Information About Pedestal Tables
In order to save space and make the download fast, PEDESTALS and RMS are saved as SHORT. So, the real pedestal value is PED/100. Similarly, in order to save tables in the database you have to multiply the real pedestal by 100. The same goes for the RMS.The pedestal table also includes the 6-bit conversion scheme used to generate the high tower and patch sum information.
Status Information
The St_emcTriggerStatus table contains the status information for each single tower, high tower and patch sum (patch sum is the sum in the 4x4 patches. It is *not* the jet patch). The status is a simple 0/1 that reflects the masks that are being applied to the electronicss where- 0 - masked out
- 1 - included in trigger
Tables Structure
/*
*
* Table: emcCalib
*
* description: //: Table which contains the trigger masks
*/
struct emcTriggerStatus
{
octet PatchStatus[300]; // Patch sum masks. the index is the patch number
octet HighTowerStatus[300]; // High tower masks. the index is the patch number
octet TowerStatus[30][160]; // Single masks. the indexex are the crate number and position in crate
};
/*
*
* Table: emcTriggerPed
*
* description: * //: Table which contains pedestal information and 6 bits conversion used in trigger
*/
struct emcTriggerPed
{
unsigned long PedShift; // pedestal shift
unsigned long BitConversionMode[30][10]; // 6 bits conversion mode. the indexex are the crate number and position in crate
unsigned long Ped[30][160]; // pedestal value. the indexex are the crate number and position in crate
};
/*
*
* Table: emcTriggerLUT
*
* description: * //: Table which contains each patch LUT information
*/
struct emcTriggerLUT
{
unsigned long FormulaTag[30][10]; // formula tag for each [crate][patch]
unsigned long FormulaParameter0[30][10]; // Parameter 0 for the LUT formula in [crate][patch]
unsigned long FormulaParameter1[30][10]; // Parameter 1 for the LUT formula in [crate][patch]
unsigned long FormulaParameter2[30][10]; // Parameter 2 for the LUT formula in [crate][patch]
unsigned long FormulaParameter3[30][10]; // Parameter 3 for the LUT formula in [crate][patch]
unsigned long FormulaParameter4[30][10]; // Parameter 4 for the LUT formula in [crate][patch]
unsigned long FormulaParameter5[30][10]; // Parameter 5 for the LUT formula in [crate][patch]
};BEMC Online Trigger Monitoring
During data taking the BEMC trigger information is monitored, and changes in the configuration (new pedestals, masks, etc.) are recorded. The code relevant to this online trigger monitoring was developed by Oleksandr, and is checked into CVS here (usage instructions in the README file). The scripts execute via a cronjob on the online machines on the starp network. In particular, there exists directories with results from previous years at /ldaphome/onlmon/bemctrgdb20XX/ on onl08.starp.bnl.gov.
The final location for this information is in the offline DB, and the definitions for the tables are given here. These DB tables are used by the StBemcTriggerSimu in the StTriggerUtilities package to replicate the BEMC trigger conditions for a particular timestamp.
The DB tables can be uploaded while taking data or stored in ROOT files to be uploaded after data taking is complete. To upload all the tables stored in ROOT files during data taking only a simple script is needed employing StBemcTablesWriter to read in a list of files and upload their information to the DB. This script (uploadToDB.C) is checked into the macros directory of in CVS here.
Yearly Timestamp Initialization
Yearly Timestamp Initialization
This page will document the yearly timestamp initialization requested by the S&C group (Run 12 for example). The purpose is to set initial DB tables for "sim" and "ofl" flavor in sync with the geometry timeline for each year. The geometry timeline is documented here.
The timestamps chosen for BEMC initialization are in the table below
| Simulation | Real Data | |
| Run 10 | 2009-12-12 | 2009-12-25 |
| Run 11 | 2010-12-10 | 2010-12-20 |
| Run 12 | 2011-12-10 | 2011-12-20 |
The "sim" tables used for initialization are ideal gains, pedestals and status tables.
The "ofl" tables used for initialization are the best known gains from previous years, and a reasonable se of pedestals and status tables from a previous year. Obviously they will be updated once the run begins and better known values are available.
To simplify the initialization process from year to year, a macro (attached below) was written which copies DB tables from previous years to the current initialization timestamp.
Hardware
BEMC_FEE_Repairs (BSMD)
Here (below) are the BSMD FEE repair record spreadsheets from Phil Kuczewski.
The one with label "BEMC_FEE_Repairs-2010.xls" is most recent, including repairs in 2010
(although on 9/8/10 Oleg says that 1 more SAS was already replaced and there likely will be 2 more)
Mapping
Information about how the BEMC detectors are indexed (Pre run14)
Oleksandr's Spreadsheet of Towers' Layout (Excel)
Oleksandr's Spreadsheet of Towers' Layout (PDF)
For run 14 there were signal cable swaps for PMT boxes 13->14, 15->16, and 45->46. The updated tower maps are here:
Run14 Tower Layout (Excel)
Run14 Tower Layout (PDF)
In these new spreasheets, the yellow, light blue, and light gray boxes are where the swaps are. On the outsides, the PMT boxes are labeled (PMB) and you can clearly see the swaps. As an example, here's how it would work:
Soft Id's 3521, 3522, 3523, 3524, ...., 3461, 3462, 3463, 3464 were swapped with
3441, 3442, 3443, 3444, ...., 3381, 3382, 3383, 3384
BSMDE 2010 mapping problem and solution
All the details of the mapping problem can be found in this ticket. This page is a summary of the problem, solution, and the implementation.
During Run 10 a problem with the BSMD mapping was discovered (details here). It was decided to continue taking data with the 2 fibers swapped for future running, and simply correct the mapping in the DB to reflect the hardware configuration before production. The mapping for the BSMD phi plane (BSMDP) was corrected (completely swapped 2 fibers in the DB) before produvtion to match the Run 10 hardware configuration, so there were no problems with BSMDP mapping in production.
Problem:
The correction to the BSMD eta plane (BSMDE) mapping, however, was incomplete and did not swap the 2 fibers in the DB completely. Ahmed found this mapping problem in "Phase I" of the 200GeV QM production (production series P10ij). All Run 10 data produced in the P10ih and P10ij production series have this BSMDE mapping issue.
Solution:
a) For "Phase II" of the Run 10 data production in the P10ik production series an updated DBV was used to include the correct mapping for both the BSMDE and BSMDP planes. This data should be analyzed as usual, with no need for a patch.
b) In an effort to recover the data produced with the BSMDE mapping problem (P10ih and P10ij) a patch was included in the SL10k and future libraries to correctly swap the BSMDE channels as an afterburner using StEmcDecoder.
Implementation:
The implementation of part b) of the solution above is similar to the patch for previous tower mapping problems. The software patch includes 3 libraries StEmcDecoder, StEmcADCtoEMaker, StEmcRawMaker.
- StEmcDecoder will use the non-corrected map by default, although it is possible to know the correction that should be applied for each channel using the method
StEmcDecoder::GetSmdBugCorrectionShift(int id_old, int& shift)
where id_old is the non-correct software id and shift is the shift that should be applied to the id. In this case:
id_corrected = id_old + shift
- StBemcRaw (in StEmcRawMaker) was updated with a method
StBemcRaw::smdMapBug(bool)
That enables (true) or disables (false) the on-the-fly correction. The default options are:
for StEmcRawMaker -> false (map correction IS NOT applied for P10ih or P10ij PRODUCTION)
for StEmcADCtoEMaker ->true (map correction IS applied for USER ANALYSIS of P10ih or P10ij produced MuDsts)
IMPORTANT: If you run your analysis with StEmcADCtoEMaker The StEmcRawHits in StEmcCollection will be automatically have the map FIXED!!!! This is not the case if you use StEmcRawMaker or StMuEmcCollection for analysis.
- muDST data is saved with the non-corrected software id
If you read muDST data directly, without running ADCtoEMaker you need to correct the ids by hand. The following code is an example how to do that correction. You need to use StEmcDecoder to get the correct id
////////////////////////////////////////////////////////////////////////////////////////////////////////// StEmcDecoder* decoder = new StEmcDecoder(date, time); // date and time correspond to the event timestamp StMuEmcCollection* muEmc = muMk->muDst()->muEmcCollection(); // get the MuEmcCollection from muDST //................... BSMDE ....................
nh=muEmc->getNSmdHits(det); if(det == BSMDE) { for(Int_t j=0;j<nh;j++) { StMuEmcHit* hit=muEmc->getSmdHit(j,det); ID = hit->getId(); ADC = hit->getAdc(); CAP = hit->getCalType(); int shift = 0; decoder->GetSmdBugCorrectionShift(ID,shift); newID = ID + shift; // newID is correct softID for this hit if(newID < 0) continue; // mask lost channels // user code starts here} } //////////////////////////////////////////////////////////////////////////////////////////////////////////
- StEmcCollection (StEvent format) after you run StEmcADCtoEMaker at analysis level is created with correct software id.
- Lost Channels : There are 498 strips which are masked by the patch (correct softID returned by decoder is -2e4) because the correct hits for that channel are not saved in the muDst at all, due to the mapping in the DB used during production.
- Database : Entries are not yet uploaded for Run 10 BSMD data, but the intention is that they will be uploaded with the correct softId mapping so no patch will be needed to get the DB.
BTOW map problem and solution
If you are not familiar with the map problem follow this discussion in the emc-list. Basically, bacause of swapped fiber optics or swapped signal cables some of the towers are not in the software_id position they are supposed to be. This corresponds to more or less 100 swaps (most in the west side) that corresponds to about 200 towers.Some of the swapped towers could be fixed because they originated from swapped signal cables. When the swap happened at fiber optics level they were left as they are because the fibers are difficult to access and are frigile. In this case, and for previous runs, a software patch was made in order to recover the swapped towers.
The list of swapped towers can be found here:
- for 2005 data
- for 2006 data (note that the commented lines correspond to towers that were fixed in hardware)
The software patch is implemented in 3 libraries: StDaqLib (StEmcDecoder), StEmcRawMaker and StEmcADCtoEMaker and the idea is the following
- for 2006 (and future) data StEmcDecoder will have the correct map and all database and productions will be done correctly. In this case the patch is invisible for the user.
- for 2004/2005 data, because of the large amount of tables in database and because of the many productions that were done, the patch in StEmcDecoder, is turned OFF by default. This was done because changing the database and old productions is too much trouble at this point. In this case, the patch works in the following way:
- StEmcDecoder will use the non-corrected map by default, although it is possible to know the correction that should be applied for each tower using the method
StEmcDecoder::GetTowerBugCorrectionShift(int id_old, int& shift)
where id_old is the non-correct software id and shift is the shift that should be applied to the id. In this case:
id_corrected = id_old + shift
- StBemcRaw (in StEmcRawMaker) was updated with a method
StBemcRaw::towerMapBug(bool)
That enables (true) or disables (false) the on-the-fly correction. The default options are:
for StEmcRawMaker -> false (map correction IS NOT applied for PRODUCTION)
for StEmcADCtoEMaker ->true (map correction IS applied for USER ANALYSIS)
IMPORTANT: If you run your analysis with StEmcADCtoEMaker The StEmcRawHits in StEmcCollection will be automatically have the map FIXED!!!! This is not the case if you use StEmcRawMaker or StMuEmcCollection for analysis.
- StEmcDecoder will use the non-corrected map by default, although it is possible to know the correction that should be applied for each tower using the method
- muDST data is saved with the non-corrected software id
If you read muDST data directly, without running ADCtoEMaker you need to correct the ids by hand. The following code is an example how to do that correction. You need to use StEmcDecoder to get the correct id
//////////////////////////////////////////////////////////////////////////////////////////////////////////
StEmcDecoder* decoder = new StEmcDecoder(date, time); // date and time correspond to the event timestamp
StMuEmcCollection* emc = muMk->muDst()->muEmcCollection(); // get the MuEmcCollection from muDST
//................... B T O W ....................for (int idOld = 1; idOld <= 4800 ; idOld++)
{
int rawAdc= emc->getTowerADC(idOld);
int shift = 0;
decoder->GetTowerBugCorrectionShift(idOld,shift);
idNew = idOld + shift;
// user code starts here}
////////////////////////////////////////////////////////////////////////////////////////////////////////// - Database is saved with non-corrected software id
- StEmcCollection (StEvent format) after you run StEmcADCtoEMaker at analysis level is created with correct software id.
- StBemcTables. To enable the tower map bug, use the flag kTRUE in StBemcTables constructor. See examples bellow
// This method returns values for NON-CORRECTED IDs (old ids, as the tables are saved in DB)
tables = new StBemcTables();
float pedestal, rms;
tables->getPedestal(BTOW, idOld, 0, pedestal, rms);
// This method returns values for CORRECTED IDs
tables = new StBemcTables(kTRUE); // Use kTRUE to enable the BTOW map correction in StBemcTables. Default is kFALSE
float pedestal, rms;
tables->getPedestal(BTOW, idNew, 0, pedestal, rms);
Marcia's BPRS mapping page
This page was written by Marcia Maria de Moura in January 2005 and ported into Drupal in October 2007
We are interested in determine in which sequence the measurements of the pre-shower "cells" come into the DAQ system.
The path from the detector to the DAQ system is not so trivial. There are many connections and they are all tagged but, sometimes, in order to allow a better assembly of the system, the final sequence in which the data from the cells is sent to DAQ is not an ordinary one.
In order to ilustrate better what is the mapping for the pre-shower, we show the correlation of some connections and also the correlation with the towers.
In figure 1 we show part of the barrel EMC corresponding to three modules. The modules are presented from η=0 to η=1. The coloured boxes are the towers. The four rows correspond to a photomultiplier box (PMB). One PMB corresponds to one entire module plus two halves of neighbor modules on each side of the central one. In the left side of the figure there is the legend for the series of conectors ST1,ST2,ST3 and ST4 for the towers. In the figure it is shown how this connectors are related to the towers.

Figure 1 - Correlation of PMT connectors and towers' positions. For a larger view, click on figure.
In figure 2 we show an example of numbering for towers for the PMB 11W (W stands for west). This numbering is the one used for analysis and we call it software id. By analogy, we aplly the same numbering for the pre-shower cells. For the complete numbering of towers and pre-shower cells, see EMC distribution.

Figure 2 - Example of tower numbering for PMB 11W
In the case of the pre-shower cells, the light is not send to the same photomultiplier tubes as the ones for towers, but to sets of Multi-Anode Photomultipliers (MPMT). There are five sets of MPMT's in each PMB and the conecctors for that are identified by MP1, MP2, MP3 MP4 and MP5. In figure 3 we show the correlation of MPX connections to the pre-shower cells, also for PMB 11W. The distribution looks similar but actually the rows are different from figure 2. In the right side of the figure is indicated which is the correspondence in rows with the figure 2. From Vladimir Petrov we obtained how the MPX connectors are related to some eletronics ids (FEE number, SCA number and SCA channel) which are correlated to the muxwire number. The muxwire number is the one that determines the sequence of data to DAQ. In figure 3 it is shown the muxwire, just below the software id.

From all the eletronics parameters above, the algorythm to associate the software id with the data from DAQ was determined, and is in the StEmcDecoder. In previous attempts. some information about the electronics ids was not updated, which caused to a wrong mapping in the first place. One parameter of the algorythm, an offset (PsdOffset_tmp[40])was wrongly determined. The electronics ids information has been updated and the algorythm has been corrected. In table 1 and 2 we show the values of some parameters for PMB 11W. They are analogous to other PMB's and the only thing that changes is the software id, but the distribution in position is the same. Among the many parameters in table 1 and 2, the updated offset values that are used in the StEmcDecoder are displayed.
Of course there are aditional parameters in the algorythm but there is no meaning in explaining all of it here. For more details, go to StEmcDecoder STAR Computing software guide.


The following image has the power supply number, module, and channel for PMT box 11 on both east and west.

Service Tasks
HIGH PRIORITY
BSMD Calibration Studies
Description: The calibration coefficients for the BSMD were derived from old test beam studies. They are set so that the energy of an SMD cluster should be equal to the energy of the tower above it. One way to check this is to select low-energy electrons and plot SMD energy vs. tower energy. Initial studies could be accomplished on a month timescale.Assigned to: Willie Leight (MIT)
Status: In Progress.
BPRS Calibration Studies
Description: We have no offline calibration coefficients for the preshower. While the absolute energy scale is not overly important, we need to verify that the channels are well-calibrated relative to each otherAssigned to: Rory Clarke (TAMU)
Status: In Progress -- see link
Neutral Pion Tower Calibration Algorithm
Description: Current BTOW calibrations rely on the TPC to a combination MIP/electron-based analysis. A calibration using neutral pions would be complementary and possibly more precise.Assigned to: Alan Hoffman (MIT)
Status: In Progress.
Trigger Simulator
Description: The goal here is to extend the existing BEMC trigger simulator to support "exact" trigger simulation using the logic that we actually use online, to include L2 triggers, and to integrate this simulator with ones provided by other subdetectors.Assigned to: Jan Balewski (IUCF -- Endcap and L2), Renee Fatemi (UK -- BEMC), and Adam Kocoloski (MIT -- BEMC)
Status: In Progress
Control Room Software Maintenance
Description: We'll hopefully be replacing most of the BEMC Control Room computing hardware before Run 8, and we'll need someone to check that everything still works as before. Additionally, we need to fix the code that auto-uploads DB tables (should be an easy fix), and we should work on uploading BSMD pedestal tables that include separate values for CAP == 124 and 125.Assigned to: ???
Online BTOW Status Table Generation Using L2
Description: L2 can accumulate sufficient statistics in real time to allow us to record BTOW status tables without waiting for fastOffline or full production. "Real-time" status tables in the DB will allow for better fastOffline QA and could decrease the amount of time needed to analyze the data.Assigned to: ???
NORMAL PRIORITY
STAR DB Browser Maintenance
Description: Not really BEMC-specific, but Dmitri Arkhipkin is looking for a maintainer for the STAR DB Browser, which is a very useful tool for people working on the BEMC.Assigned to: ???
Database-Driven BEMC Mapping
Description: We use the StEmcDecoder class to generate time-dependent mapping tables on-the-fly. I'd like to investigate using a DB to store this information. First step would be to decide on a schema (i.e. is each tower a single row, or do we do the old trick of storing an entire mapping as a blob?). Next we would populate the DB with tables that cover all the possible StEmcDecoder configurations (~20 or so). It may be that we never use this DB for more than browsing the mapping; even so, it could still prove to be a useful tool. On the other hand, we may decide to use it instead of the decoder for some uses. Minimal MySQL knowledge would be helpful, but not required.Assigned to: ???
Run 7 BTOW Calibration
Description: Begin with MIP + electron calibration procedure used in previous years and investigate refinements. Typically a couple months of work.Assigned to: Matthew Walker (MIT)
Status: Waiting on Production.
Run 7 BTOW Status
Description: Track tower status and upload DB tables for offline analysis. Timescale of ~1 month plus occasional updates, corrections. A set of tables are currently in the DB, but these ignore hot towers.Assigned to: ???
Run 7 BSMD Status
Description: Track SMD status and upload DB tables for offline analysis. Timescale of ~1 month plus occasional updates, corrections.Assigned to: ???
Run 7 BPRS Status
Description: Adapt the existing BTOW status code for the preshower and use it to generate DB tables for offline analysis.Assigned to: Matt Cervantes (TAMU)
Status: In Progress
COMPLETE
BPRS Mapping Update
Assigned to: Rory Clarke (TAMU)
Status: Complete -- mapping checked into CVS to fix Run 6 and Run 7 data at analysis level (StEmcADCtoEMaker).
Single-Pass Embedding with Calorimeters
Description: BEMC embedding is typically done as an afterburner on the regular embedding. This has the advantage of allowing multiple configurations to be run without needing to redo the full TPC embedding, but we should also support the standard embedding mode of a single BFC chain.Assigned to: Wei-Ming Zhang (KSU)
Status: Complete
Run 6 BTOW Calibration
Description: Perform MIP + electron calibration using Run 6 data. Investigate electron-only and pi0-based calibrations.Assigned to: Adam Kocoloski (MIT)
Status: Complete -- see Run 6 BTOW Calibration
Run 6 BTOW Status
Description: Track tower status and upload DB tables for offline analysis. Timescale of ~1 month plus occasional updates, corrections.Assigned to: David Staszak (UCLA)
Status: Complete -- (link goes here)
Run 6 BSMD Status
Description: Develop standard code to track SMD status and upload DB tables for offline analysis. Investigate possibility of SMD status codes for individual capacitorsAssigned to: Priscilla Kurnadi (UCLA)
Status: Complete -- (link goes here)
Of course, many others have contributed to the calibrations and physics program of the BEMC over the years. You know who you are. Thanks!
Software
- StEmcAdcToEMaker - This maker gets ADC values for all EMC sub detectors and applies the calibration to get the proper energy value.
- StPreEclMaker - This maker does clustering in all EMC sub detectors.
- StEpcMaker - This maker matches the clusters in EMC sub detectors to get the final EMC point.

Clustering
Second most important step in EMC data reduction is to find clusters from EMC data.
Main code performing EMC clustering is located in StRoot/StPreEclMaker and StRoot/StEpcMaker
The main idea behind the BEMC cluster finder is to allow multiple clustering algorithms. With that in mind, any user can develop his/her own finder and plug it in the main cluster finder.
In order to develop a new finder the user should follow the guidelines described in this page.
Display Macro
A Small cluster finder viewer was written for the BEMC detector. In order to run it, use the macro:
$CVSROOT/StRoot/StPreEclMaker/macros/clusterDisplay.C
This macro loops over events in the muDST files, runs the BEMC cluster finder and creates an event by event display of the hits and clusters in the detector. This is an important tool for cluster QA because you can test the cluster parameters and check the results online. It also has a method to do statistical cluster QA over many events.
The commands available are:
setHitThreshold(Int_t det, Float_t th)
This method defines the energy threshold for displaying a detector HIT in the display. The default value in the code is 0.2 GeV. Values should de entered in GeV. The parameters are:
- Int_t det = detector name. (BTOW = 1, BPRS = 2, BSMDE = 3 and BSMDP = 4)
- Int_t th = hit energy threshold in GeV.
next()
This method displays the next event in the queue.
qa(Int_t nevents)
This method loops over many events in order to fill some clusters QA histograms. The user needs to open a TBrowser n order to access the histograms. The parameters are:
- Int_t nevents = number of events to be processed in QA
help()
Displays a small help in the screen.
How to write a new Cluster Finder
To create a new algorithm it is important to understand how the cluster finder works.
EmcClusterAlgorithm.h
This file defines a simple enumerator for the many possible cluster algorithms. In order to add a new algorithm the user should add a new position in this enumerator
StPreEclMaker.h and .cxx
The cluster finder itself (StPreEclMaker) is a very simple maker. This maker is responsible only for creating the finder (in the Init() method) and call some basic functions in the Make() method.
StPreEclMaker::Init()
This method just instantiates the finder. In the very beginning of Init() method, the code checks which algorithm is being requested and creates the proper finder.
StPreEclMaker::Make()
The Make() method grabs the event (StEvent only) and exits if no event is found. If the event is found it calls 4 methods in the finder. These methods are:
- mFinder->clear(); // to clear the previous event local cluster
- mFinder->clear(StEvent*); // to clean any old cluster or pointer in StEvent
- mFinder->findClusters(StEvent*); // to find the clusters in this event
- mFinder->fillStEvent(StEvent*); // to fill StEvent with the new clusters
- mFinder->fillHistograms(StEvent*); // to fill QA histograms
The modifications the user should do in StPreEclMaker.cxx are only to add the possibility of instantiating his/her finder in the StPreEclMaker::Init() method.
Creating a new cluster algorithm
Before creating a new cluster algorithm it is important to know the basic idea behind the code. The basic classes are
StEmcPreCluster
There is an internal data format for the clusters in the code. The clusters are StEmcPreCluster which are derived from plain ROOT TObject. StEmcPreCluster is more complete than the regular StEvent cluster object (StEmcCluster) because it has methods to add and remove hits, split and merge clusters and well set matching id between different detectors.
StEmcPreClusterCollection
This is a placeholder for the StEmcPreCluster objects that are created. This object derives from the regular ROOT TList object. It has methods to create, add, remove and delete StEmcPreClusters. StEmcPreCluster objects that are created or added to the collections are owned by the collection so be careful.
StEmcVirtualFinder
This is the basic finder class. Any cluster algorithm should inherit from this class. It already create the necessary collections for the clusters in each detector.
To create a new finder algorithm you should define a finder class that inherits from the StEmcVirtualFinder and overwrite the method findClusters(StEvent*). Lets suppose you want to create a StEmcMyFinder algorithm. You should create a class with, at least, the following:
StEmcMyFinder.h
#ifndef STAR_StEmcMyFinder
#define STAR_StEmcMyFinder
#include "StEmcVirtualFinder.h"
class StEvent;
class StEmcOldFinder : public StEmcVirtualFinder
{
private:
protected:
public:
StEmcOldFinder();
virtual ~StEmcOldFinder();
virtual Bool_t findClusters(StEvent*);
ClassDef(StEmcMyFinder,1)
};
#endif
StEmcMyFinder.cxx
#include "StEmcMyFinder.h"
#include "StEvent.h"
#include "StEventTypes.h"
ClassImp(StEmcOldFinder)
StEmcMyFinder::StEmcMyFinder():StEmcVirtualFinder()
{
// initialize your stuff in here
}
StEmcMyFinder::~StEmcMyFinder()
{
}
Bool_t StEmcMyFinder::findClusters(StEvent* event)
{
// check if there is an emc collection
StEmcCollection *emc = event->emcCollection();
if(!emc) return kFALSE;
// find your clusters
return kTRUE;
}
The method findClusters(StEvent*) is the method that StPreEclMaker will call in order to find clusters in the event. All the StEmcVirtualFinder methods are available for the user.
The user has 4 pre cluster collections available. They are named
mColl[det-1]
where det =1, 2, 3 and 4 (btow, bprs, bsmde and bsmdp)
How to deal with clusters and collections
Lets suppose you identified a cluster in a given detector. How do I work with StEmcPreCluster objects and the collections? Please look at the code itself to be more familiar with the interface. The next lines will give basic instructions with the most common tools:
To create and add a cluster to the collection for the detector ´det´
StEmcPreCluster *cl = mColl[det-1]->newCluster();
This line creates a cluster in the collection and returns its pointer.
To remove and delete a cluster from a collection
mColl[det-1]->removeCluster(cl); // cl is the pointer to the cluster
or
mColl[det-1]->removeCluster(i); // i is the index of the cluster in the collection
This will remove AND delete the cluster.
To get the number of clusters in a collection
mColl[det-1]->getNClusters();
To add hits to a StEmcPreCluster (pointer to the cluster is called ´cl´)
cl->addHit(hit);
where hit is a pointer to a StEmcRawHit object.
To add the content of a pre cluster ´cl1´ to a cluster ´cl´
cl->addCluster(cl1);
The added cluster ´cl1´ is not deleted. This is very useful if you identified a spitted cluster and would like to merge them.
How to do matching in the cluster finder?
Depending on the cluster finder algorithm one can do clusters in one detector using the information in the other detector as seed. In this sense, it is important do have some kind of matching available in the cluster finder. In the original software scheme, StEpcMaker is the maker responsible for matching the clusters in the BEMC sub detectors. This maker is still in the chain.
Because of StEpcMaker, we CAN NOT create StEmcPoints in the cluster finder. This should be done *ONLY* by StEpcMaker. In order to have a solution for that, StEmcPreCluster object has a member that flags the cluster with matching information. This is done by setting a matching id in the cluster. Use the methods matchingId() and setMatchingId(Int_t).
The matching id is an integer number. If matching id = 0 (default value), no matching was done and the matching will be decided in StEpcMaker. If matching id is not equal to 0, StEpcMaker will create points with clusters with the same matching Id.
Using this procedure, we can develop advanced matching methods in the cluster finder algorithm.
How to plug your finder into the cluster finder
In order to plug your algorithm to the cluster finder you need to change two files in the main finder
EmcClusterAlgorithm.h
This file defines an enumerator with the cluster finders. To add your algorithm in this enumerator add an entry in the enumerator definition, for example:
enum EmcClusterAlgorithm
{ kEmcClNoFinder = 0, kEmcClDefault = 1, kEmcClOld = 2, kEmcMyFinder = 3};
StPreEclMaker.cxx
You should change the Init() method in StPreEclMaker in order to instantiate your finder. To instantiate your StEmcMyFinder object, add, in the Init() method of StPreEclMaker:
if(!mFinder)
{
if(mAlg == kEmcClOld) mFinder = new StEmcOldFinder();
if(mAlg == kEmcMyFinder) mFinder = new StEmcMyFinder();
}
Original cluster algorithm (kEmcClOld)
This page describes the original cluster finder algorithm. In order to use this algorithm you should set with the algorithm kEmcClOld.
Salient features of the method implemented in the program are,
- Clustering have been performed for each sub detector separately.
- Currently clusters are found for each module in the sub detectors. There are some specific reasons for adopting this approach especially for Shower Max Detectors (SMD's). For towers, we are still discussing how it should be implemented properly. We have tried to give some evaluation results for this cluster finder.
- There are some parameters used in the code with their default values. These default values are obtained after preliminary evaluation, but for very specific study it might be necessary to change these parameters.
- The output is written in StEvent format.
Cluster algorithm
- Performs clustering module by module
- Loops over hits for each sub detector module
- Looks for local maximums
Cluster parameters
- mEnergySeed – minimum hit energy to start looking for a cluster
- mEnergyAdd -- minimum hit energy to consider the hit part of a cluster
- mSizeMax – maximum size of a cluster
- mEnergyThresholdAll – minimum hit energy a cluster should have in order to be saved

Neighborhood criterion
Because of the difference in dimension and of readout pattern in different sub detectors, we need to adopt different criterion for obtaining the members of the clusters.
- BEMC: Tower gets added to the existing cluster if it is adjacent to the seed. Maximum number of towers in a cluster is governed by the parameter mSizeMax. It should be noted that BEMC, which takes tower as unit is 2-dimensional detector and by adjacent tower, it includes the immediate neighbors in eta and in phi.
- BSMD: As SMDs are basically one-dimensional detector, so the neighborhood criterion is given by the condition that for a strip to be a neighbor, it has to be adjacent to any of the existing members of the clusters. Here also maximum number of strips in a cluster is governed by mSizeMax parameter.
Cluster Object
After obtaining the clusters, following properties are obtained for each cluster and they are used as the members of the cluster object.
- Cluster Energy (Total energy of the cluster member).
- Eta cluster (Mean eta position of the cluster).
- Phi cluster (Mean phi position of the cluster).
- Sigma eta, Sigma phi (widths of the cluster in eta nd in phi).
- Hits (Members of the cluster).
Some Plots
BSMDE clusters for single photon events
Performance Evaluation
Note: This is a rather old study that I found on BEMC public AFS space and ported into Drupal. I don't know who conducted it or when. -- A. Kocoloski
On the subject of reconstruction made by cluster finder and matching, evaluation has been developed to determine how good is the reconstruction, efficiency, purity, energy and position resolution of reconstructed particles originally generated by simulation data.
Cluster finder is being evaluated at the moment using single particle events, which favors the evaluation of efficiency and purity. In this case, we can define efficiency and purity for single particle events as:
- efficiency - ratio between the number of events with more than 1 cluster and the total number of events.
- purity - ratio between the number of events with only 1 cluster and the number of events with at least one cluster.
There are other quantities that could be used for evaluation. They are:
- energy ratio - ratio between the cluster energy and the geant energy.
- position resolution - difference between cluster position and particle position.
All these quantities can be studied as a function of the cluster finder parameters, mSizeMax, mEnergySeed and mEnergyThresholdAll. The results are summarized below.
BTOW Clusters
mEnergyThresholdAll evaluation
Nothing was done to evaluate this parameter.
mEnergySeed evaluation
The purity as a function of mEnergySeed gets better and the efficiency goes down as this parameter increases. Some figures (the others parameters were kept as minimum as possible) are shown for for different values of mSizeMax for single photons in the middle of a tower with pt = 1,4,7 and 10 GeV/c.
The following plots were generated using energy seeds of 0.1 GeV (left), 0.5 GeV (middle), and 1.5 GeV (right). Full-size plots are available by clicking on each image:
Eta dfference



Phi difference



Number of clusters



Energy ratio



mSizeMax evaluation
Nothing was done to evaluate this parameter.
BSMD Clusters
mEnergyThresholdAll evaluation
Nothing was done to evaluate this parameter.
mEnergySeed evaluation
The purity as a function of mEnergySeed gets better and the efficiency goes down as this parameter increases. Some figures (the others parameters were kept as minimum as possible) are shown for for different values of mSizeMax for single photons in the middle of a tower with pt = 1,4,7 and 10 GeV/c.
The following plots were generated using energy seeds of 0.05 GeV (left), 0.2 GeV (middle), and 0.8 GeV (right). Full-size plots are available by clicking on each image:
Eta Difference (BSMDE only)



Eta difference RMS as a function of photon energy for different seed energies:

Phi Difference (BSMDP only)



Phi difference RMS as a function of photon energy for different seed energies:

Number of clusters for BMSDE



Number of clusters for BSMDP:



BSMDE efficiency and purity as a function of seed energy

BSMDP efficiency and purity as a function of photon energy for different seed energies

mMaxSize evaluation
The efficiency and purity as a function of mSizeMax get better as this parameter increases but for values greater than 4 there is no difference. Some figures (the others parameters were kept as minimum as possible) are shown for for different values of mSizeMax for single photons in the middle of a tower with pt = 5 GeV/c.
Point Maker
After obtaining the clusters for 4 subdetectors, we need to obtain the information about the incident shower by making the proper matching between clusters from different subdetectors.
It should be mentioned that, because of the better energy resolution and higher depth BEMC is to be used for obtaining the energy of the shower. SMDs on the other hand will be used for obtaining the position of the showers because of their better position resolution.
Currently Preshower detector (PSD) has not been included in the scheme of matching, so we discuss here the details of the method adopted for matching other 3 sub detectors.
Following steps are adopted to obtain proper matching:
- The clusters obtained from different sub detectors are sorted to obtain the clusters in a single subsection of the SMD phi.
- Each module of SMD phi consists of 10 subsections.
- Each subsection consists of 15 strips along eta, giving phi positions of the clusters for the eta-integrated region of 0.1.
- In SMD eta same subsection region consists of 15 strips along phi and the same region consists of 2 x 2 towers.
- Each module of SMD phi consists of 10 subsections.
- In the present scheme of matching, we match the clusters obtained in 3 sub detectors in each of this SMD phi subsection.
- There are two levels of matching:
- SMD eta - SMD phi match
- First matching aims to obtain the position of the shower particle in (eta, phi). Because of the integration of signals in SMD etas in the SMD phi subsection region, (i.e.. each SMD eta strip adds the signal in 0.1rad of phi and each SMD phi strip adds the signal in delta eta=0.1 region.) For this type of configuration of detectors, we have decided to get the position matching for each SMD phi subsection. Even though for cases like 1 cluster in SMD eta and 1 cluster in SMD phi in the subsection, we have mostly unique matching of (eta, phi), but for cases where SMD eta/SMD phi subsection consists of more than 1 cluster (see figure) then the possibility of matching does not remain unique. the task is handled from the following standpoint, The number of matched (eta, phi) pairs are taken as minimum of (number of clusters in SMD eta, number of clusters in SMD phi). The (eta, phi) assignment for the pairs are given considering the pair having minimum of (E1-E2)/(E1+E2), where E1, E2 are the cluster energy of SMD eta and SMD phi clusters.

- First matching aims to obtain the position of the shower particle in (eta, phi). Because of the integration of signals in SMD etas in the SMD phi subsection region, (i.e.. each SMD eta strip adds the signal in 0.1rad of phi and each SMD phi strip adds the signal in delta eta=0.1 region.) For this type of configuration of detectors, we have decided to get the position matching for each SMD phi subsection. Even though for cases like 1 cluster in SMD eta and 1 cluster in SMD phi in the subsection, we have mostly unique matching of (eta, phi), but for cases where SMD eta/SMD phi subsection consists of more than 1 cluster (see figure) then the possibility of matching does not remain unique. the task is handled from the following standpoint, The number of matched (eta, phi) pairs are taken as minimum of (number of clusters in SMD eta, number of clusters in SMD phi). The (eta, phi) assignment for the pairs are given considering the pair having minimum of (E1-E2)/(E1+E2), where E1, E2 are the cluster energy of SMD eta and SMD phi clusters.
- Position - energy match
- It should be mentioned that position/energy matching is done only when there exists a cluster in BEMC for the subsection under study. Because of the large dimension of towers, the clusters obtained in BEMC is made up of more than one incident particles. In case of AuAu data, where particle density is very large, the definition of clusters in towers become ambiguous, especially for low energy particles. In the present scheme, as we have discussed earlier, we have followed the method of peak search for finding clusters, where maximum cluster size is 4 towers. 4 towers make the region of one SMD phi subsection, so we have obtained the energy for the pairs obtained in (SMD eta, SMD phi) from the cluster energy of BEMC cluster in the same subsection. For the cases where we have 1 cluster in BEMC, 1 cluster in SMD eta, 1 cluster in SMD phi, we assign the BEMC cluster energy to (eta, phi) pairs. But for the cases when the number of matched pairs is more than one, then we need to split the BEMC cluster energy. Presently it is done according to the ratio of the strengths of (eta, phi) pair energies. This method of splitting has the drawback of using SMD energies, where energy resolution is worse compared to BEMC energy resolution.
- SMD eta - SMD phi match
Codes for the point maker are found in StRoot/StEpcMaker
Usage
The cluster finder can run in many different chains. The basic modes of running it are:
- bfc chain: This is the usual STAR reconstruction chain for real data and simulation.
- standard chain: this is the most common way of running the cluster finder. The cluster finder runs with real data and simulated data.
- embedding chain
There are some rules a user needs to follow in order to run the cluster finder properly:
- Include the file $STAR/StRoot/StPreEclMaker/EmcClusterAlgorithm.h in order to define the cluster algorithm enumerator
- Need to load the shared libraries
- StPreEclMaker should run *AFTER* the BEMC hits are created (StADCtoEMaker or StEmcSimulatorMaker)
- The cluster algorithm should be defined *BEFORE* Init() method is called
- Any change in the cluster parameters should be done *AFTER* Init() is called.
The following is an example on how to run the cluster finder in a standard chain:
// include the definitions of the algorithms
#include "StRoot/StPreEclMaker/EmcClusterAlgorithm.h"
class StChain;
StChain *chain=0;
void DoMicroDst(char* list = "./file.lis",
int nFiles = 10, int nevents = 2000)
{
gROOT->LoadMacro("$STAR/StRoot/StMuDSTMaker/COMMON/macros/loadSharedLibraries.C");
loadSharedLibraries();
gSystem->Load("StDbUtilities");
gSystem->Load("StDbLib");
gSystem->Load("StDbBroker");
gSystem->Load("St_db_Maker");
gSystem->Load("libgeometry_Tables");
gSystem->Load("StDaqLib");
gSystem->Load("StEmcRawMaker");
gSystem->Load("StEmcADCtoEMaker");
// create chain
chain = new StChain("StChain");
// Now we add Makers to the chain...
maker = new StMuDstMaker(0,0,"",list,"",nFiles);
StMuDbReader* db = StMuDbReader::instance();
StMuDst2StEventMaker *m = new StMuDst2StEventMaker();
St_db_Maker *dbMk = new St_db_Maker("StarDb","MySQL:StarDb");
StEmcADCtoEMaker *adc=new StEmcADCtoEMaker();
adc->setPrint(kFALSE);
StPreEclMaker *ecl=new StPreEclMaker(); // instantiate the maker
ecl->setAlgorithm(kEmcClDefault); // set the algorithm
ecl->setPrint(kFALSE); // disables printing
chain->Init();
StEmcOldFinder* finder = (StEmcOldFinder*)ecl->finder(); // gets pointer to the finder
finder->setEnergySeed(1,0.8); // change some setting in the finder
int n=0;
int stat=0;
int count = 1;
TMemStat memory;
while ( (stat==0 || stat==1) && n<nevents)
{
chain->Clear();
stat = chain->Make();
n++;
}
chain->Finish();
}
Data Format
BEMC data is always available using standard StEvent collections. This is true regardless of whether one is analyzing simulations or real data, or whether the actual input file is in a geant.root, event.root, or mudst.root format. The appropriate BEMC maker (StEmcADCtoEMaker for real data, StEmcSimulatorMaker for simulations) will create an StEvent in-memory if necessary and fill the BEMC collections wth the correct data.
Three different types of calorimeter objects are available:
StEmcRawHit -- a hit for a single detector element (tower, smd strip, or preshower channel)
StEmcCluster -- a cluster is formed from a collection of hits for a single BEMC subdetector (tower / smd-eta / smd-phi / preshower)
StEmcPoint -- a point combines StEmcClusters from the different subdetectors. Typically the SMD clusters are used to determine the position of points, and in the case of e.g. pi0 decay photons they also determine the fraction of the tower cluster energy assigned to each photon. The absolute energy scale is set by the tower cluster energy. Current point-making algorithms do not use the preshower information.
For more information see the StEvent manual.
Embedding
Update: New B/EEMC embedding framework from Wei-Ming Zhang currently in peer review
The present BEMC embedding works as an afterburner that must be done after the TPC embedding. Wei-Ming Zhang is working on a version that work in parallel with the TPC embedding. Here's the current workflow:
During TPC embedding
In this step, only real EMC data is processed with all of the TPC embedding. In the end, there are two files:- .event.root - This file contains the TPC reconstructed tracks (real data + simulation) and BEMC reco information (real data only)
- .geant.root - This files contains the simulated tracks (TPC + EMC simulated data)
After TPC embedding
This is where the BEMC embedding happens. The idea is to get the output from the TPC embedding (.geant.root and .event.root files) and mix the BEMC simulated data with the real BEMC data. The mixing is performed by StEmcMixerMaker and the main idea is to add the simulated ADC values to the real event ADC values. In order to do that we need to follow some simple rules:- We have to simulate the ADC values with the same calibration table used for the real data
- We cannot add pedestals or noise to the simulated data. The real data already include the pedestals and noise. If we simulate them we will end up overestimating both quantities.
- We should embed simulated hits only for the towers with status==1.
- StIOMaker - to read the .event.root and .geant.root files
- St_db_Maker - to make the interface with the STAR database and get the BEMC tables
- StEmcADCtoEMaker - reprocesses the real BEMC data and fills an StEvent object with the calibrated real data.
- StEmcPreMixerMaker - this is a simple maker whose only function is to make sure the chain timestamp is set using the real data event time. This is very important to make sure the tables are correctly retrieved from the database.
- StMcEventMaker - builds an StMcEvent object in memory. This is necessary because the simulator maker needs to get the BEMC simulated data in this format.
- StEmcSimulatorMaker - this maker gets the StMcEvent in memory that contains the BEMC simulated hits and does a slow simulation of the detector, generating the ADC values with the correct calibration tables. At this point we have two StEmcCollections in memory: the one with the real BEMC data from step 3, and the one with the simulated data from the simulator maker.
- StEmcMixerMaker - this maker gets the two StEmcCollections and adds the simulated one to the real data. This is a simple ADC_total = ADC1 + ADC2 for each channel in each detector. Only simulated hits belonging to channels that were good in the real data are added.
- StEmcADCtoEMaker - reconstructs the event once more. This step gets the new ADC values and recalibrates them.
- StPreEclMaker - reconstructs the clusters with the embedded hits.
- StEpcMaker - reconstructs the points
- StAssociationMaker - does the TPC association
- StEmcAssociationMaker - does the BEMC association
- Add your own analysis maker
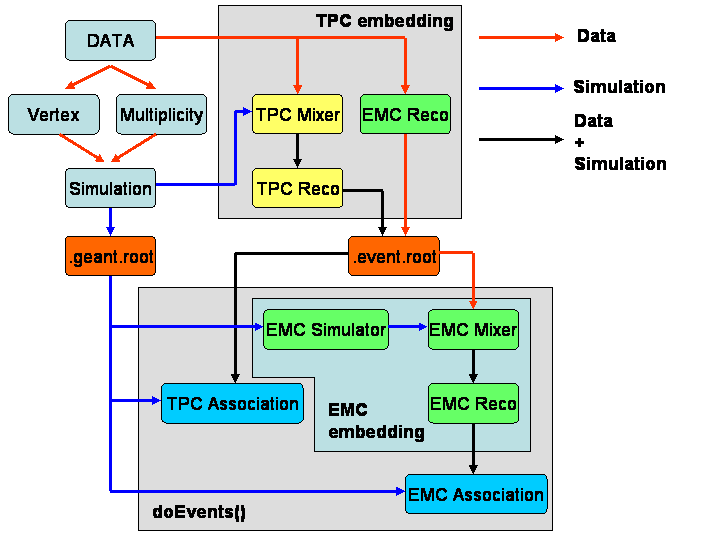
StEmcAssociationMaker
Introduction
To treat many-particle events (pp and AuAu), we need to know which particle generated which cluster/point before evaluating the reconstructed clusters and points. StEmcAssociationMaker accomplishes this by matching the many clusters and points in a given event with the respective simulated particles.Association Matrix
In order to associate the clusters/points to the corresponding particles, the Association software creates matrices. The matrix columns correspond to the reconstructed clusters/points and the lines correspond to the particles. We have three kinds of matrices:- Simple Matrix - matrix elements are 0 or 1.
- Particle Fraction Matrix - matrix elements are the fraction of the total particle energy in a cluster.
- Cluster Fraction matrix - matrix elements are the fraction of energy of a cluster that comes from a given particle.
Simple Matrix Particle Fraction Matrix Cluster Fraction Matrix
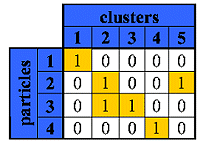
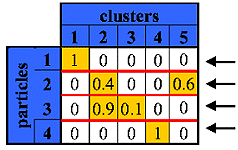
A simple example using association matrices is presented below. In the case of double photon events, we plot the purity of the measured clusters in SMD eta as a function of the photon distance. The purity is obtained from the "Cluster Fraction" Association Matrix.
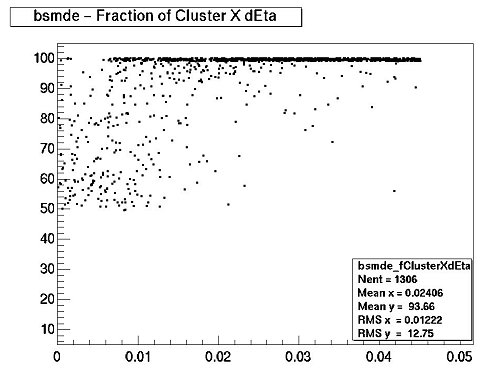
How to Use
In order to follow the same scheme done in StAssociationMaker we save the association information in multimaps. Multimaps make it very easy for the user to get the association information for a given StMcTrack, cluster or point. Detailed documentation for StAssociationMaker is available <a href="http://www.star.bnl.gov/STAR/comp/pkg/dev/StRoot/StAssociationMaker/doc/">here</a>. There are essentially four multimaps defined for the BEMC:- multiEmcTrackCluster - correlates the StMcTrack with StEmcClusters
- multiEmcClusterTrack - corrrelates the StEmcCluster with StMcTracks
- multiEmcTrackPoint - correlates the StMcTrack with StEmcPoints
- multiEmcPointTrack - correlates the StEmcPoint with StMcTracks
StEmcAssociationMaker *emcAssoc = GetMaker("EmcAssoc");
if(!emcAssoc) return;
multiEmcTrackCluster *map = emcAssoc->getTrackClusterMap(1);
if(!map) return;
for(multiEmcTrackClusterIter j=map->begin(); j!=map->end(); j++)
{
StMcTrack* track = (StMcTrack*)(*j).first;
StEmcClusterAssociation* value = (StEmcClusterAssociation*)(*j).second;
if(track && value)
{
StEmcCluster *c = (StEmcCluster*) value->getCluster();
if(c)
{
cout <<" McTrack = "<<track<<" GeantId = "<<track->geantId()
<<" pt = "<<track->pt()<<" TReta = "<<track->pseudoRapidity()
<<" Cl = "<<c<<" E = "<<c->energy()<<" eta = "<<c->eta()
<<" phi = "<<c->phi()
<<" FrTr = "<<value->getFractionTrack()
<<" FrCl = "<<value->getFractionCluster()<<endl;
}
}
} Makers
The BEMC makers available in STAR include:
StEmcADCtoEMaker - This maker converts plain ADC values in energy. It subtracts pedestals, applies calibrations and creates the StEmcRawHits in StEvent. This maker also checks for corrupted headers. The input data format for this maker can be ANY of the formats below:
- DAQ format (from DAQ files)
- StEmcRawData format (StEvent)
- StEmcCollection (StEvent)
- StMuEmcCollection (muDST)
A light version of this maker (StEmcRawMaker) runs during production. StEmcRawMaker uses only DAQ or StEmcRawData format as input.
StPreEclMaker - This maker implements clustering of the BEMC detectors.
StEpcMaker - This maker matches the clusters in the BEMC detectors making what we call an StEmcPoint. It also matches tracks with points, if the input format is StEvent.
StEmcTriggerMaker - This maker simulates the BEMC level 0 trigger response using the plain ADC information from the towers. It works both with real and simulated data and it applies exactly the same trigger algorithm as in the BEMC hardware.
StEmcSimulatorMaker - This is the slow BEMC simulator. It takes an StMcEvent as input and fills the StEmcRawHit collections of StEvent with simulated ADC responses for all subdetectors.
StEmcCalibrationMaker - This is the maker used for BEMC calibration. It has methods to calculate pedestals for all the BEMC detectors as well as detector equalization, based on spectra shape and MIP analysis. This maker runs online as our online pedestal calculator.
StEmcMixerMaker - This maker is the basic BEMC embedding maker. It mixes hits from two StEvent objects in the memory. The hits from the second StEvent are mixed in the first one. It can run in a standard BFC embedding chain or as an afterburner (afterburner mode requires an event.root file from non-BEMC embedding plus a geant.root file containing BEMC information for simulated particles to be embedded).
StEmcTriggerMaker
Documentation provided by Renee FatemiMOTIVATION:
- Apply online trigger algorithm to simulated data
- Apply "software trigger" to triggered data
- Ensure that the same code is used for case 1. and 2.
How the Code Works:
StEmcTriggerMaker is the class that provides the user access functions to the trigger decisions. The workhorse is the StBemcTrigger class. StEmcTriggerMaker passes a StEvent pointer from either StEmcADCtoEMaker (real data) or StEmcSimulatorMaker (simulated data). The code accesses all offline status/ped/calibrations from StBemcTables, which are set in the macro used to run the code (ideal status/gain/ped can also be set). Code uses StEmcCollection to access ADC for all WEST BEMC channels which are not masked out with the status code and perform FPGA+L0 trigger on 12 bit ADC and 12 bit PED.
Access Function Examples:
// if event fulfills trigger return 1 else return 0 problems return -1
int is2005HT1() {return mIs2005HT1;}
int is2005JP1() {return mIs2005JP1;}
// The ID of the candidate HT (JP)
int get2005HT1_ID() {return HT1_ID_2005;}
int get2005JP1_ID() {return JP1_ID_2005;}
// The DSM ADC of the candidate HT (JP)
int get2005HT1_ADC() {return HT1_DSM_2005;}
int get2005JP1_ADC() {return JP1_DSM_2005;}
// The number of towers(patches) and the id’s which fulfill the trigger
void get2005HT1_TOWS(int, int*);//array of tow ids passing HT1_2005 trig
int get2005HT1_NTOWS() {return numHT1_2005;}//# tows passing HT1_2005 trig
void get2005JP1_PATCHES(int, int*);//array of patches passing JP1_2005
int get2005JP1_NPATCHES() {return numJP1_2005;}//# patches passing JP1_2005These access functions exist for 2003 HT1, 2004 HT1+JP1, 2005 HT1+HT2+JP1+JP2
CODE EXAMPLE:
//get trigger info
trgMaker=(StEmcTriggerMaker*)GetMaker("StEmcTriggerMaker");
HT1_2005_evt=-1;
HT1_2005_id=-1;
HT1_2005_dsm=-1;
numHT1_2005=0;
HT1_2005_evt=trgMaker->is2005HT1();
HT1_2005_id=trgMaker->get2005HT1_ID();
HT1_2005_dsm=trgMaker->get2005HT1_ADC();
numHT1_2005=trgMaker->get2005HT1_NTOWS();
for (int i=0;i<numHT1_2005;i++){
int towerid=-1;
trgMaker->get2005HT1_TOWS(i,&towerid);
HT1_2005_array[i]=towerid;
}COMMENTs for DISCUSSION:
Conceptually this code was designed from a software/analysis user point of view. Consequently I do not explicitly calculate and store all levels of DSM logic (it is unnecessary). From my understanding this is precisely what the StEmcTriggerDetector class was written to do -- return all DSM levels. It propagates all of the trigger information to the MuDst. BUT the problem is that this class is not propagated to the simulation (as far as I can tell). Even if it was propagated we probably wouldn’t want to take this option because it limits the usefulness of the simulation, whereas the StEmcTriggerMaker allows flexibility in applying the trigger algo to any simulation set. It is certainly possible code up the 2006 part of StEmcTriggerMaker to return all BEMC and EEMC trigger patch information at all levels of DSM, but it doesn’t exist in the current code.
Utilities
These are not Makers but codes that prove useful for BEMC analyses. The headings indicate where the codes can be found in the STAR source code repository.
StRoot/StDaqLib
EMC/StEmcDecoder
This utility converts the daq indexes for any BEMC detector (crate number, position in the crate, etc) in software ids (softId, module, eta, sub).
It also converts the Level-0 BEMC trigger patches ids in the corresponding tower crate number and index in the crate. It is quite useful to determine the correspondent tower that fired the trigger
StRoot/StEmcUtil
geometry/StEmcGeom
This class is used to convert softId in real eta and phi position in the detector and vice-versa. Also converts softId in module, eta and sub indexes that are used in StEvent.
It has methods to get geometrical information of the BEMC, such as number of channels, radius, etc. This is a very important utility in the BEMC software.
projection/StEmcPosition
Utility to project tracks in the BEMC detector
database/StBemcTables
Utility to load the database tables and get any information from them. It works only in makers running in the chain and has methods to return pedestal, calibrations, gain and status values for all the BEMC detectors. To use it do, in your maker:
// in the constructor. Supposing you have a private
// member StBemcTables *mTables;
mTables = new StBemcTables();
// in the InitRun() or Make() method
// this method loads all the BEMC tables
// it is necessary to have St_db_Maker running
mTables->loadTables((StMaker*)this);
// Getting information
// for example, getting pedestal and RMS for the
// BTOW Detector softId = 100
float ped = mTables->pedestal(BTOW, 100);
float rms = mTables->pedestalRMS(BTOW, 100);
database/StBemcTablesWriter
This class inherits from StBemcTables and is useful for performing all kinds of more advanced BEMC DB operations, including uploading tables if you've got the privileges for it.
I'm not sure if anyone is actually using the rest of these, nor am I confident that they actually work in DEV. Feel free to leave some feedback if you have some experience with them. -- Adam
hadBackground/StEmcEnergy
Utility to subtract hadronic energy from EMC towers. It uses StEmcHadDE to subtract the hadronic energy in the calorimeter in a event by event basis.
hadBackground/StEmcHadDE
Utility to calculate hadronic energy profile in the BEMC. It calculates the amount of energy deposited by a single hadron as a function of its momentum, position in the detector and distance to the center of the tower.
voltageCalib/VoltCalibrator
This utility calculates high voltages for the towers for a given absolute gain.
neuralNet/StEmcNeuralNet
Basic EMC neural network interface.
filters/StEmcFilter
Event filter for BEMC (StEvent and StMcEvent only)
This utility has a collection of tools to do event filtering in the BEMC. Some of the filters available are:
- basic event filter: vertex, multiplicity, etc
- tower filters: tower isolation filter, number of tracks in tower, energy cuts, tower energy and associated pt cuts, etc.
Useful Documents
A full list of attached documents is available below, but I wanted to highlight a few here:
BEMC Technical Design Report (PDF)
Run 9 BSMD Online Monitoring Documentation
For run 9, BSMD performance was monitored by looking at non-zero-suppressed events. The code is archived at /star/institutions/mit/wleight/archive/bsmdMonitoring2009/. This blog page will focus on the details of how to run the monitoring and the importance of various pieces of code involved in the monitoring. The actual monitoring plots produced are discussed here.
A few general notes to begin:
Since the code all sat in the same directory constantly, a number of directories have been hard-coded in. Please make sure to change these if necessary.
The code for actually reading in events is directly dependent on the RTS daq-reader structure: therefore it sits in StRoot/RTS/src/RTS_EXAMPLE/.
All compilation is done using makefiles.
Brief Description of the Codes:
This section lists all the pieces of code used and adds a one- or two-sentence description. Below is a description of the program flow which shows how everything fits together. Any other code files present are obsolete.
In the main folder:
runOnlineBsmdPSQA.py: The central script that runs everything.
onlBsmdPlotter.cxx and .h: The code that generates the actual monitoring plots. To add new plots, create a new method and call it from the doQA method.
makeOnlBsmdPlots.C: Runs the onlBsmdPlotter code.
GetNewPedestalRun.C: Finds the newest BSMD pedestal run by querying the database.
onlBsmdMonConstants.h: Contains some useful constants.
cleanDir.py: Deletes surplus files (postscript files that have been combined into pdfs, for instance). This script is NOT run by runOnlineBsmdPSQA.py and must be run seperately.
In the folder StRoot/RTS/src/RTS_EXAMPLE/
bsmdPedMonitor.C: Reads the pedestal file from evp and fills and saves to file the pedestal histograms, as well as generating ps and txt files describing the pedestals.
makeMapping.C: Creates a histogram that contains the mapping from fiber and rdo to softId and saves it to mapping.root. Unless the mapping changes or the file mapping.root is lost there is no need to run this macro.
onlBsmdMonitor.C: Reads BSMD non-zero-suppressed events as they arrive and creates a readBarrelNT object to fill histograms of pedestal-subtracted ADC vs. softId and capId, as well as rates and the number of zero-suppressed events per module. When the run ends, it saves the histograms to file and quits.
readBarrelNT.C and .h: This class does the actual work of filling the histograms: used by onlBsmdMonitor.C.
testBsmdStatus.C: Checks the quality of the most recent pedestal run and generates QA ps files.
rts_example.C: This is not used but serves as the template for all the daq-reading code.
Program Flow:
The central script, runOnlineBsmdPSQA.py, has a number of options when it is started:
Script Options
-p: print. This is a debugging option: it causes the code to print the ADC value for every channel.
-n: number of events (per run). Occasionally it is useful to limit the number of (non-zero-suppressed) events the monitoring program looks at for tests. During actual monitoring, we wished to catch all possible events so the script was always initialized with -n 1000000: the actual number of non-zero-suppressed events in a run is a few hundred at most.
-t: this option is not used in the current version of the code.
-r: raw data. This option was added during testing when online reading of pedestal files had not been implemented: if it is turned on then the code will not attempt to subtract pedestals from the data it reads.
-v: mpv cut. If a channel has MPV greater than this value, it is considered to have a bad MPV. The default is 5.
-m: mountpoint. For monitoring, the mounpoint is always set to /evp/. During tests, it may be useful not to have a mountpoint and read from a file instead, in which case no mountpoint will be given.
The standard initialization of the script for monitoring is then:
python runOnlineBsmdPSQA.py -n 1000000 -m /evp/
Usually the output is then piped to a log file. For testing purposes, as noted above, the -m option can be left off and the mountpoint replaced with a file name. (Side note: if neither a mountpoint nor a file name is given, the code will look for the newest file in the directory /ldaphome/onlmon/bsmd2009/daqData/, checking to be sure that the file does not have the same run number as that of the last processed run. This last option was implemented to allow for continuous processing of daq files but never actually used.)
The main body of the monitoring script is an infinite loop. This loop checks first to see what the current BSMD pedestal run is: if it is newer than the one currently used, the script processes it to produce the pedestal histograms that will be used by the data processing code. This process happens in several steps:
Pedestal Processing
Step 1: The script calls the C macro GetNewPedestalRun.C, passing it the time in Unix time format. The macro then queries the database for all pedestal runs over the last week. Starting with the most recent, it checks to see if the BSMD was present in the run: if so, the number of that run is written to the file newestPedRunNumber.txt and the macro quits.
Step 2: The script opens newestPedRunNumber.txt and reads the run number there. It then checks to see if the pedestals are up-to-date. If not, it moves to step 3.
Step 3: The script moves to StRoot/RTS/src/RTS_EXAMPLE/ and calls bsmdPedMonitor, passing it the evp location of the newest pedestal run, /evp/a/runnumber/ (bsmdPedMonitor does take a couple of options but those are never used). The main function of bsmdPedMonitor is to produce a root file containing three histograms (BSMDE, BSMDP, BPRS) each of which has a pedestal value for each softId-cap combination. The pedestal monitoring code starts by reading in the BSMD and BPRS status table (StatusTable.txt) and the mapping histogram (from the file mapping.root) which gives the mapping from fiber and rdo to softId. Then it goes into an infinite loop through the events in the file. In a pedestal file, the pedestals are stored in the event with token 0: therefore the code rejects events with non-zero token. Once it has the token-0 event, it loops through the fibers, grabs the pedestal and rms databanks for each fiber, and fills its histograms. Finally the code generates a text file that lists every pedestal and several ps files containing the pedestals plotted vs softId and cap.
Step 4: The script calls testPedStatus.C, passing it the root file just generated. This macro checks for each good channel to make sure that the pedestals and rms just obtained are within certain (hardcoded) limits. If the number of channels that have pedestal or rms outside of these limits is above a (hardcoded) threshold for a given crate, that crate is marked as bad. A ps file is generated containing a table in which crates are marked as good or bad with green or red and several more with softId vs cap histograms in which bad pedestals are marked in red.
Step 5: The postscript files are combined into pdfs (one for the pedestals and one for the statuses), which are, along with the text file, copied to the monitoring webpage. The index.html file for the monitoring webpage is updated to reflect that there are new pedestals and to link to the files generated from the new pedestal file. Finally, the variable containing the number of the old pedestal run is changed to that of the current pedestal run.
The next step is to call onlBsmdMonitor, which reads the events as they arrive. This code has several options:
Daq Reading Options:
-d: allows you to change the buillt-in rts log level.
-D: turns on or off printing: corresponds to -p from the script.
-m: mountpoint, the same as -m from the script.
-n: nevents, the same as -n from the script.
-l: last run, which tells the code what the last run was so that it knows when a new run is starting.
-r: raw data, same as -r from the script.
The script thus picks what options to give to onlBsmdMonitor from the options it was given, as well as from the value it has recorded for the last run number (1 if the script is starting up). Output from onlBsmdMonitor is piped to a log file named currentrun.log. OnlBsmdMonitor also consists of an infinite loop. As the loop starts, it gets the current event, checks to see if we are in a new run, and if so that this new run has the BSMD in. If so, it initializes a new instance of the class readBarrelNT, which does the actual processing, and then processes the event. If instead this is an already-occuring run, it checks to make sure that we have a new event, and if so processes it. If we are in between runs or the event is not new, the loop is simply restarted, in some cases after a slight delay. The main task of onlBsmdMonitor is to obtain histograms of pedestal-subtracted ADC vs softId and capId for the BPRS, BSMDE, and BSMDP and save them to a root file. It also histograms the rate at which events are arriving and the number of zero-suppressed events per module. The root file also contains a status histogram which is obtained from file StatusTable.txt. When the run is over, the histograms are written to file and onlBsmdMonitor quits, writing out a line to its log file to indicate its status at the point at which it ends.
The script now looks at the last line of the log file. If this line indicates that the run had no BSMD, a new entry in the monitoring webpag's table is created to reflect this fact. If not, the script first checks to see if we are in a new day: if so, a new line for this day is added to the webpage and a new table is started. The script then extracts the number of non-zero-suppressed BSMD events, the total number of events in the run, the number of ZS events, and the duration of the run from the last line of the log file. If the run is shorter than a (hardcoded) length cutoff, has no NZS BSMD events, or has fewer NZS BSMD events then a (hardcoded) threshold, the appropriate new line in the table is created, with each of the values obtained from the log file entered into the table, a link to the runlog added, and the problem with the run noted. If the run passes all quality checks, makeOnlBsmdPlots is called. This code generates the actual monitoring plots: the script then takes the resulting ps files, combines them into a pdf, and creates a new entry in the table with all the run information, a link to the pdf, a link to the run log, and a link to pedestal QA pdf. The plotting code requires to be given the mpv cut value and the elapsed time, as well as the name of the root file containing the histogram for the runs. Any new monitoring plots that are desired can be added by adding a method to create them to onlBsmdPlotter.h and onlBsmdPlotter.cxx and calling them in the method doQA. Having thus completed a run, the loop restarts.
Some BSMD hardware documents
Some BSMD hardware documents, below
EEMC
Archived Endcap web pages for years 1998 -2008 at MIT 'locker' |
New place for Endcap 'unprotected' analysis
2007 run, hardware changes
April 4, 5 pm, no beam:
We would like ETOW tcd phase set from 12->19 and EMSD from 55->65 , Jeff implemented it
Will's new table (to be implemented)
Towers
TCD box dec box hex
1. 19 18 0x12
2. 19 8 0x8
3. 19 86 0x56
4. 19 80 0x50
5. 19 43 0x2B
6. 19 31 0x1f
For EEMC MAPMT -- rather than change all 48 box configs we could
start out by just adding 10 ns to the phase: 55 -> 65.
new Tower config files in /home/online/mini/tcl/ you'll have to change symbolic links tower-1-current_beam_config.dat -> 03.01.07/tower-1-current_beam_config.dat
Jim: after 8094053 should have the new tcd phase and box configuration
----
The night shift took a 300k calibration run with the ETOW and ESMD Run 8095061
----
There is a shift log entry as to the run numbers and conditions.
I shifted only the tcd phase and used the new FEE configs installed
yesterday. This should show fall off by ~10-20% on each side in towers
and flat in MAPMTs.
run ETOW tcd ESMD tcd
8095096 19 65 30k std config, for 1st daq file ETWO head=off
8095097 1 55 30k
8095098 7 60 30k
8095099 13 60 30k
8095100 25 70 30k
8095101 31 75 30k
8095102 19 65 100k std config
8095103 19 65 0k std config died
8095104 19 65 28k std config
------ April 12----
I've made these changes in 2007Production2, 2006ProductionMinBias &
2007EMC_background
a. UPC ps --> 3
b. bht1 thresh --> 16
c. raised all triggers to production
d. changed all triggers based on zdc to different production ids
-Jeff
2008 run preparation
Timinng curves for ETOW & ESMD
Timing Scan 11/23/2007
Timing Scan 11/23/2007
EEMC timing scan was taken on11/23/2007.
To generate the curves, log into your favorite rcas node and
$ cvs co -D 11/27/2007 StRoot/StEEmcPool/StEEmcTimingMaker
and follow the instructions in the HOWTO
$ cat StRoot/StEEmcPool/StEEmcTimingMaker/HOWTO.l2ped
(tried to post code, but drupal wouldn't accept it...)
Will's notes on crate configuration:
FYI here are some (old) notes on how I set up config files
for EEMC tower timing scans that were taken a few days back (BTW,
these configs are still loaded).
1) Old running settings -- config files are on eemc-sc in directory
/home/online/mini/tcl with symbolic links:
tower-"n"-current_beam_config.dat ->
dir/tower-"n"-current_beam_config.dat
We had (I believe) been using directory 04.04.07 for the run with
ETOW TCD phase of 19; crate fifo (RHIC tic) 0x13. Those crate delay
settings are:
1 -> 0x12; 2 -> 0x8; 3 -> 0x56; 4 -> 0x50; 5 -> 0x2b; 6 -> 0x1f
2) new scan settings ... for time scans using only TCD phase
we usually create special config files with approprieate box delay and
TCD values.
nominal (ns) for (eff RHIC tic
run 7 scan ns)
1 -> 0x12 (18) 0x5a (-17) fifo 0x14 (e.g., 107-90)
2 -> 0x8 ( 8) 0x50 (-27) fifo 0x14 (e.g., 107-80)
3 -> 0x56 (86) 0x42 ( 66) fifo 0x13
4 -> 0x50 (80) 0x3c ( 60) fifo 0x13
5 -> 0x2b (43) 0x17 ( 23) fifo 0x13
6 -> 0x1f (31) 0xb ( 11) fifo 0x13
Here we have shifted crates "earlier" in time: 1&2 by 35 ns and
rest by 20 ns.Starting TCD scan at 5 then should start things
~ 34 (49) ns earlier than nominal with ~ 70 ns for scan to run
(suggested TCD: 5,10,15,25,35,45,55,65,75,70,60,50,40,30,20,10)
| 8327013 | 5 | 136k |
| 8327014 | 15 | 20k |
| 8327015 | 25 | 20k |
| 8327016 | 35 | 20k |
| 8327017 | 45 | 20k |
| 8327018 | 55 | 20k |
| 8327019 | 65 | 20k |
| 8327020 | 75 | 20k |
| 8327021 | 70 | 20k |
| 8327022 | 60 | 20k |
| 8327023 | 50 | 20k |
| 8327024 | 40 | 20k |
| 8327025 | 30 | 20k |
| 8327026 | 20 | 20k |
| 8327027 | 10 | 20k |
Figure 1 --Integral from ped+25 to ped+75, normalized to total number of events, versus TCD phase delay.

Channel-by-channel plots are attached below.
Timing Scan 11/27/2007 (MuDst)
Posted results are from MuDst data of 17 runs with 50K events in each run.
2, Run Summary
Run ETOW & ESMD phase (ns) # of Events (K)
8331091 5 200
1092 15 200
1094 25 200
1097 35 200
1098 45 200
1102 65 200
1103 75 200
1104 70 200
1105 60 200
1106 50 200
1107 40 200
1108 35 200
1109 30 200
1110 25 200
1111 20 200
2001 10 109
3, Crate Timing Curves
Fig. 1 Tower Crate. It agrees with results from L2 Data
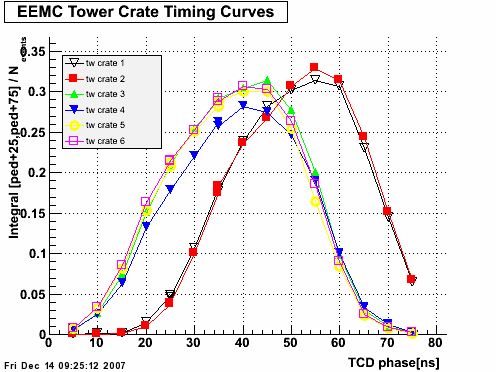
Fig. 2 Crate 64-67
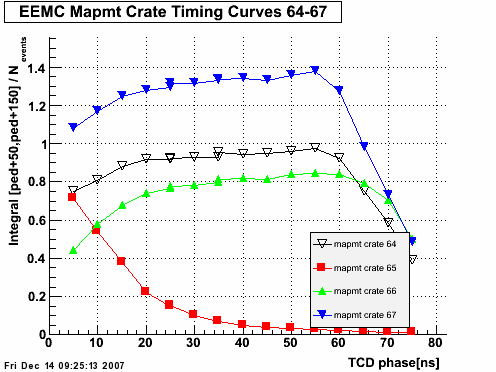
Fig. 3 Crate 68-71
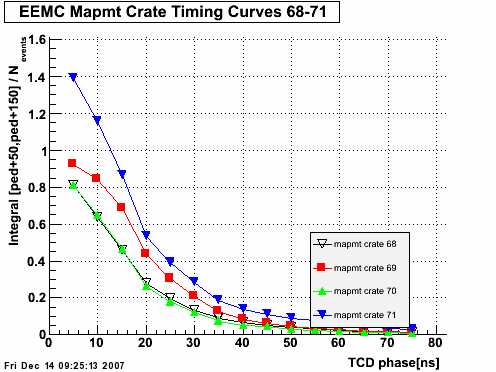
Fig. 4 Crate 72_75
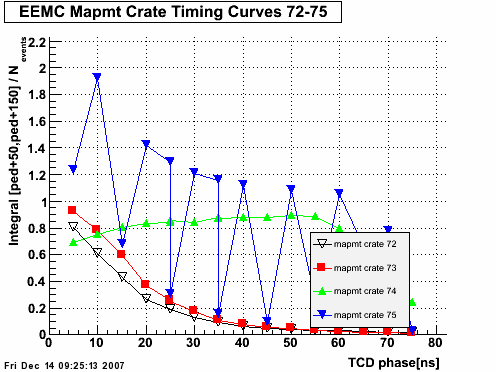
Fig. 5 Crate 76-79
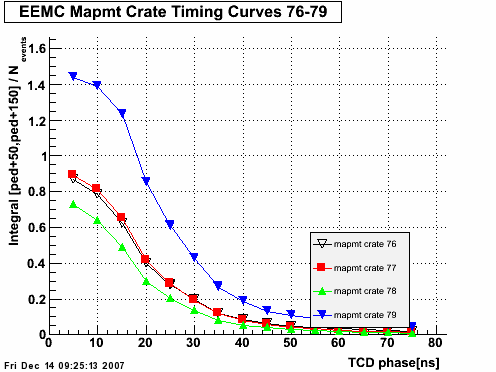
Fig. 6 Crate 80_83
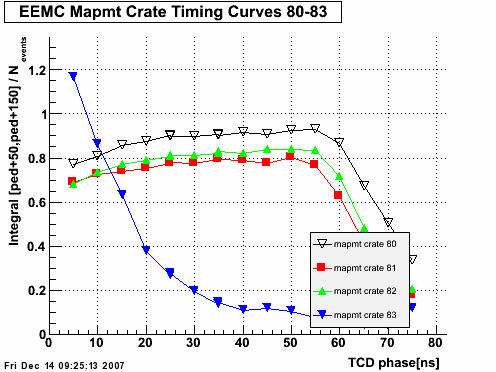
Fig. 7 Crate 84-87
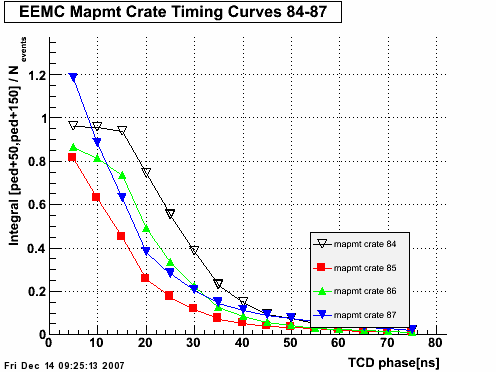
Fig. 8 Crate 88-91
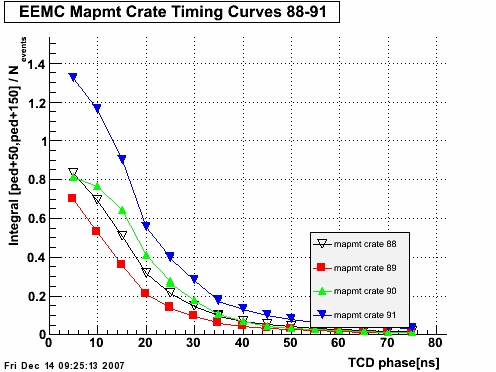
Fig. 9 Crate 92-95
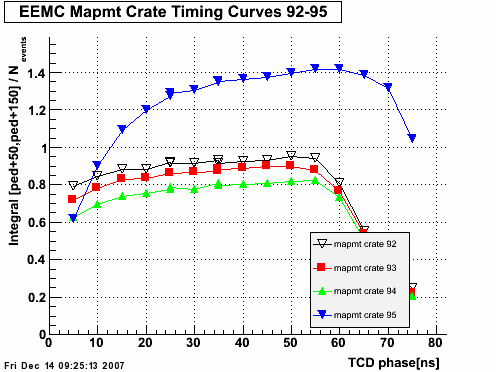
Fig. 10 Crate 96-99
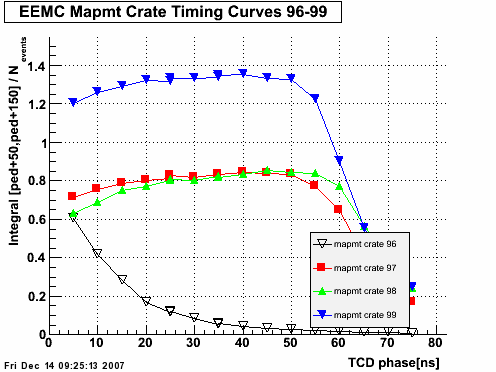
Fig. 11 Crate 100-103
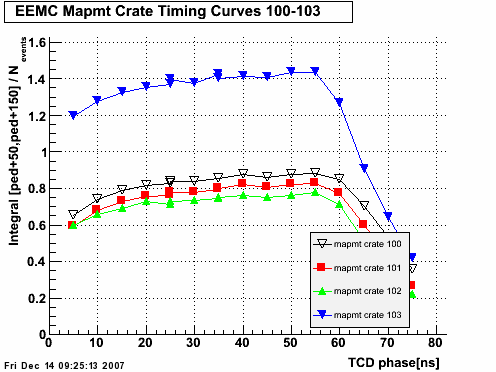
Fig. 12 Crate 104-107
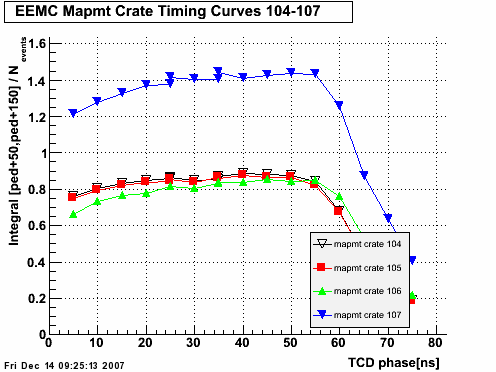
Fig. 13 Crate 108-111
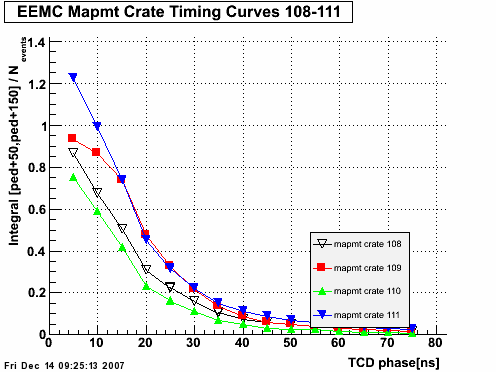
4, PDF Files of MAPMT Channel Timing Curve
tower-crate-1.pdf tower-crate-2.pdf tower-crate-3.pdf tower-crate-4.pdf tower-crate-5.pdf tower-crate-6.pdf
mapmt-crate-64.pdf mapmt-crate-65.pdf mapmt-crate-66.pdf mapmt-crate-67.pdf mapmt-crate-68.pdf mapmt-crate-69.pdf
mapmt-crate-70.pdf mapmt-crate-71.pdf mapmt-crate-72.pdf mapmt-crate-73.pdf mapmt-crate-74.pdf mapmt-crate-75.pdf
mapmt-crate-76.pdf mapmt-crate-77.pdf mapmt-crate-78.pdf mapmt-crate-79.pdf mapmt-crate-80.pdf mapmt-crate-81.pdf
mapmt-crate-82.pdf mapmt-crate-83.pdf mapmt-crate-84.pdf mapmt-crate-85.pdf mapmt-crate-86.pdf mapmt-crate-87.pdf
mapmt-crate-88.pdf mapmt-crate-89.pdf mapmt-crate-90.pdf mapmt-crate-91.pdf mapmt-crate-92.pdf mapmt-crate-93.pdf
mapmt-crate-94.pdf mapmt-crate-95.pdf mapmt-crate-96.pdf mapmt-crate-97.pdf mapmt-crate-98.pdf mapmt-crate-99.pdf
mapmt-crate-100.pdf mapmt-crate-101.pdf mapmt-crate-102.pdf mapmt-crate-103.pdf mapmt-crate-104.pdf mapmt-crate-105.pdf
mapmt-crate-106.pdf mapmt-crate-107.pdf mapmt-crate-108.pdf mapmt-crate-109.pdf mapmt-crate-110.pdf mapmt-crate-111.pdf
Timing Scan 11/29/2007
Timing Scan 11/29/2007
posted 11/30/2007 Shiftlog entryrun btow etow
8333113 12 5
115 17 15
116 22 25
117 27 35
118 32 45
120 37 55
121 42 65
123 52 70
124 57 60
125 62 50
126 36 40
127 36 30
128 36 20
129 36 10
Figure 1 -- Tower crates

Email from Will setting tower timing for this year
Below in the forwarded message you will see a link to the
analysis (thanks Jason) of the more recent (much better statistics)
EEMC tower timing scan. Based on these I set the timing for this year
as follows (from my shift log entry)
*************
> 11/30/07
> 19:49
>
> General
> new timing configuration files loaded for EEMC towers
> crate 1 delay 0x12 (no change from last year nominal)
> crate 2 delay 0x8 (no change)
> crate 3 delay 0x57 ( + 1 ns)
> crate 4 delay 0x52 (+ 2 ns)
> crate 5 delay 0x2b (no change)
> crate 6 delay 0x1f (no change)
> change ETOW phase to 21 (saved in all configs)
> above phase represents overall shift of + 2 ns
makeL2TimingFiles.pl
plotEEmcL2Timing.C
TFile *file = 0;
TChain *chain = 0;
#include <vector>
#include "/afs/rhic.bnl.gov/star/packages/DEV/StRoot/StEEmcUtil/EEfeeRaw/EEdims.h"
// summary TTree branches created by StEEmcTimingMaker
Int_t mRunNumber;
Float_t mTowerDelay;
Float_t mMapmtDelay;
Int_t mTotalYield;
Int_t mTowerCrateYield[MaxTwCrates];
Int_t mMapmtCrateYield[MaxMapmtCrates];
Int_t mTowerChanYield[MaxTwCrates][MaxTwCrateCh];
Int_t mMapmtChanYield[MaxMapmtCrates][MaxMapmtCrateCh];
Int_t mTowerMin;
Int_t mTowerMax;
Int_t mMapmtMin;
Int_t mMapmtMax;
// vectors to hold TGraphs for tower and mapmt crates
Int_t npoints = 0;
TGraphErrors *towerCrateCurves[MaxTwCrates];
TGraphErrors *mapmtCrateCurves[MaxMapmtCrates];
TGraphErrors *towerChanCurves[MaxTwCrates][MaxTwCrateCh];
TGraphErrors *mapmtChanCurves[MaxMapmtCrates][MaxMapmtCrateCh];
// enables printing of output files (gif) for documentation
// figures will appear in same subdirector as input files,
// specified below.
//Bool_t doprint = true;
Bool_t doprint = false;
void plotEEmcL2Timing( const Char_t *input_dir="timing_files/")
{
// chain files
chainFiles(input_dir);
// setup branches
setBranches(input_dir);
// get total number of points
Long64_t nruns = chain -> GetEntries();
npoints=(Int_t)nruns;
// setup the graphs for each crate and each channel
initGraphs();
// loop over all runs
for ( Long64_t i = 0; i < nruns; i++ )
{
chain->GetEntry(i);
fillCrates((int)i);
fillChannels((int)i);
}
// draw timing scan curves for tower crates
drawCrates();
// for ( Int_t ii=0;ii<MaxTwCrates;ii++ ) towerChannels(ii);
// for ( Int_t ii=0;ii<MaxMapmtCrates;ii++ ) mapmtChannels(ii);
std::cout << "--------------------------------------------------------" << std::endl;
std::cout << "to view timing curves for any crate" << std::endl;
std::cout << std::endl;
std::cout << "towerChannels(icrate) -- icrate = 0-5 for tower crates 1-6"<<std::endl;
// std::cout << "mapmtChannels(icrate) -- icrate = 0-47 for mapmt crates 1-48"<<std::endl;
std::cout << "print() -- make gif/pdf files for all crates and channels"<<std::endl;
}
// ----------------------------------------------------------------------------
void print()
{
doprint=true;
drawCrates();
for ( Int_t ii=0;ii<MaxTwCrates;ii++ ) towerChannels(ii);
//for ( Int_t ii=0;ii<MaxMapmtCrates;ii++ ) drawMapmt(ii);
}
// ----------------------------------------------------------------------------
void drawCrates()
{
// tower crates first
TCanvas *towers=new TCanvas("towers","towers",500,400);
const Char_t *opt[]={"ALP","LP","LP","LP","LP","LP"};
TLegend *legend=new TLegend(0.125,0.6,0.325,0.85);
Float_t ymax=0.;
for ( Int_t icr=0;icr<MaxTwCrates;icr++ )
{
towerCrateCurves[icr]->Sort();
towerCrateCurves[icr]->Draw(opt[icr]);
TString crname="tw crate ";crname+=icr+1;
legend->AddEntry( towerCrateCurves[icr], crname, "lp" );
if ( towerCrateCurves[icr]->GetYaxis()->GetXmax() > ymax )
ymax=towerCrateCurves[icr]->GetYaxis()->GetXmax();
}
towerCrateCurves[0]->SetTitle("EEMC Tower Crate Timing Curves");
towerCrateCurves[0]->GetXaxis()->SetTitle("TCD phase[ns]");
TString ytitle=Form("Integral [ped+%i,ped+%i] / N_{events}",mTowerMin,mTowerMax);
towerCrateCurves[0]->GetYaxis()->SetTitle(ytitle);
towerCrateCurves[0]->GetYaxis()->SetRangeUser(0.,ymax);
legend->Draw();
if(doprint)towers->Print("tower_crates.gif");
}
// ----------------------------------------------------------------------------
void mapmtChannels( Int_t crate )
{
static const Int_t stride=16;
Int_t crateid = MinMapmtCrateID+crate;
TString fname="mapmt-crate-";fname+=crate+MinMapmtCrateID;fname+=".ps";
TCanvas *canvas=new TCanvas("canvas","canvas",850/2,1100/2);
canvas->Divide(1,2);
Int_t icanvas=0;
for ( Int_t ich=0;ich<192;ich+=stride )
{
canvas->cd(1+icanvas%2);
icanvas++;
TString pname="crate";
pname+=crateid;
pname+="_ch";
pname+=ich;
pname+="-";
pname+=ich+stride-1;
const Char_t *opts[]={"ALP","LP","LP","LP","LP","LP","LP","LP","LP","LP","LP","LP","LP","LP","LP","LP","LP","LP","LP","LP","LP"};
// normalize
Float_t ymax=0.0;
Double_t sum[stride];for ( Int_t jj=0;jj<stride;jj++ )sum[jj]=0.;
Double_t max=0.;
for ( Int_t jch=0;jch<stride;jch++ ) // loop over channels in this one graph
{
Int_t index=ich+jch;
Double_t *Y=mapmtChanCurves[crate][index]->GetY();
for ( Int_t ipoint=0;ipoint<npoints;ipoint++ ) {
if ( Y[ipoint]>ymax ) ymax=Y[ipoint];
sum[jch]+=Y[ipoint];
}
if ( sum[jch]>max ) max=sum[jch];
}
if ( max <= 0. ) continue; // meh?
TLegend *legend=new TLegend(0.55,0.11,0.85,0.525);
for ( Int_t jch=0;jch<stride;jch++ )
{
Int_t index=ich+jch;
mapmtChanCurves[crate][index]->SetMarkerSize(0.75);
// offset X axis of each of these
Double_t *X=mapmtChanCurves[crate][index]->GetX();
Double_t *Y=mapmtChanCurves[crate][index]->GetY();
Double_t *EY=mapmtChanCurves[crate][index]->GetEY();
if ( sum[jch]<= 0. ) continue;
// std::cout<<"before"<<std::endl;
for ( Int_t ip=0;ip<npoints;ip++ ){
Float_t shift = 0.5+ ((float)jch) - ((float)stride)/2.0;
Double_t yy=Y[ip];
X[ip]-= 0.1*shift;
Y[ip]*=max/sum[jch];
EY[ip]*=max/sum[jch];
// std::cout << "ip="<<ip<<" y="<<yy<<" y'="<<Y[ip]<<std::endl;
}
mapmtChanCurves[crate][index]->Sort();
if ( !jch )
mapmtChanCurves[crate][index]->GetXaxis()->SetRangeUser(0.,ymax*1.05);
mapmtChanCurves[crate][index]->SetMarkerColor(38+jch);
mapmtChanCurves[crate][index]->SetLineColor(38+jch);
mapmtChanCurves[crate][index]->SetMinimum(0.);
mapmtChanCurves[crate][index]->Draw(opts[jch]);
TString label="crate ";label+=crate+1;label+=" chan ";label+=index;
legend->AddEntry(mapmtChanCurves[crate][index],label,"lp");
}
legend->Draw();
canvas->Update();
// if(doprint)c->Print(pname+".gif");
if ( !(icanvas%2) ){
canvas->Print(fname+"(");
canvas->Clear();
canvas->Divide(1,2);
}
// if(doprint)c->Print(pname+".gif");
}
canvas->Print(fname+")");
gSystem->Exec(TString("ps2pdf ")+fname);
}
// ----------------------------------------------------------------------------
void towerChannels( Int_t crate )
{
static const Int_t stride=12;
TString fname="tower-crate-";fname+=crate+1;fname+=".ps";
TCanvas *canvas=0;
canvas = new TCanvas("canvas","canvas",850/2,1100/2);
canvas->Divide(1,2);
Int_t icanvas=0;
for ( Int_t ich=0;ich<120;ich+=stride )
{
canvas->cd(1+icanvas%2);
icanvas++;
// TString aname="crate";aname+=crate;aname+=" channels ";aname+=ich;aname+=" to ";aname+=ich+stride-1;
// TCanvas *c = new TCanvas(aname,aname,400,300);
TString pname="crate";
pname+=crate+1;
pname+="_ch";
pname+=ich;
pname+="-";
pname+=ich+stride-1;
const Char_t *opts[]={"ALP","LP","LP","LP","LP","LP","LP","LP","LP","LP","LP","LP","LP","LP","LP","LP"};
// normalize
Double_t sum[stride];for ( Int_t jj=0;jj<stride;jj++ )sum[jj]=0.;
Double_t max=0.;
for ( Int_t jch=0;jch<stride;jch++ ) // loop over channels in this one graph
{
Int_t index=ich+jch;
Double_t *Y=towerChanCurves[crate][index]->GetY();
for ( Int_t ipoint=0;ipoint<npoints;ipoint++ ) sum[jch]+=Y[ipoint];
if ( sum[jch]>max ) max=sum[jch];
}
if ( max <= 0. ) continue; // meh?
TLegend *legend=new TLegend(0.125,0.15,0.325,0.45);
for ( Int_t jch=0;jch<stride;jch++ )
{
Int_t index=ich+jch;
towerChanCurves[crate][index]->SetMarkerSize(0.75);
// offset X axis of each of these
Double_t *X=towerChanCurves[crate][index]->GetX();
Double_t *Y=towerChanCurves[crate][index]->GetY();
Double_t *EY=towerChanCurves[crate][index]->GetEY();
if ( sum[jch]<= 0. ) continue;
// std::cout<<"before"<<std::endl;
for ( Int_t ip=0;ip<npoints;ip++ ){
Float_t shift = 0.5+ ((float)jch) - ((float)stride)/2.0;
Double_t yy=Y[ip];
X[ip]-= 0.1*shift;
Y[ip]*=max/sum[jch];
EY[ip]*=max/sum[jch];
// std::cout << "ip="<<ip<<" y="<<yy<<" y'="<<Y[ip]<<std::endl;
}
towerChanCurves[crate][index]->Sort();
towerChanCurves[crate][index]->SetMinimum(0.);
towerChanCurves[crate][index]->SetMarkerColor(38+jch);
towerChanCurves[crate][index]->SetLineColor(38+jch);
towerChanCurves[crate][index]->Draw(opts[jch]);
TString label="crate ";label+=crate+1;label+=" chan ";label+=index;
legend->AddEntry(towerChanCurves[crate][index],label,"lp");
}
legend->Draw();
canvas->Update();
// if(doprint)c->Print(pname+".gif");
if ( !(icanvas%2) ){
if ( doprint ) canvas->Print(fname+"(");
canvas->Clear();
canvas->Divide(1,2);
}
}
if ( doprint ) {
canvas->Print(fname+")");
gSystem->Exec(TString("ps2pdf ")+fname);
}
}
// ----------------------------------------------------------------------------
void fillCrates(Int_t ipoint)
{
#if 1
// loop over tower crates
for ( Int_t icr=0;icr<MaxTwCrates;icr++ )
{
Float_t yield = (Float_t)mTowerCrateYield[icr];
Float_t total = (Float_t)mTotalYield;
if ( total > 10.0 ) {
Float_t eyield = TMath::Sqrt(yield);
Float_t etotal = TMath::Sqrt(total);
Float_t r = yield / total;
Float_t e1 = (yield>0)? eyield/yield : 0.0;
Float_t e2 = etotal/total;
Float_t er = r * TMath::Sqrt( e1*e1 + e2*e2 );
towerCrateCurves[icr]->SetPoint(ipoint, mTowerDelay, r );
towerCrateCurves[icr]->SetPointError( ipoint, 0., er );
}
else {
towerCrateCurves[icr]->SetPoint(ipoint, mTowerDelay, -1.0 );
towerCrateCurves[icr]->SetPointError( ipoint, 0., 0. );
}
}
// loop over mapmt crates
for ( Int_t icr=0;icr<MaxMapmtCrates;icr++ )
{
Float_t yield = (Float_t)mMapmtCrateYield[icr];
Float_t total = (Float_t)mTotalYield;
if ( total > 10.0 ) {
Float_t eyield = TMath::Sqrt(yield);
Float_t etotal = TMath::Sqrt(total);
Float_t r = yield / total;
Float_t e1 = (yield>0)? eyield/yield : 0.0;
Float_t e2 = etotal/total;
Float_t er = r * TMath::Sqrt( e1*e1 + e2*e2 );
mapmtCrateCurves[icr]->SetPoint(ipoint, mMapmtDelay, r );
mapmtCrateCurves[icr]->SetPointError( ipoint, 0., er );
}
else {
mapmtCrateCurves[icr]->SetPoint(ipoint, mMapmtDelay, -1. );
mapmtCrateCurves[icr]->SetPointError( ipoint, 0., 0. );
}
}
#endif
}
// ----------------------------------------------------------------------------
void fillChannels(Int_t ipoint)
{
#if 1
// loop over tower crates
for ( Int_t icr=0;icr<MaxTwCrates;icr++ )
{
for ( Int_t ich=0;ich<MaxTwCrateCh;ich++ )
{
Float_t yield = (Float_t)mTowerChanYield[icr][ich];
Float_t total = (Float_t)mTotalYield;
if ( total > 10.0 ) {
Float_t eyield = TMath::Sqrt(yield);
Float_t etotal = TMath::Sqrt(total);
Float_t r = yield / total;
Float_t e1 = (yield>0)? eyield/yield : 0.0;
Float_t e2 = etotal/total;
Float_t er = r * TMath::Sqrt( e1*e1 + e2*e2 );
towerChanCurves[icr][ich]->SetPoint(ipoint, mTowerDelay, r );
towerChanCurves[icr][ich]->SetPointError( ipoint, 0., er );
}
else {
towerChanCurves[icr][ich]->SetPoint(ipoint, mTowerDelay, -1.0 );
towerChanCurves[icr][ich]->SetPointError( ipoint, 0., 0. );
}
}
}
#endif
#if 1
// loop over mapmt crates
for ( Int_t icr=0;icr<MaxMapmtCrates;icr++ )
{
for ( Int_t ich=0;ich<MaxMapmtCrateCh;ich++ )
{
Float_t yield = (Float_t)mMapmtChanYield[icr][ich];
Float_t total = (Float_t)mTotalYield;
if ( total > 10.0 ) {
Float_t eyield = TMath::Sqrt(yield);
Float_t etotal = TMath::Sqrt(total);
Float_t r = yield / total;
Float_t e1 = (yield>0)? eyield/yield : 0.0;
Float_t e2 = etotal/total;
Float_t er = r * TMath::Sqrt( e1*e1 + e2*e2 );
mapmtChanCurves[icr][ich]->SetPoint(ipoint, mMapmtDelay, r );
mapmtChanCurves[icr][ich]->SetPointError( ipoint, 0., er );
}
else {
mapmtChanCurves[icr][ich]->SetPoint(ipoint, mMapmtDelay, -1.0 );
mapmtChanCurves[icr][ich]->SetPointError( ipoint, 0., 0. );
}
}
}
#endif
}
// ----------------------------------------------------------------------------
void initGraphs()
{
for ( Int_t i=0;i<MaxTwCrates;i++ ){
towerCrateCurves[i] = new TGraphErrors(npoints);
towerCrateCurves[i]->SetMarkerStyle(20+i);
towerCrateCurves[i]->SetMarkerColor(i+1);
towerCrateCurves[i]->SetLineColor(i+1);
for ( Int_t j=0;j<MaxTwCrateCh;j++ )
towerChanCurves[i][j]=(TGraphErrors*)towerCrateCurves[i]->Clone();
}
for ( Int_t i=0;i<MaxMapmtCrates;i++ ){
mapmtCrateCurves[i]= new TGraphErrors(npoints);
mapmtCrateCurves[i]->SetMarkerStyle(20+i%4);
mapmtCrateCurves[i]->SetMarkerColor(1+i%4);
mapmtCrateCurves[i]->SetLineColor(1+i%4);
for ( Int_t j=0;j<MaxMapmtCrateCh;j++ )
mapmtChanCurves[i][j]=(TGraphErrors*)mapmtCrateCurves[i]->Clone();
}
}
// ----------------------------------------------------------------------------
void chainFiles(const Char_t *path)
{
chain=new TChain("timing","Timing summary");
TFile *tfile = 0;
std::cout << "chaining files in " << path << std::endl;
TSystemDirectory *dir = new TSystemDirectory("dir",path);
TIter next( dir->GetListOfFiles() );
TObject *file = 0;
while ( file = (TObject*)next() )
{
TString name=file->GetName();
// sum the event counter histogram
if ( name.Contains(".root") ) {
// open the TFile and
std::cout << " + " << name << std::endl;
// tfile = TFile::Open(name);
chain->Add(name);
}
}
}
// ----------------------------------------------------------------------------
void setBranches(const Char_t *dir)
{
chain->SetBranchAddress("mRunNumber", &mRunNumber );
chain->SetBranchAddress("mTowerDelay", &mTowerDelay );
chain->SetBranchAddress("mMapmtDelay", &mMapmtDelay );
chain->SetBranchAddress("mTotalYield", &mTotalYield );
chain->SetBranchAddress("mTowerCrateYield", &mTowerCrateYield );
chain->SetBranchAddress("mMapmtCrateYield", &mMapmtCrateYield );
chain->SetBranchAddress("mTowerChanYield", &mTowerChanYield );
chain->SetBranchAddress("mMapmtChanYield", &mMapmtChanYield );
chain->SetBranchAddress("mTowerMin",&mTowerMin);
chain->SetBranchAddress("mTowerMax",&mTowerMax);
chain->SetBranchAddress("mMapmtMin",&mMapmtMin);
chain->SetBranchAddress("mMapmtMax",&mMapmtMax);
}
runEEmcL2Timing.C
Calibrations
New EEMC Calibrations Page
2007 EEMC Tower Gains
Run 7 EEMC Tower Gains - Using Slopes
Goals: Use "inclusive slopes" from fast-detector only, min-bias runs to determine relative (eta-dependent) gains for all EEMC towers for the 2007 run. More specifically, analyze ~30k events from run 8095104 (thanks to Jan [production] and Jason [fitting] !), fit slopes to all ungated tower spectra, in order to:
- check if new / replaced PMT's (only 2 for this year) need significant HV adjustment
- make sure tubes with new / replaced bases are working properly
- search for towers with unusual spectra, anomalous count rates, or slopes that are far from the norm for that eta bin
- compare individual slopes to 2006 absolute gains (from mips) for each eta bin, to test robustness and stability of gain determinations
- for tower gains far from ideal (as determined with slopes and/or mips) consider adjusting HV
- look for anything else that seems out of whack!
Definitions:
For the gain calibration of towers, we will use
- x = channel number = ADC - ped
- E = full e.m. energy (GeV) = (deposited energy / sampling fraction) for e.m. particles
- G = absolute gain (channels / GeV) including sampling fraction
So: E = x / G
For slopes, raw spectra (y vs. x) are fit to: y = A e-bx
Thus, one expects that for a given eta bin: G ~ 1 / b
Results:
1. Two new tubes are fine! Slopes of recently replaced PMT's 04TB12 and 12TE06 are very close to those of neighboring towers at same eta, or those of same subsector in the neighboring sector:
| towerID | integral | slope | error |
| 03TB12 | 2003 | -0.04144 | 0.00181 |
| 04TA12 | 2081 | -0.04527 | 0.00177 |
| 04TB12 | 2022 | -0.04400 | 0.00173 |
| 04TC12 | 2195 | -0.03825 | 0.00170 |
| 05TB12 | 2056 | -0.04465 | 0.00177 |
| towerID | integral | slope | error |
| 11TE06 | 2595 | -0.04157 | 0.00162 |
| 12TD06 | 1965 | -0.05977 | 0.00185 |
| 12TE06 | 2535 | -0.04516 | 0.00165 |
| 01TA06 | 2124 | -0.05230 | 0.00179 |
| 01TE06 | 2070 | -0.05342 | 0.00190 |
More global comparisons to all the tower slopes in the same eta bin are given below. For both tubes, the gain is 5-10% lower than average, but well within useful range.
2. Change of base (same PMT) has little effect on tower gains. This has been confirmed for the six bases that were changed (03TA09, 06TB04, 10TE01, 12TA01, 12TC11, 12TE06), using the same comparisons to neighboring towers used in step 1 above.
3. For all 720 towers, comparison of 2007 slopes to 2006 mip-based absolute gains indicates about 6 problem towers (most "well known")
- 06TA03 - no useful mip results, fitted slope was positive! Spectra never make much sense.
- 08TC05 - didn't work last year, still not working! Spectra shows only a pedestal.
- 07TC05 - no gain determined in 2005 or 2006. Has largest slope of all towers, probably useless.
- 06TD11 - each year, everything gets replaced; each year it continues to be 'flakey,' sometimes working, sometimes not.
- 12TD01 - seemed okay last year, now has a very small slope. Maybe PMT is dying fast?
- 10TA11 - worked fine last year, recently died. HV off, only a pedestal.
In addition, 09TE01 seems to be working now, though it failed the mip gain analysis last year, and hasn't been 'fixed.'
All of these cases are easily seen in the following correlation plot:

4. See clear correlations, within each eta bin, between new (2007) slope analysis, last year's mip analysis -> gains are stable, methods are robust! On vertical scale, solid magenta line = ideal gain for that bin, dashed = +/- 15%
eta bin | correlation plot | comments |
| 1 | .gif | one high gain tube (10TA01), reasonable correlation, no obvious problems |
| 2 | .gif | looks okay, all within +/- 20% of ideal gains |
| 3 | .gif | pretty ratty - several towers ~15% off 'correlation' curve |
| 4 | .gif | one very low gain tube (01TA04), one with very small slope (02TD04), otherwise all okay |
| 5 | .gif | a couple of high-gain towers, correlation is very good |
| 6 | .gif | one low gain, a few high-gain, but good correlation. New PMT 12TE06 looks reasonable |
| 7 | .gif | overall gains a bit high compare to ideal, no real problems |
| 8 | .gif | no problems |
| 9 | .gif | no problems |
| 10 | .gif | strong correlations, tight clustering in both gain sets |
| 11 | .gif | odd shape, but okay. Only problem (lower left corner) is 06TD11 |
| 12 | .gif | everything a bit noisier, gains ~7% high overall. New PMT 04TB12 fits right in! |
5. Number of 'gain outliers' is quite small, deviation of average from ideal always < 10%. Because the endcap towers are not used for trigger decisions, no obvious advantage in making HV adjustments to large number of towers.
Conclusion: Endcap towers are in good shape! A very small number (~6 / 720) are not working well, but for these few, HV adjustment would not solve the problem. No strong argument for changing HV on any particular tube at this point.
N.B. For each eta bin, one can calculate the ratio R = G / (1/b) as a 'conversion' of slope data to absolute gains. Using the 2006 mip calibration and the 2007 slopes, one gets a fairly smooth curve, though something seems to be happening around eta bin 8.

Calculating EEMC pedestal and status tables
The instructions below are based entirely on code which exists in CVS and not any private directories.
% cvs co StRoot/StEEmcPool/StEEmcDAQ2Ped % cvs co StRoot/StEEmcPool/StEEmcPedFit % cvs co StRoot/StEEmcPool/StEEmcStatus
% cons
% cp StRoot/StEEmcPool/StEEmcDAQ2Ped/macros/plDAQ2Ped.C ./ % cp StRoot/StEEmcPool/StEEmcPedFit/macros/fitAdc4Ped.C ./ % cp StRoot/StEEmcPool/StEEmcPedFit/macros/procDAQ2Ped.sh ./ % cp StRoot/StEEmcPool/StEEmcStatus/macros/pedStat.C ./ % cp StRoot/StEEmcPool/StEEmcStatus/macros/procPedStat.sh ./
% ./procDAQ2Ped.sh
% ./procPedStat.sh
% cd StatFiles/ % ./procErrs.sh
Calculating EEMC tower ideal gains and expected MIP response
This is a quick summary of how one goes from a measured MIP peak to a final tower gain.
In the attached spreadsheet, I use the EEMC tower boundaries in eta (lower table) to determine the average eta per bin and the ideal gain in each bin, assuming our goal ("ideal") is to have an e.m. shower of transverse energy ET = 60 GeV saturate the 12-bit ADC, that is, land in channel 4096. This calculation is independent of assumed sampling fraction. The result appears in column H in the lower table, and is highlighted in yellow.
For a calibration based on MIP's, we also need to know the actual energy deposited by the MIP as it traverses all of the scintillator layers, so we need to know the total thickness of scintillator (for normal incidence) and the dE/dx of a MIP. These values appear in cells L5 and M5, respectively. All calculations are keyed to these cells, so changing these cells will propagate to all other columns.
Finally, to connect ideal gains with MIP energy depositions (so we can arrive at the quantity of direct interest for a MIP-based calculation: in which ADC channel (above pedestal) should the MIP peak appear?), we also need to know the calorimeter sampling fraction. I have used 5%, which is in cell G5. Again, changing this one cell value will fill the rest of the tables accordingly.
With these assumed values (60 GeV, 4096 channels, 99 mm, 0.20 MeV/mm, 5% - all in row 5) one can now determine the ADC channel (above pedestal) in which the MIP peak will appear, if the gain is "ideal". These are given in column N of the upper table and highlighted. For each tower, the ratio of the actual (measured / fit) MIP peak channel to this ideal channel is the factor by which the ideal gain needs to be multiplied to arrive at the "true gain" per tower, which is what is loaded into the database.
N.B. I just cut and pasted these two tables together, so there is some overlap between them. Several columns relate to estimating number of photo-electrons (pe) and high voltage (HV) and can be ignored.
EEMC Calibration Docs
This page is meant for centralizing all EEMC calibration documents.
Calibrations through 2007(MIT locker): web.mit.edu/rhic-spin/public/eemc-bnl/calibration/
Alice B.'s calibration code blog: https://drupal.star.bnl.gov/STAR/blog/aliceb/2010/oct/08/updated-eemc-calibration-code
Ting Lin's updated MIP calibration instructions: eemc_code_instruction_by_Ting_2.pdf
EEMC Tower Swaps
During the EEMC MIP calibration, we find that some of the EEMC cables are swaped.
Swaps in database:(This has been implemented during the production, you do not need to worried about these.)
1. mapping=S1 rot, P1 as in sect=5, swap TA4-5, QA11-B2, JB;
2. mapping=swap V209:216, V216-280, V265:272, Bob
3. mapping=swap 10TD04 with 10TD06, Ting and Mike(Not valid before 2015-08-13)
Swap towers found From MIP calibration:
2009 pp200:
10TD06 <=> 10TD04
11TE10 <=> 11TE12
2012 & 2013:
10TD04 <=> 10TD06
11TC05 <=> 11TC07
11TB04 <=> 11TB06
04TB01 <=> 04TB12
04TB02 <=> 04TB11
04TB03 <=> 04TB10
04TB04 <=> 04TB09
04TB05 <=> 04TB08
04TB06 <=> 04TB07
Suggestion:
You can remap the towers in your own analysis.
For example, in Jet analysis, add a small piece of code before you record the tower Id in StRoot/StJetMaker/mudst/StjEEMCMuDst.cxx at line 84.
/////////////////////////////////////////// Sample Code ////////////////////////////////////////////////////////
Overview for generating EEMC pedestals and status tables
This is an informal overview of the 'philosophy' used to generate pedestals and status tables for the STAR endcap EMC, and in particular the ESMD.
For the EEMC offline database, the default protocol is to store one set of pedestals and status tables per fill for the ppruns. In general, this information is updated less frequently for heavy-ion running, depending on user demand. For the endcap, other database information, such as detector mapping and gains, will apply for much longer timescales (like years, or at least a whole run), and so there may be a single database entry for an entire running period.
Focusing on the smd strips, our guiding assumptions are prettysimplistic: First, strips that have constant problems (i.e., thosethatstay bad after their crate is reconfigured or power-cycled, forexample)are easy to catch, and will be flagged as bad no matter what data areused for QA. These aren't the concern. The messier case is whenchannels suddenly go bad, but can be recovered later (by power-cycling,etc.). We assume that these sorts of problems, which tend to affectanentire FEE card and not individual channels, can occur at any timewhilerunning, but especially at the very start of a fill during tuning andcollimation of the beams. These problems don't often fix themselves,and so will remain until action is taken - which usually occurs onlybetween fills.
For the smd strip pedestals and status tables, we analyze one min-biasrun per fill, preferably one taken near the end of the fill. Guidedbythe above ideas, we assume that by this time we have 'accumulated' allthe problems that will arise during the fill, and we will mark them asbad for the entire fill. This means that any strip that died ordeveloped some problem _during_ the fill is marked as bad even for theruns early in the fill when it was still working. So it is aconservative approach: If a strip was malfunctioning near the end ofthe fill, we assume it was bad for the entire fill. It is clear that if suchproblems are only cured in-between fills, this all makes sense. If aproblem is truly intermittent, however, and comes and goes from run to run, then in this approach we might catch it, or we could easily miss it.
Updating the status information in the database on shorter timescales, or basingeach entry onmore than one run per fill (e.g., take an OR of problems found at thestart and at the end of each fill), is certainly possible - it justrequires more time and effort. At this point, we don't plan to change our protocol unless new and unexpected time dependences are observed for problems that don't fit into our model of channels breaking and being 'fixed.' I don't think our current assumptionsaretotally screwy. Just from watching the P-plots, one can see that theendcap smd spectra start to get 'ratty' after a few fills, as more and moregroups of four strips (which are consecutive in DAQ and P-plots, but not in the physicaldetector) start to drift around in their pedestal, or go south in someothermanner. After a thorough re-cycling, most of these problems can befixed, so things look pretty good again at the start of the next fill.
Nevertheless, at the end of the day, the most relevant question for the endcap status tables is "are we doing well enough?" and the best feedback comes from doing real analysis. So the more that people stare at spectra and find new problems,especially those with unexpected time dependences, the better we candesign our QA algorithms and protocol to identify and keep track ofthem. No matter what sorts of problems we have found in the past ormight have anticipated, nature always finds new ones, and werely on users to point these out.
Producing ADC distributions for the EMCs from raw DAQ files
For calibrations of the EMCs (eg. pedestals, status, relative gains) it is often useful to look at raw ADC distributions from a sample of minimum bias events. This can be done simply by analyzing the MuDsts once production has occured, but if one wants to proceed with calibrations before production occurs it often faster to use the raw DAQ files to produce these simple ADC distributions summed over many events. The instructions below describe an adaptation of the general daq reader (provided by Tonko et. al.) used specifically to produce these distributions.
int trigID[2]={A,B};
1 2 4 8 16 32 64 128 256 512 1024 2048... 1 2 4 8 10 20 40 80 100 200 400 800...
So for example, for the emc-check runs in Run 13,

the line should be trigID[2]={1024,0};
1) Check out the macro from cvs:
% cvs co StRoot/StEEmcPool/macros/DaqReader
2) Copy the relevant macros and scripts to your working directory:
% cp StRoot/StEEmcPool/macros/DaqReader/compile.sh ./ % cp StRoot/StEEmcPool/macros/DaqReader/emchist.C ./ % cp StRoot/StEEmcPool/macros/DaqReader/submitAll.sh ./ % cp StRoot/StEEmcPool/macros/DaqReader/addFiles.sh ./
3) Compile the macro by using the compile.sh script:
% ./compile.sh emchist.C
./emchist /star/data03/daq/2012/100/13100049w_js/st_W_13100049_raw_1340001.daq
Run 10 EEMC Calibrations
Run 11 EEMC Calibrations
This is the main page for all EEMC calibration information for Run 11
EEMC HV adjustments for "outliers"
EEMC HV adjustments for "outliers"
Using the sums method (similar to Run 9 analysis) Scott Identified some outliers who's gains were either too high or too low compared to other towers in the same eta ring. The list of towers is below in two different groups 1) known bad channels and 2) channels to adjust HV.
1) Known bad channels:
06TA03, 02TC06, 07TC05 -> all reported to still be bad and masked at L0
04TB05 -> spectra shows this channel is dead at startup
2) Channels to adjust HV
gain too high: 11TB08, 03TA06, 08TC03, 07TC07, 02TE02, 01TA04
gain too low: 12TD01, 10TA09
Procedure:
Minbias runs (12030069-73) were used to determine the slope of each channel using "Scott's method". Below is a summary of the channels slope and the median slope for towers in that eta bin as well as the current HV (HVset_ix) for each tower, all of which is used to calculate the new HV (HVset_xi) to be used to match the other towers in that eta bin.
Table 1:
The equation used to determine the new HV values is HV_1 = HV_2 * (slope_2 / slope_1) ^ (1/kappa), where the value of kappa is taken to be 8.8 from previous HV adjustments. This is equation is different than the similar equation used by the barrel becuase in the endcap gain ~ 1/slope and in the barrel gain ~ slope.
Notes:
1) 11TB08 appears to be unstable (HV status is 5 or 7 instead of 4="good") running at 517 V, so it was decided to set this tower to its original value of 699.9 V where it runs stably. Thus, this tower will continue to be masked out of L0 and L2 trigger and will need to be calibrated carefully to be used in offline analysis.
2) 12TD01 is a bit of a special case as it was "hot" in Run 8 and had its voltage lowered (946.2 -> 830.8) before Run 9, but then the gain was way too low. So it was decided to put its voltage at 880.0 to try and increase the gain without getting hot.
Runs taken to test new HV
Once new HV values were determined 2 emc-check runs were taken to check the new files. 12037043 was taken with HVset_ix and 12037046 was taken with HVset_xi. Below is a summary of the slopes for the 2 runs for the channels of interest. Unfortunately. some channels didn't get a new HV loaded because of communications problems with HVsys branch "C" (these are shown in blue).
Table 2:
For the towers where the new HV was loaded correctly (red) the slopes now match much better to the median slope in it's etabin, so the new HV values look reasonable and will be used for the remainder of Run 11. HVset_xi is used for all runs after R12038072.
Note: 10TA09 appeared to be hot after its HV was raised to 827.0 so it was set back to its HVset_ix voltage value. There was probably beam background when the original slopes were measured causing this to incorrectly be labeled an outlier.
5P1 adjustments
During the same test runs (12037043 and 12037046) a test was done increasing tube #2 of 5P1 from 750 -> 840 V, as the spectra for channels 176-191 was way down in some early runs (eg. 12034091). This increased the gain by ~2.6, but comparisons of the slopes for channels from tube #2 to other preshower channels in 5P1 showed that the gain should be increased by another factor of ~2 (see txt file with slopes for tubes of interest and median slope of other channels in run 12037046).
So the final HV used for 5P1 will be 913 V, which was determined with a similar formula as for the towers, but with kappa_mapmpt=8.3.
Run 12 EEMC Calibrations
pp500 EEMC Gain Calibration with MIPs
Note four sets of tower gains were uploaded to the database to account for gain decrease over the course of the run.
See attachments for calibration summary and masks lists.
Plots can be found here:
http://www.star.bnl.gov/protected/spin/jhkwas/calibrations/run12plots/
Run 13 EEMC Calibrations
EEMC Gain Calibration with MIPs
Note four sets of tower gains were uploaded to the database to account for gain decrease over the course of the run.
See attachments for calibration summary and masks lists.
Plots can be found here:
http://www.star.bnl.gov/protected/spin/jhkwas/calibrations/run13plots/
EEMC Status and Pedestal Tables
General Procedure:
1) Produce ADC distributions from raw daq files as outlined here.
2) Make ADC distributions for each EEMC channel and fit the histograms to get pedestal and rms values as shown here.
3) Use StEEmcStatus to get status table information. See the last two steps here.
Typical ADC Distribution of one EEMC channel:

Status codes appearing in Run 13:
ONLPED 0x0001 // only pedestal visible
STKBT 0x0002 // sticky lower bits
HIGPED 0x0010 // high chan, seems to work
WIDPED 0x0080 // wide ped sigma
"failed" status: fit fails, all entries in 1 channel, too many ADC = 0 bins, dead channel, stuck in another mode, HV was off, signal fiber broken, etc.
Lower bit(s) failed ("sticky bits"):
Entire run 13:
- a04TB07, a06TA07, a08TB07
Most of run 13:
- a05TA12
One to several runs:
- a01TD12, a04TD05, a05TA10, a06TB11, a06TE10, a08TE08, a09TA09, a11TA07
High pedestal: a05TB01 for 6 runs
Wide ADC distribution:

- a03TB09
- a12TC09, a03TB01, a03TB02, a03TB10, a06TD04, a09TD09, a11TA12, a12TD09, a02TD04, a02TD05, a03TB11, a03TD09
Status tables inserted where large time-gaps occur between emc-check runs:
Fill 17237 --> use table from fill 17250
Fill 17263 --> use table from fill 17268
Fill 17311 --> use table from fill 17312
Fill 17328 --> use table from fill 17329
Fill 17399 --> use table from fill 17402
Fill 17426 --> use table from fill 17427
Status tables inserted mid-fill due to major problems and fixes:
Fill 17333, Run 14096099 --> use table from fill 17335
Fill 17484, Run 14130003 --> use table from fill 17486
Fill 17573, Run 14152029 --> use table from fill 17579
Fill 17586, Run 14152029 --> use table from fill 17587
See this for MAPMT status info.
See this for MAPMT "diagnostic" details.
Run 15 EEMC Calibrations
Status and Pedestal Tables
We used one good emc-check run with 100k events each for each fill. Some fills did not have a good emc-check run. Below are the runs we used.
Run List
Produced ADC distributions from raw DAQ files following the instrucitons here.
Determined the status and pedestals for each tower and mapmt channel with the instructions here.
Summary of tower issues:
On average, about 2.5% of all towers are masked-out per fill.
Tower Status by Fill
02TA01: dead entire run
02TC04: bad entire run
02TC06: fail for part of the run
04TB07: stuck bit entire run
04TC01: fail for part of the run
05TA12: stuck bit entire run
06TA03: failed entire run
06TA07: stuck bit entire run
06TC08: dead for one run
06TD04: failed for one run
07TC05: failed entire run
08TB07: stuck bit entire run
10TA09: dead for two runs
10TC02: failed entire run
10TC03: failed entire run
10TC09: failed entire run
10TC11: good for only two runs
11TA08: dead entire run
11TA12: mark as stuck bit entire run
11TB08: failed entire run
11TC04: dead for part of the run
12TB02: dead part of the run
12TC05: bad entire run
12TD01: bad for part of the run
**See attached file for MAPMT pedestal widths**
Run 17 EEMC Calibrations
Status and Pedestal Tables
RunList Selection:Use one good emc-check run with at least 50k events for each fill from pp510. Some fills did not have good emc-check run.
For pp510, total emc_check run list has 227 runs, some problematic (?) runs:
18065063, only has 1 event;
18066002, second emc_check run in same fill, Shift Leader comment: 18065001 rate too high?
18113047, emc_check run pp energy < 500GeV
18115051, emc_check run pp energy, Blue 253.798GeV, Yellow 253.797GeV, smaller than normal value 254.867GeV.
Summary of tower:
tower status by fill
a01TA05: masked out on April 26th by Will
a01TC05: failed for part of the run
a02TA01: dead entire run
a02TC04: bad entire run
a02TC06: failed for part of the run
a11TB07: failed for part of the run
a12TC05: bad entire run
Summary of MAPMT:
MAPMT status by fill
MAPMT Pedestal Width
Run 8 EEMC calibrations
This is the main page for all EEMC calibration information for Run 8
Comparison of old (Run 7) to new (Run 8) EEMC tower HV's
At the end of run 7, we compared slopes for all EEMC towers with two sets of HV values in a series of consecutive runs. The goal was to see if the new HV set would change the slopes in the 'expected' way, to bring the tower hardware gains into closer agreement with their ideal values.
Here is a summary of what we planned to do:
www.star.bnl.gov/HyperNews-star/get/starops/2520/1.html
What was actually done was send in a private email to a few people. The email is attached below, along with two plots. "2006TowerGains" shows the absolute gain determined for each tower, compared to its ideal value. "2006Gains_x_SlopeRatio" is the same data, but each point has simply been scaled by the ratio of the slopes determined for the two data sets (old HV vs new HV). Note that the correction is not just a calculation, but based only the slope measured for each tower before and after the new HV set was loaded.
EEMC Pedestals and Status Tables for Run 8
Generating Pedestal and Status Table Information
Requesting Emc Check Runs
In order to produce pedestal and status table information for the EEMC, Min Bias runs must be analyzed to determine the pedestal and status for each channel (tower, preshower, or SMD strip). Thus during the running, usually once per fill an EmcCheck run is produced with approximately 200,000 of these Min Bias events. This run must include EEMC and ESMD, and it is preferable for this run to be the first run in the fill, but not absolutely necessary. A list of these runs we wish to have produced via Fast-Offline is sent to Lidia Didenko through the starprod hypernews list. These runs are usually produced to /star/data09/reco/EmcCheck/ReversedFullField/dev/ or sometimes data10. For each run there might be 20 MuDst files, that will be deleted in a week or so, so they must be processed to hist.root files quickly. A list of the runs that were requested and produced for 2008 is given here: www.star.bnl.gov/protected/spin/stevens4/ped2008/runList.html
Creating hist.root files and fit.hist.root files
In order to analyze these runs, the raw MuDst needs to be transfered hist.root fromat. This is done with the macro rdMu2Ped.C which is executed by procPeds (all of the following code can be found in my directory at /star/u/stevens4/ped08 at rcf). procPeds requires an input file Rnum.lis which has a list of the locations of all the files for a given run, this can be created via the executible filefind (Rnum is a string of Rydddnnn where y is the year, xxx is the day of the run, and nnn is the number of the run on that day). Once rdMu2Ped.C has written the .hist.root file for the given run, procPeds then executes fitAdc4Ped.C which fits each channels histogram using the code in pedFitCode/. The macro fitAdc4Ped.C also creates ped.sectorXX files which contain the pedestal information for each sector which will be loaded to the database, as well as other log files. Finally procPeds moves all these files to a directory for that particular run.
Status Tables
The code used to create these status and fail words for each channel are in the directory /star/u/stevens4/ped08/pedStatus. The source code for the program is in oflPedStat.cxx, and it is executed using oflPed. It requires and input file, runList, which contains the list of runs to be analyzed, and it requires the hist.root and fit.hist.root files to be stored in /star/u/stevens4/ped08/dayxxx/outPedRyxxxnnn. This code outputs two files, Ryxxxnnn.errs, which contains the status and fail words in hex format for each problematic channel, and Ryxxxnnn.log, which gives explanation (ie which test it failed) for why each channel was problematic. Both of these output files are written in /star/u/stevens4/ped08/pedStatus/StatFiles/. Once these files are written the script procErrs can be executed in the same directory. procErrs reads in the .errs files and writes (with DistrStat2Sectors.C) the stat-XX files containing the status and fail words that will be uploaded to the database, as well as copy each stat-XX and ped.sectorXX to the run number directory in /StatFiles/.
The current set of status bits for EEMC (usage: #define EEMCSTAT_* )
ONLPED 0x0001 // only pedestal visible
STKBT 0x0002 // sticky lower bits
HOTHT 0x0004 // masked for HT trigger
HOTJP 0x0008 // masked for JP trigger
HIGPED 0x0010 // high chan, seems to work
HOTSTR 0x0020 // hot esmd strip
JUMPED 0x0040 // jumpy ped over few chan
WIDPED 0x0080 // wide ped sigma
More information about the database usage is given by Jan at: http://drupal.star.bnl.gov/STAR/subsys/eemc/endcap-calorimeter/db-usage
Uploading Tables to Database
General information for uploading tables to the database is given by Jan at: drupal.star.bnl.gov/STAR/subsys/eemc/endcap-calorimeter/offline-db-upload-write
More specific information on uploading pedestals and status tables to the database refer to /star/u/stevens4/database/uploadinfo.txt
Run 9 EEMC calibrations
This is the main page for all EEMC calibration information for Run 9
EEMC Gain Calibration Using MIP Run9
Dead channels:
SMD strips:
03V112, 03V258, 05U212, 05U234, 05V057, 06U069, 06U091, 08U124, 09V029, 09V047, 09V113.
03U, 04V, 09U, 10V strips numbered 284-287. All the strips labeled 288.
Pre&Post:
02PA11
Tower:
02TC04, 02TC06, 06TA03, 06TE04, 07TC05, 11TD05
Bad channels:
Pre&Post:
05PA01, 05PA02, 05PA03, 05PB10, 05PB11, 05PB12, 05PC10, 05PC11, 05PC12, 05PD10, 05PD11, 05PD12, 05PE01,
05PE02, 05PE03
11PE10, 11PE12, 11QE10, 11QE12, 11RE10, 11RE12
Tower:
11TE12, 11TE10, 10TD04, 10TD06
Note: Fifteen 05Pre1 channels have PMT problem; Swaps 11TE10<->11TE12; 10TD04<->10TD06
The procedures and results can be found here:
https://drupal.star.bnl.gov/STAR/system/files/EEMC-cal-run6%2526run9forpresentation11172014_1.pdf
All the plots are in this directory:
http://www.star.bnl.gov/protected/spin/tinglin/summber2014/run9final/
Conclusion:
Pre1, Pre2 and tower's gain decreased by 10% compared to run6;
Post shower's gain remain stable.
EEMC Gains - corrected for mis-set TCD phase
EEMC TCD Phase and Effective Gains
During Run 9 the TCD phase was set incorrectly for ETOW (run < 10114054) and ESMD (run < 10140030). A study (shown here) found the slope ratio for the 2 TCD phases which was used to calculate new gain tables for ETOW and ESMD. These "mis-set" TCD phase timing settings are not optimal for the vast majority of channels, thus the data taken during these periods are more suspect to issues such as timing jitter, vertex position dependencies, etc. To account for these issues, we have set gain=-1 for these time periods for the standard "ofl" flavor of the DB. The new gains (calculated with the slope ratios) have been uploaded to the DB for the same timestamps but with a flavor of "missetTCD", so that this data is permanently flagged as having issues that data taken with optimal timing (hopefully) do not.
As a reminder, here are a few lines of code for how to read these "missetTCD" flavor tables from the DB instead of the default "ofl" tables:
stDb = new St_db_Maker("StarDb", "MySQL:StarDb");
stDb->SetFlavor("missetTCD","eemcPMTcal"); //sets flavor for ETOW gains
stDb->SetFlavor("missetTCD","eemcPIXcal"); //sets flavor for ESMD (mampt) gains
Note: the "missetTCD" flavor is valid only for Run 9 during the time periods given above, so it will return gain<0 for any other times.
EEMC Pedestals and Status Tables for Run 9
Run 9 EEMC Pedestals and Status Tables
Abstract: To produce pedestals and status tables for ETOW, ESMD, and EPRS based on zdc_polarimeter (EmcCheck) runs taken at the beginning of each fill with calorimeters only. This year the raw adc spectra were retrieved from the .daq files on HPSS using the DAQ_READER instead of waiting for these runs to be produced.
Runlist: 200 GeV
Procedure:
1) Retrieve .daq files from HPSS and use Matt Walker's version of the DAQ_READER to make 2D spectra of all EEMC components (code located at /star/u/stevens4/daqReader/ ). Output is hist.root file with 6 ETOW histograms and 48 ESMD/EPRS histograms, one for each crate.
2) Using mapping from DB create 1D histograms for each EEMC channel softID from the 2D histograms generated by the DAQ_READER (macro: /star/u/stevens4/ped09/fromDAQ/plDAQ2Ped.C). Ouput is hist.root file with 720 ETOW and 9072 ESMD/EPRS histograms.
3) Fit 1D histograms produced by plDAQ2Ped.C to get pedestal value for each channel (macro: /star/u/stevens4/ped09/offline/fitAdc4Ped.C) . Output is fit.hist.root file with fitted 1D histograms for every channel and a ped.sectorXX with pedestal values for each channel in that sector which can be uploaded to the DB.
4) Compute status for each channel and generate status table for each sector (macro: /star/u/stevens4/ped09/offline/pedStat.C).
The current set of status bits for EEMC (usage: #define EEMCSTAT_* )
ONLPED 0x0001 // only pedestal visible
STKBT 0x0002 // sticky lower bits
HOTHT 0x0004 // masked for HT trigger
HOTJP 0x0008 // masked for JP trigger
HIGPED 0x0010 // high chan, seems to work
HOTSTR 0x0020 // hot esmd strip
JUMPED 0x0040 // jumpy ped over few chan
WIDPED 0x0080 // wide ped sigma
Known problems put in status tables "by hand":
| Problem | Fills effected (based on zdc run at beginning of fill) |
| Crate 6 problem configuring | 10157048-10169028 (not all of crate 6 for all fills) |
| SMD Sectors 12 and 1 bad spectra | 10139100, 10142078-10146010 |
Note: We also had problems with counts below pedestal in the ESMD/EPRS due to "extra accepts" in the triggering. These problems are not included in the status tables because it is thought that these problems won't show up in the produced data, but we will have to wait and see.
ESMD (MAPMT FEE) Timing for Run 9
The timing scans for ESMD/MAPMT FEE for Run 9 were taken by
raising the box delay settings as far as feasible, staying
within the present RHIC tic "c" delay setting and then varying
the TCD phase delay in order to see as much as possible of the
right-hand-side timing cutoff in the scans (Note: due to present
nature of the various delays there is a timing "hole" which
cannot be accessed ... we will try to fix in future years e.g.,
by extending the delay range of the new TCD).
The new MAPMT configuration files for the scans were put on the
EEMC slow controls machine (eemc-sc) in directory:
/home/online/mapmtConfig/03-01-09_scan. The initial conditions
are outlined in cols 1-7 of the spreadsheet "MAPMT_DELAYS_v7"
(among the last attachments below). The nominal TDC phase setting
from previous years is = 65. Within allowable additions to
the box delay, we chose to divide things into 4 classes:
a) add 22 ns box delay as per cols 8-12 of spreadsheet:
(should clearly see edge as in previous years):
12S1-12P1, 2S3, 4S1-4S3, 7S1-7P1, 8S2-10P1
b) add 17 ns box delay as per cols 15-19 of spreadsheet:
(will see less but better than previous):
1S1, 1S3, 2S1, 4P1, 8S1, 11S1, 11S3
c) add 7 ns box delay as per cols 22-26 of spreadsheet:
(will see even less, etc.):
1P1, 2S2, 2P1-3S3, 5S1, 5S3, 6S1, 8S2, 6P1, 11S2, 11P1
d) delay w/ truncation @ 400 HEX as per cols 22-26 of
spreadsheet
(mistake: see notes below ... max is really 3FF)
1S2 (439), 3P1 (44E), 5P1 (40C), 6s3 (423)
Data for the scans was taken on Friday 6 March 2009:
Run ETOW TCD ESMD TCD
Phase Phase
10065031 80 80
10065032 10 10
10065033 20 20
10065034 30 30
10065035 40 40
10065036 50 50
10065037 60 60
10065038 70 70
10065039 75 75
10065040 65 65
10065041 55 55
10065042 45 45
10065043 35 35
10065044 25 25
10065045 15 15
10065046 5 5
10065047 0 0
(in last entry at "0" peds seem to indicate this didn't work
for ETOW ... too many counts in spectra)
These data were analyzed by Alice Bridgeman at link:
http://drupal.star.bnl.gov/STAR/blog-entry/aliceb/2009/mar/11/preliminary-eemc-timing-curves-crate
Attached below are the same plots from her analysis, but
annotated to show the run 8 effective timing setting (long
vertical line at 43, 48, 58 depending on box ("crate"), for
added delays of 22, 17 and 7, respectively) as well as
indication of the location of the "right edge" of the timing
scan and length of flat top region. (The files for the good
timing scans are appended first and in order below for crates
64 [e.g., mapmt-crate-64_set.pdf], 66-68, 70-78, 80-84, 86,
88-89, 91-94, and 96-111.) The associated values from this
somewhat subjective procedure (regions selected by eye and
computer drawing "straight edge"), are given in cols 29-33
(again on spreadsheet "MAPMT_DELAYS_v7) for the distance to the
edge, range of distances, flattop range and time difference to
near edge, respectively.
In the past we have tried to set the delays so that that we
sit (operating point) about 12 ns into the plateau region from
the right side timing edge ... this allows for several ns of
"time jitter" as well as possible error in determining the edge
while still maintaining a safe (estimate > 5 ns) distance of
the effective operation point from the fall off edge. The
projected adjustments are given in col 36 of "MAPMT_DELAYS_v7"
and converted to final box delay in HEX in col 39.
These scans are more definitive that those of previous years
(due to mixture of issues) and hence the new values bounce
around a bit, but in general the shifts are only ~ few ns with
a few outliers.
There are several special cases!
For boxes 65 (12S2), 69 (1S2), 79 (3P1), 85 (5S2), 87 (5P1),
90 (6S3), the box delay was set to "400" instead of the max
allowed of "3FF" (a mistake as noted above) which effectively
zeroed out the box delay causing just the left hand timing edge
to be visible in the scans (for box 95 7P1 plots there is something
else is wrong and very little is plotted).
For these special cases one can estimate the timing by looking at the
LHS edge and applying the 50-55ns flat top to guess where the leading
edge is (e.g., see the plots). But in general for these case the timing
was set by looking at neighboring boxes in the clock chain and deducing
a value to use (see spread sheet).
The final Hex delay values are indicated in one of the last columns of
the spreadsheet (MAPMT_DELAYS_v7)
Endcap Tower Timing Settings Run 9
For now see link to blog page:
http://drupal.star.bnl.gov/STAR/blog-entry/wwjacobs/2009/mar/06/run-9-calibr-qa
and go to Section IV
Uploading EEMC Pedestal, Status and Gain Calibrations to the DB
This page is intended to document the process of uploading EEMC calibrations to the DB using the "eemcDb" utility script originally written by Jan Balewski. Some old notes from Jan are here. Before we begin, a quick reminder that this is not a task many people should need to do but should be limited to one or two "experts", who will be given special DB writing priviledges by Dmitry Arkhipkin (arkhipkin@bnl.gov). The code is all in CVS though for documentation purposes.
Building the eemcDb utility:
All the uploads to the EEMC DB are handled by the eemcDb utility which Jan called the "swiss army knife" of DB uploads. The source code to build the eemcDb executible can be found in CVS. To compile the script follow these quick instructions
mkdir yourDirectory cd yourDirectory cvs co StRoot/StDbLib/ cd StRoot/StDbLib/ make cd ../../ cvs co StRoot/StEEmcUtil/database/macros/upload/src/ cd StRoot/StEEmcUtil/database/macros/upload/src/ make
Then the eemcDb executible is ready to use. It can be tested with a simple read command:
eemcDb -r -p Ver2004d/ -T
Uploading tables to the DB:
Thre are several scripts for uploading pedestal, status and gain tables to the DB located in CVS at StRoot/StEEmcUtil/database/macros/upload/. The names are fairly obvious, but just in case, here is the breakdown:
writeIdealGains.C : writes ideal gain tables in ascii files to be uploaded
writeIdealPed.C : write ideal ped tables (pedestal = 0) in ascii files to be uploaded
writeIdealStatus.C : write ideal status tables (status = 0) in ascii files to be uploaded
In the following scripts you need to specify the location of the eemcDb executible (compile instructions above) as its currently listed as "yourDirectory." Also there are various exit lines in the scripts which you'll need to comment out once you're ready to upload (they kept me from accidental uploads in the past so I kept them in place).
writeMapmtGains.sh :
- script which executes eemcDb to write MAPMT gain files to the DB
- requires user input of timestamp, table "flavor", gain file location, and comment to go in DB
- script which executes eemcDb to write tower gain files to the DB
- requires user input of timestamp, table "flavor", gain file location, and comment to go in DB
- script which executes writePed+Status.sh (below) for many runs from the input file which specifies the fillNumber, runNumber, and unix timestamp
- requires user input of list of runs and comments to go in the DB
- script which executes eemcDb to write pedestal and status files (for both towers and MAPMT) to the DB
- loadPed+Status.tcl should provide user input of timestamp, table "flavor", gain file location, and comment to go in DB
One last note that in order to upload to the DB you need write priviledges from Dmitry and to execute the following command which allows you to write to the DB. Once you're done with the upload remove this to prevent "accidental" uploads.
setenv DB_ACCESS_MODE write EEMC Maintenance/Operations Documents
ESMD (Shower Max and Pre- & Post-Shower Detectors)
ETOW (Towers)
Endcap Geometry
Geometry definition
- Detailed description of the geometry (ver 5.1) as implemented by
Oleg Rogachevski are listed in the depth.txt file - Distribution of material as fuction of eta and phi
- Mapping of SMD strips to towers (11/20/03 jwebb)
Geant pictures of calorimeter are generated with plot_geom.kumac
-
View of EndCap caloremeter (variant C) in STAR detector

-
cross section of calorimeter towers variant C
-
cross section of lower half of calorimeter plane ZY at X=0
-
cross section of calorimeter (var.C) plane ZY at X=30cm

-
cross section at eta=2.0front part with SMD
line eta = 2.0 intersects megatile (blue) at its center
and radiators (black) at forward edge.
Hub is seen at upper edge. Each megatile extends from eta=2 to hub
as nonactive plastic and radiator extends as stainless steel. -
cross section at eta=1.086 front part with SMD

line eta = 1.086 intersects megatile at its center
and radiators at the back edge of radiator
Projective (20x25 mm) bar is seen at the lower edge of calorimeter
XXX page 9 - megatile cell structure in local coordinates, particles go along Y axis on this plot. -
regular SMD sector, V plane, blue line depicts +-15 deg. between sectors

-
edge SMD sector with cutted strips, V plane

-
cross section of 1st SMD plane
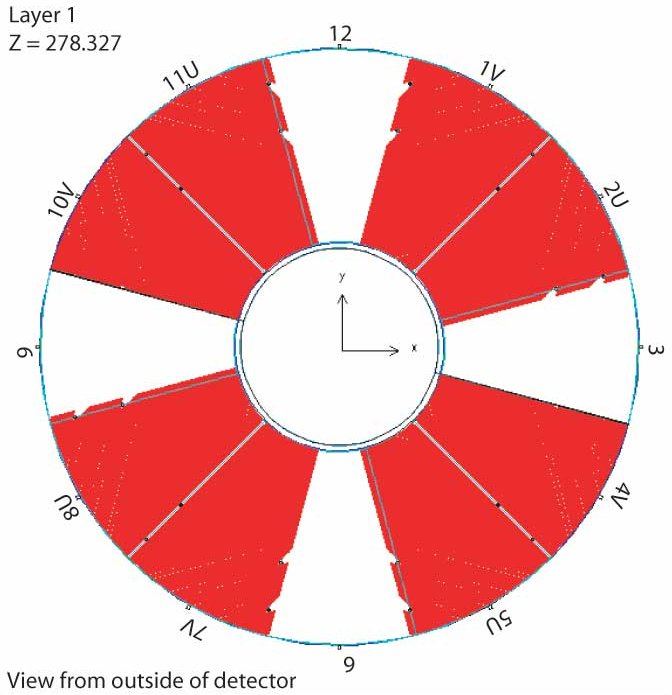
-
cross section of 2st SMD plane
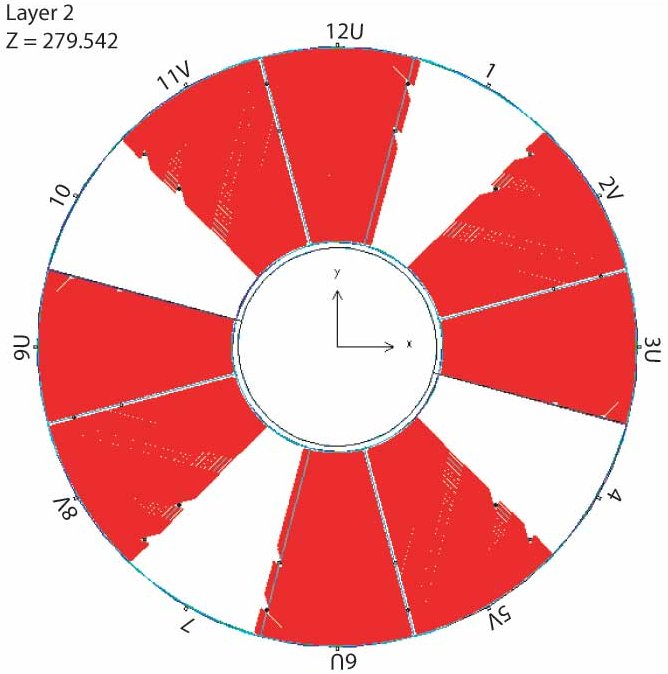
-
cross section of 3st SMD plane

-
cross section of 1st SMD plane labeled with "SUV" ordering
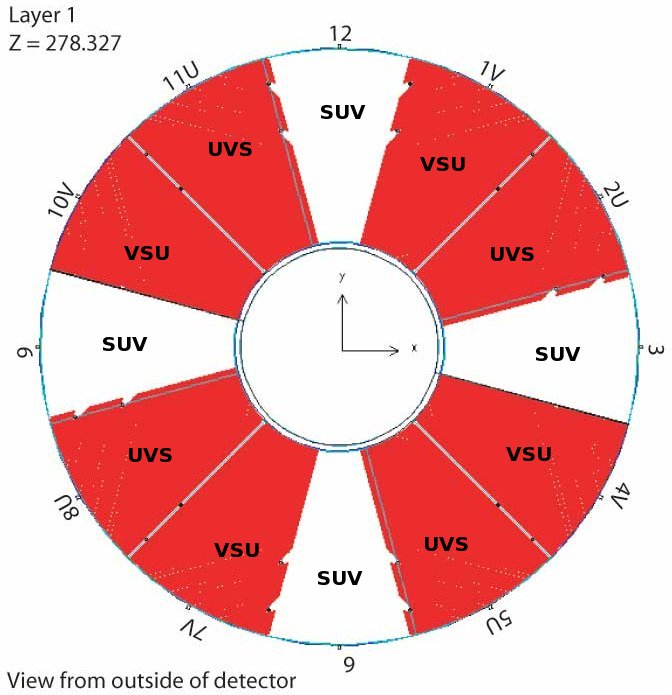
-
cross section of the gap between SMD sectors

-
cross section of the gap between tower at the sector boundary
-
cross section of the backplate
Three variants of EEMC geometry are available:
A --- lower half with only 5-8 sectors filled with scintillators
B --- fully filled lower half
C --- both halves filled with scintillators
Endcap Geometry update (2009)
EEMC geometry v6.0
Proposed name for the geometry file: pams/geometry/ecalgeo/ecalgeo1.g
List of changes
- CAir bug fixed
- Increased size of mother volume containing SMD strips
- Added material to front and back of SMD planes (material wrapping SMD planes)
- Added SMD spacer layers
- Introduced sector overlaps closer to the "as build" geometry
- Birk's law constants for SMD strips corrected
- Some dimention paramaters tuned to that in real geometry
- Code reorganized and commented
Note:
Lead alloy mixtures are not implemented
due to the problem with mixture in GSTAR/Geant (see below)
Resulting improvements in the simulated EEMC response
- Geometry configuration is closer to the "as build" geometry
- Correct simulation of the transverse shower shape profile
- Realistic (close to 5%) sampling fraction
- More realistic simulation of the tower energy profile (with LOW_EM option)
Supporting materials
EEMC sampling fraction nonlinearities and CAir bug
EEMC geometry reshape
- Jason's plenary talk at LBNL collaboration meeting
- Jason's SPIN-PWG talk at LBNL Collaboration meeting (EEMC geometry revision)
Issue with mixture in GSTAR/Geant
- Lead issue (Ilya's post)
- Lead issue (Alice's post)
- Lead issue report to STARsoft-hn list
Jason's tests and studies
- Validation of EEMC MC Geometry
- SMD Problems at the sector boundary
- EEmc MC Geometry version 5.21
- Rough cut of EEMC SMD spacer geometry
- Check of material in corrected EEMC geometry
- Linearity Check in fixed ecalgeo.g, take II
- Linearity Check in fixed ecalgeo.g
- List of small, almost trivial, problems with the Monte Carlo
- EEMC simulation study: mockup of CDF testbeam experiment
- Verify that the fast simulator sees all of the energy deposited in geant
- Energy dependence of the sampling fraction in the EEMC
- EEMC simulation studies (spin-pwg-simulations-report-07-30-2009.pdf)
Ilya's tests and studies
- new EEMC geometry: Pure lead and new SMD layers
- Jason EEMC geometry: Effect of ELED block change
- Jason EEMC geometry: results with and without LOW_EM options
- Jason EEMC geometry: Jason with ELED block from CVS file
- Jason EEMC geometry: comparison without LOW_EM option
- Jason EEMC geometry: effect of removing new SMD layers
- Jason vs. CVS EEMC: removed SMD layers
- Sampling fraction problem: full STAR vs. EEMC stand alone geometry
- Jason geometry file: Full STAR simulations (sampling fraction, shower shapes)
- Jason geometry tests: SMD energy, number of strip vs. thrown photon position
- Effect of added layers in Jason geometry file
- Volume id fix in Jason geometry file
- Jason vs. CVS EEMC geometry: sampling fraction and shower shapes
- Test of corrected EEMC geometry: LOW_EM cuts
- EEMC geometry tests: on-off SVT detector and EEMC slow-simulator
- Single particle MC with corrected geometry vs. eta-meson from data
- Corrected EEMC geometry: shower shapes
- Corrected EEMC geometry (bug 1618)
Alice's tests and studies
Log of tower base and fee issues
Attached is a text file of tower base and other issues. I went back through the electronic shift log and recorded all the bases that had been replaced and recording of other fixes and problems. The status as of the begin of the run 10 is also stated.
Jim
eemc as-built info and proto tests
Here starts 8/09 a collection of misc. information re: as-built eemc from construction documentation and prototype testing of various sorts.
... to be detailed
emc2-hn minutes (by Jan)
- xx xx, 200x
- next,
- xx xx, 200x
- next,
- xx xx, 200x
- next, I forgot to edit this
- Feb 12, 2007
- Will, run7 plans,
- Will, Jan, Endcap startup plan
- L2 algos plan: Upsilon+displVartex (by Pibero), modified L2gamma (by Saski & Jason), L2pedMon (by Jan) . some links , not much time to implement
- Jason, pi0 from Endcap from 2006 data, efficiency is low
- Will, BPRS-East gross mapping problem found, plan to replay data w/ all known corrections.
- Scott, Endcap calibration, MIP peak seen in towers, pre,post
- Feb 5 2007
- Rory, progress in BPRS mapping
- Adam, in-software mapping correction code
- Will, all, 2007 trigger discussion and Steve
- Jan, electrons in the Endcap in 2006 data
- Pibero, eta dependence of reco pi0 invM for simu for Endcap
- Jan 29, 2007
- Oleg, Barrel electronics
- Jason, new display of Endcap points,clusters , code & writeup will be in CVS soon, needs special TTree as input
- Jan, embedding of TPC+EMC is working, but ... needs 600MB for execution, code in CVS, awaits perr reviue
- Murrad, off-line jet phi anizotrophy for B & E-emc JP triggers
- Will, BPRS, suggested correlation between towers & pre-shower swaps, Rory got code from Adam for tracking toward BTOW
- Scott, ESMD calibration ready for DB upload, only slopes are used, flavor='slopes'
- Jan 22, 2007
- Murrad, offline jet phi,eta spetra
- Will, EMC fast to L2
- many: cray for Endcap off-line calibration
- Dec 18, 2006
- Jan, TPC+Endcap embedding
is operational for pp2006 chain, missing writup, peer review, few
tricks are needed to run it, ready for teasting of algo not for physics - Adam, run dependence of MIP peak for BTOW shows jump on day 114+5, 5% trend for days 120-170
- Scott, Endcap 2006 calibration will be done, status: collecting muDst on the disk
- Will, explained most of the BPRS mapping problems as hadrware swaps, photos of hadrware illustrate the causes
- Naresh, summary of e/h discrimination in the Endcap (ppt) using TPC, dEdx,E/P, and postE, current contamination 14/1, run out of time
- Dec 11,2006
- Wei Ming, evaluation of Endcap pi0 efficiency w/ embedding,
- Jason, M-C e- tracking has eff=~80% for eta<1.6
- Jason, Beam background in Endcap
not seen in 2006, for both: clusters alone & clusters matched
to Pibero's stright through tracks (flag=901) - Adam, ofl-onl BTOW gains, 136 more towers lost mainly due to the isloation cut
- Rory, BPRS mapping, identified miss-match patterns: +20 towers, backward mapping Y=-X
- Dec 4, 2006
- Jason, new Endcap point/cluster/pi0 -maker in CVS , no performance plots shown
- Weihong, Endcap pi0 algo allows to split SMD peak, avr eff of 30% for di-pi0 events
- Adam 1, 2nd iteration of BTOW ofl gains from MIP, no ele used, sizabe spread in phi seen
- Adam 2, time dependence of BTOW slopes, to be investigated, 10% change in average & width reported
- Rory, BPRS mapping , evidence of broken channels & miss-mapped small sections, should not take long to figure all out
- Will, eemc proto SLAC report from 2001
- Will, Endcap HV & FEE work prior to 2007 run
how-to by Jan
Instructions
offline DB upload (write)
Loose notes helping Justin in uploading of the offline DB tables for Endcap
1) Monitoring current content of DB,
use web interface: http://orion.star.bnl.gov/Browser/EEMC/
The following query selects pedestal tables for sector 1 (element ID) for year 2007+

results with just 2 tables:
- the official (just one) table for 2007 run (flavor 'ofl') valid since April 5, 4:40 pm GMT (note it is not EST)
- test table ( flavor=online ) for 2008 run, valid since February 22
If you click on 'Control' you will see the content of this table, but I rarely do that

2) Upload new tables to DB
- need special DB write privileges, only Jan Y Justin have such.
- setenv DB_ACCESS_MODE write
- execute _working_ version of eemcDb with proper params
- you do NOT need any more the dbServer.xml file pointing to robinson.db, so do NOT have it in your main directory
Note, the last successfully compiled and working eemcDb is located at:
/star/u/balewski/dbaseIO-2008-sc.starp/eemcDb - use it as long as it works.
The source code is at sc.starp , user=sysuser, directory: junk2/
Good luck,
Jan
offline DB usage (read)
DB usage : ped, gains, fail/stat flags for EEMC towers/pre/post/SMD
Wed Oct 27 13:09:10 EDT 2004
Key features:
Content of 'ideal' simulation tables:
* channel map as of October 2004
* tower gains : 4096 ADC=60 GeV transverse electromagnetic energy in the tower
* pre/post/smd gains : 23,000 ADC = 1 GeV of energy deposit by a MIP in scint
* all pedestals set at 0 ADC, but sigPed of 1.0 ADC for Towers and of 0.7 ADC for MAPMT
* masks: fail=stat=0 , meaning all elements are good
The above content of sim-tables is consistent with the actual fast EEMC simulator code and hits stored in StEvent & muDst.
Note, in the M-C a sampling fraction of 5% is assumed while converting GEANT energy deposit in tower scint layers to tower ADC. In order to get ~right pi0 or gamma energy a fudge factor of ~4/5 is still needed.
For 2004 data the following 'stat' bits are in use:
#define EEMCSTAT_ONLPED 0x0001 // only pedestal visible #define EEMCSTAT_STKBT 0x0002 // sticky lower bits #define EEMCSTAT_HOTHT 0x0004 // masked for HT trigger #define EEMCSTAT_HOTJP 0x0008 // masked for JP trigger #define EEMCSTAT_HIGPED 0x0010 // ped is very high but channel seems to work #define EEMCSTAT_HOTSTR 0x0020 // hot esmd strip #define EEMCSTAT_JUMPED 0x0040 // jumpy ped over several chan over days #define EEMCSTAT_WIDPED 0x0080 // wide ped over:2.5 ch towers, 1.5 ch MAPMT'sIt is up to a user what 'stat' condition is fatal for his/her analysis.
Potentaily good elements may have set the 'STKBT', meaning the lowest bit(s) did not worked and only the energy reolution is worse.
'JUMPED' bit means ped jumped by 20-40 ADC counts during one run. It is fatal for calibration with MIP's but ~OK for reco of 20 GeV gammas.
For the record the following 'fatal' bits are set and all users should reject all elements marked that way.
#define EEMCFAIL_GARBG 0x0001 // exclude from any analysis #define EEMCFAIL_HVOFF 0x0002 // HV was off #define EEMCFAIL_NOFIB 0x0004 // signal fiber is broken #define EEMCFAIL_CPYCT 0x0008 // stuck in copyCat mode
~/ezGames/dbase/src/eemcDb -p Ver2004d/sector05/eemcPMTstat -H -t 2001To see content of stat/fail table for a given time stamp type:
~/ezGames/dbase/src/eemcDb -p Ver2004d/sector05/eemcPMTstat -g -t 1080832032
Use constants defined in
$STAR/StRoot/StEEmcUtil/EEfeeRaw/EEdims.h
Access to EEMC DB-maker within the chain
In .h add
......
class StEEmcDbMaker;
class StYourAnalysistMaker : public StMaker {
private:
StEEmcDbMaker *eeDb;
....
}
In .cxx add
#include "StEEmcDbMaker/StEEmcDbMaker.h"
#include "StEEmcDbMaker/EEmcDbItem.h"
#include "StEEmcDbMaker/cstructs/eemcConstDB.hh"
#include "StEEmcUtil/EEfeeRaw/EEname2Index.h"
.....
StYourAnalysistMaker::Init() {
// connect to eemcDB
eeDb = (StEEmcDbMaker*)GetMaker("eemcDb"); // or "eeDb" in BFC
assert(eeDb); // eemcDB must be in the chain, fix it
}
Details of DB usage for muDst events , loop over hist for one event:
.....
// choose which 'stat' bits are fatal for you, e.g.
uint killStat=EEMCSTAT_ONLPED | ......... ;
.....
StMuEmcCollection* emc = mMuDstMaker- >muDst()- >muEmcCollection();
.....
//......................... T O W E R S .....................
for (i=0; i < emc->getNEndcapTowerADC(); i++) {
int sec,eta,sub,rawAdc; //muDst ranges:sec:1-12, sub:1-5, eta:1-12
emc->getEndcapTowerADC(i,rawAdc,sec,sub,eta);
assert(sec>0 && sec< =MaxSectors);// total corruption of muDst
//Db ranges: sec=1-12,sub=A-E,eta=1-12,type=T,P-R ; slow method
const EEmcDbItem *x=eeDb->getTile(sec,'A'+sub-1,eta,'T');
...... this is the same also for pre/post/smd (except ene fudge factor!)................
assert(x); // it should never happened for muDst
if(x->fail ) continue; // drop broken channels
if(x->stat & killStat) continue; // drop not working channels
if(x->gain < =0) continue; // drop it, unless you work with ADC spectra
if(rawAdc < x-> thr) continue; // drop raw ADC < ped+N*sigPed
float adc=rawAdc-x->ped; // ped subtracted ADC
float ene=adc/x->gain; // energy in GeV
if(MCflag) ene/=0.8; //fudge factor for TOWER sampling fraction, to get pi0, gamma energy right
.... do your stuff ..........
........................
} // end of towers
//......................... P R E - P O S T .....................
int pNh= emc->getNEndcapPrsHits();
for (i=0; i < pNh; i++) {
int pre, sec,eta,sub;
//muDst ranges: sec:1-12, sub:1-5, eta:1-12 ,pre:1-3==>pre1/pre2/post
StMuEmcHit *hit=emc->getEndcapPrsHit(i,sec,sub,eta,pre);
float rawAdc=hit->getAdc();
//Db ranges: sec=1-12,sub=A-E,eta=1-12,type=T,P-R ; slow method
const EEmcDbItem *x=eeDb-> getTile(sec,sub-1+'A', eta, pre-1+'P');
if(x==0) continue;
..... etc, as for towers ....
..............
}
//....................... S M D ................................
char uv='U';
for(uv='U'; uv < ='V'; uv++) {
int sec,strip;
int nh= emc->getNEndcapSmdHits(uv);
for (i=0; i < nh; i++) {
StMuEmcHit *hit=emc->getEndcapSmdHit(uv,i,sec,strip);
float rawAdc=hit->getAdc();
const EEmcDbItem *x=eeDb->getByStrip(sec,uv,strip);
assert(x); // it should never happened for muDst
... etc, as for towers ....
..............
}
}
Details of DB usage for StEvent , loop over hist for one event - posted for the record.
Remember, NEVER EVER access EEMC data from StEvent. It is so slow and clumsy. It is asking for a trouble. All EEMC analysis SHOULD work on muDst ONLY - Jan
T O W E R S
.....
// choose which 'stat' bits are fatal for you, e.g.
uint killStat=EEMCSTAT_ONLPED | .......;
.....
StEvent* mEvent = (StEvent*) StMaker::GetChain()->GetInputDS("StEvent"); assert(mEvent);
StEmcCollection* emcC =(StEmcCollection*)mEvent->emcCollection(); assert(emcC);
StEmcDetector* etow = emcC->detector(kEndcapEmcTowerId); assert(etow);
for(uint mod=1;mod < =det->numberOfModules();mod++) {
StEmcModule* module=det->module(mod);
StSPtrVecEmcRawHit& hit= module->hits();
int sec=mod ; // range 1-12
for(uint ih=0;ih < hit.size();ih++){
StEmcRawHit *h=hit[ih];
char sub='A'+h- >sub()-1; // range 'A' - 'E'
int eta=h->eta(); // range 1-12
int rawAdc=h->adc(); // raw ADC
//Db ranges: sec=1-12,sub=A-E,eta=1-12,type=T,P-R; slow method
const EEmcDbItem *x=eeDb->getTile(sec,sub,eta,'T');
if(x==0) continue;
.... now follow muDst example for towers ....
} // end of sector
}
PRE1,PRE2, and POST -all mixed together preL='P','Q','R' for pres1,pres2,post, respectively StEmcDetector* det=emcC- > detector(kEndcapEmcPreShowerId)//==(14) for(int imod=1;imod < =det- > numberOfModules();imod++) { StEmcModule* module=det- > module(imod); printf("EPRE sect=%d nHit=%d\n",imod, module- > numberOfHits()); StSPtrVecEmcRawHit& hit= module- > hits(); int ih; for(ih=0;ih < hit.size();ih++){ StEmcRawHit *x=hit[ih]; int sec=x- > module(); int ss=x- > sub()-1; char sub='A'+ss%5; char preL='P'+ss/5; int eta=x- > eta(); int adc=x- > adc(); printf("ih=%d %02d%c%c%02d ss=%d -->adc=%d ener=%f ss=%d\n",ih,sec,preL,sub,eta,ss,adc, x- > energy(),ss); }
SMD U & V are stored in SEPARATE collections StEmcDetector* det=emcC- > detector(kEndcapSmdUStripId)// U=15, V=16 for(int imod=1;imod < =det->numberOfModules();imod++) { StEmcModule* module=det- > module(imod); printf("ESMD sector=%d nHit=%d\n",imod, module- > numberOfHits()); StSPtrVecEmcRawHit& hit= module- > hits(); int ih; for(ih=0;ih < hit.size();ih++){ StEmcRawHit *x=hit[ih]; int sec=x- > module(); int strip=x- > eta(); int adc=x- > adc(); printf("ih=%d %02dU%03d -->adc=%d ener=%f\n",ih,sec,strip,adc, x- > energy()); }
Details of the DB- Maker(s) setup in the muSort.C script:
myDb=new StEEmcDbMaker("eemcDb");
....
myDb->setThreshold(2.5);
....
chain->Init();
....
St_db_Maker *dbMk=new St_db_Maker("db", "MySQL:StarDb", "$STAR/StarDb");
dbMk->SetFlavor("sim","eemcPMTcal");
dbMk->SetFlavor("sim","eemcPIXcal");
dbMk->SetFlavor("sim","eemcPMTped");
dbMk->SetFlavor("sim","eemcPMTstat");
dbMk->SetFlavor("sim","eemcADCconf");
dbMk->SetFlavor("sim","eemcPMTname");
? dbMk->SetDateTime(20031120,0); (you may need to specify the DB time stamp)
To verify the ideal DB tables were loaded you should find in the log-file the following message for every sector: ..... EEDB conf ADC map for sector=6 StInfo: EEDB chanMap=Ideal EEMC mapping, (October 2004), RF StInfo: EEDB calTw=Ideal EEMC tower gains, E_T 60GeV=4096ch, RF StInfo: EEDB tubeTw=Ideal EEMC P-names, (October 2004), RF StInfo: EEDB calMAPMT=Ideal EEMC P,Q,R,U,V gains, 23000ch/GeV, RF StInfo: EEDB ped=Ideal EEMC peds/ADC at 0.0, sig: Tow=1.0, Mapmt=0.7; RF StInfo: EEDB stat=Ideal EEMC stat=fail=0 (all good), RF ....To use Barrel ideal DB do
starDb->SetFlavor("sim", "bemcPed");
starDb->SetFlavor("sim", "bemcStatus");
starDb->SetFlavor("sim", "bemcCalib");
starDb->SetFlavor("sim", "bemcGain");
slow controls archive viewer
There is a viewer for slow controls quantities documented at
http://drupal.star.bnl.gov/STAR/subsys/ctl/archive-viewer
There is an interface through a web browser or a java script. Both must run from the starp internal network. I used the java script run from sc. Two plots of voltage tracking are attached. These were made via screen capture of the display.
trash
Trash pages for testingchain tricks
do I remember it correct the current implementation of StMaker() does
not prevent execution of subsequent makers in the chain even if the
earlier one returns:
return kStErr;
It depends. If maker is "privileged" then loop is ended.
Normal user makers are not priviliged, to avoid skipping of other users
makers.
The priviliged ones are all I/O makers and StGeantMaker (which is also I/O
maker)
User could define his maker as a priviliged:
instead of:
bfc(999,...)
user should:
bfc(0,...);
chain->SetAttr(".Privilege",1,"UserMakerName" );
chain->EventLoop(1,999);
Victor
software
Endcap Sofware 2006++
test entry
test child page control
timing_WMZ
Fig. 1 Tower Crate
Fig. 2 Crate 64-67
Fig. 3 Crate 68-71
Fig. 4 Crate 72_75
Fig. 5 Crate 76-79
Fig. 6 Crate 80_83
Fig. 7 Crate 84-87
Fig. 8 Crate 88-91
Fig. 9 Crate 92-95
Fig. 10 Crate 96-99
Fig. 11 Crate 100-103
Fig. 12 Crate 104-107
Fig. 13 Crate 108-111
Plots of channels
mapmt-crate-64.pdf
ETOF
Endcap Time Of Flight Detector
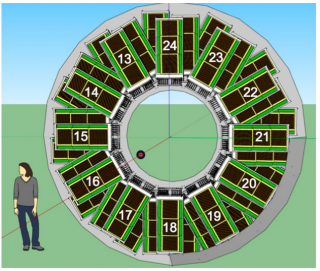
- Mailing list: star-etof-l@lists.bnl.gov
- Weekly STAR/CBM eTOF meeting: Thursdays 10.00 AM (EDT) via bluejeans
Calibration Status
Status Mach 25th 2024
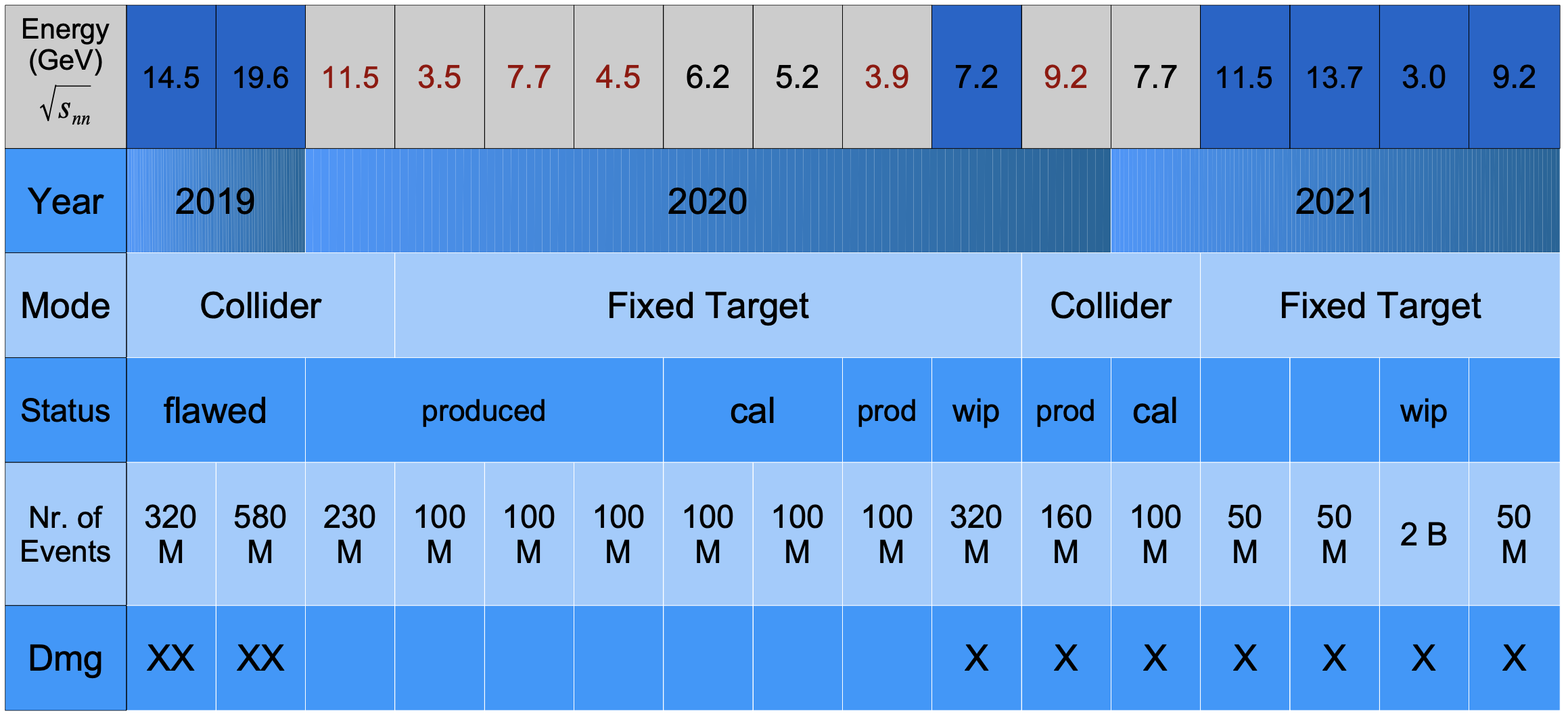
Pre-Amp damage 2020
Information slides regarding the pre-amp damage on eTOF during the 2020 run
Pre-Amp damage 2020
Information slides regarding the pre-amp damage on eTOF during the 2020 run
ProtonAnalysis
Talk Analysis Meeting 06/2022: eTOF data in Analysis
eTOF planning meeting April 9, files
eToF Runlist 9.2 GeV
https://docs.google.com/spreadsheets/d/1wycWpzHmOrwEJRk5_BpDO9fy1IvJH1hoxVB0elaC1tM/edit#gid=0
FCS
Forward Calorimeter System
FCS DB
Offline Database, Geometry for FCS
- fcsDetectorPosition.idl (1 row) : Detector Position for each [det=0~3]
struct fcsDetectorPosition {
float xoff[4]; /* x offset [cm] from beam to front of near beam corner */
float yoff[4]; /* y offset [cm] from beam to detector center */
float zoff[4]; /* z offset [cm] from IR to front of near beam corner */
};
Offline Database, Calibration for FCS
- fcsEcalGain.idl (1 row) : Ecal Gain [GeV/ch]
struct fcsEcalGain {
float gain[1496]; /* gain 2*748 */
}; - fcsEcalGainCorr.idl (1 row) : Ecal Gain Correction[unitless]
struct fcsEcalGainCorr {
float gaincorr[1496]; /* gain correction 2*748 */
}; - fcsHcalGain.idl (1 row) : Hcal Gain [GeV/ch]
struct fcsHcalGain {
float gain[520]; /* gain 2*260 */
}; - fcsHcalGainCorr.idl (1 row) : Hcal Gain Correction [unitless]
struct fcsHcalGainCorr {
float gaincorr[520]; /* gain correction 2*260 */
}; - fcsPresGain.idl (1 row) : Pres Gain [MIP/ch]
struct fcsPresGain {
float gain[384]; /* gain 2*192 */
}; - fcsPresValley.idl (1 row) : Pres Valley Position [MIP]
struct fcsPresValley {
float valley[384]; /* valley 2*192 */
}; - fcsEcalGainOnline.idl (1 row) : Ecal Gain Online[unitless]
struct fcsEcalGainOnline {
float gainOnline[1496]; /* online gain 2*748 */
}; - fcsHcalGainOnline.idl (1 row) : Hcal Gain Online [unitless]
struct fcsHcalGainOnline {
float gainOnline[520]; /* online gain 2*260 */
}; - fcsPresThreshold.idl (1 row) : Pres Threshold Position [MIP]
struct fcsPresThreshold {
float threshold[384]; /* online threshold 2*192 */
};
FGT
 |
Graphics courtesy of J.Kelsey MIT, |
| FGT. . . . . . . . . . P H Y S I C S goals, publications, presentations (PowerPoint, PDF, KeyNote, etc. presentations given by members at meetings, conferences, etc.) |
minutes, calendar |
FGT. . . . . . . . . . S I M U L A T I O N S
|
|
Hardware Thermo-model 16 cm FGT . . . . . . . . . . DAQ readout, DAQ, etc. FGT. . . . . . . . . . H A R D W A R E -- S L O W C O N T R O L S |
FGT. . . . . . . . . . S O F T W A R E muDst container, geant hits, DB tables
|
FGT . . . . . . . . . . C A L I B R A T I O N algo1, y2010 |
| FGT . . . . . . . . . . D O C U M E N T S proposal,reviews,design notes, tables, responsibilities,etc (generally text documents related to the FGT) |
FGT . . . . . . . . . . A N A L Y S I S e/h algo Endcap, high-pT tracking |
FGT. . . . . . . . . . P H O T O - - G A L L E R Y + PR figures (useful plots, drawings, pictures, etc. in original format that people can use in presentations) |
| FGT. . . . . . . . . . I N S T R U C T I O N S edit web-page, HPSS I/O |
FGT. . . . . . . . . . V A R I A |
FGT sub-system web pages use Drupal nodes: 7217, 10145-156.
FGT. . . . . . . . . . I N S T R U C T I O N S
- You do not have access to view this node
- HPSS HPSS I/O private/production files
- Navigation through FGT web pages
- Guidelines For MIT Tier2 Job Requests For MIT Tier2 Job Requests (Mike)
HPSS I/O
HTAR : save/restore private directory (large set of small files) in HPSS
http://drupal.star.bnl.gov/STAR/comp/sofi/hpss/htar
Known problems:
WARNING: htar_PreallocateSpace: HPSS OUT-OF-SPACE error preallocating
**** bytes for file=[/home/salur/myfile.tar]
This is a directory with 350G. Do I have to divide my files into smaller.
there is a 60GB max file size limit [when creating tarballs], Another
limit to be aware of, however, is an 8GB limit on member files
Mass restoring of ~100GB files from HPSS using Data Carusel
Prepare input file xxx.hpss with list of source +destination paths for all files you need, one line per file
Execute the command (at any location at rcas6nnn)
hpss_user.pl -f xxx.hpss
Wait 10-1000 minutes fro the files to show up at your destination (if all paths are correct)
Instruction for new users uploading FGT documents
Instruction for remote uploading of documents to the common FGT Drupal place to complement missing features of fgt-hn
First time setup
- You need to login to drupal as you. The password is different than your regular RCF password. If you do not remember Drupal password select 'forgot password' and new one will be sent to you by e-mail
- got to the mother-web page:
http://drupal.star.bnl.gov/STAR/subsys/upgr/fgt/hn-upload-contributions
you can also navigate: SubSystems --> Detctor Upgrades --> FGT --> FGT-HN Upload - Got to the bottom and select 'Add child page'
- Set the following fields:
* Title: yourName-FGT-HN-Uploads (edit it)
* Parent: ------FGT-HN-Upload contributions (selectable from menu)
* STAR: --FGT (selectable)
* Body: Your Name : list of attachements sent to FGT-HN (edit it, just 1 line)
Upload a test jpg file using menu at the very bottom of the page. To attache new file, first 'Choose File', next 'Attach' - Finally at the very bottom 'Submit' the whole page to Drupal.
- go to the 'mother-page' and you should see:
* in the upper part your JPG
* in the lower part (below bold text) your sub-page among other people who already joined, alphabetical order.
If you can't see your contribution at this point contact me (Jan). Do not try it over - it will add mess to Drupal. If you add more than one page only the first one will be considered
Uploading subsequent documents
- Login to drupal and go to your sub-page with this test JPEG
- Click Edit
- scroll down to upload section and add as many documents as needed, one by one
- you may change the name of uploaded file - just edit it
- Click 'Submit'
- go to the 'mother-page' and you should see your new documents listed in chronological order.
- Now you can sent an e-mail to FGT-HN referring your new uploaded documents as:
.... new docs are uploaded to: http://drupal.star.bnl.gov/STAR/subsys/upgr/fgt/hn-upload-contributions under myName, files xxx-yyy-jpg and zzz-uuu-mmm.pdf
Report to me if there are any problems,
Jan
FGT. . . . . . . . . . P H Y S I C S
- Physics motivation
- Proposal (December 2007)
- Publications
- Talks
date person format title occasion April 2006 Frank pdf ppt Development of Tracking Detectors with Industrially Produced GEM foils TPC workshop, Berkeley October 2006 Frank pdf ppt Development of Tracking Detectors with Industrially Produced GEM Foils IEEE NSS 2006, San Diego, CA, USA January 2007 Bernd pdf FGT-Technical implementation, Cost, R&D plan, Schedule BNL Detector Advisory Committee Meeting - - - - - - NIM paper on the Fermilab test beam is now published in NIM.
F. Simon et al., Nuclear Instruments and Methods in Physics Research A 598 (2009) 432–438
FGT. . . . . . . . . . S I M U L A T I O N S
Simulation of physics background for development of e/h algo. ( Physics Background Simulation)
Selected topics:
- Method of Pythia event filtering using threshold on eta-phi grid (Practical Pythia Event Filter (Jan))
- List of available M-C event samples (Jan) ( W-events, QCD background events)
- PT scan of Pythia-filter rejection for QCD events ( Jan) of # of needed M-C events for LT=800/pb
- List of MIT Simulation Productions facility (by Mike)
- Pythia analysis version 1.0 (by Brian)
Physics Background Simulation
Ongoing effort of preparing physics-background samples for developing of e/h discrimination algos for W reconstruction
Existing Framework For FGT Simulations
With the completion of the FGT hardware review, focus must now be made on the creation and implementation of efficient analysis algorithms. To this end a framework for creating simulation files must be established. Here I document the existing framework I created this past summer for a small FGT project.
The creation of simulation files within STAR is handled in two steps.
- starsim is called with a PYTHIA kumac, creating a fzd file.
- The fzd file is converted to a full muDst with the bfc.
The kumac sets all parameters of the underlying physics events, while the bfc handles the fine tuning of the reconstruction of the STAR detector.
In the following analysis the simulation was split by the underlying physics processes: those producing W bosons and those from QCD 2->2 interactions. Both are produced with the geometry UPGR13 and sqrt(s) = 500 GeV, in accordance with the FGT upgrade. Moreover, each kumac accepts a random number seed to ensure that different jobs are independent of each other. Specific details are included below,
| W | Hadron | |
| Geometry | UPGR13 | UPGR13 |
| sqrt(s) | 500 GeV | 500 GeV |
| Vertex (mean, variance) | 0 cm, 60 cm | 0 cm, 60 cm |
| Subprocesses | 2, 15, 20, 23, 25, 31 | 11, 12, 13, 28, 53, 68, 96 |
| CKIN3 | 10 GeV | 10 GeV |
| CKIN4 | None | None |
| Additional Cuts | Require electron in the endcap with pT > 15 GeV | None |
| Additional Notes | W bosons made explicitly unstable | None |
| Events / Job | 4000 | 2000 |
| Cross Section / Job | O(103 pb) | O(103 pb) |
| PYTHIA + GSTAR + BFC Running Time / Job | O(20 hours) | O(16 hours) |
| PYTHIA + GSTAR Running Time / Job | O(12 hours) | O(6 hours) |
| Memory Used / Job | O(1000 MB) | O(1500 MB) |
| Size of Output Files / Job | O(2.5 GB) | O(2.5 GB) |
bfc.C\(1,nEvents,"trs ssd upgr13 pixFastSim Idst IAna l0 tpcI fcf Tree logger ITTF Sti StiRnd PixelIT IstIT StiPulls genvtx NoSvtIt SsdIt MakeEvent McEvent geant evoutgeantout IdTruth tags bbcSim emcY2 EEfs big -dstout fzin MiniMcMk McEvOut clearmem","fileName.fzd")
Detailed log files can be found at
/star/institutions/mit/betan/FGT/Logs/while the existing files are at
/star/institutions/mit/betan/ROOT_Files/FGT/Attached are the relevant scripts (the _.txt has been added to get around DRUPAL attachment restrictions), although the hardcoded paths are no longer valid. The master script is submit_simulations.csh, which submits all the others to the RCAS queue star_cas_big. In particular, W_job.csh and hadron_job.csh are each called with the command line arguments
*_job.csh <em>nEvents fileName randomNumberSeedThe *_job.csh scrips then call the starsim and bfc with the necessary arguments passed as appropriate.
Filtered Simulations For The Development of Electron/Hadron Discrimination Algorithms
Critical to the upcoming flavor physics at STAR is efficient electron identification in the endcap, particularly amongst the dominant charged hadron/meson background. The development of such discrimination algorithms, however, requires extensive simulations. To reduce the computational burden of these simulations to a practical level we must modify starsim, reconstructing only those events of interest.
In this case we require electrons and charged hadrons/mesons in the endcap, and by adding a filter to PYTHIA we can ensure that only events matching the this criteria are reconstructed. Below is a small study showing the significant reduction in computing time gained with this filtering.
The filtered simulations required a charged hadron or meson in the endcap with pT > 15 GeV before GSTAR was allowed to reconstruct the event. Candidate refers to an event meeting the above requirements in the PYTHIA record, and projected refers to an extrapolation estimate for 80 pb-1.
| Hadrons/Mesons | Filtered | Filtered (Projected) | Unfiltered | Unfiltered (Projected) |
| Candidates | 10 | 18,604 | 10 | 18,604 |
| Reconstructed GEANT Events | 10 | 18,604 | 2863 | 5,326,325 |
| Integrated Luminousity (pb-1) | 0.043 | 80 | 0.043 | 80 |
| Starsim Running Time (hours) | 0.274 | 509 | 7.42 | 13,817 |
| BFC Running Time (hours) | 0.845 | 1572 | 24.2 | 45,023 |
Looking at the tracks in the GEANT record we see that the filtering worked as described. Here every charged hadron/meson in every reconstructed event is shown, and in the Filtered sample we see a sharp cutoff at 15 GeV exactly as expected.

The same analysis can be done for the W boson simulations, here instead requiring an electron(positron) from a W decay in the endcap with pT > 15 GeV.
| Ws | Filtered | Filtered (Projected) | Unfiltered | Unfiltered (Projected) |
| Candidates | 10 | 672 | 10 | 672 |
| Reconstructed GEANT Events | 10 | 10 | 357 | 24,020 |
| Integrated Luminousity (pb-1) | 1.189 | 80 | 1.189 | 80 |
| Starsim Running Time (hours) | 0.0361 | 2.42 | 0.822 | 55.3 |
| BFC Running Time (hours) | 0.0882 | 5.93 | 2.807 | 188.8 |
Again, comparing the two files shows the desired effects

In both cases the computational demands seem impractical, but one has to remember that this extrapolation is based on the use of a single processor. Real jobs will be run in parallel, significantly reducing the projected times to more reasonable levels. Despite the reduction, however, it might still be necessary to reduce the desired integrated luminousity slightly.
Filtering PYTHIA Events In Starsim
Within the STAR framework, simulation files are created with the command starsim which runs both PYTHIA and GEANT. Unfortunately, this means that there is no straightforward way to filter PYTHIA events before the GEANT reconstruction and producing simulation files for rare events can be very time consuming, as most of the CPU is wasted on the GEANT reconstruction of undesired events.
The trick around this is to modify the PYTHIA libraries themselves. In particular we want to modify the PYEVNT subroutine which is run during the generation of each PYTHIA event. Begin by
- Checking out a copy of the pythia libraries from cvs
- Create a back up of pyevnt.F in case anything goes wrong
- Open up pyevnt.F in your favorite text editor
- Rename SUBROUTINE PYEVNT to SUBROUTINE PYEVNT_ORG
- Now create your own subroutine, SUBROUTINE PYEVNT
- Copy the variable declarations and commonblocks from the original PYEVNT
The body of this new subroutine will in general go as the following
while(conditions have not been met)
Call the original PYEVNT
Call any necessary auxillery subroutines
Loop over particles
if(not desired characteristic a) continue
if(not desired characteristic b) continue
...
if(not desired characteristic i) continue
Calculate relevant kinematic variables
Check conditions
Call PYLIST
Note that to avoid too many nested if loops we abort when the first test fails.
For example, consider an analysis requiring a high energy electron in the endcap. The usual PYTHIA settings allow one to require a high energy electron, but there is no way to restrict its location in the detector. So in the above pseudocode becomes
while(no high pT electron in the endcap)
Call the original PYEVNT
Loop over particles
if(not electron) continue
Calculate pT
Calculate eta
if(pT < 15) continue
if(eta < 1) continue
if(eta > 2) continue
return
Call PYLIST
The main background to the above is charged hadrons/mesons. In order to filter these we require that the particle has a charge of +/- 1, that is has the PDG ID of a hadron or a meson, that it has not decayed in the PYTHIA record, and fulfills the kinematic requirements.
while(no high pT jet in the endcap)
Call the original PYEVNT
Loop over the jets at the end of the PYTHIA record
if(not stable) continue
if(charge not equal +/- 1) continue
if(not hadron or meson) continue
Calculate pT
Calculate eta
if(pT < 15) continue
if(eta < 1) continue
if(eta > 2) continue
return
Call PYLIST
Once pyevnt.F has been succussfully modified it must be compiled with cons, and the path to the compiled library itself must be explicitly set in the kumac. For example,
gexec $STAR_LIB/libpythia_6410.somust be replaced by
gexec /star/u/username/path_to_directory/.slxx_gccxxxx/lib/name_of_new_pythia_library.soExamples of modified pyevnt.F files for both the electron example and the jet example are attached, as is a kumac for use with the jet example.
List of available M-C event samples (Jan)
.
M-C Event Samples Available
- General setup, assumptions
- use UPGR13 geometry
- run in SL07e
- use PPV vertex finder in reco
- displace & smear vertex in GEANT in X-Y plane: x0=+1mm, sig=200us, y0=-2mm, sig=200um (except setA)
- beam energy sqrt(s)=500 GeV
- detectors passed by track thrown at various eta at 3 Z-vertex location of -60, -30 an 0 cm.

- setA (produced by Mike @ MIT)
- setB (pilot sample by Jan @ RCF)
- setC - Pythia macros inspected by Jim: ppQCDprod.kumac & ppWprod.kumac
Filtering of Pythia events: seed cell =10GeV ET, pair of cells>20 GeV ET,
particle eta range [0.8,2.2], grid cell size: 0.14 in eta, 9 deg in phi
* setC1: /star/institutions/iucf/balewski/2008-FGT-simu/setC2-pt-0.2inv_pbThis is LT balanced for 0.2/pb, using your ppQCDprod.kumac
pt1 pt2 neve 10 ,15 ,373 15 ,20 ,1252 20 ,25 ,2516 25 ,30 ,3367 30 ,35 ,2330 35 ,40 ,1015 40 ,45 ,705 45 ,50 ,292 50 ,55 ,114 55 ,60 ,67 60 ,65 ,28 65 ,70 ,13 70 ,75 ,8 75 ,80 ,4 80 ,85 ,2 85 ,90 ,1 90 ,95 ,1
* setC2 (only filtered events of various types)

* setC3 (filtered vs. not filtered events)

* setC4 ( filtered QCD events w/ various partonic PT )

- setC5 : QCD events , 3-stage filtering, LT~100/pb

BFC w/ generic vertex finder has ~50% efficiency,
Vertex distribution: Gauss(Z=0, sigZ=60cm, Z=Y=0, sigX=sigY=0)
| Type of events | total events | time per event |
|---|---|---|
| Pythia, minB | 400K, 100 jobs | GSTAR: 8.4 sec, BFC ??? |
Files location: 80K eve at IUCF disk: /star/institutions/iucf/kocolosk/2008-02-15-fgt-hadron-background
full sample at MIT ...
Filtering of Pythia events: seed cell =10GeV ET, pair of cells>20 GeV ET,
particle eta range [0.8,2.2], grid cell size: 0.14 in eta, 9 deg in phi
BFC w/ PPV vertex finder has ~95% efficiency, SSD, STI not used in tracking
Vertex distribution: Gauss(Z=-60, sigZ=5cm, Z,Y offset)
Pythia event generator,
BFC chain:" DbV20080310 trs -ssd upgr13 Idst IAna l0 tpcI fcf -ftpc Tree logger ITTF Sti StiRnd -IstIT -SvtIt -NoSvtIt SvtCL,svtDb -SsdIt MakeEvent McEvent geant evout geantout IdTruth bbcSim emcY2 EEfs bigbig -dstout fzin -MiniMcMk McEvOut clearmem -ctbMatchVtx VFPPV eemcDb beamLine"
| Type of events | Pythia filter | total events | time per event | job name | file size, MB |
|---|---|---|---|---|---|
| W-events (kumac) | 1/6.5 | 1K, 1 job | GSTAR 10 sec, BFC 5.3 sec | wElec4 | fzd=149, stevent=132, geant=154, McEvent=132, muDst=14 |
| 1:1 , OFF | 5K, 1 job | - | wElec5 | - | |
| QCD-events (kumac) pt=20-30 GeV | 1/40 | 1K, 1 job | GSTAR 11 sec, BFC 6.7 sec | qcd2 | fzd=203, StEvent=157, geant=212, McEvent=172, muDst=17 |
| 1:1, OFF | 5K, 1 job | - | qcd3 | - | |
| QCD-events, scan pt 10...90 GeV | varies | 100 eve, 1 job | - | qcd_pt_xx_yy | files at ...balewski/2008-FGT-simu/setB-pt-scan/ |
Files location: /star/institutions/iucf/balewski/2008-FGT-simu/setB-pilot/
Custom code : Pythia, Generic Vertex finder, same location
evaluation of Pythia Filter for QCD & W events (setC3)
Based on setC3 the number of events with reco EM cluster ET>20 GeV is similar for the filtered and unfiltered pythia samples after LT correction - compare yellow & green areas:

------------ From Brian -------
Hi Jan,
I processed the events in setC3 and I put the plots into the
fgt-hn-contributions drupal page. (All plots show unfiltered events on
the left and filtered events on the right).
Transverse energy spectrum for the QCD events:
http://drupal.star.bnl.gov/STAR/system/files/ETspectrumQCD.png
Number of events passing ET>20GeV and ET>20GeV + Eta < 1.7 for QCD
events: http://drupal.star.bnl.gov/STAR/system/files/OPcountsQCD.png
Transverse energy spectrum for the W events:
http://drupal.star.bnl.gov/STAR/system/files/ETspectrumW.png
Number of events passing ET>20GeV and ET>20GeV + Eta < 1.7 for W events:
http://drupal.star.bnl.gov/STAR/system/files/OPcountsW.png
Brian
PT scan of Pythia-filter rejection for QCD events ( Jan)
Pythia Filer: cell>10 GeV ET, cluster >20 GeV ET , grid covers Endcap Pythia events

Note, 'live' spreadsheet is attached at the bottom
Examples of event filtering for some choices partonic PT ranges:
|
partonic PT 15-20 GeV Filter=1/760 |

|

|
|
partonic PT 40-45 GeV Filter=1/3.6
|

|

|
|
partonic PT 75-80 GeV Filter=1/4.6
|

|

|
Practical Pythia Event Filter (Jan)
Filtering of Pythia events preserving those which may fire HT trigger in the Endcap.
Motivation
In order to develop efficient e/h discrimination algo for reco of electrons from Ws it is necessary to generate sizable sample of QCD physics background events with 1e5 or more events triggering Endcap HT >10 GeV. The brute force approach (run PYTHIA+GSTAR+BFC long enough) is investigated by my not succeed due to low yield of events of interests.
Therefore, we are working on the in-fly Pythia events filtering. It must be more complex than accepting events with a single Pythia track above certain threshold because multiple tracks from jet (also hadrons) may deposit in a single tower cumulative energy exceeding the HT threshold even if all tracks have energy below this threshold.
The tricky part is to decide if EEMC response may be large before GSTAR does very time consuming simulation of EM & hadronic showers for the whole event.
Proposed Method (2-stage Pythia filtering)
- Define : eta range [0.9,2.1], partonPTthres of 5 GeV, jetPTthres of 5 GeV (to be tuned later)
- Inspect lines 7 & 8 of Pythia record (counting from 1) and drop event if none of partons is within eta range and above parton PT threshold.
For survived events - Define 2D eta-phi grid covering eta [0.9,2.1] and 2pi in phi. Divide it in to cells of size 0.1x0.1. Clear grid for every event.
- Loop over Pythia record 9..max and drop: partons, gluons, unstable particles, neutrino, muons.
Retain all stable hadrons, e+, e- within eta range, project particle ET in to the eta-phi grid. - find seeds all cells with ET above 1/2 of jetThreshold.
- for every seed from 8 pairs using every of its neighbors. If any pair ET sum is above jetThreshold event will be accepted and passed to GSTAR and eventually to BFC.
Additional comments:
* for Barrel eta range should be [-0.2,1.2] and cell size 0.05x0.05 in eta x phi.
* the code should be written in F77.
* at any step priority should be given to processing speed vs. program size. E.g. use lookup tables when reasonable.
* provide few QA histos generated with Pythia using HBOOK + kumac to display them
Content of Pythia record
1 proton 1 2 proton 2 3 parton from proton1 4 parton from proton2 5 parton from proton 1 after intial state radiation 6 parton from proton 2 after intial state radiation 7 parton 1 after scatter 8 parton 2 after scatter 9 ... intermediate and final partons/particles ....
evaluation of Bates minB sample (Jan)
Evaluation of minB events ample produced by Mike at Bates in January of 2008.
Events characteristic: Pythia MinB events, sqrt(s)=500 GeV, vertex Gauss(0,60cm)
Below you see detectors acquired by e+/e- surrogate :
1st pi-,pi+ with pT>2.0 GeV and eta>0.7
FGT disks are located at Z of 70,80,...,110 cm - our best guess location.
3 events samples were chosen based on Geant vertex location of -60, 30, and 0 cm, with margin of +/-10 cm, what leads to smeared FGT disks.
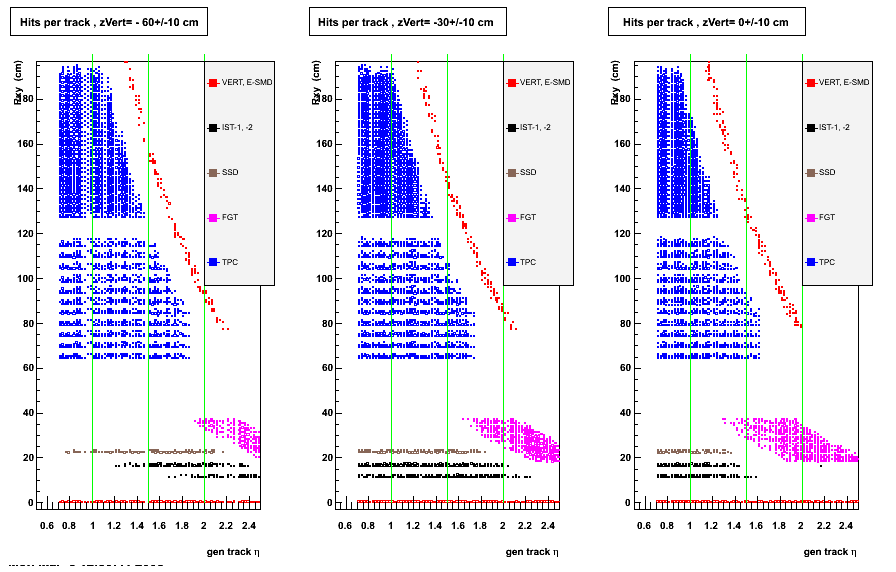
Optimization of FGT disk location
Several versions of FGT disk geometries has been studied in 2007
as documented here (disk-based HTML documentation)
Z disk location accuracy
Propagation of the Z hit location inaccuracy on to the error of predicted Rxy location of the Endcap EM shower.



geometry in MC
Documented evolution of implementation of FGT geometry in GSTAR, started on May, 2008
Our studies are below seen as child pages.
Here are links to other studies
- Weight of SSD componants (from survey), missing ladder weight in geant, total ~300g on West end, also: Jonathan
- SSD small end ring : Jonathan, total weight = 3416 g, missing in geant
- overview of Nonexistent node nid: 12480., Oct-2008, Christophe
1 content of UPGR15, May 2008
Selected cross sections of UPGR15 geometry, as of May 2008
Fig 1

Fig 2

Fig 3

Fig 4

Fig 5

Fig 5 Realistic geometry from Jim K. model, May 2008

2 UPGR15+FGT as of May 2008
UPGR15 geometry was modified to match best guess of FGT geometry as of May 2008.
The active FGT area is : Z1=70,..., Z6=120cm, DZ=10 cm, Rin=11.5cm, Rout=37.5 cm
There is 1cm of additional dead material at Rin & Rout
Fig 1. Zvertex=0 cm, green= eta [1.06,2.0]. , red=eta[2.5,4.0]

Fig 2. Zvertex=+30 cm, green= eta [1.06,2.0]. , red=eta[2.5,4.0]

Fig 3. Zvertex=-30 cm, green= eta [1.06,2.0]. , red=eta[2.5,4.0]

Fig 4. Zoom in on 1 FGT disk. Detected particle enters from the left, 'active' gas volume has depth of 3mm (between magenta ad blue lines), FGT strips collect charge on the 1st green line.
(units in cm)
Zstart = 70.0 ! starting position along Z axis
Z = { 0.0, 10.0, 20.0, 30.0, 40.0, 50.0} ! Z positions for GEM front face
FThk = { 0.05, 0.05, 0.05, 0.05 } ! foil thicknesses inside GEM
SThk = { 0.3, 0.2, 0.2, 0.2 } ! support/spacing thicknesses
SR = 1.0 ! radial size for support

USED material:
Fig 4b FGT disk front view in Geant

Fig 5. 1st FGT disk by Jim K. as of April, 2008

Fig 6. 3 FGT disks by Jim K. as of April, 2008

Fig 7 Realistic geometry from Jim K. as of May, 2008
Fig 8 Disk material budget, from Doug, as of May, 2008

Fig 9 APV location , from Doug, as of May, 2008


4 compare geom 2007 vs. UPGR16
Green dashed lines at eta=1.0,.1.06,2.0
red lines at eta=2.5, 4.0
geom=2007

UPGR16, geom=2010

Speculative FGT++
another 6 disks are added at the following Z:
Zstart = 62.98 ! starting position along Z axis
Z = { 5.4, 15.4, 25.4, 35.4, 45.4, 55.4, 75., 90., 105., 120., 135., 150.} ! Z positions of GEM front face
Green dashed lines at eta=1.0,.1.09,2.0
red lines at eta=2.5, 4.0

5 FGT cables in Geant
Notes,
If I want to know the total area for one FGT disk what is the proper multiplier : 4, 28, or 24*28 ?
Within the cable, multipliers for the individual "subcomponents" are in column L.
Then, there are overall 4 cables per FGT disk - the column B tells you number of cables and I-J tells you where they go.
In other words, for instance, overall total copper area in FGT-power cables is
24*(7*5.176E-3+1*3.255E-3) = 0.948 cm^2.
I know you asked to break out with one "line" per cable route - we can do this later but for now there are already a lot of lines... I'll leave them grouped as this and you should look at I-J to decide the lengths and where they are.
By the way, I imagine the "patch" between cone/FGT cables and "external" cables lying on TPC endwheel, through services gap, to crates, occurs somewhere just outside the cone, within the first foot or so.
6 radiation length study for UPGR16 + SSD
Study of the dead material in front and behind FGT.
3 versions of GEANT geometries were investigated:
- UPGR16 + current SSD w/ current cables
- UPGR16 w/ 'light' SSD (Alu support structure replaced by carbon, Cu cables replaced by Alu)
- UPGR16 without SSD, nor SSD cables
Plot below is just example of material using current SSD.

Many more plots are in attached PDF, in particular figs 2a-c, 3a-c, 4a-c.
7 PR track plots with UPGR16 & fixed barrel
Geometry= UPGR16, 6 FGT disks , fixed barrel geometry.
Single electrons, 20 GeV ET, thrown at eta=0, 0.4, 0.8, 1.2, 1.6, 2.0
Fig 1, Z vertex=0

Fig 2, Z vertex=+30 cm

Fig 3, Z vertex=-30 cm

FGT hits fired by backward tracks (Wei-Ming Zhang)
1, MC tracks (eta < -1.3) are thrown backwards and FGT are found fired.
Fig. 1, An events with FGT hits fired by backward tracks (UPGR16)
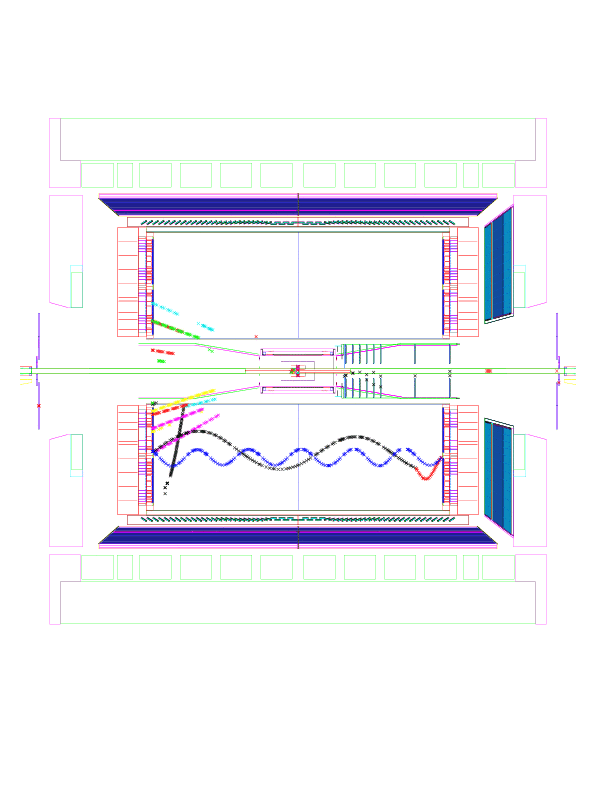
2, To investigate with tracks (1.3 |eta| < 3.1) from MC events of RQMD Au-Au 10 GeV
Fig. 2
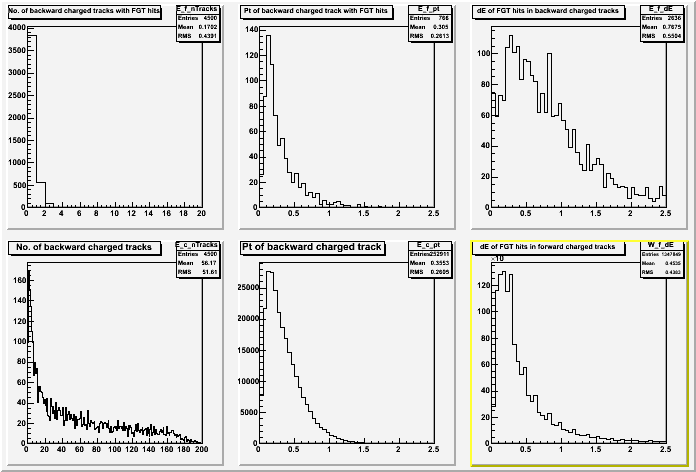
There are two rows in Fig. 2. Each row has three plots, the left is track multiplicity of events, the middle pt of
tracks, and the right dE of FGT hits in KeV. The top row is plotted for backward tracks which fire FGT and for fired FGT
hits (backward hits). The first two of the bottom are for all backward tracks. The right of the bottom is a dE spectrum
of FGT hits fired by FORWARD tracks (forward hits). From Fig. 1, we see
1, A low level of backward hits (mult_0/mult_1 = 200 shown in the top left plot)
2, A relatively large energy loss of backward hits which is 2-3 time larger than that of forward hits.
This suggests backward tracks which fire FGT have very low speed and deposit more energy than forward MIPs.
Based on the above, we believe that backward hits in FGT come from multiple scattering.
Fig. 3, Split spectra of the top row of Fig. 2 for individual FGT disks: disk1 (top) disk2 (middle)
and disk3 (bottome)
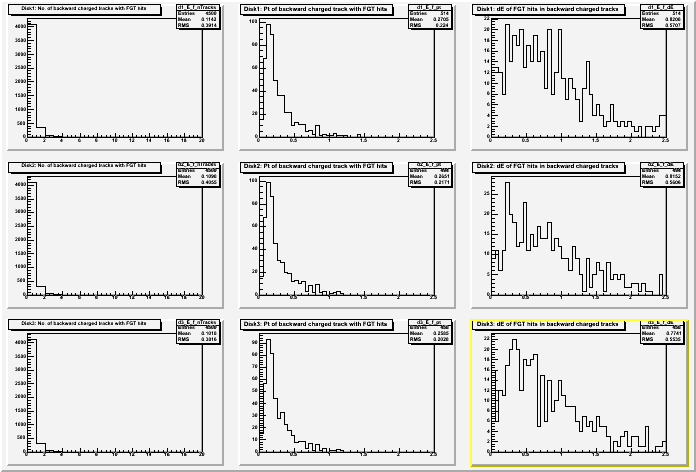
Fig. 4, Split spectra of the top row of Fig. 2 for individual FGT disks: disk4 (top) disk5 (middle)
and disk6 (bottome)
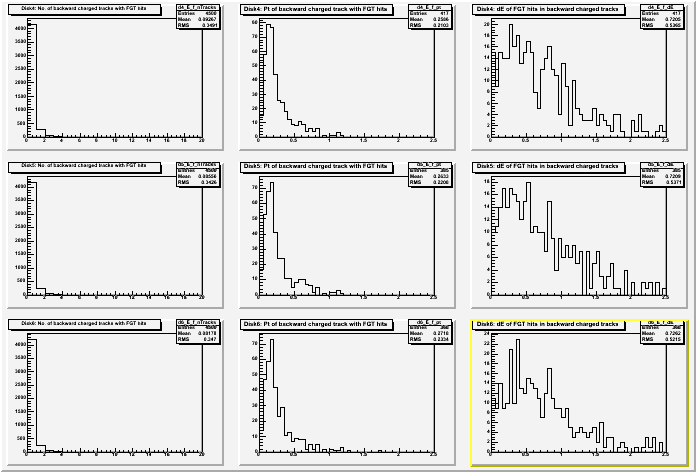
FGT. . . . . . . . . H A R D W A R E -- D E T E C T O R
- FGT foil
- FGT disk
- FGT strip design, gerber screen dumps, 2010-12-20
- strip 2 APV mapping, R-plane
- 6-disk assembly
- integration w/ STAR
date revision format component March 2008 ? revXXX? PDF west support cylinder March 2008 ? 4.0 ? PDF mounting of FGT foil quadrant
Electrostatic Calculations for West Support Cone
Hi all;
I've put some results from the latest electrostatic
calculations for the WSC at:
http://hepwww.physics.yale.edu/star/upgrades/WSC-D.ppt
http://hepwww.physics.yale.edu/star/upgrades/WSC-D.pdf
The first page shows the key elements of the model and
the changes from previous versions:
- All edges of the WSC are radius'ed with 2 cm
- The resistor chain is now from Jan's "good" drawing
- The resistior chain is not rotated 16 degrees from
top - this makes it easier to navigate the "region
of interest" for studying the high field region.
This page also shows the orientation of the coordinate
system.
The next six pages are pairs of field plots. Each pair
shows the magnitude of the electric field in a slice
normal to the Z (X, Y) axis. The slice is taken at
the location of the maximum field. The second of each
pair of plots is just a zoom in on the hot spot.
The last plot shows that maximum field in an X-slice
vs. X. If people have questions or suggestions, we
can discuss this in tomorrow's meeting.
Best regards,
Dick Majka
Electrostatic Calculations for West Support Cone
Calculations from 24-July-2008 with "corrected" resistor chain geometry.
Rusults compared using 1mm mesh and 2mm mesh
FGT Thermo-model D=16cm
Photo documentation of Thermo-model A of FGT, 2009-08-10
















FGT Thermo-model D=16cm
Photo documentation of Thermo-model A of FGT, 2009-08-10
Consistent with measurements posted by James on 2009-07-28.
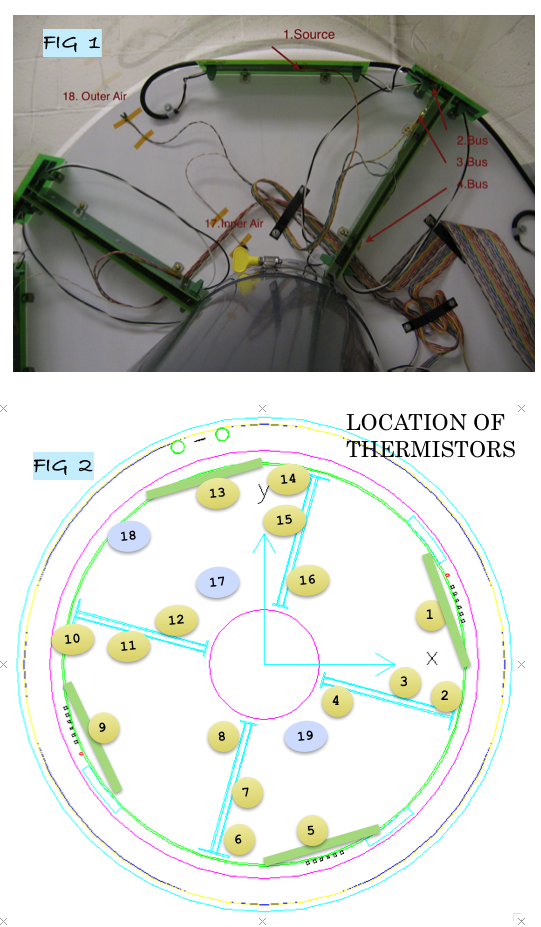
Gas system assembly drawings
Please note the following attachments:
- Gas system assembly drawings as of 5 February 2011.
- Gas system assembly drawings for cosmic ray tests in clean room at BNL: Safety review on 29 April 2011.
- Photo: front of gas system control panel for cosmic ray test - as of 10 May 2011.
- Photo: rear of gas system control panel for cosmic ray test - as of 10 May 2011
Donald Koetke
donald.koetke@valpo.edu
drawings for the FGT full-size prototype frames, HV layer, and GEM foils, August 11, 2008
These are the current drawings for the FGT full-size prototype frames, HV layer, and GEM foils.
Cheers,
Douglas
general routing for the top and bottom GEM, August 16,
these Gerber files show the general routing for the top and bottom GEM foil layers plus a representative sample of the GEM foil holes showing the spacing from frame edges and segment boundaries.
FGT . . . . . . . . . . A N A L Y S I S
see below
Estimation of error of A_L including detector response, May 2008 (Jan)
This set of analysis was done in preparation to PAC presentation at BNL, May 2008, ( Jan)
study 1 of S/B, A_L, LT=800/pb (Jan)
A_L on this has a WRONG sign, I did not know RHICBOS is using different sign convention
Section A
Definitions:
S1,S2 - "signal" yields for 2 spins states (helicity) "1", "2" , S1+S2=S
B1,B2 - "background" yields for 2 spins states "1", "2" , B1+B2=B
N1=S1+B1; N2=S2+B2; N1+N2=N=S+B - "raw" yields measured in real experiment
Assumptions:
- background is unpolarized, so B1=B2=B/2
- there are 2 independent experiments:
- measure spin independent yields for signal counts 's' and background 'b' counts, yielding the fraction w=b/s, V(w)=w2 *(1/b +1/s) ; (e.g. M-C Pythia simulation using W and QCD events)
- measure helicity dependent raw yields N1=S1+B1 and N2=S2+B2 ; (e.g. theory calculation with specific assumption of AL(W+) , fixed eta & pT ranges, assumed LT & W reco efficiency) yielding raw spin asymmetry :
ALraw=(N1-N2)/(N1+N2)= (S1-S2)/(S+B); V(ALraw)= 4*N1*N2/N3
I used capital & small letters to distinguish this two experiments.
Problem: find statistical error of 'signal' asymmetry:
ALsig= (S1-S2)/S
Solution:
- ALsig= (1+w) * ALraw
- V(ALsig)= (1+w)2*V(ALraw ) + V(w)*(ALraw)2 where V(x) denotes variance of x, V(N)=N.
Section B - theory
Model predictions of A_L for W+, W- , used files:
rb800.w+pola_grsv00_2.root, rb800.w-pola_grsv00_2.root, rb800.w+unp_ct5m.root rb800.w-unp_ct5m.root
LT=800/pb,
Brown oval shows approximate coverage of IST+FGT
Red diamond shows region with max A_L and ... little yield.

Section C - W reco efficiency, fixed ET using fact=1.25
From Brian, e/h algo ver 2.4, LT=800/pb.
This version uses only tower seed in bin 6-11, this is main reason efficiency is of 40%.
I'll assume in further calculation the W-reco efficiency is of 70%, flat in lepton PT>20 GeV.
Left: W-yield black=input, green - after cut 15.
Right: ratio. h->Smooth() was used for some histos.

PT=20.6 sum1= 1223 PT=25.6 sum1= 1251 sum2= 473 att=1/2.6 PT=30.6 sum1= 987 sum2= 406 att=1/2.4 PT=35.6 sum1= 771 sum2= 343 att=1/2.2 PT=40.6 sum1= 372 sum2= 166 att=1/2.2 PT=45.6 sum1= 74 sum2= 16 att=1/4.6
Section D - QCD reco efficiency,fixed ET using fact=1.25
From Brian, e/h algo ver 2.4, LT=800/pb. h->Smooth() was used for some histos.
This version uses only tower seed in bin 6-11
Left: QCD-yield black=input, green - after cut 15.
Right: ratio= QCD attenuation, not the a;go gets ~3x 'weaker' at PT =[34-37] GeV , exactly where we need it the most

PT averaged attenuation of QCD events
PT=20.6 sum1=2122517 PT=25.6 sum1=528917 sum2=3992 att=1/133 PT=30.6 sum1=135252 sum2= 736 att=1/184 PT=35.6 sum1= 38226 sum2= 320 att=1/120 PT=40.6 sum1= 11292 sum2= 127 att=1/89 PT=45.6 sum1= 3153 sum2= 41 att=1/77
Section E - QCD/W ratio after e/h cuts, algo ver 2.4,fixed ET using fact=1.25
From Brian. h->Smooth() was used for some histos.
Left: final yield of QCD events (blue) and W-events (green) after e/h algo.
Right: ratio.
I'll assume w=b/s is better than the red line, a continuous ET dependence:
w(pt=20)=10
w(pt=25)=1.
w(pt=40)=0.5

PT=25.6 sum1= 3992 sum2= 473 att=1/8.4 PT=30.6 sum1= 736 sum2= 406 att=1/1.8 PT=35.6 sum1= 320 sum2= 343 att=1/0.9 PT=40.6 sum1= 127 sum2= 166 att=1/0.8 PT=45.6 sum1= 41 sum2= 16 att=1/2.5
study 2 , err(AL) , eta=[1,2], LT=800/pb (Jan)
A_L on this has a WRONG sign, I did not know RHICBOS is using different sign convention, JAN
Section A) Theoretical calculations:
Assumed LT=800/pb
fpol=new TFile("rb800.w+pola_grsv00_2.root"); <--GRSV-VAL (maximal W polarization)
funp=new TFile("rb800.w+unp_ct5m.root");
histo 215
Total W+ yield for lepton ET[20,45] GeV and eta [1,2] is of 7101 for unpolarized cross section and of -2556 for the helicity dependent part.
Assuming 70% beam polarization measured spin dependent asymmetry:
eps_L= P* del/sum= -0.25 +/-0.012
(assuming err(eps)=1/sqrt(sum) )
Fig 1 , W+ : top row - unpol & pol cross section GRSV-VAL (maximal W polarization),
bottom left: integrated over eta, black=unpol, red=pol
bottom right: asy=P *pol/unpol vs. lepton PT, green=fit

Total W- yield for lepton ET[20,45] GeV and eta [1,2] is of 5574 for unpolarized cross section and of +2588 for the helicity dependent part.
fpol=new TFile("rb800.w-pola_grsv00_2.root");
funp=new TFile("rb800.w-unp_ct5m.root");
histo 215
Assuming 70% beam polarization measured spin dependent asymmetry:
eps_L= P* del/sum= +0.325 +/-0.013
Fig 2. W- GRSV-VAL (maximal W polarization)

Section B) Folding in e+,e- reconstruction and QCD background
Assumptions:
- LT=800/pb
- beam pol P=0.7
- e+,e- reco efficiency is 70%, no PT dependence
- QCD background to W contamination, after e/h algo no spin dependece
| lepton PT range | w=backg/signal |
| 20-25 GeV | 5.0 +/- 10% |
| 25-30 GeV | 1.0 +/- 10% |
| 30-35 GeV | 0.8 +/- 10% |
| 35-40 GeV | 0.7 +/- 10% |
| 40-45 GeV | 0.6 +/- 10% |
Formulas:
- Theory yields : unpol=sig0(PT) & pol=del(pt) , S1=(sig0+del)/2, S2=(sig0-del)/2
- Measured yields N1, N2 , for 2 helicity states
- N1(PT)= eff*[ sig0+del + sig0 * w) /2
- N2(PT)= eff*[ sig0-del + sig0 * w) /2
- ALraw(PT)= P* (N1-N2)/ (N1+N2)
- V(ALraw(PT))= 1/(N1+N2) <-- variance
- ALsig(PT)= (1+w(PT))* ALraw(PT)
- V(ALsig)= (1+w)2*V(ALraw ) + V(w)*(ALraw)2
- dil=1+w
- QA= |(ALsig)/err(ALsig)| - must be above 3 for meaningful result
Fig 3, Results for W + GRSV-VAL (maximal W polarization)
Left : N1(PT)=red, N2(PT) blue. Right: reconstructed signal AL

ipt=0 y-bins=[41,50] unpol=1826.5 pol=-327.3 AL=-0.125 +/- 0.0234 QA=1.8 B2S=5.0 , N1=3721 N2=3950 ALraw=-0.021 +/- 0.011, dil=6.00 ALsig=-0.125 +/- 0.069 ipt=1 y-bins=[51,60] unpol=1403.0 pol=-265.8 AL=-0.133 +/- 0.0267 QA=2.9 B2S=1.0 , N1=889 N2=1075 ALraw=-0.066 +/- 0.023, dil=2.00 ALsig=-0.133 +/- 0.046 ipt=2 y-bins=[61,70] unpol=1233.7 pol=-384.7 AL=-0.218 +/- 0.0285 QA=4.7 B2S=0.8 , N1=643 N2=912 ALraw=-0.121 +/- 0.025, dil=1.80 ALsig=-0.218 +/- 0.047 ipt=3 y-bins=[71,80] unpol=1811.9 pol=-1041.9 AL=-0.403 +/- 0.0235 QA=10.0 B2S=0.7 , N1=713 N2=1443 ALraw=-0.237 +/- 0.022, dil=1.70 ALsig=-0.403 +/- 0.040 ipt=4 y-bins=[81,90] unpol=808.8 pol=-525.2 AL=-0.455 +/- 0.0352 QA=8.1 B2S=0.6 , N1=269 N2=637 ALraw=-0.284 +/- 0.033, dil=1.60 ALsig=-0.455 +/- 0.056 sum2=7084.000000 sum3=-2544.850098 asy=-0.251
Fig 4, Results for W - GRSV-VAL (maximal W polarization)

ipt=0 y-bins=[41,50] unpol=1239.1 pol=490.8 AL=0.277 +/- 0.0284 QA=3.2 B2S=5.0 , N1=2774 N2=2430 ALraw=0.046 +/- 0.014, dil=6.00 ALsig=0.277 +/- 0.086 ipt=1 y-bins=[51,60] unpol=1452.7 pol=641.2 AL=0.309 +/- 0.0262 QA=6.6 B2S=1.0 , N1=1241 N2=792 ALraw=0.154 +/- 0.022, dil=2.00 ALsig=0.309 +/- 0.047 ipt=2 y-bins=[61,70] unpol=1426.5 pol=689.9 AL=0.339 +/- 0.0265 QA=7.5 B2S=0.8 , N1=1140 N2=657 ALraw=0.188 +/- 0.024, dil=1.80 ALsig=0.339 +/- 0.045 ipt=3 y-bins=[71,80] unpol=1135.3 pol=596.1 AL=0.368 +/- 0.0297 QA=7.6 B2S=0.7 , N1=884 N2=467 ALraw=0.216 +/- 0.027, dil=1.70 ALsig=0.368 +/- 0.049 ipt=4 y-bins=[81,90] unpol=313.8 pol=166.4 AL=0.371 +/- 0.0565 QA=4.3 B2S=0.6 , N1=234 N2=117 ALraw=0.232 +/- 0.053, dil=1.60 ALsig=0.371 +/- 0.086 sum2=5567.280273 sum3=2584.398926 asy=0.325
Another set of results for W+, W- with 2 x worse B/S (the same PT dependence).
Fig 5. W+ GRSV-VAL (maximal W polarization)

Fig 6. W- GRSV-VAL (maximal W polarization)

study 3 , cross check w/ FGT proposal, LT=800/pb (Jan)
Cross check of my code vs. A_L from FGT proposal
Input from RHICBOS , GRSV-VAL model:
if(Wsign==1) { fpol=new TFile("rb800.w+pola_grsv00_2.root"); funp=new TFile("rb800.w+unp_ct5m.root"); WPM="W+ "; } else { fpol=new TFile("rb800.w-pola_grsv00_2.root"); funp=new TFile("rb800.w-unp_ct5m.root"); WPM="W- "; }
The sign of pol cross section from RHICBOS has reversed convention, I have changed it to Medison convention.
hpol->Scale(-1.);
Fig 1 W-
from my macro, compare bottom right to blue from fig 2a

Fig 2 W-, W+ from FGT proposal

Fig 3 W+,
from my macro, compare bottom right to blue from fig 2b

study 4 , LT=300/pb, eta=+/-[1,2] , W+/- (Jan)
Calculation of error of A_L for LT=300/pb, for W± , eta=±[1,2], PT>20 GeV/c

- Input from RHICBOS , GRSV-STD model:
- The sign of pol cross section from RHICBOS has reversed convention, I have changed it to Medison convention.
hpol->Scale(-1.); - beam Pol=70%
- e+,e- reco efficiency is 70%, no PT dependence
- QCD background to W signal (B/S) contamination, after e/h algo no spin dependece
*) based on full Pythia+GSTAR+BFC simulations of QCD events,A B C ET_range
(EEMC 3x3_cluster)assumed w=backg/signal QCD eve
suppression needed for(B)20-25 GeV 5.0 +/- 20% - (for W+ or W-) 25-30 GeV 1.0 +/- 20% 1/539 or 1/520 30-35 GeV 0.8 +/- 20% 1/196 or 1/169 35-40 GeV 0.7 +/- 20% 1/43 or 1/ 69 40-45 GeV 0.6 +/- 20% 1/33 or 1/86 45-50 GeV 0.5 +/- 20% 1/119 or 1/289
(study 1 of S/B, A_L, LT=800/pb (Jan) section E)
after 3x3 EEMC cluster is found - eta of the lepton [1,2] (polarized beam is heading toward Endcap)
Formulas:
- Theory yields : unpol=sig0(PT) & pol=delL(pt) , S1=(sig0+delL)/2, S2=(sig0-delL)/2
- Measured yields N1, N2 , for 2 helicity states
- N1(PT)= eff*[ sig0 +P*delL + sig0 * w) /2
- N2(PT)= eff*[ sig0 -P*delL + sig0 * w) /2
- ALraw(PT)= 1/P (N1-N2)/ (N1+N2)
- V(ALraw(PT))= 1/P2 1/(N1+N2) <-- variance
- ALsig(PT)= (1+w(PT))* ALraw(PT)
- V(ALsig)=1/P2 (1+w)2*V(ALraw ) + V(w)*(ALraw)2
- dil=1+w
- QA= |(ALsig)/err(ALsig)| - must be above 3 for meaningful result
Fig 1, W+, eta=[1,2] , ideal detector

Fig 2, W+, eta=[1,2] , 70% W effi+QCD backg

Table 1, W+ , eta=[1,2] , LT=300/pb
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
| reco EMC ET GeV
|
reco W+ yield helicity: S1, S2 |
reco W+ unpol yield |
QCD Pythia accepted yield |
assumed B/S |
reco signal AL+err |
reco AL/err |
AL dilution: 1+B/S |
QCD yield w/ EMC cluster |
needed QCD suppression *) |
| 20-25 | 242 ,236 | 479 | 2397 | 5.0 | 0.019 +/-0.160 | 0.1 | 6.00 | ||
| 25-30 | 192 ,176 | 368 | 368 | 1.0 | 0.062 +/-0.105 | 0.6 | 2.00 | 198343 | 1/539 |
| 30-35 | 190 ,133 | 323 | 259 | 0.8 | 0.249 +/-0.109 | 2.3 | 1.80 | 50719 | 1/196 |
| 35-40 | 333 ,141 | 475 | 332 | 0.7 | 0.576 +/-0.098 | 5.9 | 1.70 | 14334 | 1/43 |
| 40-45 | 151,61 | 212 | 127 | 0.6 | 0.606 +/-0.132 | 4.6 | 1.60 | 4234 | 1/33 |
| 45-50 | 13,6 | 19 | 9 | 0.5 | 0.457 +/-0.393 | 1.2 | 1.50 | 1182 | 1/119 |
*) after 3x3 EEMC cluster is found, to obtain B/S from column 5
Fig 3, W-, eta=[1,2] , ideal detector

Fig 4, W-, eta=[1,2] , 70% W effi+QCD backg

Table 2, W- , eta=[1,2] , LT=300/pb
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
| reco EMC ET GeV
|
reco W+ yield helicity: S1, S2 |
reco W- unpol yield |
QCD Pythia accepted yield |
assumed B/S |
reco signal AL+err |
reco AL/err |
AL dilution: 1+B/S |
QCD yield w/ EMC cluster |
needed QCD suppression *) |
| 20-25 | 116,208 | 325 | 1626 | 5.0 | -0.403 +/-0.205 | 2.0 | 6.00 | ||
| 25-30 | 133,248 | 381 | 381 | 1.0 | -0.431 +/-0.112 | 3.8 | 2.00 | 198343 | 520 |
| 30-35 | 126,247 | 374 | 299 | 0.8 | -0.461 +/-0.107 | 4.3 | 1.80 | 50719 | 169 |
| 35-40 | 97,200 | 298 | 208 | 0.7 | -0.495 +/-0.115 | 4.3 | 1.70 | 14334 | 69 |
| 40-45 | 26,55 | 82 | 49 | 0.6 | -0.506 +/-0.203 | 2.5 | 1.60 | 4234 | 86 |
| 45-50 | 2,5 | 8 | 4 | 0.5 | -0.521 +/-0.617 | 0.8 | 1.50 | 1182 | 293 |
*) after 3x3 EEMC cluster is found, to obtain B/S from column 5
Fig 5, W+, eta=[-2,-1] , ideal detector

Fig 6, W+, eta=[-2,-1] , 70% W effi+QCD backg

Table 3, W+ , eta=[-2,-1] , LT=300/pb
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
| reco EMC ET GeV
|
reco W+ yield helicity: S1, S2 |
reco W- unpol yield |
QCD Pythia accepted yield |
assumed B/S |
reco signal AL+err |
reco AL/err |
AL dilution: 1+B/S |
QCD yield w/ EMC cluster |
needed QCD suppression *) |
| 20-25 | 316,168 | 484 | 2424 | 5.0 | 0.436 +/-0.175 | 2.5 | 6.00 | ||
| 25-30 | 235,137 | 373 | 373 | 1.0 | 0.375 +/-0.111 | 3.4 | 2.00 | 198343 | 531 |
| 30-35 | 189,132 | 322 | 258 | 0.8 | 0.252 +/-0.109 | 2.3 | 1.80 | 50719 | 196 |
| 35-40 | 255,223 | 479 | 335 | 0.7 | 0.094 +/-0.085 | 1.1 | 1.70 | 14334 | 43 |
| 40-45 | 109,102 | 212 | 127 | 0.6 | 0.048 +/-0.124 | 0.4 | 1.60 | 4234 | 33 |
| 45-50 | 10,9 | 19 | 9 | 0.5 | 0.027 +/-0.393 | 0.1 | 1.50 | 1182 | 119 |
*) after 3x3 EEMC cluster is found, to obtain B/S from column 5
Fig 7, W-, eta=[-2,-1] , ideal detector

Fig 8, W-, eta=[-2,-1] , 70% W effi+QCD backg

Table 3, W+ , eta=[-2,-1] , LT=300/pb
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
| reco EMC ET GeV
|
reco W+ yield helicity: S1, S2 |
reco W- unpol yield |
QCD Pythia accepted yield |
assumed B/S |
reco signal AL+err |
reco AL/err |
AL dilution: 1+B/S |
QCD yield w/ EMC cluster |
needed QCD suppression *) |
| 20-25 | 157,151 | 308 | 1544 | 5.0 | 0.024 +/-0.199 | 0.1 | 6.00 | 795943 | 515 |
| 25-30 | 187,180 | 367 | 367 | 1.0 | 0.029 +/-0.105 | 0.3 | 2.00 | 198343 | 540 |
| 30-35 | 187,179 | 367 | 293 | 0.8 | 0.033 +/-0.100 | 0.3 | 1.80 | 50719 | 173 |
| 35-40 | 151,144 | 295 | 206 | 0.7 | 0.033 +/-0.108 | 0.3 | 1.70 | 14334 | 69 |
| 40-45 | 41,40 | 81 | 49 | 0.6 | 0.026 +/-0.200 | 0.1 | 1.60 | 4234 | 86 |
| 45-50 | 3,3 | 7 | 3 | 0.5 | 0.012 +/-0.624 | 0.0 | 1.50 | 1182 | 301 |
*) after 3x3 EEMC cluster is found, to obtain B/S from column 5
study 5 charge sign discrimination

Fig 1 charge reco misidentification (details), M-C simulations
FGT 6 identical disk have active area Rin=11.5 cm, Rout=37.6 cm;
Z location: 70,80,90, 100,110,120 cm with respect to STAR ref frame.

Fig 2
Unpolarized yield for W+, RHICBOS

Fig 3
Unpolarized yield for W-, RHICBOS

Fig 4
Unpolarized & pol yield for W+, RHICBOS, ideal detector

Fig 5
Unpolarized & pol yield for W-, RHICBOS, ideal detector

study 6 final plots for PAC, May 2008
A_L on this has a RHICBOS convention to match PHENIX sign choice, opposite to FGT proposal convention.
Estimated statistical uncertainty for AL for charge leptons from W decay reconstructed in the Endcap
Fig 1 - Ideal detector

Fig 2 - Realistic detector efficiency & hadronic background, ideal charge reco
| kinematics | LT=300/pb | LT=100/pb |
|---|---|---|
| W+, forward | 8.6 | 5.3 |
| W-, forward | 6.7 | 3.9 |
| W+, backward | 5.1 | 3.0 |
| W-, backward | 0.3 | 0.2 |
| kinematics | LT=300/pb | LT=100/pb |
|---|---|---|
| W+, forward | 8.6 | 5.3 |
| W-, forward | 8.2 | 4.7 |
| W+, backward | 5.9 | 3.4 |
| W-, backward | 3.9 | 2.3 |

Fig 3 - Realistic detector efficiency, hadronic background, and charge reco
 missing
missing
study 7 revised for White Paper, AL(eta), AL(ET) , (Jan)
Plots show AL for W+, W- as function of ET (fig1) and eta (fig2,3)
I assumed beam pol=70%, electron/positron reco off 70%, QCD background included, no vertex cut (as for all earlier analysis).
For AL(ET) I integrated over eta [-2,-1] or [1,2] and assumed the following B/S(ET) = 5.0 for ET>20 GEV, 1.0 for ET>25, 0.9 for ET>30,....
For AL(Eta) I integrated over ET>25 GeV and assumed a constant in eta & ET B/S=0.8.
Fig 1. AL(ET). Only Endcap coverage is shown. ( EPS.zip )

Fig 2. AL(Eta) . Only Endcap coverage is shown. ( EPS.zip )

Fig 3. AL(Eta) has continuous eta-axis, binning is exactly the same as in Fig 2. It includes Endcap & Barrel coverage.
(PS.gz) generated by take2/do5.C, doAll21()

study 8 no QCD backg AL(eta), AL(ET), also rapidity (Jan)
Plots show AL for W+, W- as function of ET (fig1,2) and eta (fig3)
I assumed beam pol=70%, electron/positron reco off 70%, no vertex cut (as for all earlier analysis).
NO QCD background dilution.
For AL(ET) I integrated over eta [-2,-1] , [-1,+1], or [1,2] and assumed no background
For AL(Eta) I integrated over ET>25 GeV and assumed no background
Fig 1 ( PS.zip )

Fig 2 ( PS.zip )
Accounted for 2 beams at mid rapidity.

Fig 3

study 9 sensitivity of STAR at forward & mid rapidity
The goal is to provide overall STAR sensitivity for LT=100/pb & 300/pb.
Common assumptions:
- beam pol=70%
- W reco efficiency 70%
- no losses due to the vertex cut
- integrated over ET>20 GeV
This page is tricky, different assumptions/definitions are used for different eta ranges.
A) Forward rapidity: eta range [+1,+2], (shown on fig 1a+b in study 7 revised for White Paper, AL(eta), AL(ET) , (Jan))
determine the degree to which we can measure an asymmetry different from zero.
- QCD background added, B/S changes with ET.
- sensitivity is defined as 3 x stat_error of reco AL
- method: fit constant to 'data', use 3x error of the fit
| LT=100/pb | LT=300/pb | |
| W+, forward | 0.27 | 0.15 |
| W-, forward | 0.30 | 0.18 |
I fit constant to the black points what is equivalent to taking the weighted average.
B) Mid-rapidity: eta range [-1,+1], (shown on fig 2a+b in study 8 no QCD backg AL(eta), AL(ET), also rapidity (Jan) )
determine the ratio of difference of DNS-MIN and DNS-MAX to sigma(measured AL)
- account for 2x larger yield due to 2 polariazed beams
- QCD background NOT added
- sensitivity is defined as ratio
- avr difference of DNS-MIN and DNS-MAX is used
| avr(ALMIN-ALMAX) | LT=100/pb | LT=300/pb | |
| W+, mid | 0.15 | 13 | 21 |
| W-, mid | 0.34 | 13 | 22 |
C) Backward rapidity: eta range [-2,-1], (shown on fig 1c+d in study 7 revised for White Paper, AL(eta), AL(ET) , (Jan))
determine the ratio of difference of DNS-MIN and DNS-MAX to sigma(measured AL)
- QCD background added, B/S changes with ET.
- sensitivity is defined as ratio
- avr difference of DNS-MIN and DNS-MAX is used
| avr(ALMIN-ALMAX) | LT=100/pb | LT=300/pb | |
| W+, backward | 0.10 | 1 | 2 |
| W-, backward | 0.5 | 5 | 9 |
D) Mid-rapidity: eta range [-1,+1], QCD background added (fig shown below, PS.zip )
determine the ratio of difference of DNS-MIN and DNS-MAX to sigma(measured AL)
- account for 2x larger yield due to 2 polariazed beams
- QCD background added, using B/S(ET) from M-C study at forward rapidity- it is the best what we can do today
- sensitivity is defined as ratio
- avr difference of DNS-MIN and DNS-MAX is used
| avr(ALMIN-ALMAX) | LT=100/pb | LT=300/pb | |
| W+, mid | 0.15 | 7 | 11 |
| W-, mid | 0.34 | 10 | 15 |

study 9a sensitivity mid rapidity LT=10/pb
Projection of STAR sensitivity for AL for W+,W- at mid rapidity for LT=10/pb and pol=60%
Common assumptions:
Fig 1, no QCD background ( PS.zip )
Dashed area denotes pt-averaged statistical error of STAR measurement.

Fig 2, includes QCD background ( PS.zip )
Dashed area denotes pt-averaged statistical error of STAR measurement.

study 9b sensitivity at mid rapidity LT=10/pb Pol=50% or 60%
Projection of STAR sensitivity for AL for W+,W- at mid rapidity for LT=10/pb and pol=60% or 50%
Common assumptions:
- LT=10 pb -1
- beam pol=60% or 50%
- W reco efficiency 70%
- no losses due to the vertex cut
- integrated over eta [-1,+1]
- see remaining details in study 9 sensitivity of STAR at forward & mid rapidity
| beam pol | avr AL(W+)THEORY=0.35 | . | avr AL(W-)THEORY=0.15 | ||
|---|---|---|---|---|---|
| sig ALSTAR | STAR signifcance | sig ALSTAR | STAR signifcane | ||
| 50% | 0.092 | 3.8 sigma | 0.18 | 0.8 sigma | |
| 60% | 0.077 | 4.6 sigma | 0.15 | 1 sigma | |
Fig 1, Pol=60% ( PS.zip )
Dashed area denotes pt-averaged statistical error of STAR measurement.

Fig 2, Pol=50% ( PS.zip )

e/h algo for Barrel
not developed, add your analysis as child pages to this page
e/h discrimination in the Endcap
attach different analysis to this child-pages, make them self containeda) e/h isolation based on Geant Record (Mike, Mar 31)
For the new QCD background,
partonic pT 15 - 20 GeV : 50,000 events LT=8.0/pb
partonic pT 20 - 30 GeV : 20,000 events LT=0.3/b
partonic pT 30 - 50 GeV : 10,000 events LT=0.4/pb
partonic pT 50+ GeV : 1,000 events LT=0.8/pb
The high pT tail is still weak. I could run more high pT events (with the time frame of one more day) or double the bin widths to smooth out the tail and allow for an efficiency plot up to ~50 GeV (albeit with relatively large error bars). Let me know your choice.
The W files are mit0009 and the QCD files are mit0012.
I use r = 0.26 for the isolation cut, as per the original IUCF proposal, and use the jet finder for the away side veto.
-Mike

b) e/h isolation based on Geant Record (Mike, April 3)
This is geant-track based analysis
Mike:
Bottom plots are S/B ratios.
These are extremely loose cuts and I don't think you can base the entire FGT analysis on them.
First of all, the e/p cut isn't quite right. I use the actual energy of the track whereas most hadrons would just drop MIPs into the calorimeter making the e/p cut very helpful. I did try to do this in my code but the e/p cut became TOO good and I didn't want to have to deal with trying to convince people of that.
Second of all, no neutral energy isolation cut is made to veto against neutral energy depositions.
Third of all, no shower shape (transverse and longitudinal) information is used at all.
I think it's fair to say that this is a worst case scenario analysis.

Jan:
I try to understand better this last two S/B plots.
The message from the lower figure is:
* isolation cut alone results with background by a factor 2 to 3 for W+ and factor 4 to 10 for W- with reverse PT dependence for W+ & W-
* away said jet veto helps almost nothing in e/h discrimination.
* if only isolation & away side jet cuts are applied background dominates over signal by a factor of ~300 at PT of 20 GeV and improves to a factor ~2 at PT=40 GeV.
Taken at the face value Enddcap information add discrimination power of ~1000 for PT=20 GeV changing toward factor of 6 for PT of 40 GeV/c. (Assuming we want S/B=3)
My comment:
The value of 6 is in reach but value of 1000 may be not trivial.
e/p cut - I agree with Mike,
Looks like the e/p cut applied to h- reduces it up to a factor of 2
for pT of 40 GeV.
This cut needs to be dropped for real data- we will not measure PT in
FGT with reasonable accuracy at large track PT - this reduces overall
e/h discrimination power for W- at for PT>30 GeV, so more realistic
estimate of discrimination power of this (geant based) algo for W- at
PT of 40 GeV is rather S/B=0.35 and we need additional factor of 8
from the endcap.
BFC: Filtered Vs. Unfiltered Comparison
Comparison of BFC with and without filtering
See pdf file at bottom of page:
The left-hand plots are the unfiltered events and the right-hand plots are the filtered
- Page 1 shows how many events survive each individual cut. Bins 0 and 1 do not mach because there are different numbers of events in each file and because in my code bin 1 is a cut on 15GeV, not 17GeV where the filtered cutoff was set. All subsequent bins match.
- Page 2 shows how many events pass the cuts sequentially. Again, all bins from 2 onward are the same.
- Page 3-8 show the trigger patch ET spectrum after sequential cuts were applied, the spectra look the same.
- Page 9 shows the ET weighted average eta position of the trigger patch vs the PT weighted average eta position of electrons going into the endcap from the geant record.
- Page 10 shows the same information for the phi position.
- Page 11 shows the ET of the trigger patch vs the PT of the thrown electrons.
Geant Spectra for Filtered and Unfiltered W events
Non-Filtered
Electrons:
Fig1: No eta cuts

Fig 2: Eta between -1 and 1

Fig 3: Eta between 1.2 and 2.4

Positrons:
Fig 4: No eta cuts

Fig 5: Eta between -1 and 1

Fig 6: Eta between 1.2 and 2.4

Filtered on the pythia level: 20GeV in eta [0.8,2.2]
Electrons:
Fig 7: No eta cuts

Fig 8: Eta between -1 and 1

Fig 9: Eta between 1.2 and 2.4

Positrons:
Fig 10: No eta cuts

Fig 11: Eta between -1 and 1

Fig 12: Eta between 1.2 and 2.4

Pythia analysis version 1.0
Preliminary Analysis of runs in setC2
This analysis was preformed on the events in setC2. See here for details. I ran 48,000 qcd background events and 16000 W events using version 1.0 of my analysis program.

Fig 2: The number of primary tracks found for each event. The W events are on the left and the qcd background events are on the right. 
The first cut an event is required to pass is that the transverse energy in a 3X3 patch of towers, centered on the tower with the highest energy, must be greater than 15GeV. All subsequent cuts are made only on events which pass this trigger.
Fig 3: The transverse energy deposited in the trigger patch for each event. The W events are on the left and the qcd background events are on the right. 
For this analysis, I used the cuts I developed from looking at single particle events. For the 1-D histograms the W events are in black and the qcd background events are in red. For the 2-D histograms the W events are on the left and the qcd background events are on the right.
- cutOne: number of hit towers < 11
- cutTwo: number of hit U strips > 24 and < 42
- cutThree: not included
- cutFour: second pre-shower energy > 0.013
- cutFive: post-shower energy < 0.035
- cutSix: post-shower over full patch ratio < 0.0007
- cutSeven: three U strip over all U strip energy > 0.5 and < 0.8
- cutEight: seven U strip over all U strip energy > 0.65 and < 0.92
- cutNine: total U plane energy > 0.2
- cutTen: total U plane energy > 0.3
- cutEleven: post energy below line running through (0,0) and (0.3,0.05)
Fig 4. These plots show how many events passed a particular cut. W events are on the left and qcd background events are on the right. For reference, a total of 5997 W events passed the trigger and 6153 qcd background events passed the trigger. 
ver 1.2 : e/h isolation based on TPC tracks (Brian)
Hi everyone,
I have some results for my first iteration of isolation cut and I would
appreciate some feedback as to whether they look reasonable or not.
These plots were made after requiring that the 3x3 trigger patch ET be greater than 20GeV.
First I find the eta and phi coordinates of the highest tower in the end
cap. I then set a value for the radius. I then loop over all tracks and
towers and if their endcap crossing point lies within my radius I add
their Pt or Et to the total.
By highest tower you mean:
- reco vertex is found
- ADC is converted to ET in event reference frame (you are using event-
eta, not detector eta
- you find highest ET tower
I use energy to find the highest tower, not transverse energy. StEEmcTower highTow = mEEanalysis->hightower(0). And for any event to be processed further, it must have a reco primary vertex found.
By highest tower you mean:
I use energy to find the highest tower, not transverse energy. StEEmcTower highTow = mEEanalysis->hightower(0). And for any event to be processed further, it must have a reco primary vertex found.
- reco vertex is found
- ADC is converted to ET in event reference frame (you are using event-
eta, not detector eta
- you find highest ET tower
StEEmcTower StEEmcA2EMaker::hightower( Int_t layer = 0 )
Returns the tower with the largest ADC response
3x3 trigger patch is built around this tower by construction. I ask for the high tower, then I ask for all of its neighbors. The high tower and its neighbors (usually 8, but could be less for high towers on sector boundries) make up the trigger patch.
Yes, I use these QA conditions.I then set a value for the radius.I then loop over all tracksDo you mean primary tracks with flag()>0 and nFit/nPos>0.51 ?
These plots show the ratio of the transverse energy in the 3x3 trigger
patch to the total transverse energy in the isolation radius. I ran W
events from files setC2_Weve_N (black curve) and QCD events from files
setC2_qcd_N (red curve).
Trigger ET over Et in iso radius r=0.1:

Trigger ET over ET in iso radius r=0.26:

Trigger ET over ET in iso radius r=0.7:

Pythia Analysis ver 2.3: Effects of cuts
Effect of cuts on Trigger Patch ET Spectrum
Here I take a first look at how various cuts effect the trigger patch ET spectrum. For this first run, I look at 13 cuts. The first four reduce the energy range and areas of the endcap that I look in. All of these cuts are applied before any additional cuts are made. The final eleven cuts are various isolation and endcap cuts. For this analysis I used sample ppWprod from setC2 for the W sample and pt30-50 from setC4 for the QCD sampel. Details here. These figures are not scaled to 800inv_pb so all W events must be multiplied by (800/1014) and all QCD events must be multiplied by (800/12.1).
Here are the cuts:
- Cut One: This cut requires that a reconstructed vertex is found, that the vertex lies in the range z=[-70,-50] and that the trigger patch ET be at least 15GeV.
- Cut Two: This cut requires that the trigger patch ET be at least 20GeV.
- Cut Three: This cut requires that the ET weighted average eta value of the trigger patch be less than 1.7
- Cut Four: This cut requires that the highest energy tower be in etabin 6, 7, 8, 9, 10, or 11.
- Cut Five: This is a cut on the ratio of the trigger patch ET to the transverse energy of all towers within a radius of 0.45 from the hightower. The cut was > 0.96 to pass.
- Cut Six: This is a cut on the transverse distance between the point where a track crosses the endcap and the position of the high tower. The cut was set at < 0.7 to pass but this was a typo, the correct cut would have been closer to 0.07.
- Cut Seven: This is a cut on the number of tracks above 1GeV which cross the endcap within a radius of 0.70 of the hightower. There must be 0 or 1 tracks to pass.
- Cut Eight: This is a cut on the ratio of the energy of the seven highest U strips to the energy of all U strips under the trigger patch. The cut was > 0.7 to pass.
- Cut Nine: This is a cut on the ratio of the energy of the two highest towers in the trigger patch to the energy of all the towers in the trigger patch. The cut was > 0.9 to pass.
- Cut Ten: This is a cut on the number of towers with energy greater than 800MeV in the same sector as the trigger patch. The cut was < 6 to pass.
- Cut Eleven: This is a cut on the number of hit strips in the U plane in the sector containing the trigger patch. The cut was < 48 to pass.
- Cut Twelve: This is a cut on the ratio of the post-shower energy in the trigger patch to the full energy in the trigger patch. The cut was < 0.0005 to pass.
- Cut Thirteen: This is a cut on the post-shower energy in the trigger patch. The cut was < 0.04 to pass.
The following plots show the effects the above cuts had on the trigger patch ET spectrum when applied in the order given.
Fig 1: This plot shows the number of events that passed a set of cuts. Bin 1 shows the raw number of events processed and each subsequent bin shows all events that passed a given cut and all cuts before it. So bin eight will show all events that passed cuts 1-7. W events are on the left and QCD events are on the right.

Fig 2: This plot shows the effects of the four phase space cuts on the trigger patch ET spectrum. Again W events are on the left and QCD events are on the right.

Fig 3: This plot shows the effects of the remaining 9 cuts on the trigger patch ET spectrum. Here the black line, instead of representing the raw spectrum, represents the ET spectrum after the four phase space cuts have been applied. Again the cuts are sequential. W events are on the left and QCD events are on the right.

Fig 4: This plot shows the effect of all thirteen cuts in an easier to see form. The black line is the raw spectrum and the red line is the spectrum after the four phase space cuts and the blue line is the spectrum after all remaining cuts. W events on the left and QCD on the right. For the W sample: In the region 20-60, the raw sample contains 4319 events, the sample after the phase space cuts contains 2400 events, and the sample after all cuts contains 1924 cuts. For the QCD sample: In the region 20-60, the raw sample contains 7022 events, the sample after the phase space cuts contains 4581 events, and the sample after all cuts contains 160 events.

Pythia Analysis ver 2.4: Cuts on all setC4 jobs
Effect of Cuts on Trigger Patch ET
In this analysis I look at the effect the cuts I used in Ver 2.3, as well as two new cuts, have on the transverse energy spectrum of the 3x3 trigger patch. For this analysis I used all files in setC4 for the QCD background and I used setC2_Wprod_N for the W samples. Details here. I weighted all events to 800 inverse pb. As before the first four cuts restrict the energy range and the area of the endcap we look at and the final eleven cuts are endcap and isolation cuts. The black curves are the QCD events and the red curves are the W events. All ET and eta's are event eta.
Here are the cuts: (Note, ordering different from ver 2.3)
- Cut One: This cut requires that a reconstructed vertex is found, that the vertex lies in the range z=[-70,-50] and that the trigger patch ET be at least 15GeV.
- Cut Two: This cut requires that the Trigger patch ET be greater than 20GeV.
- Cut Three: This cut requires that the ET weighted average eta value of the trigger patch be less than 1.7.
- CutFour: This cut requires that the highest energy tower be in etabin 6, 7, 8, 9, 10, or 11.
- Cut Five: This is a cut on the ratio of the trigger patch ET to the total ET of all towers within a radius of 0.45 of the high tower. The cut was > 0.96 to pass.
- Cut Six: This is a cut on the transverse distance between where a track crossed the endcap and the high tower. Counts over all tracks above 1GeV within a radius of 0.70 of the high tower. The Cut was < 0.07 to pass (fixed from Ver 2.3)
- Cut Seven: (new) This is a cut on the transverse energy found in all towers (barrel and endcap) which lie in a region +/- 0.7 radians from Phi(hightower) + Pi. The cut was < 6.0 to pass.
- Cut Eight: (new) This is a cut on the transverse distance between where a track crossed the endcap and the high tower. Counts over all tracks above 0.5 GeV within a radius of 0.70 of the high tower. The cut was < 0.07 to pass.
- Cut Nine: This is a cut on the number of tracks above 1GeV which cross the endcap within a radius of 0.70 of the hightower. There must be 0 or 1 tracks to pass.
- Cut Ten: This is a cut on the ratio of the energy in the seven highest SMD strips in the U plane under the patch to the energy in all the U strips under the patch. The cut was > 0.7 to pass.
- Cut Eleven: This is a cut on the ratio of the energy in the two highest towers in the trigger patch to the energy in all the towers of the trigger patch. The cut was > 0.9 to pass.
- Cut Twelve: This is a cut on the number of towers above 800 MeV in the sector (or sectors) containing the trigger patch. The cut was < 6 to pass.
- Cut Thirteen: This is a cut on the number of hit strips in the U plane in the sector containing the high tower. The cut was < 48 to pass.
- Cut Fourteen: This is a cut on the ratio of the post-shower energy in the patch to the full energy in the patch. The cut was < 0.0005 to pass.
- Cut Fifteen: This is a cut on the post-shower energy in the patch. The cut was < 0.04 to pass.
Fig 1: This plot show the effects of all 15 cuts. The black line is the spectrum before any cuts are applied, the red line is the spectrum after the phase space cuts (1-4) are made, and the green line is the spectrum after all 15 cuts have been applied. QCD events are on the left and W events are on the right. For the QCD sample: The raw spectrum contains 718100 events in the region 20-60, the spectrum after the phase space cuts contains 452000 events, and the spectrum after all cuts contains 5215 events. For the W sample: The raw spectrum contains 3476 events in the region 20-60, the spectrum after the phase space cuts contains 1933 events, and the spectrum after all cuts contains 1407 events.

Fig 2: This plot shows the the QCD spectrum(black) after cuts 1-15 and the W spectrum(red) after cuts 1-15 on the same figure.

Analysis for Each Pt Range Seperatly(Work in progress)
Results for Each Pt Bin
The first plot shows the effects that the first four cuts (the phase space cuts) have on the trigger patch transverse energy spectrum. The black line is the raw spectrum and the subsequent lines are the cuts, detailed on the parent page.
The second plot shows the effects the remaining cuts have on the ET spectrum. The black line is the spectrum after the phase space cuts, the red line is the spectrum after the isolation cut, the green line is the spectrum after the awayside energy cut and the blue line is the spectrum after all cuts have been applied.
The QCD events are on the left and the W events are on the right. Event ET is used. This is detected ET, not thrown ET. Everything is scaled to 800 inv_pb
Pt 50-inf:


Pt 30-50:


Pt 20-30:


Pt 15-20:


Pt 10-15:


Pythia analysis ver 2.3: isolation cuts and EEmc cuts
First Set of Proposed Cuts
The following plots show the cuts I intend to use on my first iteration of the e/h discrimination code. These plots were generated using ppWprod from setC2 (row 11) for W events and mit0015>10 from set C4 (row 13) for QCD events. Details are here. All events in plots have reco vertex in range z=[-70,-50] and have a trigger patch ET > 20GeV. Furthermore the isolation cut plots have the added condition that the high tower does not fall in etabins 1-5 or 12. The W sample is in black and the QCD sample is in red.
Fig 1: Plot of the ratio of transverse energy in the 3x3 trigger patch to transverse energy of towers located inside a radius of 0.45. Cut: > 0.95. 
Fig 2: Plot of the displacement between a track and the center of the high tower when there is only one track above 1GeV in a radius of 0.70. Cut: < 0.6. 
Fig 3: Plot of the number of hit towers with energy above .8GeV that lie in the same sector as the trigger patch. Cut: < 6. 
Fig 4: Plot of the number of hit strips in the U plane in the sector containing the trigger patch. Cut: < 48. 
Fig 5: Plot of the energy in the post-shower layers of the 3x3 trigger patch. Cut < 0.04. 
Fig 6: Plot of the ratio of energy in the post-shower layers of the 3x3 trigger patch to the total energy in the trigger patch. Cut: < 0.0005.  Fig 7: Plot of the ratio of energy in the seven highest U strips under the 3x3 trigger patch to the energy in all the U strips under the trigger patch. Cut: > 0.7.
Fig 7: Plot of the ratio of energy in the seven highest U strips under the 3x3 trigger patch to the energy in all the U strips under the trigger patch. Cut: > 0.7. 
Fig 8: Plot of the ratio of the energy in the two highest towers in the 3x3 trigger patch to the energy in all towers of the trigger patch. 
BFC: 0, 1, and 2 step Filtering Comparison
Comparison Between 0, 1, and 2 Step BFC Filtering
For this analysis, I used code V2.5 which is the most recent version to use reconstructed tracks and vertices. I used a scaling factor of 1.25. Event ET used.
QCD events
Fig 1: Plot showing how many times each cut is passed individually. Values should coincide after bin 2

Fig 2: Plot showing how many events pass each cut in sequence. Values should coincide after bin 2

Fig 3: Plot showing spectrum after cuts 1-4 have been applied

Fig 4: Plot showing spectrum after cuts 1-5 have been applied

Fig 5: Plot showing spectrum after cuts 1-6 have been applied

Fig 6: Plot showing spectrum after cuts 1-7 have been applied

Fig 7: Plot showing spectrum after cuts 1-8 have been applied

W events
Fig 8: Plot showing how many times each cut is passed individually. Values should coincide after bin 2

Fig 9: Plot showing how many events pass each cut in sequence. Values should coincide after bin 2

Fig 10: Plot showing spectrum after cuts 1-4 have been applied

Fig 11: Plot showing spectrum after cuts 1-5 have been applied

Fig 12: Plot showing spectrum after cuts 1-6 have been applied

Fig 13: Plot showing spectrum after cuts 1-7 have been applied

Fig 14: Plot showing spectrum after cuts 1-8 have been applied

Investigation of ET scaling factor
ET scaling factor
In order to investigate the discrepensy between the thrown pt of a lepton and the ET that the endcap detects, I have run electron events with single energies through the big full chain Jan has used for all the simulations and ploted the detected ET. I ran three energies 20GeV, 30GeV, and 40GeV. I ran 5000 events at each energy and each event has only one electron going into the endcap.
Fig. 1: This plot shows the detected ET of the electrons which were thrown at 40GeV.

Fig. 2: This plot shows the detected ET of the electrons which were thrown at 30GeV.

Fig. 3: This plot shows the detected ET of the electrons which were thrown at 20GeV.

We see that multiplying the detected ET by a scale factor of 1.23 recovers the thrown Pt of the electron.
Plots for PAC (brian)
Transverse Energy correction factor of 1.23 included
Code Version 2.5
Fig 1: Isolation cut

Fig 2: Awayside isolation cut

Fig 3: Seven strip cut

Fig 4: Post patch over full patch cut

Fig 5: All cuts spectrum with linear scale for W signal

Fig 6: All cuts spectrum with log scale for W signal

Fig 7: All cuts spectrum showing only W+ linear scale

Fig 8: All cuts spectrum showing only W+ log scale

Fig 9: All cuts spectrum showing only W- linear scale

Fig 10: All cuts spectrum showing only W- log scale

Brief explanation of cuts found here.
Below are plots showing the contributions that other W decay channels will have to the spectrum. All spectrum are weighted to 800inv_pb. Details can be found in rows 14-18 of the plot detailing events in setC2 here.
Fig 11. Spectrum of W decay events.

Fig 12. Spectrum of Z production events.

Fig 13. Spectrum of W jet events.

Fig 14. Spectrum of Z jet events.

Fig 15 Spectrum of W Z events.

Fig 16: Table of integrated yields for W, Z processes scaled to 800 inv_pb after all cuts have been applied.
| PT>20 | PT>25 | |
| W_Prod | 1827 | 1359 |
| W_Dec | 64 | 30 |
| Z_Prod | 113 | 67 |
| W_Jet | 212 | 144 |
| Z_Jet | 18 | 8 |
| WZ | 4 | 2 |
Fig 17a,b: Table of Pythia cross section and branching ratio

Fig 18: Table of integrated QCD yields for all pT bins scaled to 800 inv_pb after all cuts have been applied.
| pT>20 | pT>25 | |
| All pT | 16460 | 4892 |
| pT50-inf | 67 | 54 |
| pT30-50 | 2247 | 1430 |
| pT20-30 | 9179 | 2611 |
| pT15-20 | 3628 | 558 |
| pT10-15 | 1032 | 86 |
| pT05-10 | 308 | 154 |
Pythia Analysis Summary
Analysis Summary
Introduction
A future goal of the STAR collaboration is the measurment of flavor separated polarized anti-quark distribution functions. To make these measurments we will be looking at charged leptons - electrons and positrons - arising from the decay of W bosons created in quark anti-quark collisions. One difficulty in making this measurment is the large flux of background hadronic particles, giving a signal to background on the order of 1/1000. The following details my efforts at developing an algorithm which can reject the hadronic background while retaining the signal leptons to achieve a S/B of greater than one-to-one over a significant portion of the observed lepton transverse energy spectrum which runs from roughly 20-50GeV.
Basic Philosophy
Discrimination between leptons and hadrons is posible because of the different processes giving rise to signal and background events as well as different showering properties of leptons and hadrons in the EEMC. Hadronic events tend to be dijets, meaning these events will deposit two blobs of energy located 180 degrees away in azimuth from eachother. Leptonic events, on the other hand, arise from the decay of W bosons which produce a charged lepton and a neutrino. The neutrino is not detected so only one blob of energy is deposited in the detector. This difference allows for the application of an away-side cut which will veto events having significant energy 180 degrees away from the candidate lepton. Hadrons and leptons also behave differently inside of the EEMC with hadrons tending to produce larger and wider showers as compared to leptons due to collisions with nuclei. This difference in shower behavior means isolation cuts on the energy around a candidate lepton can be effective. Finally, the EEMC is roughly 21 electron radiation lengths deep and only one hadron radiation length deep meaning that much more hadronic energy will escape the back of the detector, allowing for cuts based on the amount of energy leaving the detector. Below are pictures from starsim showing the evolution of hadronic and leptonic showers in the EEMC:
Fig 1: Picture of a 30GeV charged pion going into the EEMC generated using starsim.

Fig 2: Picture of a 30GeV electron going into the EEMC generated using starsim.

As described above, the algorithm discriminates between leptons and hadrons in three basic ways: looking at the number of tracks and energy around candidate leptons, vetoing events with too many tracks or too much energy 180 degrees away in azimuth from the candidate lepton, and by comparing shower evolution in the EEMC. Another important aspect of the discrimination algorithm is the trigger patch. The trigger patch is always taken to consist of the tower with the highest energy - which is also taken as the position of the candidate electron - and all adjacent towers, usually yielding a 3x3 patch. This trigger patch is the area of the EEMC where shower evolution is investigated. The investigation of shower evolution is possible in the EEMC due to the five separate readout layers: the two pre-shower layers, the two shower maximum detectors (SMDs) and the post-shower layer. The pre-shower layers are located at the front of the detector where few leptons will have started to shower, the SMDs are located five out of 24 layers deep and are positioned at the depth where there is maximum shower energy deposition, and the post-shower layer is at the back of the detector where most lepton showers will have died out. By looking at the energy deposited in the separate layers, one can get an idea of the longitudinal shower development inside the EEMC. One can also see the transverse shower development by looking at the number of hit strips in the SMD layers. Many combinations of EEMC quantites were tried over the course of developing the discrimination algorithm, but the best discrimination by far was achieved by looking at the ratio of the energies in the seven highest adjacent SMD strips under the trigger patch to the energy of all SMD strips under the trigger patch. Less effective but still usefull EEMC cuts include the ratio of the energy in the two trigger patch towers with the highest energy to the energy in the full trigger patch and the ratio of the energy in the post-shower layer to the energy in the full trigger patch. The away-side and isolation cuts provide powerful discrimination as well and are largly independent of the EEMC cuts listed above.
Code Versions
The discrimination code has gone through many versions as new cuts were tested, tracking methods were improved, and other improvements were made. Below is a brief discription of each version as well as the source code for future reference.
V1.0:
Version 1.0 is the first version of the discrimination code designed to work with the Pythia simulations run at MIT. This version borrowed heavily from earlier code designed to work on single thrown lepton and hadron events. The code used to access the EEMC information was taken directly from this earlier work. In addition to the EEMC anlysis this version includes code to access tracking information from the MuDst files as well as a function to determine if a track passed close to the tower with highest energy. Also included was a primative function which looked at the awayside energy only in the endcap. This code looked at approximately eleven different cuts and displayed what the trigger patch transverse energy spectrum would look like after each one was applied as well as what the spectrum would look like when several different combinations of cuts were applied.
V1.1:
Version 1.1 follows the same basic pattern as version 1.0 detailed above. The major difference is in the trigger criteria used to determine wether an event should be analysed. In version 1.0, all events needed to have a trigger patch ET greater than 15GeV in order to be processed further. In addition to the 15GeV condition, version 1.1 requires that all events have a found vertex and that that vertex be found in within ten centimeters of z=-60. (The simulations were generated with the interaction point at -60 cm so that tracks with large etas would pass through more TPC volume). The next significant change was the inclusion of a function which calculated the transverse energy deposited in a tower taking into accout the z position of the vertex as ET value for a particle originating at z=-60 can be significantly different from the ET value gotten assuming the particle originated at z=0. Minor changes include the addition of a function which allows the setting of the energy threshold needed to consider a tower hit, a function which gives the ET weighted position of the trigger patch, and the investigation of several new cut quantities.
- Original source code can be viewed here
V2.0:
Version 2.0 differs from the 1.x versions in that it implements functions allowing isolation cuts, both same side and away side, utilizing tower energies, track momenta, and barrel information. Simulations done by Les Bland showed that these kinds of cuts had the potential to provide nearly two orders of magnitude in background reduction. These functions add up the transverse energy/momentum of all towers/tracks which fall within a user set region. For the same side isolation cut, this region is a circle with user set radius centered on the high tower. For the away side isolation cut, the region is a slice in phi with a user set width around the line which is 180 degrees away in azimuth from the high tower. In addition to the isolation cut functions, this version addopts the new cuts from version 1.1 and adds histograms exploring various radii for the isolation cuts. The code to calculate the transverse energy was also changed again, this time to set the 'center' plane of the tower to the position of the SMD plane as opposed to the actual physical center because we expect the most shower activity at the SMD depth.
- Original source code can be viewed here
V2.1:
Version 2.1 is very similar to version 2.0 and contains only minor changes. One concern with previous versions was that events occuring at high eta did not have reconstructed tracks because of poor TPC tracking in this region and thus it was hard to get a good idea of how well cuts using tracking were doing. To investigate this problem, several isolation cuts and histograms were made with the condition that the hightower not be located in etabins 1-5 - which excluded high eta events - or etabins 11&12(because of edge effects around the transition from endcap to barrel). In addition to this bin restriction investigation, new histograms were made to study the effects of moving the trigger patch ET threshold from 15 to 20GeV on the cut quantites from version 2.0. Other small changes included the addition of a crude function to determine approximately how many electrons/positrons were going into the endcap and a modification to the away side isolation function to read out the track, barrel, and endcap energies separately.
- Original source code can be viewed here
V2.2:
Version 2.2 adds two functions which provide a different way to carry out the same side isolation cuts. The first function counts the number of tracks above a certain threshold which cross the endcap within some radius of the high tower and also calculates the transverse displacement between the track and the high tower if there is one and only one track in the radius. This one and only one track scheme is flawed and is modified in later versions. The second function calculates the transverse energy deposited in the barrel and endcap towers within a certain radius. The idea behind the new isolation cuts was that QCD events should have many tracks around the high tower while W decay events should have few, maybe only one. It was also thought that events with one and only one track in the isolation radius may only be displaced some slight amount from the high tower and that this could give good lepton hadron discrimination. There are many new histograms exploring these ideas.
- Original source code can be viewed here
V2.3:
Version 2.3 makes many changes to how the cuts are organized. The trigger patch ET spectrum is shown after each individual cut as well as after each cut in succession. The cuts in this version were chosen from the cuts in the previous version which showed the best discrimination power, all other cuts were removed. In addition to re-organizing the cuts, new trigger conditions were included. Along with the trigger conditions from previous versions, events now must have a trigger patch ET greater than 20GeV, have the high tower be in etabins 6-11, and have the ET weighted trigger patch eta position be greater than 1.7 to be processed further.
V2.4:
Version 2.4 is very similar to version 2.3 in terms of cuts. Cuts on the away side energy and the displacement between tracks and the high tower have been added. This version of the code has also been cleaned up significantly, with many extraneous histograms and function calls being removed. This version also allowed for overall weighting of the event samples being processed. This allows for the scaling of all pythia samples to the same integrated luminosity. This method of weighting the samples was cumbersome because the code must be recompiled for each seperate simulation batch and if a mistake were made, the whole pythia sample would need to be rerun. In the future, this method is dropped in favor of a script which weights the batches while merging the seperate event files.
V2.5:
Version 2.5 is the last version of the code to use cuts based on reconstructed tracks from the TPC. It is also the version used to produce plots for several presentations and proposals. As such, it has many histograms which were specifically requested for those presentations, chief among them histograms showing the effects of cuts on the trigger patch ET spectra for electrons and positrons separately. In anticipation of using GEANT tracking in future versions a function was created which would count tracks going into a isolation region using the GEANT record. This function looped over all vertices within three centimeters of the primary vertex and counted all the tracks above a certain threshold which made it into the isolation region. This method often double-counts tracks and is modified in later versions. In addition to the new functions and histograms, two glitches in the code have been fixed in this version. The first is the addition of an ET scaling factor which single particle simulations had shown were needed to make the thrown electron pt and detector response agree, the value used is 1.23. The second correction fixed a problem in calculating the phi displacement between two objects in the endcap. Because the endcap coordinate system splits the detector into two halves and maps one 0 -> 180 and the other 0 -> -180, just taking the difference between phi coordinates will occasionaly lead to the wrong actual displacement. To rectify this, the difference in phi is now calculated as acos(cos(phi1 - phi2)) instead of just (phi1 - phi2). In this version the cuts remain the same as in version 2.4.
- Original source code can be viewed here
V3.0:
Version 3.0 uses GEANT for tracking and vertex finding information. Looking at the results from previous code, it was thought that tracking efficency and vertex finding were still too poor. It was decided to use GEANT tracking in anticipation of the improved tracking which would be available with the FGT upgrade. With the perfect tracking from GEANT, it was possible to explore the upper limit of how much discrimination track cuts could provide. Because of the perfect tracking, the volume of the detector looked at would not need to be restricted as much. Thus, the trigger conditions were changed from version 2.5 to eliminate the restriction that the ET weighted eta position of the trigger patch must be less than 1.7. The restriction on the etabin of the high tower was also relaxed so that it could be located in bins 2-11 (bins 1 and 12 were still excluded to reduce edge effects). The isolation cuts are now handled by four functions, two calculate the energy deposited in the calorimeters for the same side and away side cuts, and two count the number of tracks above a certain pt threshold going into the same side and away side regions. The track counting functions still have the double counting problem in this version. The last major change to this code is the way in which the cuts are organized and displayed. In this version the cuts are divided into three groups, the initial trigger cuts that all events must pass, the isolation cuts and the EEMC cuts. Each cut quantity is displayed after the trigger cuts as usual, but now each cut is displayed after the trigger cut and the isolation cuts have been applied and each cut is displayed again after all other cuts have been applied so that in the end, each cut is displayed three separate times. This was done to see which cuts where independent of each other.
V3.1:
Version 3.1 of the code solves the double counting problem that the previous track counting functions had. In this version the track counting is done recursively. The GEANT track and vertex infromation is set up as a network of connected nodes. Each node is a vertex and represents a particle decay and the lines coming out of each node represent the resultant particles of this decay. These lines will then connect to other nodes if that particle decays. The track counting function loops through all the particle lines coming from the primary vertex and asks where the next vertex connected to that line is, if there is no other vertex or the vertex is located greater than three centimeters away from the primary vertex, the particle is considered stable and is counted (if it is heading into the proper region). If the next vertex is less than three centimeters from the primary vertex however, the function is called again and loops over the tracks coming from this secondary vertex and the process is repeated until all tracks have been looped over. In this way, the code avoids counting the track of a particle which decays along with the tracks of its daughter particles. In addition to the double counting problem the values of the cuts were changed in this version. Version 3.0 threw away too many signal events so version 3.1 used the same set of cuts but just loosened the values where the cuts were made so they did not throw away as many events.
V3.2:
Version 3.2 is very similar to version 3.1, the major differences are the values used for the cuts. The quantities cut on are the same as in version 3.0 and 3.1, but now the values have been tightened slightly compared with version 3.1, so now each cut throws away around 2 or 3% of the signal. In addition to this tightening, the away side energy and track quantities were plotted against the trigger patch ET in a 2-D plot. This allowed for cuts which rejected much more background at low pt than was possible before with the same 1-D cuts.
V3.21:
Version 3.21 is almost exactly the same as version 3.2, the major difference is that this version introduces an ineffiecency into two of the track cuts. The cuts on the number of charged tracks above .5 and 5GeV going into the same side isolation circle both have large numbers of events with zero tracks in the QCD background sample and very few events with zero tracks in the signal sample. It is likely that many of these neutral tracks are Pi0's. With GEANT tracking, these Pi0's can be identified with 100% efficiency, but for real data, material in front of the detector will cause many of the Pi0's to convert giving rise to charged tracks. This conversion process will make the zero charged track cuts less efficient. To explore the effects of these conversions, a random number generator was used to pass 30% of events with zero charged tracks in both cuts. The only other change from version 3.2 was to move the 2-D histograms showing the trigger patch ET vs the cut quantites after all other cuts but themselves were applied so that they would be incremented properly.
Results
Detailed results from the latest version of the discrimination code can be found on the pages linked to in sections 3.2 and 3.21 but the major points as well as some summary plots will be shown here.
Fig 3: This plot shows the final trigger patch ET spectra after all cuts have been applied. The QCD background is in black and the W signal is in red. The plot on the left is from v3.2 and the plot on the right is from v3.21.

Fig 4: This plot shows the signal-to-background ratio for versions 3.2 and 3.21 after all cuts have been applied.

Fig 5: This table shows the effectivness of each cut for version 3.2.
| Cut | QCD Events Cut | Signal Events Cut |
| Iso Cut | 235 of 754: 31% | 18 of 1151: 2% |
| Small Iso Track | 82 of 536: 15% | 11 of 1131: 1% |
| Away ET Cut | 1300 of 1754: 74% | 9 of 1135: 1% |
| Away Track Cut | 924 of 1378: 67% | 45 of 1165: 4% |
| Big Iso Track | 3542 of 3997: 89% | 4 of 1124: <1% |
| 2 Highest Towers | 63 of 521: 12% | 21 of 1141: 2% |
| 7 U Strips | 527 of 1195: 44% | 31 of 1175: 3% |
| 7 V Strips | 579 of 1195: 48% | 33 of 1175: 3% |
| Hit U Strips | 7 of 468: 1% | 10 of 1138: <1% |
| Hit V Strips | 8 of 468: 2% | 10 of 1138: <1% |
| PS patch/Full patch | 151 of 606: 25% | 10 of 1130: <1% |
Fig 6: This table shows the effectivness of each cut for version 3.21.
| Cut | QCD Events Cut | Signal Events Cut |
| Iso Cut | 739 of 2852: 26% | 17 of 1107: 2% |
| Small Iso Track | 1042 of 2931: 36% | 11 of 1089: 1% |
| Away ET Cut | 3983 of 5897: 68% | 15 of 1093: 1% |
| Away Track Cut | 3461 of 4897: 71% | 63 fo 1121: 6% |
| Big Iso Track | 3310 of 5171: 64% | 4 of 1080: <1% |
| 2 Highest Towers | 110 of 2024: 5% | 19 of 1097: 2% |
| 7 U Strips | 1194 of 3620: 33% | 30 of 1131: 3% |
| 7 V Strips | 1323 of 3620: 37% | 32 of 1131: 3% |
| Hit U Strips | 27 of 1966: 1% | 10 of 1096: 1% |
| Hit V Strips | 44 of 1966: 2% | 10 of 1096: 1% |
| PS patch/Full patch | 189 of 2095: 9% | 10 of 1088: 1% |
Figures 5 and 6 show the effect of each cut after all other cuts have been applied. (The exception is for cuts on U and V plane quantites, in which case all other cuts but the similar cut on the other plane are applied). For each cut, the number of events which survived the other cuts and the number of those events which the cut removes are shown. So for example, looking at the iso cut in figure three, 754 background events survive the thirteen other cuts and the iso cut removes 235 of these surviving events. This can be taken as a way to measure how independent a cut is from all the others. The tables show that with perfect tracking, the cut on the number of charged tracks above 5GeV is by far the best cut, but with the 30% ineffieciency added in the effectiveness of this cut is reduced so that it is around parity with the away side cuts.
Conclusions
As the figures above show, the discrimination code achieves a signal-to-background ratio of greater than one-to-one over a significant portion of the lepton transverse energy range, indicating that background should not be an insurmountable barrier to preforming the W analysis at STAR. These results were obtained using GEANT and any analysis of real data will need to monitor vertex finding and tracking efficency to ensure they do not degrade the effectiveness of the cuts too much. The addition of the FGT should help with these issues and it is likely that the code will need to be optimized to take advantage of the improved tracking of the FGT. Finally, this analysis is based on a powerful discrimination code which can be refined and modified to suit future analyses.
Pythia Analysis ver 3.0: Analysis of set C4 events using geant record
Analysis of all setC4 events using geant tracks and vertices
In this analysis, I looked at all QCD background events from setC4 as well as W events from setC2 Wprod detailed here. I used version 3.0 of my analysis code which uses geant vertices and tracks instead of reconstructed vertices and tracks as version 2.5 did. I have also made changes to the quantities I make cuts on, see below. All transverse energy is event ET and an energy scaling factor of 1.23 is used.
Cuts:
I make 14 cuts described below. Plots of the cut spectra can be found here. Pages 1-11 show the cut spectra after 3 preliminary phase space cuts have been made (spectra of the first 3 cuts are not shown). Every event must pass the first three cuts to be considered. Pages 12-18 show cut spectra 8-14 after cuts 1-7 have been applied. Pages 19-29 show cut spectra after all cuts but its own have been applied. Pages 30-32 show a possible alternative cut.
- Cut 1: Require that the geant vertex be in the region [-70,-50]
- Cut 2: Require that the trigger patch ET > 20GeV
- Cut 3: Require that the high tower not be in eta bin 1 or 12
- Cut 4: Isolation cut - Ratio of the ET in the trigger patch to the ET in an iso cone with r=0.45. Require > 0.96 to pass
- Cut 5: Track iso cut - Number of geant charged tracks with pT>0.5GeV in an iso cone with r=0.7. Require < 3 to pass
- Cut 6: Awayside isolation cut - ET in a region Pi +/- 0.7 radians from the high tower in phi. Require < 6.0 to pass
- Cut 7: Awayside track cut - Number of geant charged tracks with pT>0.5GeV in same region as cut 6. Require < 7 to pass
- Cut 8: Track near high tower - Number of geant charged tracks with pT>5.0GeV in an iso cone with r=0.7. Require < 2 to pass
- Cut 9: Ratio of energy in two highest towers in trigger patch to energy in all towers in trigger patch. Require > 0.9 to pass
- Cut 10: Ratio of energy in 7 highest adjacent U strips under the patch to the energy in all U strips under the patch. Require > 0.7 to pass
- Cut 11: Ratio of energy in 7 highest adjacent V strips under the patch to the energy in all V strips under the patch. Require > 0.7 to pass
- Cut 12: Number of hit U strips in sector containing the trigger patch. Require < 48 to pass
- Cut 13: Number of hit V strips in sector containing the trigger patch. Require < 48 to pass
- Cut 14: Ratio of energy in patch post-shower layer to full energy in patch. Require < 0.0005 to pass
I have also made several 2-D plots of other quantities which may provide good electron/hadron discrimination. These plots can be found here.
- Page 1 is a plot of the trigger patch energy Vs. the post shower energy
- Page 2 is a plot of the energy in both the U and V strips under the trigger patch Vs. the energy in all post shower layers in the trigger patch
- Page 3 is a plot of the energy in both the U and V strips under the trigger patch Vs. the energy in all 2nd pre-shower layers in the trigger patch
- Page 4 is a plot of the trigger patch energy Vs. the energy in all 2nd pre-shower layers in the trigger patch
Spectra
The plots showing the effect of the various cuts on the trigger patch ET spectrum can be found here. Pages 1-14 show the effect that the first 3 cuts plus the individual cut has on the trigger patch ET spectrum. So, for example, page 7 shows the spectrum after cuts 1, 2, 3, and 7. Pages 15-26 shows the effects that a number of cuts applied sequenitally has on the spectrum. In all plots the black curve is the detected ET spectrum before any cuts have been made and the red curve is the ET spectrum after the cuts in question have been applied.
Fig 1: This plot shows the effects of all the cuts applied in sequence on the trigger patch ET spectrum

Fig 2: This plot shows the final trigger patch ET spectra after all cuts have been applied. The QCD background is in black and the W signal is in red.

Pythia Analysis ver 3.1: Analysis of set C5 events using geant record
Analysis of all setC5 events using geant tracks and vertices
In this analysis I looked at all QCD background events from setC5, which has an integrated luminosity on the order of what we expect to get in data. I also looked at W events from setC2 Wprod. The details of both event samples can be found here. This analysis was done using version 3.1 of my code which uses geant vertices and tracks, meaning we have perfect tracking for the cuts. All transverse energy is event ET and an energy scaling factor of 1.23 is used. All samples are scaled to LT=800 inverse pb.
Cuts:
I make 14 cuts which are described below. These cuts have been loosened compared to those in version 3.0, now each cut throws away no more that 1% of the signal. I have also added conditions to cuts 5 and 8 to reject events where no charged track was found. Plots of the cut spectra can be found here. Pages 1-11 show the cut spectra after the 3 preliminary phase space cuts have been made (spectra of the first 3 cuts are not shown). All events must pass the first three cuts to be analysed further. Pages 12-18 show cut spectra 8-14 after cuts 1-7 have been applied to them. Pages 19-29 show all the cut spectra after all cuts but their own have been applied.
- Cut 1: Require that the geant vertex be in the region [-70,-50]
- Cut 2: Require that the trigger patch ET>20GeV
- Cut 3: Require that the high tower not be in eta bin 1 or 12
- Cut 4: Isolation cut - Ration of the ET in the trigger patch to the ET in an iso cone with r=0.45. Require > 0.94 to pass
- Cut 5: Track iso cut - Number of geant charged tracks with pT>0.5GeV in an iso cone with r=0.7. Require < 5 and > 0 to pass
- Cut 6: Awayside isolation cut - ET in a region Pi +/- 0.7 radians from the high tower in phi. Require < 9.0 to pass
- Cut 7: Awayside track cut - Number of geant charged tracks with pT>0.5GeV in same region as cut 6. Require < 10.0 to pass
- Cut 8: Track near high tower - Number of geant charged tracks with pT>5.0GeV in an iso cone with r=0.7. Require there be 1 and only 1 track to pass
- Cut 9: Ratio of energy in two highest towers in trigger patch to energy in all towers in trigger patch. Require > 0.75 to pass
- Cut 10: Ratio of energy in 7 highest adjacent U strips under the patch to the energy in all U strips under the patch. Require > 0.45 to pass
- Cut 11: Ratio of energy in 7 highest adjacent V strips under the patch to the energy in all V strips under the patch. Require > 0.45 to pass
- Cut 12: Number of hit U strips in sector containing the trigger patch. Require < 52 to pass
- Cut 13: Number of hit V strips in sector containing the trigger patch. Require < 54 to pass
- Cut 14: Ratio of energy in patch post-shower layer to full energy in patch. Require < 0.002 to pass
I have also made several 2-D plots of other quantities which my provide good electron/hadron discrimination. These plots can be found here.
- Page 1 is a plot of the iso radius (r=0.7) ET Vs. the trigger patch ET
- Page 2 is a plot of the away side ET Vs. the trigger patch ET
- Page 3 is a plot of the trigger patch ET Vs. the number of charged tracks above 0.5GeV in the away side region
- Page 4-6 show the same plots as pages 1-3 after cuts 1-7 have been applied
- Page 7-9 show the same plots as pages 1-3 after all cuts have been applied
- Page 10 is a plot of the trigger patch energy Vs. the post shower energy
- Page 11 is a plot of the energy in both the U and V strips under the trigger patch Vs. the energy in all post shower layers under the trigger patch
- Page 12 is a plot of the energy in both the U and V strips under the trigger patch Vs. the energy in all 2nd pre-shower layers in the trigger patch
- Page 13 is a plot of the trigger patch energy Vs. the energy in all 2nd pre-shower layers in the trigger patch
- Page 14-17 show the same plots as pages 10-13 after cuts 1-7 have been applied
- Page 18-21 show the same plots as pages 10-13 after all cuts have been applied
Spectra
The plots showing the effect of the various cuts on the trigger patch ET spectrum can be found here. Pages 1-14 show the effect that the first 3 cuts plus the individual cut has on the trigger patch ET spectrum. So, for example, page 7 shows the spectrum after cuts 1, 2, 3, and 7. Pages 15-26 show the effects that a number of cuts applied sequentially has on the spectrum. In all plots the black curve is the detected ET spectrum before any cuts have been made and the red curve is the ET spectrum after the cuts in question have been applied.
Fig 1: This plot shows the effects of all the cuts applied in sequence on the trigger patch ET spectrum. For the QCD sample: The raw spectrum contains 2.6E6 events in the region 20-70, the spectrum after the phase space cuts (1-3) contains 2.2E6 events, and the spectrum after all cuts contains 1.5E4 events. For the W sample: The raw spectrum contains 4645 events in the region 20-70, the spectrum after the phase space cuts contains 3747 events and the spectrum after all cuts contains 3378 events.

Fig 2: This plot shows the final trigger patch ET spectra after all cuts have been applied. The QCD background is in black and the W signal is in red.

Pythia Analysis ver 3.21: Analysis of set C5 events using geant record
Analysis of all setC5 events using Geant tracks and vertices
In this analysis I attempt to get a feeling for the effects that imperfect tracking will have on the trigger patch ET spectrum while still using geant tracking information. My main focus was on the inefficencies which will arise in trying to identify converting Pi0's, so I focused on cuts 5 and 8. Both of these cuts have large numbers of events with no charged tracks and it is likely that many of these events are Pi0's. In v3.2 of the analysis code cuts 5 and 8 both throw away events with no charged tracks, so to simulate the tracking inefficency I use a random number generator to allow 30% of events with zero charged tracks to pass each cut. The code I used for this analysis is v3.21 which uses the same cuts as v3.2 except for the code introducing the 30% inefficency. Descriptions of the cuts used as well as explanations of the plots in the pdf files can be found on the page describing v3.2 of my code found here. I have also changed the 2-D plots of the trigger patch ET Vs. the cut quantities found on pages 23-33 of the 2-D plot pdf. They now show the plots after all cuts but themselves have been applied as opposed to v3.2 where they were shown after all cuts were applied.
Fig 1: These plots show the effects of all the cuts applied in sequence on the trigger patch ET spectrum. The top plot is from v3.2 and the bottom plot is from v3.21. The number of events cut for v3.2 can be found on the main page for that analysis. The numbers for v3.21 are given here. For the QCD sample: The raw spectrum contains 9.9E5 events in the region 20-70, the spectrum after the phase space cuts (1-3) contains 8.2E5 events, and the spectrum after all cuts contains 1906 events. For the W sample: The raw spectrum contains 1671 events in the region 20-70, the spectrum after the phase space cuts contains 1347 events and the spectrum after all cuts contains 1078 events.


Fig 2: This plot shows the final trigger patch ET spectra after all cuts have been applied. The QCD background is in black and the W signal is in red. The plot on the left is from v3.2 and the plot on the right is from v3.21.

Pythia Analysis ver 3.2: Analysis of set C5 events using geant record
Analysis of all setC5 events using Geant tracks and vertices
In this analysis I looked at all QCD background events from setC5, which has an integrated luminosity on the order of what we expect to see in the data. I alo looked at W events from setC2 Wprod. The details of both event samples can be found here. This analysis was done using version 3.2 of my code which uses geant vertices and tracks, meaning we have perfec tracking for the cuts. All transverse energy is event ET and an energy scaling factor of 1.23 is used. All samples are scaled to LT=300 inverse pb; note that the samples in all previous versions were scaled to 800 inverse pb.
Cuts:
I make 14 cuts which are described below. These cuts have been tightened slightly compared to those in version 3.1, now each cut throws away between 2-3% of the signal, except for cuts 6 and 7. For cuts 6 and 7, I have used a 2-D plot of the patch ET Vs. the cut quantity to cut harder on the low pT background. I have also included plots of quantites which we thought had potential to be used as cuts.
Plots of the 1-D spectra can be found here. Pages 1-11 show the cut spectra after the 3 preliminary phase space cuts have been made (spectra of the first 3 cuts are not shown). All events must pass the first three cuts to be analysed further. Pages 12-18 show cut spectra 8-14 after cuts 1-7 have been applied to them. Pages 19-29 show all the cut spectra after all cuts but their own have been applied. Pages 30 and 31 contain plots showing the ratio of U(V) strips above 0.5MeV under the trigger patch to the total number of U(V) strips under the patch. Pages 32 and 33 contain plots showing the number of U(V) strips above 0.5MeV in the sector(s) containing the trigger patch. Pages 34-37 contain the last four plots with cuts 1-7 applied and pages 38-41 contain the last four plots with all cuts applied.
Plots of the 2-D spectra can be found here. Pages 1-33 show the trigger patch ET Vs. the cut quantites so we can fine tune the cuts to eliminate background in particular ET ranges. Pages 1-11 show the cut spectra after the 3 phase space cuts have been made. Pages 12-22 show the cut spectra after cuts 1-7 have been applied. Pages 23-33 show the cut spectra after all cuts have been applied. Pages 34 and 35 show the trigger patch Energy Vs. the ratio of energy in the 7 highest adjacent U(V) strips under the trigger patch to all U(V) strips under the trigger patch. Page 36 shows the trigger patch Energy Vs. the ratio of pre-shower energy in the trigger patch to all energy in the trigger patch. Pages 37-39 show the last three quantities with cuts 1-7 applied and pages 40-42 show the same quantities with all cuts applied. Pages 43 and 44 show trigger patch ET Vs. the ratio of U(V) strips above 0.5MeV under the trigger patch to the total number of U(V) strips under the patch. Pages 45 and 46 show the trigger patch ET Vs. the number of U(V) strips above 0.5MeV in the sector(s) containing the trigger patch. Pages 47-50 show the last four plots with cuts 1-7 applied and pages 51-54 show the plots with all cuts applied. Page 55 is a plot of the trigger patch energy Vs. the post shower energy. Page 56 is a plot of the energy in both the U and V strips under the trigger patch Vs. the energy in all post shower layers under the trigger patch. Page 57 is a plot of the energy in both the U and V strips under the trigger patch Vs. the energy in all 2nd pre-shower layers in the trigger patch. Page 58 is a plot of the trigger patch energy Vs. the energy in all 2nd pre-shower layer in the trigger patch. Pages 59-62 show the last four plots after cuts 1-7 have been applied and pages 63-66 show the same plots after all cuts have been applied.
- Cut 1: Require that the geant vertex be in the range [-70,-50]
- Cut 2: Require that the trigger patch ET>20GeV
- Cut 3: Require that the high tower not be in eta bin 1 or 12
- Cut 4: Isolation cut - Ratio of the ET in the trigger patch to the ET in an iso cone with r=0.45. Require > 0.96 to pass (1-D cut)
- Cut 5: Track iso cut - Number of geant charged tracks with pT>0.5GeV in an iso cone with r=0.7. Require < 4 and > 0 to pass (1-D cut)
- Cut 6: Awayside isolation cut - ET in a region Pi +/- 0.7 radians from the high tower in phi. (2-D cut)
- Cut 7: Awayside track cut - Number of geant charged tracks with pT>0.5GeV in same region as cut 6. (2-D cut)
- Cut 8: Track near high tower - Number of geant charged tracks with pT>5.0GeV in an iso cone with r=0.7. Require there be 1 and only 1 track to pass (1-D cut)
- Cut 9: Ratio of energy in two highest towers in trigger patch to energy in all towers in trigger patch. Require > 0.83 to pass (1-D cut)
- Cut 10: Ratio of energy in 7 highest adjacent U strips under the patch to the energy in all U strips under the patch. Require > 0.6 to pass (1-D cut)
- Cut 11: Ratio of energy in 7 highest adjacent V strips under the patch to the energy in all V strips under the patch. Require > 0.6 to pass (1-D cut)
- Cut 12: Number of hit U strips in sector containing the trigger patch. Require < 52 to pass (1-D cut)
- Cut 13: Number of hit V strips in sector containing the trigger patch. Require < 52 to pass (1-D cut)
- Cut 14: Ratio of energy in patch post-shower layer ot full energy in patch. Require < 0.001 to pass (1-D cut)
Specta
The plots showing the effect of the various cuts on the trigger patch ET spectrum can be hound here. Pages 1-14 show the effect that the first 3 cuts plus the individual cut has on the trigger patch ET spectrum. So, for example, page 7 shows the spectrum after cuts 1, 2, 3, and 7. Pages 15-26 show the effects that a number of cuts applied sequentially has on the spectrum. In all plots the black curve is the detected ET spectrum before any cuts have been made and the red curve is the ET spectrum after the cuts in question have been applied.
Fig 1: This plot shows the effects of all the cuts applied in sequence on the trigger patch ET spectrum. For the QCD sample: The raw spectrum contains 9.9E5 events in the region 20-70, the spectrum after the phase space cuts (1-3) contains 8.2E5 events, and the spectrum after all cuts contains 455 events. For the W sample: The raw spectrum contains 1742 events in the region 20-70, the spectrum after the phase space cuts contains 1405 events and the spectrum after all cuts contains 1120 events.

Fig 2: This plot shows the final trigger patch ET spectra after all cuts have been applied. The QCD background is in black and the W signal is in red.

FGT . . . . . . . . . . C A L I B R A T I O N
- Algorithm for calibration
- status tables for year 2010
Beam Test at DESY, May 2011
Planning the Beamtest at DESY
Important Dates:
Scheduled from May 16-30
Contacts:
general:
Anselm Vossen (avossen@indiana.edu)
DESY testbeam page:
http://adweb.desy.de/~testbeam/
People that are going
Equipment that has to be shipped
|
Equipment |
Qty | Size | Weight | ? | Contact Person/Institution | Shipping Details (from where to where) | When? |
Comments (e.g. shipping details safety aspects) |
|
| FGT Quadrants | MIT | ||||||||
| Det Fixture | MIT | ||||||||
| positioning/alignment | MIT | ||||||||
| gas-setup | Valpo/MIT | might be available at DESY - see below | |||||||
| bottled gas (premixed?) | DESY | ||||||||
| FEE board | 6 | MIT | |||||||
| terminator board | MIT | ||||||||
| interconnector board | MIT | ||||||||
| cable and patch | MIT | ||||||||
| signal cables | IU/UKY | ||||||||
| power cables | IU/UKY | ||||||||
| RG-59 HV cables | 3 | DESY? | |||||||
| readout crate | 1 | 2.5'x 4'x 3.5x | 100 lbs | ANL | |||||
| ARC | 1 | 1'x 1'x 0.3' | 4 lb | ANL | |||||
| ARM | 3 | 1'x1'x0.3' | 4 lb | IU | |||||
| HVPS | 1 | 1'x1'x0.3' | 8 lb | IU | |||||
| computer incl. DRORC | 1 | 1'x3'x4' | 73 lb | DESY? | |||||
| Nim logic | DESY | ||||||||
| data fiber | 1 | IU | |||||||
| hand tools and scope | DESY | ||||||||
| diff probe | 1 | IU | |||||||
| Sys clock source | already provided by ARC | ||||||||
| Misc computer equipment (PC etc) |
Gas at Desy
The DESY gas group can supply premixed gas. We have to ask well in advance.
Flowmeters etc. should also be available. We have to bring tools
Test Beam Description
can be found here:
adweb.desy.de/home/testbeam/WWW/Description.html
Safety at DESY
Inspection List for equipment
General:
adweb.desy.de/~testbeam/documents/AllgemeineSicherheitsunterweisungD5englisch.pdf
Radiation protection
adweb.desy.de/~testbeam/documents/RadiationProtectionInstructionsTestBeam-NM-1-2006.pdf
Testbeam safety briefing:
adweb.desy.de/~testbeam/documents/SafetyBriefingTestBeam.pdf
We have to assign one person responsible for radiation safety
That person is:
Travel Infos for Hamburg/Germany
Fly into Hamburg
Today the price from JFK is ~$950 roundtrip
Within Germany, rail is good idea if you book in advance
www.bahn.de/i/view/USA/en/index.shtml
ask me if you want to look for special fares ( I saw that that site is in German)
HOUSING
DESY hostel:
guest-services.desy.de/hostel_in_hamburg/hostels_info/
I haven't been at DESY, so if somebody else has a better idea, please tell me
CHECKLIST
OPEN ISSUES
Gas
Planned Measurements
Planned Measurements
For each of these measurements we should have a plan/protocoll what we want to do (conditions, time, software...)
-
Normal
0false
false
falseEN-US
X-NONE
X-NONE/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin:0in;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri","sans-serif";
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}Reproduction of test beam results at FNAL: drupal.star.bnl.gov/STAR/blog/surrow/2011/feb/02/fgt-testbeam-fnal-prototype-triple-gem-detectors
- Cluster reconstruction, Cluster size,
- R-Phi Correlations
- Efficiency
- Cluster amplitude
- HV scans
- Residuals
- Dependence on
Normal
0false
false
falseEN-US
X-NONE
X-NONE/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin:0in;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri","sans-serif";
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}on inclination angle for P/Phi reconstruction
- Noise (i.e. electronics noise of the readout). RMS of pedestals calibrated to MIP. Optimum parameters for APV in FGT. (Parameters will affect gain as well as noise, of course.) Necessity (or hopefully not) of tracking pedestals by capid.
- Number of timebins to use in readout, and algorithm to get pulse amplitude/time from the timebin data. Uniformity of signal shape over the detector.
-
Crosstalk
-
Normal
0false
false
falseEN-US
X-NONE
X-NONE/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin:0in;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri","sans-serif";
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}Rate dependence (trigger rate and signal rate).
-
Normal
0false
false
falseEN-US
X-NONE
X-NONE/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin:0in;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri","sans-serif";
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}.Radiation effects on the frontend electronics
-
Normal
0false
false
falseEN-US
X-NONE
X-NONE/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin:0in;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri","sans-serif";
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}EMI issues. (For the most part if there are any, have to be
addressed first and independently of the rest of the testing, test
beam or otherwise.)
-
Normal
0false
false
falseEN-US
X-NONE
X-NONE/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin:0in;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri","sans-serif";
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}Optimum gain setting for the FGT in consideration of the limited dynamic range of APV. What tail of large events can we afford to cut off and still make the position resolution? Conversely how much noise is affordable and still make the position resolution. Presumably get to a plot of resolution as a function of HV setting.
-
Normal
0false
false
falseEN-US
X-NONE
X-NONE/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin:0in;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri","sans-serif";
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}Survival of FEE to breakdown/discharges in detector
FGT . . . . . . . . . . D O C U M E N T S
- Proposal (December 2007)
- Project documentation on deltag5 at MIT server
- Tree-structure of FGT web page (graph)
- Conclusions of Reviews
date place format occasion January 2008 MIT pdf STAR Forward GEM Tracker Review Committee - NIM paper from the 2007 FermiLab beam test of GEM disks is available on ArXiv http://arxiv.org/abs/0808.3477
OTHER DOCUMENTS
- RHIC long range plan as of December 2006 (out link)
- RHIC PAC, May 2008, STAR BUR
- STAR Detector West Side Pictures: Click Here (deltag5 @MIT)
- Frank's Thesis
Documents/Minutes of prelimnary safety review, Sept. 09
Files from the prelimnary safety review at BNL Sept 09
FGT . . . . . . . . . . DAQ
DAQ related information for FGT
APV Readout System Long Cable Test Setup
The APV front-end ASIC which forms the core of the Forward GEM Tracker readout system combines a sensitive preamplifier, switched-capacitor analog memory array, and low-voltage differential analog output buffer.
Operating such an ASIC directly over a long cable, with the analog output digitized at the far end of the cable, potentially presents some challenges. Of course, there are are also opportunities, to minimize the power dissipation inside the inner field cage region, minimize dead materials, and to maximize reliability by placing most of the electronics in an easily serviceable location on the STAR electronics platform.
At IUCF we are constructing a pair of test boards, one which models the APV readout module "ARM", the other which models the APV cable connector board.
Besides testing the performance of the MIT APV motherboards with a long cable interface, this set of test boards is important to:
- Develop the interface definitions between the IUCF "ARM" and the MIT "APV Motherboard"
- Demonstrate a low-dropout low-voltage regulator for the APV power, and characterize its performance
- Demonstrate the control of APV chips and an I2C temperature sensor via the UART - I2C bridge chip
- Evaluate the effects of various thermal and grounding options for the FGT
- Run the APV's for detector testing (either with an external ADC and clock source, or with the connector board here and the full ARM to be developed
Here are the design files:
- Mock readout board
- schematic 314837-000.pdf (component values are preliminary)
- layout 314838-000.pdf
- CAD (zip)
- picture
- Prototype APV cable connector board
- schematic 314945-000.pdf (component values are preliminary)
- layout 314946-000.pdf
- CAD (zip)
- picture
The connector board should be compatible with a pair of FGT APV Motherboards, a total of 10 APV chips. The mock readout board provides only two channels of analog line receiver, testing two different concepts for this. One is a DC coupled line receiver using Analog Devices # AD8129, the other is a transformer-coupled line receiver using a TI # OPA684 opamp. The transformer solution should have superior noise and common-mode rejection and lower power, but it is of course not DC coupled as we would wish. It could be used if DC restoration is applied digitally in the FPGA (on the real ARM).
First results:
Here is the APV readout sequence, looking good:

The "noise" which is apparent here is merely crosstalk from the clock signal, and as such will be easily removed by the filter in front of the ADC. Neither that filter nor the cable frequency equalization filter is in place for the measurement above.
Clock frequency was 40 MHz; APV was triggered at 1 kHz from a pulse generator. No inputs connected, no shield box. Cable is Belden 1424A, 110 feet, coiled up on workbench.
ARM - FEE Final Interface Prototype
Details of final prototype of FEE interface circuitry for FGT APV Readout Module "ARM". This includes the isolated remote-regulated power supplies, the isolated I2C line interface, the isolated LVDS clock & trigger line drivers, and the differential analog receiver. Cable connectors and pinouts here are proposed for final application. (In actual ARM, cables interface through a rear transition board in the crate through the 96-pin DIN connector to ARM module. This is not implemented here - cables connect directly using same connector type and pinouts on the cables.)
Here are the details:
- schematic (component values are preliminary)
- board fab data
- picture
Brief overview of FGT FEE/Readout electronics chain
This is a short overview of the front end and readout electronics of the FGT. The emphasis is on providing some documentation on all the components. At present most of the items exist only as prototypes, I will try to keep this page current as things get finalized.
First, the front end board, which has 5 APV chips. Two front end boards are used per FGT quadrant (24 quadrants total). One sits at each end of the quadrant. As four quadrants fit together to form an FGT disk, the pairs of front end boards from adjacent quadrants physically sit close to each other. They are serviced by a common cable, interconnect board, and terminator board (to be described shortly).
Below is a picture of the first FGT quadrant (actually just a mechanical test assembly, the pad plane is an old design and is defective). Apologies this is a shiny object photographed on a shiny table in the Bates cleanroom. What you see here is mainly the aluminized mylar gas window which is also the ground plane, sits a couple of mm above the pad plane. On each end of the quadrant is a row of five Samtec MEC6 card-edge connectors (0.635 mm contact pitch): four 140 pin connectors and one 80 pin in the center of the other four. This connects the 640 = 5 APV * (128 ch/APV) signals from the pad plane to the FEE board. The ground is carried separately (see description below). The constraints on FGT inner and outer radius do not permit assigning any of these connector contacts to grounds.

Below is a picture of a front end board installed on an FGT quadrant. This is a view from "outside" i.e. this is the side of the front end board that does not have the APV chips. Actually in this picture is a mechanical mockup board, but is mechanically identical to the final design. The white RTV which can be seen in this picture is covering the edge of this quadrant assembly.

And here is the actual front end board. In this and the picture above you can see the two ground contact points which will be fastened with screws and washers to wide contact strips extending from the ground foil. This provides the connection of APV signal ground. The ground foil is also similarly connected to the bypass capacitor feeding bias voltage to the bottom of the last GEM foil (connections not detailed here).

Note that it is the back side of this board that would be seen in the quadrant picture above. The two front end boards serviced as a pair have the APV chips mounted on the outward facing sides. Similarly the ground foil connections are made on this outward facing side. From the quadrant's perspective, the chip side of the APV board faces in toward the center of the quadrant.
The front-end board is serviced by the "interconnect board" on one end and a "terminator board" on the other. All interface lines run through from end to end so that the design is symmetrical. Half of the frontend boards have the terminator on the right in this picture, half have the interconnect board on the right. There is only a single flavor of front end board.
The schematic of the front end board is (here). It consist only of five APV chips and a minimal set of support components.
The APV chip is a 128-channel preamp / shaper / SCA / readout mux chip developed for CMS tracker silicon, and also subsequently deployed for GEM readout in COMPASS. Most of the operational details are described in the user guide and in presentations available on the CMS tracker web pages. The APV chip incorporates an analog FIR filter (what the user guide refers to as deconvolution mode) for tail cancellation / pileup reduction at the expense of higher noise. We don't intend to make use of it. It should be noted that the appropriateness of the (fixed) filter coefficients is of course dependent on the sample clock rate. Which is another reason we don't intend to use it.
The APV chip sample clock can be run at least as fast as 40 MHz (as in CMS). For RHIC, we prefer to lock to a multiple of our collision frequency so that the signals can be synchronously sampled avoiding any additional complications or errors from asynchronous sampling. We will use 4x RHIC strobe, 37.532 MHz, a reasonable match to the capability of the APV chip.
The APV chip readout clock can be the sample clock or 1/2 the sample clock rate. With 1/2 the sample clock a single-point readout requires 280/37.532 MHz = 7.46 us. This is amply fast in comparison with other STAR detectors even if multi-point readout is employed. So we will use only the 1/2 rate readout because it significantly eases the signal transport problem.
[Insert here description of the interconnect board / terminator board. (voltage reg, clk/trig receiver, temp sensors, POR circuit, terminations)]
The above comprises the front end electronics subsystem. The interfaces from the front end electronics to the readout electronics are, in total:
- Power supplied at +/-1.8 V with remote sense of +1.8, ground, and -1.8 at the terminals of the front end electronics (interconnect board). The power supply is in the readout electronics, and is isolated from ground.
- SCL/VSS pair and SDA/VSS pair that connect to the APV chips and other devices, e.g. temperature sensors, on the front end electronics. This I2C interface runs with 2.5 V logic and complies with the I2C standard except in regard to line capacitance limitations where special considerations are taken. The pull-up current source is in the readout electronics. The I2C master in the readout electronics is isolated from ground.
- CLK+/- low voltage differential logic signal (continuously running). Source is isolated from ground (transformer coupled) in the readout electronics. The line is terminated at the front end electronics and at the readout board (double-termination).
- TRIG+/- low voltage differential logic signal. Source is isolated from ground (transformer coupled) in the readout electronics. The line is double terminated.
- 10x (in case of FGT) or up to 12x (in case of IST) analog signal output lines each from one APV chip. All are double terminated and are received at the readout board with a high common-mode impedance line receiver.
(more description/documentation of the readout system to come...)
Event size estimation
Estimation of FGT event size for pp events @ 500 GeV is 20KB/eve after ZS, physics event will use 80% of this volume.
- empty event: 3.7KB Concluding: for 3-sample empty events we need 3.7 KB 300*(2+2+2+2)+30000*(2+2+2+2)/200+100=3700 bytes.
- total # of channels: 128 ch X 10 APV x4 quad x 6 disks = 30K channels.
- zero suppression (ZS) is aiming to keep 1/100 of ADC channels, set to about 3 sigma above ped. Needs testing with data & real electronics, time stability, beam halo, AC-noise . Perhaps we can ZS more.
- with ZS we need 4 bytes per hit:
- we need 2 bytes (log2(30k)=14.9) for channel ID
- ADC value needs up to 12 bits, assume we write it as 16 with 4 bits unused, as with ESMD
- we may want to keep ADC for 3 time slots per event (using 25 ns integration window) increasing hit size to 8=4+2+2 bytes.
- it is enough to keep 1/1000 events w/o ZS for monitoring of pedestals
- event header needs 100 bytes
- pp data taking
- assume every track fires 5 strips (will be more at Rin and less at Rout due to varied width of phi strips)
- trigger event is always embedded in 6 minBias pileup events
- at top RHIC luminosity we have 1.5 minB interactions per bXing
- 300 nsec of analog pulse --> need to account for 4 pre-trigger bXings --> 4x1.5=6 minB eve/trig eve
- based on OLD Pythia simulations (obsolete disk size & location) @ 500 GeV one expects 1 track per quadrant per minB event.
conclusion: 1440 ADCs will fire due to underlying pileup event (4 tracks * 6 disks * 2 planes *6 events *5 strips= 1440 - W-trigger will fire mostly on jets, ASSUME HT consumes lot of jet energy and there is 10 charged (low pT) tracks in such jet. 10 tracks * 6 disks * 2 planes * 5 strips= 600 ADCs. total physics event content will be 2000 ADC channels. This requires 16KB (2000 *8 bytes)
- Heavy Ion even - no study was performed so far.
FGT DAQ drawings and hardware documentation
These are the official drawings and documentation used for fabrication of the FGT "DAQ" hardware. We will try to maintain this page up-to-date with any revisions.
APV Readout Controller (ARC)
- Pictures
- Schematic (pdf)
- Schematic (format=?)
- BOM
- Layout (format=?)
- Board fabrication data
- Assembly data
APV Readout Module (ARM)
- Pictures
- Schematic (pdf)
- Schematic (P-CAD)
- BOM
- Layout (P-CAD)
- Board fabrication data
- Assembly data
- Firmware
ARM Back-of-Crate Board (ABC)
- Pictures
- Schematic (pdf)
- Schematic (Altium)
- BOM
- Layout (Altium)
- Fabrication data files
FGT FEE Patch Panel
- Pictures
- Schematic (pdf)
- Schematic (..)
- BOM
- Layout (..)
- Fabrication data files
Other documentation
FGT . . . . . . . . . . M E E T I N G S
TIME is going backwards.
2009-05-21 , RHIC user meeting @ BNL
2009-05-12 , quarterly review presentation of the FGT project
2009-03-23, RCS presentation, Bernd
2009-08-08, 3rd quarterly review at BNL,Bernd
FGT-HN Upload site (StarTube) : You do not have access to view this node , Instruction for new users uploading FGT documents
Weekly FGT phone meetings (minutes by Doug Hasell or Gerard)
2009
2008
March: 7, 14, 21, 28
April 11 : Brian e/h-algo , Dave: X/X0 in Endcap
May 2 ,
IEEE in Dresden, 2008, Frank's talk about FGT
You do not have access to view this node, September 2008 GT meeting at BNL
September 2008, Local seminar at MIT by Jan
Title: The STAR Forward GEM Tracker, Talk (PDF), abstract
2nd STAR IFC integration meeting, BNL, July 23, 2008
You do not have access to view this node
Forward Tracking Extension Meeting at MIT, June, 2008
STAR Collaboration Meeting, Davis, June, 2008
- Agenda
- see slides from Doug (construction) , Jan
STAR IFC integration meeting, BNL, May 16, 2008
- You do not have access to view this node
- see slides from Jim K. , Doug, Jan
BNL PAC, May 8, 2008,
- RHIC SPIN program (Bernd)
IEEE NSS 2008 in Dresden, Germany, May 2008,
FGT meeting at IUCF on April 24-25 on April 24-26, 2008
RSC meeting on April 21, 2008 , all talks , DG, W, ppTrans ,
DIS2008, London April 2008, web-page, some talks: ppTrans RHIC program (PPT) Jan
FGT review at MIT, January 7-8, 2008 ( detailed agenda )
- Monday, January 7, 2008: MIT-LNS, 13:00-18:00 , Talks (tmp link to MIT)
- Tuesday, January 8, 2008: MIT-Bates, 09:00-17:00 Talks (tmp link to MIT)
Cosmic Stand Safety Review April 29th 2011 at BNL
Date: Friday April 29, 2001
Time: 1:30 pm
Place: C-AD LCR
overview cosmic teststand: Anselm
FGT disks (internal HV distribution etc) : Ben/Jason
electronics/cables/etc. : Gerard
Gas system (short) : Don
FGT. . . . . . . . . . H A R D W A R E -- E L E C T R O N I C S
01 2D_GEM Sensor Board for test at FANL / Miro
In this document one can find schematic topology and architecture of 2D_GEM Sensor Board which was used for test at FANL.
02 2D_GEMCU for Test in FANL / Miro
In this document one can find complete schematic topology and block diagrams for 2D_GEM Readout Control Unit which was used in test run at FANL.
03 APV Module for Test 2D_GEM at FANL / Miro
In this document one can find complete schematic topology and hardware architecture for APV Module which was used for test of 2D_GEM at FANL.
04 APV Motherboard Design / Miro
Document "APV Motherboard Design" for FGT April's meeting at IUCF on April 24, 2008.
05 APV_MODULE for STAR/FGT READOUT
APV_MODULE is PCB where on top of APV_BOARD is bond with epoxy glue SIG_BOARD
06 BNL 26Sep@008 Meeting
FEE Design
07 Document for Charge Sharing 2D_Readout module / Miro
In this document one can find GERBER files for Charge Sharing 2D_Readout module. This module will be used for test and study charge sharing effect in GEM detectors. All other components for assembling of this charge sharing setup we will use from old GEM detectors which we used for test purposes at FANL last year.
NOTE: Files in "TSTBOARD.zip" are possible open with P-CAD2004 software tool and file "tstboard.pdf" is "pdf" accessible file where one can see architecture of mentioned unit.
07 Document for GEM/FANL prototype / Miro
This document was requested by Dave Underwood and Gerrard Visser for they purposes to compare they design with GEM/FANL prototype buildup at MIT/Bates Linear Accelerator.
08 Module for FGT Mechanical Test / Miro
In attached document is multipurpose module with which one can test all mechanical and connectivity features.
09 VHDL Programs and State Machines for GEM/FANL / Miro
In this document one can find VHDL Programs and State Machines for 2D_GEM Control Unit which was engaged in readout process from GEM detector at FANL.
10 WSC and the GEM quarter section frames (Jason)
drawings showing the final dimensions of the WSC and the GEM quarter section frames,
8-19-2009, Jason Bessuille
Front End Electronics Drawings and Hardware Documentation
These are the official drawings and documentation used for fabrication of the FGT Front End Electronics hardware. We will try to maintain this page up-to-date with any revisions.
To view design files, download the Altium Viewer (no cost).
FGT Readout Module (FRM)
- Pictures
- GND2 Explanation
- GND2 Explanation Photo
- Schematic (pdf)
- Design Files (Altium)
- BOM
- Fabrication data files (Gerber)
- APV Connection Map
- Simplified APV Connection Map (DAQ Perspectave)
Terminator Board
Interconnect Board
High Voltage Board
- Pictures
- Schematic - Linear with clear naming of pins (pdf) (rev3)
- Schematic - Linear (pdf) (rev2)
- Schematic - Gradient (pdf) (rev1)
- Design Files (Altium)
- BOM
- Fabrication data files
FGT. . . . . . . . . . H A R D W A R E -- S L O W C O N T R O L S
Documentation of FGT Slow Controls Subsystem
(add child pages with specific documents below)
The manufacture's calibration for these flow meters is shown here. It is nonlinear as you can see. So, going from ~40 mm to >65 mm more than doubles the flow rate: it is well over 100 cc/min.
Scale reading Flow Rate
(mm) (cc/min)
---------------------- --------------
65 104.0
60 91.5
55 79.5
50 69.0
45 59.2
40 49.5
35 41.7
30 34.2
25 27.7
20 22.0
15 17.5
10 13.4
5 10.0
Regards,
Don
FGT. . . . . . . . . . P H O T O - - G A L L E R Y
Fig 1 HOW GEM foil works

Fig 2 Filed lines through GEM foil

Fig 3 triple GEM HV

Fig 4 FOM for AL vs. lepton eta & PT, RHICBOS, GSRV-STD

Fig 5,Graphics courtesy of Tai Sakuma, MIT 
Fig 6,Graphics courtesy of Jim Kelsey, MIT
more plots like this is here PPT , PDF presented at BNL, May 16, 2008.
Fig 7. Assembled setup for mechanical and electrical test for Quadrant STAR/FQT/FEE

See other (large) photos below
Fig 8. Y2008, full STAR

Fig 9. UPGR16, full STAR

Fig 10. UPGR16,inner trackers , side view

Fig 10. UPGR16,inner trackers , side view

Fig 11. Full size GEM foil , December 2008

Fig 12. APV bonding, Januar 2009

Fig 13a-d. Photos of the APV-on-a-cable test setup for FGT (full size in attachments at the bottom), May 2009.




FGT. . . . . . . . . . S O F T W A R E
Current Software task list. Manpower and results
docs.google.com/spreadsheet/ccc
Database Access
How to access database:
- Instantiate StFgtDbMaker -> StFgtDbMaker *myStFgtDbMaker=new StFgtDbMaker();
- Then get tables -> StFgtDb * fgtTables = myStFgtDbMaker->getDbTables();
- Now you can go get whatever geometry stuff you might need from StFgtDb. For example:
- fgtTables->getPhysicalCoordinateFromGeoId(geoId, &disc, &quad, &layer, &ordinate, &lower, &upper);
- fgtTables->getGeoIdfromElecCoord(rdo, arm, apv, ch);
Electronic ID Formula:
if ( apv > 11 ) apv = apv - 2;
ElectId = channel + 128 * ( apv + 20 * (arm + 6 * ( rdo - 1) ) );
General Database Info (from Dmitry)
1. For real .daq files processing, timestamp is taken from event - it cannot be set by user. For example, if event timestamp is XYZ, then db maker will get db entries with time validity spanning from [XYZ - some_time_1] to [XYZ + some_time_2] where some_time1 is the beginTime of the db entry received, and some_time_2 is the beginTime of the next db entry with beginTime > XYZ.
2. DBV option (in chain) only freezes validity range, which means "do not consider calibrations uploaded later than DBVXXYYZZ". This allows to reproduce any past conditions. So, if you set DBV to today's date, you will get latest calibration dataset. If you set it to some past date (e.g. 2010-01-01) then you will get only those datasets which were uploaded before 2010-01-01. So, tables are read using both beginTime and entryTime..
FGT Pedestal Maker, Reader, and Plotter
See Renee's instructions how to create and upload pedestals/status attached
-----------------
I had hoped to write this tutoral once all code was in CVS and I had automated all of the loading and writing scripts. Unfortunately these conditions are only partially fullfilled at this time, so this procedure describes how to make pedestal and status files needed to load to the database:
- mkdir FgtPed
- cd FgtPed
- stardev
- cvs co StRoot/StFgtPool/StFgtRawDaqReader
- cvs co StRoot/StFgtPool/StFgtCosmicTestStandGeom
- cvs co StRoot/StFgtPool/StFgtPedMaker
- cvs co StRoot/StFgtPool/StFgtStatusMaker
- cvs co StRoot/StFgtPool/StFgtQaMakers
- cons
- cvs co StRoot/StFgtPool/StFgtQaMakers/macro/makeFgtPedAndStat.C
You will need to open makeFgtPedAndStat.C and set the database time manually (next step is to automate this). This timestamp is used to get the correct mapping:
- dbMkr->SetDateTime(20121108,000000);
- Filename.FGT-ped-DB.dat
- Filename.FGT-ped-stat-info.txt
- Filename.FGT-ped-stat.pdf
- Filename.FGT-ped-stat.ps
- Filename.FGT-ped-stat.root
- Filename.FGT-ped-stat.txt
- Filename.FGT-stat-DB.dat
- fgtMapDump.csv
- cvs co StRoot/StFgtUtil/database/macros/write_fgt_pedestal.C
- cvs co StRoot/StFgtUtil/database/macros/write_fgt_status.C
- cvs co StRoot/StFgtUtil/database/macros/fgtPedestal.h
- cvs co StRoot/StFgtUtil/database/macros/fgtStatus.h
Software for computing (making), reading (from file or DB) and plotting pedistals has been written. The DB functionality is not fully implemented as of Jan 10, 2012.
Files
The current code for reading and writing pedistals is contained in the following files
$CVSROOT/offline/StFgtDevel/StRoot/StFgtPedMaker/StFgtPedMaker.h $CVSROOT/offline/StFgtDevel/StRoot/StFgtPedMaker/StFgtPedMaker.cxx $CVSROOT/offline/StFgtDevel/StRoot/StFgtPedMaker/StFgtPedReader.h $CVSROOT/offline/StFgtDevel/StRoot/StFgtPedMaker/StFgtPedReader.cxx
An example of using the pedistal maker is in the file
$CVSROOT/offline/StFgtDevel/StRoot/StFgtPedMaker/macro/makeCosmicPeds.C
An example of using the pedistal reader is in the file
$CVSROOT/offline/StFgtDevel/StRoot/StFgtPool/StFgtPedPlotter/macro/plotPedsFromFile.C
An auxillary class to make a nice plot of pedistals is found in the files
$CVSROOT/offline/StFgtDevel/StRoot/StFgtPool/StFgtPedPlotter/StFgtPedPlotter.h $CVSROOT/offline/StFgtDevel/StRoot/StFgtPool/StFgtPedPlotter/StFgtPedPlotter.cxx
After the software review, it is expected to move these files to StRoot instead of offline/StFgtDevel/StRoot
StFgtPedMaker
The StFgtPedMaker is designed to use the FGT online containers in StEvent. The pedistals are the mean ADC value over all events processed by the chain, while the "RMS" is actually the standard deviation. Running sums are computed in the StFgtPedMaker::Make function, and the final values are computed in ::Finish member function. The values can then be written to a file, which contains four columns: (1) geoId of the strip (2) timebin (3) pedistal, i.e. mean ADC (4) RMS, i.e. st. dev.
The pedistal maker has the following user functions to modify the options:
void setToSaveToFile( const Char_t* filename ); void setToSaveToDb( Bool_t doIt = 1 ); void setTimeBinMask( Short_t mask = 0xFF );
To save to file, one uses the "setToSaveToFile" function and passes the filename to which the information should be saved. The "setToSaveToDb" function is not yet implemented. It was decided not to allow this functionality in this class, but rather have a decidated macro to upload a text file generated by this class into the DB. The time bin mask is set via the "setTimeBinMask" function. All time bins which are flagged "false" in the mask will be ignored. Note: time bin 0x01 is the 0th time bin, 0x10 is the 4th time bin, etc.
The status of the strips (e.g. dead, broken, and/or hot strips) is not considered in making the pedistals. All pedistals are computed for the time bins specified in the time bin mask. As status of the strips is given by the StFgtStatusMaker/Reader, it is expected that the code querying the StFgtPedReader for a pedistal will also query the StFgtStatusReader for a status of the strip, and then choose to act accordingly. In this manner, the status does not have to be computed before computing the pedistals, but instead should be computed before using the pedistal information.
StFgtPedReader
It was anticipated that all calls for pedistals, in all software, would use the StFgtPedReader. The StFgtPedReader initially either loads the pedistals from file, or from the database, and holds them in an associative array, allowing both sparse data and for fast look ups. In future versions, one could change the implimentation to a static array, if one desired faster processing but a larger memory imprint. The code has the following accessor function, to read the time bine for a given geoId and time bin:
// accessor: input is geoId and timebin, output is ped and // st. dev. (err). Returns error if pedistal not found for given geoId and timebin Int_t getPed( Int_t geoId, Int_t timebin, Float_t& ped, Float_t& err ) const;
One can also set a time bin mask via
void setTimeBinMask( Short_t mask = 0xFF );
Time bins with bits set to false will be ignored. The fewer time bins loaded, the faster the initial load and the faster the look up time for each individual geoId afterwards.
The DB interface still needs to be programmed as of Jan 10, 2012.
StFgtPedPlotter
This produces a nice plot of the pedistals for a given quadrant (10 APVs). The procedure is straight forward. See the macro and the code for an example of how this is done. Note: the ped. plotter gives an example of how to use the ped. reader.
Comments
Usually 2,000 are used to compute pedistals. The amount of time taken by the StFgtPedReader/Maker is significantly less than the amount of time used by the RawMaker to create the FGT containers in the StEvent and read the DAQ file from disk, and therefore can be considered negligible for the present.
An example pedistal file is attached. This file is from the cosmic test stand, when quadrants 008, 018, 007 were on the top, middle, and bottom possition, respectively. Plots of typical pedistal RMS can be found on page 1 of the QA plots produced during the cosmic test stand. The base directory is http://www.star.bnl.gov/protected/spin/sgliske/fgtCosmicQA/, from which you can then select a quadrant, and then select a .pdf file. The files are named via the quandrant and the time the data was taken.
FGT Simulation
Random notes from email exchanges:
A bfc that produces muDsts from simulation files looks like this
root4star -b bfc.C'(10,"MakeEvent,ITTF,NoSsdIt,NoSvtIt,Idst,VFPPVnoCTB,logger,-EventQA,-dstout,tags,Tree,EvOut,analysis,dEdxY2,IdTruth,useInTracker,-hitfilt,tpcDB,TpcHitMover,TpxClu,McAna,fzin,y2012,tpcrs,geant,geantout,beamLine,eemcDb,McEvOut,bigbig,emcY2,EEfs,bbcSim,ctf,-CMuDST,sdt20120501.060500","pp200_QCDprodMBc.fzd")' -q > & Log1
There is an fzd file in avossen/tmp/4jason/
The code is available at
StRoot/StFgtSimulator/
and should also be available as
The bfc to run it is in StRoot/StFgtSimulator/macros/bfc.C
You can run it from the StFgtDevel dir with the following
command line:
%root4star -b
StRoot/StFgtSimulator/macros/bfc.C'(10,"MakeEvent,ITTF,NoSsdIt,NoSvtIt,Idst,VFPPVnoCTB,\
logger,-EventQA,-dstout,tags,Tree,EvOut,analysis,dEdxY2,\
IdTruth,useInTracker,-hitfilt,tpcDB,TpcHitMover,TpxClu,\
McAna,fzin,y2012,tpcrs,geant,geantout,beamLine,eemcDb,\
McEvOut,bigbig,emcY2,EEfs,bbcSim,ctf,-CMuDST","pp200_QCDprodMBc.fzd")'
Legend for Status in DB
Strip Status
Status bits are failure states, i.e. status of 0 is good, anything else is bad. Strip status bits are defined as
- bit 1: pedestal out of range (current range is 100-1200 ADC)
- bit 2: RMS out of range (current range is 10-80 ADC)
- bit 3: Fraction of integral near pedestal value (i.e +/- 1 RMS of the pedestal) out of range (current range is 0.6 to 0.95)
- bit 4: not used
- bit 5: APV chip bad (threshold is currently 64 dead strips)
- bit 6: strip not connected
Note, for bit 5, all strips are set to have this bit fail if more than the threshold number of strips on this APV failed the tests corresponding to bits 1-3.
Mapping for Run13
See
drupal.star.bnl.gov/STAR/event/2012/12/07/fgt-weekly-meeting-0/fgt-run13-daq-cable-mapping
Offline Software
Getting started with plots for the FGT
(some old documentation on how to read MuDSTs: drupal.star.bnl.gov/STAR/blog/avossen/2012/apr/26/how-read-mudsts)
Prepare your libraries
If you're brand new or starting fresh directory for FGT, you'll need to check out some files... This is a list of all the offline FGT software you're likely to need for whatever it is you're working on...
> mkdir mydir
> cd mydir
> cvs co StRoot/RTS
> cvs co StRoot/St_base
> cvs co StRoot/StEvent
> cvs co StRoot/StFgtA2CMaker
> cvs co StRoot/StFgtClusterMaker
> cvs co StRoot/StFgtDbMaker
> cvs co StRoot/StFgtPool
> cvs co StRoot/StFgtRawMaker
> cvs co offline/StFgtDevel/StRoot/StMuDSTMaker
> ln -s offline/StFgtDevel/StRoot/StFgtMuDSTMaker/ StRoot/StFgtMuDSTMaker
The last step is necessary since StFgtMuDSTMaker is not yet in devel.
Make sure you are in the proper STAR version (you want "development") and compile...
> starver dev
> cons
Pick your data
After your libraries installed correctly, pick a daq file for your FGT studies... (If you're using MuDST files this will be different..)
> ls /star/data03/daq/2012/xxx/13xxxyyy
where 13xxxyyy is the run number you want. (If the run number you want isn't there, restore the daq files yourself or ask somebody to do it.)
Before running over data, make sure to run klog to ensure you get a token to communicate with the database..
> klog
>For MuDSTFiles the corresponding #define directive in StFgtPool/StFgtClusterTools/StFgtGeneralBase.h has to be set.
Run over the data
To fill all the plots you want, you'll need to run this command (when sitting in mydir)...
> cd mydir
> root4star -b -q StRoot/StFgtPool/StFgtClusterTools/macros/agvEffs.C'("/star/data03/daq/2012/131/13173068p_rf/st_physics_13173068_raw_202001.root",10,10000,2)' > & output.txt
The above command will attempt to run over 10,000 events from the example daq file, using disc 2 as the disc that is removed for efficiency calculations. Piping the output to file is necessary in order to cut down on running time. On average, 10,000 events takes ~45 minutes as long as you use an output file.
Look at the plots
The agvEffs.C macro will output some .root files...
-clusterEff.root
-clusterPics.root contains visual "pictures" of the first 1000 clusters found in the daq file.
-pulses.root counts pulses in the electronics etc
-signalShapes.root contains a whole heck of a lot of plots... To see exactly all that is put into signalShapes.root, take a look at StFgtClusterTools/StFgtGenAVEMaker.cxx
There are some friendly macros to help you pull out the plots you want in an organized way. Run these guys to output a whole ton of .png files. A few examples are...
> root4star -b -q StRoot/StFgtPool/StFgtClusterTools/macros/saveSignalChar.C'("signalShapes.root")' //this will output histograms per quadrant
> root4star -b -q StRoot/StFgtPool/StFgtClusterTools/macros/saveSignalCharAPV.C'("signalShapes.root")' //this will output histograms per APV
> root4star -b -q StRoot/StFgtPool/StFgtClusterTools/macros/saveClusterSizes.C'("signalShapes.root")' //this will output cluster size histograms per quadrant
For now it's been most convenient to just dump the .png files into your protected directory but hopefully something a little more elegant is on its way very soon...
Streamlining the process
Right now we have a shell script that pulls daq files name from a list and then runs over them one after the other, dumping the output .root files into a directory. Look around for things like "runChain.sh" and "l13173068.list" if you want to have a go at that.
> ./runChain.sh > & output.txt
Coming soon: pre-written xml job for STAR scheduler.
Available data sets
Most recent runs are located in http://www.star.bnl.gov/protected/spin/ezarndt/fgt/
Coming soon: plots better organized into a scroll-friendly format.
Online Software
The online software uses the 'JPlot' framework:
> cvs co OnlTools/Jevp
> cvs co OnlTools/PDFUtil
> cvs co StRoot/RTS
> cvs co StRoot/StDaqLib
>cvs co StRoot/StEvent
The framework currently only compiles correctly with the 'pro' library version:
> starver pro
> cons
To run do:
> OnlTools/Jevp/launch fgtBuilder -file filename -pdf outputfilename.pdf
Jevp instructions can be found in
OnlTools/Jevp/readme.txt
The fgt specific code is in OnlTools/Jevp/StJevpBuilders/fgtBuilder.{h,cxx}
Test Stand
FGTEventDisplay Overview and Instructions
At the moment FGTEventDisplay incorporates much of the code that we've been using to generate plots, and allows the viewing of individual events. It's certainly not perfect (and it will likely be replaced at some point in the near future), but since it contains this functionality, I thought I might give a brief overview of what it can currently do and how to use it.
Here's what it can do:
* Calculate and display pedestals
Currently, pedestals are calculated from the first 1000 events in a file. These pedestals are only calculated the first time a daq file is viewed using the FGTEventDisplay, when the APV range is changed, and when you force the pedestals to be recalculated. Otherwise, it saves the pedestals to a file in the FGTEventDisplay directory.
When the pedestals are displayed, they are displayed as ADC response per channel. Three graphs are shown with error bars, at 1, 2 and 3 sigmas. Many of the algorithms in the code use the three sigma cutoff when accepting an ADC response for use.
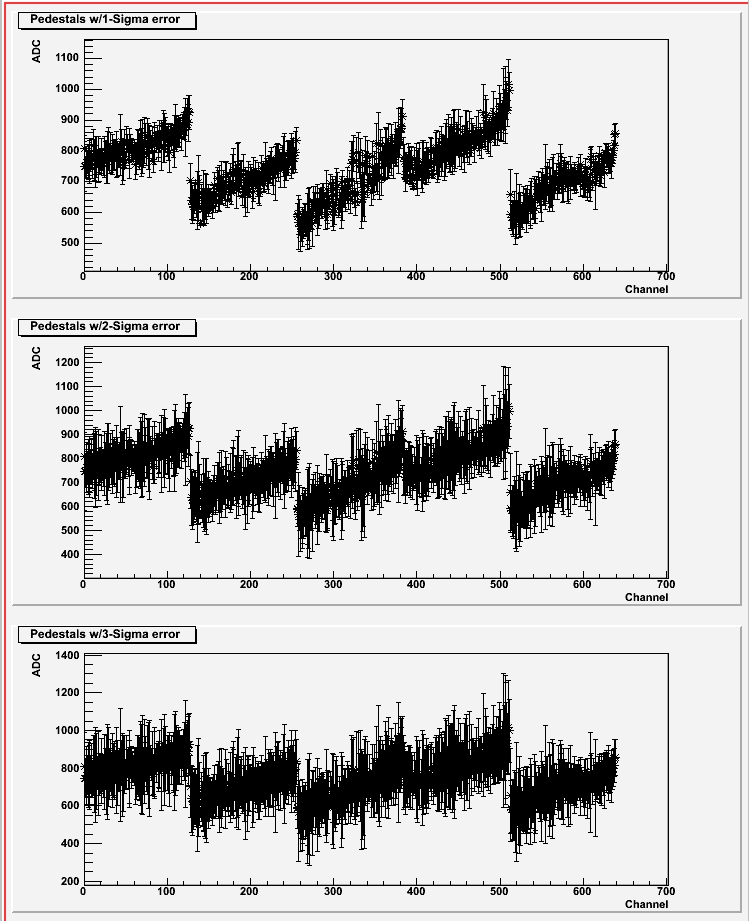
Figure 1: Example pedestal plot
* Generate Radio Hits graphs
The code can generate and save radio hits plots, similar to those that I have been posting to track down the APV mapping problem. The graphs that are generated are just raw 2-D histograms that are then saved to root files. The processing done to improve the appearance of those graphs as well as applying the device boundaries are actually done by a utility macro included with FGTEventDisplay. This macro is called Display.C and is in the same directory as FGTEventDisplay.
Note that all 7 time bins are accumulated by this code separately, and all 7 time bins are saved as separate histograms to the root file.
There are two types of radio hits graphs that are generated. The first plots only the maximum hits. The algorithm finds the maximum value for each event that is above the pedestal 3*sigma and then fills that location in the histogram/radio plot. The second algorithm finds all values that exceed 3*sigma above pedestal and then fills those locations in the histogram/radio plot. These two types of graphs are saved in separate root files.
Figure 2: Example max hits plot
Figure 3: Example all r/phi matches plot
* Generate ADC Response graphs
This code generates and saves per-phi, per-r, and per-channel ADC response plots. Once again, these are just 2-D histograms that are then saved to a root file, and processing to improve the appearance of these plots was done in Display.C. The algorithm selects all ADC responses greater than 3-sigma over pedestal for each event. The channel number in this case is the APV number (offset so that all APV ranges start at 0) times 128 plus the actual channel number. Phi and R values are determined based on the mapping that is included with the FGTEventDisplay (this is located in fgt_mapping.txt). Once again, note that all 7 time bins are accumulated by this code separately, and all 7 time bins are saved as separate histograms to the root file.
Figure 4: Example ADC response vs channel plot
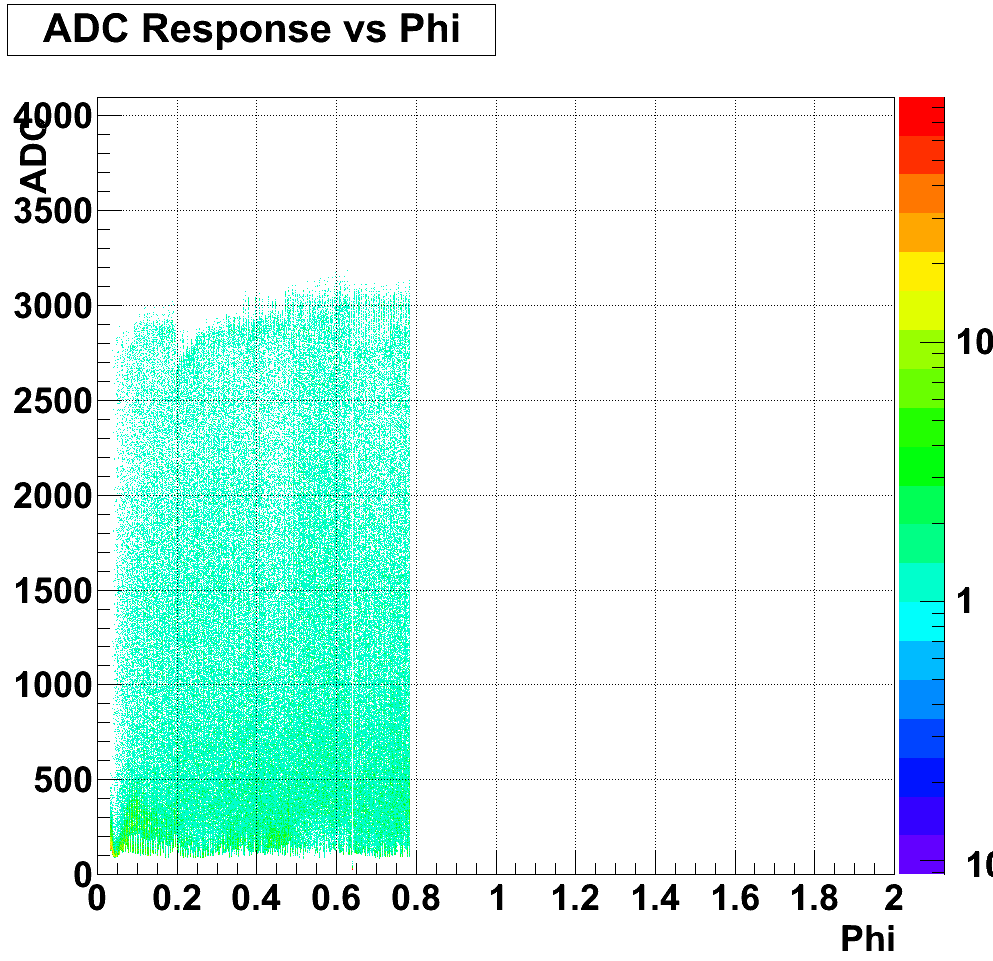
Figure 5: Example ADC response vs phi plot
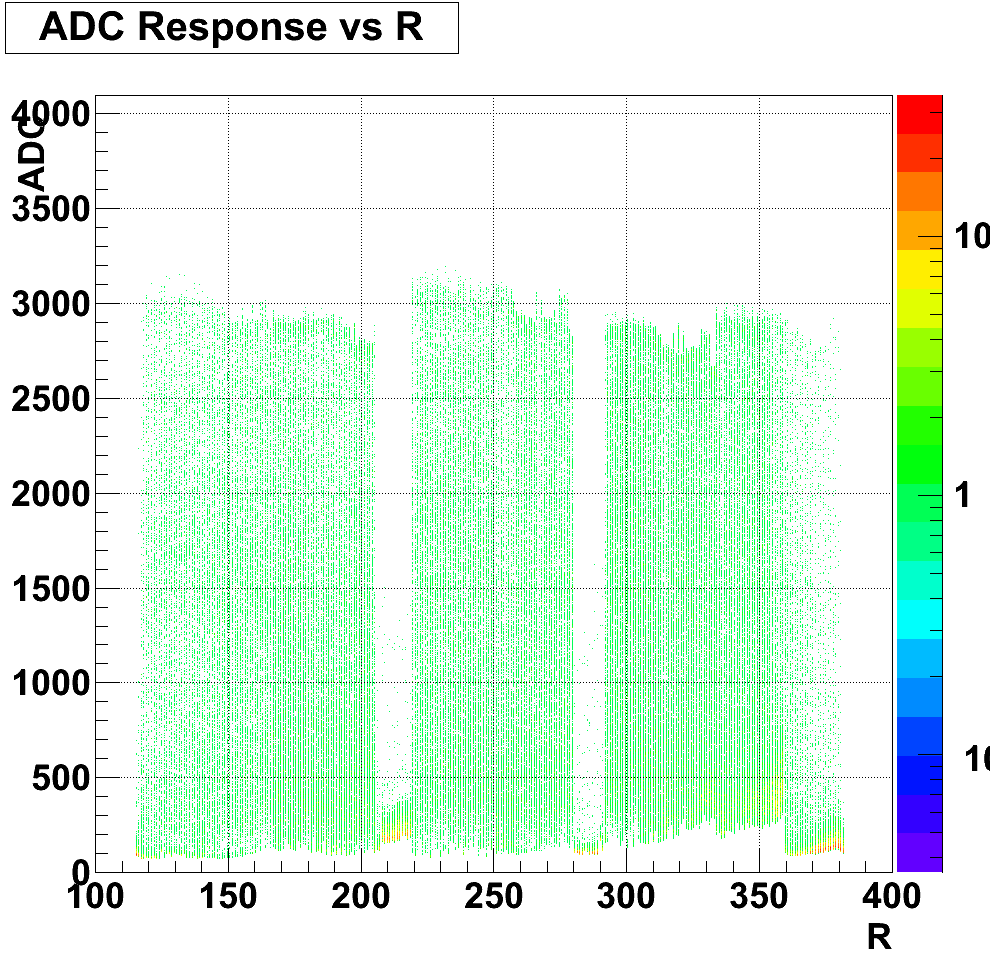
Figure 6: Example ADC response vs r plot
* Generate Raw ADC Response graphs
This code generates and saves per-phi, per-r, and per-channel ADC response plots, very similar to the above, but it does not apply pedestal subtraction or thresholds. The channel number is still the APV number (offset so that all APV ranges start at 0) times 128 plus the actual channel number. Phi and R values are determined based on the mapping that is included with the FGTEventDisplay (this is located in fgt_mapping.txt). Once again, note that all 7 time bins are accumulated by this code separately, and all 7 time bins are saved as separate histograms to the root file.
Figure 7: Example raw ADC response vs channel plot
Figure 8: Example raw ADC response vs phi plot
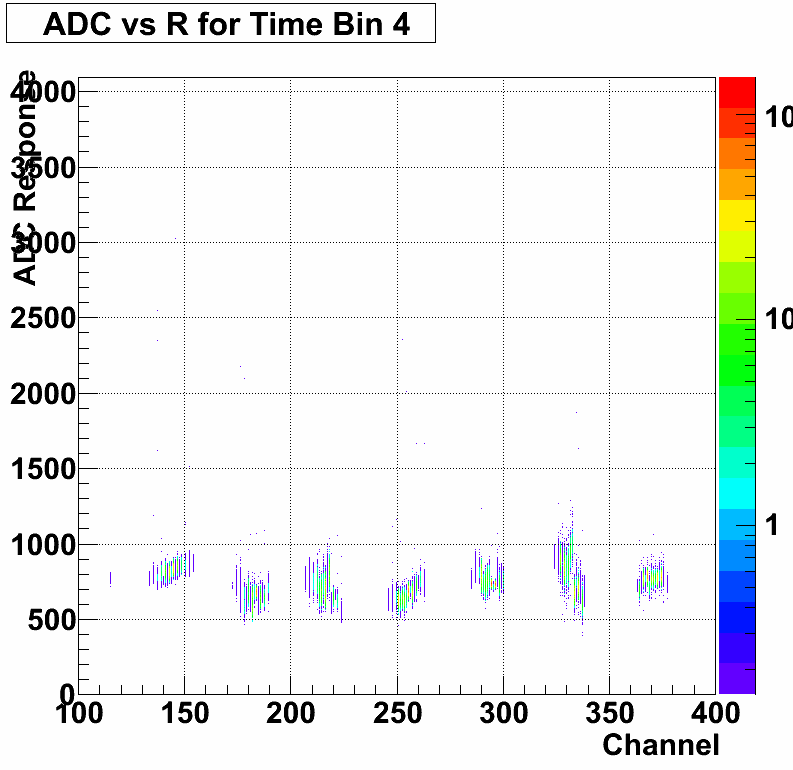
Figure 9: Example raw ADC response vs r plot
* Display individual events
FGTEventDisplay allows you to iterate both forward and (slowly) backwards through individual events in a daq file, as well as jump (slowly) to individual events. For each event, at least three graphs are shown, possibly four. The three that are always shown are ADC response versus R, ADC response versus Phi, and ADC response versus channel (using the same channel calculation method and mapping as described earlier).
The fourth graph will only display if the values for the current event are found that exceed 3*sigma over pedestal. It shows all possible hit locations in R and Phi for these values. Currently this is not a radio plot, but this may change in the future for clarity.
The time bin selected for display here is always the fourth time bin.
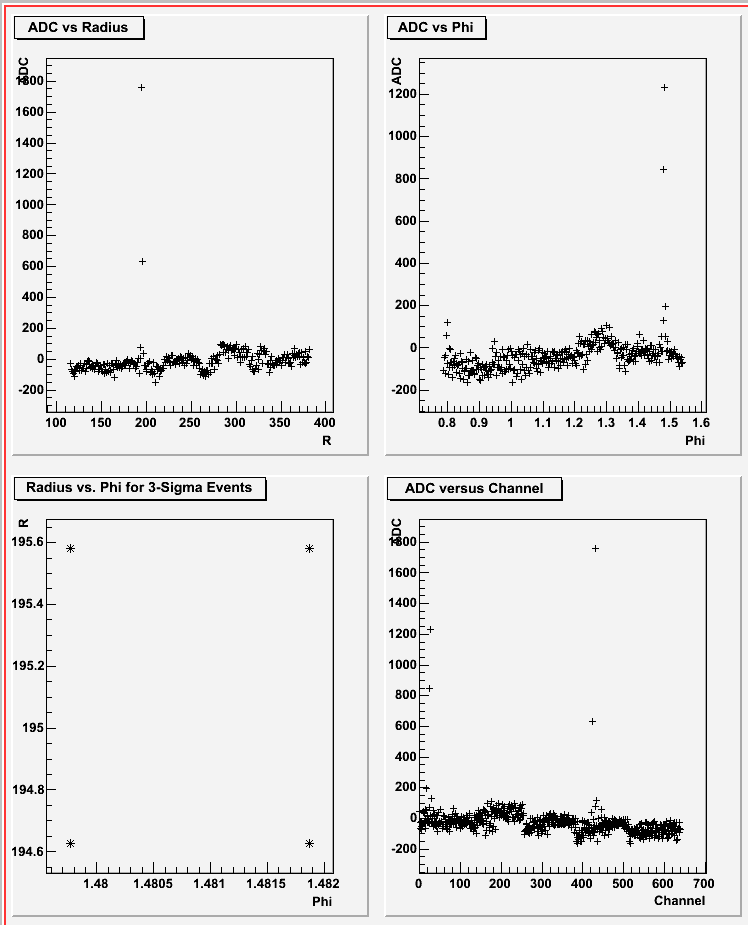
Figure 10: Example default event display plot
Anselm's clustering code is currently in a developmental version of FGTEventDisplay. We are working on incorporating a correction for common mode noise, relative R/Phi gains, and gain matching into this clustering code.
Here are instructions for downloading, compiling, and using FGTEventDisplay:
To download:
FGTEventDisplay is currently stored in a googlecode SVN repository. In order to use this repository, you have to set up your svn proxy properly so that you can contact the googlecode.com (this has already been done on fgt-ops). Probably the easiest way to do this is to attempt to download the code first by issuing the command:
svn co https://fgt-daq-reader.googlecode.com/svn/trunk/FGTEventDisplay FGTEventDisplay
This will almost certainly fail, but it should create the file ~/.subversion/servers. You will need to edit that file and by adding the following two lines to the end of the file:
http-proxy-host=proxy.sec.bnl.local
http-proxy-port=3128
Once that is done, try issuing the command again. This time it should work (let me know if it doesn't), and it should create a directory FGTEventDisplay containing all the program files. From then on you can just update that working copy to get updates by issuing the command
svn update
in the FGTEventDisplay directory. This should automatically merge changes into your files, without clobbering your own changes, although if there are conflicts you may have trouble.
If you want or need access to this repository, please send e-mail to Dr. Fatemi and let her know. At that point she'll probably ask me to add you, and I'll try and remember how to do that.
To compile:
Go into your FGTEventDisplay directory and issue the command:
make
Compilation stuff should happen, and you should be left with an FGTEventDisplay executable.
Please note that you should NOT use Rts_Example.sh to compile. I can't guarantee that it will work, and it is included in the repository only for historical reasons (because, historically, we've been too lazy to remove it).
To run:
Go into your FGTEventDisplay directory (this is IMPORTANT. . . the code will not run from another directory) and issue the command:
./FGTEventDisplay <location of DAQ file>
Replacing <location of DAQ file> with the actual path to a DAQ file.
This will start the program. The code will either automatically generate or load pedestals, depending on whether or not they have already been calculated by some previous run.
Then the program will show the main text menu. The menu lists most of your options, and most of them should be pretty straight forward.
However, there are a few things that should be mentioned. First, by default, the code will assume that you are using the APV range 17 through 21. If you are using a different range, you need to set that difference in the program options, and currently the software only supports ranges 17 through 21 and 12 through 16. To get to options, just type "o" at the main menu. Once there, type "a" to change the APV range. then press "q" to return to the main menu. Doing this will now AUTOMATICALLY force pedestal recalculation, so at this point you should be able to use the code normally.
Also, in options you can tell the program to display bar graphs when displaying events (instead of scatter plots), and change the marker style in the scatter plots. These ONLY effect the event display.
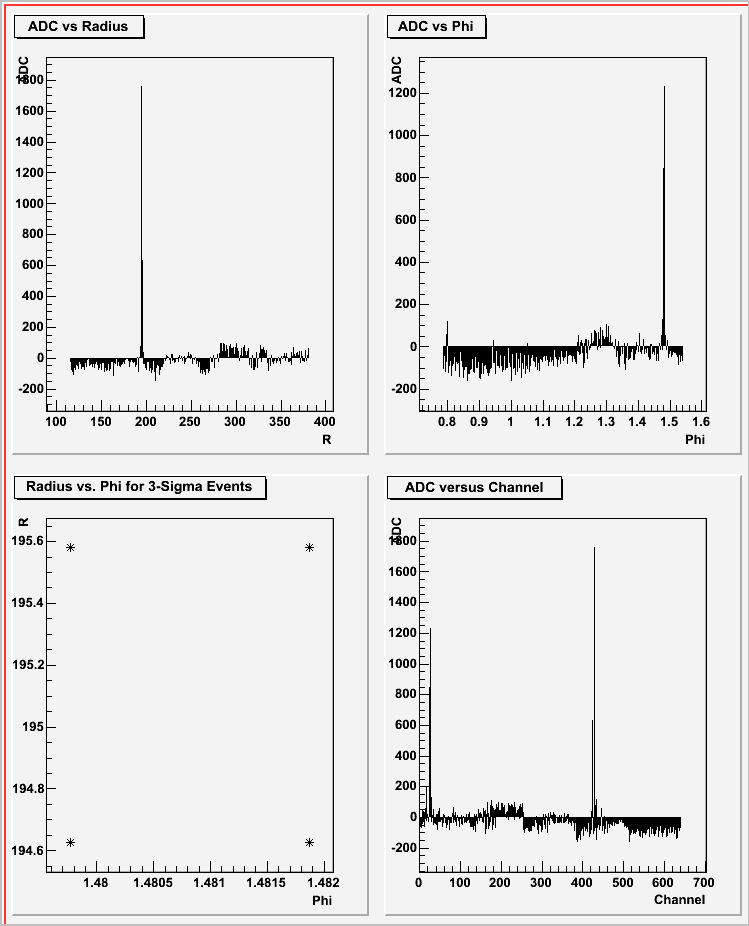
Figure 11: Example default event display with bars
The event display plots do not currently allow any user interaction. This is unfortunate, and I'm planning on fixing it in the future, but right now nearly all x-windows events are ignored by that window, so resizing and clicking and even moving it off screen (for some window managers) will not work as expected.
The daq reader does not have a mechanism for iterating backwards, or a mechanism for jumping to an arbitrary event. As such, iterating backwards (using "h" or "k") may be very, very slow, as the program has to iterate forwards from the beginning of the daq file to the previous event. Similarly, though I have tried to make it as efficient as possible, jumping to an event may be very slow (although, jumping to an event *forward* of your current position in the file will start from your current position, so it should be more efficient).
When jumping to an event directly, you should use the event number that is displayed by the program in the main menu as you are iterating through the daq file. That event number should appear right above the command prompt.
Finally, many of the plots above are colorful and contoured. These are not the raw images that the FGTEventDisplay will produce. With the exception of the individual event display and the pedestal display, FGTEventDisplay will produce root files containing histograms. Generating the plot for these histograms must be done separately. A macro, Display.C, is included with FGTEventDisplay that can be used to generate these nice, colorful plots, however it currently requires modification to function with every possible root file and contained histogram.
Organization
FGT. . . . . . . . . . V A R I A
- Frank's Web page at MIT
-
Dave's Web page Argonne
- ccc
TPC resistor chain at phi=106 deg
Here is what we know about TPC resistor chain in IFC positioned at 106 deg in phi.
- the foil covering resistors is made of the Al plus Kapton is 0.09 percent of a radiation length thick for a straight through track.
- material is used for to round cylinders supporting that foil is made of 1" pipe made from G10, wall thickness ~ 1mm
- Foils structure is described on TPC page we are using one capton foil with Al stripes
http://www.star.bnl.gov/public/tpc/tpc.html - resistors: between stripes we put 2MoM resistor, consisting of 2 with 1 MoM nominal- see picture in attachment.
i don't know a power, but it is 4 mm diameter and 13 mm ceramic body.
there are 360 ONE MoM resistors on each side of TPC We have 182 stripes to define uniform field and between each pair of stripes we put 2 MoM
As seen from the East toward West:

BAD drawing:

Good drawing:


As seen from the West toward East:

FGT. . . . . . . . . . x -T R A S H (node for recycling)
Any child pages belonging here is a trash.
Note only the owner can recycle them by attaching to a new mother-page and changing the title,URL, and content.
Jan
fgt-subpage-test-Renee
this is my link to my previous blog
my trash1- jan
this age can be used for some testes
trash1
Bhla Bhla
Deleted Documents
Deleted documents.
FPD & FMS & FPS
The STAR Forward Pion Detector (FPD) and Forward Meson Spectrometer(FMS)
[Test using 'oleg'] account - PLEASE REMOVE LATER]
Database
Now the FPD/FMS data base tables have been created including geometry, mapping and calibration tables. These pages describe the data structure and how to use the FPD/FMS database. Please note the online database browser is a nice tool to get intuitive informaton of the tables stored. StFmsDbMaker, which acts as the interface between end user makers and the database is developed and described in more details in the corresponding subsection.
Geometry & Mapping
The following FMS database tables are defined for geometry and mapping.
-
Channel geometry
$STAR/StDb/idl/fmsChannelGeometry.idl
/* fmsGeometry.idl
*
* Table: fmsGeometry
*
* description: // FPD & FMS & FHC detector geometry
*/
/* Detector Name detectorId ew ns type nX nY */
/* FPD-North 0 0 0 0 7 7 */
/* FPD-South 1 0 1 0 7 7 */
/* FPD-North-Pres 2 0 0 1 7 1 */
/* FPD-South-Pres 3 0 1 1 7 1 */
/* FPD-North-SMDV 4 0 0 2 48 1 */
/* FPD-South-SMDV 5 0 1 2 48 1 */
/* FPD-North-SMDH 6 0 0 3 1 48 */
/* FPD-South-SMDH 7 0 1 3 1 48 */
/* FMS-North-Large 8 1 0 4 17 34 */
/* FMS-South-Large 9 1 1 4 17 34 */
/* FMS-North-Small 10 1 0 4 12 24 */
/* FMS-South-Small 11 1 1 4 12 24 */
/* FHC-North 12 1 0 5 9 12 */
/* FHC-South 13 1 1 5 9 12 */
struct fmsChannelGeometry {
octet detectorId; /* detector Id */
octet type; /* 0=SmallCell,1=Preshower,2=SMD-V,3=SMD-H,4=LargeCell,5=HadronCal */
octet ew; /* 0=east, 1=west */
octet ns; /* 0=north, 1=south */
octet nX; /* # of columns, max_channel is nX*nY */
octet nY; /* # of rows, max_channel is nX*nY */
};
-
Detector position
$STAR/StDb/idl/fmsDetectorPosition.idl
/* fmsPosition.idl
*
* Table: fmsPosition
*
* description: // FPD & FMS & FHC detector width and positions
*/
struct fmsDetectorPosition {
octet detectorId; /* detector Id */
float xwidth; /* x width */
float ywidth; /* y width */
float xoffset; /* xoffset from beam line to inner edge of detector */
float yoffset; /* yoffset from beam line to center of detector */
float zoffset; /* z position where we measure x,y */
};
-
Detector map
$STAR/StDb/idl/fmsMap.idl
/* fmsMap.idl
*
* Table: fmsMap
*
* description: // FMS & FPD detector map
*/
struct fmsMap {
octet detectorId; /* DetectorId */
unsigned short ch; /* Ch 1-578*/
octet qtCrate; /* QT crate# 1-4 & 7 */
octet qtSlot; /* QT slot# 1-16 */
octet qtChannel; /* QT channel# 0-31 */
};
-
PatchPanel to detector map
$STAR/StDb/idl/fmsPatchPannelMap.idl
/* fmsPatchPanelMap.idl
*
* Table: fmsPatchPanelMap
*
* description: // FMS detector to patch panel map
*/
/* module 1=North Large, 2=South Large, 3=North Small ,4=South Small => moduleIDs */
struct fmsPatchPanelMap {
/* channel# 1-548 for L and 1-288 for S*/
octet ppPanel[548]; /* panel# 1-2 */
octet ppRow[548]; /* row# 1-20 */
octet ppColumn[548]; /* column# 1-16 */
};
-
PatchPanel to QT map
$STAR/StDb/idl/fmsQTMap.idl
/* fmsQTMap.idl
*
* Table: fmsQTMap
*
* description: // FMS patch panel to QT map
*/
/* north=1/south=2 => sideIDs */
struct fmsQTMap {
/* panel# 1-2 */
/* row# 1-20 */
/* column# 1-16 */
octet qtCrate[2][20][16]; /* QT crate# 1-4 */
octet qtSlot[2][20][16]; /* QT slot# 1-16 */
octet qtChannel[2][20][16]; /* QT channel# 0-31 */
};
R/W DB
Below is mostly copied from Akio's page on how to read/write DB tables in a macro.
FMS DB example
• Simple "how to Creating Offline DB Tables" from Dmitry
o Anyone in STAR should be able to read DB from RCAS machines
o To write to DB, you need write permission to DB. Currently only Akio and Dmitry can write. Dmitry can add people as needed.
o Only Dmitry can delete, or mark as de-activated DB entries.
o For reading DB : unsetenv DB_ACCESS_MODE or setenv DB_ACCESS_MODE read
o For writing DB : setenv DB_ACCESS_MODE write, and do not forget to unsetenv DB_ACCESS_MODE when done.
• STAR DB Broswer : Calibration DB , Geometry DB
• Look into other DB table definisions in $STAR/StDb/idl/*.idl
o Up to 3 dimensional array is supported
o Plus using one queue, DB can return array (ModuleID) of this table
o Thus 4 dimensional array (3 dim array in table + 1 module ID) used in fmsQTMap.idl (see below).
o Array is fixed length, but module ID can be variable length.
o For DB efficiencies, using big array block/blab is disfavored, and use small tables & moduleID is recomended.
• Edit Computing/Subsystem drupal page for documentation!
• To read/write into DB using macros
copy ~akio/dbServers.xml ~/
unsetenv DB_SERVER_LOCAL_CONFIG
• For usual DB access through BFC/St_db_Maker
setenv DB_SERVER_LOCAL_CONFIG /afs/rhic.bnl.gov/star/packages/conf/dbLoadBalancerLocalConfig_BNL.xml
• Proposed tables and codes to read from and write into the database (examples are located at ~jgma/psudisk/fms/)
o fmsPatchPanelMap.idl for FMS detector to patchpanel map
Input file : qtmap2pp.txt
Example root macro : fms_db_patchpanelmap.C
** To read input file and write to DB
root4star -q -b fms_db_patchpanelmap.C'("readtext writedb")'
** To read DB and write to text file
root4star -q -b fms_db_patchpanelmap.C'("readdb writetext")'
diff qtmap2pp.txt qtmap2pp.txt_dbout
o fmsQTMap.idl for FMS patchpanel to QT map
Input file for run8 : qtmap_run8.txt
Input file for run9 : qtmap2009V1.txt
Example root macro : fms_db_qtmap.C
** To read input file and write to DB for run8 (replace 2nd argument = 8 with 9 for run9)
root4star -q -b fms_db_qtmap.C'("readtext writedb",8)'
** To read DB and write to text file for run8
root4star -q -b fms_db_qtmap.C'("readdb writetext",8)'
diff qtmap_run8.txt qtmap_run8.txt_dbout
o fmsQTMap.idl for FPD,FMS,FHC detector to QT map
For FMS, combine 2 DB tables (fmsPatchPanel & fmsQTMap) to create this table
Root macro for FMS: fms_db_pp_qt_merge.C
** To read 2 maps from DB (fmsPatchPanel & fmsQTMap) and write fmsMap to DB for run8 (replace 2nd argument = 8 with 9 for run9)
root4star -q -b fms_db_pp_qt_merge.C'("merge writedb",8)'
** To read fmsMap DB and write to text file for run8
root4star -q -b fms_db_pp_qt_merge.C'("readdb writetext",8)'
more fms_db_pp_qt_merge.txt
Root macro For FPD : fpd_db_map.C
o fmsChannelGeometry.idl for FPD,FMS,FHC detector basic numbers (id, type, Easr/West and North/south, # of row/column)
Root macro : fms_db_ChannelGeometry.C
o fmsDetectorPosition.idl for FPD,FMS,FHC detector position in STAR frame
Root macro : fms_db_detectorposition.C
o fmsGain.idl/fmsGainCorrection.idl for FPD,FMS,FHC gain(detectorId, channel number, gain/gaincorr)
Root macro : fms_db_fmsgain.C/fms_db_fmsgaincorr.C (they work in a similar way) ** To read input gain file and write gain information to DB for run8 pp200 (the macro takes combined option of run8/run9 and dAu200/pp200)
root4star -q -b fms_db_pp_fmsgain.C'("readtext writedb", "run8 pp200")'
** To read fmsGain DB and write to text file for run8 pp200
root4star -q -b fms_db_fmsgain.C'("readdb writetext", "run8 pp200")'
StFmsDbMaker
StFmsDbMaker is the interface between the STAR FMS database and user makers. It provides access methods to all FPD/FMS related data in the STAR database such as mapping and calibration. (currently only at /star/u/jgma/psudisk/fms/StRoot/StFmsDbMaker) Small chain to test : root4star -q -b /star/u/jgma/psudisk/fms/mudst.C. The following is a list of functions provided by StFmsDbMaker. Please refer to the source code under CVS for details (will be checked in to CVS after peer review.).
List of functions
//! getting the whole table
fmsDetectorPosition_st* DetectorPosition();
fmsChannelGeometry_st* ChannelGeometry();
fmsMap_st* Map();
fmsPatchPanelMap_st* PatchPanelMap();
fmsQTMap_st* QTMap();
fmsGain_st* Gain();
fmsGainCorrection_st* GainCorrection();
//! utility functions related to FMS geometry and calibration
Int_t maxDetectorId(); //! maximum value of detector Id
Int_t detectorId(Int_t ew, Int_t ns, Int_t type); //! convert to detector Id
Int_t eastWest(Int_t detectorId); //! east or west to the STAR IP
Int_t northSouth(Int_t detectorId); //! north or south side
Int_t type(Int_t detectorId); //! type of the detector
Int_t nRow(Int_t detectorId); //! number of rows
Int_t nColumn(Int_t detectorId); //! number of column
Int_t maxChannel(Int_t detectorId); //! maximum number of channels
Int_t getRow(Int_t detectorId, Int_t ch); //! get the row number for the channel
Int_t getColumn(Int_t detectorId, Int_t ch); //! get the column number for the channel
Int_t getChannel(Int_t detectorId, Int_t row, Int_t column); //! get the channel number
StThreeVectorF detectorOffset(Int_t detectorId); //! get the offset of the detector
Float_t getXWidth(Int_t detectorId); //! get the X width of the cell
Float_t getYWidth(Int_t detectorId); //! get the Y width of the cell
Float_t getGain(Int_t detectorId, Int_t ch); //! get the gain for the channel
Float_t getGainCorrection(Int_t detectorId, Int_t ch); //! get the gain correction for the channel
StThreeVectorF getStarXYZ(Int_t detectorId,Float_t FmsX, Float_t FmsY); //! get the STAR frame coordinates
Float_t getPhi(Int_t detectorId,Float_t FmsX, Float_t FmsY); //! get the STAR frame phi angle
Float_t getEta(Int_t detectorId,Float_t FmsX, Float_t FmsY, Float_t Vertex); //! get the STAR frame pseudo rapidity
//! fmsMap related
Int_t maxMap();
void getMap(Int_t detectorId, Int_t ch, Int_t* qtCrate, Int_t* qtSlot, Int_t* qtChannel);
//! fmsPatchPanelMap related
Int_t maxModule();
//! fmsQTMap related
Int_t maxNS();
//! fmsGain/GainCorrection related
Int_t maxGain();
Int_t maxGainCorrection();
//! set time stamp
//void setDateTime(Int_t date, Int_t time);
//! text dump for debugging
void dumpFmsChannelGeometry(Char_t* filename="dumpFmsChannelGeometry.txt");
void dumpFmsDetectorPosition(Char_t* filename="dumpFmsDetectorPosition.txt");
void dumpFmsMap (Char_t* filename="dumpFmsMap.txt");
void dumpFmsPatchPanelMap (Char_t* filename="dumpFmsPatchPanelMap.txt");
void dumpFmsQTMap (Char_t* filename="dumpFmsQTMap.txt");
void dumpFmsGain (Char_t* filename="dumpFmsGain.txt");
void dumpFmsGainCorrection (Char_t* filename="dumpFmsGainCorrection.txt");
How to use it in user maker
#include "StFmsDbMaker/StFmsDbMaker.h"Then use the global pointer to get access to all the FMS db table information by the methods above. For example to dump one table to a text file:
gStFmsDbMaker->dumpFmsChannelGeometry("ttest.txt");To get a pointer to the channel geometry table:
fmsChannelGeometry_st *channelgeometry = gStFmsDbMaker->ChannelGeometry();In your macro you'll need to load the .so files and create maker instances in the chain:
gSystem->Load("StDbBroker.so");
gSystem->Load("St_db_Maker.so");
gSystem->Load("StFmsDbMaker.so");
cout << "Setting up chain" << endl;
StChain* chain = new StChain;
cout << "Setting up St_db_Maker" << endl;
St_db_Maker* dbMaker = new St_db_Maker("db", "MySQL:StarDb", "$STAR/StarDb");
dbMaker->SetDEBUG();
dbMaker->SetDateTime(20090601, 0);
cout << "Setting up StFmsDbMaker" << endl;
StFmsDbMaker* fmsdb = new StFmsDbMaker("fmsdbmaker");
fmsdb->setDebug(1);
//Then your makers...
Please pay attention to the SetDateTime option, it sets the timestamp so the data extracted from the db will be corresponding to this time stamp. Please refer to Dmitry's page for more information about time stamp.
Timedep corrction for run 11 and tower masking
Since tower masking is done with the same inputs in database by setting time dep. correction values negative for bad towers, 1) how towers are masked 1) how time dep. correction files are written, 3) how they are loaded in datbase, and 4) how the information can be fetched from database are explained below .
- How towers are maseked
The xml file(Sub_L.xml) take run by run jobs and list towers for each run.
Channels are populated in different ADC & energy thresholds :
/star/data01/pwg/mriganka/fms2015/jetData2011/new/hotCh/StRoot/StFmsHitMaker/StFmsHitMaker.cxx
SET-1
h0->Fill(((d-8)*1000)+c);
hh0->Fill(((d-8)*1000)+c,adc);
SET-2
if(adc>10){
h10->Fill(((d-8)*1000)+c);
hh10->Fill(((d-8)*1000)+c,adc);
}
SET-3
if(adc>50){
h50->Fill(((d-8)*1000)+c);
hh50->Fill(((d-8)*1000)+c,adc);
}
SET-4
if(adc>100){
h100->Fill(((d-8)*1000)+c);
hh100->Fill(((d-8)*1000)+c,adc);
}
SET-5
he0->Fill(((d-8)*1000)+c);
hhe0->Fill(((d-8)*1000)+c,e);
SET-6
if(e>1){
he1->Fill(((d-8)*1000)+c);
hhe1->Fill(((d-8)*1000)+c,e);
}
SET-7
if(e>10){
he10->Fill(((d-8)*1000)+c);
hhe10->Fill(((d-8)*1000)+c,e);
}
SET-8
if(e>20){
he20->Fill(((d-8)*1000)+c);
hhe20->Fill(((d-8)*1000)+c,e);
}
For each SET 4 top bincontent towers are being selected. A tower is being marked to be masked if belong in the 4*8 set. There are several common.
Generally the number is ,ess than 20.
Writes hot channels run by run in "txt" directory with gif files in "gif" : the inputs from the txt file will be used when writing in database. Each *.txt file for one run.
/star/data01/pwg/mriganka/fms2015/jetData2011/new/hotCh/test/run.C. The information from *.txt files will be used when database would be written run by run.
- How time dependent files are prepared
Basic concept is to mark channels for which correction is significnat. It is such that with minum inputs in database, we can perfrom time dep. correction without overloading the database.
Some details are written here : https://drupal.star.bnl.gov/STAR/blog/mriganka/fms-led-time
In starver SL14i from PSU TimeDepCorr.root was locally generated. We are listing the channels to be corrected for each time slot. Each time slot is a section of 10k data. Since the evnets nummber is unique in trigger file and microDst files there is one to one relation with time slots and MuDst event numbers.
/star/data01/pwg/mriganka/fms2015/jetData2011/old/led/test1
running the macro txt1/read.C lists : Run Number #Events(fms_st) time-slots Entries in Database
taking f_runNumber.txt which is generated Sub_L.xml(RunFastJet.C) take list(schedA96107FA7AD49F7008BAA3DE299BDEE7_$JOBINDEX.list) file which written for each run.
-- inputs in the file(f_runNumber.tx) written in StRoot/StJetMaker/mudst/StjFMSMuDst.cxx
StjFMSMuDst::RCorrect(TMatrix* padc,TMatrix* pEmat,Int_t det,Int_t iEW,Int_t runnum,Int_t EvNum,Int_t SegNM)
/star/data02/pwg/mriganka/root12fms/fmstxt/RunDep.root (Steven Heppelmann run11 list)
fprintf(f,"%10d %6d %6d\n", mCurrentRunNumber, nEnt, timeSlot);
fprintf(f," %hu %hu %lu %f \n", detectorId, ch, 999000000, 1); -- for last time slot
fprintf(f," %hu %hu %lu %f \n", detectorId, ch, endEvent, corr); -- for time slots where chages are required
- Writing in database
In couple with time dependent masked tower inputs are set into database (time dep. correction values are set to negative for mased towers).
/star/data01/pwg/mriganka/fms2015/jetData2011/old/led/test1/AKIO/writeFMSAll.C
Masked tower inputs : sprintf(fileTowers,"/star/data01/pwg/mriganka/fms2015/jetData2011/new/hotCh/test/txt/tower_rejected_%d.txt",iR);
Time dep. correction inputs : sprintf(fileTimeDep,"txt/f_%d.txt",iR);
- Reading after implementation of time dep. and hot tower rejection in StFmsHitMaker
The macro is running for Jet recontruction with FMS towers using tower masking and tome dep. correction.
/star/data01/pwg/mriganka/fms2015/jetData2011/new/hotCh/t/mod/RunJetFinder2009pro.C
Two switches are set in StFmsHitMaker
fmshitMk->SetTimeDepCorr(1); // does time dep, correction : default is "0"
fmshitMk->SetTowerRej (default = 1) // how tower rejection
Software
The FPD/FMS related software page.
FMS data model
StFmsHit, StFmsCluster and StFmsPoint are the data model defined for storing FMS data in StEvent/StMuDST:
- StFmsHit
protected:
UShort_t mDetectorId; // Detector Id
UShort_t mChannel; // Channel in the detector
UShort_t mQTCrtSlotCh; // QT Crate/Slot/Ch, 4 bits for Crate and Slot, 8 bits for channal
UShort_t mAdc; // ADC values
UShort_t mTdc; // TDC values
Float_t mEnergy; // corrected energy - StFmsCluster
protected:
Int_t mDetectorId;
Float_t mTotalEnergy ; // total energy contained in this cluster (0th moment)
Float_t mX ; // mean x ("center of gravity") in local grid coordinate (1st moment)
Float_t mY ; // mean y ("center of gravity") in local grid coordinate (1st moment)
Float_t mThetaAxis; // theta angle in x-y plane that define the direction of least-2nd-sigma axis
Float_t mSigmaX ; // 2nd moment in x
Float_t mSigmaY ; // 2nd moment in y
Float_t mSigmaMin; // 2nd sigma w.r.t to the least-2nd-sigma axis
Float_t mSigmaMax; // 2nd sigma w.r.t to the axis orthogonal to the least-2nd-sigma axis
StPtrVecFmsHit mHits; - StFmsPoint
protected:
Int_t mDetectorId;
Int_t mCategory ; // catagory (1: 1-photon, 2: 2-photon, 0: could be either 1- or 2-photon)
Float_t mFittedEnergy ; // fitted energy of the hit
Float_t mX ; // fitted x in local grid coordinate (1st moment)
Float_t mY ; // fitted y in local grid coordinate (1st moment)
Float_t mChiSquare; // Chi-square of the fitting
StPtrVecFmsCluster mMotherCluster;
StPtrVecFmsPoint mSiblingPoint;
StFmsCollection is the entry point to FMS related data in StEvent/StMuDST.
public:
void addHit(StFmsHit*);
void addCluster(StFmsCluster*);
void addPoint(StFmsPoint*);
unsigned int nHits() const;
unsigned int nClusters() const;
unsigned int nPoints() const;
StSPtrVecFmsHit& hits();
const StSPtrVecFmsHit& hits() const;
StSPtrVecFmsCluster& clusters();
const StSPtrVecFmsCluster& clusters() const;
StSPtrVecFmsPoint& points();
const StSPtrVecFmsPoint& points() const;
protected:
StSPtrVecFmsHit mHits;
StSPtrVecFmsCluster mClusters;
StSPtrVecFmsPoint mPoints;
StFmsPointMaker
This page describe the StFmsPointMaker.
FTPC
Welcome to the  FTPC Homepage
FTPC Homepage

First FTPC Event
Detector Operation - all information necessary to operate FTPCs
Data Quality Assurance
Pad Monitor
Calibrations
Documentation
Software
Hardware
DAQ
InterlockSystem
SlowControl
Calibrations
FTPC Calibration Home Page
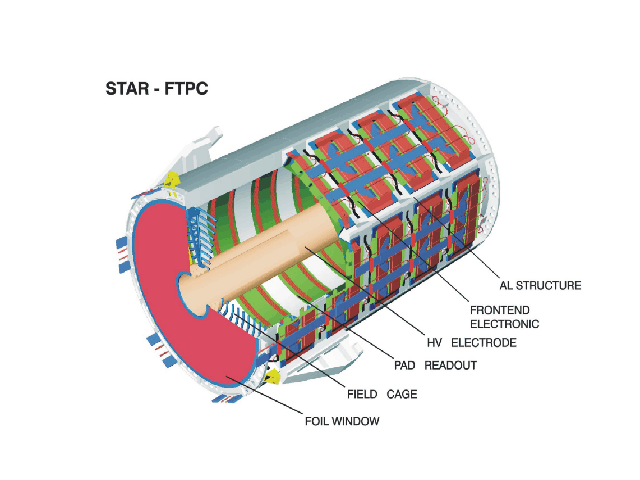 |
Overview of calibration tasks (v2.2)
FTPC Calibration Run-VIII(dAu)-Procedure
Studies of Embedding in the FTPC for 2008 p+p Runs
Software
Databases
Laser system
Electronics
Coordinate systems
Temperature pressure corrections
Rotation
Simulations
Drift maps
Cathode displacement
protected
FTPC Home Page
DAQ
FTPC DAQ
The FTPC data aquisition system is tied in with the main STAR DAQ. From the receivers onward, all hardware components are identical. The software for the electronics channel mapping is committed to the STAR cvs repository $CVSROOT/online/ftpc/MapFtpcElectronicsToDaq
The signals from the FTPC electronics are sent to DAQ where each
readout board,mezzanine card,asic is mapped to an FTPC sector,daqrow,daqpad.
HARDWARE:
2 identical FTPCs - Ftpc West = 1, Ftpc East = 2
5 rings/FTPC
2 padrows/ring
10 padrows/FTPC
6 sectors/padrow
6 sectors/padrow x 10 padrows/FTPC = 60 hardware sectors/FTPC
160 pads/sector
9600 pads/padrow
= 19200 electronics channels for both FTPCs
ELECTRONICS:
20 readout boards (RDOs)
10 RDOs/FTPC
3 mezzanine cards/RDO
= 3 mezzaanine cards/RDO x 10 RDOs/FTPC = 30 electronic sectors/FTPC
DAQ:
The signals from the FTPC electronics are mapped to the hardware with the FTPC_PADKEY.h file.
DAQ notation:
30 daqsectors/FTPC (Ftpc West 1-30, FtpcEast 31-60)
2 daqrows/daqsector
320 daqpads/daqsector = 2 x 160 daqpads/daqrow
Ftpc Ring Padrow Sector daqrow daqpads
1 1 1,2 1,7 1,2 1-160
2,8 1,2 161-320
3,9 1,2 321-480
4,10 1,2 481-640
5,11 1,2 641-800
6,12 1,2 801-960
2 3,4 13,19 1,2 1-160
14,20 1,2 161-320
15,21 1,2 321-480
16,22 1,2 481-640
17,23 1,2 641-800
18,24 1,2 801-960
3 5,6 25,31 1,2 1-160
26,32 1,2 161-320
27,33 1,2 321-480
28,34 1,2 481-640
29,35 1,2 641-800
30,36 1,2 801-960
4 7,8 37,43 1,2 1-160
38,44 1,2 161-320
39,45 1,2 321-480
40,46 1,2 481-640
41,47 1,2 641-800
42,48 1,2 801-960
5 9,10 49,55 1,2 1-160
50,56 1,2 161-320
51,57 1,2 321-480
52,58 1,2 481-640
53,59 1,2 641-800
54,60 1,2 801-960
2 1 1,2 6,12 1,2 1-160
5,11 1,2 161-320
4,10 1,2 321-480
3,9 1,2 481-640
2,8 1,2 641-800
1,7 1,2 801-960
2 3,4 18,24 1,2 1-160
17,23 1,2 161-320
16,22 1,2 321-480
15,21 1,2 481-640
14,20 1,2 641-800
13,19 1,2 801-960
3 5,6 30,36 1,2 1-160
29,35 1,2 161-320
28,34 1,2 321-480
27,33 1,2 481-640
26,32 1,2 641-800
35,31 1,2 801-960
4 7,8 42,48 1,2 1-160
41,47 1,2 161-320
40,46 1,2 321-480
39,45 1,2 481-640
38,44 1,2 641-800
37,43 1,2 801-960
5 9,10 54,60 1,2 1-160
53,59 1,2 161-320
52,58 1,2 321-480
51,57 1,2 481-640
50,56 1,2 641-800
49,55 1,2 801-960
Data Quality Assurance
FTPC Data Quality Assurance and Quality Control
FTPC Data Quality Assurance and Quality Control
During data taking it is very important to monitor the quality of the data being taken. This should be done at least once a day and whenever the FTPC has been turned back on.
- Online histograms - "Panitkin Plots"
- FTPC Fast Offline QA histograms
- FTPC temperature readings - check if the FTPC temperature readings are in the You do not have access to view this node. There should be readings for both Ftpc body (West 6 readings, East 6 readings) and Ftpc extra (West 6 readings, East 7 readings) temperatures. It is especially important to check these after the FEEs have been turned off; there is a non-negligible possibility that the body temperature readings for FTPC East do not come up again. If this is the case, call an expert.
Fast Offline QA Histograms
FTPC Fast Offline Histograms
- Use the Offline Automated QA Browser to fetch the latest set of Fast Offline or DST production jobs.
- Compare the "General Hists" and the "Multiplicity Class Hists" to the appropriate set of FTPC reference histograms:
Online histograms - "Panitkin Plots"
During a run, online histograms are collected for each sub-system. The online histograms give the first indication of detector hardware problems. Therefore it is extremely important to check these histograms in the control room on evp.starp.bnl.gov at the end of each run. They should also be saved so that they are available for future viewing via the RunLog Browser.
A histogram description has 9 arguments:
1 for 1-D, 2 for 2-D histo
histogram name
histogram title
number of bins x-axis
lower bound x-axis
upper bound x-axis
0 for 1-D histos, number of bins y-axis for 2-D histos
0 for 1-D histos, lower bound y-axis for 2-D histos
0 for 1-D histos, upper bound y-axis for 2-D histos
The following histograms are collected for the FTPC (they are on pages 25-27 up until January 3, 2008 when BEMC histograms were added. The FTPC histograms moved to pages 30-32 starting with run 9003070):
Please inform the FTPC group if you observe large scale changes in any of the FTPC histograms.
The plots on page numbers 26 and 27/ pages 31 and 32 starting with run 9003070 are the most important. They must be checked for every run.
Currently the sample histograms shown below are for the dAu 2007 Run 8340066 - page 6: FTPC event size on a log10 scale
Contains the event size histograms for TPC, BEMC, FTPC, L3, SVT and TOF
Args: 1,h11_ftp_evsize,log of FTPC Buffer Size,50,0.,10.,0,0,0
- page 7: FTPC fraction of total event in %
Contains the event size fraction histograms for TPC, BEMC, FTPC, L3, SVT and TOF
Args: 1,h105_ftp_frac,FTP Event Size Fraction (%),50,0.,100.,0,0,0
- page 8: FTPC event size on a log10 scale for the last 2 minutes
Contains the event size vs time histograms for the TPC and FTPC
Args: 2,h337_ftp_time_size_2min,FTPC Event Size vs time(sec),600,0.,600.,80,0.,8.
- page 25/page 30:
% of FTPC occupied channels
Args: 1,h49_ftp,FTPC Occupancy (in %),100,0.,100.,0,0,0
FTPC event size on a log10 scale
Args: 1,h11_ftp_evsize,log of FTPC Buffer Size,50,0.,10.,0,0,0
% of FTPC occupied channels for laser runs
Args: 1,h51_ftp_OccLaser,FTPC Occupancy (in %) Lasers,100,0.,100.,0,0,0
Total charge in FTPC on log10 scale
Args: 1,h48_ftp,log of Total FTPC Charge,30,0.,6.,0,0,0
% of FTPC occupied channels for pulser runs
Args: 1,h50_ftp_OccPulser,FTPC Occupancy (in %) Pulsers,100,0.,100.,0,0,0 - page 26/page 31: FTPC chargestep histograms
Args: 1,h109_ftp_west_time,FTPC West timebins,256,-0.5,255.5,0,0,0
Args: 1,h110_ftp_east_time,FTPC East timebins,256,-0.5,255.5,0,0,0
The chargestep corresponds to the maximum drift time in the FTPC (clusters from inner radius
electrode) and is located near 170 timebins. This position will change slightly with atmospheric
pressure. The other features of these plots are due to electronic noise and pile-up background.
If there is no step visible near 170, something is wrong. Please contact an FTPC expert.
- page 27/page 32:
Args: 2,h338_ftp_west,FTPC West pad charge: pad vs row,10,0.,10.,960,0.,960.
Args: 2,h339_ftp_east,FTPC East pad charge: pad vs row,10,0.,10.,960,0.,960.
Red areas = hot FTPC electronics
White areas = dead FTPC electronics
Always check these 2 plots in the first run after an FTPC trip. If new red or white areas show up,
first check the FTPC anode voltages. If the anode voltage readings are correct, please contact
an FTPC expert.
On December 17, 2007, Alexei masked out RDO 10 East. On page 27/32 RDO 10 East is now a white area.
Contains the event size histograms for TPC, BEMC, FTPC, L3, SVT and TOF
Args: 1,h11_ftp_evsize,log of FTPC Buffer Size,50,0.,10.,0,0,0
Contains the event size fraction histograms for TPC, BEMC, FTPC, L3, SVT and TOF
Args: 1,h105_ftp_frac,FTP Event Size Fraction (%),50,0.,100.,0,0,0
Contains the event size vs time histograms for the TPC and FTPC
Args: 2,h337_ftp_time_size_2min,FTPC Event Size vs time(sec),600,0.,600.,80,0.,8.
% of FTPC occupied channels
Args: 1,h49_ftp,FTPC Occupancy (in %),100,0.,100.,0,0,0
FTPC event size on a log10 scale
Args: 1,h11_ftp_evsize,log of FTPC Buffer Size,50,0.,10.,0,0,0
% of FTPC occupied channels for laser runs
Args: 1,h51_ftp_OccLaser,FTPC Occupancy (in %) Lasers,100,0.,100.,0,0,0
Total charge in FTPC on log10 scale
Args: 1,h48_ftp,log of Total FTPC Charge,30,0.,6.,0,0,0
% of FTPC occupied channels for pulser runs
Args: 1,h50_ftp_OccPulser,FTPC Occupancy (in %) Pulsers,100,0.,100.,0,0,0
Args: 1,h109_ftp_west_time,FTPC West timebins,256,-0.5,255.5,0,0,0
Args: 1,h110_ftp_east_time,FTPC East timebins,256,-0.5,255.5,0,0,0
The chargestep corresponds to the maximum drift time in the FTPC (clusters from inner radius
electrode) and is located near 170 timebins. This position will change slightly with atmospheric
pressure. The other features of these plots are due to electronic noise and pile-up background.
If there is no step visible near 170, something is wrong. Please contact an FTPC expert.
Args: 2,h338_ftp_west,FTPC West pad charge: pad vs row,10,0.,10.,960,0.,960.
Args: 2,h339_ftp_east,FTPC East pad charge: pad vs row,10,0.,10.,960,0.,960.
Red areas = hot FTPC electronics
White areas = dead FTPC electronics
Always check these 2 plots in the first run after an FTPC trip. If new red or white areas show up,
first check the FTPC anode voltages. If the anode voltage readings are correct, please contact
an FTPC expert.
On December 17, 2007, Alexei masked out RDO 10 East. On page 27/32 RDO 10 East is now a white area.
Detector Operation
FTPC expert(s) currently on call:
Alexei Lebedev alebedev@bnl.gov Phone: 3101 Cell phone: 631 255 4977
TO ALL DETECTOR OPERATORS:
Please remember to place the FTPC into "Physics" mode and verify anode voltages (1800 W, 1800 E) after taking pedestals.
In case of an FTPC alarm,please check the "Temperature-Pressure" window - if ALL readings in FTPC East and/or West = 0, call Alexei.
In case of an anode trip, please enter the time the trip occurred and which FTPC and sector tripped into the FTPC log book.
Y2004 Standard set points
- Detector always ON
Change configuration to operate in different modes or to set the detector to rest waiting for beam
Set the system in ``Magnet ramp'' configuration ONLY when the magnet is ramping
ALWAYS!!!!!! verify Anode Voltages = voltages for selected run mode !!!
| Voltage Settings | |
| Cathode voltage (2 channels) | -10kV±5V |
| Anode voltage (2x6 channels), Physics | +1800V ±2V West, +1800V ±2V East |
| Anode voltage (2x6 channels), laser | +1200V±2V West, +1200V±2V East |
| Anode voltage (2x6 channels), pedestals | +1000V±2V West, +1000V±2V East |
| Anode voltage (2x6 channels), stand by | 0V West/East, (+~15V are displayed) |
| Gating grid (2x4 channels) | -76V±2V open, -76V±115V closed |
| Y2007/2008 Standard Values | |
| Water pressure in (West/East) | -400mbar -> -100mbar |
| Water temperature (West/East) | <31 C |
| O2(ppm) (West/East) | <10ppm |
| H2O (dp C) Westt/East) | <-50 C dp |
| Ar flow = CO2 flow (West/East) | 72l/h->78l/h; West=East |
| Cathode current | 0.14mA |
| Anode current | -15nA < I < 15nA |
For more information, please consult:
 FTPC Operations Manual
FTPC Operations Manual
FTPC Shift Checklist
FTPC Run School
Documentation
FTPC Documentation
Hardware
FTPC Hardware
InterlockSystem


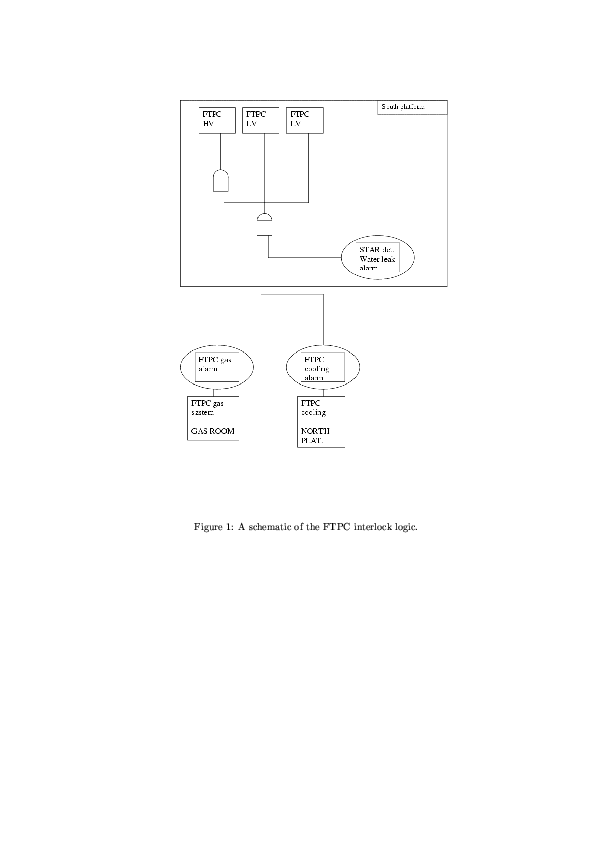
Pad Monitor
FTPC Pad Monitor
The pad monitor we use was developed by Andreas Schuettauf. It is referred to as the Munich Pad Monitor. (The FTPC pad monitor development was started by Jennifer Klay in Davis. Her documentation contains alot of useful information. Unfortunately, Jennifer left STAR before she finished the pad monitor.)
- How to run the Munich Pad Monitor
- sample Munich Pad Monitor screen
- hardware sector notation (receiver boards)
- hardware sector notation (lasers)
documentation
FTPC PadMonitor Project
Welcome! You have found the webpage dedicated to providing information and documentation on the FTPC PadMonitor. The FTPCs (Forward Time Projection Chamber) are a key sub-system of the STAR Experiment at RHIC. The PadMonitor is a software program designed to allow for monitoring of FTPC performance. The program can be separated into two basic parts: the GUI (Graphical User Interface) and the data I/O interface. The GUI has been designed using Java with the data I/O interface provided by the Java Native Interface to C and C++ code. This choice of languages reflects the desire to marry cross-platform transportability with legacy code already written for STAR DAQ data. In addition, we hope to be able to run the PadMonitor as a Servlet or Javascript from the Web, allowing collaborators access to view detector performance or issue trigger commands from a distance.
Raw Data Format
STAR DAQ Links
STAR DAQ Home Page This is the local working home page for the DAQ Group. Specific links of interest on this site include:
FTPC Raw Data Format
Main TPC
24 Sectors-each one handled by a single VME crate
Each VME crate contains 6 receiver boards and one "Sector Broker" (to handle global sector characteristics and communication)
Each receiver board contains 3 mezzanine boards which buffer the data and host the STAR Cluster Finding ASICs (pedestal subtraction,gain correction, 10bit->8bit data conversion, 2D cluster finding)
To reconstruct a single sector's data, one must gather:
From each of six receiver boards, the contributions from all three mezzanine boards
384 pads per sector
45 padrows per sector
Number of pads per padrow variable (due to wedge-shape of sectors)
512 timebins per pad
Forward TPCs
2 Chambers-each one handled by a single VME Crate
Each crate contains 10 receiver boards and one "Chamber Broker" (performs the same functions as the Sector Broker but for a single FTPC Chamber)
Each receiver board handles three FTPC Sectors (30 sectors per chamber)
Each receiver board has 3 mezzanine boards. The simplest sector->mezzanine mapping is 1:1, but may not necessarily be so. In order to be general, the pointer structure is set up such that from the receiver board, one points to a sector and from the sector one points to the mezzanine board.
To reconstruct a single sector's data, one must gather:
From one receiver board, the sector via contribution from one mezzanine board
30 sectors per chamber
320 pads per sector
2 padrows per sector
160 pads per padrow
512 timebins per pad
Ideally, one would like to hide this heirarchy behind a simpler user interface. This has been done by making the FTPC Format Reader very similar to the main TPC. Users request data from a specific sector, numbered 1 to 60 (1-30 for West FTPC, 31-60 for East FTPC). The user numbering scheme follows the FTPC Cabling design drawings. The mapping to correct receiver board and mezzanine contributions for a given sector is provided by a header file included with the Format Reader.
FTPC Raw Data Format Document (postscript)
DAQ/Data Schematics
View some schematic pictures of the DAQ design and the current Raw Data Format:
The following is a diagramatical sketch of the information path explained in the DAQ Raw Data Format Document.
SlowControl
FTPC Slow Control
- FTPC Slow Control documentation FTPC related slow control and interlock documentation
- FTPC slow control schematics
- FTPC slow control screens
- FTPC Slow Control Monitor List and/or plot the FTPC hardware readings from the slow control archives
Software
FTPC Software
Calibration Software
- StRoot/StFtpcDriftMapMaker
- StRoot/StFtpcCalibMaker - includes the Ftpc offline database macros
- Online
- Offline
Simulation and Reconstruction Software
- Simulation
- Reconstruction
- Association Maker
- SEE Obsolete FTPC Makers and PAMs for outdated FTPC software
- SEE FTPC in ITTF for information on Maria Mora's integration of the FTPC into ITTF
How to
List
|
Group |
Task Description/Problems |
Location of Source Code |
Contact |
|
DAQ |
|
|
|
|
|
Map FTPC electonics to DAQ |
$CVSROOT/online/ftpc/MapFtpcElectronicsToDaq |
Janet |
|
|
FTPC "gain table" for DAQ |
|
Frank |
|
Online |
|
|
|
|
|
FTPC Detector Control |
/afs/rhic.bnl.gov/star/doc_public/www/ftpc/Operations |
Terry |
|
|
Slow Control |
|
Terry |
|
|
FTPC Slow Control Monitoring Facility |
|
Terry |
|
|
Pad Monitor |
$CVSROOT/online/ftpc/FtpcPadMonitor |
Janet |
|
|
Online Tools: |
|
Terry Janet |
|
|
Online histograms ("Panitkin plots") |
|
Janet |
|
Drift Velocity Monitor |
OBSOLETE |
|
|
|
|
LabView program running on bond.starp |
|
|
|
|
bond.starp -> virgo.starp samba connection |
|
|
|
|
virgo.starp cron job - copies files from /DV2/Today to /DV2/Store |
|
|
|
|
Conversion of DVM data files to root format |
|
|
|
|
StFtpcDVMMaker - DVM data analysis programs |
$CVSROOT/offline/StFtpcDVMMaker |
|
|
Calibration |
|
|
|
|
|
Noise Finder: |
|
Terry |
|
|
Drift Maps:
Magboltz2 |
$CVSROOT/StRoot/StFtpcDriftMapMaker $CVSROOT/online/ftpc/Magboltz2 |
Janet |
|
|
Laser Analysis: |
|
Terry |
|
Databases |
|
|
|
|
|
Slow Control -> Online database -> Offline database |
|
Terry |
|
|
Offline database: |
|
Terry |
|
|
StDb/idl - idl definition files for FTPC database tables |
$CVSROOT/StDb/idl |
Janet |
|
Simulation/ Reconstruction |
|
|
|
|
|
StFtpcSlowSimMaker |
$CVSROOT/StRoot/StFtpcSlowSimMaker |
Frank |
|
|
StFtpcClusterMaker |
$CVSROOT/StRoot/StFtpcClusterMaker |
Joern |
|
|
StFtpcTrackMaker |
$CVSROOT/StRoot/StFtpcTrackMaker |
Markus |
|
|
pams/ftpc/idl |
$CVSROOT/pams/ftpc/idl |
Janet |
|
QA |
|
|
|
|
|
St_QA_Maker |
$CVSROOT/StRoot/St_QA_Maker |
Gene Janet |
|
Embedding |
|
|
|
|
|
StFtpcMixerMaker |
$CVSROOT/StRoot/StFtpcMixerMaker |
Frank |
|
Analysis |
|
|
|
|
|
StFtpcMcAnalysisMaker |
|
Frank |
|
ITTF |
|
|
|
|
|
StiFtpc |
$CVSROOT/StRoot/StiFtpc |
Maria Mora-Corall |
|
Documentation |
|
|
|
|
|
Web pages |
/afs/rhic.bnl.gov/star/doc_public/www/ftpc /afs/rhic.bnl.gov/star/doc_private/www/ftpc |
Janet |
This page was written by Janet Seyboth on Febuary 10, 2004
Online
FTPC "Online" Calibration Software
The FTPC "online" calibration software is a collection of programs and macros which run on the FTPC
online machines (virgo-run09.starp,cassini-run09.starp) processing either data directly from the event pool or from
a *.daq file.
All the FTPC calibration software is committed to the online/ftpc branch of the STAR CVS reposititory.
Each committed module contains a README file and a doc subdirectory which contain all the pertinent
information regarding the purpose and use of the program and/or macros contained in the module.
The FTPC "online" calibration program library is located on virgo-run09.starp in /data/FtpcOnlineLibrary
and can be used from the ftpccrew account on virgo-run09.starp.
Attention: The FTPC 3-D display software does not run with ROOT_LEVEL 4.04.02
Programs in the FtpcOnlineLibrary
Calib_Tool:
calib_tool creates a graphical user interface which allows the user to interactively analyze
the *.root files produced when the daq files from an FTPC laser run are processed
with the FTPC "private chain". The FTPC "private chain" produces a special output
file when DEBUGFILE is defined in StFtpcClusterMaker and StFtpcTrackMaker.
CardFinder:
The CardFinder utilities,PadAnalysisCreate and PadAnalysisWrite, analyze the pads, locate
the bad and/or noisy chips and produce lists of the bad electronics.
EvpPoolReader:
Reads, processes and displays event(s) from the event pool: /evp/a, /evp/b or
the "live" stream (the event which is currently being input into the event pool).
Due to firewall restrictions you can only access the event pool and the live stream from the starp sub-net .
Click here for running instructions.
FtpcPadMonitor:
padmon is a software program designed for monitoring the FTPC hardware performance.
NoiseFinder:
NoiseFinder contains the programs and macros which produce the FTPC online and offline
gain tables.
Run the NoiseFinder programs GetGain and FindNoise from the FtpcOnlineLibrary
on virgo.starp.bnl.gov to create a gain table. The gain table flags out dead
and/or noisy pads. The NoiseFinder utility, WriteAmpSlope_cc.so, converts the
gain table into an ftpcAmpSlope.C file which is added to the offline data base
in the Calibrations_ftpc/ftpcAmpSlope table.
Online_Tool:
Online_Tool contains the shell script ftpc_display and the L3 display
macros. The ftpc_display shell script provides an interface to FTPC online
event processing. An event from the event pool or from a daq file is read in
and the cluster finding and tracking results are displayed with the 3-D viewer.
Click here for running instructions.
calib_tool
FTPC Calib_Tool
calib_tool creates a graphical user interface which allows the user to interactively analyze
the *.root files produced when the daq files from an FTPC laser run are processed with
the FTPC "private chain"
"ftpc db globT detDb tpcDb dbutil in dst event"
The FTPC "private chain" produces a special output file when DEBUGFILE is defined in
StFtpcClusterMaker and StFtpcTrackMaker.
For information on calib_tool, type
calib_tool -h
Which will print the following
Usage: calib_tool [-l] [-b] [-n] [-q] [dir] [file1.root]
Options:
-b : run in batch mode without graphics
-n : do not execute logon and logoff macros as specified in .rootrc
-q : exit after processing command line macro files
-l : do not show splash screen
dir : if dir is a valid directory cd to it before executing
? : print usage
-h : print usage
--help : print usage
-config : print ./configure options
Choose [dir] and [file] via panel. There is a sample *.root file in the examples
sub-directory.
This page was created by Janet Seyboth on March 7, 2006
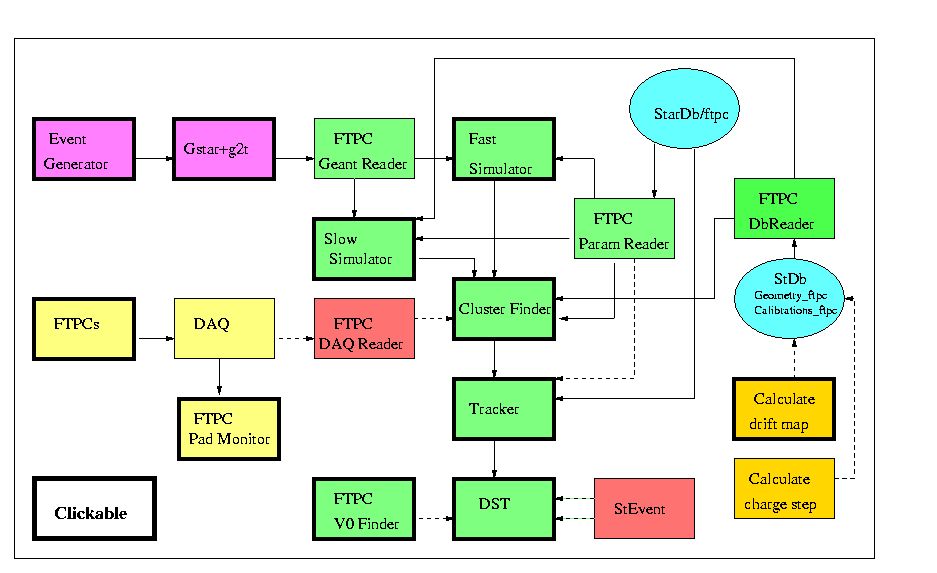
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
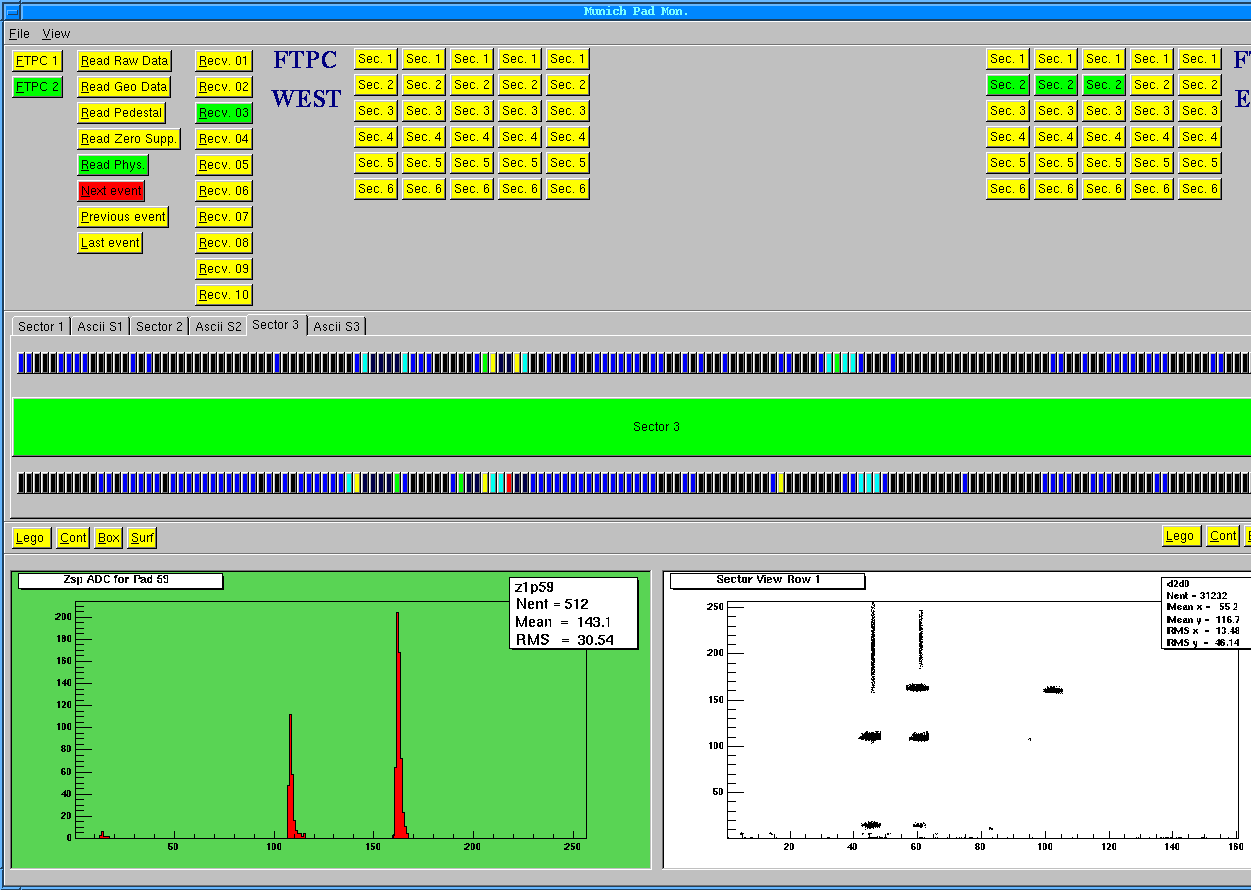{kind=link}
Reconstruction
FTPC Reconstruction
Hit Finding
StFtpcClusterMaker Documentation
If raw data already exists, either produced by the FTPC slow simulator (StFtpcSlowSimMaker) or from a daq data import, StFtpcClusterMaker will immediately invoke the cluster finder StFtpcClusterFinder . Otherwise, the FTPC fast simulator StFtpcFastSimu will be invoked to generate hits from geant data.
Tracking
StFtpcTrackMaker - FTPC Conformal Mapping Tracker
The StFtpcTrackMaker replaces St_fpt_Maker in the FTPC reconstruction chain.
StFtpcTrackMaker uses the clusters from StFtpcClusterMaker to reconstruct the tracks in the FTPC using conformal mapping. A list of all the "found" hits along with the number actually found and the maximum number of hits possible are saved for each track.
Then these "found" hits are fit using a 2x2-D track fitter. The impact parameter at the pre-vertex is calculated. All tracks with an impact parameter less than max_Dca are flagged as primary track candidates whose vertex is the pre-vertex. The momentum fit results for the unconstrained fit are saved in the track table.
14553 Geant hits (about 1000 tracks per Ftpc) after being tracked with the new Conformal Mapping Algorithm.

Markus Oldenburg
Last modified: Apr 20 2005
Simulation
FTPC geometry
- ftpcgeo - FTPC geant geometry definitions
Momentum Resolution
- HF Momentum Resolution Study Simulations about the performance of the FTPCs in a 0.25T magnetic field
Mock Data challenges
FTPC Fast Simulator
FTPC Slow Simulator
- TUNING
- Sim vs. Real Data - AuAu (behaviour of number of hits-on-track with event multiplicity)
- Sim vs. Real Data - dAu (behaviour of number of hits-on-track and residuals)
- StRoot/StFtpcSlowSimMaker pdf ps
- ftpcsim - Wen Gong's original stand-alone version
- pams/ftpc/fss -> StRoot/St_fss_Maker: now obsolete
HF Momentum Resolution Study
FTPC Half Field Momentum Resolution Study
This page shows results of some tests done in Munich to estimate the effect running at half the normal magnetic field strength would have on the FTPCs' momentum resolution.
The tests were done comparing the momentum resolution of two venus runs produced for mock data challenge 2. MDC 2 data is not very suitable for FTPC testing as it was calculated at extremely high geant resolution, so that each track caused several hits in each padrow. However, all the available data at half field is from MDC 2.
One event of each run was processed through the fast simulation chain, assuming that the quality of ExB corrections will not change with the field strength. Fast simulation makes it possible to compare reconstructed tracks to geant tracks by simply comparing the constituent points.
The plots show the reconstructed momentum divided by the geant momentum and are in good agreement with earlier studies done with realistic simulation parameters and the measured magnet field. (Earlier simulations done by Michael Konrad assuming a perfectly uniform field looked somewhat better.) Only perfectly reconstructed tracks with 10 hits that actually belonged to the same geant track are used in the plot.
The first plot shows the resolution at full magnetic field, the second at half field. Both peaks are nicely centered around one, showing essentially correct momentum resolution, but the RMS of the distribution increases from 15 to 20 percent when going to half the magnetic field. This is in contradiction with the obvious assumption of a linear increase of the errors, which, however, is not really to be expected at closer inspection. Also, the number of properly reconstructed tracks is smaller in the second plot, but it is yet unclear if this is due to a larger range of delta spirals in the smaller field, to some other effect or just statistics.
Full field: 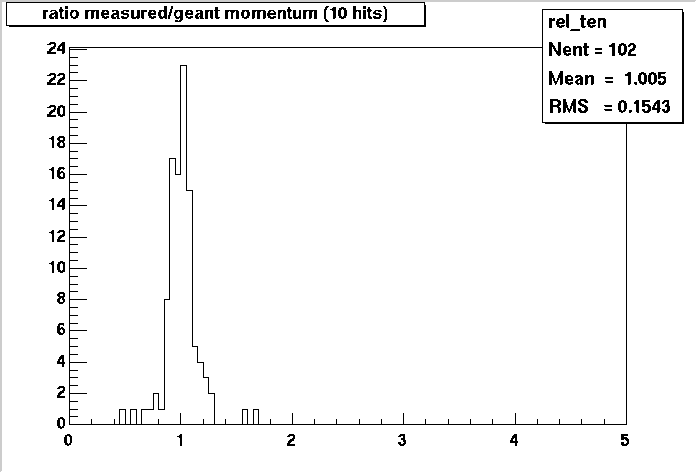
Half field: 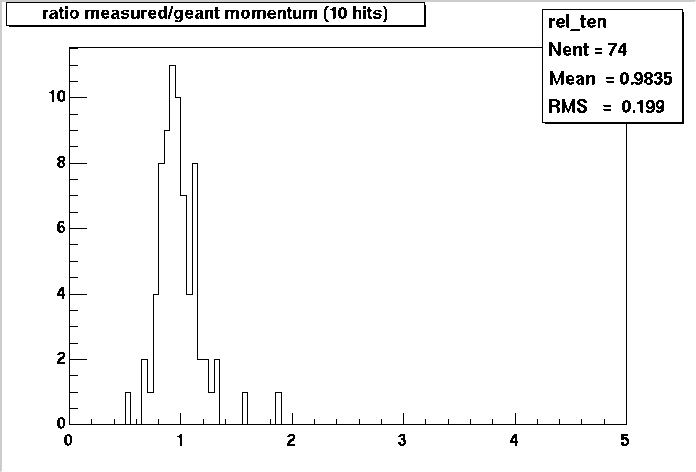
MDC1
FTPC and MDC1
The FTPC slow simulator chain:
- fss --- The FTPC Slow Simulator
- fcl --- The FTPC CLuster finder
- fpt --- The FTPC tracker
- fte - track evaluator
was included in the bfc.kumac for MDC1. NO dst information was written out.
Results:
We were able to find and correct programming errors which caused NaN's.
This page was written by Janet Seyboth on February 6, 1999
MDC2
FTPC and MDC2
In MDC2, the GEANT step size in the FTPC acceptance was reduced, so that every passing particle left a series of geant hits in every padrow. This became a serious challenge for the FTPC software and, even after optimization, increased the calculation time significantly. To get high-statistics for strangeness studies in the TPC, the planned schedule was changed in favor of more TPC fast simulator runs. Therefore, only a small number of events was run through the FTPC chain in MDC2, both with and without the slow simulator.
The complete FTPC slow simulator chain was run in the ROOT chain macro (bfc.C):
- St_fss_Maker --- The FTPC Slow Simulator
- St_fcl_Maker --- The FTPC CLuster finder
In runs when no raw_data from the FTPC slow simulator exists, St_fcl_Maker ran the FTPC fast simulator module ffs. - St_fpt_Maker --- ran the following FTPC modules:
fpt - track finder
fte - track evaluator
fde - dE/dx calculator
The FTPC track, point and dE/dx information was written out to the dst by St_glb_Maker.
This page was written by Janet Seyboth on February 6, 1999
MDC4
FTPC and MDC4
BNL, April 26 - May 10, 2001
Status History for FTPC in MDC4
Reconstruction
Purpose - MDC4 gave us the opportunity to test the performance and stability of our reconstruction chain with a large amount of simulated data before real data taking begins. It was the first large scale test of our slow simulator and cluster finder.
MDC4 Datasets - Dataset A (20,000 Au+Au MEVSIM events), DataSet B (100,000 pp PYTHIA events) and Dataset C (Au+Au peripheral STARLIGHT events) were processed in MDC4
BFC Chains - The FTPC ran only in the Au+Au BFC chain since our simulators can not handle pile-up
starnew new->SL00d
ROOT 3.00.06
bfc.C(#events,"MDC4","input dataset")
Identified Reconstruction Tasks
Implement StAssociationMaker
Pileup - we have to add pileup to our simulators in order to process pp simulation data (Contact: Akio,Jan)
Chisq - determine the correct values for the $STAR/StarDb/ftpc/ftpcClusterPars.C parameters
timeDiffusionErrors[1]
timeDiffusionErrors[2]
Reconstructed Datasets on FTPC BNL Cluster
There are 80 MEVSIM events in /cassini/data1/MDC4/Gstar/rcf0181_01_80evts.fzd
A complete set of output *.root files for these 80 events is available in /cassini/data1/MDC4
Analysis
Status - The analysis half of MDC4 was held for Friday, May 4 - Thursday, May 10
PWGs Expectations - The analysis focused on the new detectors and their physics capabilities
Spectra PWG - larger acceptance with FTPC
EbyE PWG - flow with FTPC
Strangeness PWG - first attempts to find v0's in FTPC
MDC4 Status Meetings
There was a telephone conference each Tuesday and Thursday at 3pm EST in the White Pit in Bldg. 118 (dial in x8261)
MDC4 Wrap-up Meeting
On Thursday, May 10 starting around 1:30pm EST there was a wrap-up meeting. Each sub-system was requested to summarize their experiences gained in MDC4 regarding efficiencies,problems encountered, etc. This summary should also contain a short summary on the new physics capabilities
JPWG Meeting
A PWG Workshop was held for Thursday, May 10 - Monday, May 14
This page was written by Janet Seyboth on April 27, 2001
Sim vs. Real Data - dAu
Comparison Slow Simulator and Real data dAu Min Bias
The Distribution of the number of hits-on-global-track is NOT the same for Real Data and Simulation with Hijing through the Slow Simulator (?) What happens with all this 10-hit-on-track ? The used Gain Table is not good enough to reproduce the holes?
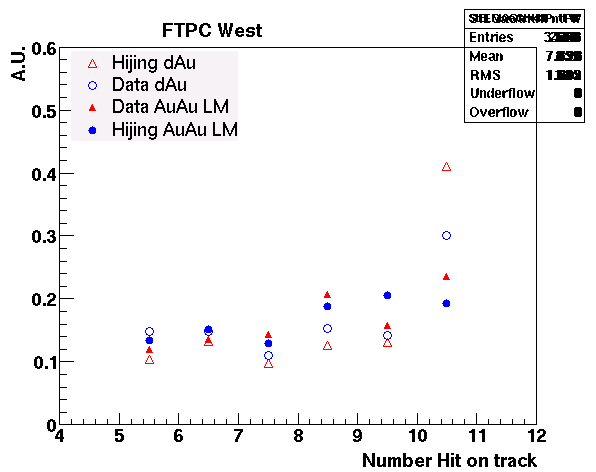 | 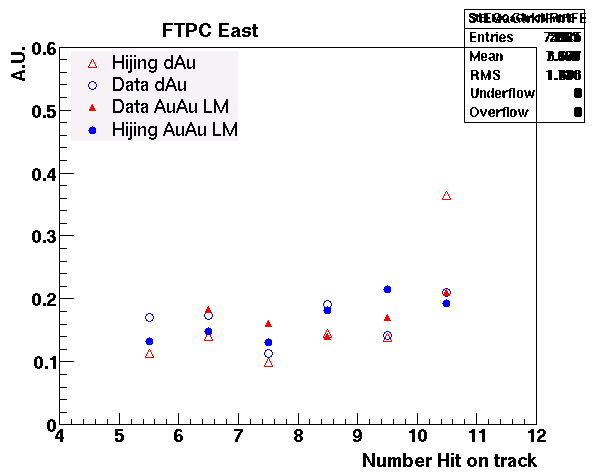 |
| FTPC West | FTPC East |
| AuAu minbias with low multiplicity in comparison with dAu min bias REAL DATA and SIMULATION | AuAu minbias with low multiplicity in comparison with dAu min bias REAL DATA and SIMULATION |
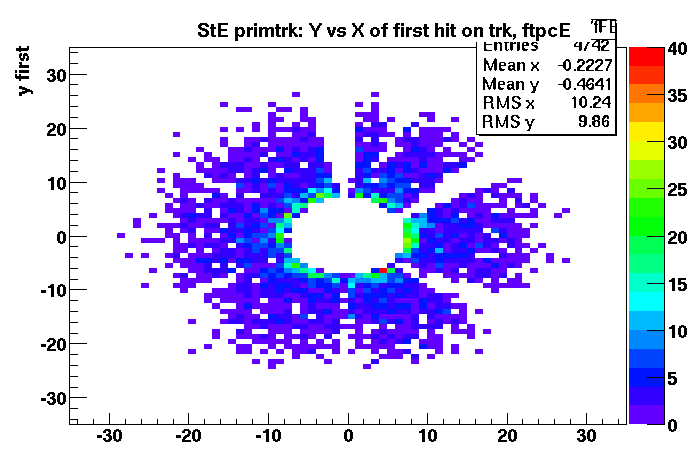 | 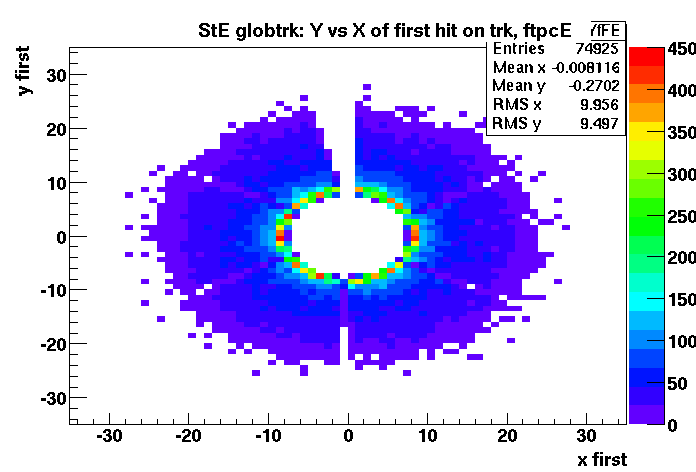 |
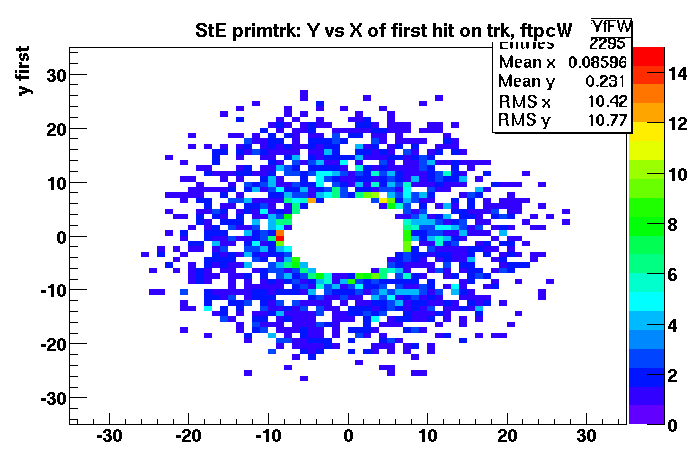 | 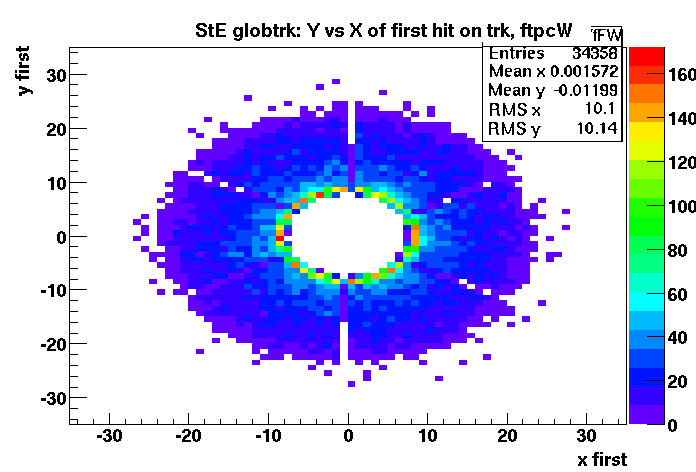 |
| REAL DATA | SIMULATION |
The residuals are much better for Simulation than for Real data. We still need to do something here )-:
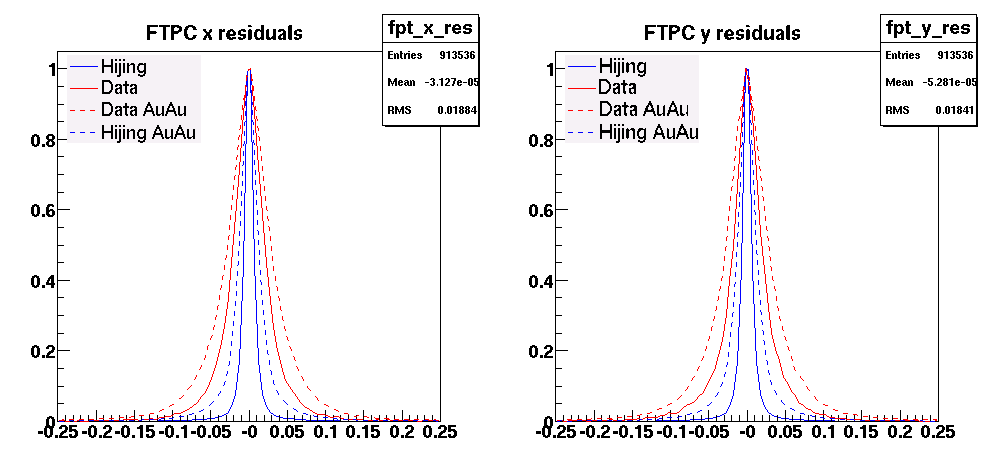
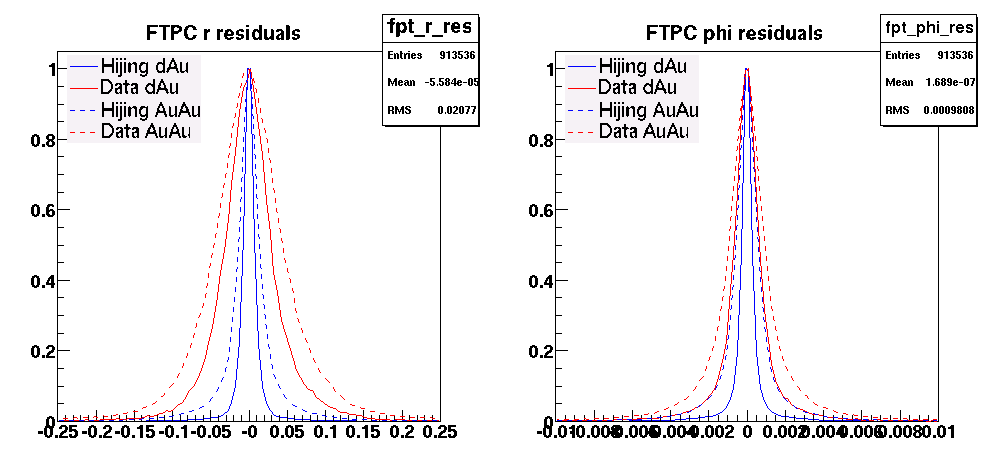
Sim vs. Real Data - AuAu
Comparison Slow Simulator and Real data for AuAu minbias events
The trend with the variation of the number of hits on track with the multiplicity is the same for Real Data and Simulation with Hijing through the Slow Simulator
| FTPC East |  |
 |
| AuAu minbias REAL DATA from Low Multiplicity (red) to High multiplicity (blue) | AuAu minbias SIMULATION from Low Multiplicity (red) to High multiplicity (blue) | |
| FTPC West |  |
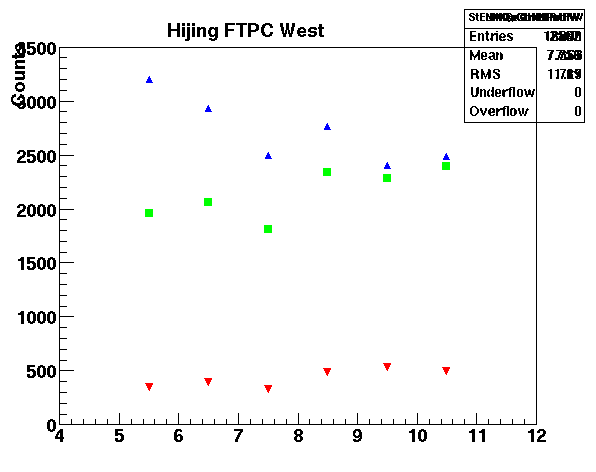 |
| AuAu minbias REAL DATA from Low Multiplicity (red) to High multiplicity (blue) | AuAu minbias SIMULATION from Low Multiplicity (red) to High multiplicity (blue) |
The residuals are much better for Simulation than for Real data. We still need to do something here )-:
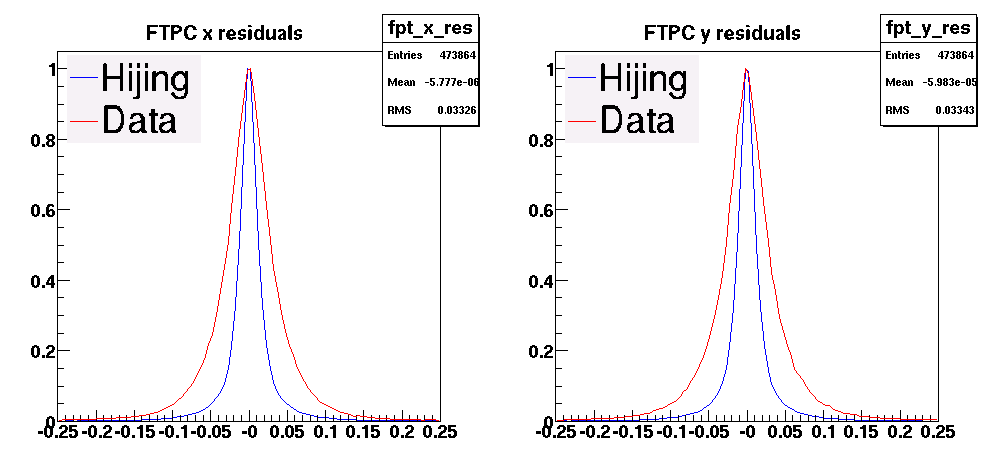
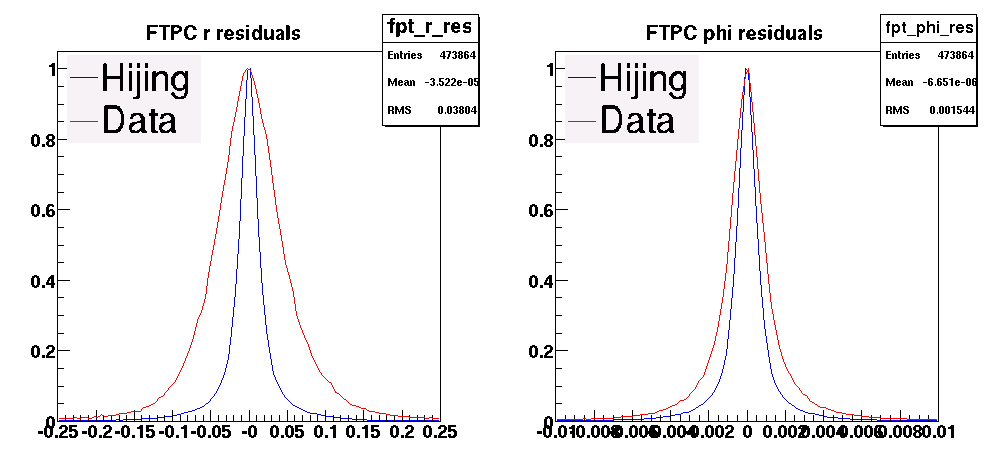
StFtpcFastSimu
StFtpcFastSimu - FTPC Fast Simulator
The FTPC fast simulator is implemented in C++ (as a part of StFtpcClusterMaker).
It was converted from Fortran (pam/ffs) to C++ by Holm Hümmler and is supported by Janet Seyboth.
StFtpcFastSimu simply takes the hit points registered by geant and turns them into FTPC points. Some cuts are applied to remove points that are outside the sensitive volume of the FTPC sectors and to account for the loss of hits due to cluster merging. Some of the geant information is kept in the gepoint table to be used in efficiency studies.
ftpcgeo
ftpcgeo.g
ftpcgeo.g defines the geometry for the FTPC in geant simulations. It contains information about the main aluminum cylinder, its support structures, the fieldcage and a rather detailed description of the readout chambers, and it defines the sensitive volumes.
Other geometry files of interest for the FTPC simulation are pipegeo.g for the beampipe and svttgeo.g with a description of the SVT, its support cone, the beampipe support and the shield layers.
This page was updated by Holm Hümmler on September 16, 1999
FTT
fobToHV Database table request
fobToHV
1) Variables and update frequency:
```
octet fob; /* fob 1-96 */
octet cable; /* HV cable 1 - 32 */
octet board; /* HV board 0 - 2 */
octet channel; /* HV channel on board 1 - 11 */
```
Update frequency:
A few times per year. In 2022 it has changed twice so far.
2) idl structure
```
/* fobToHV.idl
*
* Table: fobToHV
*
* description: // sTGC (ftt) map from FOB to HV
*
*/
struct fobToHV {
octet fob[96]; /* fob 1-96 */
octet cable[96]; /* HV cable 1 - 32 */
octet board[96]; /* HV board 0 - 2 */
octet channel[96]; /* HV channel on board 1 - 11 */
};
```
3) non-indexed, update entire database each time.
4) size of structure: 384
5) jdb
fobToStation
fobToStation
1) Variables and update frequency:
```
octet fob; /* fob 1-96 */
octet station; /* HV cable 18 - 35 */
```
Update frequency:
A few times per year. In 2022 it has changed once so far.
2) idl structure
```
/* fobToStation.idl
*
* Table: fobToStation
*
* description: // sTGC (ftt) map from FOB to Station
*
*/
struct fobToStation {
octet fob[96]; /* fob 1-96 */
octet station[96]; /* station identifier 1 - 35 */
};
```
3) non-indexed, update entire database each time.
4) size of structure: 192
5) jdb
fttDataWindows DB request
DATA WINDOWS
1) Variables and update frequency
```
octet uuid; /* fob(1-96) x vmm(1-4) = index 1 - 384 */
octet mode /* 0 = timebin, 1 = bcid */
short min; /* time window min > -32768 */
short max; /* time window max < 32768 */
short anchor; /* calibrated time anchor for BCID */
```
Update frequency:
Every single run.
This is essentially a status table which defines a few things:
uuid: identifies the VMM
mode: time mode to use for determining good data ranges (e.g. 0 OFF, 1 use timebin, 2 use bcid, etc)
min, max: define time window in timebins or bcids
anchor: calibrated bcid=0 for each VMM - changes every run
2) IDL structure
```
/* fttDataWindows.idl
*
* Table: fttDataWindows
*
* description: // sTGC (ftt) data time windows
*
*/
struct fttDataWindows {
octet uuid[385]; /* fob(1-96) x vmm(1-4) = index 1 - 384 */
octet mode[385]; /* 0 = timebin, 1 = bcid */
short min[385]; /* time window min > -32768 */
short max[385]; /* time window max < 32768 */
short anchor[385]; /* calibrated time anchor for BCID */
};
```
3) non-indexed, update entire database each time.
4) size of structure: 3080 bytes
5) jdb
fttHArdwareMap request info
1) Variables and update frequency:
Row_num
FEB_num
VMM_num
VMM_ch
strip_ch
Very rare update - stores a hardware map which is static unless there is a mistake discovered or a hardware failure that requires remapping. May be updated < 10 times in next few years.
2) IDL structure:
```
/* fttHardwareMap.idl
*
* Table: fttHardwareMap
*
* description: // sTGC (ftt) hardware map
*
*/
struct fttHardwareMap {
octet feb[1251]; /* 1-6 */
octet vmm[1251]; /* 1-4 */
octet row[1251]; /* 0-4 */
octet vmm_ch[1251]; /* 0-64 */
octet strip[1251]; /* 0-166*/
};
```
3) I am always a little confused about this. Updates rare, expect 1250 rows each with the structure above
4) size of structure
5 bytes * 1251 array lengths
Total size = 6255bytes
5) jdb
HLT
Those pages are provided for the High Level Trigger activities.
HLT Linux Cluster User's Guide
HLT Linux Cluster User's Guide
- Howe to get an account on HLT Farm
- Get an account to the STAR Protected Network. See instructions at https://drupal.star.bnl.gov/STAR/comp/onl/accessing-star-protected-network
- Once you can access STAR online gate way stargw.starp.bnl.gov, send an email to starsupport@bnl.gov (cc to me: kehw@bnl.gov) to request your access to xeon-phi-dev.starp.bnl.gov, which is the entry point to the HLT cluster.
- How to login HLT cluster
The STAR HLT cluster sites in a local network, which has an entry point to the STAR online network.
To reach the cluster, one need to jump a few time via ssh.
1. (if you are outside of BNL) Connect to the RCF gateway rssh.rhic.bnl.gov or cssh.rhic.bnl.gov.
The RCF NX service is recommended for better graphics performance.
https://www.racf.bnl.gov/docs/services/nx
2. From the RCF gateway or the NX node, connect to the STAR gateway: stargw.starp.bnl.gov
You must have a STAR online enclave account to be able to do this.
https://drupal.star.bnl.gov/STAR/comp/onl/accessing-star-protected-network
3. From the STAR gateway, connect to the HLT cluster entry point: xeon-phi-dev.starp.bnl.gov (aka L409)
Now you are on STAR HLT cluster.
The ssh ProxyJump or ProxyCommand is recommended to jump through multiple hosts
https://en.wikibooks.org/wiki/OpenSSH/Cookbook/Proxies_and_Jump_Hosts#Passing_Through_One_or_More_Gateways_Using_ProxyJump
- Computing Environment
* SL 7.3
* No STAR environment pre-configured.
* If you need the STAR environment, add the following lines in you ~/.cshrc
--------------------------------------------------------------------------
--------------------------------------------------------------------------
- NFS mounted home dir: /star/u/[user name]
Size: 1.3TB, RAID 5, no quota yet, but please use your home dir wisely
- NFS mounted Storage
/net/l401/data/scratch[1,2]
/net/l402/data
/net/l403/data
/net/l404/data
* 10+TB each, available on all HLT nodes.
- Ceph storate
On all nodes
/hlt/cephfs
- Condor Queue: Intel Xeon E5-2670 @ 2.50GHz
condor submitter: xeon-phi-dev.starp.bnl.gov (aka l409), l404
- Intel Xeon Phi coprocessor 7120P
l405-l408, l410-l417, two cards per node
l409(xeon-phi-dev) one card
In order to use the coprocessor, Intel C/C++ compiler is needed, which can be found at
/opt/intel_17
Documentation for Intel compiler and libraries can be found at
https://software.intel.com/en-us/intel-parallel-studio-xe-support/documentation
More information about Xeon Phi KNC (1st generation, x100 family) can be found at
https://software.intel.com/en-us/articles/intel-xeon-phi-coprocessor-codename-knights-corner
- PGI Compiler
The PGI compiler community edition has been installed in
/software/pgi
One need the following settings to use the compilers
% setenv PGI /software/pgi
% set path=(/software/pgi/linux86-64/18.10/bin $path)
% setenv MANPATH "$MANPATH":/software/pgi/linux86-64/18.10/man
% setenv LM_LICENSE_FILE /software/pgi/license.dat:"$LM_LICENSE_FILE"
---------------------------------------------------------------------------------
Contact Person:
Hongwei Ke
kehw@bnl.gov
631-344-4575
HLT QA
STAR HLT User's Manual
SpaceCharge and GridLeak Calibration for offline
SpaceCharge and GridLeak Calibration for online
calibaration of SpaceCharge(SC) and GridLeak(GL) with online
Tracking Focus Work
Meetings [newer on top]
April 19, 2017 Third STAR-TFG/GSI workoshop at BNL
January 17, 2017 TFG discussion on 2D cluster finder
May 2, 2016. Second STAR-TFG/GSI workoshop at BNL
December 10, 2015. BNL-GSI Tracking Workshop at BNL
Older material
****Some links from 2011 tracking review:
L3
PMD
Calibration
Procedure
STAR-PMD calibration Procedure
Experimental High Energy Physics Group, Department of Physics, University of Rajasthan, Jaipur-302004
The present STAR PMD calibration methodology is as follows:
- The events are cleaned and hot_cells are removed.
- The cells with no hits in immediate neighbours are considered as isolated hits and are stored in a Ttree
- The data for each cell, whenever it is found as a isolated cell, is collected and the adc distribution forms the mip for that cell.
- The mip statistics is then used for relative gain normalization.
The steps (1) , (2.) and (3.) have been discussed in detail in past. This writeup concentrates only on (4.) i.e the Gain Normalization Procedure. The writeup here attepts to understand the varations in the factors affecting the gains. It also attempts to determine how frequently should the gain_factors be determined.
Gain Normalization Procedure.
We studied gain normalization factors of different datasets of CuCu 200AGeV data . We observed that the gain normalization factors within the SMChain do not vary from one days dataset to another. But the gain normalization of one SMChain wrt another does. So we have represented the total gain normalization factor into two factors
Total_GNF = Cell_GNF * SMChain_GNF
- We have to use large statistics to determine Cell_GNF. Here 330K events of day22 data were used because we needed to collect enough statistics for each cell. <
- The gain_NF of one SM_chain wrt other SM_chains, SMChain_GNF, is determined as follows.
- Collect isolated cells for a small number of events.
- Using an pre-determined set of cell_GNF normalize the adc value of these isolated cells.
- Since these are now relatively normalized, the isolated cell adc distribution of all cells within an smchain are expected to fit to a single landau Even in the cases where a clearly developed mip was not seen in uncorrected data, mip was observed in corected data
- The SMChain_GNF can then be determined by two methods:
- using the MPV values of the landau fit to SMChain mips : mpv_SMChain_GNF
- using mean values of SMChain mips within the range 0-500 ADC: mean_SMChain_GNF
- The values of mean and mpv SMChain_GNF differ from each other. These factors are found to vary within short time span and as a result these are different from one day to another ( discussed later). SMChain_GNF used here are determined using 3-4% ( here 13K events for day22 data ) of the statistics required for determining cell_GNF.
{kind=link}
{kind=link}
Question: Is it okay to use Cell_GNF determined for using one set of data for normalizing another set of data ?
To prove that the cell_GNF determined for one set of data ( here day25) can be used for normalizing another day's data( here day22) we have made comparison of SMChain_GNF for day22 data determined using gain factors for day22 and day25 data of CuCu200AGeV.
- The cell_GNFs were determined for data from both these days independently.
- For a small subset of day22 data, we determined SMChain_GNF using cell_GNF for whole day22 data and hence calculated the total gain factors(total_GNF).
- For the same data of day22 but using day25 cell_GNF we have again calculated the the total gain factors.
- The difference in the cell_GNF for a smchain for two datasets , were found to be small and were of the order of 5-10%. see figure for difference between Cell_GNF of day22 and day25. Here the fractional difference between cell_GNF values for all cells of sm19 and chain 40 are plotted.
- The mean and RMS of the distbn. of fractional difference for all the smchain combinations (a total of 49 combinations) is plotted in the plot 1 of this figure. That all the mean values are close to zero shows the stability of these factors over a certain time span.
- The other plots of this figure give the difference in the total_GNF which includes the difference in cell_GNF as well as SMChain_GNF. Plot 2 gives the fractional difference when using mpv_SMChain_GNF and Plot 3 gives the fractional difference when using mean_SMChain_GNF.
- After applying only Cell_GNF and no SMChain_GNF the mean and mpv values were very scattered as expected. See the blue lines in plot 1 and plot2 of this figure
- If we apply mean_SMChain_GNF along with Cell_GNF the mean and MPV values are more clustered around a mean value. See green curves in the plot 1 and plot 2 of this figure
- If we apply mpv_SMChain_GNF along with CELL_GNF the MPV values show a sharp peak while distribution of means is also better than that observed than in (ii). See Red curves in plot 1 and plot2 of this figure
- The plots 3 and 4 of this figure show the resultant PMD mip for 13K events after applying the total_GNF using mean_SMChain_GNF and mpv_SMChain_GNF respectively
- The above study was repeated using day25 cell_GNF instead of day22 cell_GNF and the results are given in figure: See this figure
- Cell_GNF are stable and can be used for a longish span of data ( till the difference is <20%). These require a larger statistics and can be stored once for say every 5 days of data taking.
- mpv_SMChain_GNF are more effective than mean_SMChain_GNF, these 50 numbers(one for each SMChain combination) should also be stored in the DB. The numbers used in the present example are 13K event which is a very small amount of data. SMChain_GNF are fast varying but within the day they vary by ~6%. See this figure . So we need to determine these quantities more frequently than cell_GNF I would propose that they are determined twice a day.
{kind=link}
Question: Which of the two SMChain_GNF gives a better correction?
In order to determine which of the two SMChain_GNF gives a better correction, we applied these to a small dataset of unnormalized isolated cell adc values. After applying total_GNF, the mean and the mpv of the resulting SMChainMIP was collected. We observed:
{kind=link}
{kind=link}
Question: How frequently do we need to store cell_GNF and SMChain_GNF
This study shows two things:{kind=link}
PP2PP
PP2PP page
Conference proceedings
Conference talks and presentations
RICH
Roman Pot Phase II*
.png)
| Technical information |
Data analysis Elastic proton-proton scattering Central Exclusive Production Single Diffractive Dissociation pAu/pAl Ultra Peripheral Collisions |
| Software Geant4 simulation Reconstruction |
Pictures DX-D0 chamber Roman Pot Setup in the tunnel Other useful figures |
| Meetings history |
2009 setup (Phase I) Technical notes Paper reviews: A_NN and A_SS 2009 drupal website (PP2PP) |

Technical information

| Run 15 preparation Photographs of crates Roman Pot naming convention |
Trigger
|
| Alignment |
DAQ-expert materials Packages tests (Si + trig.count.) Trigger counters tests |
Detector package information
Each cell in the table below corresponds to single package (as it was assembled in 2009), whose label is given at the top of the cell.
Two tables at the bottom of the page indicate the Roman Pot in which components
of each particular package (silicon planes - A, B, C and D, and trigger counter - TC)
were installed during run 2009 and 2015.
|
A-3
Run 2009 performance: SVX pedestals:
Cluster properties (silicon data):
Trigger counter:
Pre-2015 tests:
SVX ped. and cluster properties:
Trigger counter:
|
B-4
Run 2009 performance: SVX pedestals:
Cluster properties (silicon data):
Trigger counter:
Pre-2015 tests:
SVX ped. and cluster properties:
Trigger counter:
|
A-1
Run 2009 performance: SVX pedestals:
Cluster properties (silicon data):
Trigger counter:
Pre-2015 tests:
SVX ped. and cluster properties:
Trigger counter:
|
B-1
Run 2009 performance: SVX pedestals:
Cluster properties (silicon data):
Trigger counter:
Pre-2015 tests:
SVX ped. and cluster properties:
Trigger counter:
|
|
B(A)-5
Run 2009 performance: SVX pedestals:
Cluster properties (silicon data):
Trigger counter:
Pre-2015 tests: SVX ped. and cluster properties:
Trigger counter:
|
A-6
Run 2009 performance: SVX pedestals:
Cluster properties (silicon data):
Trigger counter:
Pre-2015 tests:
SVX ped. and cluster properties:
Trigger counter:
|
B-2
Run 2009 performance: SVX pedestals:
Cluster properties (silicon data):
Trigger counter:
Pre-2015 tests:
SVX ped. and cluster properties:
Trigger counter:
|
A-4
Run 2009 performance: SVX pedestals:
Cluster properties (silicon data):
Trigger counter:
Pre-2015 tests:
SVX ped. and cluster properties:
Trigger counter:
|
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| E1U | E1D | E2U | E2D | W1U | W1D | W2U | W2D | |
| A | B-4 | A-3 | B-1 | Spare | A-4 | B(A)-5 | A-1 |
B-2
|
| B | B-4 | A-3 | B-1 | A-6 | A-4 | B(A)-5 | A-1 | B-2 |
| C | B-4 | A-3 | B-1 | A-6 | A-4 | B(A)-5 | A-1 | B-2 |
| D | B-4 | A-3 | B-1 | A-6 | A-4 | B(A)-5 | A-1 | B-2 |
| TC | B-4 | B-1 | A-4 | A-6 | A-3 | B(A)-5 | A-1 | B-2 |
| EHI | EHO | EVU | EVD | WHI | WHO | WVU | WVD | |
| A | A-3 | B-4 | A-1 | B-1 | B(A)-5 | A-6 | B-2 |
A-4
|
| B | A-3 | B-4 | A-1 | B-1 | B(A)-5 | A-6 | B-2 | A-4 |
| C | A-3 | B-4 | A-1 | B-1 | B(A)-5 | A-6 | B-2 | A-4 |
| D | A-3 | B-4 | A-1 | B-1 | B(A)-5 | A-6 | B-2 | A-4 |
| TC | A-3 | B-4 | A-1 | B-1 | B(A)-5 | A-6 | B-2 | A-4 |
Run 15 preparation
| Documents Roman Pot naming convention |
|
| Drawings / Schemes / Pictures Photographs of crates on EAST and WEST |
Photographs of crates
|
East
    |
West
    |
Map of connections
East   |
West
   |
Trigger
Data analysis
.png)
Software
Other databases created for the 2015 reconstructions
1. Calibrations/pp2pp/pp2ppPMTSkewConstants
There are 64 Skew constants, as there are 4 constants for each PMT's and there are 2 PMT's for each of the 8 RP's.
Rafal's prescription:
Implementations:
1st set:
set0.* entered at "2015-01-01 00:00:01 GMT"
2nd set:
"RTS Stop Time" for 16085055 was "2015-03-26 23:05:04 GMT"
"RTS Start Time" for 16085056 was "2015-03-26 23:06:39 GMT"
set1.* entered at "2015-03-26 23:05:05 GMT"
3rd set:
"RTS Stop Time" for 16085057 was "2015-03-27 00:07:59 GMT"
"RTS Start Time" for 16085058 was " 2015-03-27 00:14:32 GMT"
set0.* entered at "2015-03-27 00:08:00 GMT"
4th set:
"RTS Stop Time" for 16090041 was "2015-03-31 22:38:57 GMT"
"RTS Start Time" for 16090042 was "2015-03-31 22:39:59 GMT"
set1.* entered at "2015-03-31 22:38:58 GMT"
2. Geometry/pp2pp/pp2ppAcceleratorParameters
The order of entries in each set is:
Entries entered :
"2015-04-28 00:00:01 GMT" : 0 0 0 -0.003640421 0 9.8 9.8 3.7 3.7 0.011238936 0.026444185 1.8e-11
( The pp run stopped on Apr. 27 and there were a few days before C-AD could switch from pp to pAu operationally. I picked the beginning of Apr. 28 for this pAu entry.)
"2015-06-08 15:00:00 GMT" : 0 0 0 -0.002945545 0 9.8 9.8 3.7 3.7 0.012693812 0.025021968 1.8e-11
( The last *pAu* run was 16159025 on June 8 and the first *pAl* run was 16159030 which was a bad run and started at "2015-06-08 15:44:13 GMT". The previous run --- a pedestal run, 16159029, ended at "2015-06-08 14:24:54 GMT". So I arbitrarily selected the above time kind of in the middle. )
pp2ppRPpositions (STAR offline database) corrections
Originally, this is mainly to correct for the malfunctioning LVDT readings of the E1D between Mar. 18 and Apr. 6, 2015. I have come across 7 blocks/sub-periods where the E1D LVDT readings need to be corrected. Since the steps are the same 505004 (with one exception below), I have used an average of the LVDT readings closest to the period of malfunctioning (usually the good ones before but if the last good readings was too long before, I have taken the averages of those good ones shortly after the period in question). These are in the files ToCorrect1.txt, ToCorrect2.txt, .... ToCorrect7.txt. The average position of each of this period that I have used is listed at the end of the file. [ ToCorrect1.txt has one entry which I have "bracketed" as it has to be corrected with the positions of ~-32 cm, instead of ~-25 cm, and this is explained in the 1st below. ]In all cases, in the table of "Calibrations/pp2ppRPpositions", I have just inserted a set of 8 entries 1 second later in the "beginTime" than the original "beginTime" (the latter of which appears in all the .txt files listed here) as Dmitry Arkhipkin has instructed, even though there might be only one entry (E1D) that was changed.
However, I have come across the following and so I have also corrected them:
- For the run 16077055, it's ~32 cm or 449748 and so I have used the average of the last good LVDT readings corresponding to the same no. of steps (449748). The file is "ToCorrect1.exception_32cm.txt".
- On Apr. 7, there was a period that the LVDT's of E1D and E2D were swapped by mistake. I've corrected this as well. The file for this is "E2D.txt". I have needed to correct both E1D and E2D; and at the end of the file, the 1st position is for E1D and the 2nd one is for E2D.
- Accidentally, I've also come across a period (~6 pm on Apr. 3 to 10 am on Apr. 4) which had wrong entries because the online database was not updated (due to inaccessibility of CDEV/STAR portal server). Dmitry Arkhipkin has scanned the entire online database and found 5 periods which has such gap of a period > 5 minutes, including the above-mentioned one. I've checked that we only need to correct for 2, 4 runs in the above period (Apr. 4) and 6 runs on May 8 --- which was in the heavy-ion period where only the West side roman pots were actually inserted. For the other 3, they are either not in the pp2pp (roman-pot) data-taking period or the positions (the steps) remained the same before and after the gap (so that the offline database just used the previous LVDT positions available in the online database). The file for this is "NotUpdated.Apr4_.txt" and "NotUpdated.May8_.txt" respectively for Apr. 4 and May 8.
Pictures

| DX-D0 chamber | Roman Pot |
| Setup in the tunnel Roman Pot vertical station (old) |
Other useful figures |
2009 setup (Phase I)

|
|
Analysis notes |
| Drawings / Schemes / Pictures |
Other ADC and TAC distributions Silicon performance (cluster data) |
Photomultipliers data
Sets of plots below contain ADC and TAC spectra from the Roman Pot trigger counters, as they were in the sample of reconstructed elastic proton-proton scattering events (sqrt{s} = 200 GeV). Five datasets were used to prepare histograms: 0, 1, 4, 6, 9 (see numeration here).
One should take into account, that TAC spectra are sensitive to the time-space structure of colliding bunches (that's the reason why many "bumps" are presents in the distributions). Also, TAC spectra from Roman Pots were biased due to "TAC cut-off" (sharp right edge - loss of early events). Sets of points around TAC ~ 100 also results from the cut-off.
The PDF versions of the plots are listed at the bottom of the page.


Racks schemes
East   |
West
   |
Silicon performance (cluster data)
SVX chips pedestals: average and RMS (from here)
EHI (average): EHI (RMS): EHO (average): EHO (RMS):




EVU (average): EVU (RMS): EVD (average): EVD (RMS):




WHI (average): WHI (RMS): WHO (average): WHO (RMS):




WVD (average): WVD (RMS): WVU (average): WVU (RMS):




--------------------------------------------------------------
The part of page below contains sets of graphics with the data from Silicon Strip Detectors mounted in Roman Pots in 2009 run at sqrt{s} = 200 GeV. Five datasets were used to prepare histograms presented below: 0, 1, 4, 6, 9 (see numeration here). All histograms can be downloaded in the PDF format (see list of files at the very bottom).
Number and length of clusters
Sets of plots below contain distributions of the number of clusters(left) and number of strips (length) in clusters (right) in each silicon plane. Each row represents different Roman Pot, each column - a silicon plane.

Cluster energy:
Below an energy distribution of clusters is shown for each detector(file)/plane(row)/cluster length(column). Upper limit of cluster length used in reconstruction is 5.EHI: EHO: EVU: EVD:




WHI: WHO: WVD: WVU:




Cluster energy vs. strip
For clusters consisting of one strip (length=1) it was possible to draw the distribution of energy collected by the strip as a function of the strip number.EHI:




EHO:




EVU:




EVD:




WHI:




WHO:




WVD:




WVU:




Below the piece of code used to fill the histograms presented above is attached:
for(Int_t j=0; j<nOfPlanesInRpPerCoordinate; ++j){
Int_t nClusters = rps->numberOfClusters(i,Planes[coordinate][j]);
nOfClusters[i][Planes[coordinate][j]]->Fill(nClusters);
if(nClusters < maxNumberOfClusterPerPlane)
for(Int_t k=0; k < nClusters; ++k){
Int_t lenCluster = rps->lengthCluster(i,Planes[coordinate][j],k);
clusterLength[i][Planes[coordinate][j]]->Fill(lenCluster);
if(lenCluster <= maxClusterLength && lenCluster>0){
Int_t enCluster = rps->energyCluster(i,Planes[coordinate][j],k);
clusterEnergy[i][Planes[coordinate][j]][lenCluster-1]->Fill(enCluster);
if(lenCluster==1)
clusterEnergy_vs_strip[i][Planes[coordinate][j]]->Fill(1e3*rps->positionCluster(i,Planes[coordinate][j],k)/Pitch[coordinate], enCluster);
}
}
}
SSD
SSD group
Hardware and Software status
The link below points to a document detailling the current (April 2006) status of the SSD hardware and software.
List of SSD experts for Run VI
For the Run 6, the SSD experts can be reached at these numbers :Lilian MARTIN : +33 2 51 85 84 68 (lab), +33 6 88 06 45 32 (cell), +33 2 40 63 48 72 (home)
Jerome BAUDOT : +33 3 88 10 66 32 (lab), +33 6 49 19 74 42 (cell), +33 3 88 32 59 72 (home)
Web Site
These pages contain information on the SSD web site.
Latest updates
Information on the latest posts on the SSD web server
documentation on the new ADC HV decoupling capacitances
During the summer 2005 shutdown, the capacitances implemented on the adc boards have been changed. Some documents describing their specifications have been posted in a pdf file.
It can also be reached from the main page top menu : Hardware->Electronics->Ladder and "specs" in the "adc board" section.
Major changes
Up to February 2006, the SSD web site was hosted by the French computing center in Lyon. Its URL was http://star.in2p3.fr. The web server in Lyon has been modified so we decided to migrate the SSD web site into to the STAR web site. It is now located at : http://www.star.bnl.gov/STAR/ssd/.
Some pages have not been transfered yet such as the picture collection.End of the migration
The SSD web server is now fully transferred from Lyon to BNL.
The "phototheque" for instance is now accessible.
I have change several pages but some pages may still point to the old location.
West side cooling hoses -- photos
Look at the seriously kinked hoses (red arrow in one photo, red box in the other.
These photos were taken with the end cap removed, but all else intact.
Note that the kinks appear at the place where there is a bend and no outer support
tubing.
Conclusion: the inner tubing is too soft to be routed in this way -- it just folds.
SVT
The SVT Group pages are available on the old Web site.
Slow Controls
STAR Slow Control description and operations
TPC
FCF
Please attach any information about the Fast Cluster Finder (FCF) here.
Cluster flags
I am sending a short description of the
TPX cluster finder flags. This is more an Offline issue
but I guess this is a better group since it is a bit
technical.
1) The flags are obtained in the same way other
variables such as timebin and pad are obtained.
I understand that this is not exported to StHit *shrug*.
See i.e. StRoot/RTS/src/RTS_EXAMPLE/rts_example.C
2) They are defined in:
StRoot/RTS/src/DAQ_TPX/tpxFCF.h
The ones pertaining to Offline are:
FCF_ONEPAD This cluster only had 1 pad.
Generally, this cluster should be ignored unless
you are interested in the prompt hits where this
might be valid. The pad resolution is poor, naturally.
FCF_MERGED This is a dedconvoluted cluster.
The position and charge have far larger errors
than normal clusters.
FCF_BIG_CHARGE The charge was larger than 0x7FFF so
the charge precision is lost. The value is OK but the precision is
1024 ADC counts. Good for tracking, not good for dE/dx.
FCF_BROKEN_EDGE This is the famous row8 cluster.
Flag will disappear from valid clusters
once I have the afterburner running.
FCF_DEAD_EDGE Garbage and should be IGNORED!
This cluster touches either a bad pad or an end
of row or is somehow suspect. I need this flag for internal debugging
but the users should IGNORE those clusters!
-- Tonko
I commited the "padrow 8" afterburner to the DAQ_TPX
CVS directory. If all runs well, you should see no more
peaks on padrow 8. The afteburner runs during the
DAQ_READER unpacking.
However, please pay attention to the cluster finder flags
which I mentioned in an email ago. Specifically:
"FCF_DEAD_EDGE Garbage and should be IGNORED!
This cluster touches either a bad pad or an end
of row or is somehow suspect. I need this flag for internal debugging
but the users should IGNORE those clusters!"
-- Tonko
Field Cage Shorts
This page is for information regarding shorts or current anomalies in the TPC field cages.
Excess current seen in 2006
The attached powerpoint file from Blair has plots of the excess current seen in the IFC East for 2006.
Modeled distortions
Modeling the Distortion
Using StMagUtilities, Jim Thomas and I were able to compare models of the distortions caused by shorts at specific rings in the IFC with the laser data. First, I'll have to say that I was wrong from my Observed laser distortions: the distortion to laser tracks does not have the largest slope at the point where the short is. Instead, it has a maximum at that point! The reason is that the z-component of the electric field due to the distortion (withouth compensating resistor) changes signs at the location of the short. So ExB also changes directions, and the TPC hits are distorted in one rPhi direction on the endcap side of the short, and in the opposite rPhi direction closer to the central membrane.This can be seen in the following plot, where I again show the distortion to laser tracks at a radius of 60cm (approximately the first TPC padrow) versus Z in the east TPC using distored run 7076029 minus undistorted run 7061100 as red data points. Overlayed are curves for the same measure from models of a half-resistor short (actually, 1.14 MOhm short as determined by the excess current of ~240+/-10nA [a full 2MOhm short equates to 420nA difference]) located at rings 9.5, 10.5, ..., 169.5, 179.5 (there are only 182 rings).
[note: earlier plots I have shown included laser data at Z = -55cm, but I've found that the laser tracks there weren't of sufficient quality to use; I've also tried to mask off places where lasers cross over each other]
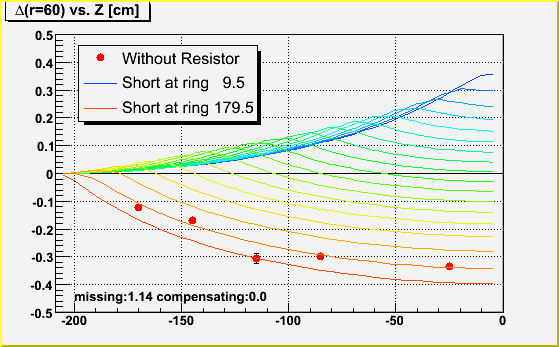
The above plot points towards a short which is located somewhere among rings 165-180 (Z < -190cm). As the previous years' shorted rings were rings 169 and 170 ( = short at ring 169.5), it seems highly likely that the present short is in the same place. More detail can be seen by looking at the actual laser hits. The first listed attached file shows the laser hits as a function of radius for lasers at several locations in Z. The dark blue line is a simple second order polynomial fit I used to obtain the magnitude of the distortion at radius 60cm, which I used in the above plot. The magenta line is the model of the half-resistor short at ring 169.5, and the light blue line is the same for ring 179.5 (the bottom two curves on the above plot). Either curve seems to match the radial dependence fairly well.
Further refinement can be achieved by modeling the exact resistor chain. We have a permanent short at ring 169.5 (rings 169 and 170 have been tied together), and have replaced the two 2MOhm resistors between 168-169 and 170-171 with two 3MOhm resistors (see the attached photo of the repair, with arrows pointing to candidate locations for shorts via drops of silver epoxy). So it is more likely that we have a 1.14MOhm short on one of these two 3 MOhm resistors. The three curves in this next plot are:
{kind=link}
- red: 1.14MOhm short on a 3MOhm resistor at 168.5, full short at 169.5, 3MOhm resistor at 170.5
- green: 1.14MOhm short on a 2MOhm resistor at 169.5, normal 2.0MOhm resistors at 168.5 and 170.5
- blue: 3MOhm resistor at 168.5, full short at 169.5, 1.14MOhm short on a3MOhm resistor at 170.5
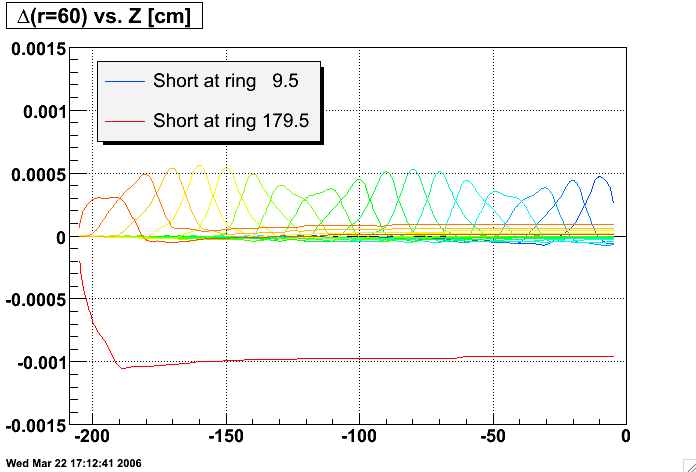{kind=link}
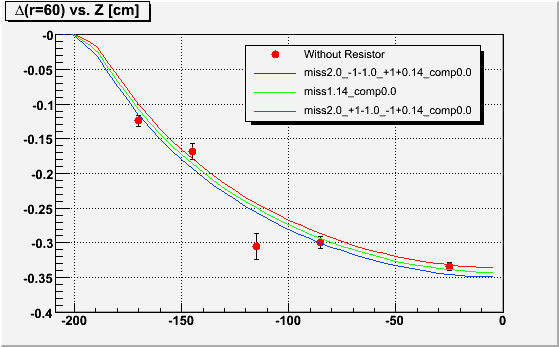
We can also take a look at the data with the resistor in. Here is the same plot as before with a 1.14MOhm short at the same locations, but with an additional compensating resistor of 1.0MOhm. The fact that all the data points are below zero points again towards a short near the very end of the resistor chain, preferring a location of perhaps 177.5 over shorts near ring 170. These plots do not include the use of the 3MOhm resistors, but that difference is below the resolution presented here.
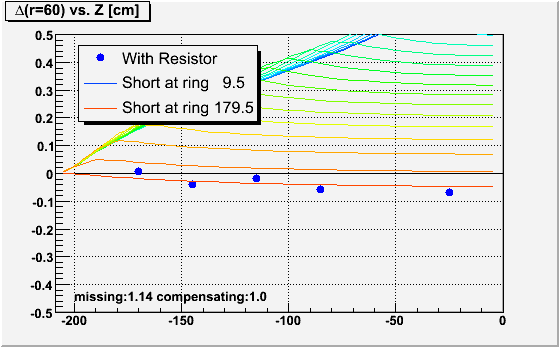
Zoom in with finer granularity between rings (every other ring short shown):
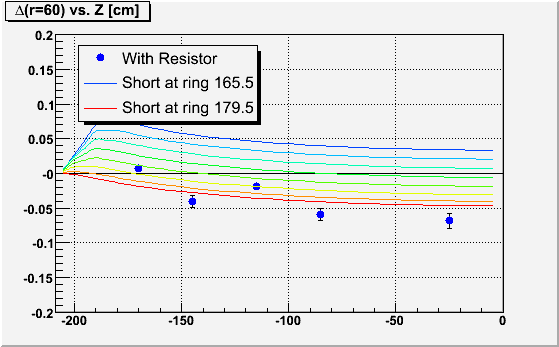
The second listed attached file shows the laser hits as a function of radius for lasers at several locations in Z for the case of the resistor in, again with magenta and blue curves for the model with shorts at ring 169.5 and 179.5 respectively.
Applying the Correction
I tried running reconstruction on the lasers using the distortion corrections for the 1.14MOhm short at three locations: 170.5 and 171.5 (two possible spots indicated in Alexei's repair photo), and 175.5 (closer to what the with-resistor data pointed to). The results are in the following plots. The conclusion is that the 175.5 location seems to do pretty well at correcting the data, slightly better than the 170.5 and 171.5 locations, for both with and without compensating resistor. For this reason (the laser data), we will proceed with FastOffline using a short at 175.5, even though we have no strong reasons outside the laser data to suspect that the short is anywhere other than the rings 168-172 area where the fix was made.
| 170.5 | 171.5 | 175.5 |
|---|---|---|

|
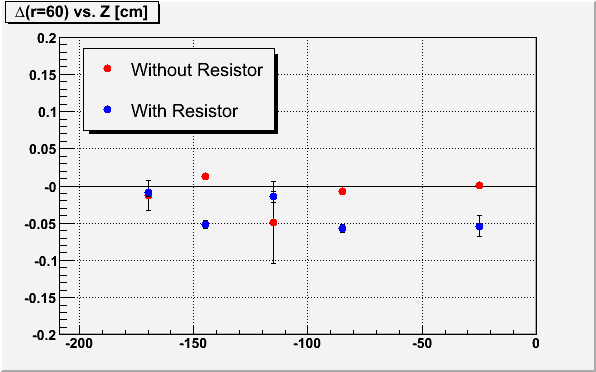
|

|
Gene Van Buren
gene@bnl.gov
Choosing an external resistance for an IFC short
It is clear that when a field cage short is close to the endcap, it is best to add an external resistance to compensate for the amount of the missing resistance from the short as that would restore the current along the length of the resistor chain and only disrupt the potential at the last (outermost) rings instead of along the full length. A short near the central membrane would benefit less from this as restoring the proper current does restore the potential drop between each ring, but leaves almost all rings at a potential offset from the intended potential, essentially tilting the E field over nearly the whole volume.But the question then comes as to whether we can decide on the best external resistance for minimizing the distortion, to align with the principle that the best distortion we can choose is the one which requires the least correction, in case we're not quite correcting it accurately. To answer that, the distortion modeling was run with a variety of locations for an IFC west 2 MOhm single-resistor short, and a variety of external resistances. The code to run this modeling has been attached as a tar file to this Drupal page in case there is interest to re-run it (e.g. for an OFC short).
Here are the results:
- Left: Surface plot showing the mean r-φ distortion we would get at the first iTPC pad row (radius = 55 cm) averaged over all active west-side z as a function of where the short is located ("ring of short") and how much external resistance is added.
- Right: Same but drawn as contours. The curve of interest to follow, that leads to <distortion>=0, is the one that starts near (ring,external resistance) = (110,0.0) and ends near (180,2.0), as indicated by the red markers. If the short is at ring 160.5, for example, then this curve indicates an external resistance of ~1.05 MΩ minimizes the distortions averaged over all active west-side z.
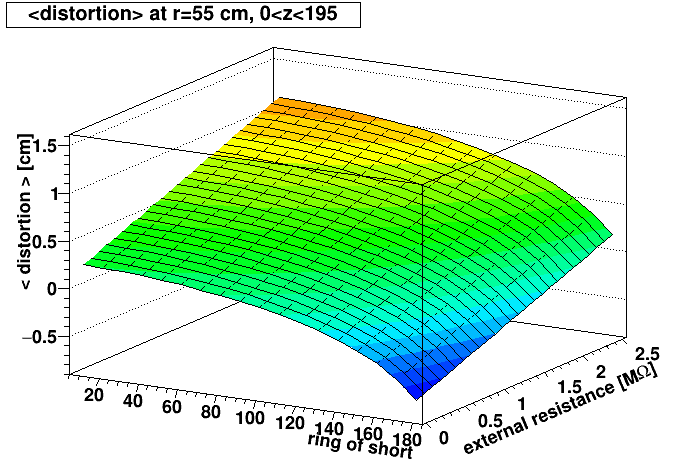
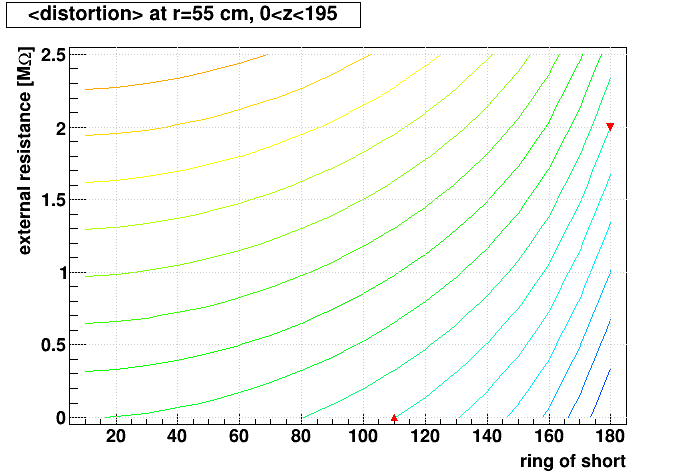
However, it may be more important to restrict the z range included in the distortion average, as most tracks of interest do not cross the inner pad rows at high z...
- Left: Similar surface plot, but restricting the average to 0 < z < 100 cm.
- Right: The curve of interest to follow in this contour plot, that leads to <distortion>=0, is the one that starts near (100,0.0) and ends near (180,2.0), as indicated by the red markers. If the short is at ring 160.5, then this curve indicates that an external resistance of ~1.25 MΩ minimizes the distortions averaged over 0 < z <100 cm.
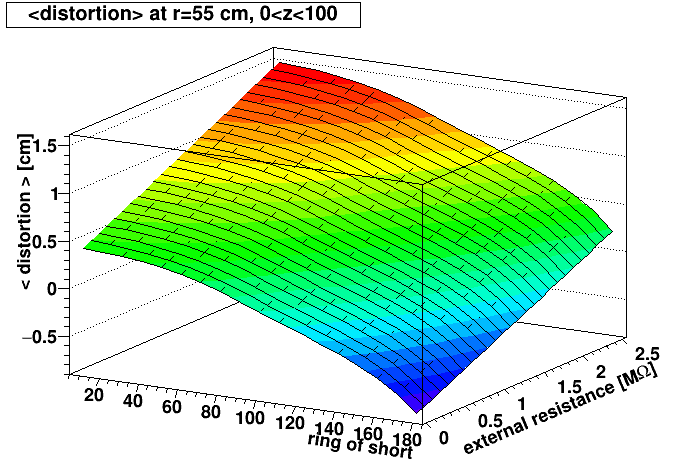
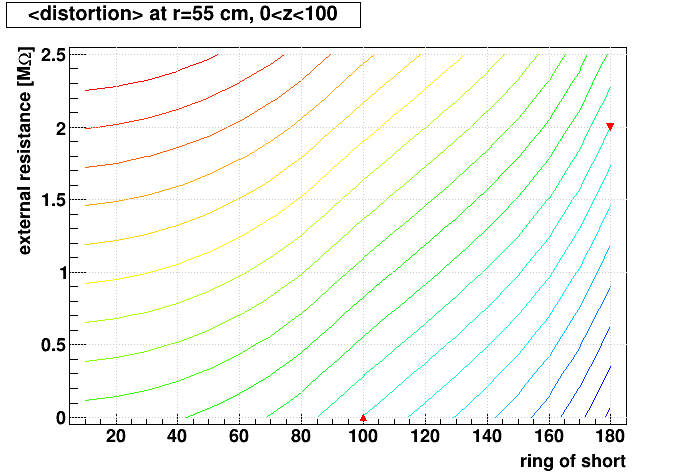
Some additional observations:
- The curve of interest should always end close to (180.5,2.0), as that approaches the condition where the external resistance is no different than an internal resistance at the very end of the chain.
- The above is a simplification of what area should be integrated, as tracks with η ≠ 0 cross a variety of z at various radii, complicating the impact on their reconstruction. A track-by-track analysis of impact would be more meaningful, but a lot more work! The modeling shown here can serve as a rough guide to the best external resistance to use, but should not be taken as definitive for all physics.
- It is interesting to note that the model implies that a negative external resistance would help minimize the <distortion> when the short is closer to the central membrane (ring 0). A way to think of this is like having a short at both ends, such that the potentials are too high near the central membrane, and then too low near the endcap, so that the E field tilts one way in the region near the central membrane, isn't tilted at half the drift length, and then tilts the other way near the endcap, resulting in opposing distortions for electrons which drift the full length that serve to cancel each other. This could in principle be achieved by reducing the overall resistance of the Resistor box at the end of the Field Cage chain. The STAR TPC has (as of this documentation) had no persistent shorts near the central membrane that would warrant this approach.
-Gene
OFC West possible distortion
There remains a possible distortion due to a potential short in the OFC west as well. We see a bimodal pattern of 0 or 80 excess nanoAmps coming out of the OFC West field cage resistor chain (it has been there since the start of the 2005 run). That corresponds to a 0.38 MOhm short (420nA = 2 MOhms). The corresponding distortion depends on the location of the electrical short. The plot shown here is the distortion in azimuth (or rPhi) at the outermost TPC padrow near the sector boundaries (r=195 cm, the pads are closer to the OFC near the sector boundaries) due to such a short between different possible field cage rings:
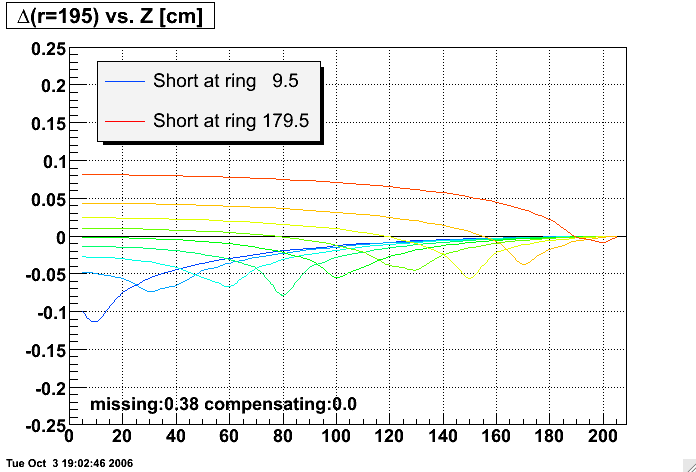
In terms of momentum distortion, a 1mm distortion at the outermost padrows would cause a sagitta bias of perhaps about 0.5mm for global tracks (and even less for primary tracks), corresponding to an error in pt in full field data of approximately 0.006 * pt [GeV/c] (or 0.6% per GeV/c of pt). This is certainly at the level where it is worthwhile to try to fix the distortion if we can figure out where the short is. It is also at the level where we should be able to see with the lasers perhaps to within 50cm where the short is.
Just as a further point of reference, the plot for radius = 189cm, corresponding to the radius of the outermost padrow in the middle of a sector (its furthest point from the OFC) can be found here.
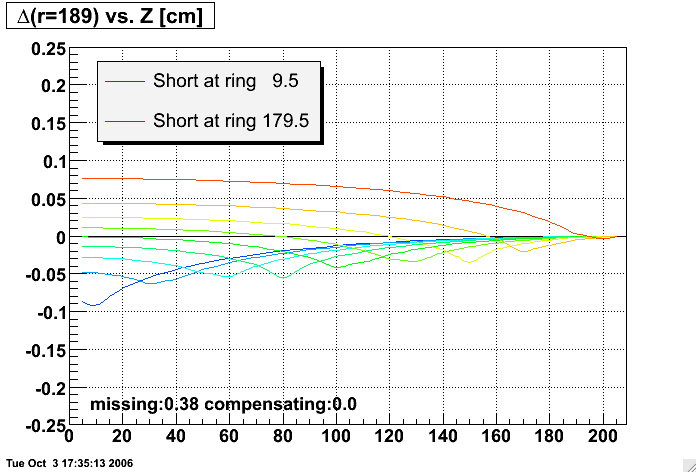{kind=link}
This possible distortion remains uninvestigated at this time.
Gene Van Buren
gene@bnl.gov
Other FC short distortion measurements
I considered the possibility that other measurements might help isolate the location of the short in the TPC. So, using the Modeled distortions, I modeled the effects of adding even more compensating resistance to the end of the IFC east resistor chain. Below are the results for shorts located at ring 165.5 (between rings 165 and 166), 167.5, 169.5, ..., 179.5 as indicated for the colored curves. All plots use a 1.0cm range on the vertical scale so that they can be easily compared. I had hoped that one resistance choice or another would cause more separation between the curves, giving better resolving power between different short locations. But this dependence is small, and actually seems to decrease a little with increased compensating resistance. Remember also that the last laser is at Z of about -173cm.Also perhaps worth noting is that the 1.0MOhm compensating resistor probably helps reduce the distortions even more than an exact 1.14MOhm would. The latter causes the distortions not to change between the short location and the central membrane, but the former actually causes the distortion to re-correct the damage done between the short location and the endcap!
| Compensating resistance [MOhms] |
Distortion on first padrow vs. Z |
|---|---|
| 0.0 |
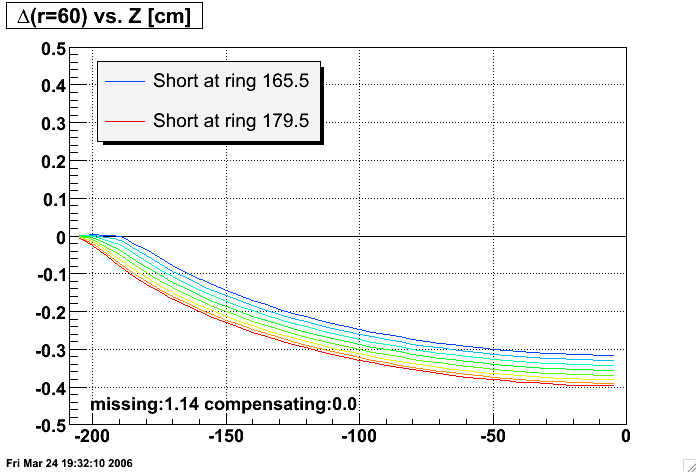 |
| 1.0 |
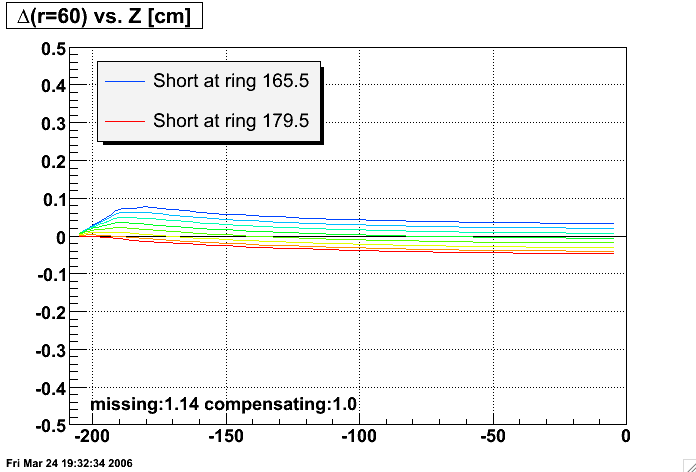 |
| 1.14 |
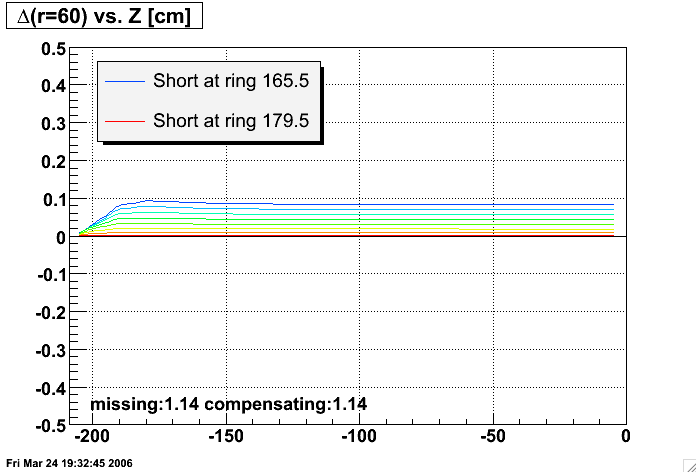 |
| 2.0 |
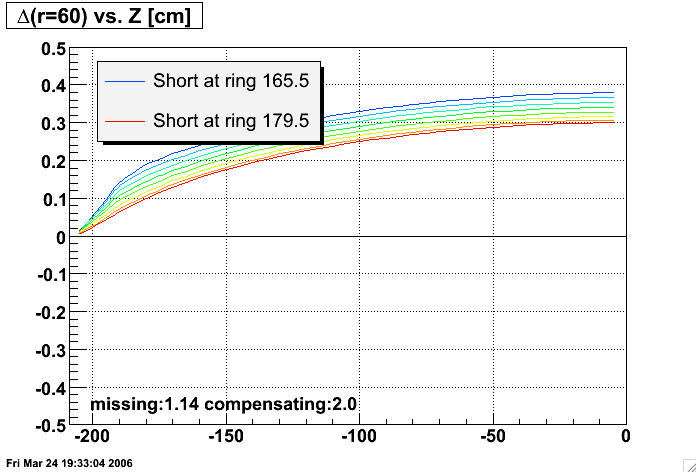 |
| 4.0 |
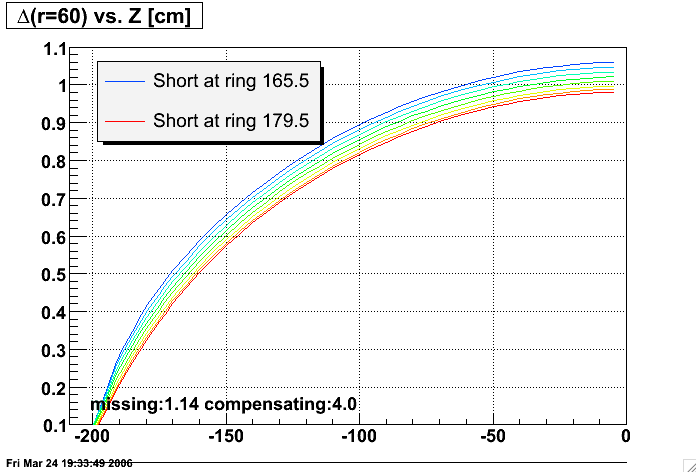 |
| 20.0 |
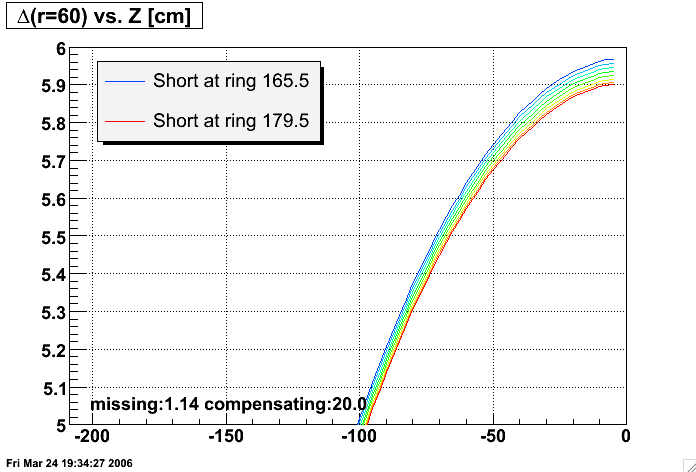 |
Gene Van Buren
gene@bnl.gov
Observed laser distortions
First look
The first listed attached file was my initial look at distortions to laser tracks in the TPC (not that it is upside down from subsequent plots as I accidentally took the non-distorted minus the distorted here). These are radial tracks, and the plots are off the difference between run 7068057 (with excess current) and 7061100 (without excess current). Also, run 7068057 was taken with collisions ongoing, so there is some SpaceCharge effect as well (7061100 was taken without beam). I believe this explains the rotation of the tracks at low positive z (west side).
Second look: dedicated runs
On March 17, we took a couple laser runs without and with a compensating resistor to get the IFC east current at least approximately correct. I plotted 1/p of laser tracks and took the profile. Straight tracks give very low curvature = low 1/p. The distortion brings up the curvature, as can be seen in the IFC east without resistor. The same plot also shows large error bars for the negatively charged laser tracks because there aren't many: the curvature tends to bring them positive. The IFC west shows the appropriately low level without any distortion, but the timing on the west lasers was wrong, so they are not reconstructed where they are supposed to be in Z. I am uncertain whether this bears any relation to the odd behavior of the first laser on the west side (showing up here at Z of about +67cm). The IFC East plot for the no-compensating-resistor run also shows that 1/p begins to drop somewhere around Z of about -100cm. The short would be located where the largest slope occurs in this plot (because the distortion to tracks is an integral of the distortion in the field, and the short is where the field distortions are largest), but the data isn't strong enough to pin this down very well. The negative tracks indicate a short between the lasers at -145cm and -115cm. But the seemingly better quality positive tracks are less definitive on a location as the slope appears to get stronger at more negative Z, implying a short which is at Z beyond -170cm.
No compensating resistor (run 7076029):
With 1 MOhm compensating resistor (run 7076032), which brings IFC east current to correct value within ~20 nAmps, according to 10:27am 2006-03-17 entry in Electronic ShiftLog:

Again, I looked at the distortion as seen be comparing TPC hits from the distorted runs to those from an undistorted run as I did at the beginning of this page (but this time taking distorted minus undistorted). For the undistored, I again have only run 7061100 to work with as a reference. The plots for each Z are in the second listed attached file below, where the top 6 plots are for the no-compensating-resistor run (7076029), and the bottom 6 are the same ones with the resistor in. I also put on the plots the value of the difference from a simple fit (meant only to extract an approximate magnitude) at a radius of 60cm (approximately the first TPC pad row). Those values are also presented in the following plot as a function of Z, confirming the improvement of the distortion with the resistor in place.
These plots seem to point at a short which is occurring somewhere between the lasers at Z = -145 and -115cm.
Gene Van Buren
gene@bnl.gov
Resistor box at the end of the Field Cage chain
After ring 181, the potentials are determined by a box of resistors which sit outside the TPC. This is well documented, but at the time of this writing is not complete. This was particularly relevant during Run 9 when an electrical short developed inside the TPC between rings 181 and 182 of the outer field cage on the west end (OFCW). Shown here is a plot of the resistors:
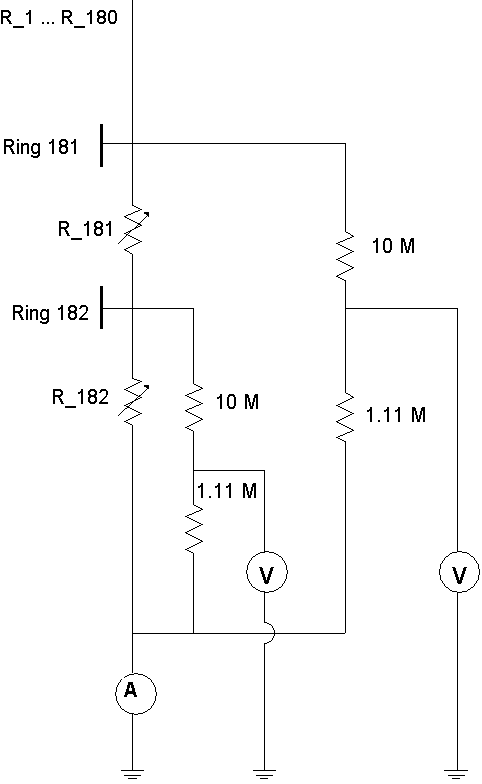
Note that the ammeter is essentially a short to ground, while the voltmeters are documented in the Keithley 2001 Manual to express over 10 GOhm of resistance (essentially infinite resistance). The latter only occurs when the input voltage is below 20 V. The voltages at rings 181 and 182 are above 20 V and below 200 V (though actually at negative voltage), so their voltage is scaled by the shown 1.11 and 10.0 MOhm resistors to be stepped down by a factor of x10. The readings are then multiplied by x10 before being recorded in the Slow Controls database.
After Run 9, this box was disconnected and resistances were measured for the OFCW portion. Because the resistors were not separated from each other, equivalent resistances were actually measured. In the below math, R182eq refers to the resistance measured across resistor R_182, while Rfull is the resistance measured between the input to the box from ring 181 to the output for the ammeter. R111 is the combined 10 + 1.11 MOhm pair.
double R111 = 10.0 + 1./(1./1.11 + 1./10000.) 11.11 double R182eq = 0.533 // measured double Rfull = 2.31 // measured double pa = R111 - Rfull double pb = R111*(R111 - 2*Rfull) double pc = (R182eq - Rfull)*R111*R111 double R181 = (-pb + sqrt(pb*pb - 4*pa*pc))/(2*pa) 2.3614 double R182 = 1./(1./R182eq - 1./R111 - 1./(R181+R111)) 0.5841 double R182b = 1./(1./R182 + 1./R111) double Vcm = 27960. double Rtot = 364.44 // full chain double Inorm = Vcm/Rtot 76.720 double V181_norm = Rfull * Inorm 177.22 double V182_norm = V181_norm * R182b/(R181 + R182b) 33.724 double Rshorted = 1./(1./R111 + 1./R182 + 1./R111) 0.5286 double Rmiss = Rfull - Rshorted 1.7814 double Ishorted = Vcm/(Rtot - Rmiss) 77.097 double V181_short = Rshorted * Ishorted 40.750 double Iexcess = Ishorted - Inorm 0.377
Note that many of these numbers would be different for the inner field cages.
External resistors to make up for missing resistance can also be added to the chain here.
GridLeak Studies
- Review of GridLeak at 2013-03-01 iTPC discussions
Floating Grid Wire Studies
Distortions in TPC data (track residuals) are seen in 2004-2006 data which are hypothesized to come from a floating Gating Grid wire. Notes from a meeting of TPC experts regarding the topic held in October 2006 can be found here.See PPT attachment for simulations of floating grid wires from Nikolai Smirnov which show that the data is consistent with two floating -190V wires in sector 8, and two floating -40V wires in sector 3 (all wires are at -115V when the grid is "open").
GridLeak Distortion Maps
Using the code in StMagUtilities, these are maps of the GridLeak distortion.
First, this is a basic plot of the distortion on a series of hits going straight up the middle of a sector (black: original hits; red: distorted hits). The vertical axis is distance from the center of the TPC (local Y) [cm], and the horizontal axis is distance from the line along the center of the sector (local X). Units are not shown on the horizontal axis because the magnitude of the distortion is dependence on the GridLeak ion charge density, which is variable.
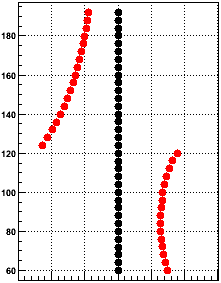
The scale of the above plot is deceptive in not showing that there is some distortion in the radial direction as well as the r-phi direction. The next pair of plots show a map of the distortion [arb. units] in the direction orthogonal to padrows (left) and along the padrows (right) versus local Y and angle from the line going up the center of the sector (local φ) [degrees].
One can see that the distortion is on the order of x2 larger along the padrows than orthogonal to the padrows. Also, it is clear that there is a small variance in magnitude of the distortion across the face of the sectors.
The next plot shows the magnitude of the distortion [arb. units] along the padrow at the middle of the sectors vs. local Y [cm] and global Z [cm]. The distortion is largest near the central membrane (Z=0) and goes to zero at the endcaps (|Z| ≅ 205 cm), with a linear Z dependence in between, which flattens off at the central membrane and endcap due to boundary conditions that the perturbative potentials are due to charge in the volume and are constrained to zero at these surfaces.
GridLeak Simulations
Nikolai Smirnov & Alexei Lebedev:Data for STAR TPC supersector. 05.05.2005 07.11.2005 Jon Wirth, who build all sectors provide these data. Gated Grid Wires: 0.075mm Be Cu, Au plated, spacing 1mm Outer Sector 689 wires, Inner Sector 681 wires. Total 1370 wires per sector Cathode Grid Wires: 0.075mm Be Cu, Au plated, spacing 1mm Outer Sector 689 wires, Inner Sector 681 wires. Total 1370 wires per sector Anode Grid Wires:0.020mm W, Au plated, spacing 4mm Outer Sector 170 wires, Inner Sector 168 wires. Total 338 wires per sector Last Anode Wires: 0.125mm Be Cu, Au plated Outer Sector 2 wires, Inner Sector 2 wires. Total 4 wires per sector
We are most interested in the gap between Inner and Outer sector, where ion leak is important for space charge. On fig. 1 wires set is shown. The distance between inner and outer gating grid is 16.00 mm. When Grid Gate is closed, the border wires in Inner and Outer sectors have -40V, each next wire have -190V and after this pattern preserved in whole sector - see fig. 2. When gating grid is open, each wire in gating grid have the same potential -115V. Above grid plane we have a drift volume with E~134V/cm to move electrons from tracks to sectors and repulse ions to central membrane. Cathode plane has zero voltage, while anode wires for outer sector holds +1390V and for inner sector +1170V.

Fig. 1. Wire structure between Inner and Outer sector.

Fig.2 Voltages applied to Gating Grid with grid closed.
Another configurations of voltages on gating grid wires are presented on fig.3. All these voltages are possible by changing wire connections in gating grid driver. Garfield simulations should be performed for all to find a minimum ion leak.

Fig.3 Different voltages on closed gating grid (top: inverted, bottom: mixed).
This is a key for Nikolai's files: there are 4 sets of files in each set there is simulation for Gating Grid voltages on last wires. Additionally he artificially put a ground shield on the level of cathode plane and simulated collection for last-thick anode wire and also ground shield and last thin anode wire.
| Setups: | Standard | Inverted | Mixed | Ground Strip | Ground Strip and Wire |
|---|---|---|---|---|---|
| Equipotentials | PS |
PS |
PS |
PS |
PS |
| Electron paths | PS |
PS |
PS |
PS |
PS |
| Ion paths (inner sector) |
PS |
PS |
PS |
PS |
PS |
| Ion paths (outer sector) |
PS |
PS |
PS |
PS |
PS |
GridLeak: Gain Study
In February 2005, Blair took some special runs with altered TPC gains so we could study the effect on the GridLeak distortion. What is shown in the following plots is the distortion (represented by the profile of residuals at padrows 12 and 14, which amounts to 0.5 * [residual at padrow 12 + residual at padrow 14]) as a function of Z in the TPC. Black points are the distortions from sectors 7-24, and red are 1-6, which are the sectors where the TPC gain was reduced. I have chosen as labels "Norm", "Half", and "Low" for these three conditions of no gain change, half gain change on the inner pads only, and half gain change on both inner and outer.
First note: the ever-present problem that our model goes to zero distortion at the endcaps, while the measured distortions do not appear to do so (though the distortion curves should flatten out [as seen in the above plots] as a function of Z near the endcap and central membrane due to boundary conditions on the fields in the TPC).
Second note: I have not excluded sector 20 from these plots, which is partly to explain why the east half (z<0) has slightly less distortions than the west in these profile plots. In reality, east and west were about even for a normal run (distortions excluding sector 20).
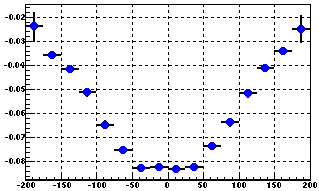{kind=link}
Here is the z-phi plot for Low (it's almost difficult to see the distortion reduction in the z-phi (in "o'clock") plot for Half):
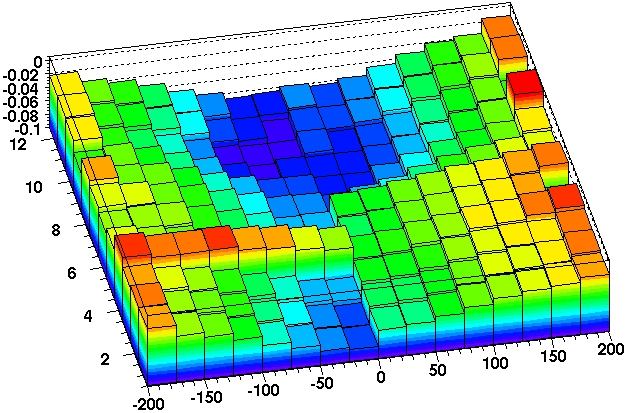
Third note: (though not too important for this study because we generally ignore east/west comparisons) the sectors between 1-6 o'clock already tend to show somewhat less distortion than the sectors at 7-12 o'clock, and because it is true on both halves of the TPC, it is more likely to be due SpaceCharge azimuthal anisotropy than asymmetries in the endplanes. Here are the distortions at |z|<50 for east (red) and west (blue) as a function of phi in "o'clock" where one can see the already present asymmetry, explaining why sectors 1-6 are already less distorted in the Norm run than sectors 7-12:
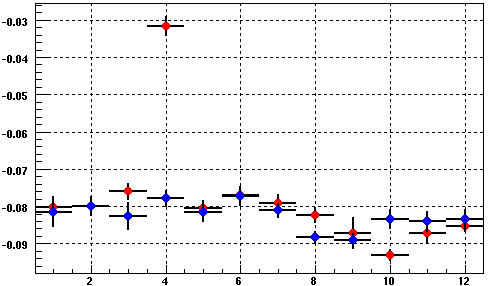
We have to normalize to sectors 7-12 to see the drop in distortions as it the runs are taken at different times when the luminosity of the machine, and therefore the distortion normalizations, are different. Here are the ratios from sectors 1-6 / sectors 7-12:

And the double ratios to see the drop in the Half and Low runs w.r.t. the Norm run:
These plots show ratios in the Z = 25-150cm range of about 0.86 and 0.59 respectively, or reductions of about 14% and 41% give or take a few percentage points. Data beyond 150cm tends to be poor and there's little reason to believe that the ratio really changes by much there. However, there does appear to be some shape to the data, which is not understood at this time.
Another way to calculate the difference in distortions is to take a linear fit to the slope of the distortions between z = 25-150cm. Those fit slopes are:
Low: 1-6: 0.000250 +/- 0.000019 7-12: 0.000420 +/- 0.000024 Half: 1-6: 0.000365 +/- 0.000023 7-12: 0.000433 +/- 0.000025 Norm: 1-6: 0.000401 +/- 0.000024 7-12: 0.000422 +/- 0.000023Again, we need the ratio of ratios:
[Half(1-6)/Half(7-12)] / [(Norm(1-6)/Norm(7-12)] = 0.89+/-0.11 (12%) [Low(1-6)/Low(7-12)] / [(Norm(1-6)/Norm(7-12)] = 0.63+/-0.08 (12%) Inner reduction = (11 +/- 11)% Outer reduction = (26 +/- 11)% Total reduction = (37 +/- 8)%These numbers are smaller than the reductions indicate by the above plot of double ratios of the distortions themselves. This likely reflects the errors in fitting the slopes. In that sense, the plot values may be more accurate. We need not worry in this study about getting the reduction numbers exact, but it is perhaps accurate enough to say that the inner sector gain drop reduces the distortion by about 13%, and the outer sector gain drop reduces it further by about 27% (about twice as much as the inner) from the original distortion. It is clear that both inner and outer TPC sectors contribute to the distortion, and that the outer TPC contributes significantly more to the distortion. If hardware improvements can only be implemented for either the inner or outer, then the outer is the optimal choice in this respect. It is not obvious offhand whether this is consistent with the GridLeak Simulations which we have done so far for these ion leaks.
Long term life time and future of the STAR TPC
In an effort to better understand the future of the TPC in the high luminosity regime, several meetings were held and efforts carried through.Present at the meeting(s) were: myself (Jerome Lauret), Alexei Lebedev, Yuri Fisyak, Jim Thomas, Howard Wiemann, Blair Stringfellow, Tonko Ljubicic, Gene van Buren, Nikolai Smirnof, Wayne Betts (If I forgot anyone, let me know).
It is noteworthy to mention that the TPC future was initially addressed at the Yale workshop in (Workshop on STAR Near Term Upgrades) where Gene van Buren gave a presentation on TPC - status of calibration, space charge studies, life time issues. While the summary was positive (new method for calibration etc...) the track density and appearance of new distorsions as the lumisoity ramped up remained a concern. As a reminder, we include here a graph of the initial Roser luminosity projection.

| 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | |
| Peak Au Luminosity | 4 | 12 | 16 | 24 | 32 | 32 | 32 | 32 | 32 | 48 | 65 | 83 | 83 |
| Average Au Store Luminosity | 1 | 3 | 4 | 6 | 8 | 8 | 8 | 8 | 16 | 32 | 55 | 80 | 80 |
| Total Au ions/ring [10^10] | 4 | 8 | 10 | 11 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 |
An update summary of the status of the TPC was given by Jim Thomas at our February
2005 collaboration meeting (A brief look at the future evolution of TPC
track distortions ; see attachement below) to adress ongoing GridLeak
issues. Slide 19 summary for teh future is added here:
Will the TPC Last Forever?
Probably of academic interest
Questions arose as per the liability of the detector itself i.e., aging issues (including shorts and side effects) were raised along with increasing concerns related to grid leak handling. Alexei Lebedev proposed a serie of hardware modification in May 2005 to account for those issues (see What we can do with TPC while FEE are in upgrade attachement).
Relevant to possible software and hardware solutions for the grid leak are GridLeak Simulations of the fields and particle paths in the region near the inner/outer TPC sector gap.
Extensive analysis are also available from the pages You do not have access to view this node and especially (for AuAu) this page QA: High Luminosity and the Future.
Anode wire aging
See the attached file: RD51-Note-2009-002.pdf
SpaceCharge studies
Studies of SpaceCharge in the TPC.
Potential distortions at projected luminosities for different species
Here I show the expected distortions in the STAR TPC as represented by the pointing error of tracks to the primary vertex (otherwise known as the DCA) due to experienced (star symbols) and projected luminosities (triangle and square symbols) at RHIC. One can think of these distortions as being caused by the accumulated ionization in the TPC due to charged particles traversing it from collisions (ignoring any background contributions), or the charge loading of the TPC.
These measurements and projections are current as of November 2008 with the exception of the pp500 (pp collisions at √s = 500 GeV) projections (open symbols) [1,2]. In 2005 the expectation was that RHIC II could achieve pp200 peak luminosities of 150 x 1030 cm-2sec-1 and pp500 peak luminosities of 750 x 1030 cm-2sec-1 [3]. Presently (2008), the pp200 peak luminosity estimate at RHIC II has dropped to 70 x 1030 cm-2sec-1, and this is what is used in my plot. I have found no current estimate for pp500. The 2005 estimate indicated a factor of x5 more peak luminosity from the 500 GeV running than 200 GeV; I do not know if that is still possible, but I have chosen to use only a factor of x2 (should be conservative, right?) in the plot shown here.
I have also had to estimate the conversion of luminosity into load in the TPC for pp500 as we have not yet run this way. We did run at √s of approximately 405 GeV in June 2005, which showed a 17% increase in load over pp200 per the same BBC coincidence rate [pp400 (2005)]. I have roughly estimate that this means approximately a 25% increase in TPC load going from pp200 to pp500, with no serious basis for doing so.
Finally, the documented projections show that RHIC II will achieve approximately a factor of x2.6 increase over RHIC I for both AuAu200 and pp200 [2]. I have taken the liberty to apply the same factor of x2.6 to CuCu200, dAu200, and pp500.
(Note: The pp data use a different horizontal axis which was adjusted to lie amidst the ion data for ease of comparison, not for any physically justified reasons.)
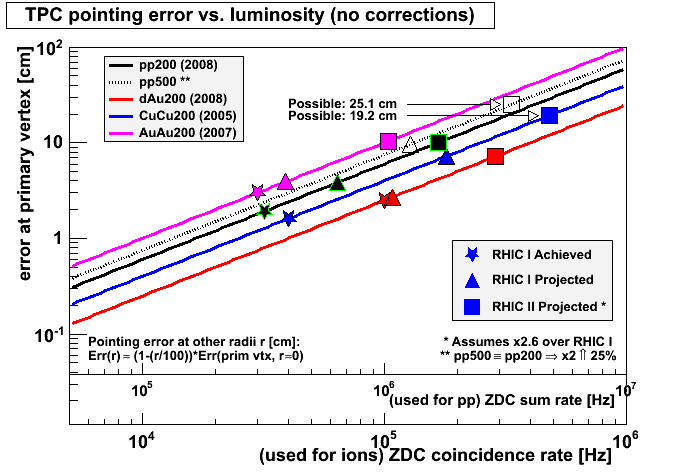
Of the data we've taken so far, AuAu collisions have presented the highest loading of the TPC. However, CuCu collisions have the potential to introduce the highest loading for ions, and the RHIC II projections lead to pointing errors close to 20 cm! Actually, SiSi may be even worse (if we ever choose to collide it), as the luminosity is expected to achieve a factor x4.2 higher than CuCu, while the load per collision may be in the 40-50% ballpark of CuCu [2,3].
Loading due to pp collisions at 200 GeV are generally similar to AuAu collisions at 200 GeV, but 500 GeV pp collisions will load the TPC much more severely. Even in RHIC I, we may have pointing errors between 5-10 cm using my conservative estimate of x2 for the luminosity increase over pp200. If the factor of x5 is indeed possible, then use of the TPC in pp500 at RHIC II seems inconceivable to me, as the simple math used here would completely break down (the first TPC padrows are at 60cm, while 2.5*25.1 cm is larger than that)**. Even with a factor of x2, things may be quite problematic for pp500 in RHIC II.
References:
Some additional discussions from 2005 regarding the TPC and increased luminosities are documented at Long term life time and future of the STAR TPC.
Note: This is an update of essentially the same plot shown in the 2007 DAQ1000 workshop (see page 27 of the S&C presentation).
** Actually, a rather major point: we never get full length tracks with DCAs to the primary vertex of more than a couple cm anyhow, due to the GridLeak distortion. These tracks get split and the DCAs go crazy at that point. Since GridLeak distortion corrections are only applied when SpaceCharge corrections are, an roughly appropriate SpaceCharge+GridLeak correction must be applied first to even find reasonably good tracks from which to determine the calibration.
SpaceCharge in dAu
In Run VIII, dAu data was acquired at high enough luminosities to worry about SpaceCharge (it was ignored previously in the Run III dAu data (2003)). Attached is initial work by Jim Thomas to determine the charge distribution in dAu.
TPC performance
Documentation on performance of the TPC
- Run 15 200 GeV p+Al Hit Errors
- Run 15 200 GeV p+Au Hit Errors
- Run 15 200 GeV p+p Hit Errors
- Run 14 (200 GeV Au+Au) TPC Hit Errors
- Run 14 (15 GeV Au+Au) TPC Hit Errors
- You do not have access to view this node (days 74-128) and You do not have access to view this node (pp510)
- Run 12 Cu+Au TPC Hit Errors
- You do not have access to view this node
- Run 12 pp510 hit errors
- You do not have access to view this node (You do not have access to view this node)
- You do not have access to view this node
- You do not have access to view this node
- You do not have access to view this node
- You do not have access to view this node, both pp500 and pp200, and re-calibrated You do not have access to view this node
- You do not have access to view this node (pp200, not certain it was Run 8 or an earlier dataset)
- You do not have access to view this node
TPC speed upgrade 2022
This page is setup to keep track of meetings documents for the task force work for thetpc speed upgrade for runs 23-25.
Status as of December 14 22,
Presentation from Tonko at collaboration meeting (pdf)
TPC meeting June 22
Update from Tonko on progress (pdf)
Meeting March 24
Discussion points send out ahead of meeting (Flemming) pdf
Progress slides - tonko pdf
minutes - Richard pdf
First meeting February 17
overview presentation and discussion (ppt)
minutes (pdf)
-
after meeting Jeff posted the projected resource needs for handling data to S&C (pptx)
Charge and Committee
TPX high rate test
- Discussion of test plans
- Discussion of test results
- Attached is a slide of the anode currents
TRG
Trigger Detectors
L2 documentation
.
2008 pp run
Details of L2-algos (triggers) as implemented for pp run in February of 2008
Mapping used during data taking is in attachment 1)
a Overview (Jan, later Ross)

Graph illustrates the key changes in L2 processing scheme allowing for fast event abortion. Jan
b) B+EEMC common calib (Jan)
Common BEMC, EEMC calibration algos (do not abort)
- Goal: calibrates Barrel, Endcap towers, result is used by other L2-algo
- RTS params:
int par_dbg; // use 0 for real event processing int par_gainType; enum {kGainZero=0, kGainIdeal=1, kGainOffline=2}; int par_nSigPed; // ADC, filters towers float par_twEneThres; // GeV, filters towers float par_hotEtThres; // GeV, only monitoring histos - Class name: L2btowCalAlgo08::public L2VirtualAlgo2008 and similar for ETOW , 1 instance of each.
- Event processing uses method calibrateBtow(int token, int bemcIn, ushort *bemcData);+ similar for ETOW
Not used: void computeUser(int token); bool decisionUser(int token) - Hardcoded params: mxListSize: BTOW =500, ETOW=200
- Details of Algo:
------- tower threshold definition------ float adcThres=x- > ped+par_nSigPed* fabs(x- > sigPed); float otherThr=x-> ped+par_twEneThres*x-> gain; if(adcThres < otherThr) adcThres=otherThr; -------- computing ideal gains ------- for(i=0;i<BtowGeom::mxEtaBin;i++ ){ float avrEta=-0.975 +i*0.05; /* assume BTOW has fixed eta bin size */ if(i==0) avrEta=-0.970;// first & lost towers are smaller if(i==39) avrEta=0.970; btow.cosh[i]=cosh(avrEta); btow.idealGain2Ene[i]=par_maxADC/par_maxET/btow.cosh[i]; } ---------- peds,gains, masking bad towers by threshold -------- if (par_gainType!=kGainIdeal) return -102; geom->btow.gain2Ene_rdo[x->rdo]=geom->btow.idealGain2Ene[ietaTw]; geom->btow.gain2ET_rdo[x->rdo]=geom->getIdealAdc2ET(); geom->btow.thr_rdo[x->rdo]=(int) (adcThres); geom->btow.ped_rdo[x->rdo]=(int) (x->ped); geom->btow.ped_shifted_rdo[x->rdo]=(unsigned short)(par_pedOff - x->ped); -------- event loop------- for(rdo=0; rdo < BtowGeom::mxRdo; rdo++){ if(rawAdc[rdo] < thr[rdo])continue; if(nTower > =mxListSize) break; // overflow protection adc=rawAdc[rdo]-ped[rdo]; //do NOT correct for common pedestal noise et=adc/gain2ET[rdo]; hit-> rdo=rdo; hit-> adc=adc; hit-> et=et; hit-> ene=adc/gain2Ene[rdo]; hit++; nTower++; } btowCalibData.hitSize=nTower; - Execution time:
L2-btowCal08 Compute CPU/eve MPV 42 kTicks, FWHM=6 Reference: L2:jet06-algo CPU/eve MPV 57 kTicks, FWHM=11
- Output files:
* ASCII logfile: run8.l2BtowCal08.log
* binary histo: run8.l2BtowCal08.hist.bin - QA info in log file:
#BTOW_hot tower _candidate_ (bHotSum=67 of 50000 eve) :, softID 1397 , crate 21 , chan 156 , name 07tj37 #BTOW_token_QA: _candidate_ hot token=2 used 13 for 50000 events, token range [1, 4095], used 4095 tokens
- QA plots : PDF
d ped-monitor (Jan)
L2-pedestal monitor-Algo ( 100% accept)
- Goal: accumulate pedestals for all towers of ETOW & BTOW.
- RTS params:
par_pedSubtr =rc_ints[0]!=0; par_speedFact =rc_ints[1]; par_saveBinary=rc_ints[2]!=0; par_dbg =rc_ints[3]; par_prescAccept=rc_ints[4];
- Meaning of speed
time spent in L2-ped is proportional to # of towers processed per event. speed=1 means for every event process all 4800+720 towers, takes 1mSec speed=2 means for the first event process tower 1,2, 5,6, 9,10,...., takes 500 uSec for the second event process tower 3,4, 7,8, 11,12,...., takes 500 uSec repeat So L2ped runs 2x faster but effectively you get 1/2 of stats for all towers. speed=4 means : 1st eve works with towers: 1,2,3,4, 17,18,19,20,... takes 250 uSec 2nd eve works with towers: 5,6,7,8, 21,22,23,24,... 3rd ... 4th eve ... repeat You got the pattern. Allowed 'speeds' are common divider of 4800 & 768. Allowed speed values: 1,2,4,8,16,32,64,192 But even if you type sth absurd L2ped will correct it to the closest correct value.
e) gamma (B=Jan, E=Jason+Paul)
RTS params
2 int dbg, prescaleAccept
4 float seedEtThres, clusterEtThres, eventEtThres,solationEtThres
two sets for B & E.
======== ALGO =======
1. Get list of towers provided by the L2 main shell
2. Sort the list in descending E_T
3. Loop over list until tower below seed threshold is found
a. Find the highest group of 2x2 clusters adjacent to seed tower
b. Form a cluster
c. Save to list of clusters
d. Mark all towers in 2x2 cluster as "used"
4. Repeat loop until all seed towers are exhausted
5. Loop over all clusters
a. Find highest E_T cluster
b. If ( cluster E_T > cluster threshold )
i. Accept event
ii. Store information in the L2Result array
- mean eta-bin
- mean phi-bin
- tower ID for seed tower
- a relative ID specifying which of the 4 possible tower
clusters was chosen
- ET of cluster
- number of nonzero towers in cluster
- an isolation E_T sum (placeholder for later, set = 0).
f) L2-jet (B+E) ver2006=Jan, ver2008=Will
Params:
// unpack params from run control GUI par_cutTag = rc_ints[0]; par_useBtowEast= (rc_ints[1]&1 )>0; par_useBtowWest= (rc_ints[1]&2)>0; par_useEndcap = rc_ints[2]&1; int par_adcThr = rc_ints[3]; // needed only in initRun() par_minPhiBinDiff=rc_ints[4]; par_oneJetThr = rc_floats[0]; par_diJetThrHigh= rc_floats[1]; par_diJetThrLow = rc_floats[2]; par_rndAccProb = rc_floats[3]; par_dbg =(int)rc_floats[4];
2009 pp run
- pre-run 2009 L2 code release , January 15, 2009, by Ross
- L2 mapping used in 2009 data taking, 56 BTOW towers were swapped (attachment 1)
0) lastDSM masks
In order to accommodate the larger number of desired triggers in the old TCU, the following algorithms can now read in masks to be checked against the 128 lastDSM input bits before decision() is called:
L2btowGamma
L2etowGamma
L2jet
L2jetHigh
L2upsilon
L2btowW
The masks are located in ~developer/emc_setup on the l2 machine, and must be named %s.lastDSM_mask , where %s is the name of the algorithm (subtract the 'L2' from the list above). These files contain 8 integersthat correspond to the 8 unsigned shorts in lastDSM[] in the trigger data.
If TCU_type!=2 we are assumed to be using the old TCU, and at the start of each run the code that initializes each l2 algorithm will attempt to read these files. If they can't be found, then the mask is assumed to be not used for that particular algorithm.
Each time decision() is about to be called for one of the above algorithms, we first pass in the lastDSM array to be checked against these 8 unsigned shorts. Each ushort in the array is byte-swapped so that the endian-ness of the two sets agrees. Note that lastDSM[0] does not seem to correspond to input channel 0 in Eleanor's LD301 documentation.
At latest look (Feb 27), the values in the array seem to be swapped in the same fashion as they are in the barrel code that looks at layer 2 of the DSM:
lastDSM[0] corresponds to input channel 3
lastDSM[1] corresponds to input channel 2
lastDSM[2] corresponds to input channel 1
lastDSM[3] corresponds to input channel 0
lastDSM[4] corresponds to input channel 7
lastDSM[5] corresponds to input channel 6
lastDSM[6] corresponds to input channel 5
lastDSM[7] corresponds to input channel 4
01 changes to L2 algos from last year
* verify every aborting algo is using random accept prescale based on prescale method and is randomly initialize upon start. I know L2-jet & L2-http-barrel are using rnd(), I suspect L2-http-endcap is not randomly initialized. Check them all.
* L2-jet needs change of jet size to 1x1.
* experiment with L2-Wbos algo in the barrel, needs TOF unpacking
* consider converting L2-http in to L2-eta , for EMC calibration purposes, Jason may have working prototype, but slow version due to memset
Jan
1) L2Result Offsets
Every algorithm has the opportunity to write out a small report into the L2Result array after each decision(). The sizes of these results are fixed within a year so that they don't overwrite others unexpectedly. They should not be changed without talking to the L2 algorithm maintainer. The starting position for each is defined in terms of the offset from the start of the L2Array. The values during the run were as follows:
| Algorith | Offset |
| (EMC_CHECK) | 1 |
| EMC_PED | 2 |
| Barrel Gamma | 3 |
| Endcap Gamma | 6 |
| Dijet | 9 |
| Upsilon | 17 |
| Barrel W | 20 |
| Dijet (Higher Et) | 25 |
| Endcap Hien | 0 |
| Barrel Calib | 0 |
| Endcap Calib | 0 |
| Barrel Hien | 0 (C2Result) |
a) L2emulL0_2009 (L0 hardware emulation)
This algorithm is intended to provide access to the 16 lastDSM output bits, and should only be needed when the old TCU is being used.
This algorithm reads in 5 ints from run control:
[0] onbits0
[1] offbits0
[2] onbits1
[3] offbits1
[4] number of onbits+offbits pairs
The logic used is as follows:
if((lastDSM & p->onbits[0]) != p->onbits[0]) return 0;
if((~lastDSM & p->offbits[0]) != p->offbits[0]) return 0;
repeated for [1] if the number of pairs is > 1. A byte swap occurs before this logic is reached, so that both ushorts should have the same endian-ness. If none of the 'if's fire, the algorithm returns 1.
b) L2btowGammaAlgo (barrel gamma algorithm)
This algorithm searches for localized energy distributions in the barrel calorimeter, and will not run if the BTOW is not in the run.
This algorithm reads in 2 ints and 2 floats from run control:
[i0] debug
[i1] Random Accept Prescale
[f0] Et threshold for seed
[f1] Et threshold for cluster
The logic used is as follows:
Every tower with Et>f0 is added to a list. The list is then checked in order, summing the cluster around it and returning Accept if sumEt>f1
The Random Accept Prescale value sets the prescale for random accept, described elsewhere.
If debug>0 debug messages are printed.
c) L2etowGammaAlgo (endcap gamma algorithm)
This algorithm searches for localized energy distributions in the endcap calorimeter, and will not run if the ETOW is not in the run.
This algorithm reads in 2 ints and 3 floats from run control:
[i0] debug
[i1] Random Accept Prescale
[f0] Et threshold for seed
[f1] Et threshold for cluster
[f2] Et threshold for event
The logic used is similar to L2btowGamma, but etowGamma saves more information about each event. All possible clusters per event are made (save for those that overlap other clusters) and added to a list if clusterEt>f1. If at least one cluster has clusterEt>f2, the event is accepted.
The Random Accept Prescale value sets the prescale for random accept, described elsewhere.
If debug>0 debug messages are printed.
The mapping is defined thusly
>> tow = EtowGeom::mxEtaBin *phi + eta;
tow = 0 ==> 01TA01
tow = 1 ==> 01TA02
..
tow 718 ==> 12TE11
tow = 719 ==> 12TE12
12 consecutive towers are in the same slice in phi.
d) L2hienAlgo (passive barrel and endcap high tower filter)
This algorithm packages tower ADC values and soft IDs for use outside of L2. It always accepts, and in the current configuration is cannot be attached to a particular trigger, but rather runs for each event.
This algorithm reads in 3 ints, which are hard-coded in algo_handler.c:
[i0] debug=0
[i1] ADC threshold=60
[i2] max L2hienList size=120
The logic used is as follows:
A switch is set in the constructor so that one instance of the L2hienAlgo reads barrel towers and the other endcap towers.
For each calibrated tower, if ADC>i1 it is added to L2hienList (up to i2 towers total). The barrel version then adds the first (up to) 40 towers (whether above i1 or not) to the L2hienResult, which is written to C2Result in l2new.
If debug>0 debug messages are printed.
e) L2jetAlgo (barrel and endcap combined jet algorithm)
This algorithm searches for jet-like energy distributions in the barrel and endcap calorimeters, and will run even if one or the other is not in the run.
This algorithm reads in 1 int from run control:
[i0] setup version, which controls which of ~developer/emc_setup/algoJet2009.setup* is used to set the parameters for the algorithm
This algorithm reads in 5 ints and 9 floats from the selected file:
[i0] What parts of the BEMC to use (1=East, 2=West, 3=both)
[i1] Whether to use the EEMC (>0 = yes)
[i2] par_adcThr (unused?)
[i3] debug
[i4] Random Accept Prescale
[f0] Et threshold for single jet
[f1] par_diJetThrHigh
[f2] par_diJetThrLow
[f3] par_diJetThr_2
[f4] par_diJetThr_3
[f5] par_diJetThr_4
[f6] par_diJetThr_5
[f7] par_diJetEtaHigh
[f8] par_diJetEtaLow
The logic is fairly complex. Brian Page is the maintainer of the jet code, so questions should be directed to him.
The Random Accept Prescale value sets the prescale for random accept, described elsewhere.
If debug>0 debug messages are printed.
f) L2pedAlgo (barrel and endcap pedestal monitor)
This algorithm records the ADC values from the ETOW and BTOW for pedestal studies.
This algorithm reads in 5 ints from run control:
[i0] ped subtraction flag
[i1] speed factor
[i2] 'save binary' flag
[i3] debug
[i4] prescale for accept
The logic used is as follows:
Each event, ADCs from 1/i1 (where i1 is rounded off to be 1,2,4,8,16,32,64, or 192) of the barrel and endcap are histogrammed by rdo. The selected regions roll, so that [0,1/i1] is histogrammed the first event, [1/i1,2/i1] the next, etc.
If i0>0, instead of histogramming the raw ADC, the pedestal is subtracted first, allowing the residual to be seen.
if i2>0 the entire histogram is saved at the end of the run rather than just keeping [-10,100] ADC.
If the prescale for accept is set greater than zero, then the algorithm no longer fills histograms, and simply does the following for every event:
if((rand()>>4) % par_prescAccept ) return false;
return true;
This is NOT the same as the procedure for the Random Accept Prescale.
If debug>0 debug messages are printed.
g) L2upsilonAlgo (barrel upsilon algorithm)
This algorithm searches for upsilons in the barrel, and will not run if BTOW is not in the run.
This algorithm reads in 1 int from run control:
[i0] setup version, which controls which of ~developer/emc_setup/algoUpsilon2009.setup* is used to set the parameters for the algorithm
This algorithm reads in 4 ints and 9 floats from the selected file:
[i0] prescale
[i1] Whether to mask hot towers dynamically
[i2] how many events to take between updates to the dynamic mask
[i3] Random Accept Prescale
[f0] fL0SeedThreshold
[f1] fL2SeedThreshold
[f2] fMinL0ClusterEnergy
[f3] fMinL2ClusterEnergy
[f4] fMinInvMass
[f5] fMaxInvMass
[f6] fMaxCosTheta
[f7] fHotTowerTheshold
[f8] fThresholdRatioOfHotTower
The logic is fairly complex. Haidong Liu is the maintainer of the upsilon code, so questions should be directed to him.
The Random Accept Prescale value sets the prescale for random accept, described elsewhere.
h) W-algo BTOW
L2 W-algo for BTOW, p+p 500 GeV , 2009 run
This algorithm searches for energy depositions in the barrel, and will not run if BTOW is not in the run.
This algorithm reads in 2 ints and 2 floats from run control:
[i0] debug
[i1] Random Accept Prescale
[f0] Et threshold for seed
[f1] Et threshold for cluster
The logic is as follows:
For each tower with Et>f0, each 2x2 tower patch around it is summed. As soon as one of these 2x2 patches has Et>f1, we accept the event.
The Random Accept Prescale value sets the prescale for random accept, described elsewhere.
if debug>0, various debug information will be printed.
Run time params 2 int dbg, randomAcceptPrescale 2 float seedEtThres, clusterEtThres (GeV) This algo works only with BTOW ADCs ======== L2 W ALGO ======= 1. Get list of towers w/ energy provided by the common L2 calib algo 2. Form smaller list of seed towers above seedTH 3. Loop over seed towers a. Find the highest cluster ET out of 4 groups of 2x2 towers containing the seed tower b. if Et > clusterET accept event, set trgBit=2, do not try any other cluster 4. try random accept - set event counter at random start - increment by 1 for every input event - issue random accept if (eventCounter % randomAcceptPrescale == 0) - if accepted set trgBit=1
5. Accept event if trgBit is 1 or 2 6. Store information in the L2wResult[.] array - seed eta-bin - seed phi-bin - seed ET - cluster ET - trgBits
Access to L2W results in muDst, also to oflTrigIds
StMuEvent* muEve = mMuDstMaker->muDst()->event();
TArrayI& l2Array = muEve->L2Result();
unsigned int *l2res=(unsigned int *)l2Array.GetArray();
printf(" L2-jet online results below:\n");
int k; for (k=0;k<32;k++) printf("k=%2d val=0x%04x\n",k,l2res[k]);
const int BEMCW_off=20; // valid only for 2009 run
L2wResult2009 *out1= ( L2wResult2009 *) &l2res[BEMCW_off];
L2wResult2009_print(out1);
StMuTriggerIdCollection *tic=&(muEve->triggerIdCollection());
assert(tic);
const StTriggerId &l1=tic->l1();
vector idL=l1.triggerIds(); printf("nTrig=%d, trigID: ",idL.size()); for(unsigned int i=0;i
Simulation of L2-W-Algo for Filtered QCD & W events , LT=~10 /pb.
Used thresholds: seedET>9 GeV, clusterET>14 GeV
Fig 1. LT=10/pb. Left: W events, right: QCD events

Fig 2. Uniformity of L2-W trigger for accepted QCD events, LT=10/pb.
It is lower only at the physical edges of barrel at eta=+/-1 due to energy leak and smaller tower size.

Below you will find full set of L2 monitoring plots for both sets of events

xxxxxxx old xxxxxx
SPARE PAGE
2011 pp run
bah.
L2 Documentation: 2014 Comments
The most current documentation can be found on Kevin Adkins blog page. It's not the 2014 comments any longer (2015 at this point!), though this page still bears that name. One should remove the following URL and add a more current one if this documentation is updated.
Current L2 Documentation as of Run15
This documentation inludes a few things:
- A detailed guide to L2 monitoring
- A detailed guide to monitoring the L2 pedestals
- A detailed guide to updating the L2 tower masking file
- A few comments about the L2 algos and how they work together
This document will probably be in other places too, but it should be safe here.
content of setup file for L2 algos
This description refers to 2011 setup, before moving L2 to HLT
The real L2 algo read all peds, status tables from the l2ana01, user=developer, dir=emc_setup (or sth similar) Only the files with the word 'current' in the name are read in. Those are symbolic links pointing to the real files. All other ped, status files, with some date attached are kept only as a record.
Those are all setup files needed by L2 algos: [developer@l2ana01 emc_setup]$ ls *current btowCrateMask.current etowCrateMask.current pedestal.current btowDb.current etowDb.current towerMask.current
Common format: all lines starting with '#' are ignorred as comments. Every file has short description of its contntent. One need to be familiar with EEMC DB to understand the details.
btowCrateMask.current, etowCrateMask.current, btowCrateMask.current etowCrateMask.current are used to mask out whole crates or individual towers. They are editted by hand as needed during the run. Typically all us unmasked at the beggining of each run.
pedestal.current is produced by L2-ped algo under different name (run12058037.l2ped.log) after every run.Once person monitoring L2 pedestal residua decideds pedestals used by L2 drifted too far, the pedestal.current is linked to the fresh runXXX.l2ped.log. Typically twice per week.
btowDb.current, etowDb.current contain full DB mapping for both EMC. Those files are produced once per year, by running $STAR/StRoot/StEEmcDbMaker/StEmcAsciiDbMaker.cxx on the offline STAR DB.If no mapping was changed in the offline DB there is no need to regenerate those 2 files.
convert L2 bin histo to root histo
Compile this stand alone code
$STAR/StRoot/StTriggerUtilities/L2Emulator/macros/binH2rootH.c
It needs L2Histo.cxx L2Histo.h from
$STAR/StRoot/StTriggerUtilities/L2Emulator/L2algoUtil/
and CERN root .
It does not need STAR root4star.
offline framework description
How to compile & run full suit of L2-algos offline.
1) take the current copy deployed at the real L2 and manage to compile and run it offline. Run over 100K events (takes ~1 minute). 2) fire the macro producing full set of L2-jet plots, so it will produce PDF with all plots fr this 100K eve. Only then you can control if the L2-jets works. 3) Next, add your changes to L2jet , compile , run, view plots. I'll ask Ross to take care of I/O new params (cuts) you have added/changed to select jets you want. Just make sure all new params are _variables_ defined in .h and have name starting with parWill_cut1, .... You just set values in initRun() and recompile each time you want to change them. Once you are happy with the cuts you tell me where is this version. Make sure to run it on full 2006 event file (~600K eve).
Detailed instruction
- create a new directory at rcas6nnn and copy the recent version of code
mkdir aaa cd aaa cp -rp XXX/onlineL2 . cp -rp XXX/StRoot . (ask Ross for actual location of both directories)
- compile full version of library (no exec yet)
cd onlineL2 make lib
- compile & exec the main code
make m 5000
- To modify L2jet finder code open another terminal on rcas6nnn
xterm& cd ../StRoot/StTriggerUtilities/L2Emulator/L2jetAlgo/ edit the code you want make make install
go back to primary terminal in "onlineL2" and type: touch multiTest.c make Now you can run 'm' again - to view plots convert hist.bin to hist.root and run root macro (for the moment all output files are stored with the name: out5/run8...)
binH2rootH-exe out5/run8.l2jet.hist.bin out5/run8.l2jet.hist.root root.exe plJetsL2.C
Now you can display one age at a time by typing within root sessionplJetsL2(1) plJetsL2(2)..
Note, for L2jet algo the valid pages are: {1,2,3,4,5,6,10,20,21,22}
production of binary events for L2 algos
Here is prescription how to convert any muDst to the binary event format, needed to run L2-algos stand alone (by multiTest.C)
Let me start with a warning - this procedure requires execution of some additional code not relevant for this task ( being production of binary event files), but I wanted to reuse existing offline trigger simu code and there was no consensus how to rearrange it.
The goal is to produce events consisting of 2 data blocks : BTOW & ETOW - equivalent to raw data saved in the daq file.
- Prescription to produce R9067013.eve.bin from muDst from run9067013 :
mkdir aaa cd aaa mkdir out2 stardev cp $STAR/StRoot/StTriggerUtilities/macros/rdMu2binL2eve.C . cp /star/institutions/mit/balewski/2008-L2events/R9067013.lis . root4star -b -q rdMu2binL2eve.C >& L1 &
You need no private code, just the .C macro, setup to read the run-list, muDst must still exist on the disk (fix it if needed). - Inspect the .C macro to find out how to change # of processed events, # muDst to read in. If you use muDst from M-C you need to activate useMC-switch in the macro and decide on the time stamp - this is on of this irrelevant things I have warned you. Current default is reasonable.
- Output: the binary event file (R9067013.eve.bin) will show up in the 'aaa/' directory. The content of binary events is different for real data vs. M-C. This can be fixed later (by Ross?), but for now you must take it in to account while reading such events by multiTest.C
- binary events for real data contain raw BTOW & ETOW data blocks. This is certainly true for the Endcap, I'm less sure for the barrel, since I'm forced to use StEmcADCtoEMaker and I do not if it removes ADC for masked towers. You need to figure it out. The main point is for real data you will see 4800+720 non-zero ADCs before pedestal subtraction. This is exactly what L2-algo receive on-line.
Note, your L2-algo will receive data after ped subtraction. - binary events for M-C contain only fired towers, peds are not added, nor smeared. Therefore, you must use different L2-pedestal files while reading such events, with ped set to 0 - otherwise the common L2-calib algo will subtract peds anyhow.
This could be changed if one activates properly slow simu for BTOW & ETOW - talk to Ross. The advantage would be identical L2-peds & status tables could be used for M-C events and for real data. The disadvantage of using slow simu is now you must set DB time stamp during production of binary events and have L2-peds for exactly the same time stamp - or you will end up residual energies seen by L2-algos.
- binary events for real data contain raw BTOW & ETOW data blocks. This is certainly true for the Endcap, I'm less sure for the barrel, since I'm forced to use StEmcADCtoEMaker and I do not if it removes ADC for masked towers. You need to figure it out. The main point is for real data you will see 4800+720 non-zero ADCs before pedestal subtraction. This is exactly what L2-algo receive on-line.
- QA output: look at the file: aaa/out2/run9067013.l2ped.out it will show pedestal residua using online L2 peds as R9067013. This is one of those confusing steps. While producing binary events the rdMu2binL2eve.C runs also L2-ped algo (I can't turn it off due to code dependencies), but L2-ped does NOT affect content of the output binary event file. But you can use L2-ped output to monitor if reasonable ADC have been found in muDst.
This is an ASCII file, on the top there are 720 Endcap pedestals residua:#L2-ped algorithm finishRun(9067013), compiled: Jan 30 2008 , 23:25:07 #params: pedSubtr=1 speedFact=8 saveBin=0 debug=0 prescAccept=0 #L2H10,6,total event counter; x=cases,100,13,13,0,0,0, #L2ped CPU/eve MPV 27 kTicks, FWHM=2, seen eve=100 # L2ped-Adc spectra, run=9067013, Z-scale is ln(yield), only first digit shown; maxPedDev=5 table format: # name, ped, sigPed, crate, chan, softID-m-s-e, RDO_ID; # ADC spectrum: [-20 ... <=-10 ... *=0 ... >=+10 ... :=+20 ... 100], Xaxis=ADC - ped + 20 01TA01 0 1.3 0x01 0x38 P01TA01 336 :.........<.........2211......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TA02 1 0.9 0x01 0x39 P01TA02 342 :.........<........1121..1....>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TA03 2 0.9 0x01 0x3a P01TA03 348 :.........<.........2121.1....>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TA04 0 0.9 0x01 0x6d P01TA04 654 :.........<.......112121......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TA05 0 0.9 0x01 0x6c P01TA05 648 :.........<........1211.......>......1..:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TA06 0 1.3 0x01 0x6e P01TA06 660 :.........<........122........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TA07 0 0.9 0x01 0x6f P01TA07 666 :.........<........1311...1...>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TA08 -1 1.3 0x01 0x3b P01TA08 354 :.........<........221........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TA09 0 1.3 0x01 0x3c P01TA09 360 :.........<........1221.......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TA10 0 0.9 0x01 0x3d P01TA10 366 :.........<........222........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TA11 1 0.9 0x01 0x3e P01TA11 372 :.........<.........231.......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TA12 0 0.9 0x01 0x3f P01TA12 378 :.........<........1311.......>.........:...1.....:.........:.........:.........:.........:.........:.........:......... qa=0 01TB01 0 1.7 0x01 0x40 P01TB01 384 :.........<.......1121111.....>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TB02 0 0.9 0x01 0x41 P01TB02 390 :.........<.......1121111.....>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TB03 0 1.7 0x01 0x42 P01TB03 396 :.........<........222........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TB04 -1 0.9 0x01 0x70 P01TB04 672 :.........<.......1221........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TB05 0 0.9 0x01 0x71 P01TB05 678 :.........<.......112.1....1..>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0
Once you scroll about 1000 lines, you will see 4800 barrel pedestal residua:01tg22 0 1.3 0x1d 0x19 id0122-004-1-02 754 :.........<.........221.......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01tg23 0 1.7 0x1d 0x1a id0123-004-1-03 784 :.........<........1222.......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01tg24 1 0.9 0x1d 0x1b id0124-004-1-04 814 :.........<........2121.......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01tg25 2 0.9 0x1d 0x38 id0125-004-1-05 1684 :.........<.......121121......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01tg26 0 1.3 0x1d 0x39 id0126-004-1-06 1714 :.........<........1221.......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01tg27 1 0.9 0x1d 0x3a id0127-004-1-07 1744 :.........<........1231.......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01tg28 0 1.3 0x1d 0x3b id0128-004-1-08 1774 :.........<......1..221.......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01tg29 1 1.3 0x1d 0x58 id0129-004-1-09 2644 :.........<.......1122.1......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01tg30 1 1.3 0x1d 0x59 id0130-004-1-10 2674 :.........<.......11221.......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01tg31 -1 0.9 0x1d 0x5a id0131-004-1-11 2704 :.........<........21111......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01tg32 -1 1.7 0x1d 0x5b id0132-004-1-12 2734 :.........<.......2221..1.....>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01tg33 1 1.3 0x1d 0x78 id0133-004-1-13 3604 :.........<........1221.......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01tg34 -1 1.3 0x1d 0x79 id0134-004-1-14 3634 :.........<.......122.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01tg35 -1 1.7 0x1d 0x7a id0135-004-1-15 3664 :.........<........222........>.........:..1......:.........:.........:.........:.........:.........:.........:......... qa=0 01tg36 0 1.3 0x1d 0x7b id0136-004-1-16 3694 :.........<........2211.......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01tg37 1 1.3 0x1d 0x98 id0137-004-1-17 4564 :.........<........1221.......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01tg38 0 0.9 0x1d 0x99 id0138-004-1-18 4594 :.........<........1221.......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01tg39 -20 -0.4 0x1d 0x9a id0139-004-1-19 4624 :.........<.........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=? 01tg40 0 1.3 0x1d 0x9b id0140-004-1-20 4654 :.........<.......1221........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01th01 0 1.3 0x0e 0x8b id4460-112-1-20 4187 :.........<........122.1......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01th02 -20 -0.4 0x0e 0x8a id4459-112-1-19 4157 3.........<.........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=? 01th03 -2 2.2 0x0e 0x89 id4458-112-1-18 4127 :.........<......12221........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01th04 -1 1.3 0x0e 0x88 id4457-112-1-17 4097 :.........<......112211.......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01th05 0 2.2 0x0e 0x6b id4456-112-1-16 3227 :.........<.......112211......>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0
The above files are for real data, when peds seen by L2-ped algo match the real pedestals.If you display the same file for M-C events, you will see just high-energy ends of ADC spectra, because at this moment binary events for M-C do not include pedestals.
# ADC spectrum: [-20 ... <=-10 ... *=0 ... >=+10 ... :=+20 ... 100], Xaxis=ADC - ped + 20 01TA01 -17 0.9 0x01 0x38 P01TA01 336 :..3......<.........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TA02 -12 0.9 0x01 0x39 P01TA02 342 :.......3.1.........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TA03 -20 -0.4 0x01 0x3a P01TA03 348 :.........<.........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=? 01TA04 -20 -0.4 0x01 0x6d P01TA04 654 :.........<.........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=? 01TA05 -20 -0.4 0x01 0x6c P01TA05 648 31........<........1*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=? 01TA06 -20 -0.4 0x01 0x6e P01TA06 660 31........<.........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=? 01TA07 -20 -0.4 0x01 0x6f P01TA07 666 :.........<.........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=? 01TA08 -20 -0.4 0x01 0x3b P01TA08 354 3.........<.........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=? 01TA09 -12 0.9 0x01 0x3c P01TA09 360 :.......3.<.........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TA10 -20 -0.4 0x01 0x3d P01TA10 366 31........<.........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=? 01TA11 -4 0.9 0x01 0x3e P01TA11 372 :.........<.....1...*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TA12 -17 0.9 0x01 0x3f P01TA12 378 :..3......<.........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TB01 -20 -0.4 0x01 0x40 P01TB01 384 :.........<.........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=? 01TB02 -15 0.9 0x01 0x41 P01TB02 390 :....1....<.........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TB03 -20 -0.4 0x01 0x42 P01TB03 396 :.........<.........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=? 01TB04 -16 0.9 0x01 0x70 P01TB04 672 :...3.....<1........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=0 01TB05 -20 -0.4 0x01 0x71 P01TB05 678 :.........<.........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=? 01TB06 -20 -0.4 0x01 0x72 P01TB06 684 :.........<.........*.........>.........:.........:.........:.........:.........:.........:.........:.........:......... qa=?
Simulator Documentation
The STAR trigger simulator is designed to
- reproduce trigger algorithms in offline software that can be run on Monte Carlo or real data ("online" mode)
- allow for use of improved calibration coefficients, pedestals, status tables, etc. to "clean up" trigger spectra ("offline" mode)
- aid in the development of new triggers ("expert" mode)
It should provide a common framework for simulators of all trigger detectors.
How to Run
Ideally, this could be as simple as adding StTriggerSimuMaker to your chain and then asking
trigSimu->isTrigger(trigId);in your analysis Maker. Because the trigger simulator is still in development this is not always the case. Here is a "straight from real-life" description of how to get it running:
( don't ask me, I'm just writing the docs .... )
Code Structure
Everything lives in StRoot/StTriggerUtilities. StTriggerSimuMaker is the "head Maker" and owns all of the subdetector simulators. Each subdetector simulator inherits from StVirtualTriggerSimu, which requires an implementation of isTrigger(int trigId). This means that a user can
- ask the head Maker if the trigger fired for this event.
- ask the head Maker for a pointer to a subdetector simulator, and then ask this subdetector if the event passed the trigger. For instance, a simple BEMC HT trigger is typically run in coincidence with a minbias trigger from the BBC, ZDC, or VPD. By querying the BEMC and BBC/ZDC/VPD separately a user can find out why a particular event might have failed a HT trigger (i.e. was it because the HT threshold wasn't satisfied, or was it because the minbias condition failed?).
Subsystem Simulators
Detailed documentation of the subsystem simulators follows below:
BBC
Detailed docs for the BBC trigger simulator
BEMC
Detailed docs for the BEMC L0 simulator.
EEMC
Detailed docs for the EEMC L0 simulator.
L2
L2 simulator details.
ZDC
Hardware and software related to ZDC
VPD
Vertex Position Detector (VPD)
Procedural Notes and Run Operations
- VPD trigger-to-TOF Channel Map - 2014 (Daniel's blog)
TOF noise rate pattern
VPD Operations (HV Scan Instructions)
[from Isaac Upsal's instructions to star-ops, dd.May 17, 2023]
If stable collisions are available and the BBC (ZDC) is ready to use as a trigger then we can take the VPD gain scan. The procedure is as follows:
Make sure that you are using a **non-VPD-based** Trigger for all data taking.
First :
On the sc3 machine there needs to be a "small GUI" for the VPD with 4 buttons - upVPD HV A, upVPD HV B, upVPD HV C, and Default. If it is not open or you are unsure open a terminal and execute "upvpd_settings". I just opened this ~an hour ago.
"large GUI" shows all the channel values, and where one powers them on/off.
"small GUI" selects between different gain sets A, B, C, & default.
start with the VPD HV **OFF**
1) On the small GUI choose the HV Gain setting *A*
2) On the large GUI power on the VPD HV
3) Make sure that the upper-left corner (channel 13-0) of the large GUI reports a voltage of ( 1101, 1251, 1401 ) for gain setting A, B, and C respectively.
4) Wait about a minute or two for the VPD PMT channel voltages to settle
5) Start run: TRG+DAQ+TOF (it is OK to include other detectors in if you want, but those are required), 200k events. Use string "VPD HV A" (or B, C as needed) in the shiftlog entry
6) Use the "large GUI" to power off the VPD HV
7) Wait for all channels to read a voltage of 0
Repeat these steps for each of the gain settings (A, B, C) - making the appropriate entry in the shiftlog to identify which gain setting is used (upVPD HV A, upVPD HV B, upVPD HV C ).
Once this is complete, use the "small GUI" to select "default" then power the VPD HV back on. Now you can close the "small GUI".
More information on the software and analysis workflow can be found at this GitHub repository: https://github.com/RiceU-HeavyIons/BTOF-online/tree/master/gainfit
VPD Run17 HV Map
VPD Run18 HV Map
VPD Run22 HV Map
Vpd Simulation Database Table
Variables:
short tubeRes[38]; // The resolution of a single Vpd tube in picoseconds to be simulated.
octet tubeId[38]; // The offline ID (0-37) of the Vpd tube
octet tubeStatusFlag[38]; // Flag for whether tube was active (True) or not (False) in a given Run
octet tubeTriggerFlag[38]; // Flag for whether tube was triggered on (True) or not (False) in a given Run (again, simulation). Note that there will be overlap with the tubeStatusFlag, but could be additional False entries as well.
Frequency:
This table will be updated whenever the Calibrations_tof::vpdTotCorr table is updated, generally once per RHIC Run
Index:
*table is not indexed
Size:
The cumulative size of the 4 arrays is 190 bytes.
Write Access:
jdb - Daniel Brandenburg (Rice University)
nluttrel - Nickolas Luttrell (Rice University)
See below the full .idl file
VpdConfig.idl:
/* vpdSimParams.idl
*
* Table: vpdSimParams
*
* description: Simulation Parameters for use in StVPDSimMaker
*
* author: Nickolas Luttrell (Rice University)
*
*/
struct vpdSimParams{
short tubeRes[38]; /* Single Tube Resolutions for Vpd tubes in picoseconds*/
octet tubeID[38]; /* Vpd Tube ID, values of 0-37 */
octet tubeStatusFlag[38]; /* Flag for whether tube was active (True) or not (False) */
octet tubeTriggerFlag[38]; /* Flag for whether tube was triggered on (True) or not (False) */
};
/* End vpdSimParams.idl */
test